國立交通大學
管理學院碩士在職專班管理科學組
碩士論文
半導體廠生產電力品質管理之研究
Case Study of Electric System with Using Multivariate Statistical
Process Control
研究生 : 陳崇智
指導教授 : 蔡璧徽 博士
半導體廠生產電力品質管理之研究
Case Study of Electric system with Using Multivariate Statistical
Process Control
研 究 生: 陳崇智 Student:Chung-Chin Chen 指導教授:蔡璧徽 Advisor:Bi-Huei Tsai 國 立 交 通 大 學 管理學院碩士在職專班管理科學組 碩 士 論 文 A ThesisSubmitted to Department of Management Science College of Management
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of
Master in Business Administration
July 2008
Hsinchu, Taiwan, Republic of China
半導體廠生產電力品質管理之研究
學生:陳崇智 指導教授:蔡璧徽
管理學院碩士在職專班管理科學組
摘 要
電力系統對於半導體產業而言,是製造生產的中樞神經。一旦電力系統 發生故障或供電品質異常,將會引起生產線的機台跳機,而中斷生產流程, 且隨著復電時間的延長,時間與金錢的損失上也就愈來愈大。因此,半導 體產業對於電力系統品質的好壞相當注重。為了有效監控廠區電力系統品 質與異常的變化,本篇論文建構多變量統計製程管制法,來監測電力系統 異常。透過所建立的多變量管制圖之監控模式,可在 95%信賴區間下,可 以有效監控與預警電壓品質異常之變化,以有效的警報發佈,降低誤警次 數,提供現場工程師緊急應變處理之判斷,提升工程師的工作效率。 關鍵字:T2 管制圖、多變量管制圖、主成分分析法、單變量管制圖Case Study of Electric system with Using
Multivariate Statistical Process Control
Student:Chen,
Chung-Chin
Advisor:Tsai, Bi-huei
Department of Management Science National Chiao Tung University
ABSTRACT
Electric System is like as central nervous system for hi technology industries. As electric system is broken down, it could be leade to the interruption of production line. However, with increasing recovery time of electric system, the cost of time and money becomes huge problems. In order to monitor the change of electric system, this paper utilizes the Multivariate Statistical Process Control method ( T-Square, SPC ) to predict the qualities of electric voltage. These considered factors refer to Busbar, TR1, TR2, TR3, FAB1 of VA, VB and VC. This paper also sets up MSPC of monitoring model with 95% confidence level. It is not only can supervise and prewarn the changes of voltage, but also reduce the probabilities of fault detection. On site engineers can effectively achieve the fault treatment of electric system.
致謝
回顧在交大管科所二年求學期間,感謝指導教授蔡璧徽老師在學業研 究上的指導與照顧,並從中學習許多的寶貴的經驗,使學生在學業研究上 受益良多,學位方得以順利完成,在此獻上最誠摯的敬意與謝意。同時, 感謝口試委員王泰昌教授、沈大白教授與黃仁宏教授,於百忙中撥冗指導, 並給與本論文的指正與建議,使本論文更臻完善。此外,感謝元培科大張 哲維教授,給與個人寶貴的建議與指教,在此表示由衷的感謝。 感謝班上同學,在求學生活及學業上的相互扶持與學習,讓我留下許 多美好的同窗情誼回憶。在此也銘謝,公司同仁在公餘之時協助資料搜集 及數據分析的幫忙,使作者研究得以順利完成。 最後,謹以此碩士學位與本論文呈獻給關愛我的家人,感謝親愛的父 母親與內人在求學期間,默默的支援與鼓勵,提供我一個無後顧之憂的學 習與工作環境,方使作者能專心致力於求學研究。目錄
摘 要 ... i
ABSTRACT... ii
致謝
... iii
圖目錄
... vi
表目錄
... viii
第一章 緒論 ... 1
1.1 研究背景與動機... 1 1.2 研究目的... 5 1.3 研究限制... 6 1.4 研究流程... 7第二章 文獻探討 ... 9
2.1 QC 七大手法 ... 10 2.2 T2 管制圖 ... 212.3 主成分分析法(Principle component analysis, PCA)... 23
2.4 SPC 管制圖... 27 2.5 預測方法之研究... 29
第三章 建模步驟 ... 42
3.1 多變量管制圖推導過程... 44 3.1.1 主成份分析法推導過程... 44 3.1.2 T2管制圖推導過程... 50 3.2 抽樣管制計畫... 52 3.2.1 T²管制圖 ... 52 3.2.2 主成份分析法管制圖... 53 3.3 電腦系統模擬流程... 54第四章 個案研究與分析... 56
4.1 個案說明... 56 4.2 電腦模擬分析與系統建模程式 ... 574.4 測試組資料驗證與異常分析 ... 66 4.4.1 GIS 電壓數據分析 ... 66 4.4.2 TR1 電壓數據分析 ... 73 4.4.3 TR2 電壓數據分析 ... 76 4.5 SPC 建模分析... 81 4.5.1 SPC 建模分析 GIS 電壓數據分析... 81 4.5.3 SPC 建模分析 TR2 電壓數據分析 ... 87 4.6 小結... 90
第五章 結果與後續研究... 93
5.1 結論... 93 5.2 後續建議... 94參考文獻
... 95
圖目錄
頁次 圖 1 研究流程圖... 8 圖 2 親和圖法... 14 圖 3 關連圖法... 15 圖 4 系統圖法... 16 圖 5 矩陣圖法... 17 圖 6 過程決策計畫圖法... 18 圖 7 箭形圖法... 19 圖 8 矩陣數據分析法... 20 圖9 T2 管制圖之橢圓管制區塊 ... 22 圖 10 T2 管制圖 ... 23 圖11 主成份分析法轉軸概念... 25 圖 12 建模步驟... 43 圖 13 監測設備電力品質異常狀態與分析流程圖... 58 圖 14 以 T-Square 管制圖之顯著水準α = 0.01 檢定之誤警率... 61 圖 15 T2模型檢測第 934 點壓降情形 ... 62 圖 16 SPC 管制圖檢測第 934 點壓降情形... 63 圖 17 主成分分析法計算造成第 934 點壓降之變數貢獻度... 64 圖 18 T2多變量管制圖檢測 1103 點異常分析 ... 67 圖 19 主成分分析法檢測 1103 點異常之變數貢獻度... 68 圖 20 T2多變量管制圖檢測 2029 點異常分析 ... 69 圖 21 主成分分析法檢測 2029 點異常之變數貢獻度... 70 圖 22 每分鐘監視一次,連續二或三點超過管制界限再發警報 ... 71圖 24 T2檢定 TR1 變數之電壓模型 ... 73 圖 25 載入 TR1 測試資料之 T-Square 檢定分析... 74 圖 26 以 T2檢定測試資料TR1 變數之穩定模型 ... 75 圖 27 T2檢定 TR2 變數之電壓模型 ... 76 圖 28 去除異常點之 T2穩定性之檢定模型... 77 圖 29 載入 TR2 測試資料之 T2檢定分析... 78 圖 30 以 T2檢定測試資料TR2 變數之穩定模型 ... 79 圖 31 以 SPC 建模分析警報發佈狀況... 81 圖 32 以顯著水準 0.005 進行 TR1 變數之 SPC 模型檢定測試資料 ... 84 圖 33 T2管制圖分析 TR1 變數資料之異常情形 ... 85 圖 34 SPC 管制圖分析 TR1 變數資料之異常情形 ... 86 圖 35 以顯著水準 0.005 進行 SPC 模型檢定測試資料 ... 87 圖 36 T2管制圖分析 TR2 變數資料 ... 88 圖 37 SPC 管制圖 TR 變數資料... 89
表目錄
頁次 表 1 新舊 QC 七大手法之比較 ... 12 表 2 新 QC 七大手法 ... 12 表 3 灰色理論、機率及模糊理論之區別... 36 表 4 灰色預測與傳統預測方法之比較... 37 表5 訓練組數據說明... 59 表 6 訓練組數據建模結果分析... 65 表 7 TR1 資料建模分析與檢定結果... 83 表 8 T2建模分析與檢定結果... 90第一章 緒論
1.1 研究背景與動機
隨著科技日漸的進步,用電量劇增,加上自然現象(如雷擊、地震、塵
害 等) , 引 起 之 電 力 系 統 故 障 的 問 題 更 是 層 出 不 窮 (Ranasweera, 1994;
Oyama, 1993; Hsu, et al., 1990)。若供電發生異常或故障,容易造成系統之元 件或設備之損害、燒毀等;更嚴重可能造成區域性的大規模停電,所以電 力系統之供電品質對於用戶影響甚钜(Eleri, et al., 1988; Sekine et al., 1993; Cho et al., 1997; Duncan, et al., 1987; Anderson, et al., 1977; Bergen, et al.,1999)。 在我國的產業結構中,半導體產業一直位居於舉足輕重的地位,不論 是在提升國家競爭力,或是對於國家經濟成長的貢獻,都有其實質的效用 及意義。因此,若能有效率、計畫性的實施節能工作,將有助於能源產業 的運作及相關單位整體能源的調度及分配作業。由於半導體產業,對於能 源需求量大,如何節約能源,一直是半導體產業相當棘手的問題。因此, 工業技術研究院研院能源與環境研究所,研發無塵空調節能、排氣系統、 整合型電力監控系統、高效率照明技術等方面,來協助半導體產業真正地 落實節能的工作。在整合型電力監控系統應用方面:所謂的電力監控系統, 具有可以改善用電的安全、降低用電的費用、減少超約罰款、提供統計數 據等效益。然而,完整的電力監控系統的功能應包括:合理需量的評估、
供電品質監視、監視受電與配電設備、各迴路用電資料的統計與分析、電 力需量控制與網路資訊的整合等方面。也就是經由合理需量的評估後,考 慮全年的負載型態,在基本電費與超約罰款間,尋求平衡點,將可減少超 約罰款及電費。另外,藉由整合式的自動讀表技術,可瞭解各用電迴路的 負載分佈及長時間的用電資料記錄,做為用電管理與實施節能策略及降低 溫室效應的依據。 林家宏(民93)提出電力品質是目前台灣電力公司與工業界共同重視的 課題,不良的電力品質包括:諧波、電壓驟降、電壓陡升及電力中斷等事 件。為能有效掌握電力品質的狀況,必須長期監控電壓與電流波形,藉由 分析結果辨識電力品質幹擾變數。近年來由於靈敏電子負載的增加及大量 的電腦設備與精密儀器的使用,可靠的電力供應對於工廠用戶變成一個相 當重要的問題,雖然電力公司改善系統供電品質與可靠度,但由於電力系 統固有性質、電力故障和電壓波動、電壓驟升、電壓驟降等因素,必須採 用多重品質之管制方法才能有效監控電力系統品質異常(Tsutomu, 1993; Yang and Huang, 1995; Lee, 2000)。
在生產管理上常用之七大QC手法來管理製程品質,QC七大手法包括
如下:(1)管制圖,其特色為抽樣結果連續7個樣本點同時往上或往下代表流
程有問題,及代表製程已經出現問題、(2)柏拉圖又稱ABC管制圖,其特色 為大部分的問題(80%)來自少數的原因 (20%),然後把有限的資源獲得最佳
的利用、(3)流程圖其特色為將系統中的各個不同組成,以具有邏輯性的關 係串聯在一起的圖形,可協助確認可能發生問題所在、(4)魚骨圖又稱要因 圖或石川圖,此管制圖主要目的是探索原因,缺點是探索出來的原因無法 串連起來、(5)直方圖其特色為由直立的條狀圖形構成,高度代表問題發生 的次數或頻率,可以找到發生最多次的產品或流問題、(6)散佈圖其特色為 用來找出兩個變數之間的關係,由資料點的散佈,可知道變數之間是否是 正、負相關或不相關,資料點越向45度線集中表示兩者越相關及(7)趨勢圖 其特色用來呈現資料隨著時間進展的變化圖,可以清楚看出生產產品的不 良是越來越多,還是越來越少,成本及進度績效指標是越來越多,還是越 來越少。以上QC七大手法,在生產線上若處理單一變數,檢測效果較為精 確;當面對微小製程變化時,仍無法有效診斷出異常變化。 在統計製程管制法主要的有:Shewhart (1924)提出的蕭華特管制圖,此 管制圖是利用基本的統計及機率原理,分別訂定出管制圖的中心線及管制 界線。此法並未考量歷史數據的變化情況,因此無法迅速有效的偵測到製
程的微量變異。Page(1954)提出累和管制圖 (Cumulative Sum, CUSUM)來改
善對於微量製程變異來偵測。Lucas (1982)合併蕭華特-累和 (Combined
Shewhart-CUSUM) 管制法,此法對於製程大量變異以及累和管
制法對於
製程微量變化之優良偵測能力,使管制法具有偵測不同程度之製程變
異能力。
Robert (1959) 提出加權指數移動平均 (Exponentially Weighted
Moving Average, EWMA) 管制法對於製程微量變異,亦具有 CUSUM
管制法近似之偵測能力,此法
可對異常製程特性的微小偏移可以很快的 偵測及警示出來,對單一品質特性之監控能有良好監測效果。以上單一品 質特性管制圖,主要的功能為檢測製程是否穩定,若有異常時可以幫助檢 測人員找出幹擾製程的可歸屬原因,以達到改善及維持製程品質的目的。 但是這些單變量管制圖只能對單一品質特性作個別監控,無法同時對多重 品質特性作監控,然而目前產品品質的特性越來越多,因此製程變數的複 雜度也日漸提升,為了確保有效監控電力品質,就必須考慮監控更多的變 數,因此多變量管制圖的使用就相當重要了。Logothetis and Haigh (1988) 提出使用統計檢定的基本假設,運用了多 元分析、線性規劃和多目標決策分析等多種數理方法來解決多重品質特性 製程最佳化的問題,其演算過程較為繁雜,因而使得運用上有所限制。當 使用迴歸分析預測品質值特性時,若迴歸係數不顯著時,則結果之正確性 更值得商確。多重品質特性之製程最佳化的方法。蕭鋼衡(民 79)以個別品 質特性的 S/N 比之加權和取代多重品質特性之整體 S/N 比來作分析。此法 雖然簡單,但易發生各品質特性的權重值不易確定。況且,此方法視品質 特性總損失為個別品質損失的權重次方再相互乘積,由田口的損失觀點來 看,無法解釋其意義。陳啟斌等(民 89)及陳啟斌和林進財(民 91)運用灰色關
論大量樣本之最佳化問題。在電力品質之管制上,面對的是大量樣本與多 重品質的問題,檢測上仍有不足之處。 多變量管制圖能夠對多個品質特性和製程變數產生一個綜合統計量, 並對此統計量作監控以判別製程變數是否發生異常。由此可知,多變量統 計製程管制圖就是利用各種統計方法處理、計算、分析、圖示、列表找出 變異的原因,並立即採取修正行動,消除或抑制變異的原因,以達到預先 防止管制要求的方法(Kourti, et al., 1996)。 為了有效監控電力品質,本文應用統計製程管制法之多變量管制圖包 括:T2管制圖及及主成分分析法,來建構電力品質異常管理與偵測之評估 決策模式,透過所建構之決策分析模式,來偵測製程中非隨機原因發生之 異常圖形。統計製程管制法是一種統計的工具,經過產品特性數據的收集 來偵測出製程上有無非隨機之變動,在更多不良品被製造出來之前,就先 找出製程變異的原因,避免不必要的損失(Anderson, et al., 1977; Graninger, et al., 1998; Acha, et al., 2000)。如此,不但可以清楚地瞭解電力系統的運轉 情形,還可在第一時間內發現系統異常的現象。
1.2 研究目的
為了有效監控廠區電力系統(王木連(2005)、吳建欣(2003)、蔡世育 (1997)et al.)之電壓及時變化,本篇論文中採用多變量統計製程管制方法,
來分析電力系統數據,並建立預警機制,即時有效管制電力系統,協助工 程師做好電力及時監控。本研究有兩個目的,分別敘述如下:
(一) 以多變量統計製程管制方法,方法包括:(1) T 2 管制圖(Mason et al., 1999; Rencher, 1993)與(2)主成分分析法管制圖(Harris et al., 1991; Montgomery et al., 1991; Alwan, 1988)等兩個管制方法,評估並分析電 壓數據,當警報發生時,工程師即可做好即時電力的管控。 (二) 透過案例分析協助工程師熟悉多變量統計製程管制之手法,分析案例 包括: (1)GIS 電壓數據分析 (2)GIS.TR1/TR2 相關數據分析:分析變數包括:電流、功率、線圈溫 度、油溫與外氣溫度,並找出外氣溫度對線圈溫度與油溫之關係。
1.3 研究限制
本文研究範圍擬以 A 半導體廠之廠務電力系統作為個案研究對象,並 針對廠區電力需求來進行多變量管制圖之分析與應用,其驗證研究過程力 求客觀、嚴謹,但仍有以下兩點限制: (一) 本文評選模式之研究對象乃以 A 公司為主,目前尚未對其他半導體廠 區電力系統做模式之驗證,其理應針對各類型半導體廠做模式之驗證。(二) 本文對於半導體廠區電力品質異常管理與評估模式採用 T 2 管制圖與 主成分分析法兩種方法,因計算過程繁瑣與複雜,對於數量方法較無 涉略之評估或決策者,其可能必須克服此難關。
1.4 研究流程
本文的研究過程,首先必須清楚地定義且確認研究主題、範圍與對象, 接著蒐集、整理相關之文獻,進而構建出一套半導體廠之廠務電力系統品 質異常管理與評估模式。最後,以進行 A 公司實例驗證並加以分析、探討 及研究。最後,提出本文之結論與建議。研究流程,如圖1 所示:圖 1 研究流程圖 確認研究問題 文獻回顧 資料蒐集 確認研究目的 構建評選模式 資料分析與驗證 結論與建議 進行多變量管制圖之模式構建 構建 T 2 管制圖評估模式 構建主成分分析法評估模式
第二章 文獻探討
我國自 1980 年代開始發展半導體產業,由於半導體產業面臨全球化競 爭激烈,面臨低成本、高品質、穩定的產品、更彈性的全球化組織設計, 半導體製造商常導入品質管理之手法如 6σ、及時化(Just-In-Time,JIT) 等其他改善製造效率與週期的製造計畫,面對及時化的製造環境,用少量 的存貨來緩和生產問題,製造商開始瞭解供需夥伴策略性與合作關係的重 要性與潛在利益。 另一方面企業在面臨提昇企業本身競爭力的同時,還需降低成本,提 昇產品競爭力。而降低成本之方法,可在生產線上降低機台當機率及企業 節能進行管理。因此,本研究主要是研究半導體廠區及機台電力品質之管 控,將低機台當機率,以穩定之電壓達到節能之效果。在半導體廠區需要 監控之變數屬於多變量分析,以下針對本研究的研究目的與研究範圍,探 討(1) T 2 管制圖、(2) 主成分分析法管制圖等統計製程管制與(3)預測方法等 相關的文獻,經由文獻的探討找出切實可行的研究方法與研究範圍,再找 出值得投入的研究目標,經過實際資料的驗證,做出結論與建議。2.1 QC 七大手法
經營環境變化的不確定性因素,常會影響企業的營運,因此,方向正 確而有效的經營是企業追求永續盤存的先決條件,然而,有效的經營必須 借助有效的方法,早期,「方針管理」被有效應用於全面品質管理(TQM, Total Quality Management) ,演變至今,與企業策略規劃相互結合,是一套綜合 公司使命、經營理念、公司價值、文化願景、方針目標、策略方案、執行 計畫以及公司資源的全面性管理系統,實務上,日本為數不少的企業透過 方針管理的實施,適切引領各階層管理者的工作,朝向組織的整體目標邁 進,但國內此方面的應用與著墨不多,有者,亦多用於品質管理的領域範 疇,因此,國內企業透過方針管理的推動能否為其組織帶來綜效,使企業 得以順利達成組織的目標,殊値研究,另外,企業的經營策略須透過其所 擁有的資源持續推動,轉化策略為具體行動,使策略目標能夠實現,而策 略的執行成果,將表現在經營績效上,惟企業欲藉由方針管理的推動將策 略化為具體行動的過程中,常因執行力不佳,造成營運表現無法獲致預期 效果。 方針管理涵蓋策略規劃與年度方針展開兩個層面,策略規劃層面係從 總公司經營理念、使命、範圍、政策、至遠景的形成,經由環境與趨勢分 析制定中長期策略規劃而成為全公司的基本方針;年度方針展開層面係根上一階的目標逐次展開到執行計劃的負責人,據此將策略依序展開到行動 對策與戰術上。 品管七大手法是七種極有用的管理工具,其廣泛應用在製造、服務、 商業流程的管理中。七大手法包括如下:(1)管制圖、(2)柏拉圖(3)流程圖、 (4)魚骨圖、(5)直方圖、(6)散佈圖及(7)趨勢圖。於 1972 年日本科技聯盟的 納谷嘉信教授,從眾多推行全面品質管理建立體系的手法中,研究歸納出 一套有效的品管手法,此方法恰巧有七項,且有別於原有的「QC 七大手 法」,又稱為「新QC 七大手法」(納穀嘉信,1990)。新 QC 七大手法主要 運用在生活及工作中當遇到問題時,需要透過問題分析與解決的程式加以 處理,利用「QC 七大手法」與「新 QC 七大手法」兩個工具搭配使用,能 讓我們迅速找到問題解決之道。新QC 七大手法是將語言數據加以整理、組 合,將混沌之問題整理成能夠解決的狀態,在具有計劃階段即能毫無遺漏 的引導出創造、發想等特徵,因此可作為TQM 推行時解決問題的新手法。 此法主要運用於全面質量管理 PDCA 迴圈的 P(計劃)階段,用系統科學 的理論和技術方法,整理和分析數據資料,進行質量管理。常用的質量控 制方法主要運用於生產過程質量的控制和預防,新的七種質量控制工具與 其相互補充(納穀嘉信,2003)。 QC 七大手法早期在生產管理使用時,手法著重在整理問題數值資料取 得後的管理手法。新QC 七大手法著重在整理問題數值資料取得前的管理手
法;兩者都是品質管理手法,彼此並不相衝突。新舊QC 七大手法比較整理 如表 1 所示。接下來將新 QC 七大手法的用途與內容歸納,如表 2 所示(新 QC 七大手法研究會,2003)。 表 1 新舊 QC 七大手法之比較 新 QC 七大手法 舊 QC 七大手法 形成 以語言為主、圖形為主是 思維工具 以數據為主,是整理分析數據 的工具 運用特點 預見性強,多用於 P 階段 屬於思考型。圖形互法比 較靈活,自由度大,難度 大,表現比較複雜, 一切 從實際出發 鑑別性強,多用於調查分析問 題,屬於判斷型,多用於 P 、 C 階段。圖形互法固定,表現 清楚, 一切從數據出發 應用範圍 主要用於管理決策 主要用於生產現場 表 2 新 QC 七大手法
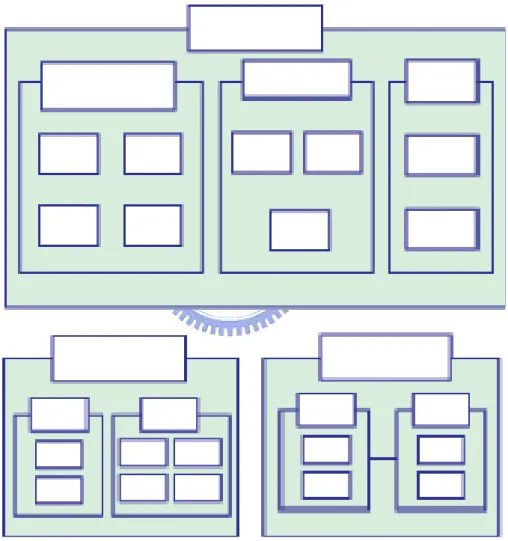
使用新 QC 七大手法有以下五項好處,分述如下:: (1) 迅速掌握重點:即時掌握問題重心,不似無頭蒼蠅般地找不到重點。 (2) 學習重視企劃:有效解析問題,透過手法的運用,尋求解決之道。 (3) 重視解決過程:重視問題解決的過程,不只是要求成果。 (4) 瞭解重點目標:擁有正確的方向,不會顧此失彼。 (5) 全員系統導向:強化全員參與的重要性,進而產生參與感與認同感。 新QC 七大手法,包括以下七項輔助圖來檢視與尋找問題發生的原因, 茲將此七個圖分述如下: (1) 親和圖法(Affinity Diagram) (A)大意:由繁入簡 (B)用途說明:是將處於混亂狀態中的語言文字資料,利用其間的內在 相關關係加以歸類,找出解決問題的方法,針對一件大家想認清的事實 做情況分析,親和圖法之圖例,此法針對某一問題廣泛收集資料,按照 資料近似程度,內在聯繫進行分類整理,抓住事物的本質,找出結論性 的解決辦法。這種方法是開拓思路、集中集體智慧的好辦法,尤其針對 未來和未知的問題可以進行不受限制的預見、構思、對質量管理方針計 劃的制定、新產品新工藝的開發決策和質量保證都有積極的意義,如圖
2 所示。
(C)適用於:討論未來問題,或未曾經驗過的問題,還不知道下一步的 情況時。如用於認識事實、用於確立觀念、用於打破現狀、用於脫胎換 骨及用於籌劃組織。
圖 2 親和圖法
(B)用途說明:以「原因-結果」不斷展開進行分析;類似 QC 中的「魚 骨圖法」,是用圖示法將主要因素間的因果關係箭頭連接起來,確定終 端因素,提出解決措施有效方法。基本形式是把問題和要因用「○或□」 把短文、語言圈起來,並以箭頭符號表示共同因果關係。 箭頭的方向 總是從原因→結果、目的→手段應解決的問題用「◎或回」圈起來。如 圖3 所示。 (C)適用於:適用於:因素間有複雜的關係存在,想要知道會產生什麼 樣的結果。 圖 3 關連圖法 (3) 系統圖法(End-means)
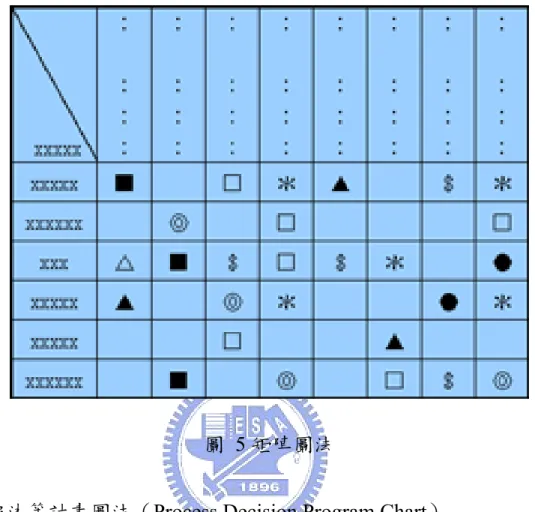
(A)大意:層級清楚 (B)用途說明:以「目的」、「手段」不斷循環展開的進行分析,是尋求 實現目的前最佳手段的方法,如圖4 所示。 (C)適用於:利用不斷問「為什麼」尋找彼此間的關係。 圖 4 系統圖法 (4) 矩陣圖法(Matrix Diagram) (A)大意:簡單易懂 (B)用途說明:多方面的思考:不只是一個問題,對一個答案的模式, 而是一件事中,多個因素對多個因素的討論,從作為問題的事項中找出 對應因素,排列成行和列的形式,然後找出其中的密切關係的關鍵,再
(C)適用於:兩種因素以上的問題事件中,尋找解決問題之適當對策。
圖 5 矩陣圖法
(5) 過程決策計畫圖法(Process Decision Program Chart) (A)大意:事先預備
(B)用途說明:為尋找最佳決策的手法,對事態進展過程可以設想各種 可能的結果,是在籌學中的整體性原理,動態管理,時空有序化及控制
反饋性原理。如圖6 所示。
圖 6 過程決策計畫圖法
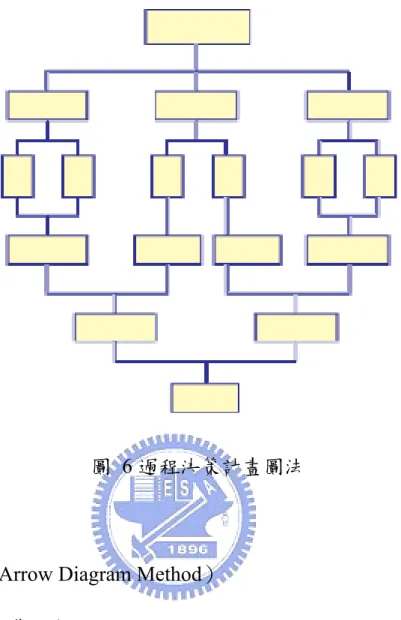
(6) 箭形圖法(Arrow Diagram Method) (A)大意:主導進度
(B)用途說明:由箭、線、基點、虛工序組成,箭頭表示具體活動過程, 箭線的方向表示工序進行的方向,箭尾表示工序的開始,箭頭表示該工
序結束。想要發現某一工作之進度的路線時,如圖7 所示。
圖 7 箭形圖法 (7) 矩陣數據分析法(Factor Analysis) (A)大意:數據完整 (B)用途說明:根據多方面的數字資料及不同狀況,做品質評價整理, 以兩個方向上把行和列分析,並用符號或數據在該欄內記入其關連程度 圖法,如圖8 所示。 (C)適用於:複雜多變且需要解析的方案。
圖 8 矩陣數據分析法 使用新QC 七大手法的好處有以下五點: (1) 迅速掌握重點:即時掌握問題重心,不似無頭蒼蠅般地找不到重點。 (2) 學習重視企劃:有效解析問題,透過手法的運用,尋求解決之道。 (3) 重視解決過程:重視問題解決的過程,不只是要求成果。 (4) 瞭解重點目標:擁有正確的方向,不會顧此失彼。 (5) 全員系統導向:強化全員參與的重要性,進而產生參與感與認同感。
2.2 T2 管制圖
T2 管制圖是 Hotelling 於 1947 年所發展之多變量管制圖,為目前最普 遍使用的多變量管制圖,可用來同時監控多個製程變數的問題,主要是透 過管制數據離中心點(平均值)之距離,來做檢測,以下介紹有關 T2 管制圖 的基本概念。 在圖 9 定義 A 是二維空間的一觀察值,B 是所有歷史資料的平均值,A 與B 之間的距離 D 表示為: 2 2 2 2 1 1 2 ( ) ( ) X X X X D = − + − 當A 樣本點離 B 樣本 點越來越遠時,D2越來越大,當 D2大到一定程度時,則A 樣本點是顯著的。 這時忽略A 與 B 之間的關係,利用 A 與 B 的共變異數(σ11, σ12)或 A 與 B 的自我相關性來修正此方程式,得到一個卡方統計量,如:式 1 所示。 (1) 此統計量是自由度為 2 的卡方分配,上式可說是多元管制圖的基礎, 其意義即方程式所代表二次平面上橢圓形的軌跡,此方程式在管理義含 上,表示橢圓的方程式,根據此方程式,若 2 2 , 2 0 Xα X > ,則判定製程此時是超 出管制界線之外。反之,若 2 2 , 2 0 Xα X < ,則判定此時製程是控制在這個橢圓的 管制圖中,決策者可利用樣本點是否在橢圓形外來判斷製程正常與否,故 稱之橢圓管制圖。圖9 T2 管制圖之橢圓管制區塊 以雙變量的橢圓管制圖作為基礎,Hotelling 拓展這個概念成為具有 p 個變數的T2 管制圖。若得到一個新的樣本點 X0 = [X01, X02, X03,... X0p],則 可用式2 與式 3 計算出 T2統計量與管制圖的管制界線。 (2) (3) 其中:X =
[
X1,X2,L,Xn]
為樣本平均數,⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = pp p S S S S S S O M L 22 1 12 11 為樣本共變異數矩陣, S-1 是樣本共變異數矩陣的反矩陣, Fa, p, m - p是一個自由度為p及m-p,且具單邊α值的F統計量,則判定 此觀察值出現異常。 依據上述之數學式子,T2管制圖可表示如圖3所示。 圖 10 T2 管制圖
2.3 主成分分析法(Principle component analysis, PCA)
使用主成分分析的目的有五項:(1)可概述變數間的關係、(2)可將原來 變數轉換成新的沒有相關的變數、(3)可用來簡化多變量資料的維度,即降 低變數個數,但亦會喪失部分資訊、(4)可解決迴歸分析裡共線性問題、及
(5)可用來作一組變數的綜合指標。 主成分分析法最常被用來降低緯度(dimensionality),當要觀察的變數很 多時,主成分分析可以利用轉軸的方式,將原始的變數線性組合後產生新 的變數,代替原先所要觀察的變數,如此可以幫助決策者減少所需觀察變 數的數目(Bakshi, 1989)。因此,主成分分析法是著重於如何「轉換」原始 變項使之成為一些互相獨立的線性/組合變數,而且經由線性組合而得的主 成分仍保有原變數最多的資訊,其關鍵在「變異數」問題,利用求特徵值 (Eigenvalue)及特徵向量(Eigenvector),過濾出佔最大變異數的型態,此為最 主要之型態。以二維為例,假設此兩變數之問為線性關係,設在平面有七 點,其關係為X2=2X1: 經旋轉座標後,此七點的新作標為: 由上可知,利用新變數Y1即可完全表示其變異,此線性組合為: Y1=0.447X1+0.894X2 Y2=0.894X1-0.447X2
本來需要X1與X2兩個變數來描述的資料,但經過轉軸後,只需用Y1一個 變數即可描述這些資料的變異,如圖4所示 圖11 主成份分析法轉軸概念 將兩個變數,推廣至p個變數時,主成份分析的步驟處理如下:(1)由歷 史資料(X)求算出共變異數矩陣S(covariance matrix)。(2)求算共變異數矩 陣的p個特徵值(Eigenvalue),並將特徵值依大小順序排列為分別λ1, λ2, …, λp (即λ1≧λ2≧…≧λp≧0),及特徵值λi所對應的特徵向量(Eigenvector)為ei。(3)
利用ei將將第i觀察值xi = (xi1, xi2, …, xip)轉換成yi=(yi1, yi2, …, yip),其轉換的
計算式,如式4: yik=ek´xi= ek1xi1+ek2xi2+…+ekpxip k=1,2, …, p (4) 其中ek
[
ek1,ek2,Lekp]
, = 為第k個特徵向量k=1,2, …, p。當k=1時表示為第一主成 份是解釋變異最大的線性組合;當k=2時表示為第二個主成是解釋變異性第 X1 X1 X2 X2 Y1二的線性組合,其餘依此類推。 主成分的重要性質如下: (1) 第i個主成份變異數等於第i個特徵值,且各主成份之間的共變數為零表示 如下: i i Y Var( )=λ , i = 1,2, … p (5) 0 ) , (Yi Yk = Cov i, k = 1,2, …, p, i≠k (6) (2) 原始變數的變異數和等於新變數的變異數和,即: 第k個變數所解釋的變異佔總變異的比例﹦ p k λ λ λ λ L + + 2 1 可找前k個主成份的新變數來代替原有的p個變數,當變數之間相關性高 時,所需的k就愈小,其能解釋的變異佔總變異的比例也會相對的較高,如 此便可以達到降低變數個數的目的。另外,每一個觀察值均可用主成份變 數來表示,計算方式如下: p ip i i p p i i i i e y e y e y e e x e e x e e x x L L + + = + + + = 2 2 1 1 ' 2 2 ' 1 1 ' ) ( ) ( ) ( 當取前k個主成份,觀察值x的近似值,如式7
∑
= = k j j ij i y e x 1 ~ (7)Mardia,et al., 1979 and Jackson (1991)利用主成分變數可將T2管制圖分 解成下式: (6) 由式6 可看出T2值是將每一個ti 平方後除上變異數加總後的結果。選出 i i t λ 2 較大的幾項;其中,
∑
= − = p j j j j i i e x x t 1 ' , ( ),再藉此找出哪些原始變數x對ti有較大 之貢獻。2.4 SPC 管制圖
統計製程管制圖無法在製程呈現小偏移時很靈敏的偵測出來,使得管制 圖在使用上,必需等到製程超出管制界線外,才會發出異常警訊,而尚失 改善品質的機會。因此,Roberts(1959)提出EWMA管制圖,根據資料的先 後次序給予不同權數,使得資料呈現指數遞減之狀態,當製程在呈現微小偏移時,即可有效的偵測出來。 其形式如(7)式所示:
(
1)
1, 1, 2, ..., , t t t Z =λ
X + −λ
Z− t= n (7) 其中,λ表示權重因數,範圍介於0~1之間; X 表示在時點t之分組群組之t 平均值。 假設EWMA 管制圖的測量值 X t 即為實際值 Yt 以數學式表式為: X t = Y t , t = 1, 2, L, n 假設在製程穩定之狀態下,實際值Yt 之分配服從 2 0 0 ( , ) Nμ σ
,並建立管制圖 之樣本平均數 2 0 0 ~ ( , ) t X N nσ
μ
。Loon and Su (1999)使用EWMA管制圖來檢測製程產生微小偏移,並發 出警報。在半導體產業,發展EWMA-based 控制器做回饋控制防止因批量 生產而產生不穩定之品質特性(Butler and Stefani, 1994; Del Castillo and Hurwitz, 1997; Somerville and Montgomery, 1996-1997)。Alejandro et al., (2001) 應用蕭華特(Shewhart)及EWMA管制圖,來檢測半導體製程特定目標
值的偏移。Reynolds and Stoumbos (2001)研究指出,用EWMA管制圖檢測微
標準差的兩個EWMA管制圖合併變成一個EWMA管制圖。透過一個EWMA 管制圖可同時監控平均值與標準差之變化。
Kourti and MacGregor (1996)認為當有異常值發生時,則此點一定會脫離 當初建立的主成份模式。因此,可藉由主成分的近似值與原始值之差,來 評斷此新觀察值是否仍在歷史資料所建立的投影。 求法如下:
∑
(
)
= − = p j j new j new X x x SPC 1 , , ˆ (8) j new xˆ , 可由式8 求得。當製程在管制界線內時,其Tk2與SPCx 值非常小。2.5 預測方法之研究
企業在做預測時,常用的傳統預測方法有以下幾種:主觀意見預測法 (Subjective opinion forecast)、時間序列分析法、移動平均法(Moving - Average)、指數平滑法等。近幾年來發展出來的方法包括:灰色預測法與 類神經網路等。以下就針對這些方法做一些文獻上的探討,並分述如下:(1) 主觀意見預測法:
一般企業若資本額或銷售額為達一定規模之前,其預測模式多半使用 「主觀意見預測法」,如獨資企業,或中小企業等,必須依照客戶意見,
或股東、企業主、企業領導者的看法,或個人對內外在情勢的主觀評估, 來對企業未來的銷售做預測。 當主事者為該產業專業人員時,或許預測模式不致偏離過大,反而可能 因為人為的判斷,而考慮得到一些無法由單一理論或統計法計所得之變 因,如政治情勢、國際局勢、天災、市場劇烈變動等對銷售市場所可能造 成的影響。但過於主觀的預測方式,通常會造成企業過多的風險承擔,且 無法針對問題有較佳的決策原因解釋,以及說服力。故如果以統計、類神 經等預測方式算出來的預測值配合修正。不僅能以較客觀的角度來看待問 題,也會使預測的值較為準確,確度也會較為穩定平均。 通常在缺乏或較少歷史資料的狀況下,使用定性分析來做預測,此類 別包括:行銷研究、德菲法、市場調查及焦點團體座談法等。主要方式是 經由整理收集來的資料或分析或觀察問題,討論問題的經濟面行為,如焦 點團體座談法是一種質性研究方法,被認為是瞭解一般人的感覺、看法、 意見與態度之最有效方法(Merton et al., 1990)。焦點團體座談法是一種侷限 於少數主題且深入探討,並選擇具共同經驗,或類似背景者來參與團體討 論。在開放輕鬆的討論空間,期望參與討論者,對某些研究主題的認知、 態度與行為之研究方法(Margan, 1996)。於研究進行中,首先設計討論問題 與討論指引,訓練討論會之主持人。然後由目標母群體中徵求參與者,討
論一般以8至12人,由具經驗之主持人依事先準備之討論指引,且在參與者 不受主導下,對研究主題,自由表達意見,互相討論,並觸及問題之核心(吳 淑瓊,民81;胡幼慧,民85;Krueger, 1995)。焦點團體座談法不但可蒐集 到非常深入之資料,更重要的是,蒐集到參與討論者真正之看法,並以實 況錄影、錄音或筆記方式記錄全程討論,以供分析之用。 主 持 人 是 攸 關 焦 點 團 體 座 談 成 敗 之 關 鍵 靈 魂 人 物 ,Stewart and Shamdasani (1990) 提出一位成功的主持人應具備之特質、技巧與角色,分 述如下: (一) 特性方面:應具備友善、易處及隨和的個性,易於適應環境、對社會環 境具備高度之警覺性、高度企圖心和成就導向、明確、合作、堅定、獨 立、有影響他人的願望與支配力、精力旺盛、堅持、對壓力有高度的容 忍、及勇於負責等。 (二) 技巧方面:包括智慧、有統整概念的技巧、有創造力、人際圓融、口才 流利、熟悉團體事務、有組織及行政能力、有說服力、有社會人際處理 技巧及自信等。 (三) 扮演之角色: (1) 清楚瞭解所要研究之目標,設計焦點團體進行之程式,並成功獲取 有效之資料。
(2) 在參與者與自己之間建立平等互動的關係,消除參與者的疑慮與不 安。 (3) 告知參與者參與座談之目的、目標、釐清問題,並說明座談內容機 密程度之等級,及確保成員必須遵守保密原則。事先安排並隨時營 造舒適安全的環境與氣氛,使參與者在無顧忌下暢所欲言。 (4) 控制座談的進行,深入導引參與者陳述完整之經驗;隨時掌控座談 方向,避免討論偏離主題,並鼓勵參與者能互動式的參與,而非少 數權威式的闡述。 (5) 掌控口語及非口語之訊息,運用團體動力技巧,引發參與者全面經 驗及觀點互動。 焦點團體座談法之優點有: (一) 對質與量之研究,提供多元與多用途之方法。焦點團體法於研究中可單 獨使用,亦可搭配其他研究方法使用;焦點團體法可做為先驅研究(pilot study),亦可做為檢核或追蹤其他研究法之研究成果,也可搭配數量方 法共同來檢驗經驗與實際之差異,具多元與多用途之特性,使用上非常 有彈性。 (二) 於訪談內容之設定上,具相當的結構性,且在討論中鼓勵團體成員,對
性,注重研究者與反應者間之多元互動,以描述特別情境中之發現。從 多元觀點,對知覺、信念、態度與經驗引發較深入之瞭解,蒐集受訪者 工作經驗之質化資料,並記錄其脈絡。 (三) 能促進成員勇於表達,引發豐沛之反應。焦點團體法能於放鬆效應下, 輕鬆的團體情境中,讓參與者覺得他們的意見與經驗受到重視,便較喜 歡公開表達他們的意見和知覺,提供引發各種層次意見之機會。 (四) 可在短時間內快速蒐集有意義之資料。 (2)時間序列分析法: 時間序列分析法理論源自1920年代Undy Yule教授,至1970年初由
George E. P. Box 與 Gwilym M. Jenkins 兩位教授發展完成自我迴歸整合 移動平均模式(Autore- gressive Integrated - Moving Average Models ),簡稱 ARIMA模式。時間序列分析是一個「根據過去,預測未來」的統計方法, 它在商業、貿易、政府及學術研究等領域中廣泛地被運用著。時間序列的 方式主要是以「固定時間間隔」做為時間軸的計算模式,時常可見到短期 預測使用此模式。依據某變量過去曾發生的資料及過去曾發生的誤差為基 礎往前推算,預測尚未發生的變量。 (3) 指數平滑法:
移動平均法是利用平均的方式,對時間序列分析法中某些較大的變數使 其平滑,因為資料中差異較大的值在組成一平均數時就會彼此相互抵消一 些。移動平均值就是一平均值一直反覆的被修正,當新的觀察值變得可行, 數列中的舊值就被刪除,因此保持平均值為最新的。其他還有加權移動平 均法(Weighted Moving Average)、指數平滑法(Exponential Smoothing) 等均屬為此類作法。移動平均法只適合沒有明顯的長期成長趨勢與季節變 動性小的資料模式。同屬時間序列(Time Series)數學方法,但較為複雜的還
有 Box-Jenkins 法、自迴歸移動平均模式(Autoregressive Moving-Average
Model;ARMA)、雙指數平滑分析法(Double - Exponential Smoothing Method) 等。 簡易移動平均法是將期數T內所有的觀察值加總後再除以期數。亦即算 出最近某一期間的時間數列平均值,並把該平均值視為即將來臨的期間之 預測值 Xt+1。二次移動平均法是將簡易移動平均法所得的值再做第二次的移 動平均運算。 加權平均法是期數內的每一個觀察值,給與不同的權數α(權 數總合為1),最後再求其總合。由於有選擇權數的考慮,它可達到反應出 變化的功能。 以指數平滑法及自我迴歸移動平均整合模式做為預測,以MAPE對預測樣 本進行精確性評估直到滿意為止。黃庭鍾(民91)以我國主機板製造業廠商
為例討論企業因應長鞭效應之存貨政策研究,為利用指數平滑法為下期加 訂修正策略對中游製造商影響。王富恩(民91),針對不同需求型態對長鞭 效應的探討以四種時間序列需求型態及二種預測方法,分別推導零售商及 配銷商之訂單變異度,並分析其關鍵因數。王瓊敏(民88)以灰色預測、時 間數列、類神經網路等方法建構的價格預測模式,並評估分析各方法之優 缺點以及準確度,以供筆記型電腦廠商選擇預測關鍵零組件價格方法之參 考。 (4) 灰色預測: 灰色理論之「灰色」,乃結合「黑色」與「白色」而成。「黑色」表示 對資訊完全不瞭解;「白色」則為資訊完全;所謂「灰色」則為資訊不完全, 即「部分清楚」及「部分不清楚」之資訊貧乏狀態下去,去挖掘系統本身 之特性及結構,並適時補充資訊,使系統由灰色狀態轉為白色狀態,發展 而成之理論。 在現實的世界中,存在著許多的系統,任何一個系統又隱含著若干個 子系統,且同時又被若干子系統所包圍。由於系統的複雜與多層次子系統 的集合,若想對一個系統做全面的瞭解,往往會因所得之資訊不完全或不 確定,而無法一窺全貌。當面對一個無法具體描述的系統時,稱之為「灰 色系統」。Deng(1982)於提出灰色系統理論,主要是在研究系統模型之不確
定性、資訊不完全及運行狀況不清楚下,做系統的關聯分析、模型建立、 預測及決策。此理論對事務的「不確定性」、「多變量性輸入」及「離散的 數據」能做有效的處理(Deng, 1989;鄧聚龍與郭洪,民 86)。鄧聚龍(民 89) 整理灰色理論、機率及模糊理論之特點及適用時機,如表3 所示。 表 3 灰色理論、機率及模糊理論之區別 灰色理論 機率論 模糊集 內涵 小樣本不確定 大樣本不確定 認知不確定 基礎 灰朦朧集 康托集 模糊集 依據 信息覆蓋 機率分佈 隸屬函數 手段 生成 統計 邊界取值 特點 少數據 多數據 經驗(數據) 要求 允許任意分佈 要求典型分佈 函數 目標 現實規律 歷史統計規律 認知表達 思維模式 多角度 重複再現 外延量化 信息準則 最少信息 無限信息 經驗信息 資料來源:鄧聚龍,民89 灰色系統理論將一切隨機變量看成是一定範圍內變化之灰色量,及與 時間相關之灰過程。對灰色量之處理並非藉尋找統計規律的方法達成,而 是將雜亂無章之原始數據經過處理後,來尋找數的內在規律性,經由處理 過後之數列轉化為微分方程,建立灰色模型,之後再以此進行預測,即稱 為「灰色預測」。鄧聚龍(民 89)整理灰色預測及幾個傳統常用的預測方法, 並比較所需數據、數據型態、數據間隔、準備時間及數學需求等,如表 4
表 4 灰色預測與傳統預測方法之比較 預測模型 所需數據 數據型態 數據間隔 準備時間 數學需求 灰色預測 4 個 等間距及等間距 短、中或長間隔 短 基本 簡單指數型 5~10 個 等間距 短間隔 短 基本 Holt’s 指數型 10~15 個 同趨勢 短或中間隔 短 稍高 Winter’s 指數型 至少 5 個以上 同趨勢且具規律性 短或中間隔 短 中等 迴歸分析 10~20 個以上 同趨勢且具規律性 短或中間隔 短 中等 Causal 迴歸法 10 個以上 同型態相互配合 短、中或長間隔 長 高 時間序壓縮法 2 個峰值以上 同趨勢且具規律性 短或中間隔 短(稍常) 基本 Box Jenkins 法 50 個以上 等間距 短、中或長間隔 長 高 資料來源:鄧聚龍,民 89
吳漢雄等(民 85)提出灰色預測具有以下優點:(1)灰色預測需要少數 據。只需根據實際狀況,選擇適當數量的數據即可,而不須大量的歷史數 據,甚至只用四個數據就可建模,進行預測,還能得到精確的結果。(2)一 般情況下,灰色預測不須太多關聯因素。因此,簡化資料蒐集之工作。(3) 灰色預測既可用於短期,也可用於中長期預測。(4)灰色預測精準度高。在 相同之少量數據下,比其他法的模型預測誤差還小。 灰生成即為補充資訊之數據處理,是一種就數找數的規律方法,在一 些雜亂無章的數據中,設法將其被掩蓋的規律及特徵浮現出來,降低數據 中的隨機性,並提升其規律性,此一過程稱為白化過程。江金山等(民國 87 年)整理灰色理論中常用的生成有兩種。一是整體生成又分為累加生成及逆 累加生成兩種;另一為局部生成,主要的作用是在非等間距之下,或序列 在剔除不當的數據時所出現的空穴
φ
( )k 時,做填補空穴φ
( )k 數據之用。又 可分為差值生成及均值生成兩種。將生成方法分述如下: (1)累加生成(AGO):將數據依次累加。 (2)逆累加生成(IAGO):將序列之數據前後相減,所得之數據。目的是驗證 建模後之精確度。 (3)插值生成:這是在序列的空穴 ( )φ
k 兩端利用(9)式,取其中間值將空穴 ( )kφ
補齊,主要用於最少數據的原理。( )
φ
k =α
x k( − + −1) (1α
) (x k+ (9) 1) 其中φ
( )k 為生成數;α
為生成係數,α
∈[ ]
0, 1 ;x k( − 為前鄰值; (1) x k+1) 為後鄰值。 (4) 均值生成:將(9)式中的α
取0.5,即為均值生成。 當數據生成後,即可建立一組灰差分方程與灰微分方程之模式,稱為 灰建模。建模方式,一般可以分成GM(1, 1)、GM(1, N)與 GM(0, N),將這 三種建模之意義分述如下: (1) GM(1, 1):表示一階微分,一個輸入變數,一般做預測之用。 (2) GM(1, N):表示一階微分,N 個輸入變數,一般做多維關聯分析之用。 以GM(1, 1)模型為基礎,對現有數據進行預測的方法,實際 上是找出某一數列中間各個元素的未來動態狀況。 (3) GM(0, N):表示零階微分,N 個輸入變數,一般做多維關聯分析之用。 灰色預測在人力資源應用方面,洪欽銘與李龍鑣(民 85),將少量的歷 史資料來推估台灣地區高職教師,在未來幾年所需之人數;陳弘旭(民 86) 預測未來營造業的就業人口數;梁賢達、劉仁昌(民 87)預測臺北市高職畢 業生未來之發展趨勢。在需求量變化方面,謝坤民(民 86)以台為地區人口數,推估為來台灣 人口未來人壽保險投保率;許巧鶯與溫裕弘(民 87)以航空公司客運網路為 對象,建構航線運量預測、航空網路型態設計、航線班機頻次規劃與機型 指派模式;黃泰林等(民 87)建構兩岸海運需求量之預估模式;林進財等(民 89)以海上航行人員為對象,預測未來航行的船舶數目,及海上航行的人員 需求量;許哲強等(民 89)運用灰色預測模型及修正灰色殘差模型,來預測 台灣地區之區域用電需求量。
第三章 建模步驟
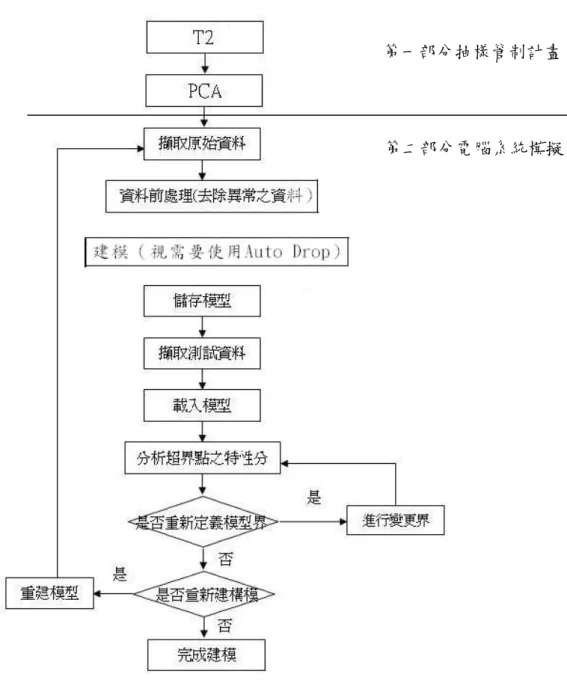
由第二章的文獻回顧,我們已經對T2及PCA 管制圖的使用方法有了認 識,本章分為兩部份,第一部分為抽樣管制計畫,首先透過 T2管制圖進行 抽樣,再檢定樣本是否合乎建模要件,再用PCA 管制圖進行多變量因素之 萃取及模式檢定,檢定資料建模是否合適。第二部分則是電腦系統模擬, 首先,透過線上擷取的資料,將資料分成訓練組與測試組資料,先用訓練 組資料來建立系統評估模型,進行離線品質管制,檢定廠區電力品質異常 狀況,並分析造成異常之原因。模式確立後,再以所建構之模型,來進行 線上模式測試,若模式無法精準預測,則模型必須重新訓練,直到模型可 以被檢驗為止。整個電力品質異常管理與評估之建模過程,如圖12 所示。圖 12 建模步驟
第一部分抽樣管制計畫
3.1 多變量管制圖推導過程
本研究採用 T2 管制圖與主成份分析法作為監控電力品質異常之研究方 法,分別在以兩小節介紹此兩個研究方法之推導過程。3.1.1 主成份分析法推導過程
本節中將對主成份分析原理由矩陣運算的代數觀點做一些介紹,主成份 分析是一個於資料壓縮和資訊萃取方面常被運用的方法,藉由分析代表變 數間相關性的互變異矩陣,找到一組由原始變數經過線性組合而成的新變 數,稱為主成份變數,且滿足以下性質: (性質 3.1) 每一主成份為原來變數的線性組合。 (性質 3.2) 第一主成份必須能解釋最大的資料變異量。 (性質 3.3) 第二主成份必須能解釋扣除第一主成份後所剩餘的最大資料變 異量。 (性質 3.4) 第 K 個主成份則解釋扣除前 K-1 個主成份後所剩餘的最大資料 變異量。 (性質 3.5) 此 K 個主成份間是不相關的。 由以上性質可以看出,主成份座標中各座標軸互相正交,並且此主成 份座標軸為唯一,也就是說在相同難度的空間中,再也找不到比此主成份 座標軸可以解釋更多資料變異量的另一組正交座標軸。假設有一個N×M 階原始資料矩陣
[
1 2 M]
X= x x LxmLx (9) = ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ M N N N M n n n M x x x x x x x x x L M O M M L M M M M L 2 1 2 1 1 12 11 = {xnm} n =1~N,m=1~M 其中 m 代表變數個數,n 則代表資料點個數,xm、μm、σm2 分別代表 第m 個變數的行向量、平均數及變異量。[
]
T Nm nm m m m x x x x x = 1 2 L L (10)∑
= = N n nm m x N 1 1 μ (11)∑
= − = N n m nm m x N 1 2 2 1 ( μ ) σ (12) 在 進 行 主 成 份 分 析 計 算 之 前 , 首 先 須 將 資 料 矩 陣 平 均 置 中 (mean-centered),亦即將矩陣中各元素減去各變數的平均數,使得矩陣中各 行向量平均數為零,則可得到[
1 2 M]
X( = x( x( Lx(mLx( (13)= ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ M N N N M n n n M x x x x x x x x x ( L ( ( M O M M ( L ( ( M M M M ( L ( ( 2 1 2 1 1 12 11 = {x(nm} n =1~N,m=1~M 其中 m nm x −μ = nm x( (14) 則經過置中之後的變數平均數均為零
∑
= = = N n nm x 1 m 0 N 1 ( ( μ (15) 其互變異矩陣(covariance matrix)可以計算如下: 1 ) cov( S − = = N X X X T ( ( ( (16) = ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ MM Mj M M iM ij i i M j M j S S S S S S S S S S S S S S S S L L M O M M M M L L M M M M M M L L L L 2 1 2 1 2 2 22 21 1 1 12 11 其中 M j M i N X X S j T i ij 1~ 1~ 1 = = − = , ( ( (17) 此互變異距陣為一對稱矩陣,其中對角線上各元素(i=j)代表了各原始 變數的變異數值,而非對角線上的元素(i≠j)則為其所在行、列代素的變數 間的共變異數(co-variance)。各變數的變異數值顯示出資料點在各變數軸上算此互變異矩陣之特徵值及特徵向量,便可以瞭解資點的分佈情況。 對於一個M×M 階的互變異矩陣,其特徵方程式為 ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = λ λ λ λ λ -S S S S S -S S S S S -S S S S S -S II -S MM Mj 2 M 1 M iM ij 2 i 1 i M 2 j 2 22 21 M 1 j 1 12 11 L L M O M M M M L L M M M M M M L L L L =0 解此M 次方程式可以得到 M 個特徵值 λ1≧λ2≧…≧λn≧…≧λM 相對於第m 個特徵值的特徵向量 Pm可以由下式求得 0 -S λmII Pm = (18) 則原始的資料點可以由下式轉換到由主成份軸所組成的新座標中 T M T m T T p p p p1 2 2 m M 1 t ... t ... t t X( = + + + + (19) ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = T M T m T M p p p t M M 1 m 1...t ... ] t [ = T TP 而經由以上計算所得的第 m 個特徵向量即為由原始變數組成第 m 個主 成份變數的係數,而所對應的第m 個特徵值則為其變異數。 一般來說,在所計算出的 M 個特徵值中,可以由設定某個界限的方式 選取前K 個特徵值為重要的特徵值,足以代表所有的資料變異量,即
λ1≧λ2≧…≧λK≧λK+1≧…≧λM 其中 λK+1 以後各特徵值可被忽略,則主成份分析將資料矩陣分解為 E p p p p T k T k T T + + + + + + =t1 1 t2 2 ... tk ... tk X( (20) =TPT +E 其中,主成份值矩陣(score matrix) ] t ... t ... t t [ T= 1 2 k k (21) T k [t t ...t ...t ] t = 1k 2k nk Nk 主成份係數矩陣(loading matrix) ] p ... p ... p p [ P= 1 2 k k (22) T Mk mk 2k 1k k [p p ...p ...p ] p = 殘值矩陣(residual matrix) ] e ... e ... e e [ E= 1 2 m M (23) T Nm nm 2m 1m m [e e ...p ...t ] e = 在以上分解中,K≦min{M,N},由此可知由主成份分析所產生的新變數 所展開的空間將小於或等於原始變數所展開的空間,且通常 K 會遠小於 min{M,N}。 透過利用原始資料所計算出來的主成份係數矩陣,主成份分析建立了一 個成份模型,可以用來描述原始變數間的關係,而由分析新的量測資料是
所顯示的有所不同。由式(23),定義主成份模型估計值為 E X TP X( = T = ( − (24) 而其中新資料點的主成份值即為新資料點在主成份座標軸上的投影座 標值 P X T= ( (25) 則式(23)變為 E X X( = ( + (26) 由此式可以看出,包含於原始資料中的資訊被分成了可以由主成份模型 描述以及不能由主成份模型描述的兩個部份。 計算主成份值的互變異矩陣 ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = = = = = Λ K K 2 1 T T T T 0 0 0 0 0 0 0 0 0 0 SP P P X X P ) T T ( E cov(T) λ λ λ λ L L L M O M M M M L L M M M M M M L M L L L ( ( (27) 其中
1 N t tT k k K = − λ k=1~K (28) 由式(28)可以看出,主成份分析所作的就是將原始資料矩陣的互變異矩 陣轉換成為一個對角矩陣,又因為互變異矩陣中非主對角線上的元素所代 表的意義為變數間的相關性,所以經過這樣的轉換之後,原始變數間的相 關性就完全被分離開來,主成份分析就是利用這樣的原理來找出多變數系 統中互不相關的新變數,以達到降低維度、簡化問題的目的。 本研究將以檢測電力品質做為研究目標,利用討論過的研究方法,做 為改善電力的預測品質的方法,運用主成份分析法可簡化多變量資料的變 數個數:(1)解釋的變異比例:若只取最大的 q 個主成分代替原有的 p 個 變 數 , 則 這 q 個 主 成 分 解 釋 的 變 異 比 例 為 一般以能解釋原有變數變異達 70% 以上為原則。(2)陡坡圖(Scree plot):由 特徵值對特徵值的總和 (即特徵值的個數) 劃散佈圖,找到開始平坦的點, 即為所求個數。(3)亦有其他多種統計上正式分析,但並無標準制式規定的 分析統計量。
3.1.2 T
2管制圖推導過程
T2值的含意為代表原始資料點的M 維向量投影在由主成份向量所包含以由主成份模型解釋的部份,其計算公式如下:
∑
= = K 1 k 2k k T k 2 s t t T (29) 式中主成份向量長度平方除以其變異數,將各主成份方向上的主成份 值分佈的變異數調整成一,如此便可以避免資料本身單位和數值大小的影 響。 Hotelling 由 Student t 分佈導出 T2的值大於、等於零,所以 T2管制圖 只有一個管制界限,可以由查表得到,但是由於 T2表並不是很普遍,所以 也可以由較常見的F 分佈值換算求得,T2分佈與F 分佈的換算公式如下: a , K M , K 2 M,a K, F K M ) 1 M ( K T − − − = (30) 其中 K:保留在主成份模型中的主成份個數 M:用來建構主成份分析模型的資料點個數 a:I 型錯誤機率 在 T2管制圖中,若是觀測點的值超出上限,代表在a 的 I 型錯誤機率 下可以判斷為程式異常情況發生,且其來源為主成份模型範圍內的偏離。3.2 抽樣管制計畫
在本節所用之多變量抽樣管制計畫包括:(1) T²管制圖及(2) 主成份分析 法管制圖。進行流程分述如下:3.2.1 T²管制圖
T²管制圖可以同時監控多個彼此之間有相關的變數,即使每個品質特 性的蕭華特(Shewhart)管制圖都在管制界線之中,也不能確保多個變數結合 而成的T²統計量不會超出管制界線。因此,在繪製T²管制圖之前,先依據機 台之電力品質參數的資料,個別繪製出用以監控個別單一變數的蕭華特 (Shewhart)管制圖。 在比較單變量與多變量的抽樣分析結果後,若在監控多個品質特性 時,單變量的蕭華特(Shewhart)管制圖並沒有任何的異常情形,但在T²管制 圖的監控表現中卻發生超出管制界線的警訊時,則表示在多變量製程中, 若沒有考慮到變數之間的相關性,而僅只以單變量角度的蕭華特(Shewhart) 管制圖進行監控,則容易發生製程已發生了偏移。因此,在做T²管制圖應 分成兩個階段,分述如下:第一階段為建立管制圖,在此階段先從歷史資 料中建構出一個初步的管制圖,經由不斷的測試及修正,最後做出製程在 管制狀態下的管制圖。第二個階段是建構好的管制圖,實際監控電力品質。 在監控電力品質狀況後,根據實際的資料進行管制圖的製作。判斷第二階段製程是否存在管制狀態下的公式(2)及公式(3)所示。
3.2.2 主成份分析法管制圖
T²管制圖是工業界應用最廣的多變量管制圖,然而當監控變數有數十 個甚至上百個時,T2指標之共變異數矩陣(covariance matrix)過於龐大,常會 導致計算速度變慢。另外,T²管制圖雖適用於多變量製程的監控,但當T² 統計量顯著而超出管制界線時,卻無法辨識是由哪些變數所造成。為彌補 此一缺陷,本文再用主成份分析法來診斷多變量管制圖,以求管制的電力 品質之評估模式之精準性。 由公式(4)可將主成份分析法「轉換」原始變項使之成為一些互相獨立 的線性組合變數,經由線性組合而得的主成分仍保有原變數最多的資訊, 再由公式(5)與(6)找出其關鍵在「變異數」問題,利用求特徵值 eigenvalue 及 特徵向量 eigenvector 之方法,過濾出佔最大變異數的型態,此即為最主要 之型態。3.3 電腦系統模擬流程
在電腦系統模擬部分,本文開發先進製程管制平臺(Advance Process Control Suite, APCSuite),本系統可以整合統計製程管制、監測點資訊、趨 勢圖、一般圖表等功能,提供工廠管理者各種進階應用之製程、工安,以 執行歷史數據分析與製程預測模擬等。如歷史警報資料擷取分析及及時資 料趨勢圖形之建立,提供業者完整的異常診斷平臺,幫助系統工程師早期 偵測異常狀態,達到現場安全及設備監控之功能。電腦模擬進行步驟如下: 步驟一:擷取原始資料 資料來源由監控設備擷取資料,擷取變數包括:BUSBAR, TR1, TR2, TR3, FAB1 之 VA, VB 與 VC 電壓值等,共 15 個變數。 步驟二:資料前處理 在建模前,須將無數據時間點剔除,然後再系統進行建模。 步驟三:進行T2建模與分析 在 此 步 驟 , 透 過 APCSuite 系 統 提 供 線 上 警 報 效 能 評 估 (Alarm
Performance Assessment, APA)分析,提供人員線上資訊交換中心,對於異 常警報點的數值異常監控,並發佈異常警報,可對異常做及時的處理,有 助於廠區安全、資料管理、紀錄及查詢提供有用的資訊,協助工程師與操
作員更加瞭解電力品質的特性 提供統計製程管制工具(SPC),針對製程操 作變數對產品的品質變數(或生產安全變數)進行預測性監控。 步驟四:進行主成分分析法之建模分析 由步驟三建模分析所得之結論,進行主成分分析法之建模分析,可以 讓工程師瞭解,從15 個量測與監控電力品質異常變數,造成電力系統品質 異常之主要原因,工程師可藉此找出造成電力品質異常的變數,進而建立 預警措施,降低工程師線上判斷不準確性的負擔,以增加工作效率。
第四章 個案研究與分析
4.1 個案說明
本案例為某竹科半導體廠,由於廠方廠務負責人員需要瞭解廠房內所有 相關電力系統設備不正常電力供應與可能設備劣化問題,造成電力故障與 電壓不穩定。同時 根據廠方表示,由於這種不正常的電力供應品質,將會 影響製程中的良率,造成在生產管理中,重大的經濟損失。因此,在廠區 提供內部15 個重要電力設備供應點,提供廠區電力品質異常管理與評估。 並籍由本研究運用T2、SPC 及主成分分析法來開發 APCSuite 之先進製程管 制平臺系統進行電力品評估管理,本研究所開發之系統可以整合統計製程 管制、監測點資訊、趨勢圖、一般圖表等功能,提供工廠管理者各種進階 應用之製程、工安,以執行歷史數據分析與製程預測模擬等。如歷史警報 資料擷取分析及及時資料趨勢圖形之建立,提供業者完整的異常診斷平 臺,幫助系統工程師早期偵測異常狀態,達到現場安全及設備監控之功能。 而用來電力系統品質供應管理評估的方法,本文應用統計製程管制法之多 變量管制圖包括:T2管制圖及及主成分分析法,用來有效進行監測。4.2 電腦模擬分析與系統建模程式
在進行半導體設備之電力品質異常與診斷之前,首先要先確認所開發之 APCSuite 監控系統之建模是否準確。因此,提出兩階段之資料建模與驗證 分析,以期APCSuite 監控系統能做出精準的預警,降低現場工程師之誤判 情形,減少工程師之工作負荷,進而降低半導體設備因供電系統品質異常 而造成當機率。 兩階段建模分述如下:第一階段為從半導體機台現場,蒐集資料,作為 訓練組資料,然後再以 T2管制圖來檢定供電品質異常之狀況及確認發出警 報是否為異常,若確實發生異常,則建立異常分析原因,再由線上工程師 確認,發生異常原因,如為供電品質異常,則建入異常警報資料庫,作為 異常警報發佈時之比對參考。緊接者再以主成份分析法來從15 個變數中計 算分離出,造成電力品質異常的變數,這些經過縮減後變數可簡化多變量 管制圖,提供工程師或決策者作為當電力異常之判斷。第二階段為線上測 試,將第一階段所得之結果,直接以 T2與主成分分析法所立之模型進行線 上監控電力品質,並驗證所建立之模型之有效性及精準性。整體半導體設 備之電力品質之異常分析、監控之操作步驟,如圖13 所示。希望藉由本由 就所運用之T2、SPC 及主成分分析法來開發 APCSuite 之先進製程管制平臺 系統進行電力品質評估與預測管理。圖 13 監測設備電力品質異常狀態與分析流程圖 擷取原始資料 資料前處理(去除異常之資料) 建模(視需要使用Auto Drop) 儲存模型 擷取測試資料 載入模型 分析超界點之特性分 進行變更界線 是 否 是 重建模型 是 否 重 新 建 構 模 型 是否重新定義模型界 否 完成建模 訓練組資料 測試組資料 模型檢定正確性 是 完成建模 否