國立臺東大學資訊管理學系 碩士論文
指導教授:林俊男 博士
以資料探勘技術分析消費者消費偏好 ─ 以某女裝品牌為例
研 究 生: 陳慧軒 撰
中華民國一百零九年一月
國 立 臺 東 大 學 資 訊 管 理 學 系
○ ○ 論 文 碩 士 論 文
以 資 料 探 勘 技 術 分 析 消 費 者 消 費 偏 好 ─ 以 某 女 裝 品 牌 為 例
研 究 生 : 陳 慧 軒 撰 指 導 教 授 : 林 俊 男 博 士
中 華 民 國 一 百 零 九 年 一 月
摘要
隨著網路科技的發展及互聯網的盛行,行銷(Marketing)與科技(Technology)的跨 界結合,帶動了整個行銷產業模式的轉變,品牌如何能跟上數位行銷的創新腳步,是 每個企業或多或少都正在經歷的。即將迎接2020 年的現在,善用科技賦能,整合所 有消費者的行為資料數據,進而串連起有意義的消費者旅程,掌握更深刻的消費者輪 廓,且當所有數據整合妥當,也更有機會因應日後人工智慧科技發展,真正實現全媒 體管道綜效最大化。
本研究以資料探勘技術進行個案公司線上官網銷售資料之深入解析,透過敘述性 統計、交叉分析,彙整出個案公司不同地區產品銷售情況,以及不同地區之顧客消費 偏好;並透過三種分群方法(k-means, EM, Two-Steps)演算法進行顧客購買特徵的剖析,
以及透過三種分類方法(C4.5, REP Tree, Random Forest)建立消費者購買行為之預測模 型進行比較分析,結果發現在分群的過程中,k-means 演算法的分群結構相較其他兩 種方法更為具備鑑別能力;C4.5 演算法在建構預測模型的整體正確性與 FP rate 表現 優於其他兩種方法。本研究成果將可以提供個案公司進行社群行銷投放時,廣告受眾 範圍制定的參考依據;另亦以此結果為基礎將可提供業者建立銷售決策模式,提供品 牌電商在行銷與廣告投放上的策略支援。
關鍵字:資料探勘、C4.5 演算法、隨機森林演算法、快速決策樹演算法、K 平均演 算法、最大期望演算法、二階段群集演算法
Abstract
With the development of the Internet and technology, the cross-border combination with Marketing and Technology has driven the transformation of the whole marketing industry. How a brand could keep up with today’s relentless pace of digital marketing change, is what every business more or less going through. Making good use of technology and empowerment, consolidate behavioral data of consumers and then connect consumer journeys to Master ingly consumer persona is the most important issue for the upcoming 2020. Moreover, when all data are integrated, we have better chance of responding to the development of artificial intelligence technology in the future in order to maximize omni- channel effectiveness.
We applied data mining techniques to analyze the case company’s sales records from online official website in this study. Descriptive statistics and cross-analysis were used to analyze the case company’s sales overview in different regions and different customer preferences. Three classification methods (C4.5, REP Tree, Random Forest) were builded the prediction models of consumer purchase behavior for comparative analysis. It turns out that in the process of classification, k-means algorithm is more discerning than the other two methods. Also C4.5 algorithm performs better than the other two methods in constructing the overall correctness of the prediction model and FP rate. The results will provide case company a reference basis for ad audience constructing and social marketing. Also, the results can provide operators with a sales decision model. Provide strategic support for brand e-commerce not only marketing and also advertising.
Keywords:
Data mining, C4.5 algorithm, Random forest algorithm, REP tree algorithm, k-means, Expectation-maximization algorithm, Two-steps clementine致謝
這份論文,首要感謝俊男教授,孜孜不倦地在旁協助,給予極大的支持與幫助,
指導我在論文研究上的疑惑,不管是在撰寫上面的建議,以及論文架構上的調整,再 到時程上的協助安排。俊男教授亦師亦友一般,在需要的時候伸出援手,能完成這份 論文,真的非常非常地感謝他。很榮幸能成為俊男教授的學生。
同時也謝謝我的爸爸、媽媽,在工作忙碌之餘,給我許多關心和支持,能有今天 的成就與結果、能完成碩士學業,都是因為有你們這麼好的父母,我愛你們。另外也 要感謝我的未婚夫陳庭忠,在寫作的期間的陪伴與支持,以及在遣詞用字上適時的給 予建議;也感謝庭忠在生活上的照顧,讓我無後顧之憂的寫作,沒有任何怨言,只有 滿滿的鼓勵,甚至還敦促我,鞭策我完成寫作;要同時兼顧工作與寫作,下班後的時 間都花費在寫作上了,沒有太多額外的娛樂,這段時間真的非常謝謝你在身邊,未來 的日子,還請繼續多指教了!
熬過身體與心理的壓力,終於迎來畢業的這個時刻,可以好好休息一番;謝謝臺 東大學資管所教給我的一切,不管是在學術方面、資訊管理的相關知識以及思考邏輯 的訓練,在工作上也都能將所學的專業盡情發揮。
行筆至此,從求學至今的回憶一幕幕浮現在心頭,學習生涯暫時告一段落,同時 也即將步入婚姻,迎向人生的另一個新的開始,也祝福在這一路上,給過我幫助的每 一個人,事事順心。
陳慧軒 謹誌于 臺北 2020.01.17
目錄
摘要 ... I
Abstract ... II
致謝 ... III 圖目錄 ... VI 表目錄 ... VIII第一章 緒論 ... 1
第一節 研究背景與動機 ... 1
第二節 研究目的 ... 4
第三節 研究流程 ... 5
第四節 研究範圍 ... 6
第五節 論文結構 ... 7
第二章 文獻探討 ... 8
第一節 資料探勘 ... 8
第二節 群集分析 ... 21
第三節 分類與預測方法 ... 28
第三章 研究方法 ... 31
第一節 研究流程 ... 31
第二節 資料收集及前置處理 ... 32
第三節 資料探勘工具 ... 34
第四節 模型驗證 ... 35
第五節 分析結果與衡量 ... 36
第四章 研究結果與分析 ... 38
第一節 敘述性統計 ... 38
第二節 群集分析 ... 43
第三節 分類方法 ... 46
第五章 結論與建議 ... 58
第一節 研究討論 ... 58
第二節 研究結論 ... 59
第三節 研究貢獻 ... 60
第四節 研究限制 ... 60
第五節 未來研究建議 ... 61
參考文獻 ... 63
圖目錄
圖 1 新零售三大特徵 ... 3
圖 2 研究流程 ... 6
圖 3 資料庫知識發掘的步驟 ... 14
圖 4 KDDs 參考步驟 ... 15
圖 5 資料探勘跨產業標準處理程序 ... 17
圖 6 找到最佳的群中心 ui 及 xj 所屬的群 ... 23
圖 7 初始群中心 u1~uk ... 23
圖 8 xi對應到最短距離的群中心 ... 24
圖 9 分類重新計算群中心 ... 24
圖 10 KDDs 程序 ... 31
圖 11 ROC 曲線圖 ... 36
圖 12 年齡層統計 ... 38
圖 13 居住地區統計 ... 39
圖 14 配送方式統計 ... 40
圖 15 付款方式統計 ... 40
圖 16 付款方式統計 ... 41
圖 17 購買顏色統計 ... 42
圖 18 星座統計 ... 42
圖 19 第一群集 Purchase Level 決策樹 ... 49
圖 20 第一群集 Quantity Level 決策樹... 50
圖 21 第二群集 Purchase Level 決策樹 ... 51
圖 22 第二群集 Quantity Level 決策樹... 52
圖 23 第三群集 Purchase Level 決策樹 ... 53
圖 24 第三群集 Quantity Level 決策樹... 54
圖 25 第四群集 Purchase Level 決策樹 ... 55
圖 26 第四群集 Quantity Level 決策樹... 55
圖 27 第五群集 Purchase Level 決策樹 ... 56
圖 28 第五群集 Quantity Level 決策樹... 57
表目錄
表 1 各學者對於資料探勘的定義解釋 ... 9
表 2 資料轉換代碼表 ... 32
表 3 AUC 判別規則 ... 37
表 4 分群結果 ... 43
表 5 基於 k-means 演算法分群成果的分類演算法結果比較 ... 46
表 6 第一群集的分類模型正確率比較 ... 48
表 7 第二群集的分類模型正確率比較 ... 51
表 8 第三群集的分類模型正確率比較 ... 53
表 9 第四群集的分類模型正確率比較 ... 55
表 10 第五群集的分類模型正確率比較 ... 56
第一章 緒論
本研究聚焦於藉由資料探勘的技術中的集群分析與分類方法,幫助個案公司分析 與瞭解其顧客購買偏好,期望藉由本研究探討,除可深入了解「數據」引導思維的資 料探勘主要應用範圍,融入數位創新,提升消費者在品牌官方網站的消費體驗,創造 更貼近消費者需求的購物模式,提供更精準的行銷策略。
第一節 研究背景與動機
行銷科技(Marketing Technology)源於 2013 年舊金山 MarTech Conference,為行銷 結合科技應用來幫助企業進行網路商業行為,而科技發展的同時也扭轉了行與商業模 式,包含使用大量非結構化或是多結構化的資料來進行商業數字等巨量分析,也透過 結合顧客標籤,來輔助企業達成精準行銷。標籤化的目的在於更有效率地鎖定目標客 群,以聚焦於特定消費者的策略方式,許多線上、線下的品牌透過分析顧客的消費行 為,找出屬於自身品牌的特徵及模式。因此,本研究期望藉由資料探勘的技術,利用 集群分析與分類方法,幫助個案公司瞭解分析其顧客資訊與其購買偏好,期望可以透 過這次的研究探討,一方面的除可深入了解「數據」引導思維的資料探勘的主要應用 範圍,另一方面亦也讓我們在這個資訊革命的時代,能夠更快速的掌握資訊,提供更 多的行銷策略。
因著科技創新,交易行為已為零售商帶來巨量且龐雜的資訊,包括各類交易數據
(例如,購買品項、購買價格、購買數量、購物車組成、結帳方式等)、人口統計數 據(例如,性別、年齡、居住地區和教育程度等)和環境數據(例如,氣候等)。零 售業者可以從這些大數據中獲得有效的洞察,並對消費者行為做出更好的預測,設計 更具吸引力的商品以及定價。藉由更準確地分析並優化,讓消費者擁有更佳的購物體 驗與品牌偏好度,近一步提升回購率與自主口碑傳播。因此,善用「大數據」便可啟 動消費者有益的、週期性的消費和參與品牌體驗,進而提高品牌獲利能力。
德魯夫·格魯瓦爾等學者指出,新興的科技力量正不斷影響顧客購買行為,數位 與實體世界亦在快速融合,了解這兩個世界之間的差異與相似之處,以及新興技術將 如何影響兩者,對於未來的零售業至關重要。自從馬雲拋出新零售說後,零售業開始 產生劇烈的變化,在這個社會逐漸轉變成科技的時代,人們與網際網路的關係已密不 可分,商業的經營模式、行銷手法也一直不斷地在改變。近幾年大數據也不斷的被各 報導提出,世界經濟談報告中提及:「數據的價值,就等同於石油與黃金」,以及馬雲 提出的新零售說,促進零售業的改變由此可知資料之重要性。因此,本研究期望藉由 資料探勘的技術,利用數據分析,幫助個案公司瞭解分析其顧客資訊與其購買偏好。
期望可以透過這次的研究探討,一方面除可深入了解「數據」資料探勘的主要應用範 圍,融入數位創新,提升消費者在品牌官方網站的消費體驗,創造更貼近消費者需求 的購物模式,提供更精準的行銷策略。
阿里研究院描述了新零售在2017 年~2020 年的場景:商業元素數據化、重構人 貨場、內生零售形態、產生新零售物種、C2B 生產等,根據阿里研究院在「C 時代新 零售」中指出新零售是以消費者體驗為中心的數據驅動的泛零售形態,並且提出新零 售以心為本、零售二重性以及零售物種大爆發的三大特徵(圖1):
1. 以心為本:掌握數據就是掌握消費者需求,應用數據分析技術,讓資料更可 能的貼近顧客內心需求。
2. 零售二重性:二維思考下的理想零售,任何零售主體、消費者或商品,既是 物理性(實)的,也是數字性(虛)的。
3. 零售物種大爆發:孵化多元零售新形態與新物種,應用數據技術,讓其他服 務業衍生出更多零售型態,人人皆可做零售。無論從新零售的定義及特徵來 看,數據應用是實際上貫穿整個新零售概念的根本。
圖 1 新零售三大特徵 資料來源:阿里研究院
新零售將通過數據與商業邏輯的深度結合,真正實現消費方式逆向牽引生產變革。
掌握新零售所帶來之機會,企業必須強化數據應用的能力。傳統零售業態透過數據的 加持,優化資源配置,孵化新型零售物種,重塑價值鏈,創造高效企業,引領消費升 級,催生新型服務商並形成零售新生態,是零售業發展的新契機。
新零售被定義為「線下與線上零售將深度結合,輔以現代物流,服務商利用大數 據、雲計算等創新技術,構成未來新零售的概念」。以實體門市、電子商務、大數據 分析為核心,通過線上線下的整合,完成將實體商品、會員、交易、行銷等所有數據 的串聯。並透過數據分析找出最有價值的顧客,找出最適合品牌投注資源去維繫關係 的顧客,並針對不同消費程度的顧客,提供相對應的資源和服務。當然亦可挽回近乎 失去的顧客,檢視手上握有的數據與資源,在檢測出問題點後,傾聽顧客心聲,促進 顧客重新體驗改善後的商品或服務,以把握機會掌握顧客的心。
根據資策會 MIC 研究指出,臺灣網路商店跨實體經營漸成趨勢,純網路商店占
45.6%,另外 32.4%為實體商店橫跨虛擬通路經營,而有 8.1%為線上跨實體商店的經 營型態。在獲利上,同時經營虛實商店的商家仍較純網路商店獲利佳,有46.3%的商 家由虛擬跨實體經營獲利,其次有37.6%實體商店跨虛擬模式經營商店有獲利,顯示 虛實雙通路漸成主流,未來純網路商店比例會逐漸減少。
臺灣網路商店對於開拓海外市場躍躍欲試,據資策會MIC 執行 ITIS 計畫調查,
已有28.4%的網路商店進行跨國銷售,而未來希望跨國銷售地區以中國大陸為首選,
其次為香港澳門。與其他海外市場相比,中國大陸語言及文化隔閡較低、消費者對臺 灣商品接受度高,尤其中國大陸的上億網購人口相當有潛力。然而,跨國經營最大的 障礙為缺乏物流管理及配送機制,其次為通關、倉儲與關稅等問題,相關解決方案需 求,未來可能成為資訊服務業者的新興商機。
第二節 研究目的
隨著近幾年電子商務的蓬勃發展,民眾的網路購物行為更為盛行,有愈來愈多的 交易在線上發生。最新的經濟部統計顯示,近五年來,臺臺灣電子網購與郵購平均每 年成長超過 7.5%,且預期未來幾年仍會持續增長,電子商務對各產業的影響力不容 小覷。本研究個案公司主要為生產並販售女裝服飾,從品牌創立之初的直營門市販售,
到目前於全臺包含直營與加盟店已超過70 個門市店點,並架設線上官網經營電子商 務,同時透過網路平臺通路販售商品,除朝向新零售典範邁進外,也不斷嘗試多種新 型態的行銷策略與推廣活動,而這些線上與線下的策略佈局,正需要數據分析的支持。
科技越趨普及的時代,企業所握有的數據資料非常龐雜,如何在有限的資源條件下,
利用會員交易資料,透過資料探勘技術,找出資料間的規則,協助個案公司保有競爭 力,並提供企業行銷方針,是本文要探討的議題。本研究期望透過資料探勘技術協助 該個案公司分析其線上通路的銷售與顧客資料,除建置出銷售決策模型外,亦深入探 討顧客特徵與偏好,作為行銷與廣告投遞的參考依據,在數位時代顧客體驗的路徑不 一,可能會有非常多的接觸點跟組合,品牌必須在路徑中的每個階段提供實體和網路
通路的導引,發揮數據分析於「釐清目標客群的需求與輪廓」,以及結合「販售商品、
提供服務」的主要優勢。當消費者在購買商品之外,還有品牌體驗、消費體驗的額外 價值,對消費者就會產生吸引力,進而成為品牌大使,主動為品牌發聲。透過消費行 為區分出不同的族群,再以相關性商品做關聯性行銷,不僅是在行銷操作上可針對特 定消費者制定內容,更可以對消費者投遞客製化的廣告內容,以達到提升銷售額的目 的,本研究以實際案例驗證此程序的可行性,且可擴展至其他產業,提供一新零售的 成功範例。
第三節 研究流程
本研究流程詳如圖2 所示,主要分為 7 個步驟,詳述如下:
1. 研究問題探討
本研究首先從問題的探討著手,並搜尋網路行銷及電子商務、新零售、資料探勘 等相關資料,找出研究主題及範圍。
2. 相關文獻探討
依據研究主題蒐集及整理有關資料探勘、群集分析及分類分析等之國內相關文獻。
3. 蒐集相關資料及資訊
取得個案公司相關會員資料及交易資料,並對資料檔案之綱要及關連進行分析。
4. 資料淨化及前置處理
針對所取得之交易資料進行分析,去除無效資料,並將資料進行編碼轉換成適合 進行資料分析之格式。
5. 利用資料探勘技術進行分析
依據資料特性選擇適合之資料探勘技術進行分析。
6. 資料探勘結果分析
依資料探勘所獲得之結果進行分析。
7. 提出結論及建議
歸納整理及解釋分析結果,對個案公司提供行銷策略之建議。
圖 2 研究流程
第四節 研究範圍
本研究範圍以個案公司目前所擁有的線上官方網站之顧客與交易資料為基礎,以 顧客購買行為與主要資訊獲得來源進行深入解析,期望找出顧客與所購買的產品間之 關聯性,並透過解析出顧客特徵作為社群廣告投放的受眾條件制定,以驗證本研究結 果的實務應用價值。因此,本研究範圍僅侷限於本研究個案與其相似背景、經營方針 與策略等企業,並無法完整推論至其他不同產業。
另外,本研究聚焦於程序方法的可行性,其資料探勘方式的優缺比較,或其演算 法的改良與創建等,則並不在本研究的範圍內。
提出結論及建議 資料探勘結果分析 利用資料探勘技術進行分析
資料淨化及前置處理 蒐集相關資料及資訊
相關文獻探討 研究問題探討
第五節 論文結構
本研究共分為五章,結構說明如下:
第一章 緒論
針對本研究進行概括性的介紹,包括:研究目的、研究流程、研究範圍以及論文 結構。
第二章 文獻探討
進行本研究相關文獻的回顧,第一節探討資料探勘的相關文獻,接著探討群集分 析的相關文獻,第三節探討分類與預測方法之相關文獻。
第三章 研究方法
第一節論述本研究之研究流程,接著說明資料的收集以及前置處理,第三節探討 資料探勘工具的使用,第四節闡述模型將建構出的分類模式進行驗證,最末節則 闡述衡量分群與決策模型的衡量指標。
第四章 研究結果與分析
探討本研究主題,首先敘述本研究樣本資料的分布情況,接著說明透過統計分析 軟體針對資料進行分析,並針對本研究各項結果進行解析。
第五章 結論與建議
針對第四章的實證結果進行整理與歸納,第一節說明提供具體可行的行銷方案建 議給個案公司,接著敘述本研究結論,第三節整理本研究在學術以及實務上的貢 獻,最四節闡述本研究所面臨的研究限制,最末節提出未來相關的研究可延伸應 用的建議。
第二章 文獻探討
針對本研究的背景和目的,本章文獻探討分成兩大部分,第一部分探資料探勘的 定義相關文獻,並定義資料探勘的相關步驟與處理程序;第二部分為資料探勘相關的 演算法文獻探討,由主要使用的演算法:k-平均演算法(k-means Clustering)、最大期望 演算法(Expectation-maximization Algorithm)與二階段群集演算法(Two-Step Clustering),
進一步延伸討論分類與預測的方法,本研究裡運用 C4.5 演算法,及隨機森林演算法 (Random Tree) ,以及快速決策樹(REP Tree)對資料進行探勘分析,比較三者之預測正 確率。
第一節 資料探勘
一、資料探勘定義
資料探勘(Data Mining) 為從存放於資料庫、資料倉儲或其他資訊儲存器的大量 資料中,挖掘出具有價值的知識之過程 ,其近年來廣泛應用在行銷、財務、銀行、
製造、通訊、保險等,用以發掘潛在客戶、管理突發狀況、管理客戶關係、或作為企 業決策的參考如運用於發掘顧客的消費模式。並利用所發掘的消費模式擬定行銷或銷 售策略,以提昇營業額。
資料探勘被定義為從一個大型的資料庫中,在無預設立場的情況下,找出資料型 樣以及資料間關係的一個過程(Hambaba, 1996)。目的是從一個資料叢集中提取資訊,
並將其轉換成可理解的結構,以進一步使用。除了原始分析步驟,同時還涉及到資料 庫和資料管理方面、資料前處理、模型與推斷方面考量、興趣度度量、複雜度的考慮,
以及發現結構、視覺化及線上更新等後處理。資料探勘是「資料庫知識發現」
(Knowledge-Discovery in Databases, KDDs)的分析步驟 ,本質上屬於機器學習的範疇,
亦稱為「資料考古學」(Data Archaeology)、「資料樣型分析」(Data Pattern Analysis)或
「功能相依分析」(Functional Dependency Analysis),目前已被許多研究人員視為結合 資料庫系統與機器學習技術的重要領域,業界人士也認為此領域是一項增加各企業潛
能的關鍵因素。此領域蓬勃發展的原因:企業仰賴科技的進步,蒐集海量數據,包括 市場、競爭對手、顧客、供應商與將來趨勢等重要資訊,若能透過資料探勘技術,從 海量的資料集合中,發掘出不同的洞察與知識,作為決策制定的參考,必能為企業提 升競爭優勢(鄭宇庭與蘇志雄,民 91)。
下列是各學者對於資料探勘的定義解釋,如表1 所示。
表 1 各學者對於資料探勘的定義解釋
學者 資料探勘的定義
Frawley, Piatetsky- Shapiro & Matheus (1991)
資料探勘是在大量的資料中挖掘出隱含的、先前尚未發現的 知識,並萃取出可能有用之資訊的過程,藉由此過程中能夠 發現令人感興趣或存在規則的資訊。
Agrawal, Imielinski
& Swami(1993)
運用大量的資料調查與分析,來發現有意義的模式(Pattern)
與規則(Rule)的程序。
Grupe & Owrang (1995)
資料探勘為從現有的資料中分析出事實,並且發現專家學者 尚未知曉的新關係。
Curt(1995)
資料探勘是一種結合資料視覺化、機器學習、統計與資料庫 等多種技術,以從大量資料中獲取規則或模式的過程。
Fayyad & Stolorz (1996)
Fayyad 等學者認為資料探勘與知識發現(KDD)是不相同的,
資 料 探 勘 為 資 料 庫 的 知 識 發 現 (Knowledge Discovery in Databases, KDD)過程中的其中一步驟;知識發現是從資料中 發現有用、新奇、未知的知識的整個過程。
Fayyad & Stolorz (1997)
資料探勘是知識發現的其中一個步驟,目的為找出資料庫中 有效的、新的、潛在有用的及容易瞭解的模式
Berry & Linoff (1997)
資料探勘的目的為針對大量的資料,運用自動或半自動的方 法分析探索,以萃取其中有意義的模型或規則。
表1 各學者對於資料探勘的定義解釋(續)
學者 資料探勘的定義
Friedman (1997)
資料探勘是一種搜尋、挖掘資料的一種商業行為(轉引自廖 述賢與溫志皓,民101)。
Friedman (1997)
資料探勘是一種搜尋、挖掘資料的一種商業行為(轉引自廖 述賢與溫志皓,民101)。
Peacock (1998)
狹義資料探勘 (Narrow Scope)
自動發現隱藏在資料中有趣但不明顯的樣 本,這裡所謂的有趣指的是有可能會影響到 策略、甚至是組織目摽的資料,這種資料探 勘圍繞在電腦操作的基本層面,可統稱作
「機器學習方法」(轉引自林國孟,民100)。
Peacock (1998)
廣義資料探勘 (Broad Scope)
是指過程中欲測試兩者或多者間的關係,使 用統計方法、建立假說,研究並確認關係以 支持在狹義的資料採礦
中所形成的模式。
最 廣 義 資 料 探 勘 (Very Broad Scope)
內外部的資料取得、資料的轉換、清理與格 式化、分析、確認、再給予資料定義、評分 資料庫、建立與執行決策支援工具與系統 等,讓資料探勘的結果能夠決策者加以運 用。
Cabena & Peter (1998)
從大型資料庫中,發掘出先前未知、有效、可利用的資訊,並 利用這些資訊做出正確商業決策的一種程序(轉引自何欣容,
民103)。
Kleissner (1998)
資料探勘為一種新的分析過程,能夠從資料中找出被隱藏的 有價知識並支援決策,並幫助企業專業人員理解。
表1 各學者對於資料探勘的定義解釋(續)
學者 資料探勘的定義
Roiger & Geatz (2003)
資料探勘是一種從資料庫中,使用一種或多種電腦技術去 處理或擷取資料而產生知識的過程(轉引自何欣容,民 103)。
陳文華 (民 88)
從一個龐大資料庫中將正確、以前未發覺卻非常重要資訊 加以抽離出來,利用這資訊來做出重要策略過程(轉引自 何欣容,民103)。
Hand, Mannila &
Smyth (2000)
資料探勘是一個從大量的資料當中,尋找有趣或有用資訊 的過程。
Hui & Jha (2000)
資料探勘是一種可協助分析、瞭解及群集大量資料的新技 術。從儲存的大資料中找到類型、關聯、改變、異常及重 要結構的知識過程。
Han & Kamber (2000)
資料探勘是從大量的資料中擷取出隱藏、不知道的、可信、
新的、有效的及能成為被瞭解模式的高階處理過程。
Berry & Linoff (2000)
任務範圍:包括分類、推估、預測、同質分組、群集化以 及描述等六大項目。
Han & Kamber (2001)
資料探勘是從大量的資料中挖掘和提煉知識的一個程序,
並運用此步驟發掘有用的意義或規則。
謝邦昌 (民 90)
資料探勘亦即將資料中隱藏訊息挖掘出來的過程,如趨勢 (Trend)、特徵(Pattern)及關聯性(Relationship),也就是從資 料中挖掘資訊或知識。
Keima, Pansea, Sipsa
& Northb (2004)
資料探勘從觀察的資料中,萃取人們感興趣的模式或模型。
表1 各學者對於資料探勘的定義解釋(續)
學者 資料探勘的定義
Nicholson (2006)
利用資訊科技系統,使所有使用者依照其所需尋找的資 料,更進一步的篩選,而不是搜尋到其所不需的資料(轉 引自何欣容,民103)。
張云濤與龔玲 (民 96)
從大量的資料中發現有意義的模式。
廖述賢與溫志皓
(民 100)
資料探勘是從大型資料集中探索有趣及有價值的問題,並 可付諸行動之方案的一個過程,可以衍生/呈現存在於資 料中的某一種模式和趨勢,這些模式和趨勢可收集在一 起,並定義為資料探勘的模型。
資料來源:本研究整理
二、知識發掘之步驟
資料探勘的實質工作是對海量資料進行自動或半自動的分析,以提取過去未知且 有價值的潛在資訊,例如資料的分類(通過群集分析)、資料的異常記錄(通過異常檢測) 和資料之間的關係(通過關聯式規則挖掘)。這些潛在資訊可通過對輸入資料處理之後 的總結來呈現,之後可以用於進一步分析,比如機器學習和預測分析。
知識發現的過程對資料探勘相當重要,才能確保資料探勘可以獲得有意義的結果,
Fayyad et al.(1996)認為資料探勘就是從大量資料中將隱含的、未知的、潛在有用的資 料萃取出來,是資料庫知識發掘過程中的主要步驟之一。 在實作方面,Han &
Kamber(2006)將資料探勘技術挖掘知識的流程步驟整理如下: :資料選取(Data Selection)、資料前置處理(Data Pre-processing)、資料轉換(Data Transformation)、資料 探勘(Data Mining)及解釋與評估(Interpretation and Evaluation)等五大步驟(如圖 3):
(一)資料選擇(Data Selection)
在進行知識發掘之前,應先對要分析的領域或主題有所認識,選擇資料搜集目標 及資料挖掘程序,確認被挖掘的資料,然後選擇適當的輸入屬性和輸出資訊,從中選 擇與目標相關之資料,建立目標資料(Target Data)。
(二)資料前置處理(Pre-processing)
針對目標資料的內容進行分析,定義資料的形態與綱要,並將重複、缺漏、錯誤、
不一致及與後續分析無關的資料去除。
(三)資料轉換(Transformation)
依據目標及任務找出有用的代表性資料,並以所需的方式來組織資料,轉換資料 成另一種型態(如從文字符轉成數值),且定義新的屬性,並減少資料維度,移去雜 訊(noise)、特異數值(outliers)等資料,決定處理遺失資料的策略並進行資料一般 化,以去除不變的資料、縮小資料範圍及減少變數。
(四)資料探勘(Data Mining)
依據目標及任務選擇適當的資料探勘演算法,並使用該演算法找出資料間的樣式 (Pattern)或模型(Model),使用者可以藉由事先預定好的步驟,並透過一種或多種的技 術,來萃取出資料中隱含的重要資訊及模式。
(五)解釋與評估(Interpretation / Evaluation)
解釋資料探勘所發掘出來的重複行為,並將之轉化為知識;評估該重複行為及利 用該行為去進行預測的準確性
圖 3 資料庫知識發掘的步驟 資料來源:Fayyad(1996)
資料經由萃取,並經由統計或其他技術來確認其結果,且所萃取資訊描述範圍可 以擴展到資料庫中未曾察覺或包含的資料,針對資料探勘所得到的結果加以解釋與評 估,將分析結果轉換成對使用者有幫助的資訊,協助使用者解決問題。
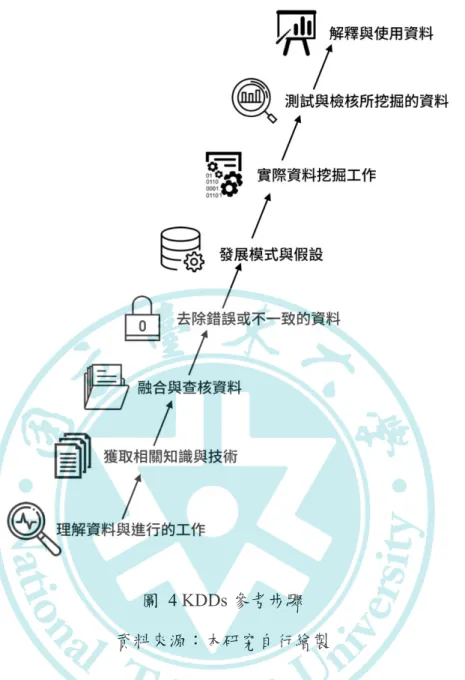
另外,根據Glymour, Madigan, Pregibon, & Smyth (1996)等人之研究,提出一個 KDD 的參考步驟如下(如圖 4):
(1) 理解資料與進行的工作
(2) 獲取相關知識與技術 (Acquisition)
(3) 融合與查核資料 (Integration and Checking) (4) 去除錯誤或不一致的資料 (Data Cleaning)
(5) 發展模式與假設 (Model and Hypothesis Development) (6) 實際資料挖掘工作
(7) 測試與檢核所挖掘的資料 (Testing and Verification) (8) 解釋與使用資料 (Interpretation and Use)
圖 4 KDDs 參考步驟 資料來源:本研究自行繪製
資料探勘為知識發掘的主要步驟之一,然而在不同的產業及不同環境因素影響下,
不同領域的開發者所使用的流程不盡相同,為了提升效率及減少錯誤,許多廠商紛紛 投入資料探勘流程標準化的工作,其中以 SPSS & NCR 於 1997 年所提出之資料探 勘跨產業標準處理程序(Cross-Industry Standard Process for Data Mining, CRISP-DM)為 代表,是目前使用最廣泛之程序,這是一套可以跨產業、 跨商業、跨工具且可不斷 重複修正的資料探勘標準化流程,共分為下列六個階段 (如圖 5 所示):
(1) 商業理解(Business Understanding)
商業理解包括決定商業目標、形勢評估、決定資料探勘目標,並將此商業上的問 題轉換成資料探勘的問題,並據此擬訂定初步專案計畫。
(2) 資料理解(Data Understanding)
蒐集與專案有關的資料,並瞭解相關資料的特性、資料的品質,找出變數間的影 響關係及隱藏於資料中的資訊。
(3) 資料預備(Data Preparation)
收集完整資料,將原始資料加以處理與分類作初步分析,準備過程包括選擇、清 理、重構、整合及格式化資料包含屬性的選擇、資料淨化及資料轉換等,以做為下一 階段塑模的輸入資料。
(4) 塑模(Modeling)
依專案欲達成的目標,選擇且應用一或多種資料探勘技術並用上一步驟的資料建 立模型並反覆進行參數調整以求獲得最佳結果。
(5) 評估(Evaluation)
針對塑模完成後所建立的模型進行評估,以確認是否符合專案目標,分析結果並 證實前一步驟設計的模型是否符合,進一步的決定將來是否繼續採用此一模型以避免 有所疏漏。
(6) 部署(Deployment)
若所建立之模型符合企業目標,則再進一步擬定該模式之推動計畫將模型實際運 用於專案工作上,並蒐集相關資訊與問題,供分析人員做為後續改進之參考。
圖 5 資料探勘跨產業標準處理程序 資料來源:本研究自行繪製
三、資料探勘功能
過往受限於傳統統計分析技術的侷限於小樣本問題的限制,無法從大量的資料中 發現潛在的規則和關係。由於大量資料的增長以及將其轉換為可用訊息或知識的需求,
資料探勘逐漸受到社會與資訊業的重視(Han & Kamber, 2006),有別於傳統分析技術,
資料探勘不受限於樣本數量,其除了能夠整合各資料庫資料,也能夠支援多維度分析 和決策(Witten et al., 2011),以人工智慧、資料庫與統計等相關技術,從大量資料中挖 掘不易發現且有用的資訊或知識,以萃取的方法(Pattern Extraction Methods)將資料中 的知識聚集與公式化的步驟(Cios, 2002),進而從大量資料中獲取其所潛藏之明確且有 用之資訊。
資料探勘所使用的技術可概分為傳統技術與改良技術兩大類,傳統技術方面以統 計分析為主,如因素分析(Factor Analysis) 、區別分析(Discriminated Analysis) 、群集
分析(Cluster Analysis) 等,而改良技術則是採用人工智慧,如類神經網路(Artificial Neural Network)、決策樹(Decision Tree)、基因演算法(Genetic Algorithms)、規則推論 法(Rules Induction)以及模糊理論(Fuzzy Logic)等(Tseng et al., 2005)。
資料探勘資料探勘的功能大致可分為預測型和描述型兩種類型,在這兩種類型下 包含下列五項(Berry & Linoff, 1997),而這些功能所使用的理論技術大多為已建構的 計量及統計分析方法,分別為:分類(Classification)、推估(Estimation)、預測(Prediction)、
關聯分組(Affinity Grouping)、叢集(Clustering)。說明及常用技術簡述如下:
1. 分類(Classification)
屬於監督式的學習 (Supervised Learning),使用訓練資料集來建構分類或群集模 式,之後再利用建構的模式進行資料的分類,將一個新的範例分類到一個定義明確的 範例(Roiger & Geatz, 2003)。分類使用的技術包含了決策樹(Decision Tree)、記憶基礎 推理(Memory - Based Reasoning)及連結分析(Link Analysis)、判別分析(Discriminant Analysis)等,目前較普遍被使用的分類方法為決策樹(Decision Tree),除了可產生樹狀 決策結構外,亦可轉換為 IF-THEN 的規則以供決策者參考。
2. 推估(Estimation)
推估主要於處理連續性的資料,藉由輸入資料,用來推估一些未知的連續性變數。
類似於分類,但推估用於決定數值與特定輸出屬性的對應,且推估問題輸出屬性為數 值而非類別(Roiger & Geatz, 2003),根據現有的連續性數值之相關屬性資料,對未知 連續數值的趨勢與走向或某屬性未知的值做出預測。推估使用的技術包含了相關分析 (Analysis of Correlation) 、 迴 歸 分 析 (Regression Analysis) 及 類 神 經 網 路 (Neural Networks)。
3. 預測(Prediction)
預測是去推估未來的數值以及趨勢,常用來判斷未來的結果(Roiger & Geatz, 2003),從資料中根據對象屬性之過去觀察值確知屬性,並建構可預測的特定事件未
來的結果公式,預測使用的技術包含了迴歸分析(Regression Analysis)、時間數列分析 (Time Series Analysis)及類神經網路(Neural Networks)。
4. 關聯法則(Association Rule)
關聯法則主要描述在資料間某些資料項目間彼此之關聯性,發覺哪些事件總是同 時發生,此狀況稱為一種頻繁樣式(Frequent Patterns),代表在資料集中出現頻繁的 樣式,頻繁樣式的探勘主要是找尋資料集中重複出現的關係,其形式為,其中 X 及 Y 分別表示資料庫中不同之項目組。關聯規則最早應用於超市的購物籃 (Market Basket Data),藉由消費者的交易記錄,找出商品彼此的相關性,做為超市商品擺設以 及進貨存貨之參考,例如美國零售龍頭業者沃爾瑪(Walmart)每到星期五尿布與啤 酒銷量會特別佳的經典案例。而購物籃分析是一種在關聯規則中最早期的頻繁樣式探 勘,能夠在商業應用中幫助決策者決定交叉銷售、產品目錄設計及消費行為分析等決 策(Han & Kamber, 2001)。
5. 分群(Clustering)
分群屬於非監督式學習 (Unsupervised Learning),其基本概念為物以類聚,將欲 分析的數值,有效地分割成各個群組(Cluster),使得每個群組都有較高的相似度;不同 的群組,所顯示之特徵亦不盡相同,而這與分類不同的是,分群並沒有依靠事先明確 定義的類別進行分類,由資料中應用演算法自然產生區隔。分群使用的技術包含了k- means 法、兩階段方法(Two-Steps)及判別分析等。
6. 序列型樣(Sequential Pattern)
序列型樣與關連法則最大的相異之處,便是考量了時間因素的影響,利用此方法 分析不同時間點上各事件的關聯性。序列型樣主要分為順序性型樣與週期性型樣兩種,
順序性型樣乃考慮事件發生之時間先後關係,而週期性型樣乃考慮時間區段的變化,
分析時間區段內所發生的事情,是否其他相同時間區段內也會發生。
四、資料探勘應用
欲將資料探勘導入企業之重點在對於企業領域方面的知識,結合企業中使用者的 語言和分析過程,才能發揮工具的效益與企業的智慧。企業必須能夠從龐大的資料庫 中挖掘到解析過、之前未知、可被理解的資訊,並從使用中獲利。
資料探勘對每個企業而言,皆為一項重要的策略性計畫,並將之列為高度機密,
因此要調查各個企業使用資料探勘來做什麼樣的事,事實上相當不易。根據 Two Crows Corp.最近的調查顯示,資料探勘主要的三個應用方式都在市場推廣方面,分別 是:顧客分析、目標市場分析、以及 購物籃分析。
(1) 顧客分析(Customer Profiling):希望找出客戶的一些共同的特徵,並藉此預測可 能成為客戶的對象,以幫助行銷人員找到正確的行銷受眾。資料探勘可以從現有 客戶資料中找出他們的特徵,再利用這些特徵到潛在客戶資料庫裡去篩選出可能 成為我們客戶的名單,作為行銷人員推銷的對象。
(2) 購物籃分析(Market-Basket Analysis):主要是用來協助零售業者透析消費行為,
例如哪些產品會讓消費者同時購買,或是消費者在買了某一款產品之後,多久之 內會再購買另一樣產品等等。透過資料探勘的運用,零售業者可以更精準的決定 進貨量或庫存量,或是店內層架如何將商品陳列與擺設,同時間亦也可用來評估 線上或線下的促銷活動成效。
(3) 目標市場分析(Targeted Marketing):從既有消費者資料中找出共同的特徵,再利 用這些特於潛在客戶資料庫內篩選出可能成為客戶的名單,作為行銷人員行銷的 對象。行銷人員就可以只針對這些名單投遞廣告相關資訊,以期降低成本,也提 高行銷的轉換率。
資料探勘在各個領域中被廣泛的使用,只要該產業擁有具分析價值與需求的資料 倉儲或資料庫,皆可利用探勘工具進行有目的的分析。而一般常見的應用案例多在零 售業、行銷產業、製造業、財務金融保險、通訊業以及醫療服務等。
第二節 群集分析
群集分析(Cluster Analysis),又稱聚類分析,可視為多變量分析(Multivariate Analysis)中精簡資料(Data Reduction)的一種技術,目的是企圖從一大堆雜亂無章的原 始資料中,找出少數幾個較小的群體,使得群體內的分子在某些變項的測量值均很類 似,而群體與群體間的分子在該測量值上差異較大,將一大筆資料精簡成少數幾個同 質性次群體(Homogeneous Subgroups),達到分類、分群的目標。因此集群分析又稱為
「數值分類法」(Numerical Taxonomy)(余民寧,民 89)。群集分析可分為(黃志民,民 106):
1. 分層式分群演算法(Partitional Clustering Algorithms, PCA)
最早發展的群集分析技術,必須事先決定分割的群集數和挑選初始群集中心,再 以最佳化的切割標準為目標進行切割,以k-means 分群法為代表。可彈性調整並節省 運算時間,但必須事先設定群集數才能進行分析。
2. 階層式分群演算法(Hierarchical Clustering Algorithms, HCA)
利用分裂或聚合的方式,將相似度高的小群集合併成大的群集,或將大的群集分 離、分解成多個相似度低的小群集。
此兩類的分群方法有其各自的優點和限制,分層式分群演算法可彈性調整並節省 運算時間,但須事先設定群集數才能進行分群分析;而階層式分群演算法雖然不需要 事先知道群集數,但資料數目龐大時運算成本將增加,另階層式分群演算法對於已歸 併錯誤的樣本無法進行再變動與調整。
群集分析的階段主要分為四項,如下所述:
(1) 資料準備與選取分群特徵:根據問題特性、資料類型及分群演算法等,選取 具代表性的變數作為分群特徵屬性。
(2) 相似度衡量:使用歐式距離來衡量相似度,計算資料點與資料點之間的距離,
距離近代表資料點相似度大,距離遠則反之,由此方法來判定資料點間的相
似程度。在選擇衡量相似度的方式時,需考慮資料類型以及後續使用的分群 演算法。
(3) 分群演算法:為群集分析中最重要的階段,利用分群演算法將資料分組,有 些分群演算法可能需要自行決定群數,目的在於使各資料點到所屬群集中心 的總距離變異平方和最小。
(4) 結果評估討論與解釋:當分群結束之後,必須檢視分群結果是否合理。另外,
由於分群結果可能作為另一個方法的輸入資料,必須對群集結果進行定義或 命名。
(一) k-means
本研究主要採用k-means 分群演算法,其概念詳述如下:
k-means 屬於分割式演算法(Partitioning Algorithms),此種為亦稱非層次化方法,
目標通常是將 n 個資料物件分割為 k 個類似的小組,創造分群的集合,在此每一筆 資料必會被歸到某一組。此方法具有探索式(Heuristic)的分群特質,優點是可以反覆 修正結果,缺點則是會花費許多時間在計算每種可能的分組組合上,同時也傾向於找 到較圓球狀的群集。
k-means 分群演算法其主要目標是要在大量高維的資料點中找出具有代表性的資 料點,這些資料點可以稱為是群中心(Cluster Centers)、代表點(Prototypes)、Codewords 等,然後在根據這些群中心,進行後續的處理,這些處理可以包含資料壓縮與資料處 理。k-means 主要透過歐氏距離(Euclidean Distance)進行資料點間的相似度計算,其公 式如下:
「k-means」以群中心來分群,相似的分為一群,給予一組資料,將之分為 k 類 (k 由使用者設定) 就是「k-means」(如圖 6 所示)。
圖 6 找到最佳的群中心 ui 及 xj 所屬的群
所有資料點將對應群中心相似的分為同一群,並找出最佳的群中心作為標準用以 分群,達到最終目的。k-means 完整流程如下:
(1) 隨機選取資料組中的 k 筆資料當作初始群中心 u1~uk(如圖 7 所示)。
圖 7 初始群中心 u1~uk
(2) 計算每個資料 xi 對應到最短距離的群中心(固定 ui 求解所屬群 Si) (如圖 8 所 示)。
圖 8 xi對應到最短距離的群中心
(3) 利用目前得到的分類重新計算群中心(固定 Si 求解群中心 ui) (如圖 9 所示)。
圖 9 分類重新計算群中心
(4) 重複 step 2 與 3 直到收斂(達到最大疊代次數 or 群心中移動距離很小)。
(二) 最大期望演算法
最大期望演算法是一種迭代優化方式,並在模型中尋找最大似然估計值,且因為 此計算方法每一次迭代都分為兩步,其中一個為期望步(E 步),另一個為極大步(M 步),
所以演算法被稱為EM 演算法(Expectation Maximization Algorithm)。EM 演算法最初 是為了解決資料缺失情況下的引數估計問題。其基本思想是Dempster, Laird, & Rubin
(1997)在初始時兩者都是未知的,而根據已經獲得的觀察資料,將模型引述的值推估 出來;接著再依據上一步估計出的引數值估計缺失資料的值,再根據估計出的缺失資 料加上之前己經觀察到的資料重新再對引數值進行估計,然後反覆持續這個過程,直 到最後收斂為止。
EM 演算法作為一種資料新增演算法,在近幾十年得到迅速的發展,主要源於當 前科學研究以及各方面實際應用中資料量越來越大的情況下,經常存在資料缺失或者 不可用的的問題,這時候直接處理資料比較困難,而資料新增辦法有很多種,常用的 有神經網路擬合(pytorch)、填補法(Data Imputation)、卡爾曼濾波法(Kalman filter)等,
而 EM 演算法能夠被普及的原因,主要是來自於其簡單且能夠穩定可靠地找到“最佳 的收斂值”。隨著理論的發展,此演算法除了處理缺失資料的問題以外,透過這種思 想的運用,能處理的問題更加廣泛。缺失資料有時是為了將問題簡單化而採取的策略,
這時EM 演算法被稱為資料新增技術,所新增的資料通常被稱為“潛在資料”,透過引 入適合的潛在資料,能夠有效地解決複雜問題。
本研究採用EM 演算法,其概念詳述如下:
最大期望演算法(EM 演算法)是在概率(Probabilistic)模型中尋找引數最大似然估 計或者最大後驗估計的演算法,其中概率模型依賴於無法觀測的隱藏變數(Latent Variable)。EM 演算法的核心思想在於引入一個隱變數作為條件,在此條件下將似然 方程的引數求解拆分為E-step 與 M-step,通過不斷迭代直到收斂,進而得到相應的引 數
EM 是一個在已知部分相關變量的情況下,估計未知變量的疊代技術。EM 的算 法流程如下:
1. 初始化分布參數 2. 重複直到收斂:
(1) E 步驟:根據參數的初始值或上一次迭代的模型參數來計算,給出未知 變量的期望,作為未知變量的估計值。
(2) M 步驟:根據未知變量的估計值,將似然估計函數最大化以獲得新的參 數值,給出當前的參數的極大似然估計。
EM 演算法的推導過程和其原理,需要具備兩個基礎知識:“極大似然估計”和
“Jensen 不等式”。
1. 極大似然估計原理
給定一個概率分布D,已知其概率密度函數(連續分布)或概率質量函數(離散 分布)為 fD
,
以及一個分布參數θ,我們可以從這個分布中抽出一個具有n個值 的採樣X1, X2, … , Xn,利用fD計算出其似然函數:若是D離散分布,fθ即是在參數θ 為時觀測到這一採樣的概率。若其是連 續分布,fθ則為X1, X2, … , Xn聯合分布的概率密度函數在觀測值處的取值。一 旦我們獲得X1, X2, … , Xn,我們就能求得一個關於θ的估值,最大似然估計會 尋找關於θ的最可能值(即,在所有可能的θ取值中,尋找一個值使這個採樣的
「可能性」最大化)。從數學上來說,我們可以在θ的所有可能取值中尋找一個 值使得似然函數取到最大值。這個使可能性最大的值𝛉̂即稱為 θ 的最大似然估 計。由定義,最大似然估計是樣本的函數。而這裡的似然函數是指X1, X2, … , Xn
不變時,關於θ的一個函數。最大似然估計不一定存在,也不一定唯一。
2. 延森不等式(Jensen's Inequality)
延森不等式(Jensen's Inequality)是以丹麥數學家約翰·延森(Johan Jensen)命名。
他定義出積分的凸函數值和凸函數的積分值間的關係。延森不等式有以下推論:
過一個凸函數上任意兩點所作割線一定在這兩點間的函數圖象的上方,即:
在EM 算法中,收斂性的證明即是透過 Jensen 不等式 。
(三) Two-Steps 演算法
「Two-Steps 集群分析」又稱二階段群集演算法(Two Clementine)是一種分層集群 演算法(Hierarchical Algorithms),是設計用來顯示資料集中自然分組(或集群)的探索工 具。目前多用於資料採擷與多元統計的交叉領域,其演算法適用於任何尺度的變數。
該演算法主要處理非常大的資料,可自動確定類的數目,能夠處理連續變數和分類變 數的混合資料。
本研究主要是透過SPSS 所提供的 Two-Steps 集群分析,Two-Steps 分群法是使用 凝集聚群法的一種演算法,可以幫助我們處理大量數據資料的分群工作,並且能處理 連續和某一範圍的變數或屬性。透過 Two-Steps 分群分析,可以把數據資料歸類,因
此在同一組內的記錄則會有較高相似度。Two-Steps 演算法是分前後兩步進行的,也 即『二階』的意義所在,Two-Steps 分群法的演算步驟如下︰
步驟一準集群過程:在預先分群階段根據群集距離接近的 順序來分群,可以一 筆一筆的瀏覽資 料記錄並且決定目前的資料記錄是否應該和以前形成的群集合併,
或是根據距離標準自己形成一個新的群集。這一步使用的是分層集群中針對大樣本集 群產生的BIRCH(Balance Iterative Reducing and Clustering Using Hierarchies)演算法,
分成許多子類(Sub-Cluster)。該演算法是傳統分層集群演算法的改進,其實質是把層 次集群方法與其他集群方法相結合的多階段集群。
步驟二:這個分群階段採取來自預先分群階段的輸入和群集所產生子群集,將其 加入所屬的群集。方法為把第一步聚成的子類利用分層集群方法再次集群,使用對數 似然函數作為距離測量公式,利用第一步的結果對每個樣本進行再次集群,對在一定 的範圍的每個集群成員計算一些判別值(如 AIC 或 BIC),並用來估計類的最初數目。
常用的演算法是分層集群演算法。
第三節 分類與預測方法
分類(Classification)是由已知的物件集合中,根據其屬性建立類別的過程,目的是 產生一個分類模式以描述物件與屬性的關聯性,進而可對未知類別或新資料作出預測;
預測(Prediction)是從資料中根據對象屬性之過去觀察值確知屬性,並建構可預測的特 定事件未來的結果公式。其中,最為常見的演算法包含 C4.5 演算法、隨機森林演算 法,以及快速決策樹演算法。本研究裡運用 C4.5 演算法,及隨機森林演算法(Random Tree) ,以及快速決策樹(REP Tree)對資料進行探勘分析,比較三者之預測正確率。
C4.5 決策樹演算法其分類的程序共有三階段,分別為建立模型、模型評估、使用 模型(曾憲雄等,2005)。
1. 建立模型:將資料的分類規則建立出來,分類規則有許多種最常用的就是決 策樹。
2. 模型評估:通常建立模型資料中會分為訓練樣本及測試樣本,使用訓練樣本 建立模型然以測試樣本驗證模型正確性,而影響正確性的原因有許多如資料 前處理沒做好,或是訓練區無法代表分類特徵、 樣本太少、抽樣問題等,
要解決此問題只有不斷的測試。
3. 使用模型:分類模型符合要求後,開始使用方式有兩種一是分析建立模型資 料分類的原因,二是預測新進資料的屬性類別。
決策樹修剪方法可以分為事前修剪(Pre-pruning)與事後修剪(Post-pruning)。前剪 枝的意義就在於決策樹控制生長,事後修剪則是以精度較差的分枝手動去除。本研究 使用事後修剪並採用降低錯誤剪枝REP(Reduced Error Pruning)剪枝策略,該剪枝方法 透過自底向上剪枝法,將每個節點作為修剪的候選對象,決定是否修剪這個結點透過 以下步驟決策:
(1) 刪除以此結點為根的子樹。
(2) 使其成為葉子結點。
(3) 賦予該結點關聯的訓練數據的最常見分類。
(4) 當修剪後的樹對於驗證集合的性能不會比原來的樹差時,才真正刪除該結點。
在分類方法中,決策樹演算法是最常見的方法之一,決策樹是屬於一種監督式 學習法(Supervised Learning),建立模型之前要指定要觀察的類別屬性,根據已知的進 行分類。決策樹的目標就是建立分類模型,在不同節點選擇與建立上各有不同變化,
如ID3、C4.5、PRISM、Gini、CART 等。
決策樹演算法先以熵值(Entropy)選擇屬性作為根節點,該屬性的不同數值則成為 分支(Branches),所有的訓練資料再被分於各分支下。若分支所有物件屬於同樣結果 類別則以此結果類別標記該節點,並結束分支,若分支中有多種結果類別,將以啟發 式方法(Entropy Heuristic)來選擇適合成為下一個節點的屬性,在實作中,普遍使用 熵值(Entropy),衡量變數之區別能力。透過決策樹演算法可以預測使用者行為,可 藉此從結果中尋求有利於管理的作法。(Quinlan, 1993; Kennedy et al., 1997; Cabena et al., 1997; Olson & Shi, 2007)
隨機森林(Breiman & Cutler, 2001)則是通過自助法(Bootstrap)重取樣技術,指的是 利用多顆樹並對樣本進行訓練並預測的一種分類方法,其概念為從原始訓練樣本集 n 中有放回地重複隨機抽取 k 個樣本生成新的訓練樣本集合,然後根據自助樣本集生成 k 個分類樹組成隨機森林,新資料的分類結果按分類樹投票多少形成的分數而定。其 實質是對決策樹演算法的一種改進,將多個決策樹合併在一起,每棵樹的建立依賴於 一個獨立抽取的樣品,森林中的每棵樹具有相同的分佈,分類誤差取決於每一棵樹的 分類能力和它們之間的相關性。特徵選擇採用隨機的方法去分裂每一個節點,然後比 較不同情況下產生的誤差。能夠檢測到的內在估計誤差、分類能力和相關性決定選擇 特徵的數目。
快速決策樹(Quinlan, 1987) 是一種比較簡單的後剪枝的方法,在該方法中,可用 的資料被分成兩個樣例集合:一個訓練集用來形成學習到的決策樹,一個分離的驗證
集用來評估這個決策樹在後續資料上的精度,確切地說是用來評估修剪這個決策樹的 影響。這個方法的動機是:即使學習器可能會被訓練集中的隨機錯誤和巧合規律所誤 導,但驗證集合不大可能表現出同樣的隨機波動。所以驗證集可以用來對過度擬合訓 練集中的虛假特徵提供防護檢驗。
第三章 研究方法
本章節根據前述研究背景與動機、目的,以及探討相關理論與文獻,並針對個案 公司之顧客資料進行資料探勘,並將其做交叉驗證比對,接著可從分析結果中篩選出 有用的資訊。第一節敘述本研究樣本資料的分布情況,接著說明透過統計分析軟體針 對資料進行分析,並針對本研究各項結果進行解析。
第一節 研究流程
本研究程序遵照 KDD(如圖 10 所示),首先將蒐集來的資料建置於資料庫中,接 著將資料作整理、除去重複或缺少的資料,再使用分類與分群等相關技術進行資料的 探勘,並將其做交叉驗證比對,接著可從分析結果中篩選出有用的資訊,最後利用其 資訊擬定出相關的策略等。其中關於資料蒐集、資料前置處理與資料探勘方式分述如 下。
圖 10 KDDs 程序 資料來源:本研究自行繪製
第二節 資料收集及前置處理
本研究以個案公司線上官方網站交易與會員資料,共11124 筆交易。建置於資料 庫中,扣除重複與不完整資料後,可使用資料為9567 筆,有效資料為 86%。其資料 欄位包含訂單配送方式、訂單結帳方式、地址、購買品項、訂單金額,與出生年月日 等。
由於研究中主要資料探勘的資料包括交易紀錄及會員資料。因為資料量大,其中 可能包含許多錯誤、不完整或是不一致的資料,為提高資料正確性,先將資料做清理 與一致性的調整,並對部份資料做轉換與分類。例如:為簡化資料複雜度,本研究將 出生年月日轉換為星座,並將年齡作區間分類。另外,我們亦採資料編碼方式簡化資 料,把個案公司所提供的線上購物資料與會員資料進行整合,包含地區分為20 個縣 市、生日分為12 個星座以及以 5 歲為一個區間分為 12 類、配送方式分為 3 類,最後 則是購買品項。如此一來可精簡資料量,使探勘執行效率更好。將資料匯入程式中進 行分析、產生訓練模型並且可以預測資料及分析結果。
資料經前置處理及轉換處理後之購買者資料的欄位,欄位相關代碼如表2 所示。
表 2 資料轉換代碼表
欄位名稱 資料型態 描述 編碼
Location 類別 居住地資料
KLC:基隆 NTPC:新北市
TPC:臺北 TYH:桃園 HCH:新竹 MLH:苗栗 TCC:臺中 CHH:彰化
Location 類別 居住地資料
YLH:雲林 NTC:南投 CIC:嘉義 TNH:臺南 KHC:高雄 PTH:屏東 ILH:宜蘭 HLH:花蓮 TTH:臺東 PHC:澎湖 KMC:金門 LCC:馬祖連江縣
Horoscopes 類別 星座
CP:摩羯座 AQ:水瓶座 PI:雙魚座 AR:牡羊座 GE:雙子座 TA:金牛座 CA:巨蟹座 LE:獅子座 VI:處女座 LI:天秤座 SC:天蠍座
Horoscopes 類別 星座 SG:射手座
Age 類別 年齡
TWFI:20-25 TWTH:26-30
THFI:31-35 THFO:36-40 FOFI:41-45 FOFT:46-50
FIFI:51-55 FISI:56-60 SIFI:61-65 SISE:66-70 SEEI:76-80 EIFI:81-85
Shipping Method 類別 配送方式
Supermarket Home
Store
第三節 資料探勘工具
本研究利用資料探勘中的分類與群集分析則進行交易資料與顧客特性分析,主要 的資料探勘工具為「WEKA」與「SPSS」。WEKA 是基於 JAVA 環境下開源的機器學 習以及數據挖掘軟體。提供的功能有數據處理,特徵選擇、分類、回歸、聚類、關聯 規則、可視化等。 WEKA 為懷卡托智慧分析環境(Waikato Environment for Knowledge Analysis)的簡稱,是 GNU General Public License 授權的開放原始碼程式,由 University of Waikato 所開發的,為免費、非商業化且功能完備,以 JAVA 環境開發的機器學習
(Machine learning)及資料探勘(Data Mining)軟體,具備資料探勘所需求的機器學習演 算法,包括對資料進行預處理、分類、回歸、聚類、關聯規則以及在新的互動式介面 上的視覺化。SPSS 是 Statistical Package for the Social Science 的縮寫,為一用於社會 科學研究上的統計套裝軟體。SPSS 採用類似 EXCEL 表格的方式輸入與管理數據,
能方便的從其他資料庫中導入數據。
SPSS 的基本功能包括數據管理、統計分析、圖表分析、結果輸出與管理等等。
SPSS 統計分析過程包括敘述性統計、均質比較、一般線性分析、關聯分析、迴歸分 析、對數線性模型、群集分析、數據簡化、存活分析、時間序列分析、多變量分析等 幾大類。本研究主要是透過SPSS 所提供的 Two-Steps 集群分析,Two-Steps 分群法是 使用凝集聚群法的一種演算法,可以幫助我們處理大量數據資料的分群工作,並且能 處理連續和某一範圍的變數或屬性。透過 Two-Steps 分群分析,可以把數據資料歸類,
因此在同一組內的記錄則會有較高相似度。Two-Steps 分群法的演算步驟如下︰
步驟一:在預先分群階段根據群集距離接近的 順序來分群,可以一筆一筆的瀏 覽資 料記錄並且決定目前的資料記錄是否應該和以前形成的群集合併,或是根據距 離標準自己形成一個新的群集。
步驟二:這個分群階段採取來自預先分群階段的輸入和群集所產生子群集,將其 加入所屬的群集。
第四節 模型驗證
十摺交互驗證法(10-Fold Cross Validation)常用以評估分類模式演算法的優劣,其將 所取得的資料集合隨機分成約十等份的子資料集,作法是先將其中一份子資料集作為驗 證模式效能的測試資料(Testing Data),建立模式的訓練資料(Training Data)則為剩下的九 份子資料集;為使每份子集都能以測試資料作驗證,因此重複進行十次上述實證實驗動 作, 確保可靠性,因此稱為十摺交互驗證法。本研究以十摺交互驗證法對建構出的分類 模式進行驗證。
第五節 分析結果與衡量
本研究為衡量分群與決策模型的優劣,本研究所採用的衡量指標如下:
(1) Correctly Classified Instances:正確率,指模式整體辨識的機率。
(2) Incorrectly Classified Instances:錯誤率,指模式整體辨識錯誤的機率。
(3) TP Rate:True Positive Rate,指類別正確辨識率, TP Rate 越高表示該模式 擁有越高的正確辨識率。
(4) FP Rate:False Positive Rate,指他類別的錯誤辨識率,在實際應用時,FP Rate 越低越好。
(5) Precision:指的是實際值與模式正確辨識比率,實際應用時,Precision 越高 表示模式越精準。另外,precision rate 亦等於敏感度(sensitivity),另一類的 precision rate 則等於特異性(specificity)
(6) Recall:與 TP Rate 相同。
(7) ROC Area:Receiver Operating Characteristic Area,亦稱 ROC 曲線,ROC 曲 線(Receiver Operating Characteristic Curve)是以 FP Rate(1-明確性)為 X 軸,
TP Rate 為 Y 軸(靈敏度),以對角線為參考線,分類器的 ROC 曲線越往參 考線移動則越缺乏鑑別度;反之若是越向圖形左上方移動,也就是明確性與 靈敏度越高,則表示分類器越具鑑別度,如圖 11。
圖 11 ROC 曲線圖
當 ROC 曲線越向左上方移動時,同時也代表曲線下的面積(Area Under Curve, AUC)越大,因此 ROC 曲線形成的曲線下面積常被運用以判別 ROC 曲線的鑑別力,
ROC 曲線下面積公式:
當 AUC 值越接近最大值 1 時,鑑別力越接近完美,AUC 值接近 0.5 時,鑑 別力並不比隨機猜測強(Chung & Fabbri, 2003)。Lee & Glass (2008)提出 AUC≧0.9 可 評估為極佳(Excellent),0.9>AUC≧0.8 為佳(Good),0.8>AUC≧0.7 為尚可(Fair),
0.7>AUC≧0.6 為差(Poor),AUC<0.6 為極差(Very Poor),如表 3。
表 3 AUC 判別規則
ACU 值 鑑別力判別 AUC<0.6 極差(Very Poor) 0.7>AUC≧0.6 差(Poor) 0.8>AUC≧0.7 尚可(Fair) 0.9>AUC≧0.8 佳(Good)
AUC≧0.9 極佳(Excellent)
第四章 研究結果與分析
本研究先將源自個案公司的資料進行資料前處理,將編碼欄位清理並轉換成可分 析的資料編碼轉換為便於分析的資料,運用三種分群演算法先進行第一階段的集群分 析,在比較第一階段的分群結構後,再以三種分類方法建構預測模型,最後以十折交 叉驗證的方式比較預測模型間的準確率與錯誤率等。
第一節 敘述性統計
本研究資料源自個案公司的年度線上官網銷售與顧客資料,共蒐集2018 年 11 月 至2019 年 10 月總資料數為 11124 筆,刪除資訊不完整後,實際有效資料為 9567 筆,
佔86%。
一、 基本資料分析
(一)年齡:針對購買者居年齡層區間分別統計,由圖12 可知以 41~45 歲的年齡 區間所佔的比例最高有26.12%,其次為 46~50 歲有 23.40%,最少為 66 歲 以上之年齡區間,佔總人數 0.3%,表示消費人口集中在中壯年,顧客平均 年齡為44 歲。
圖 12 年齡層統計
116 437
832 1898
2498 2238
1144
278 94 0
500 1000 1500 2000 2500 3000
20-25 26-30 31-35 36-40 41-45 46-50 51-55 56-60 61-65 66-70 71-75 76-80 81-85
年齡
20-25 26-30 31-35 36-40 41-45 46-50 51-55 56-60 61-65 66-70 71-75 76-80 81-85