以資料探勘的技術建構焦點護理記錄與護理診斷關係模型
To Establish a Model of Connection between Focus Nursing Records and Nursing
Diagnosis by Data Mining Technologies
廖珮宏
a,c, 孫吉珍
b, 谷幼雄
b, 曾尹俊
c, 朱唯勤
c*Pei-Hung Liao
a,c, Chi-Chen Sun
b,
You-Shyong Goo
b, Yin-Jiun Tseng
c, Woei-Chyn Chu
c*a
經國管理暨健康學院護理系講師
b振興復健醫學中心護理部
c 陽明大學醫學工程研究所
*通訊作者: 朱唯勤, [email protected]
摘要 資訊科技於健康照護的運用,自2000年至今已在台灣 蓬勃的發展。根據文獻指出,臨床照護工作的時間分 配約略可分為四大區塊,如護理評估、護理活動、護 理紀錄及其他,其中又以護理紀錄佔37%為最耗時, 因此護理紀錄資訊化建置是目前臨床上最迫切的需 求。護理記錄的研究結果提到,護理紀錄主要書寫內 容 以 北 美 護 理 診 斷 (NANDA) 為 依 據 , 以 P.O.M.R.(SOAP)為記錄方法,核心是以病人為中心, 收集病患的主、客觀資料,經由護理人員分析、歸納 資料,並依據鑑定性特徵(症狀)來確立護理診斷,再提 供照護活動。但在床邊的即時紀錄是護理人員可直接 將 症 狀 成 立 一 個 焦 點 問 題 , 並 以 DART ( Data 、 Activity、Response、Teaching)的方式來書寫。為了避 免重覆書寫的情形,本研究提出一個以關聯式的資料 探勘理論,應用資料擷取技術中的關聯法則,探討焦 點護理問題與護理診斷之間是否有某種程度上的關 聯。以焦點問題、鑑定性特徵進行護理診斷分析,得 到護理診斷之支持度與信賴度,說明此區間之護理診 斷的高頻項目集合,再進行護理診斷間的關聯分析, 推測同時確立不同護理診斷間的支持度與信賴度,進 而預測出當個案出現哪些焦點問題時,他可能會被確 立哪些護理診斷,輔助護理人員縮短紀錄的時間,並 以作為未來人工智慧建置護理資訊系統的考量。本系 統實施與導入後的成效初探係採準實驗研究方法,初 探結果發現:1.可以縮短書寫護理紀錄時間2.可以提升 護理人員工作滿意度。 關鍵詞:資料探勘、關聯法則、護理資訊、護理紀錄 AbstractThe application of information technology on healthcare has been prevailing in Taiwan since 2000. According to literature, time allocation of clinical nursing works could be divided into nursing evaluation, nursing activities, nursing records, and others,. The one taking the most hours or 37% of total clinical nursing time is nursing records. Thus, the implementation of nursing record information is the most essential needs in clinical works. The research results of nursing records indicate that the contents of hand-writing are based on NANDA while the recording method adopts P.O.M.R. (SOAP). The total process is centered on patients, in which nursing staff collects patients’ subjective and objective data to analyze and sort them out. Next, we establish nursing diagnoses according to characteristics of appraisal (symptoms) before providing nursing activities. However, the real-time bedside recording is made by DART (Data, Activity, Response, Teaching) when nursing staff establishes a focus issue directly from symptoms. To avoid repeated handwriting, the study brings out a data mining theory for connected information by adopting the association rule in the data abstracting skills to explore if there is any certain degree of connection between focus nursing issues and nursing diagnosis. We use focus issues and characteristics of appraisal to analyze nursing
diagnoses in order to obtain the supporting level and confidence level of nursing diagnoses. Thus, we could address the concentration of items of high frequency in a certain area of nursing diagnoses and then analyze the connections among nursing diagnoses. We aim to establish the supporting level and confidence level among various nursing diagnoses so as to predict what kind of nursing diagnoses could be established for what focus issues appearing in what kind of cases. Therefore, we could effectively help nursing staff to shorten their recording time and use such method for future consideration of artificial intelligence, such as nursing information system. We adopted research methods of quasi-experiment to conduct a preliminary study on the effect of introducing and implementing such system. Our preliminary results showed that: (1) the time spent on transcribing and recording could be shortened; (2) the job satisfaction of nursing staff could be promoted. Keywords: Data Mining, Association Rule , Nursing Informatics. Nursing Record.
Introduction 1-1 臨床照護工作的時間分配約略可分為四大區塊, 護理評估(偵測生命徵象及病患症狀),護理活動(給藥 及具體的照護),護理紀錄及其他,根據文獻及臨床實 務中皆發現護理紀錄佔 37%為最耗時(Yang,2003) [1],原因分析中提到,護理紀錄單張多且重覆性高; 書寫內容以北美護理診斷(NANDA)為主,主要是依鑑 定性特徵(症狀)來確立護理診斷,但文辭較為咬文嚼字 及部份概念模糊的護理診斷名稱易影響即時記錄時間 (Liao,2008) [2],因此國內外有半數醫院為了避免護 理人員於床邊即時記錄時工作壓力過大,採用焦點護 理記錄法(Focus charting)作為記錄範本,焦點記錄法是 以 DART(Data、Action、Response、Teaching)的記 錄方式,可直接將症狀來成立一個焦點問題整個護理 診斷(Figure1),此記錄方式以簡單、易懂、意義正確 的專用術語為主(黃,2003)[3],如此雖提供了簡便 的方法,但護理人員仍需重覆抄寫兩種不同的護理紀 錄單張。 護理紀錄的語言較為口語化且缺乏一致性(蕭, 2006)[4],電腦化資訊系統是依據護理診斷、護理成 果分類(NOC)及護理活動分類(NIC)中文版的標 準詞彙所建置,持續性的紀錄過程會產生的大量資 料,這些大量資料中所潛藏的、未知的資訊,如果能 有效挖出來,將可帶來更多的效益,而資料探勘就是 目前公認最具備這種能力的技術之一(林,2007)[5] [6],本研究主要是在發掘焦點問題與護理診斷之間的 關聯性(Figure2),關聯法則之意圖則是在指出龐大的 資料庫中,某一些物件間存在彼此的關聯性,當符合 超過最小支持度且超過最小信賴度時,所產生的關聯 法則方可被視為具有意義的,本研究即是運用關聯法 則 進 行 資 料 探 勘 以 建 構 出 護 理 診 斷 的 關 聯 模 型 (Figure3)。 1-2 關聯法則(association rule)主要是在大量的資料中 找尋出不同項目集合間的交互關係[6] [7],關聯法則 (association rule)的形式為 X Y,其中 X、Y I,且
X Y = 。每一條規則(rule)有一強度的度量單位為信
賴度(Confidence),而 Confidence ( X Y ) = Support ( X Y , D ) / Support ( X , D )。依照條件機率,若某 關聯法則的信賴度超過一定限度時,其意義為若此交 易包含 X,有很高的機率會包含 Y。因此,關聯法則 也就是要找出所有 X Y 形式的關聯法則,並且滿足 下列條件:Support ( X Y , D ) Min_Support 且 Sonfidence ( X Y ) Min_Confidence。 Apriori 演算法 (1) 首先訂定過濾規則強度的門 檻值─最小支持度及最小信賴度。(2)使用了候選物項 集合(Candidate Itemset)的觀念,先產生出物項集合, 稱為候選物項集合,若候選物項集合的支持度大於或 等於最小支持度 minisup,則該候選物項集合為高頻物 項集合(Large Itemset)。(3)由資料庫讀入所有的交易, 得出候選單物項集合(Candidate 1- itemset)的支持度, 再找出高頻單物項集合(Large 1- itemset),並利用這些 高 頻 單 物 項 集 合 的 結 合 , 產 生 候 選 2 物 項 集 合 (Candidate 2- itemset)。 (4) 再掃描資料庫,得出候選 2 物項集合的支持度以後,再找出高頻 2 物項集合, 並利用這些高頻 2 物項集合的結合,產生候選 3 物項 集合。(5) 重覆掃描資料庫、與最小支持度比較,產生 高頻物項集合,再結合產生下一級候選物項集合,直
到不再結合產生出新的候選物項集合為止[8] [9]。 目前 Apriori 演算法於醫學上的應用有藥物交 互作用資訊查詢對選擇性醫療項目做群聚分類,並 提供基礎醫令組合建議根據腦中風疾病的流程記 錄,找出共同的時間相依性模式,安排治療活動及執 行的時間等(林,2007)[5] [10]。 Figure1 護理紀錄流程圖 Figure2 焦點問題與護理診斷概念圖 Figure3 焦點問題與護理診斷關聯架構圖
Materials and Methods
2-1 本研究步驟為:(一)先將標準化的護理診斷及收 集臨床制定的焦點問題建置於資料庫(二)建置過程 中持續討論與線上測詴約六個月,(三)建置完成並於 實際使用前教育訓練三個月,(四)使用後三個月再作 初步成效探討。 2-2 本研究主要是針對焦點護理問題與護理診斷之關 係,以 Data Mining 與 Apriori 演算法,就病患的相關 症狀等作為可能有關之屬性,並以關聯法則進行資料 探勘,先將護理診斷的鑑定性特徵及焦點問題名稱建 立資料倉儲(Data Warehouse),再將欲分析的資料以 關聯式演算法來取得資料的分析度、信賴度做資料的 分 析 , 即 所 謂 資 料 探 勘 ( Data Mining ) 的 流 程 (Figure4),最後再以資料擷取技術,依症狀和護理診 斷進行資料分析。 先針對資料庫進行搜尋比對,篩選症狀類別以使 用宣告式篩選條件比對,篩選條件是護理診斷核心元 件,依快速的執行速度目標而設計。每個篩選條件實 作都已針對護理診斷進行的特定比對種類而最佳化。 篩選應用程式必頇處理任何鎖定語意。例如焦點問題 (症狀)為低血壓(BP) 70/56mmhg, 舒張壓 70 ,收 縮壓 56 、心跳緩慢、膚色蒼白、心輸出量不足、低 血容量等都是鎖定的語意,找出所有高頻項目集的長 度,即每項相關症狀出現的次數,將次數不符合支持 度的症狀去除,其餘符合的挑選出來,作為第一層次
的支持條件;如心輸出量不足、低血容量、低血壓、 缺氧等;之後利用所搜尋到的第一層次進行排列組合 (join),將產生的候選項目歸類為第二層,利用第二層 進行對資料庫的搜尋,進行第二次高頻項目集長度的 尋找,便可以獲得第二層次的支持條件,如心輸出量 不足、低血壓、組織灌流不足等;以此類推,便可以 透過與資料庫的比對找出符合支持度的症狀,進而產 生護理診斷。例如,組織灌流不足(Figure5)。 以 Apriori 演算法來應用,篩選由各組類別所組 成,此症狀類別會有效地判斷哪一組篩選條件是針對 特定診斷而設定為真(true)。首先在資料庫中進行比 對,接收到症狀條件之後,會執行篩選,篩選是分派 症狀至適當應用程式診斷類別(class)的程序一部分。篩 選條件的設計能夠滿足 NANDA 分類型態 II 系統的需 求,包括健康促進、營養、排泄、活動或休息、知覺 或認知、自我知覺、角色、性學、調適或壓力耐受、 生命原則、安全或保護、舒適、生長或發育 歸類診斷。 篩選引擎主要元件:篩選條件(Filter Table) 和症狀類 別資料表(class table)。篩選條件會根據使用者指定的邏 輯 條 件 , 做 出 相 關 訊 息 的 布 林 值 決 策 Boolean-FP- tree。使用字串的 match 方法,可在一個字串中,取 出符合某個正規表示式的子字串,判斷訊息是否符合 症狀類別篩選條件。其中一個方法是用症狀(Symptom) 的 keyword 比 對 。 其 他 方 法 則 會 將 症 狀 緩 衝 區 (Symptom Buffer) 當做輸入參數,而且可以檢核症狀 特徵資料表。篩選資料表是 Create Table 方法建立的 一般類別。每一種篩選條件都會特製化為比對特定病 徵類別的布林值條件。一旦建構篩選條件,篩選條件 使用的準則亦同時成立。動作(Action) 包含字串的清 單。如果篩選條件清單中的任何動作符合篩選條件或 病徵緩衝區中的動作 keyword,比對符合支持度就進入 第一層,如果篩選條件清單中沒有任何動作符合篩選 條件或病徵緩衝區中的動作 keyword,就直接去除。篩 選資料表是用來儲存索引鍵值組,其中篩選條件是索 引鍵,而一些關聯的資料為值。篩選資料可以用來表 示當病徴符合篩選條件,並且篩選資料的型別為篩選 資料表類別的泛型參數時所要採取的動作。篩選資料 表具有數個方法,這些方法會根據資料表中的所有篩 選條件比對是否符合,並且傳回符合篩選條件或資料 的未排序集合。有些比對方法屬於多重比對,一對多 符合並且會傳回所有符合的項目。其他方法則是一對 一比對(Compare),只傳回一個項目,並且如果有一個 以上的篩選條件相符,則會擲回 多重交叉比對過濾條 件。 篩選條件(Filter Table) 為普遍的實作。可以在資 料表中儲存所有類型的篩選條件。指派數值優先順序 給篩選條件,其中最大數字表示最高優先順序。多種 篩選條件類型可以具有相同的優先順序。特定類型的 篩選條件可以顯示在一個以上的優先順序層級中。比 對會從最高優先順序開始進行,一旦以指定的優先順 序找到符合的篩選條件,就不會檢查較低優先順序的 篩選條件。因此,如果正在使用單一篩選條件比對方 法,並且有一個以上的篩選條件符合,但每個符合的 篩選條件具有不同的優先順序,那麼就不會擲回任何 例外狀況,而是會傳回具有最高優先順序的篩選條 件。同樣地,多重篩選條件比對方法只會傳回具有最 高優先順序的符合篩選條件。 2-3 (一)本研究於 97 年 6 月開始至北區某教學醫院收集 現行的焦點問題,並觀察護理人員執行護理記 錄模式,97 年 9 月開始建立資訊系統,98 年 1 月執行系統測詴與改善,98 年 3 月始進行兩個 病人照護單位的護理人員教育訓練 3 個月,98 年 6 月~12 月進行臨床使用測詴,將在使用後 3 個月、6 個月做此初步的經驗探討與分享。 (二)研究方法及工具 本研究將採用套裝軟體 SPSS 11.5 for Windows 英文版進行資料的處理與分析。基本資料調查 表採用百分比、平均值等統計方法,書寫紀錄 時間及滿意度於使用護理資訊系統前後之差 異,採用配對 t 檢定(Paired-Samples t-test)檢 測是否有顯著差異,本研究所有統計水準皆以 p <0.05 表示有統計上之意義。 本研究工具為問卷調查,問卷內容包含兩大部 份,第一部份為基本資料,第二部份為紀錄時 間及滿意度評估,分述如下。 1. 基本資料調查表
內容包括:年齡、教育程度、年資、電腦基 本操作(word、excel、power point)(表一)。 2. 護理人員自行估算使用資訊系統前、後書寫 護理紀錄花費的時間。紀錄時間是指書寫護 理紀錄單張時間,並不包括其他評估單張的 書寫。 3. 滿意度調查表僅粗略對於手工書寫及資訊化 輸入之滿意程度作調查,本表為 liker 5 分法 方式,以等距數字 0-4 分量表,0 分為非常不 滿意,1 分為不滿意,2 分為尚可,3 分為滿 意,4 分為非常滿意。 問卷調查對象為三個測詴單位中 18 位使用過系 統 的 護 理 人 員 , 統 計 資 料 顯 示 Reliability Coefficient Alpha 為.83。
Figure4 Data mining flow chart
Figure 5 Apriori Algorithm flow chart
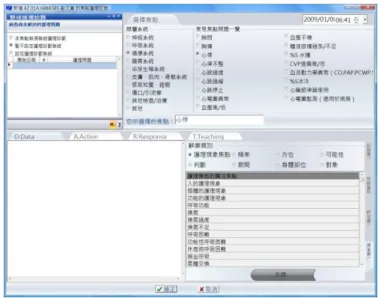
Figure 6 焦點問題與護理診斷聯結畫面 Results 本研究團隊於北區某教學醫院進行臨床測詴,在 前驅性回溯性的研究中,回顧 96 份病歷,系統根據焦 點護理問題所聯結出的護理診斷項目與護理人員所確 立的診斷有 82%的完全符合性,機率選擇於前 3 位者 有 62%。 一、Data mining 方法運用於系統可以縮短記錄時間 護理紀錄是護理人員工作中需花較多時間的一部 分最,在系統建置前,研究單位的書寫護理紀錄時間 約占 2 小時/每班(加總每次書寫),系統建置後約 1.2 小時/每(Table1)班。 護理人員頇三班制輪替,而照護的個案數也因各 班別而有所不同平均每位護理人員 1 人照護個案數約 為:白班 9-10 人,小夜 12~16 人,大夜 16~20 人,紀 錄的內容則以白班最為詳盡,夜班多為紀錄評值結 果,所以夜班雖有個案增加,但紀錄時間並無顯著差 別(黃,2003),因此研究中並未詳細區別三班。 二、焦點問題與護理診斷聯結系統可以提升護理人員 工作滿意度 護理人員在床邊執行照護作業時,透過觸控式螢 幕,可以迅速聯結常見焦點護理問題、北美護理診斷 (Figure 6),即時寫下來焦點護理紀錄之部份或完整 的內容作暫存,以解決傳統手工作業需大量重複抄寫﹐ 或甚至發生遺忘漏寫的情形﹐如此便利即時的作業方 式使得護理人員對護理紀錄書寫的工作滿意度由 56% 提升至 72%。
Discussion and Conclusion 一、未來研究方面 (一)本研究僅在北部某區域教學醫院收案,建議可 在不同區域的醫院複製,增加實證性的探討。 (二)由於研究時間上限制,只追蹤三個月的使用成 果,由研究結果可知,資訊化可幫助資料準確 性,建議未來研究可探討此介入措施更長期的 成效至 6 個月到 1 年。 二、護理實務方面 (一)由本研究與其他研究(蕭,2006)皆發現,以護理 診斷為主的問題導向紀錄法的使用測詴成效結 果: (1)護理評估的項目與提供紀錄的內容不 足,對於記錄時間的改變不大(2)未與其他相關 資訊系統連結,工作效率改善有限(3)等待系統 反應時間長等。在本焦點護理紀錄資訊系統的 使用成效中有縮短記錄時間與增加工作滿意度 等顯著差異。 參考文獻
[1] Ke-Ping Yang., “The Journal of Nursing Research: The connection between nursing human resource and
patient conditions, ” 11. Vol.3, pp. 49-158 , 2003. [2] 廖珮宏、王文琳、曾尹俊、朱唯勤,以人工智慧置
入護理資訊系統協助護理診斷產生之成效初探, 2008JCMIT Poster present,台北, 2008。
[3] 黃芳子,比較護理診斷為主的問題導向記錄法與焦 點護理記錄法之成效差異‧未發表的碩士論文,台 北:臺北醫學大學護理學研究所,2003. [4] 蕭如玲、黃興進,發展護理計劃系統之探索性研究 ∙ 志為護理‧6(1) ,pp80-89,2006 ∙ [5] 林俊榮、張立興、林俊廷、王藝臻、劉靜怡、 林麗芬,以Apriori演算法建構季節流行病關係模 型,未發表的碩士論文,台中:弘光科技大學資 訊管理學研究所,2007. [6] 陳佳楨,「資料探勘應用於就診行為與醫師排班之 研究-以埔里基督教醫院為例」,國立暨南國際大 學資訊管理研究所碩士論文,2003.
[7] Giuseppe Polese, Massimiliano Troiano, Genoveffa Tortora, System applications and experience: A data mining based system supporting tactical decisions, Proceedings of the 14th international conference on Software engineering and knowledge engineering , pp.681-684, 2002.
[8] 李卓翰,「資料倉儲理論與實務」,台北:學貫行銷
股份有限公司,2003。
[9] K.E. Burnthornton and L.denbrand,
Myocardial-infarction-pinpoint the key indicators in the 12-lead ECG using data mining, Computer and biomedical research, Vol.31, Iss.4, pp293-303, 1998. [10] 林俊榮、陳玉豐、吳帆,運用資料擷取技術建構 輔助臨床處置專家系統知識庫,第十四屆國際資 訊管理研討會,pp.981-988,中正大學,嘉義,2003。