IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 16, NO. 7, JULY 2006 859
An Efficient Binary Motion Estimation Algorithm
and its Architecture for MPEG-4 Shape Encoding
Esam A. Al_Qaralleh, Tian-Sheuan Chang, Member, IEEE, and Kun-Bin Lee, Member, IEEE
Abstract—This paper presents a fast binary motion estimation
(BME) algorithm and its architecture for MPEG-4 shape encoding. The proposed algorithm explores the property of the binary-value in BME to quickly skip the unnecessary sum of absolute differ-ences (SAD) computation. When comparing with the full search algorithm, simulation results show that it can efficiently save in the search positions to an average 99.58% of that in the full search algorithm with the same PSNR quality. Due to the algorithm’s sim-plicity and regularity, the resulting hardware implementation also exhibits simple and regular control and data flow. It can achieve real-time encoding with only 11582 gate count.
Index Terms—Binary motion estimation(BME), MPEG-4, shape
coding, video object plane (VOP).
I. INTRODUCTION
M
PEG-4 is an object-based video standard that allows the transmission of arbitrarily shaped video objects [1]. The purpose of using shape is to achieve better subjective picture quality, increased coding efficiency as well as the possibilities for user interaction. In the MPEG-4 shape coding, the binary motion estimation (BME) has been adopted [1] to exploit the temporal redundancies inherent within image frames, and thus gain more compression ratio. However, due to its high com-putation complexity and huge memory bandwidth, it has been shown that BME occupies about 91% of computational com-plexity in MPEG-4 shape encoder, up to 4GOPS [2], [3] and far from real-time requirement [2]. Therefore, optimization on BME is essential to remove the bottleneck to achieve real-time shape encoding. Hence, various fast algorithms and hardware design were proposed [2]–[6] to reduce the computational com-plexity.The fast algorithm approaches use various skipping tech-niques to speed up the BME. In [3] and [4], they skipped those search positions which are depart from the contour line of the object. In [5] it skipped computations of boundary alpha blocks (BABs) by testing if the motion compensation error for that BAB is less than a predefined threshold value. In [6], it generated a mask for the points close enough to the object boundary, and limited the search process only to those points. These fast algorithms are usually implemented by software. However, software implementation of BME on processors is not efficient since processors are more efficient at the word Manuscript received May 11, 2005; revised November 1, 2005. This work is supported by the National Science Council, Taiwan , R.O.C., under Grant NSC-93-2200-E-009-028. This paper was recommended by Associate Editor K. Aizawa.
The authors are with the Electronics Department, National Chiao Tung University, Hsinchu 300, Taiwan, R.O.C. (e-mail: [email protected]; [email protected]; [email protected]).
Digital Object Identifier 10.1109/TCSVT.2006.878148
TABLE I
16-CLASSESCLASSIFICATION, SHOWING THENUMBER OF“1”INEACHCLASS,
AND THERANGE OF“1”INEVERYBAB THATMATCHESWITHEACHCLASS
level instead of the bit-level operation as in BME. For hardware implementation, the data in BME is just a one-bit binary value (0/1), which can be easily represented by hardware, and achieve computation speedup by bit parallelism. The hardware design in [2] presented BME architecture by employing bit parallelism technique using 1-D systolic array to perform a full search BME. In all the above approaches, none have explored the property of binary-value in the BME for the algorithm and architecture design.
In this paper, we propose a fast BME algorithm and its hard-ware design that significantly reduces the number of search po-sitions for the block matching. The proposed algorithm explores the binary value property in BME to efficiently skip the highly unlikely search positions. The motivation of our approach is that, BME only deals with binary values (1 or 0) instead of the 8-bit pixel values in the texture ME. Hence, the block matching of BME can be regarded as a comparison of number of “1” con-tained in each candidate block with that of the current block. Thus, the proposed algorithm classifies each candidate block according to the number of “1” it contains, and only performs the block matching between those blocks belonging to the same class. Furthermore, we also present a hardware design for the proposed algorithm. Hardware design can make the binary bit-level processing much easier and faster than the software ap-proach since traditional processor only deals with word-level processing. The simplicity and regularity of the proposed algo-rithm leads to a simple and regular hardware design.
This paper is organized as following. In Section II, an intro-duction to BME will be presented. Section III will describe the proposed algorithm. In Section IV, we will present the simu-lation results of the proposed algorithm. Then, the architecture for the proposed algorithm will be shown in Section V. Finally conclusions will be made in Section VI.
II. INTRODUCTION TOBME
BME can remove temporal redundancy by searching in the reference video object plane (VOP) for a candidate BAB that 1051-8215/$20.00 © 2006 IEEE
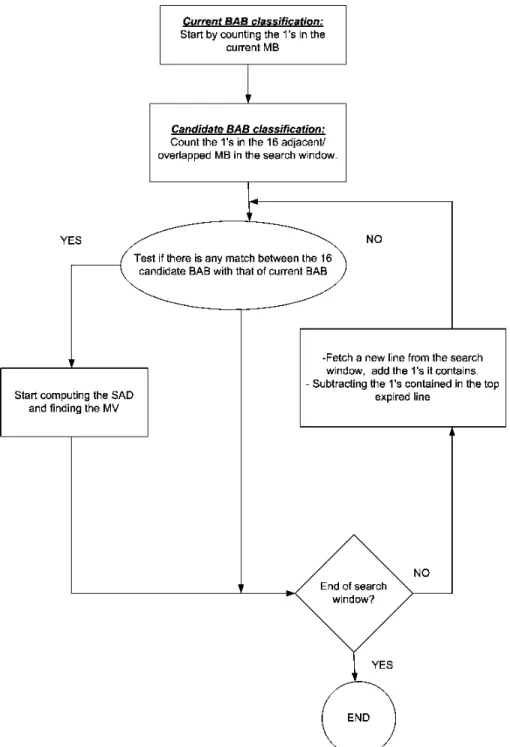
Fig. 1. Flowchart for the proposed algorithm.
is most similar to current BAB. Based on the assumption that the movement of an object is homogeneous, motion vector of neighbor BAB or texture block is used as the motion vector predictor for shape (MVPs). The block matching is performed around the MVPs to compute the sum of absolute differences (SAD) by comparing the BAB indicated by the motion vector and the current BAB. The SAD between the current BAB lo-cated at in the current VOP and a reference BAB lo-cated at a displacement of relative to current BAB in the reference VOP is given as
(1)
The motion vector that minimizes the SAD is taken as MVS and this is further interpreted as motion vector difference for
shape (MVDs), i.e., .
III. PROPOSEDALGORITHM
Fig. 1 shows the proposed algorithm flowchart. First, we clas-sify the current BAB according to the number of “1” it contains. Then, for each search position in the search window, we also classify the candidate BAB using the same method (counting “1” contained in the BAB). If both the current BAB and the can-didate BAB are in the same class (called a match), we start com-puting SAD for that position. Otherwise, we skip that position and start testing the next search position. The main concept be-hind this algorithm is that BME only deals with binary values.
AL_QARALLEH et al.: AN EFFICIENT BME ALGORITHM AND ITS ARCHITECTURE FOR MPEG-4 SHAPE ENCODING 861
TABLE II
PERFORMANCE OF THEPROPOSEDALGORITHM ANDTHEFULLSEARCHMETHODWHENSEARCHWINDOW IS616AND255 CLASSESWITHOUTOVERLAPPING
TABLE III
PERFORMANCE OF THEPROPOSEDALGORITHM ANDTHEFULLSEARCHMETHODWHENSEARCHWINDOWIS616AND255 CLASSESWITH6 CLASSES
OVERLAPPING
Thus, we can use the number of “1” contained by the BAB to ap-proximate the BAB’s data and classify it into different classes. Hence, we can quickly skip SAD computation between different classes and only compute the SAD for the same class.
Table I represents an example for classifying each BAB ac-cording to the number of “1” it contains, i.e., if a BAB contains 20 pixels marked as “1”, it will be classified as class 2. Fig. 2(a) shows a BAB, where the shadowed pixels represent “1” in the BAB. This BAB is classified as class 3 according to the classifi-cation in Table I (contains 34 pixels representing “1”). Fig. 2(b) represents the search window that shows two BABs: one with almost the same number of “1”, classified as class 3 (contains 35 pixels representing “1”), while the other classified as class 12 (contains 189 pixels representing “1”). It is clear that the BAB with almost the same number of “1” is more likely to be a match to the current BAB rather than the other one with larger number of “1”.
Classification and matching rule will severely affect the quality of searching results. The matching rule can be gener-alized from the same-class matching to the adjacent-classes matching. Thus, a matching could be hold for those belonging to the same class or adjacent classes. This feature (overlapping
between one or more adjacent classes) gives us the ability to refine the MVS to be more accurate, which will be presented later.
IV. SOFTWARESIMULATIONRESULTS ANDANALYSIS In the following two subsections, we will show the efficiency of the proposed algorithm by integrating it into the MPEG-4 ver-ification model V18.0 [7]. All the following test sequences are in CIF format with 300 VOP and one Video Object (VO). Then we will show how to explore the flexibility of our algorithm (the classification and the matching rule) to control both the search positions and the bit rate to get more refined MVS.
A. Simulation Results
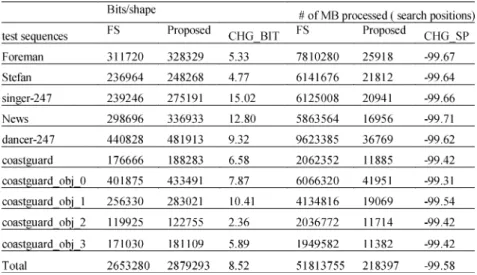
Tables II and III summarize the results compared with the full search algorithm, where CHG_BIT denotes the change of bits in percentage, and CHG_SP denotes the change of search position. Table II assumes search window with nonover-lapping 255 classes (every two adjacent classes differ only by one pixel value). Due to the strict nonoverlapping class parti-tioning, the search positions saving (CHG_SP) is 99.58% (the negative sign indicates saving, in other words the percentage of
Fig. 2. (a) Current BAB contains certain number of “1” bits and belongs to class 3. (b) Search window showing two BABs, each one from different classes. The SAD operation will hold only for the left BAB in the search window, since it is more likely to be a match to the Current BAB, and hence belongs to the same class.
Fig. 3. Impact of classes overlapping on bits/shape, total encoded bit-stream, and the number of search positions.
search positions to that of the full search is 0.42%) of that in the full search algorithm. Such reduction comes with the cost of av-erage 8.52% increase in the encoded shape bit rate (bits/shape). Table III shows the effect of overlapping classes with the same 16 search window. With class overlapping, the increase in the bits/shape is significantly reduced to 0.65%, but it also reduces the CHG_SP to 95.68% compared with the nonover-lapping case. This is because class overnonover-lapping will enable more class matching for BABs with slight difference in number of
“1”. Thus, the increase in the encoded bit stream will be smaller than the nonoverlapping case at the cost of more search posi-tions. Without class overlapping, we may skip possible search positions due to small difference. Fig. 3 shows the effect of over-lapping on bit rate and search positions, it shows that, the extra bit rate increase reduced significantly with just two or three pixel overlapping. On the other hand, the required search positions are linearly increased as the number of classes overlapped is in-creased.
Table IV shows the effect of class partitioning. As the number of classes decreases (that is, count number of “1” in each class increases), the increase in encoded bit stream will be lower with the cost of increased search positions. This is because more BABs in the search window will be classified to be a match. This increases the required search positions but also reduces the bit rate due to more accurate motion matching, as shown in Fig. 3.
B. Consideration for the Classification and Matching Methods
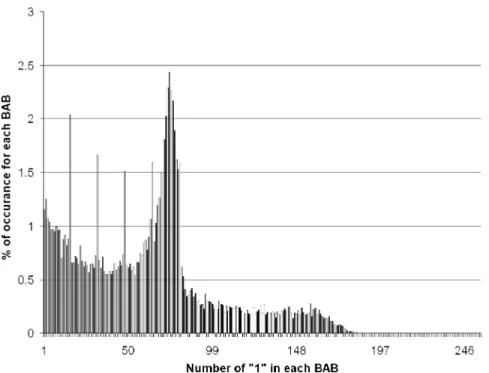
The optimum classification of classes and class-overlapping are highly content dependent. For some test sequences, the prob-ability of classes are not uniformly distributed (BABs belonging to a certain class are more probable than others). Fig. 4 shows the probability distribution for the 255-classes of the test sequence “container_2_obj”. It is clear that, BABs in which the number of “1” in the range 1–83 are more probable, among which the range 57–81 has higher occurrence. Thus, we can divide the in-tervals for each class according to the probability density such that, 1–56 to 8-classes (each class differs by 7 bits of “1” from the neighbor classes), 57–81 to 25-classes (each class differs by one bit “1” from the neighbor classes), and the remaining into 4-classes. We ran three tests for the same test sequence,
AL_QARALLEH et al.: AN EFFICIENT BME ALGORITHM AND ITS ARCHITECTURE FOR MPEG-4 SHAPE ENCODING 863
Fig. 4. Probability distribution for the 256 classes in the container_2_obj.
TABLE IV
COMPARISONBETWEENDIFFERENTCLASSES
TABLE V
RESULTS FORDIVIDINGCLASSESACCORDING TO THEPROBABILITY OF
CONTAINER_2 TESTSEQUENCE
as shown in Table V. For the case-1 without overlapping be-tween classes, we got a smaller number of search positions but larger bits/shape. In the case-2, we ran the same test with uni-form overlapping between classes, and as expected this resulted in a higher number of search positions with fewer bits/shape. The case-3 compromises between reduction in search positions and bits/shape by overlapping only in the range of high prob-ability, in the range of 57–81. We got lower search positions than the case-2, and lower bits/shape compared to case-1. By applying overlapping to those classes with more probable ones will refine the MVS with a little increase in search positions.
Statistics in Fig. 4 can be calculated at the run time, by accumulating the occurrence of every class, overlapping those of high probability, and joining more than one class for those with less probability. The statistics can be made according to a “frame window,” such that, for a predefined number of frames (e.g., ten frames window) we count the statistics and consider
the results for the coming frames. This will be explored in a future work by dynamic class assignment and overlapping.
V. ARCHITECTUREDESIGN
A. Architecture Design
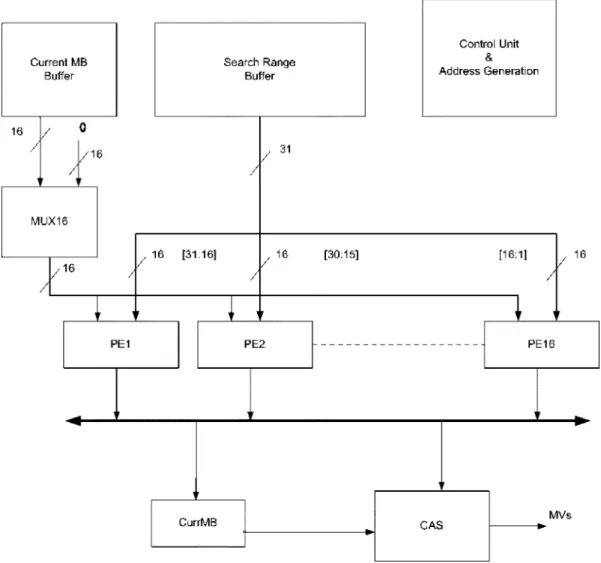
Fig. 5 shows the block diagram of BME architecture. Due to the simplicity and regularity of the proposed fast algorithm, the whole architecture is similar to the full search architecture pre-sented in [6]. However, instead of full search, we adopt the fast algorithm but maintain the regularity of full search. The extra hardware needed is the modification to the accumulator to sup-port addition and subtraction, and also extra registers to save the accumulated count for “1” in every BAB. The addressing and control unit is simple due to regular data flow. In Fig. 5, the search window buffer (SR buffer) stores partial search window data that can be reused by PE array to reduce data transfer from off-chip frame memory. The PE array contains 16 processing el-ements, and each can compute the SAD of one candidate BAB. Another function of the PE is to count the “1” within every can-didate BAB. Thus, a MUX (Multiplexer) will be used to select the operation for the PE between counting “1” and computing the SAD. A compaand-select (CAS) module compares re-sults of PE and selects the motion vector of minimal SAD. Con-trol/Address generation (AG) module generates address for ac-cessing SR buffer and control signals to other modules. Regis-ters are used to store the count of “1” for each BAB in the SR, in which each register is 8-bit (enough to count up to 255).
B. PE Design
Fig. 6 shows the architecture of a single PE, it consists of anXOR circuit followed by an adder tree, and ended with an accumulator. The accumulator supports both addition and sub-traction. For SAD computation, one row of current BAB and one row of candidate BAB are compared by bit-wiseXOR. The
Fig. 5. Architecture block diagram of the proposed algorithm.
Fig. 6. (a) The SAD architecture, and (b) the tree adder.
resulted row of binary data represents the difference values be-tween pixels of these two rows. The adder tree will sum up those binary data as partial SAD. The accumulator sums up 16 rows of partial SAD to obtain the SAD of one candidate position in SR (the SAD of one candidate BAB is produced every 16 cycles). In each PE there are two registers, one to save the partial SAD for later use as final SAD for that search position (sad_reg). The other register will hold the count of “1” pixels of candidate BAB (count_reg).
C. Data Reuse and Data Flow
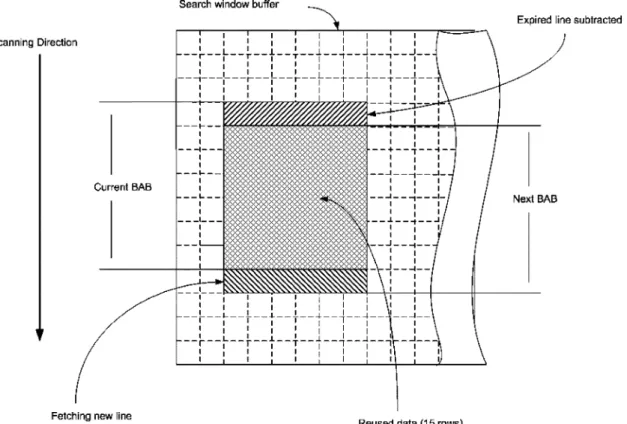
Data reuse concept should be explored while reading from the search window buffer. Data redundancy exists in both di-rections, horizontally and vertically. The horizontal data redun-dancy could be due to computing SAD for more than one adja-cent candidate BABs in the search window buffer. The vertical data redundancy could be due to counting “1” of adjacent can-didate BABs. Since PEs in the PE array take responsibility for adjacent candidate BABs, the input data from search window for every PE have large redundancy. To reduce the data redun-dancy, we use the sliding widow scanning along with data dis-patching to obtain and distribute the data. With data disdis-patching, we can achieve better data reuse utilization. As shown in Fig. 5,
AL_QARALLEH et al.: AN EFFICIENT BME ALGORITHM AND ITS ARCHITECTURE FOR MPEG-4 SHAPE ENCODING 865
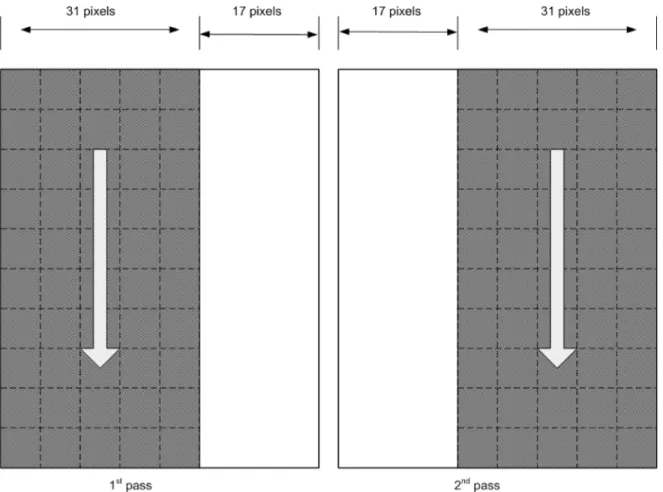
Fig. 7. Two passes needed to cover the search window.
data dispatch is implemented by hardwiring the desired refer-ence data into each PE. Data [31:16] are dispatched to PE1, and data [30:15] are dispatched to PE2 and so on. The search window width is 48 pixels [for search range ], while the data fed into 16 PE are 31 bits, which leaves 17 bits to be scanned. Thus, only two passes will be needed to cover the en-tire search window, as shown in Fig. 7. Each pass will cover part of the search window, supplying the 16 PE with proper data to do the match. To facilitate the counting of “1” and SAD compu-tation, the proposed design adopts the sliding window approach to read the pixel from the search window by sliding vertically, as shown in Fig. 8. Sliding down in the search window will keep tracking of the “1” counting for every adjacent candidate BAB by adding a new row, and subtracting the top expired row. As we slide down by one row, we still make use of the remaining 15 rows (the area marked by crossed bars). This will just add an overhead of 2-clock cycles to keep tracking of the “1” count for every BAB (2-clock cycles rather than 16-clock cycles to per-form full SAD computation). We can summarize the procedure of the architecture operation as follows.
1) Current BAB classification: Count the number of “1” in the current BAB, and store the result into “CurrMB” register (this step needs16-clock cycles).
2) Candidate BAB classification: Start counting the number of “1” for 16 adjacent BABs within the search window, and store the results into each specified register (
). Each register located inside the PE, as shown in Fig. 6(a) (this step needs 16 clock cycles).
3) Class match and SAD computation: The comparison cir-cuit will classify the results stored in the registers and de-termine which one matches the current BAB class. If a match occurs, start calculating the SAD for that position only (16-clock cycles when a match occurs to compute the SAD).
4) Proceeding to new data: If there is no match, we proceed to the next row by the sliding window approach (2- clock cycles overhead to count the number of “1” in this way). 5) Repeat steps (4) and (3) to the end of the search window.
D. Experiments Results
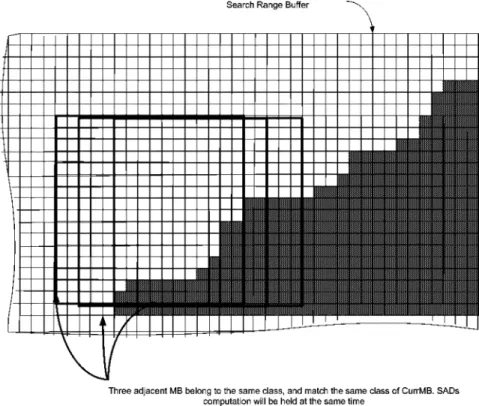
Since the architecture consists of 16-PEs working simulta-neously, it is highly probable that more than one match could occur (two or more adjacent BAB belong to the same class, as shown in Fig. 9), and hence performs the SAD computation for more than one match at the same time. This will save the pro-cessing time since more than one match to be processed in one time slot needed to do one match. The whole design has been implemented in Verilog code and synthesized by Synopysis De-sign Compiler. The synthesized gate count for the architecture is 11582 for the total design, using 0.18- m cell library.
The required cycle count is quite low due to our simple scheme to skip unlikely search positions. The cycle count to perform one full search can be calculated as follows; as an initial step we need to count “1” for the current BAB (16 clock cycles) and for the first 16 rows in the search window buffer (16 clock cycles). Then proceeding by adding new row and
Fig. 8. Sliding window approach: counting the “1” in BABs.
subtracting the top expired row (Fig. 8), this will consume two clock cycles. Since we can scan the search window in two passes, so
are needed to scan the search window. When a match occurs, 16 clock cycles are needed to compute SAD for that match (i.e., we express the number of matches or search positions by #SP). The
total clock cycles will be .
These cycles are needed to find one BAB MV.
Table VI gives the average clock cycles consumed to scan one search window for different classes overlapping. From Table VI, the average clock cycles to complete one frame in case of 32 classes overlapping (worst case) is 563. From which we can cal-culate the total clock cycles to complete one frame. Assuming the percentage of BABs to be 50% of the total alpha blocks (e.g., for CIF 352 288, the BABs will be 198), we need
to complete one frame. From the above calculations, the overhead of our algorithm will be as follows: 16 clock cycles to count the “1” of the current BAB, another 16 clock cycles to count “1” for the first search position in the search window, the latter will be repeated twice, since we scan the search window twice, 2 clock cycles for every search po-sition to add and subtract one row of pixels. Theoretically, the clock cycles needed to perform one full search window using
one PE would be ( ), and for 16-PE would
be , while the worst case in
our design is 563 clock cycles.
TABLE VI
HARDWARESIMULATIONRESULTS FORDIFFERENTCLASSESOVERLAPPING
E. Comparison
Tables VII and VIII show the comparison results between our proposed algorithm, and other fast algorithms. The pro-posed algorithm can achieve lower search positions and still has lower bit rate increase. Moreover, the flexibility of our pro-posed algorithm which lies in the classification of classes, and overlapping between classes, according to run time statistics, will benefit in tradeoff between reduction in search points and bits/shape. The comparisons are based on bits/shape and reduc-tion in search posireduc-tions. Bits/shape presented by [4] is based on WSAD (weighted SAD) which gives lower bit rate and different
AL_QARALLEH et al.: AN EFFICIENT BME ALGORITHM AND ITS ARCHITECTURE FOR MPEG-4 SHAPE ENCODING 867
Fig. 9. Adjacent BABs belong to the same class, and match the same class of CurrMB. SAD calculation will be held at the same time in hardware implementation.
TABLE VII
CHG_SPFORVARIOUSSEARCHALGORITHMSRELATIVE TO THEFULL
SEARCHALGORITHM
TABLE VIII
AVERAGEBIT-RATE FORVARIOUSSEARCHALGORITHMS. ALL ARERELATIVE TO THEFULLSEARCHALGORITHM
values than normal SAD implemented by MPEG-4 VM, even for full search algorithm. Besides, they employed the diamond search algorithm to minimize the number of search positions that is not regular and is not suitable for hardware design. The average reduction in search positions achieved by our proposed algorithm is larger compared to others. The average search po-sition reduction in [5] is 90.95%, and that for [4] is 96.78%, while it varies from 96.59% to 99.69% for our proposed al-gorithm. The minor increase in bits/shape produced by the pro-posed algorithm is not much deviating apart from other fast al-gorithms. The software implementation of the proposed algo-rithm has comparable performance to the algoalgo-rithm presented
in [5] which is a software approach. Thus, our proposed algo-rithm is suitable for software and hardware implementation.
For hardware design comparison, the proposed algorithm is simple to be implemented in hardware and similar to the full search scheme. No special computation circuitry is needed, which can make it switched to a full search without disabling any extra hardware. Control circuit and address generator is simple. For portable devices where the power is critical, when a match occurs, we can disable those PEs which are not a match to save power. BME architecture presented in [2] employs a full search algorithm, and needs a gate count of 9666 while operated at 7.29 MHz for core profile at level two. In comparison, our implementation needs slightly larger gate count of 11582 but needs fewer cycle count and lower frequency, only 3.34 MHz.
VI. CONCLUSION
In this paper, fast binary motion estimation for shape coding is proposed to save the required search positions to 99.58% of that in the full search algorithm. Due to its simplicity and reg-ularity, we also propose a hardware implementation that only requires 11582 gate-counts with low computational cycle. The flexibility of this algorithm could be further explored through choosing the number of classes, and overlapping between classes to compromise between computational complexity and bit stream length.
REFERENCES
[1] N2502a, Generic Coding of Audio-Visual Objects: Visual 14496-2, Final Draft IS ISO AEC JTC1/SC29/WG11, Atlantic City, NJ, 1998. [2] Y.-C. Wang, H.-C. Chang, W.-M. Chao, and L.-G. Chen, “An efficient
architecture of binary motion estimation for MPEG-4 shape coding,” in Visual Commun. Image Process., San Jose, CA, Jan. 2001.
[3] T.-H. Tsai and C.-P. Chen, “An efficient binary motion estimation algo-rithm and its architecture for MPEG-4 shape coding,” in Proc. ISCAS, May 2003, vol. 2, pp. 496–499.
[4] ——, “A fast binary motion estimation algorithm for MPEG-4 shape coding,” IEEE Trans. Circuits Syst. Video Technol., vol. 14, no. 6, pp. 908–913, Jun. 2004.
[5] D. Yu, S.-K. Jang, and J.-B. Ra, “Fast motion estimation for shape coding in MPEG-4,” IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 4, pp. 358–363, Apr. 2003.
[6] K. Panusopone and X. Chen, “A fast motion estimation method for MPEG-4 arbitrarily shaped objects,” in Proc. IEE Int. Conf. Image
Pro-cessing, Sep. 2000, vol. 3, pp. 624–627.
[7] MPEG-4 Video Verification Model Version 18.0 ISO/IEC JTC1/SC29/ WG11 N3908, 2001.
Esam A. Al_Qaralleh was born in Karak, Jordan, in
1972. He received the B.S. degree in electrical engi-neering in 1995 from the Jordan University, Amman, Jordan. He is currently working toward the Ph.D. de-gree in the Institute of Electronic Engineering De-partment, National Chiao Tung University, Hsinchu, Taiwan, R.O.C.
His research interests are video compression, mo-tion estimamo-tion.
Tian-Sheuan Chang (S’95-M’99) received the
B.S., M.S., and Ph.D. degrees in electronics en-gineering from National Chiao-Tung University, Hsinchu, Taiwan, R.O.C., in 1993, 1995, and 1999, respectively.
During 2000 to 2004, he was with Global Unichip Corporation, Hsinchu, Taiwan, R.O.C. He is cur-rently with Department of Electronics Engineering, National Chiao-Tung University, Hsinchu, Taiwan, R.O.C., as an Assistant Professor.
His research interest includes IP and SOC design, VLSI signal processing, and computer architecture.
Kun-Bin Lee (S’02–M’04) received the B.S. degree
in electrical engineering from National Sun Yat-Sen University in Taiwan, R.O.C., in 1996, and the M.S. and Ph.D. degrees in electronics engineering from National Chiao-Tung University, Hsinchu, Taiwan, R.O.C., in 1998 and 2003, respectively.
He is currently with MediaTek, Inc., Hsinchu, Taiwan, R.O.C. His current research interests include processor architecture, digital signal processing, and system-level exploration with focus on data transfer optimization and memory management for image and video applications.
In 2004, Dr. Lee received the Long-Term Paper Award from Acer, Professor Wen-Zen Shen Thesis Award from Taiwan IC Design Society, and Outstanding Design Award of University LSI Design Contest from ASP-DAC. In 2005, he received Outstanding Paper Award from MediaTek. He is a member of Phi Tan Phi.