國立交通大學
資訊科學與工程研究所
碩士論文
應用於 Java 加速器的堆疊記憶體及系
統軟體設計
應用於 Java 加速器的堆疊記憶體及系統軟體設計
Design of Stack Memory Device and System Software for Java Accelerator IP
研 究 生:林子剛 Student:Zi-Gang Lin
指導教授:蔡淳仁 Advisor:Chun-Jen Tsai
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science
June 2011
Hsinchu, Taiwan, Republic of China
摘要
本論文試著提出以軟硬體協同設計的方式,設計一個 JAVA 加速處理器(Java Accelerator IP, JAIP)配合任何通用處理器(General Purpose Processor, GPP)來執行 JAVA 程式。論文的重 點分成軟體架構和硬體架構的設計。在硬體方面,我們設計了一個針對 Java Virtual Machine (JVM) 運作特性所設計的客製化 4-port memory,做為在 Java 加速器的 stack memory,在較 低的硬體成本的情形下,可以降低 Java 加速器 double-issue 時因為 local variable accesses 所 造成的結構危障(structure hazard)。
在軟體方面,我們是以 Java 語言的 dynamic class loading 的運作模式,來設計我們 GPP 和 JAIP 的系統軟體整合介面。我們設計的介面,僅需 GPP 系統平台提供中斷服務的功能以 及標準 C 語言的函式庫,就可以讓我們整合 JAIP 至任何作業系統的環境裡。另外我們在系 統軟體中設計了快速原生方法(Native Method)呼叫的功能,以支援 JAVA 系統物件型別 (system classes)中的系統功能呼叫。整體而言,我們所提出的軟硬體協同設計的 Java 加速 系統同時具備易整合以及高相容的特性。
配合這樣的架構底下,論文當中也在 Xilinx 的 FPGA 上實作出我們所提出的堆疊記憶體, 以及完整的系統軟體以進行驗證。特別是我們完整的支援 JAVA 物件導向特性中的繼承與介 面機制、以及動態連結等機制。並把 Java Micro Edition 中 CLDC 的大部份系統物件型別移 植到我們的平台上。
誌謝
終於能夠寫到這一頁,我相信這是所有學生都期盼的一刻,而如果有幸能讓你翻開這篇 論文,希望你能知道這頁也是我寫得最認真的部分之一,因為在我念大學的時候,有很長的 一段時間都在圖書館打工,其中一項工作就是將每年畢業的碩博士論文建檔,那時候的我總 會翻開來看的,就是這頁的內容,最大的理由當然不外乎是這頁我比較看得懂(笑),一邊看 著誌謝一邊評論著這個人應該沒什麼朋友又或是這個人應該過得很充實之類的,所以我希望 本文寫下的內容可以不至於讓我的青春留白。 首先能順利在一年半的時間內完成碩士學位,最要感謝的就是我的指導教授-蔡淳仁老 師,感謝老師在求學期間對我的諄諄教誨,雖然在研究過程中遇到諸多瓶頸,但是沒有磨練 也就不會有成長,老師常提的學校其實給了學生許多犯錯的機會,我想我將來一定會很懷念 在老師指導的這段歲月,懷念老師對學生的寬容以及關心;再來要感謝的就是我的家人,感 謝父母對我的栽培以及兄長在我人生及求學上的諸多指引,家人的支持是我總是能夠面對挫 折與失敗的力量,而我求學的生涯能夠如此順遂,其實是因為我總是走在別人已經走過的路 上,感謝上天賜給我一位比我還優秀的哥哥;另外還要感謝在交大幫助過我的許多人,包括 實驗室的成員、NCTU 健身猛男壯女團、修課認識的朋友以及大學認識的同學,這些都是陪 我在異鄉一同打拼的好夥伴,也要感謝陪我走過低潮的小學同學欣眉、大學同學裴呱、陳承 聖以及實驗室學弟子敬。 文末,我很想學網路上的老梗說,我要感謝我的女朋友,感謝你這二十多年來沒有出現 過,讓我得以致力於學業,但是沒想到在這邊我確實需要感謝這麼一個人,謝謝妳短暫的出 現點綴了我的碩士生涯,讓我有哭有笑的渡過最後的學生生活,謝謝這些發生在我生命中, 最大與最小、最重要也最微不足道的事。目錄
摘要 ... I 誌謝 ... II 目錄 ... III 圖目錄 ... VI 表目錄 ... VIII 第一章 前言 ... 1 1.1. 研究動機 ... 1 1.2. 研究目的及貢獻 ... 1 1.3. 論文架構 ... 3 第二章 相關研究 ... 4 2.1. 提升JAVA執行效率的方法 ... 4 2.2. JAVA處理器的堆疊架構 ... 5 2.3. 動態載入物件型別的機制 ... 7 2.4. 處理器溝通介面設計 ... 8 第三章 硬體架構介紹 ... 10 3.1. JAVA核心管線硬體架構 ... 11 3.1.1. TRANSLATE STAGE說明 ... 113.2.2. 使用 4LV(LOCAL VARIABLE)REGISTERS說明 ... 15 3.2.3. 呼叫方法(INVOKE)及結束方法(RETURN)時的操作說明 ... 16 3.2.4. 外部訊號功能簡介 ... 17 3.3. ON-CHIP MEMORY測試架構設計 ... 20 第四章 系統軟體介紹 ... 21 4.1. 物件型別解析器(CLASS PARSER)說明... 21 4.1.1. 常數索引區段(CONSTANT POOL)的結構修改 ... 23
4.1.2. SUPER CLASS RESOLUTION及INTERFACE RESOLUTION ... 24
4.1.3. FIELD_INFO/METHOD_INFO STRUCTURE RESOLUTION ... 24
4.1.4. REFERENCE FIELD/METHOD RESOLUTION ... 25
4.1.5. CLASS DATA RESOLUTION ... 26
4.1.6. LDC DATA RESOLUTION ... 27 4.1.7. RUN TIME IMAGE格式介紹 ... 27 4.2. 繼承(INHERITANCE)機制說明 ... 28 4.3. 介面(INTERFACE)機制說明 ... 33 4.4. ISR介紹 ... 37 4.4.1. ISR狀態變化圖示說明 ... 37 4.4.2. ISR流程圖 ... 39 4.4.3. 原生方法的機制(NATIVE METHOD)說明 ... 43 第五章 效能評估 ... 50 5.1. 實驗環境 ... 50 5.2. 關於軟體部份的分析 ... 51
5.2.1. 軟體大小的比較 ... 51
5.2.2. 動態物件型別載入(DYNAMIC CLASS LOADING)機制的效能分析 ... 51
5.3. 整體系統分析評比 ... 53
第六章 結論 ... 56
圖目錄
圖 1. 2-LEVEL堆疊記憶體架構 ... 6 圖 2. JAIP中實作的 2-LEVEL堆疊記憶體架構 ... 7 圖 3. JVM物件型別載入的機制 ... 8 圖 4. 系統軟硬體的功能描述 ... 10 圖 5. JAVA位元組碼執行引擎的管線架構 ... 11 圖 6. STORE-ALU對堆疊記憶體的操作 ... 14 圖 7. LOAD-LOAD對堆疊記憶體的操作 ... 15 圖 8. 堆疊記憶體架構圖 ... 16 圖 9. 抽象化後FOUR-PORT記憶體的對外訊號線 ... 17 圖 10. 雙指令封包對堆疊記憶體存取指令在管線架構中的關係 ... 18 圖 11. FOUR-PORT BANK電路架構圖 ... 19 圖 12. 使用ON-CHIP記憶體架構 ... 20圖 13. 在CROSS REFERENCE TABLE上每一個CLASS的資料結構 ... 21
圖 14. 物件型別解析器演算法流程 ... 22
圖 15. 常數索引區段上一個以UTF8 字串定義物件型別名稱的範例 ... 23
圖 16. FIELD_INFO/METHOD_INFO STRUCTURE RESOLUTION演算法流程 ... 24
圖 17. REFERENCE FIELD/METHOD RESOLUTION演算法流程 ... 25
圖 18. CLASS INFO的資料表示 ... 26
圖 19. 實際RUN TIME IMAGE格式範例 ... 28
圖 20. 在物件型別解析的流程中實作繼承的機制 ... 29
圖 21. 產生新物件時在記憶體中配置的情形 ... 30
圖 22. 關於物件型別所定義的資料在資料結構中的表式 ... 31
圖 23. 舉例描述物件型別資料結構中FIELD DATA對應物件在HEAP MEMORY上的關係 ... 32
圖 24. 介面與實作其方法的物件型別例子 ... 33 圖 25. 透過呼叫介面方法的方式呼叫實作其的物件型別方法 ... 34 圖 26. 一般物件型別與介面在方法參照資料上的差異 ... 35 圖 27. 在物件型別解析的流程中實作介面的機制 ... 36 圖 28. 堆疊抽象化的簡圖 ... 37 圖 29. HOST ARG抽象化的簡圖 ... 37 圖 30. 用來表示目前執行的指令及其OPERAND意義 ... 38 圖 31. ARRAY FORMAT ... 39 圖 32. NEWARRAY ISR執行時的狀態變化 ... 39 圖 33. ANEWARRAY ISR執行時的狀態變化 ... 40 圖 34. NEWARRAY/ANEWARRAY ISR程式實作流程 ... 40
圖 35. NEWOBJ ISR執行時的狀態變化 ... 41
圖 36. NEWOBJ ISR程式實作流程 ... 41
圖 37. LDC ISR執行時的狀態變化 ... 42
圖 38. LDC ISR程式實作流程 ... 42
圖 39. BAD INDEX ISR執行時的狀態變化 ... 43
圖 40. 原生方法參照資料(REFERENCE DATA)的格式 ... 43
圖 41. NATIVE METHOD機制 ... 44
圖 42. INVOKE NATIVE METHOD執行時的狀態變化 ... 44
圖 43. COPY_ARRAY(REF)流程 ... 47 圖 44. COPY_OBJ(REF)流程 ... 48 圖 45. 系統架構圖 ... 50 圖 46. 在XC5VFX70T上的系統合成報告 ... 51 圖 47. 對動態載入物件型別的機制分析其解析時間造成的負擔,載入類別為隨機挑選 .. 53 圖 48. 同圖 47 的數據,減去解析物件型別時其解析父物件型別的時間 ... 53 圖 49. 執行CAFFEINMARK與CVM/CVM-JIT評比效能 ... 54 圖 50. 執行循環呼叫及計算PI程式的效能評估 ... 55
表目錄
表 1 Class info中的Type列舉說明 ... 26 表 2 列舉Field Tag所表示的意義 ... 31 表 3 傳遞不同參數個數時,參數位在register file上的位置,最多支援 8 個參數 ... 45 表 4 目前對System Class所支援的原生方法 ... 45 表 5 我們系統與CVM/CVM-JIT的軟體執行檔大小比較 ... 51 表 6 CLDC and AWT與其轉換後的執行映像檔大小統計及取平均後的大小 ... 52 表 7 測試平台對不同記憶體存取的效能 ... 54第一章 前言
1.1. 研究動機
自 1995 年 Java 程式語言問世至今,隨著其具備安全、跨平台、物件導向...等優點,一 直備受矚目,而現今更因為其跨平台的特性,在愈來愈多的嵌入式平台應用上都廣泛的被選 擇做為開發程式的主要語言。 跨平台的特性來自於透過 JAVA 虛擬機器(JVM)[2]的技術,使得相同的程式可執行於 不同的平台上,達到高可攜性,然而為了實現這項特性,所付出的代價是效能上的損失,其 原因在於 JAVA 程式在被執行前會先轉譯成位元組碼(bytecode),再透過各平台上的 JVM 來 執行,在此特性下,我們要探討的一點就是當隨著消費性電子的需求增加,使得在愈來愈多 的嵌入式系統中都需要具備能夠執行 JAVA 程式的環境,其伴隨著的就是我們需要移植 JVM 的平台也增加許多的問題。 而在此研究中,我們試著提出高整合性的解決方式,以 JAVA 加速處理器並透過軟硬體 協同的設計架構來執行 JAVA 程式,這樣不同於一般在作業系統上安裝 JVM 的做法,可以避 免在移植 JVM 上所需要花費的時間,而且透過我們設計簡易整合的介面,僅需系統平台提 供中斷服務的功能以及標準 C 語言的函式庫,便可將我們的軟硬體整合至系統中,加上無需 仰賴作業系統的設計,更可以讓我們整合至已安裝任何作業系統的環境裡,期望透過其具備 易整合以及高相容的特性來解決前段所述的問題。執行級的雙指令,可能會對堆疊記憶體進行存取的行為,造成系統出現結構危障的情形,雖 然在任何處理器的設計上,危障的發生都是無法避免的問題,但是由於 JAVA 語言所產生的 虛擬機碼是將指令與其操作的運算元,會合併一起放在轉譯完成的映像檔(.class 為副檔名) 上,這樣交錯指令與運算元的設計,會讓電路在偵測對堆疊記憶體操作時,部分指令需要解 讀完所需的運算元資訊才能判斷其危障產生與否。 而為了配合在新架構中提出將危障偵測機制提前至提取級處理的設計,針對這樣的考量, 我們提出以增加四個暫存器做為堆疊中呼叫方法的前四個區域變數的快取設計,屏除新架構 中仍會在解碼級及執行級出現結構危障發生的原因,最後再將 2-level 中的第二層堆疊記憶體 包裝成模組,在其內部實作 forwarding 的機制,以簡化外部對堆疊記憶體的控制訊號。 第二部分則是針對系統軟體設計的實作,首先針對 JAVA 語言在物件導向的特性-繼承 及介面,繼承這項特性在 JAVA 語言中指得是允許物件型別的部分內容是來於其他的物件型 別所定義,而介面的特性指得是當我們在不同的物件型別中都實作相同的介面時,我們能透 過這個統一的介面去操作這些所屬於不同物件型別的物件內容及方法。 我們透過對物件型別解析器(Class Parser)的修改實作出支援物件型別的繼承與介面呼 叫兩項特性所需要的相關資料結構,完成系統這兩項重要的功能,並針對新修改的資料結構, 我們需要再對原先系統已提供的 ISR 重新再做修正;最後我們實作在 JAVA 語言中呼叫由系 統物件型別(System Class)裡所提供原生方法(Native Method)的機制,支援原生方法的呼 叫在我們的設計中,一樣是先透過發出中斷的方式,使得 RISC Core 跳到其原生方法實作的 ISR 中,最後再根據我們系統平台所定義的資料結構去撰寫符合我們需求的原生方法,完成 以上軟體的實作,也讓我們的系統對 JAVA 語言在支援上更完備及有彈性。
1.3. 論文架構
本論文一共分為六章,本章是一個概括性的導論,說明背景、動機以及貢獻;第二章為 文獻探討,會先介紹目前增進對 JAVA 執行效能的做法,並接著介紹與論文實作相關的 JAVA 處理器堆疊架構的設計方式,之後再針對軟體的部分開始介紹動態載入的機制及處理器溝通 介面等的相關研究;第三章開始是對全系統架構的說明,並以硬體的修改實驗為主;第四章 則是從軟體部分對其系統延伸的功能實作部分做詳細介紹;第五章則分析各項實驗的結果; 最後在第六章則是提出結論及未來可能的研究方向。第二章 相關研究
2.1. 提升 JAVA 執行效率的方法
早期的 JAVA 虛擬機器在實作時都只是軟體解譯器(Interpreter),而這些虛擬機器又大 多都需仰賴底層作業系統的幫忙,像是 Sun 的 CVM[7]與 KVM[8]就是在嵌入式裝置中利用軟 體實作 JAVA 虛擬機器的直譯器[9],但是透過實作解譯器(Interpreter)完成以堆疊為基礎的 虛擬機器在執行 Java 程式時相當沒有效率。因此大部份商用的 Java 執行環境都會提用加速 化的虛擬機器。目前常見的做法主要有三種[3][10]:不相容於標準 Java VM 的最佳化 interpreter (利如 Android 的 Delvik VM)、JIT(Just-in-Time compilation)[12][13]即時編譯的 Java 加速技術、及使用硬體加速的方式。我們提出的系統,將針對嵌入式的環境底下,對記憶體資源的要求較為嚴苛的應用設計, 所以我們是採用硬體加速的方式來設計 Java 加速系統。常見使用硬體執行 JAVA 的方式有四 種[10]:獨立式的處理器像是 Sun 的 picoJava[17][18]及 aJile 的 aJ-100[15][16]屬於此類,其處 理器的設計可單獨執行 JAVA 程式,協同式的架構像是 InSilicon 的 JVXtreme[19][20]屬於此 類,在使用上需搭配其他處理器來完成執行、內嵌轉譯器(embedded Java translator)的像是 ARM 的 Jazelle[22]及 Nazomi 的 JSTAR[21]屬於此類,其具備可以切換成執行 JAVA 位元組碼 的處理器設計,最後一種是以硬體實作即時編譯器的機制,像是 Chicory System 的
HotShot[14][23]屬於此類;而我們系統選擇以協同式架構設計,其最大的原因在於可以將其 架構設計成具備易整合的特性,並且因為在我們的架構中,JAVA 位元組碼(byte code)的指 令絕大部分執行上,是不需要仰賴 RISC Core 來執行 ,僅在有需要呼叫底層方法實作的指令, 才會透過 IPC 介面呼叫 RISC Core 來協助,這樣的設計下使得我們無需像其他 JAVA 加速處 理器的設計[10][11],會有需要移植 KVM 至平台中讓 RISC Core 也能執行 JAVA 位元組碼(byte code)的負擔。
2.2. JAVA 處理器的堆疊架構
因為 JAVA 語言被設計為執行在堆疊機器[3]上,所以在執行的指令中充斥大量對堆疊的 操作,這邊將介紹關於不同 JAVA 處理器,為了加速 JAVA 處理器在堆疊操作上,各平台所 提出不同架構的堆疊快取機制,這邊將常見的架構分為三類,像是有使用 Register file 作為快 取的設計、on-chip 的記憶體作為快取的設計以及同時使用 Register file 與 on-chip 記憶體作 2-level 的快取;使用 Register file 作為處理器的堆疊快取架構,舉凡像是 Sun 所設計的
picoJava[17]、 aJile’s JEMCore[24]及 Ignite[25] processor 皆是以這樣的架構去設計堆疊的快取, 然而在這樣的設計下因為暫存器的資源昂貴,所以都會有數量上的限制,以上的處理器在使 用 reigster file 作為堆疊快取的數量介於 16~64 個,當使用超過數量的資料時便需要對記憶體 與堆疊的快取暫存器做般進(Fill)與搬出(Spill)的動作,當系統需要執行複雜程式時會這 樣的情形也就容易發生。
第二類使用 on-chip 記憶體作為堆疊快取的像是 Komod[26]oand FemtoJava[27],使用 on-chip 記憶體的好處在於快取大小的尺寸就不會受到第一類的限制那麼大,但是使用這樣架 構的設計會衍生出的問題是,當處理器使用管線技術來加快效能時,在同一個週期內對堆疊 存取會造成需要使用三個阜(port)的情形,舉例來說在 Store 指令後接的是 ALU 的動作, 則執行第一個指令時會需要先在寫回堆疊資料時,而同時第二個指令需要抓取堆疊上的兩個 值,會造成硬體上的結構危障,避開這樣情形的解決方案是使用 three-port 的 on-chip 記憶體, 但相對的成本也就高出許多。
圖1. 2-level 堆疊記憶體架構 在此我們的堆疊架構承繼 JOP 的設計,並更進一步因為我們系統的 JAVA 處理器採用雙 指令的架構,所以除了 2-level 以外,還需要再提供額外的設計,包含增加第一層暫存器的數 量至三個,以供我們雙指令同時執行的運算,在第二層的將採用交錯式的記憶體架構,因為 當堆疊最上層移除一個運算元時,我們需要對堆疊的內容做調整,將 B 暫存器移至 A,C 暫 存器移至 B,並從第二層抓取最上層的值至 C 暫存器,而這樣調整的動作就需要使用交錯式 記憶體的架構才能同時完成;另外針對 JAVA 位元組碼(byte code)的特性,去增加四個暫
存器至我們堆疊的架構,以滿足特殊指令對堆疊的操作,(如圖 2 所示)。 Stack RAM Read Addr Write Addr Write data A B
圖2. JAIP 中實作的 2-level 堆疊記憶體架構
2.3. 動態載入物件型別的機制
這部分要介紹的是關於動態載入 JAVA 程式的機制,在 JVM 的實作中提供了幾種關於將 JAVA 的物件型別檔載入時機[29][30]的可供選擇,像是非主動式(lazy)的載入行為或是由 使用者自行定義載入的行為等,而 JVM 在嵌入式的平台預設的就是以非主動式方式去做載 入,(如圖 3 所示)是 JVM 實作物件型別載入的機制。 First Level Java stack Second Level Java stack Four Port Memory Waddr2 W2_en A B C Wdata2 Wdata1 load immediate1 Raddr1 Raddr2 Waddr1 W1_en Rdata1 LD1 Rdata2 LD2 load immediate2 Bank1 (dual-port SRAM) Bank2 (dual-port SRAM) LV3 LV2 LV1 LV0 ALU圖3. JVM 物件型別載入的機制
延續我們之前的研究,在我們的平台將動態載入物件型別的機制分為兩部分,第一部分 是解析的動作,而為了實作繼承、介面的機制所以對我們系統中所提供的物件型別解析器 (Class Parser)做了適當的修改,並在這部分新增了支援由原生方法中的-”forName”所觸發 的動態載入物件型別時機;第二部分為載入的機制,這邊的載入動作指得是將執行解析過後 的執行映像檔(Run time image)載入至我們 JAVA 加速電路中的快取記憶體,針對載入的時 機仍保留 JVM 在嵌入式平台的設計,以非主動式(late-resolution 或 resolution-on-demand) 的方式去載入。
2.4. 處理器溝通介面設計
在目前愈來愈複雜的行動多媒體應用的嵌入式系統,由於任務的多樣性,使用單一處理 器的設計架構未必能滿足其所有需求,相反的在這樣複雜的系統下卻相當適合以異質 (Heterogeneous)整合的雙核心甚至多核心平台來處理,常見以這樣方式為解決方案(solution) 的應用像是整合了一個精簡指令集處理器(RISC Core)和數位訊號處理器(DSP)的架構[31], 這邊我們在設計執行 JAVA 這樣跨平台特性語言的複雜系統,也同樣提出了以異質雙核心的架構來使用 JAVA 加速處理器協助執行 JAVA 程式。
而在實作關於 IPC(inter-process communication)的部分,其中一種方式是透過實作 Java Native Interface(JNI)的[32][33]機制,JNI 的機制是 JAVA 所提供的應用之一,其使用的方 式有兩種,一種是讓 JAVA 撰寫的程式,能夠呼叫到由底層實作的程式語言撰寫的原生方法 (native method),另一種則是可以讓原生方法撰寫的程式透過 JNI 存取 JAVA 的資源,因為 其設計需考量到其通用性及彈性,在實作上會造成許多額外的負擔,像是去做堆疊記憶體資 料結構的轉換以及要能動態去載入相關的函式庫(仰賴作業系統的輔助)等,故因其額外的 負擔以及對作業系統仰賴的特性,不適用在我們的架構;所以在我們系統的實作上,我們採 用較簡單的介面完成單方向呼叫的機制,即讓 JAVA 加速處理器可以透過這個機制呼叫到 RISC Core 所提供的服務,設計上我們採用 8 個暫存器做為 MailBox 的傳遞機制,以透過中 斷處理的方式,將 JAVA 加速處理器所要傳遞的參數,傳遞給 RISC Core,並執行相對應觸發 的 ISR,這樣簡易的設計也有助於我們未來整合系統至其他平台中。
第三章 硬體架構介紹
在這篇論文裡,我們提出一個可供應用於嵌入式環境底下,具備可重複性使用及易於整 合的 Java Accelerator IP (JAIP)電路架構,JAIP 為一個用於加速執行使用 JAVA 程式語言 所撰寫程式的執行引擎,並透過我們提供的系統軟體輔助來對完整的 JAVA 特性提供支援。
圖4. 系統軟硬體的功能描述
對於整個系統分為兩個部分,(如圖 4 所示),第一部分為執行 JAVA 程式的電路執行引
擎,用來執行我們 JAVA 位元組碼(byte code),第二部分則是透過 RISC Core 來執行我們所
提供的系統軟體,這部分包括物件型別解析器(class parser)、對 JAVA 部分指令支援所提供 的程序以及實作系統物件型別所提供的原生方法(Native Method)實作,並且在系統軟體上 的實作上,我們是採用 Sun Microsystems 所提出的 JavaOS model [1][2] 僅需仰賴平台提供的 精簡系統函式庫,做為底層硬體的 Hardware Abstraction Layer (HAL)無需仰賴全功能作業系
Class parser,
service routines f or JAIP and native methods support
Java Accelerator IP (JAIP)
RISC Core IPC Java Core
JRE system classes (OS classes written in Java)
in on-chip f irmware Applications (written in Java) Java-side system sof tware (provision of application platform) RISC-side JRE sof tware
(provision of low-level services)
統(如 Linux、WinCE 等等)的支援,這樣的特性也讓我們可以整合至任何現有的作業系統 中。 這一章著重的方向為對硬體層面的描述,我們主要會在開始說明硬體實作部分前,先在 3.1 節簡介 JAIP 內的各個模組,等對 JAIP 有初步的認識之後,從 3.2 節之後再說明本論文對 硬體架構實作上的貢獻。
3.1. Java 核心管線硬體架構
在 JAIP 內部的設計我們主要切分為四級的管線設計,(如圖 5 所示)。以下分別針對不 同級的功能做介紹。 圖5. JAVA 位元組碼執行引擎的管線架構3.1.1.
Translate Stage 說明
Translate Stage bytecodes/operands Bytecode classif ier Fetch Stage Fetch controller µ-code inf o. Microcode sequence ROM Decode Stage IPC request controller Double-issue microcode decoder µ-codes Execute StageTwo-level Java stack (with specialized 4-port memory) Double-issue datapath ctrl. signals, operand info branch f lag IPC request Hazard detector 48-bit Instruction buf f er Lookup ROM Dynamic resolution circuitry operands branch f lag IPC request branch dest. en
幾個 bytecode,並將其轉換。Translation 是透過一個 ROM 來實作。使用 Java bytecode 當作 address 到 ROM 去讀取該 instruction 的資料。每筆資料都含有三項資訊:instruction 長度、 IsComplex、mapping data。
Mapping data 會隨著 instruction 不同,而代表不同意義。Simple instruction 直接 map,所 以 mapping data 即為 ISA instruction。若為 complex instruction,則 mapping data 為 u-code address, Fetch stage 便根據此 address 讀出一連串預先寫好的 instruction pair。而 Operand 的取用是由 decode stage 與 execute stage 依狀況至 instruction buffer 內取出,理論上並不用轉換 Operand, 但是因為是以 ROM 為實作方式,在 Translate stage 無法得知更多訊息,所以 Operand 轉換後 的資訊也會送到 Fetch stage,而到 Fetch stage 才有足夠訊息去判斷是否為 Operand,若是則忽 略之。
3.1.2.
Fetch Stage 說明
Fetch stage 的工作主要有三項,從傳送真正要執行的指令給 Decode stage、控制 Translate stage 的 instruction buffer 解讀方式以及當 branch 相關的 instruction 出現時,記錄該 instruction 所在的 program counter。
經由從 Translate stage 透過 ROM 解讀出的資料判斷分析後,即可分類由 Translate stage 傳來 的 16bit 的資料,前後位元組各屬於 simple、complex、operand 哪一種,最後在根據這三種的 排列組合傳送指令給 Decode stage,這邊包含傳送複雜指令轉換後的 u-code sequence、合併簡 單指令...等等。
3.1.3.
Decode Stage 說明
當 Fetch stage 把真正要執行的指令傳到 Decode stage 之後,Decode stage 便會 decode 傳 過來的 instruction 並產生相應的 control signal 以及拉起某些 flag,Decode stage 大致可分成幾 個部份 ,控制 operand source 的 MUX、special decode unit、normal decode unit、branch destination 計算。
operand 目前在 instruction buffer 內的位置也不同,而在 Decode stage 也需做出相對應的調整; 一般 instruction 進到 Decode stage 後都會交由 normal decode unit 分析並產生 control signal, 但是有些 instruction 的行為較特殊,不可與其它 instruction 並行執行(ex: branch),所以其 control signal 須透過 special decode unit 來產生;一般而言 branch destination 的計算是愈早愈好,但 是由於在 Java bytecode 的指令中,其計算需要使用到 operand,而且若為 condition branch, 還需要參考到 top of stack 的 data,所以我們 branch destination 的計算安排在 Decode stage 中。
3.1.4.
Execute Stage 說明
Execute stage 的工作為忠實的執行由 Decode stage 所傳來的 control signal 而在 Execute stage 最為重要的部分即 stack 與 stack operation 的實作,Java virtual machine 為 stack machine, 所以 stack 與 stack operation 的實作亦為設計重點(我們在 3.2 節討論堆疊架構設計時會另外
詳細說明這部分的架構)。
3.2. 堆疊記憶體架構設計
我們在 JAIP 使用的堆疊記憶體是採用 2-level 的設計架構,第一層使用的是三個暫存器 表示在堆疊中最上面的三個值,分別以 A、B、C 從堆疊最上層開始依序命名,第二層則是 使用兩塊 Dual-Port BRAM 來實作交錯式(Interleaving)的記憶體架構,並針對每一塊 BRAM 我們將 Dual-Port 分成 Read-Only 以及 Write-Only 的兩個 Port,雖然在 Dual-Port BRAM 的使 用上原先並無這樣的限制,但這樣的使用方式可以簡化我們在解碼級(Decode Stage)的所 需送出控制訊號線的複雜度,有助於我們的硬體設計。
3.2.1.
2-level 設計架構說明
圖6. Store-ALU 對堆疊記憶體的操作 使用三個暫存器表示堆疊最上層三個值,這樣設計的理由是因為我們在雙指令架構處理 器執行的過程中,排列各種指令的組合,以目前不支援長整數型態運算的設計下,最多只會 同時使用到堆疊上的三個值,我們實際以 Store-ALU 指令的執行為例,(如圖 6 所示),因為 雙指令會同時執行的關係,處理器會將 A 暫存器的值存回堆疊中,B 暫存器跟 C 暫存器運算 的結果會存入 A 暫存器,最後在同時從第二層交錯式的記憶體中讀取兩個值更新至 B、C 暫 存器,接著調整堆疊的指標(SP)位置減二,完成執行 Store-ALU 後堆疊上資料變化的操作 (這邊 A、B、C 暫存器內執行指令前的值以 operand#0~operand#2 表示)。 在原有的堆疊記憶體架構中,第二層的記憶體已採用交錯式的架構實作,為的是能夠支 援我們雙指令架構處理器的設計,如前段所描述的操作,用來輔助三個暫存器的機制能從第 二層記憶體讀取兩筆資料至 B、C 暫存器,也因為 A 暫存器的值需要寫回,所以同時間至少 需要對第二層記憶體做三筆資料的存取,也是我們使用兩塊 Dual-Port Bram 的原因,而本篇 論文在堆疊記憶體設計貢獻其中之一,即實作將交錯式記憶體的架構包裝成模組,抽象化包 裝之後來簡化外部控制訊號的複雜度,像是 Forwarding 的機制在新設計中也將由記憶體內部 來實作。 odd entries A B C operand #3 . . . local var #n . . . local var #n+1 even entries Interleaving dual-port RAM banks as 2nd-level Java stacksp ← sp–2
1-st level Java stack
3.2.2.
使用 4 LV(local variable)registers 說明
圖7. Load-Load 對堆疊記憶體的操作 另外一項貢獻為提出區域變數快取設計的機制,因為 Sun 在 JAVA 語言制定上了解在程 式執行的過程中對前四個區域變數的使用率最高,所以在指令集設計中對前四個區域變數存 取的指令是不需要使用 Operand,而這樣的設計會讓我們雙指令架構的處理器,會同時出現 兩個存取堆疊的指令,在部分狀況下便有可能需要同時讀取同一個 BRAM,造成結構危障的 發生,實際以 Load-Load 指令的執行為例,如(圖 7 所示),當我們執行 Load-Load 指令時, 我們會需要將 A 暫存器值寫入 C 暫存器,而 B、C 暫存器值寫回第二層交錯式的記憶體中, 接著從堆疊中取出區域變數,放置 A、B 暫存器中,但是在從堆疊中取出兩個區域變數的動 作,即有可能造成對同一塊 BRAM 做讀取的動作,所以針對這樣的特性,我們在堆疊記憶體 odd entries operand #3 operand #4 . . . local var #n . . . even entries sp ← sp+2Interleaving dual-port RAM banks as 2nd-level Java stack
B C A 1-st level Java stack local var #n+1
Stage)實作,有助於我們減低在後幾級電路才偵測到危障發生時的負擔。圖 8 是我們設計出 來的堆疊記憶體架構。 圖8. 堆疊記憶體架構圖
3.2.3.
呼叫方法(invoke)及結束方法(return)時的操作說明
使用暫存器為前四個區域變數作快取的機制,這邊要討論在呼叫方法及方法結束時的機 制設計,需要額外做更新快取暫存器的值或是將快取暫存器值寫回 BRAM 中的處理,先介紹 當方法結束時電路的機制,當方法結束時需要拉起 Mem2Reg 並送入適當的 BRAM 位址來將 前一個呼叫方法的區域變數放回暫存器上,這邊如果前一個方法使用的區域變數少於四個, 仍抓取四個連續記憶體的值放上暫存器,因為指令不會使用到超過擁有的區域變數,所以不 影響運作,而當我們去呼叫方法的步驟就相對比較繁複,需先將目前方法的區域變數寫回 BRAM,如果目前方法使用小於四個區域變數時,仍會將暫存器上無效資料寫入 BRAM,而 寫入的位址為記憶體最高位 ,並將 呼叫的下一個方法需要傳入的參數寫到暫存器上,所以 在 呼叫方法時 Reg2Mem、Mem2Reg 兩個訊號都要拉起,目前設計為可以同時拉起,故我們呼 TOS_A (stack 0) TOS_B (stack 1) TOS_C (stack 2)Stack (in J AIP)
Register file stack 3 stack 5 : BRAM stack 4 stack 6 : Local variable 1 Local variable 2 Local variable 3 Local variable 4 Register file
Four port bank Top of stack
First level
叫方法及結束方法時在理想情況都只需要兩個周期,但這邊拉起訊號的時機主要是配合電路 的 code sequence 來運 作,設計上會安排將更新區域變數暫存器的這些時間隱含在原先呼叫方 法及結束方法的時間中,使得不影響電路執行的效能。
3.2.4.
外部訊號功能簡介
我們所設計的 4-port memory 並不是通用型的 4 通道記憶體,而是針對我們所設計的 double-issue JAIP 的堆疊存取需求所設計的。該邏輯單元的對外連接埠設計如圖 9 所示,而 其內部架構則是在圖 11。 RD1 RD2 R1_RegFlag R2_RegFlag W1_RegFlag W2_RegFlag Mem2Reg Reg2Mem clk Rst R1_en R2_en W1_en W2_en R1 R2 W1 W2 WD1 WD2能會有讀取 R(Read)的需求,另一組來自於執行級的為對堆疊的操作可能會有寫入 W(write) 需求,而 1 跟 2 的編號在這邊分別表示來自於同一組雙指令封包內的第一個指令或是第 2 個 指令。 圖10. 雙指令封包對堆疊記憶體存取指令在管線架構中的關係 Reg2Mem:用來觸發將暫存器上四個區域變數寫回 BRAM 的訊號線,外部仍需送寫入位址。 Mem2Reg:用來觸發從 BRAM 抓取四個區域變數寫到暫存器的訊號線,外部仍需送寫入位 址。
(#U) = W (write) or R (read)
(#U)1_RegFlag:表示來自於目前周期雙指令中的第一個指令存取對象是暫存器或 BRAM 。 (#U)2_RegFlag:表示來自於目前周期雙指令中的第二個指令存取對象是暫存器或 BRAM。 (#U)1_en:表示來自於目前周期雙指令中的第一個指令存取是否有效。 (#U)2_en:表示來自於目前周期雙指令中的第二個指令存取是否有效。 (#U)1:表示來自於目前周期雙指令中的第一個指令存取的位址。 (#U)2:表示來自於目前周期雙指令中的第二個指令存取的位址。 (#U)D1:表示來自於目前周期雙指令中的第一個指令存取的資料。 (#U)D2:表示來自於目前周期雙指令中的第二個指令存取的資料。
Translate Stage Fetch Stage Decode Stage Execute Stage R1 R2 W1 W2
Translate Stage Fetch Stage Decode Stage Execute Stage R1 R2 W1 W2 Now
R1 R2 RD1 RD2 W1 W2 WD1 WD2 Local_Reg_0 Local_Reg_1 Local_Reg_2 Local_Reg_3 S_reg_select L_reg_select_1 L_reg_select_2 S_mem_select_2 S_mem_select_1 S_mem_select_1 S_mem_select_1 S_mem_select_2 S_mem_select_2 L_mem_select_1 Clk 0 0 1 1 forward_flag_1 forward_flag_2 L_data_select_1 L_data_select_2 stack_rdaddr2 stack_we2 stack_wddata2 stack_wdaddr2 stack_rdaddr1 stack_we1 stack_wddata1 stack_wdaddr1 Bank 1 Bank 2 S_mem_select_2 Clk forward_flag_2 stack_rdaddr2 stack_we2 stack_wddata2 stack_wdaddr2 Bank 2 WD1 WD2
sta ck_rdda ta1
sta ck_rdda ta2
Loca l_Reg_0 Loca l_Reg_1 Loca l_Reg_2 Loca l_Reg_3 S_reg_select
3.3. On-chip Memory 測試架構設計
為了對目前平台效能的評估,我們在實驗中也設計了使用不同記憶體配置來測試對整體 效能的影響,包括參照資訊表(reference information table)所存放的空間以及 JAVA Heap 的
空間都是放在 on-chip 記憶體上的(圖 12)。參照資訊表是當 JAIP 要存取 field data 或是 invoke
method 時需要查找的資料,而 JAVA Heap 上的資料則包含了程式執行中的陣列、物件型態及 靜 field data。這邊的設計是將 Local Bram Access Control Unit(包含存放上述兩塊資訊的記憶 體空間)放在 Top Module 外面,其原因在於實際測試時,我們整合至 JAIP 中可以保留原有 內部對外記憶體存取的控制訊號設計。
圖12. 使用 on-chip 記憶體架構
Externa l Memory Access Control Unit
Loca l Bra m Access Control Unit (Hea p a nd Cross Reference Da ta ) Top Module User Logic IP2BUS BUS2I P mst_store_data mst_load_req mst_address mst_store_req mst_load_data complete_ack
Externa l Memory Access Source Select Unit
cls_load_mst_address cross_table_address_reg mst_address_reg TOS_B<<2 + TOS_C TOS_B + TOS_A<<2 mst_store_req cls_load_mst_req mst_load_req_reg TOS_A mst_store_data_top
第四章 系統軟體介紹
4.1. 物件型別解析器(Class Parser)說明
關於物件型別解析器的功能在於當 JAIP 執行的過程中,對 JAIP 所需要執行的物件型別
檔,產生適用於我們平台的映像檔(Run Time Image),以非主動的方式去對原始的物件型別
檔做解析,並因為完成解析的物件型別其映像檔會在記憶體中保留一份,所以對物件型別作 解析僅為一次性的動作,對於長時間在運作的系統也能接受這樣額外增加的負擔。
圖13. 在 Cross Reference Table 上每一個 Class 的資料結構
物件型別解析器會針對要解析的物件型別檔,先在 JAR 檔上做搜尋,我們的系統在啟動
Cross reference table
Class [x]
Attributes Class I D , Class name, image address, etc
Parent_id Class ID
Object Size Size (byte)
IsParsed 1 or 0
Interface Info IsInterface (1 or 0) Interface Count Interface List
Field Data[i] Field Name Class I D & Field Offset Field Tag
Method[i] Method Name Class I D & Method Offset
Ldc[i] Data Type
String Pool The whole string data stored in constant pool
記憶體空間,這個資料結構欄位中放的只是指向另外記憶體空間的位址,會這樣做的原因在 於硬體電路在做 Field Data 存取及 Invoke Method 都需要經常查找這個資訊,所以將存放這項 資訊的記憶體會統一整理安排在 on-chip 的 BRAM 上用來加速查找的動作,在圖 13 上這兩個 欄位先以簡化的方式表示其意義。 圖14. 物件型別解析器演算法流程 上圖 14 是我們物件型別解析器在先不考慮繼承以及介面機制的實作,只是針對單一物件
p
ar
se
_c
las
sfi
le
(cl
as
s_l
oa
de
r.c
)
re
sol
u
ti
on
par
si
ng
Constant pool reconstructing
Super class resolution
Field_info structure resolution
Method_info structure resolution
Reference field resolution
Reference method resolution
Return to Java core
Ldc data resolution
Class simple table resolution
Class data resolution
Interface resolution
型別去做解析的流程,這邊將流程中的行為主要區分為 parsing 及 resolution 兩大 類,其 parsing 所表示的意思是其行為發生在解析物件型別格式(class format)內容時會做的,而 resolution 則是指對常數索引區段中部分會使用到的資訊,做進一步的轉換,接著我們針對流程中每一 個步驟去做說明。
4.1.1.
常數索引區段(Constant pool)的結構修改
物件型別解析器主要提供的功能其中一項是對 JAVA 物件型別檔中的常數索引區段 (Constant Pool)進行結構修改,以簡化電路查找特定參考值的流程,原始的常數索引區段 使用不同的標籤去表示每一個欄位的資料意義,並在每一筆資料內可以藉由常數索引區段的 索引值再去找到其他欄位的資料來定義自己,如此反覆的查找最後才能知道完整的資訊,這 邊 圖 15 是使用常數索引區段的索引值定義物件型別名稱的例子,而這樣在常數索引區段查 找的動作(Resolution)會在執行解析的過程中頻繁出現,並且在不同標籤所代表的欄位資料 在常數索引區段中的長度上也不是統一的,所以在查找的過程中需要逐一掃過小於索引值的 所有欄位,當我們今天執行在執行的 JAVA bytecode 跟隨 Operand 是指向的是常數索引區段 中的索引值時,這樣查找的動作更會影響我們在執行上的效能,所以在解析的過程中,我們 這邊針對常數索引區段的處理會在第一次掃過所有常數索引區段時建立索引記錄每個欄位的 起始位址,加快在後續解析物件型別時查找的動作,並將需要後續處理的一併資料紀錄起來。index tag content
: : :
4.1.2.
Super class resolution 及 Interface resolution
在 JAVA 語言中,其物件導向的特性具有繼承及介面功能(如 1.2 說明),而在物件型別
的結構中(Class Format),裡面有兩個項目分別描述這個物件型別繼承的父物件型別為何以 及實作的介面有哪些,這邊解析的動作會透過查找(Resolution)的方式建立此物件型別的父 物件型別及有實作的介面資訊,並更新至 XRT 資料結構中。
4.1.3.
Field_info/Method_info structure resolution
圖16. Field_info/Method_info structure resolution 演算法流程
上圖 16 是如何把某一個物件型別的 Field_info 及 Method_info 加入 XRT 的演算法, 其中解析的欄位表示屬於目前解析的物件型別中所屬的 Field Data 或是 Method。因為我 們使用的是 lazy 的方式去決定解析物件型別的時機,所以當別人有參照使用到此物件型 別的 Field Data 或 Method 時,會先幫在此物件型別建立 Field_info 及 Method_info 的欄 位並填入部分資訊,等到真正解析此物件型別時才會將正確的參照資料(Reference Data)
Search the method/field data in this class’s XRT
Modify reference data
Add the method/field data to this class’s XRT No Yes No Yes Check the method/field data is exist Check all methods/field data finished
填入,所以當我們建立 Field_info 及 Method_info 時也要確認其參照資料是否已建立,這 邊參照資料對於 Field Data 其 32bit 的內容代表的意義為所屬的物件型別、屬性及其相對 於產生物件後,相對物件在記憶體中起位置的位移量,對於 Method 則是要表是其所屬 的物件型別及執行的位元組碼在執行映像檔(Run Time Image)上的位置,不過在 Method 的參照資料處理上在建立的是物件型別跟介面會有些微不同的處理,詳細不同在 4.3 節 關於介面部份會有更進一步的說明,演算法流程如圖 16。
4.1.4.
Reference field/method resolution
圖17. Reference field/method resolution 演算法流程 Search reference method/field
data in its class’s XRT
Store the address about reference data
Add reference method/field data to its class’s XRT and store reference data [class id | 0x0000] No
Yes
No
Yes Check the reference
method/field data is exist
Check all reference methods/field data finished
建立,並在參照資料(reference data)內填入[Class ID | 0x0000],最後再將指向參照資料的 位址做紀錄,之後一併整理至 Class Simple Table 中,4.1.7 會為 Class Simple Table 的功能做 解釋。
4.1.5.
Class data resolution
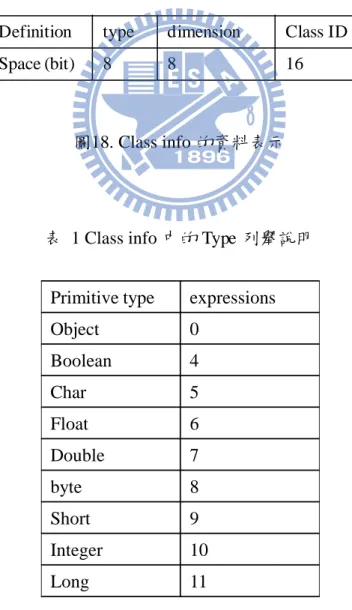
此資訊是列在常數索引區段中的 class tag 中,這部分的資訊透過查找後也會一併整理成 class info 至 Class simple table,class info 如圖 18、表 1,之所以會有維度資訊是因為在常數 索引區段中關於陣列資訊也會以 class tag 表示,但最後這 class info 資訊並不會存放在 XRT 資料結構中,因為這資訊僅會在該物件型別的方法中像是 newobj、anewarray...等等的 bytecode 使用到。
圖18. Class info 的資料表示
表 1 Class info 中的 Type 列舉說明
Definition type dimension Class ID
Space (bit) 8 8 16
Primitive type expressions
Object 0 Boolean 4 Char 5 Float 6 Double 7 byte 8 Short 9 Integer 10 Long 11
4.1.6.
Ldc data resolution
此資訊是取出列在常數索引區段中的 Integer、Float 及 String 的 tag 中所記載的資訊,一 樣會透過查找的方式將這些資訊存到 XRT 的資料結構中,為了之後當 JAVA 程式執行到 Ldc 的指令時,可以透過發出中斷觸發 Ldc 指令對應的 ISR,再將資料傳回 JAVA 處理器的堆疊 上,以完成對 Ldc bytecode 的執行,所以需要在解析的階段,先將這些資訊整理至 XRT 的 Ldc data 中。
4.1.7.
Run time image 格式介紹
最後要介紹的是完成解析的物件型別檔所產出的 run time image 結構,對 run time image 我們主要分為兩個部分,上半部稱為 class simple table,在 class simple table 中我們可以再細 分切為三塊,最前面是我們自訂的 magic number 佔 4 個 byte,接著會使用每 2 個 byte 為一個 欄位的方式,使用與常數索引區段欄位相同的個數,目的在於當 bytecode 使用的 Operand 指 的是常數索引區段上的索引值時,可以直接查找到其對應的資料,這邊內容存放的是一個索 引值,它指向位在第三塊上的資料,而在第三塊上的資料分為兩種,一種是物件型別方法所 會參照到的 method 及 field data,在這邊會以 32bit 來表示其參照資料(reference data)所在 記憶體的位置,第二種是直接存放 4.1.5 所提到的 class info,下半部則是將物件型別中所有 的方法直接貼入,這邊在貼入時每個方法僅會保留 max_stack、max_local 及 bytecode 的資訊, 最後產生的格式如圖 19 所示。
圖19. 實際 run time image 格式範例
4.2. 繼承(Inheritance)機制說明
在物件導向(Object-Oriented)的程式語言,繼承是相當重要的一個特性,在談實作繼承 機制前我們先對繼承的行為做說明,所謂繼承,是指物件型別物件的資源可以延伸和重複使 用,像是可以透過子物件型別或是子物件型別產生的物件呼叫繼承至父物件型別實作的方法、 存取父物件型別宣告的 field data,在使用上,我們在程式中可以利用 extends 關鍵字來表示 繼承關係,而 JAVA 的語法只允許單一繼承(Single Inheritance),也就是說子物件型別同時只 能繼承一個父物件型別,這邊需注意的一點在 JAVA 語言中雖然只允許單一繼承,但是當我 們卻可以使用 extend 讓介面去繼承多個介面時,但是在物件型別格式(Class format)上形式 會將繼承的介面資訊放在表示這個物件型別有實作的介面資訊上,而非放在表示這個物件型 別的父物件型別資訊上,實作介面的資訊如何解讀這部份我們放在後面章節討論。 為了實現上述特性,我們在物件型別解析的流程設計上,需要在解析每個物件型別檔時
4D4D 4553 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0044 0000
0000 0000 0000 0000 0000 0000 003C 0000
0040 0000 0000 0000 0000 0000 0063 18D4
0063 18D8 0063 18C8 0001 0001 0001 0001
2AB7 000C B100 0001 0003 0002 0003 2A1B
B500 142A 1CBC 0AB5 0016 B100
Class Simple Table
先完成其父物件型別的解析,以建立完整的子物件型別映像檔,這邊是以遞迴的方式去解析 物件型別檔,所以愈上層的物件型別會愈先被完成解析,其遞迴演算法的流程如圖 20 所示。
圖20. 在物件型別解析的流程中實作繼承的機制
除了解析父物件型別外,我們還需要從父物件型別的資料結構上複製部分資訊到目前解
析物件型別的資料結構中,這邊包含了物件大小、介面資訊(interface info)、Field Data 以及
Parse constant pool
Check this class’s
parent class has been
parsed or not.
Continue parse this class
No
Yes
Parse parent class
Continue parse this class
Copy info from parent class
圖21. 產生新物件時在記憶體中配置的情形
介面資訊(interface info)主要複製內容包含實作的介面數量以及被實作介面的 Class ID,
讓呼叫介面方法時透過父物件型別實作的介面,也可以找到子物件型別有繼承或覆寫的方法, 這邊關於介面的應用詳細內容以及複製介面資訊的原由我們保留在下一個章節 4.3 來討論。
另外這邊在說明複製 Field Data 資訊前,我們先針對 Field Data 的參照資料(Reference Data)上的資料結構再做詳細的描述,在 32bit 的 Field Data 參照資料中我們使用前 16bit 表 示 Class ID 表示 field data 所屬的物件型別,當繼承至父物件型別時這部分會替換成子物件型 別的 Class ID,而後半段的 16bit 拆成 4bit 表示 Field Tag,Field Tag 分別表示其是否為靜態的 Field Data、基本型態、長整數型態以及當 Field Data 存放的是記憶體中的位址時,所表示的 是陣列或是物件的起始位置,另外在 XRT 上我們還新增了 32bit 的 Static Field Address 欄位 用以存放當今天是靜態 Field Data 時,所有物件應該都會參照到的相同記憶體空間位址,以
上結構的說明,(如圖 22、表 2 列舉 Field Tag 所表示的意義所示),要特別注意的是除了長
整數的 Field Data 在物件上是佔 64bit 的空間,其他型態的資料都是以 32bit 的空間來存放, 在位移量也除了長整數型態是加二表示佔兩個 words 的空間,其餘每增加一個資料量為加一,
最後我們以實際例子來描述資料結構及其對應到的記憶體配置關係,(如圖 23 所示)。
Heap Memory Space
Class ID Field data
( inherited parent class) Field data
(define by this class)
圖22. 關於物件型別所定義的資料在資料結構中的表式
這邊對於 Field Tag 的意義除了在幫助我們分辨是否為靜態 field data 外,在後面章節所 提到的 Native Method 實作中也會需要參考其他 flag 資訊。
表 2 列舉 Field Tag 所表示的意義
所以在實作繼承機制時,子物件型別透過先複製父物件型別的靜態與非靜態 Field Data Cross reference table
Class [x]
: :
Field Data[i] Field Name Class ID & Field Offset Field Tag
: :
Definition Access flag Reserve Primitive flag Long Type flag Array/Obj flag
Space (bit) 8 5 1 1 1 Field Tag Long Access Flag 00000 | 110 Int 00000 | 100 Short 00000 | 100 Char 00000 | 100 Array 00000 | 001 Object 00000 | 000
圖23. 舉例描述物件型別資料結構中 Field Data 對應物件在 Heap Memory 上的關係
最後實作繼承至父物件型別的方法,僅需在子物件型別複製一份完整父物件型別方法的 資訊,包含方法的名稱、描述以及父物件型別方法完整的參照資訊[父物件型別 Class ID |
Method Offset],這邊之所以不用替換 Class ID,是因為在我們設計的機制中當 invoke method
時,執行的位元組碼(bytecode)仍是使用位在父物件型別的執行映像檔(run time image) 上某個方法中。
Cross reference table
Class [5]
: :
Field Data[0] field_test_1 0x00056001 0x0106
Field Data[1] field_test_2 0x00054003 0x0104
Field Data[2] field_test_3 0x00051004 0x0101
Field Data[3] field_test_4 mem_addr 0x0904
: :
Heap Memory Space
5 (Class ID) Long Type D ata
Other Primitive Type Data Array Address
Static Data
Object base address
0x001 0x000 0x003 0x004 Array Data Example :
public class test {
long field_test_1; int field_test_2;
int field_test_3[] = new int[64]; static int field_test_4;
: }
4.3. 介面(Interface)機制說明
在前面已經提過繼承是物件導向語言中的重要特性之後,這邊還要介紹另一項特性-介 面,而在說明實作部分之前,我們這邊一樣也先對介面的功能以及意義做說明,最後再接著 描述這些機制在我們平台上實作的方式。 介面的宣告像是在定義一個東西應有的行為,所以介面本身只有行為名稱,卻沒有描述 行為的詳細動作,若是某個物件型別實做了一個介面,則該物件型別必須把介面的所有方法 都實作出來,這麼的規範也表示任何實做了某介面的物件型別,我們可確信其必具有介面應 有的方法,就算方法內容的動作大不相同,我們仍然可以呼叫,而在使用上,因為在 JAVA 語言本身並不提供多重繼承的功能,所以一般也會透過介面的使用上來達到多重繼承的效果, 因為 JAVA 支援一次實作多個介面,就像是同時繼承多個抽象物件型別(實際上這是 C++中 多重繼承的一個實際運用方式),以下(圖 24)是一個介面的例子,我定義了一個 Interface 叫 phone,他必具備一個叫 dial 的方法,但是在介面裡並不會詳述要怎麼動作,而右邊是實 做了這個介面的物件型別,在這物件型別裡面就必須把介面裡的方法完整的描述出來。 圖24. 介面與實作其方法的物件型別例子 Interface: phonepublic interface phone { public void dial(); }
Class: nokia
public class nokia implements phone{ public void dial(){
… }; }
法(invokespecial、invokevirtual、invokestatic)會直接連結到屬於該物件型別方法的參考資 訊(reference data)。 圖25. 透過呼叫介面方法的方式呼叫實作其的物件型別方法 上圖 25 是一個實際呼叫介面方法的例子,左半邊是一個程式片段,接續前段的例子,這 邊另外又多加了個物件型別,也同樣實做了 phone 這個介面,這邊 n3310 與 T28 是兩個具有 相同介面屬性的物件,而他們真正的身分是個別是 nokia 與 ericsson,接下來呼叫使用該介面 裡定義的行為 dial,所以就透過了 Invokeinterface dial 來呼叫,然而因為 n3310 跟 T28 是不同 身分的物件,所以在 Java 雖然使用同樣的 byte code,最後卻會呼叫到的 dial 其 code 會不同。
如何透過指向相同的參照資料(reference data)找到不同的方法,在這邊我們對資料結 構提出新的修改,建立介面的資料結構時,會將 XRT 上指向一般物件型別方法的參照資料改 成指向鏈結串列的資料結構,而這串列上每個節點有三個資訊,包含此方法所屬的 Class ID、 方法的參照資料、下一個節點的位置,注意這邊之所以除了原來方法的參照資料還增加所屬 的 Class ID,目的在於解決子物件型別繼承至父物件型別方法時,參照資料上的 Class ID 會
Code fragment
…
phone n3310= new nokia(); n3310.dial();
phone T28= new ericsson(); T28.dial();
…
Class: nokia
public class nokia implements phone{ public void dial(){
… }; }
Class: Ericsson
public class ericsson implements phone{ public void dial(){
… }; }
Invokeinterface
是來自於父物件型別,而在語法中我們可以透過父物件型別實作的介面來呼叫子物件型別的 方法,這邊子物件型別的方法定義包含子物件型別有覆寫(over write)的方法或是僅繼承至 父物件型別,當子物件型別未覆寫其繼承的方法時,若不增加此欄位的話,我們當
Invokeinterface 時會在 method list 上找不到屬於子物件型別 Class ID 的方法,所以之後我們在 解析一個物件型別時,會將它每個實作的方法加到其有實作介面的 method list 上面,新的資 料結構如圖 26 所示。
圖26. 一般物件型別與介面在方法參照資料上的差異
Class ID Method Offset
Cross reference table
Class [X]
: :
Interface Info IsInterface (1 or 0) Interface Count Interface List
0 int short array
Method Info Method Name Reference Data
Method[x] char array ptr
: :
On-chip memory (BRAM) in JAIP
Cross reference table
Class [X]
: :
Interface Info IsInterface (1 or 0) Interface Count Interface List
1 int short array
Method Info Method Name Reference Data
Method[x] char array ptr
: :
Class ID
Class ID Method Offset ptr
Class ID
Class ID Method Offset ptr
在解析子物件型別實作介面前,會先完成其父物件型別及其實作介面的解析,可以順利建立 完整的介面資訊。
圖27. 在物件型別解析的流程中實作介面的機制 Parse constant pool
Check this class’s parent class has been parsed or not.
Add interface info from parent class No
Yes
Parse parent class
Add interface info from own interface Check the interface
implemented by this class has been parsed or not.
Yes
No
Parse interface
Maintain interface’s method list
Continue parse this class Continue parse this class
4.4. ISR 介紹
在我們系統所提供 ISR 的部分,這邊將它們分為兩類,其中一類是由 JAIP 執行電路的
過程所啟動的,另一類則是由系統物件型別(system class)所提供的原生方法(native method),
在開始說明這些 ISR 的內容流程前,先對 JAIP 與 RISC core 溝通的介面做介紹,之後我們會 再對其在執行 ISR 時的狀態變化做說明,最後再解釋各 ISR 實作的內容。
4.4.1.
ISR 狀態變化圖示說明
圖28. 堆疊抽象化的簡圖 ISR 所需傳遞的參數其中一部分資訊是透過 stack 中最上層的三個暫存器來傳遞,這邊會 以抽象的圖示來表示 JAIP 所使用的 2-level 及交錯式的記憶體,之後再以抽象圖,(如圖 28 所示),來表達執行 ISR 時的 stack 狀態變化。 abstract viewStack (in J AIP)
TOS_A (stack 0) TOS_B (stack 1) TOS_C (stack 2) TOS_A (stack 0) TOS_B (stack 1) TOS_C (stack 2)
Stack (in J AIP)
Register file stack 3 stack 5 : BRAM stack 4 stack 6 : Local variable 1 Local variable 2 Local variable 3 Local variable 4 Register file
Four port bank Top of stack
First level
Second level stack 3
: stack n
JAIP 用來傳遞參數的 register file,這裡的參數指的不是出現在 operand 上的,而是另外 用來幫助我們軟體執行的額外資訊,在實做原生方法的機制時也用來當呼叫方法所傳遞參數 來使用,抽象圖如圖 29 所示。
圖30. 用來表示目前執行的指令及其 operand 意義
這邊的圖 30 表示用以表示觸發 ISR 時,目前執行的 bytecode,以及之後跟隨著 operand 意義,而 type 中的 u(N),N 指得是資訊佔多少 byte。
Bytecode
Type Bytecode
: :
4.4.2.
ISR 流程圖
首先在這邊說明 newarray 與 anewarray 的 ISR 內容時,先解釋 array 在我們平台實作上的 資料結構,我們對 array 的表示會分為三個欄位,以圖 31 說明,array tag 依序表示的有陣列 存放的是不是 primitive 的 tpye、每個元素佔的空間,這邊不同於 field data 的處理,在 field data 中除了長整數是佔 64bit,其餘皆是 32bit 的大小,而在陣列上的元素除了 boolean 是佔 8bit 以外,其他元素皆是配剛好跟資料所需空間相符的大小,這樣的設定也是符合 JAVA 在 SPEC 中的規範,接著的 flag 如同 field data 會表示元素中存放的是位址時,指向的是物件還是陣列 的起始位址,下一個欄位是 length,用來支援 arraylength(0xBE)的 bytecode,之後接的才 是實際陣列的資料,之後圖 32-圖 39 分別表示執行其 ISR 時系統的變化以及演算法的流程。
圖31. Array format
Array tag Length Array data
Definition Primitive flag Data size Array/Obj flag Reserve
Space (bit) 1 4 1 26 Size N : : stack Before After : array reference : type Size N : TOS_A TOS_B TOS_C Process
圖33. anewarray ISR 執行時的狀態變化 圖34. newarray/anewarray ISR 程式實作流程 : : Class info Size N : : stack Before After array reference : : Process
Type Byte code u1 OP(BD) u2 ind ex bytecode
Type Byte code u1 Next OP
: :
(1) pre-process that translate index to class info (2) transfer class info into host argument host_arg : : : : : : hos_a rg1 hos_a rg5 : TOS_A TOS_B TOS_C
Get array tag by analyze type/ class info
Copy size to length
Allocate memory space
圖35. newobj ISR 執行時的狀態變化
: : Class info
Before
Process
After
: : : : : :
Type Byte code
u1 OP(BB)
u2 ind ex
bytecode
Type Byte code
u1 Next OP
: :
(1) pre-process that translate index to class info (2) transfer class info into host argument : : :
stack
object reference : :host_arg
hos_a rg1 hos_a rg5 TOS_A TOS_B TOS_CCheck the class is already parsed
Allocate memory space Get class id by analyze class info
No
圖37. ldc ISR 執行時的狀態變化 圖38. ldc ISR 程式實作流程 : : : stack Before After ldc data : : ind ex : : Process
Type Byte code u1 OP(12) u2 ind ex
Type Byte code u1 Next OP
: :
(1) push operand to stack : : : : : : : : : : Class ID : host_arg hos_a rg1 : hos_a rg5 TOS_A TOS_B TOS_C bytecode hos_a rg4
Check the String class is already parsed
Check the ldc data type is integer, float or string
Return ldc data to JAIP Search the index of ldc data in this class
string
integer or float
New string object by ldc data
Parse the String class No
最後介紹的這個 ISR 稱作 bad offset,觸發此中斷的原因在於我們對物件型別作解析的動 作為非主動式的,所以當 JAVA bytecode 做 field data 存取或是方法的呼叫,其參照資料為未 被解析的物件型別,則會抓取到[Class ID | 0x0000]的參照資料,這邊需要透過對物件型別 作解析才能抓取到正確的參照資料。
圖39. Bad index ISR 執行時的狀態變化
4.4.3.
原生方法的機制(Native method)說明
因為原生方法的呼叫在 bytecode 層級來看是與一般呼叫方法是相同的,透過 invokevirtual、 invokestatic 指令後面接的常數索引區段索引值,一樣以間接的方式最後取到參照資料在記憶 體中的位置,並抓取參照資料,而我們實作原生方法的機制是透過在物件型別解析時,檢察 所屬其物件型別的方法是否為原生方法,如果是的話,我們則會在參照資料裡上放入屬於原 生方法格式的資料,格式如圖 40,我們會犧牲 0xFF 開頭的 Class ID 用以表示此參照資料為Before Process After
: : Class ID | 0x0000 : : host_arg : : : : : : Class ID | Offset : : hos_a rg1 hos_a rg3 hos_a rg4 hos_a rg2 Reference data hos_a rg5
我們在 ISR 的 ID 上會用前 16bit 以 0 或 1 區分是否會為 Native method 所觸發,當 JAIP 發出中斷時,我們會先確認其是否為 Native method 所觸發的,之後跳去執行我們建立的 native method table 上對應到的 function,機制如 0 所示,其執行 Native method 實的系統變化如 0 所示。
圖41. Native method 機制
圖42. Invoke native method 執行時的狀態變化
Native method table 0 Function ptr
1 :
: :
ISR ID
Definition Native flag ID
Space(bit) 16 16 Native method code
void method(){ : implementation ; : } ind ex Parameter N-3 : Parameter 1
stack
: : : Sta ck 3 : Sta ck n : : : :Before
After
Parameter N-3 : Parameter 1 :process
host_arg
hos_a rg5 : hos_a rg1 Parameter N : Parameter N-2 : : Return value TOS_A TOS_B TOS_C :而為了配合電路在 native method 的結束時對 stack 的整理操作方便,我們在傳遞不同個 數的參數時,擺放在 register file 上的順序也不同,擺放順序如表 3 所示,而目前實作的原生 方法如表 4 所列。 表 3 傳遞不同參數個數時,參數位在 register file 上的位置,最多支援 8 個參數 Parameter order Parameter count 1 2 3 4 5 6 7 8 TOS_A ○3 ○4 ○5 ○6 ○7 ○8 TOS_B ○2 ○2 ○3 ○4 ○5 ○6 ○7 TOS_C ○1 ○1 ○1 ○2 ○3 ○4 ○5 ○6 Host_Arg 5 ○5 Host_Arg 4 ○4 ○4 Host_Arg 3 ○3 ○3 ○3 Host_Arg 2 ○2 ○2 ○2 ○2 Host_Arg 1 ○1 ○1 ○1 ○1 ○1 表 4 目前對 System Class 所支援的原生方法 Java_java_lang_Object_getClass Java_java_lang_Class_forName Java_java_lang_Class_newInstance Java_java_lang_Thread_yield Java_java_lang_System_arraycopy Java_java_lang_System_currentTimeMillis
實作原生方法的依據主要參考自 KVM 當中實作的原生方法的邏輯,並撰寫符合我們平 台的版本,接下來會說明各原生方法的實作內容。
java/lang/Object/getClass
因為在我們配置一個新產生的物件時,其在記憶體中最前面 32bit 的資料就是存放此物件所 屬的 Class ID,所以當我們今天取得 Object reference 時,我們即可以透過這個位址讀取 Class ID,並回傳給 JAIP。
java/lang/Class/forName
透過取得的 String Object 參數,我們取出其字串的 field data,並以此為要解析的物件型別名 稱呼叫物件型別解析器,最後再回傳一個 Class Object 給 JAIP,但是其所屬的 Class ID 我們 會填入此次解析物件型別的 Class ID,而非 Class 這個物件型別的 Class ID。
java/lang/Class/newInstance
透過傳遞出的由 Class 造出的 Object,我們取出其存放的 Class ID,再透過此 Class ID 去配置 一個新物件記憶體空間,並回傳 object reference 給 JAIP。
java/lang/Thread/yield
目前平台尚未提供多執行緒的功能,但此方法會去確認目前系統中的執行緒個數,當個數大 於一時,我們會去設定切換執行緒的訊號,之後可以延伸做為觸發電路做切換執行緒的機制。
java/lang/System/currentTimeMillis
這邊我是透過讀取 JAIP 內部的 timer 暫存器的值,再去對系統頻率換算得到 JAIP 啟動之後 的毫秒數,再將這個時間資訊傳回給 JAIP。
java/lang/System/arraycopy
arraycopy 會使用到五個參數,其中兩個分別代表陣列的記憶體位址、另外兩個表示從陣列上 要開始複製及貼上的起始位置,最後一個表示要複製資料的長度,在這部分實作兩個遞迴呼
叫的函式 copy_obj 及 copy_array 來實作,這兩個函式的流程如圖 43、圖 44 所示,當呼叫 arraycopy 時會根據 array tag 去決定呼叫 copy_obj、copy_array 或是直接複製內容,也因為實 作這個原生方法,所以我們對陣列及 field data 都做了額外的 tag 表示其中的意義,來幫助我 們在複製物件及陣列時,使用正確的複製的方式。
圖43. copy_array(ref)流程
Check all elements are finished Check all elements
are finished Check element is
array type Yes
Check element is object type Call copy_obj(ref) Yes No Call copy_array(ref) Copy primitive data
Get array t ag
No
No No
圖44. copy_obj(ref)流程 java/lang/System/getProperty0 透過取得的 String Object 參數,取出其字串內容的資訊,這邊參考自 KVM 中實作的方式會 再呼叫 getSystemProperty 的函式,取得表示系統資訊的字串,並以此字串產生一個 String Object 回傳給 JAIP。 java/lang/String/charAt
在 String 的 field data 中,其中一項是用來描述另一個 field data 字元陣列的有效起始位置,當 我們得到 String Object 參數時,會在其字元陣列中,將其起始位移量加上索引值得字元回傳 給 JAIP。
Check all field d ata is finished
Get field tag
Check field data is
array type Yes
Check field data is object type
Copy field data
Yes No Call copy_array(ref) Yes No Call copy_obj(ref) No