IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 13, NO. 12, DECEMBER 2003 1161
An Image-Sharing Method With User-Friendly
Shadow Images
Chih-Ching Thien and Ja-Chen Lin
Abstract—This study presents a user-friendly image-sharing
method for easier management of the shadow images. The sharing of images among several branches (distributed disks) using the proposed method has several characteristics: 1) fast transmission among branches; 2) fault tolerance; 3) a secure storage system; 4) reduced chance of pirating of high-quality images (as explained in Section V); and 5) most importantly, the provision to each branch manager an easy-to-manage environment (because each shadow image looks like a shrunken version of the original image). The current approach still has the small-size and channel-indepen-dent properties of our previous work, , namely, the size of each shadow image is only1 of that of the original image, and any shadow images can be used for restoration (the restored image is independent of which shadow images are used).
Index Terms—Fault tolerance, image sharing, shadow images,
user-friendly.
I. INTRODUCTION
T
HE ( , ) image-sharing method proposed in [1], where , divides each input image into shadow im-ages (also known as shadows). The method exhibits two prop-erties: 1) any shadow images can be used to restore the input image [2]–[6] and 2) the size of each shadow image is only of that of the input image. In this study, the above properties will be used to develop an image-sharing scheme. The structure and operation of the scheme are described below. The proposed scheme consists of several distributed storage branches, each of which stores one of the shadow images. When someone needs the original image, each branch can transmit its own shadow image to the receiver, and all branches may transmit simultane-ously in parallel. The size of each shadow image is times that of the original image, so the transmission time also de-creases. Besides, as stated earlier, a property of sharing is such that only received shadow images are required to restore the original image. The scheme is inherently fault-tolerant (because channels are allowed to be out of order). This fault tol-erance makes the scheme more robust and useful in network transmission. In fact, it handles the crashing of not only some network channels but also storage disks of some branches.Although the sharing method in [1] can be applied directly to establish the scheme, managing the generated scheme is not easy because the shadow images thus generated [1] look noisy.
Manuscript received October 17, 2001; revised July 31, 2003. This was supported by the National Science Council, R.O.C., under Grant NSC91-2213-E-009-097. This paper was recommended by Associate Editor H. Zhang.
The authors are with the Department of Computer and Information Science, National Chiao Tung University, Hsinchu 300, Taiwan, R.O.C. (e-mail: [email protected]; [email protected]).
Digital Object Identifier 10.1109/TCSVT.2003.819176
(For example, see Fig. 1 in which any two of the four shadow images in (a)–(d) can be used to reconstruct the original image (e).) From the viewpoint of a local manager (the manager of a branch), the noise-like shadow images are difficult to identify and manage; that is, they are not user-friendly. The aim of this study is to develop another image-sharing method such that the shadow images look like portraits of the original image. Hence, identifying and managing the shadow images will no longer be difficult for the local manager. The rest of this paper is orga-nized as follows. Section II presents an overview of the pro-posed method. Sections III and IV then introduce sharing and recovery phases of the proposed image-sharing method, respec-tively. Section V shows experimental results. Conclusions are drawn in Section VI.
II. REVIEW, OVERVIEW,ANDNOTATION
First, [1] is reviewed. The method in [1] first divides the orig-inal image into several nonoverlapping blocks, each of which have pixels. For block , a corresponding shadow pixel value
is generated for the th pixel of each shadow image where
(1) Here, are the gray values of the pixels of block . (Notably, the prime number used in [1] for the mod function is 251, which is the prime number closest to and lower than 256 since the gray values are between 0 and 255). Now, consider any specified shadow, say, Shadow 1; clearly, each -pixel block of the original image only generates one pixel for Shadow 1. Therefore, each shadow is only times the size of the original image.
Now, consider the visual behavior of the shadow images of [1]. Without loss of generality, and are con-sidered as an example. A two-pixel block whose gray values are (110, 112) will generate four shadow values— ,
, , and where
is the polynomial used in [1] to generate shadows, as mentioned in the preceding paragraph. The differ-ence between any one of the input pixel values and any one of the shadow pixel values can fall anywhere in the range 0 255. Hence, the gray values of the shadow images (for ex-ample, 222, 83, 195 and 56 above) may differ considerably from the input gray values (for example, 110 and 112 above). The shadow images therefore do not resemble the original image at all. (For example, 56 is not close to any of the two gray values 110 and 112 that generate 56). In the current study, an attempt is made to make each shadow image look like the original image
Fig. 1. Results of the method in [1]. (a)–(d) Shadow images of size 2562 512, generated by the sharing method in [1]. Notably, all the shadow images look like noise images. (e) The 5122 512 image recovered from any two of the images in (a)–(d).
for user-friendly management, without increasing the size of the shadow image (which remains at times the size of the orig-inal image).
A few methods for sharing images have been developed. Chang and Hwang [7] used the vector quantization (VQ) technique to generate a codebook useful for restoring a secret image and then shared the codebook among participants by directly applying the method introduced in [2]. The method in [7] is an elegant method that prevents hackers from seeing secret images. However, their shadows also look like noise and so are not suitable for supporting a user-friendly envi-ronment, as required here. Chen and Chang [8] used several processes to create auxiliary images (the so-called “sig-nificant images” in [8]); they used these images as the shadow images to restore the secret image. Their method is efficient for generating the shadow images. However, since their method is an ( , ) scheme (in which no shadow image may be lost during restoration), it is not fault-tolerant. Visual cryptography [9] can also be viewed as a type of image-sharing method. It has the advantage that people can see the original image by the superposition of the received shadow images, without the need for complicated computa-tion. However, each shadow image (treated as a transparent sheet in [9]) is of equal size to or larger than that of the
orig-inal image, rather than of the small size ( of the original) obtained using the proposed method.
An overview of the proposed user-friendly image-sharing method is presented below. The encoding phase can be divided into two steps, both of which are applied to each not-yet-pro-cessed block until all blocks are pronot-yet-pro-cessed (assuming that the original image has been divided into nonoverlapping blocks and that each block contains only pixels). These two steps, which will be detailed in the next section, are as follows.
Step 1) Classification:
The block is classified as a smooth block or a coarse block.
Step 2) Sharing:
The block is encoded according to its type (coarse versus smooth).
Notably, smooth blocks can be recovered completely without any loss, whereas coarse blocks can be recovered with partial loss, which is not severe. (The difference between the original and restored gray values is at most eight for each pixel in the coarse block, as will be seen in (22) later.) The notation used throughout the paper is now defined. The letter is used to de-note the gray values of the full-sized original image, the symbol is used to denote the gray values of the small shadow images,
THIEN AND LIN: AN IMAGE-SHARING METHOD WITH USER-FRIENDLY SHADOW IMAGES 1163
and the symbol is used to represent the gray values of the full-sized recovered images. In short,
III. ENCODINGPHASE OF ABLOCK
This section details the two steps of the encoding phase.
A. Step 1: Classification
In this step, the just-read-in block is classified as a smooth block or a coarse block. Suppose the gray values of the pixels in the just-read-in block are . Also as-sume that the previous block has been coded, and so can also be decoded (according to Section IV). Let the decoded gray value of the last pixel in the previous block be . (If no previous block exists, as at the very beginning of the program, let be 0.) Now let
(2)
where is the gray value of the pixel
in the just-read-in block, with the largest difference from . If , then the just-read-in block is classified as a coarse block, otherwise the block is a smooth block.
B. Step 2: Sharing
The procedure for sharing the block
depends on its block type (smooth versus coarse). The procedure for a smooth block is described as Tool 2a and that for a coarse block as Tool 2b.
1) Tool 2a—Sharing a Block When it is Smooth: Recall
that the gray values of the pixels in the current block are , and the (recovered) gray value of the last pixel in the previous block is . Once the block is classified as smooth, then
(3) is evaluated. A polynomial similar to (1) (the one used in [1]) is then applied (but the prime number 251 used throughout [1] is replaced by 17) to transfer the input integers
into transformed numbers . This procedure can be represented as
(4)
where for
each . Here, each is associated with its index . Since the prime number used in the modulus function is 17, the modulus function ensures that all the numbers
are in the range 0 16. The output pixel value that the th shadow image obtained from the current block is defined by (5)
is used as the pixel value for painting the current ( th) pixel of the th shadow image. Since is an integer in the range 0 16, the difference between and is very small, as stated in Lemma 1 [which can be proven using (5)].
Lemma 1: If the shadow gray value is derived from a smooth block , then
Moreover, the definition of a smooth block implies that the dif-ferences between and the gray values in the smooth block are also small [ 8; see the definition immediately below (2)]. Accordingly, from Lemma 1, the shadow pixel gray value resembles all the gray values in block . (The difference
is at most .)
1) Tool 2b—Sharing a Block when it is coarse: As
before, assume that the gray values of the pixels in the current block , which is now a coarse block, are and that the recovered gray value of the last pixel in the previous block is . Now, let be as defined in (2), and then use the floor and ceiling functions to evaluate
if
otherwise. (6)
Notably, is a multiple of 17 and is very close to the number . Also evaluate by the definition
(7)
where [ ] is the rounding function that rounds a number to its nearest integer. Now, the sharing transformation is applied to
convert to as
(8)
where for
each . Note that each is again in the range 0 16 and each is generated using index .
Now, using the evaluated and , the output gray value created for each shadow image can be evaluated. The output gray value for painting the current pixel (the th pixel) of the th shadow image is given by
(9) The difference between and exceeds 8 (as proven by Lemma 2), which property is crucial in the recovery phase (Section IV). Also note that this property (
for the shadow image pixel ) is very similar to the
require-ment for the original image pixel of
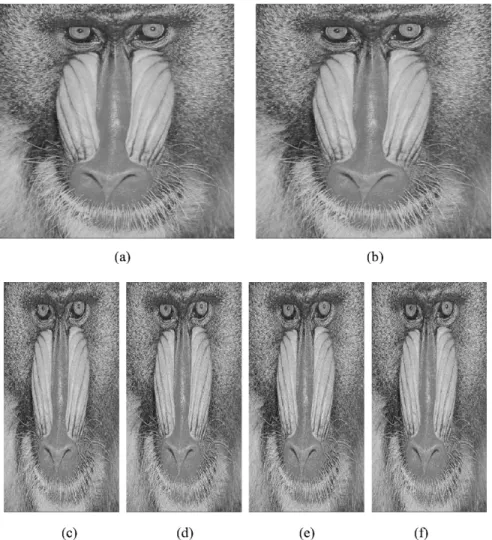
Fig. 2. Implementation of the proposed method. (a) A 5122 512 input image. (b) Image recovered from “any” two of the images in (c)–(f). (c)–(f) Shadow images whose sizes are all 2562 512 bytes.
Lemma 2: If the shadow gray value is derived from a coarse block , then
Proof: If is derived from a coarse block, then [see (2)]. Case 1) (i.e., ). From (6), . Therefore, (10) (11) (12)
Equation (10) follows from (9), while (11) follows from . Finally, (12) follows from
. Case 2) (i.e., ). From (6), . Therefore, (13) (14) (15)
Equation (13) follows from (9), while (14) follows from . Finally, (15) follows from
. End of proof.
This section is summarized below as an encoding algorithm.
Encoding algorithm
Step 0) Divide the original image into nonoverlapping blocks of pixels each.
Step 1) (Classification)
Read in a block. Use (2) to clas-sify the just-read-in block as a smooth or coarse block.
Step 2) (Sharing)
If the block is smooth, then go to 2a; else go to 2b.
THIEN AND LIN: AN IMAGE-SHARING METHOD WITH USER-FRIENDLY SHADOW IMAGES 1165
Fig. 3. Similar to Fig. 2, except that Lena is replaced by Jet. (a) A 5122 512 input image. (b) Image recovered from “any” two of the images in (c)-(f). (c)-(f) Shadow images whose sizes are all 2562 512 bytes.
Evaluate by (3);
then share using (4)
to get the transformed numbers . Use (5) to obtain the
gray values to paint
the th pixel of the shadow images.
Case 2b. (Coarse block) Evaluate and
using (6) and (7), respec-tively; then share
using (8) to get the trans-formed numbers . Sub-stitute the obtained values of
and into (9) to
get the gray values
to paint the th pixel of the shadow images.
Step 3. Repeat steps 1–2 (until all blocks have been processed).
IV. RECOVERYPHASE OFBLOCK
Assume that out of shadow images have been received. (More precisely, assume that the first pixels of each of these
shadows have been received.) Let be the indices of these images. (For example, if the available shadow images
are , then,
Assume that the previous block has been recovered and that the recovered gray value of the final pixel in the previous block is . (Let if no previous block exist.) Now, to recover the current block , and to generate gray values for this -pixel block, the next not-yet-used pixel (the th pixel) from each of the shadow images (one pixel per shadow image) is read in. Let be the read-in gray value associated with the th pixel of the shadow image whose index is . Then, the block must be classified. According to Lemmas
1 and 2, either for all , or,
for all . Hence, if ,
then the block is classified as a coarse block; otherwise, it is a smooth block. The block type then determines the procedure.
1) Case a (Smooth Block): If block is a smooth block, then use the following procedure to recover the block. Let
Fig. 4. Similar to Fig. 2, except that Lena is replaced by Monkey. (a) A 5122 512 input image. (b) Image recovered from “any” two of the images in (c)–(f). (c)–(f) Shadow images whose sizes are all 2562 512 bytes.
and then evaluate the numbers using
(17)
(This is a numerical problem of finding an interpolation
polyno-mial such
that where . The solution can be found using, say, Lagrange polynomials. [See [2], [7] or any book on numerical methods.]) Finally, based on (3), can be recov-ered using
(18)
Notably, the gray values of the smooth block can be recovered without any loss. (In contrast, as ex-plained below, a coarse block can only be recovered using a distorted value , although the distortion in that case is still small.)
2) Case b (Coarse Block): If block is coarse, then use the following procedure to recover the block. For each
evaluate
if otherwise
(19)
and then evaluate the numbers using
(20) Finally, based on (7), compute
(21)
and use as the recovered gray values
of the block . Notably, the
dif-ference between the recovered gray value and the gray value of the coarse block (of original image) is small. In fact,
THIEN AND LIN: AN IMAGE-SHARING METHOD WITH USER-FRIENDLY SHADOW IMAGES 1167
Fig. 5. Direct expansion of the shadow images. (a)–(c) Expanded from Figs. 2(d), 3(d), and 4(d), respectively. The value ofr is only 2. (A greater r would make these images look even worse).
because (7) and (21) imply is
the “nearest multiple of 17” to the number . (The nearest multiple of 17 to any given number is at most units away from that number.)
This section is summarized below as a decoding algorithm.
Decoding algorithm
Step 0) Receive available shadow images to recover the original image. Let
.
Step 1) (Classification)
To recover Block , read in the th pixel value for each shadow
. Let be the recovered gray value of the final pixel of the previous block . ( if no
previous block.) If ,
then is coarse; otherwise is smooth.
Step 2) (Inverse sharing) Go to if is smooth; else go to .
Case . (Smooth block)
Evaluate using (16);
then implement the inverse
sharing procedure ((17)) to obtain . Then, use (18) to
obtain the recovered pixels without loss for the -pixel block .
Case . (Coarse block)
Evaluate using (19);
then implement the inverse sharing procedure ((20)) to
obtain . Now, directly
multiply each by 17
to obtain the recovered pixels for the -pixel block .
Step 3) and go to step 1, unless all blocks have been recovered.
V. EXPERIMENTALRESULTS
The ( , ) image sharing is considered as an ex-ample. Fig. 2 shows the results obtained when the input image is Lena. Fig. 2(a) shows the original image whose data size is 512 512 bytes. Fig. 2(c)–(f) present the four shadow im-ages, the size of each of which is 256 512 bytes. Notably, each shadow image looks like a portrait of the original image (a). Fig. 2(b) displays the image recovered by “any” two of the four shadow images; for example, the image in (b) obtained from the set {(c), (d)} is identical to that obtained from the set {(e), (f)}. The quality of the recovered image is evaluated by the
TABLE I
PSNRANDMSEOF THERECOVEREDIMAGES AND THEEXPANDEDSHADOWIMAGES
peak signal-to-noise ratio (PSNR), which is defined as PSNR . For an image, the mean-square error (MSE) is defined as MSE
, where is the original pixel value while is the re-covered pixel value. The PSNR of the rere-covered image in (b) is 37.98 dB, and the visual quality of that image is also good. The good quality of the recovery follows from that fact smooth blocks are lossless, so information loss only occurs in coarse blocks, while human vision is less sensitive to distortion in a coarser area [10], [11]. (Even in the coarse blocks, the distor-tion of gray values is very small, no more than eight in the gray value for each pixel, as determined by (22) in Section IV.) The experiment performed to obtain Fig. 2 was repeated to process the images Jet and Monkey, yielding Figs. 3 and 4, respec-tively, which support similar observations. Some readers might wonder why the (smaller) shadow images should not just be expanded into a full size replacement of the original image. Fig.5 (a)–(c) shows the images derived by performing a direct expansion to 512 512 of the 256 512 shadow images in Figs. 2(d), 3(d), and 4(d). The expanded shadow images look like the original images, but the quality is not good enough (24.20, 24.59, and 20.12 dB, respectively) for the practical ap-plications. Table I lists the PSNR and MSE of the recovered and expanded shadow images. The recovered images have the higher PSNR (34.56 39.93 dB), and the expanded shadow im-ages have the lower PSNR (16.71 24.59 dB).
Generally, the recovered images [such as the one in Fig. 2(b)] can be used to replace the original images [such as the one in Fig. 2(a)], while the shadow images of lower quality (and smaller image size) are suitable for managing (easier to identify and smaller) in a branch. In Table I, the quality advantage of the images recovered by the proposed over the directly expanded shadow images becomes more obvious as the in the ( , ) system increases. (For example, the PSNR advantage for Jet (2, ) is 39.93 versus 24.59, while the PSNR advantage for Jet (4, ) is 38.14 versus 20.47). Consequently, using a larger might be more suitable when a local manager (the manager of one of the branches) is strictly forbidden to sell a shadow image on
the black market, because the expanded shadow image will have a poor quality and thus attract no customers.
The method in [1] is appropriate for special applications that require lossless restored images, while the proposed method fa-cilitates management since the shadows look like portraits of the original image. Moreover, the shadows of the proposed method might be more efficiently coded if the shadow images need to be compressed further to save storage space or transmission time.
VI. CONCLUDINGREMARKS
This paper presents a user-friendly image-sharing method that facilitates management of shadow images. The proposed approach has several characteristics: 1) fast transmission (the transmission time is only times the period needed to transmit a full-size image); 2) fault tolerance is maintained (because channels are allowed to be out of order); 3) a secure storage environment (because some branches are al-lowed to crash); 4) reduced chances of pirating of high-quality images (since shadow images (each of lower quality) are required to reveal a high-quality image); and 5) the provision to each local manager of an easy-to-manage environment, as stated in the next paragraph.
The proposed user-friendly image-sharing method causes the shadow images to look like portraits of original images and the size of each shadow image to be only times that of the orig-inal images. Hence, the identification and management of the shadow images becomes easy for a local manager. Notably, a tradeoff exists between the shadow image’s size and the quality of the recovered image in the ( , ) system. A smaller corre-sponds to recovered images of higher quality, whereas a larger corresponds to smaller shadow images and, hence, shortened transmission time.
The proposed method may be used by a parent company with several branches in various cities. In general, the storing of every image by the parent company is dangerous (since any damage to the parent company may destroy some images permanently) and also depends on a very large storage space. Storing the images
THIEN AND LIN: AN IMAGE-SHARING METHOD WITH USER-FRIENDLY SHADOW IMAGES 1169
among all branches helps to prevent nonrecoverable damage, and reduces the amount of storage space at the parent company. Meanwhile, as explained in Section V, the local manager of a branch is less likely to pirate and sell shadow images on the black market because the expanded shadow images are of poor quality, especially if a larger is used. (For example makes the Jet and Lena images have PSNR values of nearly 20.5 dB, and Monkey has a PSNR of nearly 16.7 dB).
Recently, video on demand (VOD) has become a popular re-search topic [12]. The direct extension of our method here is not practical for VOD use, however. Therefore, the authors will need several years to adapt the current approach so that it can eventually be extended to a VOD system. As a final remark, the proposed method can be applied not only to gray-valued im-ages but also to color imim-ages (just apply the method to each of the three components of the color images, then combine the results). Some experiments have been performed on color ages; color shadow images have been generated, and color im-ages have been reconstructed. The shadow imim-ages still look like portraits of the input images and the reconstructed color images are also of high quality. To save space, the figures showing the experimental results of sharing color images are not included here.
ACKNOWLEDGMENT
The authors wish to thank the three referees whose comments have greatly improved this paper.
REFERENCES
[1] C. C. Thien and J. C. Lin, “Secret image sharing,” Computers & Graphics, vol. 26, pp. 765–770, 2002.
[2] A. Shamir, “How to share a secret,” Commun. ACM, vol. 22, no. 11, pp. 612–613, 1979.
[3] R. Ahlswede and I. Csiszàr, “Common randomness in information theory and cryptography—part I: secret sharing,” IEEE Trans. Inform. Theory, vol. 39, pp. 1121–1132, Aug. 1993.
[4] D. R. Stinson, “Decomposition constructions for secret-sharing schemes,” IEEE Trans. Inform. Theory, vol. 40, pp. 118–124, Jan. 1994. [5] A. Beimel and B. Chor, “Universally ideal secret-sharing schemes,”
IEEE Trans. Inform. Theory, vol. 40, pp. 786–794, May 1994. [6] , “Secret sharing with public reconstruction,” IEEE Trans. Inform.
Theory, vol. 44, pp. 1887–1896, Sept. 1998.
[7] C. C. Chang and R. J. Hwang, “Sharing secret images using shadow codebooks,” Inform. Sciences, vol. 111, no. 1–4, pp. 335–345, 1998. [8] T. S. Chen and C. C. Chang, “New method of secret image sharing
based upon vector quantization,” J. Electron. Imaging, vol. 10, no. 4, pp. 988–997, 2001.
[9] D. Stinson, “Visual cryptography and threshold schemes,” IEEE Poten-tials, vol. 18, pp. 13–16, Jan. 1999.
[10] J. F. Delaigle, C. De Vleeschouwer, and B. Macq, “Watermarking algo-rithm based on a human visual model,” Signal Processing, vol. 66, no. 3, pp. 319–335, 1998.
[11] C. I. Podilchuk and W.Wenjun Zeng, “Image-adaptive watermarking using visual models,” IEEE J. Select. Area Commun., vol. 16, pp. 525–538, Apr. 1998.
[12] L. Golubchik, J. C. S. Lui, and M. Papadopouli, “A survey of approaches to fault tolerant design of VOD servers: techniques, analysis and com-pression,” Parallel Computing, vol. 24, pp. 123–155, 1998.
Chih-Ching Thien was born in 1975 in Taiwan, R.O.C. He received the B.S.
degree in computer and information science from National Chiao Tung Univer-sity, R.O.C., in 1997. He is currently working toward the Ph.D. degree at the same university.
His recent research interests include data hiding, image compression, and in-formation security.
Mr. Thien is a member of Phi Tau Phi.
Ja-Chen Lin was born in 1955 in Taiwan, R.O.C. He received the B.S. degree
in computer science and the M.S. degree in applied mathematics, both from National Chiao Tung University, Taiwan, in 1977 and 1979, respectively, and the Ph.D. degree in mathematics from Purdue University, West Lafayette, IN, in 1988.
In 1981–1982, he was an instructor at National Chiao Tung University. From 1984 to 1988, he was a graduate instructor at Purdue University. He joined the Department of Computer and Information Science, National Chiao Tung Uni-versity, in August 1988 and is currently a Professor there. His recent research interests include pattern recognition and image processing.
![Fig. 1. Results of the method in [1]. (a)–(d) Shadow images of size 256 2 512, generated by the sharing method in [1]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7645239.138723/2.918.204.692.86.645/fig-results-method-shadow-images-generated-sharing-method.webp)