多功能虛擬實境動態模擬系統
Multipurpose Virtual-Reality-Based Motion Simulator
計畫編號:NSC-88-2213-E-009-114
執行期間:88年8月1日至89年7月31日
主持人:林進燈 教授
[email protected]執行機關:國立交通大學電機與控制工程研究所
計畫摘要與目的
工安是目前台灣社會的一個重要課題,其 中有關各種載具及機器設備的安全操控,更是 各方矚目的重點。為了避免利用在實際環境中 以真實載具或機器進行人員訓練或測試所造 成之高消費(包括時間、空間及金錢)及高危 險性,本計畫將發展一個多功能的虛擬實境動 態模擬系統,經由虛擬實境(VR)與運動模擬 器的結合,以逼真地模擬實際場景與設備或載 具,而協助達到工安所要求的多種訓練與考核 任務。本計畫執行期限共計三年,在第一年執 行成果中,我們已經初步結合各個子計畫的第 一年成果,完成虛擬車輛駕訓的工作。在目前 第二年的執行中,進一步打算完成虛擬遊艇操 控系統。本計畫乃以四個子計畫的型式所合力 完成,以下分別就各個子計畫所完成的工作做 簡要報告。子計畫一:虛擬實境動態模擬系統中之
行為轉換及階層式控制法
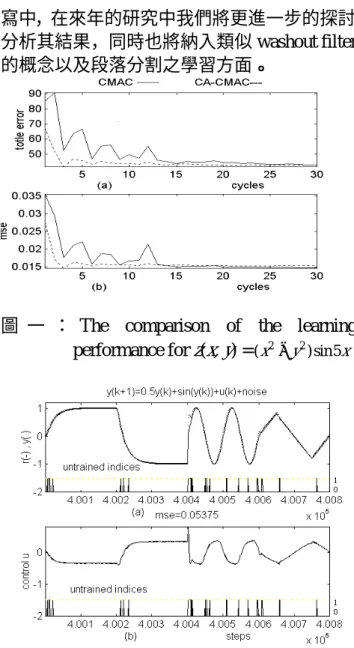
在虛擬實境的動態模擬系統中,當虛擬 系統接收到控制命令而設法產生應有的運動 行為描述時,在虛擬實境的顯示以及在模擬運 動平台的運動行為則是要儘可能地模擬並使 其有身歷其境的感受,以達到虛擬實境的目 的。而為了達到此一目標,上述的運動行為描 述必須恰當的轉換給虛擬實境的顯示系統以 及運動平台的控制系統。本子計畫是將相關之 運動行為提供給顯示子系統,而以階層式的智 慧控制 概念 來追 求更 高階 而抽 象之 控制 目 標,也就是說將六軸運動平台的運動控制當成 低階控制系統,而我們的系統則是設法設定控 制輸入以使運動行為更符合需求。 在去年第一年計畫裡,主要的研究為階 層式控制器的理論探討及預估器的建立及分 析比較。在階層式控制中,我們以模糊預估器 之建立來產生對控制輸入之可能結果並加以 評估。在此一階層式控制架構中,我們以模糊 預估器之建立來產生對控制輸入之可能結果 並加以評估。以模糊法則庫的模糊控制需要一 些比例因子將實際所獲得之資訊,轉入其相對 應之陳述空間及由推論結果轉換為明確輸出 值。而為了獲得理想的響應,依照設定的性能 指標,建立一些對比例因子調適之規則,重複 調整比例因子,直到其響應符合設定之性能指 標,稱此為自我調適。在本研究中我們依據上 述的自動調適求得之比例因子,依據對系統之 響應評估,做重覆的自我調整。上述是在理論 之研究探討方面的方法,而在實際運作上等到 六軸系統以及虛擬實境的顯示部分可供測試 時,其子計畫將對平台控制的行為分析以及感 受力靈敏度的實驗等進行探討,以利未來之發 展。在控制輸入的修正方面,過去文獻都是以 預估器的概念來做控制行為之修正,可是這樣 的修正法則常需要搜尋才能產生較佳的控制 行為,可是由於這是即時操控系統,即時性的 反應性能保證便是一個重要的研究課題,必須加以克服,也就是說如何在有限的時間內找到 到目前為止的最好控制輸入,而不會造成系統 之問題。當然亦有文獻提出一簡單的規劃、搜 尋及暫存的處理方法來避免回尋,以保證解答 之可用性。另外亦有文獻利用模糊法則以簡單 之增減量的修正演算法,常因為每次都要求即 時最佳之反應而產生每次控制輸入都是在飽 和區的地方而使得控制的效果不好。而在此第 二年度本計畫所提的研究,主要是延續第一年 中的探討,而在前一年度的階層式智慧控制 器,我們僅是利用簡單的輸入修正和低階同步 進行,可是由於高階智慧系統必須搜尋及可利 用不同解析度的特色。為了更有效地搜尋及在 固定有限的時間中避免無效的處理,以及為了 能使搜尋之結果具較好之特性,我們增加了高 階系統之 sampling time 可是在低階系統之 sampling time 則不變,使得欲搜尋之目標已經 不是單一控制輸入而是一串之控制輸入。所以 如何地設計搜尋法則及控制輸入之表示法便 是我們必須克服的問題。而在 multi-rate 的階 層式控制器中我們主要是先以第一年的架構 為基礎,並設計串列控制的類別,以供在控制 選擇時使用,而串列控制類別之可行,乃是由 於針對較長時段下之行為模式的認知及控制 行為是對同一系統而為,因此可透學習建立及 系統反應之調適而得。 而在學習方法上,我們將針對不同的方法 來分析。探討的方向分為 on-line 學習及 off-line 學習兩部分。傳統的學習方式大部分都是以 off-line 學習來完成的,例如倒傳學習式網路學 習系統。雖然我們也做相關的探討,可是由於 階層式控制器是必須 on-line 執行的,因此本 計畫無法納入該研究結果。在 on-line 學習方 面,目前我們是以模糊系統及以小腦模式運算 (CMAC)為基礎的線上學習系統。而在模糊 系統學習部分,在第一年的研究已有探討。本 年度主要是探討 CMAC 的 on-line 學習能力。 在研究中,我們發現若以文獻上的學習方法, CMAC 的 on-line 效率並不好。這是因為其誤 差修正是以平均的方式來修正權重。如是的學 習違反了 credit-assignment 的觀念。因此我們 提出以學習頻率來當 confidence,並據以做誤 差修正比例的分配參考。如是簡單的學習改 變,確實增加了 CMAC 的學習速率。這可從 圖一中看出。而我們也利用了以 CMAC 為基 礎的 on-line learning control 上。我們可以從軌 跡追隨效果看出其效果是相當好的(見圖二)。 在行為的轉換方面,目前文獻上所提到的 是利用 washout filter 的方式來處理的。如是的 方式是可以將在無限空間中的運動設法在有 限空間中呈現,可是在動態模擬器中許多的運 動效果並非只是簡單的物理運動定律所能描 述的。較多而必要的是若干的特效運動感受, 而這些感受則是要利用所謂 motion cue 來設 計。而傳統的動態模擬器,由於其設計上也不 是利用真實的運動物体的模擬建構來產生虛 擬之運動感受,而是去設計不同的 motion cue 來搭配。因此本計劃在第二年的研究中即去了 解 motion cue 及其效果。而研究主要是提出以 訓練的方式來達到對 motion cue 設計的探討。 目前主要的構想是利用使用者的回饋信息來 修正 motion cue 的內容。而修正的標的則可分 為參數修正及段落重分。而由於回饋信息是由 使用者所給的,目前探討的學習主要是針對信 息 的 認 定 , 本 年 度 的 簡 單 作 法 是 利 用 reinforcement learning 修正。而信息的內容則 是使用 者對 動態模 擬器 的動作 行為 加以 評 分,而由於必須在 try-and-error 的情形下學 習,模擬器動作是由若干 motion cue 所組成而 後 重覆 的 操 作 , 因 此 使 用 者 的 評 分 行 為 和 motion cue 的修正能產生有義意的比對。而目 前我們只考慮到參數修正部分,也就是針對每 一段 motion cue,我們以 TSK Fuzzy 模式來表 達 , 因 此學 習 的 行 為 就 化 約 為 membership function 及後件部參數的修正,在這一方面傳 統的倒傳學習法被用來修正參數(由於沒有確 實想要的輸出值,最小平方差(LS)修正法無法 使用)。而在內部加強式信號的產生部分,目 前我們是以傳統的 Temporal Difference (TD)預 估的方式來進行。由於最近的研究大都使用遺 傳演算法,我們也會考慮使用,整個研究的進 行在本年度中目前仍只是系統建立及程式撰
寫中,在來年的研究中我們將更進一步的探討 分析其結果,同時也將納入類似 washout filter 的概念以及段落分割之學習方面。
圖 一 : The comparison of the learning performance for z(x, y) =(x2−y2)sin5x
圖二:The trajectory following for unlearned functions in on-line learning control
子計畫二:虛擬實境動態模擬系統中之
人機溝通技術及其方法
如何表示動態模擬系統使用者之感覺概 念,並忠實地傳遞給本系統中之行為轉換與控 制模組以及力回饋模組做適當的參數調整與 控制,是本子計畫之重點。模糊集合的提出雖 然對人類常用概略性質描述提供一個表示方 法,但是對於人類之概念或觀念的描述,模糊 集合則明顯的不足。本子計畫擬採用日本學者 T. Takagi,M. Sugeno,及 T. Yamaguchi 等人所 提出的觀念模糊集,此法在觀念的對應上,可 大大地彌補模糊集合的不足。在觀念模糊集 中,每一個觀念節點代表一個抽象或具體的觀 念,而節點的活性的就等於傳統模糊集合歸屬 函數的歸屬度值,由零到 1 之間的數值表示觀 念的符合程度,每一個觀念的意義,則是以標 示節點的活性度分佈來表示,因此觀念模糊集 有別於一般模糊集合,它不需要有一歸屬函 數,也不需要有一數值集合點來映射出歸屬函 數值,在觀念的意義上,更可以有多重的表示 方法。T. Takagi 等人提出以聯想記憶體來實現 觀念模糊集,但由於聯想記憶體在實現上需使 用二元表示法,由於觀念節點活性度皆為 0 到 1 之間的實數,因此,若使用此法,精確度非 常差且可供記憶的觀念個數有限,並不實用, 因此我們在這一年的計畫中提出以下幾種方 法來實現觀念模糊集的對應。 第一種實現方法為模糊關係方程式法。此 方程式的輸入與輸出皆為模糊向量,每個向量 中的元素為 0 到 1 之間的實數,若使用模糊運 算,例如取大取小合成,則是非常簡易且迅速 的,與一般模糊關係方程式不同的是,由於觀 念模糊集必須作雙向的對應,因此除了正向對 應關係矩陣外,我們還需要一個反向關係的對 應矩陣來達成雙向觀念的溝通,經過我們的研 究,以模糊關係方程式實現觀念模糊集,多半 是無解的,因此必須以特殊的學習方法來求取 最佳近似解。首先我們應用基因演算法來求取 模糊方程式的關係矩陣 ,我們使用不同的模糊 運算,如取大取小合成以及取大乘積合成,配0.87 0.08 0 0.75 0.25 0 0 0 0 0 Tall Medium Short 140 CM 150 CM 160 CM 170 CM 180 CM 190CM 200 CM 合不同的參數編碼方式,包括實數型編碼以及 二進位編碼來進行學習。另一種嘗試求取模糊 關係矩陣之最佳近似解的學習法則為 Fuzzy Delta Rule。此學習方法可以求得最大解並且具 有一定的收斂性的性質。接下來我們以一身高 的觀念模糊集對應實例來測試模糊關係方程 式表示法於觀念對應的效果。如圖三所示,上 層有三個觀念節點,分別為矮,中等,與高, 皆是比較抽象的觀念,下層具有七個觀念節 點,由身高約 140 CM 到 200 CM 等。經使用 基因演算法或是 Fuzzy Delta Rule 的模擬結果 (詳細結果請見子計畫報告) ,得知我們應用模 糊關係方程式的效果不如預期中理想。 鑑於觀念的對應多半是高度非線性,而類 神經網路不但具有高度非線性的特性,又隱藏 層層數和節點個數可根據觀念節點的多寡、對 應之複雜度,及要求之精確度做適當調整。故 若以類神經網路模型進行觀念模糊集對應,應 可大為超越使用模糊關係方程式效果。我們在 此應用放射狀基底函數網路來進行觀念對應 的學習,結果如圖四所示。我們發現使用類神 經模型來實現觀念對應遠比模糊關係方程式 效果為佳,且能忠實反應抽象的觀念對應。 圖三:身高的觀念模糊集對應實例 圖四:使用類神經網路於觀念對應之結果
子計畫三:虛擬實境動態模擬系統中之
六軸運動平台的智慧型控制
本子計畫可視為整個計畫的控制本體,而 負 責 在 虛 擬 世 界 中 複 製 真 實 載 具 的 動 態 反 應。在第一年執行裡,我們已初步針對六軸運 動平台作了一些分析與控制法則發展,第二年 將再深入探討一些問題,整體發展成果將在後 面一一介紹。另外在本年度,本子計畫負責與 其它各子計畫搭配,發展出虛擬遊艇操控系 統,以完成第二年整體計畫之目的。 1. 對於六軸平台工作空間的分析: 六軸運動平台雖有極佳的負載能力,但也 因此犧牲了部份工作空間。在第二年度裡,我 們除了針對萬向接頭的研發來補強平台的工 作空間外,並具体分析平台工作空間的限制。 以下圖五的模擬結果展示我們以平台位於中 心位置(0,0,110,roll,pitch,yaw)時,平台對 X、 Y 和 Z 軸的旋轉(即 roll、pitch 和 yaw)所得到 的平台實際工作空間。 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 M e m b e rs h ip D e g re e圖五:六軸運動平台的工作空間 2. 順向運動學探討(Forward Kinematics): 在第一年計畫執行中,我們已針對平台做 了逆向運動學分析,進一步在第二年計畫裡, 對於平台的順向運動學做了一些探討。這裡順 向運動學問題與其逆向運動學的情況正好相 反,為在已知六個致動器長度L 的前題下,欲i 得知相對應可動平台的位置姿態(x, y, z, α, β,γ)。其解決的方法有好幾種,此處我們選 擇 Newton-Raphson 數值法。圖六為我們以 Newton 數值法在處理順向運動學問題時,每次 所需使用的疊代次數。 0 500 1000 1500 2000 2500 0 20 40 60 80 100 120 140 160 180 It e ra ti o n N u m b e r P os e Numbe r 圖六:Newton-Raphson 法於順向運動學運算 的疊代次數 3.六軸平台之控制 有關平台控制方面,在第二年度的執行, 我們於理論上提出另一種控制方式:N 次補償 控制法。我們所提出的 N 次補償控制架構除了 有二維控制器架構的優點外,其尚具有一些二 維控制器所沒有的優點,如其可應用於非線性 系統及具有非常 Robust 特性。這裡用來進一 步改進 PI 控制器效能之 N 次直接補償控制法 的架構如下圖七所示,詳細的理論與模擬結果 請見子計畫之報告。 Desired Output D(S) Control System C(s) ErrorN EN(s) + -Error0 E0(s) + + Error1 E1(s) + + ErrorN-1 EN-1(s)
.
.
.
.
.
.
OutputN 圖七:N 次補償控制法架構圖4. 海上虛擬場景之發展 由於第二年總計畫的目的在於發展一虛 擬遊艇操控系統,因此在虛擬場景的開發上, 我 們 針 對 海 上 場 景 來 發 展 。 此 處 我 們 選 用 WTK(World ToolKit 7.0)這套虛擬實境場景 開發工具來發展海上虛擬場景,並使用 TCP/IP 網路傳輸協定作為場景與六軸運動平台控制 器之間的通訊協定,詳細內容亦請見子計畫之 報告。以下展示海上虛擬場景之發展流程圖及 所開發出的部分海上虛擬場景。 3D Studio MAX製作物件, 產生.3ds檔 WTK Modeler 產生地形, 產生.nff檔 撰寫 C 程式,所有的物件位置及 姿態都要先經過安排並寫入程式內 WTK library 編譯 連結 WTK虛擬場景 產生場景的執行檔 .exe 圖八:海上虛擬場景之發展流程圖 圖九:海上場景展示
子計畫四:虛擬實境動態模擬系統中之
六軸運動平台的影像定位系統研發
在第一年我們所研究的計畫中,我們所提 出的立體影像定位系統是經由三部雙眼 CCD 取 得目標物的影像,接著使用自我校正(self-calibration) 的過程而得到目標影像在三度 空間絕對座標系統中的位置,進而利用三個目 標點來估測六軸平台在三度空間絕對座標系 中的姿態 本年度,我們進一步研發這一套立體影像 定位系統,並將其獨立於六軸平台之外,而估 測平台運動時絕對座標中的姿態。再詳細來 看,利用此種方式可以將立體影像定位系統所 估測的值傳回六軸平台內部以修正其運動時 的誤差,而大幅提高閉迴路控制模式的效能。 目前,我們完成了兩部立體影像定位系統,並 已達到即時追蹤定位的效果。以下簡述完成的 影像定位系統所建構之硬體與執行方式。 首先所完成的硬體機制,包含二部單色雙 眼 CCD(如圖十所示)及 RGB 三色影像擷取卡。 主要的處理機制為 P 2- 450 MHz 個人 PC,其 提供即時的影像追蹤及三度空間定位處理。 圖十:單色雙眼 CCD 硬體裝置 接著配合硬體設備,以軟體完成下列四項 步驟,而達成即時目標物件追蹤及三度空間的 座標定位的目的。(1) 估測出三度空間到二度空間的轉換矩陣。 此將可讓我們可以知道 3D 空間和 2D 影像 空間的轉換關係。這裡假設三度空間實際 點M(x,y,z),二度空間影像點 m(u,v),相 互間的轉換矩陣如下: 1 4 4 3 34 33 32 31 24 23 22 21 14 13 12 11 1 3 × × × = t z y x q q q q q q q q q q q q s v u (2) 利用影像處理對於目標點的追蹤與鎖定之 技巧,傎測出目標點影像在兩個影像平面 中的位置。這裡臨界值法,重心法則皆有 拿來使用,詳細成果請見子計畫報告。 (3) 以目標點的影像座標重建三度空間的對應 座標。此處作法為使用兩隻單色雙眼 CCD 所得到的個別目標點的影像平面座標,帶 入數學模型中,反推而得到目標點在三度 空間的絕對座標位。詳細步驟亦請見子計 畫報告。 (4) 於人機界面上即時顯示出目標物位在三度 空間中的座標。下圖十一為我們設計出的 人機界面,並展示所擷取的目標點影像及 估測到的三度空間座標。 圖十一:影像擷取人機介面 在完成上述的軟硬體設施後,,我們已經 可以將三度空間中的目標點的運行軌跡及座 標點完全的呈現,下圖展示我們利用實際的目 標點在已知的三度空間座標系中移動,所描繪 出的運動軌跡。 圖十二:動態目標點的追蹤及定位