亞東技術學院
亞東技術學院
亞東技術學院
亞東技術學院
資訊與通訊工程研究所
碩士論文
無線通訊里德所羅門渦輪乘積碼於軟體定
無線通訊里德所羅門渦輪乘積碼於軟體定
無線通訊里德所羅門渦輪乘積碼於軟體定
無線通訊里德所羅門渦輪乘積碼於軟體定
義無線電
義無線電
義無線電
義無線電(SDR)
(SDR)
(SDR)
(SDR)系統之設計與實現
系統之設計與實現
系統之設計與實現
系統之設計與實現
研 究 生 : 林
昆
鋒
指 導 教 授 :
陳
益
華
老
師
蕭
如
宣
老
師
中 華 民 國
1 0 1
年
2
月
2 2
日
誌謝
誌謝
誌謝
誌謝
完成本論文的同時也代表即將結束研究所生涯,在這兩年半的時間 中,指導教授陳益華老師不論是課業上的指導或是生活上的照顧與關 心,都讓我的人生階段與心靈都提升到了不同的層次,在此由衷感謝。 特別感謝資策會強哥、Nash、ken,讓我可以在資策會學習開發的工作, 也謝謝在這段時間的照顧與幫忙,可以學習到很多工作經驗。 在此也要感謝學長王宗仁,研究所兼大學同學劉邦復,學弟妹葉純君、 何政璿,謝謝你們在這兩年的時間中的幫忙與包容,有你們的幫忙才得 以順利完成這個人生階段。最後感謝我的爸媽及我的家人,在這兩年中 有快樂有難過都有你們的陪伴,讓我可以通過許多的困難關卡,謝謝!!
摘要
摘要
摘要
摘要
本論文中利用了錯誤更正能力很接近雪農極限(Shannon-limit)理論
的渦輪乘積碼(Turbo Product Code, TPC),及被認為是目前最有效更正隨 機錯誤(Random error)和叢集錯誤(Burst error),可以更正 8 個符號(symbol) 的里德所羅門碼(Reed-Solomon Code, RS)兩種錯誤更正碼的組合方式,且
TPC 使用軟式決策解碼(Soft-Decision Decoding),使效能曲線大為提升。
本論文詳細探討與分析 TPC 及里德所羅門碼錯誤更正碼的編解碼機 制,訊號流程及其實際開發於軟體定義無線電(Software Defined Radio,
SDR)系統之設計過程,並完成 Labview FPGA 程式碼效能曲線之軟體驗
證。
為解決硬體與軟體的要求不斷提升的問題,在開發錯誤更正碼時就
必須要快速且準確的得到驗證,並測試是否可以依照硬體規格達到應有 的效能。故將開發之錯誤更正碼實現於軟體定義無線電系統(Software
Defined Radio, SDR)中的 FPGA 模組上,可以得到快速且準確的驗證。本
文程式碼部分由 Labview FPGA 所撰寫而成,而錯誤更正碼編解碼系統則 建置於 NI PXIE-5641R FPGA 模組平台。本論文使用之 NI 軟體定義無線 電系統是由控制器(NI PXIE-8106)、收發器(NI PXIE-5641R)、降頻轉換器
(NI PXI-5600)、升頻轉換器(NI PXI-5610)這些模組所組合而成。其中, 5641R 是一個具有 20 MHz 頻寬的 IF 收發器 - 搭載 DSP - optimized Xilinx Virtex-5 SX95T FPGA (NI PXIe-5641R) 具備中頻 (IF) 輸入與輸
出,包含 A/D、D/A 轉換器,可介接類比升/降轉換器,以擷取並產生 RF 訊號。此介面卡的 FPGA 亦可透過 LabVIEW FPGA 進行程式設計,於 硬體中執行複雜的調變與訊號處理作業;而其高傳輸率與低延遲,均為 軟體定義的無線電系統所必備。
本論文實現於 NI PXIE-5641R 軟體定義無線電系統的 Labview FPGA
的列、行編碼之 TPC 效能曲線比較,其錯誤機率同樣在 10-3時,使用 m =5 二維的 RS(31,15,17)之 TPC 碼,其 Eb/No 約在 3.9 dB,而比較本文所使 用 m =8 的 RS(31,15,8)與 RS(63,47,8)組合之 TPC 碼時約在 ﹣0.4 dB,表 示本文使用 m =8 的 RS 可以減少功率的使用,達到約 4.3 dB 的編碼增益。 一般於 FPGA 上的開發必須先透過軟體模擬及驗證,根據其模擬結果 才能撰寫實現於 FPGA 的程式碼,就實現的 FPGA 程式碼來說其延伸的 使用性較低,而 SDR 系統的優點在於可以直接透過 Labview FPGA 撰寫 FPGA 程式碼,且完成的程式碼可以用於軟體上的模擬及驗證,也可直接 使用於 NI PXIE-5641R 的 FPGA 模組平台,理想的情況下可以完全不需 修改程式碼使用於硬體與軟體之間,視硬體規格限制而定才可能需要做 優化的動作。本論文結果已於 SDR 系統上完成 TPC 與 RS 編碼結合的 Labview FPGA 開發,且程式碼經過軟體驗證及模擬,並與其他相關文獻 研究比較其效能。至於程式碼優化與硬體驗證及模擬結果為下一步實現 目標。
關鍵字: 里德所羅門碼(Reed-Solomon Code, RS)、渦輪乘積碼(Turbo
Product Code, TPC)、Labview PFGA、軟體定義無線電系統(Software Defined Radio, SDR)、軟式決策解碼(Soft-Decision Decoding)。
Abstract
In this paper, the error correction capability we use is very close to the Shannon-limit theory of Turbo Product Code, TPC, and is considered to be the most effective way to correct random errors, and Burst error, we can correct 8 symbols of Reed Solomon code, and the TPC use soft decision decoding, it’s greatly enhance the performance curve.
In this paper, we explore and analysis TPC and Reed Solomon code error correction code about encoding and decoding mechanisms, signal flow and its development of software-defined radio system of the design process, also complete the LabView FPGA program code performance curve in the software.
To resolve ever-increasing problems of hardware and software requirements, we must be fast and accurate to get the verification when we develop error correction codes, and exam whether we can achieve the proper performance with the hardware specifications. Therefore, we implement the development of error correction code in software-defined radio system of the FPGA Module. The codes in this paper were written on LabView FPGA, and the error correction encoder and decoder system was built on the NI PXIE-5641R FPGA module platform. The SDR system is composed of modules including controller (NI PXIE-8106), transceiver(NI PXIe-5641R), down-converter(NI PXI-5600), and up-convertor(NI PXI-5610). 5641R is an IF transceiver of bandwidth at 20 MHz – equipped with DSP - optimized Xilinx Virtex-5 SX95T FPGA (NI PXIe- 5641R) with IF (intermediate frequency) input and output, also including the Analog to Digital converter and the Digital to Analog converter that can be interfaced with analog up/down converter to capture and generate RF signals. The FPGA of this interface card can be programmed through LabView to execute complex modulation and signal processing of the hardware. Its high transmission rate and low latency are necessary for software defined radio systems.
In this paper achieves the performance curve results of the LabView FPGA soft verifies by TPC decoding on NI PXIE-5641R software-defined radio software systems, comparing the TPC performance curve with row encoder and column decoder in the two-dimensional RS (31,15,17), when the error probability is the same in 10-3, using the TPC code in m equals 5 of two-dimensional RS (31,15,17), the Eb /No will approximately be 3.9 dB, comparing in this paper, using the TPC code in m equals 8 of RS (31,about -0.4 dB, 15.8)and RS (63,47,8) together, that the article
uses m = 8 RS can reduce the power, and the coding gain can reach to 4.3 dB. General in the development of the FPGA must be past the software simulations and verifications, according to the simulation results, we are able to write code in the FPGA, the utilization is lower to extend in FPGA code. The SDR system has the advantage that it can write directly to the FPGA pass on LabView FPGA code and the completed codes can be used from the NI PXIE-5641R FPGA module platform directly for simulating and verifying on the software, the ideal situation can be completely without modifying the code between the hardware and software, IP core optimization is based on the hardware specifications. In this paper, we were completed he results of which TPC and RS encoders combined with the LabView FPGA development on the SDR system , and the codes are past the software verification and simulation, and compare their performance with other relevant reference. As regards the IP core optimization and hardware verification and simulation results are the next targets.
key word: Reed-Solomon, Turbo Product Code, Labview PFGA, Soft
目錄
目錄
目錄
目錄
第一章 緒論...1 1.1 研究背景...1 1.2 數位通訊系統與通道編碼...2 1.3 渦輪乘積碼及里德所羅門碼...3 1.4 研究動機...5 第二章 里德所羅門碼...6 2.1 伽羅瓦場元素的建立...6 2.2 里德所羅門碼定義與參數...10 2.3 里德所羅門碼之編碼...11 2.4 里德所羅門碼解碼...14 2.4.1 計算徵候值(Syndrome polynomial)...152.4.2 求出錯誤位置多項式(error location polynomial)...16
2.4.3 尋找錯誤位置之方法(Chien Search)...23 2.4.4 尋找錯誤值大小之方法(Forney Algorithm)...24 第三章 渦輪乘積碼...28 3.1 渦輪乘積碼編碼...28 3.2 渦輪乘積碼解碼...29 3.2.1 軟式判斷...30 3.2.2 Chase Algorithm...32 3.3 TPC 與 RS 碼完整架構說明...43 第四章 NI Labview FPGA 實作里德所羅門碼與渦輪乘積碼...52 4.1 Labview FPGA 簡介...52 4.2 里德所羅門編碼設計與實作...55 4.2.1 g(x)程式碼設計...56 4.2.2 編碼位元與 g(x)相除取餘數設計...57
4.2.3 里德所羅門編碼...60 4.3 里德所羅門解碼設計與實作...61 4.3.1 syndrome, S(x)程式碼設計...61 4.3.2 error location, σ (x) 程式碼設計...63 4.3.3 chien search 程式碼設計...65 4.3.4 Forney Algorithm 程式碼設計...66 4.3.5 里德所羅門解碼...67 4.3.6 里德所羅門碼於 Labview FPGA 設計之附件...53 4.4 渦輪乘積碼設計與實作...81 4.4.1 渦輪乘積碼解碼設計與實作...83 4.4.2 Chase 子程式...85 4.4.3 Correct 子程式...87 4.4.4 Union 子程式...87 4.4.5 Revision 子程式...89 4.4.6 TPC 於 Labview FPGA 設計之附件...91 4.5 程式碼驗證...98 第五章 結果與討論...100 第六章 結論與未來展望...104 參考文獻...105
表目錄
表目錄
表目錄
表目錄
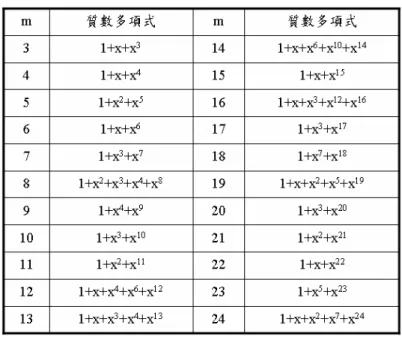
表 2.1 p(x) = 1 + X + X3 基底元素與場元素對應關係圖...7 表 2.2 p(x) = x8 + x4 + x3 + x2 + 1 基底元素與場元素對應關係圖...9 表 2.3 一般常見的質原多項式...10圖目錄
圖目錄
圖目錄
圖目錄
圖 1.1 數位通訊系統架構圖...2 圖 2.2 里德所羅門碼位元架構示意圖...11 圖 2.3 RS(7, 5, 1)例子運算過程及 GF(23 )表...12 圖 2.4 里德所羅門電路示意圖...13 圖 2.5 解碼流程區塊圖...14 圖 3.1 渦輪乘積碼行(row)編碼示意圖...25 圖 3.2 渦輪乘積碼列(column)編碼示意圖...25 圖 3.3 渦輪乘積碼編碼完成示意圖...26 圖 3.4 Chase Algorithm 解碼流程圖...30圖 4.1 Labview Front Panel (人機操作介面) ...34
圖 4.2 Labview Block Diagram (程式設計區) ...34
圖 4.3 Labview FPGA module 元件符號...34
圖 4.4 建立對應表的程式碼...37 圖 4.5 g(x)程式碼...38 圖 4.6 長除法疊代示意圖...39 圖 4.7 相除運算過程多項為零時示意圖...39 圖 4.8 長除法程式碼...40 圖 4.9 switch case 程式碼...41 圖 4.10 判斷是否為零程式碼...41 圖 4.11 里德所羅門編碼程式碼...42 圖 4.12 里德所羅門碼 Pseudo code...42 圖 4.13 syndrome 計算程式碼...44
圖 4.14 syndrome 計算 Front Panel 預設值...44
圖 4.15 >255 子程式程式碼...44
圖 4.17 ∆k計算所需使用的 syndrome...46 圖 4.18 BMA 程式碼...46 圖 4.19 chien search 程式碼...47 圖 4.20 < 0 子程式程式碼...48 圖 4.21 σ (x)與 S(x)相乘子程式程式碼...48 圖 4.22 Forney Algorithm 程式碼...49 圖 4.23 reset 為 true 時清除暫存器...49 圖 4.24 由內部控制 reset...50
圖 4.25 ready for output 控制接腳用途...50
圖 4.26 ready for input 控制接腳用途...51
圖 4.27 進入 BMA 運算...52
圖 4.28 進入 Chien search 及 Forney Algorithm 運算...52
圖 4.29 運算結束輸出位元...53 圖 4.30 渦輪乘積碼編碼程式設計...63 圖 4.31 渦輪乘積碼列編碼部分...63 圖 4.32 Chase Algorithm 流程圖...64 圖 4.33 000 與 111 的判斷...67 圖 4.34 1、2、5、6 的判斷部分...68 圖 4.35 3、4 的判斷部分...68 圖 4.36 Correct 子程式...69 圖 4.40 Revision 程式碼...71 圖 4.41 Chase Algorithm 子程式...71 圖 4.42 渦輪乘積碼程式碼...72 圖 4.43 RS(255, 239, 8)程式驗證...80 圖 4.44 TPC ( RS(31, 15, 8) ) 錯誤機率...81
第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
1.1 研究
研究
研究
研究背景
背景
背景
背景
近幾年來國內在無線通訊方面快速的發展,從最近剛起步的全球互通微波存取(Worldwide Interoperability for Microwave Access, WIMAX), 到即將發照的 3GPP 長期演進技術(3GPP Long Term Evolution, LTE),意 味著在進入 4G 時代的同時,必定需要更多的研究與技術的支援。未來的 通訊傳輸資料量將會更大,且要求更快的傳輸速度和更低的位元錯誤機 率,所以資料傳輸的可靠度必然影響著效能提升的關鍵。資料在傳遞的 過程中,或多或少會因為內在和外在的因素所干擾(如通道的雜訊干擾、 元件本身的雜訊干擾等)而發生錯誤,為了避免這樣的錯誤發生,我們必 須在資料傳遞前加入一些可以檢查及更正錯誤的機制,同樣的在接收端 也必須要有這樣的機制才有辦法將錯誤的資料更正回原始未發生錯誤的 資料,目前大部分的通訊系統都會加上這樣的前饋式錯誤更正技術
1.2 數位通訊系統與通道編碼
數位通訊系統與通道編碼
數位通訊系統與通道編碼
數位通訊系統與通道編碼
在現今無線通訊系統中,數位訊號的傳遞通常都包含了通道編碼的 應用,它是將原本要傳遞的訊號加上多餘的資訊位元,以利於在無線通 道的傳遞過程被干擾使訊號能藉由這些多餘的資訊位元偵測並更正受到 干擾的位元。以單一種錯誤更正碼來說,就編碼效率及硬體複雜度而言, 里德所羅門碼(Reed-Solomon code)算是較好的錯誤更正碼[13],也正因為 如此,里德所羅門碼已被廣泛使用在各類無線網路、光網路傳輸與 CD、 DVD、HDTV 等之傳輸[14]。 數位通訊系統之所以吸引人是因為我們對於資料通訊不斷增加的需 求,以及因為數位傳輸提供資料處理多樣的選項與彈性,這些都是類比 傳輸所不及的。我們時常在衛星通訊鏈結的背景裡討論數位通訊,有時 候也會在行動無線電系統的脈絡裡進行討論,在這種情況下,訊號傳輸 經常遭受到一種所謂衰退(fading)的現象,而這樣的情況通常發生在通訊 系統中的通道部分,如圖 1.1 為基本的數位通訊系統架構圖。 圖 1.1 數位通訊系統架構圖 圖中大致可分為傳送端、通道、接收端。在數位通訊系統中,由訊 源(source)產生的訊息會轉換成二近位數字序列。這種有效地將類比或數位訊息轉成二進位數字序列輸出的過程,稱為訊源編碼器(source coding) 或資料壓縮(data compressing)。經過訊源編碼後的數字序列,我們稱為資 訊序列(information sequence),接著送到通道編碼器(channel encoder)。編 碼器的原理是當資料要傳送出去時,我們會在此資料的後面多加一些訊 息,也就是將訊息編碼以便在接收端收到此資料時能依據這冗餘位元 (redundant bytes)判斷接收訊號的正確性,目的是為了在傳送的通道 (channel)中,訊息會因為雜訊與干擾的關係造成錯誤。經過通道編碼後, 在經由調變器(modulator)將送出的訊號轉變為適合於通道傳輸的訊號規 格,並經數位類比訊號轉換成傳輸介質所使用的訊號,升頻後傳送到通 道。 而在接收端則是依據傳送端所進行的編碼步驟,反向解編碼回原始 的訊息位元,而本文所探討的重點在於通道解碼(channel decoder),當通 道解碼的效能越好時,我們就可以得到越正確的原始訊息。
1.3 渦輪乘積碼
渦輪乘積碼
渦輪乘積碼
渦輪乘積碼及
及
及
及里德所羅門碼
里德所羅門碼
里德所羅門碼
里德所羅門碼
錯誤更正碼大致上可分為兩類:區塊碼(Block Code)及迴旋碼 (Convolutional Code)。其中區塊碼和迴旋碼最大的不同在於區塊碼的編碼 過程中,不會影響到以後的資料,也就是不像迴旋碼一樣具有時間相關 性,資料的影響是一個區塊一個區塊為主,不會有連續的影響,在解碼 時能採用數學代數的方式來解碼。而迴旋碼解碼時需要追蹤很長的一段 時間的資料,才能將原本的資料還原,與區塊碼相比其解法較為複雜。 本文所使用到的錯誤更正碼為渦輪乘積碼,屬於區塊碼的一種。 Berrou 在[1]中,研究出渦輪碼在加成性白色高斯雜訊通道下能夠達到接 近雪農(Shannon) 極限的性能。Pyndiah 將渦輪碼中反覆解碼的觀念,用 於乘積碼(Product Code)中,稱之為渦輪乘積碼,在[2]中可以看出渦輪乘 積碼的強大更錯能力,不僅是在加成性白色高斯雜訊通道,有很大幅度的效能改善,在瑞利衰減通道一樣有很好的改善。
1954 年 Elias 提出了乘積碼[3],乘積碼的編碼方式,利用現有的區
段碼,如 Bose-Chaudhuri-Hocquenghem (BCH) Codes,Hamming Codes 來 編成不同碼率及更正能力的乘積碼。在這種設計下,可以輕易且有效率 編成長度相當長的碼。
藉由原始的渦輪乘積碼,我們將其 Bose-Chadhuri-Hocquenghem Code(BCH Code) 及 Hamming Code 替換為 RS 碼。RS 碼為 BCH 碼的延
伸,BCH 碼僅適用於二進制編碼,而 RS 碼因使用代數符號可適用於多 進制編碼,在同樣訊息位元的情況下可獲得最大的漢明距離(Hamming
distance),因此有更強的糾錯能力。
由於 RS code 具有優異的錯誤偵測與訂正能力,目前愈來愈多的應用 採用 RS 碼來保證資料的正確性,且由於對傳輸速度的要求,相對的對
RS code 的效能要求亦是與日俱增。1958 年 12 月 I. S. Reed 和 G. Solomon
於 M.I.T Lincoln 實驗室完成題目名為“在有限場(finite field)中的多項 式碼”的報告[4][5]。在 1960 年,稍微改報告於針對工業和應用數學 (SIAM)的社會期刊中,以研究報告發行。這五頁研究報告描述了一個 新的錯誤更正碼種類,現在被稱為 RS 碼。自從他們發現 RS 後的數十年 中,從室內的 CD 和數位電視到外太空的太空梭和衛星已經有無數的應 用。直到 1967 年,當 E. Berlekamp 展示一個針對 BCH 和 RS 兩者都極 為有效的解碼演算法時,才有了重大的突破。Berlekamp 的演算法在一 些效力強大的 RS 碼上,予許快速且有效地解許多的符號錯誤(symbol errors) 。在 1968 年,Massey 表示 BCH 解碼問題是相當於合成最短線性-迴授移位暫存器,它有能力產生序列[6][7][8]。Massey 接著針對 BCH 和 RS 碼展現了一個以快速移位為基礎的演算法,它相當 Berlekamp 的原始 版本。這個以移位暫存器為基礎的方法在現在普遍稱為 Berlekamp-Massey(BM)演算法[9][10]。Euclidean 演算法用來解決關鍵的
方程式(key equation) ,第一次在 1975 年被 Sugiyama 等人發展出來。 由於本論文所使用的 RS(255, 239, 8)具有可以更正 8 個符號的糾錯能 力,因此目前常見將 RS 碼使用於超長距的 Dense Wavelength Division
Multiplexer(DWDM)系統或衛星系統上,使用方式是採用 RS(255,239)與 RS(255,223)或 RS(255,239)與 Convolutional Code 的聯級碼( Concatenated Code)編碼方式,RS(255, 239)編碼可以比無編碼時 BER 情況改善 5dB 左 右,使用在 DWDM 系統上可達到 800 ~ 1000 km 傳輸距離[42][45]。
1.4 研究
研究
研究
研究動機
動機
動機
動機
由於 RS 碼的解碼演算法議題一直不斷的被研究並討論直到今日, 遂因其優越的叢集錯誤及突發錯誤的錯誤更正能力,從 CD、DVD、HDTV 到太空通訊皆可看到其應用,再搭配渦輪乘積碼的行、列編碼架構,使 其編碼率可以彈性調整,且編碼效能更提升至接近雪農極限。而考慮到 這樣的編碼方式是否可用於現行的硬體架構,我們使用軟體定義無線電 系統將其設計並實現於 NI PXI-5641R 硬體模組,方便調整其參數以因應 不同的硬體規格節省開發的時間。 目前常見將高糾錯能力的 RS 碼應用實例,多半實現於長距離有線的 光纖系統或無線的衛星系統上[42][45],其使用方式是與 Convolutional Code 作為聯級碼的應用,而效能與未編碼時作比較約可達到 9 dB 的編 碼增益(coding gain),但近年來開始有人提出將 RS 碼與 TPC 做結合,其 使用的 RS 碼糾錯能力低於聯級碼的 RS 碼,卻能達到相近的效能 [40][39],因此我們嘗試將同樣高糾錯能力的 RS 碼與 TPC 作結合,然而 考慮到其開發後的結果是否可實現於硬體,我們選用 SDR 系統實現。
第二章
第二章
第二章
第二章 里德所羅門碼
里德所羅門碼
里德所羅門碼
里德所羅門碼
里德所羅門碼是一種非二元的循環碼,為了理解非二元碼的編碼與 解碼原理,我們必須先探討所謂伽羅瓦場(Galois Field, GF)的理論[7]。伽 羅瓦體理論是以 19 世紀初天才法國數學家 Evariste Galois 為名的,其大 意為使用代數在有限的定義範圍中,做任意的四則運算。2.1 伽羅瓦
伽羅瓦
伽羅瓦
伽羅瓦場
場
場
場元素的建
元素的建
元素的建
元素的建立
立
立
立
在基本代數運算中,定義一個元素數目有限的場,我們可以稱它為 有限場(Finite Field)或伽羅瓦場。一個場的定義,除了必須具有封閉性的 的性質外,還尚須滿足一些條件: 1. 交換性(Commutative)、加法一致性(Additive Identity)、乘法一致性 (Multiplicative Identity)與分配性(Distributive)。 2. 對於任何質數 p,存在一個有限體 GF(p),其中包含了 p 個元素 3. 將 GF(p)擴充為 pm個元素的體,稱為 GF(p)的擴張體(extension field) 記為 GF(pm),其中 m 是非零正整數。 GF(p)是 GF(pm)的一個子集合,用來建構符號(symbol)里德所羅門碼 的就是來自於擴張體 GF(2m )的符號。而在建立擴張體 GF(2m)時,還必須 要運用質原多項式(primitive polynomial) p(x)定義有限體。 定義: 1. 質元多項式,這種函數可以定義為有限體 GF(2m) 2. 次數為 m 的不可約多項式稱為質原多項式 p(x) 3. 如果使得 p(x)整除 Xn + 1 的最小正整數 n 是 n = 2m-1 4.不可約多項式(irreducible polynomial)是指多項式無法再進一步因分 解舉例來說,若其質原多項式為 p(x) = 1 + X + X3,這一個多項式定義出出 一個有限體 GF(2m),其中多項式的次數是 m=3,因此,p(x)所定義的有限 體中有 2m = 23 = 8 個元素,要解 p(x)的根就是找出滿足 p(x)=0 的值 p(x) = 0 1 + α + α3 = 0 α3 = 1 + α (110) α4 = α‧α3 =α‧(1 + α) = α + α2 (011) α5 = α‧α4 =α‧(α + α2) = α2 + α3 = 1 + α + α2 (111) α6 = α‧α5=α‧(1 + α + α2) = α + α2 + α3 = 1 + α2 (101) α7 = α‧α6=α‧(1 + α2) = α + α3 = 1 =α0 (101) 根據上述的運算,我們可以知道基底元素與場元素的對應關係。 表 2.1 p(x) = 1 + X + X3 基底元素與場元素對應關係圖 本論文所使用的擴張體為 GF(28),表示使用了 8 個基底元素來表示 符號,而其質原多項式為 p(x) = x8 + x4 + x3 + x2 + 1,根據前例的運算方式 我們可以建立表 2.2 的基底元素與場元素對應關係圖[12]。
表 2.2 p(x) = x8
+ x4 + x3 + x2 + 1 基底元素與場元素對應關係圖
質原多項式一般都由數學家已定義好,可從一些書籍或是參考文獻
表 2.3 一般常見的質原多項式
2.2 里德所羅門碼定義與參數
里德所羅門碼定義與參數
里德所羅門碼定義與參數
里德所羅門碼定義與參數
根據西元 1960 年由 I. Reed 以及 G. Solomon 所定義的里德所羅門碼 (n, k, t),n 表示編碼後的碼字長度,k 代表未編碼前的碼字長度,t 代表在 此 n, k 值下所可以更正的錯誤符號數。假設 α 為 GF(2m ) 之本質元素,對 任意一個正整數 2m −1,必定存在一組可去除 t 個錯誤符號的里德所羅門 碼,其中 m 代表 1 個 symbol 含有 8 個位元,其各項參數定義如下: 碼字長度 n = 2m - 1 更正錯誤符號數 2t = n - k 兩碼字間最小距離 dmin = 2t + 1 碼字生成多項式 g(x) = (x + α) (x + α2) ....(x + α2t)本論文所使用的各項參數分別為: n = 28 - 1 = 255 k = 239 t = 255 - 239 / 2 = 8 g(x) = (x + α0) (x + α1) ....(x + α15) 由上述參數可知,在定義中此里德所羅門碼(255, 239, 8)具有可以更 正 8 個符號的能力,而 n, k 值的部分表示其最大值可到(255, 239),但特 殊的 shorten 形式可將 n, k 値設定在 n = 0 to 255, k= 0 to 239 之間,只要符 合 t = n - k / 2 = 8 的規範都可以使用,例如(31, 15, 8)、(63, 47, 8)等。而 在 g(x)方面,α 的次方起始值可以依據自己的需求而使用不同的起始值, 但必須注意的是,此起始值會影響未來在解碼時的結果,因此在設定時 必須編碼端與解碼的設定一至。
2.3 里德所羅門碼之編碼
里德所羅門碼之編碼
里德所羅門碼之編碼
里德所羅門碼之編碼(Encode)
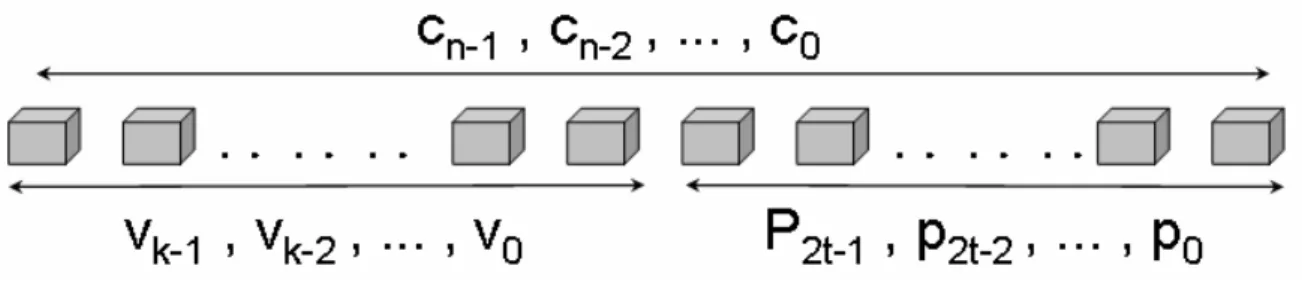
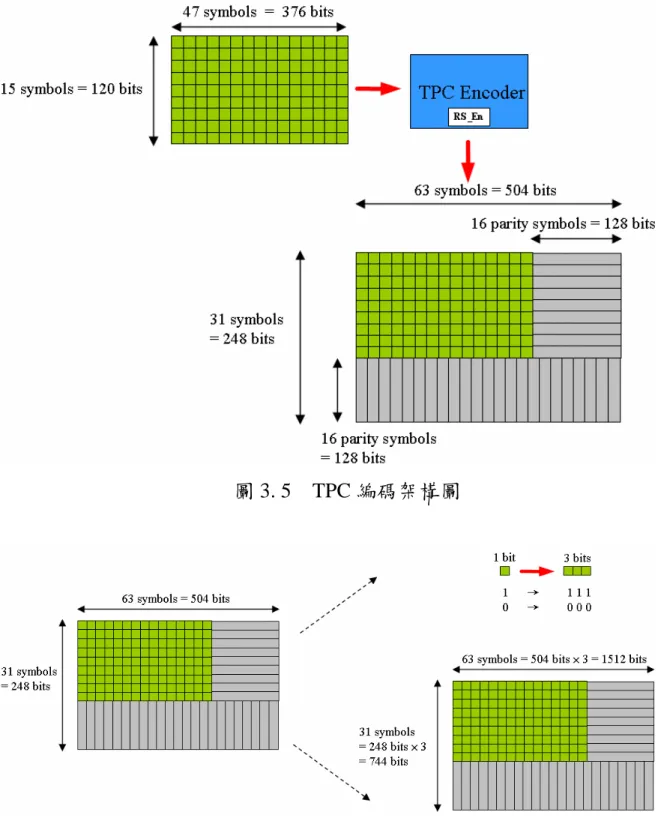
里德所羅門碼屬於區塊碼的一種,所謂區塊碼就是訊號在傳送時是 將資料分成區塊的形式傳送。每個資料區塊除了未編碼前的原始訊息 外,還加上了編碼過後具有保護作用的冗餘位元(parity bits) 或稱檢查位 元(parity check message)。圖 2.1 表示了里德所羅門碼中,原始訊息與冗 餘位元的架構示意圖。圖 2.2 中,V 代表原始訊息(information polynomial, V(x)),P 代表冗
餘符號(parity polynomial, P(X)),C 代表整個區塊碼字多項式(codeword
polynomial, C(x)),下標部分代表各個符號在區塊中的位置;首先,進行 編碼前我們可以得到一組原始訊息,根據前一節的定義 g(x) = (x + α) (x + α2) ....(x + α2t),要產生 P(X)必須將 V(x)多項式使其成為 g(x)的倍數,而 V(x)加上 P(X)即可以被 g(x)整除,故我們必須先將 V(x)往高次方位移 x2t, 接著找出 V(x)除以 g(x)的餘數,也就是說 P(X) = (V(x)‧x2t ) mod g(x)。而 其餘數加上原始的訊息便可使多項式成為 g(x)的倍式,其公式為 C(x) = x2t ‧V(x) + P(X) = x2t ‧V(x) + (V(x)‧x2t) mod g(x) (2-1) 在此舉一個 RS(7,5,1)的例子來說,其 p(x) = 1 + x + x3, g(x) = (x+α)(x+α2) = α3 + α4x + x2 假設所要傳送的 V(x) =α2 x2 +α4x4,則所要產生的 P(X)可以經由圖 2.3 的運 算過程得到 P(X) = a3 x1。 圖 2.3 RS(7, 5, 1)例子運算過程及 GF(23 )表
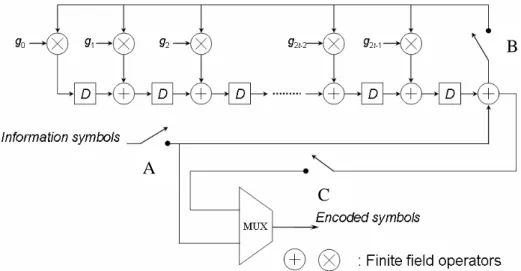
圖 2.4 里德所羅門電路示意圖
而一般常見的里德所羅門碼電路設計可以表示為圖 2.4,首先先將
A、B 兩節點接上(connect),此後訊息符號開始依序送入,當送入 k 個訊
息符號(message symbol)時也會輸出 k 個訊息符號,此後 A、B 兩節點則 斷路(disconnect)改由下方節點 C 接上,此時電路會繼續動作直至 n - k 個
clock 後,開始輸出編碼後的冗餘符號(parity symbols)。最後此 n - k 冗餘
符號與 k 個訊息符號結合為 n 個編碼符號(encode symbol),即完成編碼後 的碼字 (Codeword)。 藉由 RS(7, 5, 1)的例子,表示其電路圖與編碼過程。將節點 A 與節點 B 同時接上後,在 clock 0 時會將 α4輸入編碼電路,接著更新暫存器的值 並輸出訊息符號 α4,此後每個 clock 皆會重複上述動作,直至輸入 k 個訊 息符號後 A、B 兩節點斷路改由節點 C 接上,此時暫存器得到的值即為 冗餘符號,待 n-k = 2 clock 後與 k 個訊息符號結合即為完成編碼的碼字。 B A C 輸入訊息符號:0 0 α2 0 α4
2.4 里德所羅門碼解碼
里德所羅門碼解碼
里德所羅門碼解碼
里德所羅門碼解碼(Decode)
在進入里德所羅門碼解碼前,首先針對解碼的用意說明一下,假設
訊息在傳輸期間,這些碼字變成有所訛誤的,使得有某幾個訊息符號並 非原始發射端送出的訊息符號,我們就必須將錯誤的訊息找出並加以修 正。而錯誤多項式(error polynomial)可以表示成 e(x),
=e0 + e1X + ... + enX n (2-2) 接收到的碼字訊號也就可以表示成 r(x) = C(x) + e(x)。里德所羅門碼這種 非二元符號的解碼,我們不僅要知道錯誤的位置,還要判斷錯誤的這些 位置上正確的符號值,因此接下來介紹的解碼過程依序是先找出錯誤模 式的計算(Syndrome Calculator)、找尋錯誤位置(error location)、找尋錯誤 位置上的錯誤向量(error magnitude)。 圖 2.5 解碼流程區塊圖 0 ( ) n n n n e x e x = =
∑
2.4.1 計算徵候值
計算徵候值
計算徵候值
計算徵候值(Syndrome)及徵候值多項式
及徵候值多項式
及徵候值多項式
及徵候值多項式(Syndrome
polynomial)
當接收到訊息資料後,第一步驟必須先知道此訊息資料是否有發生 錯誤,所以計算徵候值就是在判斷訊息資料是否有發生錯誤。若所有的 徵候值都為零,則表示所收到的訊號皆為正確的訊息。在 2.2 章節中提 到,里德所羅門的編碼多項式 g(x)是包含碼字生成多項式中的所有獨立的 因式,因此計算徵候的原理是將收到的訊號除以碼字生成多項式的所有 因式,也就是(x + α)、(x + α2 )、....、(x + α2t)。所以若將 α、α2、...、α2t依 序代入接收的訊號 r(x)中,若 16 個根的結果都為零則表示沒有發生錯誤 的情況,反之則表示有錯誤。其公式的表示法如下: 此公式若使用在電路設計上,由於硬體及軟體的考量,通常不會一次將 所有的訊號全部收集完才做計算徵候的動作,因此後人提出了 Horner's Rule 的計算方式[10],其公式表示如下 在此我們以本論文所使用的 RS 其 n, k 値設定為(20, 4, 8)為例子, 假設收到的訊號為 r(x) =α166 x19 + α104 x18+ α162x17 + α58x16+ α14x15+ α24x14+ α52x13+ α243x12+ α193x11+ α22x10+ 0x9+ α84x8+ α23x7+ α150x6+ α139x5+ α231x4+ α163x3+ α165x2+ α165x1+ α140,則其計算的方式可以表示為 S1(α 0 ) =((((((((((((((((((α166α0+α104) α0+α162) α0+α58) α0+α14) α0+α24) α0+α52) α0+α243) α0+α193) α0+α22) α0+0) α0+α84) α0+α23) α0+α150) α0+α139) α0+α231) α0+α163) α0+α165) α0+α165) α0+α140 1 0 2 1 1 ( ) ( ) 1 2 ( ) (2 3) n i i j i j j t i i i S r r i t S x S x α − α = − = = = ≤ ≤ = −∑
∑
1 2 3 1 0 ( i) (...((( i ) i ) i... ) i (2 4) i n n n S α = r−α +r− α +r− α +r α +r −S2(α1) =((((((((((((((((((α166α1+α104) α1+α162) α1+α58) α1+α14) α1+α24) α1+α52) α1+α243) α1+α193) α1+α22) α1+0) α1+α84) α1+α23) α1+α150) α1+α139) α1+α231) α1+α163) α1+α165) α1+α165) α1+α140 ⋮ S16(α 15 ) =((((((((((((((((((α166α15+α104) α15+α162) α15+α58) α15+α14) α15+α24) α15+α52) α15+α243) α15+α193) α15+α22) α15+0) α15+α84) α15+α23) α15+α150) α15+α139) α15+α231) α15+α163) α15+α165) α15+α165) α15+α140 最後可以產生出16個syndrome,S1=α221, S2=α225, S3=α232, S4=α197, S5=α96, S6=α 156 , S7=α 63 , S8=α 92 , S9=α 124 , S10=α 120 , S11=α 229 , S12=α 248 , S13=α 7 , S14=α 190 , S15=α173, S16=α243,其徵候多項式可以表示為 S(x) =α221x+α225x2+α232x3+α197x4+α96x5+α156x6+α63x7+α92x8+α124x9+α120x10+α229x11+ α248x12+α7x13+α190x14+α173x15+α243x16
2.4.2 求出錯誤位置多項式
求出錯誤位置多項式
求出錯誤位置多項式
求出錯誤位置多項式(error location polynomial)
計算錯誤位置多項式為整個里德所羅門碼的核心所在,因為最原始 的計算過程在電路上實現不易,從發明里德所羅門碼來不斷的有人提出 了新的方法,其計算方法其中一種為 " PGZ Algorithm " ,此種方法一般 用於t較小的情況,且在計算過程中必須使用反矩陣的運算,過程太過複 雜導致解碼速度變慢而沒效率,且在硬體實現困難,因此後人又提出了 許多的新方法,其中較為多人使用的方法為 " Berlekamp - Massey
Algorithm, BMA ",為 E. Berlekamp在西元1967 年[12]提出的新演算法, 此演算法是利用反覆疊代運算的技巧來避開必須使用反矩陣的方式。
以下為BMA演算法之運算步驟,首先定義以下參數: Connection
次數, L為判斷是否需要更新的依據
Step 1. 將求出的 2t個徵候值依照順序及 k值,代入此演算法當做輸入
Step 2. 對演算法中的各項變數初始化:
k = 0, Λ0 (x) = 1, L = 0, T(x) = x Step 3. 令 step parameter k = k + 1 並計算差異值
1 1 1 k L k k k i k i i S S − − − = ∆ = −
∑
Λ Step 4. 假若 ∆k= 0,跳至Step 7. Step 5. 計算更新多項式 Λk( )x = Λk−1( )x − ∆kTk−1( )xStep 6. 假若 2*L ≧ k,跳至步驟7,否則更新length parameter L及T(x)
L = k - L T(x)=Λk-1 (x) / ∆k Step 7. T(x) = x* T(x) Step 8. 假若 k < 2t,則重複3~7 步驟,所求得之 Λk(x) 即錯誤位置多項 式 σ (x) 根據以上步驟在此舉一個例子說明,假設一個 t = 2的 RS碼(請使用 圖2.3 GF(23)表),經過徵候的計算得到S0= α 3、 S1= α 5、 S2= α 6、 S3= 0 初值設定: k = 0, Λ0(x) = 1, L0 = 0, T 0 (x) = x First Loop (k = 1) 1. ∆1 = S1− Λ0S0= α3 2. ∆1≠ 0 , Λ1(x) =Λ0( )x − ∆1T0( )x = 1 –α3x 3. (2×L = 2×0) < (k = 1)
4. L1 = k – L0 = 1– 0 = 1 更新 T0(x) =Λk-1 (x) / ∆k = 1 /α3 = α4 T1 (x) =α4 x Second Loop (k = 2) 1. ∆2 = S2 − Λ1S1= α5 – α6 = α 2. ∆2≠ 0 , Λ2(x) =Λ1( )x − ∆2T x1( )= 1 – α3 x – αα4 x = 1 – α2 x 3. (2×L = 2×1) = (k = 2) 4. L1 = L2 = 1 T2 (x) = α4 x 2 Third Loop (k = 3) 1. ∆3 =S3− Λ2S2 + Λ2S1= α6 – α2α5 = α2 2. ∆3≠ 0 , Λ3(x) = Λ2( )x − ∆3T2( )x =1 – α2 x – α2α4 x 2 = 1 – α2 x – α6 x 2 3. (2×L = 2×1) < (k = 3) 4. L3 = 3 – 1 = 2 更新 T2 (x) = 1 – α2 x / α2 = α5 – x T3 (x) = α5 x – x 2 Fourth Loop (k = 4) 1. ∆4 =S4 − Λ3S3 + Λ3S2 + Λ3S1= 0– α2α6 – α6α5 = α2 2. ∆4 = 0 , Λ4(x) =Λ3( )x − ∆4T3( )x = 1 – α2x – α6x 2 – α2 (α5x – x2) = 1 – α6x – x2 L4 = 2 T4(x) = T3(x) * x 3. k < 2t (false) then σ (x) = 1 – α6x – x2 經由以上例子及實際的疊代運算,我們可以知道當徵候值有多少個
時就必須疊代多少次,因此若以本論文上節計算syndrome的例子,我們 假設接收到錯了3個symbol的訊息,可以產生16個徵候值S1=α 221 , S2=α 225 , S3=α232, S4=α197, S5=α96, S6=α156, S7=α63, S8=α92, S9=α124, S10=α120, S11=α229, S12=α248, S13=α7, S14=α190, S15=α173, S16=α243,也就必須疊代16次,最後就可 以得到錯誤位置方程式σ (x) = σ0 + σ1x + σ2x 2 + ... + σtx t 。 First Loop (k = 1) 1. ∆1 = S1− Λ0S0 =α221 2. ∆1≠ 0 , Λ1(x) =Λ0( )x − ∆1T0( )x = 1 – α221x 3. (2×L = 2×0) < (k = 1) 4. L1 = k – L0 = 1– 0 = 1 更新 T0(x) =Λ0 (x) / ∆1 = 1 / α221= α34 T1 (x) =α34x Second Loop (k = 2) 1. ∆2 = S2 − Λ1S1=α225– α221α221= α116 2. ∆2≠ 0 , Λ2(x) =Λ1( )x − ∆2T x1( )= 1 – α221x –α116α34x = 1 – α4x 3. (2×L = 2×1) = (k = 2) 4. L1 = L2 = 1 T2 (x) =α34x 2 Third Loop (k = 3) 1. ∆3 =S3− Λ2S2 + Λ2S1=α232–α4α225 + 0 =α197 2. ∆3≠ 0 , Λ3(x) =Λ2( )x − ∆3T2( )x = 1 – α4x–α197α34x 2 = 1 – α4x–α231 x 2 3. (2×L = 2×1) < (k = 3) 4. L3 = k – L2 = 3 – 1 = 2 更新T2 (x) =Λ2 (x) / ∆3 = 1 – α4x / α197 =α58+α62 x
T3 (x) = α58 x +α62 x2 Fourth Loop (k = 4) 1. ∆4 =S4 − Λ3S3 + Λ3S2 + Λ3S1=α197–α4α232 +α231α225=α167 2. ∆4≠ 0 , Λ4(x) =Λ3( )x − ∆4T3( )x = 1 – α4x–α231 x 2–α167(α58 x +α62 x2) = 1 –α106x–α24x 2 3. L4 = k – L3= 2 T4(x) =α58 x2+α62 x3 First Loop (k = 5) 1. ∆5=S5 − Λ4S4 + Λ4S3+ Λ4S2 + Λ4S1=α96 –α106α197+α24α232=α32 2. ∆5≠ 0 , Λ5(x) =Λ4( )x − ∆5T4( )x =1 –α106x–α24x 2–α32(α58 x2+α62 x3) = 1– α106x – α54x 2 – α94x3 3. L5 = k – L4= 3 4. 更新T4 (x) =Λ4 (x) / ∆5 = 1 –α106x–α24x 2 / α32 = α223 + α74x + α247x2 T5 (x) =α223x+ α74x2+ α247x3 Second Loop (k = 6) 1. ∆6 =S6 − Λ5S5 + Λ5S4 + Λ5S3+ Λ5S2 + Λ5S1= α156 –α106α96+α54α197+α94α232 = α79 2. ∆6≠ 0 , Λ6(x) =Λ5( )x − ∆6T5( )x =1– α106x – α54x 2 – α94x3–α79(α223x+ α74x2 + α247x3)= 1–α129x–α67x 2–α12x 3 3. L6 = k – L5= 3 T6 (x) =α223x2 +α74x3+α247x4 Third Loop (k = 7) 1. ∆7=S7 − Λ6S6 + Λ6S5+ Λ6S4 + Λ6S3 + Λ6S2 + Λ6S1= α63–α129α156+α67α96+α12α197=0 2. ∆7 = 0 , Λ7(x) = 1–α129x–α67x 2–α12x 3 3. L7 = 4 T7 (x) =α223x3 +α74x4+α247x5
Fourth Loop (k = 8) 1. ∆8= S8− Λ7S7 + Λ7S6 + Λ7S5+ Λ7S4 + Λ7S3 + Λ7S2 + Λ7S1= α92–α129α63+α67α156+α12α96= 0 2. ∆8= 0 , Λ8(x) = 1–α129x–α67x 2–α12x 3 3. L8 = 4 T8 (x) =α223x4 +α74x5+α247x6 Fourth Loop (k = 9) 1. ∆9=S9 − Λ8S8 + Λ8S7 + Λ8S6 + Λ8S5+ Λ8S4 + Λ8S3 + Λ8S2+ Λ8S1= α124–α129α92+α67α63+α12α156= 0 2. ∆9= 0 , Λ9(x) = 1–α129x–α67x 2–α12x 3 3. L9 = 5 T9 (x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 10) 1. ∆10= 9 9 9 9 9 9 9 9 9 10 9 8 7 6 5 4 3 2 1 S − Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S =α120–α129α124+α67α92+α12α63= 0 2. ∆10= 0 , Λ10(x)= 1–α129x–α67x 2–α12x 3 3. L10 = 5 T10 (x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 11) 1. ∆11= 10 10 10 10 10 10 10 10 10 10 11 10 9 8 7 6 5 4 3 2 1 S − Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S =α229–α129α120+α67α124+α12α92= 0 2. ∆11= 0 , Λ11(x) =1–α129x–α67x 2–α12x 3 3. L11= 6 T11(x) =α223x5 +α74x6+α247x7
Fourth Loop (k = 12) 1. ∆12= 11 11 11 11 11 11 11 11 11 11 11 12 11 10 9 8 7 6 5 4 3 2 1 S − Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S =α248–α129α229+α67α120+α12α124= 0 2. ∆12= 0 , Λ12(x) = 1–α129x–α67x 2–α12x 3 3. L12= 6 T12(x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 13) 1. ∆13= 12 12 12 12 12 12 12 12 12 12 12 12 13 12 11 10 9 8 7 6 5 4 3 2 1 S − Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S =α7–α129α248+α67α229+α12α120= 0 2. ∆13= 0 , Λ13(x) =1–α129x–α67x 2–α12x 3 3. L13 = 7 T13 (x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 14) 1. ∆14= 13 13 13 13 13 13 13 13 13 13 13 13 13 14 13 12 11 10 9 8 7 6 5 4 3 2 1 S − Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S α190–α129α7+α67α248+α12α229= 0 2. ∆14= 0 , Λ14(x) = 1–α129x–α67x 2–α12x 3 3. L14 = 7 T14 (x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 15) 1. ∆15= 14 14 14 14 14 14 14 14 14 14 14 14 14 14 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 S −Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S +Λ S α173–α129α190+α67α7+α12α248= 0 2. ∆15= 0 , Λ15(x) = 1–α129x–α67x 2–α12x 3
3. L15= 8 T15(x) =α223x5 +α74x6+α247x7 Fourth Loop (k = 16) 1. ∆16= 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 S −Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S + Λ S α243–α129α173+α67α190+α12α7= 0 2. ∆16= 0 , Λ16(x) = 1–α129x–α67x 2–α12x 3 3. L16 = 8 T16 (x) =α223x5 +α74x6+α247x7 4. k < 2t (false) then σ (x) = 1–α129x–α67x 2–α12x 3
2.4.3 尋找錯誤位置之方法
尋找錯誤位置之方法
尋找錯誤位置之方法
尋找錯誤位置之方法(Chien's Search)
在此說明由上節所計算出的錯誤位置多項式 σ (x),是由於編碼時所 使用的generator包含了我們所選用的根,因此若接收到的訊息不是由我 們選用的根所產生的訊息,則在經過syndrome 計算後的S(x)就包含了錯誤的訊息,再經過BMA、秦式搜尋演算法(Chien's Search Algorithm)的計
算後可以得到這些錯誤訊息的位置,最後由Forney Algorithm的計算後可 以得到錯誤位置的錯誤値。 在此我們透過一種秦式搜尋演算法來找尋所有的錯誤符號的位置。 做法是將 α-i ( i = 0 to 20)代入錯誤位置多項式 σ (x),若代入後其結果為零 則表示此 α-i為錯誤位置方程式σ (x) = 0的根,而 i值表示為接收訊號多 項式r(x)中錯誤符號位置。我們以上節的 σ (x)當作例子依序代入 α0 ~ α-20 找尋錯誤位置(在此只列出0 ~ 9,因為此例錯誤符號位置發生區間)。 σ (α0) =1–α129–α67–α12 = 25 σ (α-1) =1–α129α-1–α67(α-1) 2–α12(α-1)3=0 σ (α-2) =1–α129α-2–α67(α-2) 2–α12(α-2)3= 44
σ (α-3) =1–α129α-3–α67(α-3) 2–α12(α-3)3= 0 σ (α-4) =1–α129α-4–α67(α-4) 2–α12(α-4)3= 225 σ (α-5) =1–α129α-5–α67(α-5) 2–α12(α-5)3= 129 σ (α-6) =1–α129α-6–α67(α-6) 2–α12(α-6)3= 82 σ (α-7) =1–α129α-7–α67(α-7) 2–α12(α-7)3= 10 σ (α-8) =1–α129α-8–α67(α-8) 2–α12(α-8)3= 0 σ (α-9) =1–α129α-9–α67(α-9) 2–α12(α-9)3= 154 ⋮ 由以上結果我們可以知道,錯誤發生在r(x)的 x、x3、x8的位置。
2.4.4 尋找錯誤值大小之方法
尋找錯誤值大小之方法
尋找錯誤值大小之方法
尋找錯誤值大小之方法(Forney Algorithm)
在找尋錯誤值大小之前,里德所羅門碼定義了一個關鍵方程式(key equation) Ω(x),其原理是利用徵候多項式與錯誤位置多項式的關係導出可以找出錯誤值的多項式(Error Magnitude Polynomial, E(x)),因為徵候多項 式中含有錯誤的符號關係,而錯誤位置多項式含有位置的關係。其關鍵 方程式 Ω(x)表示如下: Ω(x) = [σ (x)‧S(x)] mod X2t σ (x)與S(x)相乘後的結果會因為(2-5)式限制x 次方項數,因此mod x2t的 部分可以忽略,以(2-5)式的 x次方為限制基準。得到了關鍵方程式後, 在藉由2.4.3小節所求得的錯誤位置方程式σ (x),再運用佛尼演算法 (Forney Algorithm)求解出錯誤值E(x)的大小。錯誤值的多項式 E(x)計算公 式為 : ( ) ( ) (2 6) ( ) ( ) i i i i i i i odd E α α α σ α α σ α − − − − − − Ω Ω = = − ′ ⋅ ⋅ 1 0 ( ) (2 5) t i i i x X − = Ω =
∑
Ω −公式中的 α-i即代入上節所求得的錯誤位置,而 odd
σ 表示為 σ (x)的殘餘奇
數次方項(odd power terms)。因為σ (x)經過一次微分後為σ α′( −i),其偶數
次方項均被消去為零,例如,σ (x) = 1–α129x–α67x 2–α12x 3,經過一次微分 後為σ α′( −i) =α129–2α67x–3α12x 2,而 2α67x =(α67+α67) ‧x = 0,由此可知若 x 次方項為偶數時,其一次微分的結果皆為零,因此σ α′( −i)=σodd( )x = α129–α12x 2。將所有錯誤位置依序代入E(x)後,個別得到其 r(x)中 x次方數 位置的修正量,因此還必須將r(x)在 α-i位置的值與 E(x) xor,最後的結果 才是正確的訊息符號。
運用Forney Algorithm方式來計算前面章節的BMA及Chien's search 例子所得到的結果,其關鍵方程式 Ω(x)結果如下 Ω(x) =[(1–α129x–α67x 2–α12x 3) ‧S(x)] mod X2t =α221– α164x– α219x 2 將上節所得到的錯誤位置 α-1、α-3、α-8分別代入錯誤值的多項式E(x): 得到三個錯誤值E(x)後與接收訊號r(x)在位置x、x3、x8的值分別進行 xor 運算。接收訊號r(x)表示如下: r(x) = α166 x19 + α104 x18+ α162x17 + α58x16+ α14x15+ α24x14+ α52x13+ α243x12+ α193x11+ α22x10+ 0x9+ α84x8+ α23x7+ α150x6+ α139x5+ α231x4+ α163x3+ α165x2+ α165x1+ α140. 由上式可知,接收訊號r(x)在位置 x、x3、x8的值分別為 α165x = 145、α163x3 = 99、α84 x8 = 107進行xor的結果等於 α89x、α198x3、α9x8,即為正確的訊 221 164 1 219 1 2 1 202 1 1 ( ) ( ) 112 ( ) E α α α α α α α α σ α − − − − − − − = = = ′ ⋅ 221 164 3 219 3 2 3 195 3 3 ( ) ( ) 100 ( ) E α α α α α α α α σ α − − − − − − − = = = ′ ⋅ 221 164 8 219 8 2 8 208 8 8 ( ) ( ) 81 ( ) E α α α α α α α α σ α − − − − − − − = = = ′ ⋅
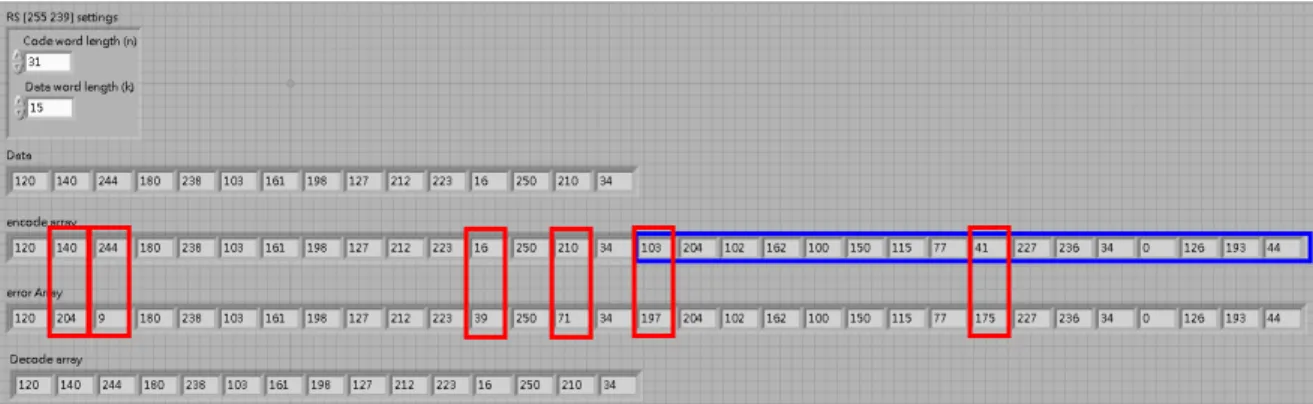
息表示如下: V(x) = r(x) + E(x) = α166 x19 + α104 x18+ α162x17 + α58x16+ α14x15+ α24x14+ α52x13+ α243x12+ α193x11+ α22x10+ 0x9+ α84x8+ α23x7+ α150x6+ α139x5+ α231x4+ α163x3+ α165x2+ α165x1+ α140+ α202x+ α195x3+ α208x8 V(x)= α166 x19 + α104 x18+ α162x17 + α58x16+ α14x15+ α24x14+ α52x13+ α243x12+ α193x11+ α22x10+ 0x9+ α9x8+ α23x7+ α150x6+ α139x5+ α231x4+ α198x3+ α165x2+ α89x1+ α140 RS(31, 15, 8)及RS(63, 47, 8)電路圖 首先先將A、B兩節點接上,此後訊息符號開始依序送入,當送入15 訊息符號時也會輸出15訊息符號,此後A、B兩節點則斷路改由下方節 點C接上,此時電路會繼續動作開始輸出編碼後的16 個冗餘符號,直至 31個clock後。 在此以本論文中所使用到的RS(31, 15, 8)及RS(63, 47, 8)做實際說 明。圖2.6為使用 RS(31,15,8)進行編碼的解碼的過程,首先將15 個訊息 符號做為訊息輸入RS Encoder,而每個訊息符號皆由8 個位元組成,經 過編碼器即可產生16個冗餘符號如圖 2.6中藍色框部分所示。編碼完成 的訊息經過通道後有可能發生訊息錯誤的情況,因此假設接收端收到的 訊號為圖中的error array,與發射訊號比較可以發現共有6 個符號發生錯 誤,將接收到的訊號經過RS Decoder解碼後,會將錯誤訊號更正回原始 發射的訊息,同時也會將編碼器的所產生的16個冗餘符號移除,只保留 原始未編碼的訊息符號。
第三章
第三章
第三章
第三章 渦輪乘積碼
渦輪乘積碼
渦輪乘積碼
渦輪乘積碼
1954年Elias提出了乘積碼的編碼方式[3],它是利用兩種區塊碼
(Bose-Chaudhuri-Hocquenghem, BCH code及 Hamming codes)來編成不同
碼率及更正能力的乘積碼,而後Pyndiah將渦輪碼中反覆解碼的觀念使用
於乘積碼上,稱其為渦輪乘積碼。渦輪乘積碼不僅在加成性高斯雜訊通 到(AWGN)有強大的更錯能力,在瑞利衰減通到(Rayleight Fading Channel) 一樣有著很好的改善。
3.1 渦輪乘積碼編碼
渦輪乘積碼編碼
渦輪乘積碼編碼
渦輪乘積碼編碼
渦輪乘積碼之編碼方式如同乘積碼之編碼方式,是將一個k x k 大小 的訊息區塊先由列(row)進行編碼,當所有的列編碼完成後進行行(column) 的編碼,其編碼示意圖如圖3.1至 3.3所示。 圖3.1 渦輪乘積碼列(row)編碼示意圖 圖3.2 渦輪乘積碼行(column)編碼示意圖圖3.3 渦輪乘積碼編碼完成示意圖 渦輪乘積碼的更正能力及碼字長度與選用的組成碼有關,假設以 C1 = (n1, k1, d1)與 C2 = (n2, k2, d2)為渦輪乘積碼的組成碼,則其參數定義為 min 1 2 d = ×d d code rate = (k1/n1)(k2/n2)
dmin = dmin1 × dmin2
渦輪乘積碼中的列、行編碼,就是使用了先前提到的 RS碼作為核心 的區塊編碼,而本論文所使用的列編碼為RS(64, 47, 8),行編碼為RS(31, 15, 8)。
3.2 渦輪乘積碼解碼
渦輪乘積碼解碼
渦輪乘積碼解碼
渦輪乘積碼解碼
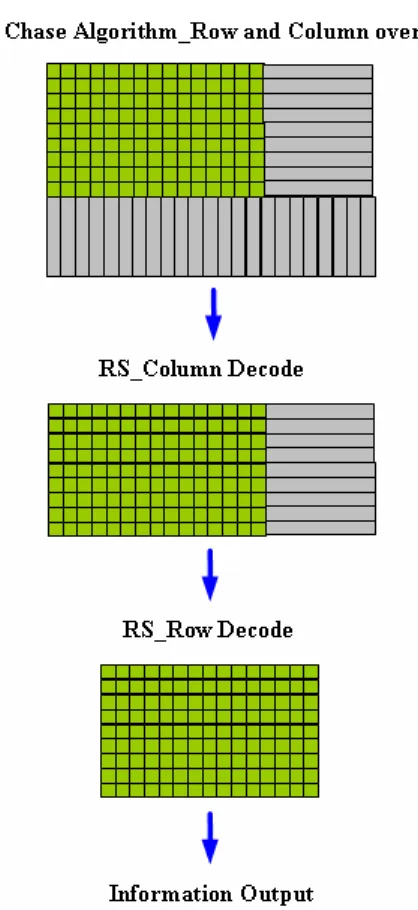
渦輪乘積碼是將渦輪碼中反覆解碼的觀念,用於乘積碼中。而渦輪 乘積碼必須使用軟式解碼判斷(Soft Decision),是由計算碼字的最短歐式 距離(Euclidean distance)後得到的第一及第二候選碼字(Candidate Codeword),其關係所產生的係數,軟式判斷影響著渦輪乘積碼的解碼效果。經過軟式判斷後的結果,再由1972年David Chase 所提出,使用Chase
演算法可以降低軟式解碼的複雜度[16],所以接下來的解碼順序為軟式判 1 2 2 d d t= ×
斷、Chase Algorithm、行列解碼,而行列解碼的部分也就是先前提到的 RS碼。
3.2.1 軟式判斷
軟式判斷
軟式判斷
軟式判斷
假設接收到一個向量為 y = (y1,y2, ...,yn),由於在傳送的過程可能使得 原始訊號為0、1的值,經過通道的干擾造成値的改變-1.5、0.2、-0.6等 等之類的情況,因此我們會先將向量作硬式解碼,最直接的判斷就是大 於0 為1,小於0 為0,即可得到向量y' = (y1', y2', ..., yn')。但這樣的判斷 還是不夠準確,因此我們還要計算位元的可靠度,例如0.1與 1.5相比, 同樣都會被判斷為1,但 0.1的可靠度卻比1.5 來的小許多,我們必須挑 選出這樣不可靠的位元出來計算可靠度。在計算位元可靠度(Likelihood)時,要使用Log-Likelihood Ratio 來計
算假設一高斯通道[17][20][21],平均值為0,變異數大小 σ2,則每個位元 yj' 的可靠度,可用下列的關係式表示 分子部分可以表示為 其中ej = +1、ej = -1的機率都為1/2,所以(3-2)式可以表示為 由於是高斯分佈,將 Λ(yj) 做正規化(normalize), 將代入(3-3)式可以得到 1 ( ) ln (3 1) 1 j j j j j P e y y P e y + = Λ = − =− ( 1) ( 1) ( 1 ) (3-2) ( ) j j j j j j p e p y e P e y p y = + ⋅ = + = + = 1 ( 1) 2 ( 1 ) (3-3) 1 1 ( 1) ( 1) 2 2 j j j j j j j j p y e P e y p y e p y e ⋅ = + = + = ⋅ = + + ⋅ = − 2 1 ( ) exp( ) 2 2 z z φ π = ⋅ −
整理後可以得到(3-4)式,定義了yj'的可靠度為∣yj∣。 經過以上步驟計算出位元的可靠度後,並未完成軟式解碼,還必須將軟 式解碼輸出,其算法與計算可靠度類似,只是將計算位元的可靠度改為 對接收向量的可靠度。定義 1 j S+ 是碼字 C,cj = +1的位元集合;S−j1是碼 字C,cj = −1的位元集合。C =