應用類神經網路方法於金融時間序列預測之研究--以TWSE台股指數為例 - 政大學術集成
76
0
0
全文
(2) 誌謝. 首先由衷的感謝指導教授,姜國輝老師悉心的指導,不時給予提攜和指點學 生正確的方向,教導我獨立思考的重要性和做學問應有的態度,使學生在碩士生 涯中獲益匪淺,老師對學問的嚴謹更是學生學習的典範。再來誠摯的感謝林文修 老師、季延帄老師、謝明華老師,因為諸位老師的幫忙、細心指導和給予肯定, 使得本論文能夠更加完整而嚴謹,學生亦得以窺探該領域的廣大和深度。. 政 治 大 生周宣光老師給予的關於待人接物方面的指導,系辨的詩晴和雨儒助教給予的幫 立 在碩士班的日子裡,感謝前系主任管郁君老師給予學生生涯方面的建議,導. 忙。資管系充滿了生活的點點滴滴,感謝多位學長姐、學弟妹、同學們的共同砥. ‧ 國. 學. 礪,除了課業上的討論,不棄不離的友情往往是我堅持下去的毅力,感謝同門的. ‧. 雋傑在課業上和各方面伸出的援手、亞霖、章威、育聖、威豪、智民、柏均、振. y. Nat. 和、雋文、奕齊、雅菱、佳穎、志傑、邵晏、依儒、凱仁、政宏、金翰、柏羽,. er. io. sit. 以及我在政大認識的許許多多的朋友,研究所時光有你們的陪伴,成為我人生中 不可抹滅的回憶。謝謝你們,祝你們在畢業後的人生能夠一帆風順。. n. al. Ch. engchi. i n U. v. 最後,謹以此論文獻給我摯愛的雙親,求學的旅途中,你們給了我最大的關 懷、信心和支持,讓我能不負期許,在此以最大的感謝報答你們為我付出的辛勞。. 張永承 謹誌於 國立政治大學資訊管理研究所 民國 101 年 1 月. i.
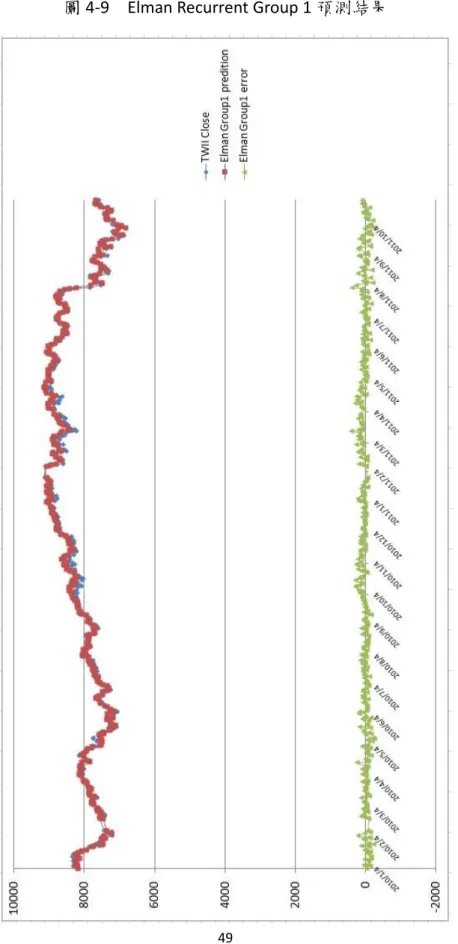
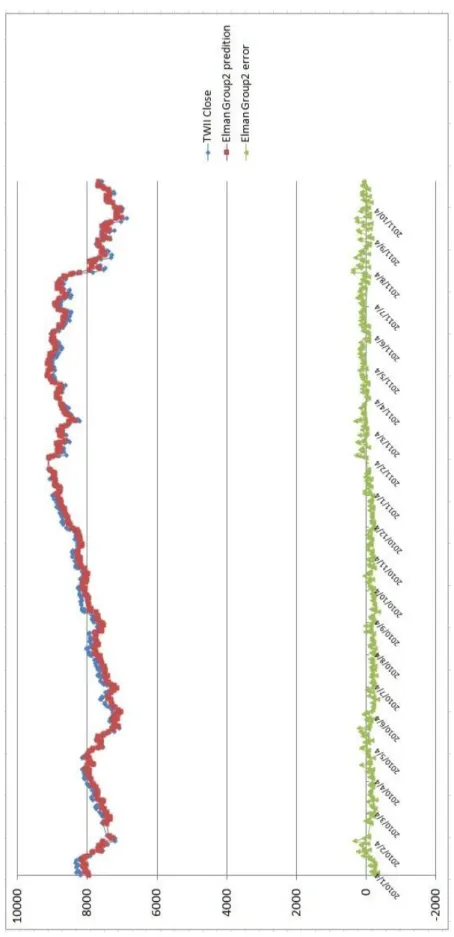
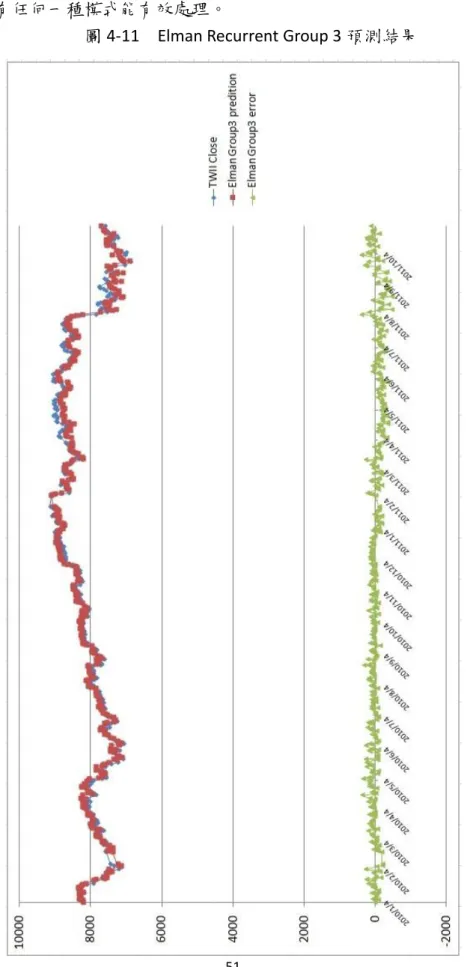
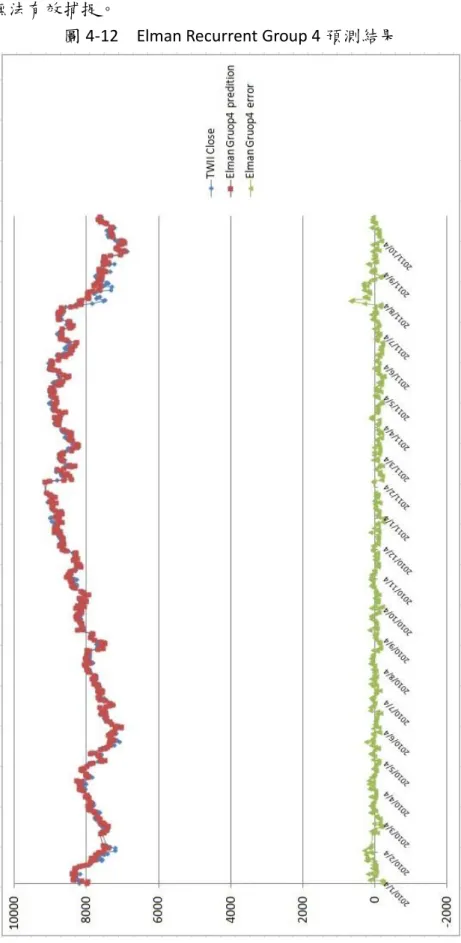
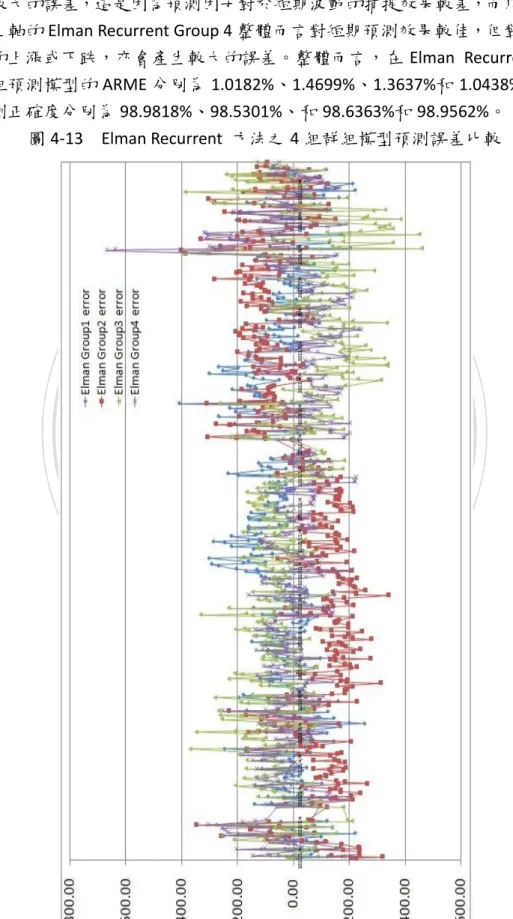
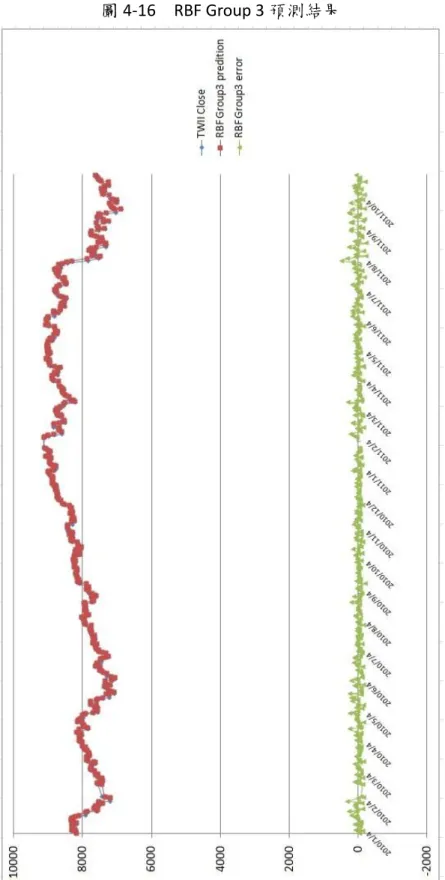
(3) 摘要 本研究考慮重要且對台股大盤指數走勢有連動影響的因素,主要納入對台股有領頭作用的美 國三大股市,那斯達克(NASDAQ)指數、道瓊工業(Dow Jones)指數、標準普爾 500(S&P500)指數; 其他對台股緊密連動效果的國際股票市場,香港恆生指數、上海證券綜合指數、深圳證券綜合指 數、日經 225 指數;以及納入左右國際經濟表現的國際原油價格走勢,美國西德州原油、中東杜 拜原油和歐洲北海布蘭特原油;在宏觀經濟因素方面則考量失業率、消費者物價指數、匯率、無 風險利率、美國製造業重要指標的存貨/銷貨比率、影響貨幣數量甚鉅的 M1B;在技術分析方面則 納入多種重要的指標,心理線 (PSY) 指標、相對強弱(RSI) 指標、威廉(WMS%R) 指標、未成熟隨 機(RSV) 指標、K-D 隨機指標、移動帄均線(MA)、乖離率(BIAS)、包寧傑%b 和包寧傑帶狀寬度 (BandWidth%);所有考量因素共計 35 項,因為納入重要因子比較多,所以完備性較高。. 政 治 大. 本研究先採用的贏者全拿(Winner-Take-All) 競爭學習策略的自組織映射網路(Self-Organizing Feature Maps, SOM),藉由將相似資料歸屬到已身的神經元萃取出關聯分類且以計算距離來衡量. 立. 神經元的離散特徵,對於探索大量且高維度的非線性複雜特徵俱有優良的因素相依性投射效果,. ‧ 國. 學. 將有利於提高預測模式精準度。在線性擬合部分則結合倒傳遞(Back-Propagation, BP)、Elman 反 饋式和徑向基底函數類網路(Radial-Basis-Function Network, RBF)模式為指數預測輸出,並對台股 加權指數隔日收盤指數進行預測和評量。而在傳統的 Elman 反饋式網路只在隱藏層存在反饋機制,. ‧. 本研究則在輸入層和隱藏層皆建立反饋機制,將儲存在輸入層和隱藏層的過去時間資訊回饋給網. y. Nat. 路未來參考。在徑向基底函數網路方面,一般選取中心聚類點採用隨機選取方式,若能有效降低. sit. 中心點個數,可降低網路複雜度,本研究導入垂直最小帄方法以求取誤差最小的方式強化非監督. n. al. er. io. 式學習選取中心點的能力,以達到網路快速收斂,提昇網路學習品質。. i n U. v. 研究資料為台股指數交易收盤價,日期自 2001/1/2,至 2011/10/31 共 2676 筆資料。訓練資. Ch. engchi. 料自 2001/1/2 至 2009/12/31,共 2223 筆;實證測試資料自 2010/1/4 至 2011/10/31,計 453 個日 數。主要評估指標採用帄均相對誤差(AMRE)和帄均絕對誤差 (AAE)。在考慮因子較多的狀況下, 實證結果顯示,在先透過 SOM 進行因子聚類分析之後,預測因子被分成四個組別,分別再透過 BP、Elman recurrent 和 RBF 方法進行線性擬合,帄均表現方面,以 RBF 模式下的四個群組因子表 現最佳,其中 RBF 模式之下的群組 4,其 AMRE 可達到 0.63%,最差的 AMRE 則是群組 1,約為 1.05%;而 Elman recurrent 模式下的四組群組因子之 ARME 則介於 1.01%和 1.47%之間;其中預測效 果表現最差則是 BP 模式的預測結果。顯示 RBF 具有絕佳的股價預測能力。最後,在未來研究建 議可以運用本文獻所探討之其他數種類神經網路模式進行股價預測。. 關鍵字: 自組織特徵映射網路、倒傳遞類神經網路、Elman 反饋式類神經網路、徑向基底函數類 神經網路、台灣股價加權指數、股票指數預測. ii.
(4) Abstract In this study, we considering the impact factors for TWSE index tendency, mainly aimed at the three major American stock markets, NASDAQ index, Dow Jones index, S&P 500, which leading the Taiwan stock market trend; the other international stock markets, such as the Hong Kong Hang-Seng Index, Shanghai Stock Exchange Composite Index, Shenzhen Stock Exchange Composite Index, NIKKEI 225 index, which have close relationship with Taiwan stock market; we also adopt the international oil price trend, such as the West Texas Intermediate Crude Oil in American, the Dubai crude oil in Middle Eastern, North Sea Brent crude oil in European, which affects international economic performance widely; On the side of macroeconomic factors, we considering the Unemployed rate, Consumer Price Index, exchange rate, riskless rate, the Inventory to Sales ratio which it is important index of American manufacturing industry, and the M1b factor which did greatly affect to currency amounts; In the part of Technical Analysis index, we adopt several important indices, such as the Psychology Line Index (PSY), Relative Strength Index (RSI), the Wechsler Memory Scale—Revised Index (WMS%R), Row Stochastic Value Index (RSV), K-D Stochastics Index, Moving Average Line (MA), BIAS, Bollinger %b (%b), Bollinger Band Width (Band Width%);All factors total of 35 which we have considered the important factor is numerous, so the integrity is high.. 立. 政 治 大. ‧. ‧ 國. 學. sit. y. Nat. n. al. er. io. In this study, at first we adopt the Self-Organizing Feature Maps Network which based on the Winner-Take-All competition learning strategy, Similar information by the attribution to the body of the neuron has been extracted related categories and to calculate the distance to measure the discrete characteristics of neurons, it has excellent projection effect by exploring large and complex high-dimensional non-linear characteristics for all the dependency factors , would help to improve the accuracy of prediction models, would be able to help to improve the accuracy of prediction models. The part of the curve fitting combine with the back-propagation (Back-Propagation, BP), Elman recurrent model and radial basis function network. Ch. engchi. i n U. v. (Radial-Basis-Function Network, RBF) model for the index prediction outputs, forecast and assessment the next close price of Taiwan stocks weighted index. In the traditional Elman recurrent network exists only one feedback mechanism in the hidden layer, in this study in the input and hidden layer feedback mechanisms are established, the previous information will be stored in the input and hidden layer and will be back to the network for future reference. In the radial basis function network, the general method is to selecting cluster center points by random selection, if we iii.
(5) have the effectively way to reduce the number of the center points, which can reduces network complexity, in this study introduce the Orthogonal Least Squares method in order to obtain the smallest way to strengthen unsupervised learning center points selecting ability, in order to achieve convergence of the network fast, and improve network learning quality. Research data for the Trading close price of Taiwan Stock Index, the date since January 2, 2001 until September 30, 2011, total data number of 2656. since January 2, 2001 to December 31, 2009 a total number of 2223 trading close price as training data; empirical testing data, from January 4, 2010 to September 30, 2011, a total number of 433. The primary evaluation criteria adopt the Average Mean Relative Error (AMRE) and the Average Absolute Error (AAE). In the condition for consider more factors, the empirical results show that, by first through SOM for factor clustering analysis, the prediction factors were divided into four categories and then through BP, Elman recurrent and RBF methods for curve fitting, at the average performance , the four group factors of the RBF models get the best performance, the group 4 of the RBF model, the AMRE can reach 0.63%, the worst AMRE is group 1, about 1.05%; and the four groups of Elman recurrent model of ARME is between 1.01% and 1.47%; the worst prediction model is BP method. RBF has shown excellent predictive ability for stocks index. Finally, the proposal can be used in future studies of the literatures that we have explore several other methods of neural network. 政 治 大. 立. ‧. ‧ 國. 學. y. Nat. n. er. io. al. sit. model for stock trend forecasting.. Ch. i n U. v. Keywords: Self-Organizing Feature Map Neural Network(SOFM) ,Back Propagation Neural Network(BPN), Elman Recurrent Neural Network(Elman), Radial Basis Function Neural Network(RBF), Taiwan Stock Exchange Weighted Index(TWSE), Stock Index Forecasting. engchi. iv.
(6) 目錄 摘要................................................................................................................................ ii Abstract ......................................................................................................................... iii 1. 緒論............................................................................................................................ 1 1-1 研究背景與動機........................................................................................ 1 1-2 研究目的與架構........................................................................................ 2 2. 文獻探討 .................................................................................................................. 4 2-1 自組織神經網路........................................................................................ 4 2-1-1 Kohonen 競爭式學習 .................................................................... 5 2-1-2 競爭式贏家全拿(Winner-take-all)學習策略 ................................ 8 2-1-3 內星學習(Instar learning)規則與 Kohonen 學習規則 ................. 9 2-1-4 自組織特徵映射網路(Self-Organizing Feature Maps, SOFM) .... 10 2-1-5 自組織特徵映射網路學習演算法.............................................. 13 2-2 倒傳遞類神經網路(Back-Propagation Network) .................................... 14 2-3 Elman 反饋式類神經網路 ...................................................................... 15 2-3-1 動態反饋與 Elman 反饋類神經網路架構 ..................................... 15 2-3-2 Elman 反饋式學習 .......................................................................... 16 2-3-3 Elman 反饋式網路演算法 .............................................................. 16 2-4 徑向基底函數類神經網路(Radial-Basis-Function Network) ................. 18 2-4-1 徑向基底函數架構 ......................................................................... 18. 立. 政 治 大. ‧. ‧ 國. 學. y. Nat. sit. n. al. er. io. 2-4-2 徑向基底函數演算法 ..................................................................... 19 2-5 其他類神經網路方法與支撐向量機器.................................................. 20 2-5-1 機率類神經網路(Probabilistic Neural Network) .............................. 20 2-5-2 廣義迴歸類神經網路(General Regression Neural Network) ........... 20 2-5-3 學習向量量化網路(Learning Vector Quantization) ......................... 21 2-5-4 支撐向量機器(Support-Vector Machine) ......................................... 21 2-6 股價影響因素選取與應用類神經演算法於股價預測之探討.............. 22 2-7 重要隔日波段技術分析指標之探討...................................................... 24 3. 研究設計 ................................................................................................................ 26. Ch. engchi. i n U. v. 3-1 預測模式設計 ............................................................................................ 26 3-2 測試結果與評估 ........................................................................................ 35 4. 實證結果與討論...................................................................................................... 36 4-1 聚類結果與模式 ........................................................................................ 36 4-2 BP 模式之 4 組群組因子預測結果 ........................................................... 41 4-3 Elman 反饋式模式之 4 組群組因子預測結果 ......................................... 48 4-4 RBF 模式之 4 組群組因子預測結果 ......................................................... 54 4-5 BP、Elman recurrent、RBF 三種模式之各個群組預測結果比較........... 61 v.
(7) 5. 結論與建議.............................................................................................................. 63 5-1 結論 ............................................................................................................ 63 5-2 建議與未來研究方向 ................................................................................ 64 參考文獻...................................................................................................................... 65. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vi. i n U. v.
(8) 1. 緒論 1-1 研究背景與動機. 台灣為一依賴外銷貿易發展為主的經濟體,台股深受外國股市表現和總體經 濟變化影響,而台股表現又深受台灣主要出口產業表現影響,其出口方面不論是 國際間合作的供應鏈生產環節、需求和製造產品出口有近四成外銷到美國,相對 於中國、香港的出口比重亦達到 20%~32%之譜。台灣產業結構又以電子業所生 產的電子 產品 為 主要 出口,因 此 台灣 股票 加權指數 (Taiwan Stock Exchange Weighted Index, TWSE)的動向有很大的程度受到由美國大型科技廠商所組合而成 的那斯達克指數(NASDAQ)、30 支藍籌股組成的道瓊(Dow Jones)工業指數和美國 前五百大企業組成之標準普爾 500(S&P 500)指數,這三大美國主要市場所連動, 而其他國際各主要市場,如日經 225 指數、恆生指數、上海證券綜合指數和深圳 證券綜合指數在近幾十年來與台股指數之間產生相互依賴且緊密的互動,日益扮 演動長期穩定的雙向因果關係。而在能源市場方面,考慮美國西德州中級原油、 中東杜拜原油和由歐洲 15 種原油綜合而成的北海布蘭特原油價格的波動對台股 呈現非線性正向衝擊關係,亦是不可忽視的影響因子。. 立. 政 治 大. ‧. ‧ 國. 學. y. Nat. 宏觀構面的總體經濟因素指標如台灣或美國的失業率、消費者物價指數、匯 率、用以衡量美國製造業庫存和出貨重要指標的存貨/銷貨比率、美國聯準會公. sit. n. al. er. io. 佈的 FED 利率和影響資金流通數量多寡的 M1B 貨幣供給量,皆對於台灣股票加 權指數(Taiwan Stock Exchange Weighted Index, TWSE)的表現存在著根本性的連動 相依。在技術分析指標因素方面,本研究考量了重要的心理線(PSY)、相對強弱(RSI)、 威廉 WMS%R、未成熟隨機值(RSV)、K-D 隨機指標、移動帄均線(MA)、乖離率 (BIAS) 和俱有統計基礎的包寧傑%b 值和帶狀寬度(BandWidth%)技術指標。. Ch. engchi. i n U. v. 本研究所考量對台股有相關性之國際股票市場、原油市場、總體經濟因素和 波段技術分析指標皆有代表性,而且探討預測因素具有規模效果,若能夠正確判 讀將有助於台股價格的預測。透過因素指標變化的分析對於股市情勢判讀一直都 是非常重要。股票市場乃是經濟櫥窗,雖然股市並不能就此為經濟發展狀況之代 表,但股市的表現經常能提前反應經濟發展的變化。股市表現也深深影響著人民 食、衣、住、行、就業和生活中的各個面向。而且,對於股價預測模型之準確度 是許多人追求之目標。因此,若能運用較新型之類神經網路方法,若能運用所有 宏觀經濟因素正確判讀股市狀況,若能建構一套量化宏觀面的數據分析方法來預 測金融市場脈動,將可提供給投資人、機構單位、主管機關、支領固定薪水之上 班族等族群,一個股市循環盛衰之行情判讀與投資決策參考價值。. 1.
(9) 股價預測的方法常見有時間序列領域的 ARIMA 模式 (自回歸移動帄均模型, Autoregressive Integrated Moving Average Mode)、GARCH 模式(廣義自回歸條件異 方差模型, Generalized AutoRegressive Conditional Heteroskedasticity)和倒傳遞類 神經網路 BPN 模式,然而 GARCH 模型沒有考慮金融時間序列的非常態性及非線 性,BPN 模式 (倒傳遞網路, Back-Propagation Network)因迭代學習效果差,且計 算量過於龐大,對於非線性函數能力的適應度不佳,進而嚴重影響其非線性處理 能力。而另外在股票指數影響因素的探討和採用方面,對於預測結果輸出的優劣 也佔了很重要的關鍵角色。 因此,本研究採用的贏者全拿(Winner-Take-All)競爭式學習方式之 SOM(自組 織映射網路, Self-Organizing Feature Maps ),SOM 主要精神是以競爭式學習,藉 由將相似資料歸屬到已身的神經元萃取出關聯分類法則來解釋輸入資料的推理 法則。且以距離衡量神經元特徵屬性值變異為基的屬性離散化演算法。對於探索 大量且高維度的非線性複雜特徵資料分析有很優良的效果。. 立. 政 治 大. ‧. ‧ 國. 學. 在 因 素 輸 出 的 線 性 擬 合 部 分 方 面 , 則 分 別 結 合 傳 統 BPN( 倒 傳 遞 網 路 Back-Propagation Network);及具時間資訊回饋、網路的高穩定性、高可塑性與收 斂極快,但理論複雜的非定性動態系統之 Elman 反饋式網路,考量到傳統 Elman 反饋式網路只有在隱藏層存在反饋機制,本研究在 Elman 反饋式網路的輸入層和 隱藏層皆建立反饋機制,將儲存在輸入層和隱藏層的過去時間資訊回饋提供給網 路未來所使用;另外亦結合利用統計原理經由訓練資料進行最佳的調整,將輸入. y. Nat. sit. n. al. er. io. 空間透過非線性映射至隱藏空間的功能,再藉由輸出層的權重,將隱藏空間經線 性映射至輸出空間,由於徑向基本底函數網路在中心點選取方面是採取隨機選取 的方式,若能降低中心點個數,即可有效降低網路複雜度,中心點初始位置的決 定對網路訓練速度和品質很重要。因此,本研究則導入垂直最小帄方法以求取誤 差最小,再挑選誤差下降比率最大值為其中心點選取依據。此方法強化了非監督 式學習選取中心點和監督式學習調整權重向量特性的 RBF(徑向基底函數網路, Radial-Basis-Function Network)幾種類神經網路方法,再納入國際主要市場、經濟 因素和技術分析指標進行台灣股市指數預測,期望能在預測正確度方面找到最佳 模式。. Ch. engchi. i n U. v. 1-2 研究目的與架構. 本研究借由 SOM 良好的模式判別與聚類能力,針對與台灣貿易相依性高的 美國、中國、日本和香港股市,總經因素的貨幣供給量、利率、失業率以及國際 各主要原油市場。另外,由於技術分析能在與歷史資料相較之下,以統計的方法 呈現出,目前價格所處位置與價格趨勢的重要資訊,所以在技術指標方面,亦選 2.
(10) 擇和計算重要價格指標和綜合性指標。針對所有因素進行聚類分析,得出的群聚 因子再結合 BP、Elman recurrent 和 RBF 三種性質不相同之類神經網路,以此基 礎建立股價預測模型並提升預測效果。 本論文在章節規劃將如下圖所示: 第一章介紹本論文之研究動機與目的; 第 二章文獻部分在類神經網路模型方法方面探討 SOM 聚類辨識能力、Elman 反饋 式與 RBF 神經網路分別有時序遞延與函數逼近學習能力優點,特別適用於非線 性的金融時間序列分析。而在股價相關因子則主要探討國際股市、總體經濟因子 和台灣股市之間的連動性,以此作為預測模型之輸入因子; 第三章說明預測模式 方法的建立; 第四章則呈現預測的實證分析結果; 第五章 針對研究結果作進一 步的探討。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 1-1 研究架構圖. 3. i n U. [本研究整理]. v.
(11) 2. 文獻探討 2-1 自組織神經網路. 自組織網路係由芬蘭學者 Kohonen 於 1982 年提出,為一種提供較為完整、 分類性能較好、具有將資料維度縮減,也就是說可以將樣本空間(Data space)轉換 到特徵空間(Feature space),以較少之特徵描述原始資料之能力的非監督式學習 之網路學習模式。其目標在於要找出神經元之組合,使神經元之輸出排列能表現 出原始輸入樣本空間之相對關係。一般在設計輸出神經元以二維型態排列居多形 成正方形優先。以二維為例,每一神經元會由神經鏈連結到輸入向量之每一變數, 由連結之神經鏈值(或稱權重)映射樣本空間。所以必頇借由調整神經鍵值之大小 以提高網路系統對輸入樣本空間之拓樸順序(Topological order)靈敏度。由所有之 神經元彼此間競爭,以決定哪一個神經元將被赋予模擬之任務。競爭學習方式則 基於神經元神經鍵值向量是否相似於輸入向量,經過多次之訓練(Training),獲勝 之神經元,其神經鍵值向量會逐漸地相似於輸入向量。[中央大學商業智慧中心,2010]. 立. 政 治 大. ‧ 國. 學. ‧. Kohonen 指出 SOM 能將高維度資料序列分佈以映射方式轉化成有規律的低 維度網格呈現。如圖 2-1 和圖 2-2 之 Kohonen 模型,亦即 SOM 能夠轉換複雜、 非線性統計關聯的高維度資料轉化成簡單低維度之幾何型態。SOM 通常由二維. n. al. er. io. sit. y. Nat. 有規律的網格節點組成,每一個節點之間都是由一些有相似關聯觀察資料組成的 模型其鄰近節點值都非常相似,SOM 計算此模型使其能最佳的描述觀察值(離散 性或連續性)的值域概率分佈,最終模型自動組織成有意義的二維度排序網格, 具有相似的特徵值相較不相似的特徵值彼此之間會組成緊緊相連的聚類圖 (Kohonen et al. 2002)。. Ch. engchi. 圖 2-1 一維 Kohonen 模型. 4. i n U. v. [Kohonen, 2001].
(12) 立. 政 治 大. 圖 2-2 二維 Kohonen 模型. [Kohonen, 2001] [Kohonen, 2001]. ‧ 國. 學. 2-1-1 Kohonen 競爭式學習. ‧ y. Nat. 在類神經網路中,對於其輸入樣本、輸入模式和輸入樣本模式這類術語經常. sit. n. al. er. io. 混用,只要涉及辨識、分類性問題時,常常運用到輸入模式的概念。而模式是指 對某些感興趣客體的定量描述或結構描述,模式類則是指具有某些共同特徵的集 合。分類是指在監督式學習演算法進行類別辨識時,其類別知識取得監督訊號後, 將待識別的輸入模式對應到各自所屬的模式類中。而非監督式學習演算法進行類 別辨識稱作聚類(Clustering),聚類的目的是將相似的模式樣本歸劃成同類,而將 不相似的模式樣本分離,結果實現了模式樣本的類別內相似性和類別間分離性。 非監督式學習的訓練樣本不含期望輸出,對於某一輸入模式樣本應歸屬於哪一類 別並沒有任何事先已驗證的知識可供參考依據。所以對於一組輸入模式,僅能依 據輸入模式之間的相似度分成若干種類,因此相似性是輸入模式的聚類依據。. Ch. engchi. i n U. v. 輸入模式以向量表示,比較兩個不同模式的相似性可轉化比較兩個向量之間 的距離,然後依據兩個向量距離作為聚類判斷。常用有歐氏最小距離和餘弦法。 (1) 歐氏最小距離: Euclidean(X,Y) = || Xi-Yi || = 當計算得出的歐氏距離最小,兩向量愈接近,則兩模式愈相似。若兩模式完 全相同,則歐氏距離為零。因此可以設定屬於同類別的門檻值 T。如果 Euclidean (X,Y)<T,則歸為相同聚類,即向量 X 和 Y 屬於同一類別。如果 Euclidean (X,Y)>T, 則歸為不同聚類,即 X 和 Y 屬於不同類別。 5.
(13) (2) 餘弦法: 若兩模式向量愈接近,夾角愈小,餘弦愈大。當兩個模式向量方向完全相同 時,其餘弦等於 1。因此可以設定同一類別歸屬的門檻值角度為最大夾角 α。如 果 <α,則向量 X 和 Y 屬於相同聚類。反之,如果 α,則向量 X 和 Y 為 不同聚類(Kohonen et al. 2002)。 [Kohonen, Somervuo, 2002]. 由於不同向量的長短並不一致,所以實際上我們會對向量進行正規化 (normalization)。即對一已知向量建構其同方向之單位向量,所以其向量長度為 1。 二維和三維單位向量即可在單位圖和單位球體上展示, 表正規化後之單位向量, 向量正規化公式如下所示: ,…, 政 治 大 假設在輸入神經元間存在某種形態的競爭,而在競爭群體中,只有一個神經 立 元會被激發成活化狀態(Active State),即輸出為 1,而其他神經元會被抑制成休 =. ‧. ‧ 國. 學. 止狀態(Inactive State),即出為 0。競爭完成之後,只有獲勝神經元會進行學習調 整,落敗神經元則保持不變。競爭學習法又稱「贏家全拿」(Winner-take-all)。網 格上的神經元會彼此競爭而只有對輸入最有反應的神經元取的活化的機會,也就 是輸出值最大者為贏家,其鏈結值會被調整,以便更增加其與此時輸入之間的相 似性。因此,利用側抑制(Lateral Inhibition)來達成「贏家全拿」目的,主要是藉. y. Nat. sit. n. al. er. io. 由輸出神經元交互作用找出最大值;由圖 2-3 得知,每個輸出神經元會產生自我 激發訊號(+),並試圖抑制其他神經元的活動(-),只有獲勝者才能繼續活動。. Ch. engchi. 圖 2-3 側抑制(Lateral Inhibition)競爭. i n U. v. [Kosko, 1991]. 特徵映射圖形成的原因,除了非監督式學習是個重要關鍵之外,“側向聯結” 也是不可或缺的要素之一。在許多生物的腦部組織中會有大量的神經元,彼此之 間有側向聯接,側向聯結的回饋量,通常是以「墨西哥帽函數」來代表 。. 6.
(14) 圖 2-4 墨西哥帽函數. [Kosko, 1991]. (1)具有一個短距離的側向激發作用區域,圖 2-4 中標示為 1 區域。 (2)具有一個較大的側向抑制作用區域,圖 2-4 中標示為 2 區域。 (3)一個強度較小的激發作用區域,其涵蓋區域包圍著抑制區域,圖 2-4 中標示為 3 區域。 位在半徑 r1 之內的神經元,將受到比較大的激勵作用,而且這個激勵作用 會隨著神經元距離的增加而減少。而位在半徑 r1 和 r2 之間的神經元,將受到 負向的抑制作用。至於半徑 r2 以外的神經元,則只能感受到很小的激勵作用。 側向聯結作用不再只是一種單純的競爭關係,而是一種競爭(抑制作用)加上合 作(激發作用)的關係。. 立. 政 治 大. ‧ 國. 學. ‧. Kohonen 提出了一種簡化的非監督式類神經網路來模擬上述神經元間之側 向聯結作用: (1) 我們可以簡化墨西哥帽函數的側向聯結作用。也就是說我們可以用被激發類. y. Nat. sit. n. al. er. io. 神經元的「鄰近區域」的概念來取代側向聯結作用,他假設在「鄰近區域」 內的交互作用具有相同的振幅如圖 2-5 所示。 (2) 對側向聯結鏈結值的修正則以可改變的 「鄰近區域」 來取代;也就說,當 鄰近區域設定的越大就表示側向聯結的正向回授越強,相反地,當鄰近區域 設定的越小也就表示側向聯結的負向回授越強。 (3) 可將被激發類神經元 j 的輸出轉化下列法則,其中 1 為活化函數之極限值:. Ch. engchi. i n U. v. 其中 Winj (yj)為勝利輸出神經元,x 代表輸入向量,mj 代表在輸出網格上第 j 個神經元之權重值, mk 則代表輸出網格上之第 k 個勝利神經元權重值。. 圖 2-5 簡化之墨西哥帽函數. [Kosko, 1991] [Kosko, 1991]. 7.
(15) 2-1-2 競爭式贏家全拿(Winner-take-all)學習策略. 「贏家全拿」(Winner-take-all)的策略可分成三個步驟。 步驟 1: 向量正規化 先對輸入模式向量 Xj(j=1,2,…,m)和競爭層中各神經元對應之內星權重向量 Wj(j=1,2,…,m)進行正規化處理,依照 2-2 節之正規化公式得到 和 步驟 2: 尋找獲勝神經元 一個輸入向量 會和競爭層中所有神經元對應的內星權重向量. j(j=1,2,…,m)。. j(j=1,2,…,m). 進行相似性比較,和 最相似的內星權重向量判定為競爭勝利神經元,記為 測量相似性方法是計算歐氏最小距離或餘弦最小夾角。. *。. = –. –. –. 政 治 大 因此為使兩單位向量之歐氏距離為最小,必頇使兩向量內積為最大。公式轉 立 化成求解最大內積,而權重向量和輸入向量之內積即為競爭層神經元的淨輸入。 =. =. =. =. ‧ 國. 學. 如下列公式所示:. 步驟 3: 神經網路輸入與權值調整. ‧. 勝利節點設定,勝利神經元輸出為 1,其餘輸出為 0。而勝利神經元 得到權重向量的調整。. Nat. io. sit. y. 方能. n. al. er. η 為學習速率, 隨著學習次數而減小。t 代表權重值學習次數,可以 看出當神經元 j 為勝利神經元時,即 ,該神經元 j 則被勝利神經元 所激活 化,所以此神經元可得到權重值調整。權重學習過程會一直重復步驟 1 至步驟 3, 直到學習收斂係數 η 減少至 0 為止。學習過程如下圖 2-6 所示:. Ch. engchi. 圖 2-6 鍵結值向量調整公式. i n U. v. [Kohonen, 2006] [Kohonen, 2006]. 8.
(16) 2-1-3 內星學習(Instar learning)規則與 Kohonen 學習規則. 自組織競爭神經網路經常採用用內星學習(Instar learning)規則發展而來的 Kohonen 學習規則。因為內星學習規則是由 S.Grossber 所發展出來的一種用來訓 練辨認一個向量的競爭式學習法結構。. 立. 政 治 大 圖 2-7 內星神經元. [14]. ‧. ‧ 國. 學. 假設圖 2-7 中共有 n 個輸入單元,若干個輸入值 xi 組成輸入向量 X,而 X 又 和權重向量 W 對應,多個輸入單元 xi 通向並指向單一輸出單元。內星輸入和輸 出的轉換函數(Transfer function)是使用硬限函數(Hard limiter function)。經過學習 規則訓練,使的某一神經元只對特定的輸入向量產生影響,借由調整網路權重向 量 W 使之近似於輸入向量 X。其網路學習規則如下公式:. sit. y. Nat. n. al. er. io. 其 j=1,2,…,n,其內星權值為 W,而 wj 為 W 的第 j 個元素,xj 為第 j 個輸入向 量元素, 表示學習速率。因此,可看出 wj 的 變化和輸出成正比關係。內星 網路的硬限函數 輸出為 1 或 0,分別表示高值和低值。如果 輸出能 逐漸減少, 逐步接近 ,最後 一直保持高值時,就可透過學習使變化量 ,內星權重向量 W 因此能對輸入向量 X 進行識別。如果 輸出一直 保持低值則網路權重學習過程可能無法進行。. Ch. engchi. i n U. v. 假設有兩個輸入向量 X1,X2 進入同一內星網路時,而此內星權重向量為 W。 可先對兩向量 X1,X2 進行向量正規化處理。先將第一個向量 X1 輸入內星網路進行 訓練使其權重得到 W = X1,然後再輸入第二個向量 X2。使兩向量進行內積計算, 加權輸入和,如下列公式所示: =. 更新後的加權向量 ,為新輸入向量 X2 和原輸入向量 X1 的內積,因為兩 向量已進行正規化兩輸入向量之內積為 1,加權輸入即為兩輸入向量之餘弦夾角。 內星加權輸入可分成三種情況: 情況 1: ,兩夾角 ,為同向單位向量,內星加權輸入和為 1。 9.
(17) 情況 2: 直到 情況 3:. ,隨著 X2 向著遠離 X1 的方向移動,內星加權輸入和會逐漸減小, 為止,即 ,即. ,而內星加權輸入和為 0。 ,內星加權輸入和達最小,其值為-1。. 內星會獲得值為 1 之加權輸入;如果輸入為和訓練樣本不相同向量,產生的 加權輸入和小於 1。硬限函數對於已學習之輸入向量,內星之輸出為 1,其他則 為 0。權重向量 W 和輸入向量 X 的內積,反應了輸入向量 X 和權重向量 W 的相 似度。因此當多個相似輸入向量 X 進入內星時,最後的訓練結果使網路權重接近 多個相似輸入向量 X 的帄均值。內星網路相似度由偏差 b 控制,相似度值為-0.95, 即輸入向量 X 權重向量 W 之間夾角小於 ′。 Kohonen 學習規則是由內星規則發展而來,只對競爭中勝出的神經元進行調 整。. 政 治 大. 其中 p(q)為輸入向量,q 為迭代次數, 為調整係數,其範圍值介於 0~1,w 代表每個輸入所對應之權重值,Kohonen 的權重向量可以透過學習一個輸入向量 達到模式辨識。經過學習後,距離輸入向量最近的神經元的權重向量將會更加接 近輸入向量(見下圖 2-8)。隨著輸入向量的增加,競爭層中每個距離這一組輸入 向量最近的神經元權重將會向著這些輸入向量的方向調整。最後,如果有夠多的 神經元,每一個類似的輸入向量將會令一個神經元產生 1 活化狀態,而其他神經 元則產生 0 的側仰制狀態,因而能達成分類的效果。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 2-8 權重調整學習. i n U. v. [Kohonen,2001] [Kohonen,2001]. 2-1-4 自組織特徵映射網路(Self-Organizing Feature Maps, SOFM). 自組織競爭網路,在基本是讓競爭層各神經元與輸入模式進行配對,最後只 有一個神經元成為競爭的勝利者,獲取神經元的輸入就代表對輸入模式的分類。 而自組織特徵映射網路不僅能夠像自組織網路一樣學習輸入樣本的分佈情況,還 可以學習神經網路的拓撲結構。 10.
(18) 由於競爭式學習是用於具有聚類特性的大量目標數據的辨識,但遇到大量具 有概率分布的輸入向量時就會產生偏差。因此 Kohonen 提出模擬大腦神經系統 的自組織特徵映射網路功能。採用非監督式學習網路訓練,此網路廣泛應用於模 式樣本分群、排序和樣本檢測方面。 自組織映射網路特別的地方在於,輸入向量與輸出神經元的權重互相聯結。 在輸出神經元之間進行競爭選擇,輸出神經元之間存在側抑制。它能夠將單一神 經元的變化規則與一層神經元的群體變化規則產生聯系。SOMF 網路由輸入層和 競爭層組成,屬於單層網路架構。輸入層是一維神經元具 n 個節點,競爭層的神 經元處於二維帄面的網格上共有 m 個節點(見圖 2-9 所示)。SOFM 具有兩種權重, 一種在於神經元對外路輸入的鏈結權重,另一種是神經元之間的互連權重。它的 大小控制著神經元之間相互作用的強弱。而競爭層又是輸出層,競爭層的神經元 通常選擇線性函數當作轉換函數。SOFM 透過運用網格組成自組織映射輸出空間, 並且在各神經元之間建立拓撲鏈結關聯,神經元之間的關聯由它們在網格上的相 互位置所決定,這種關聯進而模擬人腦中的神經元側抑制功能,達成競爭成學習 的基礎。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 2-9 自組織映射網路. i n U. v. [18]. SOFM 採用無監督聚類學習法,能夠把任意模式的輸入在輸出層映射成一維 或二維的離散圖形並保持拓撲結構不變。透過無監督學習的反復學習,SOFM 能 夠使鏈結權重空間分佈密度和輸入模式的機率分佈趨於一致,並且將輸入的分群 投射在二維圖形拓撲上,又不會改變拓撲形狀。因而可以透過權值的空間分佈反 映輸入模式的統計特徵。 SOFM 採用和自組織競爭網路相同的學習規則獲得勝利神經元,將此神經元 以 j*表示,但 SOFM 跟競爭式學習網路不同的是,SOFM 所採用 Kohonen 學習規 11.
(19) 則不僅更新單一勝利神經元的權重,而是對一鄰近區域. 內的神經元全部. 進行權重更新。. 圖 2-10 勝出神經元 j. [18]. 圖 2-11 鄰近節點. [18]. SOFM 權重更新表達式如下所示: or 其中鄰近區域. 政 治 大. 包括了與勝利神經元 j*的距離 t 在一定範圍的神經元。. 立. ‧ 國. 學. 因此,當網路獲得一個輸入向量 P 時,競爭中勝出的神經元以及其鄰近區域 內的神經元的權重向量會朝著輸入向量 P 的方向移動,經多次反復訓練後,鄰近 區域內的神經元整體上會比較類似。如圖 2-11 中, 、 、 分別代. ‧. 和勝利神經元 j 相差 1、2、3 個單位範圍的鄰近區域。當訓練開始後,神經元彼 此互相競爭,具有最大輸出的神經元成獲勝者,勝利者會對其他競爭神元產生抑 制作用,同時又對其鄰近區域內的神經元產生活化作用。只有與勝利神經元相鄰. y. Nat. sit. n. al. er. io. 的神經元的權重會取得更新。然而在訓練一開始時,鄰近半徑通常較大,調整的 節點數量也較多,隨著訓練的進行,鄰近半徑會漸漸縮小,最終縮小為只包括競 爭獲勝節點本身,只有勝利節點才是輸出圖形的最佳匹配。. Ch. engchi. i n U. v. 鄰近區域函數控制鄰近係數和「鄰近半徑 R」與「鄰近距離」的關係函數。 即:. ,因此,當 rj=0 時 Kj=1;rj=時 Kj=0。. 鄰近區域收縮式子記為 鄰近區域會在網路學習過程中逐漸縮 小,其中 <1 為鄰近半徑縮小因子。通常以學習循環為單位,網路每執行一個學 習循環鄰近半徑收縮一次。 另一種 SOFM 訓練規則是採用批次處理法,網路一次獲得整組輸入樣本,然 後根據訓練規則決定對應各個輸入向量哪一個神經元會勝出。勝出的神經元及鄰 近區域內的所有神經元權重向量都朝著所有輸入向量的帄均位置移動。 [Jang, Sun, Mizutani, 1996]. 12.
(20) 2-1-5 自組織特徵映射網路學習演算法. (1)初始化網路: 隨機設定輸入向量和映射層之間的權重初始值。 (2)輸入向量: 把輸入向量 給輸入層。 (3)計算映射層的權值向量和輸入向量之間的距離: 使用歐氏定理計算各神經元權值向量和輸入向量的歐氏空間。依照歐氏公式 計算: 其中 wij 為輸入層第 i 神經元和映射層第 j 神經元的權值。 (4)選擇與權值向量距離最小的神經元: 計算並選擇使輸入向量和權值向量的距離最小之神經元,如 dj 為最小,稱為 勝利神經元記為 j*,並算出其鄰近神經元集合 。 (5)權重之學習: 勝利神經元和其鄰近神經元的權重調整公式:. 立. 政 治 大. ,k 為小於 1 之折減係 如下所示:. Nat. er. io. sit. y. ‧. ‧ 國. 學. 其中 ,為學習速率,可表達成 數。R 為鄰近半徑, , <1。而鄰近函數. al. 會隨著學習進行逐漸變小,因此. 的範圍在學習初期時很大,隨著. n. v i n Ch 學習的進行會變小。勝利神經元和其附近的神經元全部接近初期的輸入向量。學 engchi U 習初期, 附近有很多神經元形成粗略的映射,隨著學習的進行, 變窄,局部微調使勝利神經元附近的神經元數目變少以提高辨識能力。 (6)重復步驟(2)到(5)的學習過程,直到學習速率 收斂為止。 [Kohonen, 1998]. 13.
(21) 2-2 倒傳遞類神經網路(Back-Propagation Network). Rumelhart 和 McClelland 成立 PDP(Parallel distributed processing)研究機構, 並提出以多層感知前饋式架構為基礎的倒傳遞類神經網路,這也是應用最為普及 的類神經演算法。主要用最除坡降法(Gradient steepest descent method)進行學習。 其網路架構下圖 2-12 所示:. BP 網路架構 [20]. ‧. n. al. er. io. sit. y. Nat. BP 之誤差函數 E:. 圖 2-12. 學. 輸出函數 y:. ‧ 國. 立. 政 治 大. 最除坡降法調整權重 w:. Ch. engchi. i n U. v. 所以權重學習為:. [Rumelhart, McClelland, PDP, 1989]. 14.
(22) 2-3 Elman 反饋式類神經網路. 2-3-1. 動態反饋與 Elman 反饋類神經網路架構. Elman 反饋式網路(Elman Recurrent Network)是由 Elman 在 1990 年提出一種 帶反饋的雙層神經網路,即反饋鏈結(Recurrent link)或稱為動態神經元(dynamic neuron)從第一層輸出連接到輸入端,以時間延遲方式達到網路記憶的效果。 Elman 反饋式網路為一個動態反饋動力學系統,能夠檢測和適應時間變動的模式。 此即把時間因素所給出的資訊直接以特定的方式呈現在網路結構中,亦即將現階 段的樣本所給出的訊息,藉由回饋(feedback)的方式保留在網路結構中,作為處 理下一階段輸入值的參考訊息,此網路考量了「過去」的資訊,因為光靠「現在」 的訊息當作輸入項會忽略掉許多重要的相關因子,即資訊的時間前後具有相關性, 網路透過回饋的方式能達到時間延遲,非常適合處理非線性時序問題。. 立. 政 治 大. ‧. ‧ 國. 學. Elman 反饋式網路是一個時間延遲類神經網路(Time-Delay Neural Networks), 能將時間序列轉換成空間序列的型態輸入,即可將與輸出值相關之的不同橫向時 間序列,截取並轉換成縱向時間序列輸入,然而若 Elman 反饋式神經網路單純只 具備時間延遲特性並無法構成一個動態反饋式系統,動態指的是神經元之間的回 饋互動,每一個神經元彼此之間存在動態遞迴,能使網路有動態記憶能力。在相 互連接的神經元之間無限制的進行回饋,並以局部記憶來儲存網路早期資訊,提. Nat. y. sit. n. al. er. io. 供給未來運用,因此能有效處理時序變動系統。Elman 反饋式網路結構如下圖 2-13 所示,輸入序列 X 進入處理層,處理層節點之間進行自我反饋,資訊進入輸出層 節點 Z 之前,再反饋回處理層節點完成時間延遲的動態反饋效果。回饋式類神經 網路具有學習速度快、快速收斂、運作時間短、良好穩定性等優點。對於複雜且 有回饋特性的非線性系統之模擬有良好的效果。. 圖 2-13. Ch. engchi. Elman 反饋式網路架構. i n U. v. [Elman, 1990]. [Elman, 1990] 15.
(23) 2-3-2. Elman 反饋式學習. Elman 反饋式網路採用以瞬間時序誤差函數為目標的方式進行學習:. 輸出節點:. 處理層與輸出層權重 v 調整: ′. 權重學習式為:. 立. η. 政 治 大 η. ′. 學. ′. ‧. 權重學習式為:. ‧ 國. 輸入層與處理層權重 w 調整:. η. n. al. er. io. sit. y. Nat. 2-3-3. Ch. Elman 反饋式網路演算法. 圖 2-14. engchi. Elman 反饋式網路學習 16. i n U. v. [Mathworks]. [Pearlmutter, 1990].
(24) 如圖 2-14 所示,設. 為縱向輸入向量;. 為輸入層與處理層之間的權. 重值; 為處理層與輸出層之間的權重值,D 為時間延遲(Time-delay)反饋遞 迴,η代表學習速率。則其每一輸入神經元的之學習演算法如下: (1) 把橫向時序輸入向量 轉化成縱向時序輸入 (2) 以時間延遲(Time-delay)學習調整輸入向量和處理層的權值 (3) 將. 給出資訊再傳給輸出層,調整處理層和輸出向量的權值. 。 及偏差值 : 及偏差值 :. (4) 重復步驟(1)~(3),直到學習速率 收斂為止。 [Psent, Llut, 1996]. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 17. i n U. v.
(25) 2-4 徑向基底函數類神經網路(Radial-Basis-Function Network). 2-4-1. 徑向基底函數架構. 徑向基底類神經網路又稱為輻狀基底神經網路是以函數逼近(Curve Fitting) 的方式建構網路學習架構,以統計原理訓練資料找尋不規則位置的資料點作為與 之相對應徑向函數,使訓練資料與曲面間誤差達最小,能夠減少學習速度,以解 決高維度曲線調適問題。徑向基底網路的每一個神經元由高斯(Gaussian)函數(圖 2-15)構成。其主要透過計算輸入向量和隱藏層各神經元中心點的歐氏距離並轉 換成高斯核心函數輸出。而徑向基網路採用高斯轉換函數,x 表示輸入向量, 為 第 k 單元核心之第 i 個輸入變數 x 的中心值, 代表第 k 神經單元之核心半徑, 且 。. 政 治 大. 則從訓練範列資料中以隨機選取固定數量 m,核半徑標準偏差值 則為:. 立. 學. ‧ 國. 中心值. 因此徑向基的高斯轉換函數:. ‧ sit. n. al. er. io 其誤差學習函數:. y. Nat. 隱藏層結構:. Ch. engchi. 權重 W 調整: η. 中心值 C 調整: η. 核半徑 調整: η. 18. i n U. v.
(26) 圖 2-15 高斯函數單元. [24]. [Park, Sandberg, 1991] [Park, Sandberg, 1993]. 2-4-2. 立. 徑向基底函數演算法. 政 治 大. ‧. ‧ 國. 學. 徑向基底函數網路架構:. n. er. io. sit. y. Nat. al. Ch. 圖 2-16. eRBFn網路架構圖 gchi. i n U. v. [25]. (1) 從圖 2-16 之輸入向量 尋找隨機中心點 C,中心點數量 m, 計算核半徑標準偏差值 ,並以隨機分佈設定權重值 W (2) 計算輸出值 (3) 透過誤差學習函數 更新權重值 W 權重 W 調整:. η. 中心值 C 調整:. η. 核半徑 調整:. η. (4) 重復步驟(2)~(4),直到學習速率η η η 皆收斂為止。 [Park, Sandberg, 1991] [Park, Sandberg, 1993] 19.
(27) 2-5 其他類神經網路方法與支撐向量機器. 2-5-1 機率類神經網路(Probabilistic Neural Network) 機率神經網路(Probabilistic Neural Network, PNN)由 Donald F. Specht 於 1988 年提出,以四層神經元構成之網路,屬於向前式類神經網路,理論基礎建立於貝 氏分類法則(Bayes’ Methed)。其網路連結權重值採一次設定完成,且直接自訓練 樣本中截取特徵值,無需迭代過程,固學習速度接近 0。且對樣本容錯率高,即 使樣本空間分佈零散,亦可針對問題調整參數,假設將一問題 C 分成 K 個類別:. C1 , C 2 ,..., C k 此一問題之分類規則由 M 維特徵向量組成. 政 治 大. X ( X 1 , X 2 ,..., X m ). 立. 所決定,即在此 M 維樣本空間中,各分類的機率密度函數為特徵向量的函數:. ‧ 國. 學. f1 ( X ), f 2 ( X ),..., f k ( X ) 則貝氏分類決策公式: 對所有的. ji. y. Nat. er. io. sit. f k 為第 k 類的機率密度函數. al. ‧. hi ci f i ( X ) h j c j f j ( X ). n. c k 則代表應為第 k 類,但被誤判的評估函數值. Ch. engchi. hk 是第 k 類的事前機率(Prior Probability). i n U. v. [Specht, 1990]. 2-5-2 廣義迴歸類神經網路(General Regression Neural Network) 廣義迴歸類神經網路(General Regression Neural Network, GRNN)屬於向前式 類神經網路,由 Donald F. Specht 在 1991 年提出,理論亦是根據貝氏機率模型所 演變而來,為徑向基底函數類神經網路之變化型式,擁有強大的非線性映射能力, 更快的學習收斂速度,非常適合應用於線性擬合。它將一組 M 維度訓練樣本視 為 M 維空間之樣本點,廣義迴歸網路運用這些樣本點估計一個未知樣本點函數 值並以機率密度函數呈現。而此網路之學習過程主要目的在於尋找最佳帄滑參數 σ,且神經元數量是由訓練樣本所決定,σ之大小影響一個網路訓練結果之品質 好壞; 若σ太小則只受到鄰近樣本影響,若σ太大會受到所有樣本影響。即設定 20.
(28) 太大或太小只會在回想過程中受雜訊干擾,固設定適中的帄滑參數就會把雜訊帄 滑掉。其機率密度函數表示為:. [Specht, 1991]. 2-5-3 學習向量量化網路(Learning Vector Quantization) 學習向量量化網路(Learning Vector Quantization, LVQ)是由 Kohonen,為解決 無監督式學習之缺點,在 1988 年提出一種將競爭式學習和有監督式學習整合之 新演算法,此演算法和 SOM 相似,以尋找最接近輸入向量權重值為學習方式, 但 LQV 具有目標輸出值。假設有一群 M 維訓練樣本可視為一個 M 維空間中的一 群樣本點,而且一個分類其樣本點可能散佈成數群,各有各的聚類點,LVQ 即藉 樣本點來估計各分類之各群組的聚類點位置,即是在樣本空間中搜尋各分類的聚 類點座標。首先在 n 組輸入向量中,依分類個數 m,取前 m 筆為初始權重值陣 列,剩餘 n-m 個樣本則供訓練之用,再以亂數設定介於 0~1 之權重值陣列,然 後再運 k-means 或 SOM 方法決定權重值陣列之權重分佈。以下表達其演算法, 為學習速度,. η 相同類別. 和. 不同類別. io. sit. 和. n. er. Nat. al. Ch. 為類別判別式,. y. 為分類類別,η. ‧. 其中 為輸入向量, 為 Kronecker delta。. 學. ‧ 國. 立. 政 治 大. 2-5-4 支撐向量機器(Support-Vector Machine). engchi. i n U. [Kohonen, 1998]. v. 支撐向量機器(Support-Vector Machine, SVM)由 Vapnik 在 1995 年提出,針對 有限樣本之統計學習理論,專門研究小樣本情況下網路學習規律理論,根據給定 訓練樣本估計系統輸入和輸出之相依關係,能夠針對未知樣本之輸出做出盡可能 準確的預測,主要是根據所定義之風險函數對學習效果進行評估。以下表達風險 函數,其中 為預測函數,w 為廣義參數, 險函數俞小代示學習效果愈佳。. 為損失函數,而只要風. SVM 可針對線性可分問題進行分析,亦可針對線性不可分問題分析,對於 線性不可分主要透過非線性映射演算法將低維度輸入向量空間不可分樣本轉化 為高維度特徵空間使其成為線性可分,從而得到高維度特徵空間,再採用線性演 算法對樣本的非線性特徵進行線性分析;最後再根據上述之風險函數最小化,在 21.
(29) 特徵空間中建構最佳化分割帄面,使分類機器能夠最優化。以下表達輸出函數。. [Cortes, Vapnik, 1995]. 2-6 股價影響因素選取與應用類神經演算法於股價預測之探討. 以利率、所得、物價,及匯率建構 OLS 貨幣供給迴歸方程式,藉此探討各項 因子和股價之間的影響,發現 M1 貨幣供給量對股市變動有很大的敏感度。[余世 昌, 2002]. 政 治 大. 以台灣加權股價指數、台灣貨幣供給量 M1b、台灣領先指標綜合指數年增 率和美國股市等總體經濟因子進行共整合檢定,結果指出所檢定變數中,變數組 合之間存在共整合向量,即各變數間存在長期穩定均衡關係。台灣加權股價指數 受前一期台灣領先指標綜合指數年增率、M1b 和美國非農業新增就業人數所影 響。[吳津苗, 2008]. 立. ‧. ‧ 國. 學. y. Nat. 運用 VAR 方法檢定得知在長期,貨幣和匯率存在單向因果關係,貨幣和類 股會互相影響且亦存在單向因果關係,在匯率和類股之間,如果是出口導向產業. al. er. io. sit. 和匯率存在回饋、雙向因果關係,非外銷型產業則存在單向因果關係。[蔡曉玲, 1993]. n. 運用向量自我回歸模型(VAR)、誤差修正模型(ECM)和卡爾曼濾嘴模型(KFM) 時間序列模型以總體經濟變數預測台灣股價(或報酬率),顯示油價和 M1b 因素對 台灣股市具重要衝擊反應。[邱建良, 1998]. Ch. engchi. i n U. v. 運用雙變量 GARCH 模型分析台灣市場股價、匯率和貨幣供給量三者的關連 性,並融入衝擊反應分析股市受到衝擊的變動狀況。實證指出,M1b 對股價呈 現正向單向關係,匯率直接對股價的影響則不顯著,因為兩者間均是透過 M1b 為媒介間接影響。而衝擊反應分析發現任一變數波動,其反應方向與雙變量 GARCH 檢定結果相同,且均會對其它變數產生 10 期以上影響。[鄭婉秀等., 2005] 以近月份 CME 原油期貨價格和道瓊工業指數進行門檻共整合檢定和門檻誤 差修正模型,利用線性或非線性單檢定模型實證分析得出兩變數之間具有長期均 衡關係及非對稱關係。亦即,在短期間,股價指數報酬對油價期貨的影響報存在 單向的因果關聯;而在長期間,則是油價報酬對股價指數報酬的影響存在單向的 因果關聯。[聶建中, 2005] 22.
(30) 以 1988~2008 年的原油歷史價格區分成穩定期 1988~1999 和大漲時期 2000~2008,顯示在穩定時期原油與各國股市存在右尾尾部相依(RTDC),即油價 大幅上漲、股價大幅下跌;而油價在大漲時期則多存在左尾尾部相依(LTDC),即油 價大幅下跌、股價大幅上漲。[陳芝瑋, 2005] 以 Johansen 共整合實證油價、金價、美元兌各國貨幣匯率,對德國、日本、 台灣及大陸股市存在長期穩定的均衡關係,油價對股價及金價皆具有雙向回饋關 係。[黃姿穎, 2009] 以 STAR(smooth transition autoregression)模型分析 NASDAQ 股價波動、WTI 西德州原油和台灣股價指數,指出 NASDAQ 股價對台灣股市的顯著受 9 天前油價 波動影響呈現非線性關係。[鄭鳳媚, 2010]. 政 治 大 使用 ARCH/GARCH 模型來檢視石油衝擊對股票市場的反應,實證顯示石油價 立 格透過資金流動對道瓊工業指數負向衝擊,對台股有正向影響。 [張尹華, 2008]. ‧ 國. 學. ‧. 以倒傳遞類神經網路納入技術指標變數來預測吉隆坡股票市場明日收盤價。 採用的技術指標包括了昨天收盤價、MA、動量(momentum),RSI、KD 指標。並 與時間數列 ARIMA 比較預測準度。結果發現應用三層(6-4-3-1)的類神經網路較 其它網路模式擁有較佳的預測結果與報酬率。[Yao etc al., 1999]. sit. y. Nat. n. al. er. io. 運用 Reasoning Neural Networks (RN)結合期貨預測模型(FFM)並納入技術指 標 RSI、MA、線性迴歸式等因子,以進行預測標準普爾 500 股價指數期貨(S&P 500 stock index futures) 之當日價格變動,其預測結果和準度明顯優於 BP 式類神經網 路。[Tsaiha etc al., 1998]. Ch. engchi. i n U. v. 以倒傳遞類神經運用 NN5 架構建構一個股票買賣預警系統,選取香港股市 中最穩建的香港匯豐銀行(HSBC)歷史股價資料進行測試,在實證中,整體得到 78%的命中率。[Tsang etc al., 2007] 以香港股市中波動性較小的香港匯豐銀行(HSBC)股票為目標,選取美國股市 道瓊工業指數(DJIA)、那斯達克指數(NASDAQ)、經濟因素作為影響因子,並採用 HSBC 之短期預測指標移動帄均線 MA、RSI 和 MACD 技術分析因子並建構以 NN5 和 SVM 為架構的類神經交易預警系統,採用三種策略,分別為買入持有(Buy and hold)、根據 NN5 提供之交易訊號進行當日沖銷和依據 NN5 輸出之買賣訊號進行 買多賣空交易。則 NN5 提供的買多準確率達 71.8%,賣空訊號達 75.5%;SVM 提 供的買多準確率僅達 46.2%,賣空訊號高達 80.1%;整體準確率 NN5 達 74.2%,SVM 23.
(31) 則為 64.4%.。[Tsang et al., 2007] 根據台股的短期趨勢預測和價格動能為基礎,運用雙模組(Dual-module)類神 經網路分別利用短期和長期移動視窗為訓練樣本,以權重學習價格動能趨勢和技 術分析指標之間的相關性,結果顯示雙模組的效果優於單一模組,能提供較低風 險,較高報酬的交易訊號。[Jang et al., 2004] 主要運用支撐向量機器(SVM) 採納 S&P500 和日元走勢預測日經 225 指數 (Nikkei 225) 之一個星期的動能變動走向,並與分類模式的判別分析法(LDA)、二 次判別分析法(QDA)、倒傳遞模式進行比較,實證結果顯示 SVM 得到準確率 73% 的績效均優於其他模式介於 50%~69%的準確率。[Huang etc al., 2005] 在可視覺化高維度因素變量選取方面,Simila 和 Laine 在多種複雜且不同領 域的問題中,證實自組織映射網路技術在樣本特徵截取能力,在與其他多種傳統 統計方法以及 K-mean 方法相比較,具備提供一個穩定、強大、可解讀性高的隱 藏資訊辨識能力,且經過群聚分析後之資訊將有助於大力提昇,解決問題領域的 決策和預測品質。[Simila et al, 2005][ Laine et al, 2004]. 立. 政 治 大. ‧ 國. 學. ‧. 2-7 重要隔日波段技術分析指標之探討. y. Nat. 在技術指標方面,本研究主要探討了,以漲跌幅報酬率為基礎的心理線指標. sit. n. al. er. io. (Psychological Line)、相對強弱指標(Relative Strength Index)、威廉指標(Williams Overbought/Oversold Index)、未成熟隨機值(Raw Stochastic Value)、K-D 隨機指標 (Stochastics)、以衡量中長期股價趨勢變化之移動帄均線(Moving Average)、乖離 率(Bias)以及以統計方法衡量目前價格位置之包寧傑帶狀指標 (Bollinger Bands) 最主要的%b 值和 BandWidth%帶狀寬度。. Ch. engchi. i n U. v. (1) PSY: 心理線指標(Psychological Line) 日內上張天數. (2) RSI: 相對強弱指標(Relative Strength Index;RSI). RSI6 . 6日內上漲幅度帄均值 *100 6日內上漲幅度帄均值 6日內下跌幅度帄均值. (3) WMS%R: 威廉指標(Williams Overbought/Oversold Index;WMS%R) H 9 Ct *100 WMS % R9 H 9 L9 24.
(32) 其中, H 9 為 9 日內最高價; L9 為 9 日內最低價; Ct 為當日收盤價。. (4) RSV: 未成熟隨機值 (Raw Stochastic Value). (5) K-D 隨機指標 (Stochastics): K 線:. Kt RSVt 1 3 Kt 1 2 3. Ct Ln *100 % H n Ln . RSVt . 政 治 大 其中, C 表當日收盤價; L 表九日內的最低價; H 立 n. n 表九日內的最高價。. 學. D 線:. ‧ 國. t. Dt Kt * 1 3 Dt 1 2 3. ‧. n. al. MA10 . Ch. Pi. i k. 10. engchi. BIAS10 . O. i. sit. k 9. er. io (7) BIAS: 乖離率(BIAS). y. Nat. (6) MA: 移動帄均線 (Moving Average;MA). i n U. v. MA10 100 % 10. 其中, Oi 為 i 日開盤價。 [姜林杰佑, 2009]. 包寧傑帶狀指標 (Bollinger Bands): 包寧傑帶狀是一個以簡單移動帄均為中心點,在其上、下區間建立交易帶狀 (Trading bands),衡量價格目前狀況。帶狀的價格波動率(Volatility)則以移動的 標準差(Moving standard deviation) 。若以 為樣本個別資料項, 為樣本帄均數, n 為資料數目,則標準差 的公式為: 25.
(33) 帶狀寬度則在樣本移動帄均之上、下區間建立兩倍之標準差值 。. (8) %b 為包寧傑用以表示目前價格位於帶狀之間的位置: 目前價格. 帶狀下限. 帶狀上限. 帶狀下限. (9) BandWidth%表示帶狀寬度資訊,為辨識「擠壓」(Squeeze 指價格波動率在歷 史偏高或低的狀態,價格即將發生「物極必反」的現象): 帶狀上限. 帶狀下限. 帶狀中點. ‧ 國. 預測模式設計. ‧. 3-1. [Bollinger, 2001]. 學. 3. 研究設計. 立. 政 治 大. Nat. y. sit. n. al. er. io. 本研究運用 Matlab R2009b 開發類神經網路模組,先以自組織映射網路(SOM) 針對外國股市、總體經濟變數與台股技術指標因素進行時間序列模式分群,將因 素群組分別結合倒傳遞類神經網路(BPN) 、Elman 反饋式類神經網路和徑向基底 函數類神經網路(RBFN),三種類神經方法預測台灣股市加權指數。. Ch. engchi. i n U. v. 本研究採用 SOM 的贏者全拿(Winner-Take-All)競爭式學習方法,在未事先分 類下,發掘資料本身結構及群聚之間的關係。並在競爭(competitive)階段篩選出 得勝利者再依據獎勵(reward)進行權重之調整作改良。本研究將勝利者神經元 j* 的鄰近區域函數 Aj*,依側向聯結的距離予以遞減,令 j,j* 代表第 j 個類神經 元與勝利者類神經元 j* 的側向聯結距離,其距離的計算方式是以輸出空間 A 中,與第 j* 個類神經元的歐幾里德距離,令 dj,j*代表得勝者類神經元 j*的鄰近 區域函數的強度,由於鄰近區域函數的強度是側向聯結距離的函數,因此可以得 出:. ,網路權重修正為. ,. 在 Elman 反饋式網路部分,傳統的 Elman 反饋式網路只在隱藏層和輸出層存 在時間延遲機制,而本研究所應用的反饋機制與傳統方法不同之處,在於輸入層 26.
(34) 與隱藏層之間,以及隱藏層和輸出層之間,皆有存在時間延遲遞迴連結,在輸入 層與隱藏層的連結中,首先儲存來樣本的過去時間資訊,然後當樣本進入網路中 的隱藏層後,再將已經過反饋處理後的資訊,透過隱藏層進而和其他因素產生相 互反饋影響。因此,儘管兩個階層的 Elman 反饋式類神經元網路都具有相同的 權重值和偏權值,並且都會在一個給定的時間階段內,給定一致的輸入資訊,而 它們的輸出,則會因為不同的回饋狀態,可能產生不同的結果,網路因而能夠儲 存過去和現在的資訊,提供給予更久的未來參考。 在 RBFN 在中心點選取的非監督式學習方面,降低中心點個數,可有效地降 低網路複雜度,也等於決定了網路的大小,而在中心點初始位置的決定對於網路 訓練收斂速度與網路品質有很大的影響,而以往 RBF 在選取中心點的方式採取隨 機選取固定個數中心點的方式。因此,本研究導入垂直最小帄方法求取神經單元 之誤差最小;得出之權重值最佳解為 ;求 得之網路輸出值即為 ;而輻狀基底高斯函數單元 則以上三角. 政 治 大. 立. ‧ 國. 學. 對角行列式單位向量矩陣表達成. ‧. ,其中 X 代表輸入向量,H 代表 X 和 X 之轉置矩陣的乘積, h 則代表 H 之最小單位。. n. al. Ch. ,而以 G ,透過最小帄方法. sit er. io. 求得. y. Nat. 在目標值 t 的推估方面: 代表上三角矩陣 A 和最佳權重值 W*,兩者之乘積,. i n U. v. ,固 G 的單位值折解為. engchi. ,所. 以目標值帄方和為 ,其中 為 X 之虛反 轉(Pseudo inverse)矩陣,運用虛反轉矩陣是因為,可克服矩陣的行列式皆為 0 及 奇異點的情況,且虛反轉矩陣透過奇異值分解函數求得最小模組之合理解使整個 系統得到最佳。 在網路預測輸出值和實際值之間的比值,知其 則為:. 預測值 目標值. ,比值. ,所以在對應第 i 個中心點時,誤差下降(error. reduction)比率為:. ,中心點的選取流程因此可從訓練範例中,挑選誤. 差下降比率最大值. ,將其累加直到所設定之正確率門檻即可。即 。. 27.
(35) 一、預測模型與步驟: 在資料前置處理方面,本研究透過各主要機構所發佈的經濟指標歷史數據、 各主要股市歷史價格、原油歷史價格,等資料進行收集、使其他主要市場資料與 台股指數進行日期之一致性處理,根據台股歷史資料計算台股技術分析指標。最 後將所有變數作正規化處理,設定樣本之訓練期日數、測試期日數以及預測樣本 之驗證期。 本研究運用自組織特徵映射網路的分群技術,對所有樣本進行分群,相似的 樣本被分為若干群組,將各個群組分別透過倒傳遞類神經網路、Elman 反饋式類 神經網路和徑向基底函數網路,以三種類神經網路針對股價影響因子,台股收盤 指數進行線性擬合預測。最後,比較三種類神經網路之下四個群組因素的預測績 效。圖 3-1 為本研究架構圖:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 28. i n U. v.
(36) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 3-1 研究架構圖 [本研究整理]. 29. v.
(37) 演算法步驟: 步驟 1: SOM 網路模式 (1) 隨機分佈介於 0 和 1 之間的權重值 w 給予自組織映射網路初始化輸出層 (2) 以批次處理將輸入樣本向量 向量公式計算樣本之相似度並進行分群。 (3) 輸入向量 X 與輸出層權重值. 輸給 SOM 網路,依據歐氏. 透過最小化. 公式. 進行計算,勝利神經元即為:. 。. (4) 調整勝利節點之鄰近函數. ,調整鄰近. 政 治 大,其中 k 為折減系數。 (5) 調整勝利神經元和其鄰近神經元的權重 立 (6) 聚類分析結果為群組輸入向量因素: 。 節點半徑. ,網路學習速率. ‧ 國. 學. Nat. 輸出分群因素之預測結果 。. n. a l,. Ch. sit. 。. er. io. 並調整學習權重: 調整學習速率:. y. ‧. 步驟 2: 輸入向量群組類別,再分別結合 BP、Elman recurrent 和 RBP 網路,進行線 性擬合運算。 (1) 設定 BP 模式. engchi. i n U. v. (2) 設定 Elman 反饋式模式 把橫向時序群組輸入向量因素 轉化成縱向時序輸入 以時間延遲(Time-delay)調整輸入向量和處理層的權值 及偏差值 : 將群組因素透過輸出公式 調整網路學習速率. 。. 將預測結果輸出。 , 0<k<1。. (3) 設定 RBP 模式 透過最小帄方法決定中心點 C,中心點數 m,核半徑標準差值 ,隨機分佈權 重值 W 計算群組輸入向量因素 G 之高斯函數 。 以最小化學習函數 更新權重值 W 調整權重 W,中心值 C,核半徑 。 30.
(38) 權重 W 調整:. η. 中心值 C 調整:. η. 核半徑 調整:. η. 調整權重 W 學習係數: η η 調整中心值 C 學習係數: η η 調整核半徑 學習係數: η η 步驟 3: (1) 輸出 SOM-BP network 之隔日台股指數預測結果。 (2) 輸出 SOM-Elman network 之隔日台股指數預測結果。 (3) 輸出 SOM-RBF network 之隔日台股指數預測結果。. 政 治 大. 立. ‧ 國. 學. 步驟 4: 重復步驟 1~步驟 3,直到所有網路樣本向量 X 輸入完成和所有網路之學習速 率 收斂為止。. ‧. 二、訓練、驗證和測試期資料. y. Nat. 本研究依照分群之後的時間序列資料,將樣本區分成訓練組樣本、驗證組樣. sit. n. al. er. io. 本及最終的測試組樣本實證。資料期間依照台灣股市交易日從 2001/1/2,至 2011/10/31,共 2676 個日數,以移動視窗(Moving Window)預測下一個交易日價 格,故訓練期間從 2001/1/2 至 2009/12/31,計 2223 個日數,驗證組以台股隔日 收盤價格為預測目標,實證資料測試期間從 2010/1/4 至 2011/10/31,計 453 個 日數。圖 3-2 呈現樣本移動視窗,而所有輸入資料會經過正規化處理並介於[-1,1] 之間。. Ch. engchi. i n U. v. 圖 3-2 研究樣本之移動視窗圖 [本研究整理] 31.
(39) 三、變數收集與處理 資料收集與處理部分參考文獻所指出與台灣股市具有領先連動關係之主要 國際股市與原油市場價格共 10 項變數;對股市影響重要的 M1B 貨幣供給量與總 體經濟變數共 9 項變數;重要技術分析指標 11 項;台股盤後資訊 5 項,總計輸入變 數 33 項;然而,各國之股市與原油交易市場會因為節慶假期或天災人禍交易日期 會有不一致的情況,本研究一律以台灣股市交易日為基準,所以若遇到台灣股市 交易所有進行交易,而國外市場無進行交易之日期,則以國外市場上一筆有開盤 之交易日為資料;但若遇到國外市場有進行交易,而台灣股市交易所卻無開盤之 交易日,則忽略此筆國外市場交易日。所有樣本數據之處理皆依照此機制以確保 期間交易資料的齊一性。 資料來源參考部分,台灣經體經濟資料來自中央銀行[1]、行政院主計處[2]、 中華民國統計資訊網[3]和經濟部[4];台股盤後資訊來自台灣證券交易所[5];國際 主要股市與原油市場則來自 Yahoo! Finance[6];美國總體經濟指標來自鉅亨網[7]、 MoneyCafe.com[8]和美國商務部[9];技術指標根據技術分析公式計算而成。下表 則為股價預測輸入因子:. 政 治 大. 立. ‧ 國. 學. ‧. 表 3-1 台股價格預測因素. 一、總體經濟指標. y. Nat. (1) 台灣無風險利率 (Riskless rate), 6 個月國庫券利率. sit. (2) 台灣失業率 (TW Unemployed rate). al. n. (4) 台灣貨幣供給量 (Monetary Aggregate M1b). Ch. (5) 美元對台幣匯率 (Exchange rate). engchi. er. io. (3) 台灣消費者物價指數 (TW Consumer Price Index ,CPI). i n U. v. (6) 美國聯邦基金利率(Federal Funds Rate ,FED rate) (7) 美國失業率(Unemployed rate US,UR). (8) 美國消費者物價指數(U.S. Consumer Price Index ,CPI) (9) 美國存貨/銷貨比率(Inventory to Sales Ratio, ISRATIO). 二、國際主要股市與原油市場 (1) 道瓊工業指數 (Dow Jones Industrial Average Index, DJI) (2) 那斯達克指數 (NASDAQ) (3) 標準普爾 500 指數 (Standard & Poor's 500 Index, S&P 500) (4) 日經 225 指數 (NIKKEI 225) (5) 恆生指數 (Hang Seng Index, HIS) (6) 上海證券綜合指數 (Shanghai Stock Exchange Composite Index, SSE) (7) 深圳證券綜合指數 (Shenzhen Stock Exchange Composite Index, SZSE) 32.
(40) (8) 西德州中級原油 (West Texas Intermediate Crude Oil, WTI) (9) 杜拜原油 (Dubai crude oil, Dubai) (10) 布蘭特原油 (Brent crude oil, Brent). 三、隔日波段與綜合技術分析指標 (1) 心理線指標 (Psychological Line, PSY) (2) 相對強弱指標 (Relative Strength Index,RSI) (3) 威廉指標 (Williams Overbought/Oversold Index,WMS%R) (4) 未成熟隨機值 (Raw Stochastic Value, RSV) (5) 隨機指標 (Stochastics, K-D) (6) 10 日移動帄均線 (Moving Average, MA10) (7) 20 日移動帄均線 (Moving Average, MA20) (8) 10 日乖離率 (BIAS 10) (9) 20 日乖離率 (BIAS 20). 立. 政 治 大. (10) 包寧傑%b 指標 (Bollinger %b, %b). (11) 包寧傑帶狀寬度 (Bollinger Band Width, BandWidth%). ‧ 國. 學. 四、盤後資訊. ‧. (1) 台灣股市加權指數開盤價 (TWII Open Price) (2) 台灣股市加權指數最高價 (TWII High Price). y. Nat. (3) 台灣股市加權指數最低價 (TWII Low Price). n. al. Ch. engchi. er. io. (5) 台灣股市加權指數日報酬率 (TWII Daily Return rate). sit. (4) 台灣股市加權指數收盤價 (TWII Close Price). i n U. v. 三、研究流程 本研究首先運用自組織映射網路針對所有的輸入因子進行聚類,再將聚類分 析過後之變數因子群組分別結合倒傳遞神經網路、Elman 反饋式神經網路和徑向 基底函數類神經網路。本研究在 Elman 反饋式網路建立雙層的自反饋時間遞延項 目,以遞迴反饋過去資訊給予未來,將期望能模擬一個真實動態的環境。而在徑 向基底函數網路採用高斯函數作為傳遞函數,再導入最小帄方法找尋中心點,提 升實現非線性關係映射能力,期望在函數逼近、時間序列分析有良好的效果。最 後,將此兩種方法與倒傳遞神經網路的結果進行比較。圖 3-3 為研究流程圖:. 33.
(41) 政 治 大. 立. 表 3-2 SOM 聚類分析模型參數 2001/1/2~2009/12/31. 目標分類訊號. 檢視樣本之間存在的相似性. y. sit. n. al. er. 1000. io. Epochs 學習次數. 2010/1/4~2011/10/31. Nat. Input test pattern 輸入測試樣本. ‧. Input train pattern 輸入訓練樣本. 學. ‧ 國. 圖 3-3 研究流程圖 [本研究整理]. Kohonen 學習速率. 0.01. 學習速率縮小因子. 0.95. 鄰近半徑縮小因子. 0.95. Ch. engchi. i n U. v. 表 3-3 預測模型參數 模型 A:. 模型 B:. 模 型. Back-propagation. Elman recurrent. basis function. Input train pattern 2001/1/2~ 輸入訓練樣本 2009/12/31 Verification Value 隔日台股收盤價 驗證值. 2001/1/2~ 2009/12/31 隔日台股收盤價. 2001/1/2~ 2009/12/31 隔日台股收盤價. Input test pattern 輸入測試樣本. 2010/1/4~ 2011/10/31. 2010/1/4~ 2011/10/31. 2010/1/4~ 2011/10/31. Hidden Neural. 40. 40. 演算法根據輸入. 34. C:. Radial.
(42) 隱藏神經元. 樣本數目決定. Recurrent Layer 反饋層函數. tansig 雙區正切函 NA 數. NA. Epochs 學習次數. 1000. 1000. 1000. Learn Objection 學習目標. 1e-10. 1e-10. 1e-10. Spread 神經元散布常數. NA. NA. 100~500. Learning rate 學習速率. 0.01. 0.01. 0.01. 神經元中心點 c. NA. NA. 隨機選取. 核半徑. NA. 由歐氏 (Euclidean) 向量計算 高 斯 (Gaussian) 核 心函數. 學. 測試結果與評估. ‧. 3-2. ‧ 國. 輸出函數. NA 政 治 大 purelin purelin 線性 立線性. n. al. er. io. sit. y. Nat. 本研究針對所有因子所組成的四個群組,分別再運用三種類神經網路所測試 之結果進行誤差比較,探討四個不同聚類因子和三種類神經演算法所產生之結果 優劣;藉此找出較佳的預測模式作為價格走勢判斷的參考。評估面向分成集中趨 向程度評量:. Ch. engchi. i n U. v. 集中趨向程度採取的誤差評估方法為帄均相對誤差(Average Mean Relative Error, AMRE)和帄均絕對誤差 (Average Absolute Error, AAE)。當 AMRE 或 AAE 愈低, 整體預測誤差效果愈小,則模型預測結果愈佳。 預測值. 實際值. 實際值. 預測值. 實際值. 其他比較項目分別是比較 SOM 聚類方法搭配 BP、Elman recurrent 和 RBF 三 種類神經預測模型產生之預測值與實際值之間的最大誤差、最小誤差、最大高估 值和最大低估值,以及計算樣本誤差的標準差。 35.
(43) 4. 實證結果與討論. 4-1. 聚類結果與模式. 利用第 3 章之研究方法所決定之實證模型,將本研究所運用三種模型之預測 成果進行分析比較。所有預測輸出結果將以 Excel 呈現和分析。首先透過 SOM 演 算法對樣本相似性進行計算,將相似的輸入因子進行聚類分組,31 種輸入因子 得到之 SOM 輸出分類訊號,如圖 4-1 所示; 透過聚類分析在網格上所輸出的分類 訊號,則如圖 4-2 所示;經過模式辨別過程之後所學習調整之權重向量則以圖 4-3 呈現;. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 4-1 股價因子分類訊號. 36. v.
(44) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4-2 分類訊號輸出結果. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 4-3 權重學習調整向量圖 37. v.
數據
![圖 2-3 側抑制(Lateral Inhibition)競爭 [Kosko, 1991]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8277339.172996/13.892.145.755.449.989/圖23側抑制LateralInhibition競爭Kosko1991.webp)
+5

相關文件
mid: 左半部 array 的最大 index high: array 最大的 index.. 股市大亨 之
使用 AdaBoost 之臺股指數期貨當沖交易系統 Using AdaBoost for Taiwan Stock Index Future Intra-.. day
This thesis applied Q-learning algorithm of reinforcement learning to improve a simple intra-day trading system of Taiwan stock index future. We simulate the performance
Without making any improvement in the surface treatment of the solar cell, due to the refractive index of incident medium refractive index and different, which led to the
This study integrates consumption emotions into the American Customer Satisfaction Index (ACSI) model to propose a hotel customer satisfaction index (H-CSI) model that can be
This study therefore aimed at Key Success Factors for Taiwan's Fiber Active components Industry initiative cases analysis to explore in order to provide for enterprises and
股市預測在人工智慧領域是一個重要的議題。我們的研究使用混合式的 AI 以預測 S&P 500 芭拉價值指標和 S&P 500 芭拉成長股之間的價值溢價;S&P 600 小
Based on a sample of 98 sixth-grade students from a primary school in Changhua County, this study applies the K-means cluster analysis to explore the index factors of the
