運用混合演算法於田口動態特性之參數設計最佳化
91
0
0
全文
(2) 運用混合演算法於田口動態特性之參數設計最佳化 Optimizing Parameter Design for Taguchi’s Dynamic Characteristics with Hybrid Algorithms. 研 究 生:詹曉苓. Student:Hsiao-Ling Chan. 指導教授:梁馨科 博士. Advisor:Dr. Shing-Ko Liang. 國 立 交 通 大 學 工業工程與管理學系 博 士 論 文. A Thesis Submitted to Department of Industrial Engineering and Management College of Management National Chiao Tung University In partial Fulfillment of the Requirements For the Degree of Doctor of Philosophy In Industrial Engineering August 2006 Hsinchu, Taiwan, Republic of China. 中華民國九十五年八月.
(3) 運用混合演算法於田口動態特性之參數設計最佳化 研究生:詹曉苓. 指導教授:梁馨科 博士 國立交通大學 工業工程與管理學系博士班. 摘要 田口玄一所提倡的參數設計,主要目的是要決定產品或製程的因子水準等設定 值,使其對雜音變數的敏感性最小。但多數侷限於單一品質特性之靜態特性問題,對 於連續型參數無法求取真正的最佳參數解。 本研究應用混合演算法的求解程序,來協助解決田口動態特性的多品質特性問 題。首先,利用類神經網路模擬出控制因子與反應值的關係,再利用啟發式演算法求 取最佳參數設定值。對於多重品質特性最佳化問題,利用望想函數或指數望想函數綜 合衡量多個品質特性,以克服田口方法無法考量多重品質特性同時最佳化的缺點。室 內無線區域網路傳輸品質評估系統的實際案例,說明方法之可行性。本研究之結果, 將可協助區域網路工程師減少網路規劃所耗費的時間與判斷上的難度。. 關鍵詞:參數設計、動態特性、類神經網路、混合演算法、啟發式演算法。. I.
(4) Optimizing Parameter Design for Taguchi’s Dynamic Characteristics with Hybrid Algorithms Student: Hsiao-Ling Chan. Advisor: Dr. Shing-Ko Liang. Department of Industrial Engineering and Management National Chiao Tung University. ABSTRACT Parameter design is critical to enhancing a system’s robustness by identifying specific control factor and their levels that make the system less sensitive to noise. Most engineers applied Taguchi methods to optimize parameter design. However, Taguchi methods can only obtain the discrete optimal solution. They cannot identify the real optimum when the parameter values are continuous. The multi-response problem is too difficult to be considered by engineers with limited statistical knowledge. This research proposes a hybrid approach for combining neural networks and meta-heuristic algorithm to optimize the continuous parameter design problem. First, neural networks are used to simulate the relationship between the control factor values and corresponding responses. Second, meta-heuristic algorithm is employed to obtain the optimal parameter settings. The desirability function (or exponential desirability function) is utilized to transform the multiple responses into a single response. The real case of the propagation system evaluation of indoor wireless LAN is presented to demonstrate the practicability of the proposed procedure. Keywords: Parameter Design, Dynamic Characteristic, Neural Network, Hybrid Algorithm, Meta-Heuristic Algorithm.. II.
(5) 誌. 謝. 本論文得以順利付梓,首先感謝指導教授梁馨科博士的悉心指導與啟迪鼓勵。承 蒙恩師在學問上不厭其煩的耐心解惑及待人處世等多方面的引導,使學生在課業與生 活中都獲益匪淺,師恩浩瀚永銘於心。論文口試期間,感謝陳義揚教授、徐世輝教授、 廖又生教授及陳安斌教授不辭辛勞審閱論文,給予諸多精闢的建議並逐字斧正,使本 論文更臻完備與嚴謹,謹此致上無限的謝意。 此外,特別感謝明新科技大學前電算中心主任張玉山教授,及中華大學系統網路 中心研究助理江漢清先生,不吝提供該校建置校園無線網路的寶貴經驗。 感謝大華技術學院資訊管理系的長官及所有同仁,在我進修博士學位過程中的諸 多配合與協助,讓我能兼顧學業與工作,順利完成論文。 謝謝產業管理研究室的學弟們,在行政事務處理上提供充分的協助。 感謝一直陪伴在身邊鼓勵我的先生,悉心地照顧我及我們即將出世的女兒,使我 的生活充滿歡笑與活力。在研究這條寂寞而漫長的道路上,有他的相伴讓我不覺孤單。 最後謝謝親愛的雙親與弟妹,由於他們長久以來毫不保留的支持、關懷與包容, 使我得以順利完成學業。. 僅以本文獻給摯愛的家人及所有關心我的朋友,願你們平安喜樂!. 詹曉苓. 謹誌. 中華民國九十五年八月 於新竹交通大學. III.
(6) 目. 次. 中文摘要…………………………………………………………………………………….I 英文摘要…………………………………………………………………………..….……II 誌謝…………………………………………………...…………………………..….……III 目次…………………………..……………...……………….……………...….…………IV 表目次………………………..…………………………...….………………….……...…VI 圖目次…………………..……………………………….…..…………………..….……VII. 第一章 緒論………………..………………………..…….……………..…...……………1 1.1 研究動機與背景…………………………..…….………..…………....……1 1.2 研究目的……..………………………………….…………..………………1 1.3 論文架構……..…………………………..……...…………..………………2. 第二章 文獻探討…………..………………………….…….……………..………………3 2.1 田口方法動態特性………………………..…….………….….……………3 2.2 類神經網路..……………………………..…..….………..…………....……6 2.3 分散式搜尋法…..………………………………….….…….…….…………9 2.4 基因演算法.………………………………..…..…….……..…..….………14 2.5 模擬退火法…..……………………………..….…………………………..15 2.6 望想函數…..……………………………..….………..….…...……………15 2.7 混合演算法……………………………..….………...…..….……………..17 2.7.1 結合類神經網路與分散式搜尋法….………………….…………..18 2.7.2 結合類神經網路與基因演算法….………………..……..…….…..18 2.7.3 結合類神經網路與模擬退火法….………………..……..…….…..19. 第三章 研究方法…………..………………………..…….…………...…………...…….20 3.1 整合田口方法與倒傳遞類神經網路演算法……..…..…..……...………..20 3.2 整合倒傳遞類神經網路與基因演算法……..…….….………………...…21 3.3 整合倒傳遞類神經網路與分散式搜尋法…..…...….………………...…..22. IV.
(7) 3.4 整合倒傳遞類神經網路與模擬退火法…..…….…………...……...……..25 第四章 室內無線區域網路傳輸品質評估系統之實證分析….…...……………...…….28 4.1 問題描述………….….………………………….…………………...…….28 4.2 研究設計之架構……………………..…….………...……………..……...30 4.3 利用田口方法求解…………..……………………….….….…...………...33 4.4 利用混合演算法求解…………………………….………….……..….…..36 4.5 確認實驗與比較…………….…….…………………….…...….….….…..39. 第五章 結論與建議…………………………………..…….…………..…….……...…...41 5.1 結論………..………………………..…….……………..…….….….…….41 5.2 建議………….………………………..…….……………..….……...…….42. 參考文獻…………..………………………..…….……………………....…..……….…..43 附錄………….…………………………..…….…………………………...………….…..50. V.
(8) 表. 目. 次. 表 4-1 實驗的控制因子與水準……………………..…….……………..……………….31 表 4-2 實驗結果……………………..…….…………...………………...……………….32 表 4-3 SN 比的回應值表…………..…….………………...…………………………….34 表 4-4. β 的回應值表………………..…….……………...………………………….…..34. 表 4-5 實驗的變異數分析表(SN) …..…….………………...……………………...……35 表 4-6 實驗的變異數分析表 ( β )…..…….………………...……………...……………36 表 4-7 類神經網路訓練結果…………..…….………………...……...………………….37 表 4-8 基因演算法的執行結果 (指數望想函數) …………...…...……………………..38 表 4-9 基因演算法的執行結果 (望想函數) .………………...………...……………….38 表 4-10 參數設定值………………..…….…………...………………...………………...38 表 4-11 四種方法求得各控制因子最佳值……………………..………….…………….39 表 4-12 確認實驗數據…………………………………………..…….………………….39. VI.
(9) 圖. 目. 次. 圖 2-1 田口問題之動態系統參數圖……..…….……………..…………………………...3 圖 2-2 動態系統的理想函數圖…..…….………………..………………………………...4 圖 2-3 動態特性的參數設計流程圖….………………...…………………...………..…...6 圖 2-4 類神經網路架構:以倒傳遞類神經網路為例.……………………………..….....8 圖 2-5 二維空間參考集合……..…….……………….………………………….……….11 圖 2-6 重劃路徑……..…….………………..…………………………………………….11 圖 2-7 分散式搜尋法的流程圖……………...……………………………………..…….14 圖 3-1 整合倒傳遞類神經網路與分散式搜尋法流程圖………………………..………22 圖 3-2 整合倒傳遞類神經網路與基因演算法流程圖…………………………..………24 圖 3-3 整合倒傳遞類神經網路與模擬退火法流程圖…………………………..………26 圖 4-1 教學大樓平面圖….………………...……………………………………..………29 圖 4-2 建立目標函數…………...………………………………………………...………30 圖 4-3 SN 比的回應圖…………...………………………………………………………34 圖 4-4. β 的回應圖….………………...…………………………..……………………...35. VII.
(10) 第一章. 緒論. 1.1 研究動機與背景 參數設計主要目的是要決定產品或製程的因子水準等設定值,使其對雜音變數的 敏感性最小。由於田口方法(Taguchi methods)強調在設計階段即考慮品質觀念,依成 本效益的觀念找出最佳的因子水準組合,且計算方法簡單、試驗次數少,故成為工業 上最常被使用的參數設計工具之一。雖然線上工程人員時常運用田口方法來解決最佳 化問題,但由於田口方法在實際應用上只能找出原先設定好的因子水準值,無法處理 因子水準為連續型的問題。因此,工程人員在進行實驗時,通常是根據工程知識訂出 大約的因子水準,而這些水準值並不一定是最佳值。針對田口方法無法處理因子水準 為連續型問題,有兩位學者提出以反應曲面法(Response Surface Methodology; RSM) 來解決這個問題(Vining 與 Mylers, 1990)。然而,也有學者提出,若實驗設計無法蒐 集到正確的資料,則反應曲面依然無法正確有效的預估參數值(Montgomery, 2004)。 本研究基於品質工程中,以直交表配置之實驗數據轉換為訊號雜音比,來尋求最 適組合之設計參數與水準的技法上,仍有藉助主觀決策的缺憾,故應用混合演算法 (hybrid algorithms)的求解程序來解決連續型參數設計問題。首先,利用類神經網路 (neural network)模擬出控制因子與反應值(responses)的關係,再利用啟發式演算法 (meta-heuristic algorithm)求取最佳參數設定值。對於多重品質特性(multiple responses) 最 佳 化 問 題 , 利 用 望 想 函 數 (desirability function) 或 指 數 望 想 函 數 (exponential desirability function)綜合衡量多個品質特性,以克服田口方法無法考量多重品質特性 同時最佳化的缺點。最後,本研究以室內無線區域網路傳輸品質評估系統為實證案例 來說明本研究所應用方法之可行性。. 1.2 研究目的 本研究使用混合演算法的程序,考量在多重品質特性下,解決田口動態特性的參 數設計最佳化問題。 1.. 降低變異性(variability)與調整靈敏度(sensitivity)為田口動態特性主要的兩 個最佳化程序,將變異性與靈敏度同時最佳化為本研究目的之一。. 2.. 本研究使用望想函數與指數望想函數將多重品質特性轉換為單一品質特. 1.
(11) 性(single response)。望想函數(或指數望想函數)的優點是容易了解,而且 使用者可以根據反應值的重要性加以調整權重值。 3.. 本研究利用混合演算法解決田口方法無法處理因子水準為連續型的問 題。田口方法雖然由於計算簡單、試驗次數少等原因,使得它成為工業上 最常被使用的參數設計工具之一。但是田口方法在實際應用上仍有一些不 足,例如無法處理因子水準為連續型數值的問題。換言之,工程人員在進 行實驗時,通常僅根據工程知識大約訂出幾個因子水準,但這幾個水準值 並不一定是最佳的。因此,本研究利用混合演算法,以倒類神經網路建立 目標函數,再結合啟發式演算法最佳化其連續型的參數設計問題。. 4.. 實例研究是以台灣某技術學院之室內無線區域網路傳輸品質評估系統為 例。經由實證研究證實本研究方法的可行性,本研究也比較實驗中各種混 合演算法的有效性與優缺點。. 1.3 論文架構 本研究共分為五章,第一章為緒論,說明研究動機與背景、研究目的、論文架構 等。第二章介紹田口方法動態特性相關文獻,及論文中所使用的啟發式演算法。包含 類神經網路、分散式搜尋法、基因演算法、模擬退火法、望想函數及混合演算法之文 獻探討。第三章利用四個小節說明本研究所應用之四種混合演算法如何執行。第四章 則提出「室內無線區域網路傳輸品質評估系統案例」之實證分析。第五章為本論文之 結論與建議。. 2.
(12) 第二章 文獻探討 本研究使用混合演算法來解決田口動態特性案例的問題。本節介紹田口方法動態 特性相關文獻,與論文中所使用的啟發式演算法,包含類神經網路、分散式搜尋法、 基因演算法和模擬退火法,以及各種啟發式演算法與類神經網路所結合的混合演算法 相關文獻。. 2.1 田口方法動態特性 田口玄一博士在1949年發展一透過實驗進行系統參數最佳化設計的方法。田口方 法的主要目標為提昇品質使其能達到目標值並減少變異,該法強調在產品與製程設計 時就應考慮品質問題。田口方法發展初期以探討靜態系統方面的文獻較多(Logothetis 與 Haigh,1988; 蕭綱衡,民79),然而針對工業界的實際需求,田口方法在動態系統 方面的應用也日益增多(Taguchi, 1990)。國內學者提出利用多項迴歸模式解決田口方 法動態系統的問題(陳明宏,民83;洪饒峰,民85)。也有學者提出以柔性演算法為基 (soft computing-based)的求解程序來解決田口方法動態特性問題,並利用模擬實驗結 果證明方法論的有效性(張旭華,民88)。針對血糖測試片的製程改善,學者也針對田 口方法動態特性的問題,成功的解決製程不良率偏高的現象,並建議適當之製程參數 (Su 等, 2005; Chan 與 Liang, 2005 )。 所謂靜態系統是指品質特性的目標值只有一個。動態系統中除了控制因子與雜音 因子外,還較靜態系統多了信號因子(signal factor),品質特性的目標值會隨著信號 因子水準的不同而有所改變(Phadke, 1989; Fowlkes 與 Creveling, 1995)。田口問題之 動態系統參數圖如下(蘇朝墩,民91): 雜音因子. 信號因子的 輸入. 系統. 控制因子 圖 2-1 田口問題之動態系統參數圖. 3. 輸出 (與信號因子成正比例).
(13) 信號因子水準可由產品設計者或使用者自行設定以達到所需的產品功能,亦即可 任意調整信號因子而降低雜音因子的影響以使得品質變異最小。田口動態系統在理想 狀態下,可將品質特性與信號因子的關係視為線性,如公式(2-1)所示:. Yijk = β i M j + eijk. (2-1). 其中 Yijk 為品質特性,假設有 i 個控制因子, j 個信號因子與 k 個雜音因子;M 為 信號因子; β i 為斜率且 σ i2 = Var (eijk ) ,代表系統的靈敏度; eijk 為隨機誤差項。圖2-2 為零點比例式的動態系統理想函數圖(蘇朝墩,民91)。. y. • • • M1. • • •. • • •. 最佳配適線. β = 斜率 =. M2. dy dM. M3. M. 圖2-2 動態系統的理想函數圖 在動態系統中,評量系統績效所使用的特徵有以下三種(Fowlkes 與 Creveling, 1995): 1. 靈敏度:當信號因子改變一單位時所造成品質特性的變化量稱為靈敏度或敏感 度,亦即為公式(2-1)中之斜率β。靈敏度的理想值是因個別的動態系統要求而異, 例如一般工業製造系統大多數希望靈敏度愈大愈好;量測系統方面則認為靈敏度的 理想值為1;而對於某些輸入信號值較難更動的射出成型製造系統而言,則可利用 調整靈敏度的方式來改變輸出值。 2. 線性關係 (linearity):在動態田口方法中,信號因子與品質特性間呈線性關係是非 常重要的,其目的是希望若品質特性與信號因子間存在著線性關係,除了可簡化分 析過程外,並能藉由調整信號輸入更容易達到所要求之品質輸出目標。 3. 變異性:在動態系統中,我們希望在每個信號因子水準下,品質特性都盡可能地 4.
(14) 接近目標值,並希望降低在每一信號因子水準下品質特性對於其目標值的變異。 為了能量化以上的這三種評估準則,動態系統中用信號雜音比(signal to noise ratio, SN 比)與靈敏度作為衡量品質變異與敏感度的指標,此二指標之表示方法如下 (Fowlkes 與 Creveling, 1995): ⎛β2 ⎞ SN i = 10 ⋅ log10 ⎜⎜ i2 ⎟⎟ ⎝σi ⎠. S i = 10 ⋅ log10 β i2. (2-2). (2-3). 其中 σ i2 通常以均方誤(mean square error, MSE)來估計, β i2 則是以最小平方法估計而 得。 由於動態系統有信號因子用以調整輸出值,所以根據以上兩個評估指標,田口博 士發展出一個含有信號因子的兩階段最適化法(Taguchi, 1990):. 1.減少伴隨著線性函數關係的變異:找出影響SN比的顯著因子,再找出這些因子的最 佳水準設定值,以達成一個穩定的機能。. 2.調整信號因子以使輸出值能調整到目標值:利用調整因子來調整線性關係的斜率, 以達到所要求的靈敏度。 執行動態特性的參數設計實驗必須先將問題定義清楚。辨認理想的函數之後再發 展出信號因子與雜音因子。與相關工程人員討論後確定實驗中的控制因子,並設定其 水準值。選定適用的直交表後,依表指派直交表中的控制因子。實驗規劃完成後即開 始執行實驗並收集數據。根據實驗所收集的數據來分析資料,首先計算直交表中的SN 比及 β 值,並畫出其回應圖。接著執行上述的兩階段最適畫法,評估最佳水準組合下 的SN比及 β 值。代入最佳實驗結果執行確認實驗後,判斷是否可行。若確認實驗結 果不可行,則從規劃實驗開始檢示每一步驟的缺失;若接受確認實驗的結果,則執行 最佳參數設計值的結果。圖2-3為動態特性的參數設計流程圖。. 5.
(15) 規劃實驗 定義問題 辨認理想函數 發展信號因子與雜音策略 確定控制因子及其水準值 選定直交表中並指派表中的控制因子. 執行實驗與收集數據. 分析資料 計算直交表中的 SN 比及 β 值 畫出 SN 比及 β 值的回應圖 執行兩階段最佳化程序 預估最佳水準組合下的 SN 比及 β 值. 執行確認實驗. 否. 是否確認? 是 執行結果. 圖 2-3 動態特性的參數設計流程圖. 2.2 類神經網路 類神經網路是近年來熱門的話題,由於使用類神經網路時並不需要複雜的計算或 太多的假設,只需有一些輸出、輸入的例子就可以利用網路學習建立模式(model), 因此被應用在許多的領域中,如工業、醫療、股市預測、手寫辨識、商業等都有很大 的成效,近幾年來常被做為預測、醫療、分類的重要工具(鄒文杰,民 91)。 類神經網路最早由兩位數學家所提出(McCulloch 與 Pitts, 1943),到了 1950 年代 感知機(Perceptron)利用簡單的網路模式和簡單的學習法則,可以解決一些簡單的分類 問題,造成感知機曾經被廣泛被使用。1969 年時被其他學者證實感知機只能解決線 6.
(16) 性分類的問題,1980 年代這樣的情形有重大改變,有許多學者著手開始解決感知機 的問題,其中較重要的突破網路有霍普菲爾( Hopfield neural network;HNN)與倒傳遞 網路(back-propagation network;BPN),這兩個網路藉由隱藏單元(hidden unit)使用, 使得類神經網路可以解決更複雜的問題(Behzad 等,1990)。 神經生物學家和神經解剖專家在許多實驗後,發現人類腦細胞是由幾百億的神經 元細胞連結而成,於是許多的學者就模擬生物神經元網路而發明了類神經網路. (Kohonen, 1989)。類神經網路使用人工神經元簡單模擬生物神經元,利用神經元之間 的連結給於輸出輸入,利用學習法則來學習,這樣可以完成模式建立 (Funahashi,. 1989)。 類神經網路主要有兩種分類,分別為監督式學習網路(supervised learning network) 和非監督式學習網路(unsupervised learning network):. (1)監督式學習網路:在網路的訓練過程中,一組輸入值(input)必須有對應的輸出 值(output),利用和目標輸出值的差異進行網路學習,建立輸出值和輸入值的 規則模式,一般常被使用到的監督式學習網路有感知機、倒傳遞網路、學習向 量量化網路(learning vector quantization;LVQ)、放射基準機能網路(radial basis. function;RBF)、反傳遞網路(counter-propagation network;CPN)等網路。 (2)非監督式學習網路:在網路的訓練過程中,只需要有輸入值而不需要輸出值, 這類的神經網路會自己學習找出聚類規則,自己產生對應的輸出,一般常見的網路有 自組織映射圖網路(self-organizing map;SOM)、自適應共振理論(adaptive resonance. theory;ART)等網路。 類神經網路在運作前必須對網路結構和各階層的節點屬性作定義,然後輸入要訓 練的樣本,之後網路對輸入的樣本進行訓練。訓練結果後可以得到一輸出值,此時和 目標值作比較,調整網路連結的加權值來修正兩個值的誤差,經過重複多次的學習訓 練可以得到一個網路模式,最後會輸入一組測試樣本,這些樣本是用來評估所訓練網 路的精確度。 我們要決定一個類神經網路的好壞,常使用一個指標誤差均方根 (root mean. square error,RMSE),RMSE 越小越好。在選擇網路時先看訓練樣本的 RMSE 值,如 果訓練樣本(training)沒有辦法比較出優劣,這時要把測試(testing)樣本的 RMSE 加入 考慮,希望兩者 RMSE 同時小且趨於一致,也就訓練樣本和測試樣本這兩者的 RMSE 要越接近越好。 7.
(17) 倒傳遞類神經網路模式最早出現在 1974 年,當時被命名為動態回饋演算法. (dynamic feedback algorithm),直到 1988 年才正式確定命名倒傳遞類神經網路,解決 了感知機只能解線性分類的問題,使得類神經網路領域有所突破(Nitta, 1994)。 倒傳遞類神經網路屬於監督式學習網路,由於它有學習精度高、回想(recall)速度 快、理論簡明、應用普遍,造成它最近幾年最常被使用的類神經網路。基本原理是利 用最陡坡降法(the gradient steepest descent method)的觀念,使得誤差函數越來越小來 提昇網路準確率。它最大的特點在於增加隱藏層,可以將輸入神經元之間的交互作用 表現出來,它所使用的轉換函數也和之前感知機時代有所不同,採用平滑可微分的轉 換函數,這兩個特點使得類神經網路在理論和模式開發上有重大的突破 (Funahashi,. 1989)。 倒傳遞類神經網路的架構如圖 2-4 所示,包含三個層級:輸入層、隱藏層、輸出 層。輸入層為讀取外界資訊用,而輸出層將網路訓練學習的結果讀出,這兩層的個數 依問題而定,最重要的是隱藏層的功用,負責將資料分類或是結果間關係作過濾的工 作。隱藏層的層級和各層級單元的個數有一些學者提出證明和建議,隱藏層層級一般 一至二層就可以解決大部分的問題,至於隱藏層各層級單元的個數要在 2n+1 以下,其 中 n 為輸入層個數,也有學者提出第二層隱藏層單元的個數要為第一層的一半,但一 般都使用經驗法則加上試誤法。倒傳遞類神經網路最常使用的激發函數為雙彎曲函數. (sigmoid function),其定義為 f (x) =. 1 ,當輸入值大於 3 時函數值會趨近於 1, 1 + e −x. 輸入值小於-3 時其函數值會趨近於 0,這個激發函數的值域是界於 0 和 1 之間。 輸出向量 輸出層. ‧‧. 隱藏層. ‧‧. ‧‧. 輸入層. 輸入向量 圖 2-4 類神經網路架構:以倒傳遞類神經網路為例. 8.
(18) 倒傳遞類神經網路的計算方式分為向前 (forward) 和向後 (backward) 兩方面。首 先,我們將資料從輸入層輸入後,網路會將這些資料直接送至隱藏層,隱藏層這時對 這些資料作加權計算,在利用事先定義的激發函數將加權後的值轉換成激發值傳送至 輸出層,輸出層也會和隱藏層做一樣的動作,將加權計算後的值給激發函數作計算, 最後把計算後的值輸出,因為倒傳遞類神經網路是監督式的學習網路,所以會有輸出 的目標值,這時網路會比較輸出值和目標值的差異,利用學習法則對權重作調整,一 直重複進行直到滿足停止條件,一般停止條件為訓練次數或是誤差值小於設定的值。 倒傳遞類神經網路的訓練過程如下:. (1) 設定網路架構,隱藏層層數及各層級神經元個數。 (2) 設定起始權重,一般由電腦自動隨機產生。 (3) 選擇網路訓練的激發函數。 (4) 設定學習率 (learning rate)、動量 (momentum)和學習次數。 (5) 利用輸入值和起始的權重,在隱藏層中計算各隱藏層神經元的輸出值。 (6) 利用隱藏層的輸入值和起始的權重,在輸出層中計算各輸出層神經元的輸出值。 (7) 求出輸出值和目標值的差異。 (8) 計算隱藏層神經元和輸出層神經元的修正差異量。 (9) 修正輸出層至隱藏層和隱藏層至輸出層的權重。 (10) 重複(5)~(9)步驟直到到達停止條件為止。 由於倒傳遞類神經網路在建立函數有很精確的效果,使用上方便快速,所以在本 研究中我們使用倒傳遞類神經網路來適配(fit)輸入層和輸出層的函數關係。. 2.3 分散式搜尋法 分散式搜尋法(Scatter Search; SS)最原始的概念與原則是由學者於 1977 年所提 出,當時被應用在整數規劃問題上(Glover, 1986)。1994 年 Glover 提出一個改良過的 分散搜尋法,結合了禁忌搜尋法(Tabu Search)裡的一些技巧。這些技巧主要被用來控 制新解進入參考解集合的許可和從參考解集合中選出某些參考解來繁衍下一代,且將 兩個候選解配對後進行直線搜尋,再配合加權合成(weighted combination)機制選出新 的試驗解。權重值不是隨機產生的,而是事先設定好幾個特定值,此版本的分散式搜 尋法應用在解決非線性最佳化問題、二元和排序問題上(Fleurent 等,1996; Cung 等,1997;. Laguna 等, 2000)。 9.
(19) 分散式搜尋法主要的想法起源於結合決定法則(combination decision rule)和代理 者限制(surrogate constraints)觀念(Glover, 1965),利用這兩個想法而產生了重劃路徑. (path relinking) 的 觀 念 , 最 後 發 展 出 具 體 的 演 算 法 。 有 別 於 一 般 演 進 搜 尋 法 (evolutionary search)皆由隨機方式開始,分散式搜尋法一開始就使用具體化的方式產 生初始解,來增加求解過程的效率和品質,在求解過程中和禁忌演算法一樣利用記憶 的方式,對搜尋過程中作紀錄,幫助更廣泛的尋找更佳的解和避免陷入局部最佳解 中。分散式搜尋法的許多想法都是很簡單而且方法具體化,現在很多學者把分散式搜 尋法的想法方法放入基因演算法中,當成加強型策略。由於分散式搜尋法在每個步驟 都可以隨著問題的不同由使用者自己設計的特色,近幾年來被許多學者當成求取最佳 解的一個重要工具(Glover, 1999 與 Glover 等人, 2000)。目前運用在半導體製程(鄒文 杰,民 91;周柏宏,民 92)、備用零件庫存管理問題(陳士偉,民 93)、車輛途程問題、 二次指派問題和求取函數最佳解這些領域中都相當成功(劉吉峰,民 93)。 由於分散式搜尋法主要的好處之一是使用者可對問題的不同,自行採用適合的方 法並不是固定的,在使用上有很大的好處,所以使用 SS 除了必須注意參數設定和執 行步驟外,對於它的基本想法也必須了解。在分散式搜尋法的起始想法中於結合決定 法則是很重要的一個,其觀念是把目前的解以特定的結合規則產生新的解。首先使用 者可以自行定義規則,從目前所有解中找出有興趣值得觀察的解,將這些解成為一個 新的解集合,利用權重(weights)的方式將集合中的解結合而產生新的解,這樣的方式 讓解集合成為一空間,將單一的解組合後相當於在空間中搜尋,可以得到比一般產生 新解方式得到更好的效果。 分散式搜尋法的另一個重要的想法是代理者限制觀念,和結合決定法則不同的是 利用非負權重(nonnegative weights)的方式產生新的不等限制式,首先將原本的限制利 用規則分成不同的集合,將這些集合用非負權重方式結合成新限制式,重新對問題求 解,這樣的方式被發現隊線性規劃和非線性規劃的求解有很大的幫助。結合決定法則 和代理者限制主要的功能是提供評估的規則,可以幫助產生較好的新解或對目前的解 做修正。 分散式搜尋法最重要的觀念在於參考集合和重劃路徑:. (1)參考集合 分散式搜尋法利用前面的想法將搜尋的方式成為空間上的搜尋,先選取搜尋結果 好或有興趣的幾個解成為一個集合,稱為參考集合(reference set),利用這個集合產生 10.
(20) 新的解,這樣的方式好處可以減少搜尋的個數,因為一般來說參考集合只要小於 20 個就夠用了,像基因演算法每一代的個數最常使用是 100 個,相對於分散式搜尋法就 小多了,而且基因演算法在交配的階段是以隨機的方式由兩個染色體組合而成新的 解,而分散式搜尋法是用系統化的方式產生新的解,基因演算法利用大量的染色體維 持求解的多樣性,而分散式搜尋法利用系統化的方式維持,所以分散式搜尋法可以詳 細紀錄求解過程,利用和禁忌搜尋法類似的長期搜尋策略來降低發生局部最佳解機 率。 我們使用圖 2-5 說明參考集合,一開始有三個元素 A、B、C 成為一個參考集合, 利用不同權重組合產生 1、2、3、4、5 五個新元素。. A. 4. A 5. 2 1. B C. 3. 圖 2-5 二維空間參考集合. (2)重要路徑 重劃路徑之觀念是在參考集合產生新的路徑時,利用一些引導的準則幫助產生較 好的移動方向,其目的在於減少求解的步驟可以快速找到解,利用這種加強型的策略 增加求解的品質,圖 2-6 中實線為原來路徑,虛線為重劃路徑後的路徑。. x′′. x′. 圖 2-6 重劃路徑 11.
(21) 在重劃路徑中縮短路徑時並不一定要在可行解(feasible)當中,可以繞過不可行解 的範圍裡,在參考集合中可能會產生不可行的解,藉由這樣的方式可以處理,同時也 希望從不可行解中獲得一些資訊。重劃路徑的想法中使用許多這樣的機制,目的都在 增加求解的可能性加強求解的速度,而分散式搜尋法主要的精神也在這裡(鄒文杰, 民 91)。 分散式搜尋法有五個基本的執行步驟或稱為基本元素,分別為:(1)多樣化解產 生方法 (diversification generator method; DGM. );(2)改進方法(improving method;. IM) ;(3)參考解結合更新方法(reference set update method; RSUM) ;(4)子集合產生 方法(subset generation method; SGM) ;(5)新解合成方法(solution combination method;. SCM)。分述如下: (1)多樣化解產生方法 「多樣化解產生方法」的功能,是製造一組多樣化解以提供初始化和重組解集合 時被挑選使用。在整個搜尋過程中,「多樣化解產生方法」也是最早被用來製造且存 放在集合 P 裡的 Psize 個初始多樣化解。Psize 值一般設定為 max(100, 5*b),而 b 則 代表參考解集合的大小。這個方法著重於解的多樣性(diversificaiton)而不是品質,換 言之,在製造解的過程裡將不考慮問題的目標函數。 「多樣化解產生方法」強調利用 有系統或受控制的隨機化(controlled randomization)的方式來製造解,而不是採用完全 隨機化的方式。原因是利用前者方式所產生的初始多樣化參數解將兼具解的品質與多 樣性,若採用後者方式則所產生的初始多樣化參數解雞大量偏向解的多樣性。. (2)改進方法 這個步驟是利用一些簡單改進方法,將上一步驟中產生的初始解改進成品質較好 的解。雖然一般簡單改進方法產生的解並不是很好,但目的只在於將解做初步改善, 可以避免運算的複雜增加求解速度。改進方法可隨問題而定,但必須要有能力處理可 行的初始解和不可行初始解,例如 Glover(1994)對沒有限制連且續函數求取極值時採 用禁忌演算法當改進方法,利用以前有效的方法當成分散式搜尋法的一部分,再加上 分散式搜尋法的基本想法可以改善過去的方法缺點,所以有許多人將分散式搜尋法和 舊有的啟發式演算法作結合。. (3)參考解結合更新方法 在分散式搜尋法的想法中參考集合是很重要的一部分,在前面我們知道參考集合 如何產生新解和使用的好處,在這部份介紹如何選取參考集合。首先將參考集合分成 12.
(22) 兩部分,第一部分 b1 選取方式是針對加強型策略,使用選取想興趣值得觀察的解加 入第一部分,一般方式是選取目前解中將好的,第二部分的參考集合 b1 選取方式是 針對分散策略,選取和第一部分 b1 距離最近或最遠的解,可以幫助求解的廣泛性,. Glover 以實際的問題研究發現,當 b1 個數等於 b2 個數時效果最好。至於如何參考解 結合更新方法和下面兩個元素有很大的關係,利用下面元素產生品質比 b1 更好解就 加入 b1,而 b2 的更新方式和前面相同,差別只重複執行前兩步驟產生新解,而不是 利用原先的初始解。. (4)子集合產生方法 「子集合產生方法」將參考解集合裡的 b 個優良解分成一組組的子集合,以提供 新解合成時取用。這個步驟 Glover 提出四種方式:. (1) 兩兩相配而成,每一組子集合擁有兩個優良解。 (2) 由一個擁有兩個優良解的子集合加上參考解集合剩下的解中最好的一個所組 成,每一組子集合擁有三個優良解。. (3) 由一個擁有三個優良解的子集合加上參考解集合裡剩下的解中最好的一個所 組成,因此每一組子集合擁有四個優良解。. (4) 每一組子集合擁有 i 個優良解,其中 i=5~b。 選取的個數多或寡,只是在求解的廣度和廣度上作互補,經過實際驗證發現第一 種方式是較佳的。. (5)新解合成方法 這個步驟是利用結合決定法則想法,將上一步集合中的解作權重組合,再利用 特定選取規則產生新解。其規則由問題而定,一般採取可以多選取 b1 中品質較好的 解,較少選取 b2 的想法定立規則,再重複執行改進方法與參考解結合更新方法法, 經過一定的次數後得到最佳解。 一般使用的停止條件有兩種,一種是參考集合 b1 的解趨於一致,也就是解幾乎都 一樣,另一種是參考集合 b2 更新的次數。 分散式搜尋法由這五個基本元素組成,在介紹過程中不難發現分散式搜尋法使 用許多加強型策略和分散型策略,利用這些系統化方法來解決問題,可以清楚追蹤求 解的過程,不像其他演算法無法對解的來源作解釋。分散式搜尋法的流程圖如 2-7 所 示(葉謀銓,民 92):. 13.
(23) 子集合產生方法. 參數初始化. 參考解集合更新方法. 多樣化解產生方法. 改進方法. 改進方法. 參考解集合更新方法. 關連集合更新方法 否. 使否滿足 停止條件? 是 停止. 圖 2-7 分散式搜尋法的流程圖. 2.4 基因演算法 達爾文在經過多年的研究提出了「物競天擇」的理論,認為在自然界的生物是以 「適者生存、不適者淘汰」的規則演進,適合目前生存條件的物種擁有較大的機率存 活下來,這樣的想法被Holland (1975)應用到人工智慧的領域中,而提出基因演算法. (Genetic Algorithm; GA)。隨後有學者陸績深入探討並加以推廣(De Jong, 1987)。1989 年確定了基因演算法的三種基本演算因子-複製、交配、突變。經由複製、交配及突 變的方式產生下一代染色體,其平均表現會比上一代染色體好,如此重複可以求得最 佳解。 遺傳演算法結合交配、篩選、突變三個機制,讓隨機選取的動作,具備了強大的 搜尋能力,能夠解決許多非線性的問題,目前已經廣為應用於許多領域,如財務決策 和投資決策問題(Leinweber與Arnott, 1990; Bauer,1994 ),Goldberg(1989) 則利用遺傳 演算法作為機器學習辨識系統的處理機制,而經濟學家更利用遺傳演算法來做時間序 列的預測。 14.
(24) 使用遺傳演算法搜尋最佳解,同時執行多點搜尋而非單點搜尋,比較不容易陷入 局部最佳解,且在基因演算法的程序中是對編碼後的字串來做運算,只要對問題作合 適的編碼都可以使用,因此基因演算法可以適用於不同領域的最佳化問題。近年來有 學者將此方法運用於室內定位系統最佳化、及解決無線通訊頻道指定等問題皆有良好 的成效(章俊彥,民93;李善誠,民94)。. 2.5 模擬退火法 模擬退火演算法(Simulated Anneal; SA)是模擬物質結晶的退火(annealing)程序之 演算法。Metropolis 等人首次在 1953 年提出 SA 的演算法,1983 年時 Kirkpatrick 等 運用模 SA 來解決組合最佳化的問題(盧炳勳等,民 86),之後 Cerny (1985)利用 SA 來 解決旅行推銷員工作排程問及與 VLSI 設計問題。1986 年,Hinton 等人從原有的 SA 架構中發展出波茲曼機(Boltzmann mechanism)(Kirkpatrick 等,1983),以及 Miller 等 人以模擬退火法為基礎發展出退火神經網路(Cerny, 1985)。 假設我們要極小化目標函數 f ( x) ,SA 一開始先隨機產生一個可行解 x ,再由我 們所定義好的鄰域中產生新解 x' 。接下來計算ΔE= f ( x' ) − f ( x) ,如果ΔE<0 就將新 解取代舊解,如果ΔE ≥ 0 時計算一個機率指標 e ∆E / T ,其中 T 是一控制參數稱為溫度, 由這個指標決定是否接受新解。如此在同一個溫度 T 下重複 N 次,N 次後將溫度 T 下降,如此重複搜尋至設定好的最小溫度後停止。SA 利用 e ∆E / T 的指標可以接受較差 的解,因此有避免陷入局部最佳解的能力。 假設我們求一個方程式 F ( x) 的最大值, x 的可解區域為 X 。SA 是單點搜尋,首 先要由電腦隨機產生一個可行解 x ∈ X ,然後要定義鄰近解的區域,一般鄰近解設定 方式隨問題而有所不同。. 2.6 望想函數 望想函數(Desirability Function)是由 Derring 與 Suich(1980)所提出,代表任一反應 值(response value)在可接受區域(region of acceptance)內與目標值的接近程度。其目的 是將多品質特性問題轉換為單一變數的評估指標,以供決策方便。Young 等學者於. 1991 年應用田口方法中損失函數的概念,推導出望想函數的期望損失,並將其用來 解決超大型積體電路製造的問題;Chang 與 Shivuri(1995)則結合望想函數與多目標決 15.
(25) 策(multiple-objective decision-making)方法,發展出一多品質特性問題的分析模式;. Goik 等學者(1995)則結合望想函數與反應曲面法,發展出一解決產品設計問題的分析 模式;Chapman 結合望想函數與非線性規劃(nonlinear programming)方法,解決光化 學(photochemistry)製程的問題。 就實務上而言,品質特性與控制因子間的關係通常是未知的。經過實驗後,便可 利用實驗所得的數據來求得兩者間的關係。一旦得到品質特性與控制因子間的函數關 係後,即可對品質特性做預測,接下來便可導入望想函數的應用(洪饒峰,民 85)。 假設將任一品質特性與多個控制因子間的關係以下列函數表示:. Yi = f i ( X 1 , X 2 ,....., X P ) + ε i. (2-4). 其中,Y 為品質特性,X 表控制因子, ε 為隨機誤差。通常以下式估計兩者間的 關係:. ) Yi = f i ( X 1 , X 2 ,....., X P ). (2-5). 因此可根據不同的控制因子設定來得到不同的品質特性預測值。 當品質特性屬於望大時,公式如下:. ⎧0 ⎪ r ⎪⎪⎡ Yˆi − Ymin ⎤ d i = ⎨⎢ ⎥ ˆ ⎪⎣ Ymax − Ymin ⎦ ⎪ ⎪⎩1. Yˆi ≤ Ymin Ymin < Yˆi < Yˆmax. 0 ≤ di ≤ 1. (2-6). 0 ≤ di ≤ 1. (2-7). Ymax ≤ Yˆi. 當品質特性屬於望小時,其表示如下:. ⎧0 ⎪ r ⎪⎪⎡ Yˆi − Ymax ⎤ d i = ⎨⎢ ⎥ ˆ ⎪⎣ Ymin − Ymax ⎦ ⎪ ⎪⎩1. Yˆi ≥ Ymax Ymax < Yˆi < Yˆmin Yˆi ≤ Ymin. 當品質特性有一最佳的目標值,即望目的問題時,公式如下:. 16.
(26) ⎧⎡ Yˆ − Y ⎤ s min ⎪⎢ i ⎥ ⎪⎣ ci − Ymin ⎦ ⎪ t ⎪⎡ Ymax − Yˆi ⎤ d i = ⎨⎢ ⎥ ⎪⎣ Ymax − ci ⎦ ⎪ ⎪ ⎪0 ⎩. Ymin ≤ Yˆi ≤ ci ci < Yˆi ≤ Ymax. 0 ≤ di ≤ 1. (2-8). Yˆi < Ymin or Yˆi > Ymax. 其中: Yˆi :為第 i 組因子組合(Run)經轉換後的品質特性預測值。 Yˆmax :為預測所得到品質特性的最大值。. Yˆmin :為預測所得到品質特性的最小值。 Ymax :為已做實驗結果實際最大值。 Ymin :為已做實驗結果實際最小值。. ci 為品質特性的目標值;r、s、t 為表示重要程度的參數,值愈小表示其相對重 要性愈大。. 實際應用時,必須先將品質特性與控制因子間的關係找到後,得到品質特性的預 測值後再代入 d i 的公式,以求其值,而 d i 具有愈大愈好的特性。經過對同一因子水 準組合所產生的每一個品質特性轉換為 d i 之後,將所有的 d i 相乘並取其幾何平均數. (geometric mean),可得到該組因子水準組合的綜合判斷指標 D,其公式如下所示: D = (d1 * d 2 * ...... * d k ) k. 1. 0 ≤ D ≤1. (2-9). D 為多品質特性問題中,任一因子組合所產生的結果接近理想狀態的程度。D 與 d i 相同,也具有愈大愈好的特性,且最大值為 1,即愈接近 1 愈能符合使用者的理想。 最後可以 D 作為決定最佳因子水準組合的依據。. 2.7 混合演算法 由於各種啟發式演算法因其本身的特性,有其不同的優缺點,故許多學者致力於 實驗各種啟發式演算法以解決組合最佳化問題,諸如:基因演算法、禁忌搜尋法、模 擬退火法等。有部分學者結合不同的演算法來作為求解基礎模式,期望藉由良好的結 合方式,讓演算法之間產生互補的效果;而許多組合問題的研究結果亦顯示:混合演 17.
(27) 算法無論在求解的品質或效率上常常比單一演算法為佳 (Yamada 與 Nakano, 1996;. Balas 與 Vazacopoulos, 1998; Kolonko, 1999; Pezzella 與 Merelli, 2000; Chang 與 Lo, 2001; Wang 與 Zheng, 2001; Murovec 與 Suhel, 2004)。 2.7.1 結合類神經網路與分散式搜尋法 學者運用類神經網與分散式搜尋法的技術來求取參數的最佳設計。亦即,使用類 神經網路學習田口實驗的結果,模擬系統輸入輸出之間的關係,以突破田口方法在非 線性上的限制;再使用分散式搜尋法求取參數的最佳設計,並本提供一個二階段的求 解程序並以積體電路焊線製程為例進行最佳化參數設計 (鄒文杰,民 91) 。. 2.7.2 結合類神經網路與基因演算法 Kumar 與 Smuda(1994)將傳遞類神經網路模式中隱藏層的連結關係以基因演算 法的 Simple GA 表示之,並將 0 與 1 代表各層有無連結,目的在求取連結架構的最佳 值,以新的判斷值衡量其所呈現出的誤差程度。Ichimura、Oeda 和 Yoshida(2001), 提到以基因演算法與類神經網路的結合方式。假設整個類神經網路的架構,是由基因 演算法搜尋倒傳遞類神經網路模式架構的每個世代(generation)而來。即把類神經的每 個參數,以基因演算法搜尋可能的最佳解再去架構倒傳遞類神經網路模式,則連結的 權重與學習速率則被倒傳遞類神經模式所限定,其方法可以很穩健的架構傳遞類神經 網路模式。但對傳遞類神經模式的參數因子,需定其區域值以找最佳解。Chelouch 與 Siarry(2003)也發展出一個兩階段的混合演算法來求解全域最佳解。周立德(民 83) 結合類神經網路及基因演算法應用於非同步傳送模式網路之研究。先利用類神經網路 預估每一可能之控制參數組未來的服務品質, 再由基因演算法選取最適當的一組參 數用以動態地調整控制真實網路。詹緒林(民 86)也結合類神經網路與基因演算法,利 用具自我學習能力之類神經網路使電腦自動的編寫音樂的和弦,再利用基因演算法選 取適當的和聲基礎,完成電腦輔助和聲編寫系統。姜台林(民 90)提出三種整合式智慧 型方法,整合類神經網路、基因演算法及模糊理論,以解決田口方法靜態特性只能獲 取間斷型參數的問題,並以台灣三家半導體廠商的實際操作結果說明方法的可行性。 涂育瑋(民 91) 基於品質工程中,以直交表配置之實驗數據轉換為訊號雜音比,來尋 求最適組合之設計參數與水準的技法上,仍有藉助主觀決策的缺撼,於是提出結合類 神經網路與基因演算法則,於最適產品特徵之參數水準值的求取。最後,並將所求得 之參數水準值,導入實際產品特徵,建構一結合類神經網路與基因演算法則之最適化 18.
(28) 搜尋平台。張家瑲(民 91)嘗試結合類神經網路與基因演算法,藉由基因演算法預先搜 尋類神經網路訓練的初始權重值,再由類神經網路訓練以求取系統的估測反應,並根 據所定義的誤差指數,透過基因演算法進行反覆的選擇與複製、交配、突變等演算過 程,直到搜索出最符合系統的初始權重值。. 2.7.3 結合類神經網路與模擬退火法 林正鄰(民 82)提出以類神經網路作為製程輸出入的關係經驗模式,而以模擬退火 為實驗設計法,規劃建立模式所需之資訊的蒐集。這種最佳化的經驗模式建立程序, 應用於具有多個局部最佳解的函數時,可以成功地求得整體最小值;應用於函數在陡 峭峽谷的區域,能夠如梯度法般很快地找到谷底,而在目標函數為平坦之谷底區,又 能比梯度法更有效率地找到最佳值。因此可利用類神經網路建立最適化變數,設計出 具有穩健性的控制參數,證明以模擬退火與類神經網路結合之實驗設計法在製程最佳 化的應用極具潛力。江欽源(民 83) 改進林正鄰(民 82)提出來的實驗設計法,用統計 上 F-test 的方法來決定遞回式類神經網路結構中隱藏層神經元的數目,找到一個適 當的神經元數目,可避免學習時訓練不足或是過度訓練(over-training)的現象,改進以 往使用過多神經元的缺點,故加快了學習的速度。改進後的實驗設計法,具有廣泛搜 尋的能力,作為搜尋實驗點的方法,可以避免傳統用最陡梯度搜尋法被陷在局部極值 的缺點。由於倒傳遞類神經網路面臨不同的問題時,所需的參數與架構也有所不同, 常要讓使用者進行類似「試誤」的動作,林欣志(民 95)提出使用模擬退火法尋找倒傳 遞類神經網路中的架構、參數並進行屬性篩選,挑選出對於預測正確率有助益之屬 性。證實過去的研究只考慮參數與架構調整的做法,若同時考慮屬性篩選時,在大部 分的資料集測試正確率皆提高,除了可以有效找到良好的網路架構與參數,並可以找 出有幫助的屬性,提高分類正確率。. 19.
(29) 第三章. 研究方法. 混合演算法無論在求解的品質或效率上常常比單一演算法為佳,故本研究採用混 合演算法來解決多重品質特性下參數設計於田口動態特性的問題,期望藉由良好的結 合方式,讓演算法之間產生互補的效果。四種混合演算法包含:(1)整合田口方法與 倒傳遞類神經網路演算法,(2)整合倒傳遞類神經網路與分散式搜尋法,(3)整合倒傳 遞類神經網路與基因演算法,(4)整合倒傳遞類神經網路與模擬退火法,四種方法皆 利用望想函數及指數望想函數來解決多重品質特性問題。. 3.1 整合田口方法與倒傳遞類神經網路演算法 本研究使用此方法分為兩個階段。第一階段採用最佳化兩段步驟分析資料,第二 階段使用倒傳遞類神經網路得到輸入參數值與輸出反應值之間的關係。藉由訓練出來 的網路可以精確的預估各種可能的參數組合,故我們可藉由訓練輸入的參數值來獲得 與反應值之間的關係。最後利用望想函數及指數望想函數將多重品質特性轉換為單一 品質特性。綜合執行步驟如下: 步驟一:定義輸入參數與相關的反應值。 步驟二:規劃並執行田口實驗,以取得實驗數據資料。 步驟三:發展倒傳遞類神經網路獲知輸入參數值與輸出反應值之間的關係。 步驟四:透過田口方法及變異數分析法,確認重要的控制因子及其水準。 步驟五:利用倒傳遞訓練參數值與反應值之間的關係。 步驟六:經由輸入目標反應值至訓練完成的類神經網路獲得最佳參數設定。 步驟七:執行確認實驗並產生實驗結果。 步驟八:將結果代入實際案例中執行。. 20.
(30) 3.2 整合倒傳遞類神經網路與分散式搜尋法 本研究使用此方法分為兩個階段。第一階段使用倒傳遞類神經網路得到輸入參數 值與輸出反應值之間的關係,藉由訓練出來的網路產生各種可能的參數組合。最後利 用望想函數及指數望想函數將多重品質特性轉換為單一品質特性。第二階段利用分散 式搜尋法獲得滿意度(degree of satisfaction; λ )的最佳值。綜合執行步驟如下,執行流 程如圖 3-1 所示: 步驟一:定義輸入參數與相關的反應值。 步驟二:規劃並執行田口實驗,以取得實驗數據資料。 步驟三:發展倒傳遞類神經網路獲知輸入參數值與輸出反應值之間的關係。 步驟四:利用望想函數及指數望想函數將多重品質特性轉換為單一品質特性。 步驟五:設定分散式搜尋法的起始參數。 步驟六:多樣化解產生器從初始解開始製造儲存在 P 集合裡的 Psize 個初始多樣化 解,這個步驟使用了分散式搜尋法的第一個特定方法。 步驟七:將步驟六所產生出來的每一個初始多樣化解交由「改進方法」處理,以鄰近 搜尋機制產生品質較佳的解。 步驟八:利用「參考解集合更新方法」對 Psize 個品質被提升後的解進行進入參考解 集合的資格檢定,從中選出 b1 個高品質解和 b2 個高相異解來成為參考解集 合的成員。 步驟九:將參考解集合中的解以「子集合產生方法」組成子集合,以提供「新解合成 方法」步驟的取用。 步驟十:利用「新解合成方法」將步驟九所組成的每一個子集合轉換成一個或多個新 解。 步驟十一:將「新解合成方法」所產生的新解交由「改進方法」處理之後,才進行檢 定,考慮是否放入參考解集合。 步驟十二:利用「參考解集合更新方法」將具有資格放入參考解集合的新解,替換原 有參考解集合裡相對最差的解。 步驟十三:重複執行步驟九至步驟十二,直到符合迴圈停止條件。最常被選用的迴圈 停止條件是反覆次數達一特定值或當最佳解收斂時。. 21.
(31) 信號因子. 反應值. 倒傳遞類神經網路. 控制因子. 子集合產生方法. 參數初始化. 參考解集合更新方法. 多樣化解產生方法. 改進方法. 改進方法. 參考解集合更新方法. 關連集合更新方法 否. 使否滿足 停止條件? 是 停止. 圖 3-1 整合倒傳遞類神經網路與分散式搜尋法流程圖. 3.3 整合倒傳遞類神經網路與基因演算法 本研究使用此方法分為兩個階段。第一階段採用倒傳遞類神經網路來建立田口方 法中品質特性和實驗因子之間函數的關係,訓練出來的網路產生可能的參數組合。利 用望想函數及指數望想函數將多重品質特性轉換為單一品質特性,第二階段利用基因 演算法獲得滿意度(degree of satisfaction; λ )的最佳值。染色體代表可能的各種解,染 色體中的每個基因代表輸入的參數值。執行步驟綜合如下,執行流程如圖 3-2 所示:. 步驟一:蒐集輸入參數值與各反應值數據。 步驟二:發展倒傳遞類神經網路獲知輸入參數值與輸出反應值之間的關係。. 22.
(32) 步驟三:利用望想函數及指數望想函數將多重品質特性轉換為單一品質特性。 步驟四:設定基因演算法的執行條件,例如族群(population)個數、基因個數、參數個 數、交配率及突變率等。 步驟五:從輸入參數值中隨機選擇初始族群。 步驟六:不斷重複步驟七至步驟十一直到符合停止條件為止。 步驟七:由輸入參數值至配適函數(fitness funciton)計算出配適值。 步驟八:根據計算出的反應值選擇參數值。 步驟九:進行配適參數值的交配。首先計算交配的個數,其值是由群體個數乘以 交配率而得,決定個數後從母代中隨機選取成對的染色體出來交配。 步驟十:突變參數值以改進下一代基因。首先設定突變率參數,計算母代要進行 突變的個數,其值由族群個數乘以突變率而得,然後從母體中隨機產生要突變的 染色體。 步驟十一:經由交配與突變步驟產生的新染色體取代母體的染色體,獲得新一代 的染色體,即最佳參數值條件。 步驟十二:獲得最佳參數值設定。. 為了結束基因演算法的演化循環,必須事先設定終止規則,當基因演算過程中滿 足所設定的終止規則時,能夠停止演化循環。常見的終止條件包括 (黃寶賢,民 91): 一、設定誤差範圍:即到達使用者可以容許與接受的誤差範圍內而終止。 二、根據統計資料:如果適應函數的分布已達某統計特性即終止,如達到高斯分 布即終止。 三、設定最大運算時間:當達到所設定之最大運算時間及宣告終止。 四、設定最大世代:利用程式計算合理的觀察出最大世代數,達到所設定的最大 世 代數則宣告終止。 本研究是採用設定最大演化世代數的方式來做為測試收斂性的依據。. 23.
(33) 信號因子. 反應值. 倒傳遞類神經網路. 控制因子. 使用望想函數及指數望想函數將 多重反應值轉換為單一反應值. 設定執行條件. 由訓練完成的倒傳遞類 神經網路估求回應值. 估求配適值. 是 是否達到停 止條件?. 獲得最佳條件. 否 複製. 交配. 突變. 圖 3-2 整合倒傳遞類神經網路與基因演算法流程圖. 24.
(34) 3.4 整合倒傳遞類神經網路與模擬退火法 本研究使用此方法分為兩個階段。第一階段採用到傳遞類神經網路來建立田口方 法中品質特性和實驗因子之間函數的關係,訓練出來的網路可以精確的預測出可能的 參數組合,故我們可藉由訓練輸入的參數值來獲得與反應值之間的關係。利用望想函 數及指數望想函數將多重品質特性轉換為單一品質特性後,第二階段利用模擬退火法 獲得最佳解。執行步驟與參數設定如下,執行流程如圖 3-3 所示: 步驟一:隨機由直交表中選擇資料以獲得倒傳遞的訓練及測試組合值。 步驟二:發展倒傳遞類神經網路預測控制因子、信號因子及反應值之間的關係。 步驟三:將能階函數(energy function)公式化。 步驟四:根據問題的品質特性將關係函數轉換成能階函數。 步驟五:隨機選取候選值 x。 步驟六:設定起始條件,首先要決定起始溫度 T 和終止溫度 T*,其中 T>T*,一般起 始溫度設定隨問題而變,不過一般都設較高一點可以比溫度設低更容易找到 最佳解,Kirkpatrick 等建議 T 的設定最好可以使初期鄰近解被接受機率 0.8 以上,而 T*一般都設接近 0。 步驟七:先定義每個溫度搜尋次數 M,一般都設固定值也有學者採用不同溫度不同 M, Kirkpatrick 建議為決策變數的倍數,不過實際上還是必須看問題大小 而定。然後設定降溫梯度α,一般α越大越好最好在 0.5 以上,如果設太小 容易陷入區域最佳中,建議值為 0.8~0.99。 步驟八:重複步驟九到步驟十四直到搜尋溫度 T 小於停止溫度 T*。 步驟九:重複步驟十到步驟十三直到在溫度 T 下搜尋次數大於 M。 步驟十:由電腦在鄰近解中產生一個新解 x' 。 步驟十一:計算ΔE= f ( x) − f ( x' ) 步驟十二:由電腦隨機產生一個均勻分布於 0~1 的值 r。 步驟十三:如果ΔE<0 表示新解比就解好以新解取代舊解,如果ΔE>0 如果 r< e ∆E / T , 我們以新解取代舊解。 步驟十四:降低搜尋溫度 T,T=αT。 步驟十五:求得最佳解 x * 。. 25.
(35) 信號因子. 反應值. 倒傳遞類神經網路. 控制因子. 使用望想函數及指數望想函數將 多重反應值轉換為單一反應值. 設定 T 值 產生 x1 令 x* = x1. 產生 x2. 是否接受? 否 是. x* = x2. 減少 T. 是否平衡?. 否. 是 否. 是否收斂? 是 停止. 圖 3-3 整合倒傳遞類神經網路與模擬退火法流程圖. 26.
(36) 停止準則為用來判定是否結束模擬退火演算法的最主要依據。Johonson(1989)提 出,計數值在鄰近解沒有取代現行解時應加 1,當現行解被取代時,計數值應歸零重 新計算,模擬退火法在計數值達到預定上限時應停止。Van Larrhoven(1992)等人認 為,模擬退火法應在溫度下降到預設的最後溫度時停止。常見的停止準則有(盧研伯, 民 92): 一、當溫度已達到每一溫度 Tk 時,則停止此演算法。 二、當連續降溫 t 次,始終無法達到較佳解時,停止演算法。 三、當所求之解已達到下限值之某個比例,則停止演算法。 在本文中所採用的停止準則,考慮上述的前兩項,以增加演算法的效率。若單純考慮 停止溫度時,當系統達到最佳解後或許已經失去向上爬升的能力,限制降溫的次數, 將有助於演算法的求解效率。. 27.
(37) 第四章 室內無線區域網路傳輸品質評估系統之實證分析 為了驗證第三章所建構模式的可行性,本章節提出「室內無線區域網路傳輸品質 評估系統」案例。根據本文所敘述的方法論規劃實驗,進而從實際的案例中蒐集數據 並作分析,以證實本研究方法論之可行性與有效性。. 4.1 問題描述 隨著資訊時代的全面來臨及網際網路普及,無線通信、寬頻網路及數位傳播的啟 用等,使資訊的傳遞更加迅速,人們使用資訊的分式將更多元化(潘泰吉,民 88)。對 於許多人來說,網路不只是消遣般的休閒娛樂活動,更是每日工作與生活不可或缺的 重要部份,在工作上常免不了要做資訊交換的動作。透過電腦與電腦、電腦與電腦週 邊設備的連結,來處理資料的存取與列印、或檔案交換等(陳文江,民 88)。然而有線 的連結方式,不管是透過電話線、電纜線或是光纖,人們始終受到纜線的禁錮,所有 活動都必須在網路連接埠附近進行,大大的侷限了活動的空間範圍。另外對於一些大 型展覽或是大型會議等臨時性需求的通訊傳輸、具有歷史紀念價值的古蹟建築、或有 地形地物障礙無法佈線的地方,也有眾多的限制與不便!同時,網路線的鋪設與維護 花費的成本,也是一筆不小的開銷。 由於無線區域網路(wireless local area network; WLAN)標準 IEEE 802.11 的制 定,不僅無線區域網路系統的發展隨之蓬勃,且依據行政院挑戰 2008 國家發展重點 計畫,科技顧問組規劃 e-Taiwan 計畫中之「寬頻到家」項下,規劃「推廣無線寬頻 網路計畫」以強化台灣無線寬頻網路之建設與應用發展。目前全台灣無線上網據點已 超過千個,地方政府如台北市、台中市也積極佈建全市涵蓋的無線網路,打造無線城 (經濟部工業局,民 94)。其中台北市政府更榮獲美國世界電信協會(WTA)所屬「智 慧社區論壇」(ICF)頒發 2006 年年度智慧城市首獎(彭佳芸,民 95)。透過無線區域 網路的推廣,不僅可解決有線網路不便的問題,更可享受「無線」所帶來隨時隨地的 上網或進行資料存取傳輸的「無限」便利性與移動性! 雖然無線區域網路具有許多傳統有線網路所沒有的優點,但當我們在規劃室內 無線區域網路時,卻發現一些尚待解決的問題。由於室內無線電的傳播環境相當複 雜,不論是建築物的隔間材質、室內的擺設等都會造成不同的傳播損失,因此在傳統 上會在一層樓層中放置一個以上的存取點(access point; AP),以期能增加無線電波的 28.
(38) 覆蓋範圍。 傳統上,AP 的數量及位置的選擇經常是由工程師依據經驗採用試誤法(trial and error)來做決定,不同的工程師常會做出不同的判斷結果。一般判斷擷取位置與數目 的標準,傳統上是以某一特定訊號強度的涵蓋範圍作為指標(Cheung, 1998; Chiu, 1996; Panjwani, 1996),各種指標雖然彼此之間有一定程度的相關性,但使用者卻可以在需 求不同時,選擇不同的參考指標作為無線區域網路傳輸品質評估的標準,才能讓當時 的無線電波傳輸環境品質評估,能夠以最適當的方式表達出來。 本研究提供一個二階段的求解程序並以無線區域網路估測系統為例,以某技術學 院之教學大樓來建構此估測系統的模型,利用類神經網路與分散式搜尋法、基因演算 法和模擬退火法進行最佳化參數設計,未來即使要估測不同隔間、擺設的大樓,皆能 以此估測系統為基礎。只要量測的數據準確且數目足夠,再經由輸入變數的決定,與 類神經網路中各層神經元的調整,及不同網路架構、演算法的修正,本系統即可對其 他室內無線網路的通訊品質做出正確的估測,圖 4-1 為該技術學院教學大樓的平面圖。. R513. R512. R511. R515. R517. R516. 5009 專題教室. 5010 專題教室 R514. 廁 所. R518. 12U 壁掛式機櫃. D.V.O. PVC管. R510. R506. 5011 專題教室. Rack Backbone No: L5F01-05 R5F01-03. 5003 專題教室 R504. R508. R507. R505. R509. Rack 5020 管道間. L513 L5F06. L503 L5F04. 5016 P C教室 L512 L5F05 L509. L511. L508. 5017 專題教室 L510. 5 討 02 論 1 室. 廁所. 5015 P C教室. 5 休 00 息 2 室. 5 交 00 誼 1 室. Rack. L501. L502. 5019 PC教室. L505. L504. 5018 專題教室 L507. L506. 圖 4-1 教學大樓平面圖 29. R502 R501. R503.
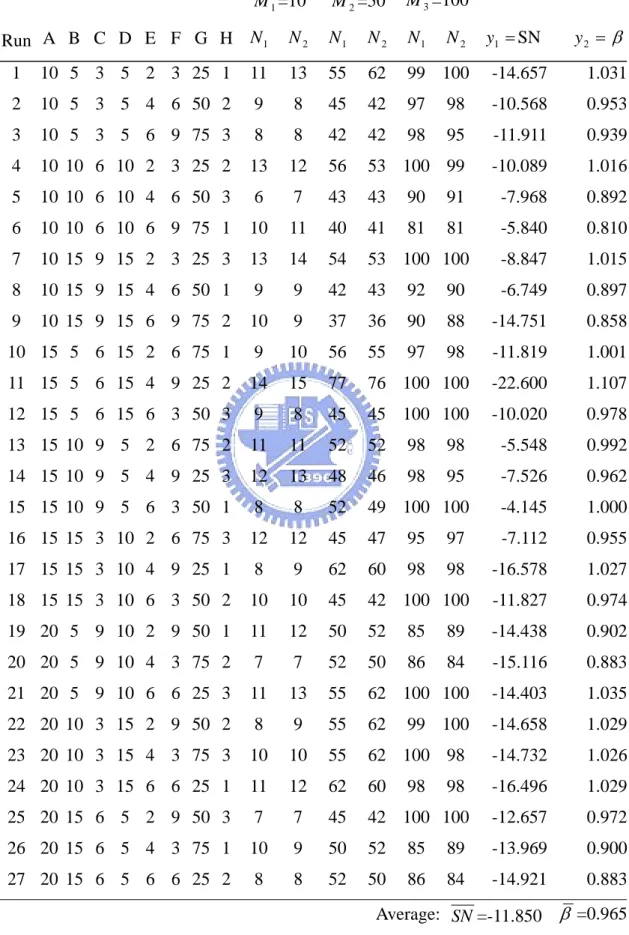
(39) 4.2 研究設計之架構 在田口的參數設計法中使用直交表來配置實驗,利用 SN 比與 β 值來分析各因子 影響程度,以達到工程品質目標。本研究方法分為兩階段: 第一階段為「建立模式階段」 ,共分為兩個步驟:步驟一為設計並執行「田口實驗」, 對於一個品質問題,考慮信號因子、雜音因子與控制因子水準組合,利用直交表進行 田口實驗,取得實驗數據及 SN 比、 β 值等基本資料。步驟二則「利用倒類神經網路 建立模式」,進行田口實驗時,使用 SN 比的好處在於簡單計算就可以釐清各個控制 因子的影響,而且同時考慮品質特性的平均和變異效果。本論文利用倒傳遞類神經網 路建立直交表中各因子水準組合和 SN 比及 β 值的函數關係,將這個網路模式當成目 標函數,如圖 4-2 所示。 雜音因子. 信號因子的 輸入. 倒傳遞類神經網路. SN 比. β. 控制因子水準組合 圖 4-2 建立目標函數 第二階段「利用啟發式演算法,最佳化階段一所建立的目標函數」。本實驗採取 的啟發式演算法有三個,分別為分散式搜尋法、基因演算法和模擬退火法,其中模擬 退火法所採取方式和 Su 與 Chang (2000)之差異在於鄰域選取方式及停止準則。執行 模擬退化法時我們產生新解的方式有兩種,一種是由現在解的位置,以隨機增加方式 向解的最大值方向增加,另一種是向解的極小值方向減少,由電腦進行隨機選擇採取 哪一方式。而停止條件考慮限制降溫的次數,以增加演算法的效率。而基因演算法所 採取方式和 Su 與 Chiang (2002)的差別,在於採用設定最大演化世代數的方式來做為 測試收斂性的依據參數,且執行條件設定上亦不相同。 針對室內無線區域傳輸品質問題,我們進行田口實驗。首先,先選取品質特性 y, 會影響傳輸品質的品質因素有很多,我們選取最重要的接收訊號強度(Received Signal Strength Index; RSSI)為品質特性。. 30.
數據




+7





相關文件
float voxelToPos(int p, int axis) const { return bounds pMin[axis]+p*Width[axis];. return
Average earnings of resident and non-resident full-time paid employees by gender, occupation and industry - excluding double-pay, year-end bonuses, profit-sharing bonuses and
[r]
In this report, formats were specified for single, double, and extended precisions, and these standards are generally followed by microcomputer manufactures using
強制轉型:把 profit轉換成double的型態
int main(int argc, char** argv).
There would be no special value in "creative leaps," no fundamental gap between solving a problem and recognizing the solution once it's found. Everyone who could
public static double calculate(int i, int j) throws ArithmeticException,
