Mining fuzzy generalized association rules from quantitative
data under fuzzy taxonomic structures
Tzung-Pei Hong*
Department of Electrical Engineering National University of Kaohsiung
Kaohsiung, 811, Taiwan, R.O.C. E-mail: [email protected]
Fax: +886+7+5919138
Kuei-Ying Lin
Institute of Information Engineering I-Shou University
Kaohsiung, 840, Taiwan, R.O.C. E-mail: [email protected]
Fax: +886+7+6577711
Shyue-Liang Wang
Department of Information Management National University of Kaohsiung
Kaohsiung, 811, Taiwan, R.O.C. E-mail: [email protected]
Fax: +886+7+5919000
Abstract
Due to the increasing use of very large databases and data warehouses, mining
useful information and helpful knowledge from transactions has become an important
research area. Most conventional data-mining algorithms identify the relationships
among transactions using binary values and find rules at a single concept level.
Transactions with quantitative values and items with taxonomic relations are, however,
commonly seen in real-world applications. Besides, the taxonomic structures may not
be crisp. This paper thus proposes a fuzzy data-mining algorithm for extracting fuzzy
generalized association rules under given fuzzy taxonomic structures. The proposed
algorithm first generates expanded transactions according to given fuzzy taxonomic
structures. It then transforms each quantitative value into a fuzzy set in linguistic
terms. Each item uses only the linguistic term with the maximum cardinality in later
mining processes, thus making the number of fuzzy regions to be processed the same
as that of the original items. The mining process based on fuzzy counts is then
performed to find fuzzy generalized association rules from these items. The algorithm
can therefore focus on the most important linguistic terms and reduce its time
complexity.
Keywords: data mining, fuzzy set, fuzzy taxonomic structure, generalized association
1.
Introduction
The rapid development of computer technology, especially increased capacities
and decreased costs of storage media, has led businesses to store huge amounts of
external and internal information in large databases at low cost. Mining useful
information and helpful knowledge from these large databases has thus evolved into
an important research area [2][4]. Years of effort in data mining has produced a
variety of efficient techniques. Depending on the types of databases to be processed,
mining approaches may be classified as working on transactional databases, temporal
databases, relational databases, and multimedia databases, among others. Depending
on the classes of knowledge sought, mining approaches may be classified as finding
association rules, classification rules, clustering rules, and sequential patterns, among
others [4].
Deriving association rules from transaction databases is most commonly seen in
data mining [1][2][4]. It discovers relationships among items such that the presence of
certain items in a transaction tends to imply the presence of certain other items. Most
previous studies concentrated on showing how binary-valued transaction data on a
single level of items may be handled. However, transaction data in real-world
applications usually consist of quantitative values and items are often organized in a
quantitative data on multiple levels of items presents a challenge to workers in this
research field.
In the past, Agrawal and his co-workers proposed several mining algorithms for
finding association rules in transaction data based on the concept of large itemsets
[1-2, 13]. They also proposed a method [14] for mining association rules from data
sets using quantitative and categorical attributes. Their proposed method first
determined the number of partitions for each quantitative attribute, and then mapped
all possible values of each attribute onto a set of consecutive integers. Other methods
have also been proposed to handle numeric attributes and to derive association rules.
Fukuda et al. introduced the optimized association-rule problem and permitted
association rules to contain single uninstantiated conditions on the left-hand side [5].
They also proposed schemes for determining conditions under which rule confidence
or support values were maximized. However, their schemes were suitable only for
single optimal regions. Rastogi and Shim extended the approach to more than one
optimal region, and showed that the problem was NP-hard even for cases involving
one uninstantiated numeric attribute [13][14].
Recently, the fuzzy set theory has been used more and more frequently in
intelligent systems because of its simplicity and similarity to human reasoning [11].
designed and used to good effect with specific domains. Strategies based on decision
trees were proposed in [12, 18-19]. Wang et al. proposed a fuzzy version-space
learning strategy for managing vague information [17]. Hong et al. also proposed a
fuzzy mining algorithm for managing quantitative data [6].
In [10], we proposed a data-mining algorithm able to deal with quantitative data
under a crisp taxonomic structure. In that approach, each item definitely belongs to
only one ancestor in the taxonomic structure. The taxonomic structures may, however,
not be crisp in real-world applications. An item may belong to different classes in
different views. This paper thus proposes a new fuzzy data-mining algorithm for
extracting fuzzy generalized association rules under given fuzzy taxonomic structures.
The proposed algorithm first generates expanded transactions according to given
fuzzy taxonomic structures. It then transforms each quantitative value into a fuzzy set
in linguistic terms. Each item uses only the linguistic term with the maximum
cardinality in later mining processes, thus making the number of fuzzy regions to be
processed the same as that of the original items. The mining process based on fuzzy
counts is then performed to find fuzzy generalized association rules from these items.
The algorithm can therefore focus on the most important linguistic terms and reduce
its time complexity. The rules mined are expressed in linguistic terms, which are more
The remaining parts of this paper are organized as follows. Data mining with
fuzzy taxonomic structures is described in Section 2. A novel data-mining algorithm
for quantitative values under fuzzy taxonomic structures is proposed in Section 3. An
example to illustrate the proposed algorithm is given in Section 4. Experimental
results are shown in Section 5. Conclusions and future works are stated in Section 6.
2. Data mining with a fuzzy taxonomic structure
Previous studies on data mining focused on finding association rules on a
single-concept level. Mining multiple-concept-level rules may, however, lead to
discovery of more general and important knowledge from data. Relevant taxonomies
of data items are thus usually predefined in real-world applications. An item may,
however, belong to different classes in different views. When taxonomic structures are
not crisp, hierarchical graphs can be used to represent them. Terminal nodes on the
hierarchical graphs represent the items actually appearing in transactions; internal
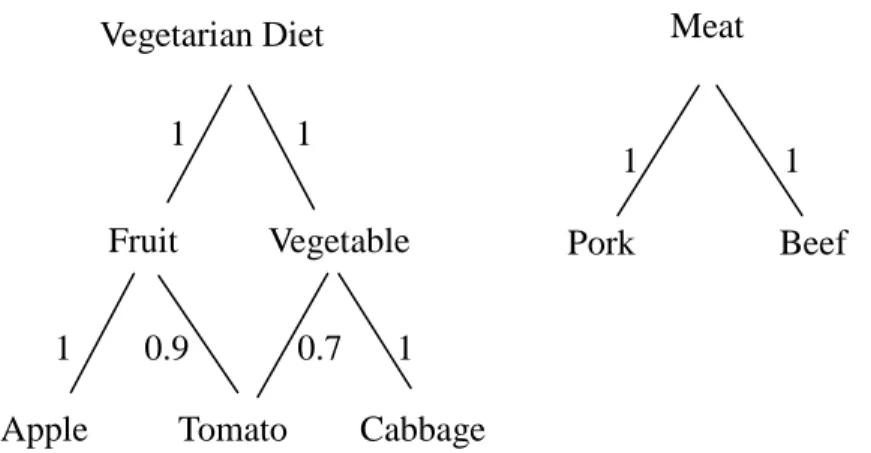
nodes represent classes or concepts formed by lower-level nodes. A simple example is
Figure 1. An example of fuzzy taxonomic structures
In this example, vegetarian diet falls into two classes: fruit and vegetable. Fruit
can be further classified into apple and tomato. Similarly, assume vegetable is divided
into tomato and cabbage. Note that tomato belongs to both fruit and vegetable with
different membership degrees. It is thought of as fruit with 0.9 membership value and
as vegetable with 0.7. The membership value of tomato belonging to vegetarian diet
can be calculated using the max-min product combination. Since both fruit and
vegetable belong to vegetarian diet with membership value 1, the membership value
of tomato belonging to vegetarian diet is then max(min(1, 0.9), min(1, 0.7))=0.9. Only
the terminal items (apple, tomato, cabbage, pork and beef) can appear in transactions.
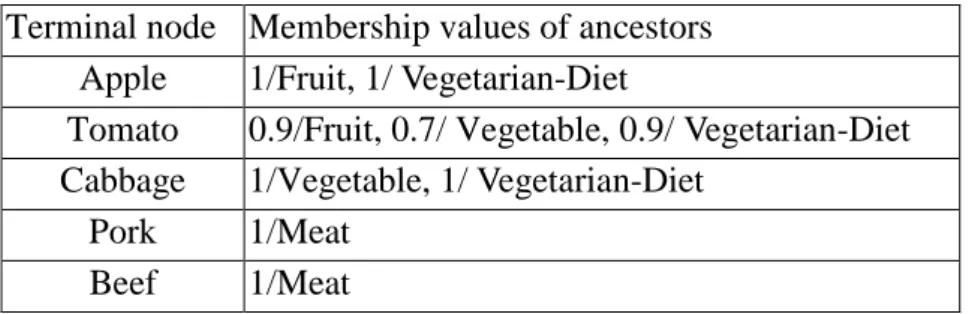
The membership degrees of ancestors for each terminal node are shown in Table 1.
Vegetarian Diet Meat
Fruit Vegetable
Apple Tomato Cabbage
Pork Beef 1 1
1 1
Table 1. The membership degrees of ancestors for each terminal node in this example Terminal node Membership values of ancestors
Apple 1/Fruit, 1/ Vegetarian-Diet
Tomato 0.9/Fruit, 0.7/ Vegetable, 0.9/ Vegetarian-Diet Cabbage 1/Vegetable, 1/ Vegetarian-Diet
Pork 1/Meat Beef 1/Meat
Wei and Chen proposed a method to find generalized association rules under
fuzzy taxonomic structures [16]. The items to be processed in their approach are
binary. Their mining process first calculated the membership values of ancestors for
each terminal node in the manner mentioned above. It then added the ancestors of
items to the given transactions as Srikant and Agrawal’s did [15]. Candidate itemsets
were generated and counted by scanning the expanded transaction data. If the number
of an itemset appearing in the expanded transactions was larger than a pre-defined
threshold value (called the minimum support), the itemset was considered a large
itemset. Itemsets containing only single items were first processed. The 1-large
itemsets derived were then combined to form candidate itemsets containing two items.
This process was repeated until all large itemsets had been found. After that, all
possible generalized association rules were induced from the large itemsets. The rules
with confidence values larger than a predefined threshold (called the minimum
and interesting rules were output. An interesting rule must satisfy at least one of the
following three interest requirements:
1.a rule with no ancestor rules (by replacing the items in a rule with their
ancestors in the taxonomy) mined out,
2.the support value of a rule being R-time larger than the expected support
values of its ancestor rules, and
3.the confidence value of a rule being R-time larger than the expected
confidence values of its ancestor rules.
Wei and Chen’s concepts will be used in our approach to mine fuzzy interesting
generalized association rules from quantitative transaction data. The rules mined are
expressed in linguistic terms, which are more natural and understandable for human
beings.
3. Mining fuzzy generalized association rules from
quantitative data under fuzzy taxonomic structure
The proposed generalized mining algorithm integrates fuzzy-set concepts and
generalized data mining technologies to find cross-level interesting rules from
taxonomy. The knowledge derived is represented by fuzzy linguistic terms, and thus
easily understandable by human beings.
The proposed fuzzy mining algorithm first calculates the membership values of
ancestors for each terminal node as Wei and Chen’s approach did [16]. It then forms
expanded transactions and uses membership functions to transform each quantitative
value into a fuzzy set in linguistic terms. It adopts an iterative search approach to
finding large itemsets. Each item uses only the linguistic term with the maximum
cardinality in later mining processes, thus making the number of fuzzy regions to be
processed the same as the number of original items. The algorithm therefore focuses
on the most important linguistic terms, which reduces its time complexity. A mining
process using fuzzy counts is performed to find fuzzy multiple-level association rules.
Fuzzy interest requirements are then checked to remove uninteresting rules. Details of
the proposed fuzzy mining algorithm are stated below.
The fuzzy generalized mining algorithm for fuzzy taxonomic structures:
INPUT: A body of n quantitative transaction data, a set of membership functions, a
fuzzy taxonomic structure, a minimum support valueα , a minimum
confidence valueλ, and an interest threshold R.
OUTPUT: A set of fuzzy generalized association rules.
given fuzzy taxonomic structure.
STEP 2: Calculate the quantitative value vik of each ancestor item Ak in transaction
datum Di (I=1 to n) as:
) ( * ∑ = i j k D in T ij A j ik v T v µ ,
where Tj is a terminal item appearing in Di, vij is the quantitative value of Tj ,
and µAk(Tj) is the membership value of item Tj belonging to ancestor Ak.
STEP 3: Add ancestors of appearing items to transactions with their quantities
calculated from STEP 2.
STEP 4: Transform the quantitative value vij of each expanded item name Ij (terminal
item or ancestor item) appearing in transaction datum Di (I=1 to n) into a
fuzzy set fij represented as
+ + + j j jh ijh j ij j ij R f R f R f .... 2 2 1 1
using the given
membership functions, where hj is the number of fuzzy regions for Ij, Rjl is
the l-th fuzzy region of Ij, 1≤l≤hj, and fijlis vij’s fuzzy membership value
in region Rjl.
STEP 5: Calculate the scalar cardinality countjl of each fuzzy region Rjl in the
transaction data as:
∑
= = n i ijl jl f count 1 .STEP 6: Find max-
(
jl)
h l j MAXcount count j 1 =
will be used to represent the fuzzy characteristic of item Ij in later mining
processes.
STEP 7: Check whether the value max-countj of a region max-Rj, j = 1 to m, is larger
than or equal to the predefined minimum support value α . If a region
max-Rj is equal to or greater than the minimum support value, put it in the
large 1-itemsets (L ). That is, 1
{
R count j m}
L1 = max− jmax− j ≥
α
,1≤ ≤ .STEP 8: Generate the candidate set C2 from L1. Each 2-itemset in C2 must not include
items with ancestor or descendant relations in the fuzzy taxonomy.
STEP 9: For each newly formed candidate 2-itemset s with items (s1, s2) in C2:
(a) Calculate the fuzzy value of s in each transaction datum Di as fis = fis1Λfis2 ,
where
j is
f is the membership value of Di in region sj. If the minimum
operator is used for the intersection, then fis =min(fis1,fis2). (b) Calculate the scalar cardinality of s in the transaction data as:
counts =
∑
= n i is f 1 .(c) If counts is larger than or equal to the predefined minimum support value
α
,put s in the large 2-itemsets (L2).
STEP 10: IF L2 is null, then exit the algorithm; otherwise, do the next step.
current large itemsets.
STEP 12: Generate the candidate set Cr+1 from Lr in a way similar to that in the
apriori algorithm [1]. That is, the algorithm first joins Lr and Lr assuming
that r-1 items in the two itemsets are the same and the other one is different.
Store in Cr+1 itemsets having all their sub-r-itemsets in Lr.
STEP 13: For each newly formed (r+1)-itemset s with items
(
s
1,
s
2,
...,
s
r+1)
inCr+1:
(a) Calculate the fuzzy value of s in each transaction datum Di as
1 2 1Λ Λ...Λ + = is is isr is f f f f , where j is
f is the membership value of Di in
region sj. If the minimum operator is used for the intersection, then
j is r j is Minf f 1 1 + = = .
(b) Calculate the scalar cardinality of s in the transaction data as:
counts =
∑
= n i is f 1 .(c) If counts is larger than or equal to the predefined minimum support value
α
,put s in Lr+1.
STEP 14: If Lr+1 is null, then do the next step; otherwise, set r=r+1 and repeat STEPs
12 to 14.
STEP 15: Construct the association rules for all the large q-itemset s containing items
(a) Form all possible association rules thusly:
s1Λ...Λsk−1Λsk+1Λ...Λsq → sk, k=1 to q.
(b) Calculate the confidence values of all association rules using the formula:
∑ ∑ = = Λ Λ Λ Λ − + n i is is is is n i is q K K f f f f f 1 1 ) ... , ... ( 1 1 1 .
STEP 16: Keep the rules with confidence values larger than or equal to the predefined
confidence thresholdλ.
STEP 17: Output the rules without ancestor rules (by replacing the items in a rule with
their ancestors in the taxonomy) to users as interesting rules.
STEP 18: For each remaining rule s (represented as s1Λs2Λ...Λsr →s(r+1)), find the
close ancestor rule t (represented as t1Λt2Λ...Λtr →t(r+1)) and calculate
the support interest measure Isupport (s) of s as:
( )
t t r k s r k s support count count count count s I k k × Π Π = + = + = 1 1 1 1 ,and the confidence interest measure Iconfidence (s) of s as:
( )
t t s s confidence confidence count count confidence s I r r × = + + 1 1 ,where confidences and confidencet are respectively the confidence values
of rules s and t; output the rules with their support interest measures or
threshold R to users as interesting rules.
Note that in Step 17, an ancestor of a fuzzy rule is formed by replacing the items in the rule with their ancestors in the fuzzy taxonomy, but the linguistic terms in both the rules must be the same. The rules output from Steps 17 and 18 can then serve as meta-knowledge concerning the given transactions.
4. An example
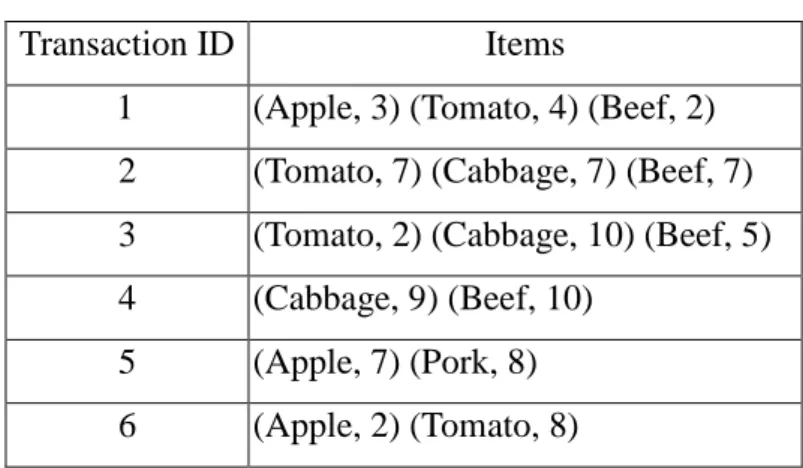
In this section, an example is given to illustrate the proposed fuzzy generalized mining algorithm. This is a simple example to show how the proposed algorithm generates fuzzy generalized association rules from quantitative transactions under a fuzzy taxonomic structure. The data set includes the six transactions shown in Table 2.
Table 2. Six transactions in this example
Transaction ID Items
1 (Apple, 3) (Tomato, 4) (Beef, 2) 2 (Tomato, 7) (Cabbage, 7) (Beef, 7) 3 (Tomato, 2) (Cabbage, 10) (Beef, 5) 4 (Cabbage, 9) (Beef, 10)
5 (Apple, 7) (Pork, 8) 6 (Apple, 2) (Tomato, 8)
Each transaction includes a transaction ID and some purchased items. Each item
transaction consists of nine units of cabbage and ten units of beef. Assume the
predefined fuzzy taxonomy is as shown in Figure 1. For convenience, the simple
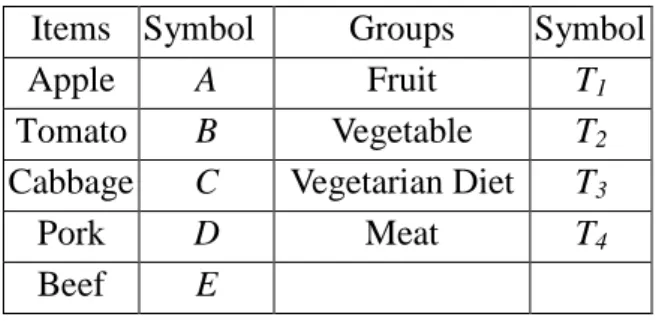
symbols in Table 3 are used to represent the items and groups.
Table 3. Items and groups are represented by simple symbols for convenience Items Symbol Groups Symbol
Apple A Fruit T1
Tomato B Vegetable T2
Cabbage C Vegetarian Diet T3
Pork D Meat T4
Beef E
Also assume that the fuzzy membership functions are the same for all the items
and are as shown in Figure 2.
Figure 2. The membership functions used in this example
In the example, amounts are represented by three fuzzy regions: Low, Middle
and High. Thus, three fuzzy membership values are produced for each item amount
Low Middle High
1 0 Membership Value Item Amount 0 1 6 11
Low Middle High
1 0 Membership Value Item Amount 0 1 6 11
according to the predefined membership functions. For the transaction data in Table 2,
all the expanded transactions are shown in Table 4.
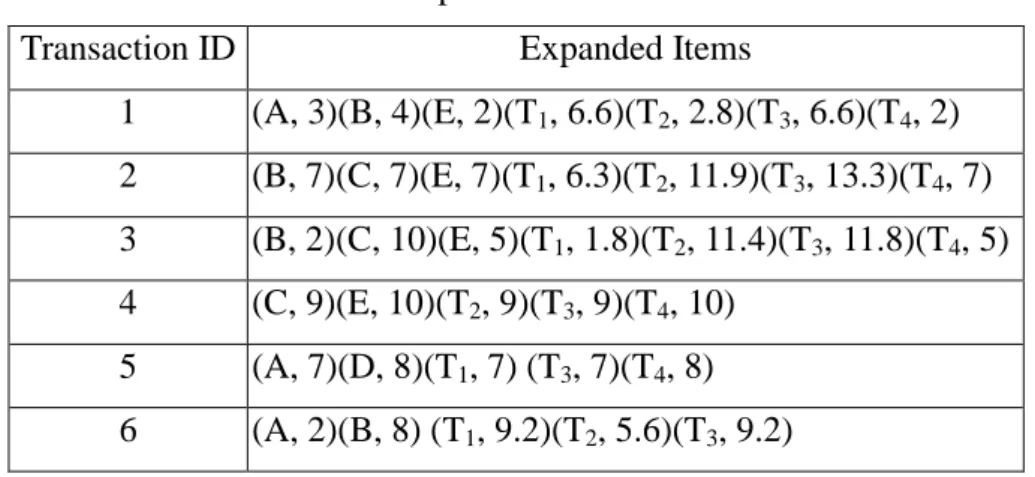
Table 4. The expanded transactions
Transaction ID Expanded Items
1 (A, 3)(B, 4)(E, 2)(T1, 6.6)(T2, 2.8)(T3, 6.6)(T4, 2) 2 (B, 7)(C, 7)(E, 7)(T1, 6.3)(T2, 11.9)(T3, 13.3)(T4, 7) 3 (B, 2)(C, 10)(E, 5)(T1, 1.8)(T2, 11.4)(T3, 11.8)(T4, 5) 4 (C, 9)(E, 10)(T2, 9)(T3, 9)(T4, 10) 5 (A, 7)(D, 8)(T1, 7) (T3, 7)(T4, 8) 6 (A, 2)(B, 8) (T1, 9.2)(T2, 5.6)(T3, 9.2)
The quantitative values of the expanded items are represented using fuzzy sets,
which are shown in Table 5, where the notation item.term is called a fuzzy region.
Table 5. The fuzzy sets transformed from the data in Table 4
TID Fuzzy set
1 ) . 2 . 0 . 8 . 0 )( . 12 . 0 . 88 . 0 )( . 36 . 0 . 64 . 0 )( . 12 . 0 . 88 . 0 )( . 2 . 0 . 8 . 0 )( . 6 . 0 . 4 . 0 )( . 4 . 0 . 6 . 0 ( 4 4 3 3 2 2 1
1MiddleTHighTLow TMiddleTMiddleTHighTLow TMiddle
T Middle E Low E Middle B Low B Middle A Low A + + + + + + + 2 ) . 2 . 0 . 8 . 0 )( . 0 . 1 )( . 0 . 1 )( . 06 . 0 . 94 . 0 )( . 2 . 0 . 8 . 0 )( . 2 . 0 . 8 . 0 )( . 2 . 0 . 8 . 0 ( 4 4 3 2 1
1MiddleTHighTHighTHighTMiddleTHigh
T High E Middle E High C Middle C High B Middle B + + + + + 3 ) . 8 . 0 . 2 . 0 )( . 0 . 1 )( . 0 . 1 )( . 16 . 0 . 84 . 0 )( . 8 . 0 . 2 . 0 )( . 8 . 0 . 2 . 0 )( . 2 . 0 . 8 . 0 ( 4 4 3 2 1
1Low TMiddleTHighTHigh TLow TMiddle
T Middle E Low E High C Middle C Middle B Low B + + + + + 4 ) . 8 . 0 . 2 . 0 )( . 6 . 0 . 4 . 0 )( . 6 . 0 . 4 . 0 )( . 8 . 0 . 2 . 0 )( . 6 . 0 . 4 . 0 ( 4 4 3 3 2
2Middle T High T Middle T High T Middele T High
T High E Middle E High C Middle C + + + + + 5 ) . 4 . 0 . 6 . 0 )( . 2 . 0 . 8 . 0 )( . 2 . 0 . 8 . 0 )( . 4 . 0 . 6 . 0 )( . 2 . 0 . 8 . 0 ( 4 4 3 3 1
1MiddleTHighTMiddle THighTMiddleTHigh
T High D Middle D High A Middle A + + + + + 6 ) . 64 . 0 . 36 . 0 )( . 92 . 0 . 08 . 0 )( . 64 . 0 . 36 . 0 )( . 4 . 0 . 6 . 0 )( . 2 . 0 . 8 . 0 ( 3 3 2 2 1
1Middle THigh TLow TMiddleTMiddle THigh
T High B Middle B Middle A Low A + + + + +
and T4, and "High" is chosen C, T2 and T3.
The count of each region selected is then checked against the predefined
minimum support value α . Assume in this example,α is set at 1.5. L1 is shown in
Table 6.
Table 6. The set of large 1-itemsets in this example
Itemset
count
B.Middle 2.2 C.High 1.6 E.Middle 2.0 T1.Middle 3.14 T2.High 2.6 T3.High 3.56 T4.Middle 2.6Similarly, L2 includes (E.Middle, T2.High), (E.Middle, T3.High), (T1. Middle,
T4.Middle), (T2.High, T4.Middle) and (T3.High, T4.Middle). L3 is null.
Assume the given confidence thresholdλ is set at 0.7. The following three rules
are thus kept:
If E = Middle, then T2 = High, with a support value of 1.8 and a
confidence value of 0.9;
If E = Middle, then T3 = High, with a support value of 1.92 and a
confidence value of 0.96;
If T4 = Middle, then T3 = High, with a support value of 2.12 and a
confidence value of 0.82
out, it is thus output as an interesting rule. Assume the given interest threshold R is set at 3. Since the support and the confidence interest measures of the remaining two rules are less than 3, they are thus not interesting rules.
5. Experimental Results
The section reports on experiments made to show the effect of the proposed
approach. They were implemented in C on a Pentium-III 700 Personal Computer. The
number of levels was set at 3. There were 64 purchased items (terminal nodes) on
level 3, 16 generalized items on level 2, and 4 generalized items on level 1. Each
non-terminal node had four branches. Only the terminal nodes could appear in
transactions. Totally 10000 transactions with an average of 12 purchased items in each
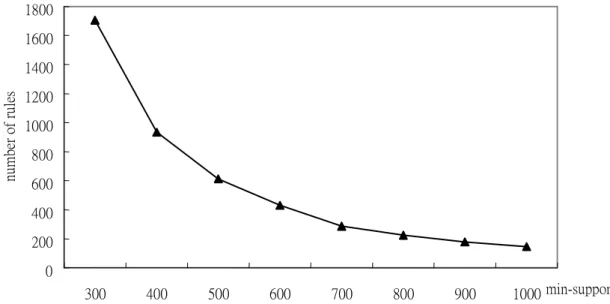
transaction are generated in each run. The relationships between numbers of rules
mined and minimum support values for minimum confidence value set at 0.7 are
Figure 3. The relationships between numbers of rules mined and minimum supports
From Figure 3, it is easily seen that numbers of rules mined decrease along with
increase of minimum support values. This is quite consistent with our intuition.
6. Conclusions and future works
In this paper, we have proposed a fuzzy generalized mining algorithm for
processing transaction data with quantitative values and discovering interesting
generalized association rules among them. The rules thus mined out exhibit
quantitative regularity under given fuzzy taxonomic structures and can be used to
provide suggestions to appropriate supervisors. Compared to conventional crisp-set
mining methods for quantitative data, our approach gets smoother mining results due
to its fuzzy membership characteristics.
0 200 400 600 800 1000 1200 1400 1600 1800 300 400 500 600 700 800 900 1000 min-support nu m be r of r ul es 0 200 400 600 800 1000 1200 1400 1600 1800 300 400 500 600 700 800 900 1000 min-support nu m be r of r ul es
Although the proposed method works well in data mining for quantitative values,
it is just a beginning. There is still much work to be done in this field. Our method
assumes that membership functions are known in advance. In [7-9], we proposed
some fuzzy learning methods to automatically derive membership functions. We will
therefore attempt to dynamically adjust the membership functions in the proposed
fuzzy generalized mining algorithm to avoid the bottleneck of membership function
acquisition. We will also attempt to design specific data-mining models for various
problem domains.
Acknowledgment
The authors would like to thank the anonymous referees for their very
constructive comments. This research was supported by the National Science Council
of the Republic of China under contract NSC 90-2213-E-390-001.
References
[1] R. Agrawal, T. Imielinksi and A. Swami, “Mining association rules between sets
of items in large database,“ The 1993 ACM SIGMOD Conference, Washington DC,
USA, 1993.
perspective,” IEEE Transactions on Knowledge and Data Engineering, Vol. 5, No.
6, 1993, pp. 914-925.
[3] L. M. de Campos and S. Moral, “Learning rules for a fuzzy inference model,”
Fuzzy Sets and Systems, Vol. 59, 1993, pp. 247-257.
[4] M. S. Chen, J. Han and P. S. Yu, “Data mining: an overview from a database
perspective,” IEEE Transactions on Knowledge and Data Engineering, Vol. 8, No.
6, 1996.
[5] T. Fukuda, Y. Morimoto, S. Morishita and T. Tokuyama, "Mining optimized
association rules for numeric attributes," The ACM SIGACT-SIGMOD-SIGART
Symposium on Principles of Database Systems, June 1996, pp. 182-191.
[6] T. P. Hong, C. S. Kuo and S. C. Chi, "A data mining algorithm for transaction
data with quantitative values," Intelligent Data Analysis, Vol. 3, No. 5, 1999, pp. 363-376.
[7] T. P. Hong and J. B. Chen, "Finding relevant attributes and membership functions," Fuzzy Sets and Systems, Vol.103, No. 3, 1999, pp. 389-404. [8] T. P. Hong and J. B. Chen, "Processing individual fuzzy attributes for fuzzy
rule induction," Fuzzy Sets and Systems, Vol. 112, No. 1, 2000, pp. 127-140.
[9] T. P. Hong and C. Y. Lee, "Induction of fuzzy rules and membership functions
[10] T. P. Hong, K. Y. Lin and S. L. Wang, “Fuzzy data mining for interesting generalized association rules”, accepted and to appear in Fuzzy Sets and Systems. [11] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca Raton, 1992, pp. 8-19.
[12] J. Rives, “FID3: fuzzy induction decision tree,” The First International
symposium on Uncertainty, Modeling and Analysis, 1990, pp. 457-462.
[13] R. Srikant, Q. Vu and R. Agrawal, “Mining association rules with item
constraints,” The Third International Conference on Knowledge Discovery in
Databases and Data Mining, Newport Beach, California, August 1997, pp.67-73.
[14] R. Srikant and R. Agrawal, “Mining quantitative association rules in large
relational tables,” The 1996 ACM SIGMOD International Conference on
Management of Data, Monreal, Canada, June 1996, pp. 1-12.
[15] R. Srikant and R. Agrawal, “Mining Generalized Association Rules," The
International Conference on Very Large Databases, 1995.
[16] Qiang Wei and Guoqing Chen, “Mining Generalized Association Rules with
Fuzzy Taxonomic Structures,” The 18th International Conference of the North
American Fuzzy Information Processing Society, NAFIPS, 1999, pp. 477 –481.
[17] C. H. Wang, T. P. Hong and S. S. Tseng, “Inductive learning from fuzzy
examples,” The Fifth IEEE International Conference on Fuzzy Systems, New
The Second International Conference on Fuzzy Logic and Neural Networks,
Iizuka, Japan, 1992, pp. 265-268.
[19] Y. Yuan and M. J. Shaw, “Induction of fuzzy decision trees,” Fuzzy Sets and