一個監督式學習與非監督式學習技術應用於多國語言文件探勘之比較研究
114
0
0
全文
(2) 一個監督式學習與非監督式學習技術應用於 多國語言文件探勘之比較研究 An Comparative Study of Supervised and Unsupervised Machine Learning Techniques for Multilingual Text Mining. 研 究 生:馬聖 珉 指導教授:李俊宏. Student:Sheng-Min Ma Advisor:Dr. Chung-Hong Lee. 國立高雄應用科技大學 電機工程系碩士班 碩士論文. A Thesis Submitted to Institute of Electrical Engineering National Kaohsiung University of Applied Sciences in Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering July 2006 Kaohsiung, Taiwan, Republic of China 中華民國九十五年七月.
(3)
(4)
(5)
(6) 一個監督式學習與非監督式學習技術應用於 多國語言文件探勘之比較研究. 學生:馬聖 珉. 指導教授:李俊宏博士. 國立高雄應用科技大學電機系碩士班. 摘要 隨著網際網路上多國語言文件的增加,多國語言文件探勘(Multilingual Text Mining)技術的應用成為一個重要的研究課題;透過機器學習方法的處 理下,能有效降低人為處理的時間成本與主觀意識所導致的誤差,因此如 何利用不同種類的機器學習方法(例如監督式學習或非監督式學習)來輔助 完成多國語言文件探勘工作將成為一個重要課題。 本研究針對多國語言文件探勘應用領域分別以監督式學習(Supervised Learning)以及非監督式學習(Unsupervised Learning)的方法來進行系統實現 並量測其效能表現,同時進一步提出了一個結合多語類別中心 (Multilingual Category Centroid) 與 使 用 多 個 單 語 文 件 語 料 庫 (Monolingual Corpora) 在 Latent Semantic Indexing(LSI)空間上的多國語言文件分類方法來解決文件 分類上缺乏訓練語料庫的限制。本研究實驗證實在多語文件分類上以 LSI 為主的方法較 Self-Organizing Maps(SOMs)技術有較好的分類準確度與效 能,包括 Precision, Recall 以及 F1 效能量測。並且 LSI 為主的方法應用於文 件之語意相關性量測上與 Support Vector Machines 的多分類器方法相較之 下,也呈現出較佳的實驗結果。. I.
(7) A Comparative Study of Supervised and Unsupervised Machine Learning Techniques for Multilingual Text Mining. Student: Sheng-Min Ma. Advisors: Dr. Chung-Hong Lee. Institute of Electrical Engineering National Kaohsiung University of Applied Sciences. ABSTACT With the increasing amount of multilingual texts in the internet, multilingual text mining techniques have become an important research issue. Through the processes of machine learning methods, the time costs and bias caused by individual’s subjective viewpoints can be effectively reduced. Thus it is also critical to make use of appropriate machine learning techniques (e.g. supervised learning and unsupervised learning) to assist the multilingual text mining tasks. In this study, we adopt both the supervised and unsupervised machine learning techniques to implement the multilingual text mining applications and evaluate their performance respectively. Meanwhile we propose a novel multilingual text classification approach that combines a multilingual category centroid and several monolingual corpora to tackle the limitations of lacks of training corpora in text mining process. The experimental results show that, for multilingual text categorization the adaptive LSI (Latent Semantic Indexing) technique developed in this research can perform better than SOMs (Self-Organizing Maps) based techniques in terms of performance measures (e.g. precision, recall and F1 evaluation). Also, the adaptive LSI approach for evaluation of semantic relatedness among texts obtained better performance results, compared with those of the SVMs (Support Vector Machines) techniques in the similarity measures.. II.
(8) 誌. 謝. 光陰似箭,歲月如梭,轉眼碩士兩年的努力也畫下了休止符。在此感謝 指導教授李俊宏博士兩年來對學生無怨無悔的指導以及付出,在學生的實 驗以及撰寫論文的過程當中提供了許許多多的意見以及批評,讓學生能夠 順利在碩士兩年完成學業。以及感謝梁廷宇博士在學生入學的時候提供了 完善的訓練過程以及日後不管在學業上以及生活上的許許多多指導與建 議,使得學生在碩士這兩年過得相當充實與快樂。並且要感謝口試委員楊 新章博士在口試時提供學生許多很好的建議與指教,使得學生的碩士論文 漸臻完美。 其次要感謝我的父母無怨無悔的付出與包容,使得學生能夠專心於碩士 的課業上;以及感謝同窗好友廷忠、家禾、良毅、竟閔、傳能、慶鴻以及 學弟妹惠絹、忠謀、聖元以及詠竣在學生遇到困難時給予相當好的意見; 以及女友琇瓔在旁不斷地給予學生支持與鼓勵,使得學生在沮喪的時候給 予相當大的安慰。 最後謹將本論文獻給所有關心我的人們,並希望與你們共同分享這份喜 悅與成果。. 馬聖 珉 謹致於 國立高雄應用科技大學電機工程研究所 民國九十四年七月. III.
(9) 目 錄 摘要 ................................................................................................................................... I ABSTACT ........................................................................................................................II 誌 謝 .............................................................................................................................III 目 錄 ............................................................................................................................ IV 圖 目 錄 ........................................................................................................................ VI 表 目 錄 ........................................................................................................................ IX 第一章 緒論 .......................................................................................................... 1 1.1. 研究背景 .................................................................................................. 1 1.2. 研究動機 .................................................................................................. 3 1.3. 問題領域 .................................................................................................. 4 1.4. 論文架構 .................................................................................................. 6 第二章 相關文獻探討與回顧 .............................................................................. 7 2.1. 單語文件探勘(Monolingual Text Mining).............................................. 7 2.1.1. 監督式學習應用於文件分類 .......................................................... 8 2.1.2. 非監督式學習應用於文件分群 ...................................................... 8 2.1.3. 監督式學習與非監督式學習的差異 .............................................. 9 2.1.4. 監督式學習與非監督式學習相關文獻之探討 .............................. 9 2.2. 多國語言文件探勘(Multilingual Text Mining) .................................... 10 2.2.1. 多語文件探勘的特點 .................................................................... 11 2.2.1.1. 多國語言文件的特徵型態 ............................................ 12 2.2.1.2. 多國語言文件的探勘觀點 ............................................ 12 2.2.1.2.1. 以語料庫為基礎 .................................................... 12 2.2.1.2.2. 以知識庫為基礎 .................................................... 14 2.2.1.3. 多語文件探勘的流程 .................................................... 16 2.2.2. 監督式與非監督式學習技術應用於文件探勘上之相關文獻探討 18 第三章 非監督式學習技術的應用 .................................................................... 22 3.1. 分割式分群技術(Partitional Clustering Techniques)............................ 22 3.1.1. K-Means 分群技術 ....................................................................... 22 3.1.2. Bisecting K-Means 分群技術 ....................................................... 23 3.2. 階層式分群技術(Hierarchical Clustering Techniques)......................... 23 3.2.1. 分裂式階層分群演算法 ................................................................ 23. IV.
(10) 3.2.2. 聚合式階層分群演算法 ................................................................ 24 3.3. 自我組織映射分群技術(Self-Organizing Maps).................................. 25 3.4. 潛在語意索引技術(Latent Semantic Indexing) .................................... 26 第四章 監督式學習技術之應用 ........................................................................ 31 4.1. k 最近鄰居演算法(k Nearest Neighbor) ............................................... 31 4.2. 貝氏分類器(Naïve Bayesian Classifier) ................................................ 32 4.3. 支撐向量機(Support Vector Machines) ................................................ 34 第五章 研究方法與實驗設計 ............................................................................ 39 5.1. 多國語言文件分類器的設計 ................................................................ 39 5.1.1. 多國語言文件資料集合 ................................................................ 40 5.1.2. 多國語言文件的前置處理 ............................................................ 41 5.1.2.1. 文件剖析 ........................................................................ 41 5.1.2.2. 移除停止文字 ................................................................ 41 5.1.2.3. 字幹萃取 ........................................................................ 42 5.1.2.4. 詞彙加權 ........................................................................ 42 5.1.2.5. 特徵選取 ........................................................................ 43 5.1.3. 多國語言文件分類器 .................................................................... 43 5.1.3.1. SOMs 多國語言文件分類器......................................... 45 5.1.3.2. LSI 多國語言文件分類器 ............................................. 47 5.2. 應用多國語言文件分類器進行文件相關性量測 ................................ 51 第六章 實驗成果與比較分析 ............................................................................ 54 6.1. 多國語言文件自動分類 ........................................................................ 54 6.1.1. 語料庫的選擇 ................................................................................ 54 6.1.2. 效能評估的方法 ............................................................................ 55 6.1.2.1. 分類效能評估: ............................................................ 55 6.1.2.2. 文件之間相關性效能評估: ........................................ 56 6.1.3. 多國語言文件分類之實驗設計(LSI,SOMs)與結果分析比較 .... 58 6.2. 應用文件分類技術(LSI,SVMs)於語意相關性量測 ............................ 79 第七章 結論與未來研究方向 ............................................................................ 88 7.1. 實驗結果討論 ........................................................................................ 88 7.2. 章節回顧 ................................................................................................ 90 7.3. 結論與本研究之貢獻 ............................................................................ 91 7.4. 本研究之未來研究方向與重點 ............................................................ 93 參考文獻 ........................................................................................................................ 95. V.
(11) 圖 目 錄 圖 2. 1 圖 2. 2 圖 2. 3 圖 2. 4 圖 2. 5 圖 3. 1 圖 3. 2 圖 3. 3 圖 3. 4 圖 4. 1 圖 4. 2 圖 4. 3 圖 4. 4 圖 4. 5 圖 4. 6 圖 4. 7 圖 5. 1 圖 5. 2 圖 5. 3 圖 5. 4 圖 5. 5 圖 5. 6 圖 5. 7 圖 5. 8 圖 5. 9 圖 5. 10 圖 5. 11 圖 6. 1 圖 6. 2 圖 6. 3 圖 6. 4 圖 6. 5. 監督式學習與非監督式學習的分類圖 ........................................... 7 跨語言文件檢索方法 ..................................................................... 11 標準向量空間與 LSI 語意向量空間的詞彙的分布圖 ................. 18 雙語 LSI 語意向量空間文章與詞彙的分布圖 ............................. 19 Segmented-LSI 示意圖 ................................................................... 19 自我組織映射類神經網路模型 ..................................................... 25 矩陣 Ak 的數學表示法.................................................................... 28 詞彙匯入的數學表示圖 ................................................................. 29 文件匯入的數學表示圖 ................................................................. 30 訓練樣本 2D 分布圖 ...................................................................... 31 測試文件估算 5-NN 分布圖 .......................................................... 32 訓練階段的類別分佈圖 ................................................................. 33 測試文件 di 的類別分佈圖............................................................. 33 SVM 最佳分割超平面(一)............................................................. 34 SVM 最佳分割超平面(二)............................................................. 35 引入鬆弛變數的 SVM 最佳分割超平面 ...................................... 37 系統流程圖 ..................................................................................... 39 多語文件分類─SOMs 系統架構圖 ............................................... 44 多國文件分類─LSI 系統架構圖 ................................................... 45 多國語言文件映射圖(5x5 Map, 2 Category and 2 Language) ...... 46 多國語言文件映射圖(3x3 Map, 2 Category and 2 Language) ...... 46 多國語言文件映射圖(7x7 Map, 2 Category and 2 Language) ...... 47 正相關為基礎的文件中心(Similarity Threshold = 0) ................... 49 負相關為基礎的文件中心(Similarity Threshold = 0) ................... 50 正相關為基礎的文件中心(Similarity Threshold = 0.1736) .......... 51 LSI 文件相關性量測方法 ............................................................ 52 SVMs 文件相關性量測方法........................................................ 53 相似臨界值 0,維度對準確率的影響 .......................................... 58 相似臨界值 0,維度對召回率的影響 .......................................... 58 相似臨界值 0,維度對 F1 的影響 ................................................ 59 相似臨界值 0.087,維度對準確率的影響 ................................... 59 相似臨界值 0.087,維度對召回率的影響 ................................... 60. VI.
(12) 圖 6. 6 圖 6. 7 圖 6. 8 圖 6. 9 圖 6. 10 圖 6. 11 圖 6. 12 圖 6. 13 圖 6. 14 圖 6. 15 圖 6. 16 圖 6. 17 圖 6. 18 圖 6. 19 圖 6. 20 圖 6. 21 圖 6. 22 圖 6. 23 圖 6. 24 圖 6. 25 圖 6. 26 圖 6. 27 圖 6. 28 圖 6. 29 圖 6. 30 圖 6. 31 圖 6. 32 圖 6. 33 圖 6. 34 圖 6. 35 圖 6. 36 圖 6. 37 圖 6. 38 圖 6. 39. 相似臨界值 0.087,維度對 F1 的影響 ......................................... 60 相似臨界值 0.173,維度對準確度的影響 ................................... 61 相似臨界值 0.173,維度對召回率的影響 ................................... 61 相似臨界值 0.173,維度對 F1 的影響 ......................................... 62 維度 100,相似臨界值對準確度的影響 .................................... 63 維度 100,相似臨界值對召回率的影響 .................................... 63 維度 100,相似臨界值對 F1 的影響 .......................................... 64 維度 80,相似臨界值對準確度的影響 ...................................... 64 維度 80,相似臨界值對召回率的影響 ...................................... 65 維度 80,相似臨界值對 F1 的影響 ............................................ 65 維度 60,相似臨界值對準確率的影響 ...................................... 66 維度 60,相似臨界值對召回率的影響 ...................................... 66 維度 60,相似臨界值對 F1 的影響 ............................................ 67 平均準確度 ................................................................................... 68 平均召回率 ................................................................................... 68 宏觀 F1 .......................................................................................... 68 微觀 F1 .......................................................................................... 69 負類別中心-維度 100,相似臨界值對準確度的影響............... 69 負類別中心-維度 100,相似臨界值對召回率的影響............... 70 負類別中心-維度 100,相似臨界值對 F1 的影響..................... 70 負類別中心-維度 80,相似臨界值對準確度的影響................. 71 負類別中心-維度 80,相似臨界值對召回率的影響................. 71 負類別中心-維度 80,相似臨界值對 F1 的影響....................... 72 負類別中心-維度 60,相似臨界值對準確率的影響................. 72 負類別中心-維度 60,相似臨界值對召回率的影響................. 73 負類別中心-維度 60,相似臨界值對 F1 的影響....................... 73 負類別中心的平均準確度 ........................................................... 74 負類別中心的平均召回率 ........................................................... 74 負類別中心的宏觀 F1 .................................................................. 75 負類別中心的微觀 F1 .................................................................. 75 SOMs 的準確率............................................................................ 76 SOMs 的召回率............................................................................ 76 SOMs 的 F1 量測.......................................................................... 77 SOMs 的整合 F1 量測.................................................................. 77. VII.
(13) 圖 6. 40 圖 6. 41. 監督式語意相關性量測架構 ....................................................... 80 非監督式語意相關性量測架構 ................................................... 80. VIII.
(14) 表 目 錄 表 5. 1 表 5. 2 表 5. 3 表 5. 4 表 5. 5 表 6. 1 表 6. 2 表 6. 3 表 6. 4 表 6. 5 表 6. 6 表 6. 7 表 6. 8 表 6. 9 表 6. 10 表 6. 11 表 6. 12 表 6. 13 表 6. 14. 語料庫來源 ..................................................................................... 40 語料庫類別與文件個數 ................................................................. 41 部份停止字元的列表 ..................................................................... 42 字幹萃取的範例 ............................................................................. 42 多國語言文件探勘的方法 ............................................................. 43 二階列聯表 ..................................................................................... 55 SOMs 與本研究方法(正相關類別中心)在藝術類的 F1 評估 ..... 78 SOMs 的整體 F1 評估.................................................................... 78 本研究方法(正相關類別中心)的整體 F1 評估 ............................ 79 奧運相關主題文件之語意向量 ..................................................... 81 總統選舉相關主題文件之語意向量 ............................................. 81 股市相關主題之文件語意向量 ..................................................... 82 颱風相關主題之文件語意向量 ..................................................... 82 金馬獎相關主題之文件語意向量 ................................................. 83 透過距離量測語意向量之間的相關性(SVMs,LSI) ................... 84 透過 Cosine 量測語意向量之間的相關性(SVMs,LSI) .............. 85 透過 Dice 量測語意向量之間的相關性(SVMs,LSI).................. 85 透過 Jaccard 量測語意向量之間的相關性(SVMs,LSI) ............. 86 SVMs 與 LSI 在語意相關性量測的差異.................................... 87. IX.
(15) 第一章 緒論 機器學習(Machine Learning)是泛指電腦透過適當地學習進一步取代傳 統人工的處理工作的相關技術。一般而言,常見的機器學習根據學習方式 的不同可分為兩種,分別為監督式學習(Supervised Learning)以及非監督式 學習(Unsupervised Learning),顧名思義,監督式學習需要受到額外的監督 機制來輔助學習的過程,也就是需要額外的資訊輔助;而非監督式學習則 不需要。機器學習由於學習模式與特性的不同,所延伸出的應用也有所不 同,譬如:常見的監督式學習演算法多半是應用在分類的工作上,而非監 督式學習則是應用在分群的工作上。以文件探勘為例,自 90 年代起機器學 習 已 經 廣 泛 地 被 應 用 於 文 件 分 類 (Text Categorization) 與 文 件 分 群 (Text Clustering)上,更於 2003 年延伸到跨語言文件分類(Cross Lingual Text Categorization)(CLTC)與多國語言文件探勘(Multilingual Text Mining)上。由 於多語文件探勘發展較為後期,不同機器學習的方法在效能比較上的相關 文獻探討可說是相當的少,故本研究將針對監督式學習方法以及非監督式 學習方法應用於多國語言文件探勘做比較研究,以找尋出適合於多國語言 文件分類的機器學習方法。. 1.1. 研究背景. 隨著電子化時代的來臨,數位化文件也同樣地快速增加,如電子書、電 子郵件訊息、電子化新聞以及網頁,隨著數位化資料不斷地充斥於網際網 路當中,使用者面對這茫茫的資料網路中也就開始感到資訊過載,如何從 大量的文件中萃取出使用者有興趣的資訊與知識也就成了一個相當大的挑 戰。因此,在這種情況下必須藉由合適的機器處理方式才能夠有效加速資 料處理的速度,而以機器學習為主的文件探勘技術也就是針對上述問題所 被發展出來的相關技術。 在眾多的機器學習方式中如何選取出切合功能需求的文件探勘技術則 須視探勘目的使用不同的機器學習方法,譬如在文件分類上,由於分類的. 1.
(16) 目的是將文件根據預先定義的類別來進行分類,其過程偏向於監督性的動 作,所以在文件分類上大多數是採用監督式學習的方法;而文件分群上, 由於分群的精神是在於將相似的文件群聚在一起,因此往往是透過比較文 件內的特徵,其過程偏向於非監督式的動作,所以在文件分群上大多數是 採用非監督式學習的方法。常見的監督式學習有貝氏分類器(Naïve Bayesian Classifier) 、 k- 最 近 鄰 居 法 (k-Nearest Neighbor) 以 及 支 撐 向 量 機 (Support Vector Machines);而非監督式學習有產生樹狀結構的階層式分裂演算法和 階 層 式 聚 合 演 算 法 、 K 個 樣 本 中 心 法 (K-Means) 以 及 自 我 組 織 映 射 法 (Self-Organizing Maps)。透過機器學習的方式應用在文件探勘的技術中,監 督式學習與非監督式學習有時候是可以交互使用。例如:非監督式學習的 SOM 透過在群聚的過程中將訓練文件的類別標籤標記於映射圖上就可以應 用在文件分類上,還有非監督式學習的 LSI 透過估算測試文件與訓練文件 的相似程度進一步可應用於文件分類上。如上所述,許多非監督式學習方 法將可應用於分類的工作上。在這種情況下,機器學習則必須透過比較的 方式才能夠有效的評估監督式學習與非監督式學習在分類上的效能差異。 近年來由於網際網路技術發展成熟,使用網際網路的人口也日漸普及。 因此散佈於網際網路上的文字文件已經不再侷限於特定的語言種類,長久 以來由於西方資訊處理技術發展較早,故英文文件在網際網路上一直扮演 著最主要資料來源的語種。然而隨著時代的變遷以及世界潮流的影響,英 文已經不再是唯一的資訊來源,其他語言的使用(如:中文、日文、德文等 等)也逐漸受到了重視。隨之而來的多國語言資料管理也就愈趨困難,因此 有效的多國語言文件組織機制也因此受到了重視,多國語言文件的檢索與 探勘技術的需求也就是在這種環境下孕育而生。不同於單語文件探勘,多 語文件探勘是一個探討複合式文件特徵的研究領域,由於複合式文件特徵 在分類與分群上較單語文件特徵來的複雜且困難,所以必須結合一些解決 語 言 障 礙 的 方 法 , 例 如 Corpus-Based Approach 或 Knowledge-Based Approach 才能有效透過不同機器學習的方法來完成多語文件探勘的工作。 多國語言文件探勘泛指利用不同文件探勘技術於多國語言文件上進行 有效的知識發掘,一般而言,最常見到的多國語言文件探勘為「跨語言文 件分類」,透過跨語言訓練的資料針對多種語言特徵進行學習,在分類時 可將兩個不同語言但卻是相同主題的文件歸類到單一語系的同一個類別 中,以及多國語言文件分類(Multilingual Text Categorization-MLTC),將多. 2.
(17) 種語言的文件透過單一個文件分類系統將具有相關主題的文件分類在一 起。比較兩種不同的多語文件探勘, CLTC 發展在 2003 年,其技術大多基 於 Cross-Lingual Information Retrieval 的方法而進一步延伸,而在多語文件 分類則是屬於一個新的研究領域。. 1.2. 研究動機. 近年來,機器學習普遍地被應用於文件探勘與資訊檢索上,如 SVMs 應 用於文件自動分類與語意相關性量測、SOMs 應用於相似文件群聚以及 LSI 應用於解決詞彙問題的檢索系統上等等,但隨之而來也將影響不同類型的 機器學習方法限定在特定的應用領域上,降低了機器學習方法的彈性。在 群聚研究上具有較好效能的 SOMs,由於透過模擬大腦神經元的分佈能將功 能相近的神經元聚集在某個區域上,致使在進行文件分群的時候會有較好 的效能呈現。而在檢索研究上具有不錯成果的 LSI,由於處理影響檢索效能 的“一詞多義”以及“同義詞”的問題有顯著的效能改善,致使在文件檢索的過 程中能有效地命中相關的文件。如上所述,如果能夠有效地將不同種類的 機器學習演算法應用到其他相關領域當中將有可能產生意想不到的實驗成 果。 在許多應用監督式學習或是非監督式學習於文件探勘的文獻當中,常常 能夠發現實驗在數據的部份往往是針對同一類型的機器學習方法來相互比 較,很少發現會有透過不同機器學習的方法來比較,這可能是因為要保留 演算法的原生性(Native)所導致的結果。然而這種比較往往是必要,由於文 件在處理的過程當中,常常會依據文件自我的特徵或外在給予的標籤來適 應不同環境的需求,也因此在文件探勘的時候常常會交互使用不同類型的 演算法來評量其優異性。譬如在資訊過濾中為了找尋一個適合的資訊過濾 方法,我們必須從分類方法與分群方法下做個抉擇,還有在圖書系統上管 理歸類與未歸類的文件都必須透過不同類型學習演算法的比較來找出適當 的方法等等都是相當典型的例子。 由 於 目 前 多 國 語 言 文件 探 勘 的 重 點 幾 乎 是著 重 多 國 語 言 文 件 分類 [4][1][8][5][28],以致於非監督式學習的方法很少拿來應用在多國語言文件. 3.
(18) 探勘[14][18],如此一來容易使得多國語言文件探勘的發展大多傾向於監督 式學習的方式,導致文件探勘的不平衡發展。在文件探勘的觀點上,不一 樣的機器學習方法其最終目的都是同一個,那就是對文件組織提供一個有 效的解決方式或演算法,如此有效地改良學習方法來因應不同文件探勘領 域將有可能會是未來多國語言文件探勘發展的重心與主軸。. 1.3. 問題領域. 傳 統 的 多 國 語 言 文 件 探 勘 的 方 法 , 由 於 現 有 知 識 庫 輔 助 技 術 (e.g. EuroWordNet, WordNet) 的 發 展 已 經 漸 臻 成 熟 , 使 得 以 知 識 為 基 礎 (Knowledge-Based)的方法來進行多國語言文件探勘已經十分常見,但隨之 而來所要面對的問題亦隨之衍生,其中詞彙之間的一詞多義(synonmny)以及 同義詞(polysemy)問題就是一個非常典型的例子,由於單一詞彙的意義不確 定性將會導致知識庫在翻譯的解讀上將可能導致錯誤的多語詞彙對應,例 如:英文中學校內的班級(class),將可能被翻譯為類別等等問題,使得文件 探勘的效能降低。此外由於大部分的知識庫取得較不容易且操作較為複 雜,所以很難有效的轉移到一些文件探勘的方法之中,如此一來又增加了 以知識為基礎的多國語言文件探勘的困難度。 取代了以知識為基礎的方法,以語料庫為基礎(Corpus-Based)的多國語言 文件探勘方法可有效改善上述詞彙的問題,由於以語料庫為基礎的方法是 基於不同領域的語料庫透過數學中的統計理論(statistics theory)或代數理論 (algebra theory)來針對語料庫進行分析,也因此詞彙之間的關係將會是根據 語 料 庫 中 詞 彙 出 現 的 次 數 (term frequency) 以 及 其 高 階 關 係 (high order relation)所主宰著,不再是透過既有的多語知識庫進行呆板的轉換或是翻 譯,因而可有效的解決詞彙之間的問題。 然而面對到與以知識為基礎的文件探勘方法所同樣遭受到的“知識庫(平 行語料庫)取得不易問題”,將使得缺乏多國語言平行語料庫成為以語料庫為 基礎的致命傷。所以如何有效地透過其他的方法來改良缺乏平行語料庫的 闕失,將可解決多語知識共享困難的問題。. 4.
(19) 綜合上述,我們將多國語言文件探勘的困難與問題歸納如下 (1)對母語的依賴性: 對於大部分的使用者而言多半只熟悉自己的母語(native language),而在 其他的語言方面則無法像自己的母語那麼的熟悉。這種情況將使得在不同 語系的的使用者將有可能面臨到因語言的隔閡所造成資訊交換困難的窘 境,譬如大部分的太空科學文章是由俄文以及英文所撰寫的、汽車工程的 文章是由日文以及德文所撰寫以及一般常見的國際公約是由法文所撰寫等 等。 (2)詞彙之間對照的複雜性: 一般的使用者在遇到陌生的文字時,大多數會藉由字典或百科全書來找 尋解答。但同樣地會面臨到詞彙在轉譯時“一詞多義”以及“同義詞”的問題, 由於詞彙在不同的使用環境下會被解釋成不同的意義,如果沒有一個正確 的意義識別,將會在文字轉譯之前就已經失去文章中原來的意義,也因此 要準確的翻譯更會是難上加難。 (3)平行語料庫的缺乏: 有些學者嘗試著透過使用平行語料庫並結合 Corpus-Based 的文件探勘方 法來解決詞彙之間對照的複雜性問題,但是這種方法將受限於有提供平行 語料庫的領域之下,並沒有辦法有效地且廣泛地應用到一般的生活上。在 缺乏平行語料庫的情況下,要如何建立起文件之中多語詞彙的關係將又會 回到問題(2)的謎團當中。 本研究綜合上述多語文件探勘所會遭受到的問題,試圖開發一個以概念 為基礎(Concept-Based)的方法能夠有效地將非平行語料庫的多語詞彙與文 件建立起關係,透過多語類別中心的概念導引不同語言但相關的文件聚集 在一起,最後經由與不同類型的機器學習的方法來相互比較,量測不同的 學習方法針對多語文件探勘的效能表現並提供一個客觀的實證量測與研 究。. 5.
(20) 1.4. 論文架構 本論文共分成七個章節,在第一章中將描述本研究的研究背景與動機, 並針對問題領域提出解決的方法;在第二章中,將針對監督式學習與非監 督式學習的差異以及單語文件探勘與多國語言探勘發展的近況做詳盡的描 述。在第三章中將詳細介紹現有監督式機器學習的應用;第四章則為非監 督式機器學習的應用;而在第五章將描述本研究所提出的以概念為基礎的 多國語言文件分類架構以及流程包括 SOMs 和 LSI 以及應用 LSI 多國語言 文件分類器的語意相關性量測模型;第六章則比較本研究的方法與其他現 有的方法在進行多國語言文件分類與文件之間的語意相關性量測的效能評 估;第七章則對本研究工作做結論與討論以及本研究之未來研究方面之描 述。. 6.
(21) 第二章 相關文獻探討與回顧 多國語言文件探勘技術是由單一語言文件探勘(Monolingual Text Mining) 技術所衍生出來的,最早發展於 90 年代末期,其目的在於將傳統單語言文 件探勘方法有效地應用到多國語言的文件上,進而萃取出多國語言文件之 間的相關性。 2.1. 單語文件探勘(Monolingual Text Mining) 在探討多語文件探勘之前,本研究首先針對單語文件探勘做個概略性的 回顧,文件探勘根據學習學習大致上分成下列兩種,分別為監督式學習以 及非監督式學習。監督式學習與非監督式學習的主要差異在於監督式學習 的方法在學習的過程中需要透過額外的文件資訊輔助,例如:類別標籤, 而非監督式學習則不需要。由於在文件探勘中所追求目的的不同,文件探 勘常常被分成兩個領域來討論,分別為“文件分類”與“文件分群”。常見的監 督式學習的方法多半是應用在文件分類上,而在非監督式學習的方法大多 應用在文件分群上。以下我們將針對圖 2.1 來說明並且比較監督式學習與非 監督式學習的原理與差異。. 圖 2. 1. 監督式學習與非監督式學習的分類圖. 7.
(22) 2.1.1. 監督式學習應用於文件分類 文件分類,又稱作主題識別(Topic Spotting),是一個使用監督式學習所 構成的研究主題。其目的為針對預先定義的標籤(label)透過已標記的訓練集 合進一步猜測未標記文件的類別可能性。隨著時代的變遷,將機器學習應 用到文件分類上可以在不失分類準確性的情況下取代傳統的人為分類,並 且能夠有效降低時間與經濟成本。文件分類透過數學的表示法可表示為(2.1) 式,. true, d i is assigned to ci di , c j (2.1) false, d i is not assigned to ci. 許多機器學習演算法,例如透過機率模型的貝氏分類器、基於結構風險 最小化的支撐向量機以及 k-最近鄰居法都是被應用在文件分類上。而在不 同分類演算法中,其優異性則是透過準確性(accurary)來評估。準確性根據 Yang 的論文可分成 precision,recall 以及 F-measure,根據不同觀點使用不 同量測方法來檢視效能。上述三個方法的細節將在第六章做討論。. 2.1.2. 非監督式學習應用於文件分群 不同於文件分類,文件分群是一個使用非監督式學習所構成的研究主 題,它不需要預先定義好的類別標籤以及已標記的文件。分群的宗旨在於 聚集高相似性的文件(Intra-group similarities are high),並使得群體與群體之 間產生較低的相似度(Inter-group similarity are low)。 常見的文件分群有使用樹狀結構進行文件群聚的聚合式群聚法以及分 裂式群聚法、以 k 個中心點為基礎的 k-Means 演算法以及結合上述兩種的 Bisecting k-Means。一般被用來量測文件分群效能的方法可分成 Overall Similarity、Purity 以及 Entropy。其中,Overall Similarity 是所有群體的群體 內相似度的總值,Purity 為量測同類別的文件分群到同一群體的比例,而 Entropy 則是量測群體之內文件之間的同質性。. 8.
(23) 2.1.3. 監督式學習與非監督式學習的差異 本研究將兩個不同的機器學習方法的差異歸類如下: (1). (2). (3). (4). 探勘目的的不同:監督式學習應用於文件分類,非監督式學習應 用於文件分群。分類目的為依據預先定義的類別標籤對未標記文 件作分類,而分群目的為依據文件的特徵進行相似性的群聚。 資料來源的差異:監督式學習需大量已經被標記過的訓練文件來 完成機器學習。而非監督式學習不需要任何被標記過的訓練文 件,只要是一般的文件即可。 演算法理論的差異:監督式學習的過程透過特徵向量與標籤來反 覆根據學習函數不斷地學習,以達到使用者預期的目標為止,如 Support Vector Machines。然而非監督式學習屬於自然式學習的方 法,透過代數或統計的方法挖掘出隱藏於資料底下的知識,如 K-Means、SOM 以及被廣泛應用在資訊檢索的 LSI。 評估效能的差異:在文件分類上效能評估的基準是準確度;而在 文件分群上效能評估的基準則為群體內的相似度。而兩種方法應 用在資訊檢索上時,評估的基準則變成排名的命中率(Rank-N)。. 2.1.4. 監督式學習與非監督式學習相關文獻之探討 (1) 非監督式學習應用於文件分群與資訊檢索之文獻探討: 非監督式學習應用於資訊檢索上,較常見的方法就是自我組織映射 以及潛在語意索引(Latent Semantic Indexing),由於自我組織映射是屬於一 個分群演算法,它可以有效將相似的文件群聚在一起以幫助文件在檢索的 時候縮小文件搜尋的範圍。如 Kohonen[13]提出的 SOMs 以及 LVQ,以及 Honkela[9]以及 Kaski[12]在後來所提出的變形 SOMs─“WEBSOM” 都是被 廣泛應用在資訊檢索上。WEBSOM 不同於傳統的 SOM 的地方在於, WEBSOM 透過兩階的 SOMs 來完成文件分群的動作,其中第一個分群為詞 彙群聚,將原來文件向量的元素由詞彙改為以映射圖為基礎的概念來進行 第二個分群,也就是文件群聚。而近幾年還有 Ampazis 所提出將 LSI 技術 導入 SOMs 的 LSISOM 以及導入多語文件探勘的 CL-LSISOM[2]。. 9.
(24) (2) 非監督式學習應用於文件分類之文獻探討: 非監督式學習應用於文件分類上必須透過額外的改良才能夠有效 的被應用。例如 SOM 應用於文件分類上的變形;SOM 是一個將相似文件 群聚在一起的演算法,透過在映射圖產生的過程中將原來的訓練文件替換 成已經標記的訓練文件,因此在映射圖上的每個座標點將會被多個類別所 標記,在一個座標點一個類別標籤的情況下,主宰該點的類別將是訓練樣 本點個數為最多的類別,如 Wermter[34]所提出的自我組織分類。另外 LSI 應用於文件分類上,首先必須將測試樣本與每個類別的所有訓練樣本作相 似性的評估,而獲得最高相似度的類別將指定給測試文件。將 LSI 應用於 文件分類的文獻有 Liu[17]的 Local LSI 方法、Zelikovitz[37]的結合背景知識 的 LSI 以及 Sun[30]的監督式 LSI 等等。. (3) 監督式學習應用於文件分類之文獻探討: 監督式學習,如同 2.1.1 所描述的,是一個被使用在文件分類上的 學習方法,而 k-NN[19]、貝氏分類器[19]以及 SVM[10][31][32][33]都是常 常被拿來做比較的對象,當然其文獻的記載也是相當多的。其中,三個方 法主要差異為,k-NN 是一個以樣本空間為基礎的分類方法、貝氏分類器則 是一個以機率模型為基礎的分類方法而 SVMs 則是基於結構風險最小化的 類神經模型。. 2.2. 多國語言文件探勘(Multilingual Text Mining) 在探討多國語言文件探勘之前,我們先透過 Oard[23]所提出的跨語言文 件檢索方法來做初步的介紹。. 10.
(25) 圖 2. 2. 跨語言文件檢索方法[23]. 由於多國語言文件探勘與跨語言文件探勘在系統架構上極為類似,故引 用圖 2.2 來做介紹。針對多國語言文件探勘技術與跨語言文件探勘技術,其 差異點在於多國語言文件探勘的精神為透過探勘單一語系資料可獲得多種 語系文件的相關資訊,而跨語言文件探勘所獲得的相關資訊僅能涵蓋兩種 語言,換言之,跨語言文件探勘只是多國語言文件探的其中一個特例。 以下首先將針對多國語言文件探勘的特點做介紹,並闡述目前多國語言 文件探勘的研究概況,針對先前研究的缺失進而提出本研究的方法來加以 改善,並且其他方法相互比較。. 2.2.1. 多語文件探勘的特點 多語文件探勘不同於單語文件探勘的地方主要是在特徵型態的不同,兩 個語意相關的詞彙因為語言的不同將會使得該詞彙之間彼此相互獨立。如 何 解 決 這 個 問 題 將 必 須 透 過 不 同 探 勘 觀 點 的 方 法 (Corpus-Based or Knowledge-Based)來有效解決,並評估其實用性與可行性。因此,多國語言 文件探勘不只在文件前處理不同於單語文件探勘,在探勘的過程中也會有 所差異。以下將針對特徵型態與探勘觀點來詳細的介紹。. 11.
(26) 2.2.1.1. 多國語言文件的特徵型態 在文件探勘的過程中,首先必須要進行的就是特徵萃取(Feature Extraction),在此可分為兩種特徵萃取的策略,第一個策略為使用受控制的 詞彙集合(Controlled Vocabulary)為特徵做萃取,此種方法的成本較高,因為 此方法是採用人工選取的方式將文件經由預先定義的詞彙集合成為索引, 由於透過人工的方式來進行故在文章的表示上可有效減低一詞多義 (polysemy)在效能上所造成的損失。一般而言,在多國語言文件探勘中,受 控 制 的 詞 彙 集 合 方 法 是 將 文 章 透 過 多 國 語 言 百 科 全 書 (Multilingual Thesaurus)將每篇文章用一個以概念為基礎(Concept-Based)的向量來表示, 取代原本以詞彙為基礎(Term-Based)的向量。此方法的主要缺點是需要透過 人工的方式來建構詞彙集合及將文件就進一步的轉換,相較於一般的方法 較費時費力,在維護方面也比較麻煩。第二個策略是使用文章中所出現的 詞彙、片語做為文件集合的詞彙集(vocabulary),也就是所謂全文(Full Text) 的方法也或稱做自由文字(Free Text)的方法,全文的方法剔除了使用多國語 言百科全書的技術而改用直接以詞彙為基礎來表示文字文件,由於剔除了 使用百科全書的技術,在整個文件特徵萃取的過程可完全的自動化。在兩 種策略當中,全文的方法較受控制詞彙集的方法常被使用,除了可完全自 動化的原因外,主要是因為其容易實作的特色,也因此吸引了大部分研究 文件探勘的人廣泛的使用。. 2.2.1.2. 多國語言文件的探勘觀點 從多國語言文件的探勘觀點出發,兩個或多個不同語系的詞彙或片 語該如何建立起關連,將主宰著多國語言文件探勘的效能表現。不論是以 文件分類技術(Text Categorization)或是文件群聚技術(Text Clustering)來進 行文件探勘工作,大致上可分成兩種方法,第一種稱做以語料庫為基礎 (Corpus-Based)的方法;第二種稱做以知識為基礎(Knowledge-Based)的方法。 2.2.1.2.1.. 以語料庫為基礎. 以語料庫為基礎的文件探勘技術係指針對不同的語料庫集合建立 一個以領域導向(domain-specific)為基礎的的文件向量,換言之,以同樣的. 12.
(27) 詞彙所建構的文件將會根據不同領域語料庫的選擇將會對文件向量產生不 一樣的詮釋,也就是說“多國語言詞彙之間的關聯性並非是絕對的”,例如: computer 和 calculator 在金融領域可能相似度很高,因為它們都是拿來做數 值計算,但是在電腦科學就有可能將它視為是不一樣的物件。一般來說, 單一語言的語料庫取得容易,可從各大入口網站(Yahoo!、MSN 或 Sina)的 新聞取得,但是針對探討同一主題的多國語言平行語料庫取得就比較困難 些,例如:科學人雜誌,時代雜誌以及光華雜誌等等。大致上被應用於多 國語言探勘的語料庫可分成三種: (1)平行語料庫(Parallel Corpora) 平行語料庫是將一定數量的文件經由專家對該文件進行多種語言 翻譯所組成的集合,其中文件向量是由多種語系的詞彙所組成的,例如: 中英文平行語料庫內有 10 個中文詞彙,同樣的該篇文件會有 10 個英文相 對應的詞彙,由於他們大多數都是多語對照,故稱做平行語料庫。針對平 行語料庫對齊的型態,大致上可分成三種,文件對齊式(Document -aligned)、 句對齊式(Sentence-aligned)以及詞彙對齊式(Term-aligned),至於更加詳細的 還有細分成:段落對齊式(Paragraph-aligned)、區段對齊式(Segment-aligned) 以及字元對齊式(Character-aligned)。一般較常見的對齊方法是句對齊式。 (2)可比較的語料庫(Comparable Corpora) 由於一般的平行語料庫取得較不容易,且文章的來源可能只侷限於 某個特定領域(人文、科學),導致其應用將可能受到了限制,透過可比較的 語料庫替代了平行語料庫可進一步改善上述的缺失。何謂可比較的語料 庫?其定義如下: 【一群探討同一個主題但卻使用不同語言做描述的文章集合,稱為 可比較的語料庫】 舉例來說:震撼全球的恐怖攻擊活動 911,在當下全球不同的新聞 社使用不同的語言描述了美國世界貿易大樓遭被恐怖份子挾持的飛機迎面 而撞上的新聞,這就是一個很典型的多國語言可比較的語料庫。由於可比 較的語料庫在文章的對齊上並沒有直接對照的關係,所以應用在文件探勘. 13.
(28) 時效能往往會比平行語料庫低一點。 (3)單一語言語料庫(Monolingual Corpora) 單一語言語料庫替代了上述的兩個語料庫,單一語言語料庫是由多 個單一語言語料庫所組成的。由於散佈在世界各地的文章大多數只探討著 本地的社會現象、教育發展與科學研究等等,所以往往無法提供一個跨地 域性相同主題的文章,因而只應用於單語文件探勘的領域內。為了使得這 些文章能夠被應用於多國語言文件探勘的領域,可透過一個半監督式學習 將文章根據其預先記載的資訊給予一個語言中立(Language-Neutral)標記, 進而可以達到多國語言資料探勘的目的。 2.2.1.2.2.. 以知識庫為基礎. 以知識為基礎的多國語言文件探勘是利用現有的多語知識庫— 例 如“雙語辭典”以及“雙語百科全書”等等來解決多國語言文章的翻譯問題,由 於透過翻譯的方式來解決語言之間的障礙,所以可採用一般單一語言文件 探勘的方法來進行多國語言文件探勘。其中以知識為基礎的方法又可分 做 : 以 字 典 為 基 礎 (Dictionary-Based) 的 方 法 以 及 以 百 科 全 書 為 基 礎 (Thesaurus-Based)的方法 (1) 以字典為基礎 以字典為基礎的多國語言文件探勘方法是轉換多種不同的語言至 單一型態的語言來進行探勘,而通常轉換的對象多半是詞彙對詞彙(term by term)的翻譯。因為詞彙之間往往存在著一詞多義或同義詞的問題,所以在 翻譯的過程中可能會出現一些文不切題的情況出現,如何克服因翻譯過程 而產生的不相關詞彙的問題,很多研究也朝著這個方面努力。我們將以字 典為基礎所可能遇到的問題分成兩類: 《1》一詞多義與同義詞的問題: 一詞多義和同義詞不管在資訊檢索或文件分類都是影響效能展現 的重要因子。由於一詞多義在文件分類會使得由同型異義不相關的詞彙所 組成的文件被分類為相關,導致系統的精確度(precision)降低;另外,同義. 14.
(29) 詞可能因為使用不同字彙描述相同主題使得系統無法正確辨識該兩篇文件 為彼此相關,致使系統的召回率(recall)下降。 《2》缺少具有正確翻譯的機制: 一般的多語辭典並沒有辦法涵蓋所有領域的專有名詞,使得在文件 翻譯的時候找不到適當的對照詞;同樣地,因個人書寫文章的方式不同, 在慣用俚語與縮寫的使用將會造成雙語字典無法正確的翻譯。由於兩個因 素將會降低整個探勘的效能結果。 (2) 以百科全書為基礎 不同於一般以詞彙為基礎的文件探勘,使用百科全書進行文件探勘 所獲得的是一個以概念為基礎的輸出,透過概念可有效地減少因詞彙所導 致一詞多義與同義詞的問題。一般典型的以百科全書為基礎的方法就是 WordNet。 《1》WordNet: WordNet 1.5 是一個由英文詞彙資料庫所組成的線上詞彙參照系統 (Online Lexical Reference System),當中記載著英文辭彙之間的語意相關性 (semantic relation),並且將相關的字彙建立連結。其中 WordNet 只處理四種 詞彙類別:名詞(nouns)、動詞(verbs)、形容詞(adjectives)以及副詞(adverbs), 並將詞彙之間的連結分成了四種型態: 一、同義詞(Synonymy):由多個相同意義的詞彙所組成,在 WordNet 裡面我們稱他叫做同義集合(synset)。 二、上義詞/下義詞(Hypernymy/Hyponymy):上義詞為該詞彙更為 廣泛的詞彙,例如:Tree is a kind of woody plant;下義詞為該詞彙更為細分 的詞彙,例如:Maple is a kind of tree。一般而言,下義詞擁有上義詞的所 有特性,並且會加入至少一個可以辨認的特徵來識別下義詞的詞意。. 15.
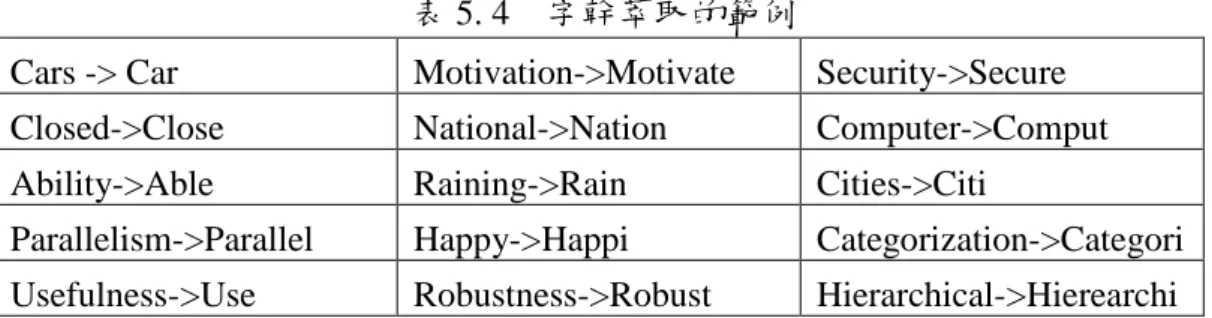
(30) 三、完全/附屬關係(Holonym/Meronym):完全關係(is a part of)就是 該詞彙屬於完全關係詞彙的一部分,例如:tree is a part of forest;附屬關係 則是附屬詞彙是該詞彙的一部分,例如:tree truck is part of tree。 四、反義詞(Antonym):反義詞為該詞彙相反意義的詞彙,例如: Love is antonym of hate。 此外在歐洲已經有一群學者發展了一個多國語言的 WordNet,稱作 EuroWordNet,當中包含了四種語系的詞彙資料庫分別為 Dutch(荷蘭文)、 Italian(義大利文)、Spanish(西班牙文)以及 English(英文)。 Corpus-Based 與 Knowledge-Based 方 法 的 主 要 差 異 在 於 Corpus-Based 多國語言文件特徵是需要透過額外的語料庫分析與統計方可 建立起詞彙之間關係;相反的,Knowledge-Based 則是透過類似多語辭典或 百科全書的方法將所有不同語言的詞彙轉換至單一語言的詞彙,進一步建 立起詞彙之間的關係。. 2.2.1.3. 多語文件探勘的流程 文件探勘不管是單語文件還是多語文件,其流程主要分成三個階 段,分別為文件的前處理(Text Preprocessing)、文件探勘程序(Text Mining Process)以及探勘結果的分析(Result Analysis)。 (1)文件的前處理: 文件的形成大多是由字元(character)、詞彙(word)以及符號(symbol) 三個元素所組成,但並非所有的元素都主宰著文章的表現,唯有“詞彙”足以 成為一篇文章的特徵,如何從一篇文章中萃取出有意義的詞彙將會是文件 探勘中一個非常重要的步驟。文件的前處理大致上可分成三個子程序分別 為 : 特徵萃 取 、特徵 選取 (Feature Selection)以及文 件的表示 (Document Representation)。其中前兩個步驟是為了選擇該語料庫內關鍵的詞彙,第三 個步驟是將文章以一個數學向量來表示。. 16.
(31) 特徵萃取的目的是為了過濾詞彙中的雜訊(無意義的辭彙,如冠詞、 be 動詞以及助動詞)並使用 stemming 演算法[26]保留詞彙中的主要字幹(去 除詞彙的時態、單複數與變形詞)。由於中文詞的時態與單複數並不會表現 在詞彙上,所以中文系統並沒有 stemming 演算法。 特徵選取是將已萃取的特徵根據語料庫所提供的資訊,進一步過濾 掉常用但不具鑑別能力的詞彙,最常見的過濾方法是文件頻率(Document Frequency)的設定,一般而言假設一個詞彙出現超過 90%的總文件量,那該 詞彙可能是該領域的共用字(common word),或是該文件出現在文章的頻率 過低,例如:文件頻率只有一,那麼該詞彙將成為該語料庫的雜訊詞彙。 透過這樣的作法,將可以有效減低文件向量的維度。 文件經過特徵萃取與特徵選取後,下一步將把文件根據選取後的特 徵向量化。文件依據在詞彙列表(term list)的詞彙逐一地進行權重的配置, 最常見的 Weighting Scheme 有詞彙頻率(TF),二元權重(Binary Weighting) 以及詞彙頻率乘以文件頻率的倒數(TFIDF)。經過權重的配置後,文章將形 成一個以詞彙為基礎的文件向量,最後將所有在語料庫的文件向量結合在 一起形成一個 Term-Document 矩陣,也就是所謂的向量空間模型(Vector Space Model)。 (2)文件探勘程序 文件探勘依據不同的目的會有不同的探勘方法,最常見的文件探勘 有文件分類(Text Classification)、文件群聚(Text Clustering)以及資訊檢索 (Information Retrieval)。基於向量空間模型,各種演算法將對此模型進行不 同目的的文件探勘,所得的結果也將有所差異。 (3)結果分析: 針對文件探勘中文件分類與文件群聚的結果,大多數評估其優異性 的方法為量測系統的精確度、召回率以及 F-量測。而在資訊檢索的效能評 估上大多藉由相似性(similarity)量測來完成。相似性量測最常被使用的方法 有 cosine,dice 以及 jaccard 等方法。. 17.
(32) 上述三個過程的將會於第三章與第四章做更詳盡的描述。. 2.2.2. 監督式與非監督式學習技術應用於文件探勘上之相關文獻探討 (1)非監督式學習應用於多(跨)國語言文件檢索文獻探討 檢索理論最早起源於 1957 年 Fredrick Jonker 的研究,之後於 1975 年 Salton[39]進一步提出了文件索引向量。到了 90 年代,Dumais, Littleman 以 及 Landauer 等人開始將資訊檢索擴大到多國語言資訊檢索的領域,較著名 的研究也就是 CL-LSI[6],往後許多研究[27] [20] [21]都是基於 CL-LSI 所衍 生出來。 Dumais, Littleman 以及 Landauer 於 1996 提出了將 LSI 技術應用到多國 語 言 ( 英 語 與 法 語 ) 的 方 法 , 稱 作 Cross-Language Latent Semantic Indexing(CL-LSI),此方法利用 Latent Semantic Analysis(LSA)的分析方法, 將平行語料庫的向量空間模型透過奇異值分解後獲得一個語言中立的語意 表示法,任何文章與詞彙都可透過語意空間的映射進而可量測出彼此之間 的語意相關性。圖 2.3 為原始以詞彙為基礎的向量空間與 LSI 語意向量空間 詞彙與文件的分布圖,圖 2.4 為在雙語 LSI 語意空間詞彙與文件的分布圖 (EFDoc 訓練的雙語文件向量,)。. 圖 2. 3. 標準向量空間與 LSI 語意向量空間的詞彙的分布圖[6]. 18.
(33) 圖 2. 4. 雙語 LSI 語意向量空間文章與詞彙的分布圖[6]. Rehder 與 Dumais[27]等人隔年將原本使用兩種語言的平行語料庫延伸至 三種語言(英文、法文與德文)的平行語料庫,透過實驗數據的展現,同樣地 也獲得很好的效能。 Mori[20][21]針對 LSI 處理因矩陣過大而無法計算的特性,發展了一個切 割式 LSI(Segmented-LSI)專門處理龐大資料量的多國語言平行語料庫。Mori 在進行 SVD 分解前,先將龐大的多語平行語料庫切割成 N 個子集合,之後 分別進行 CL-LSI 分解產生 N 個語意空間。當 Query 進行檢索時,透過 SVD 的 fold-in 方法,將 Query 送至這 N 個語意空間進行映射,最後選取擁有相 似 性 最 高 的 子 集 合 的 文 件 集 合 進 行 Relevant Feedback 。 圖 2.5 為 Segmented-LSI 的示意圖。. 圖 2. 5 Segmented-LSI 示意圖[21]. 19.
(34) Nie[22]在 SIGIR’99 會議中提出了另外一個思維,由於透過機器翻譯與 雙語字典(bilingual dictionary)的方法將有可能因為一詞多義的問題導致錯 誤的翻譯,所以 Nie 提出一個以 Corpus-based 的方法取代 Knowledge-Based 的方法,Nie 透過機率翻譯模型(probabilistic translation model)去估算在平行 語料庫中可能的跨語言配對文章(cross-language mate),並加以將此方法延伸 到在 Web 上的自動平行語料庫挖掘(automatic mining of parallel text)。 Ampazis[3]提出一個方法利用單語文件檢索中常用的 LSISOM,並將其延伸 到多國語言的領域,透過結合 LSISOM 與平行語料庫,發展了一個相較於 CL-LSI 更為傑出的技術 CL-LSISOM。. Gilarranz[7]提出了一個基於 EuroWordNet 詞彙資料庫的概念性文件檢索 方法;Wim[35]透過叢集演算法將多國語言的 EuroWordNet 根據不同的概念 作分群的動作;Steinberger[29]使用受控制的詞彙集合來編碼文件並結合 Eurovoc 百科全書將多國語言文件集合完成自動索引的動作。. (2)非監督式學習應用於多國語言文件分類文獻探討 Bel、Koster 以及 Villegas[4]在 2003 年 ECDL 會議上提出了一個不同於 多 ( 跨 ) 語 言 資 訊 檢 索 技 術 的 跨 語 言 文 件 分 類 (Cross-Lingual Text Categorization)技術,簡稱 CLTC,當中 Bel 提出了在 CLTC 中針對不同的 訓練策略將會影響文件分類的效能的兩個實例,分別為多種語言訓練策略 (Poly-lingual training)以及跨語言訓練策略(Cross-Lingual training);多種語言 訓練策略是使用超過一種的語言的文件集合做為分類器訓練文件的來源, 在測試時可同時分類多種語言文件透過單一個分類器,然而跨語言訓練策 略是透過單一語言的文件作為分類器的訓練資料源,在測試時,其他語系 的文件必須先由機器翻譯(MT)的方法將測試文件轉換至訓練文件的語言之 後再透過分類器完成分類的工作。Bel 在此篇論文中,使用了 Rocchio 分類 器與 Winnow 分類器作為此實驗的主要分類技術,並比較兩種分類器的效 能展現。在語料庫來源則由國際勞工組織(International Labour Organisation) 提供,其中包含了三種語言的文件,分別為英文,西班牙以及法文,其主 要內容是在談論有關大會的組織、批閱的資訊、專家委員會的意見等相關. 20.
(35) 文章。Chau[5]提出了一個使用類神經網路模型的方法進行階層式多國語言 文件分類。Chau 為了避免 MT 所產生的雜訊,將平行語料庫中的詞彙使用 自我組織映射的方法進行詞彙群聚的動作,將多語相關的詞彙群聚在一 起,並由概念來表示相關的多語詞彙,之後將文件使用這些概念重新編碼, 產生了一個語言獨立的文件表示法。為了針對使用者習慣於階層式導覽的 習慣,在分類前會先使用階層式群聚的方法將文章做階層式分類,最後透 過三層前餽式網路將文件完成分類的動作。. (3)監督式學習應用於多國語言文件分類文獻探討 Adeva 與 Calvo[1]為了改善於多語文件分類前須先透過機器翻譯將測試 文件轉換至特定的語言的缺點,設計了一個以 N-Gram 為基礎的語言識別方 法。在測試文件分類前首先必須先辨識語言種類,在根據不同語種的分類 器進行分類。Adeva 在這篇論文中評估了貝氏分類器、kNN 分類器以及 Rocchio 分類器在效能上的展現。Gliozzo 與 Strapparava 針對醫學類與電腦 科學類文章提供一個跨語文件分類的方法,並以可比較的語料庫作文訓練 分類器的來源。由於平行語料庫的來源獲得不易,Gliozzo 透過可比較的語 料庫結合 Support Vector Machine 並引入 Multilingual Domain Kernel 的方式 解決在兩種語文上面分類的困難。Rigutini 與 Maggini[28]為了解決缺乏平行 語料庫而難以建構跨語言文件分類系統的問題,提出一個以 EM-Based 的學 習演算法,並應用在貝氏(Bayesian)分類器。Rigutini 首先將在 L1 語言的訓 練文件轉換至測試文件的 L2 的語言,經過貝氏分類器學習由 L1 轉換至 L2 的訓練文件。透過已學習的貝氏分類器分類 L2 的測試文件集合,由於在機 器翻譯的過程中會產生雜訊(翻譯後意義錯誤),故必須根據分類結果的收斂 狀況選擇性地執行 EM 程序,直到分類的結果收斂為止。其中在特徵選取 的過程中,Rigutini 使用了 Informaiton Gain 的方法選取富有資訊(Rich Informative)詞彙。最後根據類別個數,複製此方法至不同的 N 個類別即可 產生 N 個跨語言文件分類器。. 21.
(36) 第三章 非監督式學習技術的應用 非監督式學習的主要精神在於機器學習的過程中不需要透過額外的知 識或者人工的介入即可完成。資料群聚就是一個非常典型的非監督式學習 的例子。一般我們將群聚演算法分成三種,分別為分割式分群演算法、階 層式分群演算法以及自我組織映射分群演算法。另外我們在非監督式文件 分類技術額外引入潛在語意索引來探討。. 3.1. 分割式分群技術(Partitional Clustering Techniques) 分割式分群演算法是產生一個非巢狀且非重疊的文件分割。其分群的方 法大致上可分成下列兩個步驟,首先指定分群的個數 n,且初始化(隨機選 取 n 個點,並設為中心點)。第二個步驟,針對每個文件與中心點不斷的調 整自己到最適合的群聚裡。大部分評估群聚的優異是採用每個文件點到中 心點距離平方和,距離平方和愈小愈好,如(3.1)式。. e j i j1 ( xi x j ) 2 n. (3.1). (3.1)式稱作目標函數(objective function),其中{x1,x2,… ,xnk}為第 j 群的文 件,ej 為第 j 群的平方錯誤值,xj 為第 j 群的中心文件,nj 為第 j 群的文件個 數。常見的分割式分群演算法可分成兩種: 3.1.1. K-Means 分群技術 K-Means 演算法又稱做 Forgy’s Algorithm,其概念為群體可以一個 中心向量來表示,而中心向量為該群文件向量的平均。K-Means 分群方法 主要是重複下列兩個步驟: <1> 重新指定所有文件至他們最近的中心點(centroids) <2> 根據被分配的文件,重新計算群聚的中心點. 22.
(37) 在開始執行上述步驟前,會先指定 k 篇文件作為群聚的中心點,之 後上述步驟開始執行直到重新指定不再發生時。群聚的中心向量如(3.2)式, d 為文件向量,|C|為在群聚內文件的個數。. c. . d C. d. C. (3.2). 3.1.2. Bisecting K-Means 分群技術 Bisecting K-Means 不同於基本的 K-Means 演算法的地方在於, K-Means 是預先找出 K 個點作為群聚的中心點,之後不斷的調整中心點; 而 Bisecting K-Means 則 是結 合 Hierarchical Clustering 以 及 Partitional Clustering,一開始先將群聚分成兩類(K=2)針對這兩個群聚執行 K-Means 的微調,找出最佳的中心。將最大樣本點的群聚,或最小“總相似性”(overall similarity)的群聚做切割,並重複上述步驟直到預期的 K 群產生為止。. 3.2. 階層式分群技術(Hierarchical Clustering Techniques) 階層式分群技術產生了一個階層式群聚,也就是樹狀的分群。其中,階 層 式 分 群 技 術 可 分 類 成 分 裂 式 (divisive)( 由 上 至 下 ) 以 及 聚 合 式 (agglomerative)(由下至上)。 3.2.1. 分裂式階層分群演算法 分裂式分群技術是從樹狀結構的頂端(所有樣本組成的群體)開始, 將最大的群聚(直徑最大)一分為二,一直重複不斷的分裂,直到停止條件成 立為止。最大半徑定義如(3.3)式. D(Cluster ) . max. xCluster , yCluster. d ( x, y ). (3.3). 分裂分群演算法可分為下列幾個步驟 <1> 在樹狀的頂端,整個文件集合視為一個群體. 23.
(38) 在現有群體中,找出最大直徑的群體 A 針對 A,找出最不相似的一點 z 由 z 點分裂出一個新的群體 B。剩餘在群體 A 的樣本數為 N 計算剩餘樣本距離 A 與 B 的距離,將每個剩餘樣本歸類至最 短距離的群體中 <6> 若群體個數達到停止條件則結束分群,否則回到步驟二 <2> <3> <4> <5>. 3.2.2. 聚合式階層分群演算法 聚合式分群技術與分裂式的方法相反,聚合式分群是由樹狀結構的 末端(單一文件)開始,將每一篇文件視為是一個獨立的群體,聚合兩個具有 最短距離的群體,並反覆執行直到停止條件成立為止。 聚合式分群技術可分為下列幾個步驟 <1> 將文件集合的每一篇文件形成為單一個群體 <2> 找尋所有群體之間最近的兩個群體,將其聚合 <3> 若群體個數達到停止條件則結束分群,否則重複上述步驟 在“最近的兩個群體”的定義:我們可分成下列三種 <1>單一連結式(single-linkage):群體之間的距離可定義為“不同群體 中最近兩點間的距離”。 d (C i , C j ) min d ( x, y ) xci , yc j. (3.4). <2>完全連結式(complete-linkage):群體之間的距離可定義為“不同 群體之間最遠兩點間的距離”。 d (C i , C j ) max d ( x, y ) xci , yc j. 24. (3.5).
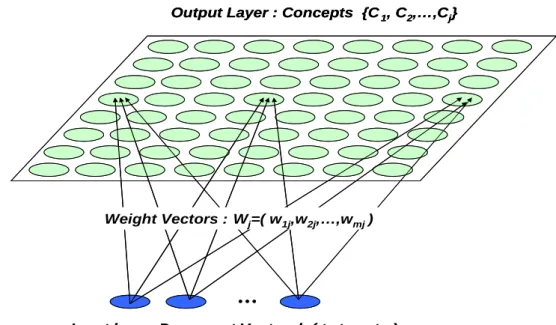
(39) <3>平均連結式(average-linkage):群體之間的距離可定義為“不同群 體間各點與各點間距離總和的平均”。(3.6)式中,Ni 表示為第 i 群體文件總 數,Nj 則為第 j 群體文件總數。 d (C i , C j ) . 1 d ( x, y ) Ni Nj xci , yc j. (3.6). 3.3. 自我組織映射分群技術(Self-Organizing Maps) 自我組織映射(SOMs)是由 Kohonen 所提出的一個群聚演算法,是屬於類 神經網路(Artificial Neural Network)中競爭式學習(competitive learning)的一 種。透過 SOMs 的映射,可將高維度的文件向量映射到一個以概念為基礎 的二維映射圖,將相似的文件映射(群聚)到座標上的同一點或鄰近的點。圖 3.1 為自我組織映射的類神經網路模型 Output Layer : Concepts {C 1, C2,… ,Cj}. Weight Vectors : Wj=( w1j,w2j,… ,wmj ). … Input layer: Document Vector d=( t 1,t2,… ,tm ). 圖 3. 1 自我組織映射類神經網路模型 在圖 3.1 中,輸入向量為文件向量,文件由慈慧所組成,輸出為概念映 射圖,屬於文件群聚;同樣地也可應用到詞彙群聚。自我組織映射的分群 技術可分成下列幾個步驟:. 25.
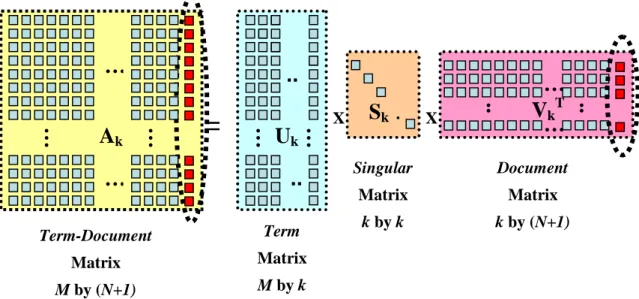
(40) (1) 指定輸出層映射圖的大小,並且初始化所有權重。 (2) 指定映射圖的拓樸形態,一般可分成:矩形(rectangle)或是六角形 (hexagon) (3) 針對 BMU 的鄰近單位指定一個鄰居函數(neighbor Function),一般 可分成階層函數(step Function)以及高斯函數(gaussian Function)。 (4) 針對所有輸入向量 x 找尋最佳配對的單位 mc(BMU),如式(3.7). x mc min{ x mi } i. (3.7). (5) 並且根據 BMU 以及鄰近的的單位進行更新動作,如式(3.8)。 mc (t 1) mc (t ) (t ) [ x(t ) mc (t )]. (3.8). 其中,α(t)為鄰居函數。 (6) 反覆執行步驟 4 與步驟 5 直到達到預期結果為止。. 3.4. 潛在語意索引技術(Latent Semantic Indexing) Latent Semantic Indexing(LSI)潛在語意索引,是透過奇異值分解(Singular Value Decomposition)將語料庫中以詞彙為基礎的字詞空間轉換為以概念為 基礎的語意空間的一種技術。語料庫經過奇異值分解後,將原來的文章與 詞彙的維度縮減至 K 個概念維度,也就是說文章與詞彙分別是以 K 維的向 量來表示,因而可簡易的透過距離或是餘弦的方法量測出文章間、詞彙間 或文章與詞彙的語意關係。同時因為奇異值分解的的特性,K 值會甚小於 原來空間的維度,因而有效達到維度的縮減、增加了檢索的效率以及減少 儲存空間。 (1) 奇異值分解 Singular Value Decomposition(SVD)是一個常被使用在解決線性 最小平方(Linear Least Square)問題、矩陣中秩的估算(Rank Estimation)、以 及標準關聯分析(Canonical Correlation Analysis)。假設在一個 m n(m n) 的. 26.
(41) 矩陣 A 中, rank ( A) r ,A 矩陣的奇異值分解定義如下: A USV T (3.9). 在 (3.9) 式 , U 、 V 和 S 滿 足 下 列 方 程 式 U T U V T V I n 、 S diag ( s1 , s 2 ,..., s n ) 。其中 U 為左特徵矩陣(left eigenvector matrix)、V 為右 特徵矩陣(right eigenvector matrix)、 S 為特徵值矩陣(singular value matrix), 其元素是經由大至小排列過後的特徵值序列。在矩陣 U 及 V 內的前 r 個行 向量被定義為相對於 ATA 與 AAT 的單位正交特徵向量,而 S 對角矩陣中的 對角元素被定義為矩陣 AAT 中 n 個特徵值的平方根。透過下列定理,可進 一步瞭解 SVD 可有效萃取出潛藏於矩陣中的重要特性 Theorem 1. 假設 A 的奇異值分解如(3.9)式,並且 s1 s 2 .... s r s r 1 ... s n 0 (3.10) 透過二元分解(Dyadic Decomposition),矩陣 A 可被表示為 r. A u i si vi. T. (3.11). i 1. 在(3.11)式中, u i 、 vi 分別為 U、V 矩陣的行向量。由(3.11)式可得 知矩陣 A 可經由 r 個 triplets 乘積相加後所表示,換句話說當我們減少 triplet 的個數來近似矩陣 A,可有效減少矩陣儲存所需的空間成本並且可在不失 資訊有效性的情況下達到維度縮減的目的。透過定理 2 則可印證上述理論 Theorem 2.假設 A 的奇異值分解如(3.9)式,並且 r rank( A) p min(m, n) , 定義 Ak 為 k. Ak u i i vi. T. (3.12). i 1. min A B. rank ( B ) k. 2 F. A Ak. 2 F. 27. k21 ... 2p (3.13).
(42) 透過 k 個最大的 triplet 所建構的 Ak 也就是最接近於矩陣 A 的 rank-k 矩陣。 圖 3.2 為矩陣 Ak 在(3.12)式的數學表示法。. …. ... … Term-Document. Term. Matrix. Matrix. M by N. M by k. 圖 3. 2. X. … VkT …. Singular. Document. Matrix. Matrix. k by k. k by N. ... Uk. .. ... Sk. X. …. =. …. …. …. Ak. ... 矩陣 Ak 的數學表示法. 如圖 3.2 所示,詞彙向量(row of Uk)及文件向量(column of VkT)可由 k 個概念(維度)來做表示,因此文件與詞彙可在同一個空間做比較,相較於 向量空間模型只能比較等價的物件,LSI 會具有較好的彈性。 (2) 查詢轉換(Query Transform) 向量空間模型經由 SVD 之後,可將文件與詞彙映射到一個 k 維的 語意向量,並且所有的應用都是在語意空間上執行。查詢(query),可視為 是一個文件,又稱做假文件(pseudo-document),透過(3.14)式可將其映射到 語意空間上,進而與其他詞彙與文件作比較。. q qTerm Based U k S k T. (3) 詞彙與文件的匯入(Folding-In). 28. 1. (3.14).
(43) 由於上述的語意空間是針對原來的向量空間模型進行奇異值分 解,所涵蓋的詞彙以及文件已經在分解的過程中轉換了。若要額外的新增 一個新詞彙或新文章到這個語意空間下,則必須透過適當的轉換。 O’Brien[25]提出兩個做法,第一個做法是將要新增的文件或詞彙加入原來 的向量空間模型,並且重新執行奇異值分解,進而將所有文件及詞彙提供 一個全新的語意空間。由於這個方法較不經濟,且成本過高,因而提出了 另外一個替代方案“匯入”。匯入的方法是建構在原來的語意空間,將詞彙或 文章透過映射的方式匯入原來的語意空間下,(3.15)為將原來以詞彙為基礎 的文件映射到預先建立的語意空間,(3.16)為將原來以文件為基礎的詞彙映 射到預先建立的語意空間。 d p d term based U k S k. 1. t p t document based Vk S k. 1. t. (3.15) (3.16). 圖 3.3 為匯入詞彙的數學表示圖,圖 3.4 為匯入文件的數學表示圖。 匯入文件的動作會將映射過後的 dp 加在 Vk 的最後一列,同樣的匯入詞彙的 動作會將映射後的 tp 附加在 Uk 的最後一列。. …. . .. …. Term-Document. Term. Matrix. Matrix. (M+1) by N. (M+1) by k. 圖 3. 3. .. X. Singular. Document. Matrix. Matrix. k by k. k by N. 詞彙匯入的數學表示圖. 29. … VkT …. ... Uk. Sk. ... X. …. =. …. …. …. Ak. . ..
(44) …. ... … Term-Document. Term. Matrix. Matrix. M by (N+1). M by k. 圖 3. 4. .. X. Singular. Document. Matrix. Matrix. k by k. k by (N+1). 文件匯入的數學表示圖. 30. … VkT …. ... Uk. Sk. ... X. …. =. …. …. …. Ak. ...
(45) 第四章 監督式學習技術之應用 監督式文件分類技術是假設在文件中的類別結構是已知的情況下。在監 督式演算法中,它必須由一定數量已經預先定義類別的訓練文件,並且針 對文件中的類別標籤來訓練,最後能夠將未知的文件透過演算法予以分類 至預先定義的類別。以下我們將介紹數個比較受歡迎的監督式演算法,譬 如:k 個最近鄰居演算法、貝氏分類器以及支撐向量機。. 4.1. k 最近鄰居演算法(k Nearest Neighbor) k 最近鄰居演算法,簡稱 k-NN,是一個基於實例(Instance-Based)的學習 演算法。測試文件經由量測訓練文件在空間上的分布情形,進一步估算類 別標籤的可能性。圖 4.1 為訓練樣本的 2D 分布圖。. Instance Space. POS Instance NEG Instance. 圖 4. 1. 訓練樣本 2D 分布圖. k-NN 演算法可分成兩個步驟, (1) 針對測試樣本 x 找出最近的 k 個訓練樣本點(Nearest(x))。 (2) 針對這 k 個訓練樣本並根據(4.1)式,估算測試文件的類別標籤 cj(獲 得最高分數的類別標籤)。. 31.
(46) Score(Cj ) d Nearest ( x ) y (di , c j ) i. 1 , if document d belongs to category c y (d , c) 0 , otherwise.. (4.1). 圖 4.2 為測試文件估算 5 個最近鄰居的分布圖,如圖所示測試文件將會 被標記為 POS(Score(POS)>Score(NEG))。. Instance Space. POS Instance NEG Instance. TEST Instance. 圖 4. 2. 測試文件估算 5-NN 分布圖. 除此之外,Weighted k-NN 是一種改良式 k-NN。不同於傳統的 k-NN 演 算法只考慮鄰居類別的存在與否而忽略了樣本之間的相似性,Weighted k-NN 將(4.1)式改寫成(4.2)式。 Score(Cj ) d Nearest ( x ) y (di , c j ) cos( x, di ) i. 1 , if document d belong to category c y (d , c) 0 , otherwise.. (4.2). 4.2. 貝氏分類器(Naïve Bayesian Classifier) 貝氏分類器是一個使用詞彙與類別之間的聯合機率模型來估算一個測 試文件在不同類別上的機率。由於在估算的過程中,詞彙與詞彙之間是視. 32.
數據
![圖 2. 2 跨語言文件檢索方法[23] 由於多國語言文件探勘與跨語言文件探勘在系統架構上極為類似,故引 用圖 2.2 來做介紹。針對多國語言文件探勘技術與跨語言文件探勘技術,其 差異點在於多國語言文件探勘的精神為透過探勘單一語系資料可獲得多種 語系文件的相關資訊,而跨語言文件探勘所獲得的相關資訊僅能涵蓋兩種 語言,換言之,跨語言文件探勘只是多國語言文件探的其中一個特例。 以下首先將針對多國語言文件探勘的特點做介紹,並闡述目前多國語言 文件探勘的研究概況,針對先前研究的缺失進而提出本研究的方法來加以 改善,](https://thumb-ap.123doks.com/thumbv2/9libinfo/8827587.234417/25.892.189.760.178.489/語言換言之跨語言文件探勘只是多國語言文件探其中一個本研究改善.webp)
![圖 2. 4 雙語 LSI 語意向量空間文章與詞彙的分布圖[6] Rehder 與 Dumais[27]等人隔年將原本使用兩種語言的平行語料庫延伸至 三種語言(英文、法文與德文)的平行語料庫,透過實驗數據的展現,同樣地 也獲得很好的效能。 Mori[20][21]針對 LSI 處理因矩陣過大而無法計算的特性,發展了一個切 割式 LSI(Segmented-LSI)專門處理龐大資料量的多國語言平行語料庫。Mori 在進行 SVD 分解前,先將龐大的多語平行語料庫切割成 N 個子集合,之後 分別進行 CL-LS](https://thumb-ap.123doks.com/thumbv2/9libinfo/8827587.234417/33.892.378.591.192.397/陣過大而無法計算特性發展了一個切割式專門處理龐大量的在進行CLLS.webp)
+7

相關文件
“Transductive Inference for Text Classification Using Support Vector Machines”, Proceedings of ICML-99, 16 th International Conference on Machine Learning, pp.200-209. Coppin
Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval pp.298-306.. Automatic Classification Using Supervised
A dual coordinate descent method for large-scale linear SVM. In Proceedings of the Twenty Fifth International Conference on Machine Learning
Hofmann, “Collaborative filtering via Gaussian probabilistic latent semantic analysis”, Proceedings of the 26th Annual International ACM SIGIR Conference on Research and
Pantic, “Facial action unit detection using probabilistic actively learned support vector machines on tracked facial point data,” IEEE Conference on Computer
Lessons-learned file (LLF) is commonly adopted to retain previous knowledge and experiences for future use in many construction organizations.. Current practice in capturing LLF
(1999), "Mining Association Rules with Multiple Minimum Supports," Proceedings of ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
