國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
利用最小成本的文法剖析來產生機器碼
Code Generation with a Least-Cost Parsing Technique
研 究 生:徐德發
指導教授:楊武 教授
利用最小成本的文法剖析來產生機器碼
學生:徐德發 指導教授:楊武博士
國立交通大學資訊科學與工程研究所
摘要
在編譯器領域中有許多自動產生程式碼的技術,一種稱作BURS 的樹狀樣 式比對配合動態規劃的演算法是其中流行的一種做法。但是在本篇論文中,樣式 比對改由文法剖析的方式來進行,亦即,利用文法剖析器依據指令文法來針對中 間表示法(Intermediate Representation)去進行樣式比對。但指令文法是一個模糊文 法,因此要由一個更為通用的剖析器,稱作GLR parser 來處理。因為我們語法 剖析器也是採用原本BURS 演算法中的成本機制來去找尋成本最低的剖析方式, 所以若要解決在模糊文法中所存在的兩種衝突:S/R conflict 和 R/R conflict 時, 必須保證不會影響GLR parser 尋找最低成本的結果。因此,我們針對這兩種衝 突,提出新的方法來處理,前者是在runtime 之前處理,藉由分析文法的方式來 找出在該文法中每個S/R conflict 相關的規則,並判斷哪些規則屬於 shift,哪些 規則屬於reduce,然後比較彼此的成本大小;後者則是在 runtime 時處理,針對 由相同衝突衍伸出來的剖析堆疊做比較,比較的是其剖析路徑。這兩個解決衝突 的技術雖無法解決所有的衝突,但從測試的結果中仍可看出當這兩個技術被執行 時,確實可以減少GLR parser 剖析所需的時間。此外,因為我們要將 GLR Parser 當作一個指令選取器,來跟BURS 演算法做個比較,因此我們會將 GLR Parser 整合到一個現存的編譯器,而該編譯器的指令選取機制就是使用BURS 演算法。 但我們並未完全取代該編譯器的後端部分,而是要用GLR parser 來取代原本的 BURS 指令選取機制,然後比較兩者所產生出來的指令序列是否相同。Code Generation with a Least-Cost
Parsing Technique
Student: Te-Fa Hsu Advisor: Dr. Wuu Yang
Institute of Computer Science and Engineering
National Chiao Tung University
Abstract
There are many automatic code generation techniques in a compiler. A tree- pattern matching algorithm with dynamic programming called BURS is one of the most popular. However, in this thesis, pattern matching is performed as a parsing process for code generation. The set of pattern rules in an instruction grammar is transformed into a context-free grammar and a Generalized LR parser is used to do the matching work with the transformed instruction grammar since the grammar is usually ambiguous. Each pattern rule in the transformed grammar is equipped with a numeric cost and this cost criterion is used to select the least-cost result among all the final parsing results and is also used to reduce the overhead of parsing process.
誌謝
這篇論文的完成,首先我要感謝我的指導教授楊武博士。在研究所的時光, 多虧老師耐心、細心的指導,並且適時的指點我正確的方向,所以我才能解決論 文中的諸多難題,真的很感激老師的許多付出。同時,也要感謝每位口委老師所 給予的諸多寶貴意見。 而這段學生生涯,也要感謝實驗室裡的每位學長和同學及學弟妹們,大家共 同營造了一個真的是充滿「正面能量」和歡笑的實驗室,也讓我在遇到瓶頸的時 候可以放鬆心情,真的很感謝實驗室的每個成員。 當然,我能夠讀到研究所,最重要的是我爸媽在背後的諸多付出,因為沒有 他們的辛勞,不可能有今天的我,同時也要感謝容忍我脾氣的哥哥。當然,還有 我的女友,因為她,讓我人生有了努力奮鬥的目標。 謝謝大家,謝謝老天!The work reported in this paper is partially supported by National Science Council, Taiwan, Republic of China, under grants NSC 96-2628-E-009-014-MY3, NSC 98-2220-E-009-050, and NSC
目錄
第一章 緒論 ... 1 第二章 相關研究 ... 2 2.1 模糊文法 ... 2 2.1.1 shift/reduce conflict ... 3 2.1.2reduce/reduce conflict ... 32.2 Generalized LR Parser(GLR parser) ... 3
2.2.1 GLR parser 的觀念 ... 3 2.2.2 Graph-Structure Stack(GSS) ... 4 2.2.3 兩種常見的實作技術 ... 4 2.3 一個 Java 虛擬機器:CVM ... 5 2.3.1 CVM 的介紹 ... 5 2.3.2 CVM 的即時編譯器 ... 5 2.3.2.1 即時編譯器的 IR ... 6
2.3.2.2 Java Code Select 和目的碼產生器 ... 7
2.4 BURS 理論 ... 8
2.4.1 建立 BURS tree automaton ... 8
2.4.1.1 建立 tree automaton 的每個狀態 ... 9 2.4.1.2 建立 tree automaton ... 13 2.4.2 執行時的指令選取工作 ... 16 2.5 樹狀樣式比對和字串樣式比對 ... 17 第三章 GLR parser 設計與實作 ... 19 3.1 GLR parser 的實作 ... 19 3.1.1 實作技術 ... 20 3.1.2 成本機制 ... 22 3.1.3 運作範例 ... 23 3.2 衝突解決技術 ... 28 3.2.1 解決 shift/reduce conflict ... 28 3.2.2 解決 reduce/reduce conflict ... 34 第四章 實驗設計與結果分析 ... 35 4.1 實驗環境 ... 35 4.1.1 剖析器產生器的選擇 ... 35 4.1.2 編譯器的選擇 ... 35 4.2 實驗一:GLR parser 的驗證 ... 37 4.3 實驗二:指令選取的比較 ... 38 4.3.1 實驗設計 ... 39 4.3.2 實驗結果 ... 40
4.4 實驗三:測試 GLR parser 剖析時間 ... 41
4.4.1 實驗設計 ... 41
4.4.2 實驗結果 ... 42
第五章 結論 ... 44
圖目錄
Figure 2.1: 一個模糊文法的範例 ... 2
Figure 2.2: 兩種不同的剖析過程 ... 2
Figure 2.3: 兩種不同的剖析樹 ... 2
Figure 2.4: 含有 shift/reduce conflict 的模糊文法 ... 3
Figure 2.5: 含有 reduce/reduce conflict 的模糊文法 ... 3
Figure 2.6: 一個 GSS 的範例 ... 4 Figure 2.7: 即時編譯器的架構 ... 6 Figure 2.8: 一個指令文法的範例 ... 9 Figure 2.9: 狀態 1 的內容 ... 9 Figure 2.10: 狀態 2 的內容 ... 10 Figure 2.11: 狀態 3 的內容 ... 11 Figure 2.12: 狀態 4 的內容 ... 11 Figure 2.13: 狀態 5 的內容 ... 12 Figure 2.14: 狀態 6 的內容 ... 12
Figure 2.15: INEG32 的 tree automaton 表格... 14
Figure 2.16: IADD32 的 tree automaton 表格 ... 14
Figure 2.17: 兩組互比大小的規則 ... 15
Figure 2.18: ASSIGN 的 tree automaton 表格 ... 16
Figure 2.19: ISUB32 的 tree automaton 表格 ... 16
Figure 2.20: 一個樹狀樣式比對的例子 ... 18 Figure 2.21: 暫時的剖析結果 ... 18 Figure 2.22: 一個字串樣式比對的例子 ... 18 Figure 3.1: GLR parser 演算法 ... 20 Figure 3.2: 一個縮減路徑的範例 ... 21 Figure 3.3 一個含有成本觀念的文法範例 ... 23 Figure 3.4: 「a+a-a」的一個剖析樹 ... 23 Figure 3.5 「a+a-a」含有的兩個剖析樹 ... 23
Figure 3.6: 處理 shift/reduce conflict 的演算法 ... 30
Figure 3.7: 含有 shift/reduce conflict 的模糊文法 ... 30
Figure 3.8: 一個目標句子 ... 30
Figure 3.9: 含有移動策略的剖悉樹 ... 31
Figure 3.10: 含有縮減策略的剖悉樹 ... 31
Figure 3.11: 兩個不同的剖析樹分別會執行的規則 ... 32
Figure 3.12:一個剖析堆疊的範例 ... 34
Figure 3.13: 含有 reduce/reduce conflict 的模糊文法 ... 34
Figure 4.1: Java 程式轉成相對應的 bytecodes ... 36
Figure 4.2: Java bytecodes 轉成相對應的 IR ... 37
Figure 4.3: 將 GLR Parser 整合到 CVM 的即時編譯器中 ... 37
表目錄
Table 4.1 驗證程式正確的文法 ... 38 Table 4.2 JIT grammar 的資訊 ... 40 Table 4.3 由不同的 Java 程式檔找到的測試檔 ... 錯誤! 尚未定義書籤。 Table 4.4 我們 GLR parser 執行所花時間 ... 42
第一章
緒論
在編譯器領域中有許多自動產生程式碼的技術,一種稱作BURS(Bottom-Up Rewrite System)的樹狀樣式比對配合動態規劃(tree pattern matching with dynamic programming)的演算法是其中流行的一種做法。但是在本篇論文中,樣式比對的 過程是改由文法剖析的方式來進行,亦即,利用文法剖析器(parser)依據指令文 法來針對Intermediate Representation 去進行樣式比對。 一個指令文法可以設計成去代表某個目標機器的指令集,而且指令文法通常 是一個模糊的文法,因此要處理這樣的文法就需要一個更為通用的剖析器,也就 是稱作GLR parser 的語法剖析器。GLR parser 在剖析的過程中會找出所有的剖 析樹(parse tree),因此必須有一套機制去幫助 GLR parser 如何從這些不同的剖析 樹當中去挑選一個最好的語法剖析方式。
在BURS 演算法中所採用的成本機制則移植到此語法剖析器,亦即文法中 的每個規則都有一個數值型態的成本,此成本可以代表該規則對應的機器指令所 消耗的記憶體使用量或機器周期等。如此GLR parser 即可計算每個剖析樹的總 成本並選出總成本最小的剖析樹,亦即最佳的目標碼。
因為我們希望將GLR Parser 當作一個指令選取器(instruction selector),來跟 BURS 演算法做個比較,因此我們會將 GLR Parser 整合到一個現存的編譯器, 而該編譯器的指令選取過程就是使用BURS 演算法。但我們並未完全取代該編 譯器的後端部分,而是要用GLR parser 來取代原本的 BURS 指令選取機制。因 此,真正要取代的是BURS 機制在執行時剖析的兩個階段:第一階段是以由下 往上的追蹤方式,依照BURS 的有限狀態機表格去為 Intermediate Representation 的每個節點指定一個狀態,而第二階段則是以由上往下的追蹤方式去萃取每個節 點該執行其指令文法中的什麼規則。亦即,BURS 機制在執行時的指令選取過程 改由我們GLR Parser 去剖析 Intermediate Representation 來找出最佳的指令序列。
另外,因位指令文法是個模糊的文法,所以其中存在有許多的S/R conflict 和R/R conflict,因此我們希望應用成本機制來解決這樣的衝突,但又不能違背 我們GLR parser 的最終目標—找出總成本最小的剖析樹,因此提出新的方法來 解決這兩種衝突。對於S/R conflict,我們是在產生 GLR parser 的同時,藉由分 析文法的方式來找出在該文法中每個S/R conflict 相關的規則,在判斷哪些規則 屬於shift,哪些規則屬於 reduce,然後比較採取 shift 策略和採取 reduce 策略的 成本大小再做決定,但並非每個S/R conflict 能夠被解決,主要就是可能違背我 們GLR parser 的最終目標。對於 R/R conflict,我們是在 GLR parser 執行剖析工 作時,針對由相同衝突衍伸出來的剖析堆疊做比較,比較他們的剖析路徑。這兩 個解決衝突的技術經由我們實驗的測試可看出可減輕一些GLR parser 執行剖析 時的負擔。
第二章
相關研究
2.1 模糊文法
如果一個與前後文無關文法(context-free grammar)所產生的句型會有兩個或 兩個以上的剖析樹(parse tree)時,則表示此文法是模糊的(ambiguous grammar)。 舉一個簡單的與前後文無關文法(context-free grammar)為例。
(1)Stmtif Expr Stmt else Stmt
(2)Stmtif Expr Stmt
Figure 2.1 一個模糊文法的範例
「if Expr if Expr Stmt else Stmt」是一個字串,如果使用 Figure 2.1 中的模糊 文法來去剖析此字串,則會如Figure 2.2 中所示有兩種不同的剖析過程。
Stmt if Expr Stmt else Stmt Stmt if Expr Stmt
if Expr (Stmt) else Stmt if Expr (Stmt)
if Expr (if Expr Stmt) else Stmt if Expr (if Expr Stmt else Stmt)
(a) (b)
Figure 2.2 兩種不同的剖析過程
而這兩種不同的剖析方式代表在剖析的過程中會有兩種不同的剖析樹(parse tree),如 Figure 2.33,因此 Figure 2.1 中的文法就是一個模糊文法。
(a) (b)
Figure 2.3 兩種不同的剖析樹
一個文法是一個模糊文法,表示它存在衝突的情況,而所謂的衝突可以包括 shift/reduce 衝突或 reduce/reduce 衝突。以下就介紹這兩種衝突。
2.1.1 shift/reduce conflict
Figure 2.4 是一個含有 shift/reduce 衝突的範例文法,假設其中的 ICONST_32 和IADD32 都是 terminal,其餘則是 non-terminal。當一個剖析器的剖析堆疊的內 容是「IADD32」,此時又讀取到一個新的標誌是 ICONST_32,這時可以選擇使 用第一條規則進行縮減策略,但同樣的也可以採取移動策略,因此在這樣的情況 下就形成了shift/reduce conflict。Bison 對於這樣的衝突所採取的解決方法就是固 定選擇移動策略,所以在這個例子中,Bison 就會選擇「reg16: IADD32
ICONST_32 reg32」這條規則。
(1)reg32ICONST_32
(2)reg32IADD32 ICONST_32 reg32
Figure 2.4 含有 shift/reduce 衝突的模糊文法2.1.2 reduce/reduce conflict
Figure 2.5 是一個含有 reduce/reduce conflict 的範例文法,假設其中的 IADD32 是terminal,其餘則是 non-terminal。當一個剖析器的剖析堆疊的內容是「IADD32 reg16 reg16」,這時可以選擇使用第一條規則進行縮減策略,但同樣的也可以採 用第二條規則進行縮減策略,因此這時候就形成了reduce/reduce 衝突。Bison 對 於這樣的衝突所採取的解決方法就是固定選擇縮減策略中的第一條規則,因此在 這個例子就會選擇「reg16: IADD32 reg16 reg16」這條規則。
(1)reg16IADD32 reg16 reg16
(2)reg32IADD32 reg16 reg16
Figure 2.5 含有 reduce/reduce 衝突的模糊文法
2.2 Generalized LR Parser(GLR parser)
2.2.1 GLR parser 的觀念
GLR parser 的概念最先是被學者 Tomita[10]所提出,用來當作自然語言方面 的剖析器,以處理在自然語言文法中容易出現的模糊情形,並且保留在剖析過程 中所有可能的剖析方式。之後,GLR parser 的應用也從原本處理自然語言的範疇 擴展到處理程式語言。GLR parser 的運作機制其實很類似一般的 LR parser,但 前者可以處理模糊文法,並且使用一個圖形資料結構來紀錄剖析過程所有的可能 性。2.2.2 Graph-Structure Stack(GSS)
當GLR parser 去處理模糊文法時,所使用的剖析堆疊結構和一般 LR parser 中所 使用的剖析堆疊結構會有所不同。前者所使用的剖析堆疊結構其實是被稱做 Graph-Structure StackSS(GSS)的一個圖形結構。Figure 6 是一個 GSS 的例子,包 含了三個各自獨立的剖析堆疊,其中每個節點都會有一個狀態和一個指標去指向 其父節點。這三個剖析堆疊會有共用父節點的情況,主要是希望減輕GSS 所形 成的負擔。 GLR parser 是一個通用的剖析器,也就是其使用模糊文法去剖析一個句子 時,若遇到shift/reduce 或 reduce/reduce 衝突的存在,其剖析過程的堆疊會產生 分裂,形成兩個各自獨立的堆疊,這跟LR parser 這樣的剖析器就有所不同。 Figure 2.6 一個 GSS 的範例 在此GSS 中,含有三個不同的剖析堆疊 維持整個GSS 會有一個問題就是需花費許多的時間與空間,這是因為當一 個剖析堆疊要採取shift 策略時,一個新的節點會被推入到堆疊中,而當要依照 某個規則去採取reduce 策略時,該規則的右側(right-hand side)有多少個元素,則 堆疊就必須推出多少個節點。在這些節點被推入與推出圖狀堆疊的過程中,指標 必須不斷的在這些節點之間來回移動,因此就會浪費不少的時間與空間。2.2.3 兩種常見的實作技術
維持整個GSS 會浪費不少的時間與空間,因此有兩種主要的改進技術應用 在GLR parser 的實作上。 第一個技術就是讓在GSS 中,從相同剖析堆疊衍伸出來的所有不同的剖析 堆疊都會使用指標去指向其共同的剖析堆疊,如此一來這些不同的剖析堆疊就可 以共享相同的一連串節點。也就是圖型堆疊是使用鏈結串列的方式來實作,每個 節點都擁有指標去指向其父節點,因此當一個剖析堆疊要分裂時,新加入的節點 會用指標去指向其父節點。 第二個技術就是去合併擁有相同頂端狀態的剖析堆疊。也就是在剖析過程 中,兩個各自獨立發展的剖析堆疊在擁有相同的頂端狀態時,會共享一個節點,如此一來也可以節省GSS 所需要的節點數了。
2.3 一個 Java 虛擬機器:CVM
2.3.1 CVM 的介紹
本篇論文因為希望能夠比較兩種指令選取的機制:以BURS 的樹狀樣式比 對配合動態規劃的演算法為基礎的指令選取機制和以我們GLR parser 為基礎的 指令選取機制,因此我們需要一個在指令選取的部分就是使用BURS 演算法的 編譯器。我們選擇了一個應用在嵌入式環境,稱作CVM(CDC Virtual Machine) 的Java 虛擬機器所含有的一個即時編譯器(just-in-time compiler),此即時編譯器 在指令選取的部分就是使用BURS 演算法。在 CVM 中,不只含有一個傳統的直譯器(interpreter),也有一個動態編譯器 (dynamic compiler),也就是即時編譯器(just-in-compiler)。當一個 Java 程式碼被 當成CVM 的輸入時,會被轉成一連串的 Java byte-codes,然後這些 bytecodes 會 被執行,執行時CVM 有一個 profile 機制去辨認出哪些 Java 程式碼相對應的 bytecodes 執行的次數是比較多的,而在超過一個門檻值時,就會認為這些程式 碼是比較常執行的,而這樣比較常被執行的程式碼就稱作「Hot method」。
並非經常被執行的程式碼都會交由直譯器來處理,而經常被執行的「Hot method」則是交由即時編譯器來處理:將相關的 bytecodes 翻譯成目標機器的原 生指令(native machine codes),如此一來就不需要每次執行那些 Hot method 時都 還要重新翻譯,也就是可以直接執行該bytecodes 編譯好的原生機器碼來取代原 本bytecodes 直譯的過程。 CVM 這樣的 Java 虛擬機器使用直譯器和即時編譯器的主要理由在於執行一 段bytecodes 編譯好的原生機器碼會比原本 bytecodes 直譯再執行的過程還要快, 但如果以bytecodes 的編譯時間及執行時間和 bytecodes 直譯再執行的過程相比, 則前者反而比較慢,因此就出現了一個取捨的問題,哪些程式碼會經常執行或者 僅執行一兩次而已。因此CVM 使用一套測量機制來去辨認出哪些程式碼執行的 次數是比較多的,也就值得花時間由即時編譯器去進行編譯,否則由直譯器在程 式碼要被執行時再來直譯就可以。
2.3.2 CVM 的即時編譯器
CVM 的即時編譯器產生原生機器碼的元件可以分成兩部分,也就是前端和 後端。前端部分的元件會將一段Java bytecodes 轉換成一種樹狀的 Intermediate Representation,而許多關於 bytecodes 的資訊,例如資料型態和數值等都隱藏在 這個Intermediate Representation(IR)中。前端元件也會處理其他的事情,像是驗 證和安全檢查的工作、針對IR 去進行多種最佳化的工作。後端部分主要是利用由Java Code Select(JCS)這個剖析器產生器(parser generator)所產生出來的一個目 的碼產生器(code generator)去剖析由前端所產生出來的 IR。在剖析的過程中會執 行相關的函式去產生目標機器的原生指令。
後端部分還有三個重要的元件:暫存器管理者(Register Manager)、常數池管 理者(Constant Pool Manager)和堆疊管理者(Stack Manager)。暫存器管理者主要負 責的是持續追蹤在編譯過程中所有暫存器的使用情況,也使用一個資料結構來去 紀錄已評估過的計算表示式(evaluated expressions)目前是儲存在記憶體或者是暫 存器中。常數池管理者則是用來管理所產生出來的原生機器碼所參考道的32 位 元或64 位元的常數。堆疊管理者則負責管理在編譯時會被推入到 Java expression stack 中的一些方法的參數。後端部分的元件可以利用堆疊管理者和暫存器管理 者所負責的事項來去追蹤在Java 堆疊中被當作參數使用的一些數值。 Figure 2.7 即時編譯器的架構 接下來則是要分別介紹在CVM 的即時編譯器中和我們研究相關的元件,包 括IR 產生器(IR generator),Java Code Select 以及目的碼產生器。
2.3.2.1 即時編譯器的 IR
bytecodes 在設計上就有堆疊的概念在裡頭。在評估一個計算表示式時會使用一 個堆疊,有些值會被推入到堆疊中,等到要計算時再被推出來,然後結果計算完 了,該結果又會被推回到堆疊中,而一些方法的參數和傳回值也都會被傳遞到堆 疊中以供後續的使用。這樣以堆疊概念所設計的架構適合用在直譯的情況下,但 若應用在以暫存器為基礎的架構中則顯得較沒效率。因此,CVM 的即時編譯器 的目標就是要將堆疊導向的bytecodes 翻譯成原生機器碼。 在翻譯的過程中,前端元件會將bytecodes 翻譯成與硬體平台無關的
intermediate representation,而所有隱含的 Java 語意(Java semantics)都會顯現在這 樣的表示法中。這樣樹狀的表示法架構很適合用來表示將堆疊導向的bytecodes 轉換成以暫存器為基礎的底層機器架構的原生碼。這樣的IR 比起堆疊導向的 bytecodes 來說,也是更為適合去分析和操控程式碼,亦即,進行最佳化的處理 或是移除一些重複的計算過程。IR 其實是一連串的表示樹(expression tree)所組成 的,而這些表示樹如果以後序追蹤的方式來看的話,其實就容易看出所代表的 bytecodes 計算式。 由IR 產生器最終所產生出來的 IR 會被傳給目的碼產生器,然後再由目的碼 產生器轉成原生機器碼。而目的碼產生器是以後續追蹤(post-order traversal)的方 式來走訪整個樹狀IR。 每拜訪一個IR 的節點,就會去讀取其中的資訊來知道該執行怎樣的指令, 而計算完的結果也可以傳遞給其他IR 中相關的節點以便更進一步的使用。當目 的碼產生器走訪完整個樹狀的IR 時,Java 原始程式的翻譯過程就算是完成了, 也就是Java 原始程式轉成位完組碼再轉成原生機器碼的過程就完成了。
2.3.2.2 Java Code Select 和目的碼產生器
Java Code Select (JCS)是一個產生剖析器的工具,其功能類似 Yacc 或 Bison, 但不同的是 Yacc 或 Bison 所建立出來的剖析器是以字串樣式比對(pattern
matching with streams)為基礎,JCS 所產生出來的剖析器則是以樹狀樣式比對為 基礎(pattern matching with tree-based data structures)。
JCS 所接受的輸入是一個稱作 JIT grammar 的指令文法(instruction
grammar),文法中的每個規則都會有一個數值成本,然後,JCS 就能依此產生一 個目的碼產生器,稱作JIT code generator。這個目的碼產生器其實就是個剖析器, 以由下往上且由左而右的樣式比對方式去針對Intermediate Representation 來進行 剖析。
由於JCS 是以 BURS(Bottom-Up Rewrite System)這樣的樹狀樣式比對演算法 為基礎,所以在產生目的碼產生器的同時,其實也產生了一個BURS 的 tree automaton(tree automaton)以供使用。而在建造 tree automaton 的時候,已經利用 成本的觀念來去決定每個情況下最佳的指令序列,因此目的碼產生器在執行時剖 析IR,只需要兩個階段就可以找出該 IR 最佳的指令序列,然後再去執行相關的
函式以產生原生機器碼。 目的碼產生器在真正產生原生機器碼之前會設定一些細節或者是限制。然 後,目的碼產生器就會呼叫在目的碼發出器(code emitter)中的相關函式去真正產 生原生機器碼。目的碼發出器是位在即時編譯器的最底層,能為特定的硬體架構 去產生其相關的目標機器指令。
2.4 BURS 理論
BURS(Bottom-Up Rewrite System)演算法是一種樹狀樣式比對配合動態規劃 的演算法,是應用在編譯器領域中自動產生程式碼的技術,而此技術最主要的特 點在於會根據所給定的輸入文法去產生一個目的碼產生器和一個tree automaton 資料。BURS 演算法因為在執行時間之前的編譯-編譯時間(compile-compile time) 就利用動態規劃的方式作了大量的計算,考慮所有可能的情況,然後根據成本的 觀念去找出最佳的解,因此其所建立出來的目的碼產生器在真正執行時就不需要 太多的計算,所以速度相當的快。但也因為大量的計算集中在建立tree automaton 時,能夠有效率去產生BURS tree automaton 的過程就相當重要了。
對於一些典型的機器架構來說,由於直接產生BURS 的 tree automaton 所需 的狀態和狀態轉移表是很耗費空間的,所以顯得沒有效率。一些學者如Proebsting [9]就提出藉由許多不同的優化技術來去減輕 BURS 狀態轉移表所佔的空間,因 此可以讓以BURS 為基礎所設計的目的碼產生器的產生器(code-generator generator)顯得更有效率一些。
2.4.1 建立 BURS tree automaton
假設在一個指令文法中有6 個規則(Figure 2.8),然後假設每個規則的成本都 是1。現在以這個例子來說明 BURS 演算法建立 tree automaton (tree automaton) 時的過程。
tree automaton 其實也是一種狀態機,但處理的是樹狀架構而非傳統的狀態 機所處理的字串。因此在BURS 演算法中所使用的指令文法就含有樹狀架構的 概念,更精確的說是二元樹的概念,也就是其中的terminal 可分成零維、一維和 二維,而BURS 在建造 tree automaton 時,就分別為零維、一維和二維的 terminal 來建造它們的狀態轉移表,如此合起來就形成一個完整的BURStree automaton。 因此我們假設在Figure 2.8 的文法中,LOCAL32、INEG32、IADD32、ISUB32 和ASSIGN 都是 terminal,且 LOCAL32 是零維,INEG32 是一維, IADD32、 ISUB32 和 ASSIGN 則是二維。在說明如何建立自動機的轉移表時,要先說如何 建立所需要的狀態。
(1)statementASSIGN LOCAL32 reg32 1
(2)reg32LOCAL32 1
(3)reg32INEG32 reg32 1
(4)reg32IADD32 reg32 reg32 1
(5)reg32ISUB32
reg32
reg32
1
(6)reg32IADD32 reg32 INEG32 reg32 1
Figure 2.8 一個指令文法的範例
在 tree automaton 中,一個狀態會包含一些資訊:能夠完全比對的規則(full match rule)、部分比對的規則(partial match rule)和使用包覆(closure)運算涵蓋進來 的規則,以及相關規則的成本。所謂的包覆運算是指當一個狀態的完全比對規則 的左半部non-terminal(left-hand-side non-terminal)會出現在哪些規則的右半部 中,就將那些規則涵蓋進來。以下分別說明建造每個狀態的過程。
2.4.1.1 建立 tree automaton 的每個狀態
在建造狀態1 時,會先考慮維度是零的 terminal,而在此零維的就只有 LOCAL32,也就是要考慮「LOCAL32」。能夠和「LOCAL32」達成完全比對的 就是「reg32: LOCAL32」這條規則,達成部分比對的則是「statement: ASSIGN LOCAL32 reg32」這條規則,此外,因為「reg32: LOCAL32」是完全比對規則, 其左半部的non-terminal 是 reg32,因此可以根據包覆運算將右半部含有 reg32 這 個標誌的規則給涵蓋進來。Figure 2.9 顯示了狀態 1 所包含的相關資訊。State 1
(1)full match rule
reg32[LOCAL32]
(2)partial match rule
statementASSIGN [LOCAL32] reg32
(3)closure
statement ASSIGN LOCAL32 [reg32]
reg32INEG32 [reg32]
reg32IADD32 [reg32] reg32
reg32IADD32 reg32 [reg32]
reg32ISUB32 [reg32] reg32
reg32ISUB32 reg32 [reg32]
reg32IADD32 [reg32] INEG32 reg32
reg32IADD32 reg32 INEG32 [reg32]
在建造狀態2 時,因為維度是零的 terminal 已經處理完了,所以考慮維度是 1 的 terminal,而在此一維的就只有 INEG32,也就是要考慮「INEG32 reg32」。 能夠和「INEG32 reg32」達成完全比對的就是「reg32: INEG32 reg32」這條規則, 達成部分比對的則是「reg32: IADD32 reg32 INEG32 reg32」這條規則,此外,因 為「reg32: INEG32 reg32」是完全比對規則,其左半部的 non-terminal 是 reg32, 因此又可以根據包覆運算將右半部含有reg32 這個標誌的規則給涵蓋進來。 Figure 2.10 顯示了狀態 2 所包含的相關資訊。
State 2
(1)full match rule
reg32[INEG32 reg32]
(2)partial match rule
reg32IADD32 reg32 [INEG32 reg32]
(3)closure
statement ASSIGN LOCAL32 [reg32]
reg32INEG32 [reg32]
reg32IADD32 [reg32] reg32
reg32IADD32 reg32 [reg32]
reg32ISUB32 [reg32] reg32
reg32ISUB32 reg32 [reg32]
reg32IADD32 [reg32] INEG32 reg32
reg32IADD32 reg32 INEG32 [reg32]
Figure 2.10 狀態 2 的內容
在建造狀態3 時,因為維度是一的 terminal 已經處理完了,所以考慮維度是 二的terminal,而在此二維的就有 IADD32、ISUB32 和 ASSIGN,因此分別考慮 這三個terminal的情況。在此先處理IADD32,也就是要考慮「IADD32 reg32 reg32」。能夠和「IADD32 reg32 reg32」達成完全比對的就是「reg32: IADD32 reg32 reg32」這條規則,但卻沒有任何規則可以達成部分比對,此外,因為「reg32: IADD32 reg32 reg32」是完全比對規則,其左半部的 non-terminal 是 reg32,因此 又可以根據包覆運算將右半部含有reg32 這個標誌的規則給涵蓋進來。Figure 2.11 顯示了狀態3 所包含的相關資訊。
State 3
(1)full match rule
reg32[IADD32 reg32 reg32]
(2)partial match rule
(3)closure
statement ASSIGN LOCAL32 [reg32]
reg32INEG32 [reg32]
reg32IADD32 [reg32] reg32
reg32IADD32 reg32 [reg32]
reg32ISUB32 [reg32] reg32
reg32ISUB32 reg32 [reg32]
reg32IADD32 [reg32] INEG32 reg32
reg32IADD32 reg32 INEG32 [reg32]
Figure 2.11 狀態 3 的內容
在建造狀態4 時,就來考慮 ISUB32 這個二維的 terminal,因此考慮「ISUB32 reg32 reg32」。能夠和「ISUB32 reg32 reg32」達成完全比對的就是「reg32: ISUB32 reg32 reg32」這條規則,但也如同狀態 3 一般沒有任何規則可以達成部分比對, 此外,因為「reg32: ISUB32 reg32 reg32」是完全比對規則,其左半部的 non-terminal 是reg32,因此又可以根據包覆運算將右半部含有 reg32 這個標誌的規則給涵蓋 進來。Figure 2.12 顯示了狀態 4 所包含的相關資訊。
State 4
(1)full match rule
reg32
[ISUB32 reg32 reg32]
(2)partial match rule
(3)closure
statement ASSIGN LOCAL32 [reg32]
reg32INEG32 [reg32]
reg32IADD32 [reg32] reg32
reg32IADD32 reg32 [reg32]
reg32ISUB32 [reg32] reg32
reg32ISUB32 reg32 [reg32]
reg32IADD32 [reg32] INEG32 reg32
reg32IADD32 reg32 INEG32 [reg32]
Figure 2.12 狀態 4 的內容
LOCAL32 reg32」。能夠和「ASSIGN LOCAL32 reg32」達成完全比對的就是「reg32: ASSIGN LOCAL32 reg32」這條規則,但也如同狀態 3 和狀態 4 一般沒有任何規 則可以達成部分比對,此外,因為「reg32: ASSIGN LOCAL32 reg32」是完全比 對規則,其左半部的non-terminal 是 statement,因此又可以根據包覆運算將右半 部含有statement 這個標誌的規則給涵蓋進來,但並未有這樣的規則存在。Figure 2.13 顯示了狀態 5 所包含的相關資訊。
State 5
(1)full match rule
statement[ASSIGN LOCAL32 reg32]
(2)partial match rule
(3)closure
Figure 2.13 狀態 5 的內容
這時候就剩規則6 還沒被處理,所以考慮 IADD32 另外一個子樣式:[IADD32 reg32 INEG32 reg32]。能夠和「IADD32 reg32 INEG32 reg32」達成完全比對的就 是「reg32: IADD32 reg32 INEG32 reg32」這條規則,但也如同狀態 3、狀態 4 和 狀態5 一般沒有任何規則可以達成部分比對,此外,因為「reg32: ASSIGN LOCAL32 reg32」是完全比對規則,其左半部的 non-terminal 是 reg32,因此又可 以根據包覆運算將右半部含有reg32 這個標誌的規則給涵蓋進來。Figure 2.14 顯 示了狀態6 所包含的相關資訊。
State 6
(1)full match rule
reg32[IADD32 reg32 INEG32 reg32]
(2)partial match rule
(3)closure
statement ASSIGN LOCAL32 [reg32]
reg32INEG32 [reg32]
reg32IADD32 [reg32] reg32
reg32IADD32 reg32 [reg32]
reg32ISUB32 [reg32] reg32
reg32ISUB32 reg32 [reg32]
reg32IADD32 [reg32] INEG32 reg32
reg32IADD32 reg32 INEG32 [reg32]
Figure 2.14 狀態 6 的內容
其狀態轉移表。以下就來說明建立狀態轉移表的過程。
2.4.1.2 建立 tree automaton
在這個指令文法的6 個規則中,零維的terminal只有LOCAL32,而其 tree automaton 表格就會是個零維的表格,也就是一個常數而已。因為狀態 1 的完全比對規則是「reg32: LOCAL32」,因此,LOCAL32 的 Tree Automaton Table 就是狀態 1。這是表示當以 BURS 為基礎所產生的目的碼產生器,例 如:前面章節所提到即時編譯器中的目的碼產生器,去剖析樹狀的
Intermediate Representation 時,若碰到 LOCAL32 這個節點則會直接指定狀 態1 給該節點。
零維的terminal處理完,就來處理一維的terminal,也就是INEG32, 其tree automaton table 會是個一維的表格。Figure 2.15 顯示 INEG32 的轉移 表,左邊欄位代表其子節點的狀態,右邊欄位則代表父節點相對應的狀 態。現在舉其中的兩個項目來說明此表格建立的過程。
當子節點的狀態是3 時,從 Figure 2.11 中狀態 3 的內容可以發現其完 全比對規則(full-match rule)是「reg32: IADD32 reg32 reg32」,這就是子節 點會執行的規則,而當子節點執行完此規則時,父節點INEG32 該執行什 麼規則可從狀態3 的包覆運算結果來看。因為父節點是 INEG32,所以在 包覆運算結果中只有「reg32: INEG32 reg32」這個規則符合,亦即,父節 點該執行這條規則,而此規則相對應的狀態是2。因此,當子節點的狀態 是3 時,父節點的狀態應該是 2。 當子節點的狀態是 5,父節點的狀態卻是-1,這是因為從狀態 5 的內 容來看,當子節點在執行其完全比對規「statement:ASSIGN LOCAL32 reg32」時,由於狀態 5 的包覆運算結果是空的,也就是父節點 INEG32 無 法執行什麼規則,因此父節點的狀態被設定為-1。這其實從 Figure 2.8 所 示的指令文法中就可以看出INEG32 的子節點所會執行的規則必須是左半 部的non-terminal(left-hand-side non-terminal)為 reg32,而非 statement。
Figure 2.15 INEG32 的 tree automaton 表格
一維 terminal 處理完,就來處理二維 terminal,也就是 IADD32、INEG32 和ASSIGN,在此僅以IADD32 的轉移表建立過程來做說明。Figure 2.16 顯示 IADD32 的轉移表,左邊欄位代表其左子節點的狀態,右邊欄位代表其右 子節點的狀態,中間欄位則代表父節點相對應的狀態。現在也舉其中的兩 個項目來說明此表格建立的過程。
Figure 2.16 IADD32 的 tree automaton 表格
當左子節點的狀態是3,右子節點的狀態是 2 時,從 Figure 2.11 中狀 態3 的內容和 Figure 2.10 中狀態 2 的內容可以發現,兩者各自的完全比對 規則(full-match rule)是「reg32: IADD32 reg32 reg32」和「reg32: INEG32
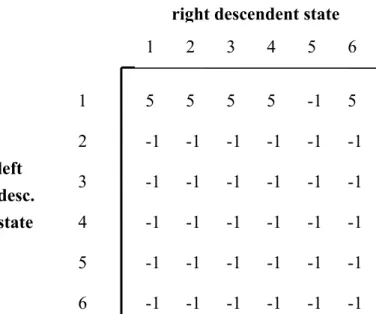
1 2 3 4 5 6 1 2 3 4 5 6 3 6 3 3 -1 3 3 6 3 3 -1 3 3 6 3 3 -1 3 3 6 3 3 -1 3 -1 -1 -1 -1 -1 -1 3 6 3 3 -1 3 left desc. state descedent state 1 2 3 4 5 6 2 2 2 2 -1 2 result state
reg32」,亦即,這是兩個子節點各自會執行的規則,而當兩個子節點執行 完各自的規則時,父節點IADD32 該執行什麼規則可從狀態 3 和狀態 2 的 包覆運算結果來看。因為父節點是IADD32,所以在包覆運算結果可發現 有兩個選擇符合所需,也就是「reg32: IADD32 reg32 reg32」和「reg32: IADD32 reg32 INEG32 reg32」,如果父節點選擇執行前者的話,則總共執 行的規則就是Figure 2.17 中的 Option 1 的三條規則,所以所花成本是 1+1+1=3;選擇執行前者的話,則總共執行的規則就是 Figure 2.17 中的 Option 2 的兩條規則,所以所花成本是 1+1=2。因此相比之下,這時候父 節點就該執行後者的規則,所以父節點的狀態就是6。
Option 1:Total Cost = 3
reg32:IADD32 reg32 reg32 reg32:INEG32 reg32
reg32:IADD32 reg32 reg32
Option 2:Total Cost = 2
reg32:IADD32 reg32 reg32
reg32:IADD32 reg32 INEG32 reg32
Figure 2.17 兩組互比大小的規則
這兩組規則在經過大小比較後,Option 2 的成本較小所以被保留。 當左子節點的狀態是3,右子節點的狀態也是 3 時,從 Figure 2.11 中狀態 3 的內容可以發現,兩者的完全比對規則(full-match rule)都是「reg32: IADD32 reg32 reg32」,亦即,這是兩個子節點各自會執行的規則,而當兩個子節點執行完相同 的規則時,父節點IADD32 該執行什麼規則可從狀態 3 的包覆運算結果來看。因 為父節點是IADD32,所以在包覆運算結果中只有「reg32: IADD32 reg32 reg32」 這個規則符合,亦即,父節點該執行這條規則,而此規則相對應的狀態是3。因 此,父節點的狀態就是3。
至於ASSIGN 和 ISUB32 的 tree automaton 轉移表的建立過程如同 IADD32 一般,就不再贅述。Figure 2.18 和 Figure 2.19 顯示兩個轉移表的內容。
Figure 2.18 ASSIGN 的 tree automaton 表格
Figure 2.19 ISUB32 的 tree automaton 表格
從以上的說明可以發現,BURS 演算法花了大量的時間在建立 tree automaton 轉移表,而表格在建立時就有使用成本觀念來找出最佳的指令序列,因此當 BURS 所產生的剖析器,或稱作目的碼產生器,在執行時就只需要查詢這些表格 以找出所剖析的對象最佳的指令序列。
2.4.2 執行時的指令選取工作
在執行時間時 BURS 技術需要兩個階段來完成指令選取(instruction 1 2 3 4 5 6 1 2 3 4 5 6 4 4 4 4 -1 4 4 4 4 4 -1 4 4 4 4 4 -1 4 4 4 4 4 -1 4 -1 -1 -1 -1 -1 -1 4 4 4 4 -1 4right descendent state
left desc. state 1 2 3 4 5 6 1 2 3 4 5 6 -1 -1 -1 -1 -1 -1 5 5 5 5 -1 5 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
right descendent state
left desc. state
selection)的工作。 第一階段就是使用由下往上的追蹤方式(bottom-up traversal)來去走訪整個 IR 的樹狀資料結構(intermediate-representation tree),同時指定給每個節點一個狀 態,而一個狀態代表了會在以該節點為跟節點的子樹中,達成完全相配(full match) 或部分相配(partial match)的所有可能規則。因為是用由下往上的追蹤方式去走訪 IR,所以樹葉節點是直接根據它自己擁有的一些資訊,例如:運算子的型態,以 決定該被指定為什麼狀態。而每個內部節點除了要參考自己的資訊,還要參考其 子節點的資訊,來決定該被指定為什麼狀態。在依照由動態規劃(dynamic programming)方式建立的狀態轉移表去完成指定狀態給每個節點的工作後 就可 以辨認出最佳的指令序列(optimum instruction sequence)為何。
第二階段則是採用由上往下的追蹤方式(top-down traversal),來去走訪整個 IR 的樹狀資料結構,然後根據前一階段所得到的資訊來取決定該執行其指令文 法中的什麼規則,然後執行每條規則所相對應的函式。 從以上兩階段的說明來看 可以發現所需的計算量遠小於 tree automaton 的計 算量,因此目的碼產生器執行的速度就相當的快。
2.5 樹狀樣式比對和字串樣式比對
從學者Shankar 等人[15]的研究可以發現要找出一個字串文法(string grammar)G 所有能推導出的序列是等價於找出一個樹狀文法(tree grammar)G’所 有能推倒出的序列。還有,我們可以藉由將樹狀文法G’中所有樹狀規則(tree patterns)的右側(right-hand-side)轉換成一個前序表示法來去建立一個字串文法 G,而轉換後所得到的字串文法 G 就可能是個模糊文法。因為樹狀樣式比對(Tree Pattern Matching)和字串樣式比對(String Pattern Matching)某種程度是相當類似的,而 BURS 演算法使用的就是樹狀樣式比對, 我們GLR parser 剖析器則是使用字串樣式比對,因此在這個章節,我們舉了一 個簡單的範例來說明這兩個技術在概念上的差異。
Figure 2.20 是一個樹狀樣式比對的例子,包含了一個所要剖析的目標樹以及 兩條用來進行目標比對的樹狀規則(tree pattern rule)。而整個樹狀比對的過程是: 首先使用Rule 1 去比對目標樹,然後執行該規則相關的函式並產生目的碼「SUB R, B, C」,然後原本的目標樹變成像 Figure 2.21 中的樣子,所以很顯然可以再用 Rule 2 去比對該目標樹,因此就會執行該規則相關的函式並產生目的碼「MOV A, R」,最終該目標樹變成了 ε,也就完成了樹狀樣式比對。
Subject Tree: =
/ \
A -
/ \
B C
Rule 1: R - {SUB R, B, C}
/ \
B C
Rule 2: ε =
/ \ {MOV A, R}
A R
Figure 2.20 一個樹狀樣式比對的例子=
/ \
A R
Figure 2.21 暫時的剖析結果 Figure 2.22 是一個字串樣式比對的例子,仍然如同 Figure 2.20 一般,包含了 一個所要剖析的目標字串以及兩條用來進行目標比對的規則。而整個字串比對的 過程是:首先使用Rule 1 去比對目標字串,然後執行該規則相關的函式並產生 目的碼「SUB R, B, C」,然後原本的目標字串變成「=AR」,所以很顯然可以再 用Rule 2 去比對該目標字串,因此就會執行該規則相關的函式並產生目的碼 「MOV A, R」,最終該目標字串變成了 ε,也就完成了字串樣式比對。 Subject String:
= A – B C
Rule 1:
R- B C {SUB R, B, C}
Rule 2:
ε = A R {MOV A, R}
Figure 2.22 一個字串樣式比對的例子 從以上的說明可以發現樹狀樣式比對和字串樣式比對是可以互相轉換的,因 此在將我們GLR parser 應用在以 BURS 的樹狀樣式比對演算法為基礎的指令選 取過程中,就需要一項重要的轉換:將一個IR 的樹狀架構變成字串形式,在這 樣的轉換後,我們GLR parser 才有辦法進行剖析。第三章
GLR parser 設計與實作
在這一章將會說明實作我們GLR parser 的過程,以及在使用 cost 機制的情 況下,如何解決文法中所含有的衝突。
3.1 GLR parser 的實作
藉由實作2.2.2 章所說的兩個主要改進 GLR parser 實作的技術,Graph- Structure Stack 確實可以變小。但因為本篇論文主要希望將 GLR parser 應用在指 令選取的過程,所以為了更加簡化其GSS 的架構,因此以陣列來實作該堆疊。 Figure 3.1 列出我們 GLR parser 的演算法。
Input: The input string
Output: The input string’s least-cost parse stackMethod:
1. GLRParser(Input String) 2. { 3. FrontierSet is the set which collects each stack-top state of each parse stack;
4. TempSet is the set which collects the newly-added stack-top state during one parsing stage in the parsing process; 5. Push a new state 0 into FrontierSet; 6. while(1){
7. T:= Choose a token from the input string
8. While(FrontierSet is not empty) { 9. S1:= Choose a stack-top state from FrontierSet arbitrarily;
10. for each action in ActionTable[S1, T] { 11. case Shift: 12. Search the entry ActionTable[S1, T] to find what the
new stack-top state S2 is; 13. Add the new stack-top state S2 to the TempSet; 14. Add the new parent-child relationship “S2 is S1’s parent” to the ParentArray; 15. case Reduce: 16. S2:= DoReduceAction(S1, T);
17. while(S2 has a reduce action to do) 18. S2:= DoReduceAction(S2, T);
19. Add the new stack-top state S2 to the TempSet; 20. case Error: 21. discard the parse stack represented by this stack-top state S1;
22. } 23. } 24. for each state in the TempSet {
25. Find out what parse stacks are derived from the same R/R conflict; 26. Check whether their parsing paths are the same or not.
27. If the same, use their RuleList to calculate their own costs. 28. Compare their costs, and leave the least-cost parse stacks. 29. }
30. FrontierSet:= TempSet;
31. if(T is the last token in the input string) break; 32. }
33. }
34. int DoReduceAction(state_number S1, token T) 35. {
36. Search the entry ActionTable[S1, T] to find what the reduce rule R should be executed;
Add the rule R into this parse stack’s RuleList; 37. NT:= Left hand side non-terminal of rule R;
38. L:= the length of Right hand side of rule R ;
39. for i:= 1 to L {
40. Use the ParentArray to find the state S1’ s parent state P; 41. S1:= P;
42. }
43. Search the entry ActionTable[P, NT] to find what the new stack-top state S2 is.
44. Add the new parent-child relationship “S2 is P’s parent” to the ParentArray; 45. return S2; 46. } Figure 3.1 GLR parser 演算法
3.1.1 實作技術
因為使用陣列來實作GSS,所以有三項實作上的技術需使用到。 記錄每個剖析堆疊的頂端 使用一對數字來定址每個節點 記錄每個剖析堆疊的規則接下來我們就分別敘述這三項實作上的技術。 【技術1: 記錄每個剖析堆疊的頂端】 為了控制GSS 中所有各自獨立的剖析堆疊,我們使用一個鏈結串列的資料 結構,稱作Frontier List,來去紀錄圖狀結構中每個剖析堆疊頂端的狀態。當我 們GLR parser 從輸入序列中讀取一個新的標誌(token)時,我們稱作一個新的階段 開始。在每一個新階段開始時,若Frontier List 中有多個相同的狀態存在,則表 示有多個各自獨立的剖析堆疊有相同的堆疊頂端。 在剖析過程結束時,由此鏈結串列中即可知道最終到底有多少個剖析堆疊存 在於GSS 中,亦即,有多少種不同的剖析方式同時存在。因此,就需要一套機 制以便我們GLR parser 能在多個剖析方式中選出一個。這部分我們使用的是成 本機制,在後面章節會作說明。 【技術2: 使用一對數字來定址每個節點】 因為使用節點的方式來建立GSS 去維持整個剖析的過程會比較花時間與空 間,又我們希望減少剖析過程中當執行縮減策略時,節點指標所需的移動時間, 所以我們並未用節點方式來維持整個GSS,而是利用一對數字來定址原本 GSS 中的每個節點。 每一個節點所對應的一對數字(state_num, state_count)會紀錄該節點的狀態 以及該裝態在相同的狀態中是第幾次出現的情況,因此每一對數字可用來唯一定 址一個節點。為了建構原本在GSS 中每個節點之間的父子關係(parent-child relationship),因此使用一個二維陣列,稱作 Parent Array 來做這樣的紀錄。 當一個剖析堆疊在執行過程中要使用某個規則去進行縮減策略時,該規則的 右半部有多少個標誌,原本在GSS 中就需要推出多少個節點以找出其縮減路徑 (reduction path)中的根節點,但在我們 GLR parser 中則是使用該剖析堆疊頂端節 點的一對數字,然後去Parent Array 中搜尋該次數以找出其根節點,以利後續其 他操作的進行。如此一來可以省卻許多節點增刪和指標移動的時間。
Figure 3.2 是一個縮減路徑(reduction path)的範例。其中剖析堆疊是以節點來 建立,它的頂端狀態是9,而當此剖析堆疊要使用一個規則去進行縮減策略,而 該規則的右半部有3 個標誌時,則此剖析堆疊就必須推出三個節點,如此才可以 找到所需要的根節點,也就狀態為4 的節點。
Figure 3.2 一個縮減路徑的範例
右半部標誌個數是 3,則該堆疊就必須要推出圖中 的三個紅色節點,因此該三個節點就稱為縮減路徑。 【技術 3: 記錄每個剖析堆疊的規則】
因為我們希望將GLR parser 應用在指令選取的過程,所以當我們 GLR parser 剖析一個目標句子時,必須要詳實紀錄在剖析過程中,每個各自獨立的剖析堆疊 會執行文法中的哪些規則,因此我們使用一個稱作Rule List 的相鄰串列(adjacent list)的來作紀錄。 在使用Rule List 完全紀錄 GSS 中每個剖析堆疊所會執行的規則有哪些之 後,可以輔助我們判斷最終該留下哪一個剖析堆疊。
3.1.2 成本機制
當我們GLR parser 根據一個模糊文法去剖析一個目標句子時,若遇到有移 動/縮減或 reduce/reduce 衝突的情況,則原本在 GSS 中的一個剖析堆疊就會因此 而分裂成兩個剖析堆疊,也就等於有兩個不同的剖析樹存在,亦即,存在著兩組 不同的指令序列會被編譯器後端的目的碼產生器給使用,但這當然不合理,因此 需要有一套機制讓我們在所有不同的剖析樹中做選擇。 我們使用如同BURS 演算法中的成本觀念去設計一個成本機制來解決因為 模糊文法所引起的這種問題。在我們的成本機制中,每個文法中的規則都會有一 個數值型態的成本(numeric cost),此成本可以代表該規則對應的機器指令所需要 的執行時間、消耗的記憶體使用量或機器周期等,而在將文法中的每個規則搭配 一個成本後就可以幫助我們計算在剖析過程中所有剖析樹的總成本。 因為在剖析樹中的每個內部節點其實就是一個縮減節點(reduce node),暗示 著在該節點會有一個縮減的動作發生,加上我們的GLR parser 使用的是由下往 上的剖析技術(bottom-up parsing),因此剖析樹中的每個內部節點其實都只會被它 所有的子節點給影響,而從這樣的觀點來看,一個剖析樹的成本其實就是去計算 它所有內部節點的成本,也就是我們GLR parser 在剖析過程中若執行了一個縮 減的動作時,勢必會有一個規則被執行,而該規則的數值成本就會被加入到目前 剖析樹的總成本中,如此一來,每個剖析樹有了自己的總成本,我們GLR parser 就可以據此來比較各剖析樹的成本大小,而保留成本最小的剖析樹。 接下來我們使用一個例子來說明成本觀念。在figure 3.3 是一個範例文法, 存在著三條規則,其成本分別是20、15 和 10。當使用我們的 GLR parser 依此文 法來去剖析一個目標句子「a + a - a」時,其剖析過程會形成像 figure 3.4 中的剖 析樹,從這個剖析樹就看得出來,剖析過程分別會執行的規則是規則3、規則 3、 規則3、規則 2 和規則 1,在將每個規則的成本相加起來就可以得到該剖析樹的 總成本,因此「a + a - a」的剖析樹其成本就是 10+10+10+15+20=65。
(1)
AA + A20
(2)AA – A 15
(3)Aa 10
Figure 3.3 一個含有成本觀念的文法範例 每個規則都附有一個數值成本,如此可輔助計算每個剖析樹的成本 Figure 3.4「a+a-a」的一個剖析樹 在這樣的成本機制下有一個問題需要特別注意,就是若多個剖析樹有相同的 總成本,則無法分辨該選擇哪一個。例如使用figure 25 中的文法去剖析目標句 子「a + a - a」就會產生兩個不同的剖析樹(figure 27),而很明顯可以看出兩個剖 析樹都具有相同的成本,也就是65。因此使用者在設計文法中每個規則的成本 時必須特別注意這樣的問題。 Figure 3.5 剖析「a+a-a」產生的兩個剖析樹3.1.3 運作範例
我們使用一個假設的模糊文法來說明我們GLR parser 在實作上的方式。如同 前面所述,若將這個模糊文法交由NewBison 當作輸入文法來處理後,可發現 會有shift/reduce 衝突或 reduce/reduce 衝突的存在,而產生出來的有限狀態機就 可以保留這些所有的衝突資訊。由狀態機去剖析「minus NUM」這樣假設的字串來顯示每一步的過程中幾個重要 資料結構的變化,以說明我們GLR parser 實作的技術。
Stage 0
在一開始的時候,一般GLR parser 使用的 GSS 中只會有一個起始狀態為 0 的節點,因此我們GLR parser 所使用的 Frontier Set 中也就只會有一個狀態為 0 的節點。而此狀態0 是第一次出現,因此使用(0, 1)來代表此第一次出現的狀態 0。 又因為此狀態0 並沒有任何的父節點,所以(0, 1)在 Parent Array 的欄位是 NULL。
GSS:
FrontierSet: {0}
ParentArray:
Stage 1: minus
在這階段開始的時候,Frontier Set 僅有一個狀態 0 的元素,我們 GLR parser 再根據這個狀態0 和新讀入的標誌 minus 去有限狀態機表格(FSM table)中搜尋相 關的欄位,判斷該執行移動策略或縮減策略。而假設由有限狀態機表格可知共有 兩個策略該執行:
「Shift 1」、「Reduce 2」。
1st action: FSMTable[state 0][minus] = “Shift 1”
一個狀態為1 的節點會被推入到 GSS 中。所以這時候 GSS 的內容如下:
2nd action: FSMTable[state 0][minus] = “Reduce 2”
使用規則2 來縮減,假設其右半部並沒有任何的標誌,縮減路徑(reduction path)長度就是 0,所以 GSS 中不需要推出任何的節點,因此可以找出根節點就 是狀態0,又假設該規則的左半部 non-terminal 為 TokenA,因此我們 GLR parser 就去有限狀態機表格中搜尋FSMTable[state 0][TokenA]的欄位,發現該執行「go to 0 1 0 0 1 NULL
5」的移動策略,因此一個狀態為 5 的節點被推入到堆疊中,則 GSS 的內容變成 如下:
然後我們GLR parser 再去有限狀態機表格查詢 FSMTable[state 5][minus]的 欄位,發現要執行「shift 2」,所以一個狀態為2 的節點被推入到堆疊中。則 GSS 的內容又變成如下: 此時會有兩個各自獨立的剖析堆疊存在,而因為狀態1、狀態 5 和狀態 2 都 是第一次出現,所以分別使用(1, 1)、(5,1)和(2, 1)這樣的數字組合來去定址 GSS 中的這些節點,而這三個節點在GSS 中的父節點分別是狀態 0、狀態 0 和狀態 5, 這樣的父子關係資訊也就會紀錄在Parent Array 中。還有,堆疊頂端是(2, 1)的剖 析堆疊則在Rule List 紀錄它所執行過的規則。 GSS: FrontierSet {(1,1), (2,1)} Parent Array: (0, 1) (5, 1) 3 4 5 0 1 NULL (0, 1) 2 1 0 1 5 0 1 5 2 0 1 5 2
Rule List: Stage 2: NUM 在這階段開始的時候,GSS 中有兩個剖析堆疊,因此 Frontier Set 包含了兩 個元素,我們GLR parser 再分別根據這些狀態和新讀入的標誌 NUM 去有限狀態 機表格中搜尋相關的欄位,判斷該執行移動策略或縮減策略。先處理第一個剖析 堆疊,然後假設由有限狀態機表格可知要執行「shift 2」的策略,所以此時 GSS 變成如下:
1st action: FSMTable[state 1][NUM] = “Shift 2”
一個狀態為2 的節點會被推入到 GSS 中。所以這時候 GSS 的內容如下:
接著再來處理第二個剖析堆疊,而假設由有限狀態機表格可知共有「Shift 5」、「Reduce 3」兩個策略該執行:
2nd action: FSMTable[state 2][NUM] = “Shift 5”
一個狀態為5 的節點會被推入到 GSS 中。所以這時候 GSS 的內容如下:
3rd action: FSMTable[state 2][NUM] = “Reduce 3”
使用規則3 來縮減,假設其右半部有 1 個元素,則其縮減路徑(reduction path) 長度就是1,所以 GSS 中需要推出一個節點,但由於該節點被另外一個剖析堆疊 所使用,因此不會真正推出該節點。因為縮減路徑為1,因此可找到所需的根節 點就是狀態5,又假設規則 3 的左半 non-terminal 為 TokenB,因此我們 GLR parser 就去有限狀態機表格中搜尋FSMTable[state 5][TokenB]的欄位,發現該執行「go to 6」的移動策略,因此一個狀態為 6 的節點被推入到堆疊中,則 GSS 的內容變成 如下: 0 1 5 2 0 1 5 0 1 5 2 6 (2, 1) 2
然後我們GLR parser 再去有限狀態機表格查詢 FSMTable[state 6][NUM]的欄 位,發現要執行「shift 3」,所以一個狀態為 3 的節點被推入到堆疊中。則 GSS 的內容又變成如下: 此時GSS 終會有三個各自獨立的剖析堆疊存在,而每個新加入的節點都會 有適當的一對數字來定址,也會將節點之間彼此的父子關係紀錄在Parent Array 中,然後有執行過一些規則也會紀錄在該剖析堆疊的Rule List 中。 GSS: FrontierSet: {(2,2), (5,2), (3,1)} ParentArray: 0 1 NULL (0, 1) (5, 1) (6, 1) (0, 1) 2 3 4 5 1 (1, 1) (2, 1) (5, 1) 6 0 1 5 2 2 5 6 3 0 1 5 2 2 5 6 3 2
Rule List:
3.2 衝突解決技術
因為當我們GLR parser 依照一個模糊文法來剖析一個句子,而在剖析的過 程中因為shift/reduce 衝突或 reduce/reduce 衝突而使得 GSS 中有多個剖析堆疊的 存在,如此會浪費空間,加上我們GLR parser 為了加快剖析的過程而使用一個 二維陣列來紀錄整個GSS,因此需要有一些技術來處理這樣的衝突情況,以減輕 這樣的負擔。 一般剖析器用來解決這樣衝突情況的技術如同 2.1 章所述,對 shift/reduce conflict 的解決方法是固定選擇移動策略,而對 reduce/reduce conflict 的解決方法 則是固定選擇第一條的縮減規則(reduce rule),但這樣的經驗法則並不適用於我 們GLR parser,主要原因在於我們 GLR parser 必須要能夠保證最終挑選出來的 是總成本最小的剖析方式,因此我們提出不同的方法來處理這樣的衝突問題。3.2.1 解決 shift/reduce conflict
為了讓我們GLR parser 在剖析時所維持的剖析堆疊數可以減少,以減輕其 執行時的負擔,因此設計一個演算法(Figure 3.6)來解決 shift/reduce 衝突,使得在 建立有限狀態機表格時就能解決這樣的衝突問題。由於並非在執行剖析的過程處 理,因此無法知道我們GLR parser 真正所要剖析的目標句子為何,也無法知道 一個目標句子的剖析樹的真正長相,也無法去計算出該剖析樹真正的總成本。因 此需要一個方法讓我們可以在不需要知道目標句子為何的情況下,就可以知道對 於一個shift/reduce 衝突來說,採取哪個策略可以讓我們 GLR parser 得到成本最 低的剖析樹。接下來我們先以一個例子來說明我們設計該演算法的背後想法。Input: A context-free grammar G with S/R conflict(s)
Output: If G‘s one S/R conflict can be solved, the S/R conflict can be solved by shift action or reduce action.
Method:
1. PreprocessSRconflict(G) 2. {
3. for each S/R conflict in LR(1) parse table { 5. int Flag:= -1; //Flag=0 represents shift action, Flag=1 represents reduce action.
(2, 1) 2
6. int Flag2:= -1;
7. Find out all of the corresponding shift rules and reduce rules; 8. for each shift rule RuleS do {
9. if(Flag2 == 0) break;
10. for each reduce rule RuleR do { 11. if(Flag2 == 0) break;
12. for each parent rule RuleP of RuleR do {
13. Compare RuleS’s RHS symbols with RuleP’s RHS symbols, from left to right to see if each two symbol is the same. If not the same, stop comparing;
14. Symbol1:= RuleP’s symbol;
15. Compare RuleS’s RHS symbols with RuleP’s RHS symbols, from right to left to see if each two symbol is the same. If not
the same, stop comparing; 16. Symbol2:= RuleP’s symbol;
17. if(Symbol1 == Symbol2) {
18. if(Symbol1 ==RuleR’s LHS non-terminal) {
19. Use the RuleR’s RHS to replace that LHS non-terminal in RuleP’s RHS;
20. } 21. }
22. if(RuleS’s RHS == RuleP’s RHS) {
23. if(RuleS’s LHS non-terminal ==RuleP’s LHS non-terminal or one non-terminal can become the same with another
through using chain rules or
the two can become the same through using chain rules) 24. {
25. Flag2:= 1;
26. Calculate all the shift action’s rules’ total costs; 27. Calculate all the reduce action’s rules’ total costs; 28. if(shift action’s cost < reduce action cost) {
29. if(Flag == 1) the S/R conflict can not be solved; 30. Flag:= 0;
31. }
32. else if (shift actoin’s cost > reduce action’s cost) { 33. if(Flag == 0) the S/R conflict can not be solved; 34. Flag:= 1;
36. } 37. } 38. } 39. if(Flag2 == -1) Flag2:= 0 40. } 41. } 42. if(Flag2 == 1) {
43. if(Flag == 0) choose the shift action; 44. else if(Flag == 1) choose the reduce actoin; 45. else choose the shift actoin;
46. }
47. else the S/R conflict can not be solved; 73. }
74.}
Figure 3.6 處理 shift/reduce conflict 的演算法
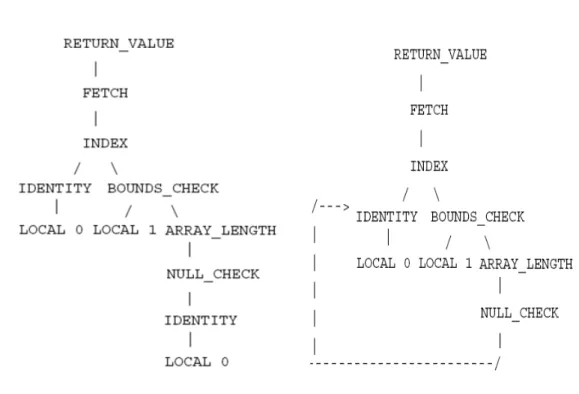
在Figure 3.7 中所顯示的是 CVM 的即時編譯器所擁有的一部份指令文法, 共有五條規則,其中BOUNDS_CHECK 和 ICONST_32 是 terminal,其餘則是 non-terminal。因為規則(1)和規則(2)的同時存在,因此該文法會在 ICONST_32 的地方有一個shift/reduce 衝突。現在假設我們 GLR parser 要利用即時編譯器完 整的指令文法來處理Figure 3.8 中的目標句子。當我們 GLR parser 在讀取到第二 個ICONST_32 時,就會面臨到前述的 shift/reduce 衝突,而因為這樣的衝突,所 以使得在剖析過程中,我們GLR parser 必須去維持兩個獨立的剖析堆疊。
(1)iconst32IndexBOUNDS_CHECK ICONST_32 reg32
(2)reg32ICONST_32
(3)reg32BOUNDS_CHECK reg32 reg32
(4)arraySubscriptreg32
(5)arraySubscripticonst32Index
Figure 3.7 含有 shift/reduce conflict 的模糊文法
ASSIGN INDEX IDENTITY NEW_ARRAY_BASIC ICONST_32
BOUNDS_CHECK ICONST_32 IDENTITY ARRAY_LENGTH IDENTITY NEW_ARRAY_BASIC ICONST_32 ICONST_32
Figure 3.8: 一個目標句子
當我們GLR parser 處理完整個目標句子時,最終就會含有兩個剖析堆疊在 GSS 中,而這兩個剖析堆疊各自相對應的剖析樹則如 Figure 3.9 和 Figure 3.10 所
示,其中,前者在遇到shift/reduce 衝突時,採取的是移動策略,後者則是採取 縮減策略。觀察這兩個不同的剖析樹可以發現它們長得很像,不同點就僅在於衝 突發生之處,因此若要比較這兩個剖析樹的成本大小,其實只要比較因為衝突所 造成的成本差異變化即可,亦即,採取移動策略所花的成本跟採取縮減策略所花 的成本相比較。 Figure 3.9: 含有移動策略的剖析樹 Figure 3.10 含有縮減策略的剖悉樹
從Figure 3.7 中的規則來看可以發現,採取移動策略的剖析樹會執行的是規 則(1)和規則(5),而採取縮減策略的剖析樹則會執行規則(2)、規則(3)和規則(4)。 Figure 3.11 就顯示這樣的資訊。因此我們就可以計算採取移動策略所會執行的規 則的總成本,以及採取縮減策略所會執行的規則的總成本,然後再做個比較,如 此就可以得知兩個剖析樹中誰的成本比較低。從此說明中可以發現,即使我們不 清楚那兩個剖析樹的總成本到底為何,但由於他們的差異僅存在於該shift/reduce 衝突所造成的部分,因此我們依然可以只計算採取移動策略和縮減策略所造成的 成本差異來做比較。
(1)iconst32IndexBOUNDS_CHECK ICONST_32 reg32
(5)arraySubscripticonst32Index
(a)含有移動策略的剖析樹會執行這些規則
(2)reg32ICONST_32