國立臺中教育大學教育測驗統計研究所理學碩士論文
指導教授:郭伯臣 博士
一個基於相關矩陣之特徵萃取法
A Feature Extraction Method Based on Correlation Matrix
研 究 生:張偉民 撰
誌謝
首先要感謝指導教授郭伯臣老師的提攜與指導,不論是在研究上還是待人處 事上都給了我很大的幫助及體會,也感謝輔大教授黃孝雲老師,特地抽出時間來 擔任我的口試委員,也給了我許多建議及意見,讓我的論文內容能更加地豐富。 感謝博士後研究員政軒學長,協助指導我的程式撰寫及研究內容,使我的論文能 夠順利的完成。 在兩年的研究求學生活中,也要特別感謝一起為論文打拼的同學們韋任、宗 恩、芷寧,還有慧珉、育隆、智為、筱倩、鎧誌、俊彥、暄博等學長姊的照顧, 還有研究室的學弟妹們,使我的研究生活充滿著歡笑與淚水。感謝為我的論文潤 稿的敏嫻助教,使我的論文能夠更加完整。感謝與我同住兩年宿舍的室友們,與 你們的相處真的很開心,讓我的生活能夠多采多姿。 最後要特別感謝我的家人們,給予我的支持與肯定,讓我能夠順利的完成碩 士學業,並將我的所學能夠回饋到社會上。還有感謝在這一路上曾經幫助過我的 師長們與朋友們,謝謝你們。 張偉民 謹致於台中教育大學教育測驗統計研究所 中華民國一百零一年七月摘要
近年來,許多研究利用鄰近頻譜值具有高相關的特性,來設計特徵萃取或特 徵選取演算法,藉以增加分群或分類之效能。然而,在使用相關矩陣做特徵萃取 時會遇到兩個問題,一個是要怎麼把相關較高的頻譜群聚在一起,一個是怎麼決 定門檻值(threshold values)來分割這些特徵,因此本研究發現可以使用譜聚類 (spectral clustering),是一個基於相似矩陣的一個分群的演算法,可以解決上述所 說的兩個問題。在本研究中,提出了一個非監督式特徵萃取法:基於譜聚類之相 關矩陣特徵萃取法。基於模糊分群演算法之譜聚類將被應用至相關矩陣上進行頻 譜的模糊分群,而相對應的隸屬度值可以決定在非監督式特徵萃取的轉換矩陣上。 從實驗中可看出教育測驗資料集、Indian Pine Site 之子資料集、Washington DC Mall 資料集與 UCI 資料集使用基於譜聚類之相關矩陣特徵萃取法及核化模糊演 算法之分群結果可以達到最佳的分群正確率。 關鍵字:相關矩陣特徵萃取法、非監督式特徵萃取、譜聚類Abstract
Recently, the high correlation property between neighboring bands is usually used for dimension reduction on data clustering or classification by grouping similar bands. However, there are two main difficulties. One is how to cluster similar bands based on the correlation matrix of bands. The other one is how to determine the thresholds for splitting the similar bands. Fortunately, the spectral clustering, a clustering algorithm based on a similarity matrix, can be used to solve the two problems simultaneously. In this study, we propose an unsupervised feature extraction method based on the correlation matrix of bands. The spectral clustering based on fuzzy c-means is applied to the correlation matrix of bands (CMFESC), and the corresponding membership values determine the transformation matrix. Experimental results on the educational measurement dataset, Indian Pine Site dataset, Washington DC Mall dataset, and some UCI data sets, show that the proposed method achieves good segmentation performance compared with principal component analysis (PCA) and independent component analysis (ICA).
Keyword : Correlation Matrix Feature Extraction, CMFE, Unsupervised Feature Extraction, Spectral Clustering
目錄
摘要 ... I ABSTRACT ... II 目錄 ... III 表目錄 ... V 圖目錄 ... VI 第一章 緒論 ... 1 第一節 研究動機 ... 1 第二節 研究目的 ... 4 第二章 文獻探討 ... 5 第一節 特徵萃取 ... 5 壹、主成份分析 ... 5 貳、獨立成份分析 ... 6 第二節 模糊分群演算法與其核化版本 ... 7 壹、模糊分群演算法 ... 7 貳、核化模糊分群演算法 ... 8 第三節 譜聚類 ... 11 第三章 基於譜聚類之相關矩陣特徵萃取法 ... 18 第一節 基於模糊分群演算法之譜聚類 ... 18 第二節 基於譜聚類之相關矩陣特徵萃取法 ... 19 第四章 實驗設計 ... 21 第一節 資料描述 ... 21 壹、教育測驗資料 ... 21貳、Indian Pine Site 影像資料 ... 22
肆、UCI 資料集 ... 26
第二節 實驗描述 ... 27
第五章 實驗結果 ... 28
第一節 教育測驗資料集 ... 28
第二節 Indian Pine Site 資料集的實驗結果 ... 30
壹、實驗結果一 ... 30 貳、實驗結果二 ... 31 參、實驗結果三 ... 32 第三節 Washington DC Mall 資料集 ... 34 第四節 UCI 資料集 ... 35 第六章 結論與未來發展 ... 37 參考文獻 ... 38 中文部分 ... 38 英文部分 ... 38 附錄一 微分四則運算專家知識結構 ... 44 附錄二 教育測驗資料試題 ... 45
表目錄
表4-1 微積分單元的錯誤概念分類表 ... 21
表4-2 INDIAN PINE SITE 影像各類別所含有圖素 ... 22
表4-3 INDIAN PINE SITE 影像各類別所含有之圖素(四類) ... 24
表4-4 WASHINGTON DC MALL 影像各類別所含有之圖素 ... 25
表4-5 UCI 資料集之資料描述 ... 26
表5-1 教育測驗資料集分類正確率 ... 28
表5-2 INDIAN PINE SITE 資料集分類正確率 ... 33
表5-3 WASHINGTON DC MALL 資料集分類正確率 ... 34
表5-4 WINE 資料集分類正確率 ... 35
表5-5 PIMA 資料集分類正確率 ... 36
圖目錄
圖1-1 IPS 資料集中紫色線條(SOYBEANS-MIN TILL)與黃色線條(CORN-NO
TILL)的頻譜值... 2
圖1-2 相關矩陣 ... 2
圖1-3 HUGHES PHENOMENON... 3
圖2-1 相似度矩陣 ... 11
圖2-2 相關矩陣 ... 11
圖4-1 INDIAN PINE SITE 影像 ... 23
圖4-2 INDIAN PINE SITE 的 GROUND TRUTH 影像 ... 23
圖4-3 INDIAN PINE SITE 影像(四類) ... 24
圖4-4 INDIAN PINE SITE 的 GROUND TRUTH 影像(四類) ... 24
圖4-5 WASHINGTON DC MALL 影像 ... 26
圖4-6 WASHINGTON DC MALL 人工定義類別影像 ... 26
圖5-1(A)-(D)為未排列與已排列之相關矩陣... 29
圖5-2(A)-(D)為未排列與已排列之相關矩陣... 31
圖5-3 LAPLACIAN 矩陣對應的特徵值幅度與特徵萃取之後的分群正確率比較 32 圖5-4 INDIAN PINE SITE 的 GROUND TRUTH 影像(四類) ... 33
圖5-5 CMFESC 分群結果 ... 33
圖5-6 PCA 分群結果 ... 33
第一章 緒論
第一節 研究動機
集群分析(clustering analysis)是一種多變量的統計方法及機器學習理論 (machine learning theorem)中最被廣為使用的方法之一,它是屬於非監督式分 類(unsupervised classification)的一種資料探勘方法,依照資料的型態將它分為 若干個群聚,再針對不同的群聚資料做進一步的分析。非監督式的學習方法並不 會先給資料所代表的意義,而是利用分群演算法將相似的資料群聚在一起,最後 在定義這些資料的意義。 近年來,由於資料收集的自動化及普及化,加上相關科技不斷進步,高維度 資料之分析方法與需求與重要性與日俱增。如教育測驗資料、高光譜影像資料之 分群與分類、基因微陣列資料分析、手寫辨識、人臉辨識等。而大部分的高維度 資料,相鄰或是鄰近的光譜波段會呈現相當高的相關(Cariou, Chehdi, & Moan, 2011; Jia & Richards, 1994)。以 Indian Pine Site(IPS)高光譜遙測影像資料為例,
圖1-1 為 IPS 資料集中,紫色線條(Soybeans-min till)與黃色線條(Corn-no till)
(Landgrebe, 2003)的頻譜值,由圖中可以看出相鄰的頻譜波段呈現高度相關。
圖 1-2 為 Indian Pine Site 資料集之子資料集(Camps-Valls, Gomez-Chova,
Munoz-Mari, Vila-Frances, & Calpe-Maravilla, 2006; Gualtieri, Chettri, Cromp, & Johnson, 1999)中,頻譜之間的相關矩陣,從此圖中亦可看出相鄰的頻譜波段呈 現高度相關。此外,也可看出部分不相鄰的頻譜值,也具有高度相關的性質。
圖1-1 IPS 資料集中紫色線條(Soybeans-min till)與黃色線條(Corn-no till)的頻譜值
圖1-2 相關矩陣
因此,移除過多的特徵將會增加分群正確率(clustering accuracy)的效果。
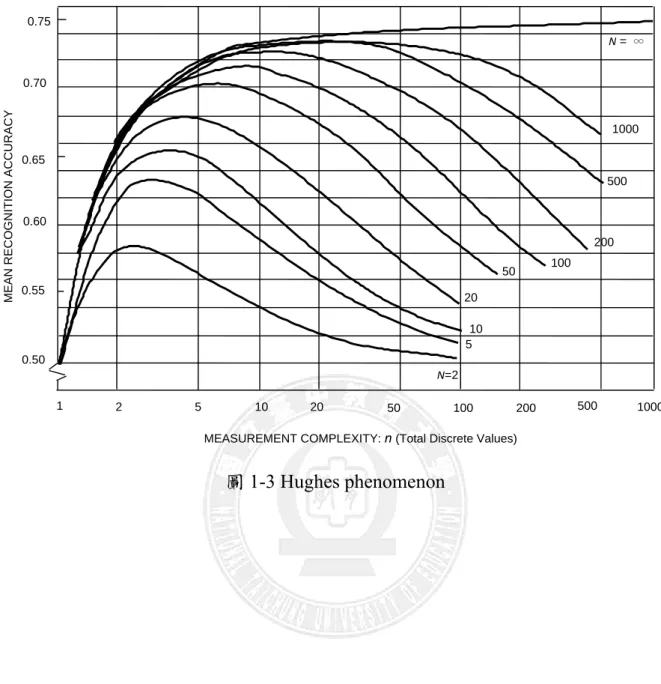
除此之外,使用特徵萃取也可以減少 Hughes phenomenon(Hughes, 1968)如圖
1-3 所示的現象。Hughes phenomenon 是維度詛咒(curse of dimensionality)的一 部分,當資料的維度數越來越高時,如果不增加資料的訓練樣本時,就會使得辨
識的正確率下降。為了要減少Hughes Phenomenon 現象的發生,必須增加訓練樣
本數或是降低維度。通常在降低維度上有兩種情況可以解決此種問題,分別是特 徵萃取(feature extraction)以及特徵選取(feature selection)(Fukunaga, 1990)。 特徵選取是把樣本中的所有的特徵選出一個最佳的使其辨識正確率達到最高、特 徵萃取則是把資料群從較高的維度空間投影至較低的維度空間。近年來,使用特 徵萃取的技術已被廣泛使用,例如主成份分析(principle component analysis, PCA) (Jlliffe, 1986; Zubko, Kaufman, Burg, & Martins, 2007)以及獨立成份分析 (independent component analysis, ICA)(Hyvrinen, Karhunen, & Oja, 2001),皆 可以改善分群的效果(Chatzis & Varvarigou, 2009; Nasser & Hamad, 2006; Weike, Azad, & Dillmann, 2006; Honda, Notsu, & Ichihashi, 2010)。
圖1-3 Hughes phenomenon
MEASUREMENT COMPLEXITY: n (Total Discrete Values)
1 2 5 10 20 50 100 200 500 1000 0.50 0.55 0.60 0.65 0.70 0.75 N=2 5 10 20 50 100 200 1000 500 N = ∞ MEAN RECOGN ITION ACCU RA CY
第二節 研究目的
在使用特徵萃取的過程中主要目的是要將有利於樣本的特徵萃取出來以提
升影像辨識的正確率。由於鄰近之頻譜值具有高度相關性,如圖1-2 所示,很多
選取之方法已藉由循序向前選擇法(sequential forward selection, SFS)(Jain & Zongker, 1997)或是藉由相似的波段的分組組合而成(Cariou, Chehdi, & Moan, 2011)。然而,在使用相關矩陣做特徵萃取時會遇到兩個問題,一個是要怎麼把 相關較高的頻譜群聚在一起,一個是怎麼決定門檻值(threshold values)來分割
這些特徵,因此本研究發現可以使用譜聚類(spectral clustering, SC)(Shi & Malik,
2000; Ng, Jordan, & Weiss, 2002; Camps-Valls, Marsheva, & Zhou, 2007),是一個 基於相似矩陣的一個分群的演算法,加上模糊分群演算法(Fuzzy C-means Clustering, FCM)(Bzedek, 1973)。此方法是透過模糊邏輯的概念,希望能使分 群的效果明顯提升,在分群的過程中,每個資料的樣本點都會賦予它一個隸屬度 值(membership value),最後再利用這些隸屬度值來決定這些樣本點是屬於那一 個群集。來同時解決這兩個問題。譜聚類已經成為一個流行的分群演算法,特別 是用在非線性的問題。一般來說,相似矩陣或者是經過正規化的核化矩陣(kernel matrix)已被應用至譜聚類分群演算法當中。 在本研究中,利用基於模糊分群演算法之譜聚類來解決相關矩陣之特徵值。 此外,相對應的隸屬度值可以決定在非監督式特徵萃取的轉換矩陣上,提出了一 個基於譜聚類之相關矩陣特徵萃取法(correlation matrix feature extraction based on spectral clustering, CMFESC)。
第二章 文獻探討
第一節 特徵萃取
特徵萃取是一種可以找到一個轉換矩陣(transformation)A,使得原始空間 的資料X 被轉換另一個新的特徵空間Y,一般來說經過特徵萃取轉換後的空間維 度會比原來的空間維度小,所以一個好的特徵萃取法在做降低維度時可以去除原 空間中的雜訊,而不是將原空間中的有用資訊刪除。以下將介紹常用的兩種特徵 萃取方法。壹、主成份分析
主成份分析(principal component analysis, PCA)(Jlliffe, 1986; Zubko, Kaufman,
Burg, & Martins, 2007)是一種在做高維度資料處理時常見的方法,主要的目的是 要降低資料維度,且盡量保留原始資料的變異及原始資料在空間中分布的情形。 PCA 定義為以下的轉換: T Y A X (2-1) X(x x1, , ,2 xn)代表在原始空間中的資料樣本,Y則是轉換之後的空間樣本,A 為根據以特徵值Λ所對應之特徵向量而成的轉換矩陣: A S (2-2) S 矩陣稱為共變異數矩陣,m0為樣本的平均值,定義如下: 0 0 1 1 ( )( ) n T i i i S x m x m n
(2-3) 0 1 1 n i i m x n
(2-4)A矩陣稱為Karuhnen-Loeve 轉換。可以利用比較少的主要成份,來顯示出樣 本的最大變異程度。 PCA 的演算法概述如下: 步驟1:計算樣本的共變異數矩陣 S 步驟2:計算出特徵向量 步驟3:選擇特徵值Λ中所對應最大的k個特徵向量Φ,定為A。 步驟4:利用方程式 2-1 將樣本從原始空間轉換至新的空間。 PCA 的優點是可以保留原始資料的變異以及分布的情形,但還是存在著缺點, 例如轉換矩陣是由共變異數矩陣而來,在小樣本的情況下共變異數矩陣容易 變的不穩定。
貳、獨立成份分析
獨立成份分析(independent component analysis, ICA)(Hyvrinen, Karhunen, &
Oja, 2001)是一種用來找出隨機辨識中隱藏因子的統計方法。ICA 是假設在觀測 的隨機變數是由潛在變數(latent variable)以線性方式組合而成。這些潛在變數 在假設互為獨立下被稱為觀察資料的潛在來源(latent sources)。ICA 就是在只 有觀察到的隨機變數資料中,找出獨立成份以估計潛在來源的方法。假設有一個 資料矩陣X [ , , , ]x x1 2 xn ,n表示變數的個數。資料矩陣X 可以用線性組合組成m 個獨立成份 [ , ,1 2 ] T m S s s s ,m n ,定義如下: X BS (2-5) 其中B是一個未知的混合矩陣(mixing matrix)定義為B[ , ,b b1 2 bn]。一般來說, 我們只能知道資料矩陣X ,S與B通常為未知,所以獨立成份分析主要的目的是 從資料矩陣X 去算出混合矩陣B與獨立成份S。
第二節 模糊分群演算法與其核化版本
壹、模糊分群演算法
模糊分群演算法是Bezdek(Bezdek, 1973)於 1973 年所提出的 c-means 演算 法而衍生出來的,主要是利用模糊邏輯的概念讓分群方法的效果能夠提升,其目 標函數(objective function)公式定義如下: 2 1 1 ( ) ( , ) c n m ij j i i j J u dist x v
(2-7)其中m是一個介於[1, ) 的權重係數(weighting exponent),而dist x v( , )j i 則是xj與
i v的距離函數U為c n 的隸屬矩陣(membership matrix),代表著每一個樣本點 對於每一個群聚的隸屬程度,而樣本裡的任一樣本點隸屬於每個群聚的總和為 1。 1 1, 1, 2, , c ij i u j n
(2-8)上式搭配限制條件,可以利用Lagrange function 得到一個新的目標函數Jnew:
2 1 1 1 1 ( ) ( , ) ( 1) c n n C m new ij j i j ij i j j i J u dist x v u
(2-9)其中j為Lagrange multipliers。接著為了要最佳化目標函數Jnew,所以針對所傳入
的參數分別進行微分,得到以下兩個方程式: 1 1 ( ) ( ) n m ij j j i n m ij j u x v u
(2-10)與 2 1 1 1 ( , ) ( , ) ij m c j i k j k u dist x v diist x v
(2-11) 模糊分群演算法步驟如下: 步 驟 1:隨機填入矩陣U 中所有數值但是需要滿足限制條件,並設定 0 n 與誤差上限 。 1, 2 步驟2:計算出所有叢集的中心點vi。 步驟3:計算目標函數 n new J 。 步驟4:計算出新的矩陣U,並設定n n 1 步驟5:重複步驟 2 至步驟 4,直到或 1 2 2 n n new new J J 則停止演算法。貳、核化模糊分群演算法
核化模糊分群演算法(kernel fuzzy c-means clustering, KFCM)(Wu, Xie, & Yu,
2003)是用模糊分群演算法之基礎做延伸,故架構的流程與模糊演算法相同,以 下將詳細敘述公式與演算法。 首先,我們定義一非線性映射函數:x ( )x ,F xX,X 為輸入資料原 本所屬空間,F為經過Φ轉換後的特徵空間。並且在此定義核函式(kernel function) 為K x y( , ) ( )x T( )y 與FCM 演算法相同,KFCM 演算法亦有目標函式,而分群 演算法其目的在於最小化目標函式Jm如下: 2 1 1 ( , ) c n m ( ) ( ) m ik k i i k J U V u x v
(2-12) 而 2 ( )xk ( )vi K x x( , )k k K v v( , ) 2 ( , )i i K x vk i (2-13)在本公式中,c為叢集(cluster)數,n為資料的總數,xk為n筆資料中第k個 資料,v為代表各個叢集的質量中心點,vi為第i個質量中心點,為權重係數,m 是一個介於[1, ) 的權重係數,當m值越大時表示訓練向量與質量中心點之間的關 係越模糊。而K x y( , )為核函式,在本研究中,我們使用高斯函式做為我們分群演 算法中的核函式。如下: 2 2 2 ( , ) exp x y K x y (2-14) 核函式中,x與y為一向量,維度不限, 為高斯函式的變異係數(variance), 在許多文獻中有對 的數值進行討論,本研究則將此變異係數當作初始設定的參 數。依據核函式之定理,K x x( , ) 1 ,我們可以簡化算式2-13,如下: 2 ( )xk ( )vi 2 2 ( , )K x vk i (2-15) 將2-15 代入原本的 2-12 目標函式中,我們可得到簡化後的目標函式Jm為: 1 1 ( , ) 2 c n m(1 ( , )) m ik k i i k J U V u K x v
(2-16) 將2-13 式代入原始 FCM 演算法的權重係數函式與質量重心更新函式,可以得到 KFCM 演算法的K(xk,vi)與簡化後權重係數函式: 1 1 ( , ) ( , ) n m il k l l k i n m il l u K x v K x v u
(2-17) (2-18) 而資料xk在每一個質量重心vi的歸屬程度介於0~1 之間,如 2-19 式表示。 1 1 c ik i u
(2-19)公式2-17 為權重係數公式,負責計算每一筆資料xk對於每一個質量中心點vi 的權重值;公式2-18 則為計算新的質量中心點公式。反覆計算公式 2-17 與公式 2-18 使公式 2-12 的J值,當J值的改變量小於某一臨界值時,則視其為一穩定狀 態,最後得到一組新的質量中心點{v v1, , ,2 vc},分別代表c個群組。對於每一個xk, 我們將利用以下計算公式: 1 arg max jk j c i u (2-20) 來決定其所歸屬之類別。以下為KFCM 演算法的流程。 步驟 1:隨機填入矩陣U中所有數值但是需要滿足限制條件,並設定分群群 數c,收斂條件ε以及模糊程度m值,與核函式的變異係數值 。 步驟2:計算公式 2-17 中的K(xk,vi)。 步驟3:將步驟 2 的結果代入公式 2-18,以得到更新過後所有資料再全部質 量重心的權重係數值。 步驟4:將步驟 3 的結果帶入公式 2-12,計算新的目標函式J值。 步驟 5:判斷J值的運算結果與前一次運算結果之間的差值比例是否小於收 斂條件,若達到收斂條件,表示此演算法已經趨於穩定;反之,則將新計算 出的權重係數值取代舊的權重係數值,回到步驟2 繼續。 步驟6:將收斂條件後的權重係數值代入 2-20 運算式,得到收斂後資料中每 個點的分群結果。
第三節 譜聚類
譜聚類是一個基於相似度矩陣(similarity matrix)如圖 2-1,或是基於正規化 後的核化矩陣(Bach & Jordan, 2004)。而相關矩陣(correlation matrix),如圖 2-2,則可以用在相似度矩陣波段的一種類型。本研究發現也可以應用譜聚類在相 關矩陣上。 圖2-1 相似度矩陣 圖2-2 相關矩陣 假設現在有x筆資料(x x1, ,2 xn)位於Rl空間,想要將它分群可以使用下列 的演算法,概述如下; 步驟1:建立一個相似矩陣C。 步驟2:定義一個對角化矩陣D,其中第( , )i i 個元素為矩陣C之第i列的元素 總合,接著計算L D CD 1/2 1/2,L為Laplacian 矩陣。 步驟 3:將L對角化之後找出k個最大特徵值的特徵向量v v1, 2,vk,之後在 令矩陣 [ ,1 2 , ] n k k V v v v R 。
步驟 4:將V 矩陣正規化之後成一個新的矩陣V 使得矩陣V 的每一列都具有 單位長度 2 ij ij ij j V V V
步驟5:把V 矩陣中的每一列都視為Rk 空間中的一個資料點,接著可以使用 這些資料樣本來進行分群,可利用K-means 或是其它的分群演算法,本研究 將使用FCM 演算法。 步驟6: 將V 矩陣中每一列表示的歸屬群組,對應於原始資料,也就是說, 如果V 矩陣的第i列歸屬為第 j群,則定為原始資料pi為第 j群。 接下來將舉三個例子說明此演算法的步驟: 給定五個樣本點x x x x x1, , , ,2 3 4 5,其中假設x x x1, ,2 3為第一類,x x4, 5為第二類。 一個極端的相似矩陣如公式2-21 所示, 1 1 1 0 0 1 1 1 0 0 1 1 1 0 0 0 0 0 1 1 0 0 0 1 1 C (2-21) 對角線的區塊值皆為 1,非對角線的區塊值皆為 0。接下來計算對角矩陣D,把 各個列加總之後放在矩陣對角線的位置,其餘元素皆為0,如公式 2-22 所示。 3 0 0 0 0 0 3 0 0 0 0 0 3 0 0 0 0 0 2 0 0 0 0 0 2 D (2-22) 接著利用L D 1/2AD1/2算出Laplacian 矩陣,一種正規化矩陣的方法,如公式 2-23 所示。1 1 1 0 0 3 3 3 1 1 1 0 0 3 3 3 1 1 1 0 0 3 3 3 1 1 0 0 0 2 2 1 1 0 0 0 2 2 K (2-23) 再算出Laplacian 矩陣之特徵值與特徵向量。其特徵值如公式 2-24 所示, 1 0 0 1 0 (2-24) 觀察其特徵值可以發現只有兩個特徵值為 1,其餘為 0,表示此樣本是分為 2 類 的,其中一個特徵值1 代表第 1 類,另一個特徵值 1 代表第二類。公式 2-25 為將 此兩個特徵值 1 相對應之特徵向量堆疊成V 矩陣,再將V 矩陣的每一個列正規 化, 0.5774 0 0.5774 0 0.5774 0 0 0.7071 0 0.7071 V (2-25) 即V 的列向量長度皆為1 如公式 2-26。 1 0 1 0 1 0 0 1 V (2-26)
最後使用FCM 演算法可以輕易得出x x x1, ,2 3為第一類,x x4, 5為第二類,如公式2-27 所示。 1 0 1 0 1 0 0 1 0 1 V (2-27) 因為真實資料並無法得知其樣本點真正類別與順序,故在第二個例子中,將 樣本點隨機排序。給定五個點x x x x x1, , , ,2 3 4 5,其中假設x x x1, ,2 3為第一類,x x4, 5為 第二類。一個經過隨機排列後的極端相似矩陣如公式2-28 所示, 1 0 1 0 0 0 1 0 1 1 1 0 1 0 0 0 1 0 1 1 0 1 0 1 1 C (2-28) 接下來仍計算對角矩陣D,如公式2-29 所示, 2 0 0 0 0 0 3 0 0 0 0 0 2 0 0 0 0 0 3 0 0 0 0 0 3 D (2-29) 與Laplacian 矩陣,公式 2-30。
1 1 0 0 0 2 2 1 1 1 0 0 3 3 3 1 1 0 0 0 2 2 1 1 1 0 0 3 3 3 1 1 1 0 0 3 3 3 K (2-30) 再算出Laplacian 矩陣之特徵值與特徵向量。其特徵值如公式 2-31, 1 1 0 0 0 (2-31) 觀察其特徵值可以發現只有兩個特徵值為 1,其餘為 0,表示此樣本是分為 2 類 的,其中一個特徵值1 代表第 1 類,另一個特徵值 1 代表第二類。公式 2-32 為將 此兩個特徵值1 相對應之特徵向量堆疊成矩陣V , 0.7071 0 0 0.5774 0.7071 0 0 0.5774 0 0.5774 V (2-32) 再將V 矩陣的每一個列正規化,即V 的列向量長度皆為1 如公式 2-33。 1 0 0 1 1 0 0 1 0 1 V (2-33)
最後使用FCM 演算法仍然可以得出x x x1, ,2 3為第一類,x x4, 5為第二類,如公式2-34 所示。故SC 的結果並不會受到樣本點順序的影響。 1 0 0 1 1 0 0 1 0 1 V (2-34) 接下來在第三個例子中,我們將考慮真實資料可能會遇到的情況,同類之間 的相似程度不再是極端值 1(除了自我之相似程度外),不同類之間的相似程度 不再是極端值0。一個模擬的相似矩陣如公式 2-35 所示, 1 0.9103 0.8905 0.1610 0.0456 0.9103 1 0.8856 0.0152 0.0906 0.8905 0.8856 1 0.0160 0.0515 0.1610 0.0152 0.0160 1 0.8043 0.0456 0.0906 0.0515 0.8043 1 C (2-35) 對角線區塊的值都很接近1。接著仍算出其 Laplacian 矩陣與相對的特徵值與特徵 向量。其特徵值如公式2-36, 1 0.8627 0.0176 0.0103 0.0410 (2-36) 觀察其特徵值可以發現有一個值為 1,另一個值為 0.8627,第三大的特徵值為 0.1176,遠小於 1 與 0.8627。表示此樣本是分為 2 類的,其中特徵值 1 代表第 1 類,另一個特徵值 0.8627 代表第二類。公式 2-37 為將此兩個特徵值相對應之特 徵向量堆疊成矩陣V ,
0.4858 0.2957 0.4772 0.3303 0.4724 0.3430 0.3958 0.5862 0.3954 0.5850 V (2-37) 再將V 矩陣的每一個列正規化,即V 的列向量長度皆為1,如公式 2-38。 0.8542 0.5200 0.8223 0.5691 0.8092 0.5875 0.5597 0.8287 0.5600 0.8285 V (2-38) 最後使用FCM 演算法仍然可以得出x x x1, ,2 3為第一類,x x4, 5為第二類,如公式2-39 所示, 0.8542 0.5200 0.8223 0.5691 0.8092 0.5875 0.5597 0.8287 0.5600 0.8285 V (2-39) 因為相對於x4與x5之列向量的第二個元素值為0.8287 與 0.8285,此兩個數值皆大 於0。但相對於x x1, 2與x3之列向量的第二個元素值分別為-0.5200、-0.5691、-0.5875, 此三個數值皆小於0,故很容易便可利用 FCM 將兩群資料分別開來。
第三章 基於譜聚類之相關矩陣特徵萃取
法
在使用相關矩陣做特徵萃取的部分時會遇到兩個問題,一個是要怎麼結合這 些相似的特徵,一個是怎麼分割這些相似的特徵來決定此門檻值,而本研究發現 基於模糊分群演算法之譜聚類將可以解決這兩個問題第一節 基於模糊分群演算法之譜聚類
步驟 1:建立一相似矩陣C R d d ,或是經過正規化之後的核化矩陣(kernel matrix)K。 步驟 2:定義一個對角矩陣D其中第( , )i i 個元素為C矩陣之第一列的元素總 合,接著計算K D1/2AD1/2,K為Laplacian 矩陣。 步驟 3:將K對角化之後找出L個最大特徵值的特徵向量v1, , vL,之後在令矩陣 1 [ , , ] n L L V v v R 。 步驟 4:將V 矩陣正規化之後成一個新的矩陣V 使得矩陣V 的每一列都具有單位 長度 2 ij ij ij j V V V
步驟5:把V 矩陣中的每一列都視為RL空間中的一個資料點,接著可以使用這些 資料樣本來使用模糊演算法進行分群。 步驟6: 可以得到一個隸屬度值將uij代表樣本xj在第i個群的程度,當做結合特 徵的權重。步驟7:將V 矩陣中每一列表示的歸屬群組,對應於原始資料,且僅當 ˆj arg max kj k y u
第二節 基於譜聚類之相關矩陣特徵萃取法
頻譜之間的相關矩陣可視為頻譜與頻譜間的一種相似矩陣,因此譜聚類可被 用至相關矩陣而隸屬度值則可用來決定轉換矩陣的值來做為結合這些特徵。以相 關矩陣為特徵萃取之譜聚類演算法(correlation matrix feature extraction based on spectral clustering, CMFESC),接下來將說明此演算法如下:給定 [ , , ] [ , , ]1 1 T n d X x x b b 在高光譜資料上所有的樣本點,其中bi的第 j個 元素是屬於樣本點xj第i個特徵。 步驟1:計算相關矩陣C R d d ,其中C的第 j個元素為 ( , ) ij i j C corr b b i b與bj的相關係數。 步驟2:執行譜聚類演算法於相似矩陣C R d d 上其中 ( 1) / 2 ij ij C C 步驟 3:在經過譜聚類演算法後,我們會將頻譜值分成p群,這裡的p指的 是降維之後的維度數,另外也會得到隸屬度值,定義如下: ( )b ij u ,i1, , , p p d j 1, ,d 步驟4:經過特徵萃取之後bi可定義如下: ( )b d ij u
也就是說轉換矩陣可定義為: ( ) ( ) 1 11 ( ) ( ) 1 1 1 ( ) ( ) 1 ( ) ( ) 1 1 1 b b p d b d b s ps s s b b pd d d b d b s ps s s u u u u A u u u u
步驟5:經過降維之後的樣本x即可定義為: T x A x第四章 實驗設計
第一節 資料描述
壹、教育測驗資料
本研究所使用的教育測驗資料為採用「行政院國家科學委員會輔助研究專題 計畫-以貝氏網路為基礎之微積分適性診斷測驗暨學習系統研發」之測驗資料,以 技專院校微積分領域中「微分四則運算」單元進行實作,共23 題,其中 18 題為 四選一選擇題,5 題為建構反應題型,以施測題目中的第 9 題當作此教育測驗資 料。 施測時使用的題目紀錄於附錄中,根據施測時所得之資料,將學生的錯誤類 型分成13 種類型,表 4-1 是類別所對應需要進行補救教學之概念。 所使用的教育測驗資料中有100 個維度,13 個類別 430 個樣本,但其中有 4 個錯誤類型之犯錯人數為0,故本研究刪除此 4 種錯誤類型,只使用其他 9 種類 別進行分群實驗。 表4-1 微積分單元的錯誤概念分類表 組別 人數 需進行補救教學之概念 1 37 錯用冪分配 2 0 受加法律影響 3 56 受乘法律影響 4 0 形式錯覺 5 0 缺乏正確的運算法則 6 17 忽略對稱性或交錯性7 13 忽略必然性 8 94 失序(或流程不完全) 9 9 順序錯誤 10 0 公式混搭 11 55 無法判斷 12 58 未作答 13 91 正確答案 合計 430
貳、Indian Pine Site 影像資料
Indian Pine Site 影像是由印地安那州西北部之農業用地中選取一百平方英里
範圍,並於1992 年 6 月收集完成,為一混合森林和農業區域的 AVIRIS 空載高光
譜影像,如圖4-1 所示。影像大小為 145145,此影像具有 220 個有效頻譜,包
含16 個類別,分別是:Alfalfa, Corn-no till, Corn-min till, Corn, Hay-windowed,
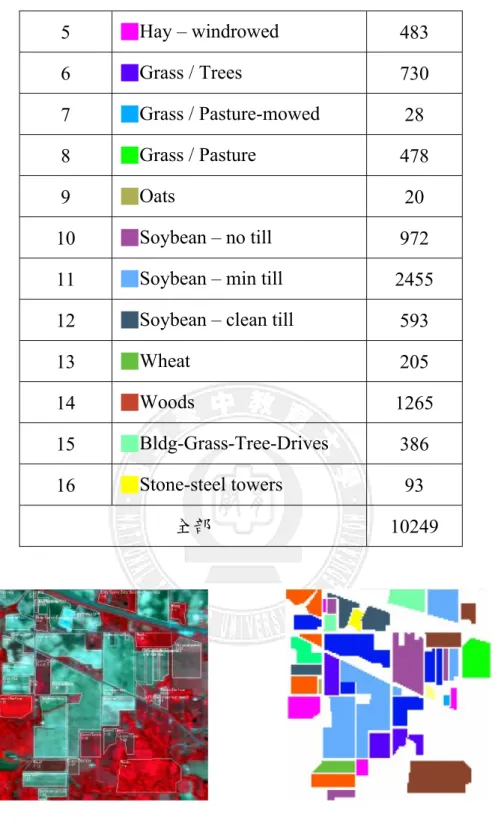
Grass/Trees, Grass/Pasture-mowed, Grass/Pasture, Oats, Soybean-no till, Soybean-min till, Soybean-clean till, Wheat, Woods, Bldg-Grass-Tree-Drives and Stone-steel towers。 此影像中各類別所含有之圖素(pixels)如表 4-2 所示。
表4-2 Indian Pine Site 影像各類別所含有圖素
類別數 類別名稱 圖素數
1 ■Alfalfa 46
2 ■Corn – no till 1428
3 ■Corn – min till 830
5 ■Hay – windrowed 483 6 ■Grass / Trees 730 7 ■Grass / Pasture-mowed 28 8 ■Grass / Pasture 478 9 ■Oats 20 10 ■Soybean – no till 972
11 ■Soybean – min till 2455
12 ■Soybean – clean till 593
13 ■Wheat 205
14 ■Woods 1265
15 ■Bldg-Grass-Tree-Drives 386
16 ■Stone-steel towers 93
全部 10249
圖4-1 Indian Pine Site 影像 圖 4-2 Indian Pine Site 的
ground truth 影像
本研究使用此農業用地影像(Indian Pine Site)的其中一個部分(Camps-Valls, Gomez-Chova, Munoz-Mari, Vila-Frances, & Calpe-Maravilla, 2006; Gualtieri,
所示,分別是Corn-no till, Grass/Trees, Soybeans-no till and Soybeans-min till,此影
像中各類別所含有之圖素如表4-3 所示。
表4-3 Indian Pine Site 影像各類別所
含有之圖素(四類) 類別數 類別名稱 圖素數 1 ■Corn-no till 1428 2 ■Grass/Pasture 483 3 ■Soybean-no till 972 4 ■Soybean-min till 2455 全部 5338
圖4-3 Indian Pine Site 影像(四類) 圖 4-4 Indian Pine Site 的 ground truth
影像(四類)
參、Washington DC Mall 影像資料
Washington DC Mall 影像為一都市區域影像如圖 4-5 所示(Landgrebe, 2003),
為飛機搭載高光譜儀低空拍攝而成。此影像大小為 205307,具有 220 個頻譜,
但部份頻譜被水吸收必須排除,因此僅具有191 個有效頻譜。此影像包含 7 個類
別,分別為:Buildings, Roads, Paths, Lawn, Trees, Water and Shadows,各類別所
含有之圖素如表4-4 所示,本研究進行之 Washington DC Mall 影像實驗,乃由各 類別中的圖素隨機各選取100 個樣本點當作資料樣本。 表4-4 Washington DC Mall 影像 各類別所含有之圖素 類別數 類別名稱 圖素數 1 ■Buildings 3834 2 ■Roads 680 3 ■ Paths 616 4 ■ Lawn 1928 5 ■ Trees 919 6 ■ Water 1224 7 ■ Shadows 221 全部 9422
圖4-5 Washington DC Mall 影像 圖4-6 Washington DC Mall 人工定義類 別影像
肆、UCI 資料集
本研究於美國加州大學爾灣分校(University of California at Irvine)資訊電腦 學院(Donald Bren School of Information and Computer Science)的 UCI Machine Learning Repository (Frank & Asuncion, 2010)提供的資料集中,挑選三種資料集
來進行實驗分析,資料描述如表4-5 所示: 表4-5 UCI 資料集之資料描述 資料名稱 類別數 樣本數 特徵數 Wine 3 178 13 Pima 2 768 8 Breast Tissue 6 106 9
第二節 實驗描述
本實驗將使用三種不同的特徵萃取的方法(CMFESC, PCA, ICA)搭配 KFCM 來探討特徵萃取法於分群正確率的影響。實驗中所提出之方法為以相關矩陣為特 徵萃取之譜聚類演算法,其中譜聚類演算法中的 FCM 停止條件為其目標函數值 達到收斂條件(<10-5)或迭代數達到 500 次。另外,本實驗利用 KFCM 來將特 徵萃取後之資料進行分群,其中參數 範圍設定為{0.1,0.2, 1 },萃取之維度數從 2 個維度數至 15 個維度數。由於每次 KFCM 演算法之初始值皆不相同,本研究 將資料樣本皆運算10 次之後取出平均值作為最後的分群正確率。 本研究之正確率計算公式敘述如下: ˆ ( ), 1 1 max j j L n y y S n j
而k,是Kronecker delta,即 , 1 if 0 if k k k L S 是一個在集合{1, 2, , } L 上的 symmetric group。而 指的是SL中的一個 permutation。第五章 實驗結果
第一節 教育測驗資料集
表5-1 呈現的實驗結果為本研究所提出之 CMFESC 與不同的特徵萃取法 PCA 及ICA 分別搭配 KFCM 演算法搭配教育測驗資料集之後所得之最高分類正確率。 以下僅挑選每個特徵萃取法再搭配 KFCM 演算法之後最高的分群正確率來進行 分析。 由表5-1 的實驗結果可知:在教育測驗資料集上,CMFESC 的最高分群正確 率為0.5978,標準差為 0.0083;PCA 最高分群正確率為 0.5553,標準差為 0.0112; ICA 最高分群正確率為 0.5474,標準差為 0.0011。由此實驗中可看出相較於其他 的特徵萃取法,本研究中提出之方法與PCA 及 ICA 之特徵萃取法比較之下,有 較好的的分群效果。 表5-1 教育測驗資料集分類正確率 特徵萃取 正確率 標準差 維度數 CMFESC 0.5978 0.0083 13 PCA 0.5553 0.0112 6 ICA 0.5474 0.0011 5 此實驗設計要探討SC 對於未經過排列的相關矩陣圖 5-1(a)的影響。圖 5-1 (b)至圖 5-1(d),為使用 SC 後,依照其隸屬度值之大小來重排後之相關矩陣, 其中頻譜之分群數分別設為2,3 與 4。很明顯可以發現,圖 5-1(b)為的確可以 分成二個大區塊,圖5-1(c)為分成三個大區塊,圖 5-1(d)為分成四個大區塊。 由圖5-1(a)可觀察到相鄰或是相近的光譜特徵之間具有非常高的相關性,因此, 對角線的亮度會比非對角線的亮度來的高。可是有一些非對角線的區塊的部分也圖5-1(d)可看出這些具有高相關性的特徵經過減低特徵給定的區塊排列之後也 可以發現對角線的亮度很明顯的比非對角線的亮度來的高。
圖5-1(a) 圖5-1(b)
圖5-1(c) 圖5-1(d)
第二節 Indian Pine Site 資料集的實驗結果
壹、實驗結果一
此實驗設計要探討SC 對於未經過排列的相關矩陣圖 5-2(a)的影響。圖 5-2 (b)至圖 5-2(d),為使用 SC 後,依照其隸屬度值之大小來重排後之相關矩陣, 其中頻譜之分群數分別設為2,3 與 4。很明顯可以發現,圖 5-2(b)為的確可以 分成二個大區塊,圖5-2(c)為分成三個大區塊,圖 5-2(d)為分成四個大區塊。 由圖5-2(a)可觀察到相鄰或是相近的光譜特徵之間具有非常高的相關性,因此, 對角線的亮度會比非對角線的亮度來的高。可是有一些非對角線的區塊的部分也 是亮的,這是不是表示非鄰近的頻譜特徵也會具有高的相關性。從圖5-2(b)至 圖5-2(d)可看出這些具有高相關性的特徵經過減低特徵給定的區塊排列之後也 可以發現對角線的亮度很明顯的比非對角線的亮度來的高。在接下來的二個實驗 中,本研究試圖將隸屬度值結合這些相關性較高的特徵,並得到新的降維空間。 圖5-2(a) 圖5-2(b)圖5-2(c) 圖5-2(d) 圖5-2(a)-(d)為未排列與已排列之相關矩陣
貳、實驗結果二
本研究說明了在特徵萃取的數量和 Laplacian 矩陣的特徵值之間的關係,這 裡的KFCM 演算法參數 設為1。圖 5-3 說明 Laplacian 矩陣對應的特徵值幅度與 特徵萃取之後的分群正確率比較。圖5-3 上方的圖顯示 Laplacian 矩陣的特徵值之 遞減幅度。圖5-3 下方顯示經過特徵萃取之 CMFESC 演算法的正確率。在此實驗 中,只列出了最大的前 51 個特徵值來進行比較,因為其餘特徵值的大小是非常 接近0(<10-4)。 在最初的幾個 Laplacian 矩陣的特徵值與特徵萃取分群之結果是相反的,一 開始如果考慮越多特徵值(使用越多的維度),分群的正確率會逐步升高,但考 慮過多的維度後,會受到Hughes Phenomenon(Hughes, 1968)的影響,分群正確 率開始明顯下降,如圖5-2 下方圖之末端所示。圖5-3 Laplacian 矩陣對應的特徵值幅度與特徵萃取之後的分群正確率比較
參、實驗結果三
表5-2 呈現的實驗結果為本研究所提出之 CMFESC 與不同的特徵萃取法 PCA
及ICA 分別搭配 KFCM 演算法之後在 Indian Pine Site 資料集所得之最高分類正
確率。以下僅挑選每個特徵萃取法再搭配KFCM 演算法之後最高的分群正確率來
進行分析。
由表5-2 的實驗結果可知:在 Indian Pine Site 資料集上,CMFESC 的最高分
群正確率為0.7117,標準差為 1.1110-16;PCA 最高分群正確率為 0.6762 標準差
為0;ICA 最高分群正確率為 0.6918 標準差為 1.1110-16。由此實驗中可看出相
較於其他的特徵萃取法,本研究中提出之方法在corn-no till 以及 soybeans-min till
表5-2 Indian Pine Site 資料集分類正確率 特徵萃取 正確率 標準差 維度數 CMFESC 0.7117 1.1110-16 2 PCA 0.6762 0 10 ICA 0.6918 1.1110-16 3
圖5-4 Indian Pine Site 的 ground
truth 影像(四類)
圖5-5 CMFESC 分群結果
圖5-6 PCA 分群結果 圖5-7 ICA 分群結果
第三節 Washington DC Mall 資料集
表5-3 呈現的實驗結果為本研究所提出之 CMFESC 與不同的特徵萃取法 PCA
及ICA 分別搭配 KFCM 演算法搭配 Washington DC Mall 資料集之後所得之最高
分類正確率。以下僅挑選每個特徵萃取法再搭配KFCM 演算法之後最高的分群正
確率來進行分析。
由表5-3 的實驗結果可知:在 Washington DC Mall 資料集上,CMFESC 的最
高分群正確率為0.7134,標準差為 0.0537;PCA 最高分群正確率為 0.6762,標準 差為1.1110-16;ICA 最高分群正確率為 0.6671,標準差為 0。由此實驗中可看出 相較於其他的特徵萃取法,本研究中提出之方法與 PCA 及 ICA 之特徵萃取法比 較之下,有較好的的分群效果。 表5-3 Washington DC Mall 資料集分類正確率 特徵萃取 正確率 標準差 維度數 CMFESC 0.7134 0.0537 3 PCA 0.6762 1.1110-16 5 ICA 0.6671 0 2
第四節 UCI 資料集
表5-4 至 5-6 所呈現的實驗結果為本研究所提出之 CMFESC 與不同的特徵萃
取法PCA 及 ICA 分別搭配 KFCM 演算法搭配三種 UCI 資料集之後所得之最高分
類正確率。以下僅挑選每個特徵萃取法再搭配KFCM 演算法之後最高的分群正確 率來進行分析。 由表 5-4 的實驗結果可知:在 wine 資料集上,CMFESC 的最高分群正確率 為0.6916,標準差為 0.0017;PCA 最高分群正確率為 0.6854,標準差為 0;ICA 最高分群正確率為 0.6854,標準差為 0.0。由此實驗中可看出相較於其他的特徵 萃取法,本研究中提出之方法與 PCA 及 ICA 之特徵萃取法比較之下,有較好的 的分群效果。 表5-4 wine 資料集分類正確率 特徵萃取 正確率 標準差 維度數 CMFESC 0.6916 0.0017 5 PCA 0.6854 0 2 ICA 0.6854 0 2 表5-5 的實驗結果可知:在 pima 資料集上,CMFESC 的最高分群正確率為 0.6826,標準差為 0.0033;PCA 最高分群正確率為 0.6602,標準差為 0;ICA 最 高分群正確率為 0.6589,標準差為 1.1110-16。由此實驗中可看出相較於其他的 特徵萃取法,本研究中提出之方法與 PCA 及 ICA 之特徵萃取法比較之下,有較 好的的分群效果。
表5-5 pima 資料集分類正確率
特徵萃取 正確率 標準差 維度數
CMFESC 0.6826 0.0033 8
PCA 0.6602 0 3
ICA 0.6589 1.1110-16 6
表5-6 的實驗結果可知:在 breast tissue 資料集上,CMFESC 的最高分群正
確率為0.5198,標準差為 0.0130;PCA 最高分群正確率為 0.4981,標準差為 0.0226; ICA 最高分群正確率為 0.5000,標準差為 0.0277。由此實驗中可看出相較於其他 的特徵萃取法,本研究中提出之方法與PCA 及 ICA 之特徵萃取法比較之下,有 較好的的分群效果。 表5-6 breast tissue 分類正確率 特徵萃取 正確率 標準差 維度數 CMFESC 0.5198 0.0130 2 PCA 0.4981 0.0226 4 ICA 0.5000 0.0277 5
第六章 結論與未來發展
在 本 研 究 中 提 出 了 一 個 方 法 為 基 於 譜 聚 類 之 相 關 矩 陣 特 徵 萃 取 法 (CMFESC),且將基於模糊分群演算法之譜聚類應用至相關矩陣的頻譜值裡。 此外,對應的隸屬度值也能夠當做轉換矩陣來使用。基於譜聚類之相關矩陣特徵 萃取法不僅能解決頻譜分群的問題也能從本研究中的實驗改善分群的正確率。從
實驗中可看出Indian Pine Site 之子資料集、Washington DC Mall 資料集、教育測
驗資料集使用基於譜聚類之相關矩陣特徵萃取法搭配核化模糊演算法之分群結 果可以達到最佳的分群正確率。
在未來將嘗試使用一些用在確定endmembers 的數目方法(Chang & Du, 2004;
Bioucas-Dias & Nascimento, 2008),讓 CMFESC 演算法能自動決定特徵萃取的數
量。也嘗試將本研究提出之 CMFESC 應用在監督式分類上,如於執行 support
vector machine(SVM)(Melgani & Bruzzone, 2004)之前,先使用本研究提出之 CMFESC 進行維度萃取。另外,也將仿照針對 SVM 之自動核函數參數選取法(Li, Lin, Kuo, & Chu, 2010),找出針對 KFCM 之自動核函數參數選取法。
參考文獻
中文部分
黃文俊(2009)。模糊權重分群演算法。國立臺中教育大學,台中市。
英文部分
Acito, N., Corsini, G., & Diani, M. (2003). An unsupervised algorithm for hyperspectral image segmentation based on the Gaussian mixture model, IEEE
Geoscience and Remote Sensing Symposium IGARSS, 6, 3745-3747.
Bach, F. & Jordan, M. (2004). Learning spectral clustering, in S. Thrun, L. Saul, and B. Schölkopf (Eds.), Advances in Neural Information Processing Systems, vol. 16 (NIPS), 305-312, Cambridge, MA: MIT Press.
Bezdek, J. C. (1973). Fuzzy mathematics in pattern classfication. PhD thesis, Applied
Math. Center, Cornell University, Ithaca.
Bioucas-Dias, J. M. & Nascimento, J. M. P. (2008). Hyperspectral subspace identification. IEEE Transactions on Geoscience and Remote Sensing, 46(8), 2435-2445.
Bruzzone, L. & Persello, C. (2009). A novel context-sensitive semisupervised SVM classifier robust to mislabeled training samples. IEEE Transactions on
Camps-Valls, G., Gomez-Chova, L., Munoz-Mari, J., Vila-Frances, J., & Calpe-Maravilla, J. (2006). Composite kernels for hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing Letters,
3(1), 93-97.
Camps-Valls, G., Marsheva, T. V. B., & Zhou, D.Y. (2007). Semi-supervised graph-based hyperspectral image classification. IEEE Transactions on
Geoscience and Remote Sensing, 45(10), 3044-3054.
Cariou, C. Chehdi, K., & Moan, S. L. (2011). BandClust: an unsupervised band reduction method for hyperspectral remote sensing. IEEE Geoscience and
Remote Sensing Letters, 8(3), 565-569.
Chang, C. I. & Du, Q. (2004). Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Transactions on Geoscience and Remote
Sensing, 42(3), 608-619.
Chatzis, S. & Varvarigou, T. (2009). Factor analysis latent subspace modeling and robust fuzzy clustering using t-distributions. IEEE Transactions on Fuzzy
Systems, 17(3), 505-517.
Fukunaga, K. (1990). Introduction to Statistical Pattern Recognition. Academic Press, San Diego, CA, 2nd edition.
Gittins, C., Konno, D., Hoke, M., & Ratkowski, A. (2008). Some effects of image segmentation on subspace-based and covariance-based detection of anomalous sub-pixel materials, International Journal of High Speed Electronics and Systems,
18(2), 349 - 367.
Goetz, A. F. H. (2009). Three decades of hyperspectral remote sensing of the earth: a personal view. Remote Sensing of Environment, 113, 5-16.
Grahn, H. & Geladi, P. (2007). Techniques and Applications of Hyperspectral Image
Analysis. Chichester, U.K.: Wiley.
Gualtieri, J. A., Chettri, S. R., Cromp, R. F., & Johnson, L. F. (1999). Support vector machine classifiers as applied to AVIRIS data. presented at the 1999 Airborne
Geoscience Workshop.
Frank, A. & Asunction, A. (2010). UCI Machine Learning Repository, from
http://archive.ics.uci.edu/ml
Hughes, G. F. (1968). On the mean accuracy of statistical pattern recognizers. IEEE
Transactions Information Theory, 14(1), 55-63.
Honda, K., Notsu, A., & Ichihashi, H. (2010). Fuzzy PCA-guided robust k-means clustering. IEEE Transactions on Fuzzy Systems, 18(1), 67-79.
Hyvrinen, A., Karhunen, J., & Oja, E. (2001). Independent copmonent analysis, John Wiley and Sons, New York.
Jain, A. & Zongker, D. (1997). Feature selection: evaluation, application, and small sample performance. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 19(2), 153-158.
Jia, X. & Richards, J. A. (1994). Efficient maximum likelihood classification for imaging spectrometer data sets. IEEE Transaction on Geoscience and Remote
Sensing, 32, 274-281.
Jlliffe, I. (1986) Principal Component Analysis. New York: Springer-Verlag.
Kuo, B. C. & Chang, K. Y. (2007). Feature extractions for small sample size classification problem. IEEE Transactions on Geoscience and Remote, 45(3), 756-764.
Kuo, B. C., Li, C. H., & Yang J. M. (2009). Kernel nonparametric weighted feature extraction for hyperspectral image classification. IEEE Transactions on
Geoscience and Remote Sensing, 47(4), 1139-1155.
Landgrebe, D. A. (2003). Signal Theory Methods in Multispectral Remote Sensing. John Wiley and Sons, Hoboken, NJ: Chichester.
Lee, C. & Landgrebe, D. A. (1993). Analyzing high-dimensional multispectral data,”
IEEE Transactions on Geoscience and Remote Sensing, 31(4), 792-800.
Li, C. H., Lin, C. T., Kuo, B. C., & Chu, H. S. (2010). An automatic method for selecting the parameter of the RBF kernel function to support vector machines.Proceedings of International Geosciences and RemoteSensing
Symposium, 836-839.
Lin, C. T. & George Lee, C. S. (1996). Neural Fuzzy Systems: A Neuro-Fuzzy
Synergism to Intelligent Systems. Prentice Hall.
Melgani, F. & Bruzzone, L. (2004). Classification of Hyperspectral Remote Sensing Images With Support Vector Machines. IEEE Transactions on Geoscience and
Remote Sensing, 42(8), 1778-1790.
Nasser, A. & Hamad, D. (2006). K-means clustering algorithm in projected spaces. in
Proc. 9th Int. Conf. Inf. Fusion, 1–6.
Ng, A. Y., Jordan, M. I., & Weiss, Y. (2002). On spectral clustering: analysis and an algorithm. in Proc. NIPS, vol. 14, Vancouver, BC, Canada: MIT Press.
Sebastiano, B.S. & Gabriele, M. (2007). Extraction of spectral channels from hyperspectral images for classification purposes. IEEE Transactions on
Shi, J. & Malik, J. (2000). Normalized cuts and image segmentation. IEEE
Transactions on Pattern Analysis and Machine, 22(8), 888-905.
Theodoridis, S. & Koutroumbas, K. (2006). Pattern Recognition. Academic Press, 3rd edition, Inc. Orlando, FL, USA.
Weike, K., Azad, P., & Dillmann, R. (2006). Fast and robust feature-based recognition of multiple objects. in Proc. 6th IEEE-RAS Int. Conf. Humanoid Robots, 264– 269.
Wu, Z. D., Xie, W. X., & Yu, J. P. (2003). Fuzzy C-means clustering algorithm based on kernel method. proceedings. Fifth International Conference on
Computational Intelligence and Multimedia Applications, 49-54.
Zubko, V., Kaufman, Y. J., Burg R. I., & Martins, J. V. (2007). Principal component analysis of remote sensing of aerosols over oceans. IEEE Transactions on
附錄一 微分四則運算專家知識結構
代數微分四則與連鎖律混合 加減乘 混合微 分 加減除 混合微 分 乘除混 合微分 乘與連 鎖律混 合微分 加減與連 鎖律混合 微分 除與連 鎖律混 合微分 加減法微分計算 乘法微分計算 除法微分計算 連鎖律微分計算 加減法微分公式 乘法微分公式 除法微分公式 連鎖律公式附錄二 教育測驗資料試題
1. ′ (A) 7 (B) 6 (C) (D) 7 2. ′ (A) (B) (C) (D) 3. √ ′ (A) √3 √ (B) √3 √ (C) √3x√ (D) √3 4. 5 ′ (A) 3‧5 (B) (C) 0 (D) 125 5. ′ (A) (B) (C) (D) 6. 若已知 與 均為可微函數,則 ′ (A) ′ ‧ ′ (B) ′ ′ (C) ′ ‧ ‧ ′ (D) ′ ′ 7. 若已知 為可微函數且 ,則 ′ (A) ′ ‧ ′ (B) ′ ′ (C) ′ ‧ (D) ′ ‧ ‧28. 若已知 與 均為可微函數,則 ′ (A) ′ ′ (B) ′′ (C) ′ ′ (D) ′ ′ 9. 若已知 為可微函數且 ,則 ′ (此題為建構反應題) 10. 若已知 與 均為可微函數,則 ′ (A) ′ ′ (B) ′ ‧ ′ (C) ′‧ ‧ ′ (D) ‧ ′ 11. 若已知 為可微函數且 ,則 ′ (此題為建構反應題) 12. 若已知 , , 均為可微函數,則 ‧ ′ (A) ′ ′ ‧ ′ (B) ′ ‧ ‧ ′ (C) ′ ′ ‧ ‧ ′ (D) ′ ′ ′ 13. 若已知 , , 均為可微函數,則 ‧ ′ (A) ′ ′ ′ (B) ′ ‧ ′ ‧ ′ (C) ′ ′
(D) ′ ′ 14. ′ (A) 4 (B) 2 2 4 (C) 2 2 4 (D) 2 2 4 15. (此題為建構反應題) 16. (A) 3 2 (B) 3 2 (C) 3 (D) 3 2 17. 1 (A) 2 1 ‧2 (B) 1 2 1 ‧2 (C) 1 ‧2 (D) 1 2 1 1 ‧2 18. ‧ 1 (A) 4 ‧10 1 (B) ‧ 1 10 ‧ 1 (C) 2 ‧ 1 20 ‧ 1 (D) 2 ‧ 1 10 ‧ 2
19. (此題為建構反應題) 20. 1 (A) 10 1 (B) 20 1 (C) 10 2 (D) 20 ‧ 1 21. 若已知 ,則 ‧ (A) ‧2 (B) ‧ 2 (C) ‧ ‧ (D) ‧ ‧2 22. 若已知 ,則 ‧ (此題為建構反應題) 23. 若已知 3 4, 3 2, 3 5, 3 3,且 ‧ ,則 3 (A) 15 (B) (C) 22 (D) 23