國立交通大學
電子物理學系
碩士論文
利用繪圖處理器平行運算技術計算電子電洞交換能
GPU’s parallel computing technology for the computation of
electron-hole exchange interaction energy
研究生:饒家祥
指導教授:鄭舜仁教授
I
利用繪圖處理器平行運算技術計算電子電洞交換能
GPU’s parallel computing technology for the computation of
electron-hole exchange interaction energy
研 究 生:饒家祥 Student:Chia-Hsiang Jao
指導教授:鄭舜仁 教授 Advisor:Shun-Jen Cheng
國 立 交 通 大 學
電子物理研究所
碩 士 論 文
A ThesisSubmitted to Department of Electrophysics College of Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in Electrophysics
2012
HsinChu, Taiwan, Republic of China
中華民國一百零一年九月
II
利用繪圖處理器平行運算技術計算電子電洞交換能
學生:饒家祥指導教授:鄭舜仁 博士
國立交通大學電子物理研究所碩士班
摘要
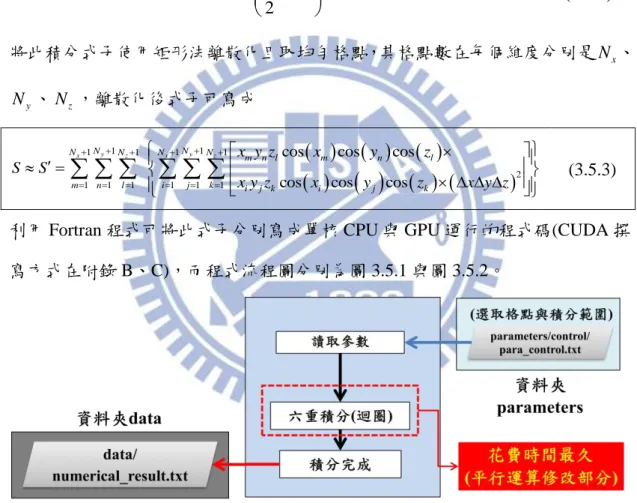
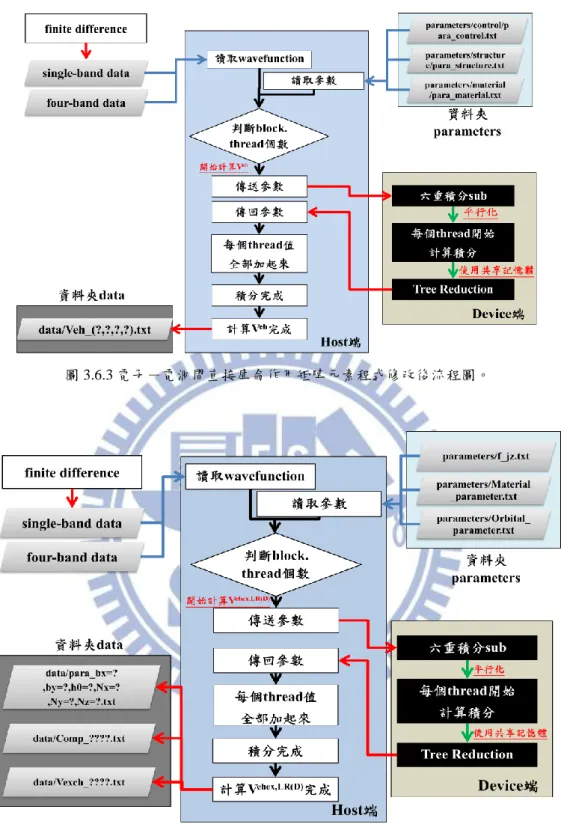
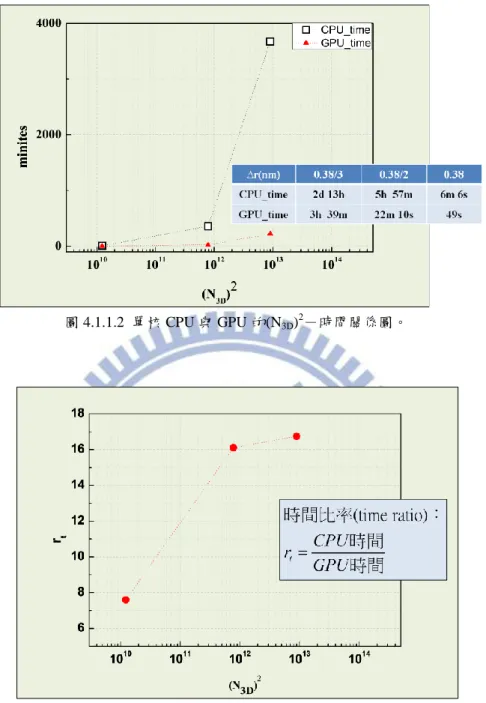
本論文主要探討繪圖處理器平行運算技術計算電子電洞交換能,將庫侖交互 作用積分式子離散化後程式中實質上是六重迴圈,因此我們將研究繪圖處理器對 迴圈增快的速率。而後會介紹一些有關繪圖處理器的每個核心是如何運行的,以 及記憶體的分配與傳遞方式,進而了解每個細節對迴圈增快的效益,使我們能更 進一步了解程式碼在程式中執行的方式,讓程式的撰寫更順利。 程式中所使用的理論則是利用量子點k p 單能帶模型和有效質量近似法的 激子系統計算庫侖交互作用,而庫侖交互作用分為直接庫侖作用與交換能。直接 庫侖作用的計算則是引用建智學長論文[1]中的程式,將程式修改成使用繪圖處 理器作程式平行運算即可;對於交換能而言,先前使用中央處理器單核心計算需 耗費大量的時間,一直無法驗證程式的正確性,而後使用繪圖處理器計算時,相 對於單核中央處理器時間減少 10 倍以上,因此我們將能驗證此程式的正確性並 討論數值解與解析解的誤差,對於將來要計算庫侖矩陣以及交換能矩陣時,能計 算的更迅速。III
GPU’s parallel computing technology for the computation of
electron-hole exchange interaction energy
Student:Chia-Hsiang Jao Advisor:Shun-Jen Cheng
Department of Electrophysics
National Chiao Tung University
Abstract
This thesis theoretically investigates GPU’s parallel computing technology for the computation of electron-hole exchange interaction energy, the Coulomb’s integration in the program is essentially the six loops, we will study the rate is accelerated by the GPU loop. Accelerated rate in order to study, will find some relevant information to understand, and thus to understand every detail of the loop to increase the amount of fast effective help when we write code, to further understand the code in the Fortran program is how to perform.
When it calculates the Coulomb’s interaction, we are based on k p theory’s
single-band model and effective mass approximation method of exciton’s system in the quantum dot to calculate, the Coulomb’s interaction divide into direct coulomb and exchange energy. Direct coulomb’s part have been calculated via Chien-Chih senior’s thesis[1], so long as the original program have to modify the GPU who can run the program;exchange energy’s part have been unable to verify the correctness of the program, the reason is that the program’s execution time is very long. When using the GPU run the program, it will speed up to 10 times than single-core CPU, so we will be able to verify the correctness of this program in short time(error less than 5%), calculating Coulomb’s matrix and exchange energy’s matrix in second quantization in the future can calculate more quickly.
IV
誌謝
首先要感謝鄭舜仁老師在我碩士生涯兩年來的指導與諄諄教誨,讓我能在固 態物理與程式理論運算能有很大的進步與了解,而在此領域中也不時的指點我正 確的方向與研究上應具備的態度,使我在這些年中獲益匪淺。感謝各位口試委員, 陳煜璋老師、張文豪老師、林炯源老師在口試時提出寶貴的意見使我受益良多。 在這兩年碩士生涯中,感謝盧書楷學長與廖禹淮學長的教導與照顧,遇到困 難時適時的指引我一盞明燈,讓我能繼續向前走。感謝研究室學長姐鄭丞偉、張 語宸、林以理、陳力瑋、張書瑜,在我剛進來時能適時的教導我一些研究上所需 的技術與基礎觀念,更要特別感謝帶領我的學長趙虔震、廖建智,教導我與研究 相關的技術和物理觀念而能有重大的突破,使論文能順利完成。感謝研究室同屆 同學余書睿、張智偉、林佩儀,不管是在課業或研究上的討論都能給予幫助,使 我能順利突破難關。也要感謝學弟妹的陪伴與幫忙,使我生活中添增了一些色彩。 感謝與我一起前來交大的同學們源龍、威霖、光彥、凱勝、軒毫、維綸,有你們 給予我鼓勵使我更有信心突破難關。 感謝我的父母與姐姐、弟弟與家人親戚能適時的鼓勵我,使我能無後顧之憂 的專心唸書與學習。以及遇到挫折時能給予我一個溫暖又舒適的家,使我有繼續 堅持下去的勇氣。由於要感謝的人太多無法在致謝一一答謝,因此最後要感謝曾 經幫助過我的親朋好友們說聲謝謝。V
目錄
摘要... II Abstract ... III 誌謝... IV 目錄... V 表目錄... VII 圖目錄... VIII 第一章、序論... 1 1.1 研究背景與動機 ... 1 1.2 GPU 歷史背景簡介 ... 2 1.3 研究目的 ... 6 1.4 論文架構 ... 6 第二章、CUDA 基礎架構 ... 7 2.1 平行運算的概念 ... 8 2.2 GPU 硬體 ... 9 2.2.1 硬體架構 ... 9 2.2.2 硬體間傳輸速率 ... 10 2.3 CUDA 程式... 11 2.3.1 thread、block 與 grid... 11 2.3.2 記憶體配置 ... 14 第三章、庫侖交互作用理論及其數值方法測試... 18 3.1 積分方法 ... 18 3.2 數值積分測試 ... 21 3.2.1 一維積分 ... 21 3.2.2 三維積分 ... 24 3.3 量子點內單一激子理論基礎 ... 27 3.3.1 單一能帶理論 ... 27 3.3.2 庫侖交互作用 ... 28 3.3.3 三維拋物線模型的解析解 ... 33 3.3.4 高斯函數積分範圍選取 ... 35 3.4 計算長程偶極-偶極交換能 ... 38 3.4.1 短程與長程交換能之間的界限 ... 38 3.4.2 分析奇異點 ... 40 3.5 單核 CPU 與 GPU 時間差異測試(6 重迴圈) ... 47 3.6 庫侖交互作用程式寫法 ... 50 第四章、結果與討論... 52VI 4.1 單核 CPU 與 GPU 的比較 ... 52 4.1.1 直接庫侖作用 ... 52 4.1.2 長程偶極-偶極交換能 ... 55 4.2 數值測試 ... 59 4.2.1 直接庫侖作用 ... 59 4.2.2 長程偶極-偶極交換能 ... 61 4.3 結果討論 ... 65 第五章、多重能帶... 66 5.1 單一激子多重能帶 ... 66 5.2 庫侖交互作用 ... 68 第六章、結論... 72 附錄 A、CUDA compiler 方法 ... 74 附錄 B-1、CUDA 基本程式編寫 ... 75 附錄 B-2、Host 端撰寫方式 ... 78 附錄 B-3、Device 端撰寫方式 ... 82 附錄 C、使用平行運算來計算簡單迴圈的範例 ... 88 附錄 D、修改庫侖交互作用程式方法 ... 95 附錄 E、辛普森法(補充) ... 99 附錄 F、GPU 相關測試 ... 101 附錄 G、閃鋅結構威格納-塞茲晶胞的形狀 ... 105 參考文獻... 106
VII
表目錄
表 1.2.1 比較 CPU 與 GPU 核心數及計算速率。 ... 3 表 1.2.2 比較目前最新 CPU(i7 系列)與 GPU(Telsa 系列)核心數及時脈。 ... 4 表 2.1 電腦專用術語中英文對照表。... 7 表 2.2 本論文計算程式使用的軟硬體名稱。... 7 表 2.2.1.1 利用 deviceQuery.cuf 測試 GPU 結果。 ... 9 表 2.2.2.1 程式運算 Host 和 Device 端傳遞可能的傳遞情況。 ... 10 表 2.2.2.2 執行 bandwidthTest.cuf 程式的電腦設備。 ... 10 表 2.2.2.3 執行 bandwidthTest.cuf 程式的結果。 ... 10 表 2.3.1.1 利用 bandwidthTest.cuf 程式測試結果一。 ... 13 表 2.3.1.2 利用 bandwidthTest.cuf 程式測試結果二。 ... 14 表 2.3.2.1 Device 端記憶體相關資訊。 ... 15 表 3.3.2.2 每一組不同的自旋、自旋軌道角動量與方向對應的係數。... 32 表 5.1.1 電子 Bloch function 的符號表示法。 ... 67 表 5.2.1 每一組不同的自旋、自旋軌道角動量與方向對應的係數。... 70表 A.1 不同廠商在 CentOS 5.4 一般 compiler 方式。 ... 74
表 B-1.1 Fortran 使用 CUDA 需要修改或增加的部分。 ... 77
表 B-2.1 CUDA 在 Host 端宣告方式。 ... 79
表 B-3.1 CUDA 在 Device 端宣告方式。 ... 83
表 B-3.2 CUDA 自動編號指令表。 ... 84
表 B-3.3 CUDA 編號與自定編號差異。 ... 86
表 C.1 CUDA Fortran 與一般 Fortran 不同的部分。 ... 90
表 D.1 測試 Host 端傳遞到 Device 端次數的結果。 ... 96
表 D.2 shared memory 在 Device 端宣告方式。... 97
VIII
圖目錄
圖 1.2.1 CPU 和 GPU 比較圖:(左)年份對每秒浮點運算效率圖;(右)年份對記憶
體寬頻圖。... 4
圖 1.2.2 CPU 和 GPU 硬體運算架構圖:一個核心擁有一個 ALU。 ... 5
圖 2.1 執行程式流程示意圖。... 8
圖 2.1.1 一個人與六個人完成工作花費時間示意圖。... 8
圖 2.2.1.1 GT200 架構示意圖:GT200 共有 240 個 SP,每個 SM 有 8 個 SP,每個 TPC 有 3 個 SM。 ... 9
圖 2.3.1.1 CUDA 架構示意圖。 ... 11
圖 2.3.1.2 使用單核 CPU 與 GPU 的計算方式:迴圈數(nx)為 36、每個 grid 內 block 個數為 3 個、每個 block 內 thread 個數為 4 個。 ... 12
圖 2.3.1.3 CUDA 架構範例說明。 ... 12
圖 2.3.1.4 一般 Fortran 修改成 CUDA Fortran 迴圈範例:詳細說明請參考附錄 B 與 C。 ... 13
圖 2.3.2.1 CUDA 內對應到的記憶體。 ... 14
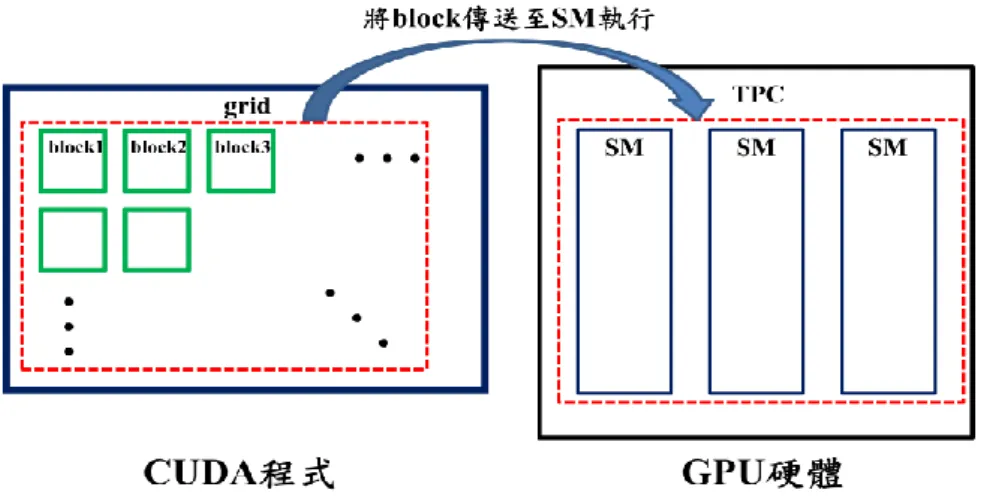
圖 2.4.1 CUDA 傳送 block 到 GPU 內的 SM 示意圖。... 16
圖 2.4.2 warp 在 1 個 SM 運作情形:假設每個 warp 需要運作的時間都是 2 個週 期。... 16
圖 2.4.3 warp 傳送至 SM 計算範例,當 warp4 不足 32 個 Thread 會造成資源浪費。 ... 17 圖 3.1.1 矩形法求定積分示意圖。... 18 圖 3.1.2 梯形法求定積分示意圖。... 19 圖 3.2.1.1 利用矩形法(黑色方形中空)與梯形法(紅色三角形)算出的數值收斂結 果。... 22 圖 3.2.1.2 利用矩形法將積分離散化的示意圖(Nx5)。 ... 22 圖 3.2.1.3 利用矩形法將積分離散化的示意圖(Nx20)。 ... 23 圖 3.2.1.4 利用矩形法和梯形法算出的結果與解析解比較後的誤差值。... 23 圖 3.2.2.1 利用矩形法(黑色方形中空)與梯形法(紅色三角形)算出的數值收斂結果。 ... 25 圖 3.2.2.2 利用矩形法和梯形法算出的結果與解析解比較後的誤差值。... 25 圖 3.3.2.1 cell i 的位置向量分解示意圖。 ... 28 圖 3.3.2.2 兩個不同 WS cell 位置向量分解示意圖。 ... 31 圖 3.3.2.3 取均勻格點且使用矩形法一維積分離散化示意圖。... 33 圖 3.3.3.1 半導體能帶 b g E 、Eh、Ee、 QD g E 關係示意圖。 ... 35 圖 3.3.4.1 高斯函數分布範圍示意圖,lx為在 x 方向的特徵長度、f(x)為高斯函數。
IX ... 36 圖 3.3.4.2 高斯函數特徵長度 lx=3,(上)LxF關係圖及(下)L -誤差關係圖。x ... 36 圖 3.4.1.1 閃鋅結構:一個單位晶胞佔有四個威格納-塞茲晶胞體積大小,在座 標上的橢圓為[100]-[010]方向上的量子點。 ... 38 圖 3.4.1.2 選取威格納-塞茲晶胞方式:(1)選擇一個晶格點(黑點)用直線連接附近 晶個點;(2)畫出這些直線的垂直平分線(和面);用此方式得到最小封閉面積 為威格納-塞茲晶胞。... 38 圖 3.4.1.3 將威格納-塞茲晶胞近似正立方體示意圖:由於量子點長軸與短軸的 方向為
110 、1 10,因此正立方體的面垂直於 110 , 1 10 , 001 。 ... 39 圖 3.4.1.2 (a)表示兩粒子交換能為短程交換能,(b)表示兩粒子交換能為長程交換 能。... 40 圖 3.4.2.1 分析 f (( 0,0,0 ),( x, y,0 )),其特徵長度=(3 nm ,2.7 nm ,2 nm)、材料參數使 用 InAs 畫出 f (( 0,0,0 ),( x, y,0 ))[eV/nm6]對x, y[nm]平面關係圖。 ... 41圖 3.4.2.2 分析 f (( 4.5,0,0 ),( x, y,0 )),其特徵長度=(3 nm ,2.7 nm ,2 nm)、材料參數 使用 InAs 畫出 f (( 4.5,0,0 ),( x, y,0 ))[eV/nm6]對x, y[nm]平面關係圖。 ... 41
圖 3.4.2.3 分析 f (( 4.5,0,0 ),( x4.5, y ,0 )) ,其特徵長度=(3 nm ,2.7 nm ,2 nm)、材料 參數使用 InAs 畫出 f (( 4.5,0,0 ),( x4.5, y ,0 )) [eV/nm6]對x , y [nm]平面關係圖。 ... 42 圖 3.4.2.4 分析 f (( 4.5,0,0 ),( x 4.5,0,0 ))[左]與 f (( 4.5,0,0 ),( 4.5, y ,0 )) [右],其特徵長度 =(3 nm ,2.7 nm ,2 nm)、材料參數使用 InAs 畫出 f (( 4.5,0,0 ),( x 4.5,0,0 )) [eV/nm6]對x[nm]關係圖與 f (( 4.5,0,0 ),( 4.5, y ,0 )) [eV/nm6]對
y
[nm]關係圖: x',y'座標在 -0.1~0.1 nm 範圍內取 50 個格點。 ... 42 圖 3.4.2.5 讓圖 3.4.2.2 分割四等份及旋轉到同一個象限示意圖... 43 圖 3.4.2.6 利用一維格點描述數值上的限制:x',y'座標在-0.00001~0.00001 nm 範 圍內取 40 個格點,再將二、三、四象限平面旋轉到第一象限。... 44 圖 3.4.2.7 格點無法相互對應相加的後果;曲線會劇烈震盪,積分後結果誤差會 相當大:x'座標在-0.00001~0.00001 nm 範圍內取 40 個格點,y'座標在- 0.00001~0.00001 nm 範圍內取 20 個格點,再將二、三、四象限平面旋轉到 第一象限。... 45 圖 3.4.2.8 分析 f ( x ,0 ) 且畫出 f ( x ,0 ) [eV/nm6]對 x'[nm]的關係圖。 ... 46 圖 3.5.1 簡單積分程式流程圖。... 47 圖 3.5.2 簡單積分程式修改後流程圖。... 48 圖 3.5.3 數值收斂結果:(N3D)2為程式所執行的迴圈個數。 ... 48 圖 3.5.4 圖 3.5.3 收斂圖對應到的時間。... 49 圖 3.5.5 CPU 時間相對應 GPU 時間的倍率。 ... 49 圖 3.6.1 電子-電洞間直接庫侖作用矩陣元素程式流程圖。... 50X 圖 3.6.2 電子-電洞間長程偶極-偶極交換能矩陣元素程式流程圖。... 50 圖 3.6.3 電子-電洞間直接庫侖作用矩陣元素程式修改後流程圖。... 51 圖 3.6.4 電子-電洞間長程偶極-偶極交換能矩陣元素程式修改後流程圖。.... 51 圖 4.1.1.1 單核 CPU 與 GPU 數值收斂圖,(上)Δr- eh, , , s s s s V 關係圖(下) (N3D)2- , , , eh s s s s V 關 係圖:Lx, Ly, Lz為三個維度的積分範圍,Nx,Ny,Nz為三個維度的格點間格數, 而 N3D=Nx×Ny×Nz,(N3D)2為程式所執行的迴圈個數。 ... 53 圖 4.1.1.2 單核 CPU 與 GPU 的(N3D)2-時間關係圖。 ... 54 圖 4.1.1.3 比較單核 CPU 與 GPU 的(N3D)2-倍率關係圖。 ... 54 圖 4.1.2.1 單核 CPU 與 GPU 數值收斂圖,(上)Δr- eh, , , s s s s V 關係圖(下) (N3D)2- , , , eh s s s s V 關 係圖,(N3D)2為程式所執行的迴圈個數。 ... 55 圖 4.1.2.2 單核 CPU 與 GPU 數值收斂圖,能隙修正前後的(上)Δr- 1,+ ,3 3,1, ( ) 2 2 2 2 , , , LR D s s s s 關 係圖,(下) (N3D)2- 1 3 3 1 ,+ , , , ( ) 2 2 2 2 , , , LR D s s s s 關係圖,(N3D)2為程式所執行的迴圈個數。 ... 56 圖 4.1.2.3 比較單核 CPU 與 GPU 的(N3D)2-時間關係圖(直接庫侖作用)。 ... 57 圖 4.1.2.4 比較單核 CPU 與 GPU 的(N3D)2-倍率關係圖(直接庫侖作用)。 ... 57 圖 4.1.2.5 比較單核 CPU 與 GPU 能隙修正前後(N3D)2-時間關係圖(長程偶極-偶 極交換能)。 ... 57 圖 4.1.2.6 比較單核 CPU 與 GPU 能隙修正前後(N3D)2-倍率關係圖(長程偶極-偶 極交換能)。 ... 58 圖 4.2.1.1 lx=3 nm , ly=3 nm , lz=3 nm 的收斂圖。 ... 59 圖 4.2.1.2 lx=4 nm , ly=4 nm , lz=4 nm 的收斂圖。 ... 59 圖 4.2.1.3 lx=5 nm , ly=5 nm , lz=5 nm 的收斂圖。 ... 60 圖 4.2.1.4 lx與直接庫侖積分矩陣元素的關係圖。 ... 60 圖 4.2.1.5 計算數值與解析的誤差值。... 61 圖 4.2.2.1 不同 a0與解析解比對能隙修正前後的Δr- 1 3 3 1 ,+ , , , ( ) 2 2 2 2 , , , LR D s s s s 收斂圖。 ... 61 圖 4.2.2.2 不同 a0與解析解比對能隙修正前後的N3D- 1 3 3 1 , , , , ( ) 2 2 2 2 , , , LR D s s s s 收斂圖。 ... 62 圖 4.2.2.3 lx=4 nm , ly=3.6 nm , lz=2 nm 能隙修正前後的收斂圖。 ... 62 圖 4.2.2.4 lx=5 nm , ly=4.5 nm , lz=3 nm 能隙修正前後的收斂圖。 ... 63 圖 4.2.2.5 能隙修正前後的 lx- 1 3 3 1 , , , , ( ) 2 2 2 2 , , , LR D s s s s 關係圖。 ... 63 圖 4.2.2.6 計算能隙修正前後數值與解析的誤差值。... 64 圖 B-1.1 使用 CPU 與 GPU 的程式流程圖。 ... 75
XI
圖 B-1.2 一般 Fortran 修改成 CUDA Fortran 簡單範例:紅色框框表示需要修改或
增加的部分。... 76 圖 B-2.1 在圖 B-1.1 中 Host 端程式碼進行分析。 ... 78 圖 B-2.2 在圖 B-2.1 中 CUDA 在 Host 端的宣告方式。 ... 79 圖 B-2.3 字串長度設定錯誤導致 compiler 沒過。 ... 79 圖 B-2.4 在圖 B-2.1 中 Host 端與 Device 端參數傳送方式。 ... 80 圖 B-2.5 在圖 B-2.1 中呼叫 kernel。... 80
圖 B-2.6 呼叫三維 CUDA 寫法:「USA CUDAFOR」表示使用 CUDAFOR 資料庫。 ... 80
圖 B-2.7 在圖 B-2.1 中宣告 device 記憶體利用 CUDAFREE 函數釋放。 ... 81
圖 B-3.1 在圖 B-1.1 中 Device 端程式碼進行分析。 ... 82
圖 B-3.2 在圖 B-3.1 中利用 MODULE 包裝 Device 端的程式碼。 ... 83
圖 B-3.3 在圖 B-3.1 中 Host 端使用 Device 端創造的 mod。... 83
圖 B-3.4 在圖 B-3.1 中 CUDA 在 Device 端的宣告方式。 ... 84
圖 B-3.5 此圖說明 CUDA 編號指令範例。我們選擇 Grid 內有 5 個 block,每個 block 有 6 個 thread,當呼叫 CUDA 副程式時,block「BLOCKIDX」會自動 編號 1~5,thread「THREADIDX」會自動編號 1~6;grid 維度「GRIDDIM」 =5,block 維度「BLOCKDIM」=6。 ... 85 圖 B-3.6 在圖 B-3.1 中自定的廣義編號:三維的廣義編號方式只是多加 2 個變數 來編號,例如多加一個維度可多加一行 「j=(BLOCKIDX%Y-1)*BLOCKDIM%Y+THREADIDX%Y」。 ... 85 圖 B-3.7 在圖 B-3.1 中 Device 端命令 4 個 thread 做運算。 ... 87 圖 B-3.8 在圖 B-3.6 中自定編號對應到圖 3.4.2.7 的平行運算。... 87 圖 C.1 使用單核 CPU 與 GPU 的程式流程圖。 ... 88
圖 C.2 使用 CPU 與 GPU 的計算方式:迴圈數(nx)為 36、每個 grid 內 block 個數 (griddx)為 3、每個 block 內 thread 個數(tPBdx)為 4。 ... 88
圖 C.3 一般 Fortran 修改成 CUDA Fortran 迴圈範例:紅色框框表示相較圖 B-1.1 迴圈新增寫法。... 89
圖 C.4 在圖 C.3 中 CUDA 在 Host 端宣告專門儲存 thread 計算結果的陣列。 .. 90
圖 C.5 一般 Fortran 宣告可變陣列及釋放記憶體與在 Host 端宣告可變陣列及釋放 device 記憶體兩者比較:與一般 Fortran 比較只有在一開始宣告有差異其他 都一樣,而可變矩陣釋放 device 記憶體不能使用之前 CUDAFREE 函數的方 法,直接使用 DEALLOCATE 即可。... 90 圖 C.6 在圖 C.3 中將迴圈分成(thread 總個數)「BLOCKDIM*GRIDDIM」等份, 利用每個 thread 做計算。... 91
圖 C.7 每個 thread 運行的狀況:此程式的 grid 內 block 個數「griddx」=3,每個 block 內 thread 個數「tPBdx」=4,因此「BLOCKDIM*GRIDDIM」=12,每 個 thread 迴圈跳躍間距為 12,這樣就不會重複計算到了。... 91
XII 圖 C.8 在圖 C.3 中每個 thread 總加起來的結果。 ... 91 圖 C.9 在迴圈內加入一個迴圈,使它不會因為數值的極限而計算錯誤。 ... 92 圖 C.10 比較單核 CPU 與 GPU 數值、時間、倍率關係:rt為增快倍率,N 為迴 圈總個數。... 93 圖 D.1 左邊表示只傳遞一次,右邊表示傳遞 Nz×Ny次。 ... 95
圖 D.2 程式同步的過程:2.3.2 小節可知 shared memory 用於同一個 block 內 thread 之間的溝通。... 97 圖 D.3 Tree Reduction 演算法。 ... 98 圖 E.1 將函數 f x 、利用拋物線線求定積分示意圖。 ... 99
圖 F.1 (上)表示 CPU↔CPU 傳送 1 次的程式碼與(下)實際時間。 ... 101 圖 F.2 (上)表示 GPU↔GPU 傳送 1 次的程式碼與(下)實際時間。 ... 102 圖 F.3 (左上)表示 CPU↔GPU 傳送 1 次的程式碼與(左下)實際時間,(右上)表示 CPU↔GPU 傳送 106 次的程式碼與(右下)實際時間。 ... 102 圖 F.4 資料碰撞示意圖。 ... 103 圖 F.5 解決資料碰撞示意圖。 ... 103 圖 F.6 (上)表示 GPU 內運算的程式碼與(中)計算記憶體使用量與(下)結果和實際 時間。... 104 圖 G.1 閃鋅結構威格納-塞茲晶胞選取方式:形狀為傾斜的平行六面體。 ... 1051
第一章、序論
1.1 研究背景與動機 隨著科技的進步,半導體產業將電晶體越做越小,以目前發展可做到奈米等 級的大小,當電晶體尺寸小於或等於德布羅伊(de Broglie)波長時,電子將不再遵 循古典物理規則,這時必須考慮量子效應(Quantum Effect)。目前量子侷限有 3 種,分別量子井(Quantum well)、量子線(Quantum wire)、量子點(Quantum dot), 而量子點三維都受到侷限近似零維[2],因此量子效應相較其他量子侷限會比較 大。 在量子資訊發展前期,D. P. DiVincenzo提出好的量子體系有5個要素[2]: 1. 要有定義明確,容易擴充(scalable)的量子位元系統。 2. 要能夠把量子位元初始化成如|000…>。 3. 量子位元要有夠長的去同調時間(decohernce time)。 4. 要能夠對量子位元實現普世量子邏輯閘。 5. 要能夠高效率的量測量子位元。 隨著量子資訊的發展,其它要素也相映著出現,但這 5 個要素仍是每個研究者追 求的目標。1997 年 Daniel Loss 跟 David P. DiVincenzo 提出了利用半導體量子 點來體現量子位元的構想[2],此構想讓量子資訊跟半導體量子點做連結,使奈 米尺度技術與量子侷限理論能被廣泛的運用。量子點具有優良的發光性質,用於量子傳輸(quantum teleportation)、量子位 元(quantum qubit)、量子密碼(quantum cryptography)應用上[3]。其中量子傳輸是 利用量子點當作發射糾纏態光子對(entangled photon-pair)的光學元件,這裡糾纏 表示量子糾纏,意旨複合的量子系統中有特定關聯,無法被分解成各自量子態的 乘積[4]。而量子點發光必須要考慮庫侖交互作用,分成電子-電洞間直接庫侖 作用與電子-電洞間交換能,而電子-電洞間交換能會使量子點內產生精細結構 匹裂(fine structure splitting,FSS),使單激子(single exciton)自旋態能階匹裂,讓 自旋不同電子電洞結合的路徑變成可分辨,妨礙糾纏光子對發生[3]。
2 庫侖交互作用實質上要計算二次量子化後的CI矩陣,當我們選擇當基底的組 態越多時,其矩陣元素會越多,而每個矩陣元素都代表是一個或多個六重迴圈的 積分,對於此模擬需使用大量的數值運算,因此會耗費大量的時間。為了將耗費 時間縮短,必需找尋變快的方法,而我們想利用或GPU硬體多核心功能,縮短數 值運算的時間;電子-電洞間直接庫侖作用目前已經有相關的程式,因此只要將 程式改成能讓GPU運算的程式碼,就能讓運算速率加快,而對於電子-電洞間交 換能雖然已經有程式,但以之前技術要計算量子點以k p 單能帶模型和有效質量 近似法計算激子系統的交換能,想將計算誤差限制5%以內並且驗證其正確性, 必須要花費極多時間,因此我們引入GPU相關技術,利用此技術驗證電子-電洞 間交換能數值結果是否正確,而本論文要驗證的是電子-電洞間長程偶極-偶極 交換能的部份。電子-電洞間交換能分成短程作用與長程作用,計算長程作用積 分時為了避免計算到短程作用的部分,將會考慮短程與長程作用之間的界限,使 我們能計算正確的結果。長程交換能又分成長程單極-單極交換能與長程偶極- 偶極交換能,目前要驗證長程偶極-偶極交換能的部份。由於研究主軸包含GPU 的使用與相關技術,因此下一小節將會介紹GPU歷史、CPU與GPU的差異及使用 GPU的好處。 1.2 GPU歷史背景簡介 這幾年來,隨著科技蓬勃發展,電腦運算速度也日益增加,GPU 也隨著時 間運算能力不斷提升,許多高階程式使用者發現 GPU 運算的潛力,在 2003 年 SIGGRAPH( 美 國 計 算 機 協 會 計 算 機 圖 形 專 業 組 ) 大 會 提 出 GPGPU(General-purpose computing on graphics processing units)的想法[5],之後引 發各大廠商的關注,因此 GPU 開發方向以固定功能單元(Fixed Function Unit)轉 成專用併行處理器為主[5]。
3
在硬體方面,在一般電腦處理資料都是由 CPU(Central Processing Unit)執行。 就目前來說,CPU 單核時脈提升已經到達一個瓶頸了,許多 CPU 廠商原以增進 單核時脈提升速度轉成發展多核心,這時需要多核心來處理圖像的 GPU 崛起。 GPU 原是為了影像處理而設計的,但近年來被運用到高速運算中,因 GPU 核心 數多且擁有可發展性。對核心數而言,GPU 個數比 CPU 來的多,因此延伸出一 個想法,將每個核心都運用到計算能力上,且提升核心時脈,可讓 GPU 運算效 能大幅提升,使運算能力遠超過 CPU。 以目前單核心來說,CPU 時脈可以到達 3.5GHz 以上[6],GPU 就只有 1.5GHz 以下[7];整體來說,CPU 核心最多 8 個核心,GPU 可以有 200 個以上甚至更多, 因此 GPU 浮點運算能力比 CPU 更為迅速。以實際例子來解釋,CPU 型號為 i7-960 與 GPU 型號為 Tesla C2050 來比較,利用以下浮點運算能力公式[6]: 浮點效能(Gflops)= 核心數×單核心頻率(GHz)×每秒運行最高浮點運算次數(flops) (1.2.1) 可計算出如表 1.2.1: 表 1.2.1 比較 CPU 與 GPU 核心數及計算速率。 CPU GPU 型號 I7-960 Tesla C2050 核心數 4 448 單核心頻率(GHz) 3.2 1.15 每秒運行最高浮點運算次數(flops) 4 1 浮點效能(Gflops) 51.2 515 因此可看出 GPU 計算能力比 CPU 還要快很多。
4 表 1.2.2 比較目前最新 CPU(i7 系列)與 GPU(Telsa 系列)核心數及時脈。 CPU 型號 處理器核心 處理器時脈(MHz) i7-3960X 6 3300 i7-3930K 6 3200 i7-3820 4 3600 i7-2600 4 3400 vs GPU 型號 CUDA 處理器核心 處理器時脈(MHz) Tesla C2050/C2070/C2075 448 1150 Tesla C1060 240 1296
表 1.2.2 為最新 CPU(i7 系列)與 GPU(Tesla 系列)的核心數與時脈比較,CPU 的核心數遠遠小於 GPU 核心數,雖然時脈比 GPU 快但考慮所有核心一起運作也 無法跟 GPU 的運算效率相比。
圖 1.2.1 CPU 和 GPU 比較圖:(左)年份對每秒浮點運算效率圖;(右)年份對記憶體寬頻圖。 資料來源:文獻[5]與文獻[8]。
由圖 1.2.1(左)得知,CPU 和 GPU 浮點運算速度隨著時間漸漸拉大,因為 GPU 有高度平行運算能力,而 CPU 一開始是以單核時脈為研究方向,因此 GPU 比
CPU 擁用更多的電晶體來做數值運算。記憶體寬頻意思是在資料傳遞時的傳送 速度,由圖 1.2.1(右)得知兩者差異隨著時間年年劇增,因為 GPU 可執行多顆核 心,所有核心同時將資料傳遞到記憶體,因此在記憶體存取的過程中,可節省更 多的時間。
5
圖 1.2.2 CPU 和 GPU 硬體運算架構圖:一個核心擁有一個 ALU。 資料來源:文獻[8]。
GPU 相對於 CPU 在運算速度及記憶體寬頻都有明顯優勢,金錢成本與功率 消耗不需花費太多,能以低成本且少量的時間完成任務。GPU 擁有高度平行性, 通過控制處理單元與儲存器控制單元個數提高運算速度與記憶體寬頻,由圖
1.2.2 知 GPU 內有許多的 ALU(Arithmetic Logical Unit,中譯為算術邏輯單元), 雖然每個 ALU 不如 CPU 的運算速度快,但 GPU 可運用平行性來提高整體的執 行效率,同時對每個核心運算。當我們做運算時,每個 ALU 都必須利用記憶體 儲存與讀取資料,而 GPU 所花費記憶體大小為: GPU 花費記憶體大小=(正在執行程式的核心數)×(單核花費記憶體容量) (1.2.2) 由上式得知 GPU 運行程式時會比 CPU 花費記憶體要多,因此在做程式撰寫有時 必須做些取捨。 隨著平行化技術被受重視與 GPU 發展快速,原本 GPU 並不支援資料運算, 只能用於 DirectX 或 OpenGL 等相關影像處理函式庫[9]。為了讓 GPU 能運用在 廣泛的計算,Nvidia 公司在 2007 年開發了 CUDA 方案[10],是一種在平行架構 下的軟體,可控制 GPU 運算方式,使設計者能利用 C/C++函式庫撰寫平行化的 程式;和 Nvidia 共同合作的公司The Portland Group (PGI), 更 是 看 重 高 效
率 運 算 專 業 人 士 所 用 的 重 要 語 言「 Fortran」,發 明 CUDA 可 寫 入 Fortran
6 1.3 研究目的 考慮使用單核 CPU 數值計算電子-電洞間直接庫侖或交換能的六重積分, 需耗費龐大的計算時間,才能使得誤差在可以接受的範圍內。藉由 GPU 對浮點 運算能力的優點,將可加速數值模擬運算,讓時間縮短 10 倍以上[9]。透過此研 究,未來計算直接庫侖或交換能時,可以更快速、更有效率的得到數值結果,讓 數值分析更加容易。另一個重點則是關於電子-電洞間交換能的驗證,電子-電 洞間交換能分成短程作用與長程作用,其中長程作用積分必須考慮不能計算到兩 粒子間的短程作用,因此要考慮到兩者邊界的長度設定,並使其數值運算結果與 解析解誤差在合理的範圍內。 1.4 論文架構
第一章探討研究背景與動機、GPU 相關背景、比較 CPU 與 GPU 的差異;第二 章簡單敘述 GPU 和 CUDA 基本架構、GPU 平行運算技術相關理論、GPU 與 CUDA 的溝通方式;第三章介紹庫侖和交換能理論基礎、定義短程交換能和長程交換能 的界線、可使用的數值積分方式以及選擇的積分方法分析、使用單核 CPU 與 GPU 的簡單積分計算比對及程式撰寫流程(庫侖、交換能);第四章比較單核 CPU 和 GPU 平行運算庫侖交互作用的數值(不同格點間距)與時間結果、計算直接庫侖作 用(不同格點、不同量子點大小)與長程偶極-偶極交換能數值解(不同格點、不同 a0、不同量子點大小)與解析解比對以及結果與討論;第五章將所有章節總結。
7
第二章、CUDA 基礎架構
以下是這章節介紹的一些 CPU 或 GPU 的電腦專有名詞,文中在介紹專有名 詞時可能會以英文型式來表示,因此為了方便對照中英文而做出表 2.1: 表 2.1 電腦專用術語中英文對照表。 中 文 英 文中 央 處 理 器 Central Processing Unit(CPU)
繪 圖 處 理 器 Graphics Processing Unit(GPU)
統一計算架構 Compute Unified Device Architecture(CUDA)
主機 Host
設備 Device
線 程 處 理 器 群 集 Texture Processing Clusters(TPC)
流 多 處 理 器 Streaming Multiprocessor(SM) 流 處 理 器 Streaming Processor(SP) 網 格 grid 區 塊 block 執 行 緒 thread 全域記憶體 global memory 常數記憶體 constant memory 共享記憶體 shared memory 暫存器 register 材質記憶體 texture memory 電腦執行程式時,必須考慮硬體及軟體的搭配,圖 2.1 表示執行流程圖。資 訊 1 表計算需要由外部輸入的資料,資訊 2 表計算完輸出的資料,CUDA 為 Host 端與 Device 端互傳的資料庫。表 2.2 為執行程式的工具: 表 2.2 本論文計算程式使用的軟硬體名稱。 軟體(程式語言) 硬體(運算) 資料庫
PGI Fortran GPU CUDA
8 圖 2.1 執行程式流程示意圖。 2.1 平行運算的概念 一般 CPU 運算時,通常都是條列式的進行運算程式,而 GPU 運算時,是利 用平行運算使計算時間縮短。如圖 2.1.1 所示,六個人同時做一件事,每個人負 責一個步驟,完成的時間遠比一個人做一件事快很多,平行運算與上述概念差不 多。一般來說,GPU 比 CPU 核心數多,表示可以使用較多的電晶體同時計算同 一個方程式,因此 GPU 計算時間會很快。在硬體方面,GPU 是利用 SP 來平行 運算,而軟體方面則是使用 thread,接下來會討論平行運算在軟硬體內部架構是 如何區分的,以及要如何將軟硬體做連結。 圖 2.1.1 一個人與六個人完成工作花費時間示意圖。
9 2.2 GPU 硬體
2.2.1 硬體架構
圖 2.2.1.1 表示 GPU 內部架構;GPU 內會先區分數個 TPC,由 GPU 型號決 定 TPC 個數;在 TPC 內為數個 SM 加上一些其他單元組成,由 GPU 型號決定 SM 個數;SM 內又分成數個 SP,SP 數量通常是 8 個一組;SP 是最基本的處理 單位,也稱為核心,所以 GPU 內部有許多 SP 在做平行運算。
圖 2.2.1.1 GT200 架構示意圖:GT200 共有 240 個 SP,每個 SM 有 8 個 SP,每個 TPC 有 3 個 SM。 資料來源:文獻[12]。
對於不同型號 GPU,內部架構也有些許不同,表 2.2.1.1 是利用 PGI Fortran 附加程式(deviceQuery.cuf)測試 GPU 型號「Tesla C2050」的結果:
表 2.2.1.1 利用 deviceQuery.cuf 測試 GPU 結果。
型號 TPC SM SP
Tesla C2050/2070 14 56 448
與圖 2.2.1.1 中 GPU 型號「GT200」相比,會發現 SP 個數、TPC 組成 SM 個數 會不一樣,可藉此比較兩者差異。
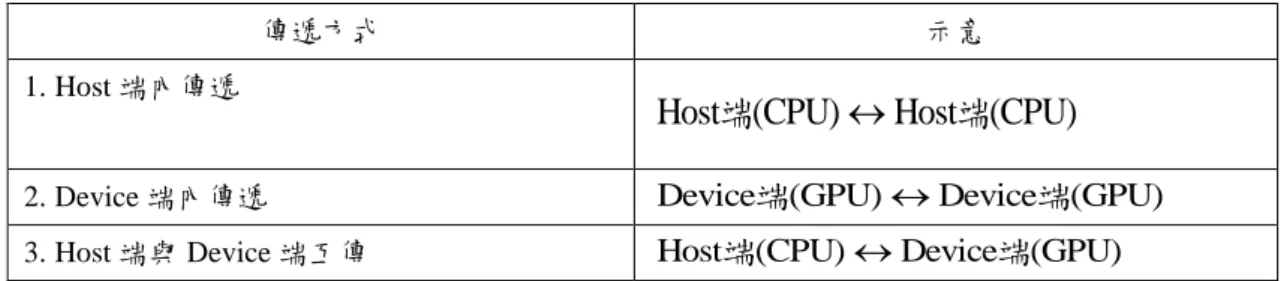
10 2.2.2 硬體間傳輸速率 當資料透過電腦做傳遞時,會發生三種情形如表 2.2.2.1: 表 2.2.2.1 程式運算 Host 和 Device 端傳遞可能的傳遞情況。 傳遞方式 示意 1. Host 端內傳遞
Host (CPU)端 Host (CPU)端 2. Device 端內傳遞 Device端(GPU)Device端(GPU) 3. Host 端與 Device 端互傳 Host端(CPU)Device端(GPU)
以上三種情形記憶體寬頻皆不相同,因此我們必須考量將資料如何做傳遞會最恰 當。當資料在 Host 端傳遞時,過程是使用 CPU 將資料讀取或計算出來,之後再 將資料傳送到記憶體儲存,記憶體寬頻大約為 5~10GB/s;在 Device 端傳遞時, 由於它是利用平行性來增快傳輸速率,因此會比 Host 端傳遞來的快,記憶體寬 頻大約為 70~100GB/s;而考慮 Host 端與 Device 端互傳時,記憶體寬頻取決於 主機板與 GPU 的插槽,例如 GPU 型號「Tesla C2050」使用的插槽為 PCI-E Gen.2 x16,記憶體寬頻大約 1~5GB/s。
利用 PGI Fortran 附加程式(bandwidthTest.cuf),測試如表 2.2.2.2 提供的硬體 配備:
表 2.2.2.2 執行 bandwidthTest.cuf 程式的電腦設備。
主機板 CPU GPU
型號 HP ML350 G6 IntelXeon E5520 2.26Ghz Tesla C2050 測試結果如表 2.2.2.3:
表 2.2.2.3 執行 bandwidthTest.cuf 程式的結果。
Device端(GPU)Device端(GPU) 71.67432(GB/s) Host端(CPU)Device端(GPU) 1.381577(GB/s) Host端(CPU)Device端(GPU) 1.502922(GB/s)
在表 2.2.2.3 測試中,CPU 型號是比較舊型的,因此 GPU 記憶體寬頻會被影響而 變慢。由上述得知,Host 端與 Device 端互傳記憶體寬頻是最慢的,而 Device 端 記憶體寬頻是最快的。因此我們在做運算時,最理想的狀況就是把要計算的數值, 在 Device 端一次計算完,再傳回 Host 端輸出我們要的資訊。
11 2.3 CUDA 程式
2.3.1 thread、block 與 grid
由 2.2.1 小節得知,硬體架構分為 TPC、SM 以及 SP,而軟體則是分為 grid、
block 與 thread 三個部分。如圖 2.3.1.1 所示,grid 包含所有的 block,表示將要執 行的任務(kernel),程式會把它直接丟給 GPU 作運算,等任務完成後才會執行下 一個任務,而 CUDA 並沒有 TPC 這層架構;block 相當於 SM,內部包含很多 thread, 主要目的在於建構 block 內所有 thread 的溝通,數量可自行設定;thread 相當於
SP,是軟體內的最小單位,主要功能是將程式做平行運算,數量可自行設定。 圖 2.3.1.1 CUDA 架構示意圖。 本節介紹的是寫程式必備的觀念,由於本論文所修改的程式皆為迴圈所構成 的,這部分的說明都是以附錄 C 為主要範例,而此範例的計算式子如下: 1 1 x n i SUM
(2.3.1.1),程式中定義每個 grid 內 block 個數為 3 個,而每個 block 內 thread 個數為 4 個 因此整個 grid 內擁有 thread 總個數為 3×4=12 個,表示我們將(2.3.1.1)式切割成
12
單核 CPU GPU
圖 2.3.1.2 使用單核 CPU 與 GPU 的計算方式:迴圈數(nx)為 36、每個 grid 內 block 個數為 3 個、
每個 block 內 thread 個數為 4 個。 我們將附錄 C 的程式以軍隊來比喻,如圖 2.3.1.3。軍隊[相當於 CUDA]發放 給連隊一個任務[相當於 grid],而連隊中共有 3 個班[相當於 block],每個班有 4 個小兵[相當於 thread],所以整個連隊共有 3×4=12 個小兵可配任務,因此可將任 務均分成 12 等分分配給每個小兵執行。 圖 2.3.1.3 CUDA 架構範例說明。 資料來源:文獻[12]。
在程式中定義參數 griddx 為每個 grid 內 block 個數、參數 tPBdx 為每個 block 內 thread 個數,程式中寫法如圖 2.3.1.4,此圖比較 CPU 與 GPU 的寫法,假設
griddx=3、tPBdx=4,所以整個 grid 內共擁有 thread 總個數為 3×4=12 個,而更詳 細說明請參考附錄 B 與C。
13
單核 CPU GPU[Host 端]
單核 CPU GPU[Device 端(kernel)]
圖 2.3.1.4 一般 Fortran 修改成 CUDA Fortran 迴圈範例:詳細說明請參考附錄 B 與 C。 Thread 與 Block 是屬於三維結構的,因此 Grid 內 block 總個數與每個 block 內 thread 總個數是所有維度乘積後的值,而 CUDA 設定 thread、block 總個數也 有數目上的限制,這裡我們利用 PGI Fortran 附加的程式(bandwidthTest.cuf)來做 測試,表 2.3.1.1 與表 2.3.1.2 為測試的結果: (以型號「Tesla C2050」為範例) 表 2.3.1.1 利用 bandwidthTest.cuf 程式測試結果一。 X 維度 Y 維度 Z 維度 最大 block 個數 65535 65535 65535 最大 thread 個數 1024 1024 64
14 表 2.3.1.2 利用 bandwidthTest.cuf 程式測試結果二。 所有維度乘積後最大 block 總個數 65535 所有維度乘積後最大 thread 總個數 1024 2.3.2 記憶體配置 在軟體內可分為 thread、block 與 grid,而每個部分所使用的記憶體又有所區 分,因此可以將 GPU 的記憶體分成: 1. 全域記憶體(global memory) 2. 常數記憶體(constant memory) 3. 共享記憶體(shared memory) 4. 暫存器(register) 5. 材質記憶體(texture memory,目前沒使用到) 以上記憶體分佈如圖 2.3.2.1 表示 CUDA 內分別對應到的記憶體。 圖 2.3.2.1 CUDA 內對應到的記憶體。
global memory 是用來存取由 Host 端傳進來的所有資訊,當存取完 Host 端 的資訊時,之後會分配到各個記憶體內,生命期為一個 grid 內所有 thread 都計 算完的時間,global memory 記憶體寬頻是最慢的;constant memory 主要是存取 由 Host 端傳遞到 Device 端的固定資訊,容量大約 64k,生命期與 global memory 一樣,記憶體寬頻比 shared memory 快;shared memory 用來存取共享資料,讓
15
GPU 在計算時可互相傳遞資訊,每個 block 都擁有 shared memory,容量大約 16k, 使 block 內的 thread 互相溝通,而生命期為一個 block 內所有 thread 計算完的時 間,記憶體寬頻比 global memory 快;register 專門存取正在做計算的暫存資料, 每個 thread 擁有數個 register,不同型號 GPU 擁有數量都不一樣,當 thread 計算 完後,儲存的資訊會自動被刪除,因此生命期只有在 thread 內計算完的時間,對 於傳送速率而言,花費時間幾乎零秒就傳完了,而 thread 內的 register 記憶體空 間不足以存取所有資訊時,thread 會將剩餘的資訊存在 global memory 內,因此 計算速度會變慢,相當於我們使用 CPU 計算程式,當電腦記憶體不足以存取所 有資訊時,會將剩餘的資訊存到虛擬記憶體內,此時計算速度會變得非常慢;
texture memory 是 GPU 還沒用於計算時的產物,原本用於儲存圖形的資訊,但 目前我們作運算並沒使用到,在此無相關討論。
表 2.3.2.1 Device 端記憶體相關資訊。
生命期 存取範圍 記憶體寬頻 Device 端存取
register 區塊 thread 即時 讀/寫
shared memory 區塊 block 140~200GB/s 讀/寫 constant memory 程式 grid 200~300GB/s 讀
global memory 程式 grid 70~100GB/s 讀/寫
2.4 GPU 與 CUDA 的溝通
在 CUDA 執行程式時,電腦會把 grid 直接丟給 GPU,再將 grid 內 block 傳 送至 GPU 內 SM 執行,如圖 2.4.1 示意圖;硬體把傳送過來的 block 當作基本單 位,而 block 內 thread 又會以 warp 分組來執行程式,目前 CUDA 的 1 個 warp 大小等於 32 個 thread。
16
圖 2.4.1 CUDA 傳送 block 到 GPU 內的 SM 示意圖。
由上述得知 CUDA 將 block 傳送至 SM,當 block 數量大於 SM 時,GPU 會 先執行與 SM 個數相符的 block 數量,其餘的 block 會閒置,等到這些 block 執 行完成後或等待時[例如存取 global memory 需要花費許多時間],才會將閒置的
block 傳送至 SM 做計算,至於先前等待中的 block 會變成閒置狀態繼續等下一 輪執行;block 可分成很多個 warp,SM 會先執行一個 warp,其餘的 warp 閒置, 等這一個 warp 執行完後才會執行下一個 warp,圖 2.4.2 表示觀察 1 個 SM 執行
block 與 warp 的順序;warp 有 32 個 thread,是利用 SM 內的 SP 運行程式,SM 通常有 8 個 SP,因此他會同時計算 warp 內 8 個 thread,計算完成後才會繼續計 算其它 thread。
圖 2.4.2 warp 在 1 個 SM 運作情形:假設每個 warp 需要運作的時間都是 2 個週期。 當 1 個 warp 沒有滿 32 個 thread 時,SM 還是一次只會執行 1 個 warp,這會 使某幾個 SP 閒置著,造成資源上的浪費。如圖 2.4.3 範例,Block 內有 99 個 thread,
17
此時 Thread 可分為 4 個 warp,分別是 32、32、32、3 個 thread,發現 warp4 只 有 3 個 Thread,而利用 SM 執行這個 warp 時,會造成 5 個 SP 閒置,使程式無 法最佳化,因此在定義 block 內 thread 個數時,最好設定能被 32 整除的數目。
18
第三章、庫侖交互作用理論及其數值方法測試
3.1 積分方法 我們積分通常會將式子離散化,其方法有分很多種,本論文將要介紹三種方 法,分別是矩形法、梯形法與辛普森法。 1.矩形法 如圖 3.1.1 所示,考慮區間xa x xb,可將此切割 N 個寬度為xi的子區間, 則各子區間的座標為
1 i a i x x i x ,i1, 2,3, ,n (3.1.1) 將定積分
b a x x f x dx
近似為xxa~xxb間的矩形總面積,以 f x
i 當作矩形的高, 可表示為
0
1 lim 1 b i a x N a i i x i x f x dx f x i x x
(3.1.2) 隨著格點數變多,矩形的寬度會越來越窄,而矩形總面積則越來越接近所求的 值。 圖 3.1.1 矩形法求定積分示意圖。 考慮均勻格點 xi x
xb xa
N,則(3.1.2)式可改寫為19
0
1 lim 1 b a x N a x i x f x dx f x i x x
(3.1.3) 將(3.1.3)式推廣到三維的狀況,則數學形式可表示
, , 0 , , lim , , b b b x y z a a a x y z N N N i j k x y z i j k x y z f x y z dxdydz f x y z x y z
(3.1.4) 其中
1
i a x x i x、yj ya
j 1
y、zk za
k 1
z a b x x x x N 、 a b y y y y N 、 a b z z z z N 2.梯形法 利用(3.1.1)式將定積分
b a x x f x dx
近似為xxa~xxb間的梯形總面積,如圖 3.1.2。而 f x
i 與 f x
i1 分別當作梯形的上底與下底,可表示為
1
0 1 1 lim 2 b i a x N a i a i i x i x f x i x f x i x f x dx x
(3.1.5) 格點數變多,寬度越來越窄,則梯形總面積則越來越接近所求的值。 圖 3.1.2 梯形法求定積分示意圖。 考慮均勻格點 xi x
xb xa
N,則(3.1.5)式可改寫為20
0 1 1 lim 2 b a x N a a x i x f x i x f x i x f x dx x
(3.1.6) 將(3.1.6)式推廣到三維的狀況,則數學形式可表示
+1 +1 +1 +1 , , 0 +1 +1 1 +1 +1 +1 +1 +1 , , , , , , , , , , lim 8 , , , , , , + , , b b b a a a y x z x y z x y z i j k i j k N N N i j k i j k x y z i j k i j k i j k i j k i j k f x y z dxdydz f x y z f x y z f x y z f x y z x y z f x y z f x y z f x y z f x y z
(3.1.7) 其中
1
i a x x i x、yj ya
j 1
y、zk za
k 1
z a b x x x x N 、 a b y y y y N 、 a b z z z z N 由上面介紹的積分方法可知:矩形法的運算式子最簡單,而梯形法的運算式子較 為複雜。當運算式子越複雜時,電腦會耗費較多記憶體相對的時間也會比較久, 使用 GPU 運算影響速率更為顯著(詳細 2.3.2 節),因此矩形法運算速率會大於梯 形法,而接下來的小節要比較矩形法與梯形法數值結果。21 3.2 數值積分測試 由 3.1 小節可知數值運算方式,接下來將分析兩個部分,分別是 1.分析格點數:證明格點數越多時越數值越準確。 2.採取的積分方法:比較矩形法與梯形法的收斂範圍。 3.2.1 一維積分 以下式子為一維積分的形式 ( ) f x dx
(3.2.1.1) 我們將以一個積分式子當作範例來做分析,採取的積分式子如下
5 2 0 cos F
x x dx (3.2.1.2) 而(3.2.1.2)式積分後的解析解為 5 1 2 F (3.2.1.3) 利用矩形法與梯形法將積分離散化且取均勻格點(格點數取N 個)後,其形式為 x
1 cos x N i i i F F x x x
(3.2.1.4)
1
1 1 cos cos 2 x N i i i i i x x x x F F x
(3.2.1.5) 其中(3.2.1.4)式為矩形法、(3.2.1.5)式為梯形法。將(3.2.1.4)式與(3.2.1.5)式利用 Fortran 程式做運算可畫出收斂結果,如圖 3.2.1.1 與圖 3.2.1.2。22 圖 3.2.1.1 利用矩形法(黑色方形中空)與梯形法(紅色三角形)算出的數值收斂結果。 由圖 3.2.1.1 可看出,不管是矩形法或梯形法,格點數取越多數值差異越小, 我們以矩形法當作範例畫出圖 3.2.1.3 與圖 3.2.1.4 證明此結果。圖中格點數取 5 個時會發現積分面積有一部分沒被計算到,而格點數取 20 個時積分沒被計算到 的面積相對於取 5 個格點就少很多了,因此格點數取越多,計算數值會越準確。 圖 3.2.1.2 利用矩形法將積分離散化的示意圖(Nx5)。
23 圖 3.2.1.3 利用矩形法將積分離散化的示意圖(Nx20)。 由 圖 3.2.1.1 比 較 矩 形 法 與 梯 形 法 的 數 值 差 異 , 可 由 誤 差 公 式 100% error 解析解 數值解 解析解 計算出圖 3.2.1.4。 圖 3.2.1.4 利用矩形法和梯形法算出的結果與解析解比較後的誤差值。 由圖 3.2.1.4 可知矩形法與梯形法在一維積分的數值結果差異不大,且兩者 數值結果很快就收斂(取N =20)。 x
24 3.2.2 三維積分 由 3.2.1 小節可知,一維積分的數值收斂結果是可接受的,接著將要分析三 維積分,以下式子為三維積分形式 ( , , ) f x y z dxdydz
(3.2.2.1) 而我們選擇三維積分範例式子如下
5 5 5 2 2 20 0 0 cos cos cos
F
xyz x y z dxdydz (3.2.2.2) (3.2.1.2)式積分後的解析解為 3 5 1 2 F (3.2.2.3) 利用矩形法與梯形法將積分離散化且取均勻格點(每個維度的格點數分別取N 、x y N 、N 個)後,其形式為 z
1 1 1cos cos cos
y x z N N N i j k i j k k j i F F x y z x y z x y z
(3.2.2.4)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1cos cos cos cos cos cos cos cos cos
cos cos cos cos cos cos
cos cos cos cos cos cos
i j k i j k i j k i j k i j k i j k i j k i j k i j k i j k i j k i j k i j k i j k i j x y z x y z x y z x y z x y z x y z x y z x y z F F x y z x y z x y z x y z x y z x y z x y
1 1 1 1 1 1 1 1 8cos cos cos
y x z N N N k j i k i j k x y z z x y z
(3.2.2.5) 其中(3.2.2.4)式為矩形法、(3.2.2.5)式為梯形法。將(3.2.2.4)式與(3.2.2.5)式利用 Fortran 程式做運算可畫出收斂結果,計算方式為Nx Ny Nz如圖 3.2.2.1,其中 3D x y z N N N N 。25 圖 3.2.2.1 利用矩形法(黑色方形中空)與梯形法(紅色三角形)算出的數值收斂結果。 比較(3.2.2.3)式和(3.2.2.4)式與(3.2.2.5)式的數值差異,而此差異可由誤差公 式error 解析解 數值解 100% 解析解 計算出圖 3.2.2.2。 圖 3.2.2.2 利用矩形法和梯形法算出的結果與解析解比較後的誤差值。
26
由一維與三維積分比較矩形法與梯形法的收斂值,數值結果差異不大。矩形 法計算式子比梯形法簡單,所以矩形法在程式的運算速率較快且式子可讀性較清 楚,因此我們之後的積分將選擇矩形法來做計算。
27 3.3 量子點內單一激子理論基礎
3.3.1 單一能帶理論
首先以 single-band model 來描述電子與電洞的行為,再由波包近似法
(envelope function approximation)將半導體內電子與電洞波函數寫成
e e z e e e i re gi r ue s re (3.3.1.1)
h h z h h h j rh gj r uh j rh (3.3.1.2)
z e s e u r 、
z h j h u r 分別表示電子與電洞的 Bloch’s function;
e e i e g r 、
h h j h g r 分別表 示電子與電洞的波包函數(envelope function);i 、e j 分別表示電子與電洞所在的h 軌域。 由於要計算電子與電洞在半導體量子點的能階能量與波函數,將利用有效質 量近似薛丁格方程(Schrödinger equation)及(3.3.1.1)式、(3.3.1.2)式可得
2 * 0 2 e e e e e e e QD e i e i i e e p V r g r E g r m m (3.3.1.3)
2 * 0 , 2 h h h HH h HH h QD h j h j j h HH p V r g r E g r m m (3.3.1.4) 0 m 為電子靜止的質量,me、mHH, (= , , )x y z 分別為電子與重電洞的有效質量且重電 洞的有效質量與方向有關[1],p
為動量算符, e
QD e V r 為電子在導電帶受量子效 應(結構與形狀)侷限的位能,而 HH
QD h V r 為重電洞在價電帶受量子效應(結構與形 狀)侷限的位能, e e i E 、 h HH j E 為電子與重電洞動能。因此決定VQDe
re 、
HH QD h V r 後,利用有限差分法(finite difference method)[13]或基底展開等方法對角化矩陣即可 得到不同能態所對應的電子、重電洞動能與波包函數。
28 3.3.2 庫侖交互作用 電子-電洞間直接庫侖作用矩陣元素定義
2
, , , 1 2 1 2 2 1 0 1 2 4 e h h e e h h e eh e h h e i j k l i j k l e V d r d r r r r r r r
(3.3.2.1) 而電子-電洞間交換能矩陣元素定義
' ' z e h h e 2 s , , , i ,j ,k ,l 1 2 2 2 1 1 0 1 2 4 z z z e h h e j j s e h h e i j k l e d r d r r r r r r r
(3.3.2.2) e 表電子電量,表材料介電常數(dielectric constant),
e e i r 、
h h j r 表電子與 電洞在空間中的波函數。而接下來將兩者分別做探討: 1. 電子-電洞間直接庫侖作用[1]: 首先定義電荷密度
*
e e e e i l (charge density)所建立的電位為
2 *
1
1 , 2 1 0 1 2 4 e e e e e e i l i l r r e U r dr r r
(3.3.2.3) 因此(3.3.2.1)式可以寫成
* , , , 2 2 2 , 2 e h h e h h e e eh h h i j k l j k i l V dr r r U r
(3.3.2.4)接下來要利用波包近似法(envelope function approximation)及拆解ri Rii(如圖
3.3.2.1)簡化積分式子。
29
i
R 表示第 i 個 Wigner-Seitz(WS) cell 的位置向量,i表示 WS cell 內的位置向量。
由文獻[14]可將將位置向量拆解,把庫侖矩陣元素 , , , e h h e eh i j k l V 分成長程部分(電子和 電洞在不同的 WS cell 內)和短程部分(電子和電洞在相同的 WS cell 內),而式子 如下
2 1 2 1 2 * * , , , 2 2 1 1 1 2 1 0 1 2 2 * * 2 2 1 1 1 2 , 1 0 1 2 1 4 1 4 cell e h h e h h e e I I cell h h e e J I N eh h h e e i j k l j k i l I r WS R r WS R N h h e e j k i l I J r WS R r WS R I J e V r r r r dr dr r r e r r r r dr dr r r
(3.3.2.5) cellN 為 WS cell 的數量,表示第 I(J)個 WS cell,而我們忽略短程部份的貢獻,則 (3.3.2.5)式可寫成
2 1 2 * * , , , 2 2 1 1 1 2 1 0 1 2 1 4 cell e h h e h h e e I I N eh h h e e i j k l j k i l I r WS R r WS R e V r r r r dr dr r r
(3.3.2.6) 由(3.3.2.3)式定義的電位可將(3.3.2.6)整理為
2 * , , , 2 2 , 2 2 1 cell e h h e h h e e J N eh h h i j k l j k i l J r WS R V r r U r dr
(3.3.2.7) 波包函數具有緩慢變化的性質且Bloch’s function 為週期性函數,如下式
i i
i g R g R (3.3.2.8)
i i
i u R u (3.3.2.9) 利用(3.3.2.8)式與(3.3.2.9)式最後可將(3.3.2.7)式化簡為
* , , , = 2 2 , 2 2 e h h e h h e e eh h h i j k l j k i l V g R g R U R dR
(3.3.2.10)
*
1 1 , 2 1 0 1 2 = 4 e e e e e e i l i l g R g R e U R dR R R
(3.3.2.11) 當R1 R2時, ,
2 e e LR i l U R 稱為長程作用(Long Range),當R1R2時, ,
2 e e SR i l U R 稱為30 短程作用(Short Range),如下式所示
, = , , e e e e e e LR SR i l h i l h i l h U R U R U R (3.3.2.12) 令R1
x y zi, j, k
、R2
xm,y zn, l
且取均勻格點及經過矩形法(如圖 3.3.2.3)離散 化可近似為
* 1 1 1 , , , 1 1 1 , , , , , = , , y x z h h e h h e e e h h N N N j m n l k m n l eh i j k l m n l i l m n l g x y z g x y z V U x y z x y z
(3.3.2.13)
* 1 1 1 2 2 2 , * 1 1 1 0 1 1 1 , , , , , , 4 , , , , y x z e e e e y x z e e e e N N N i i j k l i j k i m j n k l i m j n k l i l m n l e N N N i m n l s e m n l l m n l g x y z g x y z V x x y y z z e U x y z g x y z F g x y z
(3.3.2.14) 2 2 2 2 2 2 2 2 2 x y z s x y z dxdydz F x y z
(3.3.2.15) s F 定義單位晶胞內的積分式。由於單位晶胞內的積分使用 mathemetica 程式在短 時間內即可被計算出來,在 Fortran 程式計算當中,已經把F 當作參數來輸入,s 因此將(3.3.2.13)式與(3.3.2.14)式使用 Fortran 程式計算及為所求。 2. 電子-電洞間交換能[15]: 將(3.3.1.1)式與(3.3.1.2)式代入(3.3.2.2)經過可得
' ' z z z z e h h e e z h z ' ' h z e z 2 * s , j , j ,s 3 3 e h 2 2 2 2 i ,j ,k ,l 1 2 i s j j 1 2 0 b * h e 1 1 1 1 k j l s e δ = dr dr g r u r g r u r 4πε ε r r g r u r g r u r
(3.3.2.16)接下來要利用波包近似法(envelope function approximation)及拆解r1R11、
2 2 2
![圖 1.2.1 CPU 和 GPU 比較圖:(左)年份對每秒浮點運算效率圖;(右)年份對記憶體寬頻圖。 資料來源:文獻[5]與文獻[8]。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8250955.171692/17.892.123.761.131.385/比較圖左年份對每秒浮點運算效率圖右年份對記憶體寬頻圖來源文獻.webp)
![圖 2.3.1.2 使用單核 CPU 與 GPU 的計算方式:迴圈數(n x )為 36、每個 grid 內 block 個數為 3 個、 每個 block 內 thread 個數為 4 個。 我們將附錄 C 的程式以軍隊來比喻,如圖 2.3.1.3。軍隊[相當於 CUDA]發放 給連隊一個任務[相當於 grid],而連隊中共有 3 個班[相當於 block],每個班有 4 個小兵[相當於 thread],所以整個連隊共有 3×4=12 個小兵可配任務,因此可將任 務均分成 12 等分分配給每個小兵執行](https://thumb-ap.123doks.com/thumbv2/9libinfo/8250955.171692/25.892.129.765.108.350/我們將附程式以軍隊來比喻如圖隊相隊一個當於所以整個連隊共有.webp)