Cloning, Characterization, and Phylogenetic Analysis of a Shrimp White Spot Syndrome Virus
Gene That Encodes a Protein Kinase
Wang-Jing Liu,*,1 Hon-Tsen Yu,*,1 Shao-En Peng,* Yun-Shiang Chang,* Hsiu-Wen Pien,* Ching-Ju Lin,*
Chiu-Jung Huang,* Meng-Feng Tsai,* Chang-Jen Huang,† Chung-Hsiung Wang,‡ Jung-Yaw Lin,§ Chu-Fang Lo,*,2 and Guang-Hsiung Kou*,2
*Department of Zoology, ‡Department of Entomology, and §Institute of Biochemistry, National Taiwan University, Taipei, 106, Taiwan, ROC; and †Institute of Biological Chemistry, Academia Sinica, Taipei, 115, Taiwan, ROC
Received May 23, 2001; returned to author for revision June 7, 2001; accepted June 11, 2001
An open reading frame (ORF) that encodes a 715-amino-acid polypeptide was found in an 8421-bp EcoRI fragment of the shrimp white spot syndrome virus (WSSV) genome. The polypeptide shows significant homology to eukaryotic serine/ threonine protein kinase (PK) and contains the major conserved subdomains for eukaryotic protein kinases. Coupled in vitro transcription and translation generated a protein having an apparent molecular mass of about 87 kDa according to sodium dodecyl sulfate–polyacrylamide gel electrophoresis. For transcriptional analysis of the pk gene, total RNA was isolated from WSSV-infected shrimp at different times after infection. Northern blot analysis with pk-specific riboprobe found a major and a minor transcript of 2.7 and 5.7 kb, respectively. Rapid amplification of the 5⬘ cDNA ends of the major 2.7-kb pk transcript showed that there were two transcriptional initiation sites located at nucleotide residues -38(G) and -39(G) relative to the ATG translational start codon. Temporal expression analysis by RT-PCR indicated that the transcription of the pk gene started 2 h after infection and continued for at least 60 h. Phylogenetic analysis showed that WSSV protein kinase does not have any close relatives and does not fall into any of the major protein kinase groups. © 2001 Academic Press
Key Words: Penaeus monodon; white spot syndrome virus; WSSV Taiwan isolate; WSSV pk gene; protein kinase.
INTRODUCTION
Shrimp white spot syndrome (WSS) is one of the most serious diseases faced by the shrimp farming industry all over the world (Chou et al., 1995; Flegel, 1997; Lo et
al., 1999). White spot syndrome virus (WSSV), the
caus-ative agent of WSS, is a large, double-stranded DNA virus (Wang et al., 1995) that primarily attacks tissues originating from the ectoderm and mesoderm (Wong-teerasupaya et al., 1995; Lo et al., 1997). There is little genetic variation among WSSV isolates from around the world (Lo et al., 1999; Chang et al., 2001).
Several WSSV genes have been identified, including genes that encode the ribonucleotide reductase large and small subunits (van Hulten et al., 2000a; Tsai et al., 2000a); nucleocapsid protein VP22 and envelope protein VP25 (van Hulten et al., 2000b);3
and a novel chimeric protein of thymidine kinase and thymidylate kinase (Tsai
et al., 2000b). These studies as well as morphological
studies (Wang et al., 1995, 2000a; Wongteerasupaya et
al., 1995) have provided evidence that WSSV is a newly
isolated virus. However, genome analysis is needed to conclusively establish WSSV’s taxonomic position. As part of our continuing work to identify and define the genetic structure of the virus, we report here on a protein kinase gene (the pk gene) of WSSV.
The eukaryotic protein kinases (PK) make up one of the largest protein superfamilies, and they all feature a homologous catalytic domain (for a review, see Hanks and Hunter, 1995). These enzymes usually use the ␥ phosphate of ATP (or GTP) to generate phosphate mo-noesters, and they use the protein alcohol groups on serine/threonine or the protein phenolic groups on ty-rosine as phosphate acceptors (Hunter, 1987; Hanks and Hunter, 1995). They are thus classified into two broad groups, the protein serine/threonine kinases (PSK) and protein tyrosine kinases (PTK).
The protein kinases and the phosphoprotein phospha-tases control reversible protein phosphorylation, which is a common mechanism in eukaryotes for regulation of normal cell function such as intracellular protein sorting (Herman et al., 1991), growth, proliferation, differentiation, apoptosis, and stress responses (reviewed in Widmann
et al., 1999; Hunter, 2000). Phosphorylation of numerous
cellular and viral proteins is also observed in virally infected cells, which suggests that the protein kinases may have a role in regulating a wide variety of viral
1These two authors contributed equally to this work.
2To whom correspondence and reprint requests may be addressed. 3van Hulten et al. (2000b) originally identified these proteins as VP26
and VP28, respectively. However, Western blot analysis using antibod-ies against the recombinant proteins (Lo and Kou, unpublished data) and the N-terminal sequence data given in Wang et al. (2000b) both confirm that these two respective proteins are in fact VP22 and VP25. doi:10.1006/viro.2001.1091, available online at http://www.idealibrary.com on
0042-6822/01 $35.00
Copyright © 2001 by Academic Press All rights of reproduction in any form reserved.
infections (Leader and Katan, 1988; Burma et al., 1994; Guarino et al., 1992; Kann et al., 1999). Protein phosphor-ylation in virally infected cells may depend on cellular protein kinases (Prives, 1990) or virally encoded protein kinases (for examples, see Smith and Smith, 1989; Wu et
al., 1990; Zhang et al., 1990; Barik and Banerjee, 1992; Lin et al., 1992; Baylis et al., 1993; Bischoff and Slavicek,
1994; Reilly and Guarino, 1994; Li and Miller, 1995). These virally encoded protein kinases possess most, if not all, of the conserved motifs (subdomains I–IX as defined by Hanks et al., 1988) of the catalytic domains found in eukaryotic protein kinases.
Previous sequencing (Liu et al., unpublished data) of a 3.4-kb HindIII genome fragment from WSSV revealed a 1020-bp open reading frame (ORF) that encodes a 339-amino-acid polypeptide with a high level of homology to the eukaryotic protein kinase catalytic domain, but this protein contained only a portion of the conserved kinase domain and was thus suspected to be a partial WSSV PK. However, a recently published paper (van Hulten and Vlak, 2001) suggested that this 1020-bp ORF encodes the entire PK catalytic domain and therefore may have mis-interpreted a number of critical features of this gene. Specifically, less than half of the WSSV PK sequence is shown [although van Hulten and Vlak (2001) correctly give the ORF as 2193 bp/730 aa, they provide sequence data for only 339 amino acid residues out of 730 amino acid residues in total], the sequence of the catalytic domain is incomplete, and its location is incorrect. Fur-ther, van Hulten and Vlak (2001) locate subdomains I to V within a region that, as we show in the present paper, is in fact a large (and unique) insertion between subdo-mains V and VI. They also constructed a phylogenetic tree based on this misinterpretation of the PK catalytic domain sequence data. In this paper, we describe the cloning and characterization of the full-length pk gene, the first WSSV-encoded protein kinase gene to be iden-tified. We also investigated and discuss the phylogenetic position of this pk gene.
RESULTS AND DISCUSSION Location and structure of the WSSV pk gene
The virus used in this study was isolated from a batch of WSSV-infected Penaeus monodon collected in Taiwan in 1994 (Wang et al., 1995) and which is now known as WSSV Taiwan isolate (Lo et al., 1999). From this virus, a plasmid library (referred to as the pmh library, where pm indicates Penaeus monodon and h indicates HindIII) of WSSV HindIII genomic fragments was constructed (Wang et al., 1995). During the sequencing of a 3.4-kb
HindIII genomic fragment (pmh12), a 1020-nt ORF
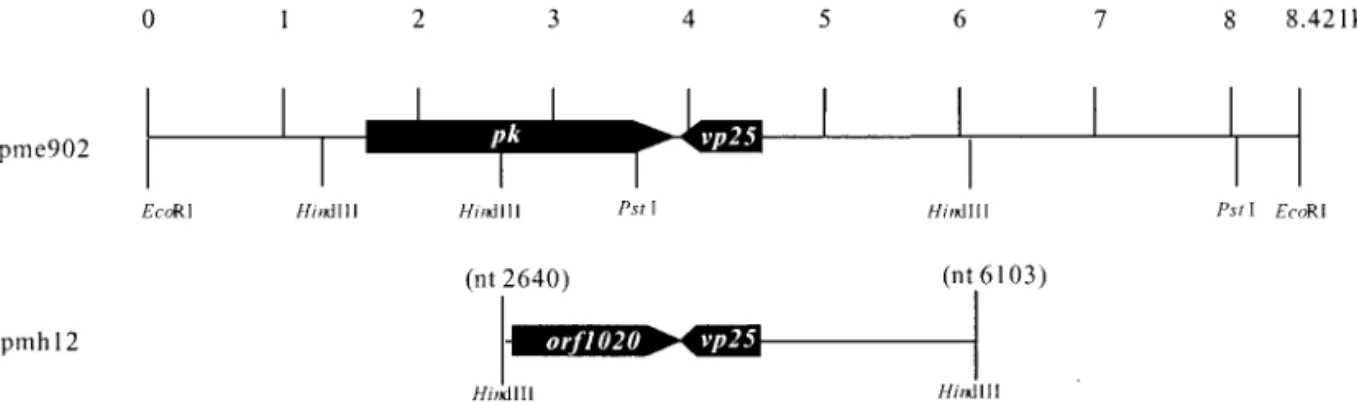
lo-cated at nucleotides 151–1170 of the pmh12 was found. When the deduced amino acid sequence of this 1020-nt ORF was compared with other sequences in GenBank at the National Center of Biotechnology Information by us-ing the BLAST network service (Altschul et al., 1990), it was found to contain only the C-terminal region catalytic domains (subdomains VI to XI) of the eukaryotic protein kinases and therefore did not appear to correspond to the complete coding region of the WSSV pk gene. Sub-sequently, from a plasmid library of EcoRI genomic frag-ments (pme library), a 1020-nt ORF-specific probe was used to identify a plasmid clone with an 8421-nt WSSV genomic fragment (pme902) containing an ORF encoding the full-length WSSV PK (Fig. 1). The putative WSSV PK ORF has two potential in-frame ATG initiation codons at nt 1617 and nt 1662. Thus the presumed PK-coding re-gion was either located between positions nt 1617 and 3809 (2193 nt in length, encoding 730 amino acid resi-dues) or nt 1662 and 3809 (2148 nt; 715 aa resiresi-dues) of the pme902 DNA fragment. The vp25 gene (GenBank Accession No. AF272979) coding for a WSSV major en-velope protein is adjacent to the pk gene and arranged in a tail-to-tail configuration (Fig. 1).
Coupled in vitro transcription and translation
To confirm that the entire length of the putative WSSV PK ORF was not interrupted by any overlooked stop codons, nt 1617 to nt 3809 of the pme902 DNA fragment FIG. 1. Restriction enzyme map of the pme902 segment of WSSV DNA showing the location (nt 1662 to 3809) of the WSSV pk gene. For reference, both the alignment of the pmh12 fragment (corresponding to nt 2640 to 6103 of pme902) and the location of the partial WSSV pk gene (orf1020) as well as the envelope protein gene vp25 are shown.
were inserted into the expression vector, which was then used for coupled in vitro transcription and eukaryotic in
vitro translation with rabbit reticulocyte lysate. The
trans-lated protein was expected to be a hemagglutinin epitope (MCYPYDVPDYASLA)-tagged polypeptide (tagged PK). As shown in Fig. 2, the synthesized HA-tagged PK had an apparent molecular mass of about 87 kDa according to sodium dodecyl sulfate–polyacrylam-ide gel electrophoresis (SDS–PAGE). It was also recog-nizable with a commercial anti-HA antibody (data not shown). At 87 kDa, the apparent molecular mass was in fairly good agreement with the size predicted from the full length PK sequence (i.e.,⬃80 kDa; this predicted size does not include the HA sequence at the N-terminus). Major transcripts of the putative WSSV pk gene in WSSV-infected shrimp
To determine whether the putative WSSV pk gene was expressed during viral infection, total RNAs extracted from WSSV-infected shrimp P. monodon at 0, 6, 12, 18, 60 h p.i. (hours postinfection) were analyzed by Northern blot hybridization using a WSSV pk-specific riboprobe. A minor transcript of approximately 1.9 kb was present throughout the 60 h of the experiment, but since it was also present at 0 h, it could not have been a WSSV-specific transcript. Two WSSV-WSSV-specific transcripts were detected: a major transcript of approximately 2.7 kb and a minor transcript of approximately 5.7 kb (Fig. 3). Neither transcript was found until 12 h p.i. The size of the major WSSV pk transcript was consistent with the predicted size of the pk mRNA after allowing for the presumed PK-coding region (2148 nt) plus stretches of 5⬘/3⬘ UTRs
(38 nt and 25 nt, respectively; see below) and a poly(A) tail (⬃500 nt).
Determination of the 5⬘ terminus of the 2.7-kb pk major transcript
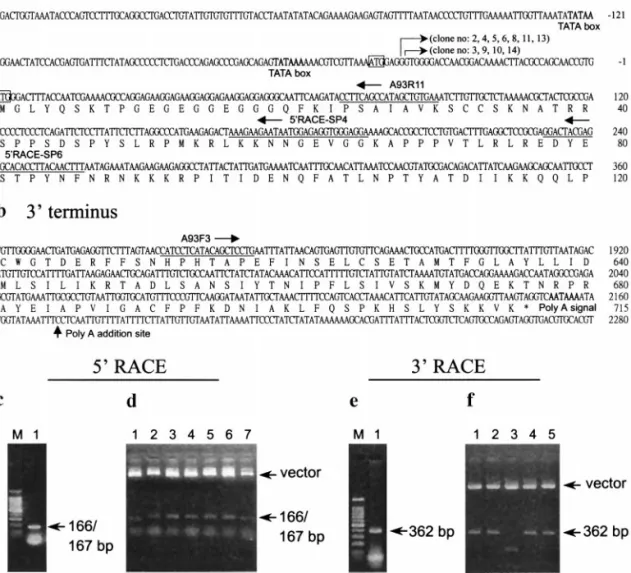
The 5⬘ region of the pk transcript was obtained by rapid amplification of the cDNA 5⬘ ends (5⬘ RACE) (Froh-man et al., 1988) using a 5⬘/3⬘ RACE kit (Roche) in which oligo(dT)-anchor primer, anchor primer, and other key reagents were included. The locations of the primers used in this study are shown in Fig. 4. For the first step of 5⬘ RACE, the appropriate gene-specific primer (5⬘ RACE-SP6 primer; Fig. 4a) was used for first-strand cDNA synthesis from the total RNA isolated from the shrimp 60 h after artificial infection with WSSV by using an AMV (avian myeloblastosis virus) reverse transcrip-tase. After the poly(A) head was added to the cDNA products, these cDNAs were used as templates for the first PCR amplification with the 5⬘ RACE-SP4/oligo(dT)-anchor primer set (Fig. 4a). The first amplification prod-ucts were then used as a template for the second PCR amplification with the A93R11/anchor primer set. The PCR products from the second amplification formed a single band in an agarose gel at ⬃166 bp (Fig. 4c). Analysis of 5⬘ RACE products cloned in pGEM-T Easy vector (Fig. 4d) revealed that all the 5⬘ termini of the first 14 randomly picked clones were located downstream of the first predicted ATG initiation codon. Contrary to the
FIG. 3. (a) Northern blot hybridization of total RNA isolated from WSSV-infected P. monodon with a pk-specific riboprobe. Size standards are by RNA marker (Promega). Lane headings show hours p.i. (b) RNA quality/quantity control; the blot was also hybridized to a-actin ribo-probe to control for the amount of RNA loaded.
FIG. 2. Coupled in vitro transcription and translation product (arrow) of the WSSV pk gene from pcDNA3PK (lane 2) and pcDNA3-HA (lane 1, as control). Protein marker size standards (Life Technologies) on the membrane are indicated.
conclusion reported in van Hulten and Vlak (2001), we therefore conclude that the first predicted ATG initiation codon did not play a role in translation initiation for the WSSV pk gene and that the second predicted ATG initi-ation codon is the transliniti-ational initiiniti-ation site. This conclu-sion is further supported by the fact that the sequences surrounding the putative second translation initiation codon (GTGATGG) conform reasonably well to the eukaryotic translation consensus sequence (Kozak, 1987, 1997).
Of the 14 clones from the 5⬘ RACE products that were subjected to sequencing, 4 had their 5⬘ termini at nucle-otide residue⫺38(G) and 7 at ⫺39(G) [relative to the A in the second potential translation initiation codon, which is defined as⫹1(A)]. The remaining 3 clones were appar-ently early termination clones (examples: clones 1 and 7 in Fig. 4d). These results suggest that for the WSSV pk gene, there are two transcriptional initiation sites, lo-cated at nucleotide residues ⫺38(G) and ⫺39(G). Up-stream of the transcriptional initiation sites, two putative TATA boxes were found at nt 59 to 64 and at nt 120 to 125.
In our previous study (Tsai et al., 2000a), we found that, for the genes encoding the WSSV ribonucleotide reduc-tase large and small subunits (rr1 and rr2 genes), the transcriptional start points were located within a consen-sus motif (TCAc/tTC). Recently, we found that the same consensus was also present in the WSSV tk-tmk gene encoding the novel chimeric protein of thymidine kinase and thymidylate kinase (Tsai et al., 2000b). However, this consensus was not present in the transcriptional start site of the WSSV pk gene. Further work is needed to confirm whether there are other WSSV genes that use the same consensus sequence for their transcription initiation sites as the WSSV pk gene.
Determination of the 3⬘ terminus of the 2.7-kb pk major transcript
To determine the 3⬘ terminus of the major WSSV pk transcript, 3⬘ RACE was performed. The first-strand cDNA was synthesized using the oligo(dT)-anchor primer FIG. 4. Determination of the termini of the 2.7-kb major pk transcript. The locations of primers used for 5⬘ RACE (A93R11, 5⬘ RACE-SP4, 5⬘ RACE-SP6) and for 3⬘ RACE (A93F3) are indicated in a and b, respectively. The bent arrows indicate the 5⬘ termini (transcriptional start points) revealed by sequencing of 11 5⬘ RACE clones. The first and second ATG initiation codons in the 2193-nt ORF are boxed. (c–f) Agarose gel analysis of RACE products (c, e) and the same RACE products cloned in the pGEM-T Easy vectors (d, f) (arrows). The predicted TATA box and polyadenylation signal (AATAAA) are in boldface type. The poly(A) addition site is indicated by the straight arrow. M in c and e represents a 100-bp DNA marker ladder (Promega).
and AMV reverse transcriptase. The amplification of the 3⬘ region of the resulting cDNA was carried out by PCR using the A93F3/anchor primer set (Fig. 4b), which yielded a PCR product of 362 bp (Fig. 4e). Sequence analysis of the cloned 3⬘ RACE products (Fig. 4f) re-vealed that poly(A) was added at a site 16 nt downstream of the AATAAA polyadenylation signal (nt 2152 to 2157), which was found 3 nucleotides downstream of the trans-lation stop codon (Fig. 4b).
Based on the above results, we conclude that the WSSV pk gene consists of 2148 nt with the potential to encode a polypeptide of 715 amino acids with a theoret-ical size of 80 kDa and a pI of 9.36. The WSSV pk gene sequence has been deposited with GenBank under Ac-cession No. AF335541.
WSSV pk transcription analysis in WSSV-infected shrimp
RT-PCR analysis was used to detect the pk-specific transcript in DNase-treated total RNAs from shrimp specimens before infection (0 h) and at 2, 4, 6, 8, 18, 24, 36, and 60 h after artificial infection with WSSV. As a control, PCR was also used to monitor the presence of the viral DNA in the infected shrimp. For the control, the total DNAs were extracted from pleopod tissues (200 mg) from each of the artificially infected shrimp. An aliquot (0.5 g) of the total DNA of each specimen was sub-jected to WSSV DNA-specific PCR using a WSSV
pk-specific primer set. As shown in Fig. 5, the viral DNA was first detected at 2 h and then continued to be found through to 60 h p.i. The relatively small amounts of WSSV DNA observed at 2 h p.i. are likely the result of some of the injected virions reaching the pleopod tissues that were used for the analysis, while the marked increase in intensity at 8 h p.i. probably indicates replication of the viral DNA. This interpretation of the data is only provi-sional, but it is consistent with what is already known about the WSSV replication cycle, which, in the cuticular epidermis of artificially infected shrimp, has been esti-mated at 22 h (Chang et al., 1996). This question is further discussed below.
For the RT-PCR analysis, total RNA extracted from the same pleopod tissues (500 mg) of each shrimp specimen was treated with DNase to eliminate any viral genomic DNA contamination in the preparations. An aliquot (10 g) of total RNA was used to synthesize the first-strand cDNA by using Superscript reverse transcriptase (Life Technologies) and oligo(dT) primer in a 20-l reaction mixture. An aliquot (2l) of the reaction product contain-ing about 1g cDNAs was then subjected to PCR am-plification with the pk-specific primer set and other ap-propriate primer sets (i.e., a primer set for the adjacent
vp25 gene for comparison and a-actin primer set for
control). The pk transcript was first detected at 2 h p.i. and continued to be found through to 60 h p.i. (Fig. 6a). The vp25 transcript was first detected at 4 h p.i. and also continued to be expressed through to 60 h (Fig. 6b). Unlike the pk gene, the intensity of the vp25 RT-PCR product band increased significantly over time, espe-cially after 12 h p.i., and during this advanced infection period, the amount of vp25 transcript was much higher than that of pk.
As a quality control, the first-strand cDNAs were sub-jected to PCR with a WSSV genomic DNA-specific IC-F2/ IC-R3 primer set derived from an intergenic region of the WSSV genome. The region delimited by this primer set should not appear in the cDNA, and no RT-PCR products FIG. 5. Amplification of WSSV DNA in artificially infected shrimp
using PCR delimited with (a) pk-specific primers and (b) decapod 18S ribosomal DNA degenerate primers 143/145 (5 ⬘-TGCCTTATCAGCT-NTCGATTGTAG-3⬘/5⬘-TTCAGNTTTGCAACCATACTTCCC-3⬘) designed by Lo et al. (1996) for template quality/quantity control. M represents a 100-bp ladder DNA marker (Promega). Lane headings show hours p.i.
FIG. 6. RT-PCR (a) with pk-specific primers, (b) with vp25-specific primers, and (c) with-actin degenerate primers (internal control). M represents a 100-bp ladder DNA marker (Promega). Lane headings show hours p.i.
were in fact yielded (data not shown), thus confirming that no viral genomic DNA was left in the prepared RNA for WSSV pk transcription analysis.
Due to the lack of a suitable shrimp cell line, it is impossible to do a temporal analysis of WSSV gene transcription in cells synchronously infected with the virus. However, WSSV, which systematically targets cells originating from the mesoderm and ectoderm (Wong-teerasupaya et al., 1995; Lo et al., 1997), is extremely virulent (this is true not only for the Taiwan isolate that we have consistently used since 1994, but also applies to isolates from other laboratories) and in infected indi-vidual shrimp it spreads rapidly (Chou et al., 1995) and infects both cuticular epithelial and connective tissue cells at a similar rate. In our previous study (Chang et al., 1996) of WSSV-specific in situ hybridization of the tissue sections of experimentally infected shrimp, WSSV-positive cells were initially observed at 16 h postinfection in the cuticular epidermis, and by 22 h p.i., WSSV-positive cuticular epidermal cells with hypertrophied nuclei and
other obvious cytopathological changes were readily ob-served in almost all the tissues examined. The sequen-tial progression of the disease is also very similar across different individual shrimp. Thus, when pleopod tissues, which most often showed the highest prevalence of the virus in early infection (Lo et al., 1997; Kou et al., 1998), are used as the source of total RNA in temporal gene expression experiments, the results are generally con-sistent and reproducible (see, e.g., Tsai et al., 2000a,b). Although this may not be an ideal assay system for temporal WSSV gene transcription analysis, the consis-tency of the results, whether using the same gene in different sets of RNA samples or different genes in the same set of RNA samples, suggests that this method can provide good estimates of the relative time and expres-sion patterns for WSSV genes.
Screening for WSSV pk homologues in the WSSV genome by Southern blot hybridization
Using Southern blot hybridization analysis, the WSSV
pk-specific probe hybridized only with a 3.4-kb HindIII
fragment and an 8.4-kb EcoRI WSSV genomic DNA frag-ment (presumably pmh12 and pme902, respectively) (Fig. 7). These data suggest that the WSSV genome does not contain other sequences encoding WSSV PK homo-logues.
Amino acid sequence alignment of WSSV PK
When the deduced amino acid sequence of WSSV PK was compared with other sequences in GenBank at the National Center of Biotechnology Information by using the Blast network service (Altschul et al., 1990), its car-boxyl-terminal region (residues 283–715; see Fig. 8) showed homology to the catalytic domain [subdomains I to IX (Hanks et al., 1988)] from a variety of eukaryotic organisms and their viruses. In particular, multiple align-ments of the highly conserved regions of each subdo-main show that the important residues with assigned functions for subdomains I and II (protein kinase ATP-binding site), subdomain VI (serine/threonine protein ki-nase active-site site), subdomain VII (Mg2⫹-binding loop),
and subdomain VIII (recognition of peptide substrate) are all conserved in WSSV PK. To take each of the subdo-mains in turn:
FIG. 7. Hybridization of a DIG-labeled WSSV pk-specific probe to Southern blots of WSSV DNA digested with HindIII (lane 1) and EcoRI (lane 2) restriction endonucleases. Size standards are from a Lambda
HindIII DNA marker (Promega).
At the N-terminal extremity of the catalytic domain of WSSV PK (Fig. 9), there is a region (subdomain I; resi-dues 283–295) containing a glycine (G)-rich stretch of residues (284GFGSKN289), and nearby (17 residues downstream) there is the lysine residue (306K) of sub-domain II (residues 303–306). The region from subdo-mains I to II has been shown to be involved in ATP binding (Hanks and Hunter, 1995). In the PROSITE data-base, this ATP-binding region is one of only two regions that have been selected to build a protein kinase signa-ture. The WSSV PK sequence in this region [283VGFG-SKNLSVLDT-x(7)-RLCK306] matches well (although not exactly) the protein kinase signature consensus pattern
I: [LIV]-G-{P}-G-{P}-[FYWMGSTNH]-[SGA]-{PW}-[LIVCAT]- {PD}-x-[GSTACLIVMFY]-x-(5,18)-[LIVMFYWCSTAR]-[AIVP]-[LIVMFAGCKR]-K, where K is the amino acid residue that binds ATP. (The convention used throughout this paper for consensus patterns is to list the acceptable alterna-tive amino acids for a given position between square brackets “[ ]” and to place between a pair of curly brack-ets “{ }” those amino acids that are not acceptable at a given position.)
The sequences of 334ESIL337, 372ASQVVMI378, 389VGVYYMLETGKVIKFM404, and 551IVNIVTRLS559 show homology to subdomains III, IV, V, and VIA, respec-tively. In subdomain VIB, which is highly conserved FIG. 9. The nucleotide sequence and deduced protein sequence of the coding region of the WSSV pk gene. The sites of the conserved catalytic subdomains are numbered I to XI and underlined.
among protein kinases and is used to build the protein kinase signature consensus pattern II, the WSSV PK sequence 563LVNPDIKSDNIVI575 matches well with the protein kinase signature consensus pattern II, [LIVM-FYC]-x-[HY]-x-D-[LIVMFY]-K-x(2)-N-[LIVMFYCT](3), where the aspartic acid residue (567D) is probably the residue important for the catalytic activity of the enzyme (Knighton et al., 1991). The residue of WSSV PK at posi-tion 569 is K, indicating that it is a serine/threonine-specific protein kinase.
Subdomain VII includes a Mg2⫹-binding loop that
con-tains a highly conserved Asp-Phe-Gly (DFG) triplet (Hanks and Hunter, 1995). In WSSV PK subdomain VII, the corresponding residues are found in a highly con-served region, 584MIDFGL589. Subdomain VIII plays a major role in the recognition of peptide substrates and contains a highly conserved Ala-Pro-Glu (APE) motif. In WSSV PK, this APE motif is located in a highly conserved region, 610SNHPHTAPE618. In WSSV PK, subdomains IX to XI are not so clearly defined, but three sites were found (amino acid residues 629 to 641, 642 to 646, and 666 to 678) that show significant homology to the corre-sponding regions of subdomains IX to XI in some of the selected protein kinases (Table 1). The WSSV PK subdo-main sequence data presented here, however, should be considered only as preliminary evidence, and further experiments on mutations should be made to confirm the validity of these sites, to precisely determine the location of each subdomain, and to identify which residues are functionally important.
The alignments also clearly demonstrate the overall similarity of the WSSV PK catalytic domain to the other selected protein kinases in terms of the order and spac-ing of the subdomains (Fig. 8). However, a very large insert (146 residues) occurs in WSSV PK between sub-domains V and VI, and this causes the WSSV PK catalytic domain (433 residues) to be considerably larger than most of the other protein kinase catalytic domains, which usually range from 250 to 300 amino acid residues (Hanks and Hunter, 1995). It should also be noted that while the location of the catalytic domain within the protein kinase is not fixed, in most single subunit en-zymes it lies near the carboxyl terminus, the amino ter-minus being devoted to a regulatory role, whereas in protein kinases having a multiple subunit structure, sub-unit polypeptides consisting almost entirely of catalytic domain are common (Hanks et al., 1988). WSSV PK re-sembles the single subunit enzymes in that its catalytic domain lies near the carboxyl terminus. The sequence of its long amino terminus (282 residues) upstream of the catalytic domain is unique, however, and more work will be needed to elucidate its function. To date, binding sites for regulatory elements such as Ca2⫹, cAMP, or phorbol
esters/diacyglycerol have not been identified in this re-gion.
Pairwise comparisons
For pairwise comparisons and phylogenetic analysis of the WSSV PK catalytic domain to the PK catalytic domains of other protein kinases, 29 viral PK (including WSSV) and 55 PK from fungi, invertebrates, vertebrates, a bacterium, and a plant were selected. Of the 55 nonviral protein kinases, 21 are representative members of the four major groups of protein kinases designated by Hanks and Hunter (1995), that is, (1) the AGC group, which includes the cyclic-nucleotide-dependent family (PKA and PKG), the protein kinase C (PKC) family, the ribosomal S6 kinase family, and other relatives; (2) the CaMK group, which includes the family of protein ki-nases regulated by calcium/calmodulin, the Snf1/AMPK (kinase essential for release from glucose repression/ AMP-activated protein kinase) family, and other close relatives; (3) the C-M-G-C group, which includes the family of cyclin-dependent kinases, the Erk (MAP) kinase (extracellular signal-regulated kinase) family, the glyco-gen synthase 3 (GSK3) family, the casein kinase II family, the Clk (Cdk-like kinase) family, and other close relatives; and (4) the “conventional” PTK group. The other 34 non-viral protein kinases fall outside these four major groups (Table 2). As for the 29 viral protein kinases, in addition to WSSV, 9 were from the Poxviridae, 8 from the
Baculo-viridae, 11 from the HerpesBaculo-viridae, 2 from the Phycodna-viridae, and 1 each from the Iridoviridae and Asfarviridae
(Table 3).
The pairwise identity and similarity (BLOSUM 35) of the WSSV PK catalytic domain to the PK catalytic do-mains of the selected PKs are summarized in Table 1. The overall homology of the WSSV PK and the protein kinases is not high: approximately 4 to 11% identity and 11 to 26% similarity was shown over the entire length of the catalytic domains. Within the subdomains, however, conservation of amino acid sequences is much higher, with the highest levels of homology [identity(%)/similar-ity(%)] for the conserved sequence in subdomains I, II, III, IV, V, VIA, VIB, VII, VIII, IX, X, and XI being 46/61, 50/50, 60/80, 42/71, 25/56, 33/66, 61/92, 83/100, 44/66, 42/71, 60/80, and 38/69, respectively.
Phylogenetic analysis
The sequences of the PK catalytic domains of all 84 of the proteins listed in Tables 2 and 3 were included in our original analysis, but it was found that WSSV PK did not cluster with any of the eukaryotic PK or with any of the viral PK (phylogenetic tree not shown). To focus on the relationships among viral PK, most of the eukaryotic PSK were therefore omitted and the phylogenetic tree was reconstructed. In addition, since all of the selected viral PK are PSK, the eukaryotic PTK group was also omitted. Thus in total 38 sequences (29 viral PK and 9 eukaryotic PK) from three of the major groups were used to con-struct the final phylogenetic trees (Fig. 10). [Note that
TABLE 1
Pairwise Comparison of the Amino Acid Sequence (Identity/Similarity; BLOSUM 35) of the Catalytic Domain of WSSV Protein Kinase (Residues 283–715) with the Consensus Regions for Subdomains I to XI of other Protein Kinases
Protein kinase source
Catalytic subdomains
Entire domain I–XI I II III IV V VIA VIB VII VIII IX X XI
1. PKA-C␣ (human) 30/46 25/25 60/60 14/42 12/50 33/33 38/76 50/83 33/44 21/50 20/40 15/46 9/19 2. PKG-I (Bos taurus) 23/30 25/25 40/60 14/57 12/43 22/33 23/76 50/100 33/44 14/57 20/40 15/46 9/20 3. cPKC␣ (Norway rat) 30/46 25/25 40/60 0/28 12/43 22/33 30/76 50/83 33/44 28/50 40/40 15/30 9/19 4.ARK1 (human) 23/30 25/25 40/60 14/42 12/31 11/44 38/69 50/83 44/55 14/42 0/20 7/46 8/20 5. S6K (human) 23/38 25/25 60/80 14/42 6/43 22/33 30/76 66/83 33/44 28/50 20/20 23/46 11/22 6. RSK1 (Nt) (human) 30/46 25/25 60/60 28/42 6/43 11/33 30/76 66/83 33/44 21/57 40/40 15/53 10/21 7. DMPK (human) 23/46 25/25 40/60 0/28 12/56 22/44 53/76 50/66 22/44 14/42 20/20 7/30 8/20 8. CaMK2␣ (Norway rat) 23/46 25/25 40/40 14/42 6/43 22/33 30/84 66/83 22/44 14/42 40/40 23/53 8/19 9. skMLCK (Oryctolagus cuniculus) 23/38 25/25 20/60 0/42 12/56 11/44 30/76 83/100 22/33 14/50 0/20 30/53 7/21 10. Mre4 (baker’s yeast) 46/53 25/25 60/60 0/42 6/37 22/44 46/84 50/83 33/44 14/50 0/20 15/30 7/19 11. PhK␥M (O. cuniculus) 23/38 25/25 60/60 0/42 12/50 11/55 38/84 50/83 33/44 14/50 20/60 23/46 8/21 12. Kin1 (baker’s yeast) 38/38 25/25 40/60 0/42 12/56 22/44 46/84 83/100 33/44 21/57 40/40 30/53 10/21 13. Snfl (baker’s yeast) 30/38 25/25 60/60 0/57 6/43 22/44 30/84 66/83 33/55 21/50 40/40 23/46 8/20 14. Polo (fruit fly) 15/23 25/25 40/60 14/28 0/43 33/44 23/69 66/83 33/44 7/42 20/20 23/38 7/20 15. Cdc5 (baker’s yeast) 15/30 25/25 40/40 14/28 6/50 11/33 30/61 66/83 33/44 14/57 20/40 7/38 7/20 16. Cdk2 (mouse) 23/38 25/25 60/80 14/42 18/50 0/33 30/76 66/83 33/44 14/57 0/40 23/53 7/19 17. Erk2 (B. taurus) 23/38 25/25 60/60 14/42 12/37 11/44 23/76 66/83 33/55 21/50 0/60 23/38 7/18 18. GSK3␣ (Norway rat) 30/38 25/25 40/60 14/42 18/43 0/33 30/69 50/66 33/55 14/50 0/60 15/53 7/18 19. CK2␣ (mouse) 23/53 25/50 60/60 0/57 6/31 0/33 30/76 66/100 22/44 28/50 0/80 15/46 7/17 20. Clk (human) 23/53 25/25 40/60 0/0 6/25 33/33 38/69 50/83 44/55 21/50 0/60 23/53 7/16 21. Ire1 (baker’s yeast) 30/61 25/25 40/60 14/28 0/31 33/44 30/76 66/83 33/33 7/42 20/40 30/69 7/17 22. Cdc7 (baker’s yeast) 30/53 25/25 40/80 28/71 12/25 0/44 30/61 66/100 33/33 14/57 40/40 7/53 5/14 23. Cot (human) 15/30 50/50 20/20 0/28 12/43 11/44 46/69 66/100 22/44 28/50 0/0 7/46 7/18 24. YpkA (Yersinia pseudotuberculosis) 7/23 25/50 20/20 0/28 11/29 11/66 46/69 66/100 33/33 7/21 0/20 7/38 7/18 25. MEK1 (human) 23/46 25/25 40/60 14/42 12/50 22/55 30/76 50/83 22/44 28/57 20/60 23/38 7/18 26. Ste7 (baker’s yeast) 23/53 25/25 60/80 0/28 18/43 22/55 38/76 50/83 22/44 21/71 20/60 15/46 8/22 27. Ste11 (baker’s yeast) 38/46 25/25 40/80 14/28 18/43 33/44 46/76 50/83 22/44 21/57 0/40 15/46 7/19 28. Nek1 (mouse) 23/38 25/50 40/80 14/28 18/43 11/33 46/76 50/83 22/44 14/50 40/60 15/69 8/21 29. NIMA (Aspergillus nidulans) 23/38 25/25 60/80 14/28 12/37 22/44 30/76 66/83 22/44 7/42 40/40 7/38 6/19 30. Fused (fruit fly) 38/38 25/25 40/40 14/57 12/43 22/55 23/76 66/83 33/44 14/42 60/60 7/53 9/19 31. NinaC (fruit fly) 15/30 25/25 20/20 0/14 12/31 11/22 38/84 66/83 33/44 14/50 0/20 23/53 7/17 32. Ste20 (baker’s yeast) 23/38 25/25 20/60 14/28 25/43 11/44 53/92 50/83 33/33 21/71 0/40 15/30 9/21 33. Cdc15 (baker’s yeast) 30/38 25/25 60/80 14/42 12/50 11/33 38/84 50/83 33/33 14/57 0/40 23/46 8/21 34. Npr1 (baker’s yeast) 30/46 25/25 40/40 0/28 6/25 33/44 53/69 66/83 44/66 7/42 20/20 38/46 8/17 35. Pim1 (mouse) 30/38 25/25 40/60 28/57 6/31 11/33 46/84 66/83 22/44 42/71 0/20 7/38 9/22 36. Rna1 (fission yeast) 23/38 25/25 20/60 0/42 18/43 11/44 30/76 66/83 22/55 21/64 0/0 15/69 7/20 37. Esk (mouse) 23/46 25/25 40/60 14/42 0/31 11/44 46/69 66/100 33/44 21/50 40/60 7/30 8/18 38. Elm1 (baker’s yeast) 23/23 25/25 40/40 14/57 6/31 11/33 38/69 50/66 33/33 14/50 0/40 15/61 8/18 39. SpWeel (fission yeast) 23/46 25/25 60/60 14/57 18/43 0/33 38/69 50/83 33/55 7/50 20/20 38/46 8/18 40. Weel (Hs) (human) 30/46 25/25 20/20 42/57 12/31 0/33 61/69 33/66 22/33 7/35 0/0 15/38 7/17 41. PKR (human) 23/38 25/50 40/40 14/28 6/56 22/33 38/69 66/83 22/44 21/57 0/40 15/61 7/18 42. Gcn2 (baker’s yeast) 23/38 25/25 40/60 28/28 6/37 11/55 38/69 66/83 22/33 21/64 0/40 23/53 6/17 43. CK1␣ (human) 23/38 25/25 20/40 14/28 0/31 0/55 38/76 83/100 0/22 21/50 20/40 7/23 5/16 44. PKN1 (Myxococcus xanthus) 23/38 25/25 20/40 28/42 0/43 0/33 46/76 50/100 33/44 7/42 20/20 7/53 6/18 45. Ykl516 (baker’s yeast) 30/61 25/25 40/60 14/42 12/43 33/44 30/84 66/83 22/55 14/42 0/60 15/30 6/17 46. Mos (human) 30/38 25/25 20/60 14/42 0/37 33/55 46/76 50/66 44/55 21/42 0/40 7/38 7/19 47. ZmPK1 (Zea mays) 23/38 25/25 40/80 28/42 12/37 11/33 30/84 66/83 33/44 14/71 0/60 7/53 6/20 48. Pelle (fruit fly) 23/30 25/25 40/40 0/42 12/31 11/22 46/76 66/83 22/33 21/71 20/40 7/23 8/19 49. TGFRII (human) 30/30 25/25 40/60 0/28 6/50 11/33 46/84 66/83 33/44 21/50 0/20 15/61 7/17 50. ACTRII (mouse) 15/15 25/25 40/40 0/28 12/43 11/33 38/76 66/83 33/44 28/50 0/20 15/53 6/16 51. Raf-1 (human) 30/46 25/25 40/80 0/42 6/31 11/22 38/84 66/83 33/44 14/64 0/60 23/46 8/21 52. Sp1A (Dictyostelium discoideum) 23/30 25/25 60/60 28/28 18/50 22/33 30/76 66/83 44/55 14/64 0/20 23/61 9/21 53. Src (human) 23/30 25/25 20/60 14/57 25/56 11/44 30/76 66/83 44/44 28/64 0/40 15/53 8/20 54. EGFR (human) 23/46 25/25 20/60 14/42 12/43 22/33 30/76 66/83 22/22 7/57 20/80 23/53 8/19 55. PDGFR (mouse) 23/53 25/25 40/60 28/42 12/43 22/55 30/69 66/83 33/33 28/64 20/40 23/61 10/26 56. ASFV-PK (swine virus) 23/46 25/50 20/60 14/42 6/50 11/55 38/84 66/83 22/33 14/57 20/20 7/30 8/21 57. PBCV1-PK (Chlorella virus) 15/38 25/25 20/80 0/42 12/37 0/33 46/76 50/66 33/33 28/42 0/40 23/46 7/19 58. FsV-PK (brown alga virus) 23/46 25/25 20/60 28/42 12/50 0/44 38/69 50/83 33/55 0/50 20/20 15/46 6/19 59. IIV6-PK (insect virus) 30/53 25/25 12/25 14/42 5/21 11/33 30/69 50/83 22/33 14/28 20/40 23/46 5/14 60. VACV-PKB1R (human virus) 30/46 25/50 12/12 0/22 0/31 22/55 46/69 50/100 11/22 14/35 0/0 0/15 6/16 61. FWPV (fowl virus) 30/38 25/50 12/25 0/11 6/50 0/44 38/76 50/100 0/33 7/35 0/40 0/0 5/17 62. MYXV-PK (rabbit virus) 15/30 25/50 37/50 11/55 12/31 11/33 46/84 33/66 33/33 7/14 40/40 7/30 7/16 63. MOCV1-PK (human virus) 15/30 25/50 25/50 11/55 12/25 11/33 38/84 33/66 22/22 7/14 20/40 0/38 5/16 64. VAR-PK (human virus) 30/46 25/50 12/12 11/22 0/31 22/55 46/69 50/100 11/22 14/35 0/40 0/15 6/16 65. VACV-PK2 (human virus) 15/30 25/50 25/50 11/55 6/25 22/33 38/84 33/66 33/33 7/21 40/60 7/38 5/15 66. MSEV-PK (grasshopper virus) 7/30 25/50 25/25 11/55 0/17 33/44 38/84 50/66 11/22 0/14 0/20 7/23 4/11 67. LdMNPV-PK (insect virus) 15/23 25/50 20/40 0/28 18/56 11/55 30/76 50/83 22/44 21/42 20/40 7/23 6/19 68. AcMNPV-PK (insect virus) 7/23 50/50 20/40 14/28 6/43 11/33 30/76 50/83 22/44 14/28 20/40 15/23 6/17 69. AfMNPV-PK (insect virus) 7/23 50/50 20/40 14/28 6/43 11/33 30/76 50/83 22/44 14/28 20/40 15/23 6/17 70. OpMNPV-PK1 (insect virus) 15/23 50/50 20/60 14/28 6/43 11/44 23/69 50/83 22/44 14/28 20/40 15/23 6/16 71. HaSNPV-PK (insect virus) 7/23 25/50 20/40 0/28 18/50 11/33 23/76 50/83 22/44 14/42 0/20 15/23 5/17 72. SpltMNPV-PK (insect virus) 15/23 50/50 20/60 28/42 12/56 11/33 30/76 50/83 22/44 7/35 20/40 15/30 6/17 73. SeMNPV-PK1 (insect virus) 15/23 50/50 20/40 0/28 6/50 11/33 30/76 50/83 22/44 14/35 20/60 15/30 5/18 74. BmNPV-PK (insect virus) 7/23 50/50 20/40 14/28 6/43 11/33 30/76 50/83 22/44 14/28 20/40 15/23 6/17 75. HHV1-PK1 (human virus) 30/61 25/50 40/60 0/42 0/31 11/55 46/84 50/66 33/33 14/50 0/20 23/38 6/18 76. SuHV1-PK (swine virus) 23/46 25/50 40/60 14/42 0/37 11/44 30/84 33/66 33/33 14/42 60/60 23/46 6/18 77. HHV1-PK2 (human virus) 23/23 25/25 33/33 12/25 6/31 22/44 38/69 50/66 22/44 14/50 0/60 23/46 6/15 78. HHV2-PK (human virus) 23/23 25/25 33/33 12/25 6/31 22/44 30/69 50/66 22/44 14/50 0/60 23/46 6/14 79. EHV1-PK (equine virus) 30/30 25/25 33/66 12/37 0/18 11/44 38/61 33/66 22/22 14/50 20/40 23/46 5/14 80. EHV4-PK (equine virus) 23/46 25/50 40/60 14/42 6/37 22/44 38/84 50/66 33/33 21/57 40/60 23/38 7/19 81. BoHV1.1-PK (bovine virus) 30/38 25/25 33/50 14/42 0/31 22/44 46/61 50/66 22/33 21/50 0/60 15/23 6/14 82. GaHV2-PK (gallid virus) 30/30 25/25 33/50 14/42 0/18 22/44 46/61 50/66 11/22 21/50 20/60 7/23 5/14 83. CeHV9-PK (simian virus) 7/38 25/50 33/33 0/42 0/31 11/44 38/76 50/66 33/33 21/57 20/80 23/46 5/18
TABLE 2
Nonviral Protein Kinases Used in the Pairwise Comparison and Phylogenetic Study
Protein kinases Source Accession No.
AGC group
1. PKA-C␣ (cyclic AMP-dependent protein kinase catalytic subunit, ␣-form) Homo sapiens OKHU2C
2. PKG-I (cyclic GMP-dependent protein kinase, type I) Bos taurus OKBOG
3. cPKC␣ (Ca2⫹-dependent protein kinase C,␣-form) Rattus norvegicus P05696
4. ARK1 (-adrenergic receptor kinase, type 1) H. sapiens A53791
5. S6K (70-kDa S6 kinase with single catalytic domain) H. sapiens NM_003952
6. RSK1 (Nt) (90-kDa S6 kinase, type 1) H. sapiens NM_002953
7. DMPK (myotonic dystrophy protein kinase) H. sapiens NP_004400
CaMK group
1. CaMK2␣ (Ca2⫹-calmodulin kinase type II,␣ subunit) R. norvegicus A30355
2. PhK␥M (skeletal muscle phosphorylase kinase catalytic subunit) Oryctolagus cuniculus KIRBFG
3. skMLCK (skeletal muscle myosin light chain kinase) O. cuniculus A35021
4. Mre4 (protein required for meiotic recombination) Saccharomyces cerevisiae P24719
5. Snf1 (kinase essential for release from glucose repression) S. cerevisiae AAA35058
6. Kin1 (protein kinase with N-terminal catalytic domain) S. cerevisiae S52687
C-M-G-C group
1. Cdk2 (type 2 cyclin-dependent kinase) Mus musculus NP_058036
2. Erk2 (extracellular signal-regulated kinase, type 2) B. taurus P46196
3. GSK3␣ (glycogen synthase kinase 3, ␣-form) R. norvegicus P18265
4. CK2␣ (casein kinase II, ␣ subunit) M. musculus CAA04753
5. Clk (Cdc-like kinase) H. sapiens NP_004062
PTK group
1. Src (cellular homologue of Rous sarcoma virus oncoprotein) H. sapiens NP_005408
2. EGFR (epidermal growth factor receptor) H. sapiens NP_005219
3. PDGFR (platelet-derived growth factor receptor, type ) M. musculus P05622
Other protein kinase families (not falling into major groups)
1. Polo (protein kinase homologue required for mitosis) Drosophila melanogaster P52304
2. Cdc5 (product of gene required for cell cycle progression) S. cerevisiae M84220
3. MEK1 (MAP ERK kinase, type 1) H. sapiens Q02750
4. Ste7 (kinase required for haploid-specific gene expression) S. cerevisiae P06784
5. Ste11 (protein required for cell-type-specific transcription) S. cerevisiae S51380
6. Ste20 (product of gene required for pheromone response) S. cerevisiae S28394
7. Nek1 (NimA-related kinase) M. musculus P51954
8. NIMA (cell cycle control protein kinase) Aspergillus nidulans P11837
9. Fused (product of gene required for segment polarity) D. melanogaster JC4243
10. Weel (Hs) (gene product able to complement S. pombe weel mutant) H. sapiens CAA43979 11. SpWeel (“Wee” size at division kinase; Cdc2 negative regulator) Schizosaccharomyces pombe AAA35354
12. PKR (double-stranded RNA-dependent kinase) H. sapiens JC5225
13. Gcn2 (protein required for translational derepression) S. cerevisiae AAA34881
14. Raf-1 (cellular homologue of retroviral oncogene product) H. sapiens NP_002871
15. ACTRII (type II receptor for activin) M. musculus P27038
16. TGFRII (type II receptor TGF-) H. sapiens P37173
17. ZmPK1 (putative receptor protein-serine kinase) Z. mays P17801
18. CK1␣ (casein kinase I, type ␣) H. sapiens NP_001883
19. PKN1 (protein kinase homologous to eukaryotic kinases) Myxococcus xanthus A41090
Other protein kinase families (each with no known close relatives)
1. Mos (cellular homologue of retroviral oncogene product) H. sapiens TVHUMS
2. Pim1 (proto-oncogene activated by murine leukemia virus) M. musculus TVMSP1
3. Cot (product of oncogene expressed in human thyroid carcinoma) H. sapiens P41279
4. Esk (“embryonal carcinoma STY kinase”; dual specificity) M. musculus AAA37578
5. NinaC (product of gene essential for photoreceptor function) D. melanogaster B29813
6. Pelle (product of gene required for dorsoventral polarity) D. melanogaster AAA28750
7. Sp1A (spore lysis A protein kinase) Dictyostelium discoideum P18160
8. Cdc7 (“cell-division-cycle” control gene product) S. cerevisiae AAA34458
9. Cdc15 (cell-division-cycle control gene product) S. cerevisiae S15038
10. Npr1 (product of gene required for activity of ammonia-sensitive amino acid) S. cerevisiae S63138 11. Elm1 (product of gene required for yeast-like cell morphology) S. cerevisiae AAA02892 12. Ire1 (required for Myo-inositol synthesis and signaling from ER to the nucleus) S. cerevisiae A47541
13. Ykl516 (putative protein kinase gene on chromosome XI) S. cerevisiae AAB21999
14. Rna1 (product of gene required for normal meiotic function) S. pombe A25685
since both the neighbor-joining (NJ) and parsimony trees generated similar results, and since the NJ tree also revealed finer structures within major phylogenetic clades, only the NJ tree (Saitou and Nei, 1987) is shown here.] On the tree, the three major PSK groups (i.e., AGC, CaMk, and C-M-G-C groups), as expected, form three major clades while the viral PK reflect their current phy-logenetic grouping. There are two well-supported (boot-strap value greater than 90%) clades within the
Poxviri-dae although the relationship between the two poxvirus
clades is not resolved. A similar situation is also found in the Herpesviridae. This suggests that, within these two viral families, there may have been two different sources for the PK genes. The baculoviruses form a well-sup-ported clade with high bootstrap value, while WSSV, one of the Iridoviridae (IIV6), the two Phycodnaviridae (FsV and PBCV1), and the type species of the newly defined family Asfarviridae (ASFV) (van Regenmortel et al., 2000) all form distinct viral groups of their own. However, the relationships among the major clades, including the eu-karyotic PK, constitute an unresolved polytomy. This star phylogeny and the relatively long branch length both suggest that WSSV is a distinct virus (likely at the family
level) that does not belong to any of the virus families that are currently recognized.
MATERIALS AND METHODS Virus, plasmid clone, and sequence analysis
The virus (WSSV Taiwan isolate) was isolated from a batch of WSSV-infected P. monodon collected in Taiwan in 1994 (Wang et al., 1995; Lo et al., 1999). From the
HindIII and EcoRI libraries of genomic fragments,
plas-mid clones (pmh12; pme902) carrying the pk gene were sequenced on both DNA strands by using universal M13 forward and reverse primers. The internal sequences of the cloned fragments were obtained by automatic se-quence walking (Mission Biotech, Taipei, Taiwan) using customed synthesized primers. All of the sequences were confirmed by sequencing both strands completely. Sequence data were compiled and analyzed using three computer programs: GeneWorks 2.5.1 (IntelliGenetics), UWGCG (release 9.0, Genetics Computer Group), and Neural Network for promoter prediction (NNPP; Reese, 1994; Reese and Eeckman, 1995; Reese et al., 1996). The DNA and the deduced amino acid sequences were com-TABLE 3
Viral Protein Kinases Used in the Pairwise Comparison and Phylogenetic Analyses
Viral protein kinase
Virus
Accession No. Reference
Species Family
1. ASFV-PK African swine fever virus Asfarviridae NP_042813 Baylis et al. (1993)
2. PBCV1-PK Paramecium bursaria Chlorella virus 1 Phycodnaviridae U14660 Que and Van Etten (1995)
3. FsV-PK Feldmannia sp. virus Phycodnaviridae AAC33140 Lee et al. (1998)
4. IIV6-PK Invertebrate iridescent virus 6 (Chilo iridescent virus) Iridoviridae AAB94478 Bahr et al. (1997)
5. VACV-PKB1R Vaccinia virus Poxviridae TVVZ9Z Lin et al. (1992)
6. FWPV-PK Fowlpox virus Poxviridae NP_039189 Afonso et al. (2000)
7. MYXV-PK Myxoma virus Poxviridae NP_051734 Cameron et al. (1999)
8. MOCV1-PK Molluscum contagiosum virus subtype 1 Poxviridae NP_043968 Senkevich et al. (1996)
9. VARV-PK Variola major virus Poxviridae AAA60910 Massung et al. (1993)
10. VACV-PK2 Vaccinia virus Poxviridae U32589 Traktman et al. (1989)
11. MSEV-PK Melanoplus sanguinipes entomopoxvirus Poxviridae NP_048244 Afonso et al. (1999) 12. LdMNPV-PK Lymantria dispar nucleopolyhedrovirus Baculoviridae NP_047639 Bischoff and Slavicek (1994) 13. AcMNPV-PK Autographa californica nucleopolyhedrovirus Baculoviridae NP_054039 Reilly and Guarino (1994) 14. AfMNPV-PK Anagrapha falcifera nuclearpolyhedrosisvirus Baculoviridae AAB53359 Federici and Hice (1997) 15. OpMNPV-PK1 Orgyia pseudotsugata nuclearpolyhedrosisvirus Baculoviridae NP_046157 Ahrens et al. (1997) 16. HaSNPV-PK Helicoverpa armigera nuclearpolyhedrosisvirus Baculoviridae JC5681 Zhang et al. (1997) 17. SpltMNPV-PK Spodoptera litura nucleopolyhedrovirus Baculoviridae AF039272
18. SeMNPV-PK1 Spodoptera exigua nucleopolyhedrovirus Baculoviridae NP_037763 Ijkel et al. (1999) 19. BmNPV-PK Bombyx mori nuclearpolyhedrosisvirus Baculoviridae NP_047416 Kamita and Maeda (1997) 20. HHV1-PK1 Human herpesvirus 1 (herpes simplex virus) Herpesviridae NP_044655 McGeoch et al. (1986) 21. SuHV1-PK Suid herpesvirus 1 (pseudorabies virus) Herpesviridae D10451 van Zijl et al. (1990)
22. HHV1-PK2 Human herpesvirus 1 Herpesviridae NP_044614 McGeoch et al. (1986)
23. HHV2-PK Human herpesvirus 2 Herpesviridae NP_044482 McGeoch et al. (1987)
24. EHV1-PK Equine herpesvirus 1 Herpesviridae NP_041058 Allen and Coogle (1988)
25. EHV4-PK Equine herpesvirus 4 Herpesviridae NP_045286 Telford et al. (1998)
26. BoHV1.1-PK Bovine herpesvirus type 1.1 Herpesviridae NP_045346
27. GaHV2-PK Gallid herpesvirus 2 Herpesviridae NP_057771 Lee et al. (2000)
pared with the latest GenBank/EMBL, SWISSPROT, and PIR databases using FASTA and BLAST. Alignments of amino acid sequences were made in CLUSTAL_X (Thompson et al., 1997) and edited in GeneDoc (Nicholas
et al., 1997).
Coupled in vitro transcription and translation
An expression vector with the full-length WSSV pk gene was constructed for in vitro transcription and translation.
The WSSV pk gene with additional EcoRI and NotI restric-tion endonuclease sites at both ends was amplified from pme902 by PCR with pk1-EcoRI/pk1-NotI primer sets
(5
⬘-CCGAATTCATGGAGGGTGGGGACCAACGGCA-3⬘/5⬘--GGGCGGCCGCCTACTTAACCTT-3⬘; where the underlined bases indicate the restriction sites) and then cloned into pGEM-T Easy (Promega). The resultant plasmid (pPK) with the correct sequence of insertion was cleaved with EcoRI and NotI and introduced into a modified form of the FIG. 10. Unrooted neighbor-joining phylogenetic tree of the WSSV PK catalytic domains of 29 viral PK (listed in Table 3) and 9 eukaryotic PK from three of the major PSK groups (i.e., AGC, CaMk, and C-M-G-C groups; refer to Table 2). Numbers indicate bootstrap values.
pcDNA3 (Invitrogen) based vector. To create this modified form (pcDNA3PK) a hemagglutinin (HA) epitope tag excised from a HA epitope-tagged mammalian expression vector (Clontech) was inserted at the HindIII and BamHI cloning sites. TNT (Promega) Quick Master Mix (20l) was mixed with 1 l [35S]methionine (1000 Ci/mmol, 10 mCi/ml) and
pcDNA3PK (1g in 5 l nuclease-free water). The reaction mixture (25l) was incubated at 30°C for 90 min, and an aliquot of the translation product (4.5l) was analyzed by 12.5% SDS–PAGE. After electrophoresis, the gel was stained, destained, dried, and exposed to Fuji medical film at room temperature for 17 h. The same reaction but with 0.5 mM methionine instead of [35S]methionine was also
carried out for Western blot analysis with PK antibodies. WSSV pk transcription analysis
WSSV-infected shrimp. Since to date no
WSSV-suscep-tible shrimp cell lines have become available, all the RNA for the transcriptional analysis was taken from WSSV-infected shrimp at different times after infection. Healthy (that is, two-step WSSV diagnostic PCR negative; Lo et al., 1996) subadult P. monodon (15–20 g) were infected with WSSV by injection using the method de-scribed previously by Tsai et al. (1999). At various times over the course of the next 60 h, two or three specimens were selected at random and their pleopods were ex-cised. The collected pleopods were immediately frozen and stored in liquid nitrogen until used for RNA isolation.
RNA isolation. For the isolation of total RNA, the frozen
pleopods (500 mg) from WSSV-infected P. monodon were homogenized in 5 ml TRIzol reagent (Life Technologies) and then subjected to ethanol precipitation according to the manufacturer’s recommendations. The total RNA was stored in 75% ethanol at ⫺20°C. Following procedures described in Lo et al. (1996), total DNA was extracted from the same tissues and used to check the viral DNA loading in the tissues using PCR with a pk-specific primer set pk-F2/pk-R7 (5 ⬘-TTTAGTCACGCTCTTGAGGG-3⬘/5⬘-GCCAGTAGCTTGAAGCATCC-3⬘).
Detection of WSSV pk transcripts in WSSV-infected shrimp by Northern blot hybridization analysis with a pk gene-specific riboprobe. A WSSV pk-specific [␣-32
P]rCTP-labeled riboprobe was used for Northern blot analysis. To generate the riboprobe, the RNA polymerase pro-moter addition kit Lig’nScribe (Ambion) was used in ac-cordance with the manufacturer’s instructions to produce templates from WSSV pk-specific PCR products for the in
vitro transcription. Briefly, the WSSV pk-specific fragment
was amplified from WSSV genomic DNA by PCR with the primer set pk-F2 and pk-R4 (5 ⬘-TTTAGTCACGCTCTT-GAGGG-3⬘ and 5⬘-ACATGCACCAATTACAGGCG-3⬘, re-spectively). An aliquot (25 ng) of the WSSV pk-specific PCR product was then ligated with T7 promoter adapter (supplied with the kit) using T4 DNA ligase. To generate WSSV pk-specific fragments that contained the T7 RNA
polymerase promoter, an aliquot (2 l) of the reaction mixture (10l) was used as a template in PCR with a primer set consisting of the PCR adapter primer 1 (sup-plied with the kit) and pk-F2 (5 ⬘-GCTTCCGGCTCGTATGT-TGTGTGG-3⬘ and 5⬘-TTTAGTCACGCTCTTGAGGG-3⬘, re-spectively). An aliquot (3.6l) of PCR product (50 l) was then used to generate the WSSV pk-specific [␣-32
P]rCTP-labeled riboprobe by in vitro transcription (Sambrook et
al., 1989) in a 20-l reaction mixture containing 40 U of T7
RNA polymerase (Roche) and 0.02 mCi [␣-32P]rCTP for
2 h at 37°C. The reaction mixture was then treated with 200 U RNase-free DNase I for 30 min at room tempera-ture, terminated at 68°C for 15 min, and filtered through a Sephadex G50 column.
For Northern blot analysis, 10g total RNA was sep-arated on 1% formaldehyde-containing agarose gel and transferred to a Hybond-N⫹ membrane (Amersham)
(Sambrook et al., 1989). The membrane was prehybrid-ized for 1 h at 65°C in a prehybridization buffer (0.25 M phosphate buffer, 1 mM EDTA, 1% BSA, and 7% SDS) and then hybridized to the WSSV pk-specific [␣-32
P]rCTP-labeled riboprobe for 16 h at 65°C. After washing, the membrane was exposed to Kodak BioMax MR film via an intensifying screen for several days at ⫺70°C and then developed.
Temporal analysis of WSSV pk transcription by RT-PCR. Total RNA in 75% ethanol was centrifuged at
14,000g for 30 min at 4°C. The pellet was resuspended in DEPC-water and quantified by spectrophotometry at 260 nm. An aliquot of 10 g RNA was treated with 200 U of RNase-free DNase I at 37°C for 30 min to remove any residual DNA and then extracted with phenol–chloro-form. The DNase-treated total RNA (⬃10g) was dena-tured by heating at 85°C for 10 min in 10l DEPC-water containing 100 pmol oligo(dT) primer (Roche). The first-strand cDNA was synthesized by the addition of 4 l Superscript II 5⫻ buffer, 1l of 100 mM DTT, 1 l of 10 mM dNTPs, 10 U RNasin (Promega), and 100 U Super-script II reverse tranSuper-scriptase (Life Technologies). DEPC-water was added to make a final volume of 20l. The reverse transcription proceeded at 37°C for 1 h, followed by heating at 95°C for 5 min to stop the reaction. One-tenth of the products of the cDNA reaction (2l; ⬃1 g) was subjected to RT-PCR in a 50-l reaction buffer con-taining 10 mM Tris–HCl, pH 8.8, 1.5 mM MgCl2, 150 mM
KCl, 0.1% Triton X-100, 0.2 mM dNTPs, 100 pmol each primer [the primer sets were pk-F2/pk-R7 (5
⬘-TTTAGTCA-CGCTCTTGAGGG-3
⬘/5⬘-GCCAGTAGCTTGAAGCATCC-3⬘) for pk and vp25-F1/vp25-R1 (5⬘-CAGTGCCAGAGTAG-GTGACG-3⬘/5⬘-ATGAAGGAAGAAGATGCGC-3⬘) for vp25, where vp25 is an envelope gene adjacent to the pk gene; it is used here for comparison], and 2 U DyNAzyme II DNA polymerase (Finnzymes). The PCR cycles were as follows: 94°C for 2 min, 40 cycles of 94°C for 1 min, 55°C for 1 min, 72°C for 1 min, followed by an elongation at 72°C for 30 min. A-actin transcript was amplified with
the actin-F1/actin-R1 primer set (5
⬘-GAYGAYATGGAGAA-GATCTGG-3⬘/5⬘-CCRGGGTACATGGTGGTRCC-3⬘) and
used as an internal control for RNA quality and amplifi-cation efficiency. A WSSV genomic DNA-specific primer set IC-F2/IC-R3 (5⬘-CAGACTATTAATGTACAAGTGCG-3⬘/ 5⬘-GAATGATTGTTGCTGGTTAGAACC-3⬘) derived from an intergenic region of the WSSV genome was used to confirm that the RNA was not contaminated by any viral DNA.
Southern blot analysis
Southern blot analysis (Southern, 1975) was used to screen the WSSV genome for possible ORFs that poten-tially encode eukaryotic protein kinase homologues. Since the 1020-nt ORF contains the conserved se-quences of the eukaryotic protein kinase subdomains VI to XI, the PCR-generated, DIG-labeled 1020-nt ORF-spe-cific probe was used for this analysis. WSSV DNA ex-tracted from virions purified from WSSV-infected P.
mon-odon (Wang et al., 1995) was digested with HindIII or EcoRI restriction enzymes, separated by electrophoresis
on a 0.7% agarose gel, transferred to Hybond-N⫹
mem-brane (Amersham), and then hybridized with the DIG-labeled probe. DIG-DIG-labeled nucleotides in the blots were detected as described previously (Lo et al., 1999). Amino acid sequence comparison and phylogenetic construction
Selected protein kinases (29 viral PKs and 55 other PKs from fungi, invertebrates, vertebrates, a plant, and a bacterium) from GenBank were used in the alignment and phylogenetic analyses (Tables 2 and 3). The multiple sequence alignments were done by the multiple se-quence alignment program CLUSTAL_X (Thompson et
al., 1997). Phylogenetic analysis based on PK sequences
was performed using NJ and parsimony methods with the PAUP 4.0b1 program (Swofford, 1998), using CLUSTAL_X (Thompson et al., 1997) to produce input files of aligned protein sequences. One thousand boot-strap replicates were generated to test the robustness of the trees.
ACKNOWLEDGMENTS
This work was supported by National Council Grants NSC89-2317-B-002-001 and NSC89-2311-B002-080 and Ministry of Education Grant 89-B-FA01-1-4. We are indebted to Paul Barlow for his helpful criticism of the manuscript.
REFERENCES
Afonso, C. L., Tulman, E. R., Lu, Z., Oma, E., Kutish, G. F., and Rock, D. L. (1999). The genome of Melanoplus sanguinipes entomopoxvirus.
J. Virol. 73, 533–552.
Afonso, C. L., Tulman, E. R., Lu, Z., Zsak, L., Kutish, G. F., and Rock, D. L. (2000). The genome of fowlpox virus. J. Virol. 74, 3815–3831. Ahrens, C. H., Russell, R. L., Funk, C. J., Evans, J. T., Harwood, S. H., and
Rohrmann, G. F. (1997). The sequence of the Orgyia pseudotsugata
multinucleocapsid nuclear polyhedrosis virus genome. Virology 229, 381–399.
Allen, G. P., and Coogle, L. D. (1988). Characterization of an equine herpesvirus type 1 gene encoding a glycoprotein (gp13) with homol-ogy to herpes simplex virus glycoprotein. C. J. Virol. 62, 2850–2858. Altschul, S. F., Gish, W., Miller, W., Myers, E. W., and Lipman. D. J. (1990).
Basic local alignment search tool. J. Mol. Biol. 215, 403–410. Bahr, U., Tidona, C. A., and Darai, G. (1997). The DNA sequence of Chilo
iridescent virus between the genome coordinates 0.101 and 0.391: Similarities in coding strategy between insect and vertebrate iridovi-ruses. Virus Genes 15, 235–245.
Barik, S., and Banerjee, A. K. (1992). Sequential phosphorylation of the phosphoprotein of vesicular stomatitis virus by cellular and viral protein kinases is essential for transcription activation. J. Virol. 66, 1109–1118.
Baylis, S. A., Banham, A. H., Vydelingum, S., Dixon, L. K., and Smith G. L. (1993). African swine fever virus encodes a serine protein kinase which is packaged into virions. J. Virol. 67, 4549–4556.
Bischoff, D. S., and Slavicek, J. M. (1994). Identification and character-ization of a protein kinase gene in the Lymantria dispar multinucleo-capsid nuclear polyhedrosis virus. J. Virol. 68, 1728–1736.
Burma, S., Mukherjee, B., Jain, A., Habib, S., and Hasnain, S. E. (1994). An unusual 30-kDa protein binding to the polyhedrin gene promoter of Autographa californica nuclear polyhedrosis virus. J. Biol. Chem. 269, 2750–2757.
Cameron, C., Hota-Mitchell, S., Chen, L., Barrett, J., Cao, J. X., Macaulay, C., Willer, D., Evans, D., and McFadden, G. (1999). The complete DNA sequence of myxoma virus. Virology 264, 298–318.
Chang, P. S., Lo, C. F., Wang, Y. C., and Kou, G. H. (1996). Identification of white spot syndrome associated baculovirus (WSBV) target organs in the shrimp Penaeus monodon by in situ hybridization. Dis. Aqua.
Org. 27, 131–139.
Chang, Y. S., Peng, S. E., Wang, H. C., Hsu, H. C., Ho, C. H., Wang, C. H., Wang, S. Y., Lo, C. F., and Kou, G. H. (2001). Sequencing and ARFLP analysis of ribonucleotide reductase large subunit gene of the white spot syndrome virus found in blue crab Callinectes sapidus collected from American coastal waters. Mar. Biotechnol., in press.
Chou, H. Y., Huang, C. Y., Wang, C. H., Chiang, H. C., and Lo, C. F. (1995). Pathogenicity of a baculovirus infection causing white spot syn-drome in cultured penaeid shrimp in Taiwan. Dis. Aqua. Org. 23, 165–173.
Federici, B. A., and Hice, R. H. (1997). Organization and molecular characterization of genes in the polyhedrin region of the Anagrapha
falcifera multinucleocapsid NPV. Arch. Virol. 142, 333–348.
Flegel, T. W. (1997). Special topic review: Major viral diseases of the black tiger prawn (Penaeus monodon) in Thailand. World J. Microbiol.
Biotechnol. 13, 433–442.
Fletcher, T. M., and Gray, W. L. (1993). DNA sequence and genetic organization of the unique short (US) region of the simian varicella virus genome. Virology 193, 762–773.
Frohman, M. A., Dush, M. K., and Martin, G. R. (1988). Rapid production of full-length cDNAs from rare transcripts: Amplification using a single gene-specific oligonucleotide primer. Proc. Natl Acad. Sci.
USA 85, 8998–9002.
Guarino, L. A., Dong, W., Xu, B., Broussard, D. R., Davis, R. W., and Jarvis, D. L. (1992). Baculovirus phosphoprotein pp31 is associated with virogenic stroma. J. Virol. 66, 7113–7120.
Hanks, S. K., and Hunter, T. (1995). Protein kinases 6. The eukaryotic protein kinase superfamily: Kinase (catalytic) domain structure and classification. FASEB J. 9, 576–596.
Hanks, S. K., Quinn, A. M., and Hunter, T. (1988). The protein kinase family: Conserved features and deduced phylogeny of the catalytic domains. Science 241, 42–52.
Herman, P. K., Stack, J. H., DeModena, J. A., and Emr, S. D. (1991). A novel protein kinase homolog essential for protein sorting to the yeast lysosome-like vacuole. Cell 64, 425–437.
Hunter, T. (2000). Signaling-2000 and beyond. Cell 100, 113–127. Ijkel, W. F., van Strien, E. A., Heldens, J. G., Broer, R., Zuidema, D.,
Goldbach, R. W., and Vlak, J. M. (1999). Sequence and organization of the Spodoptera exigua multicapsid nucleopolyhedrovirus genome.
J. Gen. Virol. 80, 3289–3304.
Kamita, S. G., and Maeda, S. (1997). Sequencing of the putative DNA helicase-encoding gene of the Bombyx mori nuclear polyhedrosis virus and fine-mapping of a region involved in host range expansion.
Gene 190, 173–179.
Kann, M., Sodeik, B., Vlachou, A., Gerlich, W. H., and Helenius, A. (1999). Phosphorylation-dependent binding of hepatitis B virus core parti-cles to the nuclear pore complex. J. Cell Biol. 145, 45–55.
Knighton, D. R., Zheng, J. H., Ten Eyck, L. F., Xuong, N. H., Taylor, S. S., and Sowadski, J. M. (1991). Structure of a peptide inhibitor bound to the catalytic subunit of cyclic adenosine monophosphate-dependent protein kinase. Science 253, 414–420.
Kou, G. H., Peng, S. E., Chiu, Y. L., and Lo, C. F. (1998). Tissue distribu-tion of white spot syndrome virus (WSSV) in shrimp and crabs. In “Advances in Shrimp Biotechnology” (T. W. Felgel, Ed.), pp. 267–271. National Center for Genetic Engineering and Biotechnology, Bangkok.
Kozak, M. (1987). At least six nucleotides preceding the AUG initiator codon enhance translation in mammalian cells. J. Mol. Biol. 196, 947–950.
Kozak, M. (1997). Recognition of AUG and alternative initiator codons is augmented by G in position⫹4 but is not generally affected by the nucleotides in positions⫹5 and ⫹6. EMBO J. 16, 2482–2492. Leader, D. P., and Katan, M. (1988). Viral aspects of protein
phosphor-ylation. J. Gen. Virol. 69, 1441–1464.
Lee, A. M., Ivey, R. G., and Meints, R. H. (1998). Repetitive DNA insertion in a protein kinase ORF of alatent FSV (Feldmannia sp. virus) ge-nome. Virology 248, 35–45.
Lee, L. F., Wu, P., Sui, D., Ren, D., Kamil, J., Kung, H. J., and Witter, R. L. (2000). The complete unique long sequence and the overall genomic organization of the GA strain of Marek’s disease virus. Proc. Natl.
Acad. Sci. USA 97, 6091–6096.
Li, Y., and Miller, L. K. (1995). Expression and analysis of a baculovirus gene encoding a truncated protein kinase homology. Virology 206, 314–323.
Lin, S., Chen, W., and Broyles, S. S. (1992). The vaccinia virus B1R gene product is a serine/threonine protein kinase. J. Virol. 66, 2717–2723. Lo, C. F., Ho, C. H., Peng, S. E., Chen, C. H., Hsu, H. C., Chiu, Y. L., Chang, C. F., Liu, K. F., Su, M. S., Wang, C. H., and Kou, G. H. (1996). White spot syndrome baculovirus (WSBV) detected in culture and captured shrimp, crabs and other arthropods. Dis. Aqua. Org. 27, 215–225.
Lo, C. F., Ho, C. H., Chen, C. H., Liu, K. F., Chiu, Y. L., Yeh, P. Y., Peng, S. E., Hsu, H. C., Liu, H. C., Chang, C. F., Su, M. S., Wang, C. H., and Kou, G. H. (1997). Detection and tissue tropism of white spot syn-drome baculovirus (WSBV) in captured brooders of Penaeus
mon-odon with a special emphasis on reproductive organs. Dis. Aqua. Org. 30, 53–72.
Lo, C. F., Hsu, H. C., Tsai, M. F., Ho, C. H., Peng, S. E., Kou, G. H., and Lightner, D. V. (1999). Specific genomic fragment analysis of different geographical clinical samples of shrimp white spot syndrome virus.
Dis. Aqua. Org. 35, 175–185.
Massung, R. F., Esposito, J. J., Liu, L. I., Qi, J., Utterback, T. R., Knight, J. C., Aubin, L., Yuran, T. E., Parsons, J. M., Loparev, V. N., Selivanov, N. A., Cavallaro, K. F., Kerlavage, A. R., Mahy, B. W. J., and Venter, J. C. (1993). Potential virulence determinants in terminal regions of variola smallpox virus genome. Nature 366, 748–751.
McGeoch, D. J., Dolan, A., Donald, S., and Brauer, D. H. (1986). Com-plete DNA sequence of the short repeat region in the genome of herpes simplex virus type 1. Nucleic Acids Res. 14, 1727–1745. McGeoch, D. J., Moss, H. W., McNab, D., and Frame, M. C. (1987). DNA
sequence and genetic content of the HindIII l region in the short unique component of the herpes simplex virus type 2 genome:
Identification of the gene encoding glycoprotein G, and evolutionary comparisons. J. Gen. Virol. 68, 19–38.
Nadala, E. C. B., Tapay, L. M., and Loh, P. C. (1998). Characterization of a non-occluded baculovirus-like agent pathogenic to penaeid shrimp. Dis. Aqua. Org. 33, 221–229.
Nicholas, K. B., Nicholas, H. B., Jr., and Deerfield, D. W., II (1997). GeneDoc: Analysis and visualization of genetic variation. EMBNEW.
News 4, 14.
Prives, C. (1990). The replication functions of SV40 T antigen are regulated by phosophorylation. Cell 61, 735–738.
Que, Q., and Van Etten, J. L. (1995). Characterization of a protein kinase gene from two Chlorella viruses. Virus. Res. 35, 291–305.
Reese, M. G. (1994). “Erkennung von Promotoren in pro- und eukary-ontischen DNA-Sequenzen durch k stliche Neuronale Netze,” Mas-ter’s Thesis. German Cancer Research Center, Heidelberg, Germany. Reese, M. G., and Eeckman, F. H. (1995). New neural network algo-rithms for improved eukaryotic promoter site recognition. In “Pro-ceedings of the Seventh International Genome Sequencing and Analysis Conference,” Hilton Head Island, SC.
Reese, M. G., Harris, N. L., and Eeckman, F. H. (1996). Large scale sequencing specific neural networks for promoter and splice site recognition. In “Biocomputing: Proceedings of the 1996 Pacific Sym-posium” (L. Hunter and T. E. Klein, Eds.), World Scientific Publishing, Singapore.
Reilly, L. M., and Guarino, L. A. (1994). The pk-1 gene of Autographa
californica multinucleocapsid nuclear polyhedrosis virus encodes a
protein kinase. J. Gen. Virol. 75, 2999–3006.
Saitou, N., and Nei, M. (1987). The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 4, 406–425.
Sambrook, J., Fritsch, E. F., and Maniatis, T. (1989). “Molecular Cloning: A Laboratory Manual,” 2nd ed. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
Senkevich, T. G., Bugert, J. J., Sisler, J. R., Koonin, E. V., Darai, G., and Moss, B. (1996). Genome sequence of a human tumorigenic poxvi-rus: Prediction of specific host response-evasion genes. Science 273, 813–816.
Smith, R. F., and Smith, T. F. (1989). Identification of new protein kinase-related genes in three herpesviruses, herpes simplex virus, varicella-zoster virus, and Epstein–Barr virus. J. Virol. 63, 450–455.
Southern, E. M. (1975). Detection of specific sequences among DNA fragments separated by gel electrophoresis. J. Mol. Biol. 98, 503–517. Swofford, D. L. (1998). PAUP*. Phylogenetic Analysis Using Parsimony
(*and Other Methods), Version 4. Sinauer, Sunderland, MA. Telford, E. A., Watson, M. S., Perry, J., Cullinane, A. A., and Davison, A. J.
(1998). The DNA sequence of equine herpesvirus-4. J. Gen. Virol. 79, 1197–1203.
Thompson, J. D., Gibson, T. J., Plewniak, F., Jeanmougin, F., and Higgins, D. G. (1997). The CLUSTAL_X windows interface: Flexible strategies for multiple sequence alignment aided by quality analysis tools.
Nucleic Acids Res. 25, 4876–4882.
Traktman, P., Anderson, M. K., and Rempel, R. E. (1989). Vaccinia virus encodes an essential gene with strong homology to protein kinases.
J. Biol. Chem. 264, 21458–21461.
Tsai, M. F., Kou, G. H., Liu, H. C., Liu, K. F., Chang, C. F., Peng, S. E., Hsu, H. C., Wang, C. H., and Lo, C. F. (1999). Long-term presence of white spot syndrome virus (WSSV) in a cultured shrimp population without disease outbreaks. Dis. Aqua. Org. 38, 107–114.
Tsai, M. F., Lo, C. F., van Hulten, M. C. W., Tzeng, H. F., Chou, C. M., Hung, C. J., Wang, C. H., Lin, J. W., Vlak, J. M., and Kou, G. H. (2000a). Transcriptional analysis of the ribonucleotide reductase genes of shrimp white spot syndrome virus. Virology 277, 92–99.
Tsai, M. F., Yu, H. T., Tzeng, H. F., Leu, J. H., Chou, C. M., Hung, C. J., Wang, C. H., Lin, J. Y., Valk, J. M., Kou, G. H., and Lo, C. F. (2000b). Identification and characterization of a shrimp white spot syndrome virus (WSSV) gene that encodes a novel chimeric polypeptide of