國立高雄大學電機工程學系研究所
碩士論文
利用大數據分析於智能工廠之研究
The Application of Big Data Analysis for Intelligent
Factory
研究生:王秉融 撰
指導教授:施明昌 博士
ii
謝誌
承蒙施明昌博士在學生修業期間,於研究方式和專業知識上的指導與建議 ,並且對學生細心指導並對論文中逐字斧正,使本論文可以順利的完成。 感謝口試委員施明昌博士、藍文厚博士及李孟恩博士在觀念上的指正與本 論文的校訂,使本論文更加完整。 感謝黃瓊宣小姐在求學期間的鼎力協助,以及行政上的協助。 在研究所的生活中,除了課業上學術知識進步外,最大的收穫就是對於技 術上思考模式,對於陌生的東西如何有效地整理認識,另外也感謝班上每位同 學,感謝各位同學在這段時間帶給我的幫助與歡笑。 最後,僅以本研究成果獻給最親愛的家人,父親、母親、姊姊以及最親愛 的朋友,文欣、張凱、建瑋、政佐、丞堯,感謝你們在這段期間無怨無悔的付 出與承受,給了我生活與精神上無盡的關懷與鼓勵,同時也感謝所有關懷我的 同事與朋友們。 王秉融 僅誌於 國立高雄大學電機工程學系 中華民國一零八年七月iii
利用大數據分析於智能工廠之研究
指導教授:施明昌 博士 國立高雄大學電機工程所 學生:王秉融 國立高雄大學電機工程所 中文摘要本論文研究針對大數據分析(Big Data Analysis)的其中一項技術,關聯規 則演算法(Association rule learning)進行研究,利用工廠 SCADA(supervisory
control and data acquisition)的整合技術,產生出廠區警報狀態的大數據資料
庫,接著再將原始資料整理出可判斷、可計算的數據,重新進行排列後,再使用
Apriori 演算法,進行依照性質較為接近的資料庫結果,交叉分析產生出所有報警 之間的連鎖反應,以及產生機率。本研究能有效提供工廠警報系統及產能系統的導 入,取代經驗論的測試。
iv
The Application of Big Data Analysis for Intelligent
Factory
Advisor: Dr.Ming-Chang Shih Institute of Engineering National University of Kaohsiung
Student: Wang,Bing-Rung Institute of Engineering National University of Kaohsiung
ABSTRACT
This thesis aims at intelligent factory y applying the big data analyzes (Big Data Analysis), the connection rule algorithm (Association rule learning), and by means of integration technique of factory SCADA and dada reprocessing to generate alert status. In addition, the Apriori algorithm is used to evaluate data of similar nature, and by cross-analysis to produces the result of Chain reaction between all the alarm’s data and the occurrence probability. The result of this thesis has been applied for a PCB (Printed circuit board) intelligent factory, and is able to merged with the factory alert system and productivity system to effectively utilize big data without putting much more efforts by laboring test.
Keywords: Big data analysis, Association rule algorithm, Apriori algorithm, Data collecti
v 目錄 第一章 緒論 ... 1 研究背景與動機 ...1 第二章 資料採集與監控系統和工業 4.0 的關係 ... 6 2.1 工業 4.0 發展現況 ...6 2.2 關聯規則 ...7 2.3 資料採集與監控系統(SCADA) ...9 第三章 系統整合的大數據研究 ... 10 3.1 基本概念 ...10 3.2 Apriori 原理 ...14 3.3 Apriori 演算法優缺點 ...15 3.4 Apriori 演算法流程步驟 ...15 3.5 SCADA 整合系統 ...16 3.6 實際範例 ...17 3.6.1 Apriori 範例理解 1 ... 17 第四章 實際系統與預測系統導入 ... 20 4.1 系統規劃 ...20 4.2 系統設計 ...21 4.2.1 PLC(可編輯邏輯控制器)設計 ... 22 4.2.2 SCADA(數據採集與監視控制系統)監控 ... 23 4.3 資料規劃 ...24 4.3.1 資料庫建立 ... 24 4.3.2 資料處理 ... 25 4.4 資料探勘 ...27 4.4.1 資料處理 ... 27 4.4.2 結果呈現 ... 30 第五章 結論與未來展望 ... 31 5.1 結論 ...31 5.2 未來研究方向與建議 ...31 參考文獻 ... 32
vi 圖目錄 圖 1-1 大數據概念 ... 2 圖 1-2 研究流程圖 ... 5 圖 3-1 關聯法則的交互關係 ... 12 圖 3-2 支持度說明 ... 12 圖 3-3 信賴度說明 ... 13 圖 3-4 關聯結構圖 ... 14 圖 3-5 關聯結構圖(塞選後) ... 15 圖 3-6 SCADA 結構 ... 16 圖 3-7 Apriori 演算過程 1 ... 18 圖 3-8 Apriori 演算過程 2 ... 19 圖 4-1 導入流程 ... 20 圖 4-2 PLC 硬體配置圖 ... 22 圖 4-3 SCADA 人機畫面 ... 23 圖 4-4 SCADA 彙整警報畫面 ... 24 圖 4-5 SQL 資料庫儲存資料 ... 25 圖 4-6 刪除保密資料 ... 25 圖 4-7 加入排列編號 ... 26 圖 4-8 資料匯出 ... 26 圖 4-9 歷史資料 ... 27 圖 4-10 範例資料演算 1(原始資料的初次計算) ... 28 圖 4-11 範例資料演算 2(資料處理後的結果計算) ... 28 圖 4-12 實際資料演算 1(原始資料的初次計算) ... 28 圖 4-13 實際資料演算 2(初次計算重新排列) ... 29 圖 4-14 實際資料演算 3(資料處理後的結果計算) ... 29 圖 4-15 導入畫面 1 ... 30 圖 4-16 導入畫面 2 ... 30 表目錄 表 3-1 範例說明 ... 10 表 4-1 實驗平台 ... 20
1
第一章 緒論
研究背景與動機
過去只要產品做的好,就不愁沒有銷路。但是製造業現在面臨的狀況大不相 同,市場快速變化、競爭加劇,需求開始走向個人化、客製化,但相應的生產條 件卻沒有辦法快速靈活應變,再加上勞動力缺乏的問題,一場席捲整個製造業的 第四次工業革命撲面襲來,跟不上大潮必然被淘汰出局。 隨著「工業 4.0」、物聯網、大數據分析、智慧製造等理念的提出,傳統的製 造企業遭受到了前所未有的衝擊,以高效率、大產量及高穩定為主的生產模式已 經不能完全適應市場需求的變化,現在需要的是,工廠的整體穩定性,以及工廠 該如何導向智能化,減少人力,提高效率才是現今工廠最大的課題。[1] 隨著「工業 4.0」、物聯網、大數據分析、智慧製造等理念的提出,傳統的製 造企業遭受到了前所未有的衝擊,以高效率、大產量及高穩定為主的生產模式已 經不能完全適應市場需求的變化,現在需要的是,工廠的整體穩定性,以及工廠 該如何導向智能化,減少人力,提高效率才是現今工廠最大的課題。 現今的工廠已經幾乎已達成機台警報的情況,並且在各個情況下都存有著紀 錄,因此如何從各種不同的機台中,找出機器的警報紀錄是非常簡單的事情,但 是,工廠內有三大指標,”預警”、”預防”、”改善”,目前大多只能做到其 中的改善,但在所有的警報中難以有效率的做到預防及預警,因此本研究將會在 各種機台因素、現場因素加入其中。 再加入不同的因素影響下產生後的結果,將透過分析來證明這些規則的原因 為何,更準確的分析現場警報的關係,從而找出預防辦法,再找出原因進行相對 印的改善,這也表示在大量的資料中找出最棒的資訊,因此也能找出真正的異常2 所在,進行更正確的決策,避免不必要的資源浪費等等,從而提高產業的效率。 大數據(Big Data)又被稱為巨量資料,其概念其實就是過去 10 年廣泛用 於企業內部的資料分析、商業智慧(Business Intelligence)和統計應用之大 成。但大數據現在不只是資料處理工具,更是一種企業思維和商業模式,因為資 料量急速成長、儲存設備成本下降、軟體技術進化和雲端環境成熟等種種客觀條 件就位,方才讓資料分析從過去的洞悉歷史進化到預測未來,甚至是破舊立新, 開創從所未見的商業模式。
一般而言,大數據的定義是 Volume(容量)、Velocity(速度)和 Variety (多樣性),但也有人另外加上 Veracity(真實性)和 Value(價值)兩個 V。但 其實不論是幾 V,大數據的資料特質和傳統資料最大的不同是,資料來源多元、 種類繁多,大多是非結構化資料,而且更新速度非常快,導致資料量大增。而要 用大數據創造價值,不得不注意數據的真實性。[2] 圖 1-1 大數據概念 眾所周知,大數據已經不單單是數據大的事實而已,最重要的是對大數據進 行分析,只有通過各種分析才能獲取很多智能、深入、有價值的信息。那麼越來 越多的應用涉及到大數據,而這些大數據的屬性,包括數量,速度,多樣性等等 都是呈現了大數據不斷增長的複雜性,所以大數據的分析方法在大數據領域就顯
3 得特別重要,可以說是決定最終訊息是否有價值的決定性關鍵因素。基於如此的 認識,大數據分析普遍存在的方法理論有哪些呢? 1. 可視化分析:大數據分析的使用者有大數據分析工程師,同時還有普通使 用者,但是對於二者來說,大數據分析最基本的要求就是可視化資料,因為可視 化資料能夠直觀的呈現大數據特點及方向,並也能夠容易被讀者所接受,就如同 看圖說故事一樣的簡單。 2. 數據挖掘演算法:大數據分析的理論核心就是數據挖掘演算法,各種數據 挖掘的演算法在不同的數據類型和格式才能更加科學的呈現出資料本身具備的特 點,也正是因為這些被全球數學家所公認的各種計算方法(可以稱之為真理)才 能深入資料內部,計算出公認的價值。另外一個方面也是因為有這些資料挖掘的 演算法才能更快速的處理大數據,假設一個演算法得花上好幾年才能得出結果, 那麼大數據的價值也就無從成立了。 3. 預測性分析:大數據分析最重要的應用之一就是預測性分析,從大數據中 計算出特性,通過科學的建立模板,之後便可以通過模板帶入新的資料,並且預 測出未來的可能性。 4. 語義引擎:非結構化數據的多元化給數據分析帶來新的挑戰,我們需要一 套工具系統的去分析,提煉數據。語義引擎需要設計到有足夠的人工智慧足以從 數據中主動地提取信息。 5.數據質量和數據管理:大數據分析離不開數據質量和數據管理,高質量的 數據和有效的數據管理,無論是在學術研究還是在商業應用領域,都能夠保證分 析結果的真實和有價值。 大數據分析的基礎就是以上五個方面,當然更加深入大數據分析的話,還有 很多很多更加有特點的、更加深入的、更加專業的大數據分析方法。[3]
4 基於前述的背景動機,本案探討能透過大數據庫,整合出工廠所有歷史數據 及狀況,後續進行大數據分析來取得所需要的資料,本文將針對連鎖反應的資料 進行分析,由大數據分析取代人員的經驗談,評估出警報關聯性,避免不必要的 時間浪費,減少設備及儀器的修機時間,減少維修人員的訓練時間,提高人員作 業效率與生產線產能。 本研究使用的 SCADA 資料庫為大陸某工廠的現場機台資訊,分別記錄著機台 運轉狀況、出貨良率、警報、周遭環境監控,所歷經之時間大致為建廠後的 3 個 月,且每隔 3 秒記錄一次資料庫。 1.警報內包含警報細項、警報分類、警報時間等。 2.周遭環境監控內包含廠務系統的 DDC、PHT、TTHT 等。
5 本研究共分五章節進行探討流程步驟如圖所示,各章節說明如下: 第一章緒論:說明本論文之研究背景與動機、目的及對象與限制及研究步驟。 第二章文獻探討:說明工廠現況及演算法的原理及使用。 第三章應用研究:演算法的使用實例及方法。 第四章應用導入:工廠導入專案後,說明專案發展過程。 第五章結論:歸納本論文研究結果,提出總結,探討未來發展與研究方向。 圖 1-2 研究流程圖 研究背景與動機 工廠現況及演算法的原理及使用 實例及方法 導入專案,專案發展過程 結論
6
第二章 資料採集與監控系統和工業 4.0 的關係
2.1 工業 4.0 發展現況
現在的工業 4.0 目標與過往不同了,並不是研發新的技術,而是著重在將現有 的工業技術、銷售與產品體驗整合起來,通過工業 AI 的技術建立具有適應性的智 慧型工廠,並在商業流程及價值流程中整合客戶以及商業夥伴,提供完整的售後服 務。其技術基礎是智慧型整合感測與控制系統及物聯網。這樣的架構雖然還在研究, 但如果可以慢慢成真並且導入,最終將能建立出一個全新的 AI 工業世界,並且能 透過分析各種大量資料,直接產生一個能滿足客戶的客製化產品,並且更可利用電 腦預測,例如大眾運輸、天氣預測、產業調查的資料等等,即時準確的生產或調度 現有資源、減少多餘成本與浪費等等(最佳化),需要注意的是,工業只是這個智 慧型世界的一個零件,需以「工業如何適應智慧型網路下的未來生活」去理解才不 會搞混其中的各種概念。[4] 預測性維護對製造業的重要性已被充分認識和廣泛接受。預測性維護是保證 未來高效、可持續服務的關鍵。雖然預測性維護所依賴的技術已經取得了快速發展 與突破,但在將數據系統地轉化成(客戶)利益並應用到特定商業模式方面,理想與 現實之間仍然存在較大距離。 預測性維護(Predictive Maintenance,簡稱 PM)是“工業 4.0”提出的關鍵 創新點之一。基於連續的測量和分析,預測性維護能夠預測諸如機器零件剩餘使用 壽命等機關指標。關鍵的運行參數數據可以輔助決策,判斷機器的運行狀態、優化 機器的維護時機。 預測性維護是從“狀態監測”這一概念發展而來。“狀態監測”收集被監測 零件狀態的實時信息;然而,狀態監測未能前瞻性地預測機器運轉中斷和磨損消耗。 因此,預測性維護的出現是一大轉折點:更加精巧的傳感器、更加高效的通信網絡、7 能夠處理大規模數據的強大運算平台,通過隨機算法將數據與機器出現問題時的 數據模式進行比對。由此,我們可以識別、模擬並解讀機器運行參數的規律。正是 這些規律幫助我們更加精準地預測機器的使用壽命,並且通過整合系統的所有操 作數據,優化服務的方面能使客戶受益,又能夠幫助供應商改進產品。[5]
2.2 關聯規則
關聯規則是最常被使用來表示產品項目之間關聯性的方法之一。挖掘關聯規 則目的,在大量的交易資料中,找出不同項目之間的關聯,從關聯規則中所顯示出 的消費傾向,對企業在從事行銷組合及市場預測等活動時,可提供非常有價值的資 訊。Agrawal and Srikant(1994)提出 Apriori 演算法,用以處理類別型資料 (categorical data),例如:消費者購買的商品。然而,在交易資料庫中的每一 筆交易資料除了包含所購買的物品之外,也同時包含物品被購買的數量,並且計算 購買的物品與物品賣出的數量這一層關係,對於行銷策略的決定也有重要的影響。
處理數值型資料的方法可以區分成兩類:離散化分割(crisp partitions)以 及模糊分割(fuzzy partitions)。
關於離散化分割(crisp partitions),Srikantetal.(1996)運用離散化分 割(crisp partitions)的方式將連續的數值型資料進行離散化成數個區間 (interval),每一個區間即是特定的類別型資料。因此,傳統處理類別型資料的 演算法便可以繼續沿用。而模糊分割(fuzzy partitions)乃是利用模糊理論(fuzzy theory )( Zadeh,1971 ) 將 連 續 的 數 值 型 資 料 進 行 離 散 化 成 各 種 語 意 變 數 (linguistic variables),此項技術已經被廣泛應用,例 如:Hongetal.(1999) 利用模糊分割(fuzzy partitions)的方法從數值型資料庫中挖掘模糊關聯規則。 Huetal.(2003)則利用模糊分割的方法分別將類別型資料及數值型資料轉換成各 種語意變數,進而挖掘有意義的模糊關聯規則。
8 另外除了類別型資料以及數值型資料之外,另一種經常出現在交易資料庫的 資料型態為序數型資料。序數型資料則是一種特殊的資料結構。不同於類別型資料, 序數型資料間,數據與數據彼此之間具有順序的排列關係。例如:彩虹的顏色(紅 橙黃綠藍)。其中顏色的相似程度,紅與橙色的相似度明顯大於紅與藍色之間的相 似度。因此,若能考量序數型資料屬性之間的相似度,將能計算出更多有意義的關 聯規則。Chen and Weng(2008)從不精確的序數資料挖掘關聯規則,其研究顯示: 若是能考量序數資料的相似程度,將可以找出更多有意義的規則。然而,考慮項目 之間的相似度固然可能產生更多有意義的高頻項目集,卻也同時產生相似度太低 的項目集。[6]
9
2.3 資料採集與監控系統(SCADA)
近年來,自動化項目變得愈來愈複雜,涉及生產線以外的許多系統,製造商正 在尋求簡化工作,藉由網路和虛擬化來從生產基礎設施中增加收益,但是技術變革 快速發展加上人員縮編,使製造商紛紛尋求控制系統整合商的幫助。 目前企業已了解到提高自動化水準有效降低生產成本,國際化競爭和分工大 環境趨勢下,SCADA(supervisory control and data acquisition)導入國內企業 生產,從最基本的機台整合到最高層的控制即時策略,反映經營階層對現場資訊的 即時需求,對於現場狀況能有最即時處理,降低不必要損失。 只要是具有資料蒐集與監控系統的軟體都可稱之為 SCADA,此類型的軟體應用 範圍廣,不論是科技產業或傳統產業皆有。 SCADA 的架構主要可分成三部分,首先是中央的監控系統,控制的主要核心, 包括監控軟體或資料蒐集的程序。其次是可程式控制器(programmeable logic controller;PLC),此控制器用於作現場設備。最後則是遠程終端軟體(Remote Terminal Unit;RTU),將產線中各式各樣的感測器所蒐集的資料,回傳至中央的 監控系統。 PLC 除了控制現場機構與 RTU 如何工作外,還扮演中央監控和遠端終端控制的 橋梁,中央的監控系統可根據產線狀況設計某些條件,再透過網路傳遞給 PLC,PLC 便根據命令進行工作安排。在產線上,由 PLC 或 RTU 來控制產線的生產環境,並藉 由 SCADA 系統的 UI 介面讓管理者了解生產情形,並設定需記錄或注意的警告條件, 如溫度過低,因此 PLC 或 RTU 會利用溫度、壓力等感測器來控制溫度或壓力,SCADA 則是扮演監控系統的角色。[7] 近年來,許多整合商以開發出許多可編程邏輯控制器(PLC),監控和數據採集 (SCADA)系統和人機界面(HMI)以及 IT 系統的控制系統連接資料庫,為了物聯網及 大數據技術做了事前的準備。10
第三章 系統整合的大數據研究
3.1 基本概念
關聯分析是一種在大規模資料集中尋找相互關係的任務。 這些關係可以有 兩種形式:
頻繁項集(frequent item sets): 經常發生且出現在一起的物品項目。
關聯規則(associational rules): 兩種物品之間可能存在很強的關係。 關聯分析(關聯規則學習): 表 3-1 範例說明 交易號碼 商品 0 牛乳,萵苣 1 萵苣,紙尿布,葡萄酒,甜菜 2 牛乳,紙尿布,葡萄酒,柳橙汁 3 萵苣,牛乳,紙尿布,葡萄酒 4 萵苣,牛乳,紙尿布,柳橙汁
11 頻繁項集:[葡萄酒,紙尿布,牛乳] 就是一個頻繁項集的例子。 關聯規則: 紙尿布 -> 葡萄酒就是一個關聯規則。這代表如果顧客買了紙尿 布,那麼他很大的可能會買購買葡萄酒。 支持度:資料集中包含該項集的記錄所佔的比例。例如,[牛乳]的支持度為 4/5(五項結果占了四項)、[牛乳,紙尿布]的支持度為 3/5(五項結果占了三 項)。 信賴度:針對一條諸如[紙尿布] -> [葡萄酒]這樣具體的關聯規則來定義的。 這條規則的信賴度被定義為支持度([紙尿布,葡萄酒])/支持度([紙尿布]), 支持度([紙尿布,葡萄酒])=3/5,支持度([紙尿布])= 4/5,所以[紙尿布] -> [葡萄酒]的信賴度= (3/5) / (4/5) = 3/4 = 0.75。 支持度和信賴度是用來數據化關聯分析是否成功的一個方法,假設想找到支持 度大於 0.8 的所有項目集,該如何去做呢?一個辦法是產生出物品所有的組合可 能清單,然後對每一種組合統計它出現的頻繁程度,但是當物品成千上萬時,上述 做法就無法適用了。因此,我們需要分析這種情況並討論 Apriori 原理,因為該 原理會減少關聯規則學習時所需的計算量,並快速的計算出各個項目的發生關係。 [8] 關聯法則(association rule)主要是在大量的資料中找尋出不同項目間的交互 關係,最常見的是在便利商店中的「牛奶→麵包」(Support:3%,Confidence:60%) 的例子,並藉由支持度(Support)及信賴度(Confidence)這兩個參數避免找出太多 沒有代表性或是不具意義的法則,整個結構圖大概如下:
12
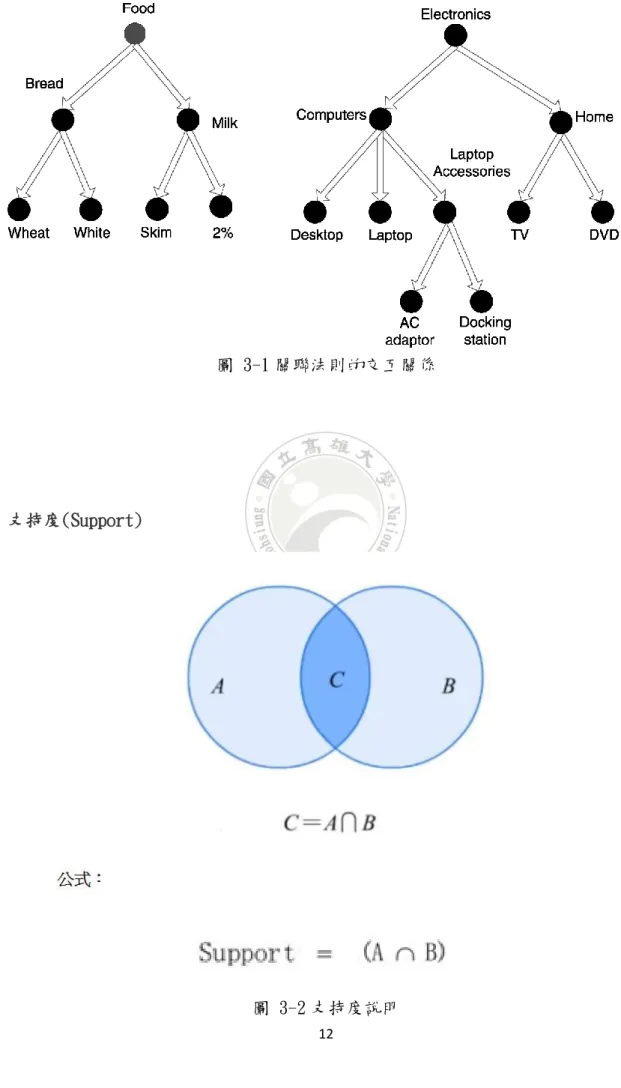
圖 3-1 關聯法則的交互關係
支持度(Support)
13
信賴度(Confidence)
信賴度是項目 A 後再取得項目 B 的條件機率,簡單來說就是交集部分 C 再 A 中比例,如果比例大,說明項目 A 後,發生項目 B 的機率比例也很大[9]
14
3.2 Apriori 原理
假設我們一共有四個項目:項目 0、項目 1、項目 2 及項目 3,所有可能的情 況如下: 圖 3-4 關聯結構圖 如果我們計算所有組合,需要計算 15 次(2^
4-1=15),隨著物品的增加,計 算的次數將隨之增長,為了降低計算次數與時間,研究人員發現一種所謂的 Apriori 原理,及某個項目組合式頻繁的,那麼它的所有子項目也是平凡的,例 如{0,1}是頻繁的,那麼{0}、{1}也是頻繁的。 該原理直觀上是沒有甚麼幫助的,但是如果反過來看就有用了,也就是說如 果有一個項目是非頻繁項目,那麼它的所有項目組合也是非頻繁項目,如下圖所 示:15 圖 3-5 關聯結構圖(塞選後) 在圖中我們可以看到,已知灰色部分{2,3}是非頻繁項目,那麼利用前面所 提的知識,我們就可以知道{0,2,3}、{1,2,3}、{0,1,2,3}皆為非頻繁的項目組 合,也就是說,計算{2,3}的組合,知道它是非頻繁的項目之後,就不需要再計 算{0,2,3}、{1,2,3}、{0,1,2,3},因為可由此得出那些組合不會滿足我們的要 求。故該原理就可以避免組合的常見狀況,以及在合理的範圍內,計算出哪些是 頻繁項目。
3.3 Apriori 演算法優缺點
優點:原理簡易,合理的範圍內,能快速得出答案 缺點:在大數據庫上,資料處理上可能較慢3.4 Apriori 演算法流程步驟
資料收集 準備資料(資料處理) 訓練資料 使用演算法 分析資料[10]16
3.5 SCADA 整合系統
SCADA 一詞是指一個可以監控及控制所有裝置的集中式系統,或是在由分散 在一個區域(小到一個工廠,大到一個國家)中許多系統的組合。其中大部份的 控制是由遠端終端控制系統(RTU)或 PLC 進行,主系統一般只作系統監控層級 的控制。例如在一個系統中,由 PLC 來控制製程中冷卻水的流量,而 SCADA 系統 可以讓操作員改變流量的目標值,設定需顯示及記錄的警告條件(例如流量過 低,溫度過高)。PLC 或 RTU 會利用回授控制來控制流量或溫度,而 SCADA 則監 控系統的整體效能。 圖 3-6 SCADA 結構 資料採集由 RTU 或 PLC 進行,包括讀取感測器資料,依 SCADA 需求通訊傳送 裝置的狀態報告。資料有特定的格式,控制室中的操作員可以用 HMI 了解系統狀 態,並決定是否要調整 RTU(或 PLC)的控制,或是暫停正常的控制,進行特殊 的處理。資料也會傳送到歷史記錄器,一般會是架構在商用的資料庫管理系統17 上,以便追蹤趨勢並進行分析。 SCADA 系統會配合分散式資料庫使用,一般稱為標籤資料庫(tag database),其中的資料元素稱為標籤(tag)或點(point)。一個點表示一個單 一的輸入或輸出值,可能是由系統所監視或是控制。點可以是硬體(hard)的或 是軟體(soft)的。一個硬體的點表示系統中實際的輸入或是輸出,而軟體的點 則是根據其他點進行數學運算或邏輯運算後的結果(有些系統會把所有的點都視 為軟體的點,無視其實際上是硬體或軟體)。一個點通常都是會以資料-時間戳記 對的方式儲存,其中有資料,以及資料計算或記錄時的時間戳記。一個點的歷史 記錄即可以用一連串的資料-時間戳記對所表示。常常也會在儲存時加上其他的 資訊,例如現場裝置或 PLC 暫存器的路徑,設計的註解及警告資訊。[11]
3.6 實際範例
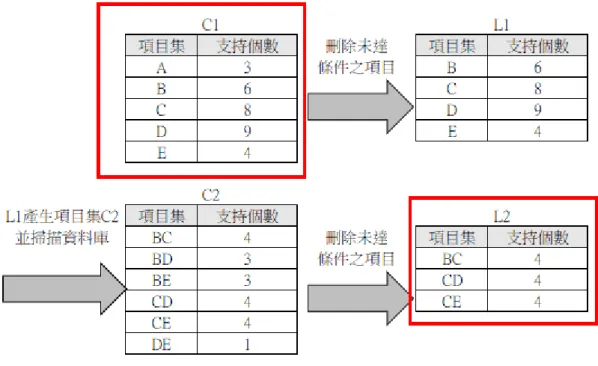
在 Apriori 演算法的歷史中,已經有許多概念式的範例產出,以下幾項較為 簡單的範例,可以了解 Apriori 的應用。3.6.1 Apriori 範例理解 1
假設交易資料庫中有五個產品,分別以英文(A~E)表示: 另外,最小支持度 門檻 Minsup(Minimum Support Threshold)設定為 3 和最小信賴度門檻18 圖 3-7 Apriori 演算過程 1 經過一次資料庫掃描後,五個項目在該資料庫出現的次數分別為{A}=3、 {B}=6、{C}=8、{D}=9、{E}=4。由最小支持度門檻值設定為 3,所以項目{A}將被 刪除。接著,利用其他頻繁項目及來產生長度為 2 的候選項目,則產生的後選項 目包含{BC}、{BD}、{BE}、{CD}、{CE}、{DE},同樣的掃描一次資料庫,獲得這 些候選項目分別為{BC}=4、{BD}=3、{BE}=3、{CD}=4、{CE}=4、{DE}=1,其中 {BD}、{BE}、{DE}皆小於最小支持度門檻 3,故刪除,後續再掃描{BC}、{CD}、 {CE}依此類推,直到沒有候選項目的支持度小於最小支持度門檻直為止。 接著,每個頻繁項目的全部可能規則皆會被產生並計算他們的信賴度,則承 續該範例:產生的規則為{BC}、{CD}、{CE}
19
圖 3-8 Apriori 演算過程 2
{BC}=0.67、{CD}=0.5、{CE}=0.5、{CB}=0.5、{DC}=0.44、{EC}=1 根據最小信賴度門檻值 Minconf(Minimum Confidence Threshold)設定為 0.6 故只有{BC}、{EC}成立。
20
第四章 實際系統與預測系統導入
首先在工廠建立的初期,SCADA 系統或資料庫系統必須完善,並且確認資料 的紀錄資料的正確性,本研究的實驗平台如下: 表 4-1 實驗平台 另外,在本研究執行中,提出 7 個執行步驟與導入架構,期待透過此導入模 式,使得工廠能夠快速地得知異常與異常之間的關聯性,以及異常之間的發生機 率,進而為企業提高人員的效率與機台的穩定性。 圖 4-1 導入流程4.1 系統規劃
對於自動化成熟的工廠而言,任何系統在變更或是修改都可能造成現有系統 的影響,因此,在初期規劃中,必須將整個工廠列入考慮,包含自動化設備、廠21 房設備及製程設備一併列入討論,並且從中了解到,使用者所期望的主要功能為 何? 一般而言,三個階層會依序導入,但也有工廠會選擇三個層次一起做。如果 從資料結構的角度來看,最底層是用控制器直接控制生產線,做一些即時處理, 往上一層到了 HMI/SCADA,就可以看到歷史資料分析及整個工廠的狀況,才能發 展到下一個階層的工廠效能、品質分析及生產管理,最後完成全廠的資料分析。
4.2 系統設計
對於這個階段而言,屬於工業自動化底層的系統設計,機台自動化運作的基 礎系統 PLC(可編輯控制邏輯器),以及自動化整合、監控的基礎系統 SCADA(資料 採集與監控系統):22
4.2.1 PLC(可編輯邏輯控制器)設計
設計 PLC 控制之前,首先要了解哪一種生產設備,投入的原料種類與方式, 輸出的成品形狀。其中控制過程與程序、控制要求。 1. 瞭解生產設備控制系統的要求 2. 控制系統初步方案規劃與設計 3. 依據控制要求確定輸入/輸出元件,繪製輸入/輸出接線圖和主線路圖 4. 依據控制要求和輸入/輸出接線圖繪製梯形圖 5. 重複完善上述設定內容 6. 利用模擬仿真軟體的程序調試 7. 設備安裝調試 圖 4-2 PLC 硬體配置圖23
4.2.2 SCADA(數據採集與監視控制系統)監控
設計 SCADA 系統時,需提前規劃整體的系統方向,並且配合 PLC 設計人員行 討論,後續再來討論,該如何呈現在 HMI。 1. 圖形操作介面需求 2. 現場狀態的動態模擬 3. 即時與歷史資料的呈現 4. 趨勢曲線顯示方式 5. 警報系統觸發條件 6. 資料記錄方式 7. 報表輸出 圖 4-3 SCADA 人機畫面24 圖 4-4 SCADA 彙整警報畫面
4.3 資料規劃
資料的收集,必須先決定現場狀況,先清楚 PLC 及 SCADA 的紀錄點位後,再 來篩選必須保存資料,因此必須分為兩個階段,資料庫的建立以及資料的前置處 理。4.3.1 資料庫建立
資料庫建立時,必須配合現場需求,將所有有關資訊按照分類條列式紀錄, 避免日後資料不足的情況。 1. 了解使用者需求 2. 了解系統分析需求 3. 建立 SCADA 與資料庫通訊管道 4. 建立各項物件分類 5. 測試及修改 6. 建立備份儲存排程25 圖 4-5 SQL 資料庫儲存資料
4.3.2 資料處理
首先需要從資料的前置處理開始,需先將保密資料剃除,後續再將本研究所 需要的因素加入其中,進而進行資料整理 1. 刪除保密資料 為求資料庫整體的乾淨度,將一些不必要的資料及保密的欄位刪除,並 將資料分類,更改為較容易處理的代號來表示。 圖 4-6 刪除保密資料 2. 加入編碼欄及匯出 加入編碼欄是為了後續的資料演算,故分類再前置資料處理,另外好的 編碼加入後,可以取代許多繁瑣的報警說明,並且加快後續程式處理的速 度,資料越單純,處理的速度越快。26
另外在資料編碼分類好以後,必須將資料匯出至可以處理 Apriori 演算 法的軟體。
圖 4-7 加入排列編號
27 圖 4-9 歷史資料
4.4 資料探勘
此步驟將處理後的資料放入演算法處理,並且在最後定下目標點,直到目標 值達到以後才可停止。4.4.1 資料處理
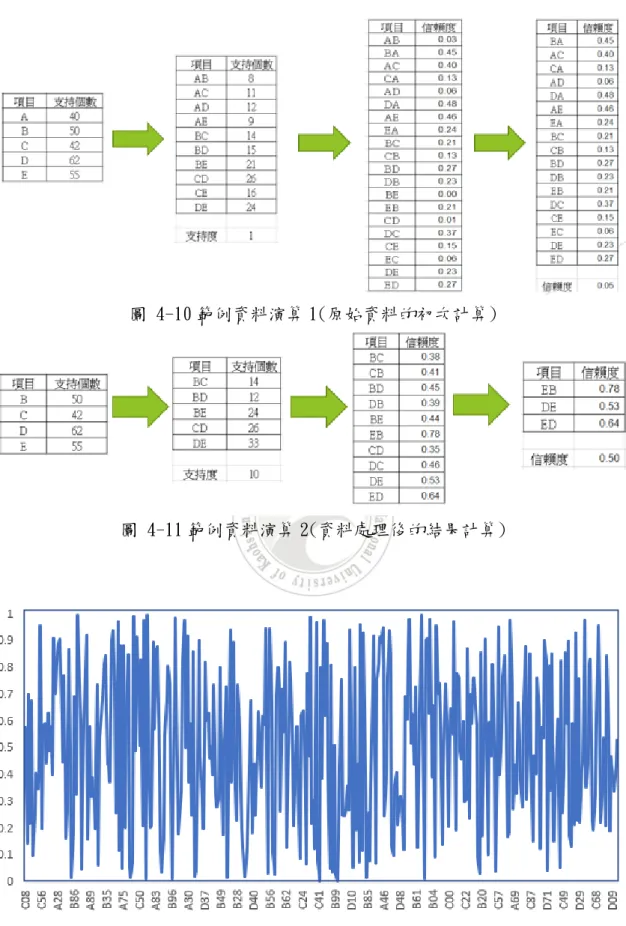
選擇使用 TOP 3 的方式,其中的支持度與信賴度由 0 開始,結果不滿足則自 動增加,支持度遞增 1、信賴度遞增 0.05,直到結果項目≦3 的時候才會停止演 算,概念如下圖 4-10、4-11 範例,現場資料演算處理流程如圖 4-12、4-13、4-14 依序表示。28
圖 4-10 範例資料演算 1(原始資料的初次計算)
圖 4-11 範例資料演算 2(資料處理後的結果計算)
29
圖 4-13 實際資料演算 2(初次計算重新排列)
30
4.4.2 結果呈現
資料處理後,將計算結果傳回 SCADA,藉由 SCADA 系統的圖控畫面呈現給使用 者,讓使用者可以藉由監控系統即時的了解目前的預測狀況。 圖 4-15 導入畫面 1 圖 4-16 導入畫面 2 報 報31
第五章 結論與未來展望
5.1 結論
本研究論文中,透過目前大數據資料的前處理技術,將智慧工廠的應用加入了 新的元素,達到工業 4.0 的目標,能以更智能的方式監控整個廠區,雖然在整體的 準確性來說,做不到百分之百的預測,但至少可以給予值班人員有個方向性的預測, 並透過大數據分析,來探討出警報間的連鎖反應,成功的將數據用淺而易懂的方式 轉換給工廠人員觀看,並且用此研究方法,代替了大多人員的經驗論。 此次研究在工廠的實測,有效達到異常警報的改善,多了有跡可循的目標,並 且提供人員防範的基準,另外,值班人員的人力降低約 15%~20%,並且在新人的訓 練時間減少了將近 50%的時間。5.2 未來研究方向與建議
基於本研究的資料蒐集、規劃設計以及演算方式,仍有美中不足之處,以下提 出未來研究方向與建議: 1. 可以加入更多的參數或監控,來達到更準確的警報預測,例如,可以加入 人力的因素進行演算。 2. 此研究將取代大多的人性經驗論,因此只需要與使用者討論出明確的目 標,即可在大多的場合進行使用。 3. 目前本研究屬於預測及預防階段,後續研究可以往自動化方向發展,預測 出必定的警報時,自動回歸到底層的 PLC 或 SCADA 進行修改,再次省去 人工的成本。32
參考文獻
[1].<工業 4.0 之路需整合思維>,2018, https://benevo.pixnet.net/blog/post/66820521-工業 4.0 之路需整 合思維 [2].<數位時代>2015.04.,李欣宜 https://bigdata.nccu.edu.tw/t/topic/76 [3].趙繼海.大數據時代圖書館面臨的挑戰機遇與對策.浙江大學寧波理工學 院 https://wiki.mbalib.com/zhtw/%E5%A4%A7%E6%95%B0%E6%8D%AE#_ref-1 [4].高野敦 2014,https://zh.wikipedia.org/wiki/工業 4.0#cite_note-商周-1 [5].先進製造業,2018,https://gongkong.ofweek.com/2018-01/ART-310002-8500-30187384_3.html [6].從購買意願資料中挖掘高度相關性的關聯規則 ,翁政雄 http://gebrc.nccu.edu.tw/jim/pdf/1804/JIM-1804-06-fullpaper.pdf [7].<智慧應用>,李威德 https://www.digitimes.com.tw/iot/article.asp?cat=130&id=000026 9152_1zy0jiqf68a0ud10uuam0 [8].<Apriori 演算法+FP-Growth 演算法>,2018, https://www.itread01.com/xixec.html [9].<BDP 諮詢顧問>熊輝,2017,https://kknews.cc/zh-tw/tech/39q4e9g.html33 [10]. <關聯規則 Apriori 演算法>2018, https://www.itread01.com/content/1544958735.html [11]. Wiki, https://zh.wikipedia.org/wiki/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9 B%86%E4%B8%8E%E7%9B%91%E6%8E%A7%E7%B3%BB%E7%BB%9F