以改良式演化計算為基礎之UAV空拍影像辨識技術
67
0
0
全文
(2) An UAV Aerial Image Recognition Based on Modified Evolutionary Computation Advisor:Dr. Lung-Jen Wang By:JIUN-HAN HUANG. A Thesis Submitted to Department of Computer Science and Information Engineering, National Pingtung University in Partial Fulfillment of the Requirements for the Degree of Master in Computer Science and Information Engineering. Pingtung, Taiwan, R.O.C July, 2017.
(3)
(4) 誌謝 自從就讀大學至研究所的整個求學過程中,我最感謝的人就是指導教授王隆 仁博士了。第一次是從大學的實務專題開始,我在老師的指導下穩扎穩打地學習 新的程式語言,新的方向,在整個專題的過程裡,老師總會適時並且盡力地給予 我們學生最多的資源與協助,同時也由於老師深厚的實務經驗與理論基礎,拓展 了我對於資訊工程不同的新視野,從那時開始,我就決心繼續跟隨老師研讀碩士 班。在碩士班的過程中,我首先必頇感謝大學同學浩庭、芳綸,他們總是適時地 提醒我在實驗室內的注意事項外,亦會在我有疑問時,不吝嗇地跟我討論解惑; 接著我必頇要感謝學弟妹顯懿、元廷、媛晶,在我負責實驗室主要運作時,盡力 地給予協助,讓實驗室的運作得以更加的充實,最後我仍然要再次感謝老師,在 就讀碩士班的過程中,賦予我執行產學合作的機會,使得我在就學期間就擁有一 定的實務經驗,也學習到了很多不同於學校的觀點,不論是實質上或者精神亦都 使我成長很多,也學習很多,謝謝老師。 在口詴期間,感謝陳毓璋教授和黃鎮淇教授對於本論文提供許多珍貴的意見, 使我得以將論文內容更加完整,在此致上最誠摯的謝意。 最後,我要感謝我的家人在我求學期間,時常打電話來關心我,提醒我生活 上的大小事以及自身安全,讓我確實感受到家庭的溫暖,也感謝我的家人得以讓 我在衣食無慮的情況下,順利完成學業。 感謝屏東市公所為本論文提供實驗用的影像資源,使本論文方能如期且順利 完成,謝謝。. 黃俊涵 謹誌 于國立屏東大學資訊工程所 中華民國 一○六 年 七 月. I.
(5) 以改良式演化計算為基礎之 UAV 空拍影像辨識技術 An UAV Aerial Image Recognition Based on Modified Evolutionary Computation 研究生:黃俊涵. 指導教授:王隆仁 博士. 國立屏東大學 資訊工程系(所) 中華民國 一○六 年 七 月 摘要 典型的航空拍攝以屏東市 66.03𝑘𝑚2 的面積為例,當 GSD 為 0.1 𝑚⁄𝑝𝑖𝑥𝑒𝑙會 產生 30,000x20,000 像素的航空影像;現今隨著技術的下放,無人機的流行夾雜 著鏡頭技術的提升,解析度從早期的 320p 提升至比 4K 更高,讓無人機配備至少 一顆的鏡頭設備得以保存更完整的資訊,替智慧生活帶來更多的便利性,同時亦 帶來演算法的高運算成本。本論文有鑒於此提出一項適用於各場景或是航照圖等 大型影像之智慧辨識技術:首先,將原影像切割成特定維度的數個子影像,建置 影像數據集,並依照尺度不變特徵轉換(SIFT)技術對待搜尋影像進行關鍵點擷取 以及描述之動作,最後透過本篇論文提出的改良式演化計算(簡稱 Sd-CMBPSO), 以鯰魚效應及突變機制改良離散型粒子群演算法所得,在資料庫中進行最佳化搜 尋,並且根據實驗數據顯示,本論文之 Sd-CMBPSO 方法比離散型的二進制粒子群 (BPSO)快上 80%的速度,並且倘若目標影像存在資料庫內,則能確保每次皆能找 到匹配率高達 90%以上的結果,可以有效用於大型影像數據集快速辨識影像物 件。. 關鍵詞: SIFT、離散型粒子群演算法、鯰魚效應、突變機制. II.
(6) An UAV Aerial Image Recognition Based on Modified Evolutionary Computation Student: Jiun-Han Huang. Advisor: Dr. Lung-Jen Wang. Department of Computer Science and Information Engineering, National Pingtung University, Taiwan July , 2017 ABSTRACT With the progress of information technology, UAV with camera for obtaining a high-resolution aerial image is becoming ever more important. It is well known that we could get 320x480 pixels images about a decade ago, but now we can easily get more than 4K resolution images in our daily life, that is, an aerial image can be high-resolution from professional UAV. In this thesis, we propose a modified evolutionary computation is called Sd-CMBPSO, to reduce the running time and keep the most key points. The Sd-CMBPSO is based on BPSO (Binary Particle Swarm Optimization), catfish effect and mutation of GAs (Genetic Algorithm). The steps of this method are described as follow: First, we divide an aerial image into several sub-images for image database. Second, we extract SIFT feature between target image and each sub-image from the image database. Finally, we use our Sd-CMBPSO method to search a large-scale image databases. Experimental results show that the performance of the proposed Sd-CMBPSO algorithm is better than the BPSO algorithm about 80%.. Keyword: SIFT, BPSO, CatFish Effect, Mutation. III.
(7) 目錄 誌謝................................................................................................................................. I 摘要................................................................................................................................ II ABSTRACT ...................................................................................................................... III 圖目錄............................................................................................................................V 表目錄...........................................................................................................................VI 第一章 緒論.................................................................................................................. 1 1.1 研究背景.................................................... 1 1.2 動機與目的.................................................. 2 1.3 相關研究與發展.............................................. 2 1.4 論文架構.................................................... 3 第二章 影像局部特徵.................................................................................................. 4 2.1 尺度空間與極值檢測(Scale-Space And Transform)............... 4 2.2 方向定位(Orientation Assignment)............................ 7 2.3 關鍵點描述 (KeyPoints Descriptor)........................... 9 2.4 特徵點比對................................................. 10 第三章 粒子群演算法................................................................................................ 15 3.1 連續型粒子群演算法(Continuous Particle Swarm Optimization,PSO) ............................................................... 16 3.2 離散型粒子群演算法(Binary Particle Swarm Optimization,BPSO) ............................................................... 18 3.3. 鯰魚粒子群演算法(Catfish Particle Swarm Optimization,CPSO) ............................................................... 21 3.4 基因演算法 (Genetic Algorithm,GA)......................... 23 第四章 以改良式演化計算為基礎 之 UAV 空拍影像辨識技術........................... 26 4.1 影像分割................................................... 27 4.2 以標準差改良鯰魚粒子群演算法............................... 36 4.3 改良鯰魚粒子群引入突變機制................................. 37 第五章 實驗結果........................................................................................................ 39 5.1 影像分割與建立子影像資料庫 ................................. 40 5.2 適應函數設定............................................... 41 5.3 比對並顯示結果 ............................................. 41 5.4 粒子重複搜尋情況 ........................................... 49 第六章 未來方向探討................................................................................................ 51 6.1 結語....................................................... 51 6.2 未來方向................................................... 52 參考文獻...................................................................................................................... 53 IV.
(8) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1. 2. 3. 4. 5. 6. 7. 8. 9.. SIFT 影像匹配方法流程圖............................................................... 2 運用改良式 SIFT 技術於航照影像物件辨識方法流程圖.............. 3 降採樣(隔點採樣)............................................................................ 5 高斯金字塔及 DOG,摘自[4]........................................................... 6 局部極值點檢測,摘自[4].............................................................. 6 SIFT 方向梯度示意圖,摘自[4]..................................................... 8 關鍵點 36 階方向直方圖,摘自[4]................................................ 9 關鍵點描述之示意圖,摘自[4].................................................... 10 K-D 空間示意圖............................................................................... 11. 圖 10. 最近鄰居與次近鄰居的距離比,摘自[4].................................. 14 圖 11. 粒子群演算法流程圖.................................................................... 17 圖 12. Sigmoid 函數與速度之關係......................................................... 19 圖 圖 圖 圖 圖 圖 圖 圖. 13. 14. 15. 16. 17. 18. 19. 20.. 位移率與速度關係圖.................................................................... 20 鯰魚粒子群演算法流程圖............................................................ 22 基因演算法流程示意圖................................................................ 24 本論文建議方法流程圖................................................................ 26 影像切割方式................................................................................ 28 子影像大小與關鍵點總數關係圖................................................ 29 匹配率實驗流程圖........................................................................ 30 匹配率平均實驗數據(子影像 4096 像素).................................. 30. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30.. 匹配率平均實驗數據(子影像 2048 像素).................................. 31 匹配率平均實驗數據(子影像 1024 像素).................................. 31 合理的匹配率平均實驗數據(子影像 4096 像素)...................... 32 合理的匹配率平均實驗數據(子影像 2048 像素)...................... 32 合理的匹配率平均實驗數據(子影像 1024 像素)...................... 33 影像尺寸與 SIFT 運算關係圖...................................................... 34 1-NN 法示意圖............................................................................... 37 突變鯰魚粒子群演算法流程示意圖............................................ 38 影像分割與建立影像資料庫........................................................ 40 編號 34848 搜尋十次之最終適應值(%)折線圖.......................... 42. 圖 圖 圖 圖 圖. 31. 32. 33. 34. 35.. 編號 34848 搜尋十次之執行最佳位置折線圖............................ 43 編號 34848 搜尋之平均迭代次數統計圖.................................... 43 編號 34848 搜尋之平均執行時間統計圖.................................... 44 搜尋十次之平均迭代次數統計圖................................................ 48 搜尋十次之平均執行時間統計圖................................................ 49. V.
(9) 表目錄 表 表 表 表 表 表 表 表 表. 1. 2. 3. 4. 5. 6. 7. 8. 9.. 子影像大小與關鍵點總數之數據.................................................. 29 SIFT 執行時間數據表..................................................................... 34 SIFT 執行時間百分比數據表......................................................... 34 粒子群演算法參數設定表.............................................................. 39 編號 34848 搜尋之平均數據表...................................................... 44 編號 60702 搜尋之平均數據表...................................................... 45 編號 60702 搜尋之最佳適應值數據表.......................................... 45 編號 60702 搜尋之最佳位置值數據表.......................................... 46 編號 72690 搜尋之平均數據表...................................................... 46. 表 10. 編號 72690 搜尋之最佳適應值數據表........................................ 46 表 11. 編號 72690 搜尋之最佳適應值數據表........................................ 47 表 12. 編號 75870 搜尋之平均數據表.................................................... 47 表 表 表 表. 13. 14. 15. 16.. 編號 75870 搜尋之最佳適應值數據表........................................ 47 編號 75870 搜尋之最佳位置值數據表........................................ 48 BPSO 重複搜尋數據表................................................................... 50 sdCBPSO 重複搜尋數據表............................................................. 50. VI.
(10) 第一章 緒論 1.1 研究背景 近幾年航空影像(Aerial Image)隨著鏡頭技術及無人飛行載具(Unmanned Aerial Vehicle,UAV,又稱無人機)的興起被廣泛地運用於日常生活,例如:地 理研究、交通建設、水利工程、急難救災、媒體轉播、警方追蹤…等層面,而不 再局限於軍事用途。航空影像利用高度與廣度的特性,搭配現今高解析度的鏡頭 設備截取高畫質影像,以達到有效地蒐集地理資訊以及保存更完整影像資訊的目 的,因此針對龐大且豐富的影像數據庫,如何快速精準的辨識則為一大課題。 影像辨識(Image Recognition)是一種透過理論分析影像特徵,結合人工智 慧,使得電腦不需人力介入即可達到自動辨識的目的。SIFT(Scale-Invariant Feature Transform,尺度不變特徵轉換)是一種偵測與描述影像局部特徵的演算 法[3][4][26],該方法主要透過降採樣(Downsampling)與高斯模糊(Gaussian blur)建立高斯金字塔(Gaussian pyramid),描繪尺度空間(Scale-Space),並且 利用影像的尺度空間提取關鍵點(Keypoints Extraction)和描述關鍵點 (Keypoints Description)的方式達到尺度不變、旋轉不變的特性。SIFT 演算法 主要透過圖層迭代(Layers Iteratiion)擷取關鍵點以及八個主方向定位 (Orientation Assignment)描述關鍵點,由此可知該方法的匹配精確率具有一定 可靠性,但是相對計算成本較高,其優點及缺點皆是很好的參考範疇。 演化式計算是一種藉由觀察生物行為並且模擬所產生的演算法,例如:基因 演算法(Genetic Algorithm,GA)模擬生物基因遺傳的情況,視每一個可能解為 一染色體,進行選擇、複製、交配、突變、淘汰等行為尋找最佳解;蟻群演算法 (Ant Colony Optimization,ACO) 模擬蟻群尋找食物時分泌的賀爾蒙特性,透 過賀爾蒙會隨時間蒸發之特性,尋找路徑最佳化;粒子群演算法(Particle Swarm Optimization,PSO)主要是透過觀察鳥類覓食行為,利用其覓食時的群聚效應、 記憶性、資訊分享之特性,尋找最佳解…等等。演化式計算主要運用在機器學習、 1.
(11) 應用數學,甚至是解決現實規畫及離散性問題等方面,致力於解決最佳化的組合 或單一解,對於本論文主要之龐大影像資料,相較於傳統的全域搜尋法(Full Search)更有助於加快整體影像匹配之處理時間。. 1.2 動機與目的 隨著無人飛行載具(UAV)的盛行,除了休閒娛樂之外,更加便利日常生活中 一些特定的時刻,例如:急難救助。無人飛行載具隨著機器等級越高,從高空所 拍攝之航空影像則越貼近衛星或者專業設備所拍攝之影像,具備更多之影像資訊 內容進行後置處理,但是基於每種器材本身高度及廣度的限制,拍攝目標區域越 大,則需要越多的影像篇幅搭載資訊量,並且越豐富的影像特徵,其運算成本則 越龐大。資訊量帶給我們更多訊息,同時也負荷更多影像處理所需要的效能負擔 以及時間成本,如何適當的降低資訊量以及提升處理速度,則為本篇論文主要研 究的議題。. 1.3 相關研究與發展 原始 SIFT 本身亦可搭配最近鄰居演算法(K-NearestNeighbor,又稱 Knn 演 算法) 分類影像特徵,使用特徵點距離以達到影像辨識之目的。其透過計算每一 對(Pair)描述子為一離散變量,透過歐式距離或者海明距離尋找變量間的距離, 若距離過大則捨棄該組匹配點,完成匹配點的搜尋。原始 SIFT 進行影像匹配之 整體流程如圖 1 所示。. 圖 1. SIFT 影像匹配方法流程圖. 2.
(12) 除了上述原始 SIFT 的方法之外,自 2004 年發表至今已經有許多學者針對 SIFT 的高運算複雜度提出各種改良方法,例如:Speeded Up Robust Features(加 速穩健特徵,又稱 SURF)[6]、SIFT-PCA[17]、SURF-PCA[27]…等等改良技術。 大多數方法皆針對 SIFT 敘述 128 維的特徵維度著手,透過減少敘述子的方向性 或者特徵矩陣之維度,適當減少圖層迭代運算以達到降低複雜度與節省時間成本 為主軸進行改善,然而,以特徵資料換取時間成本與原始 SIFT 匹配之結果相論, 其精確度則是一項值得重視的議題。本論文的核心價值在於保持較高的 SIFT 特 徵維度,利用較適當的維度進行影像分割,透過資料庫使用及演化式計算快速搜 尋相關影像,解決高運算複雜度之問題。針對大型影像搜尋之相關方法上,例如 針對航空影像,在 2015 年有由許清淵及王隆仁[36]提出利用 OTSU 簡化影像的方 式改良 SIFT 於航空影像辨識的處理效率,其方法之流程圖如圖 2 所示。本論文 將以此篇為基礎,進行更進一步的改善。. 圖 2. 運用改良式 SIFT 技術於航照影像物件辨識方法流程圖. 1.4 論文架構 本論文全文架構首先是全文之摘要,由第一章開始為緒論,介紹全文動機、 研究背景、相關方法,並且針對本論文,從第二章開始至第三章為止則是相關方 法之內容介紹及應用;第四章與第五章為本論文之研究方法介紹以及研究方法之 實驗環境、結果之實現展示;第六章則為本篇論文未來方向之說明;最後則為全 文參考論文之陳述。. 3.
(13) 第二章 影像局部特徵 影像局部特徵於計算機視覺(Computer Vision)領域內一直為一項值得重視 的議題,除了常見用於描述影像特徵的 SIFT(Scale-Invariant Feature Transform)[4]、SURF(Speeded Up Robust Features)[6]之外,亦有描述影像紋 理特徵的 LBP(Local Binary Patterns)[29][30]、HOG(Histogram of Oriented Gradient)、Haar-like[23][31]…等方法。在本章節,將針對 SIFT 尺度不變特 徵轉換進行探討。SIFT (Scale-Invariant Feature Transform,尺度不變特徵 轉換)於 2004 年由 David G. Lowe 所提出[4],基於圖層迭代找出關鍵值(Key Point),並且建立描述子(Descriptor)以及方向定位(Orientation Assignment), 以確保尺度不變、旋轉不變性,並且對於雜訊、亮度等干擾具有一定穩定性。以 下將依序對其步驟進行介紹。. 2.1 尺度空間與極值檢測(Scale-Space And Transform) 基於尺度不變性,SIFT 在載入影像後運用高斯函數(Gaussian Function)及 連續降採樣(Down-sampling)取得原始影像的各個尺度影像,以長寬各減半之方 式(如圖 3 所示)獲取不同尺度之主要影像。根據 Koederink 與 Lindeberg 二位學 者後述發現[37],高斯模糊(Gaussian Blur)依照尺度(標準差σ)所提取之模糊 影像,經過多次運算,其效果近似尺度縮放之效果,如公式(1)所示。接著考慮 各種尺度影像之特徵,以不同的尺度大小為歸類依據,形成數塔(Octave)尺度影 像,數組尺度影像則為高斯金字塔(Gaussian Pyramid)以達到定位尺度空間極值 之目的,找出關鍵點位置,如圖 3-3 所示。. L(x, y, σ) = G(x, y, σ) ∗ I(x, y). (1). 其I(x, y)為原始影像,L(x, y, σ)為高斯影像,G(x, y, σ)為含尺度變異數 σ 之高斯函 4.
(14) 數,如公式(2)所示。 L(x, y, σ)為高斯函數與原影像進行卷積(Convolved)所得之高斯影像。因此 SIFT 在不同尺度的第一張影像使用高斯濾波器(Gaussisan Filters)進行卷積(Convolved) 運算,將得到 3 至 5 張同尺度不同模糊係數之模糊影像,並且視為一個塔(Octave), 代表某一個尺度的影像特徵,接著合併所有尺度的塔(Octave)則形成高斯金字塔 (Gaussian Pyramid),代表該影像之尺度空間(Scale-Space),如圖 4 左半面所示, 最後根據尺度間計算高斯差(Difference of Gaussians, DOG)所得之高斯差分金字 塔,如公式(3)以及圖 4 右半面所示,進行極值點偵測。以檢測點為中心點,與周圍 像素以及相鄰尺度之影像進行檢測,若該點為最大值或者最小值,則定義為局部關鍵 點(Keypoint),如圖 5 所示。 G(x, y, σ) =. 1 exp(−(x 2 + y 2 )/2σ2 ) 2πσ2. (2). D(x, y, σ) = G(x, y, kσ) − G(x, y, σ) ∗ I(x, y) (3) = L(x, y, kσ) − L(x, y, σ). 2x2 4x4. 8x8 圖 3. 降採樣(隔點採樣) 5.
(15) k2σ k2σ. kσ σ. kσ σ. k2σ. 2. kσ kσ kσ σ. σ. 圖 4. 高斯金字塔及 DOG,摘自[4]. 圖 5. 局部極值點檢測,摘自[4]. 如上圖 4 所示,由原始影像開始建立尺度空間,並且同一個塔內之每個尺度 影像之間相差 k 倍的尺度σ,故可得當原影像進行關鍵點偵測時,會先以原本的. 6.
(16) 尺度取不同σ之模糊影像形成第一個塔,亦為最底層,接著利用降採樣之方法產 生下一個尺度之第一張影像,取其不同σ之模糊影像形成新塔,依此類推,直至 影像大小小於像素單位則停止。由 Lowe 實驗數據發現,每一個塔首張影像取前 一塔(pre-octave)的最後一張進行降採樣效果最佳;另外,每一個塔內所需要之 模糊影像張數以 Lowe 實驗預設 3 張(即 s=3)為基礎,普遍實驗最多取至 5 張, 並且由 Lowe 實驗發現,在計算尺度空間前先將原影像放大兩倍,尺度σ取 1.6 作為第一組尺度影像時,其特徵點所得結果較為穩定。. 2.2 方向定位(Orientation Assignment) 由尺度空間定位出關鍵點(Keypoint)後,基於旋轉不變性並且為了有效對每 一個關鍵點進行描述,因此接著需要對關鍵點計算其方向性,包含主方向以及強 度。首先以關鍵點為中心計算周圍像素之方向梯度,其半徑範圍由高斯權重區塊 (Gaussian-Weighted Circular Window)所決定,通常定義半徑為3 ∗ σ,且計算 過程需考慮周圍像素與關鍵點之間相關性比重,若離中心點越靠近,則比重越大, 反之則較小。高斯權重區塊計算周圍每個像素點之方向梯度及強度方法如下述公 式(4)(5)。. 2. 𝑚(𝑥,𝑦) = √(L(x + 1, y) − L(x − 1, y)) + (L(x, y + 1) − L(x, y − 1)). θ(x, y) = tan−1. 2. (4). (L(x + 1, y) − L(x − 1, y)) (L(x, y + 1) − L(x, y − 1)). (5). 上述公式(4)(5)中的 L 代表關鍵點尺度之高斯權重區塊,𝑚(𝑥,𝑦) 為該像素點 之梯度強度,θ(x, y)為該像素點之梯度方向。由下圖 6 所示,藍色圓圈範圍內即 為高斯權重區塊,箭頭方向即為每一個像素方向之角度,箭頭長度則為方向梯度 之強度。 7.
(17) 圖 6. SIFT 方向梯度示意圖,摘自[4]. 以高斯權重區塊內所得到的每個像素點方向,利用方向直方圖(Orientation Histogram)進行數據統計與區塊描述,以一張 2D 影像的角度會有 360 度,而 SIFT 之方向直方圖通常會以 10 度為一階進行統計,共有 36 階。當計算區塊範圍內所 有像素之方向及強度時,會依照方向直方圖所對應之角度統計出方向強度與權重 之總和,稱為權重值,如公式(6)(7)所示。最後為了精確找出該關鍵點之主要方 向(Dominant Directions),除了以方向直方圖內最高峰(High Peak)為主要方向 之外,若直方圖內尚有其他峰(Other Local Peak)為最高峰之 80%以上的話,則 保留為輔助方向。針對多重方向之可能性,根據 Lowe 實驗表示大約為 15%的機 率,但是多重方向性可以使得比對之過程更加具有穩定性。如圖 7 所示。. 權重值 = Ω(x) ∗ m(x, y). Ω(x) =. (6). −(x−μ)2 ( ) e 2σ2. (7). 上述中Ω(x)為權重比,m(x, y)為方向強度,x 為當前像素點位置,μ為特徵 8.
(18) 點位置(中心點),2σ2 為特徵點所在的影像尺度。當x = μ時,可以得到最大值 1, 也就是最大權重比。. 圖 7. 關鍵點 36 階方向直方圖,摘自[4]. 2.3 關鍵點描述 (KeyPoints Descriptor) 從上述步驟中得以了解到關鍵點的位置、尺度、方向三大資訊,最後一個步 驟即是對每一個關鍵點建立描述,使得關鍵點不易受其他因素干擾,並且在影像 比對具有一定穩健性。根據 Lowe 實驗顯示將 16x16 之像素點分割為 4x4 的子區 塊,延續上一個步驟利用公式(6)(7)進行方向直方圖統計,得到一關鍵點會有 8 階方向的直方圖,因此一個關鍵點將會有 4x4x8=128 個特徵向量為其描述,如圖 8 所示。 最後所得之描述子則具有尺度縮放、視角旋轉之特性,若再將關鍵點之特徵 向量進行正規畫之處理,則可再進一步減少光照變化之影響。. 9.
(19) 圖 8. 關鍵點描述之示意圖,摘自[4]. 2.4 特徵點比對 特徵點比對通常透過距離函數檢索影像的相似度以達到影像匹配之目的。距 離函數發展至今,已有許多應用在不同情況的演算法延伸,例如:L-Norm、餘弦 相似度、歐氏距離(Euclidean Distance)…等等。由 SIFT 運算後每張影像將關 鍵點集合進行特徵描述後,會得到一組 Nx128 維度的特徵集合(N 為關鍵點個數), 接著利用距離函數、機器學習來進行影像匹配之流程;在 SIFT 影像匹配的方法 上,較常見的匹配方法為 K-D 樹(K-Dimension Tree,K-D Tree)、BBF 搜尋算法 (Best-Bin-First)、歐氏距離(Euclidean Distance)。 K-D 樹(K-Dimension Tree,K-D Tree)是針對 K 維空間中進行資料劃分的一 種資料結構,視每個節點為 k 個維點的二元樹(Binary Tree),以利機器學習、 特徵分類與資料檢索等步驟的進行,由 Friedman 於 1977 年所提出。K-D 樹的建 構透過距離函數將數據空間劃分成數個部分,以二維空間舉例而言,假設空間內 有六筆數據分別為{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)} ,其處理流程如 下: (1) 首先找出二維上最大的變異數,並且以此維方向為分割線。此例最大變 異數 X 為 39,Y 為 28.63,故 X 軸則為分割線。 (2) 取 X 軸上的中位數 X=7,因此 X 軸以(7,2)為中心。 10.
(20) (3) 以 X=7 為分割線,分成左子樹{(2,3),(4,7),(5,4)}、右子樹 {(8,1),(9,6)},確定左右子樹的空間。 (4) 以另一維度方向為分割線,重複(2)(3)步驟,以此類推。. 圖 9. K-D 空間示意圖. 如圖 9 所示,圖左為 K 維二元樹結構,圖右為二維數據對應到座標軸位置。 圖右的紅色直線為第一次曾的 X 軸分割線,以數據(7,2)為中心,X 小於 7 的節 點則分配到左子樹空間,X 大於 7 的節點則位在右子樹空間;黑色直線為第二層 使用的 Y 軸分割線,以數據(5,4)、(9,6)為中心,根據相同的方式各別以 Y=4 以及 Y=6 在所處的子樹空間進行左子樹和右子樹的建立;紅色虛線則為第三層使 用的 X 軸分割線,依此類推的循環完成 K-D 樹的建立。 最近鄰居法(K-Nearest Neighbor,K-NN)[21]是一種用於資料分類的無母體 統計方法,屬於機器學習中的監督式學習(Supervised learning)。一般而言, 監督式學習需要透過資料訓練(Training)進行資料模型的建構,但是在最近鄰居 法中資料並不需要進行訓練的動作即可達到分類的目的。在 K-NN 法的 K 值代表 K 個最近的鄰居,K ≥ 1,常用於找出 K-D 樹節點與目標最鄰近的 K 個節點。在 K-NN 搜尋中,以遞迴的方式針對每個對象(樣本)進行距離統計,而計算距離大. 11.
(21) 多採用歐氏距離(Euclidean Distance),如公式(8),或者海明距離(Hamming Distance,又稱漢明距離)作為度量,並且由多數決的方式進行樣本分類的輸出, 其基本概念如下: (1)由樹根節點開始尋找,以待查詢節點為標準,比較該維度的分割線決定 往左子樹空間或右子樹空間移動。 (2) 在(1)的過程中,所有訪問到的節點將被列入待查詢的佇列內,直到探 訪至葉節點(Leaf Nodes),找到鄰近節點後,開始回溯比對待查詢佇列 內容,一一計算待查詢佇列內節點與目標節點的距離是否比目前的最鄰 近節點距離更小,如果有,則更新上次所設定的鄰近節點為目前節點, 並且同樣將訪問到的節點列入待查詢佇列。 (3) 重覆(1)、(2)過程,直到待查詢佇列為空時,此時則回到樹根節點,代 表找到最近鄰居。. d(x, y) = √(𝑥1 − 𝑦1 )2 + (𝑥2 − 𝑦2 )2 + (𝑥3 − 𝑦3 )2 + ⋯ (𝑥𝑛 − 𝑦𝑛 )2 𝑛. (8). = √∑(𝑥𝑖 − 𝑦𝑖 )2 𝑖=1. KNN 搜尋法以圖 9 為例,查詢節點(2,4.5)在 K-D 樹中的最近鄰居: (1)從樹根節點(7,2)開始,分割線標準為 X 方向,故樹根節點中的 X𝑟𝑜𝑜𝑡_0 = 7,查詢節點的X𝑓𝑖𝑛𝑑 = 2 < X 𝑟𝑜𝑜𝑡_0,因此進入左子樹找出節點 (5,4);接續以 Y 方向分割線為標準可以得到節點(5,4)的Y𝑟𝑜𝑜𝑡_1 = 4,並 且Y𝑓𝑖𝑛𝑑 = 4.5 > Y𝑟𝑜𝑜𝑡_1 ,因此進入右子樹找出節點(4,7),節點(4,7)是 葉節點,得到此次待查詢佇列有{(7,2)、(5,4)、(4,7)},計算查詢節點 與節點(4,7)的距離為 3.202,與節點(5,4)的距離為 3.042,因此鄰近節 點設定為節點(5,4)。 12.
(22) (2) 回朔至節點(5,4)的位置,發現左子樹中有節點(2,3)存在,因此更新待 查詢佇列為{(7,2)、(2,3)},接著訪問該節點(2,3),計算該節點與查詢 節點的距離為 1.5,發現距離小於節點(5,4)的 3.042,所以再次更新節 點(2,3)成為鄰近節點。 (3) 節點(2,3)為葉節點,並且在該位置找不到其他節點後回溯檢查待查詢 佇列{(7,2)}。節點(7,2)與查詢節點的距離無法達到更新鄰近節點的標 準,因此不更新鄰近節點之值。 (4) 回到樹根節點(7,2),最後回傳離查詢節點的最近鄰居節點為(2,3) 。. 針對 K-D 樹的時間複雜度而論,建立 K-D 樹需要O(k × N × log 𝑁)的時間成 本,搜索 K-D 樹則需要O(log 𝑁)的時間成本,因此,當數據維度越龐大時,K-D 樹的方法則越無法彰顯其效能。為了彌補 K-D 樹的效能差異,SIFT 在特徵點匹 配的方法上採用針對 K-D 樹進行改良的 BBF 搜尋演算法[25],能夠有效地在高維 空間找出 K-NN 問題之近似解。BBF 依照 K-D 樹的架構尋找最近鄰居,在探訪每 個節點的過程中以優先佇列(Priority Queue)來決定節點位置,與目標節點的維 度差值來決定節點順序,並且當訪問到葉節點時,則再回朔查看優先佇列內是否 有更小的維度差值,若目前差值為佇列內所有節點的最小值,則找到最近鄰居, 若非,則取得最小差異之節點,並且重複上述步驟,直至找到 K 個最近鄰居或者 重複搜尋 200 次(預設值)的 K 個最近鄰居[5]。. BBF 搜尋法以圖 9 為例,查詢節點(2,4.5) 在 K-D 樹中的最近鄰居: (1). 優先佇列內放置樹根節點(7,2)。. (2). 從佇列內依照優先權開始提取節點搜尋,並且取出節點(7,2)依分割線. 往左子樹找到節點(5,4),根據 BBF 機制,同時紀錄樹根(7,2)之右子樹(9,6), 查詢該節點在維度上的差值 9-2=7,最後放至優先佇列{(9,6)}。. 13.
(23) (3). 接著一路訪問至葉節點(4,7),在節點(5,4)時,依 BBF 機制已將節點之. 左子樹加入優先佇列,此時已使用差值排序的優先佇列有{(2,3)、(9,6)}。 (4). 檢查優先佇列中是否有較小差值,節點(2,3)之差值較節點(4,7)小,重. 覆上述二個動作。 (5). 優先佇列中無更小差值,則節點(2,3)為最近鄰居。. 根據上述 BBF 搜尋最近鄰居後,利用此兩個關鍵點的特徵向量以歐氏距離來 衡量相似度,作為判別標準。假設目標影像的某個關鍵點(kp0 )及查詢影像的最 近距離關鍵點(分別為kp1、kp2 ),使用歐氏距離計算關鍵點的 128 維特徵空間, 如果最近距離(d0 )除以次近距離(d1 )小於門檻值,則接受此次比對。根據 Lowe 實驗數據顯示,在此過程中門檻值設定得越低,SIFT 比對符合的關鍵點數量則 會相對的減少,但會有助穩定度的提升,然而當門檻值位於[0.4,0.5]有較好的 效果,如圖 10 所示。. 圖 10. 最近鄰居與次近鄰居的距離比,摘自[4]. 14.
(24) 第三章 粒子群演算法 演化式計算(Evolutionary Algorithms,EAs)為人工智慧之領域範疇,其精 隨在於模仿自然界各生物之行為,最佳化現實生活中常見的複雜性問題,例如: 從出發地開始有多條路徑皆可到達目的地,其中一條比較遠卻到達時間比較短, 另一條比較近,但是由於會進入交通壅塞的市區,造成到達時間比較長,針對「該 如何挑選路徑」此類非單一約束條件之最佳化問題,常以 EAs 進行求解。演化式 演算法的「隨機性」 、 「學習性」有別於傳統的爬山算法或完全搜尋法,賦予算法 強大的解題能力之外,同時伴隨著運算成本的降低,提升系統效能之優勢。 目前較廣泛被使用的演化式計算有蟻群演算法(Ant Colony Optimization, ACO)、蜂群演算法(Artificial Bee Colony)、基因演算法(Genetic Algorithms, GA)、粒子群演算法(Particle Swarm Optimization,PSO)。蟻群演算法(ACO) 是由 Macro Dorigo 在 1992 年所提出[19],藉由蟻群尋找食物的過程利用賀爾蒙 紀錄路線以及傳達訊息之特性,達到隨機搜尋以及群體經驗法則之目的進行收斂。 人工蜂群演算法[2]更進一步將蟻群演算法(ACO)的經驗法則細分為人工蜂個體 行為與蜂群的群體行為,利用蜂群分工合作之特性和搖擺舞(Waggle Dance)傳遞 個體行為,以達到全體最優的位置。粒子群演算法(PSO)[8][24]參照鳥類或魚群 的行為簡化人工蜂群的算法內容;每一隻鳥類(粒子)各別擁有記憶性、速度、位 置、慣性,並且在每一次群體(粒子群)飛行結束後,則會檢討此次飛行的歷史紀 錄,更新群體最佳的值,以達到群體最優的目的。基因演算法(GA) 的核心理念 可以追朔至 1859 年達爾文(Charles Darwin)所提出的「適者生存,不適者淘汰」 (Natural selection, survival of the fitness)之概念[38],利用基因的複製、 交配、突變來完成複雜性問題的最佳化。 在上述演化式計算的各種方法中,蜂群演算法以及粒子群演算法(PSO)相較 於蟻群演算法(ACO)增加了個體經驗更有助於避免收斂至局部最佳解之現象;粒 子群演算法(PSO)相較於蜂群演算法增加了社會心理學之理念,適當簡化算法本 15.
(25) 身的參數設定以及計算量。粒子群演算法(PSO)具有較少的參數設定以及易懂的 算法流程(粒子移動);基因演算法(GA)的突變(Mutation)機制有別於現有的生物 式計算,賦予算法跳脫局部最佳解的可能性;有鑒於此,故本章節將針對粒子群 演算法(PSO)以及基因演算法(GA)進行介紹。. 3.1 連續型粒子群演算法(Continuous Particle Swarm Optimization,PSO) 粒子群演算法是由 Kennedy 與 Eberhart 於 1995 年所提出[8][24]的生物式 計算,其靈感來自鳥類及魚群間的群集覓食行為而產生的一種演算法,其精隨涵 蓋了社會心理學原理,又稱連續型粒子群演算法(Continuous Particle Swarm Optimization)。粒子群演算法(PSO)賦予每個個體(粒子)具有記憶性,皆具有位 移向量能自主移動,擁有各自經驗,並且群體間資訊共享;透過多次自身經驗 (pbest)與群體共同經驗(gbest)的交互影響,不斷調適個體自身的移動方向,以 達到最適合之解。在粒子群演算法中,其定義每一個粒子皆具有飛行性,擁有位 置向量𝑥𝑗 (t)以及速度向量𝑉𝑗 (t),如公式(9)(10)所示。. 𝑉𝑗 (t) = 𝑉𝑗 (t − 1) + 𝐶1 × 𝜑1 × .𝑥𝑗𝑝𝑏𝑒𝑠𝑡 − 𝑥𝑗 (t − 1)/ (9) +𝐶2 × 𝜑2 ×. 𝑔𝑏𝑒𝑠𝑡 (𝑥𝑗. − 𝑥𝑗 (t − 1)). 𝑥𝑗 (t) = 𝑥𝑗 (t − 1) + 𝑉𝑗 (t). (10). 𝑔𝑏𝑒𝑠𝑡. 其中 j 為粒子編號,t 為迭代次數,𝑉𝑗 (t)為速度向量,𝑥𝑗 (t)為位置向量,𝑥𝑗. 為所有粒子曾找過的最佳解,𝑥𝑗𝑝𝑏𝑒𝑠𝑡 為個體粒子曾找過的最佳解,𝐶1 、𝐶2 為加速 函數(Acceleration Constans) ,分別代表個體係數(Individuality)以及社會 16.
(26) 係數(Sociality),𝜑1 、𝜑2 為介於 0 至 1 間的隨機變數。整體演算法如圖 11 所 示,其詳細流程步驟如下: (1)定義群體大小,以亂數決定每一個粒子初始速度及位置。 (2)評估每個粒子個體 j 之適應度(值),若比個體最佳解(Pbest)還優,則更 新。 (3)當群體中找到新的個體最佳解,若此解之適應度(值)比群體記憶中的最佳 解(Gbest)還優,則更新。 (4)若滿足結束準則,則步驟跳至(5);若非,則依循公式(9)(10)更新粒子位 置及速度。步驟回至(2)執行 (5)找到最佳解,結束搜尋。. 圖 11. 粒子群演算法流程圖. 在 1998 年 Y.Shi 和 R.C.Eberhart[33]基於上述粒子群公式及流程,在速度 更新公式中增加慣性權重(Inertia Weight)以達到控制整體粒子搜尋能力之效 果,形成現在標準的粒子群算法,如公式(11)(12)所示,並且從其實驗結果顯示: 17.
(27) 當𝑊𝑗 ≥ 1時,粒子的全域檢索能力較強,容易開發新的解空間,但是不容易找出 區域最佳解;當𝑊𝑗 < 1時,粒子的局部檢索能力較強,容易找出區域內的最佳解, 但是容易陷入局部最佳解;當1.2 ≥ 𝑊𝑗 ≥ 0.9時,面對不同的問題是較合宜的權 重設定。. 𝑉𝑗 (t) = 𝑊𝑗 × 𝑉𝑗 (t − 1) + 𝐶1 × 𝜑1 × .𝑥𝑗𝑝𝑏𝑒𝑠𝑡 − 𝑥𝑗 (t − 1)/ (11) +𝐶2 × 𝜑2 ×. 𝑔𝑏𝑒𝑠𝑡 (𝑥𝑗. − 𝑥𝑗 (t − 1)). 𝑥𝑗 (t) = 𝑥𝑗 (t − 1) + 𝑉𝑗 (t). (12). 目前粒子群演算法(PSO)已經被廣泛應用在各種領域上,例如:影像處理、 特徵辨識、生產調度、電路規劃、軍事分配…等等[1][10][11][13][15][28] [34], 與其他現有的生物式計算相比,粒子群演算法具有參數少、不需要額外針對問題 進行編碼設計、容易使用於各種問題以及針對演算法的運作容易理解之優點,但 是無法直接使用在離散型的空間中探討。. 3.2 離散型粒子群演算法(Binary Particle Swarm Optimization,BPSO) 基於第 3.1 章所介紹之粒子群演算法較適合用於優化連續性問題,在 1997 年同樣由 Kennedy 與 Eberhart 學者提出另外一種版本以解決離散性問題之搜尋 方法-離散型二進制粒子群演算法(Discrete Particle Swarm Optimization, DPSO,又稱 Binary Particle Swarm Optimization,BPSO)[9]。離散型二進制 粒子群演算法(BPSO)延伸 PSO 之核心理念,其算法流程以及速度更新公式與 PSO 相同,差別在於 BPSO 的粒子是由一串二進制編碼所組成,每一個粒子利用公式 (13)產生速度向量,接著採用 Sigmoid 函數決定該粒子下一代的位置為 0 或 1, 18.
(28) 如公式(14)(15)所示,其中 Sigmoid 函數與速度之關係如圖 12 所示。. 𝑝𝑏𝑒𝑠𝑡 𝑉𝑖,𝑗 (t) = 𝑊1 × 𝑉𝑖,𝑗 (t − 1) + 𝐶1 × 𝜑1 × .𝑥𝑖,𝑗 − 𝑥𝑖,𝑗 (t − 1)/. (13) +𝐶2 × 𝜑2 ×. 𝑔𝑏𝑒𝑠𝑡 (𝑥𝑖,𝑗. − 𝑥𝑖,𝑗 (t − 1)). 其中 i 為粒子編號,j 為位元編號,t 為迭代次數,𝑉𝑖,𝑗 為粒子 i 第 j 位元之速度 𝑝𝑏𝑒𝑠𝑡 向量,𝑥𝑖,𝑗 為粒子 i 第 j 位元之位置向量,𝑥𝑖,𝑗 為粒子 i 本身搜尋過的最佳解位置, 𝑔𝑏𝑒𝑠𝑡. 𝑥𝑖,𝑗. 為群體最佳解之位置。. 圖 12. Sigmoid 函數與速度之關係. S(𝑉𝑖,𝑗 ) =. 1 1 + exp(−𝑉𝑖,𝑗 ). (14). 1,𝐼𝐹 S(𝑉𝑖,𝑗 ) ≥ RAND() 𝑥𝑖,𝑗 (t) = { 0,𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. (15). 19.
(29) 公式(15)中,RAND()為[0,1]的隨機函數,通常算法為了避免S(𝑉𝑖,𝑗 )產生的 機率過於靠近 0 或 1,會藉由設定最大速度(𝑉𝑚𝑎𝑥 )的參數來約束速度向量,使速 度𝑉𝑖,𝑗 ∈ ,−𝑉𝑚𝑎𝑥 , 𝑉𝑚𝑎𝑥 -。在[9]中曾提及公式(14)(15):𝑉𝑖,𝑗 透過 Sigmoid 函數映 射到[0,1]所得之S(𝑉𝑖,𝑗 )值可以視為該位元位置下一代為 1 的機率,反之若下一 代位元位置為 0 的機率則表示成1 − S(𝑉𝑖,𝑗 );但是,單純以S(𝑉𝑖,𝑗 )並無法完整表 示每一個位元的位移機率p(∆)。根據[12],位置基於二進制模式在下一代粒子產 生前會有 0 跟 1 兩種狀況:當位置為 0 時,下一次位置發生改變為 1 的機率為 S(𝑉𝑖,𝑗 ),而位置維持不變的機率則為1 − S(𝑉𝑖,𝑗 );當位置為 1 時,下一次位置發 生改變至 0 的機率為1 − S(𝑉𝑖,𝑗 ),則位置不變的機率為S(𝑉𝑖,𝑗 )。綜合以上兩種情 況,當離散粒子搜尋解空間的過程,其位置改變的機率p(∆)被表示如公式(16)(17) 所示,其速度與位移率之間的關係則如圖 13 所示,並且可以由圖 13 觀察出當粒 子速度為 0 時,粒子具有最大位移率 0.25。. 圖 13. 位移率與速度關係圖. p(∆) = S(𝑉𝑖,𝑗 ) × .1 − S(𝑉𝑖,𝑗 )/. (16). 即. 20.
(30) 2. p(∆) = .S(𝑉𝑖,𝑗 ) − S(𝑉𝑖,𝑗 ) /. (17). 當粒子的位移機率越高時,粒子具有越高的可能性探索至未開發的區域,但 是面對不同的問題空間,如何適當的設定慣性權重(Inertia Weight)以控制粒子 速度探索或者收斂空間,在[20]中根據公式(13)進行極限定律來探討粒子位移的 機率:當w > 1時,lim𝑡→∞ 𝑠𝑖𝑔*𝑉𝑖,𝑗 (𝑡)+ = 1,其𝑉𝑖,𝑗 (𝑡)隨著迭代次數,增加所有位 元跳變至 1 的位置的可能性;當w < −1時,lim𝑡→∞ 𝑠𝑖𝑔*𝑉𝑖,𝑗 (𝑡)+ = 0,其𝑉𝑖,𝑗 (𝑡)隨 著迭代次數,增加所有位元跳變至 0 的位置的可能性;當−1 < w < 1時, lim𝑡→∞ 𝑠𝑖𝑔*𝑉𝑖,𝑗 (𝑡)+ = 0.5,其𝑉𝑖,𝑗 (𝑡)會使粒子具有恰當的空間探訪能力。. 3.3. 鯰魚粒子群演算法(Catfish Particle Swarm Optimization,CPSO) 鯰魚效應(Catfish Effect)是一種透過「引入強者,激勵弱者」的效應,其 源自挪威漁夫的故事:在當時,新鮮的沙丁魚比冷凍的價格還要好,但是由於沙 丁魚生性懶惰,返航時程又長,導致大部分的漁船在抵岸時沙丁魚已經奄奄一息, 其中有一艘漁船卻能夠將鮮活的沙丁魚帶上岸,而船長的秘訣則是在沙丁魚的環 境中放入鯰魚,使沙丁魚改變惰性(慣性),不停游動以求活命。運用引入異己達 到正面的群體競爭,這就是鯰魚效應,並且被廣泛應用在企業管理上。 鯰魚粒子群演算法(Catfish Particle Swarm Optimization,CPSO)[18]根 據鯰魚效應(Catfish Effect)的啟發,將未更新全域最佳值的次數作為評估次數, 適時引入鯰魚粒子(Catfish particle)激勵魚群活力。在粒子搜尋解空間的過程 中,由上述公式(13)可知粒子的速度深受pbest、gbest兩者最佳解位置的影響, 假設gbest在接下來的迭代中皆沒有更新更好的最佳解,則那些靠近最佳解位置 的粒子依照慣性會開始收斂直至停滯不動,影響整體搜尋效果,因此,鯰魚效應 (Catfish Effect)在迭代終止前視粒子所有已知的最佳解為局部最佳解,避免粒 子在還沒找到全域最佳解時過早收斂,並且以最近鄰居法(K-Nearest Neighbor, 21.
(31) K-NN)的 1-NN 評估粒子間的距離,保留 10%距離較遠的原有粒子,淘汰其他群聚 在局部最佳解的粒子,使粒子在找到全域最佳解或者迭代終止前能夠適時跳脫局 部極值,並且同時引入相同數量的鯰魚粒子(CatFish Particle),改變粒子本身 的慣性,激勵粒子群體有更多可能性找到更好的解,其方法流程如圖 14 所示。 最近鄰居法(K-Nearest Neighbor,K-NN)根據本論文第 2.4 章節所述得知, K 值表示尋找 K 個最近鄰居,因此,鯰魚粒子群演算法用來評估粒子距離的 1-NN 顧名思義係指尋找 1 個最近鄰居的搜尋法。1-NN 法因為只需要找出一個最近鄰 居,因此在所有的 K-NN 法中屬於最單純的一種設定,亦不需要考慮 k 值的設定 是否合適待處理的資料數據。1-NN 法透過迭代探訪每一項資料數據,計算其距 離並透過統計來決定最近鄰居。. 圖 14. 鯰魚粒子群演算法流程圖. 22.
(32) 3.4 基因演算法 (Genetic Algorithm,GA) 基因演算法,又稱遺傳演算法,核心理念可以追朔至 1859 年達爾文(Charles Darwin)「On the Origin of Species by Means of Nature Selection」一書所 提及的「適者生存,不適者淘汰」(Natural selection, survival of the fitness), 其中包含了演化及淘汰之概念[38],仿效自然界生物遺傳以及根據生存環境調整 自身基因組合以適應環境的進化現象;在 1965 年,德國 Rechenberg 為了求解流 體力學中的模型控制參數最佳化之問題,第一次使用了演化式的方法,正式開啟 了演化式計算的應用;在 1966 年,美國 Von Neumann,John 提出自我複製 (Self-Reproducing)之理論,奠定了基因演算法的基礎。之後,在 1975 年由 John Holland 等人正式將此基因演算法運用於計算機上模擬物種生存模式[7]。基因 演算法仿效自然界生物基因選擇、複製、交配、突變等方式來進行最佳化之搜尋, 該流程如圖 15 所示,並且步驟大致可舉列如下: (1)隨機產生 n 個染色體。 (2)利用適應性函數計算所有染色體之適應度。 (3)依照每個染色體之適應性地選擇、複製染色體。 (4)留下之染色體進行交配或者選擇。 (5)重複(2)-(4)之動作達到收斂,獲得最佳解。. 23.
(33) 圖 15. 基因演算法流程示意圖. 基因演算法(Genetic Algorithm,GA)中,最小單位的遺傳因子為基因 (Genetic),染色體(族群)則是由一串(數個)基因所組成,代表解空間的某一解。 在該方法初始化種群的過程中,基因被視為 1bit 的 0 或 1,染色體則是一串 n-bits 的二進位數值,並且需要針對問題的解空間進行不同的編碼設計,例如: (0000000000)2 表示為(0)10,(1111111111)2 表示為(1)10,而(0110001110)2 則 可以表示為(0.38)10 …等等,其中 n 為字串長度(l, string length),亦為 GA 的參數之一。根據圖 15 可以得知,基因演算法使用三種主要方式控制染色體尋 找解空間的最佳解,分別是複製、交配、突變。複製,目的用於篩選(Selection) 族群中的染色體,促使較高適應值的染色體擁有較高的機率得以保留,並且同時 淘汰較差適應值的染色體。因此在下一代子族群中,適應值低的染色體將逐漸減. 24.
(34) 少,較優良的子帶則隨之產生。交配,亦解釋為交叉(Crossover),透過隨機挑 選兩個染色體交換各自的基因以達到產生更優良的後代的目的。由於染色體若是 單純透過篩選(Selection)所繁衍的後代無法有效地演化出更佳的品種,因此需 要藉助其他染色體上的基因進行互換,發展出更完善的下一代,為基因演算法的 核心理念。突變(Mutation),提供一種跳出目前空間,避免陷入局部最佳解的方 式。突變的目的有兩種,第一種為開發新的搜尋空間,第二種是讓基因重新回到 演化過程中有可能忽略的優良基因組合,是基因演算法中一個特別的機制。 基因演算法(Genetic Algorithm,GA)與其他生物式計算如出一轍,皆擅長 解決全局最優以及最佳排程的問題,例如:時間安排、工程規劃…等等,然而, GA 演算法中,模擬自然界突變(Mutation)現象的機制除了彌補篩選(Selection) 過程中淘汰基因所造成的收斂至局部最佳解的可能性之外,與其他生物式計算相 比,基因演算法更能跳脫局部最佳解,找出全域最佳解。. 25.
(35) 第四章 以改良式演化計算為基礎 之 UAV 空拍影像辨識技術 航空影像(Aerial Image,AI)龐大的影像資訊除了提供較高的匹配精確度以 及穩定性之外,時間成本卻相對的提升,本論文基於精確性以及時間成本難以取 捨的前提下,提出一種以標準差與突變元素為基礎,進一步改良粒子群演算法之 航空影像智慧辨識技術,其目的在於維持特徵點數量與匹配穩定度,並且同時利 用生物式之隨機性有效降低影像搜尋的時間成本,方法流程如圖 16 所示。 本論文主要提出之建議方法包含下述三點,並且由第五章之實驗驗證:4.1 章節所解釋之定義分割子影像之像數大小;4.2 章節以標準差評估粒子聚散程度, 有效引入鯰魚粒子群;4.3 章節引用基因演算法的突變機制,進一步降低粒子重 複搜尋的情況,有效提升粒子的搜尋範圍,並且綜合 4.2 章節與 4.3 章節之內容 進行改良,本論文稱此新方法為基於標準差之鯰魚突變粒子群(Sd-CMBPSO)。. 圖 16. 本論文建議方法流程圖. 26.
(36) 4.1 影像分割 航空影像的高解析度保存了豐富的影像特徵以利影像匹配與搜尋的進行。在 2004 年 David G.Lowe[3][4][26]提出尺度不變特徵轉換(Scale-Invariant Feature Transform,SIFT)的方法迄今,由 SIFT 運算所得的特徵矩陣針對影像 匹配的精準度以及穩定性仍然是目前較為出色的方法,但是高維度的特徵矩陣亦 伴隨著高運算複雜度的時間成本,進而導致多數 SIFT 的相關方法皆致力於簡化 特徵維度,藉此換取更多時間成本,使局部影像特徵描述更貼近即時運算。假設 以入門級的無人機拍攝 10 張需要匹配辨識的航空影像,並且每張航空影像有賴 於鏡頭技術的提升,解析度各別為 4000x3000 像素,倘若此時直接針對影像進行 SIFT 運算提取關鍵點約莫有 224,201 至 407,861 點,然而 10 張影像共可以獲得 2,242,010 至 4,078,610 點關鍵點,經過 SIFT 特徵敘述後將會有2242010 × 128(Byte) ÷ 1024(Kilo Byte) ÷ 1024(Mega Byte) = 273.68 (MB)至497.88 (MB) 大小的特徵矩陣。在第 1.3 章所提及的 SURF[6]省略了 SIFT 的 4 個方向,特徵 維度由 128 維降低至 64 維;SIFT-PCA[17]與 SURF-PCA[27]則是以原本的 SIFT 或者 SURF 提取特徵矩陣後,利用 PCA 的概念進行簡化,效果則有限;改良式 SIFT 技術[36]利用物件提取技術[14][16][32]與 OTSU 門檻植[22][35]之概念,分離 前景(Foreground)和背景(Background),藉此簡化關鍵點數,並且當影像灰階值 相近時,容易造成物件不成像之現象,導致整體匹配的穩定性。有鑑於此,本論 文基於欲保留最完善的影像資訊之理念,在後續的搜尋中將以原始的 SIFT 進行 辨識之動作,在本章節,將以最直觀的方式來達到保存數據並且降低時間成本之 目的-切割影像,同時探討切割影像之像素大小。 在 2.1 章節提及 SIFT 採用降採樣與高斯濾波器建構尺度空間,並且藉由高 斯差分金字塔找出空間極值。現有一張解析度為 11460x12260 像素的屏東市航空 影像,針對「切割影像之像素大小」與「保存較多的影像數據」為主要目標,設 計三組實驗:首先,第一組實驗將設計三組操作變因:以 4096x4096、2048x2048、. 27.
(37) 1024x1024 像素做為切割後的子影像大小進行關鍵點與子影像像素的分析,其實 驗數據於圖 18 以及表 1。接著,第二組實驗則是透過第一組實驗的三組子影像 集合進行下列三個步驟以完成模擬,其流程如圖 19 所示,首先將現有的子影像 降採樣至維度[22 , 210 -像素以模擬存放於資料庫中的目標影像,然後將同張子影 像獨立縮放至1000x1000像素用於模擬待匹配的影像,最終以第二步產生的子影 像為基準,分別與同張影像所產生的九種像素[22 , 210 -的目標影像進行 SIFT 辨 識,評估子影像大小與匹配率(Matching Rate)的情況,並且得到圖 20 至圖 25 之實驗結果。最後,第三組實驗取第一組實驗中分割像素為 1024x1024 的子影像 集合紀錄不同分割尺度執行 SIFT 關鍵點定位時間、特徵描述時間、完成敘述的 總時間並進行分析,如表 2。 在以上幾組實驗中,第一組實驗的影像切割方法如圖 17 所示,倘若切割像 素大於剩下像素時,則重複取用上一次已切割的影像像素;第二組實驗的匹配率 (Matching Rate)公式定義如同公式(18)所示,其中𝐾𝑒𝑦𝑃𝑜𝑖𝑛𝑡_𝐶𝑜𝑢𝑛𝑡𝐺𝑜𝑜𝑑_𝑀𝑎𝑡𝑐𝑒𝑠 為好的匹配點數量,𝐾𝑒𝑦𝑃𝑜𝑖𝑛𝑡_𝐶𝑜𝑢𝑛𝑡𝑇𝑎𝑟𝑔𝑒𝑡_𝐼𝑚𝑎𝑔𝑒 則為目標影像的關鍵點數。 Matching_Rate =. 𝐾𝑒𝑦𝑃𝑜𝑖𝑛𝑡_𝐶𝑜𝑢𝑛𝑡𝐺𝑜𝑜𝑑_𝑀𝑎𝑡𝑐𝑒𝑠 × (100%) 𝐾𝑒𝑦𝑃𝑜𝑖𝑛𝑡_𝐶𝑜𝑢𝑛𝑡𝑇𝑎𝑟𝑔𝑒𝑡_𝐼𝑚𝑎𝑔𝑒. (18). 圖 17. 影像切割方式. 28.
(38) 關鍵點數(總和) 3000000. 2500000 2000000 1500000. 關鍵點數(總和). 1000000 500000 0 4096. 2048. 1024. 圖 18. 子影像大小與關鍵點總數關係圖. 表 1. 子影像大小與關鍵點總數之數據 子影像目標尺度(像素). 子影像數量(張). 關鍵點總和(個數). 4096. 9. 1529873. 2048. 36. 2414010. 1024. 144. 2527540. 根據上表 1 與圖 17 之實驗數據,當子影像切割的像素越小時,同時由 SIFT 提取的關鍵點數量則隨子影像切割張數而提升;換言之,由於 SIFT 的關鍵點偵 測利用高斯差分金字塔與周圍八個像素以及上下兩個圖層的九個像素點進行比 較,所以當影像涵蓋的範圍增大時,則越容易忽略局部較細微的關鍵點,以致於 實驗結果所示:影像分割得越小張,關鍵點個數越多的現象產生。. 29.
(39) 圖 19. 匹配率實驗流程圖. 350000.00%. 300000.00% 250000.00% 200000.00% 150000.00% 100000.00% 50000.00% 0.00% 1024. 512. 256. 128. 64. 32. 16. 8. 4. 圖 20. 匹配率平均實驗數據(子影像 4096 像素). 30.
(40) 250000.0%. 200000.0%. 150000.0%. 100000.0%. 50000.0%. 0.0% 1024. 512. 256. 128. 64. 32. 16. 8. 4. 8. 4. 圖 21. 匹配率平均實驗數據(子影像 2048 像素). 160000.0%. 140000.0% 120000.0% 100000.0% 80000.0% 60000.0% 40000.0% 20000.0% 0.0% 1024. 512. 256. 128. 64. 32. 16. 圖 22. 匹配率平均實驗數據(子影像 1024 像素). 31.
(41) 25.00%. 20.00%. 15.00%. 10.00%. 5.00%. 0.00% 1024. 512. 256. 128. 64. 32. 16. 8. 4. 圖 23. 合理的匹配率平均實驗數據(子影像 4096 像素). 12.0% 10.0% 8.0% 6.0% 4.0% 2.0% 0.0% 1024. 512. 256. 128. 64. 32. 16. 8. 4. 圖 24. 合理的匹配率平均實驗數據(子影像 2048 像素). 32.
(42) 14.0% 12.0% 10.0% 8.0% 6.0% 4.0% 2.0%. 0.0% 1024. 512. 256. 128. 64. 32. 16. 8. 4. 圖 25. 合理的匹配率平均實驗數據(子影像 1024 像素). 在第二組實驗中所定義的匹配率理應落於[0.0, 1.0]的範圍內,然而,在上 圖 20-圖 22 的實驗數據中卻發現當目標影像像素≤ 64時,會有不合理的匹配率 (Matching Rate > 100%)產生,以下探討其發生之原因:首先,由於關鍵點個數 隨著影像維度降低而減少,在影像像素≤ 64的前提下,亦有可能造成分母 (𝐾𝑒𝑦𝑃𝑜𝑖𝑛𝑡_𝐶𝑜𝑢𝑛𝑡𝑇𝑎𝑟𝑔𝑒𝑡_𝐼𝑚𝑎𝑔𝑒 )為零的情況;其二,SIFT 特徵描述由 8 種方向所 組成,在本論文第 2.4 章亦有提及特徵點比對採用距離的方式來判斷是否相似, 故影像中的一個關鍵點可能同時對應 1 個以上的匹配點。換言之,由本實驗可知, 當子影像分割的目標像素≥ 128時,仍然保有 SIFT 匹配的穩定性,並且目標像 素= 128時,單位關鍵點數量內成功匹配的點數(匹配率)是相對提高的。. 33.
(43) 表 2. SIFT 執行時間數據表 尺度. 關鍵點運算時間(秒) 描述時間(秒). 張數. 整體時間(秒). 1024. 1216.139. 49875.51. 144. 51091.65. 512. 1319.016. 12362.64. 576. 13681.65. 256. 1521.312. 5590.464. 2304. 7111.776. 128. 2074.688. 3935.424. 9216. 6010.112. 表 3. SIFT 執行時間百分比數據表 尺度. 關鍵點運算時間(%). 描述時間(%). 張數. 1024. 2.38%. 97.62%. 144. 512. 9.64%. 90.36%. 576. 256. 21.39%. 78.61%. 2304. 128. 34.52%. 65.48%. 9216. 60000 50000 40000 整體時間(秒) 30000. 描述時間(秒) 關鍵點運算時間(秒). 20000 10000 0 1024. 512. 256. 128. 圖 26. 影像尺寸與 SIFT 運算關係圖. 34.
(44) 由第一組實驗可以得到關鍵點數量會隨著子影像尺寸縮小而增加,關鍵點數 量的提升理應也會導致時間成本的增加,然而在第三組實驗所得的數據中,如表 2 所示,在整個 SIFT 運算的流程中,除了定位關鍵點的時間是隨著影像尺寸增 加之外,卻出乎意料地發現描述敘述子的部分則是呈現下降的趨勢,進而影響整 體運算時間。在本論文的第 2.2 章與第 2.3 章中可以得知 SIFT 的特徵由 16x16 像素的方格中統計而來,然而在 16x16 像素的方格中的每一個位置則是透過第 2.2 章的公式(4)與公式(5)所運算得到,在上述兩個公式中,得以窺見其算法包 含了圖層間的運算,間接解釋了當影像尺寸較大時,擁有較多塔(Octaves)的尺 度空間,在進行方向敘述時,相較於較低維的影像,則需要耗費更多的時間成本。 此外,在本實驗中亦可得知,尺度不變特徵轉換(SIFT)技術針對一張影像進行局 部特徵描述的流程中,建立描述子的時間占了整體大部分的運算時間,如表 3 所示。 本章節透過以上三組不同的實驗設定,對於 SIFT 與子影像之像素關係有以 下幾點結論: (1) 同樣大小的航空影像,以不同的像素切割數張子影像,像素越小,張數 越多,關鍵點總數越多。 (2) 影像像素≥ 128時,SIFT 匹配能維持一定的穩定度;影像像素= 128時, 有較高的匹配率,代表 128 維度的子影像有較多的關鍵點能成功匹配, 效能較優。 (3) 同樣大小的航空影像,當子影像像素越低時,由於尺度空間的關係,建 立描述的總時間相較於高維度的影像更快。 (4) 綜合上述幾點,本論文所提出之建議方法亦將分割子影像的像數設定為 128 維度。. 35.
(45) 4.2 以標準差改良鯰魚粒子群演算法 當大尺度的航空影像根據上一章節維度分割的方法分割成數張子影像形成 影像集合,甚至是大數據影像資料庫時,隨著子影像張數的提高,越彰顯搜尋演 算法的重要性。在本論文的搜尋方法中,有鑑於粒子群演算法較少的參數設定、 較簡易有效的算法理念、避免 GA 算法中淘汰機制淘汰全域最佳解以及複製機制 所造成的局部收斂的可能性,並且粒子群不需要特地針對問題進行更有效率的編 碼設計。粒子群演算法 J.Kennedy 與 R.C. Eberhart 從 1995 年提出第一版連續 型[8]至 1997 年提出離散空間的應用[9],不論是連續型或者離散型的搜尋方法 中,皆難以斷定目前所有粒子的共同最佳解是否為全域最佳解,因次在 2011 年 有學者引入鯰魚效應(Catfish Effect)[18],在搜尋終止條件到達之前,視粒子 群所有搜尋到的最佳解皆為局部最佳解,並且引入鯰魚粒子激勵原始粒子更有活 力,藉此改善粒子搜尋。 由本論文 3.3 章節的介紹中可以得知鯰魚粒子群演算法藉由 k-NN 最近鄰居 法淘汰集中在局部最佳解附近的粒子,並且使用評估次數定時引入新的鯰魚粒子 以達到激勵粒子的目的。在[18]中採用 1-NN 進行粒子間距離的評估,每個粒子 依序成為基準點,計算離基準點最近的一個鄰居點為輸出點,如圖 27 所示,在 距離空間中,綠色方形為基準點,其他粒子為圖中藍色三角形,並且計算空間中 與每個粒子之間的距離,如公式(19),最後輸出離自己最近的粒子,如圖中的紅 色三角形所示。在上述 1-NN 法的介紹中可以得知該算法的運算複雜度為∅(𝑁 2 ), 但是粒子群演算法的粒子個數設定鮮少超過 1000 個,所以鯰魚粒子群演算法中 用於評估粒子的距離,對於整體執行效果並無明顯的影響。. Dist 𝑖 = Dist 𝑖 + (Data𝑖 − Data𝑗 ). 2. (19). 36.
(46) 圖 27. 1-NN 法示意圖. 根據上述公式(19)與第五章的實驗數據可以發現此方式無法有效的評估粒 子間的離散程度,本論文意圖更有效地開發新的區域,淘汰過於集中的粒子,因 此透過標準差(Standard Deviation)的概念來改善鯰魚粒子群演算法,如公式 (20)所示,分別計算距離(Distance)與適應值(Fitness) 的標準差,最後將 SD𝐷𝑖𝑠𝑡 與SD𝐹𝑖𝑡𝑛𝑒𝑠𝑠 總和,得到粒子之間的離散程度Dist 𝑖 。. {. SD𝐷𝑖𝑠𝑡 = (Distance𝑖 − Average𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 )2 + (Distance𝑗 − Average𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 ) SD𝐹𝑖𝑡𝑛𝑒𝑠𝑠 = (Fitness𝑖 − Average𝐹𝑖𝑡𝑛𝑒𝑠𝑠 )2 + (Fitness𝑗 − Average𝐹𝑖𝑡𝑛𝑒𝑠𝑠 ). 2. 2. (20). Dist 𝑖 = 𝑆𝐷𝐷𝑖𝑠𝑡 + 𝑆𝐷𝐹𝑖𝑡𝑛𝑒𝑠𝑠. 4.3 改良鯰魚粒子群引入突變機制 粒子群演算法的根本理念視一次迭代(Iteration)為所有粒子在同樣的時間 內完成一次的位移,並且粒子之間的移動受到了個體經驗以及群體經驗的交互影 響,因此當粒子位於最佳解附近時,容易重複搜尋其他粒子曾經探訪過的解空間, 造成搜尋資源的浪費和時間成本的增加,本論文有鑒於上述之現象,參照突變機. 37.
(47) 制的原始理念,主要目的為維持與提升基因的多樣性,避免族群過於接近而減慢 或停止演化過程,並且使用隨機的方式選出下一代的基因,引入基因演算法 (Genetic Algorithm)的突變機制(Mutation)進行改善,其流程如圖 28 與公式(21) 所示。此外,本論文 5.4 節針對粒子搜尋重複的情況進行實驗及紀錄。. IF (Position𝑖 𝑖𝑠 𝑛𝑜𝑡 𝑝𝑏𝑒𝑠𝑡 𝑜𝑟 𝑔𝑏𝑒𝑠𝑡)* 𝑅𝑎𝑛𝑑𝑜𝑚(𝑃𝑜𝑠𝑡𝑖𝑜𝑛𝑖 ) +. (21). 圖 28. 突變鯰魚粒子群演算法流程示意圖. 38.
(48) 第五章 實驗結果 本章節在 5.4 節將針對 4.3 節所提及的粒子重複搜尋情況進行作證,其餘章 節則對於本論文所提出之建議方法進行不同情況的數據搜尋,並且每一種情況皆 搜尋 10 次進一步比較效能差異。本論文實驗所採用的影像來源為屏東市公所提 供,共有 10 張分別為 96dpi 解析度 11460x12260 像素之航空影像;程式來源主 要是以 Windows 7 作業系統、Visual Studio 2010 開發工具搭配 OpenCV 函式庫 為主,其餘程式碼皆為自行開發。本實驗使用之硬體規格如下:處理器為 Intel Core i7-4790 3.60GHz、顯示卡為 NVIDIA GeForce GT740、記憶體為 24.0GB DDR3 1600MHz。在粒子群參數設定的部分,除了解空間(Dim)依照航空影像分割後的子 影像數量而定與最大迭代參數(Max_itera) 以不超過傳統的全域搜尋法為前提 之外,並且設定當粒子群搜尋到最佳適應值 0.9,意即 90%以上的值時,將會提 前中斷迴圈進行結果輸出,然而其餘參數則一律採用常見的基本設定方式,如下 表 4 所示:. 表 4. 粒子群演算法參數設定表 參數名稱. 變數名稱. 設定值. 解空間. Dim. 86400. 粒子個數. Cnt. 100. 最大迭代次數. Max_itera. Max_itera = 𝐷𝑖𝑚⁄𝐶𝑛𝑡. 最大速度. Max_v. 4. 慣性權重. W. 0.5. 學習因子. C1. 1. 學習因子. C2. 1. 39.
(49) 5.1 影像分割與建立子影像資料庫 在 4.1 節可知以 128 像素作為目標像素進行分割效果尤佳;根據本章節所使 用的實驗圖資,一張航空影像為 11460x12260 像素大小,以 128x128 像素為目標 分割航空影像可以得到 8640 張子影像,現在總共有 10 張航空影像,故最後可以 得到子影像總數量為 8640x10=86400 張子影像,並且存入資料庫內保存,如下圖 29 所示,隨著航空影像的增加,形成大數據的影像資料庫以供使用。. ……………. DB. 圖 29. 影像分割與建立影像資料庫. 40.
(50) 5.2 適應函數設定 根據 4.2 節中的第二組實驗可以發現 SIFT 特徵點的比對並不唯一,同一個 特徵點可能會對應不同的匹配點,倘若單純以匹配點數的多寡進行結果輸出的依 據並不嚴謹。SIFT 的特徵點由八個方向所組成的,由於在不同的影像中可能會 存在著某一個方向較多的情況,造成匹配的點數提高,但是同時卻缺少多樣性, 形成錯誤的匹配,因此,本論文適應函數的設定針對匹配點進行約束,每一個關 鍵點僅能對應一個匹配點數,如公式(22)中的分子,並且當匹配點數唯一時,以 各自的關鍵點數與匹配點點數的比率則更能清楚匹配率的高低,舉例而言:當影 像 A 的關鍵點數為 100 點,影像 B 的關鍵點數為 150 點,匹配點數為 100 點時, 在公式(22)分母的部分若是選擇影像 A,則會判斷匹配率為 100%,造成誤判(因 為若是以影像 B 的角度來看,匹配率僅有 67%),因此分母的部分需要挑選關鍵 點數較多的一方作為判斷依據,如公式(22)中的分母。. F(X) =. 𝐶𝑜𝑢𝑛𝑡𝑔𝑜𝑜𝑑_𝑚𝑎𝑡𝑐𝑒𝑠 − 𝐶𝑜𝑢𝑛𝑡𝑟𝑒𝑝𝑒𝑎𝑡 𝑀𝐴𝑋(𝐶𝑜𝑢𝑛𝑡𝑖𝑚𝑔𝐴 ,𝐶𝑜𝑢𝑛𝑡𝑖𝑚𝑔𝐵 ). (22). 5.3 比對並顯示結果 本章節於 86400 張影像資料的影像資料庫內隨機挑選四張編號為 34848、 60702、72690、75870 為輸入影像進行搜尋,同時由資料庫內的影像張數可以得 到最大迭代次數(Max_itera)為 864 次。首先,在編號 34848 的影像搜尋任務中, 以離散型的二進制粒子群(BPSO)、鯰魚粒子粒子群(CBPSO)、以標準差改良鯰魚 粒子群(sdCBPSO)、引入突變機制改良粒子群(MBPSO),以及本篇建議方法 (sdCMBPSO)進行比較,其實驗代號依序從一至六表示,並且由圖 30 與圖 31 可以 得到在傳統的 BPSO 與 CBPSO 在十次的搜尋過程中,並無法保證每次皆能找到全 41.
(51) 域最佳解,並且由圖 32、圖 33 與表 5 可以得到 BPSO 與 CBPSO 整體的執行效率 是較差的;然而反觀本論文提出的改善思維:以標準差改良鯰魚粒子群(sdCBPSO)、 引入突變機制改良粒子群(MBPSO),以及最終引述前面兩者方法所改善的建議方 法(sdCMBPSO)則能確保每一次執行皆能找到最佳解,並且本篇的建議方法效果更 佳。. 120% 100% 80%. 實驗一. 60%. 實驗二 實驗三. 40%. 實驗四. 20%. 實驗五. 實驗六. 0%. 圖 30. 編號 34848 搜尋十次之最終適應值(%)折線圖. 42.
(52) 80000 70000 60000 50000. 實驗一. 40000. 實驗二 實驗三. 30000. 實驗四. 20000. 實驗五. 10000. 實驗六. 0. 圖 31. 編號 34848 搜尋十次之執行最佳位置折線圖. 平均迭代次數 900.00 800.00 700.00 600.00 500.00 400.00 300.00 200.00 100.00 0.00. 平均迭代次數. 圖 32. 編號 34848 搜尋之平均迭代次數統計圖. 43.
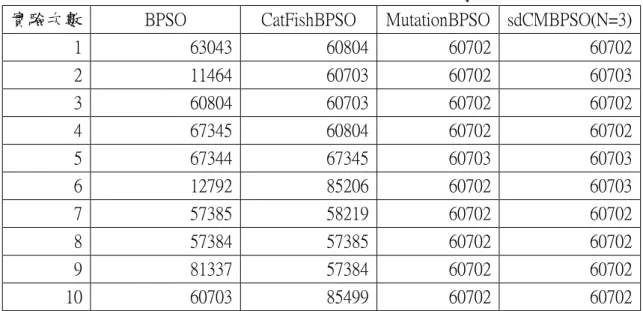
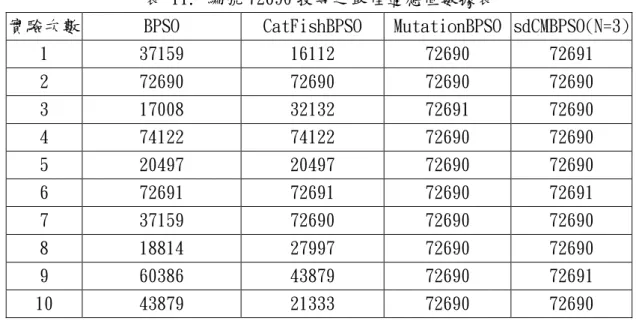
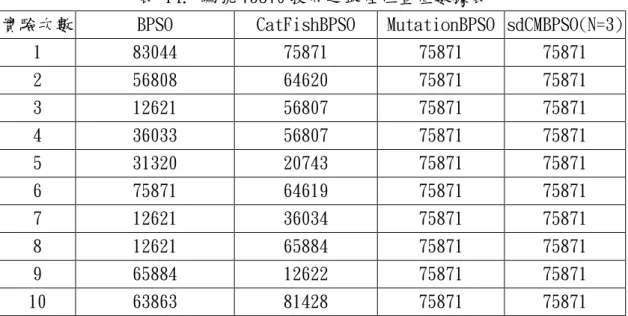
(53) 平均執行時間(秒) 45000 40000 35000 30000 25000 20000 15000 10000 5000 0. 平均執行時間(秒). 圖 33. 編號 34848 搜尋之平均執行時間統計圖. 表 5. 編號 34848 搜尋之平均數據表 實驗編號. 實驗方法. 平均迭代次數. 平均執行時間(秒). 實驗一. BPSO. 771.00. 39233.352. 實驗二. CBPSO. 612.80. 27653.736. 實驗三. sdCBPSO. 293.40. 14358.327. 實驗四. MBPSO. 281.20. 14097.60353. 實驗五. sdCMBPSO(N=3). 140.90. 6578.244. 接著,剩下的三張編號為 60702、72690、75870 的影像搜尋則以上述實驗中 較經典的實驗一(BPSO)、實驗二(CatFishBPSO,CBPSO)方法,以及效能較佳的實 驗四(MutationBPSO,MBSPO)與實驗五(sdCatFisMutationBPSO,sdCMBPSO)之方 法進行比較,其中實驗五即為本篇建議方法。編號 60702 影像搜尋結果為表 6 至表 8,編號 72690 影像搜尋結果為表 9 至表 11,編號 75870 影像搜尋結果為表 44.
(54) 12、表 14。最後挑選出效能最優的兩種方法可以總結出圖 34 與圖 35,以茲證明 本論文所提出之建議方法是普遍較快速能找出全域最佳解的。. 表 6. 編號 60702 搜尋之平均數據表 實驗名稱. 平均迭代次數. 平均執行時間(秒). BPSO. 856.3. 13442.008. CatFishBPSO. 760.9. 12408.479. MutationBPSO. 506.6. 8339.724. sdCMBPSO(N=3). 445.6. 6388.6235. 表 7. 編號 60702 搜尋之最佳適應值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 60%. 60%. 100%. 100%. 2. 60%. 100%. 100%. 100%. 3. 60%. 100%. 100%. 100%. 4. 61%. 60%. 100%. 100%. 5. 61%. 61%. 100%. 100%. 6. 61%. 60%. 100%. 100%. 7. 60%. 61%. 100%. 100%. 8. 61%. 60%. 100%. 100%. 9. 60%. 61%. 100%. 100%. 10. 100%. 60%. 100%. 100%. 45.
(55) 表 8. 編號 60702 搜尋之最佳位置值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 63043. 60804. 60702. 60702. 2. 11464. 60703. 60702. 60703. 3. 60804. 60703. 60702. 60702. 4. 67345. 60804. 60702. 60702. 5. 67344. 67345. 60703. 60703. 6. 12792. 85206. 60702. 60703. 7. 57385. 58219. 60702. 60702. 8. 57384. 57385. 60702. 60702. 9. 81337. 57384. 60702. 60702. 10. 60703. 85499. 60702. 60702. 表 9. 編號 72690 搜尋之平均數據表 實驗名稱. 平均迭代次數. 平均執行時間(秒). BPSO. 828. 12881.625. CatFishBPSO. 747.6. 11801.0405. MutationBPSO. 362.7. 6027.694. sdCMBPSO(N=3). 261.5. 3677.1934. 表 10. 編號 72690 搜尋之最佳適應值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 58%. 57%. 100%. 100%. 2. 100%. 100%. 100%. 100%. 3. 59%. 58%. 100%. 100%. 4. 58%. 58%. 100%. 100%. 5. 60%. 60%. 100%. 100%. 6. 100%. 100%. 100%. 100%. 7. 59%. 100%. 100%. 100%. 8. 59%. 58%. 100%. 100%. 9. 56%. 58%. 100%. 100%. 10. 58%. 57%. 100%. 100%. 46.
(56) 表 11. 編號 72690 搜尋之最佳適應值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 37159. 16112. 72690. 72691. 2. 72690. 72690. 72690. 72690. 3. 17008. 32132. 72691. 72690. 4. 74122. 74122. 72690. 72690. 5. 20497. 20497. 72690. 72690. 6. 72691. 72691. 72690. 72691. 7. 37159. 72690. 72690. 72690. 8. 18814. 27997. 72690. 72690. 9. 60386. 43879. 72690. 72691. 10. 43879. 21333. 72690. 72690. 表 12. 編號 75870 搜尋之平均數據表 實驗名稱. 平均迭代次數. 平均執行時間(秒). BPSO. 813.9. 13534.847. CatFishBPSO. 850.6. 12288.62. MutationBPSO. 412.5. 6569.6705. sdCMBPSO(N=3). 336.6. 4379.766. 表 13. 編號 75870 搜尋之最佳適應值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 57%. 100%. 100%. 100%. 2. 58%. 59%. 100%. 100%. 3. 59%. 57%. 100%. 100%. 4. 60%. 58%. 100%. 100%. 5. 57%. 58%. 100%. 100%. 6. 100%. 57%. 100%. 100%. 7. 59%. 58%. 100%. 100%. 8. 59%. 57%. 100%. 100%. 9. 57%. 59%. 100%. 100%. 10. 58%. 57%. 100%. 100%. 47.
(57) 表 14. 編號 75870 搜尋之最佳位置值數據表 實驗次數. BPSO. CatFishBPSO. MutationBPSO sdCMBPSO(N=3). 1. 83044. 75871. 75871. 75871. 2. 56808. 64620. 75871. 75871. 3. 12621. 56807. 75871. 75871. 4. 36033. 56807. 75871. 75871. 5. 31320. 20743. 75871. 75871. 6. 75871. 64619. 75871. 75871. 7. 12621. 36034. 75871. 75871. 8. 12621. 65884. 75871. 75871. 9. 65884. 12622. 75871. 75871. 10. 63863. 81428. 75871. 75871. 平均迭代次數 600 500 400 sdCMBPSO. 300. MPSO. 200 100 0 編號75870. 編號72690. 編號60702. 編號34848. 圖 34. 搜尋十次之平均迭代次數統計圖. 48.
(58) 平均執行時間(秒) 30000 25000 20000 sdCMBPSO. 15000. MPSO. 10000 5000 0 編號75870. 編號72690. 編號60702. 編號34848. 圖 35. 搜尋十次之平均執行時間統計圖. 5.4 粒子重複搜尋情況 在本論文 4.3 節曾提及粒子倚靠慣性、個體經驗與群體經驗移動,當位置靠 近最佳解時,容易造成重複的搜尋,導致搜尋成本的浪費。本章節使用原始的 BPSO 與改良後的 sdCBPSO 進行實驗,統計所有解空間的位置被粒子搜尋到的次 數,最後分類探訪超過一次以上與僅探訪一次的位置數,並且定義搜尋率𝑅(X)為 公式(23),可以得到表 15、表 16 之實驗結果。. 𝑅(X) =. 𝐶𝑜𝑢𝑛𝑡𝑜𝑛𝑒 + 𝐶𝑜𝑢𝑛𝑡𝑚𝑜𝑟𝑒𝑜𝑛𝑒 𝐶𝑜𝑢𝑛𝑡𝑚𝑎𝑥. (23). 其中,𝐶𝑜𝑢𝑛𝑡𝑜𝑛𝑒 為僅探訪一次的位置數,𝐶𝑜𝑢𝑛𝑡𝑚𝑜𝑟𝑒𝑜𝑛𝑒 為探訪超過一次以上 的位置數,𝐶𝑜𝑢𝑛𝑡𝑚𝑎𝑥 為預計搜尋總位置數,並且𝐶𝑜𝑢𝑛𝑡𝑚𝑎𝑥 根據上表 4 之參數設 定可以推算當粒子達到最大迭代次數Max_itera時,最理想的情況為所有解空間 的位置皆會被探訪,故𝐶𝑜𝑢𝑛𝑡𝑚𝑎𝑥 為 86400 個。. 49.
數據
![圖 8. 關鍵點描述之示意圖,摘自[4]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9012423.298281/19.892.149.745.127.405/圖8關鍵點描述之示意圖摘自4.webp)
Outline
相關文件
Although we have obtained the global and superlinear convergence properties of Algorithm 3.1 under mild conditions, this does not mean that Algorithm 3.1 is practi- cally efficient,
In this chapter, we have presented two task rescheduling techniques, which are based on QoS guided Min-Min algorithm, aim to reduce the makespan of grid applications in batch
Based on the defects of the safety control in the semiconductor electric circuit industry and the application of swarm Intelligence and knowledge management SECI model, the
Moreover, this chapter also presents the basic of the Taguchi method, artificial neural network, genetic algorithm, particle swarm optimization, soft computing and
本論文之目的,便是以 The Up-to-date Patterns Mining 演算法為基礎以及導 入 WDPA 演算法的平行分散技術,藉由 WDPA
This project integrates class storage, order batching and routing to do the best planning, and try to compare the performance of routing policy of the Particle Swarm
Therefore, this study based on GIS analysis of road network, such as: Nearest Neighbor Method, Farthest Insertion Method, Sweep Algorithm, Simulated Annealing
Regarding Flow Experiences as the effect of mediation, this study explores the effect of Perceived Organizational Support and Well-being on volunteer firemen, taking volunteer
