Transactions Papers
On (
n; n
1) Convolutional Codes With
Low Trellis Complexity
Hung-Hua Tang and Mao-Chao Lin
Abstract—We show that the state complexity profile of a
convo-lutional code is the same as that of the reciprocal of the dual code of in case that minimal encoders for both codes are used. Then, we propose an optimum permutation for any given ( 1) bi-nary convolutional code that will yield an equivalent code with the lowest state complexity. With this permutation, we are able to find many ( 1) binary convolutional codes which are better than punctured convolutional codes of the same code rate and memory size by either lower decoding complexity or better weight spectra.
Index Terms—Convolutional codes, decoding, trellis codes.
I. INTRODUCTION
C
ONVOLUTIONAL codes are widely used in many dig-ital communication systems for increasing the reliability of transmission due to the fact that convolutional codes have regular trellis structures and hence can be decoded by Viterbi algorithm [1]. For applications which require high coding rates, punctured convolutional codes [2] which are obtained from peri-odically puncturing some bits from mother codes of low coding rates are usually considered. A punctured convolutional code can be decoded by Viterbi algorithm using the decoding trellis of its mother code. Good punctured convolutional codes have been found by several researchers [2]–[7]. In particular, some of the best known punctured codes can be found in [7]. In this paper, we will show that the punctured convolutional code may not be the best choice if a rate 1 convolutional code is needed.Linear block codes can be represented by trellises [8]–[15]. In [8], Forney introduced the minimal trellis construction for the linear block code, which minimizes the number of vertices (states) at each depth, as claimed by Muder [9]. Similar con-cepts can be extended to the “minimal trellis” [17] of convo-lutional codes. Minimal trellises for convoconvo-lutional codes con-structed from the parity check matrices and from generator ma-trices have been, respectively, investigated by Sidorenko and
Paper approved by N. C. Beaulieu, the Editor for Wireless Communication Theory of the IEEE Communications Society. Manuscript received August 21, 2000; revised July 3, 2001. This work was supported in part by the National Science Council of the R.O.C. under Grant NSC89-2213-E-002-121. This paper was presented in part at the 2000 International Symposium on Information Theory and Its Applications, Honolulu, HI, November 5-8, 2000.
The authors are with the Department of Electrical Engineering, National Taiwan University, Taipei 106, Taiwan, R.O.C. (e-mail: [email protected]. tw; [email protected]).
Publisher Item Identifier S 0090-6778(01)00510-4.
Zyablov [16] and McEliece and Lin [17]. The state spaces of the minimal trellis of a linear block code can be described by its state complexity profile. It [8] has been shown that the state complexity profile of a linear block code and its dual code are identical. In Section III, we define the state complexity profile of the convolutional code in a manner similar to that of a linear block code. We show that the state complexity profiles of a con-volutional code and the reciprocal of its dual code are identical if minimal encoders for both codes are used. We also show the re-lation between minimal trellises of a convolutional code and its reciprocal dual regarding nodes which have branches emanating from them and nodes which have branches entering them.
For a communication system using an error-correcting code, a permutation may be easily applied at the receiver to achieve low trellis complexity regardless of the bit ordering at the trans-mitter. By applying a permutation to the bits of each word of an ( ) convolutional code , we have an equivalent code of . Among the equivalent codes, there is at least one for which the total number of vertices associated to its minimal trellis module [17] is the least and it is termed as an optimally equivalent code. In Section IV, we propose a method to find the permutation that leads to an optimally equivalent code of an ( 1) convolutional code. Hence, we are also able to find an optimally equivalent code of an ( 1) convolutional code.
In this paper, a good convolutional code is characterized by a large free distance and thin weight spectra and low state com-plexity. In Section V, we show that an ( 1) convolutional code with a trellis of low state complexity will also have small number of branches. With the method derived in Section IV, we are able to find good ( 1) convolutional codes with the aid of computer. We provide 6 tables which contain good ( 1) convolutional codes for 3, 4, 5, 6, 7, and 8, respectively. Many codes in these tables are better than the best punctured convolutional codes of the same code rate and memory size by either lower decoding complexity or better weight spectra.
II. PRELIMINARIES
Let , be a power series over a finite field in the indeterminate . In this paper, we only consider the case of 2 . The set of all possible is the field of Laurent series over , denoted by . If is a power series over in the indeterminate , then . The coefficients of the monomials in are called
the words of . A convolutional code with components in the field of , can be viewed as a vector space over . Let and be elements of and let and be words of and ,
respectively. Let , where
and is the standard inner product over , i.e., . Then, is an inner product of and over .
Consider an ( ) convolutional code that is defined
by a polynomial generator matrix ,
where is a polynomial over . can be re-garded as a convolutional encoder [18]. The memory size
of the encoder is is
said to be a minimal encoder for if it has the minimum memory size over all encoders realizing the code. For , there exists a dual code that is the collection of all
such that 0 for all . Let
and be minimal encoders for and , respectively. The product of and is a zero matrix. Let be the memory size of . It can be shown that
[19]. Let , that
can be viewed as a polynomial over with degree
. We may write ,
where is an -tuple over . A code is said to be the reciprocal code of if there is a minimal encoder for that is realized by the generators ,
1 . It can be checked that and . Write
as , where is a matrix
over and . The convolutional code with
can be viewed as a block code over of semi-infinite length that has a generator matrix [17] over
. ..
(1)
Let be a nonzero sequence. According
to [14], its left index, denoted , is the smallest index such that 0. Similarly, the right index of if exists, de-noted is the largest index such that 0. Whenever exists, the span of , denoted , is the discrete
in-terval 1 . Otherwise
. A nonzero sequence is said to be ac-tive at depth if both 1 and are in . A generator matrix of a linear block code is said to be a minimal span gener-ator matrix (MSGM) [14] if for any two distinct rows and of it, we have which is termed the -property and which is termed the -property. For con-volutional codes, MSGM can be similarly defined over or [17]. For a convolutional code, there are two matrices closely related to which are very interesting. One is
and the other is which is defined as .
An encoder (or ) is an MSGM if is a min-imal encoder, for which the associated is with -property and the associated is with -property.
III. CHARACTERISTICS OF THECONVOLUTIONALCODEWITH
MINIMALTRELLIS
In this section, we derive characteristics of convolutional codes with minimal trellises which are similar to the coun-terparts of block codes. Consider an ( ) linear block code . Let 0 1 1 be an index set. Define [13]
0 1 , 1 and 0
and 0 the empty set. The vertices at depth of a minimal trellis for form a state space that is isomorphic to the quotient space [13]
(2)
where and are the subcodes of consisting of all the codewords of for which the components with indices outside and are zeros, respectively. If an MSGM for is avail-able, the dimension of ,
, is in fact the number of rows of an MSGM which are active at depth .
For a convolutional code , suppose that the encoder is an MSGM. Associated with , we can obtain the min-imal trellis for [17]. In general, we are interested in the reg-ular portion of the trellis, for which the state space at depth is isomorphic to the state space at depth for any integer . The regular portion from depth to depth 1 is called a trellis module [17]. Now we can check the state spaces of the ( ) convolutional code which is generated by a min-imal encoder . The amount of ’s, for 0
and 1 , is 1 . Let
be in form of MSGM. Consider a vertical slice of that
covers the depths 1 for a given
. The nontrivial words in the slice are these ’s. For any given in the slice, it uniquely corresponds to a row
0 0 0 0 of , where is the only
element located in the slice. Note that , 0 is ac-tive at all the depths , 0 . But and may not be active at all the depths. At least is inactive at depth and is inactive at depth . Since is composed of all ’s, there are rows of which are inactive at depth , where is the space generated by rows of . Similarly, there are rows of which are inactive at depth , where is the space generated by rows of . The dimension of state space at depth
for a minimal trellis module of an ( ) code is (3) Note that is the dimension of state space for a conventional trellis module. Now we can define the set as the state complexity profile of the convolutional code .
For a linear block code and its dual code , it has been shown [8] that
. In the following, we derive a similar result for the convolutional code
be spaces generated by rows of and , respectively. In-teresting relations among , , and are given by the following lemma.
Lemma 1: (a) ; (b) .
Proof: For any rows and of and ,
respec-tively, we have 0. Suppose the degrees of and over are and , respectively. Then we have ,
, and . Since 0, then
0 and 0. Hence,
and . In [18], it has been shown that if is
a minimal encoder, then .
Simi-larly, we have . This lemma
then follows from the fact that
and .
Suppose is a subspace of . Let 0 1
be any subset of for which the complementary subset is . The projection of is the image of under the projec-tion operator that is the mapping for which the components with indices in are set to zero and other components remain unchanged. The subspace of is defined as the intersection of and . The following lemma can be easily verified from some basic concepts of linear algebra [13].
Lemma 2: If is a -dimensional subspace of and
, then (i) and (ii)
.
Theorem 1: The state complexity profiles of and with minimal encoders are identical.
Proof: It follows from Lemmas 1 and 2 that
From the fact that , we have
Consider the minimal trellis module for a convolutional code , which is closely related to its minimal encoder that is an MSGM. Every branch of the minimal trellis module is
labeled by one symbol (binary bit). Nodes of the minimal trellis module at depth are isomorphic to states of the state space at that depth. A node at depth from which two branches emanate implies there is an associated information bit triggering an impulse response beginning at depth . In other words, there is one row in which has left index . A node at depth for which two branches merge implies that there is an impulse response triggered by some information bit which is faded out at depth . In other words, there is one row in which has right index . Hence, each node at depth has two branches
ema-nating from it if 1 and has only
one branch emanating from it if .
Each node at depth has two branches merging if 1 and has only one
entering branch if . It
fol-lows from Theorem 1 that, 1
implies that . Hence, we find
the following result.
1) If a convolutional code has two branches emanating from each node at depth , then there are no two branches merging at depth 1 for its reciprocal dual code .
Similarly, we have the following results.
2) If does not have two branches emanating from each node at depth , then there are two branches merging at nodes at depth 1 for .
3) If has two branches merging at each node at depth , then there are no two branches emanating from each node at depth 1 for .
4) If does not have two branches merging at nodes at depth , then there are two branches emanating from each node at depth 1 for .
IV. OPTIMALLYEQUIVALENT( 1)AND( 1) CONVOLUTIONALCODES
In this section, we derive the state complexity profile for the ( 1) convolutional code. We also show a method to find an optimally equivalent ( 1) convolutional code. From the result of the last section, we can also find an optimally equivalent ( 1) code.
Consider a linear subspace of . Let supp
0 0 1 1 be the support
set of . For an ( 1) convolutional code with memory size and minimal encoder , it is clear that the state complexity profile is completely determined by and .
Let and . Remember that
and are the spaces spanned by and , respectively. Let
0 1 and 1 , then
and . Then, we have 1 ,
where
1 if 0 otherwise 1 if
0 otherwise. (4)
Note that and for . For clarity, we may offset the invariant quantity which is the memory size of the
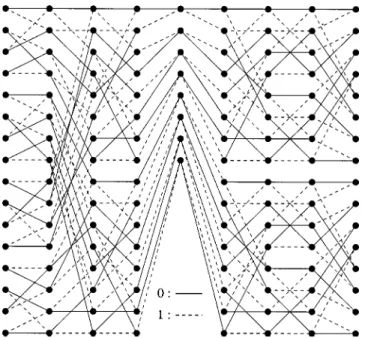
Fig. 1. The minimal trellis module for optimally equivalent code ofC, for which the minimal encoder is given in (7).
Fig. 2. The minimal trellis module for optimally equivalent code of the reciprocal dual codeC .
code . We term the set the offset state complexity profile,
where . Thus 1 is one of 1, 0 and 1.
For an ( 1) code, 1 is in 1 0 1 . The next two lemmas are derived for the ( 1) code.
Lemma 3: For an ( 1) code, the offset is either in 0 1 for all or 0 1 for all .
Proof: Suppose that 0 for an . In case that
1, then 0 which implies 0. By
(4), we have 0 0 and 1 0 for
. Hence, 1. Similarly, we also have 1 for . Therefore 0 for all . In case that 1,
then 2 which implies 1. Since
0 1 and 1 1 for , we
TABLE I
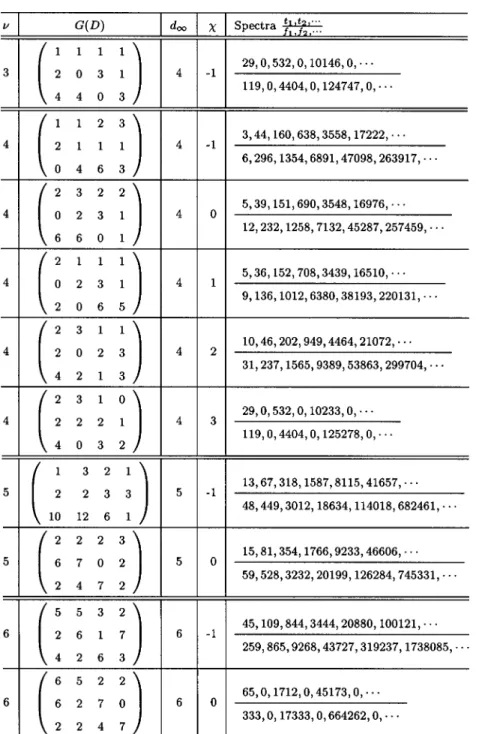
GOOD(3,2) CONVOLUTIONALCODES
have 1. Similarly, we have 1 for .
Therefore 0 for all .
Lemma 4: For an ( 1) code, the nonzero s occur consec-utively.
Proof: The offset ’s are either in 0 1 or 0 1 . For , suppose 0. Then,
0 2 . Thus , , and are all equal to , where is
either 0 or 1. Also we have .
Thus and hence .
By Theorem 1, we have the following result.
Corollary 1: For an ( 1) convolutional code, the nonzero offset ’s are equal and occur consecutively.
By applying the same permutation to the bits of each word of an ( ) convolutional code , we have an equivalent code of . Among all the possible equivalent codes, there is at least one for which the number of vertices associated to its minimal trellis
TABLE II
GOOD(4,3) CONVOLUTIONALCODES
module is the least and it is termed as an optimally equivalent code. The sum of dimensions of state spaces in the minimal trellis module for an ( 1) code is
(5)
where . By Lemma 3, we can easily check that the condition of a smaller total number of vertices associated to a minimal trellis is equivalent to a larger . For an ( 1) code, the distribution of is completely determined by the indices
and . In case , the nonzero occur
at depths from 1 to and hence there are
0’s and 1’s in the offset
state complexity profile. In case , the nonzero occur at depths from 1 to and hence there are 1’s and 0’s in the offset state complexity profile. Thus, we have .
In the following, we will show a method to find an optimally equivalent ( 1) convolutional code. From Theorem 1, we can also find an optimally equivalent ( 1) convolutional code. Theorem 2: For an ( 1) convolutional code , the permu-tation
if
if (6)
will result in an optimally equivalent code of , where means the concatenation of two ordered sets and .
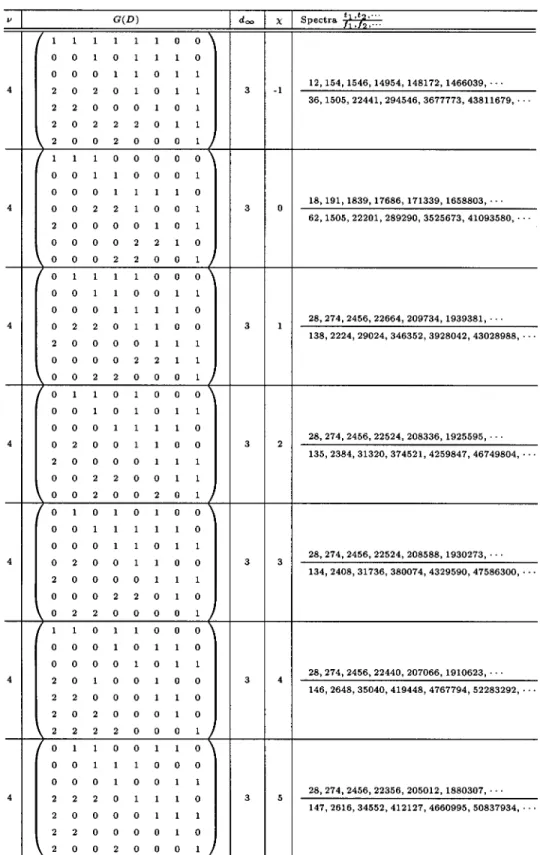
TABLE III
GOOD(5,4) CONVOLUTIONALCODES
Proof: In case that , then
for any -column permutation . We now need to find a per-mutation which leads to the largest or equivalently the least
. For , we have
. Thus for any , 1 ,
where the equality holds if is the permutation given in (6).
Consider the case of . Suppose that ,
TABLE IV
GOOD(6,5) CONVOLUTIONALCODES
is in but not in and is in but not in . Let be the permutation that switches the -th
and the -th columns. Then, and
. With this , the resultant offset state
complexity profile ( ) satisfies 1,
1 and for other than and
1. As long as , similar processes
can be continued. Since is finite, these processes can not last forever. Therefore we may assume . A permutation which leads to the largest or equivalently the largest number of 1’s is preferred. Since
1 and , then
1 1, where the
equality holds if is the permutation given in (6).
Example: Consider an (8,7,4) convolutional code with minimal encoder 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1 1 1 1 0 0 1 0 0 1 0 1 1 0 0 0 2 0 2 0 1 1 0 1 2 0 0 0 0 1 2 0 4 4 0 0 0 1 (7)
The minimal encoder for is (26,32,3,17,5,11,20,34). The components in both and are represented in octal form. The state complexity profile of either or
TABLE V
GOOD(7,6) CONVOLUTIONALCODES
is 4 5 5 5 5 5 4 4 . The associated and are 00 111 100 and 11 000 011 ,
respec-tively. For , we have = 2 3 4 5 and
= 0 1 6 7 . Hence an optimal permutation for the reciprocal dual code is 2 3 4 5 0 1 6 7 . According to Theorem 1, is also an optimal permutation for . The state complexity profile for the equivalent code of either or is 4 4 4 4 3 4 4 4 that is better than that of the original code. The minimal trellis modules for such optimally equivalent codes of and are shown in Figs. 1 and 2, respectively.
V. GOOD( 1) CONVOLUTIONALCODES
In applying the Viterbi algorithm (VA) to decoding a convo-lutional code, the decoding complexity is sometimes measured by the number of vertices per minimal trellis module or some-times by the number of branches per minimal trellis module, where each branch corresponds to one code bit. In Section IV, we have already shown that for an ( 1) convolutional code in case the decoding complexity is measured by the number
of vertices, then a large is desired. In the following, we con-sider the case that the decoding complexity is measured by the number of branches. For an ( 1) convolutional code with memory size , it has a reciprocal dual , which is an ( 1) code with indices and . For , there is only a single branch emanating from each state at depth for
and there are two branches emanating from each state at depth for , while there are two branches merging at each state at depth for 1 and there is only a single branch entering each state at depth for 1. Ac-cording to the observation given at the end of Section III, for , there are two branches emananating from each state at depth for and there is only a single branch emanating from
each state at depth for . Let , 0 1 1
be the offset state complexity profile of . Suppose that
0. Then, 0 for and
while 1 for . Hence, the decoding
complexity can be calculated to be
1 2 2 2 2 2 2 1 2
TABLE VI
GOOD(8,7) CONVOLUTIONALCODES
Suppose that 0. Then, 0 for
and while 1 for
. Hence, the decoding complexity can be calculated to be
(9)
We see that a large is desired for both measures of decoding complexity. Hence, is a good measure of decoding complexity for an ( 1) code.
If we decode an ( 1) binary convolutional code with memory size by applying VA to the conventional trellis, the decoding complexity measured by the number of branches
TABLE VII
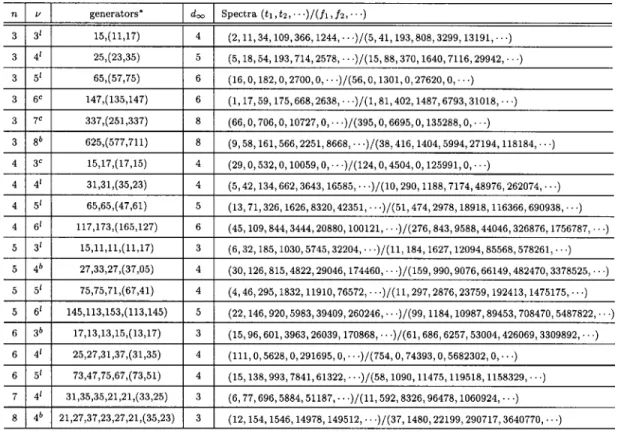
SOME OF THEBESTKNOWN(n; n 0 1) PUNCTUREDCODESSHOWN IN[7]
(each branch corresponds to 1 code bit) per trellis module is 2 . For an ( 1) binary punctured code with memory size obtained from a certain convolutional code, the decoding complexity measured by the number of branches per trellis module (each branch corresponds to 1 code bit) is 2 . The advantage of decoding for ( 1) punctured convolutional code over ( 1) convolutional code using conventional trellis is clear. However, we note that compared to an ( 1) punctured convolutional code for 1, an ( 1) convolutional code with minimal trellis module has the same decoding complexity for 1 and has lower decoding complexity for 1 in case the decoding com-plexity measured by the number of branches per trellis module and each branch corresponds to one code bit.
For a coding system, low decoding complexity as well as low error rate is desired. The error performance of an ( ) con-volutional code with free distance can be estimated by its code weight spectrum and information weight spectrum which are, respectively, represented by and , where is the total number of code sequences with weight 1 and is the total number of information bits associated to the code se-quences with weight 1. In case the code is applied over a symmetric and memoryless channel and maximum-like-lihood decoding is used, the first event error probability of the
coding system can be estimated by 1
and the symbol error probability can be estimated by
1 1 , where is the probability
of erroneously decoding a code sequence into a give code se-quence which is separated by a distance of . We see that for achieving low error rate, small and or “thin” weight spectra are desired. In [20], an algorithm called FAST algorithm is pro-posed to efficiently compute the weight spectra of convolutional codes.
With the aid of Theorem 1, 2, FAST algorithm and computer, we are able to search for good ( 1) convolutional codes. For the given , and 1, we search for ( 1) codes which have the currently best weight spectra. For the given , and , we exhaustively check all the possible ( 1) codes. For each ( 1) code to be checked, we randomly choose a generator matrix with -property for the associated recip-rocal dual ( 1) code and compute the associated weight spectra. The codes with the currently best weight spectra found in this search are listed in Tables I–VI for 3 4 5 6 7, and 8, respectively. For comparison, we also list some of the best known punctured codes in Table VII. We can see many codes in these tables are better than punctured convolutional codes of the same code rate and memory size [2], [3], [7] by either lower decoding complexity or better weight spectra. Note that we only
randomly choose one of the many possible generator matrices with -property for a given ( 1) code. It is likely that there exist better ( 1) codes if we exhaustively checking all the possible generator matrices.
VI. CONCLUDINGREMARKS
In this paper, we show that the state complexity profiles of a convolutional code and the reciprocal of its dual code are iden-tical if minimal encoders for both codes are used. We also pro-pose an optimum permutation for any given ( 1) binary convolutional code that will yield an equivalent code with the lowest state complexity. Moreover, we find many good ( 1) convolutional codes which are superior to the popular punc-tured convolutional codes by either lower decoding complexity or better weight spectra. The code search used here is not com-plete. Hence, it is likely that there exist codes better than those found in this code search. In fact, how to design a method to efficiently check the possible encoders under the restriction of -property for the reciprocal of the dual code of an ( 1) code is an interesting problem.
REFERENCES
[1] A. J. Viterbi, “Error bounds for convolutional codes and an asymptoti-cally optimum decoding algorithm,” IEEE Trans. Inform. Theory, vol. IT-13, pp. 260–269, Apr. 1967.
[2] J. B. Cain, G. C. Clark Jr, and J. M. Geist, “Punctured convolutional codes of rate (n; n 0 1) and simplified maximum likelihood decoding,”
IEEE Trans. Inform. Theory, vol. 25, pp. 97–100, Jan. 1979.
[3] P. J. Lee, “Constructions of rate(n 0 1)=n punctured convolutional codes with minimal required SNR criterion,” IEEE Trans. Commun., vol. 36, pp. 1171–1173, Oct. 1988.
[4] D. Haccoun and G. Begin, “High rate punctured convolutional codes for Viterbi and sequential decoding,” IEEE Trans. Commun., vol. 37, pp. 1113–1125, Nov. 1989.
[5] G. Begin and D. Haccoun, “High rate punctured convolutional codes: Structure properties and construction construction technique,” IEEE
Trans. Commun., vol. 37, pp. 1381–1385, Dec. 1989.
[6] M.-G. Kim, “On systematic punctured convolutional codes,” IEEE
Trans. Commun., vol. 45, pp. 133–139, Feb. 1997.
[7] I. E. Bocharova and B. D. Kudryashov, “Rational rate punctured convo-lutional codes for soft-decision Viterbi decoding,” IEEE Trans. Inform.
Theory, vol. 43, pp. 1305–1313, July 1997.
[8] G. D. Forney Jr, “Coset codes—Part II: Binary lattices and related codes,” IEEE Trans. Inform. Theory, vol. 34, pp. 1152–1187, Sept. 1988.
[9] D. J. Muder, “Minimal trellises for block codes,” IEEE Trans. Inform.
Theory, vol. 34, pp. 1049–1053, Sept. 1988.
[10] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding of linear codes for minimizing symbol error rate,” IEEE Trans. Inform. Theory, vol. IT-20, pp. 284–287, Mar. 1974.
[11] J. L. Massey, “Foundation and methods of channel encoding,” in Proc.
Int. Conf. Information Theory and Systems, vol. 65, Berlin, Germany,
1978, pp. 148–157.
[12] A. D. Kot and C. Leung, “On the construction and dimensionality of linear block code trellises,” in IEEE Int. Symp. Inform. Theory, San An-tonio, TX, 1993.
[13] G. D. Forney Jr, “Dimension/length profiles and trellis complexity of linear block codes,” IEEE Trans. Inform. Theory, vol. 40, pp. 1741–1752, Nov. 1994.
[14] R. J. McEliece, “On the BCJR trellis for linear block codes,” IEEE
Trans. Inform. Theory, vol. 42, pp. 1072–1092, July 1996.
[15] A. Vardy and F. R. Kschischang, “Proof of a conjecture of McEliece re-garding the expansion index of the minimal trellis,” IEEE Trans. Inform.
Theory, vol. 42, pp. 2027–2034, Nov. 1996.
[16] V. Sidorenko and V. Zyablov, “Decoding of convolutional codes using a syndrome trellis,” IEEE Trans. Inform. Theory, vol. 40, pp. 1663–1666, Sept. 1994.
[17] R. J. McEliece and W. Lin, “The trellis complexity of convolutional codes,” IEEE Trans. Inform. Theory, vol. 42, pp. 1855–1864, Nov. 1996. [18] P. Piret, Convolutional Codes. Cambridge, MA: MIT Press, 1988. [19] G. D. Forney Jr, “Convolutional codes I: Algebraic structure,” IEEE
Trans. Inform. Theory, vol. IT-16, pp. 720–738, Nov. 1970.
[20] M. Cedervall and R. Johannesson, “A fast algorithm for computing dis-tance spectrum of convolutional codes,” IEEE Trans. Inform. Theory, vol. 35, pp. 1146–1159, Nov. 1989.
Hung-Hua Tang was born in Taipei, Taiwan, R.O.C.,
in 1962. He received the B.S. degree in control engi-neering from Chiao Tung University, R.O.C., in 1993 and the M.S. and Ph.D. degrees, both in electrical en-gineering, from National Taiwan University,R.O.C., in 1993 and 2001, respectively. His research interests include coding theory and wireless communication.
Mao-Chao Lin was born in Taipei, Taiwan, R.O.C.,
on December 24, 1954. He recieved the Bachelor and Masters degrees, both in electrical engineering, from National Taiwan University,R.O.C., in 1977 and 1979, respectively, and the Ph.D. degree in electrical engineering from University of Hawaii in 1986.
From 1979 to 1982, he was an Assistant Scientist of Chung-Shan Institute of Science and Technology at Lung-Tan, Taiwan, R.O.C. He is currently with Na-tional Taiwan University, as a Professor with the De-partment of Electrical Engineering. Since 2000, he has been the chairman of Graduate Institute of Communication Engineering, National Taiwan University. His research interests include coding theory and ARQ techniques.