行政院國家科學委員會專題研究計畫 成果報告
適用於行動裝置的遠端檔案儲存與分享系統 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2221-E-011-060-
執 行 期 間 : 99 年 08 月 01 日至 100 年 10 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 項天瑞
計畫參與人員: 碩士班研究生-兼任助理人員:陳立昂 碩士班研究生-兼任助理人員:陳致良 碩士班研究生-兼任助理人員:李訓哲 碩士班研究生-兼任助理人員:鄭文博
公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 101 年 02 月 06 日
中 文 摘 要 : 近年來,隨著網路科技的快速發展,網路資源共享已經司空 見慣,而雲端技術更成為新興趨勢。雲端技術的應用之一為 遠端檔案儲存與分享,目前的網路檔案系統多半仰賴穩定的 網路環境及高速網路系統架構,以致遠端檔案儲存多半侷限 於研究機構或企業內部使用,而長距離的遠端儲存多半在線 上檔案更新方面有著較大的延遲。為配合使用者端的行動裝 置特性與使用成本,長距離即時檔案共享基本效能需求為快 速的檔案更新以及更新過程中的低頻寬耗損。本計畫試圖在 傳輸效能受到限制的環境下,提出遠端檔案系統存取策略,
降低遠端檔案系統的資料傳輸量。讓一般居家或行動網路的 使用者,能透過廣域網路,即使因為硬體傳輸的限制,在低 頻寬與高延遲的情況下,依然能有效率的使用遠端檔案系統 上的資源。本計畫為此研究遠端檔案傳輸協定的改進,在不 影響使用者隱私的前提下,同步達成檔案快速更新與降低實 際傳輸需求。除了模擬驗證協定效能外,本計畫亦建立虛擬 網路,並實作發展之遠端檔案存取協定至真實作業系統以進 行測試。
中文關鍵詞: 遠端儲存、隱私、雲端服務
英 文 摘 要 : From early network file systems to today’s cloud storage services, remote data access has always been an important topic. Solutions for issues such as reliability, scalability, and update efficiency have been proposed for different applications. Modern networking technologies have enabled more and more users access internet with mobile devices on Wi-Fi or cellular networks. This project proposes a strategy to access and edit remote data efficiently with relatively weak network connections. The proposed approach significantly improves the file closing latency when users update files, where data is processed in terms of blocks and file summaries are used to reduce the amount of transmission. In
untrusted network environments such as cloud storage services, the proposed method can also be adopted by encrypting data at the client-side before uploading it to the server in order to preserve
confidentiality. Simulations show that the proposed method greatly improves responsiveness while the induced networking overhead is minimal.
英文關鍵詞: remote storage, privacy, cloud services
行政院國家科學委員會專題研究計畫成果報告 適用於行動裝置的遠端檔案儲存與分享系統
國科會計畫編號:NSC99-2221-E-011-060- 執行期間:2010/08/01~2011/10/31 執行機構: 國立台灣科技大學資訊工程學系
主持人:項天瑞
Abstract
From early network file systems to today’s cloud storage services, remote data access has always been an important topic. Solutions for issues such as reliability, scalability, and update efficiency have been proposed for different applications. Modern networking technologies have enabled more and more users access internet with mobile devices on Wi-Fi or cellular networks.
This project proposes a strategy to access and edit remote data efficiently with relatively weak network connections. The proposed approach significantly improves the file closing latency when users update files, where data is processed in terms of blocks and file summaries are used to reduce the amount of transmission. In untrusted network environments such as cloud storage services, the proposed method can also be adopted by encrypting data at the client-side before uploading it to the server in order to preserve confidentiality. Simulations show that the proposed method greatly improves responsiveness while the induced networking overhead is minimal.
Keywords:Remote Storage, Privacy, Cloud Services
1. INTRODUCTION
Although high-speed internet services are widely available nowadays, remote file systems are still mostly used in environments with reliable network infrastructures such as companies and schools due to the low latency and the high bandwidth. With cloud storage services are gaining popularity in the recent years, users need to efficiently and securely access files stored at third-party storage systems from mobile devices with relatively weaker network connections.
In this study, we propose a remote file accessing strategy for users with limited networking resources. The proposed approach enables users in wide area
networks to update their files remotely with small communication overhead.
To protect data confidentiality in untrusted remote storage systems such as public cloud storage services, the proposed file accessing method only stores files encrypted by the file owner at the server. To maintain responsiveness, only modified file fragments are updated to the server when a file is being edited.
The rest of this paper is organized as follows: Section 2 reviews related remote file systems and compares their differences.
Section 3.1 introduces the environment settings of our system. Section 3.2 explains the proposed remote file accessing approach.
The performance of the proposed method is
evaluated by simulations in Section 4. And Section 5 summarizes our results and outlines future directions.
2. RELATED WORK
Remote file systems have been actively developed for more than two decades, during which solutions to deal with communication overhead, file consistency, data duplication, etc. were proposed [4, 5, 12, 15].
Early NFS [13] allow users to mount file systems across the network and use them as if they were local directories. NFS’s data write-back strategy closely mimics traditional file system’s write() procedure.
The client repeatedly sends
write()
operations to the server when user updates a file. Since those write operations are synchronous requests, the client cannot consistently perform well if it does not receive acknowledgements. Especially when the network has low bandwidth or suffers high latency, the system performance deteriorates drastically.The AFS [6] uses the write-back-on-close approach to improve remote file accessing performance. When a file is being edited, all write operations only update the cached local copy. The changes are buffered at the client side until the file is closed, then the client transfers the new file to the server. To ensure that a client’s cache does not contain stale data, the file server records the location of all file replicas. If the file has not been modified on the server on file opening, the client does not need to fetch the file from the server. Instead, it only has to verify the file recency and directly operate on the local copy.
To support operations in weaker network connections, Coda [7] explores
asynchronous write-back [9] to update files.
Coda records changes in a local log instead of propagating updates to the server and immediately responding to update requests.
Updates are asynchronously sent to the server whenever available bandwidth exists.
To reduce the amount of data that must be flushed, a Coda client tracks the log to eliminate reversed file operation. Although asynchronous write-back does optimize the amount of transporting, the status recorded at the server is stale, thus lagging the status at clients. Stale server status results in consistency problems that complicate data sharing. When an update conflict occurs, user intervention is needed. Also, servers often do not record complete update history in systems with log optimizations, and support for properties like version control are difficult [10]. [8] extends Coda to support operation-based updates. The clients move operation-based updates to network surrogates maintaining strong connections to the server. The network surrogates perform file updates and relay acknowledgements back to weakly connected clients. Using this approach, data transmission mostly occurs between strongly connected devices. Network surrogates usually are trusted components.
The file operation types that can be performed are limited by the need of data encryption at clients if network surrogates belong to an untrusted infrastructure.
LBFS [11] is a network file system designed for updating files over slow or wide-area networks. It uses a persistent cache to provide AFS-like close-to-open consistency. Once a user has written and closed a file, other users can always read the new version during simultaneously accesses.
LBFS uses the Rabin hashing to break a file into blocks of various sizes. It performs a sliding window scan through the file and compute corresponding window hash values.
This approach may identify the same block boundaries even when the file size is changed due to file updates. In order to prevent pathological cases that produce blocks of extreme sizes, LBFS sets up minimum and maximum block size limits.
LBFS uses a file summary to differentiate between versions of a file and to perform incremental updates. A file summary record contains secure hash values of the block content. Furthermore, a file summary also records the offset of each block and its length.
[2] develops the intention update mechanism in LBFS. When a client propagates changes to server, intention update divides the upgrade into a two-phase operation. In the first phase, client sends a tiny metadata to inform server about the modification. Then the client sends modified blocks to server in the second phase. This approach provides fast update visibility [1] that server can quickly follow the state of file accurately and promotes flexible scheduling of updating operations.
Table 1 compares common network files systems. In Table 1, every file system [6, 8, 11] except NFS [13] stores files in local cache to reduce RTD (Round Trip Delay) between client and server. In NFS and Coda, remote machines need to manipulate data in plaintext form, which causes data confidentiality issues in environments where the storage server is untrusted.
Table 1: Characteristics of network file systems.
Characteristi cs
NF
S AFS Cod a
LBF S Local cache
No Yes Yes YesDivide cache
No No No YesWrite-back
Syn cAsyn
c Sync Sync
Continuous
updates
Yes No No NoPrivacy
No Yes No Yes3. FILE ACCESS FOR MOBILE USERS
3.1 Network Characteristics
For a user to access remote files on network connections with low bandwidth and high latency, the system’s response time is an important factor that affects the user’s efficiency at work. The relation of network bandwidth, latency, and system’s response time can be expressed as follows,
c s c s
c s s s c s c
s
c LT
BT PT DS BT LT
RT DS
(1)
,where DS represents the data amount to be transmitted from sender to receiver, BT is the rate of data transfer between sender and receiver, LT is the one-way delay to complete a transmission, and PTs represents the processing time at server. The suffixes c→s and s→c indicate the direction in which the data are transmitted between the client and the server respectively. Different network technologies induce various latencies and bandwidths.
Among nowadays networking technologies, broadband connecting methods like cable modems and ADSL are
popular connection options for residential users and some small businesses. Although wired networking technologies provide higher bandwidth and lower latency, today’s users in fact rely heavily on wireless technologies to access computing resources.
Table 2 lists some popular network technologies and their networking capabilities in reality. Recent WiMAX technology supports bandwidth of 144Mb/s.
Newer standards of Wi-Fi promises bandwidth from 54Mb/s to a maximum of 600Mb/s. Nonetheless, actual service levels [3,14] dramatically deteriorate in practical wireless networking environments when the population of users increase in the same area. [8,11] studied networking issues in the case of remote storages.
Table 2: Common networking technologies
Network
types
Bandwidth (Kb/s)
Latenc y (ms)
100Gbase-X
108 1DOCSISv3.0
160,000/120,000 30
ADSL2+
24,576/3,584 10802.11n
288,900 10802.16e
144,000/35,000 10UMTS/SGS
M
384/64 100Network file systems are usually deployed in local area networks (LAN) with better and stable connecting conditions, where users in the same LAN can efficiently manipulate files on remote storage. In wide area networks, the last-mile connection is usually the bottleneck of data transmission. Users performing updates to remote files often suffer from unstable and slow connections.
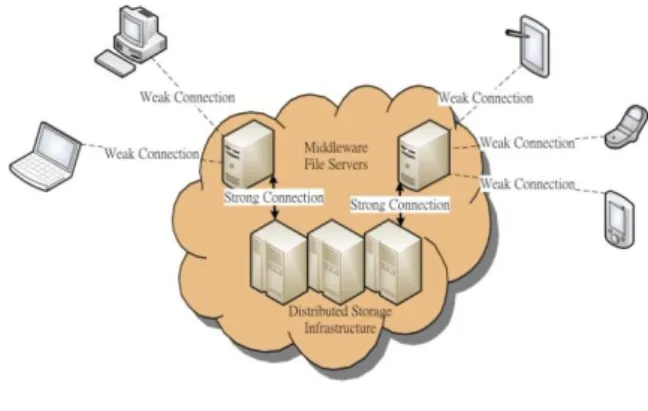
This paper proposes a remote file accessing method for mobile users to securely and efficiently update files on the server. Figure 1 illustrates our targeted application scenario, where users usually access files via relatively weak connections.
To reduce the updating latency of file operations in a remote file access system,
LBFS uses the AFS-like
write-back-on-close strategy. A file is updated to the server after a client finishes editing and closes the file. Rabin hashing helps reduce the amount of data to be transmitted to complete an update. However, the time needed to perform the update may still be too long in the case of collaborative file editing.
To further reduce the latency of the completion of a file update, our proposed method considers users’/applications’
editing patterns and starts updating continuous file segments to server while the file is still being edited. Rabin hashing is used on modified file blocks to determine the actual data to be transmitted.
Figure 1: Cloud storage file accessing scenario
While using Rabin hashing, if a user modifies data located inside the sliding window that hashes to a block boundary, the boundary fingerprint is changed. The
proposed file updating method reduces the amount of transmitted data by taking sliding windows into account. When a client edits the defining sliding window of the last block of a continuous file segment, the client recalculates the block boundary and updates the file segment up to the new boundary to the server. The defining sliding window of the new boundary never exceeds the immediate next block.
3.2 Efficient File Access Protocol
The Efficient Data Access Protocol (EDAP) for mobile users with weak connections is provided in this section.
The server maintains the summary of a file. Upon opening a file, its summary is first downloaded to the client. The client must verify that the block content at the server matches its own record, otherwise it needs to refresh the file from the server before editing.
As a file is being updated, only the newly created ones overlapping old blocks need to be uploaded. For a changed file segment, the block boundaries in the segment are recalculated. When the updating is applied in a block, only fingerprints of sliding windows with partial new content are required to be recomputed in order to reduce computation and define new block boundary.
In a cloud storage system, since files are being stored at some remote location which is out of the user’s control, some protective measures of the file confidentiality must be taken. Under this situation, data can be encrypted by the client and it is difficult for the server to decrypt the file by brute force.
However, doing so may cause the above updating procedure to create block conflicts
among different file versions since server is unable to truncate redundant data. EDAP can be adapted to work with block ciphers in either ECB (Electric CodeBook) or CBC (Cipher-Block Chaining) modes by making block sizes by making block size be multiples of the size of an encryption unit.
When ECB-mode ciphers are used, EDAP creates less storage overhead because overlapped data is smaller than one block for every modified file segment. If CBC-mode ciphers are employed, EDAP needs to store an extra block for every edited file segment in order to en- crypt/decrypt upcoming unedited file content.
Upon closing a file, the client performs hashing to all modified blocks that have not been updated to the server and updates the file summary to the server. When EDAP is working with block ciphers, files are encrypted before they are uploaded to the file server and the file summary contains hash values generated from plaintext file segments. Therefore, in an untrusted network infrastructure, EDAP can still perform efficient file access without compromising file confidentiality.
4. PERFORMANCE
EVALUATION
The proposed EDAP updates data by updating contiguous segments of blocks before the user closes the file. This section provides simulation results that estimate the communication overhead and the improvement of file closing latency improvement. The numerical results are compared with the performance of LBFS.
This section also evaluates the storage overhead created by EDAP at the
server-side.
4.1 Environment Configuration
In our simulations, a client performs a sequence of random editing to a remote text file. A client edits contiguous file segments of random lengths. Each segment has a random starting position in the file. The above editing behavior creates the most communication and storage overheads, while a user often edits files more rationally in reality.
The block size is set between 4KB and 16KB when applying Rabin hashing. The simulations further assume a CBC-mode 128-bit block cipher is employed to encrypt file content. The connection is configured to simulate W-CDMA’s bandwidth with the upload and download speeds at 64Kb/s and 384Kb/s, respectively.
4.2 Total Data Transmission
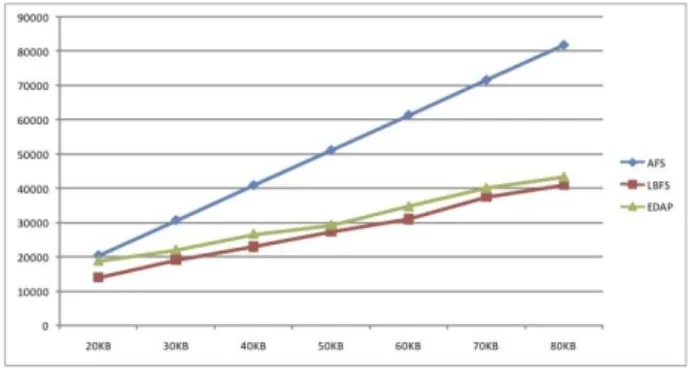
This batch of simulations compares the amount of transmitted data of AFS, LBFS, and EDAP, given the same editing sequence.
In AFS, data is sent to the server only after the client issues the close() request. In LBFS, although data is updated upon closing the file, only edited file segments are transmitted. In EDAP, contiguous blocks are sent whenever the client moves on to edit another disjoint file segment.
Files of different sizes are tested. For each file size, 50 different random editing sequences are used. The simulations record the average amount of transmitted data of the three approaches. Figure 2 shows the simulation results. The x-axis shows the file sizes used in the simulation, and the y-axis indicates the average transmitted data amount for each remote file accessing
approach.
In EDAP, when random editing is performed, a block can be updated to the server multiple times since the editing steps may move among disjoint file segments repeatedly. Therefore, the amount of transmitted data increases. As shown in Figure 2, when EDAP and LBFS perform much better with increased file size, EDAP produces slightly more communication overhead than LBFS. However, when the block updating order is more organized, the overhead is expected to decrease. Also, the slight overhead allows the server to receive the revised file much earlier, which implies that a collaborative software system using EDAP may be more responsive for users to exchange documents.
Figure 2:Total data transmission
4.3 File Closing Latency
The refresh time after closing a file is compared between EDAP and LBFS. The simulations are conducted using various number of editing operations and file sizes.
All data needed be updated is uploaded after
close() is issued in LBFS. In EDAP, a
segment of blocks is uploaded whenever the current position of editing is located in a block disconnected from this segment. For each file size and number of editing operations in the simulations, 50 differentinstances are generated and the average result is recorded.
(a) LBFS file closing latency
(b) EDAP file closing latency Figure 3: The file closing latencies Figure 3 shows the average final update times of LBFS and EDAP under different number of editing operations and file sizes.
In Figure 3(a), the required time to close a file is nearly linear to file size and number of editing operations in LBFS. When a user closes a 20KB file, it takes about 2500 ms to update the file to the server. When user edits a 120KB data with 10 updates, the time needed to close a file increases significantly. The impact of number of editing operations on the file closing time behaves similarly.
On the other hand, the time needed to close a file remains nearly constant in EDAP. It can be observed from Figure 3(b) that the difference of necessary time of
transmitting data upon file closing is much smaller in EDAP with different file size and number of editing operations. As a user close a 20KB file, the file is updated to the server in about 2300ms. When larger file sizes are considered, the file closing time remains at around 4300ms. Due to the nature of EDAP update, the file closing time is unaffected by the number of editing operations.
In the simulations, the editing operations are more likely to fall within the same block with smaller files. Since the file editing positions are randomly placed, more file blocks are changed with increasing file size.
Therefore, the file closing time grows nearly linearly to the file size and the number of editing operations. For a segment of changed blocks in the file, EDAP begins uploading the segment to the server when the updating moves outside of the segment, which successfully reduces the amount of data transmission while closing the file.
Although this approach comes with a small communication overhead, as shown in previous section, the amount of time saving is significant, thus the overhead can be considered as acceptable in nowadays wireless networking applications.
4.4 The Amount of Redundant Data Storage
Since files are encrypted by the client, in order to prevent unmodified blocks from being updated while maintaining data integrity on server, EDAP allows data blocks to overlap at the server side.
Therefore, it is necessary to estimate the amount of redundant data.
In the worst case, where data blocks are all with minimum size (that is, the number
of blocks in a file is maximized) and data blocks overlap in the maximum size, the storage overhead satisfies the following inequality:
MinBS
MaxPO2BSBC1 (2) In Equation 2, MaxPO is the maximum ratio of redundant data in the storage usage of a file, BSBC is the block size used by the block cipher, and MinBS is the minimum allowable file block size of the fingerprinting scheme. When a 128-bit (16 bytes) block cipher is employed and the minimum file block size is set as 4KB (4096 bytes), which was used in the simulations in this section, the amount of redundant data is no more than 0.76%.
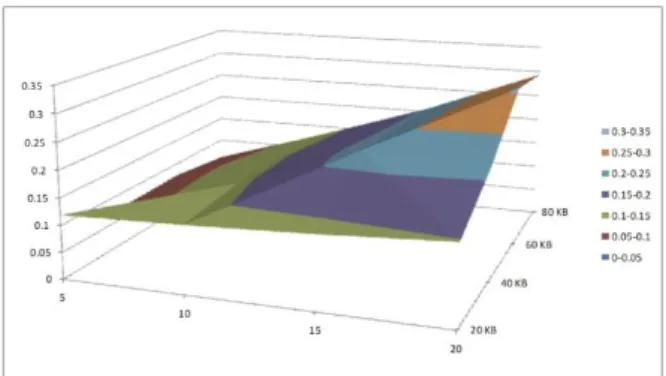
Using the same file size and number of editing operations in the previous simulation, the amount of redundant data is estimated and shown in Figure 4. Figure 4 indicates that with a fixed number of editing operations, the amount of redundant data initially increases with the file size. This because the size of a cipher block becomes less significant as the number of blocks grows larger. Therefore, when the file takes a certain size of storage, the amount of redundant data begins to decrease.
Figure 4: Storage overheads at the server.
It can be observed from Figure 4 that the amount of redundant data, as expected,
never exceeds the worst estimation, 0.76%, in all cases of the simulation. In fact, when the same file block is updated at different times, data is truncated at the client to remove the redundant portion. Therefore, the amount of redundant data does not accumulate endlessly over time.
5. CONCLUSION AND FUTURE WORK
This study proposes a remote data accessing scheme called EDAP that aims at improving the responsiveness of remote storage services. Similar to other file patching systems, EDAP updates only changed file blocks to the server. However, EDAP balances the pure synchronous updating and the write-back-on-close updating methods by synchronizing segments of consecutive file blocks ahead of closing a file. Through the simulations, it can be observed that EDAP greatly improves the responsiveness of remote file access. Although the improvement comes with a communication overhead, the overhead is only slightly over the previous write-back-on-close approach and is acceptable.
EDAP also provides a solution to the case of untrusted network infrastructure, for example, cloud storage services, by allowing the server stores only file content encrypted by client to protect client privacy.
To maintain data integrity, there is an induced storage overhead which can be bounded depending on the block size and the employed block cipher. Using the parameter settings in the simulations, the storage overhead is bounded within 0.76%.
Moreover, due to the fact that redundant storage are used only at the beginning of file
blocks and independent updating operations overwrite original file content, the redundant storage can be recycled during consecutive file updates and it will not accumulate over time.
In the simulations, the files are modified at random positions. However, users generally modify files in a more organized fashion in practical applications. Therefore, the communication overhead is expected to be reduced in reality. A prototype system using EDAP is currently under development in order to gather more realistic performance data and user experience feedbacks.
REFERENCES
[1] L. P. Cox and B. D. Noble, “Fast reconciliations in fluid replication” Proceedings of the 21th International Conference on Distributed Computing Systems, 2001, pp.
449–458.
[2] P. R. Eaton, “Improving access to remote storage for weakly connected users,” Ph.D.
thesis, EECS Department, University of California, Berkeley, 2007.
[3] M. H. Franck, F. Rousseau, G.
Berger-sabbatel, and A. Duda, “Performance anomaly of 802.11b.” Proceedings of Twenty-Second Annual Joint Conference of the IEEE Computer and Communications, 2003, pp.
836–843.
[4] C. G. Gray and D. R. Cheriton, “Leases: An efficient fault-tolerant mechanism for distributed file cache consistency,” Proceedings of the 12th ACM Symposium on Operating Systems Principles, 1989, pp. 202–210.
[5] B. Gronvall, A. Westerlund, and S. Pink,
“The design of a multicast-based distributed file system,” Proceedings of the 3rd Symposium on Operating System Design and Implementation,
1999, pp. 251–264.
[6] J. H. Howard, M. L. Kazar , S. G. Menees, D. A. Nichols, M. Satyanarayanan, R. N.
Sidebotham, and M. J. West, “Scale and performance in a distributed file system,”
Proceedings of the ACM Transactions on Computer Systems, vol. 6, no. 1, 1988, pp.
51–81.
[7] J. J. Kistler, and M. Satyanarayanan,
“Disconnected operation in the coda file system,”
Proceedings of the 13th ACM Symposium on Operating Systems Principles, 1991, pp.
213–225.
[8] Y. W. Lee, K. S. Leung, and M.
Satyanarayanan, “Operation-based update propagation in a mobile file system,”
Proceedings of USENIX Annual Technical Conference, 1999.
[9] L. M. Maria, M. R. Ebling, and M.
Satyanarayanan, “Exploiting weak connectivity for mobile file access,” Proceedings of the 15th ACM Symposium on Operating Systems Principles, 1995, pp. 143–155.
[10] K. Muniswamy-Reddy, C. P. Wright, A.
Himmer,and E. Zadok, “A versatile and user-oriented versioning file system,”
Proceedings of the 3rd USENIX Conference on File and Storage Technologies, 2004, pp.
115–128.
[11] A. Muthitacharoen, B. Chen, and D.
Mazieres, “A low-bandwidth network file system,” Proceedings of the 18th ACM Symposium on Operating Systems Principles, 2001, pp. 174–187.
[12] K. Petersen, M. J. Spreitzer, D. B. Terry, M.
M. Theimer, and A.J. Demers, “Flexible update propagation for weakly consistent replication,”
Proceedings of the 16th ACM Symposium on Operating Systems Principles, 1997, pp.
288–301.
[13] R. Sandberg, D. Goldberg, S. Kleiman, D.
Walsh, and B. Lyon, “Design and
implementation of the sun network filesystem,”
Proceedings of the Summer USENIX Conference, 1985, pp. 119–130.
[14] K. Xu, S. Bae, S. Lee, and M. Gerla, “Tcp behavior across multihop wireless networks and the wired internet,” Proceedings of the 5th ACM International Workshop on Wireless Mobile Multimedia, 2002, pp. 41–48.
[15] H. Yu and A. Vahdat, “Design and evaluation of a continuous consistency model for replicated services,” Proceedings of the 4th Symposium on Operating System Design and Implementation, 2000.
國科會補助計畫衍生研發成果推廣資料表
日期:2012/02/06
國科會補助計畫
計畫名稱: 適用於行動裝置的遠端檔案儲存與分享系統 計畫主持人: 項天瑞
計畫編號: 99-2221-E-011-060- 學門領域: 計算機網路與網際網路
無研發成果推廣資料
99 年度專題研究計畫研究成果彙整表
計畫主持人:項天瑞 計畫編號:99-2221-E-011-060- 計畫名稱:適用於行動裝置的遠端檔案儲存與分享系統
量化
成果項目 實際已達成
數(被接受 或已發表)
預期總達成 數(含實際已
達成數)
本計畫實 際貢獻百
分比
單位
備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ...
等)
期刊論文 0 0 100%
研究報告/技術報告 0 0 100%
研討會論文 1 1 100%
論文著作 篇
專書 0 0 100%
申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 0 0 100%
博士生 0 0 100%
博士後研究員 0 0 100%
國內
參與計畫人力
(本國籍)
專任助理 0 0 100%
人次
期刊論文 0 0 100%
研究報告/技術報告 0 0 100%
研討會論文 0 0 100%
論文著作 篇
專書 0 0 100% 章/本
申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 4 4 100%
博士生 0 0 100%
博士後研究員 0 0 100%
國外
參與計畫人力
(外國籍)
專任助理 0 0 100%
人次
其他成果
(無法以量化表達之成
果如辦理學術活動、獲 得獎項、重要國際合 作、研究成果國際影響 力及其他協助產業技 術發展之具體效益事 項等,請以文字敘述填 列。)
無
成果項目 量化 名稱或內容性質簡述
測驗工具(含質性與量性) 0
課程/模組 0
電腦及網路系統或工具 0
教材 0
舉辦之活動/競賽 0
研討會/工作坊 0
電子報、網站 0
科 教 處 計 畫 加 填 項
目 計畫成果推廣之參與(閱聽)人數 0
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)、是否適 合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□未達成目標(請說明,以 100 字為限)
□實驗失敗
□因故實驗中斷
□其他原因 說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:■已發表 □未發表之文稿 □撰寫中 □無 專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無 其他:(以 100 字為限)
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以 500 字為限)
From early network file systems to today’s cloud storage services, remote data access has always been an important topic. Solutions for issues such as reliability, scalability, and update efficiency have been proposed for different applications. Modern networking technologies have enabled more and more users access internet with mobile devices on Wi-Fi or cellular networks. This project developed a strategy to access and edit remote data efficiently with relatively weak network connections. The proposed approach significantly improves the file closing latency when users update files, where data is processed in terms of blocks and file summaries are used to reduce the amount of transmission. In untrusted network environments such as cloud storage services, the proposed method can also be adopted by encrypting data at the client-side before uploading it to the server in order to preserve confidentiality. Simulations show that the proposed method greatly improves responsiveness while the induced networking overhead is minimal.
![Table 1 compares common network files systems. In Table 1, every file system [6, 8, 11] except NFS [13] stores files in local cache to reduce RTD (Round Trip Delay) between client and server](https://thumb-ap.123doks.com/thumbv2/9libinfo/9123719.408282/6.892.464.804.116.392/table-compares-common-network-systems-table-stores-reduce.webp)