行政院國家科學委員會專題研究計畫 期中進度報告
應用於數位電視的雙模視訊解碼器(1/3)
計畫類別: 個別型計畫 計畫編號: NSC94-2215-E-009-046- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立交通大學電子工程學系及電子研究所 計畫主持人: 李鎮宜 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國 95 年 5 月 30 日
1
應用於數位電視的雙模視訊解碼器
(1/3)
“Dual-Mode MPEG-2/H.264 Video Decoder for Digital TV Application”
計畫編號:NSC94-2215-E-009-046 執行期間:94 年 8 月 1 日至 95 年 7 月 31 日 主 持 人: 李 鎮 宜 交大電子工程學系/電子工程學研究所教授 一、 摘要: 本計畫目的主要是針對於雙模式的視訊解 碼,以及低功率的議題來做深入的研究與探 討,尤其是應用在數位電視的視訊傳播系統當 中。 首先,由於最新視訊標準(H.264)的出現, 使得目前的視訊標準面臨標準的不相容情況。 例如傳統的 MPEG-x 系列的視訊標準便無法用 H.264 的解碼器來播放。因此,本計劃提出一個 雙模 MPEG-2 和 H.264 的視訊解碼器,以期能 夠共用相同的模組並且降低整合上的負擔。此 外針對低功率的需求,本計劃亦提出一些相關 的低功率模組,以期減少對記憶體的存取和減 少所需的工作頻率,來達到低功率的單晶片系 統設計。 關鍵詞:H.264/AVC、MPEG-2、數位電視、低 功率。 Abstract:
The objective of this project is to highlight design challenges for low-power and dual-video standard requirements, especially in Digital-TV applications. Due to the advent of newly announced H.264/AVC, a generic problem of standard-incompatibility is appeared between H.264 and prevalent MPEG-x video standards and must to be resolved both in algorithmic and architectural levels. Furthermore, several low-power techniques targeted at achieving lower memory requirements and processing cycles are also described and discussed.
Keywords: H.264/AVC, MPEG-2, Digital-TV, Low-Power.
二、緣由與目的:
Although a wide range of video coding standards have been developed, these algorithms are so diverse, leading to the lack of compatibility. For example, prevalent MPEG standards support the backward compatibility. But, the advent of H.264 and VC-1 cannot be backward compatible to the former H.26x and MPEG-x family of video coding standards. Therefore, a development of the combined video coding standard is indispensable to meet different standard requirements. Moreover, in an application point of view, digital video broadcasting (DVB) project has paved the way for the introduction of MPEG-2 based digital TV service, known as DVB-T in many countries. Recently, DVB-H, a spin-off of the DVB-T standard, adopts the transmission of H.264 for handheld digital TV due to its bandwidth efficiency. However, DVB-H is totally backward compatible to DVB-T but is transmitted with different video contents (i.e. MPEG-2 vs. H.264). In other words, a generic problem of standard-incompatibility is emerged, resulting in the design challenge for the multi-standard integration. In this project, we choose a well-known MPEG-2 and newly-announced H.264 as our decoding platform to support dual-mode video standards [1][2].
One of the primary purposes in the design of Digital-TV systems is power reduction. Although many compression techniques greatly reduce the transmission bandwidth, the introduced coding/decoding complexity and computing power become the key design challenges for real-time and battery-operated systems. We consider a newly-standardized H.264 video standard as an extreme case. There are two major factors to adversely impact the power dissipation. The first is the large memory storage including internal registers, SRAM, and external SDRAM.
2
Specifically, H.264 utilizes the neighboring pixels to create a reliable predictor, leading to the long data dependency. This problem can be solved by allocating large memory storage but introducing large memory power dissipation. The second is the computationally intensive processing unit such as motion compensation and deblocking filter. Motion compensation needs a great deal of memory accesses which degrade decoding throughput. Deblocking filter is a pixel-wise process and adaptively performs interpolation processes. In sum, they require high-speed or high-throughput hardware solutions to improve the coding/decoding performance.
三、研究方法與成果:
(A). 雙模式 H.264/AVC 和 MPEG-2 之系統整
合
This section addresses an introductory overview of dual-mode techniques from the perspective of a cost-saving design issue. Because the design goal concentrates on the low bit-rate Digital-TV systems, this report introduces a dual-mode video decoder integrating MPEG-2 simple profile (SP) and H.264 baseline profile (BP). At first, in the algorithmic point of view, motion compensation and intra prediction in MPEG-2 are just a sub-set of that in H.264. That is, they can be totally merged into H.264 by sharing the hardware resources. With regard to the entropy decoder, H.264 features to adaptively select tables, but it is still similar to variable length codes defined in MPEG-2. So far, H.264 can be partially compatible to MPEG-2 video coding standard. Nevertheless, the IDCT algorithms between MPEG-2 and H.264 are so diverse that they are difficult to combine. Similarly, the integration of deblocking filters also has the same problem. In the following, we will pay more attentions on these critical modules between MPEG-2 and H.264.
A major focus while combining MPEG-2 and H.264 is IDCT since it faces the most diverse algorithm over the whole design. Specifically, the IDCT kernel of H.264 is a 4x4 integer transform kernel but that of MPEG-2 is an 8x8 cosine transform kernel. Due to an algorithmic difference in terms of transform size and kernel characteristics, a shared IDCT structure is of great challenge. In our design, 8x8 IDCT can be
computed using 4x4 IDCT recursively. In other words, N-pt IDCT can be decomposed into N/2-pt IDCT by partitioning even and odd coefficients. It allows us to generate 8-pt IDCT from two identical 4-pt IDCTs. Therefore, one of the 4x4 IDCTs can be simultaneously shared in MPEG-2 and H.264, and the problem of different transform size can be resolved. As for kernel characteristics, both standards require addition and the input bit-width of adders in H.264 is smaller than that in MPEG-2. Thus, the common terms of addition can be shared between MPEG-2 and H.264.
In the case of the deblocking filter, it is standardized by H.264 and brought within the motion-compensated prediction loop (i.e. in-loop filter). Whereas, the deblocking filter of MPEG-x family is informative and performed outside the coding loop (i.e. post-loop filter). Although both filters feature to remove the block discontinuities and improve the visual quality, there is a main drawback when we replace an in-loop filter with a post-loop one. The experimental results reveal that the performance improvement is very small (0.04dB) if we put the in-loop filter of H.264 into MPEG-2 video decoding flows. To alleviate this problem, we derive an integration-oriented algorithm that can be reconfigured as either an in-loop or a post-loop filter without sacrificing lots of performance [3]. The derived algorithm is composed of filtering control, mode decision, and edge filter. First, the filtering control decides the filtering orders where the vertical edges will be filtered first, followed by horizontal edges. Moreover, the filtered boundaries are 8x8 and 4x4 in MPEG-2 and H.264, respectively. Second, the mode decision partitions filtering strengths into strong, weak, and skip modes. Third, an edge filter follows the filtering mode to adaptively perform interpolation processes. Altogether, the derived algorithm is totally compatible to the standardized in-loop deblocking filter but improves visual quality in the post-loop operation. In addition, it shares edge filters between MPEG-2 and H.264 and integrates other distinct blocks into a simple one.
(B). 低功率架構設計 1) 記憶體系統
To improve the memory system of the video decoder, we introduce two techniques in the following statements. First, we propose a novel
3
decoding ordering to reduce the processing cycles on intra and inter (motion compensation) prediction modules. Second, we use a new prediction method to make a better compromise between internal and external memory power consumption. (a) (b) I/O Interface Pipelined Registers Intra Pred. Loop Filter Motion Comp. 32b request 4MB SDRAM 4MB SDRAM Slice Pixel SRAM (19.2kb) TAG Buffer 0 1 2 2W-1 W = frame width D. TAG N. TAG 3rd level 2nd level 1st level LPL Unit write read (c)
Figure1: A memory system in terms of (a)(b) data organization and (c) memory hierarchy
According to the decoding flow of the specification in H.264, a 4x4 sub-block is the smallest processing unit. To efficiently transfer 4x4 pixel data among modules, we discuss two strategies to organize the word-length for data transactions [4]. One is a 4x1 row-by-row decoding ordering, and the other is a 1x4 column-by-column decoding ordering. Although the 1x4 is similar to the 4x1 within a 4x4 sub-block, the decoding orders in a 16x16 macroblock (MB) are widely different. Figure 1(a) and (b) show the 4x1 and 1x4 decoding orderings in one luma MB, respectively. A line passing through each 4x4 sub-block stands for the decoding flow of one luma MB. Compared to the 4x1 row-by-row decoding ordering, the 1x4 column-by-column decoding ordering provides a better data structure, reducing the processing cycles on intra and inter prediction modules. For example, an intra prediction module requires left
neighboring pixels to spatially create the predicted pixels. These neighboring pixels can be easily fetched through the 1x4 ordering since they behave in a column-wise manner. As for the inter prediction module, extra initialization cycles are required when a passing line turns. Therefore, the access times are related to the probability of turning events. The results proved that the 1x4 column-by-column decoding ordering reuses the neighboring pixels and reduces the turning events, yielding the cycle reduction of 17% and 28% in intra and inter prediction modules respectively [4].
Using a memory hierarchy is advantageous to a large memory system. To reduce memory power consumption, we aim at a memory hierarchy where copies of data from larger memories that exhibit high data-correlation are stored to additional layers of smaller memories. In this way, a great part of data access is moved to smaller memories and the significant power savings can be achieved since accesses to the smaller level of memory hierarchy are less power consumption. Figure 1(c) shows a three-level memory hierarchy for an H.264 video decoding system [2]. The first level of memory hierarchy includes several pipelined registers and data buffers. The second and third level of memory hierarchy are slice pixel SRAM and external SDRAM. Because intra prediction and deblocking filter modules require lots of upper neighboring pixels to construct the predicted and filtered pixels, the slice pixel SRAM, storing upper rows of pixels, is explored to break the data dependency. However, a great penalty for this row storage is the large memory size, increasing memory power consumption. To reduce the memory size, a novel line-pixel-lookahead (LPL) unit [5] is allocated in Figure 1(c). It exploits spatial locality of vertical pixels to enhance the access efficiency. Particularly, the Decoding TAG (i.e. D. TAG) forecasts that whether the neighboring pixels should be kept or not. The Neighboring TAG (i.e. N. TAG) is equal to the previous Decoding TAG after buffering one row of TAGs. W-bit TAG buffers, where W means the frame width, record each Decoding DAG. A XOR gate perceives the contrast between N. TAG and D. TAG. However, although the LPL unit pre-stores useful data and predicts data access needs in advance, an error of prediction may occur and the missed data have to be fetched from the external memory. It incurs an increment of processing cycles on the external
4
SDRAM. Hence, a better compromise has to be made between internal and external memory power. The implementation results show that 50% of power consumption can be saved compared to the conventional design without exploiting the memory hierarchy [5].
2) 低功率移動補償設計
It is obvious that reducing the processing cycles in the MC module can improve the system performance since it is a system bottleneck compared to other modules. An interpolation unit is always the most time-consuming module over the whole motion compensation. In [6], we propose a horizontal-switch approach to reuse the neighboring pixels for the interpolator design. To reduce the external memory access times, the MC module has to increase the reuse probability for overlapped regions of neighboring interpolation windows. It can be achieved by applying a content register attached to each shift register for luma interpolators. Furthermore, a chroma interpolator has a similar behavior with a luma interpolator and both of them can be simplified into a multiplication-free design approach. The simulation results exhibit that the proposed horizontal-switch approach can save 30% of memory accesses compared to conventional approaches.
Although we increase the reuse probability to reduce the access frequency to the external memory, the external memory interface has to cooperate with the MC to improve the overall access efficiency. In this design, two external frame memories are allowed for writing decoded data and reading reference data reciprocally at the same time. Compared with SRAM, SDRAM is adopted due to the cost and power issues. However, SDRAM also induces the longer access latency and degrades the decoding throughput because of the internal pipeline architectures and 3D structure of banks, rows and columns characteristics. In [2], to solve the above problems, an efficient memory interface is introduced to overlap and re-schedule each access commands to improve the bandwidth utilization. This interface is composed of the bank controller, memory scheduler, and several read/write buffers. Each bank controller generates suitable commands for read/write processes. Memory scheduler collects these commands then sends re-scheduled commands to external SDRAM. Read and write
data buffers store burst data, and read/write command queues are designed to hold successive commands.
3) 低功率去區塊雜訊濾波器設計
In general, deblocking filter contributes about one third of the computational complexity at the H.264 decoder. It operates each filtering process on the 4x4 boundaries instead of the 8x8 boundaries in former filters of H.263 or MPEG-4 video standards. Therefore, a great deal of memory accesses is its penalty for the low-power Digital-TV applications. In [7], we propose a hybrid scheduling method to re-schedule the processing orders without sacrificing the system performance. A direct approach reloads the redundant pixels to perform filtering processes when the filtering edges are switched from vertical to horizontal directions. However, these redundant accesses will increase processing cycles in the DF. To alleviate this problem, we deduce a filtering order on 4x4 sub-block levels instead of 16x16 MB levels. The main idea is that we use four pixel buffers to keep the intermediate pixel value and perform the vertical and horizontal filtering process in one hybrid scheduling flow. Therefore, the proposed method prevents the re-access for different directions and combines the vertical and horizontal edge filters at a rule of standard-compliance. Compared to existing solutions, the proposed design can averagely save about one-half of processing cycles per MB.
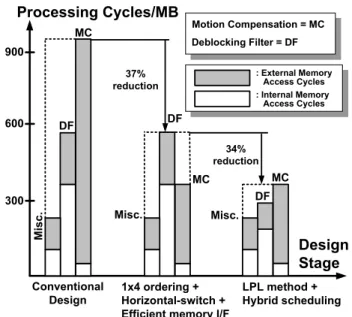
Motion Compensation = MC Processing Cycles/MB 300 600 900 Conventional
Design 1x4 ordering +Horizontal-switch + Efficient memory I/F
LPL method + Hybrid scheduling 37% reduction 34% reduction Design Stage MC DF MC Deblocking Filter = DF : External Memory Access Cycles DF MC DF Misc. Misc. Misc. : Internal Memory Access Cycles
Figure 2: Processing cycle breakdown in each architectural design phase.
5
Let’s make a brief summary in terms of processing cycles in Figure 2. In the beginning, we propose several techniques to reduce the processing cycles in the MC. They are the 1x4 decoding ordering, horizontal-switch method, and efficient memory interface. Therefore, the processing cycles are reduced by 37% as compared to conventional designs. Next, the processing cycles on the MC module have been reduced, whereas the deblocking filter becomes the cycle bottleneck in a system’s point of view. To further reduce the processing cycles, the hybrid scheduling and LPL prediction methods are proposed to improve the memory access efficiency and a 34% of cycle reduction can be further obtained compared to the previous design stage. 四、總結與討論 在本期之研究中,我們首先提出了利用演 算法以及架構上的調整來降低整合的面積。此 外,我們發展三個重要的低功率架構設計,分 別是改善記憶體階層設計,低功率的移動補償 和去區塊雜訊濾波器設計。經由本研究之進 行,發現記憶體的功率消耗可以降低 50%。而且 針對所需的工作頻率也能大大降低 60%,這對現 今低功率的視訊解碼端設計而言是相當有參考 價值的。整體而言,本期計畫之執行已產出多 樣的技術及學術論文,對現今業界及學術界提 供參考。相關重要之研究仍持續進行中,而成 果也會陸續整理發表。截至目前為止,本期計 畫所產出之研究成果詳列如下,僅此提供參考。 五、Reference (本期研究成果)
[1]. Tsu-Ming Liu, Ting-An Lin, Sheng-Zen Wang, Wen-Ping Lee, Kang-Cheng Hou, Jiun-Yan Yang and Chen-Yi Lee, “A 125μW, Fully Scalable MPEG-2 and H.264/AVC Video Decoder for Mobile Applications,” ISSCC Digest of Technical Papers, pp. 402-403, Feb. 2006.
[2]. Tsu-Ming Liu, Ting-An Lin, Sheng-Zen Wang, Wen-Ping Lee, Kang-Cheng Hou, Jiun-Yan Yang and Chen-Yi Lee, “An 865-μW H.264/AVC Video Decoder for Mobile Applications,” IEEE Asian Solid-State Circuit Conference (A-SSCC’05), pp. 301-304, Nov. 2005.
[3]. Tsu-Ming Liu, Wen-Ping Lee, Chen-Yi Lee, “An Area-Efficient and High-Throughput De-blocking Filter for Multi-Standard Video Applications,” IEEE International Conference on Image Processing, pp.
III-1044-1047, Sept. 2005.
[4]. Ting-An Lin, Sheng-Zen Wang, Tsu-Ming Liu, Chen-Yi Lee, “An H.264/AVC Decoder with 4X4-block Level Pipeline,” IEEE International Symposium on Circuit and System (ISCAS'05), pp. 1810-1813, May 2005.
[5]. Tsu-Ming Liu, and Chen-Yi Lee, “Memory-Hierarchy- Based Power Reduction for H.264/AVC Video Decoder,” IEEE International Symposium on VLSI Design, Automation, and Test (VLSI-DAT’06), pp. 247-250, April 2006.
[6]. Sheng-Zen Wang, Ting-An Lin, Tsu-Ming Liu, Chen-Yi Lee, “A New Motion Compensation Design for H.264/AVC Decoder,” IEEE International Symposium on Circuit and System (ISCAS'05), pp. 4558-4561, May 2005.
[7]. Tsu-Ming Liu, Wen-Ping Lee, Ting-An Lin, Chen-Yi Lee, “A Memory-Efficient Deblocking Filter for H.264/AVC Video Coding,” IEEE International Symposium on Circuit and System (ISCAS'05), pp. 2140-2143, May 2005.