決策資訊輔助、自我回饋與休息對動態決策作業績效之影響
128
0
0
全文
(2) 決策資訊輔助、自我回饋與休息對動態決策作業績效之影響 The Effects of Information Support, Self-feedback, and Rest on Dynamic Decision Making Performance. 研 究 生:黃富源. Student:Fu-Yuan Huang. 指導教授:洪瑞雲. Advisor:Dr. Ruey-Yun Horng. 國 立 交 通 大 學 工業工程與管理學系 碩 士 論 文 A Thesis Submitted to Department of Industrial Engineering and Management College of Management National Chiao Tung University in Partial Fulfillment of the Requirements for the Degree of Master of Science in Industrial Engineering June 2005 Hsinchu, Taiwan, Republic of China. 中華民國九十四年六月.
(3) 決策資訊輔助、自我回饋與休息對動態決策作業績效之影響 學生:黃富源. 指導教授:洪瑞雲 博士. 國立交通大學工業工程與管理學系碩士班. 摘 要 本研究的目的在探討動態決策的情境中三個可能影響人們決策表現的因 素:長期資訊的輔助、自我回饋的程度、決策間的休息。實驗中 164 名受試者, 分別被指派到 2(有資訊輔助、無資訊輔助) × 2(有自我回饋、無自我回饋) × 2(有 休息、無休息)8 種不同的情境中,每個受試者將有 200 次的決策機會。本研究預 測經過大量練習後,人們的動態決策品質(決策偏離最佳決策程度、提早結束作 業時間)將會進步,但三個自變項上的差異也會對人們在決策情境中的學習產生 影響。結果發現,自我回饋與休息均有助於改善人們在每一回合的動態決策作業 中的短期學習。就長期學習而言,當人們從事自我回饋時,資訊輔助或休息都對 動態決策的表現有所助益;但缺乏自我回饋的情形下,單有資訊輔助或休息都不 會改善人們的決策表現。. 關鍵字:決策輔助、自我回饋、休息、學習、動態系統決策. i.
(4) The Effects of Information Support, Self-feedback, and Rest on Dynamic Decision Making Performance Student:Fu-Yuan Huang. Advisor:Dr. Ruey-Yun Horng. Department of Industrial Engineering and Management National Chiao Tung University. Abstract This study investigated the effect of decision support, self-feedback, and rest on the dynamic decision making performance. A total of 164 undergraduate and graduate students were assigned to the 2(decision support) × 2(self-feedback) × 2(rest) experimental conditions. Each participant had to make 20 trials × 10 blocks of decisions. We expected decision support (that supplies the aggregated information regarding participant’s performances and its effects on the system over 20 trials), self-feedback (answers to the questions that attempt to provoke participant’s analysis of his/her decision and discrepancies between his/her expectation and system’s actual outcome), and rest (1 minute break between blocks) would improve quality of the dynamic decision making. The dynamic decision making performance was measured by the difference between the optimal solution and the outcome of participant’s decision. Result shows that self-feedback and rest may improve dynamic decision performance within each block, demonstrated by a short-term learning effect. However, supplemented with decision support or rest, self-explanation may also lead to long-term improvement in dynamic decision making. Keywords:decision support, self-feedback, rest, learning, dynamic decision making. ii.
(5) 誌. 謝. 這篇論文記載著我碩二這一年的生命,是生活縮影,是努力與成長的証明。 在提筆前,對未來充滿殺戮戰場般困難重重的忐忑幻想,但如今走到這放下筆 桿,拿起槍桿之際,心中卻對過去一年滿是依依與感謝。表面上的學術意涵之外, 這篇厚達一百多頁的論文也稱職的呈現出我這個作者的心情,或許正因為背負了 太多無法言喻的感恩,它才會變得如此肥厚吧。如果在寫作過程中少了任何一個 曾經給過我幫助與鼓勵的人,它就不會是現在的樣子,來自各方有形無形的幫 助,都讓我更堅定要把這件事情做好的信念。 我想,太多指名道姓的感謝在這裡只會顯得多餘,小小版面怎能承受得起心 中的洶湧澎湃,又怎能割捨那想跟每個受試者說聲謝謝的心情,只好在此用最簡 單的道謝,表達最真實的心情,你們是這篇論文的骨骼血肉,謝謝! 我的指導教授洪瑞雲老師,對我的影響不單只在指導我把這篇論文做完、做 好,從她身上學到更多的是身為一個學者對於學術研究該有堅持,從來沒想像過 一個老師可以對我產生這麼深遠的影響,也未曾如此深刻的感謝一個稱謂是老師 的長輩,每次的討論都讓我有所學習,每次的閒聊都讓我有所成長,洪老師對我 來說不但是良師、更是益友,對老師的喜愛與尊敬,甚至讓我有為什麼要把論文 寫完、為什麼要畢業的心情。 最後,我想感謝我的家人在做論文的過程中,對我百般的寬容與支持,之所 以能夠大膽放心的去坐一件事,完全是因為背後支持我的力量是那麼強大、溫暖 與自由,越是長大越能透明白所謂的家人,就是一種血脈相連的悸動與羈絆,毫 無理由也不需要理由就這麼默默的支持著我,讓我任性的去做我想做的事情,請 你們原諒我的任意妄為,謝謝你們。. 黃富源 謹識. 民國 94 年 6 月於交通大學. iii.
(6) 目錄 中文摘要. i. 英文摘要. ii. 誌謝. iii. 目錄. iv. 表目錄. vi. 圖目錄. vii 1. 第一章. 導論. 第二章. 文獻探討. 12. 第三章. 方法. 31. 第四章. 結果. 43. 第五章. 結論與討論. 74. 參考文獻. 81. 附錄一. 實驗指導語. 84. 附錄二. 牧場經營作業操作介面實例. 88. 附錄三. 牧場管理作業系統初始值. 91. 附錄四. 各初始條件的最佳決策. 93. 附錄五. 第一回合各階段之變異數分析. 95. 附錄六. 刪除遺漏值後偏離最佳決策程度之平均數與標準差. 97. 附錄七. 刪除遺漏值後階段 × 自我回饋之簡單主效果檢定. 103. 附錄八. 刪除遺漏值後階段 × 休息之簡單主效果檢定. 105. 附錄九. 補上遺漏估計值後偏離最佳決策程度之平均數與標準差. 107. iv.
(7) 附錄十. 補上遺漏估計值後階段 × 自我回饋之簡單主效果. 113. 附錄十一. 補上遺漏估計值後資訊輔助 × 休息之簡單主效果檢定. 115. 附錄十二. 遺漏值估計後資訊輔助、自我回饋、休息之簡單主效果. 116. 附錄十三. 遺漏值估計後階段、資訊輔助、休息之簡單主效果. 118. v.
(8) 表目錄 表 1. 第一回合結束時間點之平均數與標準差. 44. 表 2. 第一回合結束時間點之變異數分析表. 44. 表 3. 第一回合偏離最佳策略程度之平均數與標準差. 45. 表 4. 第一回合偏離最佳策略程度之變異數分析表. 46. 表 5. 十回合結束時間點之平均數與標準差. 49. 表 6. 十回合結束時間點變異數分析表. 50. 表 7. 後九回合刪除遺漏值後偏離最佳決策程度之變異數分析表. 52. 表 8. 後九回合刪除遺漏值後每回合各階段之平均數與變異數. 58. 表 9. 後九回合補上遺漏估計值後偏離最佳決策程度之變異數分析表. 61. 表 10. 後九回合補上遺漏估計值每回合各階段之平均數與變異數. 65. vi.
(9) 圖目錄 圖 1. 控制理論之結構示意圖. 24. 圖 2. 決策作業之變項關係圖. 32. 圖 3. 牧草長度與年生長量之關係圖. 33. 圖 4. 實驗流程圖. 39. 圖 5. 第一回合偏離最佳策略程度之學習曲線. 47. 圖 6. 後九回合刪除遺漏值後之長期學習曲線. 54. 圖 7. 後九回合刪除遺漏值後之短期學習曲線. 55. 圖 8. 後九回合刪除遺漏值後之回合 × 階段交互作用圖. 57. 圖 9. 後九回合刪除遺漏值後各階段經過 2~10 回合之整體學習曲線. 57. 圖 10. 後九回合刪除遺漏值後階段 × 自我回饋之交互作用圖. 59. 圖 11. 後九回合刪除遺漏值後階段 × 休息之交互作用圖. 60. 圖 12. 後九回合補上遺漏估計值後之長期學習曲線. 64. 圖 13. 後九回合補上遺漏估計值之短期學習曲線. 66. 圖 14. 後九回合補上遺漏估計值之回合 × 階段交互作用圖. 67. 圖 15. 後九回合補上遺漏估計值後各階段經過 2~10 回合之整體學習曲線. 67. 圖 16. 後九回合補上遺漏估計值後階段 × 自我回饋之交互作用圖. 68. 圖 17. 後九回合補上遺漏估計值後資訊輔助 × 休息之交互作用圖. 69. 圖 18. 後九回合估計遺漏值後資訊輔助 × 自我回饋 × 休息之交互作用圖. 70. 圖 19. 後九回合補上遺漏估計值後階段 × 資訊輔助 × 休息之交互作用圖. 72. vii.
(10) 第一章 導論 研究背景與動機 從孩童長為成人、從學生時代到出社會工作,人們每天都得做大大小小的決 定,這些決定可能沒什麼重大影響,但也可能徹底改變一生。雖然這些決定間的 差異可說是南轅北轍,但我們在面對這些問題時的內在活動卻可能是相似的,其 中所含的一連串內在的認知活動稱之為──決策。決策行為不單在個人的層次重 要,對組織而言也具有不可忽視的重要性。一個組織是否可以長期的生存往往取 決於保持好的決策品質。決策行為普遍存在於日常生活中,然而並不代表人們對 如何做決策非常熟練,也不表示每一個決策都是正確的。 做進一步的探討之前,首先要了解何謂決策,在此採用 Baron(1994)的搜尋 -推論理論說明人的決策行為。人們決策是因為存在想望達成的目標,此目標與 目前所處的情境間存在差異,為了達成目標人們必須採取某些行動。如果通往目 標的可能性是單一的,那麼人們只需要認真執行這個方案,若通往目標的方法很 多,人們就必須蒐集各種證據,透過推論各種證據中所包含的訊息來決定採取那 個方案最為合適。糟糕的是,有時可供選擇的方案並不明顯,人們要靠自己來找 出方案。簡單的說,決策是人以目標為前提,由搜尋與推論所構成的一連串的內 在認知活動。 決策在許多領域中不斷的被討論,不同的領域對於決策所抱持的觀點也不盡 相同。例如在決策分析的領域中,學者們致力於將決策轉換成量化的模型,透過 量化的方式讓決策者可以做正確的判斷。另一方面,研究行為決策的學者則對人 們真正的決策行為有興趣。他們透過實驗、觀察等方式檢視人們在各種不同情境 下的決策行為。本研究的目的即為由行為決策的觀點來檢視動態決策中人們的認. 1.
(11) 知過程中的相關因素。 動態決策的作業特徵 過去的十五年中((Hsiao & Richardson, 1999; Moxnes, 2004; Diehl & Sterman, 1989a, 1995; Rouwette & Größler, 2004)許多學者開始探究在決策間彼此相依的動 態情境中人們如何決策。典型的決策研究中為了要確認人們的各種認知特徵會在 多樣化的決策情境中穩固的出現,因此在決策作業的設計上,大多以作業簡單、 情境多樣化為主,由這些決策作業所得的研究結果雖然可以發覺許多人們在決策 上的基本特徵偏離理性模式的行為(Kahneman & Tversky, 1979),然而這些作業的 設計不是只有單一決策,就是決策與決策間沒有關聯。假如我們回想自己在日常 生活的經驗,我們將輕易的發現上一個決定會影響下一個決定的情況其實是屢見 不鮮。例如:在求學的時候可以不斷的選擇要不要認真唸書,每一次的選擇都會 影響到下一次要唸的分量與時間,這些決定對於後來的期中、期末大考的成績也 會有影響。又如,駕駛行為也是一樣,駕駛者在每個分岔路口所作的選擇都會影 響到達目的地的路程與時間。除了日常生活之外,動態的決策情境在工業、企業 中更是常見,如生產線的規劃、組織人力的掌控…等等,每一個決定都往往是牽 一髮而動全身,會引發連帶甚至不可回復的反應。 由於動態情境是如此普遍的存在,令人不禁要問與過去的典型決策研究相 比,人們在動態決策中的行為與靜態決策有什麼差異。若比較這兩種決策作業的 特性,可以發現古典的決策研究中,是把過去一段時間的情境變化轉換成靜態資 訊的方式呈現給決策者,讓決策者在單一時間點上做決策。動態決策中則是由決 策者親身經驗整個環境變化的過程。決策作業中,除了含有環境本身自然的變化 外,決策者每做一次決策都會造成情境的改變,此改變又會影響之後決策時的方. 2.
(12) 向與目標,這是動態決策一個非常重要的特性稱為「繞環式因果律(circular causality)」。因為此因果律的存在,決策不再是求單一階段的最佳解,而是必須 從長期的角度規劃,方能有效的達成目標。另一方面,在動態決策中決策者要親 身經驗環境變化,在決策初期勢必要花一段時間熟悉、理解環境,但由於人們的 注意力無法持久、及記憶的限制,可能會在過程中遺漏一些訊息,導致對環境的 理解或變化無法即時掌握,更遑論即時作出適當的反應。因此,我們可以期待動 態決策與靜態決策之間人們的行為會有差異。 與靜態決策研究相似的是,動態決策作業的研究中(如,Edwards, 1962)也發 現人們的行為往往偏離最佳化的模型,且隨著作業設計不同,人們的表現也不盡 相同,似乎作業的結構是影響人們決策的因素。隨後的許多研究(如,Diehl & Sterman, 1995 ;Gibson, 2000)指出,工作複雜度上升的確會造成人們決策的品質 下降。當人們所面對的決策系統越是龐大,各事件之間的關聯越複雜,決策所造 成的影響展現的時間(結果回饋)拖的越長,人們的表現就會下滑越多,然而其他 研 究 中 ( Kobus, Proctor & Holste, 2001; Atkins, Wood & Rutgers,2002; Moxnes,2004)也都發現,隨著同一決策作業的經驗累積,人們所做決策的績效 會逐漸改善,決策品質變異的程度也縮小,雖然不一定可到最佳的程度,但是與 一開始相比較已經有很大的進步。這顯示人們可以在動態決策的過程中獲得學 習。足夠的練習便是改善決策品質的因素之一。 既然人們可以在動態環境中穩定學習,表示人在決策的最初與最後,對環境 的理解不同,也就是對於問題的內在表徵改變了。學者們(如,Lerch & Harter, 2001)的解釋是人們透過建立和修訂內在的心智模型來適當的表達他對外在世界 的認識,並據此內在模式以適應環境。心智模型是人們將外來的訊息與自己的知. 3.
(13) 識,重新組織後形成的一個內在認知結構,其目的在於表達個人當時所處的情 境,因此心智模型也稱為情境模式(Kintsch,1988,1998)。Endsley(1995)認為動態 決策情境的心智模式的建立分成三個階段,分別是知覺、理解、規劃,統稱為情 境覺察(situational awareness)。其中,在知覺階段人們主要的作業主要在偵測、 接收來自環境中的各種訊息。如果環境中的訊息量超過人們可以接受的範圍,就 必須過濾出重要的訊息而忽略旁枝末節的訊息。接下來,人以自己知覺到的訊息 為線索進一步推論自己所處的環境中各項因素間的因果關係,若接收到的重要的 訊息可以被適當的加以組織,則個人對整個環境會有比較通盤的掌握。亦即理解 階段最主要的活動是將知覺的訊息與既有的知識組織起來,嘗試推論出隱藏在現 象表面下的底層結構。透過正確的理解,決策者對於環境的預測能力會提高,在 第三個階段規劃的工作即人們根據本身對環境的理解,尋找並評估可行的方案, 並在所有方案中挑選出最能夠達成目標的方案加以實行。此預測、規劃階段中人 們也會發展出策略來應付各種未來可能出現的情形。然而,要特別說明的是,此 三階段的區分,只是為了強調前一個階段的好壞會影響下一個階段,實際上三個 階段是同時進行的。Ensley 的理論雖然可以解釋影響人們在動態決策中的內在認 知階段,但是對於人們在動態決策過程中如何透過學習使三個覺察階段產生變化 卻沒有著墨。 另一方面,Brehmer(1995)提出了控制-預測的架構來解釋動態決策中人們 的學習歷程。他認為人們的心智模型可以進一步分成兩個子模型,一個子模型用 來執行決策,另一個子模型用來預測執行後的結果。控制子模型乃根據目前環境 狀態(St)與目標環境狀態間(Sgoal)的差異(d0)做反應,再根據上一個環境狀態(St-1) 與目前環境狀態(St)的差異(d1)作為修正 d0 差異的基準;同理,預測子模型根據. 4.
(14) 上一次的環境狀態與上一次的預測做修正,再根據目前環境狀態與控制子模型所 欲採取的行動預測可能產生的變化。在動態系統決策作業,每作一次決策人們的 心智模型中上述相關的參數就會更新一次。換句話說,人們從決策的經驗中學 習。動態環境中每一次的學習都是局部的、是漸進的,而且所建立的知識不容易 遷移到經驗範圍之外。雖然這個理論描述了人們如何利用經驗來學習去掌握動態 決策作業的品質,但卻忽略了經驗之外的因素,如決策者所具有的先前知識。其 他研究的結果發現(如,Stanley,1989),即使基底結構完全相同的作業,只要給予 不同的背景故事,人們的表現就會有差異,而且這個差異不論工作複不複雜、有 沒有經過學習都仍然存在。這暗示了人們的學習不單純來自經驗。若從情境覺察 的觀點看來,在人們理解環境時,除了經驗外,還會加入個人長期記憶中的相關 知識。不同的決策者對於各領域的知識不盡相同,所以當個人知識加入決策者的 經驗模型中時,人與人間決策品質的差異就會突顯出來。由於知識必須經過長期 的累積方可成形,因此在決策過程中獲得的學習並不足以填補不同領域的知識間 的差距。 古典的決策研究中觀察到許多人們在決策時會有偏離理性的現象 (Kahneman & Tversky, 1979),如,代表性策略(representativeness heuristic):一種 依一個物體或事件跟它所屬種類之典型有多相似,來估計它是否屬於那一種類的 一種估計或然率的方法。在動態決策中一個常見的偏誤稱為對回饋的錯誤知覺 (misperception of feedback)。這個現象是指人們會忽略或無視於非常明顯且重要 的回饋,即使他們知道那些回饋的重要性!當系統的複雜度較高時,這個現象更 為明顯。人們往往只專注於與目標直接相關的因素,例如:存貨管理人們只在意 存貨水準來進貨,但是卻忽略了出貨量的改變。從情境覺察的觀點,忽略重要的. 5.
(15) 訊息導致知覺階段不完整,理解與規劃會受到牽連;從控制-預測理論來看,被 忽略的回饋根本不會造成心智模型的修正,學習的效果就會降低。目前對於這個 現象的解釋是,人們對系統動態缺乏反應的能力,尤其當人們的決策不能馬上改 變環境,而必須潛伏一段時間後才發生影響時,人們更難處理動態系統的回饋訊 息。換句話說,人們缺乏分析、整合長期趨勢的能力,後果是人會對目前的環境 狀態看的太重,而忽略了自己過去的決策對環境造成的影響。即使經過多次練習 之後,仍然無法改善對目前環境狀態的過度重視(如,Diehl & Sterman, 1995)。 雖然許多研究都觀察到動態決策作業中決策者對回饋知覺錯誤的現象 (Moxnes,2003; Gibson,2000; Diehl & Sterman, 1995),但是這些研究中仍有未考慮 到的因素,其中之ㄧ是人的注意力資源與短期記憶能力的限制。動態決策的情境 中,人們要記住過去的資訊,同時還必須不斷接收新的訊息,可想而知人們的認 知負荷(注意力與短期記憶)相當大。然而,有的研究中提供受試者的決策時間卻 相當短,如,Gibson(1997)只給受試者 3 秒鐘下決策。在 3 秒內要完成整個決策 的歷程非常的勉強,且下一個決策的資訊馬上隨之而來,資訊的更新速率太快會 干擾原本短期記憶中的資訊,且即使短期記憶沒有受到干擾,過短的資訊處理時 間也不容許舊的資訊被區塊化或轉存入長期記憶。在這種時間壓力下人們所能保 持住的長期資訊大幅減少,更遑論同時顧及過去、評估現狀及考量未來。更進一 步來看,即使受試者在每一次決策之後都可以及時獲得回饋,在複雜度較高的動 態決策作業中,每次決策後所得的回饋內容通常也包含了較多的資訊,3 秒甚至 30 秒可能也不足以讓受試者瀏覽、理解全部的資訊。在一些無時間壓力的動態 決策研究中(如,Stanley,1989 ; Diehl & Sterman, 1995)發現,受試者平均需要花費 40~60 秒來進行一次決策,因此若只有如 3 秒的極短時間可以下決策,人們將只. 6.
(16) 能採取非常簡化的策略來應付環境的變動。 在一些實驗中(如,Stanley,1989; Moxnes 2003)的確發現人們在動態決策情境 下是使用定錨與調整的方式在進行決策。亦即,決策的最初人們會決定一個初始 值,然後在往後的每次決策時以此值作為錨點,在此錨點上下進行微調來反應動 態環境中的狀態變化,使環境的狀態逐漸趨向目摽。使用這種多退少補的定錨策 略雖可以降低心智負荷,但是缺點是可能造成決策時只專注於與目標直接相關的 情境因素,而忽略其他更好的線索,而無法找出不同但可能更佳的決策方案。此 定錨與調整策略並不足以應付高複雜度的動態決策作業,因為在高複雜度的作業 中決策者所採取的行動不一定可以立即改變環境,決策者在下一次新的決策時沒 有任何依據來調整自己的決策。 此外,在真實的環境中,在短時間內大量練習相同性質決策的決策情境並不 常見,比較常見的反而是在每一複雜的決策之後會有一段觀察及等待的時間,允 許決策者有較充裕的時間去觀察、分析與整合決策時的期待與決策後環境的變 化,並據以對環境的特徵多一層認識。根據學習理論,學習的效果在學習後的一 段時間才會到達高峰,且過度密集的練習所產生的效果往往不如分散練習(如, Bourne & Archer, 1956),在動態決策的場合,決策者頻繁的與環境互動後,需要 時間整合、分析與理解這段時間中所獲得訊息,然而,過去的動態決策研究(Atkins, Wood & Rutgers,2002; Barron, 2003),受試者常在兩百次以上的練習後才得以休 息,這樣密集連續的練習作業設計與自然決策情境不符,其研究發現也可能低估 了人在動態決策作業中真正的學習能力。本研究因此推論,在動態決策作業中提 供適當的休息時間,將有助於受試者預測與理解動態系統的情境模式。 動態決策作業中,心智模型的建立有賴於經驗的累積,而經驗則來自在決策. 7.
(17) 過程中所接收到的回饋。當人們與環境互動,改變了環境的狀態,這些改變藉由 某種管道傳達給人們稱為「結果回饋」。顧名思義,結果回饋所傳達的訊息是被 決策更改後的環境狀態。人們在動態環境中進行決策時,結果回饋有兩種功能 (如,Endsley, 1995; Gibson, 1997; Lerch & Harter, 2001),第一、根據結果回饋推 論決策作業中各因素間真正的因果關係,第二、根據結果回饋評估現狀並推論未 來所要採取的行動與策略。動態決策作業中學習的現象主要來自於決策者由經驗 中架構出情境裡各因素間的因果關係,此情境的理解與覺察降低了決策時的不確 定性,只要決策者能充分理解、掌握整個環境,方案的評估就相對簡單。換句話 說,人們的決策品質能夠進步是因為逐漸發現環境中的變項相互影響的法則,而 法則發現的研究中回饋的立即性是不可或缺的(如,Maddox, Ashby, & Bohil 2003),如在古典學習理論中,動物能夠將刺激與反應連結的能力,會因為回饋 數秒的延遲而破壞(如,Perin, 1943)。然而,動態環境中由於繞環式因果律的存 在,人們要能發展出具長期預測能力的心智模型,才能對系統有一完整的知識, 也才能獲得整體目標的達成。每次決策都立即獲得結果回饋的風險之ㄧ為人們可 能會因此只著重短期的表現,此時反而會阻礙人們對環境中長期變化的理解。為 了使人們更容易觀察到動態環境中的長期變化,提供人們較長期的整合性的資訊 可能有助人們對作業結構的正確理解。但每次決策後都立即提供長期的資訊也是 不必要的。根據對回饋錯誤知覺的現象,人們在決策時對於資訊的觀察與處理能 力相當有限,因此可以預期人們無法邊處理這麼龐大的資訊邊做決策。本研究因 此推論,若能在動態決策作業進行一段時間後提供人們有關的長期資訊,將可幫 助人們建立起具有長期預測能力的心智模型。 除了外界所提供的回饋,人們也可進行自我回饋而影響學習,在動態決策作. 8.
(18) 業中自我回饋是指受試者以自己決策造成的真正結果與當初自己預期會產生的 結果間的差異為訊息以促使人們解釋為發現自己當初假設的錯誤所在。來自外界 的回饋也可促進人們進行自我回饋,例如:Škraba(2003)的研究中在受試者進行 決策後,會得知另一位進行相同作業的受試者所作的所有決策及決策後果的整合 性訊息,此回饋可提供受試者相對的比較標準,讓受試者有更多的資訊與更高的 意願來解釋、反省自己過去的決策行為。但是自我回饋的產生並不一定需要由外 在的回饋引發,只要人們嘗試去比較自己內在的心智模型與外在真實環境間的差 異,自我回饋就會發生。我們推論當決策者若被要求去比較事實與自己的預測, 並能嘗試解釋差異形成的原因時,將有助於對系統決策作業的情境模式的學習。 研究問題與假設 本研究的主要興趣,在探討人們在動態系統進行決策時,影響學習的相關因 素。根據上述的討論,決策與決策間的休息時間會讓人們的學習效果得以發酵, 長期資訊的提供則會影響系統運作法則的發現、要求人們對作業情境進行預測並 解釋預測偏離事實的原因會有自我回饋的活動,這些都可能影響人們在動態決策 時對情境模式學習而直接影響到人們的決策品質。本研究的研究問題與假設條列 如下: 問題一:長期資訊的輔助是否會影響人們在動態決策時的決策品質? 假設一:長期資訊的輔助會提升人們在動態決策時的決策品質。 問題二:決策與決策間有休息的時間是否會影響人們在動態決策時的決策品質? 假設二:決策與決策間有休息的時間會會提升人們在動態決策時的決策品質。 問題三:自我回饋是否會影響人們在動態決策時的決策品質? 假設三:自我回饋會提升人們在動態決策時的決策品質。. 9.
(19) 問題四:休息、資訊輔助、自我回饋間的交互作用是否會影響人們在動態決策時 的決策品質? 假設四:休息、資訊輔助、自我回饋間的交互作用會影響人們在動態決策時的決 策品質。 變項定義 自變項: 長期資訊的輔助:指受試者在動態決策作業中進行 20 次決策後是否會獲得其行 為對系統所造成的影響的資訊。 分成兩種情境: 情境一:受試者進行 20 次的決策後系統會有機會得到這 20 次決策的長期資訊(受 試者所輸入牧群量的平均數與標準差、受試者所輸入之牧群量與時間的折線圖、 決策結果的平均數與標準差、決策結果與時間的折線圖)。 情境二:受試者進行 20 次的決策後系統不會得到有關這 20 次決策的長期資訊。. 決策與決策間的休息時間:指受試者進行 20 次的決策作業過程中後是否有一分 鐘的時間可不需進行任何認知作業(1 分鐘 × 9 次)。 分成兩種情境: 情境一:受試者進行 20 次的動態決策過程中,有一分鐘可不需進行任何認知作 業。 情境二:受試者進行 20 次動態決策的整個過程中,均需不斷的從事相關或無關 的認知作業。. 自我回饋:受試者進行 20 次的決策後是否有機會回顧與解釋其原先的預測與系 10.
(20) 統的真實反應間的差異。 分成兩種情境: 情境一:在每次決策前受試者要先對系統的反應進行預測,並於決策後檢討、解 釋系統的真實反應與其預測間的差異。 情境二:在決策過程中不要求受試者預測與解釋系統的變化。 依變項: 受試者在動態決策作業中決策品質。由兩個向度評估: 一、結束時間點:人們在每一回 20 次的動態決策中是否可將一回合的作業進行 完整。在一回合中進行決策的次數越少表示決策時所犯的錯誤越多。 二、受試者的決策偏離最佳決策的程度:人們在動態決策作業中所做的決策與最 佳決策間的差異程度,差異越小表示偏離最佳決策程度愈低,亦即決策績效愈佳。. 11.
(21) 第二章 文獻探討 動態決策之定義與特徵 過去在研究決策問題時大都採用單一階段的作業。這類作業的特徵是在決策 過程中環境線索為固定狀態,不受外界因素所影響(如,Kahneman & Tversky, 1979),決策者的決策與決策間亦不具關聯。然而,此種決策環境與現實環境相 比相差太大。在我們的生活或工作中,許多前後的決策間往往呈現出環環相扣的 複雜因果關係,且因果之間通常沒有明顯的線索。另外,現實的決策環境中人們 通常沒有足夠的資訊,或無法區辨出問題情境中哪些資訊是重要的、關鍵的,而 那些是無關的。在此類情境中人們的決策行為被稱為「動態決策」(dynamic decision making)(如,Lerch & Harter, 2001)。 使用動態這個詞是為了強調在決策進行的過程中決策情境會不斷的變動。在 某些作業中決策者所面對的系統變動訊息是以靜態的形式呈現,諸如統計的期望 值、機率、變異數…等等,決策者並未親身經歷系統的變化,而是就手上持有的 資訊、有關的經驗與知識進行決策作業(如,Kahneman & Tversky, 1979)。然而, 當決策者身處在一真實的環境中而面臨不斷決策以應付環境中的變動時,環境變 動的程度將會對決策者的決策品質造成很大的影響。 Edward(1962)指出動態決策具有三個特徵。動態決策的第一個特徵即決策者 需要做一連串的決策,以在變動的環境中隨時可對情境的各種改變做出適當的反 應。由於環境因素並非固定,決策者每次面對的決策情境似同而非同,上一次決 策時的最佳解不一定是這次決策的最佳解,且每一局部的最佳解不一定等於整體 最佳解,因此,人們在動態的系統中必須因應環境的改變而隨時調整自己的決策。 動態決策的第二個特性是決策者的每一個決策都會使系統狀態發生變化,此. 12.
(22) 系統狀態改變則對下次決策產生影響,下次決策又會進一步讓系統改變,亦即動 態系統包函了繞環式因果律(circular causality)。 此外,動態系統並不單單只因為決策者的決策而改變。隨著時間的進行,環 境仍然會受到其它外部因素的影響而變化,這些非預期的變化一樣可能影響到決 策者所面對的決策情境,也一樣會影響決策後果。這種外部的不可預測因素構成 了動態系統的第三個特性,亦即動態系統是開放且自變的。在這三個動態決策的 特性中繞環因果律可說是決策者所面對的最大挑戰。因為在任何一個時間點上所 犯的決策錯誤都會加大系統的自然變異而增加往後決策的困難,且錯誤的決策所 造成的後果需要一段時間才能修復,增加了達成目標的時間成本或是造成不必要 的時間壓力。 另外從資訊系統的角度來看,一個動態系統是在即時的情境下運作的(Lerch & Harter 2001)。即時的意思是指在時間的影響下,每個決策都有一定的期限。 為了在期限中完成決策並採取行動,決策者往往無法仔細評估所有可能方案,而 必須發展出策略以求一快速但可行的近似解,這種強調時間因素的動態決策被稱 為即時動態決策 (real-time dynamic decision making) 。因此,動態決策的特徵還 包括時間壓力的要素,時間限制會影響決策者考慮與探索可能方案的行為 (Brehmer,1990,1992, 1995; Edward, 1962; Rapoport, 1975)。 目前大部分的動態決策研究中,決策作業的設計是採取由事件驅動的動態系 統加上時間限制來進行(如,Moxnes, 2004; Diehl & Sterman, 1995),由事件驅動 驅動的系統是以事件的發生作為系統時間前進的根據,若沒有新的事件發生,則 系統將停留在一固定的時間點。根據 Hsiao & Richardson(1999)所整理的文獻中發 現,即時與事件驅動兩種不同的模擬系統對於人們的決策行為沒有影響。而. 13.
(23) Sterman(1989)曾驗證在簡化的模擬情境中(相對於真實世界),人們表現出的行為 與在真實情境下是相似的,因此,不論使用即時的或是由事件驅動的模擬系統來 研究動態環境決策都可反應出人們在真實情境下的決策行為。 動態系統中影響人的決策要素 動態決策的情境是由決策者、決策作業及人與作業的交互作用加上外在情 境組成,決策作業通常為一系統,系統中包含許多元件(或稱變項),決策者在決 策的過程中根據目標改變系統中某些元件的狀態以達成目標。在動態決策的研究 中常用的作業設計有:製糖工廠的人力資源管理(Stanley, 1989; Gibson,1997, 2000)、快遞公司的信件配送管理(Lerch & Harter, 2001)、生產工廠的庫存管理 (Atkins, 2002; Diehl & Sterman ,1995) 、 軟 體 專 案 管 理 作 業 (Sengupta & Abdel-Hanid,1993) 、 自 來 水 廠 水 資 源 配 送 管 理 (Gonzalez , Lerch & Lebiere,2003 )、牧場管理作業(Moxnes, 2004)。而常用的依變項根據 Hsiao & Richardson(1999)的整理可分成五類:作業績效、學習趨勢、決策時的心智負荷、 決策品質、對決策作業結構的了解。自變項則可分成三類:決策者的因素(如, 工作記憶)、作業複雜度(如,作業中變項總數)、決策介面與環境(如,背景故事)。 動態決策情境的各個成分會對人們的決策行為造成不同的影響,首先我們討 論決策作業本身。非常直覺的,決策作業的系統複雜度會對人們的決策產生影 響。雖然不同的研究對於複雜度一詞的定義不完全相同,不過大部分的研究將複 雜度指向決策作業的系統結構(Hsiao & Richardson, 1999; Moxnes, 2004; Diehl & Sterman, 1995; Rouwette & Größler, 2004) ,下面我們把系統複雜度分成幾個部 份:變項的總數量、變項間的因果強度、變項間的因果時間、變項間的因果型態, 來探討系統變項對人們進行動態決策時的影響。. 14.
(24) 變項數目。 一個系統中所包含的變項數量越多,系統越龐大,人們在理解 或管理上勢必遭遇較大的困難,因此屬於較為複雜的系統。如,Moxnes(2004) 的研究中發現,若將最簡單的系統(一個輸入值、一個庫存值、一個輸出值)稍作 改變(一個輸入值、兩個庫存值、一個輸出值),人們的達成目標的程度即變小。 因果強度。 指變項間的相關性。兩個(或多個)變項間的相關強度越強則原 因發生時結果也發生的機率相對較高,決策者較容易偵測與掌握到變項間的關聯 (如,Diehl & Sterman, 1995)。 因果時間。 指描述原因與結果間的時間線索是否清楚,原因發生後結果馬 上產生,則因果時間短,時間線索清晰,也就越容易被人所偵測到,也越容易將 此因果關係連結起來。如,Diehl & Sterman(1995)的研究中操弄系統中變項間的 相關係數(r=0.3、0.6、-0.3、-0.6),發現變數間的相關越強,人們的決策越能 接近設定的目標。此外,他們也發現若變項間的相關與人們的期待相符(r 為正), 則人們表現較佳;若變項間的相關與人們的期待相違(r 為負),則決策表現會較 差。此外,他們的實驗也操弄了變項間的因果時間(決策者輸入數值到系統真正 反應的時間),結果發現當變項間的因果時間越長,決策者達成目標的程度越差 (有關此研究的詳細討論請參考對回饋的錯誤知覺一節)。其他的研究中也發現了 類似的結果(如,Gibson, 2000)。 變項間的因果型態。 為變數間的數學關係,假設一系統中有 A、B、C 三個 變項,它們的關係可為「若 A 則 C」,也可為「若 A 且 B 則 C」。當變項間的邏 輯運算式越簡單,系統越簡單。但即使邏輯上同是「若 A 則 C」的關係,隨 A 與 C 間的數學表示式(如,A= C+10、 A=(1-C)2+10)不同,系統複雜度亦不 同。當 A、C 間呈線性關係時,則系統複雜度低;當 A、C 間的數學關係為非線. 15.
(25) 性,則系統相對的較為複雜。過去的研究大都使用線性、單純的因果型態當作實 驗材料(如,Stanley, 1989),因此沒有直接的例子可以比較,然而根據變項數量、 因果強度與因果時間對人們行為的影響,可以推測變項間的因果型態越複雜,在 動態決策作業中人們對情境的理解會越困難,決策者決策時所需要的心理演算越 複雜,決策出錯的機率也就越大。 決策者的因素。 決策者是決策環境中的另一個要素。例如:由於在動態決 策的情境中決策者需要做一連串彼此相關的決策,這意味著決策者的短期記憶容 量可能造成決策品質間的差異。 Lerch & Harter(2001)曾就如何在即時的動態決策環境中提供決策輔助 進行研究,此研究分成兩個實驗,第一個實驗主要操弄時間壓力(有、無)與受試 者工作記憶容量(高、低)兩個變項。實驗所用的決策作業為快遞公司的派信管 理,總共有 16 名受試者參加實驗。這些受試者的工作是在規定的時間內操作 5 台郵件排序機,以將所有郵件排序完成。每個受試者都要重複進行三次模擬時間 為 8 小時的作業(現實時間大約一小時),這段時間中他們將有 1008 批信件要處 理(平均大約 3.5 秒要處理 1 批信件)。依變項衡量的方式為受試者未如期完成的 信件量、機台的使用率與派信的方法。另外,每組有兩名受試者有進行口語資料 的收集。研究結果發現,就未如期完成的信件量而言,時間壓力與工作記憶容量 的交互作用有顯著的效果。這四組受試者未如期完成的信件量由多至少依序為: 高工作記憶-有時間壓力組,212.3 批,低工作記憶-有時間壓力組,77.8 批, 低工作記憶-無時間壓力組,69.7 批,高工作記憶-無時間壓力組,69.2 批。機 台利用率的結果中,時間壓力與工作記憶容量的交互作用也有顯著效果,其中利 用率最低的為高工作記憶-有時間壓力組的 81.5%,最高的為低工作記憶-無時. 16.
(26) 間壓力組的 97.2%。根據這個實驗的結果可發現,工作記憶容量的確會對人們的 決策績效產生影響,尤其是在具有時間壓力時影響更為顯著,然而,高工作記憶 者在高時間壓力下的決策表現最低,此與一般人或理論的預期都不同,Lerch & Harter 的研究假設是,具有高工作記憶的受試者在作業中的表現應該要比低工作 記憶的受試者來的好。 一般而言,高工作記憶的人在進行複雜作業時會因為有較多可利用的認知資 源,使認知負荷比低工作記憶的人低而有較好的表現,但是這個研究的結果卻出 現相反的結果。Lerch & Harter 分析了受試者在實驗進行過程中所收集的口語資 料後發現,有較高工作記憶容量的受試者在決策的過程中考慮了較多的方案,也 會比較有計畫的對系統進行測試。高工作記憶的受試者在作業開始時使用了較多 不同的策略來進行作業,使決策表現的變異較低工作記憶的受試者大,但這個研 究中,沒有將這部份的資料分開來處理,可能因此而低估了高工作記憶的受試者 的決策表現。 一個可能的解釋是練習不足使受試者的決策行為沒有被完整呈現,在動態決 策的其他研究中(如,Atkins, Wood & Rutgers,2002)發現人們會因為練習而產生學 習來改善決策表現,但是這個研究卻未發現練習的效果,Lerch & Harter 指出, 如果讓受試者可以有更多練習,則可期望高工作記憶容量的受試者之決策績效會 隨練習時間的增加而改善。 系統介面設計。 當決策者進行動態決策作業時需透過與決策作業的系統產 生互動以取得各種資訊(如,調整生產線上機器的各項參數,以取得產品品質變 化的資訊)。在真實世界中,人們可以由自然環境中取得許多資訊,例如:與人 對談時可從對方的臉部表情、動作、語氣、聲調等處獲得額外(對話內容以外)的. 17.
(27) 訊息。然而,如果在人工的環境下(如自動化工廠),人們的線索都是透過人工方 式設計出來的系統介面取得,因此在動態系統中系統介面能否提供適用且適時的 訊息也會影響人們在決策環境中的表現。 Atkins(2002)曾對結果回饋的呈現方式與人們的決策行為進行研究。他採用 Diehl & Sterman(1995)的研究中使用的庫存管理作業,不同的是這個實驗只採用 了其中 9 種不同的工作複雜度。實驗中將 18 個受試者分成兩組,一組受試者只 看到自己所下的決策與決策結果的表格,另一組受試者在結果回饋表格之外還會 同時看到決策結果對時間的折線圖。實驗中依變項的測量為:累積的總庫存成 本、花費的總時間、受試者在筆記本中所記下的資訊。研究結果發現有折線圖的 輔助下,受試者在庫存成本的管理上有相當顯著的改善。然而,只看結果回饋表 格組的受試者雖然表現的較差,但是其庫存成本也呈現出顯著下降的線性趨勢。 此外,兩組所花費的決策總時間雖然都顯著的隨練習時間增加而減少,但是兩組 間並沒有差異。由此推論,提供時間與庫存間相關程度的折線圖的輔助,可以幫 助人們在動態決策作業時看到其行為對所欲達成目標的影響,此圖示將有助於決 策表現,並減少學習所需要的時間。 系統透明度。 決策作業的透明度也是另一個影響動態決策作業中的決策者 進行決策的因素。系統透明度指人們能獲得有關於系統如何運作的訊息多寡。作 業越透明人們越能清楚看到系統如何運作,決策者在進行決策時將能可能做出更 正確的判斷。Barron(2003)的研究即探討就資訊完全不公開對人們的決策行為之 影響進行研究。他所使用的作業是提供兩種不同的獲利的方案(操弄平均值與變 異數,例如:一定可以獲得 3.2 元、有 0.8 的機會可以獲得 4 元。),要求受試者 試圖最大化獲利。實驗的過程中實驗者唯一告訴受試者的資訊只有「你面前的是. 18.
(28) 兩個不同的獲利方案」 。實驗總共有 36 名受試者,每人有 200 次的選擇機會。結 果發現當其中方案的變異數很大時,人們的行為與隨機猜測間沒有差異(受試者 選擇高獲利方案的比例為 51%)。此實驗告訴我們在作業的變異較大時,決策者 無法得到任何可靠的資訊的情況下,將很難正確的評估各個方案。相關研究也指 出,在實驗進行之初提供給受試者系統結構圖或是對系統的運作加以說明,可以 增加決策者對系統的運作的知識,的確會改善人們的決策品質(如,Young et al., 1992 ; O’neill,1992 ; Größler,1998)。 透過上述的文獻回顧可以發現,不論是作業本身、決策者或是其間的交互作 用,都會對影響人們在動態決策中的表現。接下去我們將討論為何這些因素會對 人的決策行為產生影響,以及人們在動態決策的過程中到底是如何表現的。 動態決策的理論 1.. 情境覺察理論(situational awareness) 人們在一個動態的環境中是如何做決策的呢?Endsley(1995)的情境覺察理. 論中主張,人對情境的覺察分成知覺、理解、規劃三個階段,此三階段都必須耗 費決策者的注意力資源。然而,人的注意力資源有限,無法一次偵測到環境中大 量的資訊,且人的注意力無法持久、容易受到干擾。如在知覺階段,決策者的注 意力資源主要將是用以收集來自環境的刺激,像是駕駛行為中對向的來車、交通 號誌。但來自系統的資訊不一定都是重要的,因此能否適當過濾不相關的訊息, 並掌握重要且關鍵的訊息將影響決策行為是否可以繼續下去。 Endsley 指出將所知覺的資訊加以詮釋並結構化的過程稱為情境理解。情境 理解的正確與否將決定決策者對於整個系統的運作法則是否掌握得宜。當我們能 夠正確掌握系統中訊息間的因果關係,才能知道自己所採取的每一個決策行動可. 19.
(29) 能會產生何種後果。這整個掌系統握現狀、預測未來系統變化的認知歷程構成了 情境覺察的第二個階段,簡單的說,此階段決策者的工作是去推論系統中變項間 因果關係。 然而,可以預測系統的變化不代表決策者知道下一步該怎麼走才能讓系統的 行為滿足決策者所設定的目標。因此,情境覺察理論中,動態決策的第三階段是 人們根據目前系統狀態以尋找達成目標的各種可能方案,並根據這些方案規劃、 評估可能會產生的後果,然後採取行動。此階段人們也可能因應環境的限制發展 出不同的策略來幫助自己進行決策,特別是在時間不容許做仔細的方案評估時, 策略的使用可降低人們的心智負荷,並使方案評估的過程更為迅速。因此決策者 是否能找到有效的策略來進行方案評估將會影響其決策的品質。 Lerch & Harter(2001)曾就情境覺察理論設計認知輔助系統進行研究,希望透 過強化決策者的情境覺察以改善決策時的績效。實驗使用的作業為快遞公司的派 信管理。在他們的實驗二中,操弄的自變項有二,一是受試者在決策的過程中能 否回顧過去的系統參數的變化值與自己曾做的輸入(此變項稱為有、無回饋);研 究的另一變項是受試者能否對決策方案進行模擬測試(此變項稱為有、無前饋)。 此實驗共有 24 個受試者,每個人都分成三天進行共 600 次的決策作業。實驗結 果發現,前饋與回饋的主效果與交互作用均不顯著,但是有非常顯著的練習效 果。若將每天 200 次決策的資料分開來分析後則可發現,在最後一天(第 401~600 次決策)時前饋與回饋兩個變項間出現顯著的交互作用,四個不同的情境下受試 者的決策績效以未如期完成的信件量來衡量時,平均數由大到小依序為:無回饋 -無前饋>有回饋-有前饋>有回饋-無前饋=無回饋-有前饋。根據此研究的 結果我們可以看出,前饋與回饋的效果相同,與沒有任何系統知識的情境相比,. 20.
(30) 均可改善決策表現,但同時擁有決策後果的知識及可對決策的後果進行模擬則對 決策表現並未有額外的幫助,甚至會因為資訊太多而降低決策品質,但推論原因 可能是決策者在每一次的動態作業中對於決策作業的系統結構理解並不完整而 不知該做些什麼才能讓決策績效上升。 Endsley 在他的情境覺察理論中並不認為知覺、理解、規劃三個階段具有絕 對順序性。人們不一定要充分知覺才能理解,也不一定要足夠的理解才能規劃未 來或採取行動,只是若前面的階段若有較好的表現,對後面的階段也會有正面的 影響;相反的,若前一階段的覺察不足,即使在後面的階段提供決策輔助,也不 可能造成正面的影響。 回饋的錯誤知覺(misperception of feedback) Sterman(1994)認為人們之所以在動態的環境中表現的不好是因為人們無法 建構出適當心智模式,因此無法對於系統動態做出適當反應。他認為人們無法在 動態環境中建構出正確的系統模式是來自對系統回饋的錯誤知覺(mispercep- tion of feedback)。當系統較為複雜時,系統中的資訊相對的較多,人們會忽略或無視 系統中的某些回饋,即使這些回饋的訊息非常明顯(如,Brehmer 1995)。特別是 當動態系統中人們的行動與系統實際反應間有時間上的延遲(即決策的後果是在 相隔一段時間後才發生)時,人們往往沒有估計自己先前的反應對於系統造成的 影響,而對情境中的某些現象過度反應,例如:使用網路時人們常常因為網路的 延遲在按下某個按鍵後卻沒有得到反應,便再重複按鍵,造成網路恢復順暢後, 同樣的功能重複的執行了好幾次。 Diehl & Sterman(1995)曾經就系統複雜度對決策行為的影響進行研究。受試 者的作業是管理一個工廠,其目標是配合產品的銷售狀況調整產量將存貨成本最. 21.
(31) 小化。他們在實驗中以系統延遲的時間(0 單位、1 單位、2 單位)與生產影響銷售 的程度(相關係數 0.6、0.3、0、-0.3、-0.6)為受試者內變項進行實驗。系統延 遲的時間是指系統實際反應決策者的決策行為的時間,越小表示變項間的因果時 間越清晰,而生產影響銷售的程度是指提高產品產量會促進或是抑制產品的銷 售,相關係數為正表示生產會促進銷售,將會使系統趨向不穩定;相關係數為負 表示生產會抑制銷售,會使系統趨於穩定。此實驗的受試者共有 17 人,受試者 每作 32 次決策,系統的參數就會改變一次,系統也會被重新初始化。每個受試 者都要進行 480 次的決策(實驗分成三天進行)。作業的過程中所搜集的資料含: 受試者所做的每個決策與所花費的時間、作業過程中的口語資料與筆記資料(作 業開始時會提供受試者紙筆)。實驗結果發現,不同情境下受試者達成目標的程 度明顯較最佳化模型的表現差。當作業難度提昇時,受試者達成目標的程度就會 下降。若從決策時間方面來看,練習會使決策時間顯著的下降,不同的作業複雜 度下受試者所花的時間也有顯著的差異。 當觀察系統延遲時間長的情境下受試者的決策行為時發現,受試者們對於系 統變化會產生過度調整的情形,就好像他們忘了系統要在一段時間後才會對他們 的輸入反應。隨後分析口語與筆記資料時也發現,很多受試者只注意到作業中存 貨的變化而沒有觀察銷售的變化情形,且即使有少數的人注意到銷售的變化也只 有在前面的幾個回合中,這表示即使銷售也是影響存貨的關鍵因素,但是人們卻 不認為那是重要的。不過有趣的是,雖然許多受試者提到他們對於系統延遲反應 的處理感到困難,但是卻只有非常少數的受試者提到他們有感受到生產與銷售間 的關係對存貨水準的維持有所影響,但實際上受試者們達成目標的程度的確受到 生產與銷售間關係的影響,顯示受試者對情境模式的掌握出現很大的困難。. 22.
(32) 此實驗所發現的現象是即使人們事先就知道系統的結構,也知道系統中有延 遲但人仍然無法適當的將此知識反應在決策行為上,Sterman 認為這是因為人們 所建立的心智模式中忽略了這些變項或者沒有正確估計這些變項所產生的影響 所致。其它研究也發現決策者們在動態決策的作業中有對回饋錯誤知覺的現象 (如,Atkins, Wood & Rutgers,2002; Moxnes,2004)。 2.. 控制與預測理論(control & predict theory) 雖然,過去研究的結果幾乎一致顯示出人們在動態情境中表現的很差,然而. 這似乎與生活上的經驗不符。人們在真實世界中進行決策時似乎不像上述研究般 糟糕。的確,幾乎所有動態決策的研究中都發現,人們的決策品質會隨著經驗的 累積而慢慢提升,但由於實驗所進行的練習數過少,如 Moxnes(2004)的研究只 練習了 45 次;或是實驗的重心不在研究學習,因此很少被拿來討論。但不能忽 視的是,人們雖無法準確掌握系統的動態變化,經過重複練習人們卻可以逐漸調 整自己的決策行為以適應環境的變化。換句話說,人們在動態決策作業的表現是 可能透過練習而改善的。即使在動態情境中人們無法準確計算出公式,但是他們 卻可以利用在作業過程中獲得的回饋來改善自己的表現(Hogarth, 1991)。那麼人 們怎麼在動態決策中是如何學習?可以學到什麼程度? Brehmer(1995)根據此觀點試圖發展出一理論架構來解釋決策者們如何利用 回饋來累積經驗而逐漸調整自己的決策行為以適應所處的環境。他認為人們在決 策作業的過程中會發展出兩個內在的子模式來適應動態系統-預測子模式與控 制子模式(如圖一)。控制子模式是根據目前系統狀態與目標狀態之間的差異來計 算出應該要採取的行動,然後根據是否更接近目標值的回饋來修正模式;預測子 模式則是根據目前的系統狀態與計畫中所要採取的行動來預測未來系統的變. 23.
(33) 化,再利用行動後所引起的系統變化與自己的預測相比較,以對模式進行修正。 當人們累積越多的決策經驗,兩個子模式修正的次數越多,此時決策者所建立出 來的心智模型將能夠越準確的預測外在環境的變化並採取正確的決策反應。 Brehmer 強調,人們的決策表現是否會隨練習而進步乃決定於該決策者可以 解釋回饋的程度。若決策者可將回饋解釋的越正確,他未來的表現就會跟著提 升。因此,動態決策中的學習就是決策者逐漸改善其所能解釋回饋的過程。然而, 若人們的學習完全是根據在系統中的經驗與獲得的回饋而來,則每一次練習的學 習都是局部、漸近的,而且所發展出來的知識將很難超越經驗範圍太遠。. 圖 1. 控制理論之結構示意圖. (資料來源:F. P., Gibson, M., Fichman & D. C., Plaut, (1997).Learning in Dynamic Decision Tasks:Computational Model and Empirical Evidence, ORGANIZATIONAL BEHAVIOR AND HUMAN DECISION PROCESSES, 71(1), p.8) 24.
(34) Gibson(1997)為了驗證人們在動態決策中的學習主要是來自於決策經驗的 累積而進行了一個研究,其實驗的材料是管理製糖工廠(Sugar Production Factory 簡稱SPF,在過去的研究中被廣泛的用來研究動態系統的決策行為)。受試者的作 業是管理工廠中的作業員數量,使工廠中糖的生產量可以盡量維持在目標值,目 標值有兩種,分別是3000與5000。實驗中,採用雙目標值的目的是為了使決策者 能累積較豐富的決策經驗,受試者總共要接受600個回合(每天200回合)的訓練, 每隔10回合系統都會被重新初始化(初始值為隨機數值)並且隨機指派300與5000 其中一個目標值。訓練結束後,受試者要依序回答10個用來測試其控制子模式正 確度的問題(問題中提供一個系統狀態與一個目標值,受試者要輸入可達成此目 標的數值)、18個用來測試其預測子模式正確度的問題(問題中提供一個系統狀態 與一個輸入值,受試者要說出系統的輸出值)與40回合用來測試其學習是否可以 遷移的測驗題(與原始作業相同但目標值換成4000或9000)。這三種問題都分成與 先前的決策經驗較相近或是與先前的決策經驗相去較遠的問題情境。實驗結果發 現,人們的決策績效與變異程度都顯著的隨練習而改善;而且不論是在控制或是 預測的問題上,當問題情境與練習時的決策情境較為相似時,受試者們的表現都 顯著好過與練習時的決策情境不相似的問題。此結果顯示,動態環境中學習是局 部、漸進的。但是當Gibson隨後利用類神經網路模擬此一控制與預測的理論架構 並與人們的決策行為相比時發現,類神經網路模型的績效與學習都較人們差,即 使在控制、預測與遷移三種問題的回答上也是如此,這顯示人們不只是單純靠回 饋來學習。 對於上述現象合理的解釋之一是,人類的決策者較類神經的模型擁有更多的 背景知識。Stanley(1989)為了探討人們在動態決策過程中知識狀態的改變,以作. 25.
(35) 業的背景故事、受試者是否被要求對新手進行指導語兩個自變項進行實驗。他使 用製糖工廠與人際關係管理兩種不同的背景故事(決策作業的完全相同)。一半的 受試者被要求在每 10 次決策之後假設自己是老師,要說出如何給新手管理這個 系統的建議。結果發現在人際關係管理情境下,人們的達成目標的程度顯著的較 製糖工廠情境好,而被要求給予新手建議的一組受試者的表現顯著較控制組好。 在分析所收集的口語資料後發現,受試者對人際關係管理的系統變化提出較多合 理的解釋,但在製糖工廠的情境下則相對的較少,甚至有受試者表示無法理解系 統是如何運行的。由於一般而言,人們對人際關係的問題擁有較多的經驗與知 識,這個研究的結果顯示,可發現人們對於系統提出解釋的能力與其擁有的領域 知識有關。換言之,人們是否擁有足以解釋系統變化的知識將左右其在動態決策 作業中所能獲得的學習。 結論 雖然各理論強調的重點不同,但一致認為人們在進行動態決策時須對所處系 統建立一心智模型,此心智模型是人在認識外在特定真實系統的過程中所產生的 一種內在的知識表徵方式。根據決策者所擁有的知識與他在系統中累積的經驗, 此模型會逐漸被修正以正確描述外在真實系統。在對模式修正的過程中,人們對 該真實系統的理解與預測的正確程度會增加,進一步讓決策者懂得根據目標規劃 所應採取的行動。換句話說,人們在動態系統中可隨經驗的累積表現出學習,但 此學習並不完美,尤其是在工作複雜度高的場合更是如此,本研究的目的即在探 討人在動態系統決策中影響學習的幾個因素。 動態決策情境中影響學習的因素 由於動態的決策情境是以時間軸為線索,在不同時點上情境中的各事件的表. 26.
(36) 象不相同,這些事件間可能彼此相關、互為因果,也可能毫無關聯。決策者在整 個決策作業進行的過程中始終都在對情境中變項間可能的關係進行推論,並根據 推論的結果評估方案以下決策,以求趨近目標。因此每一次的決策行為都可視為 相當於一次試誤(trial & error)的經驗,決策者會試圖由這些經驗中去組織、確立 變項間真正的關係,以建立一個可能達成目標的通用法則,稱為情境模式。本研 究認為決策者在動態系統中,心智模式的建立與修正為一歸納推理的歷程,其中 包含對情境的假設性認識,以及透過行為去產生系統變化,以測試自己對系統的 假設性認識是否正確,若不正確則修正自己原先的認識,並再度以實際的行為測 試系統的變化為何,根據此觀點本研究提出三個可能會影響學習的因素,分別 是:長期資訊的輔助、自我回饋、決策與決策間的時間間隔(休息)。 長期資訊的輔助。 在動態決策的情境中,回饋是決策者據以推論變項間正 確關係的資訊來源,所謂回饋是來自於系統或人們本身有助於整合、分析與理解 目前系統狀態的資訊。當決策者採取某個決策行為而改變了系統的狀態,此一改 變後的系統狀態稱為「結果回饋」 。結果回饋對決策者的作用有二:第一、根據 結果回饋推論決策系統中各個變項間真正的因果關係,第二、根據結果回饋決策 者可評估系統的目前狀態並規劃下一個可行的決策方案。然而,要能正確評估系 統的狀態必須對系統中各變項間的關係有足夠的理解,換句話說,決策者在動態 決策作業中的決策品質能夠提升,是因為透過結果的回饋而逐漸發現系統真正的 法則。法則發現的研究中,回饋的立即性是不可或缺的(如,Maddox, Ashby, & Bohil, 2003),尤其在法則較為複雜時,立即的回饋更是扮演了非常重要的角色。 過去動態決策的研究也發現,回饋延遲會對人們的決策績效有相當負面的結果 (Sengupta & Abdel- Hanid ,1993)。另一方面,有關決策輔助的研究(如,Atkins,. 27.
(37) 2002 ; Lerch & Harter, 2001)指出,提供結果之外的資訊(如,系統變化趨勢圖) 有助於改善人們在動態決策作業中的決策表現。然而,過去研究對於結果回饋並 沒有統一、清楚的定義,許多研究所提供的回饋包含了決策結果之外的資訊(如, Atkins,2002,提供受試者決策結果對時間的關係圖作為結果回饋),而延遲回饋 也不單純是人們接受回饋的時間往後延,還同時包含系統的長期資訊,使得立即 提供結果回饋與資訊輔助的效果間混淆不清。假若人們在動態決策環境中的學習 包含了法則發現的歷程,則可推論在有立即結果回饋時,提供系統長期變化的資 訊(如,平均數、標準差、系統變化圖)做為回饋將會是影響決策者學習的因素之 一。 自我回饋的程度。 動態決策中的自我回饋,是指決策者發現依據其所建立 的心智模型對於系統的預測時,所得結果與真實的系統反應間存在差異,而產生 的一連串嘗試去解釋這些差異,並試圖降低自己的預測的不正確性的認知歷程, 此自己的預測與系統的反應間的差異的訊息,可以促使人們發現目前自己對於變 項間關係的假設錯誤所在。自我回饋可由外界提供刺激或是由決策者透過反省、 檢討等過程產生。例如:Škraba(2003)的研究中在受試者進行決策後,會得知另 一位進行相同作業的受試者所有的決策及其決策結果,另外,也會得知所有受試 者決策結果的平均值,此回饋可使受試者有個相對的比較標準,讓他們有更多的 資訊來比較自己的決策表現與他人或母群體間的差異。在 Stanley (1989)的研究 中則是透過要求受試者假裝自己是老師提出給予新手建議的方式促使受試者比 較、解釋自己所形成的情境模式與真實系統表現間的差異。這兩個實驗結果都發 現受試者的決策績效較沒有回饋時好,然而他們並沒有探討自我回饋是如何影響 決策者對於決策情境的學習,因此,本研究推論動態決策情境中的決策者若能對. 28.
(38) 系統進行假設測試(Hypothesis testing),並嘗試對當初的假設與真實狀況間出現差 異的成因作解釋時,將有助於決策者對情境的正確理解。 決策的時間間隔(休息)。 在真實的環境中,短期間進行大量類似決策的情 形並不常見。有些情況下,決策的結果必須等待一段時間後才會顯現,此時決策 者通常會有一段較為充裕的時間觀察、整合、分析與理解決策前後的環境變化。 學習理論中也指出,學習的效果是在練習作業停止的一段時間後才到達高峰,而 且密集學習的效果往往不如分散式的學習(Bource & Archer, 1956)。然而在動態決 策研究的作業設計中,受試者常常要在 1~2 個小時之內進行兩百次左右同質異形 的決策(如,Gibson, 2000),雖然這是考慮到動態決策情境中人們的學習有賴大量 重複的練習才能掌握情境中的動態決策要件,但是在如此密集的練習中,人們不 但沒有時間進行資訊間的整合與分析,而且密集練習的作業設計也與真實環境不 全然相似,可能造成其研究結果低估了人們在動態決策作業中的學習能力。因 此,本研究推論在動態決策的過程中,如加入了適當的休息空檔以暫時解除人們 的認知負荷,將會有助於人們決策品質的提升。 總結 對於動態的決策環境,過去的研究多集中於探討系統複雜度對人們績效的影 響以及如何提供較好的決策輔助,然而,研究結果大都發現人們的表現並不如預 期。另一方面,研究也發現隨著經驗累積人們的決策績效會逐漸提升,這表示經 過重複練習後人們可以獲得學習,本研究認為人們在動態決策中的學習是一個歸 納推論的歷程,因此想進一步檢視在歸納推理的過程中構成學習並發現情境模式 的條件。從學習理論來看,學習的效果需要時間來發酵,因此本研究認為提供休 息可能對學習會產生正面的影響。另一方面,而在法則發現的研究中回饋立即性. 29.
(39) 是發現法則的重要條件,而動態決策研究中對結果的立即回饋若無法進行整合不 同時間點中不同的決策與其所得後果,將不易建立起一橫跨時間軸的情境模式, 在資訊整合的演算與結果呈現上,本研究預測提供長期資訊的輔助將會改善人們 的決策表現。當人們在發現法則時,建立假設並加以測試,再根據測試的結果解 釋並修正自己的假設是一連串自我回饋的認知活動,因此本研究將檢視自我回饋 是否會對人們在動態決策中的學習產生影響。. 30.
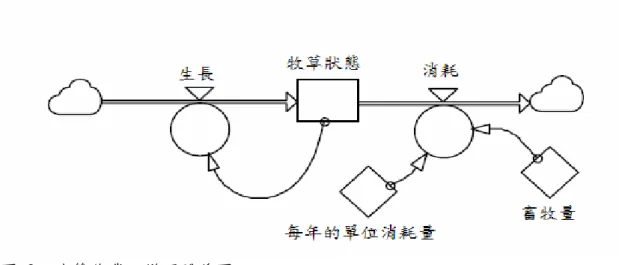
(40) 第三章 方法 受試者 本研究為 2(有資訊輔助、無資訊輔助) × 2(有自我回饋、無自我回饋) × 2(有 休息、無休息)受試者間實驗設計, 2 × 2 × 2 的實驗情境中受試者共 164 人,刪 除無效的資料後餘 143 筆有效樣本。受試者為年紀在 18~33 歲之間新竹交通大 學、清華大學的大學生與研究所學生。 動態決策作業 本研究所使用的動態決策作業修改自 Moxnes(2003)的麋鹿牧場管理系統, 決策者所面臨的為一電腦模擬的麋鹿牧場管理系統,在本作業中受試者將扮演的 牧場管理者的工作。在這個牧場中最重要的因素是麋鹿與牧草,麋鹿是牧場主要 的經濟來源,因此決策者的目標是盡可能飼養最多的麋鹿。然而,牧草是麋鹿冬 天的食物來源,飼養過多的麋鹿會造成牧草耗竭,過少則會使牧草過盛造成浪 費。在這個系統中受試者被允許自由操弄牧群的大小,但是牧草的量只能由自然 生長增加,無法以人工方式干涉。受試者的工作是透過改變牧群的大小以找出牧 草長度與所飼養的麋鹿數量間的最佳平衡點,因此決策者的目標必須轉換為「在 牧草不會耗盡的前提下」盡量飼養最多的麋鹿。 此牧場管理系統中系統動態的主要來源是牧草的長度(單位:mm),其狀態 會因為 生長與 消耗而改變(如圖 2)。本系統是以年為單位來呈現系統狀態的變 化,每一年年初(時間點 t)的牧草長度(Lt;單位:mm)會影響此年度的牧草生長 量(Gt;單位:mm/year),每年的牧草銷耗量則受到該年所飼養的麋鹿數量(Nt; 單位:頭)與每年每隻麋鹿所消耗的牧草長度(h;單位:mm/year)所影響。. 31.
(41) 圖 2. 決策作業之變項關係圖. (資料來源:E., Moxnes, (2003), Misperceptions of basic dynamics: the case of renewable resource management. System Dynamics Review 20(2), p.141) 每年年末所剩餘的牧草長度(即下年年初(t+1)的牧草長度,Lt+1)可用下面的方程 式來計算: Lt +1 = L t + Gt − hN t. (公式 1). 其中 h 為每年每隻麋鹿所消耗的牧草長度。在本實驗中 h 設定為固定值(0.004 mm/year),所飼養的麋鹿數量(Nt)則是由受試者控制。而每年的牧草生長量(Gt) 為該年年初牧草長度的函數(Lt),如圖 3 所示,以數學函式表示為: ⎛ ⎛ ⎜ ⎜L −L ideal Gt = Gmax × ⎜1 − ⎜ t ⎜ ⎜ Lideal ⎜ ⎝ ⎝. ⎞ ⎟ ⎟ ⎟ ⎠. 2. ⎞ ⎟ ⎟ ⎟ ⎟ ⎠. (公式 2). Gmax 表示本系統中牧草年生長量的最大值,Lideal 表示與該最大年生長量相對應的 牧草長度。本研究中將這兩個數值設定為:當牧草為理想長度 30 mm 時,牧草 會有最大年生長量 5 mm/year。如果牧草長度為 0mm 表示牧草被鹿群消耗殆盡, 牧場將會停止運作,作業也就提早結束。另一方面,如果牧草的長度過長(60mm) 則土地無法供給足夠的養分,牧草也會停止生長,不同的是,只要接下去可以飼 養更多的牧群,將使牧草的長度降低,不會造成系統停止。. 32.
(42) 圖 3. 牧草長度與年生長量之關係圖. (資料來源:E., Moxnes, (2003), Misperceptions of basic dynamics: the case of renewable resource management. System Dynamics Review 20(2), p.141) 在開始進行此決策作業前,實驗者會給予受試者足以推導出(公式 1)的文字 性敘述,但不會告知牧草長度與牧草年生長量的關係(公式 2)。受試者以每年一 次進行決策,而 20 年的決策稱為一回合,每一回合的系統會被重新初始化。麋 鹿的初始值是從 500~3000 的數字中隨機決定,地衣長度的初始值則是從 0~60 的數字中隨機決定,這些數字被建立成 20 種不用的初始情境(附錄四),平均分 配給八種不同實驗處理下的受試者。受試者總共會進行 10 回合的決策作業,即 總共會有 20 × 10=200 次的動態決策經驗。 最佳決策 根據上述的系統設定,可計算出牧群的最大可能飼養數量為 Nmax=Gmax/h= 1250(頭),超過這個數字牧草的消耗會大於生長,最後將會導致牧草耗盡,低於 此數字則牧草的生長會大於消耗,將使牧草過長而停止成長,而造成不必要的浪 費。根據所設定的初始條件,最佳的策略(附錄五)可分為兩類: 初始地衣長度大於理想地衣長度時:在此初始條件下,最佳的策略為第一年. 33.
(43) 時輸入會使第 2 年地衣長度為 30mm 的牧群數量,第 2 年之後隨即將牧群數量維 持在 1250 隻,此時地衣的長度會保持在 30 mm。 初始地衣長度小於理想地衣長度時:在此初始條件下,最佳的策略為剛開始 數年不飼養任何麋鹿,直到地衣長度逼近 30mm,再用一年的時間將地衣長度微 調至 30mm,之後隨即將牧群數量維持在 1250 隻,此時地衣的長度會保持在 30 mm。 自變項的操弄 本實驗的所操弄的自變項有三個,分別為:長期資訊的輔助、決策與決策間 的休息、自我回饋的程度。其操作化的方式如下:. 長期資訊的輔助 分為有資訊輔助組與無資訊輔助組。有資訊輔助組的受試者在每回合決策作 業後系統會提供受試者該回合 20 次決策的整體資訊,包含:1.該回合每年的牧 群量與地衣長度。2.該回合牧群數量之平均數與標準差。3.該回合地衣長度之平 均數與標準差。4.該回合牧群量與時間的折線圖表示。5.該回合地衣長度與時間 的折線圖表示。其中第一項資訊會一直呈現在畫面上,第二至第五項則是由受試 者決定是否需要觀看這些資訊,受試者將有 60 秒的時間可以觀看這些資訊(附錄 三)。受試者由第 4、5 項的折線圖可推知,牧群量與地衣長度間的對應關係 無資訊輔助組的受試者,在每回合決策作業之後會進行 60 秒的拼圖作業, 以控制兩種實驗處理下受試者所花費的時間是相約的。. 決策與決策間的休息時間 分為有休息組與沒有休息組。有休息組的受試者每進行一回合(20 次)的動態 決策作業後,有 1 分鐘的休息時間。沒有休息組的受試者每進行一回合(20 次). 34.
(44) 的決策後,將進行 1 分鐘的拼圖作業,以確保在這段時間中受試者的認知系統不 是處於無所事事的狀態。. 自我回饋的程度: 分為有自我回饋組與無自我回饋組。有自我回饋組的受試者在第一回合之後 每回合決策作業開始前,實驗者都會以 2 分鐘的為限,要求受試者進行下列工 作:1.回顧並解釋前一回合的決策過程與心得;2.要求受試者解釋在該期開始前 所做的預測與系統的實際反應間的差異是由何種原因造成;3.說明自己這一回合 決策所欲採取的策略與所預期的系統反應。 無自我回饋組的受試者在實驗的過程中,實驗者不會要求受試者進行任何預 測-解釋的動作,為了使兩組受試者進行實驗的時間盡可能相同,無自我回饋組 的受試者在每期的決策作業完成後,實驗者會要求受試者進行 1.5 分鐘(自我回饋 組被給予兩分鐘進行自我回饋,然而不是所有的受試者都會用完兩分鐘,此處的 1.5 分鐘是係由前測的受試者進行自我回饋的時間估計得來)的拼圖作業,以平衡 兩種不同實驗處理下的實驗所花費的時間。 依變項的評量方式 本研究的依變項是受試者在牧場經營的動態決策作業中的決策品質,在本研 究中由兩個向度來定義決策品質,分別是牧場作業之結束時間點與受試者的決策 偏離最佳決策的程度。其評量的方式分述如下:. 結束時間點 受試者進行牧場管理作業時,可能發生因為飼養過多的麋鹿使地衣消耗殆盡 而使作業提早結束。若受試者在第 t 年時因為錯誤的決策使作業提早結束,則我 們會將該受試者第 t 年輸入的資料刪除,並以 t 作為結束時間的評量。若受試者. 35.
數據



+7






相關文件
To proceed, we construct a t-motive M S for this purpose, so that it has the GP property and its “periods”Ψ S (θ) from rigid analytic trivialization generate also the field K S ,
Students are expected to explain the effects of change in demand and/or change in supply on equilibrium price and quantity, with the aid of diagram(s). Consumer and producer
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
These are quite light states with masses in the 10 GeV to 20 GeV range and they have very small Yukawa couplings (implying that higgs to higgs pair chain decays are probable)..
(A) The drought has authorities worried that the effects of climate change are larger than expected as Australia experiences half of its warmest days on record lately.. (B)
Monopolies in synchronous distributed systems (Peleg 1998; Peleg
This kind of algorithm has also been a powerful tool for solving many other optimization problems, including symmetric cone complementarity problems [15, 16, 20–22], symmetric
(2007) demonstrated that the minimum β-aberration design tends to be Q B -optimal if there is more weight on linear effects and the prior information leads to a model of small size;
