整合R與Hadoop/MapReduce來分析FOAF社群網路 - 政大學術集成
59
0
0
全文
(2) 整合 R 與 Hadoop/MapReduce 來分析 FOAF 社群網路 Using R and Hadoop/MapReduce for FOAF-based Social Network Analytics 研 究 生:孫肇祥. Student:Jhao-Siang Sun. 指導教授:胡毓忠. Advisor:Yuh-Jong Hu. 資訊科學系 碩士論文. 學 ‧. ‧ 國. 立. 政 治 大 國立政治大學. y. Nat. n. er. io. sit. A Thesis submitted to Department of Computer Science al v i National Chengchi University n Ch U i e h n c g in partial fulfillment of the Requirements for the degree of Master in Computer Science. 中華民國一百零三年七月 July 2014.
(3) 整合 R 與 Hadoop/MapReduce 來分析 FOAF 社群網路 摘要 分散式線上社群網路採用 RDF(S)為基礎的 FOAF 格式於信任的第三方 Hadoop cluster 來儲存個人資料與其社群網絡。面臨大量的社群網路資料,傳統的分析方式將 會遇到許多處理與儲存的問題。本研究透過結合 R 與 Hadoop/MapReduce 技術,提出三 種分析方式:R + Hadoop Streaming(RHS),R + MySQL(RMS),R + Hive(RH)來解決分析 大量 FOAF 資料運算與儲存的瓶頸。我們首先將 FOAF 資料集注入 Hadoop cluster 平台. 政 治 大. 並利用 MapReduce 的分散式運算,預先消化大部分的資料以解決 R 統計軟體單機記憶體 不足以應付大型檔案的問題,透過後續 R 的分析我們也同時解決 MapReduce 運算無法進. 立. 行深層社群網路分析的問題。透過預先拆解的方式以可以處理更大的 FOAF 資料使其更. ‧ 國. 學. 有延展性。這個方法可以適用於非結構化或結構化資料。面對每日激增的社群網路資料, 如何更進一步的結合 R 與 Hadoop/MapReduce,並 使用 HBase 或是與既有 R 的平行化軟. ‧. 體作結合,也是日後可以努力研究的方向。. y. Nat. n. al. er. io. 分析. sit. 關鍵字:RDF(S)、R and Hadoop/MapReduce、FOAF、Hadoop、MapReduce、社群網路. Ch. engchi. i. i n U. v.
(4) Using R and Hadoop/MapReduce for FOAF-based Social Network Analytics Abstract The decentralized online social networks are encoded as RDF(S)-based FOAF data format. These FOAF datasets, stored on the trusted Hadoop cluster, are used to represent Web users’ personal data and their social relationships. When using traditional data analysis. 政 治 大 three R and Hadoop/MapReduce 立 integration techniques for high volume FOAF data analysis, techniques, we face numerous data processing and storing challenges. In this study, we apply. ‧ 國. 學. including R + Hadoop Streaming (RHS), R + MySQL (RMS), and R + Hive (RH). We first. ingest the FOAF datasets and pre-process these datasets through the MapReduce distributed programming paradigm. Then, apply R for FOAF data analysis. This resolves the major. ‧. problems of impossibly reading high volume of big FOAF data into memory for R analysis. y. Nat. and the limitation of social network analysis by using MapReduce computation. High volume. sit. of FOAF datasets can be distributed and stored effectively in the Hadoop platform for. er. io. scalable data processing. The R + Hadoop/MapReduce techniques can be used for analysis on. al. n. v i n Ch U the HBase or parallel R effectively integrate R and Hadoop/MapReduce e n g cand h ileverage. the structured and unstructured data. In the future study, the research issues will be on how to programming for high volume big data analytics.. Keyword:FOAF、Hadoop、MapReduce、Social network analytics. ii.
(5) 致謝 研究所這些年來,首先感謝胡毓忠教授的指導,提供論文研究具體的建議與方向, 讓我能夠順利的完成論文。另外謝謝兩位口試委員葉慶隆與徐國偉教授的意見,提高我 研究論文的完整性。再來是 ENT 實驗室的濟謙與元昊學弟,提供實驗相關的經驗分享, 讓我節省寶貴的時間。同時感謝文友與宗哲口試當天的協助,讓我能專心的準備口試的 工作。再來是系辦的熊助教,謝謝你詳細的說明相關流程與快速的辦事效率。還有我也 要感謝工作上的夥伴秋霖給我寶貴的建議。 最後感謝家人的背後支持,特別是媽媽與靜怡,撰寫論文的這段日子,例假日幾乎. 政 治 大. 都埋首研究,無法陪伴你們,在經過不斷的努力奮鬥後,總算完成艱難的論文寫作。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iii. i n U. v.
(6) 目錄 摘要 ............................................................................................................................................. i Abstract....................................................................................................................................... ii 致謝 ........................................................................................................................................... iii 第一章 導論 . ........................................................................................................................... 1 1.1 研究動機 ......................................................................................................................... 1 1.2 研究目的 ......................................................................................................................... 1. 政 治 大. 1.3 各章節敘述 ..................................................................................................................... 2. 立. 第二章 研究背景 ...................................................................................................................... 3. ‧ 國. 學. 2.1 Hadoop ............................................................................................................................. 3. ‧. 2.2 Hive ................................................................................................................................... 4 2.3 R ........................................................................................................................................ 6. Nat. sit. y. 第三章 相關研究 ...................................................................................................................... 8. n. al. er. io. 3.1 FOAF(Friend of A Friend) .................................................................................................. 8. i n U. v. 3.2 社會網路分析(Social Network Analysis,SNA) ............................................................ 10. Ch. engchi. 3.3 R 與 Hadoop 的整合 ...................................................................................................... 13 3.3.1 RHadoop .................................................................................................................. 13 3.3.2 RHIPE ....................................................................................................................... 15 3.3.3 Hadoop Streaming ................................................................................................... 17 第四章 方法架構設計 ............................................................................................................ 20 4.1 研究架構 ....................................................................................................................... 20 4.2 FOAF 分析....................................................................................................................... 21 4.2.1 R+Hadoop Streaming 分析(RHS Analytics) ............................................................. 21 4.2.2 R+MySQL 分析(RMS Analytics) ............................................................................... 23 4.2.3 R+Hive 分析(RH Analytics) ...................................................................................... 26 iv.
(7) 第五章 系統實作 .................................................................................................................... 30 5.1 系統架構 ....................................................................................................................... 30 5.2 資料來源 ....................................................................................................................... 32 5.3 FOAF 資料分析............................................................................................................... 33 5.3.1 R+Hadoop Streaming 分析(RHS Analytics) ............................................................. 33 5.3.2 R+MySQL 分析(RMS Analytics) ............................................................................... 39 5.3.3 R+Hive 分析(RH Analytics) ...................................................................................... 40 5.3.4 效能分析比較 ........................................................................................................ 44. 政 治 大. 第六章 結論與未來展望 ........................................................................................................ 46. 立. 參考文獻 .................................................................................................................................. 48. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. v. i n U. v.
(8) 圖目錄 圖 1:Hadoop ecosystem .......................................................................................... 4 圖 2:Hive 架構圖 ................................................................................................... 5 圖 3:R 使用介面圖:Console(上)與 RStudio(下) ................................................... 7 圖 4:研究架構圖 .................................................................................................. 20 圖 5:R+Hadoop Streaming 分析(RHS Analytics)架構圖.................................... 21 圖 6:使用 MapReduce 分析 FOAF 關鍵字........................................................ 22. 治 政 大 圖 8:R+Hive 分析(RH Analytics)架構圖 ............................................................ 26 立 圖 9:本研究系統實作架構圖 .............................................................................. 30. 圖 7:R+MySQL 分析(RMS Analytics)架構圖 .................................................... 23. ‧ 國. 學. 圖 10:本研究系統實作流程圖 ............................................................................ 31 圖 11:Hadoop cluster 狀態 ................................................................................... 32. ‧. 圖 12:N-Quads Example ...................................................................................... 32. sit. y. Nat. 圖 13:本研究系統資料容量 ................................................................................ 33. io. er. 圖 14:使用小量資料驗證 Hadoop Streaming 分析的正確性 ............................ 35 圖 15:R+MySQL 分析(RMS Analytics)使用時間與讀取資料量 ...................... 36. n. al. Ch. i n U. v. 圖 16:Degree(最大為黃色圓圈)關係圖 .............................................................. 39. engchi. 圖 17:Degree distribution 圖 ................................................................................. 40 圖 18:Culster size 圖 ............................................................................................. 40 圖 19:Degree Centrality(最大值為右下角黃色圓圈) ......................................... 42 圖 20:betweenness(最大值為右下角紅色圓圈) ................................................. 42 圖 21:closeness(最大值為中間偏右綠色圓圈) .................................................. 43 圖 22:evcent(最大值為右下棕色圓圈) ............................................................... 43 圖 23:MySQL 與 Hive 效能圖 ............................................................................ 45. vi.
(9) 表目錄 表 1:FOAF 主要字彙 ............................................................................................ 10 表 2 :R Function Reference of RHIPE .................................................................... 15 表 3 :R 與 Hadoop 整合技術比較表 ...................................................................... 19 表 4:本研究三種分析方式比較 .......................................................................... 29 表 5:本研究系統實作規格 .................................................................................. 31 表 6:R+Hadoop Streaming 分析 FOAF Vocabulary 使用頻率-前 30 名 ........... 37. 政 治 大. 表 7 : MySQL 與 Hive 效能比較表 ....................................................................... 44. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vii. i n U. v.
(10) 第一章 導論 . 1.1. 研究動機. 社群網路活動是現代的網路使用者日常生活中很重要的一部分,Facebook、Twitter 和 Flicker 等網站擁有數百萬用戶,這些社群網路記錄使用者的朋友資訊、分享的相片、 發表的文章與其他資料,這些紀錄都保留在社群網站,使用者無法完全掌控自己的資料。 集中式架構網站形成資訊孤島(information silos),使用者不容易控制自己的個人資料如. 政 治 大. 何被利用,除了容易導致潛在的隱私問題之外,當使用者橫跨不同的社群網路,使用者. 立. 的資料也無法重複利用。基於上述的考量,分散式社群網路的架構逐漸受到注意[35]。. ‧ 國. 學. 分散式網路使用 TLS 通訊協定,個人資料結構為 FOAF[33]格式,最後將 FOAF 存放於 信任的第三方 Hadoop cluster。. ‧. Hadoop[1] MapReduce[7]架構雖然能處理大量的資料,但是僅適合做簡單的統計分. y. Nat. 析;R[34]程式本身擁有豐富的資料分析能力與擴充功能,分析運算時將資料全部放到. io. sit. 記憶體,無論是受限硬體規格或是作業系統(32/64 位元)及本身 R(32/64 位元)對於記憶. n. al. er. 體容量的限制,R 無法有效直接處理大量的資料。因此,若能結合 Hadoop/MapReduce. i n U. v. 與 R 兩者的優點,我們可以針對放在 Hadoop 的巨量 RDF[27]資料,進行 FOAF 的社會 網絡的分析。. 1.2. Ch. engchi. 研究目的. 本研究的目的在於希望透過 R 與 Hadoop/MapReduce 的技術結合,提出三種方式來 分析巨量社群 FOAF 資料。Hadoop/MapReduce 架構提供巨量資料的儲存與分析能力, 進行簡單的數值統計分析。 R 語言是開放原始碼軟體,具備統計分析、資料探勘與繪圖等功能,是近來最受歡 迎的統計分析軟體,透過安裝程式庫擴充其他功能。R 雖然有功能強大的資料處理能力, 但受限於先前提到的記憶體容量限制,R 無法直接有效的處理大量的資料。 Hadoop 的 MapReduce 概念來自於 Functional Language,主要透過 Map(映射)與 1.
(11) Reduce(化簡)來並行處理大規模的資料。首先 Map 會把巨量資料(Big Data)依據 Key 切 割分成許多小資料,完成 Map 工作之後,系統會接著對新產生的資料進行清理(Shuffle) 和排序(Sort),之後再進行 Reduce 操作,資料根據 Key 值進行適當的合併,最後系統透 過 Reduce,依據相同的 Key 值合併這些 Key/Value。雖然 Hadoop 的 MapReduce 能夠處 理巨量資料,但是僅能作比較簡單的資料分析。 本研究主要構想以 R 語言為基礎,分析集中於 Hadoop cluster 的 FOAF 社群網路資 料,之後再討論 R 使用 MySQL[23]資料庫與 Hive[31]的運算效能與分析結果。首先是 R+Hadoop Streaming 分析(RHS Analytics),在 Hadoop cluster 環境下,使用 Hadoop. 政 治 大 利用 R 軟體與 MySQL 資料庫解決 R 記憶體不足的問題,評估 MySQL 對於大量的 FOAF 立. Streaming 架構與 R 語言作簡易統計分析,第二部分是 R+MySQL 分析(RMS Analytics),. 資料處理效能,作為 R+Hive 分析的對照組;第三部分是 R+Hive 分析(RH Analytics),. ‧ 國. 學. 使用 Hive,結合 R 與 Hadoop/MapReduce 兩者的優點,得以分析處理巨量的社群網路. 各章節敘述. sit. y. Nat. 1.3. ‧. 資料,最後討論 R 使用 MySQL 與 Hive 的效能比較。. er. io. 本文第二章針對本篇論文的研究背景,研究相關的專有名詞以及技術說明,包括. al. Hadoop、Hive 與 R 語言。第三章則是針對目前的相關研究現況進行比較和分析,包含. n. v i n Ch FOAF(Friend Of A Friend)與社會網路分析(Social U Analysis,SNA),並探討本研 e n g c h iNetwork. 究與相關文獻的差異性。第四章為方法架構設計,本研究提出的三種 FOAF 資料分析架. 構,包括 R+Hadoop Streaming 分析(RHS Analytics)、R+MySQL 分析(RMS Analytics)與 R+Hive 分析(RH Analytics)等研究方法。第五章為系統實作,第六章為結論與未來展望。. 2.
(12) 第二章 研究背景 2.1. Hadoop. Hadoop 是 Apache Hadoop 的是一個開放原始碼(open-source software)計劃項目,以 Java 為基礎的軟體框架提供存儲和管理巨量資料(Big Data),同時兼具高可靠度、擴展性 的分散式運算環境。無論是結構化與非結構化資料,Hadoop 同時提供快速和可靠的分 析能力。 Hadoop 是一個受到 Google 的 MapReduce 和 Google FileSystem(GFS)[17]論文的啟. 政 治 大 MapReduce:主要的方法是將一個較大的資料區塊分割分解成更小的區塊,並分別 立 發送到許多不同的節點(node)。每部節點(node)獨立管理自己的系統資源,並於本機上處 發完成的計畫,Hadoop 的核心主要是 MapReduce 與 HDFS,說明如下:. ‧ 國. 學. 理收到的資料,當節點(node)處理完資料後,再將資料回傳給主伺服器。這種分散式架 構能有效率的處理大量資料。. ‧. . HDFS:Hadoop Distributed File System (HDFS),串連 Hadoop cluster 節點的用於資. sit. y. Nat. 料存儲的文件系統。它在許多本地節點的檔案系統連接在一起,使它們成一個大檔案系. io. 保資料的高度可靠性。. er. 統。HDFS 假設節點可能因為硬碟、網路導致故障,因此資料被複製橫跨多個節點,確. al. n. v i n C h 還包括其他重要子項目。 除了上述兩個核心組件外,Hadoop engchi U HBase[30]: HBase 的靈感來自 Google 的 BigTable[4]。HBase 具備可擴展和高容錯. . 優點,是一種架構在 HDFS 上面的非關聯式資料庫,採取 Column-Oriented 資料庫設計, 能夠處理 PB 等級以上的資料。 . Zookeeper[32]:維護與管理 Hadoop cluster 的集中式服務。Zookeeper 提供一種分散. 式配置服務,同步服務和命名註冊表中的分散式系統,簡化分散式系統管理與降低系統 複雜度。如使用 zookeeper 管理 HBase 的 HMaster 跟 RegionServer。. 3.
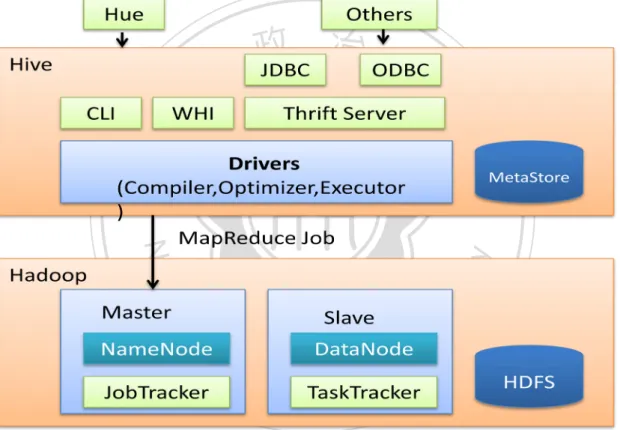
(13) 圖 1:Hadoop ecosystem. 2.2. 立. Hive. 政 治 大. ‧ 國. 學. Hive 是 Hadoop 的生態系統(Ecosystem)的一個重要工具,提供類似 SQL 語法用於查 詢存儲在 Hadoop 分散式資料系統(HDFS)的資料。Hive 是建立在 Hadoop 上的資料倉儲. ‧. (Data Warehouse )基礎構架。它提供資料處理相關的工具,對於所需之數據進行資料擷 取、轉換、載入(ETL,Extract-Transform-Load),這是一種可以存儲、查詢和分析存儲在. y. Nat. sit. Hadoop 中的大規模資料的機制。. er. io. 多數的資料倉儲應用程式使用關聯式資料,使用 SQL 作為查詢語言。Hive 降低了. al. v i n Ch 應用程式移植時到 Hadoop。Hive 使用的查詢語言稱作 e n g c h i UHive Query Language,簡稱 HiveQL n. 資料倉儲應用程式轉換到 Hadoop 的門檻,熟悉 SQL 的開發人員容易使用 Hive 將 SQL. 或 HQL,用來查詢存放在 Hadoop cluster 的資料。SQL 允許使用者在高層資料結構上工. 作。它不要求使用者指定資料的存放方法,也不需要使用者了解具體的資料存放方式, 同樣的,使用者透過 Hive 可以專注於查詢處理資料本身,Hive 轉換 HiveQL 變成 MapReduce 工作,進而充分利用 Hadoop 的特性。 Hive 的架構如圖 2,主要包括: Web GUI:Hive 提供幾種圖形操作介面服務,如商用軟體與開放原始碼的 Karmasphere 與 Cloudera 的 Hue,這些服務對應到 Hive 的 HWI(Hive Web Interface),使用前必須啟動 WHI 服務。 CLI:Hive 的指令列模式,直接使用指令操作 Hive。 4.
(14) Thrift server:Apache Thrift 是一種跨語言的軟體開發架構,Hive 使用這項服務,開發人 員可以使用 C++、Java、Python、PHP、Ruby、Erlang、Perl、C#等語言與 Hive 連結, 或是使用 JDBC、ODBC 連接外部資料庫。 Metastore:一個單獨的關聯式資料庫,系統預設的是 derby,也可以使用 MySQL,用來 儲存操作 Hive 產生的表格結構等資料。 Driver:包括 Complier、Optimizer 和 Executor 等元件,它的作用是將 HiveQL 語法進行 解析、編譯優化與產生執行計劃,然後使用 Hadoop/MapReduce 架構執行任務。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 2:Hive 架構圖. 5. v.
(15) 2.3. R. R 是一個開放原始碼的程式語言與操作環境,主要提供統計分析計算與繪圖。R 具 備整合資料處理及統計功能,包括線性與非線性模型(linear and nonlinear modelling)、統 計檢定方法( statistical tests)、時間序列分析(time-series)、分類(classification)與集群分析 (clustering)等分析方法,以及陣列、矩陣的算與繪圖工具,同時也是一種語法簡單的程 式設計語言。除了視窗介面之外,R 另外提供一項整合開發環境 RStudio,允許多個使 用者經由瀏覽器來使用操作資料與撰寫程式,除了內建的功能與函數外,R 可以透過安 裝程式庫方式來擴充。. 政 治 大 網路活動產生的資料已經超過傳統的資料處理與分析能力。R 主要的限制是記憶體管理 立 隨著科技進步,人們許多的活動行為已經透過網路所完成,如 email 與社群網路,. ‧ 國. 學. 與 CPU 使用問題,首先是 R 在處理資料時,會將資料全部讀取到記憶體,即使用不到 的資料也會耗掉記憶體空間;再來是無論電腦的 CPU 有幾個核心,R 預設只會使用其. ‧. 中一個。解決記憶體不足的辦法,除增加記憶體外,另一種方式是利用資料庫儲存資料, 執行 SQL 過濾資料後再用 R 分析,有效降低讀取至記憶體的資料量。增快 CPU 運算速. Nat. sit. y. 度的方式主要是解決方式是平行處理(Parallelism),[11]提到 R 的高性能運算與平行處理. er. io. 方式,主要可以分為平行處理、網格運算(Grid Computing)、Hadoop/MapReduce 等解決. al. n. v i n 常見的平行處理方式包括 C MPI(Message h e n g cPassing h i UInterface),是一種電腦或節點(Node). 方法。. 在叢集(cluster)環境的管理通訊標準,使用者的程式可以同時在許多電腦上執行,啟動. 平行分散式運算,有效提升執行效率。另一個是 SNOW(Simple Network of Workstations), 採用 Master / Slave cluster 架構,提供高階的溝通介面給 Master 來管理 Slave 工作站。 平行處理可以有效提升 R 的運算效率,但是 cluster 繁雜的設定與管理,通常是 R 使用 者進入平行處理的障礙,使用者本身必須對於 cluster 有深度的了解,才能有效的使用 R 的平行處理機制 另一個方式是 Hadoop/MapReduce 架構,主要的概念是把一件工作拆解成許多小工作, 最後再將小工作的輸出合併成為單一結果,有效的使用平行化技術處理大量的資料,主 流的技術有 Hadoop Streaming、RHIPE 與 RHadoop 等方式,待章節 3.3 再作詳細說明。 6.
(16) 立. 政 治 大. ‧. ‧ 國. 學. io. sit. y. Nat. n. al. er. 圖 3:R 使用介面圖:Console(上)與 RStudio(下). Ch. engchi. 7. i n U. v.
(17) 第三章 相關研究 3.1. FOAF(Friend of A Friend). FOAF(Friend of A Friend)是一種以 RDF 為基礎架構,描述個人和他們的社會網絡關 係,包括自己的名字、電子郵件信箱、個人喜好與認識的朋友等資訊。我們可以利用 FOAF-a-Matic [20]製作 FOAF 資料,命名為 foaf.rdf,放到適當的網站讓所有人可以公開 下載,網路上的搜尋機器人可以發現這個檔案,並且利用檔案內容中的 rdfs:seeAslo 發. 治 政 現其他的 FOAF 檔案,藉以串成整個社群網路。底下為 大 foaf.rdf 的範例。 立 <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" ‧. ‧ 國. 學. xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:foaf="http://xmlns.com/foaf/0.1/"> <foaf:Person> <foaf:name>Leigh Dodds</foaf:name> <foaf:firstName>Leigh</foaf:firstName> <foaf:surname>Dodds</foaf:surname> <foaf:mbox_sha1sum>71b88e951cb5f07518d69e5bb49a45100fbc3ca5</foaf:mbox_sha1sum > <foaf:knows> <foaf:Person> <foaf:name>Dan Brickley</foaf:name> <foaf:mbox_sha1sum>241021fb0e6289f92815fc210f9e9137262c252e</foaf:mbox_sha1sum > <rdfs:seeAlso rdf:resource="http://rdfweb.org/people/danbri/foaf.rdf"/> </foaf:Person> </foaf:knows> </foaf:Person> </rdf:RDF>. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. FOAF 從 OWL(Web Ontology Language)借用反函數屬性 Inverse Functional Property (IFP) [13]的概念,一個反函數屬性是一個簡單的概念,它的數值標識唯一個資源。如果 一個屬性 P 被標記爲反函數(InverseFunctional) ,那 麽對於所有的 x、 y 和 z,P(y,x) and P(z,x) implies y = z。舉例來說,若 y、z 代表不同的實例,x 為身分證號碼。如果 y、z 兩人具有相同的身分證號碼(x),那麼可以推斷這兩個實例指的是同一個人。. 8.
(18) 一般而言,從不同網站所彙整的 FOAF 檔案內可能會有相同的使用者名字,例如重 複的 foaf:name,卻不可能會有相同的 email 或是社群網路帳號,FOAF 定義代表個人的 唯一識別符號(unique identifiers)如下: foaf:aimChatID. foaf:mbox sha1sum. foaf:homepage. foaf:msnChatID. foaf:icqChatID. foaf:weblog. foaf:jabberID. foaf:yahooChatID. foaf:mbox. 政 治 大. 立. 文獻[18]利用唯一識別符號(unique identifiers)特性,從多個社群網站蒐集 FOAF 檔. ‧ 國. 學. 案,使用 OWL 推理引擎並使用與 foaf:knows 與 FOAF inverse property,進而從不同的 FOAF 檔案,推論得到同一個使用者。研究主要分析:. ‧. (1) Network Statistics:平均最短路徑(average shortest path length). y. Nat. (2) Account Statistics:多個社群網路的使用者帳號數量分析,如長尾理論結果。. io. sit. (3) Friendship Statistics:少數擁有多個帳號的使用者,具有良好的連結能力,位居各社. n. al. er. 群網路的核心與溝通橋梁。. i n U. v. 另外文獻[10]從網路蒐集的 FOAF 檔案分成 blog 與非 blog 兩類,主要分析:. Ch. engchi. (1) FOAF 文件中所使用的 foaf:mbox/ foaf:dateOfBirth 與 foaf:mboxsha1sum/foaf:homepage,後者比較沒有隱私的疑慮,因此出現的頻率較高。 (2) FOAF 文件使用 foaf:knows / rdfs:seeAlso 與其他 FOAF 文件相連接,blog 網站使用 的頻率比非 blog 網站較為頻繁。 (3) 結合網路上不同的 FOAF 檔案,拼湊完整的個人資料。 (4) Social network analysis,網路由多少人(foaf:name)所組成,分析統計入/出分支度 (in/out-degree)、Patterns of Connected Components 等。. 9.
(19) 表 1:FOAF 主要字彙. FOAF Core age made (maker) primaryTopic (primaryTopicOf). Agent Person name. weblog openid jabberID. account OnlineAccount accountName. member Document Image. mbox_sha1sum interest topic_interest topic (page) workplaceHomepage workInfoHomepage schoolHomepage. accountServiceHomepage PersonalProfileDocument tipjar sha1 thumbnail logo. 政 治 大. 立. 學. sit. y. ‧. 資料來源:http://xmlns.com/foaf/spec/. Nat. 社會網路分析(Social Network Analysis,SNA). io. er. 3.2. nick mbox homepage. Project Organization Group. ‧ 國. title img depiction (depicts) familyName givenName knows based_near. Social Web publications currentProject pastProject. 社會網絡分析是依據數學方法與圖論等理論為基礎,分析與計算個人與團體組織之. n. al. Ch. i n U. v. 間的關係,藉以找出網路中重要的個體與特性。常見的分析測量指標[14]有 Degree. engchi. centrality(分支度)、Betweenness centrality(中介中心性)、Closeness centrality(接近中心性) 與 Eigenvector centrality(特徵性)等。 . Degree centrality (分支度):. (1) 定義:在圖上與頂點相連的邊數為分支度,是圖形中最簡單的測量指標。 (2) 意義:若為有向圖(directed graph)則分入/出分支度(in/out-degree),in-degree 是 incoming edges 的數量,out-degree 則是 out-going edges 的數量;若為無向圖(undirected graphs),total degree = in-degree + out-degree。degree 主要是評估團體組織中的核心人物, degree 比較高的節點(vertex)表示與其他個體的往來較為頻繁,擁有較高的影響力。. 10.
(20) ∑ [C = g. CD. i =1. D. (n * ) − C D (i ). ]. 公式(1). [( N − 1)( N − 2)]. 其中 C D (n* ) 代表整個網路中 degree 的最大值 . Betweenness centrality (中介中心性):. (1) 定義:是指所有節點之間的最短距離通過該節點的次數。 (2) 意義:因為該點對於網路上的其他節點而言,等於是兩者之間的最短路徑。具有 Betweenness 較高的節點,代表在網路上資訊流通影響力比較大。. C B (ni ) = ∑ g jk (ni ) / g jk j <k. 立. 政 治 大. 公式(2). gjk :j 與 k 之間所有的最短路徑數目. ‧ 國. Closeness centrality(接近中心性):. ‧. . 學. gjk(ni) /gjk = 所有連結 j 與 k 的所有最短路徑中,有經過 ni 的路徑所佔的比例. y. Nat. (1) 定義:是指該節點與圖中其它所有點的路徑之距離總和。. sit. (2) 意義:因為該點與其他節點的距離比較短,能夠快速的到達其他節點,因此該點很. Cc (ni ) = ∑ d (ni , n j ) j =1 g. al. n. 人的間接社會關係。. er. io. 容易影響或是被影響。分析該節點通過社會網路對其它節點的間接影響力,藉以衡量此. −1. Ch. engchi. i n U. v. 公式(3). d(ni, nj)為兩點之間最短路徑的長度 . Eigenvector centrality(特徵性):. (1) 定義:該節點的評估指標由所有連接的節點決定。 (2) 意義:是 Degree Centrality 的改良方法,也稱作 Bonacich Power Centrality[3],對於 一樣擁有相同的 degree Centrality 的兩個節點來說,不同的相鄰的節點可能有不同的影 響力。舉例來說,認識十個普通人與認識十個企業家的影響力可能不一樣。分析這種通 過與具有高度值的相鄰節點所獲得的間接影響力。 11.
(21) C (α , β ) = α ( I − βR) −1 R1. 公式(4). α is a scaling vector, which is set to normalize the score. β reflects the extent to which you weight the centrality of people ego is tied to. R is the adjacency matrix (can be valued) I is the identity matrix (1s down the diagonal) 1 is a matrix of all ones. 另外小世界網路(small world networks / small world phenomenon) ,也稱作六度分隔理論. 治 政 大 隨機交給陌生人傳遞,平均需要經過 6 次轉寄過程。之後引申的意義是世界上原先不認 立 識的兩個人,只要中間經過少數人就能建立聯繫關係。. (Six Degrees of Separation),原始理論是 Milgram 1967 準備數百封的相同收件人的信件,. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 12. i n U. v.
(22) R與Hadoop的整合. 3.3. 在 R 尚未導入與 Hadoop/MapReduce 技術之前,R 的平行處理架構扮演分析大量資 料的重要角色,相關的 package 如 rmpi、 nws、snow、sprint、foreach、multicor 等,但 是即使使用多核心 cpu 與叢集(cluster)的平行處理技術,仍然無法提供複雜分析巨量資料 的能力。Hadoop/MapReduce 是一個功能強大的程式架構,可以有效處理儲存在 HDFS 系統的大量資料,但是對於慣用 R 的使用者來說,需要另外熟悉 Hadoop/MapReduce 的 語法與操作,解決方式是可以在 R 的環境直接使用 Hadoop/MapReduce。R 與 Hadoop 的結合有許多方式,主要包括 RHadoop[26]、RHIPE[8]與 Hadoop Streaming。. 立. RHadoop. 學. ‧ 國. 3.3.1. 政 治 大. RHadoop 是 Revolution Analytics 研發的一個開放原始碼計畫,提供 R 程式開發人. ‧. 員強大的工具來分析儲存在 Hadoop 的資料。RHadoop 提供了一個的 R 程式程式庫 rmr, 其主要的目標是提供的 map-reduce 開發人員簡單、效率、優雅的方式撰寫 Map Reduce. sit. y. Nat. 作業。使用 rmr 程式庫撰寫的程式碼可能只需要使用 Java 語言的一半,同時維持程式碼. er. io. 的可讀性,具備可重用和可擴展等特色。提供開發人員於原有熟悉的 R 環境下,使用. al. MapReduce 架構處理大量的資料。. n. v i n 除了 rmr 提供 MapReduceC 程式框架之外,另外還有 h e n g c h i U rhdfs 和 rhbase 等程式庫。rhdfs. 提供基本的連接到 Hadoop HDFS,開發人員可以瀏覽、讀取、寫入和修改存儲在 HDFS 中的文件;rhbase 使用 Thrift server 提供 HBASE 基本連接,開發人員可以瀏覽,讀取, 寫入和修改存儲在 HBASE 表。 rmr 程式庫程式提供 Hadoop 的抽象層概念,開發人員 只需要專注於大量資料的分析,不用注意分散式處理程序、系統容錯與平行處理等事 務。. 13.
(23) #設定 Hadoop 環境參數 Sys.setenv(HADOOP_CMD="/usr/local/hadoop/bin/hadoop") Sys.setenv(HADOOP_STREAMING="/usr/local/hadoop/contrib/streaming/hadoop-streamin g-1.2.1.jar") #使用 rhdfs 與 rmr2 library library(rhdfs) library(rmr2) #定義 map 函數 # keyval(key, value),指定 key 與 value 數值 wc.map = function(k,lines) { words.list = strsplit(lines, '\\s') //使用\s(space 字元)分割字元 words = unlist(words.list) return( keyval(words, 1) ) //回傳字元,數值為 1 }. 立. 政 治 大. ‧. ‧ 國. 學. #定義 reduce 函數 wc.reduce = function(word, counts) { keyval(word, sum(counts)) //計算字元總和 }. n. al. er. io. sit. y. Nat. #wordcount 主程式 # mapreduce(input, output, input.format, map,reduce,combine) #指定參數 input, output, map, reduce and input.format wordcount = function (input, output = NULL) { mapreduce(input = input , output = output, input.format = "text", map = wc.map, reduce = wc.reduce)} RHadoop WordCount 程式範例. Ch. engchi. 14. i n U. v.
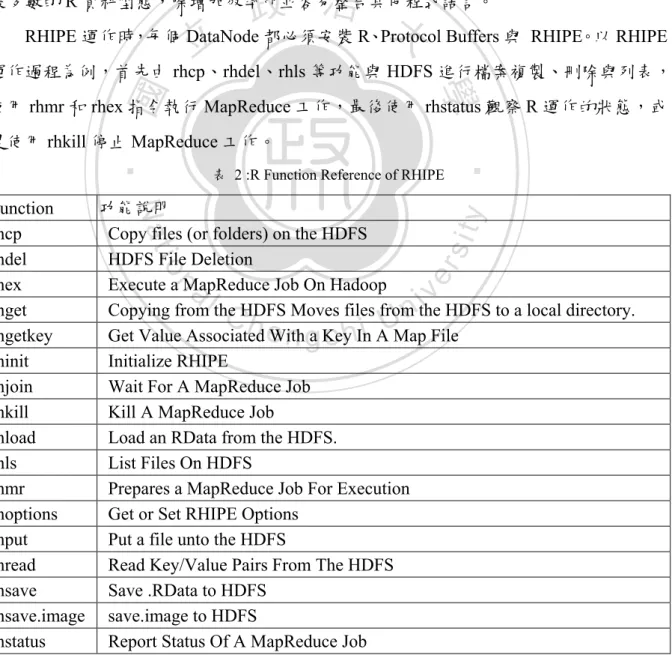
(24) 3.3.2. RHIPE. RHIPE 代表 "R and Hadoop Integrated Programming Environment",提供 Hadoop 與 R 緊密結合的介面,實現直接使用 R 來分析巨量資料。RHIPE 是一個 R 的程式庫(Library), 允許使用 R 執行 MapReduce 的工作。 RHIPE 是以 Hadoop Streaming 為基礎,並加強檔案處理能力部分功能,如提供二進 制檔案。R 程式開發人員可以在 R 的環境,直接存取 HDFS 的檔案並在 Hadoop cluster 執行 MapReduce 的工作。RHIPE 使用 Google protocol buffers 作為資料的輸出介面,支. 政 治 大 RHIPE 運作時,每個 DataNode 都必須安裝 R、Protocol Buffers 與 RHIPE。以 RHIPE 立. 援多數的 R 資料型態,除增加效率外並容易整合其他程式語言。. 運作過程為例,首先由 rhcp、rhdel、rhls 等功能與 HDFS 進行檔案複製、刪除與列表,. ‧ 國. 學. 使用 rhmr 和 rhex 指令執行 MapReduce 工作,最後使用 rhstatus 觀察 R 運作的狀態,或. 表 2 :R Function Reference of RHIPE. ‧. 是使用 rhkill 停止 MapReduce 工作。. n. al. er. io. sit. y. Nat. 功能說明 Function rhcp Copy files (or folders) on the HDFS rhdel HDFS File Deletion rhex Execute a MapReduce Job On Hadoop rhget Copying from the HDFS Moves files from the HDFS to a local directory. rhgetkey Get Value Associated With a Key In A Map File rhinit Initialize RHIPE rhjoin Wait For A MapReduce Job rhkill Kill A MapReduce Job rhload Load an RData from the HDFS. rhls List Files On HDFS rhmr Prepares a MapReduce Job For Execution rhoptions Get or Set RHIPE Options rhput Put a file unto the HDFS rhread Read Key/Value Pairs From The HDFS rhsave Save .RData to HDFS rhsave.image save.image to HDFS rhstatus Report Status Of A MapReduce Job. Ch. engchi. 15. i n U. v.
(25) 功能說明 Serialize and Unserialize See Details. Serialize and Unserialize See Details. Start and Monitor Status of a MapReduce Job Macro to Wrap Boilerplate Around RHIPE Map code Write R data to the HDFS. #RHIPE WordCount 程式範例 #載入 RHIPE library library(RHIPE) #RHIPE 系統初始化 rhinit() #定義 Map function w_map<-expression({ words_vector<-unlist(strsplit(unlist(map.values)," ")) lapply(words_vector,function(i) rhcollect(i,1)) }) #定義 Reduce function w_reduce<-expression( pre={total=0}, reduce={total<-sum(total,unlist(reduce.values))}, post={rhcollect(reduce.key,total)} ) #定義 MapReduce job object Jobwc <rhwatch(map=w_map,reduce=w_reduce, ,input="/RHIPE/input/",output="/RHIPE/output/", jobname="word_count"). 學 ‧. ‧ 國. 立. 政 治 大. n. engchi. 16. sit. io. Ch. y. Nat. al. er. Function rhsz rhuz rhwatch rhwrap rhwrite. i n U. v.
(26) 3.3.3. Hadoop Streaming. Hadoop 為了增加程式設計的使用彈性,提供 Hadoop Streaming 的 API 方式,讓使 用者除了 Java 之外,可以使用支援 stdin/stdout 的語言或可執行的腳本語言(Scripts)撰寫 map 和 reduce 功能。Hadoop Streaming 使用 Unix 的標準串流方式作為 Hadoop 和使用者 程式之間的界面,使用者藉由標準輸入(stdin)和寫入到標準輸出(stdout),可以使用多種 語言撰寫 MapReduce 程式。Hadoop Streaming 通常需要編寫兩個功能:Map 與 Reduce, 程式名稱分別為 mapper 與 reducer。Map 先將資料分割成獨立的區塊,Reduce 結合 Map. 政 治 大. 產生的結果來執行有用的分析。底下為 Hadoop Streaming 範例。. 立. $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \. ‧ 國. 學. -input myInputDirs \ -output myOutputDir \. ‧. -mapper /bin/cat \. y. Nat. -reducer /bin/wc. sit. 在上面的例子中,首先指定資料的輸入、輸出目錄與檔名,mapper 與 reducer 逐行. n. al. er. io. 從標準輸入(stdin)讀取資料,再把處理過的資料後發送到標準輸出(stdout)。Hadoop. v. Streaming 依據 mapper 與 reducer 產生對應的 Map / Reduce 作業( Job),該作業( Job)會被. Ch. engchi. i n U. 送到適當的 Hadoop cluster,並監視作業( Job)的進度直到完成。 當程式被指定為 mapper 時,如/bin/cat,map 會以獨立的程序啟動這個程式。當 mapper 執行時,它會把資料逐行分割提供給程式,當作標準輸入(stdin)的內容。在此同時,mapper 從標準輸出(stdout)收集資料,輸出(key/value)格式作為 map 的輸出結果。 同樣的方式套用在 reducer。當程式被指定為 reducer 時,如/bin/wc,reducer 會以獨 立的程序啟動這個程式。當 reducer 執行時,它會把資料逐行分割提供給程式,當作標 準輸入(stdin)的內容。在此同時,mapper 從標準輸出(stdout)收集資料,並輸出為(key/value) 格式,作為 reducer 的輸出。 Hadoop Streaming 與 R 整合變得相當簡單,但是 Hadoop Cluster 的每個 DataNode 都必須安裝 R 程式。使用 Hadoop Streaming 的優點是,它允許 Java 以及非 Java 的 17.
(27) MapReduce 程式在 Hadoop cluster 上執行,Hadoop 的 JobTracker 與 TaskTracker 會自動 管理 MapReducer 作業程序。除了 Java 之外,Hadoop Streaming 支援的語言還包括 Perl、 Python、PHP 、R、C + +與 Sehll Scripts 語言,程式開發人員需要把程式轉換為 Mapper 與 Reducer、輸出結果為 Key/Value 的架構。 . R 與 Hadoop 的整合方式如上面敘述,每種方式各有優點與限制,歸納如下:. (1) 先使用 Hadoop 彙整資料後,再提供給 R 作深入分析。 (2) 避免使用 R 作一般的 MapReduce 使用。 (3) 一般簡單的 MapReduce 工作,考慮使用 Hadoop Streaming 的處理方式,缺點是只. 政 治 大. 能處理文字資料,好處是非常容易的在非 Hadoop 的環境中作測試,例如使用 pipe 架構多個串連指令。. 立. (4) 其他狀況下,建議使用 RHIPE 或是 RHadoop。. ‧ 國. 學. RHadoop 與 RHIPE 的缺點:. ‧. (1) 需要使用 MapReduce 架構格式來撰寫 R 程式,學習曲線較久 (2) 穩定度與效能不及 Hadoop(Java)、Pig. sit. y. Nat. (3) 執行時需要載入較多的 R libraries. er. io. 本研究使用 R+Hive 架構分析大量的 FOAF 資料,對於一般的使用者而言,除了 R 語言之外,只需要具備的 SQL 語法背景。首先,將分析的資料放置 Hadoop HDFS 檔案. al. n. v i n 系統上,從 R 介面使用 RHive C 程式庫,透過 把 HQL 轉換為 MapReduce 分散式運 h e n g cHive hi U. 算架構處理,第二階段再將處理結果交給 R,依據不同需求載入需要統計分析工具作運 算,最後完成繪製圖表工作。. 18.
(28) 表 3 :R 與 Hadoop 整合技術比較表 R+Hive RHadoop RHIPE Hadoop Streaming (R+HQL+Hadoop). Snowfall/Multicore R parallel packages. User Friendly. V. V. V. X. V. Easy Learning. V. X. X. X. V. Handle Large data set. V. V. V. V. X. Apply statistical algorithm. V. V. V. X. V. Large Data visualization. V. V. V. X. X. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 19. i n U. v.
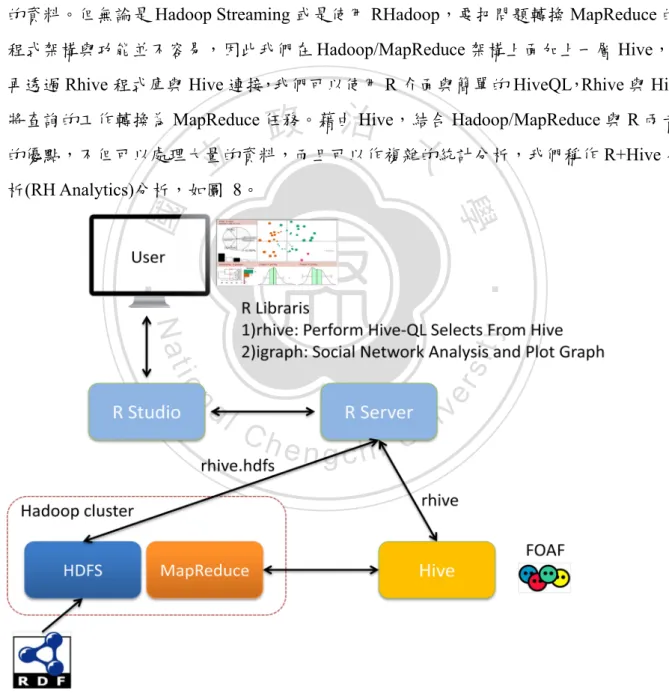
(29) 第四章 方法架構設計 4.1. 研究架構. 本研究希望透過結合 R 與 Hadoop/MapReduce 來分析處理大量的社群網路資料,我 們使用 Hadoop/MapReduce 架構對大量的資料作簡單的資料統計,再用 R 豐富的程式庫 與函數作進階的統計分析,最後使用 R 的 rhive 程式庫,透過 Hive 結合 R 與 Hadoop/MapReduce,分析處理大量的社群網路資料,如圖 4。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 4:研究架構圖. 20. v.
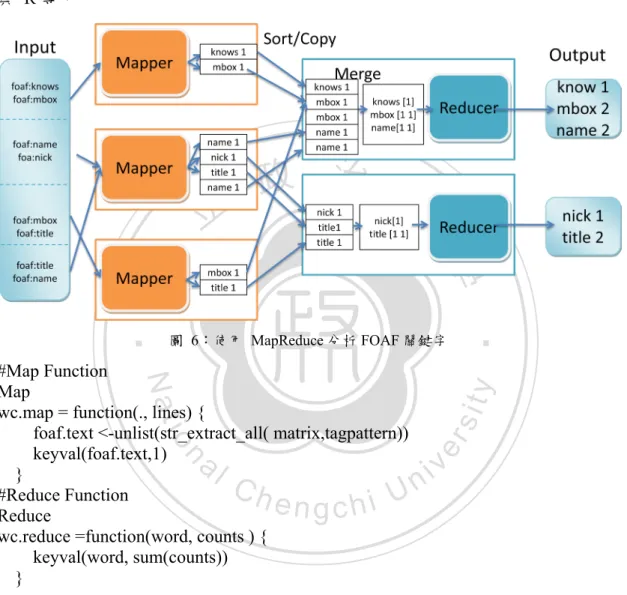
(30) FOAF分析. 4.2 4.2.1. R+Hadoop Streaming分析(RHS Analytics). 本研究將會探討使用 Hadoop/MapReduce 方式分析 FOAF 資料,在本研究的情境中, FOAF 資料儲存於 Hadoop HDFS,利用 MapReduce 架構對 FOAF 資料進行簡單的分析 運算,以達到存取巨量資料與簡易運算的目的,如圖 5。章節 3.3.3 提到支援 Hadoop Streaming 的語言包括 Java、Python、PHP、C + +、R 與 Sehll Scripts 語言,本研究使用 R 語言作為範例。. 政 治 大. 立. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 5:R+Hadoop Streaming 分析(RHS Analytics)架構圖. n. al. i n U. v. 本研究借用 WordCount 的概念,找出 FOAF 檔案中的關鍵字並加以統計字數,如圖. Ch. engchi. 6。以 foaf 為例,使用 R 的 str_extract_all 功能取出符合比對規則的字串,當作 MapReduce 中 Map 的 Key 鍵,Val 數值為"1",再由 Reduce 的 sum 作總和運算,最後再輸出分析統 計結果。 MapReduce 的運作流程如下:MapReduce 將要執行的問題,分別拆解成 Map 和 Reduce 的架構來執行,以達到分散式運算的效果。MapReduce 運算可利用兩個函數表示: map (k1,v1) → list(k2,v2) reduce (k2,list(v2)) → list(k3,v3). MapReduce 演算法: 對應演算法中的 Divide and conquer,將問題拆解為許多小問題後,再作最後的總和。雖 21.
(31) 然 Hadoop framework 是用 Java 完成,但是 Map/Reduce 不一定要用 Java 來寫,Hadoop Streaming 使用 Unix 標準的串流(streaming)當作 Hadoop 與使用者自行撰寫程式的介面, 實作上使用者可以使用其他程式語言來執行,如 Pipe 指令、PHP、Ruby、Python、C++ 與 R 等。. 學 圖 6:使用 MapReduce 分析 FOAF 關鍵字. n. Ch. engchi. sit er. io. al. y. Nat. #Map Function Map wc.map = function(., lines) { foaf.text <-unlist(str_extract_all( matrix,tagpattern)) keyval(foaf.text,1) } #Reduce Function Reduce wc.reduce =function(word, counts ) { keyval(word, sum(counts)) }. i n U. v. #完整的 MapReduce 程式 MapReduce mapreduce(input = input ,output = output, input.format = "text", map = wc.map, reduce = wc.reduce,combine = T). 22. ‧. ‧ 國. 立. 政 治 大.
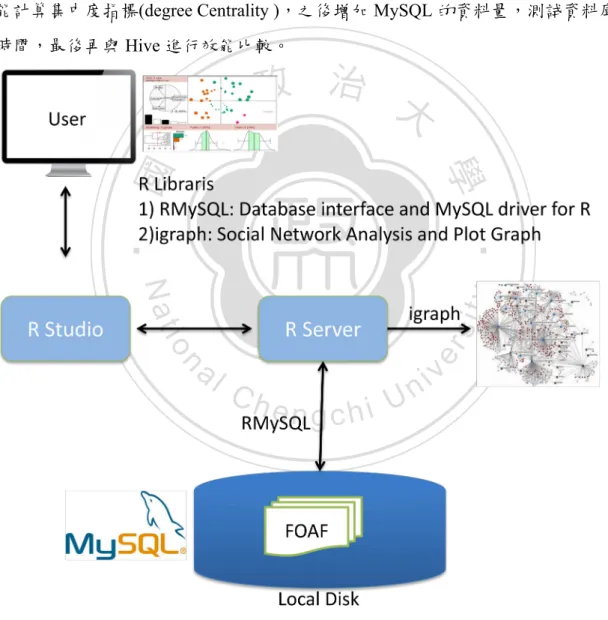
(32) 4.2.2. R+MySQL分析(RMS Analytics). 在本研究中,利用 MySQL 儲存 FOAF 資料,評估與測試 R 使用 MySQL 的極限。 我們將使用 R 豐富的程式庫與函數分析統計 FOAF 資料,利用 FOAF 中 foaf:knows 的特 性與 R 的社會網路分析工具(igraph)做方析,如圖 7。首先從 MySQL 的 RDF 資料中過 濾出 foaf:knows 關係,作為成圖形中的 edgelist,再利用 igraph 提供的社會網路分析功 能計算集中度指標(degree Centrality ),之後增加 MySQL 的資料量,測試資料庫查詢的 時間,最後再與 Hive 進行效能比較。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 7:R+MySQL 分析(RMS Analytics)架構圖. FOAF 檔案敘述自己與其他人之間的關係,包括名字(foaf:name)、認識(foaf:knows) 與 email(foaf:mbox)等資料。藉由過濾出 foaf:name 字串,得到 Subject 與 Object 確認 Person 23.
(33) A 與 Person B 的關係,如圖論中的 A 端點至 B 端點。首先從 R 讀取 FOAF 檔案,挑選 出包括 foaf:knows 的 subject 與 object 欄位。一般的資料庫都會提供外部 API 給外部程 式使用,常用的方式有 ODBC、JDBC 和 DBI。R 與 MySQL 連接的方式為 RMySQL, 允許在 R 的環境中直接操作資料庫,回傳執行結果的格式為資料框(dataframe),利於 R 的後續資料處理。 社會網路分析: 社會網絡分析是依據數學方法與圖論等理論為基礎,分析與計算個人與團體組織之 間的關係,藉以找出網路中重要的個體與特性。常見的分析測量指標(Centrality)有 Degree. 政 治 大. (分支度)、Betweenness (中介中心性) 、Closeness (接近中心性)與 Eigenvector (特徵性) 等。 建立 MySQL 資料庫. 立. 學. ‧ 國. 1.. 從 MySQL 建立資料庫,資料庫名稱為 btc。. ‧. SQL:. CREATE DATABASE btc; 建立 btc2012 表格. sit. y. Nat. 2.. io. <subject> <predicate> <object> <context> .。. n. al. Ch. USE btc; CREATE TABLE IF NOT EXISTS btc2012( subject varchar(128), predicate varchar(128), object varchar(128), context varchar(128)); 3. 載入資料至 btc2012 表格. engchi. er. 本研究的實驗資料為 N-Quads,是 N-Triples 加上 context 的擴展形式,組成格式為:. i n U. v. #將本地目錄'/home/hduser/btc2012/data-1.nq'資料載入 table btc2012,使用' '(空白 #鍵) 區分欄位,第一次載入約 7.8GB。 LOAD DATA LOCAL INFILE '/home/hduser/btc2012/data-1.nq' INTO table btc2012 FIELDS TERMINATED BY ' '; 4.. R 結合 MySQL 與社會網絡分析(使用 igraph) 本研究使用 R 的 igraph 程式庫,此程式庫提供各種社會網路分析計算工具。我們透. 過 RMySQL 得到 FOAF 認識的關係後,將資料轉換為 graph.data.frame,使用 igraph 產 24.
(34) 生社群網路的計算指標(Centrality Measures): (1)R 使用 RMySQL 與 MySQL 連接 #使用 library library("DBI") library("RMySQL") library("igraph") #Connect to MySQL conn <- dbConnect(MySQL(), dbname = "btc", username="rmysql", password="rmysql") (2)找出學術單位的認識關係 SQL 語法 foaf_know_edu_query <- (" SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>' AND subject LIKE '%edu%' ") #excute mysql foaf_know_edu_mysql_df = dbGetQuery(conn, foaf_know_edu_query). 立. 政 治 大. ‧ 國. 學. ‧. (3)計算連接中間指標(Degree Centrality):. y. Nat. 我們從 7.8GB 資料中找出教育界的認識關係,使用分群函數與顏色區分不同群組,計算. n. al. er. io (4)資料量擴充測試. sit. 連接中間指標,找出最大中間指標端點,標示出名稱與圖示。. Ch. engchi. i n U. v. 初步資料使用為 7.8GB,之後以 3000 萬筆資料(約 5GB)增加至 btc 資料庫,最後增加至 30GB,紀錄 MySQL 查詢工作所需時間,之後再與 Hive 的結果作比較。MySQL 載入資 料指令範例如下: LOAD DATA LOCAL INFILE '/home/hduser/btc2012/data-5-30M-tail.nq' INTO table btc2012 FIELDS TERMINATED BY ' '; 其中'/home/hduser/btc2012/data-5-30M-tail.nq'是檔案資料,btc2012 是表格(table),欄位分 辨使用' '(空白字元)。. 25.
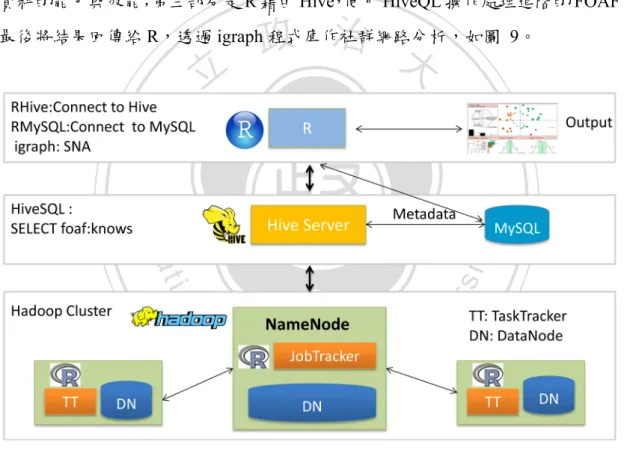
(35) 4.2.3. R+Hive分析(RH Analytics). 4.3.1 章節提到 R+Hadoop Streaming 分析(RHS Analytics)透過 Hadoop/MapReduce 架 構能夠處理大量的資料,卻只能做簡單的統計分析;反觀 R+MySQL 分析(RMS Analytics) 利用 R 優秀的資料處理與統計能力,但是受限於本機的記憶體空間因素,只能處理有限 的資料。但無論是 Hadoop Streaming 或是使用 RHadoop,要把問題轉換 MapReduce 的 程式架構與功能並不容易,因此我們在 Hadoop/MapReduce 架構上面加上一層 Hive,R 再透過 Rhive 程式庫與 Hive 連接,我們可以使用 R 介面與簡單的 HiveQL,Rhive 與 Hive. 政 治 大 的優點,不但可以處理大量的資料,而且可以作複雜的統計分析,我們稱作 R+Hive 分 立 將查詢的工作轉換為 MapReduce 任務。藉由 Hive,結合 Hadoop/MapReduce 與 R 兩者. 析(RH Analytics)分析,如圖 8。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 8:R+Hive 分析(RH Analytics)架構圖. 首先將 FOAF 資料上傳到 Hadoop cluster 的 HDFS,使用 R 介面透過 Rhive 與 Hive 連接,再用 HiveQL 查詢 FOAF 資料,查詢結果傳遞給 R,igraph 程式庫計算大量資料 26.
(36) 的社會網路分析,並使用 R 的繪圖功能製作圖表。 啟動 Hive 之後,依據 FOAF 的資料格式建立資料表格,包括 Subject、Object 與 Predicate 等欄位,再將 HDFS 的 FOAF 資料載入 Hive table。回到 R 介面,載入 Hadoop 與 rhive 等相關程式庫,使用 rhive 連接 Hive server,以 foaf:knows 當作關鍵字,最後使 用 Hive query language (HiveQL)查詢放在 Hive 的 FOAF 資料。得到 Hive 的查詢結果後, 得到兩者的認識關係,比照 R+MySQL 分析(RMS Analytics)的分析方式轉為圖形的資料 框(dataframe)格式,最後再繪製 social network 相關圖形。. 政 治 大 1. FOAF 資料存放至 Hadoop HDFS 立 執行 Hadoop HDFS 指令,把分析資料上傳至目錄/hdfs/btc2012: Hive 與 Hadoop/MapReduce、HDFS. ‧ 國. 學. hadoop fs –put file /hdfs/btc2012 建立 Hive 資料庫. ‧. 2.. y. n. al. 3.. Ch. 建立 Hive 表格與資料目錄. engchi. sit. io. CREATE DATABASE IF NOT EXISTS btc;. er. HiveQL:. Nat. Hive 建立資料庫,資料庫名稱為 btc. i n U. v. 本研究的實驗資料為 N-Quads,是 N-Triples 加上 context 的擴展形式,組成格式為: <subject> <predicate> <object> <context> .。我們使用外部表格(external table)的方式,指 定資料存放於 Hadoop HDFS 的目錄 /hdfs/btc2012 位置。 HiveQL: USE btc; CREATE EXTERNAL TABLE IF NOT EXISTS btc2012( subject STRING, predicate STRING, object STRING, context STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION '/hdfs/btc2012'; 27.
(37) 4.. 找出認識的關係(foaf:knows). 從 FOAF 資料的 predicate 欄位,選出包含 foaf:knows 的關鍵字,執行 HiveQL 時候,Hive 程式轉換 HiveQL 變為 Hadoop/MapReduce 的工作。 HiveQL: SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>'; 舉例來說,本研究找出 subject 或是 object 為學術單位的認識關係, HQL 語法為: CREATE VIEW foaf_edu_knows AS SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>' AND subject LIKE '%.edu%' OR object LIKE '%.edu%';. 政 治 大. 學. ‧ 國. 立. R 結合 Hive 與社會網絡分析(使用 igraph) R 使用 RHive 與 Hive 連接. ‧. 1.. y. Nat. 在 R 的介面中,使用 rhive 程式庫連接到 Hive,執行查詢工作或是 HDFS 的功能. sit. n. al. er. io. rhive.connect( host="192.168.1.66",port=10000, hiveServer2=TRUE, defaultFS=NULL, updateJar=FALSE, user='hive', password='hive') rhive.hdfs.ls(path="/") 2.. Ch. engchi. i n U. v. rhive 執行 HQL 語法,回傳結果為 dataframe 格式,再將 dataframe 轉換為 graph dataframe,指定 g 為 graph 物件。 foaf_know_relation_not_edu_df <- rhive.query(" SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>' AND subject NOT LIKE '%edu%' AND object NOT LIKE '%edu%' ") g <- graph.data.frame(foaf_know_relation_df,directed = TRUE) #有向圖. 3.. R 與社會網路分析 igraph 程式庫提供許多社會網路分析的工具,先將 graph 物件 g 分成群組,並將不 同的群組使用不同的顏色代表,挑選章節 4.2.2 提到計算指標(Centrality Measures) 28.
(38) 的最大數值,使用特定顏色與圖示大小表示 Degree (分支度)、Betweenness (中介中 心性) 、Closeness (接近中心性)與 Eigenvector (特徵性)等,最後再繪製圖型輸出。 #分群 components = clusters(g)$membership #colours = sample(rainbow( max( components )+ 1)) colours = (rainbow( max( components )+ 1)) V(g)$color = colours[ components +1] #集中度計算 V(g)$degree <- degree(g) V(g)$bte <- betweenness(g) V(g)$clo <-closeness(g) V(g)eig <- evcent(g). 政 治 大. #標示出指標最高者-圖形大小 V(g)$size = V(g)$degree/(max(V(g)$degree)/5)+ .3 #標示出指標最高者-圖形顏色 V(g)$color[which( degree(g) == max(degree(g)), arr.ind = TRUE )] = "blue" #圖形輸出 plot(g, layout = layout.fruchterman.reingold, vertex.size = V(g)$size, vertex.color = V(g)$color, vertex.label = V(g)$label, vertex.label.cex=V(g)$cex, edge.color = grey(0.5), edge.arrow.mode = "-"). 立. ‧. ‧ 國. 學. n. al. 項目. 主要機制. 適用分析 資料類型 優點. 缺點. Ch. er. io. R+Hadoop Streaming 分析 (RHS Analytics) Hadoop Streaming (MapReduce 架 構,Key/Value 的方 式)統計 foaf 字彙 使用頻率. sit. y. Nat. 分析. 表 4:本研究三種分析方式比較. R+MySQL 分析 (RMS Analytics). v ni. i U 與 e nRg使用 c hRMySQL MySQL 資料庫連 接,解決 R 記憶體 不足的問題. R+Hive 分析 (RH Analytics) 透過 rhive 結合 R 與 Hadoop,發揮兩者 的優點. unstructured data. structured data. structured data. 使用 Hadoop 架 構,能夠處理巨量 資料(BigData). 處理速度快,系統 架構簡單. 適合簡單數值統計 分析. 資料量與處理時間 成線性成長. Hive 語法近似 SQL, Hadoop/MapReduce 架構適合分析處理 巨量資料 效能較差,系統設 定比較複雜. 29.
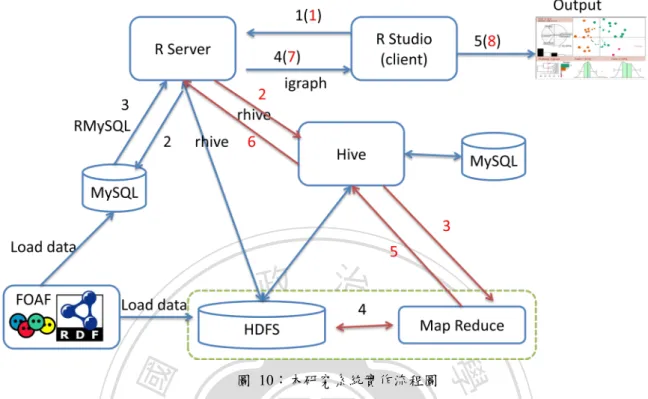
(39) 第五章 系統實作 5.1. 系統架構. 本研究的目標有三部分,首先利用 Hadoop/MapReduce 架構,從巨量的 RDF 資料中 作簡單的 FOAF 資料統計分析;第二部分是 R 使用 MySQL 測試資料庫分析與儲存 FOAF 資料的能力與效能;第三部分是 R 藉由 Hive,使用 HiveQL 操作處理進階的 FOAF 資料,. 政 治 大. 最後將結果回傳給 R,透過 igraph 程式庫作社群網路分析,如圖 9。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 9:本研究系統實作架構圖. 本研究的實驗流程如圖 10,淺綠色虛線方框為 R+Hadoop Streaming 分析(RHS Analytics) 程序,黑色數字是 R+MySQL 分析(RMS Analytics)流程,最後的紅色數字為 R+Hive 分 析(RH Analytics)流程。. 30.
(40) 政 治 大 圖 10:本研究系統實作流程圖. 學. ‧ 國. 立. 本研究使用兩部 PC 建置 Hadoop cluster 架構,PC 分別命名為 namenode 與 datanode1,. ‧. 其中 namenode 在 Hadoop 的腳色為為 Namenode 與 Datanode,另外一部則為單純的. y. Nat. Datanode,Hadoop 資料複製數量為 2,其餘參數使用 Hadoop 系統預定值,實驗環境的. 表 5:本研究系統實作規格. n. er. io. al. sit. 硬體規格與軟體版本參數如表 5。. Hadoop 角色 CPU RAM(GB) Disk(GB) Operation system Hadoop Hive MySQL R(3.0.1). namenode Namenode Datanode AMD Athlon II X4 640 4 1024 ubuntu 13.04 64 bits 1.2.1 0.11.0 5.5.37. Ch. datanode1. e nDatanode gchi. AMD Phenom II X4 945 12 1024 ubuntu 13.04 64 bits 1.2.1. RStudio Server 0.98.493 Rhive 2.0 RMySQL 0.9-3 igraph 0.71. 31. i vHadoop cluster n U 8 Cores 16 2.
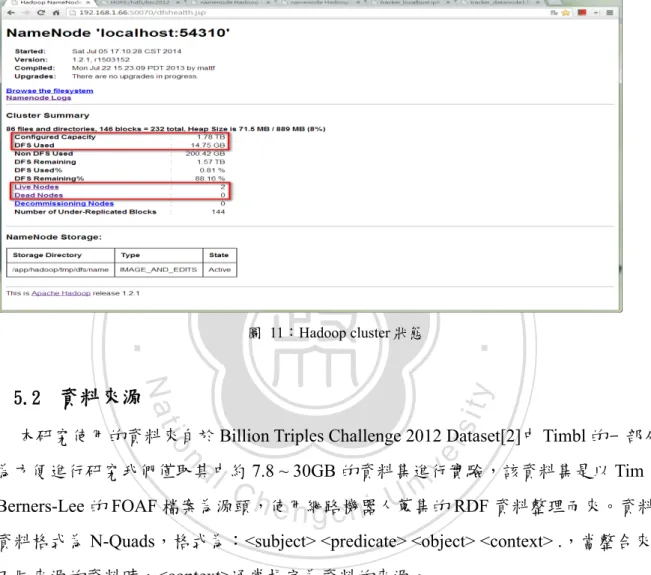
(41) 從 Namenode 觀察 Hadoop cluster 的運作狀態如圖 11。中間紅色方框表示 HDFS 容量為 1.78TB,使用的空間有 14.75GB,下紅色方框 Live Nodes:2,表示服務中的節點(Nodes) 有 2 個,即為我們的 namenode 與 datanode1。. 立. ‧ 國. 學 ‧. 圖 11:Hadoop cluster 狀態. y. Nat. 資料來源. sit. 5.2. 政 治 大. n. al. er. io. 本研究使用的資料來自於 Billion Triples Challenge 2012 Dataset[2]中 Timbl 的一部分,. v. 為方便進行研究我們僅取其中約 7.8 ~ 30GB 的資料集進行實驗,該資料集是以 Tim. Ch. engchi. i n U. Berners-Lee 的 FOAF 檔案為源頭,使用網路機器人蒐集的 RDF 資料整理而來。資料集 資料格式為 N-Quads,格式為:<subject> <predicate> <object> <context> .,當整合來自 不同來源的資料時,<context>通常指定為資料的來源。. 圖 12:N-Quads Example. 首先我們將資料集上傳至 Hadoop HDFS 目錄的/hdfs/btc2012,共分為 data-1.nq ~ data-5.nq。使用指令 hadoop fs –ls /hdfs/btc2012 檢查檔案目錄,結果如下圖. 32.
(42) 政 治 大. 立. ‧ 國. 學 y. Nat. sit. FOAF資料分析. 5.3. ‧. 圖 13:本研究系統資料容量. n. al. er. io. 為了驗證本研究假設的正確性,我們使用了系統實作的方式來驗證我們假設的可靠 度。 5.3.1. Ch. engchi. i n U. v. R+Hadoop Streaming分析(RHS Analytics). 我們以 Hadoop Streaming 架構分析作為工具,使用 R 分別撰寫 MapReduce 架構中 的 mapper 與 reducer 功能程式,依據於前一章節所建構的分析方式來統計 FOAF 使用 的字彙頻率, 程式語法如下: $HADOOP_HOME/bin/hadoop. jar. $HADOOP_HOME/contrib/streaming/hadoop-streaming-1.2.1.jar \ -input /hdfs/umbc/umbc_foaf.csv \ -output output \ -mapper /home/hduser/umbc/foaf-mapper.R \ -reducer /home/hduser/umbc/foaf-reducer.R 33.
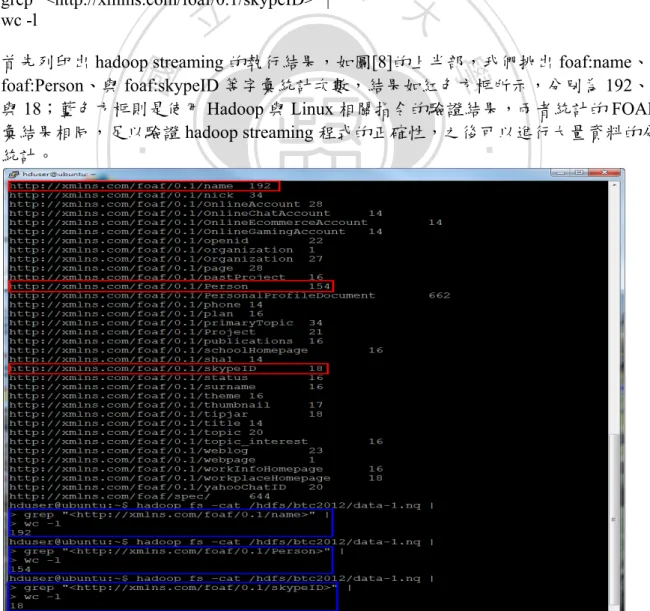
(43) #!/usr/bin/env Rscript # foaf-mapper.R - FOAFcount program in R # script for Mapper (R-Hadoop integration) # load the necessary libraries library(stringr) #FOAF Pattern like "http://xmlns.com/foaf/0.1/nick" foaf_pattern <- "http://xmlns.com/foaf/+[a-zA-Z0-9\\./_]+" getFoafKey <- function(line) unlist(str_extract_all( line,foaf_pattern)) con <- file("stdin", open = "r") while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0) { words <- getFoafKey(line) for (w in words) cat(w, "\t1\n", sep="") } close(con) foaf-mapper.R. 立. 政 治 大. ‧. ‧ 國. 學. #!/usr/bin/env Rscript # foaf-reducer.R - FOAFcount program in R # script for Reducer (R-Hadoop integration) splitLine <- function(line) { val <- unlist(strsplit(line, "\t")) list(word = val[1], count = as.integer(val[2])) } env <- new.env(hash = TRUE) con <- file("stdin", open = "r") while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0) { split <- splitLine(line) word <- split$word count <- split$count if (exists(word, envir = env, inherits = FALSE)) { oldcount <- get(word, envir = env) assign(word, oldcount + count, envir = env) } else assign(word, count, envir = env) } close(con) for (w in ls(env, all = TRUE)) cat(w, "\t", get(w, envir = env), "\n", sep = "") foaf-reducer.R. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 為驗證 Hadoop Streaming 執行結果的正確性,我們先使用小量資料測試,再使用 Linux 文字搜尋處理工具程式,比較兩者的分析統計結果是否相同。我們執行 hadoop fs -cat 與 Linux 的 grep 與 wc 指令,並用 pipe 串連多個指令進行驗證。驗證方式如下: hadoop fs -cat filename | #顯示 hadoop filename 的內容 34.
(44) grep "pattern" | #搜尋符合字串的資料 wc -l. #統計字數. 實際驗證方式如下: hadoop fs -cat /hdfs/btc2012/data-1.nq | grep "<http://xmlns.com/foaf/0.1/name>" | wc -l hadoop fs -cat /hdfs/btc2012/data-1.nq | grep "<http://xmlns.com/foaf/0.1/Person>" | wc -l. 政 治 大. hadoop fs -cat /hdfs/btc2012/data-1.nq | grep "<http://xmlns.com/foaf/0.1/skypeID>" | wc -l. 立. ‧. ‧ 國. 學. 首先列印出 hadoop streaming 的執行結果,如圖[8]的上半部,我們挑出 foaf:name、 foaf:Person、與 foaf:skypeID 等字彙統計次數,結果如紅色方框所示,分別為 192、154 與 18;藍色方框則是使用 Hadoop 與 Linux 相關指令的驗證結果,兩者統計的 FOAF 字 彙結果相同,足以驗證 hadoop streaming 程式的正確性,之後可以進行大量資料的分析 統計。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 14:使用小量資料驗證 Hadoop Streaming 分析的正確性 35.
(45) 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 圖 15:R+MySQL 分析(RMS Analytics)使用時間與讀取資料量. Ch. engchi. 36. i n U. v.
(46) 表 6:R+Hadoop Streaming 分析 FOAF Vocabulary 使用頻率-前 30 名 Order. FOAF Vocabulary. Frequency. Percentage. 1. http://xmlns.com/foaf/0.1/knows. 2,611,386. 13.196%. 2. http://xmlns.com/foaf/0.1/Person. 2,428,062. 12.270%. 3. http://xmlns.com/foaf/0.1/nick. 2,288,336. 11.564%. 4. http://xmlns.com/foaf/0.1/name. 1,370,057. 6.923%. 5. http://xmlns.com/foaf/0.1/homepage. 1,323,942. 6.690%. 6. http://xmlns.com/foaf/0.1/mbox_sha1sum. 1,316,500. 6.653%. 7. http://xmlns.com/foaf/0.1/weblog. 971,758. 4.911%. 8. http://xmlns.com/foaf/0.1/member_name. 935,970. 4.730%. 9. http://xmlns.com/foaf/0.1/tagLine. 935,970. 4.730%. 10. http://xmlns.com/foaf/0.1/image. 897,181. 4.534%. 11. http://xmlns.com/foaf/0.1/primaryTopic. 473,701. 2.394%. 12. http://xmlns.com/foaf/0.1/maker. 463,215. 2.341%. 450,798. 2.278%. http://xmlns.com/foaf/0.1/Agent. 442,420. 2.236%. http://xmlns.com/foaf/0.1/OnlineAccount. 440,741. ‧. 2.227%. 440,741. 2.223%. 439,863. 2.215%. 16. http://xmlns.com/foaf/0.1/PersonalProfileDocument. http://xmlns.com/foaf/0.1/accountName. 18. Nat. 19. http://xmlns.com/foaf/0.1/accountServiceHomepage. 20. http://xmlns.com/foaf/0.1/interest. 21. http://xmlns.com/foaf/0.1/mbox_sha1. 22. http://xmlns.com/foaf/0.1/Document. 23. http://xmlns.com/foaf/0.1/accountProfilePage. y. 17. sit. 15. ‧ 國. 14. 學. 13. 立. 政 治 大. 2.215%. 438,366. 2.152%. 425,927. 0.994%. 196,722. 0.656%. 129,878. 0.179%. http://xmlns.com/foaf/0.1/familyName. 35,481. 0.143%. 24. http://xmlns.com/foaf/0.1/givenName. 28,329. 0.142%. 25. http://xmlns.com/foaf/0.1/topic. 28,141. 0.128%. 26. http://xmlns.com/foaf/0.1/gender. 25,310. 0.090%. 27. http://xmlns.com/foaf/0.1/img. 17,727. 0.077%. 28. http://xmlns.com/foaf/0.1/Image. 15,296. 0.073%. 29. http://xmlns.com/foaf/0.1/page. 14,455. 0.069%. 30. http://xmlns.com/foaf/0.1/made. 13,728. 0.060%. io. 438,385. n. al. Ch. engchi. 37. er. http://xmlns.com/foaf/0.1/account. i n U. v.
(47) 分析效能部分,表 5 列出 namenode 與 datanode1 的設備等級並不相同,第一次使 用 namenode 以 singlenode cluster 的方式進行分析,總運算時間為 129 分鐘,第二次使 用 cluster(namenode + datanod1)架構,分析時間降低至 78 分鐘,分散式運算有效降低運 算時間。 對照表 1 的 FOAF 字彙表中,代表 email 的意義有 mbox 與 mbox_sha1sum,代表人 名的有 name、familyName(givenName)、firstName 與 lastName。mbox_sha1sum 使用 SHA1 方式代表個人的 email,代表唯一性與隱私性,並可避免遭受垃圾郵件。我們從表格 5(共 19,788,786 筆資料)發現使用 mbox_sha1sum (第 6 名,1,316,500 次,占 6.653%),相同意. 政 治 大 mailbox_sha1sum(646 次),但是 mbox 並無出現任何次數。 立. 義的還有 mbox_sha1(第 21 名,129,878 次,占 0.656%),email(693 次)、mailbox(654 次)、. 關於個人的名字除 name(第 4 名,占 6.923%)之外,還有 familyName(第 23 名,占. ‧ 國. 學. 0.143%)、givenName(第 24 名,占 0.142%),其他還有 firstName(6,398 次)、lastName(5,610 次)、family_name(3,285 次)、givenname(2,237 次)、surname(1,384 次)、firstname(698 次)、. ‧. middleName(646 次)、given_name(645 次)、surename(7 次)、fistName(1 次)、maiden_name(1. sit. y. Nat. 次)。. er. io. 從 mail 與 name 發現,除了 FOAF 字彙之外,部分字彙出現大小寫或是加上"-",拼 音錯誤(surename,正確為 surname)等與 FOAF 字彙不同的 predicate,甚至,可能是使用. al. n. v i n Ch 人工編寫錯誤,若是使用 foaf 編寫編輯介面或程式(如 FOAF-a-Matic),應該不會出現非 engchi U 正規字彙。藉由分析統計 FOAF 字彙的使用狀況,R+Hive 分析(RH Analytics)可以讀取 HDFS 的資料,使用 R 繪製 FOAF 字彙使用頻率相關圖型,也可提供 FOAF 有關單位日 後字彙的發展與改革。. 38.
(48) 5.3.2. R+MySQL分析(RMS Analytics). 我們利用 R 提供的 RMySQL 與 igraph 程式庫處理分析 FOAF 資料,首先使用 RMySQL 連結 MySQL,RMySQL 連接 MySQL 執行 SQL 查詢工作,並將資料轉換成 R 的 dataframe 格式,呼叫 igraph 的社會網路分析功能,找出 degree 最高者(黃色),並畫 出 social network 圖形。之後增加 MySQL 的資料量,評估與測試系統的極限。 本研究查詢的 SQL 語法: SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>' AND subject LIKE '%edu%' 執行最大的 IN-degree 是. 立. 政 治 大. V(g)[max(V(g)$degree)]$name [1] "_:httpx3Ax2Fx2Fsatiredunx2Elivejournalx2Ecomx2Fdatax2Ffoafxxbnode3". ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 16:Degree(最大為黃色圓圈)關係圖. 39.
(49) 5.3.3. R+Hive分析(RH Analytics). 我們利用 R 提供的 rhive 與 igraph 程式庫處理分析 FOAF 資料,首先使用 rhive 連 結 Hive,Hive 執行 HQL 轉換成 Hadoop 的 MapReduce 工作,並將資料轉換成 R 的 dataframe 格式,呼叫 igraph 的社會網路分析功能,包括 Betweenness (中介中心性)、 Closeness (接近中心性)與 Eigenvector centrality (特徵性)等分析。從 degree distribution 圖 17 與 Cluster size 圖 18 中都發現 Zipf’s distributions[15]的現象。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. i n U. 圖 17:Degree distribution 圖. Ch. engchi. 圖 18:Culster size 圖. 40. v.
(50) Degree Centrality http://www.w3.org/People/djweitzner/public/foaf.rdf 該作者 Daniel J. Weitzner[5],是 MIT CSAIL Decentralized Information Group 主席,作者認識 38 個人(out-degree),計算結果 degree(undirected)為 336,共有 296 人的 foaf 檔案敘述認識作者,但是作者不一定認識 對方。這現象與實際狀況相同,名人認識部分的人,但是有更多的人都認識該名人,如 圖 19。 R Command: > V(g)[max(V(g)$degree)] [1] "<http://www.w3.org/People/djweitzner/public/foaf.rdf#djw>" > max(V(g)$degree ) [1] 336 Between Centrality Between Centrality 的定義是:兩個非相鄰接的端點間的互動依賴於網絡中的其他端點, 特別是位於兩端點之間路徑上的那些端點。http://my.opera.com/Misseducation 位於所有 教育單位之間最短路徑的比例最高,對於教育界的影響力最大,符合現實狀況,如圖 20。 R Command:: V(g)[bte>=1100000]$name [1] "<http://my.opera.com/Misseducation/xml/foaf#me>". 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. Closeness Centrality 結果與 Between Centrality 相同,http://my.opera.com/Misseducation 與其他節點的距離比 較短,能夠快速的到達其他節點,因此該點很容易影響或是被影響,對於教育界相關人 士的間接影響力最大,如圖 21。 R Command: V(g)$label[which( closeness(g) == max(closeness(g)))] [1] "<http://my.opera.com/Misseducation/xml/foaf#me>". Ch. engchi. i n U. v. Eigenvector Centrality 章節 3.2 提到 Eigenvector Centrality 是 Degree Centrality 的改良方法,對於一樣擁有相同 的 degree Centrality 的兩個節點來說,相鄰的節點可能有不同的影響力。我們發現該點 是南加州大學 Information Sciences Institute[19]學院的研究人員 Yolanda Gil,在 FOAF 的 認識關係中找到 Berners-Lee 的 FOAF 內包括認識 Yolanda Gi,因此可以確定具有高度值 的相鄰節點所帶來的間接巨大影響力,如圖 22。 R Command: V(g)[max(evcent(g)$vector)]$name [1] "<http://www.isi.edu/~gil/foaf.rdf#me>". 41.
(51) 學 ‧. ‧ 國. 立. 政 治 大. 圖 19:Degree Centrality(最大值為右下角黃色圓圈). n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 20:betweenness(最大值為右下角紅色圓圈) 42.
(52) 立. 政 治 大. ‧. ‧ 國. 學 圖 21:closeness(最大值為中間偏右綠色圓圈). n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 22:evcent(最大值為右下棕色圓圈) 43.
(53) 5.3.4. 效能分析比較. 我們分別利用單機與 Hadoop cluster 的架構,測試 R 結合 MySQL 與 Hive 的執行效 率。FOAF 資料量從 7.8GB 至 30GB,資料依序增加至 MySQL 資料庫與 Hadoop HDFS。 從 R 介面執行 SQL(HQL)查詢資料,紀錄系統運算時間,使用的測試 SQL 語法如下: SELECT subject,object FROM btc2012 WHERE `predicate` = '<http://xmlns.com/foaf/0.1/knows>' AND subject LIKE '%edu%' 最後的執行結果如表 7。在 MySQL 部分,我們發現資料量與執行時間成正比。Hive. 政 治 大. 分成 single node 與 cluster 兩部分,single node 的執行時間比 MySQL 多,資料量與執. 立. 行時間成正比,這是因為 Hadoop/MapReduce 單機的效率不佳,無法執行平行處理;. ‧ 國. 學. 反觀 cluster 的執行過程充分發揮 Hadoop/MapReduce 平行處理的優勢,處理資料量越 大,所得效益更加明顯,資料效率約為 MySQL 的一倍。. ‧. 另外需特別注意的是,本實驗使用的 namanode 與 datanode1 的硬體規格不同(請參 考表 5),後者的處理效能較佳,若與使用兩部相同的硬體規格實驗比較,實驗數據. y. Nat. er. io. sit. 可能有些差異。. n. a l 表 7 : MySQL 與 Hive 效能比較表 v i n Ch e n g c執行時間(秒) hi U. 單機 (namenode). Single node (namenode). Cluster (namenode+datanode1 ). 資料量(GB) MySQL R+MySQL Hive R+Hive Hive R+Hive 7.8 86 93 128 142 91 96 13.3 156 157 219 240 112 143 18.1 231 233 264 313 119 169 30 345 349 424 510 187 272. 44.
(54) 450 400 處理時間 秒( ). 350 300 250. MySQL. 200. Hive. 150. Hive(Cluster). 100 50 0 7.8. 13.3. 立. 18.1. 資料量(GB) 政 治 大 圖 23:MySQL 與 Hive 效能圖. 30. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 45. i n U. v.
(55) 第六章 結論與未來展望 本研究首先針對社群網路區分為集中式(Centralized Social Network)與分散式 (Decentralized Social Network),說明選擇分析分散式社群網路的原因。分散式線上社群 網路採用 RDF(S)為基礎的 FOAF 格式於信任的第三方 Hadoop cluster 來儲存個人資料與 其社群網絡。面臨大量的社群網路資料,傳統的分析方式將會遇到許多處理與儲存的問 題,本研究透過結合 R 與 Hadoop MapReduce 技術,提出三種分析方式:R + Hadoop. 政 治 大. Streaming (RHS),R + MySQL (RMS),R + Hive (RH)來解決分析大量 FOAF 資料運算與. 立. 儲存的瓶頸。. ‧ 國. 學. R+Hadoop Streaming 分析(RHS Analytics)是使用 Hadoop 的 Hadoop Streaming 架構, 用 R 語言執行 Hadoop/MapReduce 分散式處理,從大量的 RDF 資料統計 FOAF 字彙使. ‧. 用頻率,輸出結果為文字檔並放在 HDFS,可作為後續 R + Hive (RH)進階處理,例如使 用 R 繪製 FOAF 字彙使用頻率圖;R+MySQL 分析(RMS Analytics)是使用 MySQL 資料. sit. y. Nat. 庫與 R 語言,本研究使用的中小型資料(30GB 之內),適合以 MySQL 作為儲存與分析的. al. er. io. 架構,並作為 R+Hive 分析(RH Analytics)的對照組;R+Hive 分析(RH Analytics)是 R 透. n. 過 rhive 結合 Hadoop/MapReduce 的優點,藉以分析大量的 FOAF 資料,最後結合 R 的. Ch. 社會網路分析功能,發現重要分析量測指標。. engchi. i n U. v. 我們分別就 Storage(儲存空間)、Performance(執行效能)與 FOAF SNA(Social Network Analysis),來討論本研究使用的三種分析方式: 1.R+Hadoop Streaming(RHS). Analytics. (1)Storage:使用 Hadoop HDFS 儲存 FOAF 資料,儲存空間可達 PB 以上。 (2)Performance:以 Hadoop Cluster 作分散式處理,處理速度隨 Hadoop Cluster 節點(node) 增加而提升。 (3)FOAF SNA:只作簡單的 FOAF 使用頻率統計,資料放在 Hadoop HDFS,可提供 R+Hive(RH) Analytics 作進階資料處理。. 46.
(56) 2.R+MySQL(RMS). Analytics. (1)Storage:MySQL 儲存容量因作業系統的檔案限制,而非 MySQL 本身的關係[37]。以 本實驗使用的 Linux 系統使用 ext3 檔案系統,容量上限為 4TB;Solaris 9/10 為 16TB。 (2)Performance:本實驗測試結果,處理速度隨資料增加而變慢(僅使用 namenode 單機)。 (3)FOAF SNA:使用 R igraph 計算 Social Network Centrality 指標,以 8 萬筆的圖形(Graph) 資料為例,計算時間在十分鐘以內;繪圖部分,若一個圖形包括一萬六千個點(Vertex) 與兩萬五千個邊(Edge),使用 namenode 計算耗時約 45 分鐘。 3.R+Hive(RH). 政 治 大. Analytics. (1)Storage:與 RHS 相同。. 立. (2)Performance:HQL 透過 Hive 轉換為 Hadoop/MapReduce 工作,藉由 Match(符合 FOAF. ‧ 國. 學. 字串)、Filter(過濾出屬於學術界資料)、Extract(萃取 Match 與 Filter 之後資料)資料後, 再輸出查詢結果,處理速度比 RHS 更快。. ‧. (3)FOAF SNA:與 RMS 相同。. y. Nat. sit. 本研究使用的測試資料-BTC2012 資料集,有些研究使用 SPARQL 作為查詢與分析. n. al. er. io. 工具,SQL-Like 適合作結構性資料的分析,因此除了 Hadoop 的 Hive 之外,另一項. i n U. v. HBase(Column DB)也適合作類似的研究。本研究結合 R 與 Hadoop/MapReduce 分析大量. Ch. engchi. 的社群網路資料,無論是使用 MySQL,或是 Hive 針對 FOAF 資料進行第一階段的分散 式平行處理, 之後再將結果傳遞給 R 作第二階段的社群網路分析。回到原本的 R 環境 開始計算社會網絡分析指標,即使有多核或多 CPU,最後只有單核或是單 CPU 能進行 運算。面對每日激增的社群網路資料,如何更進一步的結合 R 與 Hadoop/MapReduce, 並使用 HBase 或是與既有 R 的平行化軟體作結合,也是日後可以努力研究的方向。. 47.
數據

+7
相關文件
[r]
傳統上市場上所採取集群分析方法,多 為「硬分類(Crisp partition)」,本研 究採用模糊集群鋰論來解決傳統的分群
分析 分析 分析(Analysis) 分析 分析 組織 組織 組織 組織/重整 重整 重整 重整 綜合.
社區 社會 社會氣氛整體良好 出現了不同的行業 。 ,以切合社區的需要 弱勢社群
林旻柔 保險金融管理系 商業與管理群 已完成網路報到,且收到考生畢業證書 王美晴 保險金融管理系 商業與管理群 已完成網路報到,且收到考生畢業證書
• 1961 年Lawrence Roberts使用低速網路線 將劍橋與加州的電腦相連,展示廣域網路 (wide area network) 的概念..
根據研究背景與動機的說明,本研究主要是探討 Facebook
圖 2-13 顯示本天線反射損耗 Return Loss 的實際測量與模擬圖,使用安捷倫公司 E5071B 網路分析儀來測量。因為模擬時並無加入 SMA
