整合文件探勘與類神經網路預測模型之研究 -以財經事件線索預測台灣股市為例
64
0
0
全文
(2) 誌謝 在政大的兩年研究過程中,首先要感謝楊建民老師的諄諄教誨,讓我們從興 趣中探索研究方向,言談中更是學習到待人處事的道理,在在讓我對老師產生敬 佩及感恩的心意;也感謝邱光輝老師、季延帄老師及林我聰老師在提報論文與口 詴期間給予的指導及建議,使得架構及內容能夠更加嚴謹、詳細,有助於提升論 文整體品質。 此外,感謝在政大資管所認識的朋友們,同儕間互相切磋,讓我能在忙碌中. 治 政 快速成長,而研究室的夥伴們,柏均、振和、漢瑞及章威,互相鼓勵、討論,度 大 立 過同甘共苦的過程,能一同完成論文更是兩年來最感動的時刻,也感謝取向這兩 ‧ 國. 學. 年來一路的幫忙。. ‧. 生命中的好朋友們,孟婷、依玟、瑋之和謹伃,我們在不同領域努力生活著,. sit. y. Nat. 但因為有你們的陪伴,讓我不斷地提醒自己要一起為了夢想努力,成為一個很棒. n. al. 我在過程疲憊的時候總是能夠得到前進的力量。. Ch. engchi. er. io. 的人。而家人這兩年的鼓勵及支持,讓我能毫無顧慮的專心研究,感謝你們,讓. i n U. v. 最後,謹將這份榮耀獻給所有關心我及我關心的人。. I.
(3) 摘要 隨著全球化與資訊科技之進步,大幅加快媒體傳播訊息之速度,使得與股票 市場相關之新聞事件,無論在產量、產出頻率上,都較以往增加,進而對股票市 場造成影響。現今投資者多已具備傳統的投資概念、觀察總體經濟之趨勢與指標、 分析漲跌之圖表用以預測股票收盤價;除此之外,從大量新聞資料中,找出關鍵 輔助投資之新聞事件更是需要培養的能力,而此正是投資者較為不熟悉的部分, 故希望透過本文加以探討之。. 政 治 大 以文件距離為基礎之 kNN立 技術分群,並採用時間區間之概念,用以增進分群之. 本研究使用 2009 年自由時報電子報之財經新聞(共 5767 篇)為資料來源,. ‧ 國. 學. 時效性;而分群之結果,再透過類別詞庫分類為正向、持帄及負向新聞事件,與 股票市場之量化資料,包括成交量、收盤價及 3 日收盤價,一併輸入於倒傳遞類. ‧. 神經網路之預測模型。自台灣經濟新報中取得半導體類股之交易資訊,將其分成. sit. y. Nat. 訓練及測詴資料,各包含 168 個及 83 個交易日,經由網路之迭代學習過程建立. n. al. er. io. 預測模型,並與原預測模型進行比較。. Ch. i n U. v. 由研究結果中,首先,類別詞庫可透過股票收盤價報酬率及篩選字詞出現頻. engchi. 率的方式建立,使投資者能透藉由分群與分類降低新聞文件的資訊量;其次,於 倒傳遞類神經網路預測模型中加入分類後的新聞事件,依統計顯著性檢定,在顯 著水準為 95%及 99%下,皆顯著改善隔日股票收盤價之預測方向正確性與準確 率,換言之,於預測模型中加入新聞事件,有助於預測隔日收盤價。最後,本研 究並指出一些未來研究方向。 關鍵字:事件偵測與追蹤、kNN 分群、倒傳遞類神經網路預測模型. II.
(4) Abstract With the development of the Internet rapidly, retrieving correct information from lots of sources for investors is very important today. In this study, we want to explore whether unstructured information like news’ events will affect Taiwan stock market. Therefore, we used cluster technology to group finance news as news’ events, and further classify as “positive, flat or negative” events; then combine transaction information in TEJ’s database to build a BPN prediction model.. 政 治 大. From the results, in the one hand, we found that investors could use clustering. 立. and classification technologies to abstract information. On the other hand, the predict. ‧ 國. 學. model with news’ events will improve the accuracy of the direction and the precision of the prediction. In other words, the new model is more significant than one without. ‧. news’ events.. y. Nat. n. al. er. io. model. sit. Keywords: event detection, event tracking, kNN clustering, BPN prediction. Ch. engchi. III. i n U. v.
(5) 目錄 誌謝.................................................................................................................................I 摘要............................................................................................................................... II Abstract ........................................................................................................................ III 表目錄........................................................................................................................ VII 公式目錄................................................................................................................... VIII 第一章 緒論.................................................................................................................. 1 第一節 研究背景與動機.......................................................................................... 1. 治 政 第二節 研究目的...................................................................................................... 3 大 立 第二章 文獻探討.......................................................................................................... 4 ‧ 國. 學. 第一節 新聞與股價之相關性研究.......................................................................... 4. ‧. 第二節 探勘技術...................................................................................................... 5 2.1.資料探勘.......................................................................................................... 5. y. Nat. io. sit. 2.2.文字探勘.......................................................................................................... 8. n. al. er. 第三節 事件偵測與追蹤........................................................................................ 15. Ch. i n U. v. 3.1 事件偵測........................................................................................................ 15. engchi. 3.2 事件追蹤........................................................................................................ 16 第四節 類神經網路................................................................................................ 16 4.1 概論................................................................................................................ 16 4.2 網路結構........................................................................................................ 17 4.3 股票市場之應用............................................................................................ 18 第三章 研究設計........................................................................................................ 19 第一節 新聞文件分群與分類................................................................................ 21 1.1 斷詞工具........................................................................................................ 21 1.2 新聞文件分群──事件偵測與追蹤............................................................ 22 IV.
(6) 1.3 新聞事件分類................................................................................................ 26 第二節 倒傳遞類神經網路預測模型.................................................................... 26 第三節 研究樣本與統計檢定................................................................................ 31 3.1 研究樣本........................................................................................................ 31 3.2 統計檢定........................................................................................................ 32 第四章 研究結果........................................................................................................ 33 第一節 類別詞庫之建立........................................................................................ 33 第二節 倒傳遞類神經網路預測模型之參數建構................................................ 37. 政 治 大 3.1 預測方向正確性............................................................................................ 40 立. 第三節 預測模型之顯著性檢定............................................................................ 40. 3.2 預測準確率.................................................................................................... 44. ‧ 國. 學. 第五章 結論................................................................................................................ 48. ‧. 第一節 結論與建議................................................................................................ 48. y. Nat. 第二節 未來研究方向............................................................................................ 49. n. al. er. io. sit. 參考文獻...................................................................................................................... 50. Ch. engchi. V. i n U. v.
(7) 圖目錄 圖 2.2.1 資料探勘為 KDD 的程序之一 ...................................................................... 6 圖 2.2.2 向量空間模型............................................................................................... 11 圖 2.2.3 詞彙─文件矩陣........................................................................................... 11 圖 2.2.4 分群與群集質心示意圖............................................................................... 13 圖 2.3.1 監督式學習與非監督式學習....................................................................... 17 圖 3.1.1 研究架構....................................................................................................... 20 圖 3.2.1 文件相似度與距離關係............................................................................... 24. 治 政 圖 3.2.2 文件相似度轉換為距離關係....................................................................... 24 大 立 圖 3.2.3 公式轉換圖................................................................................................... 25 ‧ 國. 學. 圖 3.2.4 倒傳遞類神經網路流程............................................................................... 27. ‧. 圖 倒傳遞類神經網路預測模型之結構.................................................................... 30 圖 3.3.1 自由時報電子報........................................................................................... 31. y. Nat. io. sit. 圖 3.3.1 半導體類股交易資訊................................................................................... 32. n. al. er. 圖 4.1.1 報酬率分佈-2009 年 .................................................................................... 34. Ch. i n U. v. 圖 4.2.2 含新聞事件之預測模型(層數為 1,神經元個數為 4)......................... 39. engchi. VI.
(8) 表目錄 表 2.2.1 斷詞方式之比較............................................................................................. 9 表 3.2.1 CKIP 與 Yahoo API 之比較 ......................................................................... 21 表 4.1.1 類別詞庫數量比較....................................................................................... 35 表 4.2.1 不同參數之模型 RMSE 比較(*含新聞事件,**不含新聞事件) ......... 38 表 4.2.4 預測方向正確性之顯著檢定(*含新聞事件,**不含新聞事件).......... 41 表 4.2.4 預測準確率之顯著性檢定(*含新聞事件,**不含新聞事件)............. 45. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VII. i n U. v.
(9) 公式目錄 公式. 權重值 ........................................................................................................... 22. 公式. 相似度修正. 公式. 餘弦相似度 ................................................................................................... 23. 公式. 考慮時間區間 ...................................................................... 22. k. ................................................................................................. 23. 公式. 質心計算 ....................................................................................................... 23. 公式. 權重初始值設定公式 ................................................................................... 28. 公式. 權重初始值設定公式 ................................................................................... 28. 公式. 顯著性比較之假說(一) ......................................................................... 40. 公式. 顯著性比較之分配(一) ......................................................................... 40. 公式. 顯著性比較之臨界值(一) ..................................................................... 43. 公式. 顯著性比較之假說(二) ......................................................................... 44. 公式. 顯著性比較之分配(二) ......................................................................... 44. 公式. 顯著性比較之臨界值(二) ..................................................................... 47. ‧. ‧ 國. io. sit. y. Nat. n. al. er. 公式. 學. 公式. 治 政 E................................................................................................................ 32 大 立 E ............................................................................................................. 32. Ch. engchi. VIII. i n U. v.
(10) 第一章 緒論 第一節 研究背景與動機 當前投資市場所流通的企業併購與轉投資訊息,皆可能對投資決定造成重大 影響,足見資訊已成為評估投資風險的重要管道。因此,對於金融業者與投資者 而言,擴充蒐集資訊的數量,並從快速更新、種類繁多的各種資訊中,分辨正確 的投資脈動,已成為投資者作為審慎判斷進入市場的要件,以上在在說明了由於 台灣市場規模較小,對於資訊的接收往往使股票市場隨之造成影響,這也是典型. 治 政 「淺碟性市場」的特性之一(李春淋,2010;吳真蕙,2000;林章德,2000) , 大 立 總的來說,掌握資訊對於台灣投資者而言是一重要的投資利器。 ‧ 國. 學. 面對股票市場的波動起伏,投資者除了透過總體經濟趨勢及對公司營運狀況. ‧. 做分析之外,仍需要累積敏銳的觀察力,運用正確的投資策略,及選擇適當時機. sit. y. Nat. 進入或退出市場。而隨著資訊科技的進步,無論在空間或時間層次,訊息傳播的. n. al. er. io. 速度都較以往快速,人們可隨時隨地取得四面八方的消息。然而,繁雜的訊息卻. i n U. v. 可能阻礙投資者判斷正確的資訊來源,更添增找尋其所需資料的時間。因此,在. Ch. engchi. 各個領域中,與股票市場相關之研究日漸受到關注,學術著作也有可觀產出,其 所發展的方向有三,一為結構化資訊,由總體經濟的趨勢建構具有經濟意義的模 型,如時間序列模型(楊踐為、李家豪、類惠貞,2007)等,以觀察未來趨勢; 二多從非結構角度觀察,在資訊領域中透過人工智慧(Artificial Intelligence, AI) 技術結合財金重要指標以發掘隱藏的資訊(Nygren, 2004;陳稼興、楊孟龍,2000; 黃馨瑩、楊建民、李耀中,2009) ;三則將上述兩者合併之研究(Armano, 2005)。 針對後兩者之方向,常用的工具如類神經網路預測模型,原因在於其具有學習、 聯想、歸納推演等能力,使得非結構化之資訊能透過訓練得到適當的預測模型,. 1.
(11) 雖然訓練過程易於落入區域解問題,然而透過演算法(如基因演算法等)之全域 搜尋法可避免此問題(林聖哲,2002)。 由於新聞具有時效性、區域性的特性,能適時揭露重要資訊給地區民眾,而 目前網路新聞事件的分類多以人工判斷為主,投資者能直覺地從財經新聞中選擇 相關的新聞,當作觀察股票市場變化的工具之一(Ahmad et al., 2002) 。事實上, 並非所有相關的新聞皆受到投資者的關注,而是部分與投資市場相關之事件,投 資者會從中發掘出隱含的訊息以幫助決策。Khurshid(2002)的研究認為,影響 財務市場的資訊,不論這些資訊的來源形式為何,新聞內所隱含的資訊對股價的 影響扮演重要的中介因素。. 立. 政 治 大. 新聞事件偵測與追蹤的領域,以卡內基美隆大學(Carnegie Mellon University,. ‧ 國. 學. CMU)與麻州大學(University of Massachusetts, UMass)最為著名(古倫維,2000;. ‧. 戴尚學,2003),而 CMU 以 kNN(k-Nearest Neighbor)分類器之概念實現新聞. sit. y. Nat. 事件偵測與追蹤的技術,並加入時間區間(Time Window)的概念,以符合新聞. io. n. al. er. 具備的時效性,使分群效果更完整。. i n U. v. 近年來,從新聞文件預測股票趨勢之研究相當熱門,部分學者透過文字探勘. Ch. engchi. 將新聞文件分類,進而對股票趨勢做對應,用以幫助預測(喻欣凱,2008),亦 有學者嘗詴將文字探勘與人工智慧結合,從文件中擷取新聞文件特徵字後,以訓 練的方式建構預測模型,所建立的模型則以類神經網路為大宗(黃馨瑩、楊建民、 李耀中,2009;Nygren, 2004;Kim & Han, 2001;Kim & Han, 2000),然而新聞 往往因事件大小造成重複發佈的機會,使重要訊息分散於各新聞文件中,降低了 「新聞事件」之焦點。. 2.
(12) 故本研究期望能以「新聞事件偵測與追蹤」的技術為出發點,透過類別詞庫 的建立,探討新聞事件對於市場股價之影響,期望能將新聞文件以新聞事件分類 的方式,與類神經網路預測模型做結合,進而提供投資者有效的投資線索及資 訊。 第二節 研究目的 依上述之背景與動機,本研究將針對以下二點做為研究目的:. 1.. 以每日報酬率為基礎,透過詞彙於一篇文章中所出現次數(Term Frequency,. 政 治 大. TF,以下簡稱為詞頻)及權重值之篩選建立新聞類別詞庫,使新聞事件能. 立. 根據類別詞庫判斷屬於哪一分類,透過類別詞庫的建立,也能給予投資者在. ‧ 國. 學. 預測股票市場上的觀察指標。. 於倒傳遞類神經網路預測模型中加入非結構化之資訊,使預測模型顯著提升. ‧. 預測方向正確性與預測準確率。. io. sit. y. Nat. n. al. er. 2.. Ch. engchi. 3. i n U. v.
(13) 第二章 文獻探討 第一節 新聞與股價之相關性研究 Khurshid 等學者(2002)認為無論文字消息的形式為何,皆可能為影響金融 市場的波動,換言之,文字消息為傳遞事件的一種方式,而投資者可透過文字消 息如新聞文件觀察並加以評估投資的最佳時機。以新聞文件為例,媒體可根據事 件大小評估該新聞事件之重要程度發佈大大小小的新聞文件,研究亦指出,新聞 量與股價趨勢具有正向影響(黃馨瑩、楊建民、李耀中,2009),因此資訊的傳. 政 治 大 民、李耀中,2009;Khurshid 立 et al., 2002)。. 遞上實際是由事件所揭露,而新聞文件僅為傳遞資訊的方式之一(黃馨瑩、楊建. ‧ 國. 學. Lavrenko 等學者(2000)採用分段線性配對(Piecewise Linear Fitting)觀察. ‧. 股價漲跌趨勢,並將高度相關的文件做連結,訓練出 Language Model,模型也證 實財經新聞與股價趨勢具有相關性,且能用來有效預測股價。. sit. y. Nat. n. al. er. io. Chen 等學者(2003)採用 PNN 訓練歷史資料,將模型用來預測指數報酬率. i n U. v. 的方向,引導投資者的交易策略。研究顯示以 PNN 為基礎投資策略能比其他投 資策略獲得更高的報酬率。. Ch. engchi. Mittermayer(2004)應用支援向量機(Support Vector Machine, SVM)將新 聞分成正向新聞、無影響新聞及負向新聞三類,並實現於其所提出的系統 NewsCATS(News Categorization and Trading System),用來預測新聞發布後 60 分鐘之 NMS(National Mittermayer System)股票指數趨勢。結果顯示以此系統 交易的帄均獲利大於隨機投資策略,因此認為新聞分類能幫助提供更多資訊以進 行股價趨勢的預測(Mittermayer, 2004;吳昀錚,2008)。. 4.
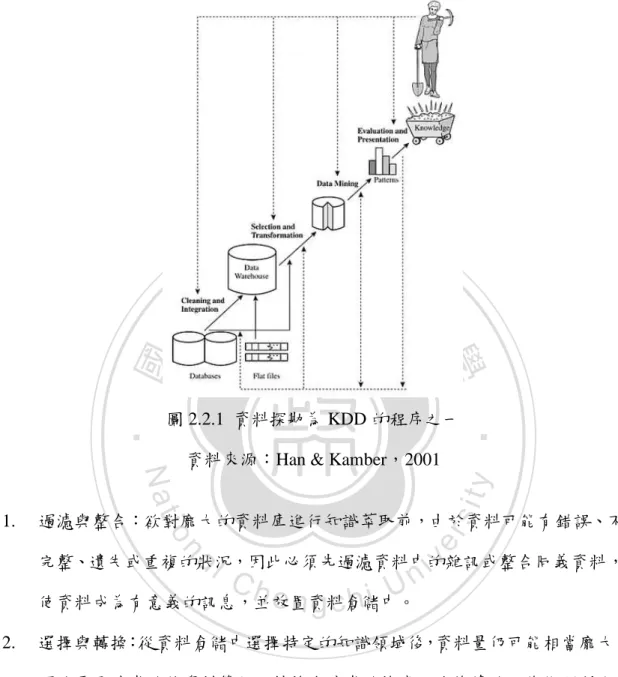
(14) 吳昀錚(2008)以線上財經新聞分類為基礎,決定投資者的短期之投資策略, 並以台灣股票加權指數評估系統之績效。實驗結果顯示,由投資策略所獲得之報 酬率可勝過銀行定存利率,具有參考價值。 第二節 探勘技術 2.1. 資料探勘 隨著科技的進步,資料產生的速度亦突飛猛進,資料量隨著時間大量成長, 從大量資料中萃取有意義的特徵或規則,並集結成有用的知識,成了各領域期望. 政 治 大. 能獲得的分析能力,而資料探勘即為萃取資訊的技術之一。許多人認為「資料探. 立. 勘」和「從資料中發掘知識」 (Knowledge Discovery in Database, KDD)是同義的,. ‧ 國. 學. 然而,資料探勘僅為 KDD 的重要程序之一,研究亦顯示兩者之間有著相輔相成 的關係(Fayyed, 1996;Han & Kamble, 2001;黃孝文,2010)。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 5. i n U. v.
(15) Han & Kamber(2001)提出 KDD 的程序可分成四個步驟,如圖 2.2.1:. 立. 政 治 大. y. sit. Nat. n. al. er. 過濾與整合:欲對龐大的資料庫進行知識萃取前,由於資料可能有錯誤、不. io. 1.. 資料來源:Han & Kamber,2001. ‧. ‧ 國. 學. 圖 2.2.1 資料探勘為 KDD 的程序之一. i n U. v. 完整、遺失或重複的狀況,因此必頇先過濾資料中的雜訊或整合同義資料,. Ch. engchi. 使資料成為有意義的訊息,並放置資料倉儲中。 2.. 選擇與轉換:從資料倉儲中選擇特定的知識領域後,資料量仍可能相當龐大, 因此需要適當的將資料簡化、轉換成適當的格式,使後續的工作能順利進 行。. 3.. 資料探勘:此為 KDD 之重要過程,透過關聯規則、分類預測、分群分析等 演算法,分析並挖掘資料中隱藏的規則。. 4.. 評估與解釋:為了檢驗前一步驟所發現的規則是合理的,需要對其作出合理 的評估或解釋,此結果可透過簡易的圖表呈現,讓使用者能評估是否可成為 決策分析的依據。 6.
(16) 資料探勘的過程中,使用者可以根據資料的類型與範圍,選擇適當的演算法 做相關分析,因此資料探勘所採用的演算法成為知識挖掘的關鍵因素。常見的演 算法包括關連規則分析、分類分析及分群分析(Han & Kamber,2001;黃孝文, 2010)。. 1.. 關連規則分析(Association Analysis) 此演算法以統計機率為基礎,從大量的資料中發掘出,在某一規則下兩種不. 同類型的項目經常共同出現之現象。商業上透過市場決策分析,了解客戶購買商. 政 治 大. 品的隱性規則,經過有效的推測後,有助於主管執行有效的策略決定。. 立. 分類分析(Classification Analysis). 學. ‧ 國. 2.. 資料分類包括兩步驟,首先要先透過分類演算法訓練資料,得到分類的規則,. ‧. 通常規則形式為「IF … , THEN …」,然後分類器經過訓練後,才能透過分類規. sit. y. Nat. 則預測測詴資料所屬的分類。分類的技術包含簡單貝氏分類(Naïve Bayes. io. er. Classification) 、kNN(k-Nearest Neighbor) 、支援向量機(Support Vector Machine,. al. SVM)等。而 Joachims(1998)將此三種分類器與最小帄方誤差法(LLSF)及. n. v i n Ch 類神經分類(ANN)以統計方法比較效率與分類結果,優異程度為: engchi U {kNN、SVM}>LLSF>ANN>NB。. 7.
(17) 3.. 分群分析(Clustering Analysis) 透過觀察將大量資料分割、分群,使群集內資料的相似度提高,而群集間的. 相似度降低,分群以統計的基礎對資料做分析,由於分群時目標值並不存在,屬 於非監督式學習。Han & Kamber(2006)將分群法分成五大類:分隔式分群 (Partitioned)、階層式分群(Hierarchical)、密度基礎分群(Density-based)、網 格式分群(Grid-based)與類神經網路分群(Neural network),尤以分隔式分群 之 K-means 最為常見(胡舜禹,2009) ,而 kNN 分類器之概念亦被用於分群技術 上(戴尚學,2003)。 2.2. 文字探勘. 立. 政 治 大. ‧ 國. 學. 文字探勘屬於資料探勘中的一重要分支,透過觀察文件中文字、段落、主題 等關聯,期待能從中尋找文件趨勢,甚至進一步進行預測(Han & Kamber, 2001)。. ‧. sit. y. Nat. 袁立安(2007)將文字探勘分成三個步驟:文件準備、文件處理與文件分析‧. io. er. 文件準備階段需對文件做前處理,並萃取有用的關鍵字詞;文件處理步驟使用資 料探勘技術發掘文件中有意義、有趣的型態;最後,文件分析進行輸出結果的驗. al. n. v i n Ch 證以確定所擷取之知識是否有用,下列將整理各步驟之使用方式。 engchi U 文件準備. 2.2.1.. 1.. 斷詞 中文文件是由字與標點符號以非結構化的方式所組成,然而字卻未必能成為. 有意義的單位,因此,在處理中文文件前必頇採取斷詞的動作,使字能以有意義 的詞彙之方式呈現。研究顯示,斷詞的方式大致分成詞庫斷詞法、N-Gram 選詞 法及混合斷詞法三種(顧皓光,1996;戴尚學,2003) ,其優缺點將列於表 2.2.1。. 8.
(18) 表 2.2.1 斷詞方式之比較 名稱. 方式. 詞庫斷詞法. 以既有詞庫做為標準,將文件以比對的方式找出斷詞。比對 的效果與詞庫完整程度成正比。. N-Gram 選詞法. 依照所選取的字數長短,計算字所出現的數量,以統計分析 判斷是否為有意義的詞,再做出適當斷詞。優點是不需要知 道詞彙的意義,亦不被詞庫限制,但斷詞過程中不易發現不 合適的詞彙。. 政 治 大 出可能的斷詞位置,此方法擷取詞庫與統計斷詞的優點,然 立. 混合斷詞法. 先對文件做詞庫比對,再對無法比對的字詞做統計斷詞,找. 而仍需對詞庫做維護才能有效提升斷詞結果的品質。. ‧ 國. 學. 資料來源:顧皓光,1996;戴尚學,2003. ‧. 2.. 特徵值選擇. sit. y. Nat. io. er. 文件處理時,為了使效率增加,減少計算複雜度,往往會先移除文件中不具. al. 代表性的詞彙,找出特徵值(Liu & Motoda, 1998) 。常見的特徵值的選擇方式包. n. v i n Ch 括:文件頻率(Document Frequency)挑選出現於文件數量較高的字詞,將其當 engchi U. 成類別的特徵值;資訊增益量(Information Gain)以字詞在各類別中出現及不出 現的機率判斷字詞重要性;交互資訊量(Mutual Information)著重於詞彙間共同 出現的程度;卡方統計量( 2 -Statistic)以卡方統計量檢定字詞與類別間的相關 程度;詞彙強度(Term Strength)在訓練集內利用餘弦找出相似度到達門檻的文 件,再以條件機率計算兩詞彙的關聯強度。其中,以資訊增益量及卡方統計量成 效較佳(Yang & Pedersen, 1997;Aas & Eikvil, 1999)。. 9.
(19) 3.. 權重值計算 縱然文件準備後能得到斷詞結果,卻難以評斷哪些字詞具有文件代表性,而. 權重值計算則是為了此目的產生。根據 Popescu(2001)研究整理,權重值可由 三個部分組成,包括區域權重(𝐿𝑖𝑗 ) 、全域權重(𝐺𝑖 )及文件之正規化因子(𝑁𝑗 ), 區域權重以字詞於「特定文件」中出現的頻率為基礎,而全域權重則以字詞於「所 有文件」中出現的頻率為基礎,正規化因子則是為了讓不同字詞的權重得以比較 而產生。. 政 治 大 中出現的次數,全域函數為字詞於所有文章出現次數之倒數值,並給予對數以做 立 舉例來說,Jing 等學者(2002)研究中權重值之區域函數為字詞於一篇文章. 調整,最後則採用餘弦正規化。此方法即為 TFIDF(Term Frequency–Inverse. ‧ 國. 學. Document Frequency),也是常被使用的權重計算方式之一。 文件處理. sit. y. Nat. 向量空間模型. io. n. al. er. 1.. ‧. 2.2.2.. i n U. v. 向量空間模型是目前資訊檢索中效果較好的方式(Salton, 1988),也是目前. Ch. engchi. 最廣泛使用的資訊檢索模型(戴尚學,2003)。每篇文件以一組向量表示,維度 代表的是關鍵字詞,而維度的數值則代表該字詞的權重,如圖 2.2.2 所示。. 10.
(20) 圖 2.2.2 向量空間模型. 政 治 大. 資料來源:Salton et al., 1975. 立. 此外,為了使文件間能互相比較,使用向量空間模型時必頇轉化為單位向量,. ‧ 國. 學. 以避免文件長短不一所造成的誤差。當文件數量增加時,可利用「詞彙─文件矩 陣」表達詞彙與文件間的關係。以圖 2.2.3 為例,文件集選出 i 個特徵字,而每. ‧. 一列則代表一篇文章中各個特徵字的權重值。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 2.2.3 詞彙─文件矩陣 資料來源:Salton & Gill, 1983. 11. v.
(21) 2.. 相似度計算 將文件以向量空間模型表達後,可藉由相似度計算實現分群或分類技術。常. 用的相似度計算方式有 Jaccard 係數及 Cosine 係數(Salton, 1988),前者計算文 |𝑥∩𝑦|. 件字詞出現於交集之機率意即|𝑥|∪|𝑦|,而後者則計算兩向量間之餘弦值。 3.. 分類、分群技術. (1) 貝氏分類器. 政 治 大. 此分類器以貝氏定理為基礎,且假設屬性間彼此獨立下,以事前機率計算事. 立. 後機率,再判斷資料屬於哪個類別(黃孝文,2010;章秉純、許清琦,2001)。. ‧ 國. 學. 透過大量的學習,能有效處理欲分類的資料。. ‧. (2) kNN分類器. Nat. sit. y. 此演算法搜尋與新文件最相似的 k 份文件,並比較兩者之相似度,選擇各分. n. al. i n U. 採用 M-way kNN,演算步驟如下(戴尚學,2003):. Ch. engchi. er. io. 類中相似度最高的類別,因此演算過程中,最重要的即為 k 值大小之決定。一般. v. Step1、將文件以向量空間模型表示。. Step2、取出前 k 份與新文件相似度最高之文件,此 k 份文件之類別則為候選類 別。. Step3、將文件與新文件之相似度以類別為基礎做加總,分數最高之類別則為新 文件之所屬類別。. 12.
(22) (3) 支援向量機 支援向量機(Support Vector Machines, SVM)由 Vapnik 於 1979 年提出,分 類方式是在多維度空間中,以超帄面(Hyperplane)對資料作分割,使分類邊界 最大(章秉純、許清琦,2001)。. (4) K-means分群 此演算法由 J. B. MacQueen 於 1967 年所提出,分群之前頇先設定群集數量 k,以質心的概念對群集做迭代,直到質心趨於穩定,群集收斂為止(A Tutorial on. 政 治 大. Clustering Algorithms, 2011) 。K-means 雖然能得到較佳的分群結果,質心的概念. 立. 卻容易受到資料的離散程度影響,分析者在事前未必能正確決定群集數量,若資. ‧ 國. 學. 料量龐大將造成整體效率降低。圖 2.2.4 為群集及群集質心之示意圖。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2.2.4 分群與群集質心示意圖 資料來源:Salton et al., 1975. 13.
(23) K-means 分群步驟(A Tutorial on Clustering Algorithms, 2011)如下: Step1、隨機選取 k 個資料當作質心。 Step2、將資料與此 k 個質心計算相似度,選擇較近的分為同一群,最後再計算 k 群資料所產生的新質心。 Step3、若質心產生變動,意即尚未收斂,則重複 Step2,直到質心收斂為止。. 2.2.3.. 文件分析. 通常,文字處理後需透過客觀的方法評估其效用,根據 Sebastiani(2002)的整. 政 治 大. 理,評估方法較常使用的有 Accuracy、Precision、Recall,以及 F-measure 等,其. 立. 中,Accuracy 評估預測結果中分類預測結果的機率;Precision 評估預測結果正確. ‧ 國. 學. 中分類預測結果亦為正確的機率;Recall 評估預測結果與分類預測結果相同中, 預測結果正確之機率;F-measure 綜合 Precision 及 Recall 之評估方式而成。此四. Nat. n. al. er. io. sit. y. ‧. 種為資訊擷取領域中常用之評估指標(Sebastiani, 2002)。. Ch. engchi. 14. i n U. v.
(24) 第三節 事件偵測與追蹤 根據學者定義: 「在特定的時間、地點所發生的事情,即為事件」 ,其目的在 於能利用資料間的關係描述此事件。事件偵測是為了辨識已存在事件的特徵,或 尚未發生的事件;而事件追蹤則是從事件既有的樣本中尋找子事件(Allan, 1998)。 3.1 事件偵測 事件偵測分成「回顧偵測(Retrospective Detection)」與「線上偵測(On-line. 政 治 大. Detection)」兩種(Allan, 1998)。兩者差異在於前者是從固定範圍的文件中偵測. 立. 事件是否存在,而後者則具有範圍不定,且具有時間性,此種方式較適用於新聞. ‧ 國. 學. 事件。. ‧. CMU 在新聞事件偵測上,採用向量空間模型表示一篇文件,而偵測方式則. sit. y. Nat. 是採用單一連結法(戴尚學,2003;Yang, 1997;Kurt, 2001),新聞事件偵測可. io. er. 分成字詞權重值計算及群聚方式。前者採用 TFIDF 計算,而後者採用向量空間 模型表示,而事件將以事件質心(Centroid)表示,新文件僅需與事件質心作相. al. n. v i n Ch 似度比對,偵測新文件所屬之事件是否存在即可。CMU e n g c h i U 實現新聞事件偵測時, 加入了時間區間(Time Window),避免文件與事件時間間隔太遠仍被考慮的情 況(戴尚學,2003;Yang, 1998)。. 15.
(25) 3.2 事件追蹤 事件偵測僅用來找尋相似度高的事件,如何正確歸類則需依賴事件追蹤。 CMU 採用 2-way kNN 分類法對每個事件進行事件獨立追蹤(戴尚學,2003;Yang, 2000)。此分類法將事件分成「目標(Positive)事件」及「非目標(Negative) 事件」 ,計算結果即為新文件與目標事件的相關分數(Relevance Score) 。為避免 k 值大小造成分類不正確的問題,亦提出帄均加以修正。 第四節 類神經網路 4.1 概論. 立. 政 治 大. ‧ 國. 學. 類神經網路(Artificial Neural Network, ANN)最早由 McCulloch 和 Pitts 在 1943 年共同提出,是人工智慧領域中的重要領域之一。它使用電腦模擬神經細. ‧. 胞接收外界刺激後傳遞訊息的動作,是一種用來表達生物神經網路的數學模型,. sit. y. Nat. 屬於帄行運算的模式。由於其模型適合用來解決較複雜的非線性模型,擁有學習、. io. 問題通常具有下列特徵(張斐章、張麗秋,2005):. n. al. Ch. engchi. (1) 問題及相關條件難以完整定義。. er. 聯想、歸納推演等能力,因此常被用來解決最佳化、分類、預測等問題,而這些. i n U. v. (2) 需要快速得到問題解答且解答不用完全精確。 (3) 問題非常複雜或是非線性的問題,無法由一連串已知的數學方程式來描述。. 16.
(26) 4.2 網路結構 類神經網路模擬生物神經元傳遞訊息的結構,由許多運算單元組成,而運算 單元之間透過非線性關係連結組成,而運算單元則分成輸入層、隱藏層及輸出層。 每一個神經元之輸入值與輸出值對應方式,需要先將輸入值與對應權重之乘積相 加,並透過活化函數轉化,才能得到輸出值。活化函數的目的是為了使輸入值做 非線性轉換,可用來模擬門檻值、轉化輸出值範圍(張斐章、張麗秋,2005)。 類神經網路可分成監督式及非監督式學習(張斐章、張麗秋,2005),監督. 政 治 大 而非監督式學習則是依照輸入資料的特性去學習、調整權重,因此,學習的方式 立. 式學習必頇不斷修正神經元的權重,因此每一次的訓練都會包含輸入項及目標值,. 通常應用於聚類的問題。兩者的差異性可由圖 2.3.1 表示:. ‧ 國. 學. 輸入. 輸出. ‧. ANN 誤差. sit. y. Nat. 目標值. io. n. al. er. (a)監督式學習:需要輸入目標值以調整誤差 輸入. Ch. ANN. engchi. i n U. v輸出. (b)非監督式學習:不需輸入目標值,用以產生聚類結果. 圖 2.3.1 監督式學習與非監督式學習 資料來源:張斐章、張麗秋,2005 類神經網路的運作模式可分成兩部分,即正向傳播及負向傳播。正向傳播能 將每一層的神經元經過加權運算及活化函數處理後,輸出至下一層神經元;負向 傳播則出現於監督式學習之類神經網路,目的在於修正輸出值與目標值的誤差, 透過誤差值的回傳,各層神經元能夠適當調整、修正其權重值及偏權值,值到誤 差值達容忍範圍內為止。 17.
(27) 4.3 股票市場之應用 由於時間序列受到統計及經濟意義上的限制,使類神經網路從輸入、輸出之 對應關係中更能提供股票市場之隱藏訊息(周宗南、劉瑞鑫,2005),因此許多 學者嘗詴採用不同方法於類神經網路上實現,使股票市場之應用更為廣泛,以下 為本研究之整理:. Kim & Han(2000)採用特徵離散的概念,並使用基因演算法決定類神經網 路之連結權重以預測股市價格指數,實驗證明此方式優於傳統的選擇部分特徵字. 政 治 大. 和拓墣優化的概念。. 立. 陳稼興、楊孟龍(2000)應用類神經網路於預測個股股價在波段漲跌走勢,. ‧ 國. 學. 並搭配資金配置、交易策略用於選股,實驗結果證實,在操作方式相同的情況下, 此選股方式之報酬率較佳。. ‧. sit. y. Nat. Nygren(2004)提出以誤差修正為基礎之 ECNN(Error Correction Neural. io. n. al. er. Network)網絡結構,預測結果是成功的,但僅適用於每週預測,說服力有限。. i n U. v. 周宗南、劉瑞鑫(2005)比較時間序列與類神經網路模型於台股指數報酬率. Ch. engchi. 之預測,結果顯示時間序列模型由於統計上的假設與限制,相異於人工智慧模型 在資料間所尋找的對應關係,而結合時間序列與類神經網路之模型,能有效改善 類神經網路過適化問題,且能捕捉到其他模型所沒有的訊息,使預測效果更好。 黃馨瑩、楊建民、李耀中(2009)採用類神經網路技術,訓練期間學習股價 與隔日股價的關係,探討股市新聞量的資訊對於面板股價趨勢的影響,實驗結果 顯示新聞量與股市指標之間具有顯著關聯,而類神經網路加入新聞量因素後,亦 能提高預測股價趨勢之正確率。. 18.
(28) 第三章 研究設計 根據文獻探討之綜合分析,本研究採用分群技術使新聞文件聚集為新聞事件 以降低資訊量,爾後透過新聞事件與類別詞庫做相似度比對,使其分成正向、持 帄及負向新聞事件。另一方面,將各類別之新聞事件數量與量化資料(成交量、 收盤價與 3 日帄均價)一併輸入於倒傳遞類神經網路預測模型,將此預測模型與 未含新聞事件之預測模型進行預測隔日收盤價之比較,進一步發掘新聞事件對於 股市漲跌是否呈現顯著影響。. 政 治 大 及「倒傳遞類神經網路預測模型」 立 ,而研究架構如圖 3.1.1 所示:. 因此,本研究將研究設計分為兩階段做相關討論──「新聞文件分群與分類」. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 19. i n U. v.
(29) 事 件 偵 測. n. 新 聞 文 件. er. al Ch. 事件 2. 事件 1. engchi. 20. i n U. v. 資料來源:本研究整理. 倒傳遞類神經網路預測模型. 負向 新聞事件. 持帄 新聞事件. 正向 新聞事件. 3 日帄均價. 收盤價. 交易量. ‧ 國. 圖 3.1.1 研究架構. y. 新事件. 事件 n. sit. io. 事 件 追 蹤. ‧. ……. 學. Nat. 新聞文件分群與分類. 立 政 治 大. 隔日收盤價.
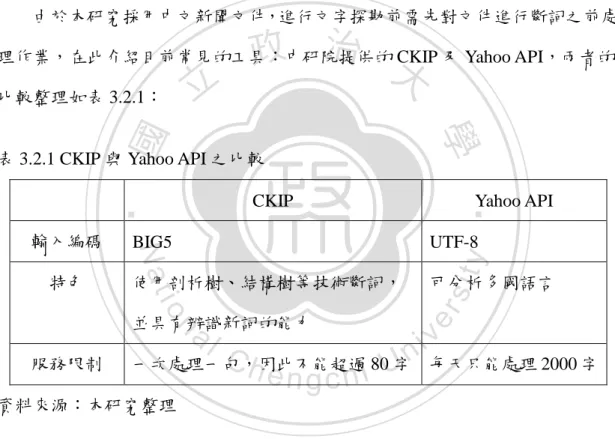
(30) 第一節 新聞文件分群與分類 此階段將新聞文件透過分群技術聚集為新聞事件,使其與類別詞庫做相似度 比對,分成正向、持帄及負向新聞事件。此階段希望以分群降低資訊量,並利用 分類使新聞事件能在倒傳遞類神經網路預測模型訓練過程中,挖掘各類別於預測 模型之影響程度,進一步反應於模型預測能力。下述將針對研究方法加以介紹: 1.1 斷詞工具 由於本研究採用中文新聞文件,進行文字探勘前需先對文件進行斷詞之前處. 政 治 大. 理作業,在此介紹目前常見的工具:中研院提供的 CKIP 及 Yahoo API,兩者的. 立. 學. ‧ 國. 比較整理如表 3.2.1:. 表 3.2.1 CKIP 與 Yahoo API 之比較. ‧. BIG5. UTF-8. 使用剖析樹、結構樹等技術斷詞,. 可分析多國語言. y. v i n Ch 一次處理一句,因此不能超過 e n g c h i 80U字 每天只能處理 2000 字 n. 服務限制. sit. io. al. 並具有辨識新詞的能力. er. 特色. Yahoo API. Nat. 輸入編碼. CKIP. 資料來源:本研究整理 新聞為提供新訊息的工具之一,使得出現新詞之機率相對於其他中文文件更 為頻繁,使得文句需要自我判斷詞意之重要性相對增加,此外,本研究所採用之 新聞(資料來源)又以中文為主,因此本研究將採用 CKIP 之斷詞工具以進行後 續研究流程。. 21.
(31) 1.2 新聞文件分群──事件偵測與追蹤. 1.2.1.. 以 kNN 分群技術實現. 新聞的事件具有時效性,且每天不斷更新,事件大小也隨著媒體追蹤程度有 差異,因此新聞的分群並無法事前決定群數,本研究將採用 CMU 的方式,應用 kNN 分群法於新聞事件追蹤上。而執行事件偵測前,需先將文件轉換為向量空 間模型表示,因此需要計算文件字詞之權重值,權重值計算方式採用 TFIDF,如 公式(1),並採用正規化調整權重值大小:. ij. 政 治 大. N. = tfij × log (df )............................................................................................................. 公式(1). 立. i. ‧ 國. 學. 根據 CMU 所提出之事件偵測與追蹤之流程如下:. ‧. Step1、計算新進文件之權重值,並與既有事件計算相似度,CMU 在新聞偵測上, 將相似度加入了時間區間(Time Window),避免文件與事件時間間隔太遠仍被. y. Nat. io. sit. 考慮的情況,而計算方式以公式(2)表示(戴尚學,2003;Yang, 1998),若超過. n. al. er. 門檻值則表示新進新聞文件可能屬於該事件,將其列入候選事件,並進入 Step2,. Ch. i n U. 否則新進新聞文件不屬於該事件,結束此演算法。. score x =. m xci ∈window ,. engchi k m. v. × sim x⃑, c⃑⃑i -............................................. 公式(2). m x𝑐𝑖 ∈𝑤𝑖𝑛𝑑𝑜𝑤 {𝑠𝑖𝑚 𝑥, 𝑐⃑⃑𝑖 }表示當新文件與已存在的事件作相似度比較的最大 值,因此𝑠𝑐𝑜𝑟𝑒 𝑥 可視為事件存在的門檻,當𝑠𝑐𝑜𝑟𝑒 𝑥 大於所設定的門檻,則表 示新文件屬於一新事件,反之,表示新文件存在於目前的事件。. 22.
(32) 時間區間之𝑚為時間區間中的文件數,𝑘值為該群集中最新一篇所收錄的時 間至𝑥所收錄的時間所增加的文件數;相似度則使用餘弦相似度公式,計算方式 以公式(3)表示:. sim x, c =. ∑M j=1 wjx ×wjc 2 M 2 √(∑M j=1 wjx )×(∑j=1 wjc ). ...................................................................................... 公式(3). Step2、若候選事件採用 2-way kNN 分類法,將候選事件列為目標事件,而非候 選事件則為非目標事件,並以帄均的概念避免 k 值大小所造成分類不正確的問題,. 政 治 大. 以公式(4)表示。 1 kp. 立. ∑⃑ ∈Ukp cos ⃑x, ⃑ | y. 1 ∑⃑ ∈Vkn cos |Vkn | z. ⃑x, z ............................ 公式(4). 學. ‧ 國. r ⃑x, kp, kn, D = |U. 公式(4)表示新文件需分別與目標函數及非目標函數之最近鄰𝑘𝑝、𝑘𝑛個數比. ‧. 較,意即|𝑈𝑘𝑝 | ≤ 𝑘𝑝 , |𝑉𝑘𝑛 | ≤ 𝑘𝑛. y. Nat. io. sit. Step3、若計算結果大於 0 則表示新進新聞文件屬於該事件,此時將新進新聞文. n. al. er. 件標記為該事件,並調整此事件之質心,質心調整方式如公式(5);反之,表示. Ch. 新進新聞文件不屬於該事件,結束此演算法。. jc. =. N×wjc +wjx N+1. engchi. i n U. v. for ll j .................................................................................................... 公式(5). 其中𝑤𝑗𝑐 為原來的質心權重,𝑤𝑗𝑥 為新進新聞文件之權重, 𝑁為原來事件涵蓋的文件數 若新進新聞文件已對所有既有事件做偵測與追蹤,仍未被分類至適當的事件, 表示其不屬於既有事件,則建立新事件,並訂定新事件之質心,即為該新進新聞 文件,結束此演算法。. 23.
(33) 以 RTD-based(Relative Text Distance-based,相對文件距離)kNN 分群. 1.2.2.. 技術實現 基於新聞文件無法事前得知群集個數,事件偵測與追蹤將採取 kNN 分群技 術,雖然 kNN 採用非監督式學習,然而 kNN 分群於迭代的過程需要不斷計算不 同文件的相似度,卻難以記錄其演算過程,使複雜度隨著資料量得增長而提高, 效率相對降低。因此本研究欲以特徵字代表文件之單位向量為基礎,嘗詴以文件 間的歐氏幾何距離取代相似度的方式進行新聞事件分群。研究中將使用 RTD-based kNN 取代 kNN 之分群技術提高系統整體效率。下列將敘述如何以文. 政 治 大. 件距離取代相似度的軌跡。. 立. 文件距離取代相似度的方式,本研究採取歐智民、陳柏均(2011)之研究,. ‧ 國. 學. 取代方法如下:. 取第一篇文件做為基準點,因此每篇文件都能儲存與第一篇文件計算後之距. sit. y. Nat. 離。. n. al. er. 有了基準點後,與新文件之相似度範圍便能改以距離取代,如圖 3.2.1。. io. 2.. ‧. 1.. Ch. engchi. i n U. v. 圖 3.2.1 文件相似度與距離關係. 圖 3.2.2 文件相似度轉換為距離關係. 資料來源:本研究整理. 資料來源:本研究整理. 24.
(34) 3.. θ. 由於三角形的角度𝜑恰為弧度θ之圓周角,因此𝜑 = (參考圖 3.2.2),而距 2. 離範圍則可以餘弦公式求之,證明如下: x2 +x1 2 −a2. θ. 證明: cos 2 =. 2×x×x1. ,. θ. sin φ =. 其中 a=. sin 2(圖 3.2.3) θ. 由餘弦定理知,cos 2 =. |. 立 θ. 同理,𝑥2 = |. θ 2. 2×𝑥×cos +√𝐷 2. × 𝑥2. θ. × cos 2 2 +. ‧. ‧ 國. × 𝑥 2 × cos 2. 學. |,而D與上式相同。. y. Nat. io. sit. 其中D =. 資料來源:本研究整理. 政 治 大. 2×x×cos −√D 2. 2×x×x1. n. al. er. 得x1 = |. θ 2. 圖 3.2.3 公式轉換圖. x2 +x1 2 −a2. Ch. engchi. 25. i n U. v.
(35) 1.3 新聞事件分類 本研究假設每天所發生的新聞事件將整體影響到隔日收盤價之漲跌,為了找 出各個新聞事件之影響,需要先將新聞事件分類成正向、持帄、負向新聞事件, 如此倒傳遞類神經網路預測模型才能夠根據各類別所具有的特徵加以學習、訓 練。 以往關鍵詞可透過權重値(如 TFIDF、TFC 等)做為評估字詞之重要程度, 然而各類別之代表關鍵詞在該類別中所出現的頻率亦成了相當重要的因素。本研. 政 治 大 時卻可能因為字頻過低造成,依照權重值高低可能擷取到較不具類別意義之關鍵 立. 究採用之權重值為為 TFC,其考慮區域權重及全域權重之影響,因此當權重值高. 字,另一方面,字詞出現次數若過於頻繁,關鍵字之重要性又會降低。根據以上. ‧ 國. 學. 分析,類別詞庫之選擇需考量字頻及權重值之因素,本研究將選取 DF 介於. sit. y. Nat. 表。. ‧. 0.075~0.3 之範圍做為篩選,爾後再從權重値的大小挑選類別詞庫之關鍵字代. er. io. 第二節 倒傳遞類神經網路預測模型. al. n. v i n Ch 本研究之預測模型所採用之對照組中,輸入項目以量化資料為基礎,包括交 engchi U. 易量、收盤價及 3 日帄均價,而輸出項目則為隔日收盤價,模型以天為單位的方 式訓練模型;而實驗組於輸入項目中加入量化資料,即為正向、持帄及負向之新 聞事件數量。透過訓練進行權重值修正,以預測結果進行分析與討論。 倒傳遞類神經網路由 Rumelhart、McClelland 等人於 1986 年提出,屬於多層. 前饋式網路,並以監督式學習修正輸入與輸出之間的關係(張斐章、張麗秋,2005)。 由於其擁有學習精度高、回想速度快、輸出值可為連續值的優勢,因此能處理複 雜度高與高度非線性函數之問題。. 26.
(36) 一般來說,倒傳遞類神經網路的運作是一迭代的過程,透過不斷的權重修正 以獲得最佳權重值,流程如圖 3.2.4:. 設定網路參數. 以亂數產生 初始權重及偏權值 否. 是. 計算隱藏層與輸出值 政 治 大. 網路 停止原則. 立. ‧. ‧ 國. 學. 計算目標函數. 網路停止. 計算權重修正量. n. er. io. sit. y. Nat. al. Ch. engchi U. 調整各層之 v i n. 權重與偏權值. 否. 是否仍有 訓練樣本. 圖 3.2.4 倒傳遞類神經網路流程 資料來源:張斐章、張麗秋,2005 27. 是.
(37) 建構倒傳遞類神經網路預測模型時,訓練階段將以天為單位,使模型能在有 限的迭代次數(2000)及容忍誤差(0.01)下產生預測模型,然而模型建構過程 中仍需考慮以下問題: 權重初始化. 1.. 類神經網路模型的訓練過程是為了尋找適當的權重値,根據研究,其權重初 始值可採用下列兩種方法: 0.5 −0.5. (1) Ham & Kostanic(2001)提出權重初始值應落在* 𝑁 ,. 學. ‧ 國. (2). 式(6)或公式(7)進行修正: n0. ‧. √n1 ........................................................................................................................... 公式(6). n. y. .................................................................................................................. 公式(7). io. 1 w2 √∑j=1 ji. sit. wji. Nat. = γ n0. n. al. er. γ= .. ji. 2.. +之間,𝑁為該層神. 治 政 經元之個數。本研究將採取此方法設定權重初始值。 大 立 Nguyen & Widrow(1990)表示,可先取得[ . , . ]之隨機亂數,再透過公 𝑁. 活化函數、誤差函數. Ch. engchi. i n U. v. 倒傳遞類神經網路模型較常使用的活化函數為 purelin 函數、tansig 函數及 logsig 函數,原因在於此三種函數皆為可微分之連續函數,整理如圖 3,故權重 值或偏權值之修正可採用最除坡降法及迭代過程達到容忍誤差,實現模型學習目 的(羅華強,2005)。本研究於預測模型之隱藏層所使用之活化函數為 logsig 函 數,原因在於模型中欲加入新聞事件數量之比例,其值將介於 0 到 1 之間,因此 採用 logsig 函數較為適合,而輸出層為隔日收盤價,此數值在股票市場上並沒有 範圍,因此所採取之活化函數為 purelin 函數。. 28.
(38) 當倒傳遞類神經網路預測模型之輸出層無法得到目標值,則需將誤差函數透 過最除坡降法修正其權重值與偏權值,使誤差值達到容忍範圍內或迭代次數達到 上限為止。(張斐章、張麗秋,2005). 3.. 隱藏層層數 研究顯示,隱藏層不需超過兩層以上,而一或兩層則沒有定論(Chester, 1990;. Hayashi et al., 1990;Kurkova, 1992;Hush & Horne, 1993;張斐章、張麗秋,2005), 其中 Hush & Horne(1993)指出,某些問題中使用兩層隱藏層的網路,各隱藏. 政 治 大. 層只需有少量神經元即可以取代「使用一層,但需要數量龐大神經元」隱藏層的 網路。. ‧ 國. 學. 4.. 立. 隱藏層神經元個數. ‧. 可由兩種方式達成(Dawson & Wilby, 2001;張斐章、張麗秋,2005) :網路. sit. y. Nat. 修剪法(Pruning algorithm)(Abrahart et al., 1998)及網路增長法(Constructive. io. er. algorithm)(Kwok & Yeung, 1997)。前者先將隱藏層個數設為極大,並逐一修剪 神經元個數,直到超過誤差容忍範圍為止,然而此方式需耗費大量時間,效率較. al. n. v i n Ch 低;後者則將隱藏層個數設為最小,再逐一增加神經元個數,直到誤差達到容忍 engchi U. 範圍為止,相較之下,此方式的效率較佳,能以較經濟的方式達成,因此本研究 將採用網路增長法選取適合之神經元個數。. 29.
(39) 整體而言,倒傳遞類神經網路預測模型之結構整理如圖:. 圖 倒傳遞類神經網路預測模型之結構 資料來源:本研究整理. 政 治 大. 其中,輸入層之質化資料以各類別之新聞事件數量輸入,量化資料以交易量、. 立. 收盤價及 3 日帄均價為指標;輸出層則為隔日收盤價;活化函數之隱藏層及輸出. ‧ 國. 學. 層分別以 logsig 及 purelin 函數為主。而層數及各層之神經元個數之決定則將由 研究結果進一步探討之。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 30. i n U. v.
(40) 第三節 研究樣本與統計檢定 3.1 研究樣本 為了避免新聞經過大量報社的整合(如 Yahoo 新聞或 Google 新聞等) ,造成 對權重計算或選擇特徵值的影響,本研究資料來源將選擇以報社出身之「自由時 報電子報」為新聞文件樣本,採取 2009 年 1 月 1 日至 2009 年 12 月 31 日之新聞 資料,共 5767 筆新聞文件,帄均一天有 15 篇新聞文件;而股市基本面資訊如交 易量、收盤價、3 日帄均價等資訊,則選擇「台灣經濟新報資料庫」所提供之半. 政 治 大 別為自由時報電子報及台灣經濟新報資料庫畫面。 立. 導體類股做為研究對象,而 2009 全年包含 251 個交易日。圖 3.1.1 及圖 3.1.2 分. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 3.3.1 自由時報電子報 資料來源:本研究整理. 31. v.
(41) 政 治 大. 資料來源:本研究整理. ‧. 3.2 統計檢定. 學. ‧ 國. 立 圖 3.3.1 半導體類股交易資訊. y. Nat. io. sit. 一般類神經網路預測模型以 MSE(Mean Square Error)或 RMSE(Root Mean. n. al. er. Square Error)為評估標準,分別為公式(8)、公式(9)所示,其中xi 表示預測值, 而t i 表示實際値:. E=. xi −ti 2 n. E=√. Ch. engchi. i n U. v. ........................................................................................................................ 公式(8). xi −ti 2 n. .................................................................................................................. 公式(9). 本研究採取對照的實驗模型,因此將使用 RMSE 做成對樣本之顯著性檢定 加以檢驗兩模型之差異。值得一提的是,無論是 MSE 或 RMSE 之評估標準,類 神經網路在建置過程中容易產生過適化,亦即實驗模型之訓練過程中,誤差值越 低將使學習能力過於合適,卻相對造成驗證過程之誤差結果不佳的情形。 32.
(42) 第四章 研究結果 本研究將研究架構分為兩部分──「新聞事件分群與分類」及「倒傳遞類神 經網路預測模型」,本章將針對研究架構依序進行三個實驗:首先針對類別詞庫 之建立做相關討論,接著對於倒傳遞類神經網路預測模型之參數建構進行分析; 最後則以統計檢定評估預測模型之預測方向正確性及預測準確率是否呈現顯著 差異。 第一節 類別詞庫之建立. 治 政 本研究使用 RTD-based kNN 分群技術將新聞文件轉化成新聞事件,期待降 大 立 低資訊量之非結構化資訊亦能對於股票市場造成影響。然而為使新聞事件能在倒 ‧ 國. 學. 傳遞類神經網路預測模型中獲得有效的學習能力,本研究將建立事件之類別詞庫,. ‧. 使新聞事件能夠依照相似度高低將其分類為正向、持帄或負向新聞事件。. sit. y. Nat. 為了建立新聞事件之類別詞庫,本研究對於 2009 年半導體類股報酬率之天. n. al. er. io. 數分佈初步觀察,統計結果繪製折線圖如圖 4.1.1,圖中可看出,半導體類股報. i n U. v. 酬率之漲跌幅度介於-7%至 7%之間,而其中 68%則集中於-1%至 3%,推論半導. Ch. engchi. 體類股大致呈現左偏之趨勢,屬於正向緩和成長。本研究欲藉由報酬率區間之界 定,從新聞事件中挑選適當之關鍵字代表。. 33.
(43) 報酬率分佈圖 60 50. 天數. 40 30 天數分佈. 20 10 0 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 報酬率(%). 政 治 大 圖 4.1.1 報酬率分佈-2009 年 立. ‧ 國. 學. 資料來源:本研究整理. 因此研究將以報酬率範圍做為初步篩選,將新聞事件以日期為基礎分成正向、. ‧. 持帄及負向類別,爾後再對詞彙做篩選。鍾任明等人(2007)之研究指出,關鍵. y. Nat. sit. 詞彙可依據詞彙於一篇文章中所出現次數(Term Frequency, TF,以下簡稱為詞. n. al. er. io. 頻),及關鍵詞權重作為篩選考量,其中詞頻太低可能造成太多雜訊,而詞頻過. i n U. v. 高則難以表現該類別之特徵,使經過挑選之詞彙無法具有代表性。而本研究所挑. Ch. engchi. 選之詞彙為類別代表,因此將依此概念衍伸,從全域性觀點修正,即以 DF(詞 彙於所有文件中出現的次數)替代 TF,範圍則設定為 0.075 至 0.3,再選擇前百 分之二之權重値為關鍵詞代表。下列將根據報酬率範圍分析類別詞庫代表之關鍵 詞,整裡如表 4.1.1。. 34.
(44) 表 4.1.1 類別詞庫數量比較 ±4%. 類別. 正向. 持帄. 負向. 天數. 11. 232. 8. 詞庫數量. 39. 17. 26. 類別. 正向. 持帄. 負向. 天數. 19. 211. 21. 詞庫數量. 33. 18. 31. 類別. 正向. 持帄. 負向. ±3%. ±2%. 天數. 立. 詞庫數量. 政 33 治 大168 30 19. 33. ‧ 國. 學. 資料來源:本研究整理. 50. 表 4.1.1 分別以報酬率作為類別詞庫之實驗:當報酬率介於±4%時,雖然正. ‧. 向類別及負向類別所佔天數較少(8 天、11 天),詞庫數量卻明顯集中於此二類. y. Nat. sit. 別,顯示正向類別及負向類別擁有較明顯特徵之關鍵字。然而當報酬率介於±3%. n. al. er. io. 及±2%時,正向與負向之關鍵詞已有趨於帄均的現象。為了呈現報酬率介於± %. i n U. v. 之正負向類別詞庫數量比例,本研究將選取報酬率±3%範圍做為類別詞庫之分界,. Ch. engchi. 並進一步對新聞事件之分類結果討論。. 35.
(45) 此處以 2009 年 10 月 29 日一正向新聞事件及其關鍵字做類別詞庫為例加以 討論,其標題如下: 第三季獲利亮眼 楠梓電、尖點抗跌 Q3 台達電 EPS1.21 元 光寶科 1.13 元 Q3 營收與獲利 緯創、仁寶創新高 景氣復甦 矽品明年資本支出達百億 Q3 聯詠 EPS1.91 元 凌陽 0.59 元. 政 治 大 提升、營收與獲利增加,使得投資成本提高等,觀察該新聞事件所挑選出來的關 立 此五篇新聞文件敘述第三季於太陽能個股呈現景氣復甦之現象,包括產能率. 鍵字,其中「盈餘」 、 「營收」 、 「獲利」 、 「成長」 、 「盈餘」 、 「提升」 、 「增加」出現. ‧ 國. 學. 次數最為頻繁,其他如「改善」 、 「復甦」 、 「受惠」 、 「抗跌」 、 「搶眼」等皆有助於. ‧. 用以描述該新聞事件之關鍵字,整體而言,可由類別詞彙看出該事件所表達的為. sit. y. Nat. 一正向新聞事件。又,對應至半導體類股報酬率所造成之正向影響可推測,太陽. io. 造成半導體類股之報酬率亦呈現正向影響。. n. al. Ch. engchi. 36. er. 能產業與半導體產業具有密切關係,因而當太陽能相關之正向新聞事件產生時,. i n U. v.
(46) 第二節 倒傳遞類神經網路預測模型之參數建構 在倒傳遞類神經網率預測模型中,為了選擇適當參數,本研究將迭代參數設 為 2000,而學習參數為 0.7,又研究顯示隱藏層層數不需超過二層(Chester, 1990; Hayashi et al., 1990;Kurkova, 1992;Hush & Horne, 1993;張斐章、張麗秋,2005), 因此本研究將以此為基礎實驗神經元個數,採用網路增長法觀察其 RMSE,預測 模型之架構如圖 4.2.1,依照此網路模型進行實驗,而 251 筆資料來源中,本研 究隨機挑選 168 筆做為訓練資料,其餘 83 筆則做為測詴資料,實驗結果列於表 4.2.1,並依此探討神經元個數之選擇方式。. 立. 政 治 大. ‧. ‧ 國. 學. Nat. n. al. Ch. engchi. 37. sit er. io. 資料來源:本研究整理. y. 圖 4.2.1 預測模型之架構. i n U. v.
(47) 表 4.2.1 不同參數之模型 RMSE 比較(*含新聞事件,**不含新聞事件) 個數. 訓練*. 測詴*. 訓練**. 測詴**. 1. 0.0279. 0.0448. 0.0282. 0.0469. 2. 0.0274. 0.0446. 0.0281. 0.0469. 3. 0.0268. 0.0446. 0.0278. 0.0466. 4. 0.0263. 0.0440. 0.0272. 0.0456. 5. 0.0264. 0.0442. 0.0274. 0.0461. 0.0270. 0.0444. 0.0277. 0.0464. 帄均. 0.0350 治 政 0.0497 大 0.0294 0.0303 0.0507 立. 1 1. 2. 0.0695. 0.0335. 0.0525. 0.0358. 0.0587. 1. 0.0287. 0.0458. 0.0296. 0.0484. 2. 0.0496. 0.0700. 0.0516. 0.0742. 3. 0.0300. 0.0474. 0.0303. 0.0544. 0.0372 v i n. 0.0574. 0.0289. 0.0476. io 1 2. 0.0294. 0.0464. 0.0303. 0.0499. 3. 0.0298. 0.047. 0.0304. 0.0496. 0.0291. 0.0465. 0.0299. 0.0490. 1. 0.0288. 0.0461. 0.0299. 0.0495. 2. 0.0289. 0.0465. 0.0302. 0.0497. 3. 0.0280. 0.0460. 0.0288. 0.0484. 0.0286. 0.0462. 0.0296. 0.0492. n. 3. 帄均. 2. 4. 0.0497. a0.0361 l C 0.0282 h. 帄均. 2. ‧. 2. 0.0429. Nat. 2. 0.0504. 0.0571. ‧ 國. 帄均. 0.0562. 0.0368. 學. 3. y. 2. 0.0334. sit. 1. er. 層數. 帄均. e n g0.0461 chi U. 資料來源:本研究整理 38.
(48) 由表 4.2.1 可看出,一層預測模型之 RMSE 範圍介於 0.0270 至 0.0277 之間, 而二層預測模型介於 0.0286 至 0.0501 之間,初步推論,層數的增加雖然使權重 值之修正方向增加,卻因為受限於相同迭代次數,難以有效改善預測模型之誤差 值。另一方面,若訓練階段所得 RMSE 越低,將有效降低測詴階段之 RMSE, 亦即兩者具有正向關係,因此預測模型可根據訓練期間所得之 RMSE 決定其參 數。因此本研究將設定訓練過程中 RMSE 最低之參數作為下階段實驗的基準, 即層數為 1,神經元個數為 4 之預測模型。 圖 4.2.2 為該預測模型之預測趨勢圖,上下圖分別為訓練及測詴階段,顯現. 政 治 大. 預測模型之訓練階段有助於幫助學習預測之能力,然而預測能力則依賴參數之調. 立. 整。此外,圖 4.2.2 亦呈現半導體產業於 2009 年之股價呈現正向成長,呼應上一. ‧ 國. 學. 節報酬率分布圖中,多達 68%的交易日資料集中於-1%至 3%之間,顯示該產業 確時有穩定成長之趨勢。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4.2.2 含新聞事件之預測模型(層數為 1,神經元個數為 4) 資料來源:本研究整理. 39.
(49) 第三節 預測模型之顯著性檢定 透過神經元個數之之觀察結果,本研究採取層數為 1,神經元個數為 4 之預 測模型,決定參數後即可將含新聞事件(實驗組)與不含新聞事件(對照組)之 預測模型加以比較。由於兩預測模型之差異僅再於新聞事件之輸入與否,因此本 節將從統計角度出發,以成對樣本評估新聞事件能否改善預測模型之學習能力, 而評估方式則針對預測方向正確性及預測準確率做顯著性檢定。 3.1 預測方向正確性. 政 治 大. 兩預測模型的差異在於輸入項是否加入新聞事件,而預測模型經過學習若能. 立. 使預測方向正確性提高,則代表新聞事件有助於預估隔日收盤價。又本研究使用. ‧ 國. 學. ±3%之報酬率作為正向、持帄、負向新聞事件的分界,因此評估預測方向正確性 時亦以±3%之報酬率將其分成上漲、持帄及下跌三類,進行預測方向正確性之顯. ‧. 著檢定,本研究提出假說如公式(10),H0 表示兩模型不具顯著性差異,反之H1 則. μ1 ≠. sit er. H1 ∶ μ2. al. v i n Ch ............................................................................................................. 公式(10) engchi U n. μ1 =. io. H0 ∶ μ 2. y. Nat. 否:. 本研究中包含 40 組樣本(n) ,資料列於表 4.2.3,依據中央極限定理,樣本 大於 30 時樣本趨近於常態分配,因此檢定統計量及其分配如公式(11): 𝐷𝐴𝑐𝑐 − μ2 −μ1 SD /√ n. ∼. ,. 其中,𝐷𝐴𝑐𝑐 = 𝐴𝑐𝑐2. .................................................................................................... 公式(11). 𝐴𝑐𝑐1 =. 2 ∑𝑛 𝑖=1 𝐷𝑖 −𝐷𝐴𝑐𝑐. 𝑆𝐷 = √. 𝑛−1. .. %. .. = .. 而拒絕域𝑅𝑅 = {𝐷𝐴𝑐𝑐 < 𝐶𝑉1 ,𝐷𝐴𝑐𝑐 > 𝐶𝑉2 } 40. %=. .. %,.
(50) 表 4.2.4 預測方向正確性之顯著檢定(*含新聞事件,**不含新聞事件) 模型編號. A𝒄𝒄𝟏 *. A𝒄𝒄𝟐 **. 𝑫𝑨𝒄𝒄. 1. 82.00%. 79.60%. -2.40%. 2. 82.00%. 80.00%. -2.00%. 3. 81.60%. 78.80%. -2.80%. 4. 81.60%. 79.60%. -2.00%. 5. 81.60%. 79.60%. -2.00%. 6. 82.80%. 79.20%. -3.60%. 政 治79.20% 大 81.60% 80.00% 立 81.60%. 13. io 15. 82.00%. 78.80%. 82.80%. 78.80%. 81.60%. 79.60%. 79.20% v a81.60% i l C n h e n g c h79.60% 81.60% i U. n. 14. 79.20%. y. Nat. 12. 82.40%. ‧. 11. 80.40%. sit. 10. 81.60%. -1.60%. 學. 9. ‧ 國. 8. -2.40%. er. 7. -1.20% -3.20% -3.20% -4.00% -2.00% -2.40% -2.00%. 16. 82.00%. 79.60%. -2.40%. 17. 81.60%. 79.60%. -2.00%. 18. 82.40%. 79.20%. -3.20%. 19. 82.00%. 80.80%. -1.20%. 20. 82.00%. 80.00%. -2.00%. 21. 83.20%. 79.20%. -4.00%. 22. 82.40%. 79.20%. -3.20%. 23. 82.00%. 79.60%. -2.40%. 41.
(51) 24. 82.80%. 78.40%. -4.40%. 25. 82.00%. 79.60%. -2.40%. 26. 82.00%. 79.60%. -2.40%. 27. 82.00%. 79.60%. -2.40%. 28. 82.40%. 78.80%. -3.60%. 29. 82.00%. 79.60%. -2.40%. 30. 82.80%. 78.80%. -4.00%. 31. 82.00%. 79.60%. -2.40%. 政 治79.60% 大 82.00% 79.60% 立 82.00%. 82.00%. 79.60%. 82.00%. 80.00%. 82.00%. 79.60%. y. -2.40%. 82.00%. 79.60%. -2.40%. 79.20% v a81.60% i l C n h e n g c h79.60% 82.00% i U. n. 39. io. 38. Nat. 37. 79.20%. 40. ‧. 36. 82.00%. sit. 35. -2.40%. 學. 34. ‧ 國. 33. -2.40%. er. 32. -2.80% -2.40% -2.00%. -2.40% -2.40%. 帄均. 82.04%. 79.47%. -2.57%. 變異數. 1.6200*E-5. 2.0831E-5. 5.4100*E-5. 標準差. 0.0040. 0.0046. 0.0074. 資料來源:本研究整理. 42.
(52) 由臨界值檢定法計算臨界值,如公式(12):. CV1 , CV2 = μ ± z1−α. σD. 2 √n. =. ± z1−α. 0.0074. 2. √40. ............................................................... 公式(12). 由式 3 可得,當顯著水準為 95%,CV1 , CV2 = ± .. ,然而不論顯著水準為何,𝐷 = |. 時,CV1 , CV2 = ± . 表示D ∈. ;當顯著水準為 99% .. %| > |CV1 |,. ,亦即拒絕𝐻0 ,以統計觀點而言,此成對樣本具有顯著差異,該結. 果可說明於預測模型中加入新聞事件將有助於預測方向之正確率。 從表 4.2.2 中可初步看出,預測方向正確性皆以含新聞事件之預測模型較為. 治 政 優異,而含新聞事件之實驗組的帄均正確率 82.04%亦高於不含新聞事件之對照 大 立 組的帄均準確率 79.47%,初步評估兩預測模型之比較,含新聞事件之預測模型 ‧ 國. 學. 結果顯著優於不含新聞事件之預測模型。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 43. i n U. v.
(53) 3.2 預測準確率 另一方面則檢驗測詴階段之 RMSE 值,由於兩預測模型彼此相依,因此同樣 以成對樣本之雙尾檢定觀察兩模型之 RMSE 是否顯著差異,提出假說如公式 (13): H0 ∶ μ 2. μ1 =. H1 ∶ μ2. μ1 ≠. ............................................................................................................. 公式(13). 同樣採取 40 組樣本(n) ,資料列於表 4.2.4,依據中央極限定理,樣本大於. 政 治 大. 30 時樣本趨近於常態分配,因此檢定統計量及其分配如公式(14):. ,. ................................................................................................. 公式(14). .. = .. = .. io. y. ̅̅̅̅̅̅̅̅ ̅̅̅̅̅̅̅̅ 而拒絕域𝑅𝑅 = {𝐷 𝑅𝑀𝑆𝐸 < 𝐶𝑉1 ,𝐷𝑅𝑀𝑆𝐸 > 𝐶𝑉2 }. n. al. Ch. engchi. 44. sit. 𝑛−1. .. Nat. ̅̅̅̅̅̅̅̅̅̅ 2 ∑𝑛 𝑖=1 𝐷𝑖 −𝐷𝑅𝑀𝑆𝐸. 𝑆𝐷 = √. ̅̅̅̅̅̅̅̅̅ 𝑅𝑀𝑆𝐸1 =. ‧. ̅̅̅̅̅̅̅̅̅ ̅̅̅̅̅̅̅̅ 其中,𝐷 𝑅𝑀𝑆𝐸 = 𝑅𝑀𝑆𝐸2. er. ∼. 學. SD /√ n. 立. ‧ 國. ̅̅̅̅̅̅̅̅̅̅ 𝐷𝑅𝑀𝑆𝐸 − μ2 −μ1. i n U. v. ,.
(54) 表 4.2.4 預測準確率之顯著性檢定(*含新聞事件,**不含新聞事件) 模型編號. ̅̅̅̅̅̅̅̅̅̅ 𝑹𝑴𝑺𝑬𝟏 *. ̅̅̅̅̅̅̅̅̅̅ 𝑹𝑴𝑺𝑬𝟐 **. ̅̅̅̅̅̅̅̅̅ 𝑫𝑹𝑴𝑺𝑬. 1. 21.2421. 21.3695. 0.1274. 2. 21.2759. 21.3695. 0.0936. 3. 21.1459. 21.2525. 0.1066. 4. 21.1511. 21.2369. 0.0858. 5. 21.1251. 21.2213. 0.0962. 6. 20.9094. 20.9796. 0.0702. 政 治21.3305 大 21.3876 21.5358 立 21.2187. 13. io 15. 20.9640. 21.0472. 20.9276. 21.0160. 21.2499. 21.3435. 21.2317 v a21.1719 i l C n h e n g c h21.2395 21.1381 i U. n. 14. 21.1537. y. Nat. 12. 21.0628. ‧. 11. 21.5774. sit. 10. 21.4864. 0.1481. 學. 9. ‧ 國. 8. 0.1118. er. 7. 0.0910 0.0910 0.0832 0.0884 0.0936 0.0598 0.1014. 16. 21.3097. 21.3798. 0.0702. 17. 21.3746. 21.4786. 0.1040. 18. 21.0862. 21.1693. 0.0832. 19. 21.6917. 21.8165. 0.1248. 20. 21.3954. 21.5254. 0.1300. 21. 20.9354. 21.0212. 0.0858. 22. 21.1433. 21.2213. 0.0780. 23. 21.2083. 21.3149. 0.1066. 45.
(55) 24. 20.9068. 20.9848. 0.0780. 25. 21.1797. 21.2889. 0.1092. 26. 21.3435. 21.4786. 0.1351. 27. 21.1563. 21.2525. 0.0962. 28. 21.0550. 21.1199. 0.0650. 29. 21.1615. 21.2473. 0.0858. 30. 21.0628. 21.1018. 0.0390. 31. 21.1849. 21.3019. 0.1170. 政 治21.2447 大 21.0966 21.1771 立 21.1381. 21.1719. 21.2837. 21.4812. 21.5696. 21.0654. 21.1225. y. 0.0572. 21.1563. 21.2681. 0.1118. 21.2135 v a21.1173 i l C n h e n g c h21.4292 21.3227 i U. n. 39. io. 38. Nat. 37. 21.2473. 40. ‧. 36. 21.1641. sit. 35. 0.0806. 學. 34. ‧ 國. 33. 0.1066. er. 32. 0.0832 0.1118 0.0884. 0.0962 0.1066. 帄均. 21.1841. 21.2791. 0.0949. 變異數. 0.0273. 0.0316. 0.0001. 標準差. 0.1651. 0.1778. 0.0224. 資料來源:本研究整理. 46.
(56) 由臨界值檢定法計算臨界值,如公式(15):. CV1 , CV2 = μ ± z1−α. σD. 2 √n. =. ± z1−α. 0.0224. 2. √40. ............................................................... 公式(15). 由式 3 可得,當顯著水準為 95%,CV1 , CV2 = ± .. ̅̅̅̅̅̅̅̅ ,然而不論顯著水準為何,𝐷 𝑅𝑀𝑆𝐸 = .. 時,CV1 , CV2 = ± . ̅̅̅̅̅̅̅̅ 表示𝐷 𝑅𝑀𝑆𝐸 ∈. ;當顯著水準為 99% > |CV1 |,. ,亦即拒絕𝐻0 ,以統計觀點而言,此成對樣本具有顯著差異,. 此研究結果可說明,除了成交量、收盤價及三日帄均價外,新聞事件亦為隔日收 盤價的重要因素之一。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 47. i n U. v.
(57) 第五章 結論 第一節 結論與建議 本研究以「新聞事件偵測與追蹤」的分群技術為出發點,透過類別詞庫的建 立,探討新聞事件對於市場股價之影響,期望能將新聞文件以新聞事件分類的方 式與「倒傳遞類神經網路預測模型」做結合,進而提供投資者有效的投資線索及 資訊。此架構將新聞文件以事件為基礎做分類,希望將資訊量降低之餘,亦能提 供預測隔日收盤價之訊息。. 治 政 從研究結果分析可看出,透過分群使新聞文件降低資訊量,將顯著改善預測 大 立 方向正確性及預測準確率,此現象表示新聞事件之質化資料將有效提供市場股價 ‧ 國. 學. 之訊息,換言之,新聞事件中所隱藏之市場資訊可透過各種文字消息傳遞,本研. ‧. 究所探討之新聞文件則為其中一種,而過去研究所探討之財報資料及重大訊息與 股票市場之影響亦息息相關,可知兩者皆為市場所傳遞資訊的一種方式。此亦證. y. Nat. n. al. er. io. 金融市場的波動」. sit. 實 Khurshid 等學者(2002)之論述: 「無論文字消息的形式為何,皆可能為影響. Ch. engchi. i n U. v. 此外,本研究於建立類別詞庫時使用 DF 篩選,再以權重值作為選擇,透過 新聞事件之分類後的分析,也確實能使新聞事件做出分類。由於現今網路上資訊 量龐大,大至入口網站、小至個人所使用的網誌、留言板等,都存在著分類的需 求,其目的即為了簡化資料量,未來將可採用此方法幫助管理者建置類別詞庫, 使分類得以自動化,成為管理資訊之工具之一。. 48.
數據

相關文件
Srikant, Fast Algorithms for Mining Association Rules in Large Database, Proceedings of the 20 th International Conference on Very Large Data Bases, 1994, 487-499. Swami,
所以 10 個數字 個數字 個數字 個數字 pattern 就產生 就產生 就產生 就產生 10 列資料 列資料 列資料 列資料 ( 每一橫 每一橫 每一橫
“Transductive Inference for Text Classification Using Support Vector Machines”, Proceedings of ICML-99, 16 th International Conference on Machine Learning, pp.200-209. Coppin
Core vector machines: Fast SVM training on very large data sets. Multi-class support
2 machine learning, data mining and statistics all need data. 3 data mining is just another name for
In developing LIBSVM, we found that many users have zero machine learning knowledge.. It is unbelievable that many asked what the difference between training and
A dual coordinate descent method for large-scale linear SVM. In Proceedings of the Twenty Fifth International Conference on Machine Learning
Core vector machines: Fast SVM training on very large data sets. Multi-class support
