Risk Signaling in the Health Insurance Market
Chu-Shiu Li*
Department of Economics, Feng Chia University, Taiwan
Abstract
This paper analyzes equilibrium health insurance premium dependencies on signaling costs given individual health states, risk types, and risk type attributes. Since precise determination of an individual’s premium is costly, insurers can categorize insureds based on relative screening costs. We show for two risk types, the equilibrium premium is either community-rated or risk-rated depending on screening costs. For multiple risk types, both policies may be concurrently available in equilibrium.
Key words: adverse selection; separating equilibrium; pooling equilibrium; signaling costs JEL classification: G22; I11
1. Introduction
Precise determination of an individual’s health insurance premium is costly and limited due to difficulties in observing all relevant individual health characteristics. Because of this, insurers “make do” with less than complete information. That is, insurers rely on more readily accessible and less costly data. Population simulation provides one method for sorting individuals into risk types. Insurers can separate insureds into different groups based on the nature of the categories and the relative costs of population simulation. In addition, insurers also can require a potential insured to submit to a physical exam to determine his presumptive health status before agreeing to issue a contract. Insureds may pay the physical examination fee in hopes of demonstrating a more favorable health condition and justifying a lower premium. In other words, for relatively healthy insureds, there is a trade-off between signaling costs and subsidy costs. The level of these signaling costs is related positively to the accuracy of observing the real risk types.
The health insurance industry is entitled to access to and benefits from any information that increases its ability to predict the probability of medical claims. Kaufert (2000) indicates that over the past century of rapid population growth,
Received July 28, 2004, revised January 18, 2005, accepted January 27, 2005.
*Correspondence to: Department of Economics, Feng Chia University, 100 Wenhua Road, Taichung,
Taiwan. E-mail: [email protected]. Tel: 886-4-24517250 ext. 4491. Fax: 886-4-24520530. The author is grateful to the Managing Editor and two anonymous reviewers for helpful advice and suggestions. Comments by Roman Gulati greatly improved the paper.
prediction accuracy has coincided with escalation in the amount of medical information collected. Various types of health information are now accessible concerning detection, costs and benefits of health care, and insurance evaluation criteria.
Based on welfare analysis, Crocker and Snow (1986) show that if the resource cost of observing the categorizing signal is negligible, then categorizing is always potentially superior to not categorizing. Hoy and Polborn (2000) demonstrate that the practice of genetic testing for life insurance has an effect on the equilibrium under adverse selection and describe conditions for Pareto improvement.
Many studies have analyzed the structure and existence of the equilibrium associated with adverse selection in a competitive insurance market (Akerlof, 1970; Rothschild and Stiglitz, 1976; Wilson, 1977). Rothschild and Stiglitz (1976) assume that each insurer follows a pure Cournot-Nash strategy in a two-stage screening game. They show that, if equilibrium exists, it must be a separating (risk-rated) equilibrium, which means that individuals with different loss probabilities will buy separate insurance policies. Differing with the Rothschild-Stiglitz model, Wilson (1977) introduces an equilibrium concept that assumes firms may take into account reactions by other firms when they change their menu of policies making only non-negative expected profits. In this way, a pooling (community-rated) equilibrium may exist such that all individuals with various loss probabilities obtain identical insurance policies. Therefore, in terms of health insurance, equilibrium pricing policy takes the form of either the community-rated contract or the risk-rated contract depending on assumptions about an insurer’s reaction to competitors.
This paper approaches equilibrium by considering the relationship between information costs and risk-rated premium differences. The equilibrium solution is either community-rated or risk-rated, depending on the level of information costs and the loss differences between relatively healthy and unhealthy insureds. In the case of multiple risk types, community-rated and risk-rated policies may co-exist in equilibrium. This is a key difference with previous studies.
The remainder of this paper is organized as follows. Section 2 derives the policy equilibrium for two risk types. Section 3 generalizes the result to n risk types and considers both risk-rated and community-rated premiums in the context of refined classification of risk type attributes. The final section concludes.
2. Two Risk Types 2.1 The basic model
Suppose for simplicity that there are only two risk types for the risk-averse insured. Medical losses are assumed to be distributed continuously, and insurers are assumed to be risk neutral in a competitive market. All policies offer full coverage. Suppose further that the two risk types correspond to medical loss distributions with possibly distinct means— µ for healthy individuals and H µ for delicate D
individuals, where µ <H µD
policy (PC) can be written as a weighted average of loss probabilities as in Equation
(1a), where λ and H λ refer to the proportions of the community population D
categorized as healthy and delicate, respectively. This implies that the community-rated premium equals the anticipated per capita medical loss to the community for full coverage policies.
In addition, let k0 denote the per person information cost (e.g., the cost of
X-rays) incurred by the insured to reveal his health status. The risk-rated premium for an individual (PR) with risk type r is the sum of his anticipated per capita
medical expenditure and the per person information cost as described in (1b), where delicate individuals have no incentive to reveal their high loss probabilities, implying the value of k0 should be zero.
D D H H C P =λ µ +λ µ (1a) . if if ) ( 0 ⎩ ⎨ ⎧ = = + = D r H r k r P D H R µ µ (1b) In sum, this study assumes that, under conditions of a competitive market, individuals bear the costs of providing relevant information to insurers in exchange for an actuarially fair premium. Delicate individuals, anticipating no advantage, do not incur information costs necessary to demonstrate their health status.
2.2 Equilibrium premium policy
In the case of only two risk types, the equilibrium premium is either PC or R
P, depending on the cost of observing the categorizing signal. Since individuals prefer insurance contracts with lower premiums, a lower information cost k0 such
that C
H
R H k P
P( )=µ + 0< provides strong incentive for healthy individuals to choose the risk-rated policy PR(H)<PR(D). Therefore the equilibrium premiums are PR(H) and PR(D), where PR(H). In contrast, if the information cost is too
high, so that C
H
R H k P
P( )=µ + 0> , both healthy and delicate individuals select community-rated policies and only PC exists.
The condition that C H P k < + 0 µ is equivalent to D H D k0<(µ −µ )λ . This implies that if the signaling cost k0 is lower than the cross-subsidy cost
D H D µ λ
µ )
( − , that is, the expected difference between the medical costs for delicate and healthy individuals times the proportion of delicate individuals, then the separating contract emerges as the equilibrium. Otherwise, if D H D
k0 >(µ −µ )λ , the equilibrium policy is a pooling contract.
Since this paper examines health insurance pricing when applicants can signal their risk type through costly examinations, separating equilibrium policies exist if the lower expected loss plus the examination cost is no greater than the lowest deductible that effectively screens out the delicate individuals in the manner of Rothschild and Stiglitz (1976). In contrast, if the community-rated premium is less than the expected loss for a healthy individual plus the examination cost, the equilibrium policy is a pooling contract. In this case, our result supports the finding
that a pooling contract without deductible is preferred to the pooling contract with deductible by healthy individuals in the manner of Wilson (1977).
3. Generalization to n Risk Types
The simple model above can be generalized to the analysis of markets with more than two risk types. As in the case of two risk types, it is assumed that all policies offer full coverage. In the case of multiple risk types, the information cost to identify an individual having a high possibility of incurring a specific disease is positively related with medical technology. Therefore we assume that informed insureds with risk type r can signal their risk types through increasingly costly examinations by spendingkr, where the function k(r) is strictly increasing in r. The
examination results for different risk types are perfectly informative.
Assume that there are n risk types ordered by the means of their medical loss distributions as 1 2 1 ... µ µ µ µn > n− > > > (2) That is, the most healthy risk type is r=1 and the most delicate risk type isr= , n given per person information costs. The discrete case also implies that a relatively delicate individual is less likely to reveal his health status. We can imagine that all potential insureds judge their health status before taking a physical examination to determine if it worthwhile to pay the information cost in exchange for a lower premium. Thus, following the order in (2), there exists a critical level of risk type h such that for the relatively healthy individuals with risk typer< , the risk-rated h premium is equal to the expected loss for their risk type µ plus the examination r
costk(r). However, the relatively delicate individual with r≥ has no incentive h to pay the high signal costs associated with a physical examination to reveal his health status. Therefore, for those individuals with risk type no less than h , the examination cost k(r) equals zero and they will be charged the highest risk-rated premium µ due to their unwillingness to provide proof of their health status. n
Figure 1 shows the determination of the critical risk type. In Figure 1, after smoothing the discrete set of risk types, the line CGB represents the risk-rated premium for all cases, where CG is the possible premium for relatively healthy individuals who choose to pay the information cost and GB shows the identical premium µ paid by relatively delicate individuals who obtain no advantage in n
spending signal costs k(r). Less delicate individuals, say with risk typen−1, still need to pay the highest risk-rated premium µ . The reason is that to prove their n
mean loss is µ , the information cost n−1
) 1 (n−
k is necessary, making the total cost ) 1 ( 1+ − − k n n
µ , which is larger than µ . The same situation applies to all n
individuals with risk type r≥ . For these cases, foregoing examinations and h accepting the premium µ is the best choice. n
. if if ) ( ) ( ⎩ ⎨ ⎧ ≥ < + = h r h r r k r P n r R µ µ (3) Equation (3) is the general form of the risk-rated policy. Ifn=2, let µ =1 µH,
D µ µ =2 , and 0 ) 1 ( k
k = . By ignoring h , which is meaningless in the case of two risk types, Equation (3) is the same as Equation (1b) in Section 2.1.
Figure 1. The Risk-Rated Premium with Information Costs
3.1 Risk-rated premiums
This section focuses on the relationship between the risk-rated premium and examination of risk type attributes. Risk type attributes are factors containing specific risk information and can be identified with varying costs depending on the degree of accessibility. For example, to predict the probability of some illnesses, gender, age, and smoking habits are readily available attributes with zero or negligible access costs. However, other attributes can only be identified by relatively more expensive means, such as by X-rays or by even more costly techniques such as positron emission tomography, a kind of nuclear medicine.
Suppose that risk types can be characterized by sets of attributes. Therefore, based on the information in one attribute set S , there exist individuals with risk type r(S) having mean medical loss µr(S) that are offered an insurance policy with risk-rated premium PR( Sr ) upon spending information cost k( Sr ) . Analogously, µr( AS, ) is the mean medical loss for risk type r( AS, ) when the classification is built on attribute sets S andA . Let PR(rS,A) denote the risk-rated premium for individuals with risk type r( AS, ). By considering the mean medical loss µr( AS, ) and information cost k(rS,A) , P(rS,A)
R can be r (risk type) PR 1 h n B μ1 C μn D μh + k(h) μr + k(r) μr G A μ1+ k(1)
calculated as ). , ( ) , ( ) , (rS A S A k rS A P r R =µ + (4)
Suppose that in order to obtain an appropriate insurance policy, basic data on
S, with corresponding information cost k( Sr ), are required. The rational insured should also consider whether it is worthwhile to provide data on attribute set A in addition to S. If the additional information cost for attribute set A is low enough, then it is beneficial to spend the information cost k(rS,A) and the result is a set of
) , (rS A
PR policies. The condition for the effectively available risk-rated policy
) , (rS A
PR is PR(rS,A)<PR(rS). However, if k( Sr ) is high enough, then only
policies PR( Sr ) using attribute set S result.
Therefore, the above analysis can be extended to multiple attribute sets. To obtain the loss distribution for a specific risk typer, the information cost of different attribute sets k( ir ) is required, where i=S,S∪A,S∪A∪B,.... The mean medical loss of risk type r when observing attribute set i is µr(i). The effectively available policy is dependent upon the cost of obtaining additional information regarding additional attributes and the potential premium differences among different attribute-based policies. The resulting risk-rated premium is
).
(
)
(
)
(
r
i
i
k
r
i
P
r R=
µ
+
(5)The marginal cost of obtaining information about additional attributes is assumed to increase at an increasing rate; that is, dk(ri) di>0 and
0 )
( 2
2k ri di >
d . Since we can refine risk classes (also ordered by their mean losses) by exploring information on sub-classes of attributes, information about additional attributes is obtained when it reduces the expected costs. Thus, information about additional attributes is assumed to lead to the lowest mean loss of sub-classes decreasing at a decreasing rate. That is, dµr(i) di<0 and d2µr(i) di2<0.
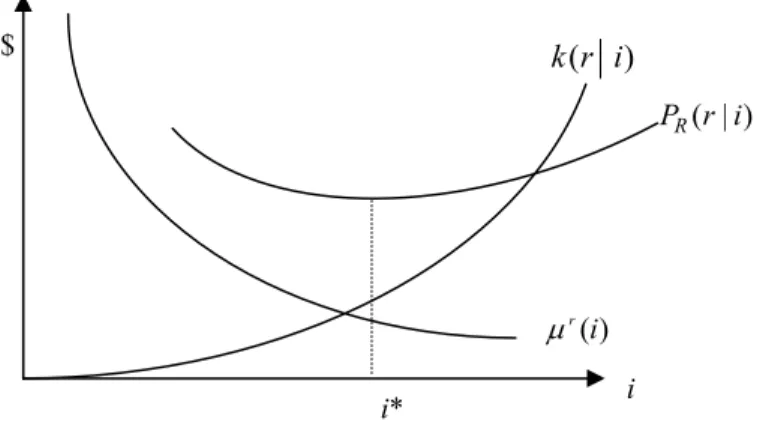
In Figure 2, PR( ir ) represents the vertical summation value of (i)
r
µ and )
( ir
k . The insured will try to minimize PR( ir ), and the optimum attribute
*
i
satisfies the following first order condition: . ) ( ) (i* di* dk ri* di* d r = − µ (6)
Equation (6) implies that the marginal benefit of refining the risk type attribute set equals the marginal cost of information.
3.2 Community-rated premiums
Intuitively, a relatively less healthy individual is less likely to reveal his health information; thus, he prefers community-rated policies. In the case of multiple risk types, the community-rated premium PC includes members with risk types ranging
from a specified type r to the least healthy risk type n, based on the assumption that risk types can be ordered as indicated in Equation (2). Hence, the pooling
contract insuring individuals with risk types between r and n has premium PC formulated as n r n r P n r j j r C =
∑
< ≤ = 1 , ) ,...., ( λ µ , (7)where λ refers to the proportion of the population categorized as risk type r . r
This implies that the less healthy the risk type r , the larger the premium PC. Figure 2. The Optimum Attribute Set for Risk-Rated Premium
3.3 Equilibrium premium policy
In the case of multiple risk types (n>2), three possible equilibria may exist. First, the community-rated equilibrium policy (PC) exists only if
, 1 ), ,..., ( ) ( ) (r k r P r n r h P C r R =µ + > ≤ < (8a) and . ), ,..., (r n h r n PC n≥ ≤ ≤ µ (8b)
The second possible equilibrium is the risk-rated policy. This situation occurs only if the signs in conditions (8a) and (8b) are reversed; that is,
, 1 ), ,..., ( ) (r P r n r h k C r+ < ≤ < µ (9a) and . ), ,..., (r n h r n PC n≥ ≤ ≤ µ (9b)
Finally, community-rated and risk-rated policies are concurrently available only if there is a risk type j satisfying the following conditions:
) (i r µ ( ) k r i ( | ) R P r i i* i $
, 1 ), ,..., ( ) (r P r n r h k C r+ < ≤ < µ (10a) . ), ,..., (r n h r n PC n≥ ≤ ≤ µ (10b)
Conditions (10a) and (10b) imply that individuals with risk types ranging from 1
=
r to r= h−1 prefer the risk-rated policy and those with risk types ranging from r= to h r= prefer the community-rated policy. n
4. Conclusion
The assumption of asymmetric information at the time of issuing a health insurance contract implies that information costs are of great importance in determining the type of equilibrium policy; it is costly to collect detailed information on the risks of individual customers. This paper analyzes how the equilibrium premium policy depends on the level of signaling costs given different assumptions about individual health states, risk types, and risk type attributes. We show that in the case of two risk types, the equilibrium premium is either community-rated or risk-rated depending on the cost of observing the categorizing signal. In the case of multiple risk types, it is also possible that these two policies are simultaneously available. The findings in this paper provide economic insights into the characteristics of the equilibrium signaling model of health insurance contracts. References
Akerlof, G. A., (1970), “The Market for ‘Lemons’: Quality Uncertainty and the Market Mechanism,” Quarterly Journal of Economics, 84, 488-500.
Crocker, K. J. and A. Snow, (1986), “The Efficiency Effects of Categorical Discrimination in the Insurance Industry,” Journal of Political Economy, 94, 321-344.
Gauthier, L., J. A. Lamphere and N. L. Barrand, (1995), “Risk Selection in the Health Care Market: A Workshop Overview,” Inquiry, 32, 14-22.
Hoy, M. and M. Polborn, (2000), “The Value of Genetic Information in the Life Insurance Market,” Journal of Public Economics, 78, 235-252.
Kaufert, P. A., (2000), “Health Policy and the New Genetics,” Social Science & Medicine, 51, 821-829.
Rothschild, M. and J. Stiglitz, (1976), “Equilibrium in Competitive Insurance Markets: An Essay on the Economics of Imperfect Information,” Quarterly Journal of Economics, 90, 629-650.
Wilson, C., (1977), “A Model of Insurance Markets with Incomplete Information,” Journal of Economic Theory, 16, 167-207.