以圖文辨識為基礎的旅遊路線規劃輔助工具 - 政大學術集成
72
0
0
全文
(2) 以圖文辨識為基礎的旅遊路線規劃輔助工具 Tour Planning Using Landmark Photo Matching and Intelligent Character Recognition 研究生:黃政明 Student: Cheng-Ming Huang 主指導教授:廖文宏 Advisor: Wen-Hung Liao 副指導教授:陳聖智 Advisor: Sheng-Chih Chen. 政 治 大 立立國立政治大學 . •‧ 國. ㈻㊫學. 數位內容碩士學位學程 . •‧. n. a. er. io. A Thesis. sit. y. Nat. 碩士論文 . v. i l C in Digital Content submitted to Master’s Program & Technologies Un hengchi. National Chengchi University in partial fulfillment of the Requirements for the degree of Master in Master’s Program in Digital Content & Technologies 中華民國一百零一年七月 July 2012.
(3) 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. II. i Un. v.
(4) Abstract The roles of smart phones have extended from simple voice communications to multi-purpose applications. Smart phone equipped with miniaturized image capturing modules are now considered standard. Users can easily take pictures of interested objects, scenes or texts, and build their own image database. Travel-type mobile app is one example that takes advantage of the array of sensors on the device. A mobile image search engine can bring much convenience to tourists when they want to retrieve information regarding specific landmarks, buildings, or other 治 政objects.. 大 立立 However, devising an effective image recognition system for smart phone is a. •‧ 國. ㈻㊫學. quite challenging task due to the complexity of image search and pattern. •‧. recognition algorithms. Image recognition techniques that strike a balance. sit. y. Nat. between accuracy and efficiency need to be developed to cope with limited. er. io. resources on mobile platforms.. al. n. iv n C h e n gtocdesign Toward the above goal, this thesis seeks h i U effective mobile visual search and intelligent character recognition systems on mobile platforms. Specifically, we propose two global feature descriptors for efficient image search. We also develop an intelligent character recognition engine that can handle both printed and handwritten texts. Experimental results show that the accuracy reaches 80% for top-3 candidates in visual search and intelligent character recognition tasks.. Key words: mobile device, landmark photo matching, intelligent character recognition. III.
(5) 摘要 智慧型手機的用途已從語音溝通延伸轉變為多功能導向的的生活工具。目 前多數的智慧型手機均具備攝影鏡頭,而此模組更已被公認為基本的標準 配備。使用者透過手機,可以輕易且自然地拍攝感興趣的物體、景色或文 字等,並且建立屬於自己的影像資料庫。在眾多的手機軟體中,旅遊類的 程式是其中一種常見整合內容與多項感測模組的應用實例。在行動平台上, 設計一個影像辨識系統服務可以大幅地協助遊客們在旅途中去瞭解、認識. 政 治 大. 立立 知名的地標、建築物、或別具意義的物體與文字等。 . •‧ 國. ㈻㊫學. 然而在行動平台上的可用資源是有限的,因此想要在行動平台上開發有效. •‧ er. io. sit. y. Nat. 率的影像辨識系統,是頗具挑戰性的任務。如何在準確率與計算成本之間. n. 取得最佳的平衡點往往是行動平台上開發影像辨識技術的最重要課題。 a v. i l C hengchi Un. 根據上述的目標,本研究擬於行動平台上設計、開發行動影像搜尋與智慧 型文字辨識系統。具體而言,我們將在影像搜尋上整合兩個全域的特徵描 述子,並針對印刷與手寫字體去開發智慧型文字辨識系統。實驗結果顯示, 在行動影像搜尋與文字辨識的效能測試部分,前三名的辨識率皆可達到的 80%。 . 關鍵字: 行動裝置、地標辨識、智慧型文字辨識 IV.
(6) 誌謝 首先,我想由衷地感謝在我碩士生涯中最重要的恩師—廖文宏教授。亦師 亦友的廖老師是我能夠從死大學生轉變成正港”研究生”最重要的關鍵人 物,不僅僅是指導我研究,更是給予了我許多正確的人生價值觀、為人處 事的態度與大大小小的幫助,在此特別感謝。也感謝另一位恩師—陳聖智 教授。陳老師勤奮不懈的研究態度是我研究路上最好的榜樣。一路上碰到 許多困難關卡,陳老師大力的力挺與建議是我能夠一路過關的良師也是益. 政 治 大. 立立 友。政明相當幸運的能夠由兩位指導教授一路指導我的碩士論文,由衷地. •‧ 國. ㈻㊫學. 感謝兩位指導教授,沒有你們真的沒有今日的我。 . •‧ er. io. sit. y. Nat. 也感謝 VIPL 的夥伴們。首先要感謝仁和學長在研究路上的提攜與帶領。還. n. 有同梯的建堡與正和,我們之間不用太多話,心意相通就好(我也追上你們 a v. i l C hengchi Un. 了)。浩瑋、柏銘與冠智,能與你們一同研究十分有趣與開心。嘉瑜、致翔 和志毓,也期許你們未來的研究順利。數位內容的同學們,課程中跨領域 的合作經驗讓我印象深刻,期許未來的大家都能擁有一大片各自的天空。 還有,特別感謝張戎(我說話算話),我們從打拼研究所開始到現在,一路都 互相力挺到底,但互相力挺到底的戲碼仍舊會持續上演一輩子,是吧?也 要真心謝謝妳,妳的陪伴與鼓勵是我度過人生低潮時最重要的力量,謝謝。 . V.
(7) 最後,我要將我的碩士論文獻給我的家人們,你們的支持與陪伴是我成長 最大的動力。不管過去發生了哪些事,我們的心仍是緊緊相扣的。碩士生 涯的結束只是個逗號,未來的我會努力一直成為你們心中的驕傲。 政明 . 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. VI. i Un. v. 於台中 2012 年盛夏 .
(8) TABLE OF CONTENTS. 1.. Introduction ......................................................................................................................... 1. 2.. Related Work ...................................................................................................................... 6. 2.2.. Case Studies ...................................................................................................................... 18. •‧. y. sit. er. io. n. al Proposed Methodology ..................................................................................................... 25 iv 4.1. 4.2.. 4.3.. 5.. HuayuNavi .............................................................................................................. 18 iConference ............................................................................................................. 21. Nat. 3.1. 3.2. 4.. ㈻㊫學. 3.. Visual Search ............................................................................................................ 6 2.1.1. Content-based Image Retrieval on PC ....................................................... 6 2.1.2. Mobile Image Search ................................................................................. 7 2.1.3. Mobile Image Search Apps now ................................................................ 9 Intelligent Character Recognition ........................................................................... 12 2.2.1. Printed Character Recognition治 12 政 ................................................................. 大 2.2.2. Handwritten Character Recognition......................................................... 13 立立 2.2.3. Mobile Character Recognition and Apps ................................................. 15. •‧ 國. 2.1.. Un. C. hengchi System Flowchart ................................................................................................... 25 Image Descriptors ................................................................................................... 28 4.2.1. Weighted Gist Descriptor......................................................................... 29 4.2.2. Average ENN Descriptor ......................................................................... 32 4.2.3. Information Fusion ................................................................................... 33 Intelligent Character Recognition ........................................................................... 34 4.3.1. Feature Extraction .................................................................................... 34 4.3.2. Recognition .............................................................................................. 35. Performance Evaluation .................................................................................................... 38 5.1.. Data Collection ....................................................................................................... 38 5.1.1. Visual Search Dataset .............................................................................. 38 5.1.1.1.. Field Study .............................................................................. 38. VII.
(9) 5.2.. 6.. 5.1.1.2. Taiwan Landmark Image Set .................................................. 40 5.1.2. Intelligent Character Recognition Dataset ............................................... 41 Experimental Results .............................................................................................. 43 5.2.1. Visual Search ........................................................................................... 43 5.2.1.1. Different Parameters in ENN.................................................. 45 5.2.1.2. Comparison of Individual and Hybrid Approaches ................ 47 5.2.2. Intelligent Character Recognition ............................................................ 49 5.2.3. Routing Implementation on Mobile Platform .......................................... 49. Comparative Analysis ....................................................................................................... 51 6.1. 6.2. 6.3.. Benchmark Database – Oxford Buildings Dataset ................................................. 51 Experiments on Oxford Building Dataset............................................................... 52 Other Approaches on Oxford Dataset..................................................................... 53. 政 治 大. Conclusion and Future Work ............................................................................................ 55 立立. 8.. References ......................................................................................................................... 57. •‧. •‧ 國. ㈻㊫學. 7.. n. er. io. sit. y. Nat al. Ch. engchi. VIII. i Un. v.
(10) LIST OF FIGURES. Fig. 1-1: Snapshots of the Funtrip App ...................................................................................... 2 Fig. 1-2: Finding information in a tour book. ............................................................................ 3 Fig. 2-1: Mobile image search architecture ............................................................................... 8 Fig. 2-2: (a) Mobile Product Recognition (b) CD Cover Recognition (c) Book Spine Recognition (d) Paper Title Identification ............................................................ 10. 政 治. 大 Fig. 2-3: (a) Google Goggles (b) Amazon Flow ...................................................................... 11. 立立. •‧ 國. ㈻㊫學. Fig. 2-4: Well-structured text documents and the recognition results. .................................... 13. •‧. Fig. 2-5: (a) on-line handwriting on mobile phone; (b) postal code recognition ..................... 14. sit. y. Nat. Fig. 2-6: Enhancing recognition results by post-processing .................................................... 16. er. io. Fig. 3-1: HuayuNavi webpage ................................................................................................. 18. n. a. v. l C platform .......................................................... Fig. 3-2: System flowchart of the HuayuNavi 19 ni hengchi U. Fig. 3-3: The user interface of HuayuNavi .............................................................................. 20 Fig. 3-4: Snap shots of iConference ......................................................................................... 22 Fig. 3-5: iConference obtains query by swiping finger ........................................................... 23 Fig. 4-1: System flowchart ....................................................................................................... 26 Fig. 4-2: Computing the weighted gist descriptor ................................................................... 31 Fig. 4-3: Some examples of average ENN............................................................................... 33 Fig. 4-4: Feature extraction stage............................................................................................. 35 Fig. 4-5: Compute the probability of a vocabulary from recognition results .......................... 36 Fig. 5-1: Brochures .................................................................................................................. 39 I.
(11) Fig. 5-2: Statistics of travel brochures collected in the train station and at the airport ........... 39 Fig. 5-3: Images from the Taiwan landmark database ............................................................. 40 Fig. 5-4: Attraction distribution of Taiwan landmark database ............................................... 41 Fig. 5-5: Test data (a) generated by computer (b) real signboards .......................................... 42 Fig. 5-6: Six different Chinese fonts ........................................................................................ 43 Fig. 5-7: Generating more samples by adding noise, applying blur and resizing (a) Presidential Office (b) Yeh-Liu ............................................................................ 44 Fig. 5-8: Snapshots of routing implementation........................................................................ 50 Fig. 6-1: Images from Oxford benchmark ............................................................................... 52. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. II. i Un. v.
(12) LIST OF TABLES. Table 2-1: Evolution of character recognition ......................................................................... 13 Table 5-1: Test data information.............................................................................................. 42 Table 5-2: Recognition rate using Taiwan landmark dataset................................................... 44 Table 5-3: 4x4 blocks............................................................................................................... 45 Table 5-4: 8x8 blocks............................................................................................................... 46. 政 治. 大 Table 5-5: 16x16 blocks........................................................................................................... 46. 立立. •‧ 國. ㈻㊫學. Table 5-6: Comparison of individual and hybrid approaches .................................................. 48. •‧. Table 5-7: Comparison of computational complexity ............................................................. 48. sit. y. Nat. Table 5-8: Recognition of character recognition ..................................................................... 49. er. io. Table 6-1: Recognition rate using Oxford dataset ................................................................... 52. n. a. v. i scale of shape context in pixel, l C The parameters nare: Table 6-2: [36] results on Oxford dataset. hengchi U. number of segmentation in scale/angle ................................................................. 53 Table 6-3: [38] results under different methods on Oxford dataset. ........................................ 54. I.
(13) 1. Introduction. In the past, the main purpose of cellular phone is to communicate with each other via phone-calling or SMS. Simply speaking, cellular phone is a communication device at that time. However, in recent years, we have all witnessed the penetration of smartphones into our daily life. Today, smartphone not only serves as a communication device, but it also provides richer functionalities, such as location-based service (LBS), multimedia streaming and photo. 政 治. taking. With stronger computing power and new array of大 sensors, mobile devices are expected. 立立. •‧ 國. ㈻㊫學. to play increasingly important roles in modern life by integrating technology and contents in a. •‧. sensible manner. Such a new trend has driven the development of digital application. sit. y. Nat. distribution platforms such as Play Store of Google, App Store of Apple and Nokia Store of. n. al. er. io. Nokia. Millions of mobile applications are blooming by taking advantage of the versatile functions of smartphones.. Ch. engchi. i Un. v. Traveling-type mobile application is a good example of utilizing smartphone in our daily life. Funtrip [1] is one of the thirty thousand apps under the ‘Travel” category in Apple’s App store. This mobile app provides a set of customized traveling selections for travelers, ranging from general tourist information, art activities, fashion to food information. Funtrip also supplies a simple tour planning function. It starts by detecting current position using GPS. It then prompts the user to set the expected period of travel time and maximum travel distance. Finally, the App presents a basic tour plan and provides related traffic and weather information, as illustrated in Fig. 1-1.. 1.
(14) 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學 sit. y. Nat. n. al. er. io. Fig. 1-1: Snapshots of the Funtrip App. Ch. i. e. i Un. v. n g c h significantly to the island’s economy. Tourism in Taiwan is vibrant and contributes World-class natural scenes and innovative buildings in Taiwan have appealed to a great amount of foreigners. Additionally, foreign visitors also anticipate to explore and experience the cultural pluralism in Taiwan. According to the report released in 2011 by Taiwan Tourism Bureau[2], the number of visitor arrivals have been steadily increasing over the past ten years. To better serve citizens and tourists, free public Wi-Fi services have launched since June 2011[3]. It is relatively easy for foreign visitors to apply for a temporary account via online registration. The policy truly benefits foreign visitors and alleviates Internet addicts as well. With the abundance of attractions around Taiwan and free public Wi-Fi access in Taipei,. 2.
(15) government and private sectors have kicked off plans to enhance travel service and experience with the assistance of new technology. “Traveling with Cloud” [4] is a concept of improving traveling experience by integrating technology. With the convenience of cloud computing, people can search for critical traveling information such as weather forecast, traffic or hotel information before journey, and then look up or receiving instant message via mobile devices while on tour. After the trip, people can easily share their experiences or photos with friends by PC or mobile devices.. Developing user-friendly mobile guide tools for foreign visitors, especially for. 政this 治 non-Mandarin speaking visitors, seems, at moment, 大a very logical step. It is true that. 立立. brochures and tour books are freely distributed in many public places and tour information. •‧ 國. ㈻㊫學. offices in several popular languages, such as English and Japanese. But whatever the language. •‧. is, people seem to be more easily attracted by photos in a document filled with textual. y. Nat. er. io. sit. descriptions. It is often observed that foreign visitors plan their trip by referring to the photos. n. al of landmarks or tourist spots in a guidebook. To do so, they i v need to cross-reference between n U i e h n c the caption under the photo and the content, agdifficult practice since the keyword is often Ch. directly translated from Chinese, as illustrated in Fig. 1-2. The task becomes more challenging if we are to make arrangements for multiple locations.. Fig. 1-2: Finding information in a tour book.. 3.
(16) Smartphones are ready to address the aforementioned problems because of a number of important advances. First, camera phones have become commonplace, and real-time visual search on mobile devices is becoming a reality. Second, global positioning system (GPS) is now a standard component in most smartphones. Although GPS was placed on satellites in a high orbit and does not work well indoor, it can provide accurate location information and navigation guide in outdoor environments. In other words, we have the hardware and the infrastructure in place. The critical issues at hand are related to usability and performance. User experience on mobile platform usually dominates 治 one’s willingness to accept or deny a. 政. 大. 立立response time should be kept short. In order to achieve particular solution. For example, the. •‧ 國. ㈻㊫學. that goal, sometimes we have to trade accuracy for the sake of efficiency. With regard to. •‧. visual search, existing content-based image retrieval systems can usually achieve satisfactory. Nat. io. sit. y. results at the cost of computation resources. Robust and efficient visual search using mobile. n. al. er. devices, however, is a more challenging problem and is now being actively pursued by major corporations.. Ch. engchi. i Un. v. It is the objective of this thesis to devise and develop a mobile application to assist tour planning using recognition of landmark photos and the associated textual information, either printed or handwritten. The proposed solution is built upon two core technologies, namely, mobile visual search, and intelligent character recognition. Mobile visual search is employed to recognize the landmarks in a tour book, and focuses on robustness and efficiency. Intelligent character recognition is required to match texts that appear in a photo, a map or the description, with special emphasis on in-between printed and handwritten character recognition. After information regarding the desired destination has been successfully 4.
(17) collected, a recommendation of the route, along with materials of interest, will be forwarded to the user by our system.. The remainder of this thesis is organized as follows. In Chapter 2 we summarize the related work regarding visual search and intelligent character recognition. Visual search includes both conventional content-based image retrieval approaches on PC and image matching on mobile platforms. We then briefly discuss past and current developments on printed and handwritten character recognition techniques. Chapter 3 presents HuayuNavi and iConference: two projects I’ve participated in and the role I play, following by some. 政 治in the大proposed system. Chapter 4 outlines discussion of the core technologies to be employed. 立立. the system architecture first, then presents the core technologies, namely, visual search and. •‧ 國. ㈻㊫學. intelligent character recognition in a detailed manner. Chapter 5 discusses experimental. •‧. results and performance evaluation. First, we describe the two databases we have collected:. y. Nat. er. io. sit. Taiwan landmark dataset and Chinese character dataset. We then demonstrate and discuss. n. al experimental results in above two subjects under different settings. In Chapter 6, we introduce iv n U i e h n c a benchmark dataset and perform comparativeganalysis using different approaches. Finally, Ch. we conclude this thesis with a summary and outlook on future improvements in Chapter 7.. 5.
(18) 2. Related Work. As the main purpose of this thesis is to improve the tour planning experience through the integration of several technologies on a mobile platform, we will recap key concepts and briefly review related work in two areas, namely, visual search and intelligent character recognition. We will discuss existing approaches as well as recent developments regarding mobile applications in this chapter.. 立立. •‧. •‧ 國. Visual Search. ㈻㊫學. 2.1.. 政 治 大. sit. y. Nat. In contrast to keyword search, visual search aims to look for similar objects by. er. io. comparing their appearances. Content-based image retrieval systems have found success on. n. a. v. PC and thus provide many useful l directions when developing mobile solutions. In the ni C. hengchi U. following, we will start with the review of existing approaches on personnel computer and then move to more recent advances concerning mobile platforms. At last, we will summarize the current progress of mobile visual search using several applications as illustrations.. 2.1.1.. Content-based Image Retrieval on PC Content-based image retrieval (CBIR) is the application of computer vision to the. image retrieval problem. Visual features such as color, texture and shape or any other information that can be represented from the image itself, are “content” in the image. 6.
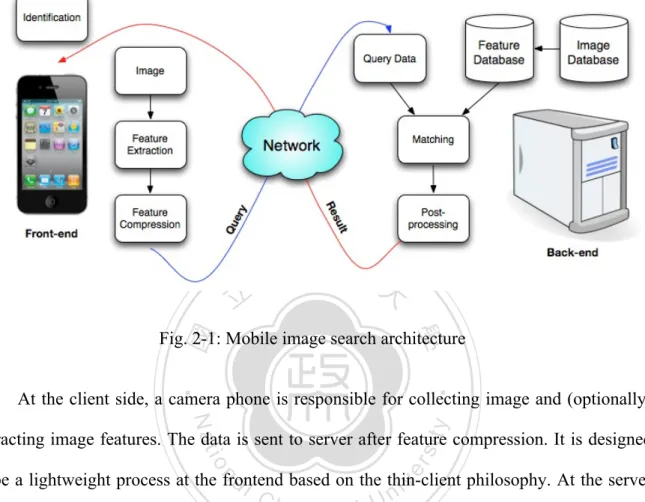
(19) In order to achieve good matching accuracy, most current content-based image retrieval systems employ a set of local features to describe the image structure. Scale invariant feature transform (SIFT)[5] is an well-known and quite robust descriptor in representing local features in image since it invariant to scale, orientation and partially invariant to affine distortion, but it requires substantial computational resources. Speeded up robust features (SURF)[6] is inspired by SIFT descriptor since SIFT is robust but slow to compute. Processing on personnel computer is not an issue due advanced processors and better computing power. In [7] , SIFT demonstrates its stability in most situations although it’s slow, SURF is faster but not as accurate as SIFT. Overall, SURF still yields acceptable performance in most circumstances.. 立立. 政 治 大. •‧ 國. ㈻㊫學. In contrast to specified local features, global features are designed to “summarize” the. •‧. structure of an image and usually require less computing resources than local features.. y. Nat. er. io. sit. However, recognition accuracy using local features usually outperforms global features.. n. a l systems employ ai vset of local features or pyramid Generally speaking, most current CBIR. n U i e h n c architectures by fusing local and global featuresgto achieve good recognition accuracy. Mobile Ch. visual search, on the other hand, is limited by computational resources and latency issue. The tradeoff between accuracy and efficiency is an important factor when designing a solution for mobile platforms.. 2.1.2.. Mobile Image Search Mobile image search has become an area of intensive research in the recent years. Due. to limited computing resources and usability concern, most mobile image search employs a. 7.
(20) client-server architecture, as illustrated in Fig. 2-1.. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. Fig. 2-1: Mobile image search architecture At the client side, a camera phone is responsible for collecting image and (optionally). y. Nat. er. io. sit. extracting image features. The data is sent to server after feature compression. It is designed. n. al to be a lightweight process at the frontend based on the thin-client philosophy. At the server iv n U i e h n c side, the system starts processing the received g query data by comparing them with the set of Ch. image descriptors built offline. The backend can be regarded as a service that is triggered when a new query arrives. The system typically employs distance measure to search for matches or best matches between the query data and database. Finally, post-processing can further be applied to refine the search result.. In this type of architecture, there are some challenging issues for current technological environments. First is the network latency problem. The authors of [8] discussed several compressing techniques to send effective information in order to reduce network bottleneck. 8.
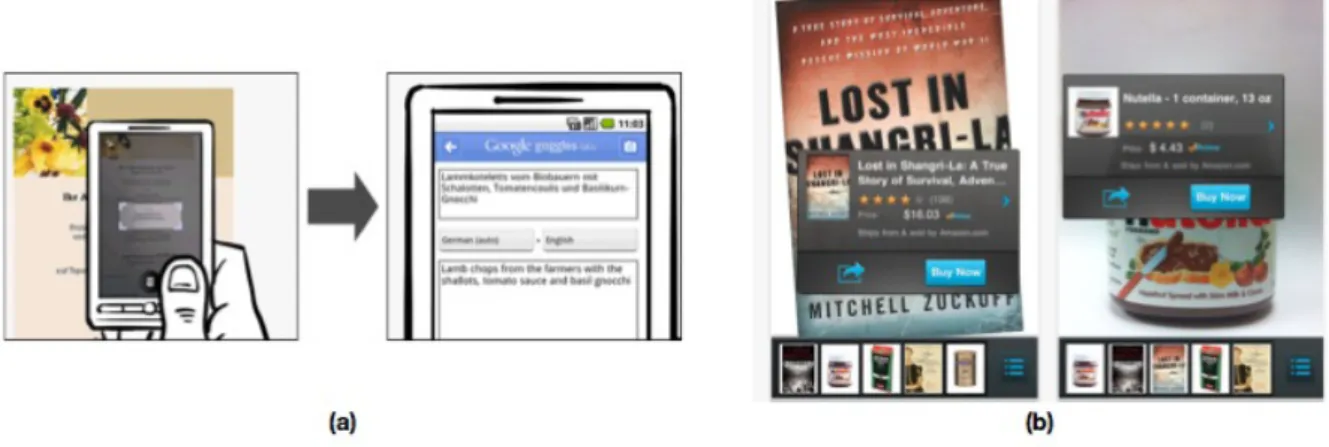
(21) for mobile image search application. Feature extraction also plays a crucial role in mobile image search. [9] compares different local feature performances, including CHoG and SIFT,descriptors on mobile image search, [10] also experiment with multiple local features in image search. In addition to the frontend, the backend system also needs to solve challenging problems because degradation or distortion in images will increase difficulties in the recognition task as well. [11] [12] propose novel matching algorithms and verification method. All of the above researches appeared in the past five years, a clear indication that mobile visual search is a new but vibrant research area that deserves continuing investigation.. 立立 now Mobile Image Search Apps. ㈻㊫學. •‧ 國. 2.1.3.. 政 治 大. •‧. Several researchers have developed novel and experimental application based on. sit. y. Nat. mobile visual search. [13] Implemented a mobile product recognition system that can. er. io. recognize products by snapping the camera phone and return corresponding product. n. a. v. information to the user. [14] reports al mobile application that n i can recognize CD covers. Some C. hengchi U. researchers try to combine visual and the associated textual information to further enhance the accuracy. For example, the app presented in [15] is designed to recognize book titles by snapping a photo of book spines on the bookshelf, a very handy tool for library and bookstore goers. The application discussed in [16] identifies the title of an academic paper by character recognition. Some examples are illustrated in Fig. 2-2.. 9.
(22) 立立. 政 治 大. •‧ 國. ㈻㊫學. •‧. Fig. 2-2: (a) Mobile Product Recognition (b) CD Cover Recognition (c) Book Spine Recognition (d) Paper Title Identification. io. sit. y. Nat. er. Aside from the above applications which are developed from researchers and. al. n. iv n C experimental, there are also other popularh mobile e n g cimage h i U search application in App stores. In the following, we will focus on two well-known mobile applications on the market, namely, Google Goggles[17] and Amazon Flow[18], as depicted Fig. 2-3.. 10.
(23) Fig. 2-3: (a) Google Goggles (b) Amazon Flow 1) Google Goggles: Released by Google in 2009, Google Goggles carries out the. 政 治. 大 devices. It allows users to get search based on the photo taken by mobile. 立立. •‧ 國. ㈻㊫學. information without traditional keyword-based approaches. However, its. •‧. performance can be poor if no specific object class is chosen. The quality of. sit. y. Nat. search varies depending on the type of object being checked. For best outcome,. er. io. the user needs to select a particular category from the list: landmarks, books,. n. a. l C info and wine. n i artwork, logos, texts, contact hengchi U. v. 2) Amazon Flow: In 2011, Amazon released an augmented-reality (AR) mobile application named Flow. Flow enables users to identify products and retrieve information from Amazon.com by simply ‘scanning’ the object of interest using camera phone. In addition to the millions of books, video games, DVDs and CDs from Amazon cover list, the application also recognizes the barcodes of all products available on Amazon.com. It is integrated with Amazon’s shopping cart so that the user can make purchase effortlessly.. 11.
(24) Apparently, Google Goggles and Flow are quite powerful mobile image search applications on the market. Both apps send query instance to the server via network, and return high quality search results using their effective cloud computing platforms. Our design is geared toward those who visit foreign countries and need instant and customized traveling information, such as tour planning, local information or weather forecasts.. 2.2.. Intelligent Character Recognition With the development of computer technology, the first character recognizer appeared. 政 治. in the middle of the 1940s [19]. After over seven大decades, technology for character. 立立. •‧. •‧ 國. ㈻㊫學. recognition has reached maturity, especially for printed and online handwritten characters.. Printed and handwritten texts are two different categories in Chinese character. y. Nat. er. io. sit. recognition. Early studies mostly focused on printed texts due to their good structure.. n. al Handwritten texts have structure deformations and shape ivariations so that the recognition v. n U i e h n c g In the following, we will briefly introduce rate is not as high as printed character recognition. Ch. the properties of printed and handwritten character recognition, respectively.. 2.2.1.. Printed Character Recognition Most researchers paid attention to the well-structured printed text in the beginning and. focused on Latin characters and numerals. Printed character recognition for English and Latin-based alphabets is considered mature nowadays (Fig. 2-4).. 12.
(25) 治 and the recognition results. Fig. 2-4: Well-structured text政 documents. 大. 立立. •‧ 國. ㈻㊫學. The earliest research on Chinese character recognition was reported in 1966 [20]. From. •‧. the literature, we observed that Chinese character recognition had become an intensive. sit. y. Nat. research around that time. However, as Chinese language contains a large set of characters. er. io. with complex structures, similar patterns, and different handwriting styles, the recognition. n. a. v. l C rate still leaves room for further improvement after four decades of continuous endeavor. ni hengchi U. 2.2.2.. Handwritten Character Recognition There are two categories in handwriting recognition, namely, online and offline. recognition. Online Chinese recognition started in mid-1960s [21] and offline recognition started in late 1970s (Table 2-1). Table 2-1: Evolution of character recognition Type Language. Printed. Handwriting. Off-line. On-line. 13. Off-line.
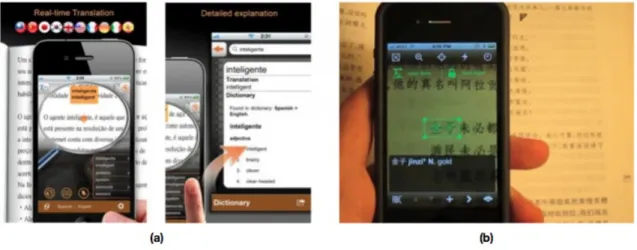
(26) Western. Middle 1940s. 1962. 1973. Chinese. 1966. 1966. Late 1970s. The online approach usually outperforms the offline method because it is able to acquire dynamic information such as the order, number, and direction of the strokes. But online recognition calls for special equipment to receive immediate feedbacks. In comparison, the offline recognition rate is lower than the online recognition due to the difficulty in getting all the information from the texts correctly. Depending on the hardware and application mode, online recognition equipment is mostly provided with pressure-sensitive functionality as commonly seen on PDA and smart phone. On the other hand, certain applications benefit. 政 治 大 from the offline recognition, such as postal address sorting, bank checks, and card reading. 立立. •‧ 國. ㈻㊫學. (Fig. 2-5) The aforementioned categories are attracting more and more researchers to keep. •‧. developing instrumental applications.. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 2-5: (a) on-line handwriting on mobile phone; (b) postal code recognition Aside from printed and handwritten character recognition, mixed-type content that contains both printed and handwritten characters are not seldom dealt with, the reason being 14.
(27) that the database will become huge since it has to cover both character datasets. Using the wrong model to perform recognition can result in unpredictable outcome. In practical situations, printed characters can be mixed together with handwritten texts. Therefore, intelligent character recognition with flexible features is anticipated in different applications, such as signboard or menu recognition.. With the recent development of China, the number of Chinese learners is increasing steadily. Application developers have started to put efforts in creating programs that utilize Chinese character recognition on mobile platforms. We will give a quick description of the. 治 mobile applications in the next section. 政 and status of mobile intelligent character recognition 大. 立立. Mobile Character Recognition and Apps. Nat. y. •‧. •‧ 國. ㈻㊫學. 2.2.3.. er. io. sit. Mobile learning is a topic that has received much attention thanks to the recent. n. a l Smart phone equipped advances of information technology. with intelligent character iv. n U i e h n c g in language learning. Worldictionary[22] recognition can be play an effective assistive role Ch. and Pleco[23](Fig. 2-6) are two noticeable examples of utilizing modern technology in optical character recognition.. 15.
(28) Fig. 2-6: Enhancing recognition results by post-processing. 治 政fundamental 1) Worldictionary: Following the 大principles in user interface design,. 立立. this App features a friendly interface that allows user to get instant translation. •‧ 國. ㈻㊫學. by pointing the camera phone at the text he or she wishes to look up. It is. •‧. reported to be able to recognize and translate more than ten languages, including. y. Nat. er. io. sit. Traditional Chinese, Simplified Chinese, English, Japanese, Korean and so on.. n. It also provides relatedainformation such as pronunciation. iv l. Ch. n engchi U. 2) Pleco: Similar to Worldictionary, Pleco works by moving the camera to a proper position in the text area to instantly look up its meaning. Pleco also provides associated information for users.. Both applications can retrieve learning materials instantly. However, according to their official description, they are confident of only printed or handwritten character recognition. Their system cannot handle mixed-type characters very well. Back to the objective of this thesis, we hope to devise an intelligent character recognition engine which can deal with most situations occurring in tour books. Since the text can be either printed or handwritten Chinese 16.
(29) characters, we have attempted to develop a solution that can handle mixed-type characters at the same time.. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. 17. i Un. v.
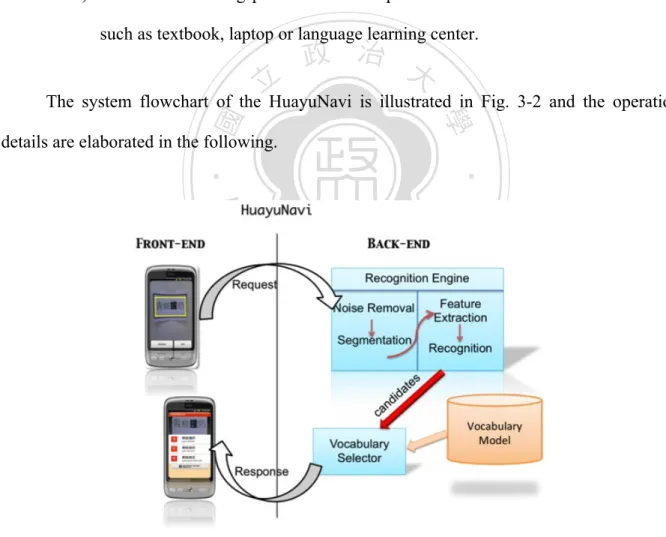
(30) 3. Case Studies. The proposed system aims to provide a mobile service for foreign tourists to plan their trips effectively and effortlessly. Since mobile applications are receiving much attention and experiencing rapid growth, we will study and analyze two use cases: HuayuNavi and iConference in this chapter, both of which I have been deeply involved in the past few months. We will then elucidate the key components of the proposed framework subsequently.. HuayuNavi. 立立. 政 治 大. ㈻㊫學. •‧ 國. 3.1.. The concepts of HuayuNavi are inspired by those who travel, work or study in the. •‧. environment of Chinese-speaking countries and have a need to understand Chinese. This. y. Nat. er. io. sit. application is designed to make Chinese learning easy for users who have never studied any. n. a l 3-1). Chinese lessons at all [24, 25](See Fig. Ch. engchi. i Un. v. Fig. 3-1: HuayuNavi webpage. 18.
(31) The motivation to design this product can be linked to three phenomena summarized as follows:. 1) Chinese is becoming a dominant language in the world.. 2) More foreigners visit Taiwan and want to explore Taiwanese culture in the past decade according to Taiwan Tourism Bureau.. 3) Traditional learning platforms are not portable and interactive simultaneously, such as textbook, laptop or language learning center.. 立立. 政 治 大. The system flowchart of the HuayuNavi is illustrated in Fig. 3-2 and the operation. •‧ 國. ㈻㊫學. details are elaborated in the following.. •‧. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 3-2: System flowchart of the HuayuNavi platform The interface of HuayuNavi allows users to take a picture and select a rectangular area 19.
(32) they want perform recognition on. In order to transmit the picture under limited bandwidth, the acquired image will be resized and compressed in advance. The interface also manages listening from the remote server and format the retrieved data to be user-readable. Of course, the user can also report problems caused by the program through the interface. The recognition engine is the core of the system. Once a picture is transmitted to the server, noise removal and segmentation are applied to clean up the image and extract a candidate region. Next, feature vectors will be extracted from the image and passed on to the classification stage. For each candidate character, its corresponding probability will be generated by the recognition engine and fed into the vocabulary selector component to search for the best. 政 治. 大 Through the cycle, a recognition matching term under domain-specific vocabulary models.. 立立. •‧. •‧ 國. ㈻㊫學. process is complete and waits for the next user request.. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 3-3: The user interface of HuayuNavi From the user’s point of view, designing an intuitive interface is a crucial part of our system, especially for foreigners. The easier and clearer the interface is, the better experience the user has. Fig. 3-3 depicts the system interface (from left to right) of the HuayuNavi application. The main menu (Fig. 3-3(a)) consists of 9 different subjects, including food, travel, position, art, culture, book, business, entertainment and landmark. Users can choose. 20.
(33) one subject he or she is interested in, e.g., in the food category. The user then takes the picture of a signboard (pearl milk drink in our example) using the camera phone. A rectangular box will appear and user can resize the box by moving the anchors. The user is advised to crop the desired area as accurate as possible in order to eliminate irrelevant content (Fig. 3-3 (c)). After cropping is finished, the recognition will start by clicking “OK” button. Top three candidates with English translation will be returned by the server and appear on the screen as shown in Fig. 3-3(d). Furthermore, the detailed explanation, pronunciation and phonetic spelling will be presented if user touches the corresponding buttons. The overall operation can finish within 3 seconds on average. We believe that a short response time is the key factor to keep users stick to this application.. •‧ 國. •‧. iConference. ㈻㊫學. 3.2.. 立立. 政 治 大. sit. y. Nat. er. io. iConference [26](Fig. 3-4) is a mobile augmented reality application designed to. n. a. v. l C facilitate social functions and ice-breaking among attendees in a conference using the ni hengchi U. combination of social networking, face recognition, intelligent character recognition and augmented reality technologies. Users are able to identify faces in the crowd and swipe name card using their mobile devices, after which they can obtain relevant user profile from social networking sites. The faces are tracked or name card are recognized and then information is overlaid on the screen.. 21.
(34) 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. io. sit. y. Nat. Fig. 3-4: Snap shots of iConference. er. In this project, my responsibility is name recognition and its user interface design.. al. n. iv n C U like most mobile image search h e n g c h ijust iConference follows a client-server architecture. applications, one reason being that it also requires substantial processing power on name recognition. The frontend captures an image and sends it to the remote server for recognition. In addition, iConference puts great attention on user interface and features an innovative way to capture query information (see Fig. 3-5).. 22.
(35) Fig. 3-5: iConference obtains query by swiping finger Fig. 3-5(a) depicts one scenario 政 attendee治might 大meet when they participate in a. 立立. conference: a name card left somewhere. In such common situations, one way to locate the. •‧ 國. ㈻㊫學. owner is to recognize his/her name first. Through recognition techniques, it is easy to obtain. •‧. er. io. sit. Nat. affiliations, nationalities, research interests, and publications.. y. the information that the attendee provides when registering for the conference, such as. al. n. iv n C h ecard In practice, the user picks up a name i Uhand and points the camera phone at n g by c hone the card with the other hand (Fig. 3-5(b)). The user then swipes one finger across the area of interest to define the query image (Fig. 3-5(c)). This is an intuitive way to obtain information from users. Technically speaking, it filters out unnecessary data. The recognition engine only needs to process the region specified by the user. Displaying the segmented region on the screen helps users to decide whether to modify the input if recognition result is not satisfactory. As the recognition engine, we employ the same framework adopted in the HuayuNavi project. The former database focuses on Chinese with mixed-type characters. The latter is concerned with English only. Therefore iConference usually returns better recognition. 23.
(36) results.. After surveying the HuayuNavi and iConference cases, we can observe that these services truly integrate intelligent character recognition with mobile application in a sensible way. Back to our problem, we are also concerned about offering an instrumental service based on mobile platform. But the objective is quite distinct. We wish to provide quick routing information for tourists while they search their destinations according to the information depicted in the travel guide. Hence, we will develop a recognition system that can recognize images or texts, depending on what type of information the travel guide provided. Next, we. 治 of the detailed processing steps. will introduce our system architecture and政 flow chart 大. 立立. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. 24. i Un. v.
(37) 4.. Proposed Methodology. In this research, we intend to propose a recognition system that can deal with image or character recognition on mobile platforms. This chapter introduces the proposed system flowchart first, and then presents the core methodologies we developed, including the descriptors for mobile visual search as well as character recognition in a detailed manner.. 4.1.. System Flowchart. 立立. 政 治 大. Following the common mobile recognition framework based on client-server. •‧ 國. ㈻㊫學. architecture, we design a system that captures query image or texts, and then returns the. •‧. recognition results at the client side, i.e., the smartphone. At the backend, the server initiates. y. Nat. n. al. er. io. illustrated in Fig. 4-1.. sit. different recognition engines based on the type of information sent from the client, as. Ch. engchi. 25. i Un. v.
(38) 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學 er. io. sit. y. Nat n. a l 4-1: System flowcharti v Fig. n Ch. engchi U. Frist, we will illustrate the role played by the client, including input and output. Next, we will briefly mention the core components of the backend server. Detailed information regarding feature representation, feature extraction and object recognition will be elucidated in the next section. •. Input at frontend:. 1) First, we will ask users to turn on GPS in order to detect user’s current location. The recorded location serves as the starting point in route planning.. 26.
(39) 2) There are two user modes to choose from, namely, mobile visual search and intelligent character recognition. Users should select the proper mode of operation before taking the photo. After that, the user can take interested picture such as landmark photo or textual information from tour books, travel brochures or photo-sharing websites.. 3) The camera phone must be registered with either Wi-Fi or 3G network in order to send the query to the remote server. •. Output at frontend:. 政 治 大. 立立. •‧ 國. ㈻㊫學. 4) Frontend will receive top-N ( N ≤ 5 in most cases) matches and the corresponding geographic information after the query. The App will display. •‧. multiple matching results to allow users to manually select the desired. sit. y. Nat. io. n. al. er. destination by themselves.. i Un. Ch. v. 5) After the user selects onee nlandmark g c h i photo from the candidates, the corresponding routing information will be presented. In other words, the navigation guide from the starting location (detected by GPS) to the final destination will be shown on the screen.. •. Image search at backend:. All feature extraction tasks for the images stored in the database can be carried out. 27.
(40) offline. It is therefore possible to build a recognition engine that responds in real time. After receiving the query image from the client, we normalize the image at first step, and then extract global features from the query data and prepare it for recognition. The output is a list of top-N matches. •. Character recognition at backend:. Similar to the visual search framework, we also extract all features from the vocabulary model offline to build a character recognition service with fast response. For the incoming query, noise removal is applied first, followed by image segmentation, feature extraction and. 政 治 大 recognition. Vocabulary selector picks 立立 top-N candidates eventually.. •‧ 國. ㈻㊫學. Simply speaking, the frontend is just an interface that is responsible for capturing the. •‧. input and presenting the recognition results. Backend process plays the crucial role of image. sit. y. Nat. io. 4.2.. al. n. next section.. er. and text recognition. The core recognition technologies we proposed will be discussed in the. Ch. engchi. i Un. v. Image Descriptors To strike a balance between efficiency and precision, this research attempts to combine. two global features, namely, weighted gist descriptor [27] and average effective number of neighbors (AENN) [28] to perform the image matching task. This section first introduces the motivation for assigning weights to the gist descriptor. The detailed process of computing the weight based on saliency measure will then be presented. Next, a novel global descriptor AENN will be defined. We will discuss the property and the type of image characteristic. 28.
(41) captured by this descriptor. We then show how this feature vector can be calculated and illustrate the process with examples. Finally, we discuss how to integrate the recognition results using mixture of these two global descriptors with a linear combination scheme.. 4.2.1.. Weighted Gist Descriptor Gist [29] is a low-dimensional representation of an image. It is designed to capture the. overall structure of the scene by partitioning the image into n × n blocks and computing the response using multi-scale oriented filters. The filtered image patch is represented using a k. 政 治. 大 n × n × k will be constructed by dimensional vector. Therefore, a gist descriptor of dimension. 立立. •‧ 國. ㈻㊫學. concatenating all vectors from the image blocks. For example, if the input image is partitioned. er. io. sit. y. Nat. feature will be 320.. •‧. into 4 × 4 blocks, and each block generates 20 coefficients, the dimension of the final gist. n. a l meaningful content Not all blocks in an image contain i v for matching. The original gist. n U i e h n c g descriptor, however, treats all image blocks equally. In order to assign more influence to Ch. image regions containing interesting features, we propose to incorporate saliency measure so that visually salient regions will play more important roles during the matching process. In [30], color, intensity and orientation have been identified to be important factors in attentional allocation. Similarly, graph-Based visual saliency [31] shows a remarkable consistency with the attentional development of human subjects through graphic theory to focus majority on activation maps using feature vectors. It also predicts human fixations and achieves 98% of the region-of-interest area of a human-based control. The term ‘gist’ is derived from spatial envelope [29], which provides a holistic description of the scene where global perceptual. 29.
(42) properties including naturalness, openness, roughness, ruggedness and expansion are extracted. Gist has been employed to classify scene categories by different spectral signatures, such as amplitude (which captures roughness) or orientation (which captures dominant edges). Our proposed modification associates weights with different blocks in the image according to the saliency measure so that blocks with higher saliency core will contribute more to the recognition process.. In our proposed framework, the saliency map of the input image is computed using the method described in [31].The input photo is then partitioned into 4x4 sub-images to prepare. 治score, which is the mean of the saliency for the extraction of gist descriptor. The政 saliency 大. 立立. measure in each sub-region, is utilized to weigh the contribution of the corresponding gist. •‧ 國. ㈻㊫學. descriptor. Unlike many previous works where the distance between two images are. •‧. computed using the sum-of-squared-difference (SSD) between gist descriptors, we fed the. y. Nat. n. al. er. io. possible matches.. sit. weighted gist descriptor to a modified support vector machine (SVM) to generate the list of. Ch. engchi. i Un. v. Fig. 4-2 summarizes the key steps of the proposed landmark photo matching algorithm. To begin with, the query image is scaled to 512x512 since both saliency map and gist descriptor depends on the layout (Fig. 4-2(a)). A graph-based visual saliency algorithm is applied to construct the saliency map and locate regions of interest (Fig. 4-2(b)). The image is then divided into 4x4 blocks. Each block is therefore of size 128x128. The saliency measure in each block is averaged to arrive at a single weight factor for that particular block (Fig. 4-2 (c)). Next, we compute the gist descriptor for each image block. We use 8 orientation channels at two different frequencies and 4 orientation channels at another frequency, totaling. 30.
(43) 20 coefficients for each block. The gist coefficients are concatenated to form a 320 dimensional feature vector. For color images, the dimension is increased to 960 as we will extract the gist features from R, G and B color channels, respectively (Fig. 4-2(d)). The concatenated gist vector is weighted according to the saliency score calculated in Fig. 4-2(c) to produce a weighted gist feature, which is then forwarded to the classifier based on support vector machine to perform the recognition (Fig. 4-2(e)).. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 4-2: Computing the weighted gist descriptor. 31.
(44) 4.2.2.. Average ENN Descriptor ENN defines a computationally effective approach to assess the sharpness of an image. so that images of poor focus can be identified. The basic idea is that well-focused images usually contain clearly defined edges and fine structures. Therefore, if we apply edge detector and retain the same amount of edges, we will get more strong and isolated peaks in the edge map for sharp images than those of the blurred images. As a result, if we retain a fixed percentage of the edge pixel, say q, and calculate the effective number of neighbors (ENN) for each edge point p with in a neighborhood (usually a D × D window) according to:. 治 政 I( p!) 大 (1) . ∑. ENN( p) =. 立立. p!∈N p , p!≠p. n. and. sit. io. al. er. Nat. d( p, p!) = x − x! + y − y! . y. •‧. •‧ 國. ㈻㊫學. where. d( p, p!). Ch. "$ 1, I( p!) = # %$ 0,. engchi. i Un. v. if p! is an edge pixel otherwise. . Then out-of-focus images will generally produce larger values of ENN because of the clustering phenomenon. Notice that denominator of Eq.1 is the Manhattan distance so that farther neighbors will get less weights, hence the term: effective number of neighbors.. Each edge pixel will generate an ENN value according to Eq.1. If we wish to examine the distribution of edges within a specific region, we can compute the average ENN for all. 32.
(45) edge pixels belonging to that region. According to our previous arguments, the smaller the average ENN is, the sharper the area. In a sense, the average ENN signifies the distribution of edge pixels in a certain image block, and can therefore be used to describe the overall structure of an image. Several examples of average ENN output are given in Fig. 4-3. For classification tasks, the average ENN from each image block is concatenated to form a feature vector, which is then forwarded to a probabilistic SVM to generate an ordered list of possible matches.. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 4-3: Some examples of average ENN. 4.2.3.. Information Fusion We have defined two global features in the previous subsections. To integrate. information obtained from these two modules, we adopt a late fusion principle. That is, we will get a list of probable matches with corresponding matching probabilities using each feature separately.. The final matching probability pm will be computed according to: 𝑝! = 𝛼×𝑝!"#$!!"#_!"#$ + (1 − 𝛼)×𝑝!"" (2) . 33.
(46) where α (0 ≤ α ≤ 1) is a parameter to adjust the contribution of each component.. Eq. (2) can be further modified to enable consensus check between two matching results. Whereas local features tend to complement each other, global features capture the overall structure and should generate consistent results if it is truly the best match. Therefore, we can check the difference between 𝑝!"#$!!"#_!"#$ and 𝑝!"" and if these two results are not consistent (meaning the difference is larger than a threshold δ), we should discount the final matching probability by an amount 𝑝!"!"#$%& .. 政 治 大. Intelligent Character Recognition. 立立. ㈻㊫學. •‧ 國. 4.3.. Intelligent character recognition refers to the processing and classification of. •‧. non-printed texts. In [25], we have surveyed and experimented with many character. y. Nat. er. io. sit. recognition algorithms and achieved certain level of success under some constraints. The. n. a l proposed route planning experience is readily applicable to the i v service. We will describe the n U i e h n c g in feature extraction and recognition. approach employed for robust character recognition Ch. 4.3.1.. Feature Extraction In order to balance the efficiency and accuracy, we adopted the framework proposed by. [32]and modified it to better suit our problem. The detailed steps of our algorithm are illustrated in Fig. 4-4.. 34.
(47) Fig. 4-4: Feature extraction stage For feature extraction, we divide the input image into 4 by 4 overlapped sub-regions. The percentage of overlapping is set to 50%. Each 治 sub-region is further divided into four. 政. 大. 立立 of gradient features are extracted from these four concentric rectangles. Then 16 orientations. •‧ 國. ㈻㊫學. concentric rectangles that are not overlapped with others. Consequently, a vector containing. •‧. 16-orientation gradient features is created by a weighted combination of the features from. Nat. io. sit. y. each of the concentric rectangle. The 16-orientation feature from each sub-region is. er. concatenated to form a feature vector of 256 dimensions. This can increase the robustness in. al. n. iv n C U feature extraction if the input character is h deformed e n g c hori skewed.. 4.3.2.. Recognition We adopted support vector machine (SVM) to train and classify the training and testing. instances. The problem can be viewed as N-category classification, where N is the number of distinct classes of characters. The benefit of SVM is that the recognition model can be built in advance, i.e., the model can be trained in off-line. The recognition engine can execute efficiently because it is simply a process of finding which hyperspace the feature vector is. 35.
(48) located. However, SVM usually returns only the best match. In our work, we wish to retrieve top k matches so that domain-specific knowledge can be incorporated with the vocabulary selector component to further improve the accuracy. As reported in [33], it is possible to record the likelihood information between every category when building the SVM model. Therefore, generation of top candidates become feasible and the probability from each candidate can be taken into consideration to increase the confidence of matching in the later stage.. The result from the recognition stage is a list of candidates along with the probabilities. 治 stage, the goal is to search for the most 政selector for each character image. In the vocabulary 大. 立立. proper term through different combination of candidates of every character image (Fig. 4-5).. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 4-5: Compute the probability of a vocabulary from recognition results This process can increase the matching confidence if only certain portion of the character images were recognized properly. To address the issue, we adopt a conservative but efficient way to collect Chinese terms belonging to the category to form a domain-specific vocabulary model. In other words, we will have different vocabulary models for different scenarios, e.g., Taiwanese snacks in our preliminary study. When searching for the most. 36.
(49) proper term, user has to assign the desired domain in advance. Once the recognition engine stage is complete, the list of candidates along with the probabilities for each character image will be used to calculate the score of terms which appear in the vocabulary model. Note that the term must exist in the repository. Here a term’s score is defined by adding together the corresponding candidate’s probability from each character image. For example, if there is a recognition result with a length of 4 characters as depicted in Fig. 4-5, the proposed vocabulary selector will use the candidates’ probabilities to compute the scores for all the terms with the same length within a specific model exhaustively. The one with the highest score is the best answer for this request. In general, only terms with length the same to the. 政 治. 大 range such as plus/minus one in number of character images will be considered. Flexible. 立立. •‧ 國. ㈻㊫學. length is more computation-demanding, but can compensate for the error made in the. •‧. segmentation stage. It is possible to replace the current scoring mechanism with other. sit. y. Nat. approaches. For example, ranking strategy is a strategy that makes use of the ranking (or order). er. io. to substitute the candidates’ probabilities. Thus, the lower the score is, the more ideal the term. n. a. v. is. A hybrid approach, in which onlyl top-N C candidates forn ieach character image are included. hengchi U. in the score accumulation, has also been considered. This can avoid a lot of candidates with very small likelihoods.. 37.
(50) 5. Performance Evaluation. To evaluate the performance of the proposed recognition systems, we conduct experiments using publicly available benchmark data as well as dataset we collected. In this chapter, we first provide a general description of the data. We then report the results of testing the proposed algorithms using these datasets.. 立立. Data Collection. ㈻㊫學. •‧ 國. 5.1.. 政 治 大. •‧. We collected two datasets for visual search and character recognition, respectively.. sit. n. al. er. io. 5.1.1.. Visual Search Dataset. y. Nat. Further details are provided in the following subsections.. Ch. engchi. i Un. v. In the area of mobile location recognition, [34] put great efforts in pushing the research forward by publishing extensive datasets. The authors focused on scenes in the San Francisco area. Along a similar line, we build our dataset using images of popular Taiwan landmarks.. 5.1.1.1.. Field Study. In order to observe possible image sources that those foreign visitors might confront once reaching Taiwan, we conducted a quick field study by collecting brochures from two 38.
(51) important traffic pivots, namely, Taipei Main Station and Taiwan Taoyuan International Airport (Fig. 5-1). We gathered 88 brochures from the train station and 71 brochures from airport. To identify the distribution of public attractions in Taiwan, we classify these brochures by counties, as illustrated Fig. 5-2.. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. al. er. io. sit. y. Nat. Fig. 5-1: Brochures. Ch. engchi. i Un. v. Fig. 5-2: Statistics of travel brochures collected in the train station and at the airport In the train station, over fifty percent of the brochures introduce Taipei’s attractions. The free travel booklets distributed at the airport cover more cities and counties. This result is 39.
(52) instrumental to us in collecting experimental materials.. 5.1.1.2.. Taiwan Landmark Image Set. Our target users are likely to visit more than one area or county during their stay in Taiwan. Therefore, the strategy we have taken here is to collect famous tourist destination around the island by referencing to the official website of Taiwan Tourism Bureau, as shown in Fig. 5-3:. 立立. 政 治 大. •‧. •‧ 國. ㈻㊫學. n. er. io. sit. y. Nat al. Ch. engchi. i Un. v. Fig. 5-3: Images from the Taiwan landmark database Based on the above guideline, we collect popular landmarks from tour books, travel brochures, official websites and photo-sharing networks. A total of 9530 images from 50 landmarks have been gathered. The dataset cover all major areas in Taiwan (refer to Fig. 5-4). On average, each landmark contains 190 images.. 40.
(53) Fig. 5-4: Attraction distribution of Taiwan landmark database •. Test dataset:. We randomly select 20 images from each category to form the test set. Training dataset:. 立立. ㈻㊫學. •‧ 國. •. 政 治 大. The remaining 8530 images are used to train the support vector machine using mixture. •‧. of weighted gist and average ENN features.. n. er. io. sit. y. Nat al. 5.1.2.. Ch Intelligent Character Recognition Dataset Un engchi. iv. In a typical pattern recognition problem based on supervised learning technique, two separate datasets are required, namely, training dataset and test dataset. Training dataset is used to train a model so that when testing dataset is ready to be recognized, the classifier can calculate the similarity between the training and testing dataset and report the classification result. Following is the training and testing dataset we adopted. •. Test dataset:. We have collected 100 character images. 60 are generated by computer and 40 are. 41.
(54) taken from real signboards (Fig. 5-5). After pruning redundant characters, a total of 326 distinct characters have been recorded.. 立立. 政 治 大. •‧ 國. ㈻㊫學. Fig. 5-5: Test data (a) generated by computer (b) real signboards. n. al. Ch. 40. engchi. sit. Real Signboard. er. io. •. y. Nat. Independently Generated by Computer 60. •‧. Table 5-1: Test data information. i Un. v. Number of Instances 100. Training dataset:. We include 945 words in the training dataset initially. These words are related to the night market topic. After pruning redundant characters, the dataset contains 612 distinct Chinese characters.. For each character, we include six different fonts (Fig. 5-6) to increase the number of training samples.. Five versions with different rotation angles with/without noise are. considered. Since there are sixty variations (6*5*2) for each character, the total number of. 42.
(55) samples in the training set is increased to 36720.. Fig. 5-6: Six different Chinese fonts. Experimental Results. 立立. 政 治 大. ㈻㊫學. •‧ 國. 5.2.. In this section, we will evaluate the performance of visual search and intelligent. •‧. character recognition based on dataset we mentioned previously. At the end, we will give a. y. Nat. n. er. io. al. sit. quick demonstration of the routing information.. 5.2.1.. Visual Search. Ch. engchi. i Un. v. A total of 9530 images from 50 landmarks have been experimented. On average, each landmark contains 190 images. We randomly select 20 images from each category to form the test set. The remaining 8530 images are used to train the support vector machine using mixture of weighted gist and average ENN features. It is possible to expand the database by adding different levels of noise, applying Gaussian blur or scaling, as shown in Fig. 5-7.. 43.
(56) Fig. 5-7: Generating more samples by adding noise, applying blur and resizing (a) Presidential Office (b) Yeh-Liu For weighted gist descriptor, we compute the vector from R, G, and B channels separately. A total of 960 dimensions are used in the weighted gist representation. For average. 政will 治 ENN, parameter selection is important. We discuss大experimental results using different. 立立. parameter settings in section 5.2.1.1. Here, we first partition the input image into 8×8 blocks,. •‧ 國. ㈻㊫學. thereby generating a feature vector of 64 dimensions. The percentage of edge retained (q) is. •‧. set to 10%. Neighborhood for computing the effective numbers of neighbors is set to 7×7.. y. Nat. er. io. sit. The results are summarized in Table 5-2 using different linear combinations of 𝑝!"#$!!"#_!"#$. n. al and 𝑝!"" . It turns out that 𝑝!"#$!!"#_!"#$ plays a more important role during the matching iv n U i e h n c process. However, the overall accuracy doesgimprove if results from both modules are Ch. integrated. The recognition rate is comparable to the results reported in previous research articles, with top matches approaching 66% and top 3 matches near 80%. Table 5-2: Recognition rate using Taiwan landmark dataset Accuracy Partition 8x8. Neighborhood size 7x7. Α. Top1. Top3. Top5. Top10. 0.5 0.6 0.7. 0.65 0.66 0.659. 0.773 0.778 0.795. 0.823 0.83 0.844. 0.909 0.914 0.917. 0.8 0.9. 0.655 0.652. 0.799 0.798. 0.849 0.85. 0.923 0.92. 44.
(57) 5.2.1.1.. Setting Different Parameters in ENN. In the previous section, we partition the input image into 8×8 blocks and compute the effective number of neighbors using a 7×7 window to obtain the matching results shown in Table 5-2. However, different numbers of blocks will result in different feature dimensions. For example, 16 dimensions for 4×4 blocks and 256 dimensions for 16×16 blocks. The size of neighborhood for calculating ENN will also have direct impact on the estimated value and computation time as well. Parameter selection is therefore a crucial factor in evaluating recognition accuracy and efficiency.. 政 治 大. 立立 parameter settings in attempt to obtain a proper We experiment with different. •‧ 國. ㈻㊫學. combination. Table 5-3 to Table 5-5 summarize the results by choosing different block size. y 0.654. e n 0.653 gchi. sit. 7x7. Top1. Top3. Top5. Top10. v0.785. 0.832. 0.897. er. 4x4. α. a l0.5 0.6C h. n. Neighborhood size. io. Partition. Nat. Table 5-3: 4x4 blocks. •‧. and neighborhood size.. i Un. 0.788. 0.836. 0.903. 0.651. 0.796. 0.847. 0.91. 0.8. 0.65. 0.792. 0.849. 0.915. 0.9. 0.645. 0.797. 0.848. 0.915. 0.7. α. Top1. Top3. Top5. Top10. 0.5. 0.651. 0.779. 0.832. 0.897. 0.6. 0.655. 0.791. 0.835. 0.907. 0.7. 0.652. 0.796. 0.846. 0.91. 0.8. 0.649. 0.795. 0.848. 0.85. 0.9. 0.645. 0.797. 0.85. 0.917. Neighborhood size. α. Top1. Top3. Top5. Top10. 15x15. 0.5. 0.645. 0.76. 0.822. 0.893. 0.6. 0.651. 0.779. 0.834. 0.899. 0.7. 0.653. 0.791. 0.84. 0.905. 0.8. 0.651. 0.791. 0.85. 0.851. 0.9. 0.645. 0.795. 0.851. 0.916. 11x11 Neighborhood size. 45.
(58) Table 5-4: 8x8 blocks Partition. Neighborhood size. α. Top1. Top3. Top5. Top10. 8x8. 7x7. 0.5 0.6. 0.64. 0.77. 0.822. 0.898. 0.65. 0.775. 0.844. 0.907. 0.7. 0.657. 0.78. 0.851. 0.909. 0.8. 0.657. 0.791. 0.846. 0.912. 0.9. 0.648. 0.798. 0.85. 0.915. Neighborhood size. α. Top1. Top3. Top5. Top10. 11x11. 0.5. 0.642. 0.767. 0.822. 0.898. 0.6. 0.65. 0.776. 0.842. 0.901. 0.7. 0.656. 0.78. 0.853. 0.907. 0.8. 0.655. 0.788. 0.848. 0.913. 0.9. 0.649. 0.797. 0.851. 0.915. Neighborhood size. α. Top1. Top3. Top5. Top10. 15x15. 0.5. 0.642. 0.767. 0.824. 0.89. 0.775. 0.84. 0.902. 0.783. 0.854. 0.905. 0.6. 立立. 0.8. 0.655. 0.79. 0.849. 0.913. 0.9. 0.649. ㈻㊫學. 0.85. 0.916. 0.797. •‧. Table 5-5: 16x16 blocks. •‧ 國. 0.7. 治 政 0.642 大 0.654. α. Top1. Top3. Top5. Top10. 7x7. 0.5. 0.65. 0.766. 0.825. 0.894. 0.6. 0.661. 0.779. 0.831. 0.896. v0.782. 0.845. 0.905. 0.79. 0.849. 0.91. 0.796. 0.851. 0.916. n. 0.9. 0.658 0.651. e n 0.648 gchi. sit. er. io. a l0.7 0.8C h. y. Neighborhood size. 16x16. Nat. Partition. i Un. Neighborhood size. α. Top1. Top3. Top5. Top10. 11x11. 0.5. 0.648. 0.766. 0.824. 0.895. 0.6. 0.661. 0.777. 0.832. 0.898. 0.7. 0.653. 0.785. 0.844. 0.904. 0.8. 0.65. 0.787. 0.849. 0.908. 0.9. 0.648. 0.795. 0.851. 0.916. Neighborhood size. α. Top1. Top3. Top5. Top10. 15x15. 0.5. 0.652. 0.768. 0.828. 0.894. 0.6. 0.659. 0.781. 0.834. 0.898. 0.7. 0.655. 0.787. 0.844. 0.904. 0.8. 0.65. 0.788. 0.851. 0.908. 0.9. 0.648. 0.794. 0.851. 0.913. Refer to Table 5-3 to Table 5-5 we can observe that the largest difference in Top10. 46.
(59) results is about 2 percent. According to these results and consider computation resources simultaneously, we decide to set the partition to 8×8 and neighborhood size to 7×7.. 5.2.1.2.. Comparison of Individual and Hybrid Approaches. In this research, we not only use weighted gist in combination with the average ENN descriptor, but also utilize separate descriptors and different combinations to evaluate the performance. Specifically, we have experimented with QC distance, which was proposed in [35]. Chi-square distance is sensitive to quantization effects, such as lighting variants or shape. 政 治. deformations. Thus, Quadratic-Chi takes into account大cross-bin relationship and tries to. 立立. •‧ 國. ㈻㊫學. alleviate the quantization problem. Also, its computation time is linear in the number of. •‧. non-zero entries in the bin-similarity matrix. Results are summarized in Table 5-6.. n. er. io. sit. y. Nat al. Ch. engchi. 47. i Un. v.
數據



+7



相關文件
/** Class invariant: A Person always has a date of birth, and if the Person has a date of death, then the date of death is equal to or later than the date of birth. To be
To convert a string containing floating-point digits to its floating-point value, use the static parseDouble method of the Double class..
This objective of this research is to develop water based sol-gel process to apply a protective coating on both optical molds and glass performs, which can effectively prevent glass
The objective of the present paper is to develop a simulation model that effectively predicts the dynamic behaviors of a wind hydrogen system that comprises subsystems
Along with this process, a critical component that must be realized in order to assist management in determining knowledge objective and strategies is the assessment of
The objective of this study is to analyze the population and employment of Taichung metropolitan area by economic-based analysis to provide for government
The purpose of this thesis is to propose a model of routes design for the intra-network of fixed-route trucking carriers, named as the Mixed Hub-and-Spoke
The purpose of this thesis is to investigate the geometric design of curvic couplings and their formate grinding wheel selection, and discuss the geometric
