國立臺灣大學管理學院資訊管理學研究所 碩士論文
Graduate Institute of Information Management College of Management
National Taiwan University Master Thesis
資料探勘應用於
臺灣低壓 AMI 用戶用電行為分析之研究 Application of Data Mining in
Taiwan’s Low-Voltage AMI User Usage Behavior Research
孫顯鈞
Hsien-Chiun Sun
指導教授:曹承礎 博士 Advisor: Seng-Cho Chou, Ph.D.
中華民國 106 年 8 月 August, 2017
doi:10.6342/NTU201702936
i
誌謝
研究所短暫的兩年,稍縱即逝。師長們的教導以及同儕間的學習交流,讓我在臺 大資管的碩士生活受益匪淺、收穫豐富。
感謝指導教授曹承礎博士一直以來的悉心指導,老師的指引與鼓勵,讓我能夠發 現自己的不足與缺失,促使我繼續學習與改進,進而有所成長。同時亦感謝陳鴻基博 士與王貞雅博士抽空擔任口試委員,提供寶貴意見與建議,使論文研究能夠臻於完 善,修訂得更加嚴謹、完整。
感謝陸臺根博士和采娟學姊提供的協助,以及學甲學長給予的寶貴建議。研究所 期間所參與的資料分析與每週的討論,除了讓我有機會在電力領域學習不少知識,也 讓我能夠持續磨練、精進自身的資訊技術。
KMLab 的中彥、郁庭、媺雅、欣柔和錢龍,有幸能和你們一同學習,讓我在研究 所的生活不會感到孤單,特別是與欣柔、媺雅在共同參與專案期間的陪伴與相互砥 礪,以及陸皞、成宇等來自其他Lab 的好朋友們,感謝大家給予我許多幫助,使我能 夠突破研究瓶頸、度過難關。和大家相處的日子,將會是我難忘的珍貴回憶。
最後,感謝一直以來在背後支持我的家人,有父母的支持、哥哥與妹妹的陪伴,
我才能在求學階段無後顧之憂,專心致志,在臺大從事研究並完成學業。謝謝你們!
孫顯鈞 謹識 于 國立臺灣大學資訊管理學研究所 中華民國一百零六年八月
doi:10.6342/NTU201702936
中文摘要
本論文研究目的為提出一資料庫架構,以有效地利用智慧電表基礎建設(Advanced Metering Infrastructure, AMI)所收集之用電資料,並進行資料探勘以瞭解目標用戶群之 用電行為。
研究對象為台電低壓AMI 用戶約 1 萬戶,資料庫建構所使用資料為 2015 年 9 月 至2016 年 10 月期間之用電資料,資料探勘所使用資料為目標用戶群於 2016 年 6 月至 2016 年 9 月夏季期間經饋線別篩選之用電資料。
研究方法首先將建構資料庫以進行資料聚合與資料預處理,針對目標用戶群以階 層式集群分析進行分群,分析群集之用電趨勢,以輸出之結果辨識用戶用電尖峰。
研究所提出的資料庫架構,能夠將原先零散的xml 格式用電資料進行聚合,並搭 配資料庫索引、固態硬碟(Solid-State Drive, SSD) 等技術有效地提升資料預處理效率。
集群分析則能夠根據用戶每日24 小時的用電趨勢辨識其用電尖峰與用電行為,並可歸 納出典型尖峰與特定時段尖峰,作為發展需量反應相關措施的重要參考依據。
關鍵詞:智慧電表、智慧型電表基礎建設、AMI、尖峰負載、需量反應、電表資料管 理系統、ETL、資料探勘、集群分析、階層式分群
iii
Abstract
The purpose of this thesis is to propose a database architecture to effectively utilize the power usage data which collected by Advanced Metering Infrastructure (AMI) and to proceed data mining to understand the power usage behavior of target user group.
Among approximately 10,000 Low-Voltage AMI users' power usage data from
September 2015 to October 2016 is collected to construct the database. The data from June 2016 to September 2016 is later filtered by selecting certain feeder line as target user group for the data mining procedure. Hierarchical clustering is used to analyze power usage trend and recognize peak user load of target user group.
The result shows that the proposed database architecture is able to aggregate power usage data, which is originally scattered in xml format. Database indexing and Solid-State Drive (SSD) techniques are also used to increase efficiency of data pre-processing. The clustering analysis recognizes peak user load and power usage behavior of target user group according to daily 24-hour data. Two peak load types can be summarized as typical peak load and peak load at certain period of time, which is also an important reference for developing Demand Response (DR) and other relevant programs.
Keywords: Smart Meter, Advanced Metering Infrastructure, AMI, Peak Load, Demand Response, Meter Data Management System, ETL, Data Mining, Cluster Analysis, Hierarchical Clustering
doi:10.6342/NTU201702936
目錄
誌謝 ... i
中文摘要 ... ii
Abstract ... iii
目錄 ... iv
圖目錄 ... vi
表目錄 ... viii
第一章 緒論 ... 1
第一節 電力需求面管理概述與研究動機 ... 1
第二節 研究目的與範圍 ... 9
第二章 文獻探討 ... 10
第一節 資料探勘技術相關研究 ... 10
第二節 用電負載分析相關研究 ... 12
第三節 國內用電負載相關研究 ... 17
第三章 研究方法 ... 19
第一節 研究方法應用 ... 19
第二節 目標用戶選取 ... 26
第三節 資料探勘流程 ... 27
第四章 AMI 用戶用電資料探勘分析 ... 29
第一節 資料探勘分析細部過程概述 ... 29
第二節 資料收集與品質 ... 30
第三節 資料庫建構 ... 33
第四節 資料 ETL(Extraction-Transform-Load)與輸出 ... 39
第五節 資料預處理 ... 42
第六節 資料集群分析工具 ... 43
v
第六章 未來發展與研究限制 ... 67
第一節 用電資料延伸發展研究 ... 67
第二節 研究限制 ... 69
參考文獻 ... 70
中文文獻 ... 70
英文文獻 ... 71
doi:10.6342/NTU201702936
圖目錄
圖 1-1 各國/州之需求面管理政策實行數 (Warren, P., 2015) ... 2
圖 1-2 台灣電力公司營運概況示意圖 (台電,2015) ... 3
圖 1-3 智慧電網定義及涵蓋範圍 (黃怡碩,2011) ... 3
圖 1-4 台灣 2014 年售電量 (台電,2015) ... 4
圖 1-5 台灣 2014 年電力用戶數 (台電,2015) ... 4
圖 1-6 台灣需量反應管理措施內容與成效 (台電,2015) ... 5
圖 1-7 需量管理定義 (FERC, 2008) ... 6
圖 1-8 所得效果影響用電行為說明 (台電,2012) ... 6
圖 1-9 AMI 資訊系統架構 (資策會,2013) ... 7
圖 1-10 電表發展演進 (智慧電網控制及智慧家庭示範中心,2014) ... 7
圖 2-1 Analysis techniques (Verdú et al., 2006) ... 10
圖 2-2 Feature extraction and load identification algorithms (Cole et al., 1998) ... 12
圖 2-3 Graph of clusters obtained with MANOVA and later multidimensional scaling (Verdú et al., 2006) ... 13
圖 2-4 葡萄牙用電負載分析之冬季工作日負載型態 (Figueiredo et al., 2005) ... 14
圖 2-5 英國住家用電負載分析結果 (Dent et al., 2011) ... 15
圖 2-6 中國 SGCG 低壓 AMI 用電負載分析結果 (Zhou et al., 2017) ... 16
圖 2-7 用電資料基序分析結果 (羅振維,2014) ... 18
圖 3-1 完全連接法產生之集群樹狀結構 ... 21
圖 3-2 平均法產生之集群樹狀結構 ... 22
圖 3-3 華德法產生之集群樹狀結構 ... 23
圖 3-4 中心法產生之集群樹狀結構 ... 24
圖 3-5 目標用戶群選取流程 ... 26
vii
圖 4-4 已建立日期時間索引之資料表查詢效能 ... 36
圖 4-5 尚未建立日期時間索引之資料表查詢效能 ... 37
圖 4-6 以傳統硬碟進行 BCP 資料輸出 ... 39
圖 4-7 以固態硬碟進行 BCP 資料輸出 ... 40
圖 5-1 8,408 戶低壓 AMI 用戶依月均度數分組 ... 44
圖 5-2 低壓 AMI 單一用戶用電資料集群分析(使用 Matlab) ... 45
圖 5-3 低壓 AMI 單一用戶用電資料集群分析(時段篩選) ... 46
圖 5-4 ZB52 饋線之目標用戶群集群分析結果 (以 maxclusters 指令進行集群) ... 50
圖 5-5 ZB52 饋線 群集 C3 用電趨勢 ... 52
圖 5-6 ZB52 饋線 群集 C4 用電趨勢 ... 54
圖 5-7 ZB52 饋線 群集 C5 用電趨勢 ... 56
圖 5-8 ZB63 饋線之目標用戶群集群分析結果 (以 maxclusters 指令進行集群) ... 58
圖 5-9 ZB63 饋線 群集 C4 用電趨勢 ... 60
圖 5-10 ZB63 饋線 群集 C5 用電趨勢 ... 62
圖 5-11 ZB63 饋線 群集 C6 用電趨勢 ... 64
doi:10.6342/NTU201702936
表目錄
表 5-1 ZB52 饋線 群集 C3 週間累積次數 ... 53
表 5-2 ZB52 饋線 群集 C4 週間累積次數 ... 55
表 5-3 ZB52 饋線 群集 C5 週間累積次數 ... 57
表 5-4 ZB63 饋線 群集 C4 週間累積次數 ... 61
表 5-5 ZB63 饋線 群集 C5 週間累積次數 ... 63
表 5-6 ZB63 饋線 群集 C6 週間累積次數 ... 65
1
第一章 緒論
第一節 電力需求面管理概述與研究動機
電力是國家發展的重要根基。隨著電力需求不斷增加,世界各國無不努力尋找解 決方案。在溫室效應帶來的全球暖化、氣候變遷、國際燃料價格波動、以及各國環保 意識提升的情況下,電力供給面必須克服傳統化石能源發電方式的瓶頸。因此,除了 努力改進現有火力發電方式,還包括太陽能、風力、水力等再生能源的開發與應用。
但是,僅倚靠開發、建置新電廠的供給面成長,容易因土地取得、技術、資金等 因素使得開發時程受到影響,造成電力開發不及。為了尖峰負載而投資過多的發電機 組,當系統的尖離峰負載差異過大,會因離峰期間機組使用率不高而形成浪費,也不 利於電力公司的資產有效運用,仍然是治標不治本。面臨到此日益艱難的處境,各國 的電力管理思維開始將重點從傳統的供給面,轉移至需求面管理(Demand-Side
Management, DSM)。
需求面管理泛指由政府機構、發電設施、第三方機構或用戶端所使用之能源需求 面的技術、行動及方案等,透過有效率地使用能源、節約能源、需量反應、就地發電 與儲能等各種方式,來管理或降低能源的使用,並期望減少能源系統的總支出、幫助 政府機構與能源公司達成排放減量、平衡供給面與需求面、減少用戶用電費用等政策 目標。(Warren, P., 2015)
若供給面管理為「開源」,需求面管理即為「節流」。與供給面管理相比,在理想 狀況下有效運作的需求面管理,更直接對用電量造成影響,達到降低尖離峰差距、穩 定電力供需動態平衡的效果。然而實際電力系統仍須透過供給面管理與需求面管理兩 者的協調,方能達到能源管理的最佳成效。
doi:10.6342/NTU201702936
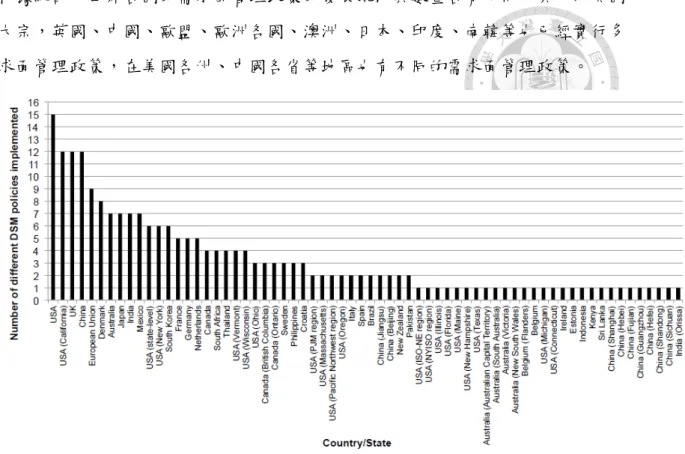
根據統計,世界各國的需求面管理政策的發展現況與數量各有不同,其中以美國 為最大宗,英國、中國、歐盟、歐洲各國、澳洲、日本、印度、南韓等也已經實行多 個需求面管理政策,在美國各州、中國各省等地區也有不同的需求面管理政策。
圖 1-1 各國/州之需求面管理政策實行數 (Warren, P., 2015)
3
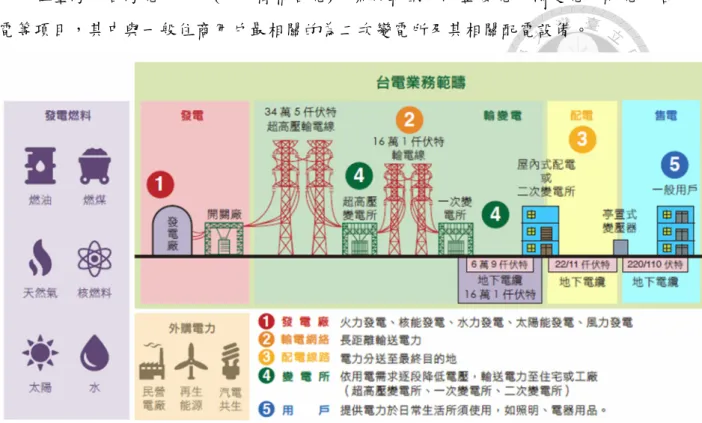
在臺灣,台灣電力公司(以下簡稱台電)的業務範圍,涵蓋發電、輸變電、配電、售 電等項目,其中與一般住商用戶最相關的為二次變電所及其相關配電設備。
圖 1-2 台灣電力公司營運概況示意圖 (台電,2015)
智慧電網的概念,則是將上述從發電端開始,經過輸配電網路直到用戶端,以資 通訊(Information and Communication Technology, ICT) 科技建置整合系統,提升整體系 統運轉效率並提升可靠度。
圖 1-3 智慧電網定義及涵蓋範圍 (黃怡碩,2011)
doi:10.6342/NTU201702936
在台灣的電力發展概況,以2014 年總售電量 2,060 億度為例,仍以工業用電為 最大宗,佔55.3%,住宅部門次之,佔 20.6%,商業部門佔 15.6%,其他類佔 8.5%。
然而在總用戶數13,369 千戶當中,工業部門佔比僅 1.6%,商業部門只有 7.5%,住宅 部門為最大宗佔89.4%。(台電,2015)
圖 1-4 台灣 2014 年售電量 (台電,2015)
圖 1-5 台灣 2014 年電力用戶數 (台電,2015)
5
台電長期推動需求面管理,在需求面管理中的需量反應方面,已實施多項措施來 抑低尖峰負載,其中又以「時間電價」最早開始實施,且適用對象最廣。
由於台灣地處低緯度的熱帶/亞熱帶地區,另有針對空調設施實施的相關需量反應 措施。而針對工業用戶實施的需量反應措施,則容易受到用戶自身營業考量、產線製 程配合、一般電價低廉等因素影響措施的參與意願與執行成效。
圖 1-6 台灣需量反應管理措施內容與成效 (台電,2015)
臺灣近年備轉容量率屢創新低的供電吃緊狀況,即為現有供給端與需求端逐漸失 衡的警訊之一。在供電能力成長速度不及尖峰負載成長的情況下,加強現有需求面管 理、政府有效推行政策、民眾與產業改變用電行為、節約用電,將會是穩定電力供需 平衡的關鍵。
doi:10.6342/NTU201702936
需量反應目前被認為是智慧電網的殺手級應用(killer application) (Nizar et al. 2006)
,然而需量反應的概念,最早於1981 年即已由美國學者 Clark W. Gellings 提出,透 過用電負載尖峰與離峰時的價格激勵機制,促使用戶改變用電行為、節能。
美國聯邦能源管理委員會(Federal Energy Regulatory Commission, FERC) 對於需 量管理的定義,可以圖一-6 簡單呈現:
圖 1-8 所得效果影響用電行為說明 (台電,2012)
藉由價格、競標與回購等誘因機制,需量反應方案可達到轉移尖峰負載、降低用 戶尖峰時段需量、改善需量曲線、穩定供需平衡等效果。
而在發展需量反應的進程中,智慧電表基礎建設(Advanced Metering
Infrastructure, AMI)扮演相當重要的角色。傳統機械式電錶仰賴人工抄表,即使是電 子式電表,其資訊更新也較為緩慢(約落後 1~2 個月),不利於電業機構進行用電預測
。利用資通訊技術所開發的AMI 系統,則改善了傳統電錶資訊更新過慢的缺點。使 用智慧電表,可經由網路與控制中心進行雙向溝通,讀取、監測用戶用電資訊,並透 過資訊系統有效地收集、處理資料。
電力事業/
電力調度中心 用戶
價格/費用補償
用電需量
圖 1-7 需量管理定義 (FERC, 2008)
7
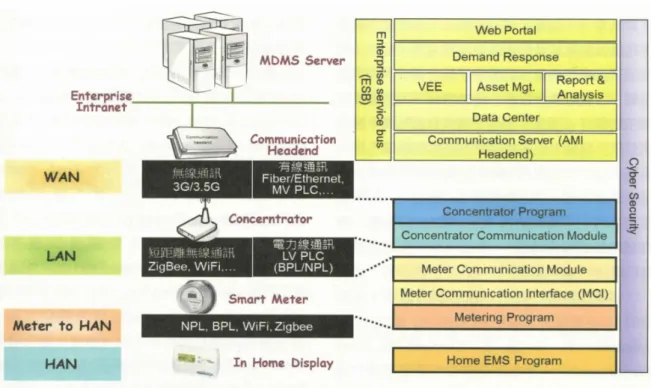
圖 1-9 AMI 資訊系統架構 (資策會,2013)
圖 1-10 電表發展演進 (智慧電網控制及智慧家庭示範中心,2014)
doi:10.6342/NTU201702936
目前台灣電力公司(以下簡稱台電)已針對所有高壓 AMI 用戶(24,624 戶) 完成 AMI 系統的建置。若以長尾理論來進行評估,用戶數佔比九成以上的住宅與商業等 一般低壓用戶同樣具有相當的節電潛力。我國規劃於民國113 年完成建置 300 萬戶低 壓AMI 智慧電表,成為推動智慧型電網的重要一環,並同時配合推行住商多元時間 電價方案,以達到降低尖峰用電負載的效果。
低壓AMI 用戶方面,國內目前僅完成約 10,392 戶智慧電表安裝,在全國總電表 數約1,300 萬之下,其占比仍過少。行政院規劃於民國 106~107 年之間完成 20 萬戶 低壓AMI 建置,但在資料庫建置方面,尚缺乏能與資料探勘分析程式有效介接的資 料庫建構程序,AMI 資訊系統未來在分析智慧電表巨量資料時,將會受限於資料格 式不統一、資料量巨幅成長等各種問題而難以進行資料探勘,使得效率降低。
過去國內外的智慧電表或輸配電用電資料相關研究,多以分類(Classification)或 集群(Clustering)等資料探勘分析方法,針對溫度﹑平日假日﹑用戶類型﹑特定場域﹑
使用電器類型等不同因素來探討用電模式與用戶類型,並對未來用電進行預測。
然而,國內仍缺乏針對大量動態用電資料的資料探勘研究,在實際應用上,智慧 電表所收集之動態用電資料會隨時間不斷累積、變化,長期收集的資料量可能多達百 萬筆以上,資料在數量級上的巨幅成長,會使得過往針對少量統計抽樣產生的研究方 法的適用性下降。
另外,各用戶的用電行為模式也可能隨時間產生潛在變化,當用戶用電行為發生 改變,以問卷法、統計抽樣等方法,針對用戶屬性、用電量等靜態資料所進行的舊有 研究之用電預測將變得不再準確。
9
第二節 研究目的與範圍
綜合前述之背景描述與研究動機,本研究為解決上述問題,將建立一套資料探勘 分析程序,採用台電的低壓AMI 用戶動態用電資料,建構資料庫系統,透過實務上處 理資料庫建構開發﹑資料介接﹑資料轉置輸出等程序來探討資料探勘技術面應用,並 進行集群分析演示。
以往研究多以小範圍資料或統計抽樣資料,以分類、集群分析等各式方法,直接 使用總用電度數等經過加總、處理的變數,並利用基本資料、用戶屬性等靜態資料建 立之變數定義來探討用電行為。本研究則利用低壓AMI 用戶之各時點用電記錄,建立 資料向量、矩陣,進行階層式集群分析,能夠更精確地分析用戶的動態用電行為,並 可根據不同的研究目的或節電策略,選取目標用戶群,從建構的資料庫輸出相對應的 原始資料,藉由用電日期標籤辨識資料點,結合台電NBS 等資料庫系統中包含的用戶 屬性資料輔以研究。即使未來用戶的用電行為發生改變、或是加入新用戶資料,仍可 透過本研究的探勘程序再度進行分析取得新的結果。同時,本研究的資料庫建構程 序,也將能作為電業機構未來針對智慧電表產生之巨量資料,開發、管理電表資料管 理系統(Meter Data Management System, MDMS)時的重要依據與基礎。
doi:10.6342/NTU201702936
第二章 文獻探討
本章將探討國內外相關研究,範圍包含資料探勘技術、用電負載分析、國內用電 相關研究等各種文獻,以瞭解針對用電資料所進行之探勘分析,為本研究之背景與相 關依據建立基礎。
第一節 資料探勘技術相關研究
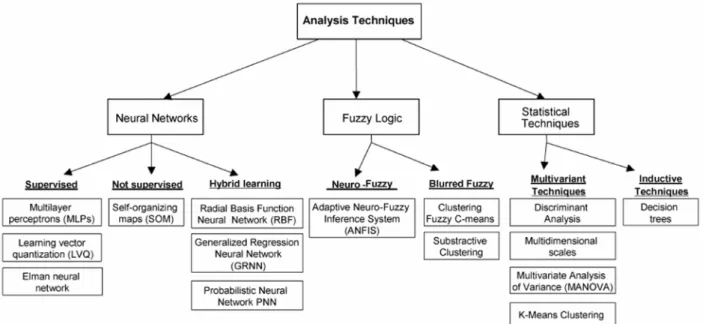
在資料探勘上,根據欲解決的的問題種類與理論基礎,資料探勘分析技術可 分成數個不同類別。如圖 二-1 所示,資料探勘分析技術可分為類神經網路、模糊邏 輯、統計學等三大類,而此三大類向下還可再細分出不同的資料探勘技術。
圖 2-1 Analysis techniques (Verdú et al., 2006)
11
資料探勘中有許多需要進行分析、解決的問題,其中分類(Classification)為最常見 的問題之一。分類的目的為預測資料群體中的個體是否屬於特定的類別。使用監督式 方法進行分析的分類問題,需要完整的資料屬性,並定義出要預測的目標屬性,最後 進行建模與訓練。另一種與分類相似的問題為集群(Clustering),其與分類最大的不 同,在於集群目的係將群體中的相似的個體聚集起來建立群組,以瞭解資料集中是否 存在某些自然形成的群集,所得到的結果可作為進行更進一步的分類、集群或其他資 料探勘分析的基礎。(Provost et al.,陳亦苓譯,2016)
在進行資料探勘之前,資料準備 (Data Preparation) 為相當重要的基礎工作,其包 含資料收集、資料預處理與整合等多種項目。由於實務上收集的資料可能為不完整、
含有雜訊或不一致的資料,容易導致資料探勘產生被誤導的分析結果,因此需透過資 料清洗、資料選取等步驟來確保資料品質,以確保分析結果的正確性。(S. Zhang et al., 2003)
doi:10.6342/NTU201702936
第二節 用電負載分析相關研究
傳統電表之用電資料收集,仰賴人工抄表,雖然成本低但耗時、效率難以提升。
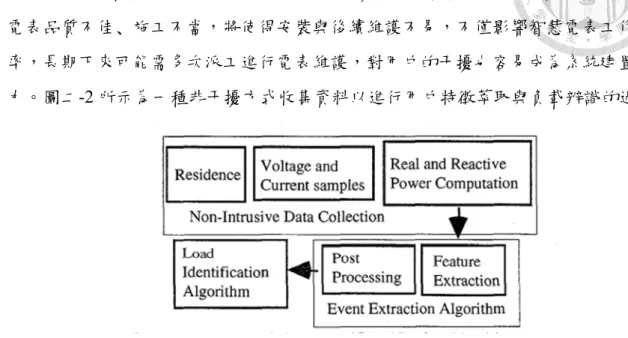
前述之AMI 智慧電表,與傳統電表相比,其優點為通訊讀表與遠端控制,但若是智慧 電表品質不佳﹑施工不當,將使得安裝與後續維護不易,不僅影響智慧電表工作效 率,長期下來可能需多次派工進行電表維護,對用戶的干擾也容易成為系統建置的阻 力。圖二-2 所示為一種非干擾方式收集資料以進行用戶特徵萃取與負載辨識的過程。
圖 2-2 Feature extraction and load identification algorithms (Cole et al., 1998)
無論是收集用戶整體用電資料、單項或多項電器用電資料,均需考量資料收集之 難易度以及成本效益,前期所收集資料的品質優劣,將會對之後資料探勘的研究過程 產生影響與相關限制。
13
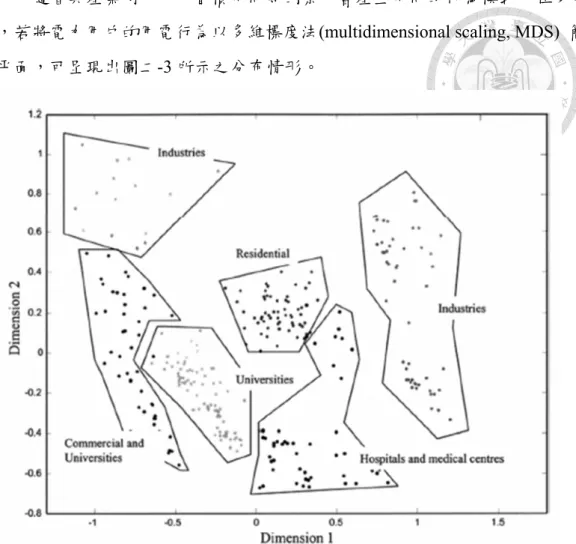
電力用戶隨著其產業別、用戶習慣不同等因素,會產生不同的行為模式。在多變 量分析中,若將電力用戶的用電行為以多維標度法(multidimensional scaling, MDS) 簡 化至二維平面,可呈現出圖二-3 所示之分布情形。
圖 2-3 Graph of clusters obtained with MANOVA and later multidimensional scaling (Verdú et al., 2006)
高壓電力用戶、工業用戶、住商用戶等不同用戶類別,以及向下細分之工商業、
住宅、教育或醫療等不同機構,可透過類似方法產生不同群集。
doi:10.6342/NTU201702936
圖二-4 顯示一使用葡萄牙用電資料進行的用電負載分析,其使用之負載參數以日 為單位。研究方法主要以k-means 方法進行用電類型集群,得到用電負載型態,同時 將集群結果輸入至C5.0 決策樹產生規則集合。
圖 2-4 葡萄牙用電負載分析之冬季工作日負載型態 (Figueiredo et al., 2005)
15
圖二-5 則顯示一英國住家用電負載分析,使用資料以小時為單位。其同樣以 k- means 方法進行集群分析,圖中紅線為各群集之代表性型態(群集中心點,由 k-means 分析得出),黑線為群集之平均型態。
圖 2-5 英國住家用電負載分析結果 (Dent et al., 2011)
doi:10.6342/NTU201702936
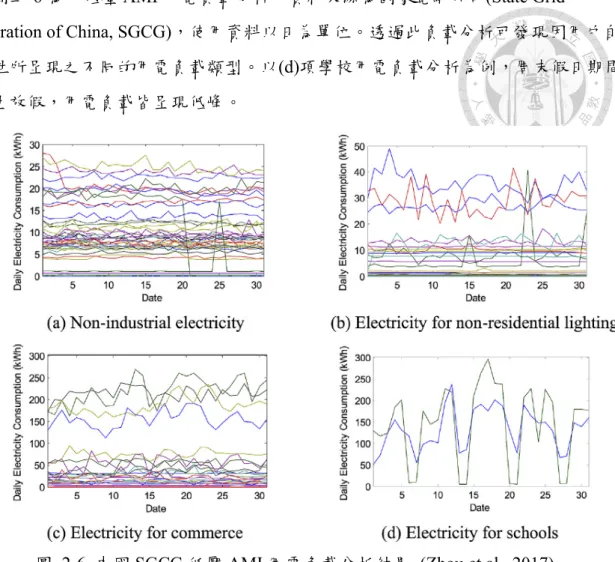
圖二-6 為一低壓 AMI 用電負載分析,資料來源為國家電網公司(State Grid
Corporation of China, SGCG),使用資料以日為單位。透過此負載分析可發現因用戶自 身特性所呈現之不同的用電負載類型。以(d)項學校用電負載分析為例,周末假日期間 因學生放假,用電負載皆呈現低峰。
圖 2-6 中國 SGCG 低壓 AMI 用電負載分析結果 (Zhou et al., 2017)
17
第三節 國內用電負載相關研究
台電過去已針對不同的用電種類完成相關的研究調查案,以瞭解各種用戶的用電 負載特性。
表 二-1 各用戶種類負載特性調查案分析 (黃鶯玲,台電負載特性調查資料可用 性探討,1999)
用電種
類 研究題目 期間(民國) 研究設計
現場訪問 郵寄問卷 裝表實測
大電 力用 戶
一千瓩以上電力用戶負載特性調查研究 74-78
(每年) V
負載管理價格需求彈性對用電特性影響 78 年 6 月-
80 年 2 月 V V V
一千瓩以上電力用戶特性資料檔建立與分析 85 年 10 月-
86 年 9 月 V
工業 用戶
鋼鐵、水泥、造紙、化工、紡織、電機電子 業用電特性對負載管理策略影響之研究
82-87
(每年) V V V 商業
用戶
商業用電負載管理策略之研究 84 年 V V V
商業大樓時間電價效益評估研究 86 年 V
住宅 用戶
台灣地區家用電器普及狀況調查研究報告 64-87
(每兩年一次) V V
表燈用電負載管理策略之研究 82 年 V V
各種 用戶
台電系統負載特性調查分析研究 82 年 5 月-
84 年 11 月 V
台灣地區冷氣用電之研究 84-85,
86-87 V V
問卷調查法是台電調查案過去最常使用的調查方法,然而此方法之成效較易受到 用戶抽樣、問卷填答方式等因素影響,容易產生問卷缺漏值或錯誤值並影響其統計結 果。近年來,隨著電腦化問卷的技術改良,問卷法雖已經比以往改善許多,但仍有受 訪者回答不完整、拒答等各種因素影響所回收之資料。
doi:10.6342/NTU201702936
在國內用電負載相關研究方面,鄭味亭 (2007)針對需量反應中的可停電力措施,
以Fuzzy c-means 方法進行目標可停電力用電用戶的分群,並以 CRUISE 分類樹方法 進行情境變動分析。王喬儀 (2007)則藉由分群與關聯規則之分析,建立可停電力之潛 在目標用戶名單以提升目標行銷效率。
羅振維 (2014)以基於 Hadoop 的基序探勘與時間區間探勘演算法,實作資料探勘 環境,分析台電之AMI 用電資料,藉由產生之不同基序,可檢視用電趨勢的波動。如 圖二-7 所示之不同類型波動,可表示為不同時段之電器使用行為。
圖 2-7 用電資料基序分析結果 (羅振維,2014)
19
第三章 研究方法
第一節 研究方法應用
本研究以建構資料探勘程序為主要目的,並將系統產出之資料以集群分析進行探 勘應用演示。集群分析目的在於將資料進行集群,在機器學習中通常以非監督式學習 方法進行,所得到的結果甚至可再延伸,用以建立預測性建模,分析分類﹑機率﹑迴 歸等資料探勘問題。
集群分析方法可分為階層式集群法(Hierarchical Clustering)和非階層式集群法(Non- Hierarchical Clustering),其中階層式集群法又可稱為系統集群法,是一種可將集群過程 利用所謂的階層式結構或是樹狀結構來描繪的方式。(謝邦昌,2017)
階層式集群法具體又可以分為聚集法(Agglomerative Clustering)和分割法(Divisive Clustering)兩種。聚集法是先將所有的資料各自算成一類,將彼此間距離最小或是相似 係數最大的資料合併成一群,再將這群和其他群中距離最小或是相似度最大的合併,
持續合併,直到所有的資料皆合併成一群為止。
分割法則正好相反,先將所有的資料看成一大群,然後分割成兩類,使一群中的 資料點盡可能遠離另外一群,再繼續分割,直到每一筆資料皆成為單一群體為止。
在聚集法中,連接法(Linkage Method)為最常用的聚集法,其根據事先定義的群與 群之間距離之計算法則,將各個群逐步合併。依照對「群集間距離」的定義不同,連 接法又可分為數種:
單一連接法(Single Linkage):也叫做最短距離法或是最近緊鄰連接法,兩個群之 間的距離定義為是分別來自兩群中的元素之間最短的距離,並依此群距離選擇最靠近 的群來合併。
完全連接法(Complete Linkage):也叫做最長距離法或是最遠緊鄰連接法,兩個群 之間的距離定義為是分別來自兩群中的元素之間最長的距離,並依此群間距離選擇最
doi:10.6342/NTU201702936
靠近的群來合併。
平均連接法(Average Linkage):兩個群之間的距離定義為各點與各點間距離總和 的平均。
華德法(Ward’s Method):又稱華德最小變異法,其主要原理為計算群集內各點至 中心點之距離平方和,並以獲得之最小距離總和作為目標函數,透過此方式不斷遞 迴,直到所有資料點皆完成集群。
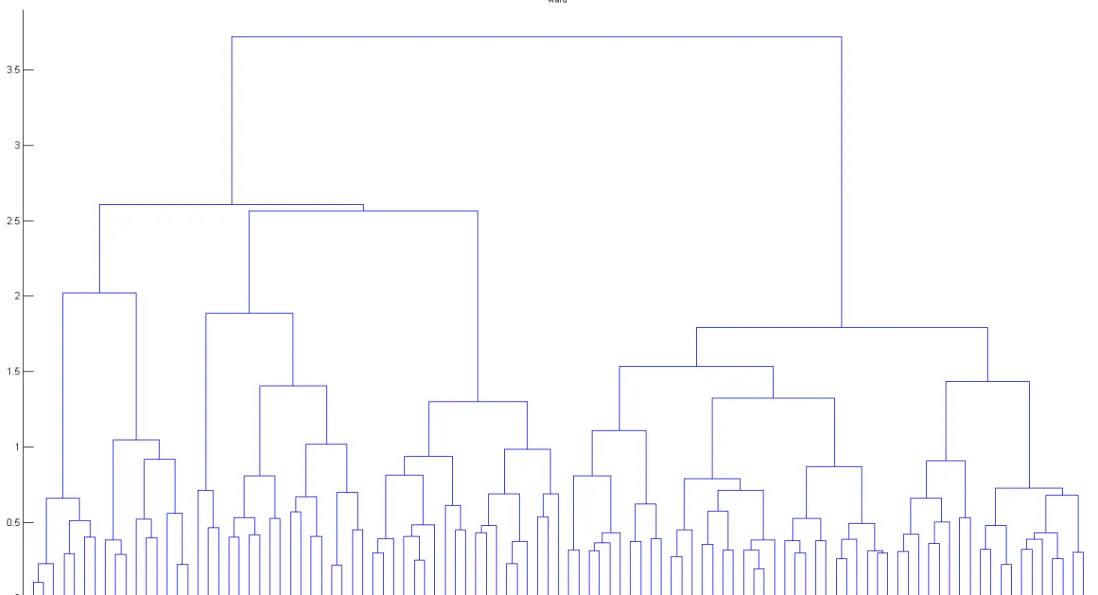
本研究利用所收集之低壓用戶AMI 用電資料,採用階層式集群法中的聚集法來進 行集群分析,聚集法會由樹狀結構底部開始將資料進行聚合,最終可產生樹狀圖 (dendrogram)以顯示資料集群分析結果。
以下將以單一低壓AMI 用戶於 2016 年 6 月至 9 月之用電資料(共計有效日數 103 日)為例,來比較完全連接法、平均連接法、華德法、中心法等方法產生之樹狀圖的不 同結果。
在所有樹狀圖中,縱軸代表群間距離,橫軸代表觀察值(資料矩陣中的第 n 行)。資 料點間距離主要採用歐幾里得距離(Euclidean distance),在不同的群間距離水平,可切 割出不同數量的群集。
由於設定了列出全部的終端節點,橫軸節點數量較多,文字標籤將無法完全顯示 而發生重疊。
圖 3-1 完全連接法產生之集群樹狀結構
doi:10.6342/NTU201702936
圖 3-3 華德法產生之集群樹狀結構
doi:10.6342/NTU201702936
25
圖三-4 中心法所產生的樹狀圖中,可發現有些節點較為反常地向下產生分支連 結。此是因為中心法在每一聚合階段會重新計算各群集的中心點,新加入的資料點有 可能會影響群集原先的中心點,最終將使得節點的連結方向產生改變。而此現象將會 增加群集分析的困難度。
圖三-3 華德法所進行的分支,其資料點多在同樣的群間距離時就完成聚集。圖三- 2 平均法則是在較低的群間距離(小於 0.8 左右)則完成大部分資料點的聚集。
相較之下,圖三-1 完全連接法的表現介於兩者之間,較不極端。本研究將選擇完 全連接法用以分析低壓AMI 用戶的用電資料,以期獲得較合適的集群分析結果。
下一節開始將介紹目標用戶選取,以及資料探勘的主要流程。
doi:10.6342/NTU201702936
第二節 目標用戶選取
在進行用電資料探勘前,需針對欲探勘之對象進行目標用戶選取。一般而言,目 標用戶可以是全體用戶群,或者視研究者、電業機構之不同目標或需求,選取特定的 用戶群作為目標用戶,並進行資料收集、彙整、分析。
以本研究為例,在全體近萬戶的低壓AMI 用戶中,挑選 2016 年 6 月~2016 年 9 月 夏季期間單月平均用電度數為70~700 度的用戶,篩選後得到的用戶數為 8,408 戶。
而在實際集群分析探勘過程中,則分別挑選ZB63、ZB52 等饋線的不同用戶群作 為主要目標用戶進行分析示範,用戶數分別為23 戶與 47 戶,其累積四個月的有效資 料筆數分別為2,512 筆與 4,743 筆。在決定目標用戶群之後,下一階段將進行資料處理 與分析。
圖 3-5 目標用戶群選取流程
全體用戶篩選
•時間區間
•度數區間
(資料篩選)
目標用戶群選取 (饋線)
•ZB63
•ZB52
27
第三節 資料探勘流程
本研究建立之資料探勘流程如下,前四項為針對用戶資料進行資料彙整、倉儲與 預處理,之後兩項為資料集群分析。
1. 低壓用戶 AMI 用電資料
收集、取得低壓用戶AMI 智慧電表用電資料。
2. 資料庫建構
取得AMI 用電資料,根據資料來源格式將資料進行彙整後,建構適當的資料 庫完成資料倉儲,並確認資料各欄位屬性、數值與缺漏值。
3. 探勘一:目標用戶選取
與本章第二節敘述之目標用戶選取過程相同。
低壓用戶AMI用電資料
資料庫建構
探勘一:目標用戶選取
資料ETL
探勘二:資料集群(Clustering)
集群資料分析
圖三-6 資料探勘分析流程
doi:10.6342/NTU201702936
4. 資料 ETL
將目標用戶的AMI 用電資料從資料庫中取出,進行萃取、轉置與載入
(Extraction-Transform-Load,為資料預處理其中一部分,簡稱 ETL),並根據進 行適當的維度、尺度精簡與標準化處理。
5. 探勘二:資料集群(Clustering)
針對完成ETL 步驟之低壓 AMI 用電資料,進行資料集群。
6. 集群資料分析
檢視、分析集群完成後的結果。
29
第四章 AMI 用戶用電資料探勘分析
第一節 資料探勘分析細部過程概述
本章將針對資料探勘流程之前四項,描述其細部過程。
1. 資料收集與品質 2. 資料庫建構
3. 資料 ETL(Extraction-Transform-Load) 4. 資料預處理
5. 資料集群分析工具
資料探勘之主要操作環境為Microsoft® Windows 10 64-bit,硬體配備為 Intel®
Core™ i5-4460 CPU @ 3.20GHz,16.0 GB RAM,儲存裝置分別有 HDD 與 SSD 兩種形 式。以下各節將詳述資料探勘各階段過程。
doi:10.6342/NTU201702936
第二節 資料收集與品質
本節介紹研究所收集之各項用電資料以及資料品質管理概述。
1. 台電低壓 AMI 用戶用電資料
低壓AMI 用戶用電資料,主要包含之時間區間為 2015 年 09 月至 2016 年 09 月。AMI 智慧電表以每 15 分鐘記錄一筆,在未缺漏的情況下,單日預期將產 生96 筆資料,每筆資料行包含了用戶表號﹑日期時間﹑KW 等三項欄位。
低壓AMI 用戶數量約 10,000 戶,以全年份為例,在經過資料預處理﹑篩選之 後,總資料量約為 10,000(戶) * 96(筆/單日) * 365(日) = 350,400,000 筆資料,
其資料數量級為億級(108)。隨著資料探勘之目標時間區間的調整或是不同的 目標用戶群,其數量級也會產生變動,如:千萬級~千級等等。
2. 台電 NBS(新電費核算開票系統)資料庫之用戶資料
NBS 資料庫之用戶資料,包含了用戶之電號﹑表號﹑(帳單)開票年月﹑用電 地址﹑總用電(收費)度數﹑饋線別等多種欄位。由於是靜態資料,可使用現有 資料庫技術進行查詢,並將資料輸出至其他統計分析軟體進行資料探勘。
資料處理為資料探勘分析最主要的部分,無論是定義資料探勘問題或是制訂資料 分析流程,都必須考慮資料處理的技術與品質,隨著資料探勘應用越來越廣泛,資料 品質的管理也逐漸受到重視。
根據 DAMA UK 於 2013 年發佈的白皮書,提出資料品質的六大向度,對應不同 的產業情境或業務需求情況,資料品質向度的定義也會有些許不同。以本研究之用電 資料探勘為例,可將此六大向度解釋為下列各項:
1. 完整性(Completeness),表示整體資料的完整性,例如:在安裝了 AMI 電表的 目標用戶當中,所能夠收集到的完整用電資料比率。
2. 唯一性(Uniqueness),在單一資料表中,資料不應錯誤地被重複記錄。例如:
單一用戶在單日的用電資料是否出現重複?NBS 資料庫中,符合電費減免的用戶或退 休人員是否出現資料重複記錄的情形?
31
戶編號是否符合編碼規則?地址是否以含有足夠長度且合適的字串資料格式儲存?
5. 精準度(Accuracy),儲存的資料是否能準確地反應其代表的涵義。例如:民國 年月日與西元年月日的轉換。
6. 一致性(Consistency),處理同時存在不同資料集或資料庫的單一資料時,此資 料是否一致。例如:某用戶於低壓AMI 用電資料中的表號,與 NBS 資料庫中的表號 是否相符?
若以上各向度的需求無法被完整滿足,在資料探勘過程,不僅會增加資料處理成 本,也可能造成資料探勘流程必須被迫改變,使得整體流程的效率下降。下列為比較 三種不同的資料探勘流程:
1. 理想探勘流程
假設收集之資料相當乾淨,也不需進行ETL,稍加處理就能進行分析。
2. 實際探勘流程(處理一般資料)
一般資料的實際探勘流程,分析前只需進行適當ETL 和預處理。
收集 乾淨資料 資料
資料倉儲 及預處理
資料 集群
一般資料 (包含少
量髒資 料)
收集 資料
進行 ETL 資料
ETL
資料倉儲 及預處理
資料 集群
doi:10.6342/NTU201702936
3. 實際探勘流程(處理混雜資料)
資料組成相當混雜,需進行多次ETL、較複雜的資料倉儲及預處理。
根據本研究收集資料之特性,其對應之資料探勘流程較接近第三種流程,需花費 較多時間進行資料前置處理、搭配多個資料庫以解決資料倉儲問題,原先的系統也可 能須進行調整以配合新進資料。
綜合上述的資料品質,可再延伸至整體專案管理進行探討。整體系統的開發時程 將受到開發人力、資源限制等不同因素的影響,資料探勘團隊必須能夠確保資料來源 穩定且格式統一,同時盡量減少髒資料的占比,降低資料預處理的複雜度,方能夠更 有效率地進行系統分析與設計,並搭配合適的軟體開發方法進行系統開發。
多種資料 (包含大
量髒資 料)
收集 資料
進行多 次ETL 資料
ETL
資料倉儲及 預處理(複
雜)
資料
集群
33
第三節 資料庫建構
本研究使用低壓AMI 用戶用電資料,牽涉到資訊安全、技術等因素,實務上無法 直接和台電現有資料庫進行連接,因此需取得資料來源檔案,先行建構中介資料庫後 再進行處理。
中介(Middleware)一詞最早出自 1968 年 NATO Software Engineering Conference,
學者Alexander D'Agapeyeff 提出倒金字塔架構,在此架構中,控制程式層、服務程序 層位於下方,而應用程式層位於上方,在中間進行承接的即為中介層。
應用程式層處理使用者的各種需求,並透過中介層讓控制程式層、服務程序層能 夠執行。然而,當底層程式有所更動時,上方層級皆會受到影響,在軟體開發上較為 敏感。
圖 4-1 D'Agapeyeff 倒金字塔架構
本研究為了解決資料來源與資料探勘問題,提出High-Performance Middleware Integrating Data Analysis Tools (簡稱 HIT)的資料處理架構。
doi:10.6342/NTU201702936
圖 4-2 HIT 資料處理架構
此處理架構下,於原始資料庫與資料探勘應用程式之間,建立HIT 以進行資料承 接。HIT 將扮演中介角色,負責從原始資料庫導入資料,並根據不同應用程式的格式 需求進行資料輸出。
傳統資料探勘程序中,原始資料庫若無法滿足資料探勘應用程式需求,將導致資 料探勘效能問題。而原始資料庫在不同的企業環境下,為了系統穩定等因素,不見得 能彈性地新增、修改功能以符合應用程式之需求。因此,透過HIT 的中介處理,可避 免應用程式受到上述之限制,滿足資料探勘需求,完成資料介接。
本研究之原始資料庫所提供資料來源為xml 檔案格式。為了處理此格式,使用 Microsoft® Access (以下簡稱 Access)進行資料聚合,最後以 Microsoft® SQL Server (以 下簡稱SQL Server) 建構資料庫。
初次輸出之資料,經過資料預處理、ETL 等步驟後,再由應用程式進行資料探 勘。以下將介紹資料庫建構過程。
Original
Database HIT
Matlab R SPSS
SAS Python
stata Excel
etc.
35
圖 4-3 資料聚合與資料庫建構過程 1. 收集欲聚合之用電資料檔案(xml)
由於取得之低壓AMI 用電資料並非完整的單日資料單一檔案,而是分散為多 個xml 檔案,因此需預先將分散的檔案進行收集,並依照需要分析的時間區 間進行整理。
2. 將用電資料進行聚合為單一資料表
使用Access 中的 Visual Basic,撰寫自動化巨集,將多個檔案聚合成單一資 料表。
3. 將聚合完畢之資料匯出至 ODBC 資料庫
透過ODBC 資料來源設定,建立 Access 與 SQL Server 之間的連接,將 Access 資料表中的大量資料匯出至 SQL Server。
4. 建立 SQL Server 資料表索引
針對 SQL Server 內匯入完成的資料表建立索引,增加資料處理效率。而索引 又可分為叢集索引與非叢集索引。以下介紹兩種索引(Microsoft Developer Network, 2017):
a. 叢集索引:將資料表或檢視中的資料列,依照其索引鍵值進行排序與儲 存。因資料列本身只能以一種順序進行排序,所以每個資料表只能存在一 個叢集索引。
只有當資料表包含叢集索引時,資料表中的資料列才會以排序後的順序儲 存。當資料表包含叢集索引時,資料表又可稱為叢集資料表。如果資料表 收集欲聚合
之用電資料 檔案(xml)
將用電資料聚合 為單一資料表
(Microsoft®
Access)
將聚合完畢之資 料匯出至ODBC
資料庫
建立SQL Server 資料表索引
doi:10.6342/NTU201702936
沒有任何叢集索引,資料列將儲存在未排序的結構中,這種資料結構又可 稱為堆積(Heap)。
b. 非叢集索引:非叢集索引含有一個與資料列分開的結構,此結構包含了非 叢集索引鍵值,而每個鍵值項目都有一個指標指向資料列。這些從非叢集 索引中的索引列指向資料列的指標,又被稱為資料列定位器。資料列定位 器的結構需視資料頁儲存在堆積或者是叢集資料表而定。若資料頁儲存於 堆積中,資料列定位器即為指向資料列的指標。若資料頁儲存於叢集資料 表中,資料列定位器即為叢集索引鍵。
以下比較建立索引的效能差異。在建立了日期時間索引的資料表中,其搜尋單日 用電資料的花費時間與運算子成本,皆比無建立日期時間索引的資料表較為節省。
圖 4-4 已建立日期時間索引之資料表查詢效能
37
圖 4-5 尚未建立日期時間索引之資料表查詢效能
doi:10.6342/NTU201702936
以搜尋全體用戶的單日資料為例,可以發現在未建立索引的資料表搜尋時,使用 了資料表掃描,而非透過索引進行搜尋,其估計運算子成本(單位:秒)約為建立索引後 的30 倍,總執行時間約為建立索引後的 5 倍(由 4 秒增加至 20 秒)。
雖然在單日搜尋資料的時間差異不大,但是以資料庫進行月資料﹑年資料查詢,
或是較複雜的複合查詢時,未建立索引而導致增加的處理時間,將隨著資料表掃描指 令的累積而巨幅增加,嚴重影響資料庫查詢執行效率。
而在輸出約8,000 名用戶的個別單日用電資料時,搜尋條件包含了表號與日期時 間,倘若只使用[日期時間]作為索引,仍將產生大量運算子成本。若搭配以[表號]建立 之非叢集索引進行查詢,能夠更大幅提昇查詢效率。
結合上述比較作為結論,針對用電資料建立適當的索引,在資料處理上是相當重 要的步驟。藉由本研究之HIT 架構所建立索引,除了可加速探勘資料輸出至應用程 式,在中介上所進行的操作也並不影響原始資料庫,因而能夠維持原資料庫的完整性 與穩定性。
39
第四節 資料
ETL(Extraction-Transform-Load)與輸出隨著硬碟技術不斷提升、儲存成本下降,資料的儲存變得更加容易,處理效率的 議題也開始受到重視。除了透過索引提升資料庫查詢效率,不同類型硬體裝置的物理 限制,也會對資料ETL 過程產生不同的影響。
透過前述的SQL Server 資料庫建構,藉由撰寫 SQL 預存程序以執行 BCP (bulk copy program) 所進行的資料庫查詢與檔案輸出,整個過程係對於磁碟中的資料庫資料 表進行讀取與查詢,並寫入輸出檔,屬於一種隨機讀寫(Random Read/Write)的行為。
本研究使用之SQL Server 進行 BCP 資料輸出 csv 檔案時,在作業系統版本 (Windows 10 64-bit)、SQL Server 版本等使用環境不變的情況下,傳統硬碟 (1TB SATAIII 7200 rpm 32MB cache) 的輸出速度約為 1~2 檔案/分鐘。
圖 4-6 以傳統硬碟進行 BCP 資料輸出
然而,使用固態硬碟 (480GB SATAIII MLC flash) 進行輸出時,輸出速度大幅提 升為 60~70 檔案/分鐘。
doi:10.6342/NTU201702936
41
在HDD 中,隨機讀寫的速度表現取決於數個因素:磁頭移動至資料位於磁盤上磁 軌所花費的時間(Seek Time)、磁盤將需要讀寫的磁區旋轉至磁頭所花費的時間
(Rotational Latency)、切換讀寫磁頭所花費的時間(Head Switch Time)等等。此多種因素 可整合為下列公式:
Data Access Time(ms) = Seak Time(ms) + Rotational Latency (ms) + Head Switch Time(ms)
相較於HDD,SSD 內部元件存有位址對映表(Mapping Table),可直接進行資料邏 輯位址與NAND Flash 物理位址的對映,快速存取資料。當資料庫需同時進行讀取資 料表與寫入輸出檔時,SSD 並不受限於 HDD 磁盤與磁頭的運作原理,讀寫效率能夠大 幅提升。
然而,SSD 在發生壞塊(Bad blocks)或其他物理性損壞時,由於牽涉到記憶元件的 操作,與可針對磁盤進行資料救援的傳統HDD 相比,其修復資料的技術門檻提高許 多。而現今SSD 與 HDD 兩者的儲存成本相比,仍以 SSD 較高,且隨著容量提升,其 成本差距也更加顯著。
綜合以上各點,企業可視自身需求採用合適的SSD 儲存方案以提升資料探勘及 IT 系統效率,同時也需更加注重資料備份,結合磁碟陣列、雲端儲存、異地備援等多種 措施,並建立完善的災後復原計畫,以備不時之需。
doi:10.6342/NTU201702936
第五節 資料預處理
此階段將延續前部分SQL Server BCP 指令順利產出的用電資料檔案(csv 格式),透 過Python 程式將其進行篩選、轉置與標準化等預處理步驟。
Python 為一種直譯式程式語言,其最初設計者與主要架構師為 Guido van
Rossum,其簡單而快速的語法特性使其能夠敏捷開發各式應用,並成為目前多數平台 中相當強大且流行的程式語言,目前由Python 軟體基金會進行管理與語言開發。
(Python.org, 2017)
在本研究中經過資料庫建構與ETL 階段的資料,仍須進行資料預處理,以提供給 分析工具進行下一階段的分析。Python 支援 csv 檔案的操作,經由 SQL Server BCP 指 令匯出之用電資料csv 檔,可透過 Python 進行資料預處理。以下是經由 Python 處理的 項目:
1. 處理資料遺漏值:尋找殘缺或不需分析的資料行,進行刪除。本研究以每日 96 筆作為低壓AMI 用戶用電資料的單日篩選基準,為了避免時間欄位被錯誤轉 置處理以及維持資料的真實性,未滿96 筆的資料將被刪除,不進行插補修 正。
2. 數值標準化:將用電資料原始值進行標準化,經過標準化後得到的資料值將介 於[0,1]之間。
3. 資料存檔:將完成上述預處理項目的資料進行存檔輸出,以供下一階段集群分 析使用。
43
第六節 資料集群分析工具
在完成ETL 及 Python 資料預處理等步驟後,本研究使用 Matlab 撰寫分析程式,
將低壓AMI 用戶用電資料進行集群分析演示。
Matlab 為 MATrix LABoratory 的縮寫,字義為「矩陣實驗室」,為美國 The MathWorks 公司所推出的商業數學分析軟體。其提供整合了數值計算、資料分析、演 算法等項目的高階語言開發環境,可呼叫C、C++、Java、Python 等多種語言編寫而成 的程式碼,也可開發資料視覺化、使用者介面等功能,並可進一步延伸至商管分析建 模、圖像與訊號處理、自然科學資料分析、工程系統控制分析等多種領域。
透過Matlab 處理的項目如下:
1. 讀入資料:讀入已完成預處理的用電資料。
2. 資料運算:將讀入矩陣中之資料進行運算,將其進行集群分析。
在Matlab 中使用之 linkage 語法為:
Z = linkage(Y,'complete') 而使用之cluster 語法為:
T = cluster(Z,'cutoff',c) 或
T = cluster(Z,'maxclust',5)
其中Y 代表相異度矩陣,Z 代表以階層式聚集法產出的集群樹矩陣,c 為切割 Z 時所設定的距離值,可輸入特定值,或是使用 'maxclust' 指令以直接指定最 大集群數目。
3. 資料視覺化:將集群分析完成的結果進行尺度縮減調整,並輸出視覺化圖表至 使用者介面。
doi:10.6342/NTU201702936
第五章 AMI 用戶用電資料探勘分析演示
第一節 用電資料分析結果
針對NBS資料庫之用戶資料,經建構SQL Server資料庫進行彙整、處理後,可根據 用電區域、用電度數、開票年月、電表裝設日期、所屬饋線等不同欄位的靜態資料進 行篩選、分析。
圖五-1 以第三章第二節所描述之根據月平均用電量進行篩選的8,408戶低壓AMI用 戶,於2016年6月至9月之月均用電度數產生的分組圖表。
45
此分組係針對月均用電度數介於70~700 度的用戶,統計其月均用電度數並進行分 組。根據分組圖示,可發現以140 度至 365 度左右的區間占比較多。
除了以NBS 的靜態資料真接針對用戶進行統計,本研究另使用低壓 AMI 用戶之 動態資料作為主要分析。圖五-2 為使用 Matlab 進行的低壓 AMI 單一用戶用電資料集 群分析。
圖 5-2 低壓 AMI 單一用戶用電資料集群分析(使用 Matlab)
在程式的使用者介面,可根據輸入的指定群數,將單一用戶於四個月內的有效用 電資料分成數個群集。
上方欄位顯示了各群集,點擊各群集後,下方欄位將顯示群集中所包含的資料內 容。透過下方欄位中各資料的日期資訊,可了解此用戶在不同群集中的用電情形。
doi:10.6342/NTU201702936
另外,也可調整時段篩選,檢視不同時段的群集結果。
圖 5-3 低壓 AMI 單一用戶用電資料集群分析(時段篩選)
將原先凌晨0 點至晚上 24 點的全天時段,調整為中午 12 點至晚上 24 點的半天時 段後,該群集將根據相對應的時段進行篩選,重新顯示群集內資料內容。
47
使用Matlab 的 cophenet 函數,可用以衡量階層式分群產生之樹狀結構,是否能忠 實地反映出所觀測資料之相異度,因此可比較多組不同集群結果的表現,以找出候選 之集群數。以下使用與前述單一用戶相同之資料進行集群分析,並列出不同
maxclusters 群集數介於 3 至 9 之間,所對應之 cophenet 函數不同的輸出值:
Maxclusters = 3, cophenet = 0.9841
Maxclusters = 4, cophenet = 0.4177
Maxclusters = 5, cophenet = 0.2376
Maxclusters = 6, cophenet = -0.2789
doi:10.6342/NTU201702936
Maxclusters = 7, cophenet = -0.0898
Maxclusters = 8, cophenet = 0.1023
Maxclusters = 9, cophenet = -0.2212
49
由以上的結果,可發現當maxclusters 群集數在 3 的時候有最大的 cophenet 輸出 值,其次為群集數4。
然而,maxclusters 與 cophenet 輸出值,兩者並非呈正向或負向關係,而是視原始 資料的特性而有所改變,因此,進行不同資料的集群分析時,其產生之maxclusters 與 cophenet 輸出值的對應結果也會不盡相同。過少的群集數會使得部分的用電行為趨勢 被併入群集中而被覆蓋掉,過多的群集數則會使得用電行為趨勢較難以解釋。一般而 言,將maxclusters 群集數限制在 10 以下,並根據不同研究需求尋找較佳群集數目,能 夠提供較合適的集群分析結果。
以下將以第三章第二節提到的ZB52 饋線之目標用戶群為例,展示低壓 AMI 用戶 集群分析結果。
doi:10.6342/NTU201702936
51
圖中顯示了ZB52 饋線之目標用戶群,於 2016 年 6 月至 2016 年 9 月之低壓 AMI 用電資料集群分析。
群集共分為C1~C8 共 8 群,以不同顏色標示各群集的用電趨勢。
縱軸為AMI 電表 KW 值經過標準化處理後之值。
橫軸為時間,由每15 分鐘一筆組成 24 小時共 96 筆時點,以 6 小時為刻度單位。
資料以 “表號-日期” 作為資料點 ID 組成方式,用以辨識用電資料點代表的不同表 號或不同用電日期。有效資料筆數為4,743 筆。
圖中可發現多數群集皆有往兩側隆起的趨勢,顯示出目標用戶群之用電在晚上逐 漸形成尖峰,而在日間時段趨於緩和。圖中又以C3、C4 與 C5 三個群集具有較高尖 峰,下列將以此三個群集進行細部分析說明。
doi:10.6342/NTU201702936
53
在 C3 群集中的用戶有 18 戶,為位於台北市萬華區中華路二段上某區段之用戶 群,多為二樓以上住宅單位(包含一公司行號)。
群集中的用電資料日期分布,六月份有21 筆,七月份有 36 筆,八月份有 26 筆,
九月份有20 筆,共 103 筆,其中以星期六累積次數較多。
表 5-1 ZB52 饋線 群集 C3 週間累積次數
C3 群集的用電趨勢在凌晨三點至晚上六點之間呈現較少用電,但在晚上六點之後 用電開始急劇增加,在晚上十點半左右達到高峰,之後開始下降。
0 5 10 15 20 25 30
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
55
在 C4 群集中的用戶有 30 戶,同樣是位於台北市萬華區中華路二段上某區段之用 戶群,多為二樓以上單位(包含一公司行號)。
群集中的用電資料日期分布,六月份有74 筆,七月份有 59 筆,八月份有 49 筆,
九月份有65 筆,共 247 筆,其中以星期四累積次數較多。
表 5-2 ZB52 饋線 群集 C4 週間累積次數
C4 群集的用電趨勢從凌晨一點半的用電高峰逐漸下降,早上六點至晚上九點之間 則呈現較少用電,晚上九點之後用電趨勢再度上升。
0 5 10 15 20 25 30 35 40 45 50
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
57
在 C5 群集中的用戶有 9 戶,同樣位於台北市萬華區中華路二段上某區段之用戶 群,多為三樓以上單位。
群集中的用電資料日期分布,六月份有11 筆,七月份有 17 筆,八月份有 8 筆,
九月份有9 筆,共 45 筆,其中以星期六累積次數較多。
表 5-3 ZB52 饋線 群集 C5 週間累積次數
C5 群集的用電趨勢具有兩個尖峰,從凌晨零點開始,在凌晨四點出現第一個尖峰 後下降,早上十點後再度上升,在下午兩點半左右達到最大尖峰,之後下降,晚上時 段則並未出現任何尖峰。
接下來另以ZB63 饋線之目標用戶群進行集群分析,並針對分析結果進行說明。
0 2 4 6 8 10 12
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
59
圖中顯示了ZB63 饋線之目標用戶群,於 2016 年 6 月至 2016 年 9 月之低壓 AMI 用電資料集群分析。
群集共分為C1~C7 共 7 群,以不同顏色標示各群集的用電趨勢。
縱軸為AMI 電表 KW 值經過標準化處理後之值。
橫軸為時間,由每15 分鐘一筆組成 24 小時共 96 筆時點,以 6 小時為刻度單位。
資料以 “表號-日期” 作為資料點 ID 組成方式,用以辨識用電資料點代表的不同表 號或不同用電日期。有效資料筆數為2,512 筆。
ZB63 饋線之目標用戶群,與前述之 ZB52 饋線之目標用戶群相似,多數群集也有 往兩側隆起的趨勢,在晚上逐漸形成尖峰,並在日間時段趨於緩和。圖中又以C4、C5 與C6 三個群集具有較高尖峰,下列將以此三個群集進行細部分析說明。
doi:10.6342/NTU201702936
61
C4 群集中的用戶僅有 5 戶,為位於台北市萬華區東園街某區段之用戶群,皆為二 樓以上單位。
群集中的用電資料日期分布,六月份有3 筆,七月份有 3 筆,八月份有 5 筆,九 月份有4 筆,共 15 筆,其中以星期五累積次數較多。
表 5-4 ZB63 饋線 群集 C4 週間累積次數
C4 群集的用電趨勢僅在晚上六點至凌晨零點之間形成尖峰,尖峰出現在晚間九點 左右,其他時段用電趨勢則無起伏。
0 1 2 3 4 5 6
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
63
C5 群集共 17 戶,同樣為位於台北市萬華區東園街某區段之用戶群,多為二樓以 上單位。
群集中的用電資料日期分布,六月份有33 筆,七月份有 54 筆,八月份有 39 筆,
九月份有28 筆,共 154 筆,其中以星期六累積次數較多。
表 5-5 ZB63 饋線 群集 C5 週間累積次數
C5 群集的用電趨勢,從凌晨一點半的尖峰開始下降直到早上六點,而後未有起 伏,在晚上六點過後,用電趨勢再度上升。
0 5 10 15 20 25 30
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
65
C6 群集共 17 戶,同樣為位於台北市萬華區東園街某區段之用戶群,多為二樓以 上單位。
群集中的用電資料日期分布,六月份有192 筆,七月份有 140 筆,八月份有 156 筆,九月份有110 筆,共 598 筆,其中以星期四累積次數較多。
表 5-6 ZB63 饋線 群集 C6 週間累積次數
C6 群集的用電趨勢,從凌晨零點開始持續上升,在凌晨四點形成尖峰,而後下降 未有起伏,晚上九點過後,用電趨勢再度上升。
0 20 40 60 80 100 120
日 一 二 三 四 五 六
次數
doi:10.6342/NTU201702936
第二節 用電資料分析結論
根據以上用電趨勢的分析結果所檢視的群集,大致可分為兩類:
1. 典型尖峰
此類用電行為於特定時段形成之用電尖峰較為常見,可視為一種較普遍的用 電行為趨勢。
2. 於特定時段所產生之尖峰
此類用電行為在特定時段與整體的趨勢相比差異較大,比其他群集的用戶更 容易在此時段出現尖峰。
第一類之典型尖峰,皆可在ZB52 饋線或 ZB63 饋線的大部分群集用電趨勢上發 現。其目標用戶群會在凌晨與晚上時段形成用電尖峰,形成兩側較高的用電趨勢圖。
此類典型尖峰通常代表一般住宅用戶於夏季晚上,洗衣機、冷氣機等耗電量大的 家用電器使用頻率上升,而形成用電尖峰。凌晨時,則可能因就寢作息、冷氣定時設 定等各種因素,用電趨勢逐漸回復至較低水平。
針對此類尖峰,可根據現有夏季節電、需求面管理相關策略,提供符合用戶需求 的電價方案,藉以達到調整、抑低用戶用電尖峰的效果。也可結合用戶之背景資料、
電器資料等更細部的用電行為分析,作為夏季時間電價等相關節電方案執行策略的參 考依據。
第二類之特定時段尖峰類型,其中可能包含單一尖峰或多重尖峰。根據ZB52 饋線 所屬之C3、C4 群集,以及 ZB63 饋線所屬之 C4、C5 與 C6 群集的分析結果,可以發 現這些群集在特定時段出現單一尖峰。而ZB52 饋線所屬之 C5 群集,則是在凌晨與下 午各出現一次尖峰,屬於多重尖峰。
若要抑低、改善群集的特定時段之尖峰,可針對該群集用戶於特定時段上的用電 行為,進一步調查用戶詳細的背景資料、電器資料、使用情況、是否有突發事件等各 種因素,以瞭解特定時段用電尖峰的成因。
67
第六章 未來發展與研究限制
第一節 用電資料延伸發展研究
藉由本研究之低壓AMI 用戶用電資料庫建構過程,電業相關機構未來能夠以此作 為依據,建置巨量用電資料處理系統、加入至現有AMI 系統架構並改善系統效率,視 不同的研究需要,以所屬區處、用電地址等其他變數進行目標用戶篩選,實現動態用 電資料的巨量資料探勘。
隨著物聯網以及家庭能源管理系統 (Home Energy Management System, HEMS)逐漸 發展普及,未來也能以本研究之資料庫建構過程為基礎,針對各電器設備的動態用電 資料,建立能夠彙整、管理資料的資料庫與處理程序。
藉由分析HEMS 當中各電器的的用電行為,將能夠更精確地對用戶進行集群分析 或分類,其分析結果可再回饋至本研究或其他相關AMI 用電資料探勘程序,進行原有 程序的驗證與改良。
doi:10.6342/NTU201702936
而結合用電日期資料標籤的集群分析,已能夠找出目標用戶群在特定時間區間內 的用電行為特徵,未來也能結合其他監督式方法,以不同的變數進一步找出具代表性 的用戶用電行為模式,協助提升時間電價等需求面管理措施的效率。
對於電業機構的的工程單位,藉由本研究的集群分析結果,可再進一步探討、利 用分析結果以降低用電饋線、輸配電設備之例行或臨時性維修對於目標用戶群的影 響,提升用戶用電品質與客戶關係管理。
在資料探勘技術方面,未來可繼續嘗試Spark、MapReduce 等相關資料處理技術,
搭配HDFS、HBase 等不同的資料儲存方式,針對巨量資料建立平行處理架構,讓多台 主機可共同進行運算處理,加快巨量資料的分析速度,在資料預處理階段時也能更有 效地過濾無用的缺漏資料,節省資料倉儲成本。
本研究針對目標用戶群的用電資料探勘,預期能提供需量管理相關措施的決策參 考,改善用電尖峰問題,協助推動需求面管理與智慧電網發展,幫助達成節能減碳、
永續能源等目標。