行政院國家科學委員會專題研究計畫 期中進度報告
超大型奈米積體電路無格線式全晶片繞線系統之研究(1/3)
計畫類別: 個別型計畫
計畫編號: NSC93-2215-E-002-029-
執行期間: 93 年 08 月 01 日至 94 年 07 月 31 日
執行單位: 國立臺灣大學電機工程學系暨研究所
計畫主持人: 張耀文
報告類型: 精簡報告
報告附件: 出席國際會議研究心得報告及發表論文
處理方式: 本計畫可公開查詢
中 華 民 國 94 年 5 月 30 日
超大型奈米積體電路無格線式全晶片繞線系統 (1/3)
Gridless Full-Chip Routing for Very-Large Scale Nanometer ICs
計畫編號:NSC 93-2215-E-002-029
執行期限:93 年 8 月 1 日至 94 年 7 月 31 日
計畫主持人:張耀文教授 國立臺灣大學電子工程學研究所
一
、
中文摘要
由於多階層繞線的架構擁有可彈性處理極大型積體 電路的良好特性,近幾年被受到很大的重視及研究。目 前文獻上的多階層繞線器大多基於以格線為基礎的模 型,且只考慮可繞度和效能(例如我們於 ICCAD-2002 所 提出的以格線為基礎的多階層繞線器 MR [21],以通用 的測試檔測試,具有文獻上最高的可繞度---因此獲得該 會議最佳論文獎提名)。然而,在奈米積體電路技術下, 設計最佳化需要能處理較精細的幾何圖形(如可變線寬 以及可變線距等),而以格線為基礎的模型卻無法有效 地處理許多重要的奈米電氣效應,如訊號完整性(如串 音)、可靠度(如天線效應、金屬電子偏移)以及可製 造性(如光學製程修正技術、相位轉移光罩、金屬填充) 等。在此為期三年的計畫中,我們將 (1) 提出上述奈米 電氣效應的模型,(2) 針對上述的效應,提出最佳化的 方法,及 (3) 發展一套以訊號完整性、可靠度,以及可 製造性為導向,並且能處理極大型積體電路、以無格線 為基礎的多階層全晶片繞線器。 關鍵詞:繞線、無格線繞線器、多階層、可繞度、 串音、天線效應、光學製程修正技術、相位轉移光罩、 金屬填充、金屬電子偏移二、英文摘要(Abstract)
The multilevel routing framework has attracted much attention recently due to its excellent scalability to handle very large-scale circuit designs. Most existing multilevel routers are based on the gridded model and consider only routability and performance. (For example, our work [21] presents a multilevel gridded-based router, called MR, which obtains the highest routability in the literature, based on a set of commonly used benchmark circuits---The work was nominated Best Paper at ICCAD-2002.) However, the grid-based model is not effective to handle many nanometer electrical effects suchas signal integrity (e.g., crosstalk), reliability (e.g., antenna effects, metal electromigration), manufacturability (e.g., optical proximity correction, phase shift mask, metal filling), for which more sophisticated geometrical patterns such as variable wire widths and variable wire spacing are needed for design optimization. In this three-year project, we intend to (1) model those important nanometer electrical effects, (2) derive optimization schemes for them, and (3) develop a signal integrity-, reliability-, and manufacturability-aware multilevel, gridless full-chip routing system for very large-scale nanometer IC designs.
Keywords: routing, gridless router, multilevel,
crosstalk, antenna effect, optical proximity correction (OPC), phase shift mask (PSM), metal filling
三、
背景和目的
Research in VLSI routing has received much attention in
the literature. Routing is typically a very complex combinatorial problem. In order to make it manageable, the routing problem is usually solved using the two-stage approach of global routing followed by detailed routing. Many routing algorithms adopt a flat framework of finding paths for all nets [1, 14, 18, 24, 25]. The major problem of the flat frameworks lies in their scalability for handling larger designs. As technology advances, technology nodes are getting smaller and circuit sizes are getting larger. To cope with the increasing complexity, researchers proposed to use hierarchical approaches to handle the problem [4, 13, 23, 26]. The two-level, hierarchical routing framework, however, is still limited in handling the dramatically growing complexity in current and future IC designs which may contain hundreds of millions of gates in a single chip. As pointed out in [8], for a 0.07 um process technology, a 2.5 x 2.5 cm2 chip may contain over 360,000 horizontal and
vertical routing tracks. To handle such high design complexity, the two-level, hierarchical approach becomes insufficient. Therefore, it is desired to employ more levels of routing for larger IC designs.
3.1 Multilevel Framework
The multilevel framework has attracted much attention in the literature recently. It employs a two-stage technique: coarsening followed by uncoarsening. The coarsening stage iteratively groups a set of circuit components (e.g., circuit nodes, cells, modules, routing tiles, etc) based on a predefined cost metric until the number of components being considered is smaller than a threshold. Then, the uncoarsening stage iteratively ungroups a set of previously clustered circuit components and refines the solution by using a combinatorial optimization technique (e.g., simulated annealing, local refinement, etc). The multilevel framework has been successfully applied to VLSI physical design. For example, the famous multilevel partitioners, ML [2], hMETIS [17], and HPM [8], the multilevel placer, mPL [3], and the multilevel floorplanner/placer, MB*-tree [19], all show the promise of the multilevel framework for large-scale circuit partitioning, placement, and floorplanning. A framework similar to multilevel routing was presented in [12, 20, 22]. Lin, Hsu, and Tsai in [20] and Hayashi and Tsukiyama in [12] presented hybrid hierarchical global routers for multi-layer VLSI’s, in which both bottom-up (coarsening) and top-down (uncoarsening) techniques were used for global routing. Marek-Sadowska [22] proposed a global router based on the outer-most loop approach. The approach is similar to the coarsening stage of multilevel routing. Cong, Fang, and Zhang proposed a pioneering routability-driven multilevel global routing approach for large-scale, full-chip routing [9]. Cong et al. later proposed an enhanced multilevel routing system, named MARS, which incorporates resource reservation, a graph-based Steiner tree heuristic, and a history-based multi-iteration scheme to improve the quality of the multilevel routing algorithm in [10, 11]. Their final results of the multilevel global routing are tile-to-tile paths for all nets. The results
are then fed into a non-multilevel gridless detailed router, called DUNE [7], to find the exact connection for each net. (Therefore, MARS is in fact a multilevel global router, but not a detailed router.) Lin and Chang also proposed a multilevel approach for full-chip, grid-based routing, which considers both routability and performance [5, 21]. This framework integrates grid-based global routing, detailed routing, and resource estimation together at each level, leading to more accurate routing resource estimation during coarsening and thus facilitating the solution refinement during uncoarsening. Their experimental results show the best routability among the previous works for grid-based routing. Recently, Ho et al. in [15] and [16] presented another multilevel framework for full-chip, grid-based routing considering crosstalk and antenna effects, respectively. The framework incorporates an intermediate stage of layer/track assignment between the coarsening stage and the uncoarsening stage. The coarsening stage performs only global routing while global routing and detailed routing are integrated together at the uncoarsening stage.
3.2 Gridless Routing
Most of the previous routing algorithms are grid-based, assuming uniform wire/via sizes. However, the grid-based approach is not effective to handle modern routing problems with nanometer electrical effects, such as optical proximity correction (OPC) and phase-shift mask (PSM). To cope with these nanometer electrical effects, we need to consider designs of variable wire/via widths and spacings, for which gridless routers are desirable due to their great flexibility. The gridless routing, however, is much more difficult than the grid-based routing because the solution space of gridless routing is significantly larger than that of grid-based routing. Cong et al. in [7] proposed a three-level routing scheme with a wire-planning phase between the global routing and the detailed routing. However, for large-scale designs, even
with the three-level routing system, the problem size at each level may still be very large. Therefore, as the designs grow, more levels of routing are needed [11]. Recently, Chen and Chang proposed an OPC-aware multilevel gridless router [6], which integrates gridless global and detailed routing at each level. Their router can handle non-uniform wire widths and reduce OPC pattern feature requirements.
四
、
研究方法
4.1 Λ-shaped Multilevel Framework
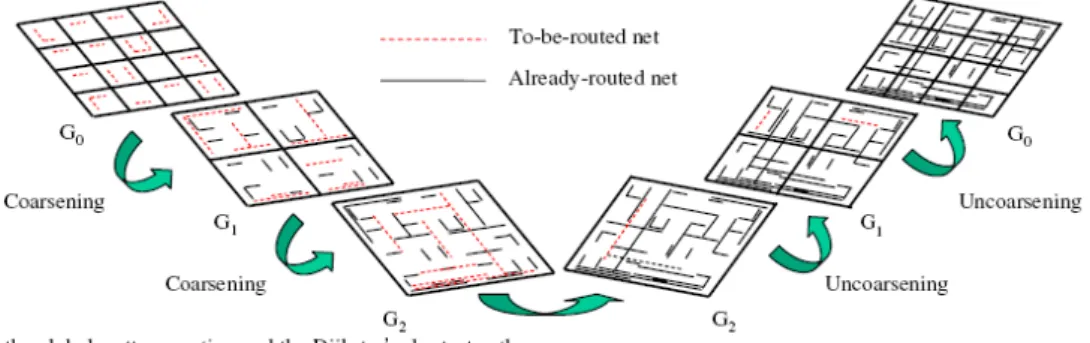
In this project, we present a novel Λ-shaped multilevel framework (LMF for short) that can better handle global circuit effects than the traditional V-shaped multilevel framework (VMF for short). VMF applies a two-stage technique of bottom-up coarsening followed by top-down uncoarsening. As an example adopted in [6] and shown in Figure 1, the coarsening stage of VMF uses a detailed router to route a local connection according to the tile-to-tile path found by a global router. Its uncoarsening stage considers the failed connections during the coarsening stage, and rip-up and re-route are performed to refine the routing solution. Experimental results showed that VMF obtains solutions of very high completion rates. Since VMF works in a bottom-up manner by processing smaller (finer) regions first, shorter local nets are routed earlier than longer global nets, and it is very likely that the shorter local nets might become routing blockages that hurt the later routing of global nets. Therefore, it is obvious that VMF is limited in handling global circuit effects such as critical path optimization, which is much more important for modern nanometer circuit designs.
Unlike VMF that adopts the V-shaped framework, LMF works in the Λ-shaped manner: top-down uncoarsening followed by bottom-up coarsening. (See Figure 2 for an illustration of LMF.) Based on LMF, we develop a
Figure 2: The Λ-shaped multilevel framework flow. Figure 1: The V-shaped multilevel framework flow.
Λ-shaped multilevel full-chip gridless router (LMGR for short) for large-scale circuit designs. The top-down uncoarsening stage of LMGR starts from the coarsest regions and then routing and detailed routing for local nets and then estimate the routing resource for the next level. Then, the bottom-up coarsening stage performs global maze routing and detailed routing to reroute failed connections and refine the solution level by level from the finest level to the coarsest one. LMF outperforms VMF in the optimization of global interconnect effects (such as wirelength, timing, and crosstalk optimization), since LMF considers the global configuration first and then processes down to local ones level by level, and thus the global effects can be handled at earlier stages. In particular, LMF is general and thus can readily apply to other problems.
In addition to the aforementioned characteristics, our LMF-based LMGR has the following distinguished features:
z The previous works [5, 15, 16, 21] are gird-based multilevel router, which cannot handle designs of variable wire/via widths and spacings. Thus, they cannot effectively handle modern routing problems with nanometer electrical effects such as OPC. z The previous works [9, 10, 11, 13, 20] are mainly for
global routing while LMGR integrates global and detailed routing.
z LMF considers the global longer nets first at the earlier uncoarsening stage, leading to better control on critical path delay and global interconnect effects. z The previous works [5, 6, 21] perform greedy global
routing, which determines the global path of the current net without considering the routing resource of succeeding nets. In contrast, LMGR employs a congestion map to guide the global routing at all stage. Initially, the map keeps the preliminary estimation of routing congestion based on the pin distribution. After routing a net, the map is updated dynamically based on the real route, previously routed nets, and estimated unrouted nets. As routing proceeds, we keep more and more accurate congestion information in the map. Therefore, we have better congestion control throughout the whole routing process.
z We use a new cost function based on both the total path congestion and the maximum channel congestion for global routing. The cost function obtains better solutions than those consider only total path congestion or the maximum channel congestion. z LMGR has higher flexibility and keeps more global
views, and thus more routing objectives (such as crosstalk and OPC) can be more easily considered in LMGR since exact track and wiring information at
each level after detailed routing is known.
Table 1 compares the existing multilevel routing frameworks among [5, 21], [6], [9, 10, 11], [15, 16], and LMF. Experimental results show that our LMGR achieves the best routability among all published gridless routers [6, 12] based on a set of commonly used MCNC benchmarks with non-uniform and uniform wire widths. Besides, LMGR can obtain significantly less wirelength and smaller critical path delay than the previous works [5, 21].
4.2 Experimental Results
We have implemented LMGR in the C++ language on a 1 GHz SUN Blade-2000 workstation with 8 GB memory. We compared our results with the gridless routers presented in [6, 11] based on the 11 benchmark circuits provided by the authors. (Note that since the results of [11] is better than those of [9, 10], we just compare our results with [11].) The design rules for wire/via widths and wire/via spacings for detailed routing are the same as those used in [11].
4.2.1 Multilevel Gridless Routing with Uniform Nets
Table 2 lists the wirelength, the critical path delay, the numbers of failed nets, and the running time obtained by the V-shaped multilevel gridless routing [6], the multilevel routing (multilevel global routing + flat gridless detailed routing) [11], and LMGR. In the table, “WL (μm)” represents the wirelength in μm, “#F. Nets” denotes the number of failed nets, “Dmax (psec)” represents the critical path delay in pico-second, and “
Time (sec)” represents
the running times in second.
Compared with [6], the experimental results show that LMGR achiseved a 2.22X runtime speedup, reduced the respective maximum and average wirelength by about 4% and 2%, reduced the respective maximum and average critical path delay by about 90% and 21%. Compared with [11], the experimental results show that LMGR achieved a 1.82X runtime speedup. (For a fair and reasonable comparison, we normalize the running time of [11] by the factor 440/1000.) Since [11] did not report their wirelength and the critical path delay in their paper, we cannot compare those results in LMGR with those in [11].
4.2.2 Multilevel Gridless Routing with Non-uniform Nets
Table 3 lists the wirelength, the critical path delay, the numbers of failed nets, and the running time obtained by the V-shaped multilevel gridless routing [6], the multilevel routing (multilevel global routing + flat gridless detailed routing) [11], and LMGR. Compared with [6], the experimental results show that LMGR achieved a 2.22X runtime speedup, reduced the respective maximum and average wirelength by about 4% and 2%, reduced the respective maximum and average critical path delay by about 90% and 21%. Compared with [11], the experimental results show that LMGR achieved a 1.82X runtime speedup. Table 1: Multilevel framework comparisons. GR, DR, and RE denote global routing, detailed routing, and resource
(For a fair and reasonable comparison, we normalize the running time of [11] by the factor 440/1000.) Since [11] did not report their wirelength and the critical path delay in their paper, we cannot compare those results in LMGR with those in [11].
五、
成果 (Publications)
1. B.-Y. Su and Y.-W. Chang, ``An optimal jumper insertion algorithm for antenna effect avoidance/fixing," to appear in Proc. DAC, Anaheim, CA, June 2005. 2. T.-C. Chen and Y.-W. Chang, "A Novel Framework for
Multilevel Full-Chip Gridless Routing," submitted to
ICCAD 2005.
3. T.-C. Chen and Y.-W. Chang, "Optical Proximity Correction-aware Multilevel Gridless Routing," submitted to IEEE Trans. Computer-Aided Design.
六
、
參考文獻
[1] C. Albrecht, “Global routing by new approximation algorithms for multicommodity flow,” IEEE Trans. CAD, vol. 20, no. 5, pp. 622–632, May 2001.
[2] C. J. Alpert et al., “Multilevel circuit partitioning,” IEEE Trans. CAD, vol. 17, no. 8, pp. 655–667, August 1998. [3] T. Chan et al., “Multilevel optimization for large-scale circuit
placement,” Proc. ICCAD, pp. 171–176, Nov. 2000. [4] Y.-W. Chang et al., “Timing-driven routing for
symmetrical-array-based FPGAs,” ACM Trans. Design Automation of Electronic Systems, vol. 5, no. 3, pp. 433–450, July 2000.
[5] Y.-W. Chang and S.-P. Lin, “MR: A new framework for multilevel full-chip routing,” IEEE Trans. CAD, vol. 23, no. 5, pp. 793–800, May 2004.
[6] T.-C. Chen and Y.-W. Chang, “Multilevel Gridless Routing considering Optical Proximity Correction,” Proc. ASP-DAC, pp. 1160–1163, Jan. 2005.
[7] J. Cong et al., “DUNE: A multi-layer gridless routing system with wire planning,” Proc. ISPD, pp. 12–18, April 2000. [8] J. Cong et al., “Performance driven multilevel and multiway
partitioning with retiming,” Proc. DAC, pp. 274–279, June 2000.
[9] J. Cong et al., “Multilevel approach to full-chip gridless
routing,” Proc. ICCAD, pp. 396–403, Nov. 2001.
[10] J. Cong et al., “An enhanced multilevel routing system,” Proc.
ICCAD, pp. 51–58, Nov. 2002.
[11] J. Cong et al., “MARS–A Multilevel Full-Chip Gridless Routing System,” IEEE Trans. CAD, vol. 24, no. 3, pp. 382–394, March 2005.
[12] M. Hayashi and S. Tsukiyama, “A hybrid hierarchical global router for multi-layer VLSIs,” IEICE Trans. Fundamentals, vol. E78-A, no. 3, pp. 337–344, 1995.
[13] J. Heisterman and T. Lengauer, “The efficient solutions of integer programs for hierarchical global routing,” IEEE Trans.
CAD, vol. 10, no. 6, pp. 748–753, June 1991.
[14] D. Hightower, “A solution to line routing problems on the continuous plane,” Proc. Design Automation Workshop, pp. 1–24, 1969.
[15] T.-Y. Ho et al., “A Fast Crosstalk- and Performance-Driven Multilevel Routing System,” Proc. ICCAD, pp.382–387, Nov. 2003.
[16] T.-Y. Ho et al., “Multilevel Routing with Antenna Avoidance,” Proc. ISPD, pp. 34–40, April 2004. [17] G. Karypis et al., “Multilevel hypergraph partitioning:
Application in VLSI domain,” IEEE Trans. VLSI Systems, vol. 7, pp. 69–79, March 1999.
[18] Lee, “An algorithm for path connection and its application,”
IRE Trans. Electronic Computer, EC-10, 1961.
[19] H.-C. Lee et al., “Multilevel floorplanning/placement for large-scale modules using B*-trees,” Proc. DAC, pp. 812–817, June 2003.
[20] Y.-L. Lin et al., “Hybrid routing,” IEEE Trans. CAD, vol. 9, no. 2, pp. 151–157, Feb. 1990.
[21] S.-P. Lin and Y.-W. Chang, “A novel framework for multilevel routing considering routability and performance,”
Proc. ICCAD, pp. 44–50, Nov. 2002.
[22] M. Marek-Sadowska, “Global Router for gate array,” Proc.
ICCD, pp. 332–337, Oct. 1984.
[23] M. Marek-Sadowska, “Router planner for custom chip design,” Proc. ICCAD, Nov. 1986.
[24] G. Meixner and U. Lauther, “A new global router based on a flow model and linear assignment,” Proc. ICCAD, pp. 44–47, Nov. 1990.
[25] J. Soukup, “Fast maze router,” Proc. DAC, pp. 100–102, June 1978.
[26] D. Wang and E. Kuh, “A new timing-driven multilayer MCM/IC routing algorithm,” Proc. Multi-chip Module
Conference, pp. 89–94, Feb. 1997.
Table 3: Comparison among (A) the V-shaped multilevel gridless routing [6], (B) the V-shaped multilevel gridless global routing + flat gridless detailed routing [11], and (C) LMGR. (Note that because the benchmark circuits S5378~S38584 violate the design rules of via spacing, we did not list these cases in this table.) (*: Since [11] did not report their wirelength in their paper, we leave the corresponding fields blank.) (#: For fair comparison, we normalize the running time of [11] by the factor 440/1000.)
Table 2: Comparison among (A) the V-shaped multilevel gridless routing [6], (B) the V-shaped multilevel gridless global routing + flat gridless detailed routing [11], and (C) LMGR. Note: (A) and (C) were run on a 1 GHz Sun Blade-2000 with 8 GB memory; (B) was run on a 440 MHz Sun Ultra-5 with 384 MB memory. (–: Because those benchmark circuits did not have the information of net sources, we cannot calculate the path delay for them.) (*: Since [11] did not report their wirelength and the critical path delay in their paper, we leave the corresponding fields blank.) (#: For fair comparison, we normalize the running times of [11] by the factor 440/1000.)
![Table 1 compares the existing multilevel routing frameworks among [5, 21], [6], [9, 10, 11], [15, 16], and LMF](https://thumb-ap.123doks.com/thumbv2/9libinfo/8782217.216376/4.892.125.765.106.305/table-compares-existing-multilevel-routing-frameworks-lmf.webp)
![Table 3: Comparison among (A) the V-shaped multilevel gridless routing [6], (B) the V-shaped multilevel gridless global routing + flat gridless detailed routing [11], and (C) LMGR](https://thumb-ap.123doks.com/thumbv2/9libinfo/8782217.216376/5.892.143.754.105.262/comparison-multilevel-gridless-multilevel-gridless-gridless-detailed-routing.webp)
