中文字轉音系統之文句分析的進一步研究
89
0
0
全文
(2) 中文字轉音系統之文句分析的進一步研究 A Further Study on Text Analysis for Mandarin TTS. 研 究 生:傅明榮. Student:Ming-Zong Fu. 指導教授:王逸如 博士. Advisor:Dr. Yih-Ru Wang. 國 立 交 通 大 學 電 信 工 程 學 系 碩 士 論 文. A Thesis Submitted to Department of Communication Engineering College of Electrical Engineering and Computer Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in Electrical Engineering July 2007 Hsinchu, Taiwan, Republic of China. 中華民國九十六年七月.
(3) 中文字轉音系統之文句分析的進一步研究. 研究生:傅明榮. 指導教授:王逸如 博士. 國立交通大學電信工程學系碩士班. 中文摘要. 在本論文中,我們建立詞綴構詞單元模組至中文斷詞器內,以改善某些衍生 詞無法窮舉於詞典的問題,使中文斷詞器的架構更加完善,並將中文斷詞器製成 一便於使用的視窗工具。整個最核心的構詞單元是採用中研院中文分詞規範所提 供的“詞綴,接頭/接尾詞"列表,經由統計整理,並以詞類作為規則法構詞的 依據。另外,從詞綴著手,並加上介詞與連結詞,觀察三者對於口語語音停頓類 型的特殊現象,從中挑選特別字詞,提供除詞類、詞長等參數外,作為未來從文 字預估停頓的研究上另一新參數。本文也針對中文語音合成系統當中,破音字的 問題作前處理,提供正確的語料可供未來研究使用。為了評量詞綴構詞單元之效 能,我們以《中研院平衡語料庫 3.0 版》作為測試語料,測試結果顯示構詞正確 率達八成左右。最後我們分析各個構詞規則的錯誤率,探討構詞錯誤的更正方法。. I.
(4) A Further Study on Text Analysis for Mandarin TTS. Student : Ming-Zong Fu. Advisor : Dr. Yih-Ru Wang. Department of Communication Engineering National Chiao Tung University. Abstract. In this thesis, the further research about text on Mandarin Text-to-Speech(TTS) System. First, we hand on the multiphone characters and affix characters which proposed by Mandarin Promotion Committee, the Ministry of Education and Chinese Knowledge Information Processing group(CKIP), Academia Sinica. We design the new word combination module after the word identification to dispose of unknown word by using 74 rules. And, we observed some special words that can affect prosodic pause. This observation may improve on predicting break indices form Chinese text. At last, the Sinica Corpus published by CKIP is used to evaluate the performance of the new combination module. We achieve a precision rate of. 0.829 in word. combination. We also analyze word combination results to give advices in furure word. II.
(5) 誌謝 首先,我要感謝指導教授王逸如老師兩年來諄諄的教導,不厭其煩的聆聽我 的報告,糾正邏輯上的錯誤,帶領我一步一步地學會做事的方法。也謝謝陳信宏 老師,在碩二的這一年間,陳老師不僅適時的給予如何做研究的建議外,對於所 作的每一步其前因後果以及未來能延伸的問題都鉅細靡遺的講解,讓我深刻感受 到老師們那清楚的思緒和思考問題的思考邏輯。讓我這兩年來獲益匪淺,也讓我 對於讀書的態度有了不同以往的大轉變。 再來,我還要感謝我的室友們阿弟、小民、輝昇、大雕、大師、問賢、神龍, 雖然認識你們短短兩年,但卻有種相見恨晚的感受。跟你們一起打球,一起聊天 真的很快樂,也能讓我從實驗室回來而煩悶疲憊的心得以紓解,沒有你們,我一 定會撐不下去的,如今要離開不能天天見到你們真有點捨不得。 實驗室的大家也是不可忘卻的,小鄧的牛頭不對馬嘴個性,小迷彩說話一針 見血,跟獻文大大討論海賊王,很愛吃麥當勞的宏宇,超愛家的啟風,超愛紅襪 的胤賢,很愛兇的友駿,很愛熱血誰呀的銘彥以及很愛打飛機的性獸、很會嗆聲 的 Barking、會陪我跑步的智合、會陪我看 NBA 的阿德以及靜悄悄的希群,有了 你們的幫忙,讓我在做事上更如虎添翼,尤其是性獸學長,沒有你就沒有現在的 我啊! 最後不免俗的要感謝我的家人,爸爸、媽媽、哥哥、姐姐以及大嫂,你們一 直以來的支持讓我沒有經濟上的問題,對我如此的好吃的用的住的玩的都會想到 我,讓我每次回家都能一再地充電以備作研究的能量,我很高興你們以我為榮, 我也盡力的做好我能做的。 經過這麼多年來的學習,在交大這兩年感觸特別深,因為讓我看見許多強 者,讓我了解「沒看見好的,不知自己能多好。」。謝謝大家,有你們才有現在 的我,未來的我會繼續努力的。. III.
(6) 目錄 中文摘要............................................................I 英文摘要...........................................................II 誌謝..............................................................III 目錄...............................................................IV 表目錄.............................................................VI 圖目錄...........................................................VIII 第一章 緒論.........................................................1 1.1 研究動機....................................................1 1.2 研究方向....................................................2 1.3 章節概要....................................................3 第二章 中文斷詞器概述...............................................4 2.1 分詞標準....................................................4 2.2 中文斷詞器系統架構..........................................5 第三章 破音字前處理及詞綴構詞單元之設計............................10 3.1 破音字前處理說明...........................................10 3.2 詞綴構詞單元之設計.........................................13 3.2.1 詞綴構詞規則的建立...................................14 3.2.2 詞綴構詞單元之演算法.................................16 3.3 漢語文句斷詞器.............................................22 第四章 詞綴構詞單元之效能分析......................................26 4.1 測試語料...................................................26 4.2 斷詞結果之評量.............................................26 4.3 詞綴構詞單元效能之分析.....................................27 第五章 文字中的特別字詞與停頓標記關係之統計........................31. IV.
(7) 5.1 從詞綴觀察停頓分佈之統計...................................32 5.2 詞類“Ng"之停頓分佈統計...................................35 5.3 詞類“VE"之停頓分佈統計...................................37 5.4 連接詞與介詞之停頓分佈統計.................................40 5.4.1 連接詞之停頓分佈統計.................................41 5.4.1.1 (Ca)並列連接詞.................................41 5.4.1.2 (Cb)關聯連結詞.................................45 5.4.2 介詞之停頓分佈統計...................................51 5.5 本章結論...................................................53 第六章 結論與未來展望..............................................54 參考文獻...........................................................55 附錄 1 .............................................................57 附錄 2 .............................................................61 附錄 3 .............................................................69 附錄 4 .............................................................73 附錄 5 .............................................................76. V.
(8) 表目錄 表 2-1:詞典詞數統計表...............................................7 表 3-1-1:依破音字修正詞典紀錄節錄..................................11 表 3-1-2:常用破音字表節錄..........................................12 表 3-2-1:詞綴規則標記..............................................15 表 3-2-2:詞綴構詞規則表節錄........................................16 表 3-2-3: 「老先生與大人們在討論事情」之詞綴規則標記集合表...........18 表 3-3-1:斷詞結果輸入至檔案格式....................................24 表 4-1:部份《中研院平衡語料庫 3.0 版》語料庫統計....................26 表 4-2: 《中研院平衡語料庫 3.0 版》語料庫統計.........................26 表 4-3:斷詞結果....................................................27 表 4-4:前詞綴構詞規則使用之分佈....................................28 表 4-5:後詞綴構詞規則使用分佈......................................28 表 5-1:Treebank 五萬字文字資料庫統計...............................32 表 5-1-1:前詞綴與接頭詞之 Break type 統計表節錄.....................32 表 5-1-2:後詞綴與接尾詞之 Break type 統計表節錄.....................33 表 5-1-3:前詞綴與前後文之停頓標記統計節錄..........................34 表 5-1-4:後詞綴與前後文之停頓標記統計節錄..........................34 表 5-2-1:後詞綴詞類“Ng"、“Ncda"與前後文停頓標記之統計節錄......35 表 5-2-2:“Ng"及“Ncda"與前後文停頓標記之統計....................36 表 5-2-3:“Ng"因“VE"而停頓後移範例..............................36 表 5-3-1:“VE"與其後接詞之停頓分佈統計............................37 表 5-3-2:“VE11"及“VE12"之停頓分佈統計..........................38 表 5-3-3:“VE2"後無停頓之分類表...................................39 表 5-3-4:“VE2"後無停頓之範例.....................................39. VI.
(9) 表 5-3-5:“VE2"停頓後移之範例.....................................40 表 5-4-1-1:對等連接詞“及"與前後成份之停頓分佈統計................42 表 5-4-1-2:對等連接詞“和"與前後成份之停頓分佈統計................42 表 5-4-1-3:對等連接詞“以及"與前後成份之停頓分佈統計..............43 表 5-4-1-4:列舉連接詞“等"與前後成份之停頓分佈統計................43 表 5-4-1-5:列舉連接詞後未停頓之範例................................44 表 5-4-1-6:列舉連接詞後有停頓之範例................................45 表 5-4-1-7:聯合複句連結詞語意及位置分類表..........................47 表 5-4-1-8:偏正複句連接詞語意及位置分類表..........................47 表 5-4-1-9:句尾連接詞“的話"與前後文之停頓分佈統計................47 表 5-4-1-10:偏正後繫連接詞“以"與前後成分之停頓分佈統計...........48 表 5-4-1-11:偏正移動性前繫連接詞“如果"與前後成分之停頓分佈統計...48 表 5-4-1-12:偏正移動性前繫連接詞“由於"與前後成分之停頓分佈統計...49 表 5-4-1-13:偏正後繫連接詞“因此"與前後成分之停頓分佈統計.........49 表 5-4-1-14:偏正後繫連接詞“而"與前後成分之停頓分佈統計...........50 表 5-4-2-1:介詞分類集合及其集合文字................................51 表 5-4-2-2:P07 與前後詞之停頓分佈統計...............................52 表 5-4-2-3:P21 與前後詞之停頓分佈統計...............................52 表 5-4-2-4:P31 與前後詞之停頓分佈統計...............................52. VII.
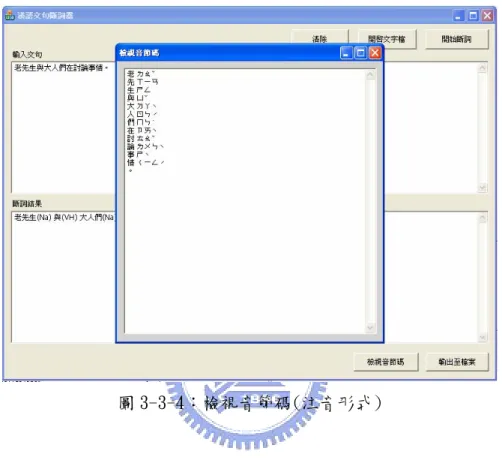
(10) 圖目錄 圖 1-1:中文斷詞器架構...............................................1 圖 2-1:中文斷詞器整體架構圖.........................................5 圖 2-2:前置構詞單元示意圖...........................................6 圖 3-2-1:構詞單元在斷詞器中的位置..................................14 圖 3-2-2:詞綴構詞單元流程圖........................................17 圖 3-2-3:Linked-list Output Words..................................17 圖 3-2-4:詞綴構詞規則比對流程圖....................................19 圖 3-2-5:建立初始樹集合............................................19 圖 3-2-6:詞綴構詞規則比對流程圖....................................20 圖 3-2-7:詞綴構詞規則樹............................................21 圖 3-2-8:更新詞串鏈結圖............................................21 圖 3-3-1:漢語文句斷詞器介面........................................22 圖 3-3-2:自行輸入與開啟文字檔......................................23 圖 3-3-3:顯示斷詞結果..............................................23 圖 3-3-4:檢視音節碼(注音形式)......................................25. VIII.
(11) 第一章 緒論. 1.1 研究動機. 目前,交通大學語音處理實驗室所研究發展的“中文文字轉語音系統" (Text-to-Speech System 簡稱 TTS System),已有相當不錯的合成品質。而此 系統的最前級必然是將輸入文句加以解析並斷詞的斷詞器。江振宇[1]的中文斷 詞器,採用中研院提出的六條斷詞規則[2],並以詞典樹(Lexicon Tree)的資料 結構儲存詞典,建立基本的斷詞單元。並將具備某種規則的詞,例如:定量複合 詞、重疊詞等,參考中研院提出的構詞規則[3,4]設計構詞單元。隨後還有給予 斷詞詞類的詞類標記單元,及將某些阿拉伯數字、詞或符號由寫法傳為語音讀法 的文字正規化單元,整體架構如圖 1-1 所示. 圖 1-1:中文斷詞器架構 1.
(12) 中文斷詞器輸出的為語言參數,這些語言參數包括詞、詞長、詞類以及基本 音節等資訊,其後將這些語言參數送往韻律訊息產生器產生所需的韻律參數,如 基頻軌跡(pitch contour)、音長(duration)、停頓(pause)和音量(energy),最 後語音合成器利用 PSOLA 的技術,依據韻律參數將基本音節調合成語音。 為了合成出來的語音聽起來自然,符合人說話的方式,這些韻律參數簡而言 之就像是人類說話的“抑揚頓挫"。而最為影響一個人了解另一個人說話的內容 的參數莫過於停頓了,一個人說話,在不該停頓的地方停頓或是該停頓的地方不 停頓都會讓人覺得不自然,進而無法了解一個人說話的真正涵義。但現在斷詞器 輸出的詞串是詞典中的詞或是構詞規則單元產生的詞,詞典大量的詞彙會造成搶 詞而造成不該出現的停頓;構詞規則可能構出太長的詞而造成該停頓的點卻沒出 現停頓,這兩種問題皆會造成人聽覺上的不舒服。所以我們希望能從文字方面得 到更多關於停頓方面的資訊,如此一來,能夠給予斷詞器更多韻律方面的資訊減 少斷出過多的短詞或是搶詞與構詞規則構出過長的詞,之後更進一步的冀望這類 停頓的資訊能幫助未來的斷詞器斷出韻律詞邊界( Prosodic Word Boundary)。. 1.2 研究方向. 本文研究的重點是希望能從斷完的短詞去預估每個短詞之間的停頓以及長 詞應斷為若干短語的停頓,將停頓的資訊送往後級的單元使用。基於這個方向, 針對短語與短語之間停頓的現象和長詞斷為若干短語的現象加以分析。首先我們 先對中研院提出的“詞綴、接頭 / 接尾詞參考表"[5]著手,此類的短詞因可與 其他短詞相接組合成另一新的短詞,所以詞典無法完全收錄,而導致斷詞時易被 斷為兩個短詞,而介詞與連接詞兩者,因為其詞類(Part of Speech)功用特別, 其停頓點應也有其特別之處。針對這兩方面,加以詞類等資訊,在未來的研究中 套用數學模型,設計一自動預估停頓標記的方法,給予中文斷詞器更多韻律方面 2.
(13) 的資訊。除此之外,我們進一步地將詞綴整理、歸納出詞綴構詞規則,並將規則 寫入中文斷詞器當中。為了之後對於破音字的研究,於本文也事先對破音字作了 前處理的工作以供未來研究之使用。我們以《中研院平衡語料庫 3.0 版》部分語 料經人工斷詞以及江振宇自動標記停頓標記的語料做為統計來源,給予詞綴、連 接詞及介詞三者,停頓分佈的詳細分析。提出特別字詞,以供未來從文字預估停 頓的研究上另一新的參數。最後,我們採用定量的測試方式來檢測詞綴構詞規則 的準確性。. 1.3 章節概要. 第一章. 緒論:介紹本論文的研究動機與方向。. 第二章. 中文斷詞器之概述:簡述目前中文斷詞器的整體架構。. 第三章. 破音字前處理及詞綴構詞單元之設計:說明對於未來必然要面對之破音 字的問題,敘述如何處理以及選定破音字等前處理工作,以及建立詞綴 構詞規則並加入中文斷詞器中的演算法。. 第四章. 詞綴構詞單元之效能分析:以《中研院平衡語料庫 3.0 版》進行加入詞 綴構詞單元的中文斷詞器之定性與定量實驗分析。. 第五章. 文字中的特別字詞與停頓標記關係之統計:說明本論文針對“詞綴、接 頭 / 接尾詞參考表"以及介詞與連接詞三者進行停頓分佈的統計結果 並給予詳細的分析。. 第六章. 結論與未來展望。. 3.
(14) 第二章 中文斷詞器概述. 2.1. 分詞標準. 交通大學所發展的中文斷詞器主要是以語音合成的角度來設計,因此希望 斷出的詞能夠適於語音合成的單位,但是,中文對於詞的定義較模糊,所以我們 的首要工作便是定義分詞單位,也就是訂定「分詞標準」。對於資訊處理而言, 根據中研院:「詞為一個具有獨立意義,且扮演特定語法功能的字串應視為一個 詞」,然而對於語音合成而言,分詞單位與資訊處理的標準不盡相同,例如「八 位學生」,依資訊處理的標準會斷成「八位」 、「學生」,「八位」含有學生的數量 資訊, 「學生」含有某個事物的名稱資訊,但對於語音合成的角度而言, 「八位學 生」應為一個分詞單位,所以可以以資訊處理標準斷詞的結果「八位」、「學生」 在構詞成一個語音合成的分詞單位。 由以上的敘述得知,如果要達到以語音合成考量的斷詞結果,可以利用「資 訊處理標準」的斷詞結果,再經由一些規則,將斷詞結果提升到適用於語音合成, 所以這裡提出的中文斷詞器,將斷詞處理依據不同的「分詞標準」可分為不同的 前後級處理,分級如下: 第一級:由「構詞單元」及「斷詞單元」構成,詞集合為「詞典」以及「構詞單 元產生的詞」,由此級斷出的詞希望能達到「資訊處理」的標準,使得 斷詞結果含有充分的語法與語意資訊,以供後級利用。 第二級:由「後置構詞單元」及「未知詞構詞單元」組成。由於第一級產生的斷 詞結果含有充分的資訊,因此第二級可以利用這些資訊再輔以一些規則 或統計資訊,將衍生詞或未知詞(如:人名、專有名詞等)斷出。. 4.
(15) 第三級:以「語音合成考量的構詞單元」。這一級的「分詞標準」是以語音合成 為考量,利用前兩級所給予的資訊,將分詞單位屬於語音合成考量的詞 構出。. 2.2. 中文斷詞器系統架構. 目前完成的系統模組已達到部份「第二級分詞標準」,系統概述如下:. 圖 2-1:中文斷詞器整體架構圖. 5.
(16) (1)前處理單元: 由於是要使用於 TTS 的斷詞器,因此輸入的字串有可能含有 ASCII code 或 是 Big-5 code,因此為了使系統處理的字串格式統一,在進入斷詞器以前,首 先我們將所有的 ASCII code 轉為 Big-5 code,例如字串 「比去年同期減少了 8.6%」 會先轉為 Big-5 字串「比去年同期減少了8‧6%」。. (2)前置構詞單元: 由於中文斷詞的方法是將輸入的文句與詞典做搜尋比對的工作,但是中文 詞無窮無盡,要將所有的詞收錄至詞典當中是不可能的,而有些具有規則而無法 詳列於詞典的詞,如定量複合詞以及重疊詞等,這些詞的組成是有規律的,可藉 由輸入的文字串中,經由構詞規則將這些詞結合出來,這般構出的詞如同比對詞 典的動作。由此模組構出的詞,會留下其構詞的結構,以便後級的模組使用。在 此級分別分為(1)定量複合詞構詞單元(包含有「定量複合詞」 、 「數詞定詞」 、 「數 量定詞」、「時間詞」、「地方詞」)、(2)重疊詞構詞單元,示意圖如下:. 輸入字串. 定量複合詞構詞規則 構詞規則詞集合詞典. 定量複合詞 構詞單元. 重疊詞 構詞單元. 構出祠. 斷詞單元. 圖 2-2:前置構詞單元示意圖. 6. 重疊詞構 詞規則.
(17) (3)詞典及外掛詞典: 由於中文斷詞的方式是將輸入的文字和詞典進行搜尋比對,詞典的好壞會 直接影響到「斷詞單元」的斷詞結果。我們先對詞典作了增減修正動作,將過於 合詞的詞自詞典中刪除,目前中文斷詞器詞典的詞數統計如下表 2-1 表 2-1:詞典詞數統計表 詞數 一字詞. 13,110. 二字詞. 64,886. 三字詞. 26,042. 四字詞. 16,066. 五字詞. 999. 六字詞. 155. 七字詞. 65. 八字詞. 9. 總計. 121,332. 除此之外,如有遇到特定使用環境的時候,會遭遇到輸入文句有許多的特 殊詞,我們可以藉著新增這些詞於外掛詞典,解決特殊詞的斷詞。. (4)斷詞單元: 此單元是中文斷詞器的核心部份,目的是將輸入的字串做適當的斷詞。此 單元分為兩大步驟(1)建立候選詞組(2)挑選候選詞組。建立候選詞組是將輸入的 文字串利用詞典、外掛詞典以及前置構詞單元構出的詞,以 Matching Algorithm 找出所有可能的詞串組合。然而,這些所有可能的詞串組合只有一組是適當的斷 詞結果,所以必須經由一些規則或是統計的方法,挑選候選詞組,選定最適合的 詞串。在此我們沿用中研院提出的六條斷詞規則,這些規則分別是(1)長詞優先 (2)標準差小的優先(3)附著語素最少者優先(4)候選詞組中定量複合詞字數和最 7.
(18) 少者優先(5)一字詞詞頻最高者優先(6)總詞頻最高者優先,最後再加上第七條規 則,以防經過六條斷詞規則仍不能選出詞組,規則為將任意選擇候選詞組中的任 一個詞組的第一個詞作為斷詞結果輸出。「斷詞單元」是最前級的分詞單元,之 後的「詞綴構詞單元」 、 「詞類標記單元」和「文字正規化單元」皆是利用此單元 的斷詞結果再做處理。. (5)詞綴構詞單元: 經由斷詞單元斷出的詞串當中,仍然含有前置構詞單元尚未構出的衍生 詞,這些衍生詞也是無法窮舉於詞典,所以經過斷詞單元,這類衍生詞會被斷為 短詞。但是我們所需要的是以語音合成為考量的斷詞器,因此這類衍生詞不應該 被斷開,我們希望能藉由「後置構詞單元」將這類衍生詞構出,如詞綴、人名等 未知詞。因此我們於斷詞單元後設計「詞綴構詞單元」 ,藉由「斷詞單元」輸出 的資訊,來將詞綴衍生詞構出。而至於人名等未知詞留待未來在做處理。詳細的 「詞綴構詞單元」設計於第三章有詳細說明。. (6)詞類標記單元: 有了斷完詞的詞串,而中文的詞有時具有多種詞類(Part of speech, POS), 因此還需對這些詞串找到其最適當的對應詞類,目前採用的「詞類標記單元」, 為沿用江振宇用《中研院平衡語料庫 3.0 版》所建立的「詞類雙連文模型」,應 用 Viterbi-search 給予斷出的詞串最佳的詞類標記串。. (7)文字正規化單元: 以語音合成為考量的中文斷詞器,在輸入的文句之中,有時會有阿拉伯數 字、詞或符號必須由書寫法轉為語音讀法,此過程稱為文字正規化,此模組利用 8.
(19) 斷詞單元及前後構詞單元留下的詞結構進行文字正規化,舉例來說「90‧5%」 應該將寫法轉為語音讀法「百分之九十點五」 。目前的文字正規化單元,針對了 以下幾種情形做正規化動作: (a) 英文字母部份:TEL、FAX、AM、PM、30cm、100kg 等 (b) 符號部份;90.5%、2007/12/25、19.6 等 (c) 數字加單位部份:100 公斤、1 月 1 日、2007 年等 針對以上情形定出數字、符號的發音方式及發音順序。. (8)輸出單元: 此單元為輸出韻律產生器所需要的語言參數:詞、詞類和音碼。. 9.
(20) 第三章. 破音字前處理及詞綴構詞規則之設計. 目前的中文斷詞器多是以利用構詞規則將含有某種特性的詞構出以及查詢 大量詞彙構成的詞典這兩部份將一句文句斷為若干個分詞。但是在這當中,給予 每個字基本音節的資訊已被詞典以及規則表兩者限制住。然而中文有許許多多的 字是具有一字多音的特性,因此會導致斷詞器斷出的詞,其中字的基本音節不符 合文句所要闡述的意義,這樣合成出來的語音聽起來會使人不舒服。所以正視破 音字的問題是必然的。 交通大學語音處理實驗室現階段的中文斷詞器[1]已將定量複合詞和重疊詞 兩類具有明顯規則的詞,設計一前置構詞單元,輔助這類無法完全收錄至詞典的 詞,避免這類詞被切分為一個一個的字。這部份的工作可在「分詞標準」三級中 的第一級完成。但是還有些可以依規則構成的詞,例如:副總統、副會長、副班 長、副廠長;大人們、家長們、小孩們、老師們等這類由中研院提出的“詞綴、 接頭 / 接尾詞參考表"中由某個雙音節的詞緊接一個單音節的詞綴所衍生出的 詞,這類型的詞可由後置構詞單元來構成,可於「分詞標準」的第二級完成。底 下分兩小節來個別詳細說明破音字前處理以及後置構詞單元之詞綴構詞單元。. 3.1 破音字前處理之說明 國語語音部份,常會有一字多音的情形,這類文字我們統稱為“破音字"。 破音字在國語語音合成系統中,易造成混淆使得系統合成出的發音與口語發音不 符,造成人聽覺的怪異感,因此針對破音字的問題做研究,對國語語音合成系統 是有其必要性的。 首先第一步需了解國語中有哪些字是破音字,我們參照教育部國語推行委員. 10.
(21) 會所制定的國語辭典當中,所審定的《國語一字多音審定表》[6]建立初步的破 音字表,此表總收錄的破音字共有 4253 個。但這 4253 個破音字當中,有許多的 古字,或是有許多的破音字只在古文當中才被使用到,這對於現今的口語習慣當 中甚少使用,因此我們並不收錄這些文字於我們所需處理的破音字當中,我們僅 只針對現今口語及書寫經常會用到的文字做處理。 依此方向作“破音字表"的收錄,我們從 4253 個字刪減至 896 個字,但仍 然過多,因此我們再針對某些破音字只有在特定的詞當中才會發生,我們將此類 破音字的詞,收錄至我們國語詞典當中,以利事後斷詞時,能使斷詞的標音正確 無誤且正規。例如: 《單》通常音【ㄉㄢ】 ,但當作地名或姓氏時常音【ㄕㄢˋ】。 而表匈奴首領一詞《單于》音【ㄔㄢˊ. ㄩˊ】。因此我們再針對此類情形,將. 大部分僅止某些詞的破音字,收錄至詞典並對我們現有的國語詞典做修正。至於 姓氏方面的單字破音字如: 《曾》通常音【ㄘㄥˊ】但當做姓氏的時候音【ㄗㄥ】, 此類姓氏暫時未做處理,留待未來斷詞器收錄姓氏的外掛詞典來處理。依此方向 下來,我們更進一步從 896 個破音字當中節錄 126 個,修正紀錄如下:. 表 3-1-1:依破音字修正詞典紀錄節錄 編號. 國字. 注音. 註解. 1. 上. ㄕㄤˇ. 字典一字詞收錄為 (ㄕㄤˋ) “上聲"一詞(詞典已有) 將"平上去入"加入四字詞中. 2. 乘. ㄕㄥˋ. 字典一字詞收錄 (ㄔㄥˊ) 其餘標記為 (ㄕㄥˋ)的詞皆已納入辭典,如:萬乘 之國、大乘、小乘等. 3. 仇. ㄑㄧㄡˊ. 辭典一字詞收錄為 (ㄔㄡˊ)、姓氏. 4. 任. ㄖㄣˋ. 姓氏,納入詞典中 合成:ㄖㄣˋ 辨識:ㄖㄣˊ and ㄖㄣˋ 皆標註. 5. 估. ㄍㄨˋ. 二字詞詞典已有"估(ㄍㄨˋ)衣"一詞 三字詞詞典新增"估(ㄍㄨˋ)衣舖"一詞 11.
(22) 表 3-1-2:常用破音字表節錄 編號 國字 1. 2. 3. 4. 5. 6. 7. 8. 9. 中. 乾. 了. 供. 便. 倒. 假. 傍. 傳. 讀音. 說明. ㄓㄨㄥ. 中央、中國、中學、中立. ㄓㄨㄥˋ. 中的、中毒、中意. ㄑㄧㄢˊ. 乾卦、乾坤、乾乾. ㄍㄢ. 餅乾、乾杯、乾淨、乾脆. ㄌㄧㄠˇ. 了結、了解、了不起、受不了. ㄌㄜ․. 「做完了!」 、「這就難怪了!」. ㄍㄨㄥ. 口供、供給. ㄍㄨㄥˋ. 供品、供奉. ㄅㄧㄢˋ. 方便、便利. ㄆㄧㄢˊ. 便宜、便辟、大腹便便. ㄉㄠˇ. 倒閉、跌倒、倒塌、顛倒. ㄉㄠˋ. 倒影、倒轉. ㄐㄧㄚˇ. 假借、假裝. ㄐㄧㄚˋ. 假期、放假. ㄅㄤˋ. 依山傍水、依傍. ㄅㄤ. 傍晚、傍午. ㄔㄨㄢˊ. 傳單、傳神、傳染. ㄓㄨㄢˋ. 左傳、傳記. …. …. …. …. 58. 暈. ㄩㄣ. 頭暈眼花、暈車、暈倒. ㄩㄣˋ. 月暈、燈暈、酒暈、血暈. …. …. …. …. 83. 種. ㄓㄨㄥˇ. 種子、種類. ㄓㄨㄥˋ. 種田、接種. …. …. …. …. 12.
(23) 表 3-1-1 是說明我們依照上述刪減某特定的破音字,對詞典做修正的紀錄,表 3-1-2 是常用破音字表的節錄,此兩表完整的內容請詳閱附錄 1、2。 完成破音字表,對於未來研究所需使用的 Treebank 文字資料庫也要做處 理,此語料庫並未經過斷詞,所以我們利用江振宇的中文斷詞器[1]做斷詞之後 再加以修正,此語料庫約十二萬字,修正記錄在此不贅述,詳閱附錄 3。. 3.2 詞綴構詞單元之設計. 中研院提出的中文資訊處理分詞規範所提及的層次劃分當中,依電腦自動 化處理分詞的難易程度及實際使用情況,分信、達、雅三級,(1)信級;凡是收 錄在標準詞典的詞一律斷開,(2)達級:能以構詞律組合出來的詞在達級合併, (3)雅級:無法完全收錄至詞典中的詞在雅級合併。但是在語音合成的角度而言, 對於分詞的標準不盡與資訊處理的標準相同,這於第二章中文斷詞器概述的起頭 就有提到,於是我們也採用了我們以語音合成角度所提出的分詞標準。在江振宇 的中文斷詞器[1]中加入了「定量複合詞」 、 「數量定詞」 、 「數詞定詞」 、 「時間詞」 、 「地方辭」 、 「重疊詞」等希望能夠經由構詞單元,將這些詞由輸入文句詞組中合 併出來,相同於查詞典的地位,因此構詞單元構出的詞與詞典中的詞皆為建立候 選詞組的詞集合。 但經斷詞單元斷出的詞串中,仍然有些字能夠彼此結合成長詞,因此我們希 望能經由後置構詞單元將能結合的詞結合成長詞,例如: 【大人們】會被斷為【大 人】和【們】、【老前輩】會被斷為【老】以及【前輩】。這類如【們】和【老】 與【大人】和【前輩】合併為另一個詞的字,我們稱為“詞綴、接頭/接尾詞", 但在此論文當中皆統稱為“詞綴"。3.2.1 將說明詞綴構詞規則的建立,3.2.2 將說明「詞綴構詞單元」在程式語言中的構詞演算法。. 13.
(24) 圖 3-2-1:構詞單元在斷詞器中的位置. 3.2.1 詞綴構詞規則的建立. 中研院提出的中文資訊處理分詞規範當中有詳細的附錄提供“詞綴、接頭 / 接尾詞參考表",除了這項資訊之外,我們再輔以清華大學張俊盛教授整理出的 前、後詞綴表務求完整。但這許許多多的詞綴當中,有某些詞綴也符合定量複合 詞的特性,因此在建構詞綴表之前,我們對江振宇的定量複合詞構詞單元瀏覽一 遍,將這些詞綴加進定量複合詞構詞規則當中,加強定量複合詞構詞規則的完整 性。而清華大學張俊盛教授整理出的詞綴表,其中含有許多數詞的詞綴,類似這 種情形的詞綴因已加入定量複合詞構詞規則當中,因此並不收錄至詞綴表。 經過上述初步的處理,我們刪減了一些詞綴,但詞綴的數量依然稍微過多。 因此我們針對五萬字的 Treebank 文字資料庫做統計,統計詞綴表當中的詞綴是 否有於語料庫當中出現,未出現的詞綴視為鮮少出現的詞綴,暫時從詞綴表當中 剔除。最後我們收錄了前詞綴 121 個、後詞綴 195 個。 由[1、3]我們得知樹狀結構的構詞規則可以用 Regular Expression 表示, 而且以 Regular Expression 表示的構詞規則使人容易看懂規則,但為了要將規 則應用在程式語言中,必須把 Regular Expression 轉為以「規則標記」表示的 14.
(25) Chomsky Normal Form 表示方法,應用在程式語言中的好處是,如果對於某一項 規則要修改或增加新規則,只需針對這些「規則標記」進行簡單的修改即可。 我們以表 3-2-1 來說明, 「規則標記」301~330 所對應的,為前詞綴的集合, 401~443 和 458 為後詞綴的集合。這些詞綴就是詞綴構詞規則的基本元素,而 同一規則標記的詞綴是具有相同詞類或是句法一致的特性,詳細的「規則標記」 請詳閱附錄 4。這些詞綴「規則標記」再搭配前後文的詞類,就可建構出「詞綴 構詞規則」,見下表 3-2-2,詳細的「詞綴構詞規則」請參閱附錄 5。. 表 3-2-1:詞綴規則標記 規則標記. Fixword. 詞類. 301. 非. 1,11,36. 302. 多. 11,20,37. 303. 老,大,小,高,低,粗,細,淡,淺,深,古 冷,長,易,乾,軟,硬,短,新,輕,薄,舊. 37. …. …. …. 307. 曾,又,剛,仍,已,正,早 即,尚,便,常,現,就,遂. 11. …. …. …. 312. 太,更,很,略,最,稍,微,極,較,頗,遠. 7,11. …. …. …. 318. 好. 7,37. …. …. …. 330. 變. 37. 401. 們. 12. …. …. …. 418. 國,省,村,鄉,鎮,縣,市,課,社. 12,14. …. …. …. 442 …. 上,中,下,內,時,前,後,來,底,起,裡,頭 9,15,23 … 表 3-2-2:詞綴構詞規則表節錄. 15. ….
(26) 規則標 記. 類別(國). regular expression. 範例 非博士,非親骨 肉. 301. 非. 非(A) + {Na}. …. …. …. 303. 老,大,小,高, 低,…. …. …. 330. 變. 變(VH) + {VH}. 401. 們. {Nab,Naea} + 們{Neqb,Naea}. …. …. 437. 賽,會,式,制. …. …. …. {老,大,小,…}(VH) +{Na,DE,Di} 老賊,老士官店 …. … 變酸,變黑. … {Na,VA,…} + {賽,會,…}{Na} …. 大人們,情侶們 … 邀請賽,季級賽 …. 至於新構出的詞其詞類,大部分的後詞綴多為名詞所以給予其詞類為「Na 普通 名詞」,剩餘的如「Nc 地方詞」給予新詞類仍為「Nc 地方詞」,「Nb 專有名詞」 給予「Nb 專有名詞」的詞類,其餘的新詞,暫定給予原本相同的詞類。前詞綴 的部份,如詞綴本身是「Na 普通名詞」 ,新詞也保留同樣的詞類。而前詞綴含有 許多的副詞以及狀態不及物動詞,這兩類的詞綴,我們給予的詞類暫設定為前詞 綴的後接詞其詞類,例如: 【老】的詞類為「VH 狀態不及物動詞」,後接詞【士 官】為「Na 普通名詞」 ,兩個詞構成一新詞【老士官】我們給予「Na 普通名詞」 的詞類;【很】的詞類為「Dfa 前程度副詞」,後接詞【高興】為「VH 狀態不及 物動詞」 ,兩個詞構成一新詞【很高興】我們給予「VH 狀態不及物動詞」的詞類。. 3.2.2 詞綴構詞單元之演算法. 由圖 3-2-1 可以看出,江振宇的斷詞器[1]已經達到我們分詞標準的第一 級,之後我們加入後置構詞單元之詞綴構詞單元。對於已經被斷詞的詞串,我們 應將那些詞綴找出,並利用詞綴構詞規則將短詞合併為長詞。整個詞綴構詞單元. 16.
(27) 的工作流程,表示在下圖 3-2-2:. 圖 3-2-2:詞綴構詞單元流程圖. 以下我們皆以文句「老先生與大人們在討論事情」作為例子說明,首先,此文句 經過前端的斷詞器會被斷為如下圖的詞串. 圖 3-2-3:Linked-list Output Words. 這些詞串會送往後級的詞綴構詞單元,經過以下幾個詞綴處理步驟:. (1)搜尋輸入詞串對應的詞綴規則標記:. 這一步驟的目的就是要將詞串當中,符合詞綴的詞找出來,並給予詞串對應 的詞綴規則標記。. 17.
(28) 類似於查詞典的方式,我們對已建立的前、後詞綴列表進行搜尋。因為詞綴 為單音節的一字詞,所以我們於搜尋之前建立一簡單的判斷機制,就是判定輸入 的詞串其詞長是否為一字詞,如並非一字詞,則進行下一個詞的比對工作。如果 符合一字詞的條件則進行比對前、後詞綴表的工作。如此一來,詞串當中符合詞 綴的一字詞將會被搜尋出來並給予詞綴規則標記,由例句說明可得到下表 3-2-3. 表 3-2-3:「老先生與大人們在討論事情」之詞綴規則標記集合表 詞串. 規則標記. 詞類. 老. 303. 37(VH). 們. 401. 12(Na). 21(Neqb). 找到所有的詞綴以及給予規則標記之後,便可以進行比對詞綴構詞規則的動作。. (2)詞綴構詞規則比對:. 此步驟的目的,是將已找出符合的詞綴文字,經由與詞綴構詞規則的比對, 進而合併成為新的衍生詞。而構詞規則是以樹狀結構表示,一個樹代表一個構詞 規則,且規則標記為 301~330 的屬於前詞綴,401~443 和 458 的屬於後詞綴, 因此我們只需針對規則標記尋找構詞規則,前詞綴則依據構詞規則比對下一個詞 的詞類;後詞綴則依據規則比對上一個詞的詞類。如符合規則,則將兩個詞合併 為一新詞輸出。詞綴構詞規則比對步驟如下:. 18.
(29) 圖 3-2-4:詞綴構詞規則比對流程圖. (2.a)建立初始樹集合:. 由於是承襲著斷詞單元的結果,每一個詞皆視為一棵樹,而且詞綴構詞規則是參 考定量複合詞構詞規則,所以我們必須將輸入的規則標記集合,轉為以樹狀結構 表示的資料結構,如下圖 3-2-5:. 詞串. 規則標記. 詞類. 老. 303. 37(VH). 們. 401. 12(Na). 21(Neqb). 圖 3-2-5:建立初始樹集合. 19.
(30) (2.b)比對規則且建立樹:. 此步驟是詞綴構詞規則比對的核心,目的是將所有可能的樹狀結構組合找出來 (可能的構詞組合),若樹集合中的前詞綴與其在詞串中的下一棵樹或是後詞綴與 其在詞串中的前一顆樹可以某構詞規則結合,我們便建立一棵新的樹(新的詞), 並給予新的樹「規則標記」(代表符合哪項規則)及詞類(一條規則對應到一個特 定的詞類)。 如果符合詞綴的特性而存在於樹集合當中,但卻不存在符合的規則,則新建 之樹必為一個空集合。如果此情形發生,我們則將新建的樹刪除,避免浪費過多 不必要的記憶體空間。整個比對流程如下圖 3-2-6. 規則標記 樹集合 構詞規則表 (Chomsky Normal Form). 比對規則. 建立樹. 新建之樹 =Null Set?. Yes. 刪除並跳至 下一個規則 標記樹. No. 輸出構出詞. 圖 3-2-6:詞綴構詞規則比對流程圖. 為了增加規則比對的速度,我們將詞綴構詞規則依照詞典樹的作法,將規則 存成樹狀結構,整個規則樹為一個 general tree,同一層的節點依照規則標記 的數字大小排序好,是一個記憶體動態改變大小的陣列,往後如有新增規則,便 會將新規則插入這樹狀結構當中。如下圖 3-2-7 20.
(31) 圖 3-2-7:詞綴構詞規則樹. 深色底的代表規則的終點,代表從根節點走到終點經過的節點為一個構詞規 則,在終點記錄這個規則所對應的規則資訊(規則標記、詞類),若無法走到終點 則表示沒有對應的規則。以「老(303). 先生」為例,由根節點 303 出發, 「老(VH)」. 符合下一個節點詞類代碼 37, 「先生(Na)」符合終端點詞類代碼 12,如此便符合 一項規則,建立一個新的樹「老先生」並給予規則標記 303 及詞類「普通名詞 Na(12)」。. (3)更新詞鏈結:. 經由上面兩步驟之後,所有能夠更進一步結合成長詞的皆已構出。但為了能 夠使後級的單元使用,我們必須更新舊的詞串鏈結。此步驟不僅更新了舊的詞串 鏈結,也將舊詞的樹狀結構保留,經由圖 3-2-8 便可一目了然。. 圖 3-2-8:更新詞串鏈結圖. 由上圖,上層為新的詞串鏈結,下層為舊的詞串鏈結。. 21.
(32) (4)輸出構出詞: 這一步是將更新詞串鏈結完畢之後的詞串鏈結輸出,最後輸出的詞串將會是 「老先生. 與. 大人們. 在. 討論. 事情」。. 經過以上四個步驟,詞綴構詞單元便算完成,而所有的規則標記與詞類資訊 皆完整保留,且規則標記與之前的定量複合詞並無重複,因此輸出的詞串送往後 級的文字正規化並不會造成混淆。. 3.3 漢語文句斷詞器. 我們將完整的中文斷詞器製作成一個獨立的工具,如此一來,能在未來幫助 中文斷詞上的研究,也能將斷詞結果輸出給予其他單位使用。首先先看下圖 1.輸入文句. 3.清除畫面. 4.開啟文字 檔案. 2.斷詞結果 7.檢視音節碼. 圖 3-3-1:漢語文句斷詞器介面 22. 5.斷詞. 6.斷詞結 果輸出.
(33) 以下我們用代號 1~7 來說明各個功能。 1. 輸入文句: 這是一個文字編輯方塊,可以自行輸入文字,也能藉由按鈕 4 開啟已存在的 文字檔案,開啟的文字檔案內容會顯示在「輸入文句」此文字編輯方塊。. 圖 3-3-2:自行輸入與開啟文字檔 2. 斷詞結果: 此為一文字方塊,無法自行輸入文字,也無法編輯,此方塊所顯示的,為啟 動按鈕 5 之後,將「輸入文句」的文字內容斷詞輸出至此文字方塊. 圖 3-3-3:顯示斷詞結果 23.
(34) 3. 清除: 此按鈕的功能為將「輸入文句」及「斷詞結果」兩文字方塊之內容清除。. 4. 開啟文字檔: 此按鈕的功能為將已存在的文字檔案內容輸入至「輸入文句」文字編輯方塊。. 5. 斷詞: 此按鈕為整體中文斷詞器的核心,按此按鈕能將「輸入文句」文字編輯方塊 中的內容,進入我們已設計的中文斷詞器,並將斷詞結果輸出至「斷詞結果」文 字方塊內。. 6. 輸出至檔案: 此按鈕為將「輸入文句」文字編輯方塊內的內容,其斷詞結果另存至一新的 檔案中,方便未來研究上的使用。儲存格式如下:. 表 3-3-1:斷詞結果輸入至檔案格式 字. 411 音節碼. 詞長及詞內位置. 詞類. 老 先 生 與 大 人 們 在 討 論 事 情 。. 3092 1261 1170 3216 4018 2137 5147 4051 3090 4365 4003 2286 6003. 301 302 303 101 301 302 303 101 201 202 201 202 101. 12 12 12 37 12 12 12 26 34 34 12 12 50. 24.
(35) 7. 檢視音節碼: 此按鈕為將「輸入文句」文字編輯方塊內的內容,經過斷詞器得到各文字的 音碼,為求便於觀察,將輸出格式由 411 個音節碼轉換為注音形式。. 圖 3-3-4:檢視音節碼(注音形式). 25.
(36) 第四章 詞綴構詞單元之效能分析 在本章中,我們將驗證之前所建立的詞綴構詞規則加入中文斷詞器[1]之 後,構出的詞在整體斷詞結果中的效能. 4.1 測試語料. 我們採用《中研院平衡語料庫 3.0 版》部份語料作為測試語料,語料庫已經 過正確之斷詞與詞類標記,以下為此測試語料的統計資訊:. 表 4-1:部份《中研院平衡語料庫 3.0 版》語料庫統計 文章篇數. 1,263. 總詞數. 880,861. 總中文詞數. 748,616. 中文專有名詞數. 12,812. 外文詞數. 2,718. 標點符號數. 129,527. 表 4-2:《中研院平衡語料庫 3.0 版》語料庫統計 文章篇數. 9,286. 總詞數. 5,841,942. 總中文詞數. 4,883,661. 中文專有名詞數. 94,121. 外文詞數. 27,502. 標點符號數. 930,779. 4.2 斷詞結果之評量. 26.
(37) 因為設計的詞綴構詞單元是利用斷完詞的結果,因此在此先評量斷詞器的斷 詞結果。由於專有名詞在整個語料庫裡佔了將近 2%,因此在評量斷詞器效能時, 同時觀察含與不含專有名詞的斷詞結果,在這裡我們定義召回率(recall)及精確 率(precision)作為斷詞結果的評量標準,定義如下: N1 = (平衡語料庫的中文詞數) N2 = (經斷詞器輸出之中文詞數) N3 = (經斷詞器斷詞且與平衡語料庫一致的中文詞數) 斷詞召回率 = N3 / N1 斷詞精確率 = N3 / N2. 斷詞結果如下表:. 表 4-3:斷詞結果 僅以詞典斷詞. 加入前置構詞單元. 含專名. 不含專名. 含專名. 不含專名. N1. 4,883,661. 4,789,540. 4,883,661. 4,789,540. N2. 4,773,152. 4,679,443. 4,434,692. 4,341,015. N3. 4,008,905. 3,964,242. 3,844,914. 3,799,378. 召回率. 0.821. 0.828. 0.787. 0.793. 精確率. 0.84. 0.847. 0.867. 0.875. 4.3 詞綴構詞單元效能之分析. 在這節我們要討論詞綴構詞單元的效能,以下以定量的方式來分析。我們依 照構詞規則編號,列出某構詞規則針對部分語料庫構出的詞數目,如下兩表. 27.
(38) 表 4-4:前詞綴構詞規則使用之分佈 規則標記. 構出詞數 正確構詞數 rate 構出詞數 正確構詞數 rate 規則標記 N1 N2 = N2/N1 N1 N2 = N2/N1. 301. 48. 43 0.896. 316. 81. 73 0.901. 302. 131. 117 0.891. 317. 10. 10 1.000. 303. 2669. 2387 0.894. 318. 262. 237 0.905. 304. 518. 473 0.913. 319. 0. 0 0.000. 305. 171. 144 0.842. 320. 1253. 1094 0.873. 306. 53. 37 0.698. 321. 177. 168 0.949. 307. 4287. 3905 0.911. 322. 127. 118 0.929. 308. 4475. 3894 0.870. 323. 8. 6 0.750. 309. 86. 86 1.000. 324. 2742. 2229 0.813. 310. 2273. 1983 0.872. 325. 67. 54 0.806. 311. 122. 106 0.869. 326. 76. 71 0.934. 312. 2921. 2384 0.816. 327. 239. 206 0.862. 313. 2151. 1648 0.766. 328. 66. 61 0.924. 314. 303. 243 0.802. 329. 867. 750 0.865. 315. 521. 482 0.925. 330. 32. 26 0.813. 26736. 22450 0.840. Total. 表 4-5:後詞綴構詞規則使用分佈 規則標記. 構出詞數 正確構詞數 rate 構出詞數 正確構詞數 rate 規則標記 N1 N2 = N2/N1 N1 N2 = N2/N1. 401. 162. 162 1.000. 412. 19. 16 0.842. 402. 51. 51 1.000. 413. 889. 814 0.916. 403. 356. 299 0.840. 414. 784. 744 0.949. 404. 0. 0 0.000. 415. 178. 144 0.809. 405. 570. 431 0.756. 416. 79. 65 0.823. 406. 71. 57 0.803. 417. 17. 11 0.647. 407. 417. 342 0.820. 418. 66. 50 0.758. 408. 58. 51 0.879. 419. 19. 19 1.000. 409. 109. 90 0.826. 420. 1525. 1378 0.904. 410. 24. 19 0.792. 421. 53. 48 0.906. 411. 25. 21 0.840. 422. 32. 26 0.813. 28.
(39) 規則標記. 構出詞數 正確構詞數 rate 構出詞數 正確構詞數 rate 規則標記 N1 N2 = N2/N1 N1 N2 = N2/N1. 423. 13. 8 0.615. 434. 691. 429 0.621. 424. 72. 63 0.875. 435. 57. 47 0.825. 425. 10. 10 1.000. 436. 21. 19 0.905. 426. 39. 30 0.769. 437. 90. 86 0.956. 427. 12. 12 1.000. 438. 0. 0 0.000. 428. 725. 604 0.833. 439. 59. 51 0.864. 429. 0. 0 0.000. 440. 0. 0 0.000. 430. 87. 87 1.000. 441. 9. 6 0.667. 431. 111. 98 0.883. 442. 9285. 7235 0.779. 432. 50. 42 0.840. 443. 11. 8 0.727. 433. 72. 61 0.847. 458. 743. 654 0.880. 17661. 14388 0.815. Total. 上述兩表中的 N1 表示經由詞綴構詞單元構出的總詞數,N2 表示經由人工檢 察構出詞是否合適,如會造成些微的不通順既屬於構詞錯誤。整體的正確率有 0.829,其中被引用最多的規則為規則標記 442,佔構詞單元構出詞的 20.5%,此 類詞綴的詞類有“Ng"、“Ncd"等方位詞,構出的詞例如有:大會中、地底下、 山上等,但其正確率只有 0.779,是因為此規則的後詞綴集合當中含有“時"、 “來"等,直接與前詞相接,會造成語意上的不通順,所以我們將這些例子不算 在正確的構詞數中。 第二多的是規則 307 與 308,這兩類前詞綴的詞集合皆屬於副詞的特性。依 照中研院的分詞規範,這類副詞並不屬於詞綴。是依據清華大學張俊盛統計 OOV(Out Of Vocabulary)列表,才將此類副詞收錄至詞綴,判斷依據也是依照 OOV 列表所列之詞。所以雖然這兩類合出的正確率將近九成,但對於斷詞後的語 意並不通順,建議將這兩類的詞從構詞規則當中刪去。. 29.
(40) 至於正確率較低的規則標記 306、323、417、441,是因為數量太少,導致 刪除部分構詞會使正確率變化較大,未來使用完整語料庫統計會更正確,而規則 標記 434,當中有個詞為“文",在測試的語料庫當中有許多人名有使用“文" 字,且因為詞綴構詞規則是利用詞類來做為判斷構詞的依據,不如定量複合詞有 固定的詞集合,易造成構詞上許多的錯誤。 其餘正確率較高的部份,其詞綴的特性較明顯,且符合構詞的詞類也較單 一,因此數量少、正確率高,除了專有名詞造成的錯誤和前級斷詞器搶詞的錯誤 使得構詞錯誤外,並沒有過於嚴重的問題。 我們在此不統計平均詞長,因為經過詞綴構詞單元之後,平均詞長必然會比 較長,但其中含有許多錯誤,所以平均詞長變長並沒有意義,因有可能造成過於 合詞使得語意更模糊。. 30.
(41) 第五章 文字中的特別字詞 與停頓標記關係之統計. 以自然語言現象為考量的文字翻語音系統,除了採用恰當的語音合成技術 外,最重要的問題即為如何從文字抽取出能夠體現人類語音特徵的韻律參數給予 後級產生合適的韻律,如:基頻軌跡、音長、停頓、能量等。在自然語音中,人 們不會將一句長句一口氣讀出,而是分成若干個短語;也不會將一句話皆一一斷 開為獨立的短語,而是根據短語之間的結合緊密程度插入不同長度的停頓間隔。 這不僅是人類生理上的限制,也含有人類說話韻律節奏上的需要以及語意上的涵 義,以利於語者和聽者間的溝通。 但是,從文字自動產生韻律參數到現今為止仍然是一個相當困難的問題。 因為,韻律其一層包覆一層的架構,從文字上並不是那麼容易就能夠辨別出來, 而且很多研究[7、8、9、10]也指出,韻律的組成跟語法上並不是那麼完全的一 致,因此這兩者之間的關係尚未被完全的了解。 經過上面的闡述發現,要去預估停頓這項韻律參數,本身能得到的信息就受 限了,再加上本實驗的結果是要整合至 TTS 系統中,使用的信息只能從文字方面 獲得,所以又更加無法使用重音或是聲學特徵,更何況重音本身就是一項需要被 預測的信息。 未來的研究是希望使文字分析器,能僅由文字去預估停頓。除了會採用前人所使 用的詞類、詞長、離句首及句尾的距離等參數,還加入了特別字詞的參數。基本 想法是以前述中,已建立的詞綴表為出發點,再加上連接詞、介詞,這三種特別 的字詞著手。採用的語料庫為五萬字的 Treebank 文字資料庫,以下表 5-1 為資 料庫的統計結果。. 31.
(42) 表 5-1:Treebank 五萬字文字資料庫統計 文章篇數. 379. 總詞數. 57,266. 中文詞數. 53,697. 標點符號數. 3,569. 因為需要觀察的特徵參數有詞類、詞長等,為求正確,因此本語料庫是經 由人工斷詞並標記詞類後,利用江振宇自動標記停頓類型的模型標註停頓標記。 而標記的停頓類型,採用中研院所提出的六種停頓標記[12],包括:B0、B1、B2-1、 B2-2、B3 及 B4。其中 B0 代表 highly-coupled 音節邊界,B1 代表 normal 音節 邊界,B2-1 代表人可分辨的 prosodic word(PW)邊界,具有 F0 movement,B2-2 代 表 人 可 分 辨 的 prosodic word(PW) 邊 界 , 具 有 停 頓 , B3 代 表 prosodic phrase(PPh)邊界,B4 代表 breath group/prosodic phrase group(BG/PG)邊界。. 5.1. 從詞綴觀察停頓分佈之統計 我們目前建立的詞綴表中,前接詞綴共有 121 個,後接詞綴有 195 個。在. 本節我們將直觀文字資料中,前、後詞綴與其接頭、接尾詞連接。因此第一步便 著手統計前、後接詞綴與其接頭、接尾詞個別停頓標記的數量,程度請見下表 5-1-1 與 5-1-2. 表 5-1-1:前詞綴與接頭詞之 Break type 統計表節錄 前詞綴. 字詞. “B0". “B1". 新. one. 2. 13. 0. 0. 0. 0. more. 2. 3. 0. 0. 0. 0. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. 32. “B2-1" “B2-2" “B3". “B4".
(43) 大 …. one. 3. 31. 2. 0. 0. 0. more. 7. 33. 0. 0. 0. 0. …. …. …. …. …. …. …. 表 5-1-2:後詞綴與接尾詞之 Break type 統計表節錄 後詞綴. 字詞. “B0". “B1". 地. one. 1. 27. 2. more. 0. 4. …. …. …. 到. one. …. “B2-1" “B2-2". “B3". “B4". 1. 0. 0. 0. 0. 0. 0. …. …. …. …. …. 0. 16. 0. 0. 0. 0. more. 4. 141. 0. 0. 0. 0. …. …. …. …. …. …. …. 上面兩表的第一列中,標記著〝B0〞、〝B1〞、〝B2-1〞、〝B2-2〞、〝B3〞、〝B4〞,在 表 5-1-1 中表示前詞綴與其後接頭詞兩者間的相接點的停頓標記,在表 5-1-2 中表示後詞綴與其前接尾詞兩者間的相接點的停頓標記。 由上述兩表可觀察到,前詞綴與其接頭詞、後詞綴與其接尾詞兩者的停頓 標記多為〝B0〞與〝B1〞,說明了,前詞綴與其接頭詞之間沒有很長的停頓,後 詞綴與其接尾詞之間同樣的也沒有很長的停頓,偶爾只有短暫的停頓或是強調重 音的形式,其餘幾乎皆是緊密相接的,這與我們的直覺也相當一致。 詞綴因點綴其他詞而成一新詞,所以上面的統計只是更進一步使我們確信 這些詞的確屬於詞綴。但詞綴不僅能與其他詞相接出現,也能單獨出現,那詞綴 在什麼情況下會是詞綴呢?詞綴這麼特殊的詞,其停頓的特徵真的只與其接頭、 尾詞緊密相接而已嗎? 為了探討詞綴與前後文的關係,我們對語料庫進行一次人工觀察,發現某 些詞綴不單單只跟其接頭、接尾詞緊密相接,某些詞綴還會有很高的機率與上下 文斷開,因此我們接著統計詞綴與前後文的停頓標記,請看下表 5-1-3 及 5-1-4. 33.
(44) 表 5-1-3:前詞綴與前後文之停頓標記統計節錄 不. 後 前 Null. Null. non. minor. major. 0. 98. 4. 0. non. 0. 141. 11. 0. minor. 0. 210. 7. 0. major. 0. 60. 6. 0. 表 5-1-4:後詞綴與前後文之停頓標記統計節錄 人. 後. Null. non. minor. major. Null. 0. 0. 0. 0. non. 0. 166. 102. 136. minor. 0. 4. 1. 0. major. 0. 0. 0. 0. 前. 如按照原本分為六類停頓標記做統計,因為各別的數量過少,對於未來的研究, 實質上並無太大的幫助,因此將六類合併為三類做統計,〝B0〞與〝B1〞併為一 類成〝non〞代表沒有停頓,〝B2-1〞與〝B2-2〞併為一類成〝minor〞代表有短 暫的停頓,〝B3〞與〝B4〞併為一類成〝major〞代表有較長的停頓,〝Null〞代 表前後文為標點符號或同為句子啟始。 經由上面的統計發現,前接詞綴當中的“不"、“可"、“無"、“全"、 “共"不僅有很高的比例與後詞相接,也有較高的比例與前接詞斷開。而後詞綴 當中的“面"、“地"、“黨"、“隊"、“力"、“感"、“家"、“權"、 “者"、“場"、“人"、“額"、“員"、“物"、“心"、“出"、“到" 等不僅會與前詞相接,還有較高的比例會與後詞斷開。 在統計的結果當中,後詞綴有一類其詞類很特別“Ng",我們在下一節討論 此詞類的停頓標記。. 34.
(45) 5.2. 詞類“Ng"之停頓分佈統計. 在 5.1 節後半的統計當中,如下表 5-2-1,我們發現了一類特別的詞綴,這 一類的詞綴其所擁有的詞類為“Ng 後置詞"以及“Ncda 位置詞"。. 表 5-2-1:後詞綴詞類“Ng"、“Ncda"與前後文停頓標記之統計節錄 上 front. 後 front. 後 前 Null. Null. non. minor. major. 0. 0. 0. 0. non. 0. 22. 7. 31. minor. 0. 0. 0. 0. major. 0. 0. 0. 0. 前 後 Null. Null. non. minor. major. 0. 0. 0. 0. non. 0. 10. 13. 66. minor. 0. 1. 0. 1. major. 0. 0. 0. 0. 在之前的統計當中,因為考量到數量的問題,並無將這兩類詞類分開統計, 且在目前的統計當中,皆只是單字詞且為詞綴的部份。但是語料庫當中,有些二 字詞或是其他詞的詞類也是“Ng"或“Ncda"。所以我們對語料庫再作了一次 “Ng"及“Ncda"兩類詞類的完整統計,在這次的統計,我們分開計算“Ng"與 “Ncda"兩類詞類其前後接詞的停頓分布,結果如下表 5-2-2. 35.
(46) 表 5-2-2:“Ng"及“Ncda"與前後文停頓標記之統計 Ng. No break. Minor break. Major break. Total. 前接詞. 535. 15. 0. 550. 後接詞. 107. 75. 368. 550. Ncda. No break. Minor break. Major break. Total. 前接詞. 112. 9. 0. 121. 後接詞. 49. 25. 47. 121. 由表中可觀察出,“Ng"與後接詞之間有停頓的的比例高達 0.805,而在 “Ng"與後接詞之間沒有停頓的 107 例中,後接詞類為 DE 的有 38 例、為 VE 的 有 10 例,為 Ng 的有 1 例。而“Ncda"經過統計,它和後接詞間的停頓關係雖然 並沒有 Ng 來的明顯,但與後接詞之間有停頓的比例也有 0.595,而沒有停頓的 49 例當中,有 17 例是後接詞類 DE,3 例是後接詞類 VE。 由觀察結果發現兩個很特別的詞類 VE 與 DE,Ng 後接此兩個詞類時,會使 得詞類為 Ng 的詞與後接詞不僅不會斷開,反而與後接詞緊密相接,而將停頓點 由 Ng 轉至 VE,例如: 表 5-2-3:“Ng"因“VE"而停頓後移範例 文章. 文句. 詞長及詞內 位置. 詞類. Prosody State. Break Type. Pause Duration. treebank_274 treebank_274 treebank_274 treebank_274 treebank_274 treebank_274 treebank_274 treebank_274. 合 議 庭 審 理 後 認 為. 301 302 303 201 202 101 201 202. Ncb Ncb Ncb VC2 VC2 Ng VE2 VE2. 13 12 10 10 12 6 6 5. 0 1 1 0 1 0 0 4. 0.001625 0.001688 0.001500 0.000500 0.001813 0.001625 0.001625 0.500870. 36.
(47) 而“DE 的"本身就形如附著語素,獨立存在並無意義,所以會與前詞緊密連接 是相當合理的。 觀察到如此特別的詞類 VE,在下一節,我們做進一步統計。. 5.3. 詞類“VE"之停頓分佈統計. 經由上一節的統計發現,詞類為“VE"的詞在語料庫當中會將詞類“Ng"本 該停頓的點沒有出現停頓,反而將停頓往後移。參閱中研院平衡語料庫的技術報 告,當中對“VE"的定義為動作句賓述詞,後接句賓語的動作及物述詞。 由定義[11]而言,此類的詞後面必須接一子句,由直觀的猜測,為了闡述後 面承接的子句,於此動詞之後應會出現停頓,將整體說話的狀態重新還原。因此 我們統計“VE"與其後接詞的停頓分佈,分佈結果如下表 5-3-1:. 表 5-3-1:“VE"與其後接詞之停頓分佈統計 VE. No break. Minor break. Major break. Total. 後接詞. 241. 210. 395. 846. 經由統計結果發現“VE"與其後接詞之間出現停頓的比例高達 0.715。且在 所有的統計量當中,“VE"與後接詞之間出現長停頓的次數是最高的,這映證了 我們的猜測,“VE"之後為了闡述一子句,不僅會停頓,還有較高的比例是產生 長停頓將整體說話的狀態重新還原。 雖然產生停頓的比例高達 0.715,但在 846 次的統計量當中還是出現 241 次 “VE"與其後接詞之間是沒有停頓產生。. 37.
(48) 因此我們更進一步的仔細探究“VE"其結構發現,“VE"依其論元個數不同共分 為兩大類。一類為三元述詞“VE1",另一類為二元述詞“VE2",而其中“VE1" 又可細分為問類“VE11"及說類“VE12"。 . 三元述詞表示:以主事者(agent)為主語,以終點(goal)為間接賓語, 客體(theme)為直接賓語(句賓語)。. . 二元述詞表示:以主事者(agent)為主語,終點(goal)為句賓語。. 由上述的定義可以得知,“VE1"後面會承接某個間接賓語之後再承接一個 句賓語,而“VE2"後面是直接承接一個句賓語。或許“VE"之後沒產生停頓的 原因,是因為“VE1"在其後承接一間接賓語造成,因此我們做了以下的統計, 請見下表 5-3-2:. 表 5-3-2:“VE11"及“VE12"之停頓分佈統計 “VE11". No break. Minor break. Major break. Total. 後接詞. 12. 2. 19. 33. “VE12". No break. Minor break. Major break. Total. 後接詞. 27. 9. 11. 47. 上表當中,“VE11"之後出現長停頓的數量最多,造成此現象的原因是因 為,“VE11"表問類,在語料庫當中後面常接標點符號,所以大多都是長停頓, 至於後面不是接標點符號但卻出現長停頓的次數只有 3 次。而“VE12"表說類, 其後較少直接連接標點符號,所以出現長停頓的次數不像“VE11"是所有統計量 當中最多的,統計結果反而如我們所預測的,沒有停頓的次數有 27 次,是所有 統計量中最高的。且“VE12"其後出現長停頓的 11 次統計量當中,有 6 次其後. 38.
(49) 是連接標點符號而造成長停頓。 經由上表的統計,確實再次映證了我們的猜測,因“VE1"會承接一個間接 賓語而導致“VE1"與間接賓語之間沒有停頓產生。但是扣除掉“VE1"的影響還 是有 202 次的統計量是沒有停頓的。因此用人工觀察這些沒有出現停頓的例子, 概要的將原因分為三類,見下表 5-3-3: 表 5-3-3:“VE2"後無停頓之分類表 “VE2"後無停 頓之分類. 承接的子句開頭為一 賓語或修飾詞. 承接的詞類為 DE、Di、Ng、T. 其他. Total. Number of “No break". 90. 78. 34. 202. 由上表可得知,第一類:“VE2"之後承接的子句開頭為一賓語或修飾詞, 會造成詞類上的混淆,使得“VE2"將承接子句的主體或修飾語作為間接賓語, 導致“VE2"與後接詞之間沒有停頓產生,舉下表 5-3-4 說明:. 表 5-3-4:“VE2"後無停頓之範例 文章. 文句. 詞長及詞內 位置. 詞類. Prosody State. Break Type. Pause Duration. treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007 treebank_007. 人 們 常 見 一 種 大 型 卷 毛 黑 犬. 201 202 101 101 201 202 201 202 201 202 201 202. Naeb Naeb Dd VE2 DM DM Nad Nad Nab Nab Nab Nab. 11 12 12 12 11 10 13 9 8 8 11 7. 0 1 1 0 1 2-2 1 1 0 2-1 1 3. 0.001063 0.013813 0.000188 0.001063 0.032938 0.124190 0.001375 0.000875 0.001063 0.001063 0.018562 0.369880. 39.
(50) 另外一類是“VE2"後面承接“DE、Di、Ng、T"此四類詞類,這四類詞類的詞本 身就是後置或是語助詞的特徵,在講話時會輕輕的帶過,而不會在此四類詞類之 前產生停頓,所以使“VE2"與此四類詞類相接時,“VE2"的停頓會往後移,等 待一更大的子句,舉下表 5-3-5 說明: 表 5-3-5:“VE2"停頓後移之範例 文章. 文句. 詞長及詞內 位置. 詞類. Prosody State. Break Type. Pause Duration. treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044 treebank_044. 以 行 動 說 明 了 他 在 乎 妳 的 感 覺 與 期 望. 101 201 202 201 202 101 101 201 202 101 101 201 202 101 201 202. P11 Nad Nad VE2 VE2 Di Nhaa VK1 VK1 Nhaa DE Nac Nac Caa Nac Nac. 13 14 15 6 7 7 5 8 9 12 11 9 9 7 9 9. 2-1 1 1 0 0 3 1 1 2-1 1 2-2 1 2-2 1 0 4. 0.001625 0.001625 0.001688 0.001688 0.001688 0.248310 0.001625 0.002500 0.001688 0.001688 0.045000 0.060000 0.118120 0.005375 0.002063 0.663310. 其餘的 34 例,尚無法歸納出是何原因造成“VE2"沒有產生停頓。. 5.4. 連接詞與介詞之停頓分佈統計. 前面三節,從詞綴作為特別字詞的初始著眼點開始,緊接著討論兩個特別的 詞類“Ng"與“VE"。這節將要討論的是連接詞與介詞。為什麼要討論這兩類詞 類,主要是因為這兩類詞類的功能單一,具備較鮮明的特徵,且這兩類詞類是使 40.
(51) 句子結構更加豐富的兩個重要詞類,以下分兩小節討論這兩類的停頓分佈統計, 並依據統計結果,粗劣的選定特殊詞。. 5.4.1 連接詞之停頓分佈統計. 連接詞,顧名思義就是連接兩個或兩個以上的語言單位,組成較大的語言單 位。連接詞所連接的範圍可能是在一簡單句內,組合兩個對等的詞組成分。不過 大部分連接詞的作用範圍超過一個簡單句,藉以標明兩分句間的承接關係。 根據連接詞作用的範圍,及其在句中扮演的角色地位,可將連結詞分為表詞 組並列關係的並列連接詞,以及表分句關係的關聯連接詞。. 5.4.1.1 (Ca)並列連接詞. 在簡單句的範圍內,連接兩個概念相似的成份,組成成份的作用與其所連接 的成份相同。由於並列連接詞具有以上功能,故將並列連接詞作為中心,觀察其 前後兩個相接成份的停頓狀態,而並列連接詞又可細分為兩類(1)Caa 對等連 接詞(如:和、跟、或者)與(2)Cab 列舉連接詞(僅只:等、等等、之類)。 因為列舉連接詞的詞有限,較好觀察。但對等連接詞不然,因此我先將語料 庫當中的並列連接詞抽出並統計數量。如某連接詞出現次數低於 20 次,因為其 本身的樣本數過少,於本文當中將不再討論。. (1) Caa 對等連接詞:. 經過統計之後,出現超過 20 次的詞共有:及、與、或、和、以及五個詞。 41.
(52) 而對等連接詞與前、後成份的停頓共有四類:(1)前後皆不停(2)前停後不停 (3)前不停後停(4)前後皆停,我們利用下表 5-4-1-1 來說明:. 表 5-4-1-1:對等連接詞“及"與前後成份之停頓分佈統計 及. 後. NULL. B0. B1. B2-1. B2-2. B3. B4. NULL. 0. 0. 0. 0. 2. 0. 0. B0. 0. 0. 0. 0. 0. 0. 0. B1. 0. 0. 0. 0. 0. 0. 0. B2-1. 0. 0. 0. 0. 0. 0. 0. B2-2. 0. 3. 5. 9. 2. 0. 0. B3. 0. 8. 21. 13. 12. 1. 0. B4. 0. 0. 0. 0. 0. 0. 0. 前. 由上表發現,大多的對等連接詞“及"都與前接成份斷開,不然就是與前後 成份皆斷開,這樣的現象不僅“及"如此而已,經過統計結果發現,另外的對等 連接詞“與"和“或",也有如此的現象。而“和"的結果如下表 5-4-1-2:. 表 5-4-1-2:對等連接詞“和"與前後成份之停頓分佈統計 和. 後. NULL. B0. B1. B2-1. B2-2. B3. B4. NULL. 0. 0. 1. 1. 1. 0. 0. B0. 0. 0. 0. 0. 0. 0. 0. B1. 0. 4. 5. 8. 3. 0. 0. B2-1. 0. 0. 0. 0. 0. 0. 0. B2-2. 0. 1. 0. 18. 3. 0. 0. B3. 0. 0. 3. 24. 8. 0. 0. B4. 0. 0. 0. 0. 0. 0. 0. 前. 由上表得知,對等連接詞“和"大多也是與前後成份斷開,但有些微的部份 是與前後皆不停或是前不停後停,而前不停後停的例子當中,與後成分之間的停 頓多在 0.03 秒以下,聽覺上不易察覺。 42.
(53) 至於“以及"的停頓統計分佈請見下表 5-4-1-3:. 表 5-4-1-3:對等連接詞“以及"與前後成份之停頓分佈統計 以及. 後. NULL. B0. B1. B2-1. B2-2. B3. B4. NULL. 0. 2. 6. 2. 2. 5. 0. B0. 0. 0. 0. 0. 0. 0. 0. B1. 0. 0. 0. 0. 0. 0. 0. B2-1. 0. 0. 0. 0. 0. 0. 0. B2-2. 0. 0. 0. 0. 0. 0. 0. B3. 0. 0. 1. 3. 2. 0. 0. B4. 0. 0. 0. 0. 1. 0. 0. 前. 由上表,只可做初步的猜測“以及"常置於句首或是與前接成分斷開。而置 於句首也表示“以及"之前常有標點符號,也可表示成與前接成分充份斷開。. (2) Cab 列舉連接詞: 這一類的詞只有「等、等等、之類」三個。而在語料庫當中“等等"與“之 類"出現次數太少,所以以下只有列舉連接詞“等"的討論,首先請先看下表 5-4-1-4:. 表 5-4-1-4:列舉連接詞“等"與前後成份之停頓分佈統計 等. 後. NULL. B0. B1. B2-1. B2-2. B3. B4. NULL. 0. 0. 0. 0. 0. 0. 0. B0. 0. 0. 0. 0. 0. 0. 0. B1. 0. 5. 10. 0. 7. 4. 10. B2-1. 0. 0. 1. 0. 1. 0. 0. B2-2. 0. 1. 0. 1. 0. 1. 0. B3. 0. 0. 0. 0. 0. 0. 0. B4. 0. 0. 0. 0. 0. 0. 0. 前. 43.
(54) 由上表得知,列舉連接詞“等"多與前詞相接,與前詞之間並沒有停頓產生,而 跟後接詞的停頓關係,初步觀察,可能是語意上的影響,如“等"之後的詞與之 前的詞有關聯(如:後成分的詞需是比前成分較高層次的集合類稱),則“等"與 後詞相接不停頓。下舉一表說明:. 表 5-4-1-5:列舉連接詞後未停頓之範例 文章. 文句. 詞長及詞內 位置. treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248 treebank_248. 其 他 內 在 性 美 、 人 之 美 。 興 趣 投 合 等 方 面. 201 202 301 302 303 101 101 101 101 101 101 201 202 201 202 101 201 202. 詞類. Prosody State. Break type. Pause Duration. 7 4 10 6 3 4 -1 13 14 12 -1 8 7 6 6 8 5 5. 1 0 1 1 0 4 -1 0 0 3 -1 1 1 1 1 1 0 4. 0.020000 0.001688 0.001688 0.001625 0.001688 0.556750 0.000000 0.001688 0.001688 0.278310 0.000000 0.001625 0.020813 0.001625 0.026437 0.001625 0.001688 0.545000. Neqa Neqa Nad Nad Nad Nv4 Nab DE Nv4 Nac Nac VH11 VH11 Cab Nac Nac. 反之,如果沒有關聯(後成分非前成分之詞集合),則“等"與後詞之間產生 停頓,而重新還原說話的狀態,闡述之後的語意,因此,統計的結果顯示,如有 停頓的發生,多為較長的停頓。下舉一表說明:. 44.
(55) 表 5-4-1-6:列舉連接詞後有停頓之範例 文章. 文句. 詞長及詞內 位置. treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298 treebank_298. 加 上 政 府 所 謂 統 派 。 反 動 派 等 保 守 人 士 之 打 壓 、. 201 202 201 202 201 202 201 202 101 301 302 303 101 201 202 201 202 101 201 202 101. 詞類 Cbcb Cbcb Nac Nac VK2 VK2 Nab Nab Nab Nab Nab Cab VH11 VH11 Nab Nab DE Nv1 Nv1. Prosody State. Break Type. Pause Duration. 5 4 13 9 5 5 4 8 -1 12 15 9 6 8 5 6 6 5 5 6 -1. 1 3 1 1 0 2-2 1 4 -1 1 1 1 2-2 1 0 1 1 1 0 3 -1. 0.001688 0.265000 0.000125 0.001688 0.001688 0.086625 0.046625 0.405000 0.000000 0.001688 0.003250 0.020000 0.180310 0.001688 0.001688 0.001625 0.001688 0.040000 0.001625 0.266690 0.000000. 5.4.1.2 (Cb)關聯連接詞. 關聯連接詞的功能是把分句連成複句的形式,是句子層次的修飾語。關聯連 接詞可以出現再前一分句或是後一分句,且多半位於一分句的動詞之前,只有少 數的例外 根據分句之間地位關係的不同,複句可分為聯合複句和偏正複句。前者分句 地位平等;後者分句有主從之分,偏句對主句有說明限制的作用。例如:. 45.
(56) (1)只要太陽一出來,雪人馬上不見。(偏正句) (2)他不但圖文並茂,而且唱作俱佳。(聯合句) 偏正句的語意可分為轉折、假設、因果、條件、取捨、目的。聯合句的語意 有選擇、遞進、並列。部分偏證據的偏句可倒置,成為後一分句。例如上例(1) 也可說「雪人馬上不見,只要太陽一出來。」 根據上述的接續關係,共可將關聯連接詞分為以下各類。在說明分類的同 時,並將在語料庫當中出現一定數量的關聯連接詞列舉出來,其餘未列舉出來的 關聯連接詞,於本節將不被討論。 1. Cba. 移動性前繫連接詞:語意上具起頭作用,後面常需接一個分句,其所在 分句可能移位至複句的後半段。(下分兩類). . Cbaa. 偏正句移動性連接詞。例:因、因為、如果、由於. . Cbab. 偏正句句尾連接詞。這一類只有“的話"和“起見"。. 2. Cbb. 非移動性前繫連接詞:語意上具起頭作用,後面常需接一個分句,位置 固定在前一分句。(下分兩類). . Cbba. 偏正句非移動性前繫連接詞。例:就是. . Cbbb. 聯合句前繫連接詞。例:首先、一來(此兩例語料庫中數量過少). 3. Cbc 後繫連接詞:能將一個分句聯繫於前一個句子的連接詞。(下分兩類) . Cbca. 偏正句後繫連接詞。例:以、而、但、然而、因此、所以、不過、 但是. . Cbcb. 聯合句後繫連接詞。例:並. 以下將上述的關聯連接詞,依其分類再加上語意劃分得下表 5-4-1-7 及 5-4-1-8. 46.
(57) 表 5-4-1-7:聯合複句連結詞語意及位置分類表 選擇. 要麼、要不. 要麼、要不. 遞進. 非但、不獨、不但、不僅. 而且、並且、且、反而. 並列. 首先、一來、一方面. 其次、二來、二方面. 表 5-4-1-8:偏正複句連接詞語意及位置分類表 前繫. 後繫. 移動性. 非移動性 而、但、然而、不過、但是. 轉折. +contrast. 因果. 因、因為、由於. 所以,因此. +reason. +result. 假設. 如果. 就是. +hypothesis. +uncondition. 目的. 以+purpose. 以下從最單一特性的詞“的話"討論起,請見下表. 表 5-4-1-9:句尾連接詞“的話"與前後文之停頓分佈統計 的話. 後. NULL. B0. B1. B2-1. B2-2. B3. B4. NULL. 0. 0. 0. 0. 0. 0. 0. B0. 0. 0. 0. 0. 0. 0. 0. B1. 0. 0. 0. 0. 0. 0. 5. B2-1. 0. 0. 0. 0. 0. 0. 1. B2-2. 0. 0. 0. 0. 0. 0. 0. B3. 0. 0. 0. 0. 0. 0. 0. B4. 0. 0. 0. 0. 0. 0. 0. 前. 由上表觀察,的確“的話"符合句尾連接詞的特性且需連結在前的分句,所以所 有的統計量皆為與前詞連接,並在最後結束。至於有一個例外的統計量,根據人. 47.
數據




+7


![表 5-1:Treebank 五萬字文字資料庫統計 文章 篇數 379 總詞數 57,2 66 中文詞 數 53,6 97 標點符 號數 3,5 69 因為需要觀察的特徵參數有詞類、詞長等,為求正確,因此本語料庫是經 由人工斷詞並 記詞類後 利用 自動 頓 型 頓標記。 而標記的停頓類型 採用中研院所提出的六種停頓標記[12],包括: 0、B1、B2-1、 B2-2、B3 及 B 中 hig y-coupl 音節邊界,B1 代 音節 邊界,B2-1 代 可 prosodic word(PW)邊界](https://thumb-ap.123doks.com/thumbv2/9libinfo/8051716.162428/42.892.284.592.111.321/中文詞標點符由人工斷詞並類後利用自動頓型頓標而標記的邊界.webp)


Outline
相關文件
EQUIPAMENTO SOCIAL A CARGO DO INSTITUTO DE ACÇÃO SOCIAL, Nº DE UTENTES E PESSOAL SOCIAL SERVICE FACILITIES OF SOCIAL WELFARE BUREAU, NUMBER OF USERS AND STAFF. ᑇؾ N
Health Management and Social Care In Secondary
printing, engraved roller 刻花輥筒印花 printing, flatbed screen 平板絲網印花 printing, heat transfer 熱轉移印花. printing, ink-jet
Teachers may consider the school’s aims and conditions or even the language environment to select the most appropriate approach according to students’ need and ability; or develop
Robinson Crusoe is an Englishman from the 1) t_______ of York in the seventeenth century, the youngest son of a merchant of German origin. This trip is financially successful,
Making use of the Learning Progression Framework (LPF) for Reading in the design of post- reading activities to help students develop reading skills and strategies that support their
Based on “The Performance Indicators for Hong Kong Schools – Evidence of Performance” published in 2002, a suggested list of expected evidence of performance is drawn up for
Then, it is easy to see that there are 9 problems for which the iterative numbers of the algorithm using ψ α,θ,p in the case of θ = 1 and p = 3 are less than the one of the
