Python平行化在SCMDS上之應用 - 政大學術集成
70
0
0
全文
(2) Python平行化在SCMDS上之應用 學生: 李沛承. 指 導 教 授 : 曾正男博士 國立政治大學應用數學研究所 要. 摘. 近年來資料產生的數量遠超過過去可處理的數量,以現今的個人電腦使用傳 統的方法已經無法處理大資料的運算與分析,所以改善傳統的方法與平行化為. 政 治 大 紹Python程式語言及其相關套件如何撰寫平行化程式,我們將拆解合成-多元尺度 立 法從原本的單核心版本改進為多核心版本,並且探索拆解合成-多元尺度法在平行. 必經的方向,本論文以拆解合成-多元尺度法的平行化為主要討論對象,除了介. ‧ 國. 學. 化過程中的計算效能,藉以了解拆解合成-多元尺度法在平行化計算時的參數要如 何設定,使得平行化的SC-MDS可以有最高的計算效率。經實驗證明多核心底下. ‧. 的SC-MDS平行化又把SC-MDS單核心的效能做個再次的提升。. n. er. io. sit. y. Nat. al. Ch. engchi. iv. i n U. v.
(3) ABSTRACT In recent years, the number of generated data is growing fast such that it is infeasible to process by using traditional methods. So improving traditional methods and developing paralled computing methods are important issues. The main contribution of this thesis is to delelope the parallel version of the split-and-combine multidimensional scaling method(SC-MDS). We will fistly introduce fundamental python program, the basic python packages and the python multi-core program. Then we will implement the serial core version of SC-MDS to the multi-core ver-. 治 政 Then we can understand how to determine the parameters 大 of the parllel version of 立 results, we successfully implement the serial core of SC-MDS. By our experimental sion. Moreover, we will discover the efficiency of the multi-core version of SC-MDS.. ‧ 國. 學. SC-MDS to the faster parallel version of SC-MDS.. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. v. i n U. v.
(4) 誌. 謝. 這次論文能夠在我的預期中順利完成,首先要先感謝我的指導教授曾正男 老師,在我剛踏進應用數學系這個領域時,曾老師就常帶領著我一起研究以 及不遺餘力地挪出時間指導我的論文,才能夠讓我對數值科學計算的分析那麼 快地從無到有,甚至還跟著老師學習平行化的程式碼並且透過老師的指導得以 將SC-MDS方法從單核心版本改進成平行化的版本,這段期間有瘋狂、有崩潰不 過最讓我得意的是那一份大大的成就感。在此特別感謝口試委員陸行老師以及舒 宇宸老師的建議才能使最終版本的論文有更好的結果。. 治 政 大 接著讓我體驗到數學的樂趣和奧妙的是陳天進老師,多虧有老師對數學的堅 立 持以及認真的態度,才能讓我比較明白數學的嚴謹以及證明的意義。在這趟數學 ‧ 國. 學. 之旅中還要感謝林澤佑同學兼學長,在許多個實變函數論的夜晚中總是能回答出 我要問的一百萬個為什麼。. ‧. 在讀書以外的時光,要感謝的人實在太多這裡只能意會了,這裡我要感謝研. sit. y. Nat. 究室的大家,在我最緊張的時候有陪伴我的兄弟江增堂、有讓我學到很多東西的. io. er. 學長李治陞、有常常照顧我和我分享事情的學長詹博翔以及李偉慈、陪伴我打屁 吃苦的同學們吳宥柔、高裕哲和陳暐哲以及常常跟我敞開心胸聊天的鄭富元還有. n. al. i n U. v. 一些常常讓我欺負的學弟學妹們以劉宇恩作代表,我知道你(妳)們都是故意逗我. Ch. engchi. 開心啦所以我才能認真的跟你(妳)們玩耍,很開心在最後的讀書時光能跟大夥玩 得這麼開心,總之真的好喜歡和謝謝各位。最後,我要感謝我家人的包容還有關 懷,在我這一大段求學的路上支持和鼓勵我,真是辛苦你們了。. vi.
(5) 目. 錄. 論文口試委員審定書 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. ii. 授權書 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. iii. 中文摘要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. iv. 英文摘要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. v. 誌謝 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. vi. 治 政 目錄 . . . . . . . . . . . . . . . . . . . . . . . . . . 大 . . . . . . . . . . . . . . . 立 表目錄 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. ‧ 國. 學. 圖目錄 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. ‧. 第一章、簡介 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. vii ix x 1. Nat. 1.2. 平行化的需求 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 3. 1.3. v i n SCMDS的基本介紹 . C . . . . . . . . . . . . . . . . . . . . . . . . . . . hengchi U. 3. er. sit. y. 為何用Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. io. 1.1. n. al. 第二章、Python之平行計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1. 5. 2.1. Python基本運算之套件與工具 . . . . . . . . . . . . . . . . . . . . . .. 5. 2.2. Python平行計算之套件與相關介紹 . . . . . . . . . . . . . . . . . . .. 9. 2.3. Python控制核心之套件 . . . . . . . . . . . . . . . . . . . . . . . . . . 21. 第三章、SCMDS與其平行化 . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 3.1. SCMDS以及單核心版本 for Python . . . . . . . . . . . . . . . . . . . 22. 3.2. SCMDS的平行化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28. 第四章、實驗結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 vii.
(6) 4.1. SC-MDS與其平行化在多核心控制下之比較 . . . . . . . . . . . . . . 31. 4.2. 多核心的操作對於SC-MDS的平行化在各個階段的影響 . . . . . . . . 38. 4.3. 多核心的操作中MDS平行化的效能比 . . . . . . . . . . . . . . . . . . 42. 第五章、結論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 參考文獻 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 附錄A:SC-MDS單核心版本的code . . . . . . . . . . . . . . . . . . . . . . . . 50 附錄B:SC-MDS拆解平行化版本的code . . . . . . . . . . . . . . . . . . . . . 60. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. viii. i n U. v.
(7) 表. 目. 錄. 4.1. SC-MDS與其平行化執行時間的比值(真實維度為50) . . . . . . . . . . 36. 4.2. SC-MDS與其平行化執行時間的比值(真實維度為100) . . . . . . . . . 37. 4.3. SC-MDS與其平行化執行時間的比值(真實維度為150) . . . . . . . . . 37. 4.4. SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為50) . . . 45. 4.5. SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為100) . . 45. 4.6. . . 46. 政 治 大 SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為150) 立 ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. ix. i n U. v.
(8) 圖. 目. 錄. 1.1. 編譯語言排行榜(www.tiobe.com/index.php/content/paperinfo/tpci/index.html). 2.1. 例子2.1-4 sin函數 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 2.2. 例子2.2-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10. 2.3. 例子2.2-2 BigCal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17. 3.1. 單核心SC-MDS流程圖 . . . . . . . . . . . . . . . . . . . . . . . . . . 26. 3.2. 找出最佳的Ng . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27. 3.3. 拆解平行化示意圖 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28. 3.4. 合成子資料的示意圖 . . . . . . . . . . . . . . . . . . . . . . . . . . . 29. 3.5. SC-MDS拆解平行化流程圖 . . . . . . . . . . . . . . . . . . . . . . . 30. 4.1. SC-MDS與其平行化的執行時間比較圖(真實維度為50) . . . . . . . . 34. 4.2. 34. 立. 9. 政 治 大. ‧. ‧ 國. 學. er. io. sit. y. Nat. al. n. v i n Ch SC-MDS與其平行化的執行時間比較圖(真實維度為100) . . . . . . . . engchi U. 4.3. SC-MDS與其平行化的執行時間比較圖(真實維度為150) . . . . . . . . 35. 4.4. SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為50) . . . 39. 4.5. SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為100) . . 40. 4.6. SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為150) . . 41. 4.7. SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為50) . . 43. 4.8. SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為100) . 43. 4.9. SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為150) . 44. x. 2.
(9) 第 一 章. 簡介. 也許很多人常常聽到平行化這個字眼,但不清楚這到底是做甚麼的、哪種資 料才能被平行化亦或是要到哪種平台上運作,對一般人而言要撰寫平行化程式也 不是一件容易的事。Python雖然在網路上有許多關於平行化的參考文件,但中文 的資料不多並且內容也不容易閱讀,本篇論文將使用Python程式語言為主要工作 語言,並提供一個從基礎開始讓大家可以進入平行化計算的參考,文中會提供一 些可平行化的範例讓大家由淺入深地了解平行化的真正意義與實際效用。. 為 何 用 Python 立. 學. ‧ 國. 1.1. 政 治 大. 如果說為甚麼要用Python這套軟體,不如先來看看它有哪些優點好了 [9]:. ‧. 直譯式語 言 它是一款比較直觀易學的程式軟體,在操作時不用先宣告變數就. y. Nat. 可以讓變數作運算並且可當做計算機來使用,直譯式也不需要先編譯. io. sit. 檔案再執行,讓初學者可以省下許多等待編譯的時間,因此它是一個類. er. 似MATLAB和R 的語法。. al. n. v i n 豐富的標 準 函 式 庫 和 眾 多 的 社C 群 與 第 三 方 程 式 庫 除了Python內建的函式庫已經 hengchi U 可以解決大部分的問題外,Python在國外也已發展十幾年了,因此累積了 相當多的社群和第三方程式庫,可以說是想得到的函式庫幾乎都有。Ex: 如果想作最佳解的問題也可以在網路上搜尋到許多可用的函式庫。 活躍的社 群 Python具有非常活躍的社群,不僅有各種討論區還常常有一些活動 與演講,並且這個程式語言也不停地在改進中。網路上也有許多Python的 社群可以讓初學者在產生問題時提供解決問題的方向以及意見。 物件導向 Python是一款完全物件導向的語言。函式、模組、數字和字串都是物 件,並且完全支援繼承、重載、衍生與多繼承,有益於增強原始碼的複用 性。因此當程式越大,物件導向的特性也讓Python用起來更得心應手。. 1.
(10) 跨平台 Python可以當成是跨平台的語言。因為Python直譯的特性,所以任何平 台上只要實作直譯器幾乎都可以執行Python,並且目前現有的平台幾乎都 有Python的直譯器版本。 被廣泛使 用 Python這套軟體在國外早已被廣泛使用,所以其穩定度和受歡迎程 度是可想而知的,然而美國太空總署NASA、Google與Youtube · · · 等也都有 使用Python,此外還有許多成功的案例,因此Python有機會成為未來更主 流的程式語言。 容易擴充 和 嵌 入 Python本身是很好擴充的,如果有非常大量的計算量並且需 要速度夠快,這時就可以考慮將負載量大的部分用C語言來寫,然後再. 政 治 大. 用Python來引入就可以加快速度了;然而Python也可以嵌入其它的程式裡. 立. 面(Ex:MATLAB、OCTAVE),而這種特性讓Python非常具有彈性。. ‧ 國. 學. Python的眾多優點不僅讓使用者更方便外也迅速地將自己推進A級的語言排. ‧. 行榜裡,並且不斷地進步跟爬升名次,爬升的比率從去年到今年就爬升了1.10%, 而爬升的比率在這10種編譯語言中僅輸Objective-C。如圖 1.1[4]. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 1.1: 編譯語言排行榜(www.tiobe.com/index.php/content/paperinfo/tpci/index.html). 2.
(11) 1.2. 平行化的需求. 到底甚麼是平行化呢,先舉一個例子好了。就像是一對夫妻一起去逛大賣 場,進了大賣場後兩個人的各自去買各自的東西,然後結束後一起在出口會合。 大家可能會驚訝,不過這就是平行化的基本意義! 那現在我們可以簡單地想像電腦中的平行化,如果要把我們想做的任務丟給 電腦處理的話,在過去單核心的電腦中,每個單位時間內一個CPU只能處理一個 任務,任務會按照編號依序被處理,但如果是雙核心的電腦,每個單位時間內就 能處理兩個任務,速度就會比單核心快上一倍!不過事實上這都是最理想的狀. 政 治 大 不會是CPU個數的倍數關係,除此之外,也不是所有任務都是可以切割的!很多 立 態,因為資料分配給不同的CPU計算需要時間、回收資料也需要時間,所以時間. ‧ 國. 學. 任務是有關聯性的,這樣如果直接切割給不同的處理核心各自去平行運算,出來. 的結果肯定是有問題的。多核心的程式在分配、等待、回收的過程中在編寫、維 護上,也都比單一核心的程式複雜上不少。那到底什麼樣的程式才是適合平行化. ‧. 的呢,如果說程式中某個迴圈的計算時間很長並且上下迴圈之間可以各自獨立運. sit. y. Nat. 作,那我們就可以把這個部分分成好多個任務丟給電腦處理,而本篇拿來作平行. io. 再好不過的了,以下為SC-MDS的基本介紹。. n. al. 1.3. Ch. engchi. er. 化的方法為SC-MDS法,因為此方法符合以上的條件,所以拿來處理這個問題是. i n U. v. SCMDS的 的基 本 介 紹. 這一節會簡單地介紹什麼是傳統的多元尺度法(Multidimensional Scaling在此 簡稱MDS)[7]以及這個方法的改進也就是拆解合成-多元尺度法(Split-and-Combine MDS在此簡稱SC-MDS)。 多元尺度法(MDS)是一種把高維度資料轉換成低維度資料的方法,在高維度 時保持彼此間的距離轉換成低維度時還能維持其資料的結構。這個方法最早是用 在如何把地球上城市與城市之間三維的距離位置轉換成二維的資料,由於人類對 於高維度的資料難以想像其結構圖形,運用此方法就能讓人們以視覺理解的方式 來解讀資料。因此多元尺度法在資料分析上是一個近年來大量被使用的工具。. 3.
(12) 多元尺度法主要是利用距離矩陣(其中距離矩陣d[i, j]代表位置i與位置j之間的 距離)經過一些運算以及平移質心後,再透過SVD分解找出我們要的資料,而這些 過程的詳細內容會在第3.1節裡介紹。一般來說多元尺度法最主要的過程是SVD, 但由於SVD的計算量是O(N 3 ),所以當矩陣很大時現今的個人電腦大概就無法 處理了,所以需要一個可以因應大資料計算的方法,就是拆解-合成多元尺度 法(Split-and-combine MDS在此簡稱SC-MDS)。它的核心精神就是把資料拆解成 很多塊有重疊的子資料,個別經過多元尺度法後轉換成新的座標位置,再把這些 有重疊的新作標位置透過旋轉加以合成(由於重疊的座標位置在原本的資料中是一 樣的座標,所以可以旋轉加以合成),而這些過程的詳細內容也會在第3.1節裡介. 政 治 大. 紹。縱使SC-MDS方法可以加快MDS的計算速度,然而SC-MDS的運算邏輯上有 許多很適合平行化的部分,因此本論文希望藉由Python程式很容易撰寫平行化程. 立. 式的特性來改良現有的SC-MDS方法。. ‧ 國. 學. 本論文的架構為第一章為基本介紹、第二章為介紹Python之平行計算,主要 是介紹Python關於平行化的一些函式與其使用方法的簡介、第三章為介紹傳統的. ‧. 多元尺度法(MDS)會詳細地介紹其推導流程以及介紹為何使用拆解合成-多元尺度. y. Nat. 法及其推導流程,並附上單核心版本以及平行化版本的程式碼,第四章為實驗結. n. al. er. io. 論文的結論。. sit. 果討論拆解合成-多元尺度法及其平行化在多核心底下的執行效率以及第五章為本. Ch. engchi. 4. i n U. v.
(13) 第 二 章 2.1. Python之 之平 行 計 算. Python基 基本 運 算 之 套 件 與 工 具. 在網路上有許多Python入門的電子書[12][14][18]、相關知識[16]以及書籍[1][2]在 這裡提供給讀者做參考,由於篇幅的關係所以詳細的使用方法以及介紹就不在這 裡多作說明了。這一章節介紹一些Python內常用的套件,有了這些套件後大部分 的問題幾乎都可以處理了;而且使用這些套件來進行科學計算,還能獲得世界各. 政 治 大. 地的開發者提供的套件資源。以下就是上述所提到的套件 [8]:. 立. Numpy 是一種Python語言的延伸,其中包含了定義數值陣列和矩陣類型與一. ‧ 國. 學. 些在上面的基本操作。這裡會介紹到兩個例子,主要的目的是要表現出不 用Numpy這個套件比起用了Numpy這個套件在處理一些簡單的基本操作中. ‧. 哪個速度會比較快,例子2.1-1會介紹到Python中不用Numpy這個套件的例. sit. y. Nat. 子、例子2.1-2則會介紹到Python中用了Numpy這個套件的例子。. io. al. n. # add.py. er. 例子2.1-1:這是不用Numpy裡陣列的方式使得數值相加。. Ch. # 把以下為add.py的程式碼 01| import time. engchi. i n U. v. # 引入time套件 02| currtime = time.time() # 起始時間。把此刻的執行時間記錄下來儲存到currtime中 03| a = range(10000000) # a是 一 個 串 列 , 其 中 第1個 位 置 是0、 第2個 位 置 是1、 以 此 類 推 到 第10000000個位置是9999999,因此串列的大小是10000000 04| b = range(10000000) # b與上述的a一樣 05| c = [] # c是一個空的串列,等等要把a與b的值相加並放入其中 # 由於兩個串列並不能直接相加,所以要透過for迴圈把個別位置的值相 5.
(14) 加後並放入c這個空的串列中 06| for i in range(len(a)): # for迴圈跑的次數是a這個串列的大小,而i的值會根據迴圈的次數依序 從0跑到9999999 07|. c.append(a[i] + b[i]) # 每一次的迴圈中會把a[i]與b[i]的值作加總並放入c這個串列中. 08| print time.time() - currtime # 把此刻的執行時間減去剛剛的起始時間則為整段程式的運行時間,並把 運行時間顯示出來. 政 治 大. ----------------------------------------------------------------# 以上為add.py的程式碼. 立. ‧ 國. 學. 09| >>> import add # 執行add. ‧. 5.51968598366 # 運行時間為5.51968598366(sec). sit. y. Nat. al. n. # add1.py. er. io. 例子2.1-2:這是用Numpy裡陣列的方法讓數值相加。. Ch. # 把以下為add1.py的程式碼 01| import time. engchi. i n U. v. # 引入time套件 02| import numpy as np # 把numpy更名為np 03| currtime = time.time() # 起始時間。把此刻的執行時間記錄下來儲存到currtime中 04| a = np.arange(10000000) # a是一個np中的陣列,其中第1個位置是0、第2個位置是1、以此類推到 第10000000個位置是9999999,因此陣列的大小是10000000 05| b = np.arange(10000000) # b與上述的a一樣. 6.
(15) 06| c = a + b # 由於np中的陣列是可以直接相加的,所以c為陣列a與陣列b的加總 07| print time.time() - currtime # 把此刻的執行時間減去剛剛的起始時間則為整段程式的運行時間,並把 運行時間顯示出來 ----------------------------------------------------------------# 以上為add1.py的程式碼. 08| >>> import add1. 政 治 大. # 執行add1 0.0789999961853. 立. # 運行時間為0.0789999961853(sec). ‧ 國. 學. 其結果可發現例子2.1-2所花的時間比例子2.1-1少上許多,時間從5.51968598366. ‧. (sec)→0.0789999961853(sec),原因在於用for迴圈相加時程式會去判斷每次運算時 的型態而導致速度有所延誤,但是用上Numpy裡的陣列相加時其結果幾乎是立即. Nat. sit. y. 運算出來的,而且Numpy這個套件不僅能簡化程式碼還可以減少運算時間,這就. io. 好用的,有興趣的讀者可以直接瀏覽官網來學習。[8]. n. al. Ch. engchi. er. 是Numpy的好用之處。而除了這個功能外,Numpy裡還有許多其它的功能也是很. i n U. v. SciPy 是另一種Python語言的延伸,其中使用Numpy作高階的數學運算、訊號處 理、優化、統計數據等等。接下來例子2.1-3會介紹三種引用套件的方法,並 介紹這些方法的優劣。 例子2.1-3: (方法一) 01| >>> from scipy import * # 從scipy這個套件中把所有的工具都引入了 02| >>> a = zeros(1000) # 這時就可以直接使用scipy套件中的zeros這個功能,並且a為一條1000維 的零向量 # 把整個套件都引入進來,所以也會引入很多不太用的套件。. 7.
(16) (方法二) 01| >>> from scipy import abs, sin, pi, dot, asarray, diag, zeros, empty # 從scipy這個套件中只引入了abs, sin, pi, dot, asarray, diag, zeros, empty 這些工具 02| >>> a = zeros(1000) # 這時就可以直接使用scipy套件中的zeros這個功能,並且a為一條1000維 的零向量 # 雖然只引入用到的套件,但是有點太過冗長。. 政 治 大. (方法三). 01| >>> import scipy as sp. 立. # 引入scipy整個套件並把scipy更名為sp. ‧ 國. 學. 02| >>> a = sp.zeros(1000). # 這 時 要 使 用sp這 個 套 件 中zeros這 個 功 能 時 就 要 寫 成sp.zeros, 並. ‧. 且a為一條1000維的零向量. # 這也是本文比較常用的方法,並且在Python寫作查詢方面就不會有一. y. Nat. io. sit. 大堆的函式,比較方便使用。. n. al. er. Matplotlib 這個套件是模仿MATLAB裡的繪圖套件,是一種Python語言的延伸. i n U. v. 來方便繪圖。以下的例子則是使用這個繪圖套件畫出sin函數圖形的範例。. Ch. 例子2.1-4:. engchi. 01| >>> import scipy as sp # 引入scipy套件並更名為sp 02| >>> from matplotlib.pylab import * # 從matplotlib.pylab裡引入所有工具 03| >>> a = sp.arange(0,2*pi,0.01) # a是一個一維陣列,裡面的值是從0到2*pi以0.01為間距的數 04| >>> b = sp.sin(a) # b是一個一維陣列,裡面的值是把a的值帶入sin函數後的結果 05| >>> plot(a,b) # 建立一個a與b對應位置的圖. 8.
(17) 06| >>> show() # 把圖展示出來. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. n. a l圖 2.1: 例子2.1-4 sin函數 i v n Ch U engchi. 2.2. Python平 平行 計 算 之 套 件 與 相 關 介 紹. 在介紹了基本的科學計算套件之後,這一節會介紹到平行化的套件,以及帶 入單核心轉平行化的例子,讓讀者更好理解如何平行化。 multiprocessing 這是一個提供平行化功能的套件,可以有效地控制process達到 平行運算的目的。其底下有幾個常用到的工具先在這邊做一個簡單的介紹, 介紹完後會帶入有程式碼的範例讓讀者能更好理解。其工具如下 [11]: 1.cpu count 回傳系統中CPUs的數目。 2.Pool 回傳一個process pool的物件。 9.
(18) 3.Process 用此物件來指示要用幾個分別的process執行當前的程式。 4.Array 製造一個同步的共享陣列。 5.Lock 讓平行進行中的process等待其所需要同步的結果。 例子2.2-1:我們先作個比較基礎的範例,這個例子要把以下這個函數轉成平 行化來計算,方法一是原本單核心的方式;方法二是使用multiprocessing的 套件改成平行化(多個process)的方式,並比較在不同的process個數底下速度 的差別。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 2.2: 例子2.2-1. (方法一:Python serial code) 01| K = 100 # 宣告接下來的迴圈中k的上界為100 02| N = 8 # 宣告接下來的迴圈中x的上界為8 03| w = 0 # 宣告w是第一個迴圈中結果的加總,起始值是0. 10. v.
(19) 04| for x in range(1,N+1): 05|. r = 0 # 宣告r是第二個迴圈中結果的加總,起始值是0. 06|. for k in range(1,K+1):. 07|. r += x*(k**2) # 在這個迴圈中r加上了x的k平方次,其中x為1~8中某一個數. 字,並且k為1到100 08|. w += r # 在這個迴圈中,w把上一行所計算的r值加總. 政 治 大. # 這裡把r與w分成兩段寫的用意是讓讀者可以比較直觀的把單核心 版本改成平行化版本. 立. # 此為非平行的版本. ‧ 國. 學. (方法二:Parallel python code). ‧. # simple.py. 01| from multiprocessing import Pool. y. Nat. sit. # 從multiprocessing這個套件中引入Pool這個工具. al. er. io. 02| import time. n. # 引入time這個套件 03| K = 100. Ch. engchi. i n U. v. # 宣告接下來的迴圈中k的上界為100 04| def Fx((x,)):. # 這個Fx函式是要拿來計算平行化部分時的值,也就是方法一中第二個迴 圈中作的事,如圖2.2 05|. r = 0 # 宣告r是Fx函式中結果的加總,起始值是0. 06|. for k in xrange(1, K+1):. 07|. time.sleep(0.01) # 由於這個函式的計算量非常小,所以在這個迴圈中的每次停. 滯0.01秒是為了讓時間拉長,並比較在不同個數的process底下到底有沒有 平行化. 11.
(20) 08|. r += x*(k**2) # 在這個迴圈中r加上了x的k平方次,其中x為1~8中某一個數. 字,並且k為1到100 09|. return r # 回傳r值. 10| def sum_Fx(N = 8,ncpu = 4): # 這 個sum_Fx函 式 是 要 把N個 平 行 化Fx計 算 出 來 的 值 作 一 個 加 總 , 其 中N的預設值(x的上界)是8,ncpu的預設值(process的個數)是4 11|. if __name__ == "simple":. 政 治 大. # 如果這個檔案的檔名是simple則作以下的事情 12|. currtime = time.time(). 立. # 起始時間。把此刻的執行時間記錄下來儲存到currtime中. ‧ 國. 學. 13|. po = Pool(processes = ncpu). # 開process的數量為ncpu個,輸入端設預設值為4個 res = po.map_async(Fx,((i,) for i in xrange(1,N+1))). ‧. 14|. # 用po.map_async這個工具可以把Fx平行計算接著把值回傳出. y. Nat. al. # 用sum把res的值加總在w裡. v i n Ch print time.time() - currtime engchi U 把此刻的執行時間減去剛剛的起始時間則為整段程式的運行 n. 16| #. er. w = sum(res.get()). io. 15|. sit. 來儲存在res裡. 時間,並把運行時間顯示出來 17|. return w # 把結果w回傳出來. ----------------------------------------------------------------# 以上為simple.py的程式碼,此為平行化的版本. 18| >>> import simple # 引入simple這個py檔 19| >>> simple.sum_Fx(8,1) # 執行simple.sum_Fx(8,1). 12.
(21) 8.11127901077 # 運行時間為8.11127901077(sec) 12180600 # 這個函數的結果為12180600 20| >>> simple.sum_Fx(8,2) # 執行simple.sum_Fx(8,2) 4.06410813332 # 運行時間為4.06410813332(sec) 12180600. 政 治 大. # 這個函數的結果為12180600 21| >>> simple.sum_Fx(). 立. 2.04466485977 # 運行時間為2.04466485977(sec). ‧. 12180600. 學. ‧ 國. # 執行simple.sum_Fx(),由於預設值N是8、ncpu是4等同執行simple.sum_Fx(8,4). # 這個函數的結果為12180600. sit. y. Nat. er. io. simple.sun Fx(”第一個值”,”第二個值”)中”第一個值”代表的是x的範圍,在這. al. 裡就是1~8;”第二個值”代表的是要分成幾個process來跑。所以simple.sum Fx(8,1). n. v i n Ch 則表示x的範圍從1~8且只用一個process來跑,換句話說simple.sum Fx(8,2)就是 U i e h n gc 用兩個process來跑,而時間從 8.09999990463(sec)→4.08899998665(sec),以此類 推。 在此版本中的time.sleep(0.01)會讓執行此副函式『Fx((x,))』的process每執行 一次則有個停滯時間以代替大計算量時的執行時間,而要檢查是否有分工給多 個process同時運作時,當分工的process變多時運行時間應該降低,這一點可從上. 述的例子則會得到驗證,當執行simple.sum Fx(8,1)(一個process)、simple.sum Fx(8,2) (兩個process)與simple.sum Fx()(4個process)的運行時間就從8.11127901077(sec)→ 4.06410813332(sec)→2.04466485977(sec),當process變多時運行時間真的有降低, 可見multiprocessing這個套件真的有平行化的功能。 接著是本篇的重點之一,在平行計算大資料時常常需要把某段資料丟入個別 要計算的副函式當中,再經由各自取值把計算後的資料重組,這不僅僅浪費過 13.
(22) 多記憶體來儲存值還會增加組合時的複雜性。所以本篇介紹一個共享記憶體的 方法shared array:這是開創一個共享的陣列以方便平行運算時資料的計算和存 放,簡單的說可以當作一個global域的共享陣列來使用。以下則為shared array的 宣告方式: shared array 01| import multiprocessing as mp # 引入multiprocessing套件並更名為mp 02| import numpy as np. 政 治 大. # 引入numpy套件並更名為np 03| import ctypes. 立. 04| class shared_array(object):. 學. ‧ 國. # 引入ctypes套件. # class是一種『類別』的寫法,它底下(程式碼05~10行)則會定義出這. def __init__(self,matrix_shape=(1,1)):. Nat. y. 05|. ‧. 個類別該有的屬性. er. (m,n) = matrix_shape. io. 06|. sit. # 這裡把shared_array這個共享陣列的預設大小為1*1的陣列. al. v i n C h = mp.Array(ctypes.c_double,m*n) self.shared_base engchi U self.array = np.ctypeslib.as_array(self.shared_base.get_obj()) n. # 如果輸入端有放入值(m,n)時,這個陣列的大小會是輸入端的m*n 07| 08|. # 07、08行是開一個共享的零陣列(裡面所有的元素都是零),陣列 大小則是輸入端的m*n 09|. self.array = self.array.reshape(m,n) # 如果宣告完成後,『新的變數名』.array則會顯示這個shared\_array的. 陣列中m*n的值 10|. self.shape = self.array.shape # 如果宣告完成後,『新的變數名』.shape則會顯示這個shared\_array的. 陣列大小 # 程式碼的01~10行完成了shared_array這個class的宣告,之後就可以使 用這個class開啟共享的零陣列 # 範例如下 14.
(23) 11| >>> A = shared_array() # 讓A成為一個共享的零陣列,shared_array的輸入端不填值則會是一 個1*1的零陣列 12| >>> A.array # 展示A的陣列內容 array([[ 0.]]) # 1*1的零陣列 13| >>> A = shared_array((2,4)) # 讓A成為一個2*4的共享零陣列, 14| >>> A.array # 展示A的陣列內容. 0.,. 0.],. 0.,. 0.,. 0.]]). [ 0.,. 學. 立 0.,. ‧ 國. array([[ 0.,. 政 治 大. # 2*4的零陣列. ‧. 在這裡的宣告共享陣列shared array只用零陣列是為了方便先預開一個共享. Nat. sit. y. 的陣列大小再把值依序填入,用法跟numpy裡的zeros很像不過是共享的。接續上. er. io. 述的程式碼,把共享的零陣列開好後本篇也提供了一個的副函式array2shared讓 值可以方便地複製到共享陣列中。. n. al. array2shared. Ch. engchi. i n U. v. 15| def array2shared(A,shared_A): # array2shared這個副函式的輸入端是A與shared_A,它的功能是把A陣 列的值複製到shared_A這個共享陣列中 16|. m1,n1 = A.shape # m1,n1為A陣列的大小. 17|. m2,n2 = shared_A.shape # m2,n2為shared_A共享陣列的大小. 18|. if m1<>m2 or n1<>n2: # 這個if判斷式是要保證m1=m2以及n1=n2,如果大小不一樣時則執行. 以下敘述. 15.
(24) 19|. print ’The size of matrices must be the same’. 20|. return. 21|. else: # 如果m1=m2以及n1=n2時,則執行以下敘述. 22|. for i in range(m1):. 23|. shared_A.array[i] = A[i] # 把A的第i列複製到shaed_A.array的第i列. # 範例如下:. 政 治 大. 24| >>> A = np.random.random((2,4)). # A為隨機產生的2*4陣列,其中值從0~1的浮點數中隨機中挑出來. 立. 25| >>> A. ‧ 國. 學. # 展示A. 0.84162458,. 0.56063487,. 0.13024106],. [ 0.77196049,. 0.84924812,. 0.32920407,. 0.50888212]]). ‧. array([[ 0.6659476 ,. # A為隨機的2*4陣列. y. Nat. sit. 26| >>> shared_A = shared_array((2,4)). al. er. io. # shared_A為2*4的共享零陣列. n. 27| >>> shared_A.array. Ch. # 展示shared_A.array. engchi. array([[ 0.,. 0.,. 0.,. 0.],. [ 0.,. 0.,. 0.,. 0.]]). i n U. v. # shared_A為2*4的共享零陣列 28| >>> array2shared(A,shared_A) # 把A陣列的值複製到shared_A共享陣列中 29| >>> shared_A.array # 展示shared_A.array array([[ 0.6659476 ,. 0.84162458,. 0.56063487,. 0.13024106],. [ 0.77196049,. 0.84924812,. 0.32920407,. 0.50888212]]). # A的值已完全的複製到shared_A裡了. 16.
(25) 接續上述的程式碼,既然共享的陣列已經可以方便的開創和使用,本篇要作 的平行計算也就能開始動工了,在這之前先介紹multiprocessing套件裡一個特殊 的功能Lock,使用這個工具就能讓多個process在平行計算中等待別個process所需 要同步與執行的結果,再接著繼續完成它的任務。 Lock 例子2.2-2:這個例子主要是要表達出當副函式裡大計算量的地方時可以讓 多個process同時平行處理,而需要同步與小計算量的地方時再使用Lock的 功能讓process作一個等待與同步的動作。而這個副函式需要同步的地方則是 當副函式被呼叫時的次數(count.array)也會加入計算,這個例子會使用到上 述shared array、array2shared與Lock的應用。如圖 2.3:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 2.3: 例子2.2-2 BigCal. 17. v.
(26) 30| import time # 引入time套件 31| def Fun_A(A,k): # Fun_A這個副函式中會把k個index個別作運算,再回傳出來 32|. start = time.time() # 起始時間。把此刻的執行時間記錄下來儲存到start中. 33|. def BigCal(shared_A,k,lock): # BigCal這 個 副 函 式 等 等 會 被 平 行 運 算 , 個 別 運 算 後 並 把 值 存. 到shared_A裡 34|. time.sleep(5). 政 治 大. # 這裡的time.sleep(5)是讓時間時間停滯5秒以此模擬大計算量時. 立. 學. 35|. ‧ 國. 的執行時間. step1_reslult = 2*k. # 而step1_result則是模擬大計算量完成的結果 with lock:. ‧. 36|. # 這裡的with lock功能會讓第一個執行到此行的process繼續執行. y. Nat. al. er. count.array+=1. io. 37|. sit. 以下的程式碼,直到此process執行結束才會讓別的proces執行. v. n. # 這裡的count當作計數器記錄這個副函式『BigCal』執行了幾次 38|. Ch. time.sleep(1). engchi. i n U. # 這裡的time.sleep(1)是讓時間時間停滯1秒以此模擬小計算量 時的執行時間 39|. step2_result = k # 而step2_result則是模擬小計算量完成的結果. 40|. shared_A.array[0][0] = shared_A.array[0][0] + count.array + step1_result + step2_result # 這裡的shared_A.array[0][0]是需要被同步的部分,其中step1_result是. 可以同時間獨立給每個process執行的部分,而count.array則是需要等待 被同步的值 41|. m,n = A.shape # m與n是A陣列的大小. 18.
(27) 42|. shared_A = shared_array((m,n)) # shared_A是一個m*n的共享零陣列. 43|. assert shared_A.array.base.base is shared_A.shared_base.get_obj() # 讓shared_A在執行結束後把共享記憶體釋放掉,不然會一直佔著記. 憶體的空間 44|. array2shared(A,shared_A) # 把A陣列的值複製到shared_A共享陣列中. 45|. count = shared_array((1,1)) # count是一個1*1的共享零陣列. 46|. 政 治 大. assert count.array.base.base is count.shared_base.get_obj() # 讓count在執行結束後把共享記憶體釋放掉,不然會一直佔著記憶體. 立. 學. 47|. ‧ 國. 的空間. lock = mp.Lock(). # 令lock為mp裡的Lock功能,也就是會等待前一個process完成工作的. 48|. ‧. 功能. procs = [mp.Process(target=BigCal, args=(shared_A,i,lock)) for. y. Nat. sit. i in range(k)]. al. for p in procs: p.start(). 50|. for p in procs: p.join(). n. 49|. Ch. engchi. er. io. # 這裡把要平行運算的副函式放入procs這個list裡. i n U. v. # 此為執行procs整個list 51|. return shared_A.array,time.time()-start # 回傳執行結果與運行時間. # 範例如下:. 53| >>> A = np.zeros((1,4)) # 令A為1*4的陣列 54| >>> A # 展示A array([[ 0.,. 0.,. 0.,. 0.]]). # 1*4的零陣列. 19.
(28) 55| >>> shared_A,time = Fun_A(A) # 令shared_A、time為Fun_A(A)的兩個輸出值 56| >>> shared_A[0][0] # 展示shared_A[0][0] 28.0 # 執行結果為28.0 57| >>> time # 展示time 9.020509004592896. 政 治 大. # 運行時間為9.020509004592896(sec). 立. 由於process在執行副函式『BigCal』裡的time.sleep(5)會讓時間停滯5秒(在. ‧ 國. 學. 此 為 模 擬 大 計 算 量 的 時 間), 接 著 副 函 式 『BigCal』 裡 的with lock功 能 會 等 待 共 享 記 憶 體 上 其 他 還 沒 執 行 結 束 的 任 務 , 在 這 裡 分 成 了4個process每 個 都. ‧. 會time.sleep(1)所以執行時間是9.020509004592896(sec),shared A[0][0]的結果則會 是28.0。而如果把with lock的功能拿掉,4個process則會同時執行『BigCal』所以. Nat. sit. y. 執行時間是6.01941990852356(sec),shared A[0][0]的結果會是34.0,時間從. er. io. 9.020509004592896(sec)→6.01941990852356(sec),結果也從28.0→34.0,原因是有. al. v i n Ch 4,而沒有with lock功能時4個process會同時執行count+=1使得count值都是4。可 i U e h n c g 發現with lock的確具有讓其他process等代的功能所以從上述例子中可以得到證 n. with lock功能時count被執行有先後順序所以在4個process中的count值是1、2、3、. 明。例子2.2-2已經可以操作共享記憶體並且還能使平行運算達到等待的功能,接 下來要介紹的是該如何控制電腦的核心,並且觀察在不同核心數底下的執行效 能。. 20.
(29) 2.3. Python控 控制 核 心 之 套 件. 除了平行運算之外,多核心操作的效能也是本篇所要探討的重點之一,在這 一節會介紹控制核心的套件以及如何操作它。 affinity 這是一個提供控制核心的套件,可以控制核心使用的數目[10]。 例子2.3-1:介紹如何知道電腦當下核心的使用數目與控制核心的數目。 01| >>> import affinity # 引入affinity套件. 政 治 大. 02| >>> affinity.get_process_affinity_mask(0). 立. # 查看當下核心的使用數目. ‧ 國. 學. 65535. # 此 輸 出 值 為2的 『 核 心 數 目 』 次 方 再 減1, 所 以65535這 個 值 為2的. ‧. 『16』次方再減1,故當下核心數目為『16』個. 03| >>> affinity.set_process_affinity_mask(0,2**8-1). sit. y. Nat. # 此輸入端的第二項為2的『核心數目』次方再減1,所以2**『8』-1則. n. al. er. io. 代表現在控制核心的使用數目為『8』個. Ch. i n U. v. 在此令affinity.get process affinity mask(0)的輸出值為K,由以上的例子我們. engchi. 可 以 得 到 這 個 公 式 ,K = 2n − 1, 其 中K代 表 的 是 輸 出 值 、n代 表 的 是 『 核 心數目』;換句話說如果我們需要控制核心數目的時候,我們就可以使 用affinity.set process affinity mask(0,2**n-1),其中n代表的就是『核心數目』。 有了這個套件之後,我們就可以方便地觀察在不同的核心數底下,多個process的 平行化在執行效能上到底有沒有影響,而執行效能的比較在第四章則會作比較詳 細的介紹。基本的操作在這一個章節告一段落,在之後的篇幅會介紹到平行計算 在其他地方上的應用。. 21.
(30) 第 三 章. SCMDS與 與其 平 行 化. 在 這 一 章 節 會 介 紹 到 傳 統 的 多 元 尺 度 法(Multidimensional Scaling在 此 簡 稱MDS)與拆解合成-多元尺度法(Split-and-Combine MDS在此簡稱SC-MDS)的概 念以及哪裡有需要平行化的地方、如何放入平行化的方法加快其速度。. 3.1. SCMDS以 以及 單 核心版本 for Python. 政 治 大 時保持彼此間的距離轉換成低維度時還能維持其資料的結構。這個方法最早是用 立. 多元尺度法(MDS)是一種把高維度資料轉換成低維度資料的方法,在高維度. ‧ 國. 學. 在如何把地球上城市與城市之間三維的距離位置轉換成二維的資料,由於人類對 於高維度的資料難以想像其結構圖形,運用此方法就能讓人們以視覺理解的方式 來解讀資料。[3]. ‧. 多元尺度法主要是利用距離矩陣(其中距離矩陣d[i, j]代表位置i與位置j之. Nat. sit. y. 間 的 距 離)透 過 一 些 運 算 以 及double centering(在 下 一 個 段 落 會 解 釋 其 作 法)的. er. io. 方 法 把 資 料 平 移 到 質 心 的 位 置 , 由 於 距 離 矩 陣 是 對 稱 矩 陣 所 以 作 完double. al. v i n 這C 個 矩 陣 平 方 根 後 取U h e n g c h i 前p項(可 寫 成Σ的 平 方 根 後 取. n. centering的矩陣亦是對稱矩陣,所以對這個作完double centering的矩陣作SVD分 解 可 寫 成ZΣZ , 把ZΣZ T. T. 前p × p項與Z取前p行後的轉置相乘)即是多元尺度法降到p維後的資料結果。這 是T orgerson [15]提出的第一個典型MDS法,它主要的作用是把笛卡兒座標系中 從給定的對稱矩陣D來重建矩陣X,其中的關鍵則是應用double centering轉換 和SVD分解。 這裡就來介紹double centering的作法,假設X是一個r × N 的矩陣,其中N 是 樣本數的個數、r是資料的維度。令D = X T X、i是N × 1的向量,其中它的每一 個元素都是1。Double centering的方法就是把D平移到質心的位置,此時 B = (X −. 1 XiiT )T (X N. = (X T − =D−. −. 1 T ii X T )(X N. 1 DiiT N. −. 22. 1 XiiT ) N. −. 1 T ii D N. 1 XiiT ) N. +. 1 iiT DiiT N2.
(31) ¯r − D ¯c + D ¯g =D−D ¯r = ,其中D. 1 ¯ r 中每列的值是矩陣D沿著列方向作平均,同一列的所有元 DiiT ,D N. ¯c = 素值都相等。D. 1 T ¯ c 中每行的值是矩陣D沿著行方向作平均,同一行 ii D,D N. ¯g = 的所有元素值都相等。D. 1 ¯ g 中每個值是整個矩陣D的平均值,所 iiT DiiT ,D N2. ¯r − D ¯c + D ¯ g 這個過程,稱為double 有元素值都相等。把矩陣D轉變成B = D − D 1 T ii ,其中I是N N. centering。若定義H = I −. × N 的單位矩陣,則矩陣B可寫成. B = H T DH ,由於矩陣D、H是對稱矩陣所以矩陣B也會是對稱矩陣,則矩陣B的SVD分解就 可以寫成. 治 政 B = (X − Xii ) (X − 大 Xii ) 立 1 N. T T. 1 N. T. ‧ 國. 學. = H T DH = ZΣZ T. ‧. 1. 1. = (ZΣ 2 P )(P T Σ 2 Z T ). sit. y. Nat. ,其中矩陣P 代表一個unitary matrix,不同的矩陣P 只是把座標作一個旋轉而 已,並不會改變資料的相對位置,為了方便通常在多元尺度法中取P = I。而. io. 1. n. al. er. 在Σ這個對角矩陣中奇異值會依照大小排序,令Σp2 為取Σ的平方根後對角線前p項. i n U. 不為零的矩陣以及令Zp 為取Z前p行,則MDS的結果就是. Ch. e n√g c h i. Y =. v. B. =X−. 1 XiiT N. 1. = Σp2 ZpT 1. ,其中矩陣Σp2 是p × p的子矩陣、ZpT 是p × N 的子矩陣、而矩陣Y 是矩陣X降成p維 後p × N 的矩陣。當然在這個分析中D不是距離矩陣,所以推導過程還沒結束,接 著要把距離矩陣d創造出來並透過一些運算取代原本的矩陣D,在此我們令d是由 p 矩陣X算出來的距離矩陣(定義d[i, j] = (X[i] − X[j])T (X[i] − X[j]),其中X[i]代 表矩陣X的第i行、也就是矩陣X第i筆樣本p維度的資料),令D1 為距離矩陣d自己 的點平方(在此所謂的點平方就是把此矩陣中的每個元素值自己平方)再乘以 −1 表 2 示為 D1 =. −1 .2 d 2. 23.
(32) ,現在D1 就是MDS中拿來取代矩陣D的距離矩陣,而且D1 的double centering等 於B,B = H T DH = H T D1 H , 依 照 剛 剛 的 方 法 把D1 作double centering後 再 作SVD分解取出矩陣B的平方根後取前r項就是MDS的結果了。但這個方法還是有 許多缺點的[5],像是資料的遺失是無法接受的以及計算量是O(N 3 ),因此要把這 個方法用在大資料上是不適合的。 一般來說多元尺度法最主要的過程是SVD,由於SVD的計算量是O(N 3 ),所 以當矩陣很大時,例如6萬的量現今的個人電腦大概就無法處理了,所以需要 一個可以因應大資料計算的方法,就是拆解-合成多元尺度法(Split-and-Combine MDS在此簡稱SC-MDS)。這在Jengnan T zeng[17]有提出SC-MDS的理論,它的核. 政 治 大 新的座標位置,再把這些有重疊的新作標位置透過旋轉加以合成(由於重疊的座標 立. 心精神就是把資料拆解成很多塊有重疊的子資料,個別經過多元尺度法後轉換成. 位置在原本的資料中是一樣的座標,所以可以旋轉加以合成)。接下來,就來介紹. ‧ 國. 學. 如何把新座標透過旋轉接在舊座標上面。. ‧. 若 假 設X1 和X2 是 從 距 離 矩 陣 中 的 兩 個 有 重 疊 且 不 相 同 的 子 矩 陣 個 別 作MDS所得到的矩陣中取重疊部分的行向量(例如:X1 和X2 是距離矩陣取1∼5和. y. Nat. sit. 3∼7的行與列作MDS得到的矩陣中取第一個矩陣的3∼5行和第二個矩陣的1∼3行),. al. er. io. 其中這兩個矩陣是重疊的所以本質上是一樣的資料且彼此距離也沒有改變,因. n. 此存在一個仿射映射(af f ine mapping)可以把X2 的座標映射到X1 的座標。現在. Ch. i n U. v. 令X¯1 和X¯2 分別是X1 和X2 行向量們的平均值(X¯1 和X¯2 是p × 1的矩陣,其中p是欲降. engchi. 至的維度),接下來先平移到質心的位置作QR分解就可以使用這些正交化的基底 來幫助旋轉,所以X1 − X¯1 iT = Q1 R1 以及X2 − X¯2 iT = Q2 R2 ,其中i是r×1的向 量它的每一個元素都是1。由於X1 和X2 本質上是一樣的,所以R1 和R2 應是一樣的 矩陣(由於QR分解不是唯一的,所以對角線上”可能”會差個負號,那就得把對應 的Q2 也乘個負號來調整),調整結束後,我們可以提出 QT1 (X1 − X¯1 iT ) = QT2 (X2 − X¯2 iT ) ,更進一步地我們可以得到 T X1 = Q1 QT2 X2 − Q1 QT2 (X¯2 iT ) + X¯1 T. ,因此找出旋轉轉換U = Q1 QT2 以及平移轉換b = −Q1 QT2 (X¯2 iT ) + X¯1 ,有了旋 轉轉換和平移轉換,我們就有了可以把X2 座標映射到X1 座標的仿射映射(af f ine 24.
(33) mapping)。由於每一塊重疊的子資料是個別透過MDS之後再把結果合成出來, 所以在主項上面可能會與使用傳統MDS方法算出結果的位置不同,因為在傳統 的MDS方法中Component放的順序是以大排到小的,所以在此以PCA的方法再把 資料作一個調整,使其結果會與傳統的MDS方法一樣,由於現在資料的維度已經 被降到真實維度的大小了,所以在計算時間上並不會太多。 現在就來分析SC-MDS的計算量究竟少的多少,假設資料的樣本數是N 個,Ng 是 子資料的寬度,Ni 是重疊的子資料中交集的寬度,當我們把樣本數N 拆解成K個 子資料時,我們可以得到KNg − (K − 1)Ni = N ,更近一步可以得到 N − Ni Ng − Ni. 政 治 大 , 對 於 每 一 個 子 資 料 作MDS時 立 , 它 的 計 算 量 會 是O(N ), 而 在 重 疊 的 部 分 是 K=. 3 g. ‧ 國. 學. 用QR分解,所以它的計算量會是O(N i3 ),因為此資料的真實維度為p,Ni 的最小. 值是p+1,這裡可以假設Ng = αp其中α是某些大於2的常數(如果α只比1大一點則 有可能使得αp − p的值趨近於零),所以當K個子資料作MDS以及K-1個重疊的部. ‧. 分作QR分解整體的計算量則會是. Nat. er. io. sit. y. N −p N − αp O(α3 p3 ) + O(p3 ) ∼ = O(p2 N ) (α − 1)p (α − 1)p. , 當p << N 時SC-MDS的 計 算 量O(p2 N )會 比 由Morrison et al.在2002年 提 出 的 √ 快 速MDS方 法[13]的 計 算 量O( N N )還 要 小 , 然 而 當p是 非 常 大 的 數 時(p2 >. n. al. Ch. engchi. i n U. v. N ),SC-MDS在計算量上沒有比較好,但是這個方法提供了一個巨型資料可 以運算的方法。而SC-MDS單核心版本的Python Code已放在附 附錄 A裡,而其中的 過程如圖3.1:. 25.
(34) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.1: 單核心SC-MDS流程圖. 在 圖3.1這 個 單 核 心SC-MDS中 , 這 裡 我 們 想 算 出 一 般 而 言 哪 部 分 是 最 占 時間的,在此以一個真實維度為50的3000*1000隨機矩陣,接著以Ni = 51、Ng = 2.2*Ni來 執 行 單 核 心scmds求 得 的 時 間 個 別 為I = 1.7811627388000488、II = 0.3949291706085205以及III = 0.03142094612121582,而在別的case中個別花的時 間在比例上是沒有很大的差異的,所以這裡可發現到最佔時間的莫過於while迴 圈裡的MDS(指的是把資料拆解出子資料後去作MDS的動作)以及Combine(指的是 把兩個算出MDS的資料其重疊的部份用QR分解找出它的仿射映射並且接上), 26.
(35) 若拆解的block(指的是資料拆解出的子資料)太大則會發生執行MDS(附 附 錄 A中 的D2X)以及Combine(附 附 錄 A中的affine solver)的時間太長而造成速度不快,而若 拆解的block太小則會發生block太多使得while迴圈執行太多遍也會造成速度不 快。 所以怎麼分配block的大小以及如何把while迴圈裡的東西平行化就成為了 加快速度的關鍵,接下來關於操作SC-MDS(附 附 錄 A中的scmdscale)的參數在這 裡作個介紹,這裡先假設真實維度為r、D是距離矩陣、p是我們想估計的真實 維度大小、Ni是重疊區塊的大小、Ng是拆解區塊的大小,其中r ≤ p、p + 1 ≤ N i、2 ∗ N i ≤ N g,這裡參考了P ei − ChiChen[6]論文中找出最佳Ni與Ng的參數,. 政 治 大 裡也作了一下測試當資料的真實維度為50,大小為3000*1000隨機的矩陣,以p = 立. 所以在接下來的操作也就取Ni = p+1以及Ng = 2.2*Ni讓執行時間達到最快。而這. 50、Ni = p+1的狀況去比較Ng為不同倍數的Ni時的執行時間可發現當Ng = 2.2時. ‧ 國. 學. 間幾乎最快,為了讓答案比較圓滑且公平所以這個例子是透過跑了16次不同的矩 陣所畫出來的,由此結果可得到就取Ni = p+1以及Ng = 2.2*Ni為搭配SC-MDS最. ‧. 好的方式。其中橫軸代表Ng取不同倍數的Ni,直軸是執行的時間,如圖3.2:. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 3.2: 找出最佳的Ng. 27. v.
(36) 3.2. SCMDS的 的平 行 化. 在這一節主要會介紹到如何用第二章所學到的方法把第3.1節所提到的SCMDS平行化,若依照最傳統的MDS法在距離矩陣D中會有很多多餘的資料是不用 被拿來計算的如圖3.3的右上角及左下角白色的部分這些都是多餘的資訊,並且整 個距離矩陣作MDS時的計算量非常大。而SC-MDS所使用的方法則是拆解出對角 線上有重疊的距離矩陣,會大幅縮減MDS時的計算量。由於距離矩陣D在拆解時 個別都是獨立的,所以正好可以拿來把MDS平行化並且再把結果放回共享的矩陣 中,而交集的部分再透過QR分解把資料合成回去,如圖3.4:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 3.3: 拆解平行化示意圖. 28. v.
(37) 立. 政 治 大. Nat. y. ‧. ‧ 國. 學 圖 3.4: 合成子資料的示意圖. sit. 圖3.4是在解釋圖3.3經過MDS平行化後的狀況,圖3.4的上半部表示的是. er. io. Shared X這個共享陣列,它記錄了本來需要大計算量的距離矩陣被拆解成小塊的. al. 距離矩陣後透過MDS平行化後的結果,這裡與SC-MDS不一樣的地方則是這裡的. n. v i n Ch 每一小塊MDS是透過平行運算的,所以可以把SC-MDS中的這部分再加速,而下 engchi U 半部表示的是這些子資料需要合成的部分,這裡是使用迴圈的方式把兩兩交集的 地方經過QR分解把子資料的圖合成回去。 接下來把SC-MDS拆解平行化的過程作一個詳細的介紹,其SC-MDS拆解平 行化的程式碼則放在附 附 錄 B中。有了距離矩陣放入Input Data後,我們得先創 造Shared momory,它們是共享的零陣列用來儲存Data與記綠MDS平行化後的結 果,接著把值複製到Shared memory上之後就可以開始執行平行化的部分了, 從共享的距離矩陣中拆解出子矩陣並且同時透過多個process把MDS平行運算,. 之後再把結果儲存到共享矩陣中以迴圈的方式把兩兩有交集的部分Combine起 來,直到把全部的子資料都Combine完後再執行PCA把主項轉到正確的位置則 是SC-MDS拆解平行化的結果了。如圖3.5:. 29.
(38) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.5: SC-MDS拆解平行化流程圖. 圖3.1與圖3.5兩張流程圖中,圖3.5中的I『Create Shared memory』與II『Copy Data To Shared memory』是比圖3.1多出來的,以及III『MDS』的部分也從單核 心被拆解成平行化的版本,其餘的部分在結構上是一樣的,所以在這裡我們期 待I與II的執行時間是短的,並且如果III的部分比單核心『MDS』的執行時間快很 多時,SC-MDS的平行化就會有其利基。. 30.
(39) 第 四 章. 實驗結果. 首先,本篇先提供所使用的硬體當參考;處理器:AMD Opteron(tm) Processor 6128 2GHz、核心數:8、記憶體:64GB、作業系統Ubuntu 64位元12.04版、 Python:2.7.1版。本章以SC-MDS以及SC-MDS拆解平行化為主要探討對象,接 著把多核心的控制帶入SC-MDS與其平行化來比較在不同核心數時對時間的差 異,接著再找出每個階段的執行時間對於核心的提升到底有沒有提升,以及其加 速最多的地方並且比較其效率。. 學. ‧ 國. 4.1. 政 治 大 SC-MDS與 與立 其平行化在多核心控制下之比較. 因為SC-MDS是應用大資料的計算所以本篇所測試的資料量會比較大,在 此估計三種不同的真實維度個別為資料一:50維度、資料二:100維度以及資料. ‧. 三:150維度的大資料在不同時的核心數底下對於SC-MDS與其平行化來進行測試. sit. y. Nat. 並比較其效率。. er. io. 在此先以資料一:50維度來當範例,這裡要測試的程式分別為SC-MDS單核. al. 心版本、2核心底下的SC-MDS平行化、4核心底下的SC-MDS平行化、8核心底下. n. v i n Ch 的SC-MDS平行化以及16核心底下的SC-MDS平行化在樣本數分別在3000、6000、 engchi U · · · 、15000這五種csae時所執行出來的時間提升狀況,把資料隨機創造出來並計算 出距離矩陣後,丟給SC-MDS單核心版本、2核心底下的SC-MDS平行化、4核心底 下的SC-MDS平行化、8核心底下的SC-MDS平行化以及16核心底下的SC-MDS平 行化來計算執行時間,其中真實維度p = 50、重疊區塊的大小(Ni)以及拆解區 塊的大小(Ng)採用3.1節所提出最佳的參數為Ni = p+1以及Ng = 2.2*Ni。範例如 下: SC-MDS的 的範 例 樣本數為3000時 01| >>> import scmds as sc # 引用附錄A、B所存成的scmds.py檔. 31.
(40) 02| >>> import affinity # 引入affinity套件 03| >>> A = sc.np.random.random((3000,50)) 04| >>> B = sc.np.random.random((50,1000)) 05| >>> C = sc.np.dot(A,B) # 這裡的C矩陣是一個真實維度為50的矩陣,矩陣大小是3000*1000,其 中樣本數為3000、維度為1000 06| >>> D = sc.pdist(C) # 此為算出彼此的距離. 政 治 大. 07| >>> D = sc.squareform(D[1]). # 此為把剛剛算出的距離放入距離矩陣內. 立. 08| >>> Y = sc.scmdscale(D,50,int(sc.np.floor(2.2*(50+1))),50+1,0). ‧ 國. 學. # 執行SC-MDS單核心版,p = 50、Ng = 2.2*Ni、Ni = p+1 09| >>> Y[0]. ‧. # 顯示執行時間 2.1422. y. Nat. sit. # 2.1422(sec). er. io. 10| >>> affinity.set_process_affinity_mask(0,2**2-1). al. # 控制核心使用數目為2顆. n. v i n Ch >>> Y1 = sc.pscmdscale(D,50,int(sc.np.floor(2.2*(50+1))),50+1,0) engchi U 執行2核心底下的SC-MDS平行化,p = 50、Ng = 2.2*Ni、Ni = p+1. 11| #. 12| >>> Y1[0] # 顯示執行時間 1.6415 # 1.6415(sec) 13| >>> affinity.set_process_affinity_mask(0,2**4-1) # 控制核心使用數目為4顆 14| >>> Y2 = sc.pscmdscale(D,50,int(sc.np.floor(2.2*(50+1))),50+1,0) # 執行4核心底下的SC-MDS平行化,p = 50、Ng = 2.2*Ni、Ni = p+1 15| >>> Y2[0] # 顯示執行時間. 32.
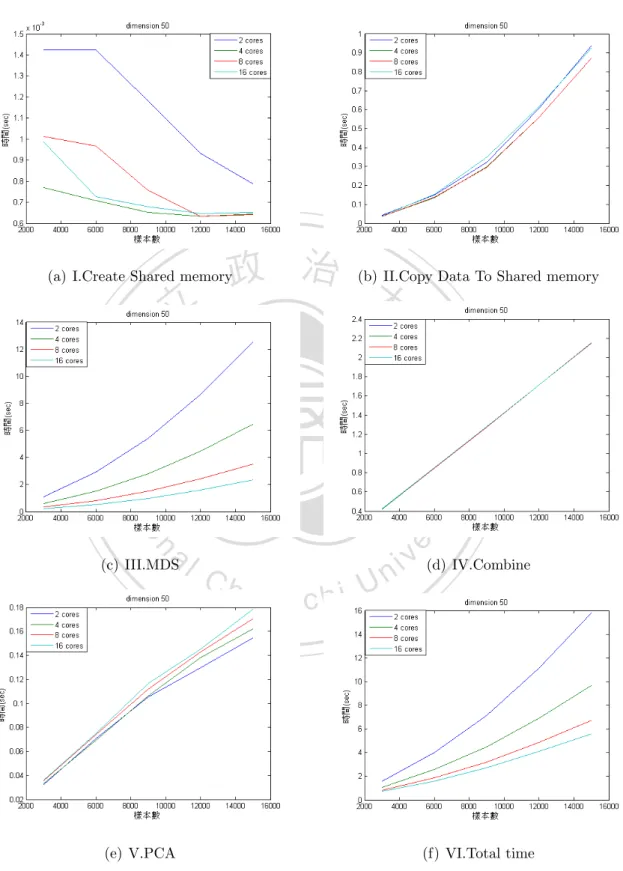
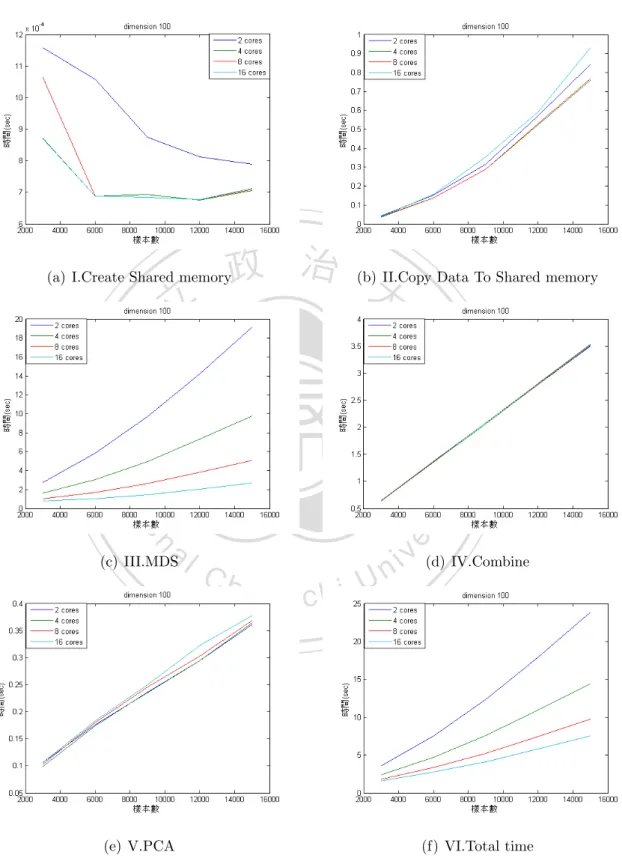
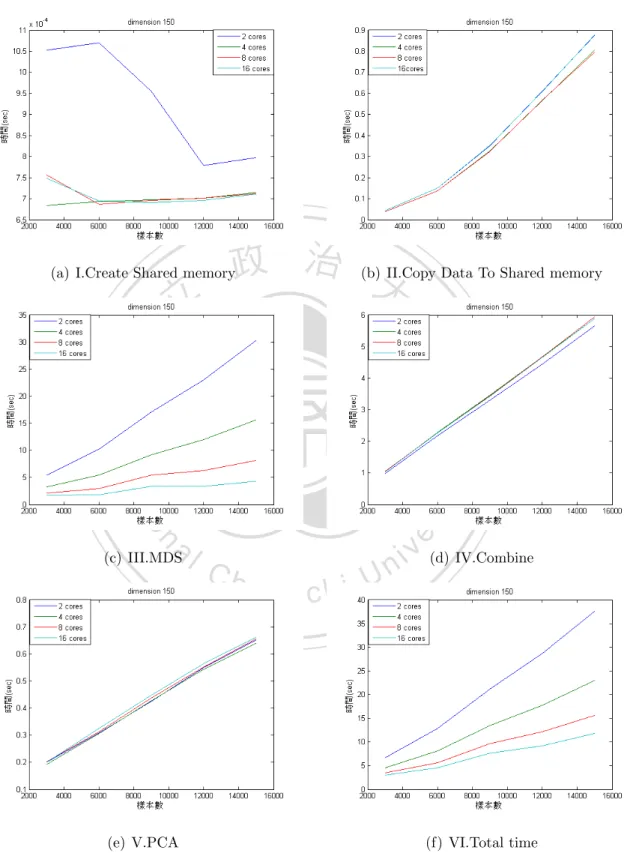
(41) 1.0969 # 1.0969(sec) 16| >>> affinity.set_process_affinity_mask(0,2**8-1) # 控制核心使用數目為8顆 17| >>> Y3 = sc.pscmdscale(D,50,int(sc.np.floor(2.2*(50+1))),50+1,0) # 執行8核心底下的SC-MDS平行化,p = 50、Ng = 2.2*Ni、Ni = p+1 18| >>> Y3[0] # 顯示執行時間 0.8424 # 0.8424(sec). 政 治 大. 19| >>> affinity.set_process_affinity_mask(0,2**16-1). 立. # 控制核心使用數目為16顆. ‧ 國. 學. 20| >>> Y4 = sc.pscmdscale(D,50,int(sc.np.floor(2.2*(50+1))),50+1,0) # 執行16核心底下的SC-MDS平行化,p = 50、Ng = 2.2*Ni、Ni = p+1. ‧. 21| >>> Y4[0]. # 顯示執行時間. sit. y. Nat. 0.7444. er. io. # 0.7444(sec). al. n. v i n Ch 依照上述範例的方式,當樣本數為3000時,把SC-MDS單核心版本、2核心 i U e h n c g 底下的SC-MDS平行化、4核心底下的SC-MDS平行化、8核心底下的SC-MDS平行 化以及16核心底下的SC-MDS平行化五種方法所得到的時間存起來則是樣本數為 為3000的結果。接著想觀察在別的樣本數下不同核心數對於執行時間的比值到底 有沒有進步,所以依序設定樣本數為3000、6000、· · · 、15000共五種case執行以上 的步驟,由於資料是隨機產生的所以為了讓資料更趨於穩定,因此在這裡的資料 都會再重新創造與執行十五次,並把十六次的執行時間作一個平均值,而這只是 資料一:真實維度為50的例子,依序把資料二:真實維度為100與資料三:真實維 度為150也拿來測試,下圖就是把執行結果畫出來,其中橫軸是樣本數的大小,直 軸是執行的時間,如圖4.1、圖4.2、圖4.3:. 33.
(42) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4.1: SC-MDS與其平行化的執行時間比較圖(真實維度為50). n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4.2: SC-MDS與其平行化的執行時間比較圖(真實維度為100). 34.
(43) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4.3: SC-MDS與其平行化的執行時間比較圖(真實維度為150). Nat. sit. y. 從圖4.1、圖4.2、圖4.3中可觀察到雖然SC-MDS單核心版本的執行時間並不. er. io. 是2核心底下的SC-MDS平行化執行時間的兩倍,以及SC-MDS單核心版本的執行. al. 時間與其它倍數核心底下的SC-MDS平行化執行時間的比值(這裡的比值代表的. n. v i n Ch 是SC-MDS單核心版本的執行時間除以別的核心數底下的執行時間)也不是核心 engchi U 數的倍率,核心的倍數雖然並沒有讓時間也達到一樣倍數的縮短,不過在執行 時間上還是少了許多,接下來就來比較這些比值究竟是幾倍,如表4.1、表4.2、 表4.3:. 35.
(44) 對應樣本數(時間和比值)\核心數. 1. 2. 4. 8. 16. 3000. 2.1422. 1.6415. 1.0969. 0.8424. 0.7444. 時間. 1. 1.3050. 1.9530. 2.5429. 2.8778. 比值. 5.3217. 4.0766. 2.6188. 1.9194. 1.6515. 時間. 1. 1.3054. 2.0321. 2.7726. 3.2223. 比值. 9.3574. 7.4448. 4.6341. 3.3021. 2.8673. 時間. 1. 1.2569. 2.0193. 2.8338. 3.2635. 比值. 14.5039. 11.6666. 7.1063. 5.0306. 4.5349. 時間. 1. 1.2432. 2.0410. 2.8831. 3.1983. 比值. 政20.5157治16.5000大 9.9324. 6.9757. 6.1258. 時間. 2.9410. 3.3490. 比值. 6000. 9000. 12000. 15000. 立. 1. 1.2434. 2.0655. ‧. ‧ 國. 學. 表 4.1: SC-MDS與其平行化執行時間的比值(真實維度為50). 2. 6.2910. 3.5839. 1. 1.7553. n. al. 1. 6000. 9000. Ch. 4. 8. 16. 1.8347. 1.5921. 時間. 3.4289. 3.9514. 比值. 4.7449. 3.4064. 2.7632. 時間. er. io. 3000. sit. y. Nat. 對應樣本數(時間和比值)\核心數. 2.4306. v i2.5883 n U. i e13.4576 n g c h7.6506 1. 1.7590. 2.8362. 3.9506. 4.8702. 比值. 21.5460. 12.5408. 7.7334. 5.3402. 4.1564. 時間. 1. 1.7181. 2.7861. 4.0347. 5.1838. 比值. 36.
(45) 對應樣本數(時間和比值)\核心數. 1. 2. 4. 8. 16. 12000. 30.6964. 18.4055. 11.2386. 7.6622. 5.9102. 時間. 1. 1.6678. 2.7313. 4.0062. 5.1938. 比值. 40.9411. 24.6853. 14.9504. 10.0390. 7.6501. 時間. 1. 1.6585. 2.7385. 4.0782. 5.3517. 比值. 15000. 表 4.2: SC-MDS與其平行化執行時間的比值(真實維度為100) 1. 2. 4. 8. 16. 3000. 11.2975. 6.6218. 4.5232. 3.4546. 2.9370. 時間. 1 1.7061 2.4977 政23.3318治13.0014大 8.1566. 3.2703. 3.8467. 比值. 5.7194. 4.5551. 時間. Nat. 15000. io. 4.0794. 5.1222. 比值. 37.3263. 21.2125. 13.2836. 9.5911. 7.6429. 時間. 1. 1.7596. 2.8100. 3.8918. 4.8838. 比值. 51.3441. 29.4349. 17.9716. 12.2554. 9.3488. 時間. 1. 1.7443. 2.8570. 4.1895. 5.4921. 比值. 67.0523. 38.4071. 23.3575. 15.9491. 12.0683. 時間. 1. 1.7458. 2.8707. 4.2041. 5.5561. 比值. n. al. 2.8605. sit. ‧ 國. 12000. 1.7946. ‧. 9000. 1. 學. 立. er. 6000. y. 對應樣本數(時間和比值)\核心數. i n U. v. 表 4.3: SC-MDS與其平行化執行時間的比值(真實維度為150). Ch. engchi. 就上述表4.1、表4.2、表4.3可觀察到雖然在核心數不高時樣本數的提升不一 定能提升比值,但在我們的測試中比值最少也有1.2432(表4.1的2核心比值)所以執 行時間還是優於SC-MDS單核心版本的執行時間,而除了在核心數低的狀況下我 們還發現到在『固定的核心數底下樣本數的提升』以及『固定的樣本數底下核心 數的提升』都會使比值提高,如果這個理論是正確的,比值的最大值應該會發生 在核心數與樣本數最高的時候,而這與我們的測試結果一致,這是非常好的事實 因為當樣本數越大時多核心的平行化效率就會越好了。. 37.
(46) 在測試中比值的最大值為5.5561(在表4.3的16核心比值),這到底是多核心的 操作對於SC-MDS中哪個階段造成的影響呢,下一節會以這個方向為主要目的並 找出其最有影響的階段。. 4.2. 多 核 心 的 操 作 對 於SC-MDS的 的平 行 化 在 各 個 階 段 的影響. 根據現在已知多核心的操作對於平行化已有顯著的成效,但是SC-MDS平行. 政 治 大 會把SC-MDS平行化各個階段的執行時間都記錄下來藉以了解在各階段的時間狀 立 況。因此這裡的測試也與4.1節採用相同的測試條件。 化版本中有很多階段在多核心的運算下效果是一樣的,所以為了公平起見在這裡. ‧ 國. 學. SC-MDS的平行化總共分為I.Create Shared memory、 II.Copy Data To Shared. ‧. memory、III.MDS、IV.Combine以及V.PCA共五個階段(如同3.2節所提及的五個 階段)。而這一節的測試則把這五種階段以及全部所花的時間VI.Total time作一個. sit. y. Nat. 比較。. er. io. 在此以三種不同的真實維度個別為資料一:50維度、資料二:100維度以. al. n. v i n Ch 小Ng = 2.2*Ni(採用3.1節所提出最佳的參數)在樣本數3000、6000、· · · 、15000共 engchi U 及 資 料 三 :150維 度 的 大 資 料 以 重 疊 區 塊 的 大 小Ni = p+1以 及 拆 解 區 塊 的 大. 五種case在不同的核心使用數下測試各階段的執行時間以及比較其效率。而這一 節資料的產生方式和4.1節相同,下圖就是把執行結果畫出來,其中橫軸是樣本數. 的大小,直軸是執行的時間,如圖4.4、圖4.5、圖4.6:. 38.
(47) 政 治 大. (a) I.Create Shared memory. 立. (b) II.Copy Data To Shared memory. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. (c) III.MDS. Ch. engchi. (e) V.PCA. i n U. v (d) IV.Combine. (f) VI.Total time. 圖 4.4: SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為50). 39.
(48) 政 治 大. (a) I.Create Shared memory. 立. (b) II.Copy Data To Shared memory. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. (c) III.MDS. Ch. engchi. (e) V.PCA. i n U. v (d) IV.Combine. (f) VI.Total time. 圖 4.5: SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為100). 40.
(49) 政 治 大. (a) I.Create Shared memory. 立. (b) II.Copy Data To Shared memory. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. (c) III.MDS. Ch. engchi. (e) V.PCA. i n U. v (d) IV.Combine. (f) VI.Total time. 圖 4.6: SC-MDS的平行化在各個階段的執行時間比較圖(真實維度為150). 41.
(50) 由圖4.4、圖4.5、圖4.6中可發現到它們的子圖(a)I.Create Shared memory在 核心使用數不同時彼此的執行時間相差很小因為它的單位是10−4 ∼ 10−3 ,而 他們的子圖(b) II.Copy Data To Shared memory、(d)IV.Combine以及(e)V.PCA在 核心使用數不同時執行時間會隨樣本數增加但彼此的執行時間在不同核心上 沒有明顯的改變,可見核心數的多寡和上述幾個階段都沒有太大的關係,而剩 下的子圖(c)III.MDS中則發現在核心使用數不同時彼此的執行時間相差很大並 且它們的曲線圖與(f)VI.Total time有直接的相關,所以這裡可以得到兩個小結 論而第一個結論是:從子圖(b) II.Copy Data To Shared memory與(c)III.MDS可 發現到當核心使用數到達16核時III.MDS的執行時間已經被縮短到幾乎不到3秒. 政 治 大. 而II.Copy Data To Shared memory卻不會因為核心數增多而降低執行時間,還 需要花0.8∼0.9秒,所以當核心使用數再增加到某個數字時就會發生II.Copy Data. 立. To Shared memory的執行時間會超過III.MDS的執行時間了,可以得到『核心使. ‧ 國. 學. 用數在提升平行化效率時有個最大值,意即超過這個最大值,多核心就不划算 了』。第二個結論是:從子圖(c)III.MDS 與(d)IV.Combine可發現到當核心使用數. ‧. 到達16核時IV.Combine的執行時間已經超過III.MDS的執行時間了,所以就算核 心數再增加多核心加速的效率還是會被IV.Combine所侷限住。. io. sit. y. Nat. 多核心的操作 平行 化 的 效 能 比 a 中MDS平. er. 4.3. n. iv l C n hengchi U 透過4.2節的討論,核心數使用的多寡和4.2節中III.MDS階段加速的效率才是. 最息息相關的,其它階段加速的效率與多核心的操作似乎沒有直接的影響,為了 客觀地比較多核心平行化與單核心的效能,這節所採取的方式是比較SC-MDS單 核心版本中的MDS階段以及在2核心、4核心、8核心以及16核心底下SC-MDS平行 化中的MDS階段。因此這裡的測試也與4.1、4.2節採用相同的測試條件。 在此以三種不同的真實維度個別為資料一:50維度、資料二:100維度以 及 資 料 三 :150維 度 的 大 資 料 以 重 疊 區 塊 的 大 小Ni = p+1以 及 拆 解 區 塊 的 大 小Ng = 2.2*Ni(採用3.1節所提出最佳的參數)在樣本數3000、6000、· · · 、15000共 五種case在不同的核心使用數下測試MDS階段的執行時間以及比較其效率。而這 一節資料的產生方式和4.1節相同,下圖就是把執行結果畫出來,其中橫軸是樣本 數的大小,直軸是執行的時間,如圖4.7、圖4.8、圖4.9:. 42.
(51) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4.7: SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為50). n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4.8: SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為100). 43.
(52) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4.9: SC-MDS與其平行化在MDS階段的執行時間比較圖(真實維度為150). y. Nat. sit. 從圖4.7、圖4.8、圖4.9中可觀察到SC-MDS與其平行化在MDS階段的執行時. er. io. 間的比值(這裡的比值代表的是SC-MDS單核心版本MDS階段的執行時間除以別的. n. al. v. 核心數底下MDS階段的執行時間)似乎與核心使用數的倍數相差不遠了,下來就. i n C 來比較這些比值究竟是幾倍,如表4.4、表4.5、表4.6: hengchi U 對應樣本數(時間和比值)\核心數. 1. 2. 4. 8. 16. 3000. 1.7061. 1.1089. 0.5865. 0.3330. 0.2221. 時間. 1. 1.5386. 2.9090. 5.1234. 7.6817. 比值. 4.3671. 2.9114. 1.5147. 0.8225. 0.5184. 時間. 1. 1.5000. 2.8831. 5.3095. 8.4242. 比值. 8.0410. 5.4152. 2.8160. 1.5187. 0.9854. 時間. 1. 1.4849. 2.8555. 5.2947. 8.1601. 比值. 6000. 9000. 44.
(53) 對應樣本數(時間和比值)\核心數. 1. 2. 4. 8. 16. 12000. 12.5504. 8.6574. 4.4802. 2.4372. 1.6073. 時間. 1. 1.4497. 2.8013. 5.1495. 7.8084. 比值. 18.0065. 12.5113. 6.4580. 3.4986. 2.3291. 時間. 1. 1.4392. 2.7882. 5.1468. 7.7311. 比值. 15000. 表 4.4: SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為50). 16. 2.7760. 1.6284. 1.0172. 0.7829. 時間. 1. 1.9888. 3.3902. 5.4272. 7.0519. 比值. 11.7333. 5.8686. 3.0312. 1.7012. 1.0550. 時間. 1. 1.9993. 3.8708. 6.8970. 11.1213. 比值. 9000. 18.9458. 9.6866. 4.9831. 2.6254. 1.4400. 時間. 1. 1.9559. 3.8020. 7.2164. 13.1570. 比值. 27.0553. 14.2258. 3.8420. 2.0726. 時間. 1. 1.9018. 7.0419. 13.0540. 比值. 9.7574. 5.0889. 2.6765. 時間. 3.7187. 7.1302. 13.5567. 比值. Nat. io. 12000. n. al. 15000. Ch. 7.3021. v i3.7051 n U. i e36.2851 n g c h19.1267 1. y. 6000. sit. 3000. ‧. 5.5207. er. 8. ‧ 國. 4. 學. 政 治 大 對應樣本數(時間和比值)\核心數 1 2 立. 1.8971. 表 4.5: SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為100). 45.
(54) 對應樣本數(時間和比值)\核心數. 1. 2. 4. 8. 16. 3000. 9.9896. 5.4291. 3.2899. 2.1606. 1.6823. 時間. 1. 1.8400. 3.0364. 4.6235. 5.9382. 比值. 20.3222. 10.2607. 5.4188. 2.9336. 1.7700. 時間. 1. 1.9806. 3.7503. 6.9275. 11.4812. 比值. 32.4566. 17.0361. 9.2043. 5.4336. 3.3713. 時間. 1. 1.9052. 3.5262. 5.9733. 9.6273. 比值. 45.3140. 23.0451. 11.9607. 6.2891. 3.3675. 時間. 1. 1.9663. 3.7886. 7.2051. 13.4561. 比值. 政60.1014治30.2908大 15.5924. 8.1968. 4.3285. 時間. 7.3323. 13.8851. 比值. 6000. 9000. 12000. 15000. 立. 1. 1.9842. 3.8545. ‧ 國. 學. 表 4.6: SC-MDS與其平行化在MDS階段執行時間的比值(真實維度為150) 就上述表4.4、表4.5、表4.6可發現到原來SC-MDS平行化中的MDS階段可以. ‧. 被多核心加速到最快13.8851倍(表4.6的16核心比值),最慢也有1.4392倍(表4.3的2核. y. Nat. 心比值)所以執行時間還是優於SC-MDS單核心版本MDS階段的執行時間,而這裡. sit. 也觀察到一點與4.1節相同的地方就是除了在核心數低的狀況下我們還發現到在. er. io. 『固定的核心數底下樣本數的提升』以及『固定的樣本數底下核心數的提升』都. al. n. v i n Ch 數越大時多核心的平行化效率就會越好了並且若只討論平行化的階段還可以使比 engchi U 會使比值提高,比值的最大值會發生在核心數與樣本數最高的時候,因此當樣本. 值達到接近核心使用數的數量。. 46.
(55) 第 五 章. 結論. 由本論文的實驗結果可得到以下結論:. 1. 在4.2節所提到的II.Copy Data To Shared memory在資料的派送上會隨著樣 本數的提升而增加執行時間。 2. 如結論1在資料的派送上會有個固定的執行時間是多核心所不能縮短的, 所以當核心使用數越高時,派送資料的時間就會佔越大部分使得多核心下. 治 政 值,超過這個最大值,多核心就不划算了。 大 立. 的SC-MDS平行化效率降低,意即核心使用數在提升平行化效率時有個最大. ‧ 國. 學. 3. 在16核底下的SC-MDS平行化時,在4.2節所提到的IV.Combine的執行時間 已經超過III.MDS的執行時間了,所以就算核心數再增加多核心加速的效率 還是會被IV.Combine所侷限住。. ‧ y. Nat. SC-MDS的方法已經把傳統的MDS方法大幅改進而SC-MDS平行化又再次的. io. sit. 提高其效率,若要再提升SC-MDS平行化的效率就得從IV.Combine的階段著手,. n. al. er. 由於在執行平行化時資料都已先被存入Shared memory所以已經省下了資料派送. i n U. v. 的時間,若能寫出其平行化的程式可望能把效率作再次的提升。. Ch. engchi. 47.
(56) 參 考 文 獻 [1] David Griffiths、Paul Barry. 深入淺出程式設計. 歐萊禮, 2011. [2] Paul Barry. 深入淺出 Python. 歐萊禮, 2011. [3] Ingwer Borg and Patrick J. F. Groenen. Modern multidimensional scaling. Springer Series in Statistics. Springer, New York, second edition, 2005. Theory and applications.. 治 政 http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html. 大 立. [4] TOIBE Software BV. Tiobe programming community index, 2013. [online]. [5] Matthew Chalmers. A linear iteration time layout algorithm for visualising. ‧ 國. 學. high-dimensional data. In Proceedings of the 7th conference on Visualization ’96, VIS ’96, pages 127–ff., Los Alamitos, CA, USA, 1996. IEEE Computer. ‧. Society Press.. y. Nat. sit. [6] Pei-Chi Chen. Optimal grouping and missing data handling for split-and-. n. al. er. io. combine multidimensional scaling. 2008.. i n U. v. [7] Michael A. A. Cox and Trevor F. Cox. Multidimensional scaling. In Handbook. Ch. engchi. of Data Visualization, Springer Handbooks Comp.Statistics, pages 315–347. Springer Berlin Heidelberg, 2008. [8] Pearu Peterson Eric Jones, Travis Oliphant et al. Open source scientific tools for python, 2001. [online] http://www.scipy.org/. [9] Python Software Foundation.. About python, 2005.. [online] http://www.. python.org/about/. [10] Python Software Foundation. affinity 0.1.0, 2005. [online] https://pypi. python.org/pypi/affinity. [11] Python Software Foundation. Process-based “threading” interface, 2005. [online] http://docs.python.org/2/library/multiprocessing.html.. 48.
(57) [12] Swaroop C H. Python入 門, 2013. [online] http://files.swaroopch.com/ python/byte_of_python.pdf. [13] Alistair Morrison, Greg Ross, and Matthew Chalmers. Fast multidimensional scaling through sampling, springs and interpolation. Information Visualization, 2:68–77, 2003. [14] Mark Pilgrim. Dive into python, 2004. [online] http://www.diveintopython. net/toc/index.html. [15] Warren S. Torgerson. Multidimensional scaling. I. Theory and method. Psy-. 政 治 大. chometrika, 17:401–419, 1952.. 立. [16] Jengnan Tzeng. Python入門, 2009. [online] http://dl.dropboxusercontent.. ‧ 國. 學. com/u/2688690/python_note.html.. [17] Jengnan Tzeng. Split-and-combine singular value decomposition for large-scale. ‧. matrix. J. Appl. Math., pages Art. ID 683053, 8, 2013.. Nat. sit. y. [18] Guido van Rossum. Python tutorial, 2008. [online] http://docs.python.org/. io. n. al. er. 2.5/tut/tut.html.. Ch. engchi. 49. i n U. v.
數據
相關文件
在上圖中,最上層的物件是 Root,代表電腦的桌面(Desktop),而 每個桌面可以有多個 MATLAB 圖形視窗(Figures),所以我們通常 定義 Figure 是 Root 的孩子(Child),而 Root
1.學校網站 2.校系介紹 3.課程地圖
左邊有一個平面紙板圖形,右邊有數個立體圖型,左邊的紙板可合成右
下圖一是測量 1994 年發生於洛杉磯的 Northridge 地震所得 到的圖形。任意給定一個時間 t ,從圖上可看出此時間所對
[r]
總圖 1 樓、2 樓與 4 樓、社科圖 1 樓及醫圖 1 樓均設 有圖書滅菌機,方便讀者就近自助使用。操作容易,.
假如上圖中的兩個人走路的速度一樣,請在圖上畫出一條可以表示一個人站在平面手扶 梯上的距離與時間關係的線。.
如圖,空間中所有平行的直線,投影在 image 上面,必會相交於一點(圖中的 v 點),此點即為 Vanishing Point。由同一個平面上的兩組平行線會得到兩個
