行政院國家科學委員會補助專題研究計畫
■ 成 果 報 告
□期中進度報告
使用分頻訊號處理之高速行動多媒體傳收器系統研究與設計
子計畫二
:無線網路串流視訊之抗錯與錯誤補償技術研究(3/3)
計畫類別:□ 個別型計畫 ■ 整合型計畫
計畫編號:
NSC-
96-2219-E-009-002
執行期間: 94 年 8 月 1 日至 97 年 7 月 31 日
計畫主持人:王聖智 (交通大學電子工程系教授)
共同主持人:
計畫參與人員:
任慈澄、曾禎宇、陳奕安、黃文中、許庭瑋
成果報告類型(依經費核定清單規定繳交):□精簡報告■完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列管計畫
及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:交通大學電子工程系
中 華 民 國 97 年 10 月 27 日
使用分頻訊號處理之高速行動多媒體傳收器系統研究與設計
子計畫二:無線網路串流視訊之抗錯與錯誤補償技術研究(3/3)
計畫編號:NSC -96-2219-E-009-002- 執行期限:94年8月1日至97年7月31日 主持人:王聖智 (交通大學電子工程系教授) 計畫參與人員:任慈澄、曾禎宇、陳奕安、黃文中、許庭瑋 (交通大學電子所研究生)中文摘要
在本次結案報告中,我們將說明此三年計畫所研 發之三項成果。 第一項成果偏向硬體實現方面,是我們針對了 H264/AVC 的影像壓縮規格,實現了一個基於 TI DSP 系統的即時影像傳輸系統,其中包含影像接 收-壓縮-網路傳送端,以及網路接收-解壓縮-播放 端,在一端送出經過 H264/AVC 編碼技術壓縮過 的資料,經過網際網路傳輸後可以被另一端收到 並進行解碼。我們使用了多線程緒的執行方式, 來達成此即時系統。針對DM642 數位處理晶片, 我們提出平行化的方法,並且也對具有多顆數位 訊號處理晶片的MEX 系統做平行化的處理。 第二項成果則是屬軟體演算法層級,是我們 改善了原始 H264/AVC 的碼率分配機制。而在此 研究中,我們首先針對影像編碼之中碼率的控制 加以研究,藉由適當的控制,使得編碼出最適合 通道狀態的編碼結果。在本次研究當中我們討論 的架構建立在H.264/AVC 影像編碼標準上,將針 對其R-D 模型加以討論,主要利用 MAD、QP 與 編碼數的關係去改變原先的模型,實驗證實能有 效的改善傳輸時 buffer 的狀態,更進一步能對影 像品質加強,而得到較佳的編碼結果。可以有效 避免因為碼率控制不當所造成的編碼瑕疵。 第三項成果同樣是屬於軟體演算法層級,是 我們在 H264/AVC 之外,我們提出了一個以模糊 邏輯為基礎的動作向量修正技術(Motion VectorCorrection with Fuzzy Logic),讓編碼的動作向量 接近真實運動軌跡,藉此提升解碼端錯誤修補的 效果。在解碼端我們提出了一種針對整張畫面損 失情況的修補方式,我們利用視訊中物體運動的 連續性,提出了後向動作投射(Backward Motion Projection),修補畫面損失對視訊品質的影響。 關鍵詞:H.264/AVC、平行化、最佳化、碼率控 制、R-D 模型、錯誤修補、運動向量修正、模糊 邏輯。
Abstract
In this report, we introduce three major achievements. The first achievement is related to hardware realization, where we implemented an H.264/AVC based real-time video communication system over a TI DSP system. This system includes video capturing, video encoding, network transmission, video decoding, and video displaying. The H.264/AVC encoded data transmit from one end to the other end. The whole procedure is implemented in terms of multiple threads. To speed up the coding process, the optimization and parallelization of the DSP codes are performed with respect to the DM642 DSP chip and the multi-DSP board, MEX. The second achievement is that we propose some modifications over the rate control technique in H.264 video compression. According to
the adaptable control, we can better encode the video to fit for channel requirement. So far, we have discussed the R-D model of the H.264/AVC video standard. Based on the relation among MAD, QP and the encoded bits, we try to modify the original R-D model. The experiments had shown that based on the new model we may better estimate the coding buffer and thus reduce some apparent coding artifacts. The third achievement is that we propose a motion vector correction technique based on fuzzy logic. In this approach, we modify the encoded motion vectors at the encoder site to better approximate the actual motion trajectories, while perform error concealment at the decoder site to further improve the video quality by using a backward motion projection method based on the continuity of object movements.
Keywords: H264/AVC、 Parallelization,
Optimization、Rate Control、R-D model、Error Concealment、Motion Vector Correction、Fuzzy Logic
成果報告
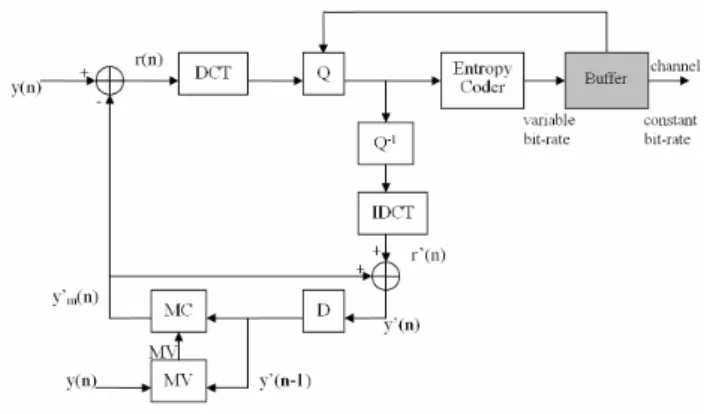
A. H.264/AVC 影像編碼系統在 TI DSP 系統平台 上之實現與加速 (1) 背景 隨著視訊壓縮規格的發展,新一代的H.264/AVC 壓縮規格提供了更適合於視訊通訊。相較於先前 壓縮規格,H.264/AVC 不但大幅在影像壓縮層級 (VCL: Video Coding Layer)提高了壓縮效率,也提 供 了 網 路 提 取 層 級(NAL: Network Abstraction Layer)的觀念,以增強了網路適應能力。跟 Motion JPEG 相比較 H.264/AVC 可以減少 80%的影像檔 案大小;而與H.263 相比,則可以減少到 50%的 影像檔案大小。但是採取各種有效的編碼方式的 同時,其演算法也相對的複雜許多,大幅增加了 實現H.264/AVC 的困難程度。 另一方面,由於DSP 的高性能以及開發成本 較低,DSP 的實現方式是一種廣泛在音訊、影像、 圖形、等應用的實現方式。而德州儀器(TI) C64x 系列中的TMS320 DM642,是採用了超長指令集 (VLIW)結構,時脈高達 600MHz 的高性能定點運 算晶片,非常適合於數位多媒體的處理。因此, 我們將會使用搭載 TMS320 DM642 的數位訊號 處理版來實現H.264/AVC 的影像編碼系統。在Vitec Mult-Media 所提供的 MEX 數位訊號
處理版上,有著四顆 TMS320DM642。於此,我 們會實現完整的視訊系統。除了影像編碼本身, 也將真實的影像擷取與播放,以及網路的傳送與 接收,都實現在此處理板。 如Figure A.1.1 所示,我們將從影像裝置擷取 類比的影像訊號,經由處理版接收並且編碼後傳 輸至網路,並且在另一塊處理板上經過網路接收 編碼後的檔案,即時的解碼並且播放到電腦上。 本文首先對H.264/AVC 影像壓縮規格做簡單 的介紹,以及介紹架設整個系統的軟體與硬體環 境。接著把整個系統的架構與組成做完整的介 紹,並且把核心的H.264/AVC 影像編碼做加速。 以及最後的實驗結果與討論。
Figure A.2.1 H.264/AVC Encoder [5] (2) 系統環境
2.1
H.264/AVC StandardH.264/AVC 視訊編碼標準是由 ITU-T 視頻編
碼專家組(VCEG)與 ISO/IEC 運動圖像專家組
(MPEG)聯合組成的 JVT(Joint Video Team) 在 2003 年制定。其壓縮效率大幅優於現存的其他壓 縮規格,迄今已廣被接受使用。 以編碼端為例,H.264/AVC 編碼的區塊圖如 圖 Figure 所示,將每張畫面(Frame)切割成以 16x16 像素點為單位的巨區塊(macroblock)做處 理。在編碼過程中,可以選擇畫面內預測(intra prediction),或是畫面間預測(inter prediction),去 除影像在空間或是時間上的累贅資訊。而原始畫 面與預測值相減的殘餘值(residual)會經過轉換、 量化,在包成網路提取單元(NAL Unit)前會再經 過熵編碼。以下列出其中幾個比較重要的編碼過 程: 1. 畫面內預測 為了去除空間上的冗餘資訊,在亮度方面以 4x4 的區塊對較為細緻的部分做預測,而用 16 x16 大小的區塊預測較平滑的區域;而在彩度使用8x8 大小的區塊做為預測。依照加權值的方向的不同 可分為數種模式,4x4 亮度區塊九種、16x16 亮度 區塊四種、8x8 彩度區塊四種,分別使用到左邊、 上面、或是右上已經編碼好的區塊。 2. 畫面間預測 採用多重參考畫面,以不同大小區塊(共七種 支援的大小)在參考畫面中做移動估測,將最佳估 測的移動向量以及相減後的殘餘值紀錄下來去做 壓縮。其中移動估測可借由內差的方式達到 1/4 個像素的精準度。 3. 轉換與量化 使用 4x4 整數轉換以降低運算複雜度,並且 避免反轉換時的誤差。在量化方面提供了52 個量 化值,每個量化步階以12%增加。 4. 熵編碼 提 供 兩 種 熵 編 碼:內容適應性編碼(context adopted variable length coding, CAVLC)與內容適 應 性 二 元 算 數 編 碼(context adopted binary arithmetic coding, CABAC)。
5. 方塊效應濾波器 在編碼與解碼端都可使用此濾波器來減少方 塊效應,而是否使用濾波器則是由邊界上鄰近的 像素值做為判斷。
2.2
Hardware Environment 我們分別在兩台個人電腦上安裝 MEX 數位 訊號處理系統版來實現我們的影像編/解碼系統。MEX 是由 Vitec Mult-Media。上面搭載了四
顆 TMS320 DM642,並且每顆 DM642 都配置 32MB 大 小 的 同 步 動 態 隨 機 存 取 記 憶 體 (SDRAM)。此外有兩顆可供調變的 FPGA,是用 來設定數位訊號處理晶片到影像晶片,或是數位 訊 號 處 理 晶 片 到 電 腦 端 的 資 料 傳 輸 方 向 。 如 Figure A.2.2 所示,除了核心的四顆數位訊號處理
晶片與兩顆 FPGA 之外,與外部的溝通界面則包 含了八個影像輸入晶片、四個音訊輸入晶片、網 路實體層晶片、以及和個人電腦連接的 PCI 界 面。由於強大的核心運算晶片,與完善的輸入輸 出介面。我們可以在此數位訊號處理板上實現 H.264/AVC 的影像編/解碼系統。
Figure A.2.2 Block Diagram of MEX board [6]
Figure A.2.3 Block Diagram of DSP Chip [9]
而MEX 板子上面搭載的 DM642 則是工作在 600MHz 的時脈下,擁有 8 個互相獨立的工作單 元,所以可以達到高達 4800MIPS 的運算。如圖 Fig. A.2.3 所示,兩層的高速緩衝結構用以提升記 憶體存取的效率。而透過Enhanced DMA 則可以 方便地記憶體、中央處理核心與周邊。以下簡述 幾個我們會使用到的晶片功能: 1. Memory Architecture DM642 有兩層的快取記憶體架構,第一層的 快取包含了 16K Bytes 的程式碼快取以及 16K bytes 的資料快取。而第二層的快取是一個 256K bytes 的快取,可供資料以及程式碼使用。並且可 以調整大小16、32、64、128K bytes 當作快取, 其餘的空間由使用者配置。搭配EDMA 的使用會 更有效率。 2. Enhanced DMA(EDMA) EDMA 負責在兩層快取記憶體與外部周邊做 資料與程式碼的傳輸、交換。與先前數位處理晶 片組不同的,在我們使用的C64x 系列中,EDMA 對於個別不同的裝置有不同的通道,可以設定不 同的優先次序,或是設定彼此連結的方式。透過 EDMA 內部記憶體、周邊裝置、與外部記憶體之 間可以互相搬運資料。 3. EMIF 在DM642 中用以配置外部記憶體裝置。而在 我們使用的 MEX 板上用於配置 32MB 的同步動 態隨機存取記憶體(SDRAM)、以及同步 FIFO 記 憶體給每個DM642。 4. Vide Port 有三個可配置的影像埠,可設定為影像擷取 埠、影像顯示埠、或TSI 擷取埠。經由 EDMA 協 助,可把影像資料搬運到記憶體內,以方便做影 像編碼處理,也把記憶體內的影像搬運到影像埠 傳送到外部。 5. EMAC EMAC 為 10/100M 乙太網路傳輸控制器,經 由此一控制器,便可以控制在 MEX 板上的網路 實體層晶片,以達到網路的傳輸功能。
2.3
Software Environment 在本節中我們會簡短的介紹我們系統的軟體 開發環境Code Composer Studio 與一些開發即時 系統所需要的軟體環境。2.3.1
Code composer studioCCS(Code Composer Studio)除了提供基本的 程式碼生成,亦提供即時偵錯以及即時分析的能 力,並且有視窗化界面可供使用。在CCS 下我們 進行開發,偵錯、並且最佳化。
2.3.2
DSP/BIOS DSP/BIOS 讓數位訊號處理晶片的程式開發 者去分析與開發即時的程式,主要提供了靜態系 統設定、即時排程、即時分析(RTA)、即時資料交 換(RTDX)。對於多執行緒的程式而言,即時排程 與偵錯是很重要的。而圖形介面化的操作方式, 讓程式開發者能更方便的去使用。2.3.3
Hardware emulation and software simulationCode composer Studio 提供了在個人電腦上 的模擬(simulation)以及數位訊號處理晶片上的仿 真(emulation)。使用模擬時只需要設定 CCS 的模 擬環境,而不需要有實際的硬體設備,即可以達 到開發、偵錯的目的。而使用CCS 做仿真時,須 透過 JTAG 傳輸規格的連接,個人電腦與數位訊 號處理晶片會進行即時資料交換(RTDX)。便可以 看到數位訊號處理晶片上真正的運作情形。 (3) 硬體實現與加速 前面的章節介紹了軟硬體的使用環境,接下 來會描述我們要實現的系統。以及如何在前述的 軟硬體下實現這個影像編碼傳輸系統。
3.1
System Architecture如Figure A.3.1 所示,整個系統分為兩塊 MEX
板,其中一個版子負責H.264/AVC 編碼的部分, 另一個則負責H.264/VC 的解碼端。連接兩塊板子 達成達完整的影像傳輸系統。 在第一個版子上,在影像裝置擷取類比的影 像訊號,經由處理版接收並且編碼後傳輸至網 路,並且在另一塊處理板上經過網路接收編碼後 的檔案,即時地解碼並且播放到電腦螢幕上。 我們把上述的每一個流程都看做獨立運作的 任務(Task)。如 Figure A.3.1 所示,編碼端有三個 主要的任務,包含了影像擷取任務、影像壓縮任 務,以及網路傳輸任務。解碼端則是網路接收, 解壓縮,撥放三個任務。
Figure A.3.1 Multitask system architecture
3.2
System Implementations 在上一節中我們把,整個系統分為數個獨立 的任務,而把這系統實現在DM642 時,我們將上 述的任務對應 DSP/BIOS 裡面的 TSK 物件(Task Object)。在 DSP/BIOS 的協助下,我們將系統套 用 到 TI 所 提 供 的 參 考 架 構 5 (Reference Framework Level 5),整個系統以多執行緒(Multi thread)的方式運行。在本節中會介紹參考架構 5 (Reference Framework 5, RF5)的組成單元、以及我 們系統中的各個任務包含影像擷取撥放、網路溝通、以及H.264/AVC 的編解碼實現的方法。
3.2.1
Multi task over Reference Framework 5參考架構5 (Reference Framework 5, RF5) 使 用DSP/BIOS 以及 TMS320 DSP 演算法標準。提 供使用者開發大量演算法、多執行緒、多通道的 應用程式。其最上層的組成單元為任務(Task),往 下依序包含了通道(channel)、小單元(cell)、以及 XDAIS 演算法。在我們實現的系統中,因為使用 到了多執行緒的機制,因此適用於RF5 中。在任 務 層 級 有 兩 種 RF5 溝 通 單 元 : 串 流 輸 入 輸 出 (Streaming I/O) 與 同 步 溝 通 (Synchronized Communication),而在小單元層級(Cell)則有跨小 單元溝通單元(Inter Cell Communication),以下做 詳細的分述:
1. 串流輸入輸出(Streaming I/O),如 Figure A.3.1 所示,使用雙緩衝的方式將任務與設備做連接, 將設備所得到的資料,迭替地放置到記憶體中, 在供給任務使用。
Figure A.3.2 Streaming I/O (SIO)
2. 同步溝通物件(Synchronized Communication, SCOM )則是負責任務與任務間的溝通,可將緩衝 記憶體位置告知下一個使用的任務,亦可藉由同 步溝通序列(SCOM Queue),來決定任務間執行的 次序,如Figure A.3.3 所示。
Figure A.3.3 Synchronized communication (SCOM)
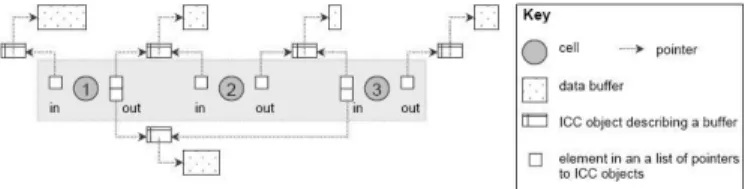
3. 小單元溝通單元(Inter Cell Communication, ICC),如 Figure A.3.4 所示,定義了每個小單元的 輸出輸入緩衝,用以溝通每個小單元間的資料傳 輸。
Figure A.3.4 inter-cell communication (ICC)
藉由上述幾個溝通的物件,再加上任務、通道、 小單元以及周邊的設備,可完成如圖 Figure A.3.5
所示,藉由RF5 所架設起來的系統區塊圖。
Figure A.3.5 System block diagram of Reference Framework level-5 在本系統中,有八個主要的任務,在壓縮端 有三個主要的工作任務(包括:影像擷取、影像壓 縮、網路傳送)以及一個控制任務。另外在解壓縮 端也有三個主要的工作任務(包括網路接收,影像 解壓,影像播放)以及控制任務。壓縮端的三個主 要任務經借由SCOM 彼此溝通,達到多執行緒的 運作方式;同樣地解壓縮端的三個主要任務也藉 由SCOM 彼此溝通,以判斷執行的時機。以下對 主要的任務分別做簡單的介紹。
3.2.2
Video capture and video display影 像 擷 取 任 務 主 要 是 設 定 影 像 晶 片 (SAA7113),並將擷取的數位影取得到記憶體中使 用。設定影像晶片的方式是使用DM642 上的 I2C 匯排流調整影像參數。設定好EDMA 對應影像埠 的通道,將擷取到的影像透過EDMA 移動到外部 記憶體,並且將影像規格從 YUV422 轉換成 YUV400。 影 像 播 放 任 務 則 是 將 YUV400 轉 換 回 YUV422 並且以 EDMA 搬運到由 EMIF 定義的 FIFO 外部記憶體。此 FIFO 可由主機電腦上存取
的到,並且在主機端撰寫 Win32 視窗介面化程
式,用以播放解壓縮完的檔案。
3.2.3
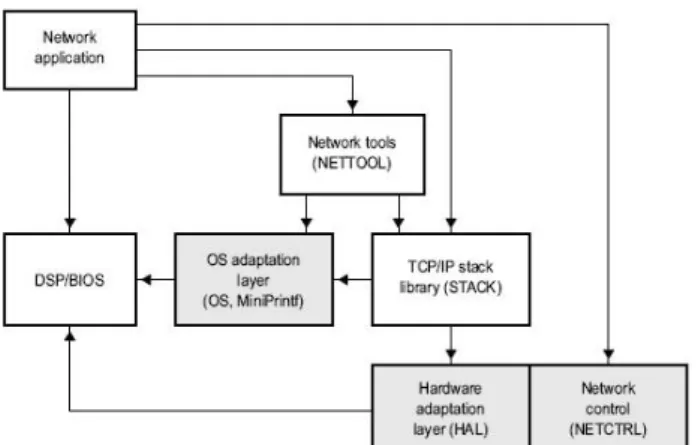
Network developer’s kit在網路通訊方面,我們採用了由德州儀器所 提供的網路開發套件(Network Developer's Kit, NDK)。NDK 只需耗用 200~250KB 大小的程式記
憶體,以及 95KB 的資料記憶體。即可達到完整
Figure A.3.6 Stack Control Flow 如圖Figure A.3.6 所示,五個網路功能對應的 函 數 分 別 為 : STACK.LIB, NETTOOL.LIB, OS.LIB, HAL.LIB, 和 NETCTRL.LIB 。 STACK.LIB 是 從 上 層 至 下 層 包 含 了 主 要 的 TCP/IP 網路功能。NETOOL.LIB 包含了所有插口 式網路服務 NDK,以及一些應用程式。OS.LIB 做為與DSP/BIOS 對應的函式。而透過 HAL.LIB 做為接面,可以連接硬體周邊。而NETCTRL.LIB 控制著TCP/IP 與外界聯繫與互動。由上述五個函 式庫彼此合作即可達成TCP/IP 的網路傳輸。
3.2.4
H.264/AVC source code在編碼端我們使用的是x264 的軟體,而在解 壓縮端我們使用的是JM 的軟體。其中 JM 是 ITU 所提供的官方參考軟體,雖然功能較為完善,但 是運算速度卻相當的慢,若是用來當編碼端,恐 難達到即時編碼的速度。另一方面,x264 則是一 自由軟體,因為 x264 較低的運算複雜度,x264 廣被接受,因此我們也特別使用x264 來實現編碼 器。在DM642 上處理 QCIF 大小時編碼器與解碼 器分別花費的時間如下表所示。
Table A.3.1 Profile of each function decoder. x264 encoder Cycle count % Inter 385955140 66.80 Intra 76744048 13.28 DCT/IDCT 36449650 6.31 Quantization. 27206566 4.71 Deblocking filter 10887230 1.88 Entropy coding 9221182 1.60 Total 577769679 100
Table A.3.2 Profile of each function of encoder. JM decoder Cycle count % Inter 55418473.24 26.96 Intra 3740215.647 1.80 IDCT 7638903.176 3.72 Quantization 42497.23529 0.02 Deblocking filter 115774629 56.32 Entropy coding 22219077.35 10.81 Total 205535479 100
3.3
System optimization on DSP 經由RF5 以及個別地完成上述的功能,我們 可以把整個H.264/AVC 影像編碼系統架設起來。 雖然說在系統中影像編碼與解碼主要是各別開發 並最佳化,但類似的最佳化方式會被使用在壓縮 端與解壓縮端,以下我們一併介紹所採取的最佳 化的手法: 1. 編譯器最佳化(Compiler Optimization):我們 使用CCS 中最高的最佳化層級 3(-o3),此時編譯 器(Compiler) 針對迴圈會使用許多的最佳化的方 式: 軟體導管化(Software pipeline)、迴圈展開,甚 至是運用到SIMD 的去做編譯。 2. 軟體導管化(Software Pipeline) 為了增加編譯器在採取軟體導管化時的效率,需 要 給 編 譯 器 額 外 的 資 訊 。 如 使 用“#pragma MUST_ITERATE”,或是” #pragma UNROLL (n)” 來告知編譯器迴圈要拆解幾次,可以避免編譯器 在最拆解時多出了冗餘的迴圈,讓軟體導管化更 好。此外,對於多重迴圈來說,編譯器只能拆解 最內部的迴圈,外部的迴圈無法自動做拆解,因 此我們也手動做了迴圈拆解的動作,增加軟體導 管化的程度。 3. 配置記憶體位置:在程式的執行中會有常存 取的資料,如熵編碼中所查的表、畫面間預測的 小數精準度的宜動向量時的內插。因為要使用 NDK 而無法將所有 ISRAM 指定為 Cache[17],至 少要配置128KB 當做一般內部記憶體,因此我們 可以配置這些常存取的資料到內部記憶體。所使 用 的 語 法 主 要 有 , 針 對 資 料 區 塊 使 用 " DATA_SECTION” 以 及 針 對 程 式 區 塊 使 用#pragma CODE_SECTION”來做記憶體的配置。 4. 本質函數(intrinsic functions)的使用。本質函 數 是 經 過 組 合 語 言 層 級 最 佳 的 程 式 , 可 供 給 C/C++開發者使用。在這邊我們使用了 max_2、 min_2、abs_2 等的本質函數,直接取代原本的 C 函數即可。 5. 開啟快取(Cache) 由於使用 NDK 之故無法完全將記憶體配置給快 取使用,故在我們的系統中使用了128KB 大小的 快取。
Figure A.3.7 Data dependency induced by(a)Intra prediction (b)Deblocking filtering (c)Inter prediction.
Figure A.3.9 Multi DSP macroblock parallelization
3.4
Parallelization of H.264/AVC 在使用上一節中所提到的最佳化的方法之 後,我們仍要做更進一步的加速。因此我們在最 核心的地方,也就是H.264/AVC 的部分考慮加速 的方式。在這裡我們考慮如何將H.264/AVC 在我 們使用的硬體上做平行化的處理。3.4.1
Parallelization of H.264/AVC 在平行化之前,必須先把欲平行化的單位與 單位間的相關性排除。在本文中我們以巨區塊 (macroblock)做為單位,而巨區塊與巨區塊之間的 相關性如Figure A.3.7(a)~(c)所示。畫面內預測需 要以上方的巨區塊,左方的巨區塊以及右上方的 巨區塊當作參考。而去方塊效應濾波器則需要上 方與左方的巨區塊。而在做畫面間預測時則須要 參考畫面中移動搜尋範圍內的所有巨區塊。若要 達成H.264/AVC 的平行化,則需要滿足這些相依 性。3.4.2
Parallelization over One DSP在單一晶片中,由於EDMA 的幫助,可以達
成雙緩衝的機制(double buffer),如 Figure A.3.10
所示。借由ping 緩衝區與 pong 緩衝區交互作用,
在EDMA 搬運 pong 的資料時,ping 可以做運算, 反之亦然。所以可以減少整體運算時間。
Figure A.3.10 Ping-Pong buffering diagram
在單一晶片中在,我們實行空間上的平行 化,主要需要滿足畫面內預測與以及去方塊濾波 器所產生的資料相依性。如Figure A.3.8 所示,將 欲平行化處理的兩個巨區塊分別放到ping 緩衝區 與pong 緩衝區裡,在時間點 N~1 時 ping 緩衝區 裡的資料被處理,而隨即在 N~2 的時間點 pong 緩衝區的資料也被處理,中間省去了記憶體搬運 的時間,這樣一對 ping 與 pong 的緩衝區稱為一 對,在Figure A.3.10 中可以看到,時間點 3 時間 點4 與時間點 7 的幾個 ping-pong 對。
3.4.3
Parallelization over Multi DSP而在多晶片中我們實現時間上的平行化處 理。前一小節中,我們克服畫面內預測與去方塊 效應濾波器所產生的資料相依性。同樣的,我們
以 Figure A.3.9 所表式的方式克服由畫面間預測 所產生的資料相關性。當欲執行I+1 frame 中(1,1) 與(3,0)巨區塊時,第 I frame 的(3,2)之前的巨區塊 都要先執行完畢。因此在此時 I+1 frame 中(1,1) 與(3,0)巨區塊以及 I frame 的(3,2) (1,3)的巨區塊 可以同時處理。 (4) 模擬結果
4.1.1
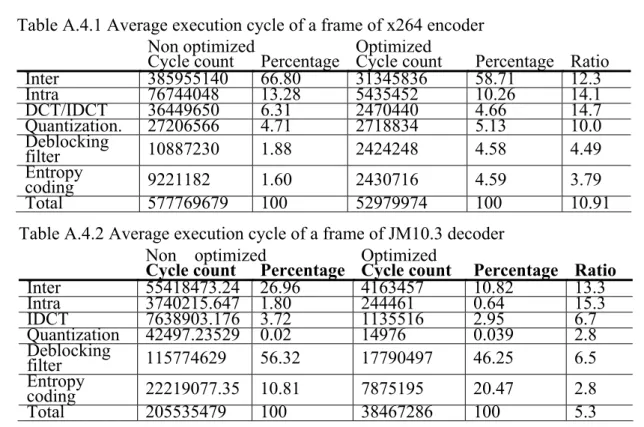
Single DSP Optimization 為了了解程式最佳化的效果,我們使用模擬 器去量測最佳化前與最佳化之後,H.264/AVC 各 個重要功能所增進的速度以及整體增進的速度。 比較結果如Table A.4.1,Table A.4.2 所示,在壓縮 端或是解壓縮端,畫面內預測以及畫面間預測都 會有不錯的速度提升,這是因為此兩功能大量了 使用重複的迴圈,經由最佳化的展開迴圈之後, 有著不錯的效果。然而如去方塊效應濾波器則是 因為大量的資料存取而比較慢,所以在最佳化之 後無法有明顯的效能提升,也導致速度只增加五 倍。4.1.2
Single DSP Parallelization 我們使用 ping-pong 緩衝機制以達成的平行 化的處理,與使用模擬器模擬的4.1.1 不同,此部 分使用的是仿真器模擬,可得出真正硬體實現後 的速度。然而如Table A.4.3,Table A.4.4 所示,經過單晶片的平行化增進的速度只有 1.199 以及 1.033,主要是因為 EDMA 搬運的時間與 CPU 運 算的時間相差甚遠,所以能夠減少的EDMA 搬運 時間相對於整體時間只有一小部分,導致增進的 效能不彰。
4.1.3
Multi-DSP Parallelization Table A.4.5 是 多 顆 DSP 平 行 化 處 理 H.264/AVC 壓縮解壓縮的情形。因為相較於壓縮 端,解壓縮端的運算時間遠小於壓縮端的運算時 間。因此我們只對壓縮端做多顆DSP 的平行化。 我們可以看到增進的效能只達到1.63 倍。主要是 因為 DSP 與 DSP 之間的傳輸沒有經過硬體上的 加速,導致平行化的效果不彰。若要更進一步增 加平行化的效果則需要針對 DSP 間的傳輸做修 改。Table A.4.1 Average execution cycle of a frame of x264 encoder
Non optimized Optimized
Cycle count Percentage Cycle count Percentage Ratio
Inter 385955140 66.80 31345836 58.71 12.3 Intra 76744048 13.28 5435452 10.26 14.1 DCT/IDCT 36449650 6.31 2470440 4.66 14.7 Quantization. 27206566 4.71 2718834 5.13 10.0 Deblocking filter 10887230 1.88 2424248 4.58 4.49 Entropy coding 9221182 1.60 2430716 4.59 3.79 Total 577769679 100 52979974 100 10.91
Table A.4.2 Average execution cycle of a frame of JM10.3 decoder Non optimized Optimized
Cycle count Percentage Cycle count Percentage Ratio
Inter 55418473.24 26.96 4163457 10.82 13.3 Intra 3740215.647 1.80 244461 0.64 15.3 IDCT 7638903.176 3.72 1135516 2.95 6.7 Quantization 42497.23529 0.02 14976 0.039 2.8 Deblocking filter 115774629 56.32 17790497 46.25 6.5 Entropy coding 22219077.35 10.81 7875195 20.47 2.8 Total 205535479 100 38467286 100 5.3
Table A.4.3 Single DSP parallelization of x264 encoder
Non- parallelized Parallelized Ratio
ms per frame 491.26 475.53 1.033
Table A.4.4 Single DSP parallelization of JM10.3 decoder
Non- parallelized Parallelized Ratio
ms per frame 76.44 63.73 1.199
Table A.4.5 Multi DSP parallelization result
(5) 結論與未來工作 在本文中,我們在 MEX 版子上建立了一個 H.264/AVC 的 影 像 通 訊 系 統 , 與 其 他 只 做 H.264/AVC 的不同而直接使用檔案做為 IO 不 同,我們以多執行緒的方式實現了影像擷取、壓 縮、網路傳輸、網路接收、解壓縮以及影像撥放 的系統。我們主要建置一個較現實的 H.264/AVC 系統。將系統以多執行緒的方式實現,並且將系 統對於編譯器做最佳化,以及提供了單一晶片可 能平行化的方式,最後還有多顆晶片平行化的實 現。 未來若要增加速度,可以再對程式進行組合 語言的撰寫。若需要讓平行化更有效率,要改善 DSP 與 DSP 間的溝通機制。 Reference
[1] JVT “Draft ITU-T recommendation and final draft international standard of joint video specification (ITU-T rec. H.264– ISO/IEC 14496-10 AVC),” March 2003, JVTG050
available on
http://ip.hhi.de/imagecom_G1/assets/pdfs/JVT-G050.pdf .
[2] R. Schäfer, T. Wiegand and H. Schwarz, “The Emerging H.264/AVC Standard”, EBU Technical Review, Jan. 2003.
[3] I.E.G. Richardson, H.264 and MPEG-4 Video
[4] Compression, John Wiley & Sons, 2003. [5] Thomas Wiegand, Gary J. Sullivan, Gisle [6] Bjontegaard, and Ajay Luthra, “Overview of
the H.264/AVC Video Coding Standard,” IEEE Trans. on Circuits Syst. Video Technol., Vol. 13, No. 7, pp.560 – 576, July 2003.
[7] J. Ostermann, J. Bormans, P. List, D. Marpe, M. Narroschke, F. Pereira, T. Stockammer and T. Wedi, “Video Coding with H.264/AVC: Tools, Performance, and Complexity”, IEEE Circuits and Systems, Vol. 4, No. 1, 2004.
[8] www.vitecmm.com, Preliminary of MEX [9] www.blackhawk-dsp.com/Usb560bp.aspx,
Preliminary of USB 560BP
[10] Texas Instruments, “TMS320C6414T, TMS320C6414T, TMS320C6416T fixed point Digital Signal Processor”, Literature Number SPRR226, November 2003.
[11] Texas Instruments, “TMS320DM642 Video/Imaging Fixed-Point Digital Signal Processor: Data manual ”, Literature Number SPRS200G, July 2002 – Revised August 2004. [12] Texas Instruments, “TMS320C6000 CPU and
Instruction Set Reference Guide”, Literature Number SPRU189F, January 2000.
[13] Texas Instruments, “TMS320C64x DSP Two-Level Internal Memory Reference Guide”, One DSP
(original) Two DSP Three DSP Four DSP ms per frame 475.53 397.55 323.81 290.75
Literature Number SPRU610C, August 2004. [14] Texas Instruments, “Video port/VCXO
Interpolated Control (VIC) Reference Guide”, Literature Number SPRU629F, January 2007. [15] Texas Instruments, “TMS320C6000 DSP
Ethernet Media Access Controller (EMAC)/Management Data Input/ Output (MDIO) Module Reference Guide”, Literature Number SPRU628A, March 2004.
[16] Texas Instruments, “TMS320C6000 Code Composer Studio Tutorial” Literature Number SPRU301C, February 2000
[17] Texas Instruments, “TMS320C6000 DSP/BIOS User's Guide”, Literature Number SPRU303B, March 2000
[18] Texas Instruments, “TMS320C6000 Optimizing Compiler User’s Guide” Literature Number SPRU187G, March 2000
[19] Texas Instruments, “TMS320C6000 TCP/IP Network Developer’s Kit (NDK) Technical Data Quick Reference GuideTMS320C6000 TCP/IP Network Developer’s Kit (NDK) Technical Data Quick Reference Guide”, Literature Number SPRU568, October 2001
B. H.264/AVC 之碼率控制技術研究 (1) 背景 現今通訊系統的發達,使得及時視訊傳輸的 重要性變的更加重要,而龐大的視訊資料在有限 的頻寬下傳送,必須仰賴高效率的壓縮技術,目 前 較 廣 泛 被 研 究 與 應 用 的 壓 縮 技 術 , 是 由 JVT(Joint Video Team) 組 織 所 制 定 出 的 H.264/AVC(Advance Video Coding) 影 像 壓 縮 標 準,它提供了比先前所有壓縮標準更高的壓縮效 率,特別在高壓縮率的應用,因此在無線通訊上 的應用,使用H.264/AVC 可以提供相當好的壓縮 效果。 而在通訊的傳輸上,通道將會影響影像的壓 縮品質,低頻寬所可以傳送的資料較少,因此影 像品質會較差,而在高頻寬則能傳送較佳的影像 品質。在影像的編碼端提供了一個機制,可以依 照頻寬的特性調整影像的壓縮率,進而提供最適 合當時頻寬的壓縮品質,這個機制稱之為碼率控 制(Rate Control)。在圖 Fig. B.1 中,當資料做完 Entropy Coding 後,會先送到 encoder 的 buffer 等 待 送 入 channel , 太 多 的 資 料 量 會 使 得 buffer overflow,而太少的資料量則會造成使用的效率過 低,因此我們往往藉由控制壓縮時的量化係數 (Quantization Parameter)去達到最佳的使用效率, 這個過程就是所謂的Rate Control。在過去的影像 壓 縮 標 準 都 已 經 制 定 出 適 合 的 Rate Control Model,例如:MPEG-2 的 TM5[1]、H.263 的 TMN8[2] 和 MPEG-4 的 VM-18[3] 。 而 在 H.264/AVC 標準當中,目前也提供了一套 Rate Control 的機制在 Joint Model(JM)[4]之中。而我們
演算法的架構將會建立在此Joint Model 上面。
Fig B.1 Rate Control 在影像編碼架構圖 (2) 架構
2.1 Joint Model 中 Rate Control 的架構 在JM 的 Rate Control 的架構當中主要分為三 個階段。1.GOP(Group of pictures)層級,2.Pictures 層級,3.Basic Unit 層級。在 GOP 層級當中會計
算此GOP 總共應該編碼出的資料量,例如:如果 頻寬為64Kbits,每秒傳送 15 張畫面,一個 GOP 大小為30 張時,則一個 GOP 內可使用的資料大 小則為 128Kbits,而在此層級會控制使得壓縮出 來的資料量不會超出原本預期的大小。另外,在 此層級也會決定每個GOP 第一張畫面的 QP 值。 而在 Picture 層級,將會決定出每張畫面的 QP 值,主要會分成 Stored 跟 Non-stored 畫面,在 Stored 畫面會利用當時 buffer 的狀況跟這個 GOP
剩下可用的資料量來決定出這張畫面的QP,數學 式可以表示成: , , , , , ( ) ( ) ( ( ) ( )) 0.5 ( 1) ( ) ˆ ( ) ( 1) ( 1) ˆ ( ) ( ) (1 ) ( ) 0.5 i i i i p i i i p i p r b i b r i i i R j T j S j V j f W j B j T j W j N W j N T j T j T j γ γ β β β = + × − = − × = − × + − × = × + − × = % % (1) 在這邊,T 代表要用來編碼的 Target Bits,而 R 代表通道每秒可傳送的資料量,f 則是每秒須送幾 張畫面,S 是預期 buffer 飽滿的程度,而 V 是當 時buffer 飽滿的程度,B 代表當時 GOP 內剩下可 以用的bits 數,W 代表畫面的複雜度,而 N 則是 畫面的數量。當決定好Target Bits 後,則需要一
個model 來預測要用多大的 QP 才能達到此 Target Bits,在 JM 裡面所使用的是之前在 MPEG-4 當中 被 提 出 來 使 用 的 quadratic Rate-Distortion model[5],數學式如下: 1 2 2 , , , ( ) ( ) ( ) ( ) ( ) ( ) i i i h i step i step i j j T j c c m j Q j Q j σ σ = × % + × % − (2) 在 這 裡 σ 表 示 做 完 運 動 補 償 後 兩 張 畫 面 的 MAD(Mean of Absolute Difference )值,而 m 表示 header bits 的大小,T 則是之前已經求得的 Target Bits,經由這個式子可以求得出 Quantization Step size(Qstep)的值,最後經由簡單的轉換就可以得到 QP 值。而在 Basic Unit 層級當中,將會更進一步 決定每個Basic Unit 的 QP 值。首先說明 Basic Unit 的定義,Basic Unit 是由一張畫面中連續的幾個 macroblock 組成的單位,假設今天使用 Basic Unit 的大小為11 個 macroblock,則整張畫面將會被分 成數個Basic Unit,以 QCIF 影像(176×144)為例, 共有 99 個 macroblock,將會被分成 9 個 Basic Unit,所以在此層級當中將會決定出每個 Basic Unit 的 QP 值。如果 Basic Unit 的大小愈小,則愈
能夠滿足一張畫面Target Bits 的值。上面簡單的
介紹完在JM 裡面所提供的 Rate Control 後,本研 究將會針對裡面的架構作調整,進而希望能得到 更佳的控制。
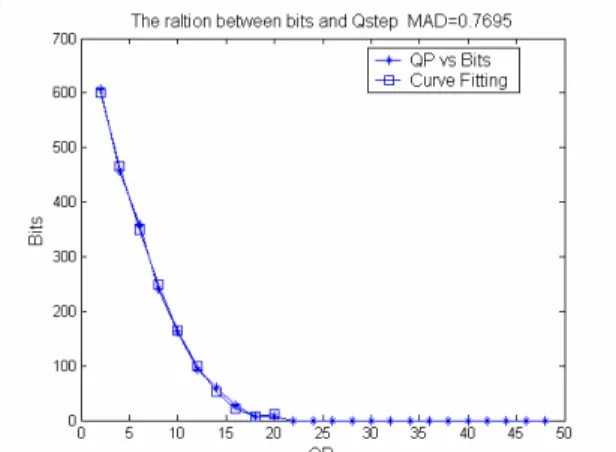
Fig. B.2 固定 MAD 時,QP 跟 Bits 的關係
Fig. B.3 MAD=0.7695,QP 跟 Bits 的關係
Fig. B.4 MAD=2.7383,QP 跟 Bits 的關係
Fig. B.5 MAD=3.9297,QP 跟 Bits 的關係 2.2 Rate-Distortion model 在上面已經介紹過目前在 JM 裡面所使用的 quadratic R-D model,而在最近的研究裡面有其他 人提出不同的R-D model[6][7][8],而我們將會先 分析 QP、MAD 跟壓縮出資料量(Bits)關係,在 Fig. B.2 當我們固定 MAD 之後,可以發現 QP 跟 Bits 之間可以用二階的多項式來描述,因此接下
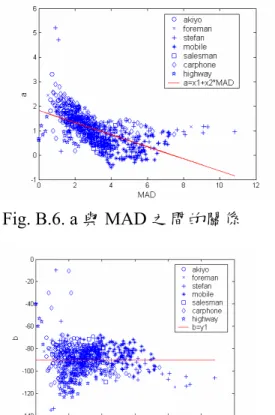
來我們利用二階多項式針對不同的 MAD 值作實 驗,觀察是否皆能符合此特性,Fig. B.3、B.4、 B.5 各代表當 MAD 等於 0.7695、2.7383 和 3.9297 時的結果,各可以代表小中大的 MAD 值。而二 階的多項式可以表示如下: 2 Bits a QP= × + ×b QP c+ (3) 在這裡 a、b、c 代表此多項式的係數,我們用最 小平方誤差可以求得此係數,因此不同的 MAD 可以得到不同的係數。 接下來我們利用大量的數據去觀察這些係數 和MAD 的關係。Fig B.6 是針對不同的影像與不 同的MAD 值所得到 a 跟 MAD 的關係圖,在這邊 我們用簡單的一維線性來描述此關係;Fig. B.7 則 是b 跟 MAD 的關係圖,可以明顯的發現 b 跟 MAD 並沒有明顯的關係存在,所以係數我們假設維持 不變,最後Fig. B.8 則是 c 與 MAD 的關係圖,在 此可以發現有很重要的關係存在,經過不同的數 學式實驗,最後發現使用下面式子得到的誤差最 小,而且對整體式子簡化最有幫助: 1 2 c z= ×MAD z+ × MAD (4) 接下來可以將上面得到的關係,將原本的式子(3) 改寫如下: ( ) 2 2 1 2 1 1 2 2 1 2 2 3 4 5 2 2 2 2 1 2 3 4 5 Bits a QP b QP c x x M AD QP y QP z M AD z MAD k MAD QP k MAD k QP k MAD k QP k A B k A k B k A k B A MAD B QP = × + × + = + × × + × + × + × = × × + × + × + × + × = × + × + × + × + × = = (5) Fig. B.6. a 與 MAD 之間的關係 Fig. B.7 b 與 MAD 之間的關係 Fig. B.8 c 與 MAD 之間的關係
而在上面的式子裡面只適用在 non-zero 的壓
縮結果,因為當 QP 值超過某個值時,編碼出來
的量都會是零,從Fig. B.3 到 Fig. B.5 可以看得出
來,當 QP 超過某個值後壓縮出的 Bits 數都會是
零,在這邊我們稱此QP 為 Zero Point,而 Fig. B.9 是Zero Point 與 MAD 的關係,由圖可以發現 Zero Point 與 MAD 值呈現正比關係,也就是說愈大的 MAD 值需要愈大的 QP 才會編碼為零,所以可以 利用此線性關係針對式子(5)加以限制,改寫如 下: 2 2 1 2 3 4 5 1 2 1 2 1 t t t t t t t
Bits k MAD QP k MAD
k QP k MAD k QP MAD h QP QP h QP MAD h QP QP h σ σ = × × + × + × + × + × − ⎧ ≤ × ⎪⎪ = ⎨ − ⎪ − > × ⎪⎩ (6) 上面我們已經建立出了壓縮資料量跟MAD 與 QP 之間的關係,在這邊的壓縮資料指的是做完 DCT 轉換、量化一直到 Entropy Coding 後的資 料,尚未包含Header Bits,而在 Rate Control 決定
的Target Bits 是兩者一起包含的數量,所以接下
來我們將針對Header Bits 的特性作一些分析。
Fig. B.10. Macroblock 種類,使用於移動補償[9]
2.3 Header Bits 分析
首先說明在H.264/AVC 的 Inter Prediction 提供有
多種的 Macroblock Mode,能夠針對不同的影像
內 容 找 到 最 適 合 的 mode , 進 而 能 增 加 inter prediction 的效能。Fig. B.9 就是 Macroblock Mode 的種類,愈大的愈適合使用在影像細節較少的部
分,而愈小的block size 則適合在較複雜的部分。
而不同的Macroblock Mode 所需儲存的 Header
Bits 也有不同,Fig. B.11 針對 16×16、16×8、8×16 和8×8 四種形式的 Header Bits 跟 MAD 的比較, 在這邊可以發現16×16 的 Header Bits 比其他三種
來的低,而且跟MAD 大小沒有關係,而 16×8 跟
8×16 兩種形式的 Header Bits 大小相當接近,而且
也跟 MAD 大小關係不明顯,但是在 8×8 的
macroblock mode, 可以發現 Header Bits 數量與 MAD 呈現正比的關係,要說明這個原因首先要先 分析Header Bits 的組成成分。由表一可以發現, 因為16×16 只需要存一個移動向量,而 16×8 跟 8 ×16 需要存兩個移動向量,所以後面的 Header Bits 平均來看會比前者來的高,而在8×8mode 裡面因 為可以更細分為四種8×8 的 types,所以需要儲存 的移動向量差異較大,從四個到十六都有,而我 們更進一步觀察造成Header Bits 差異是否是因為 移動向量的差別,根據Fig. B.12 我們可以了解切 的愈細的 block 需要存愈多的移動向量,而所產 生的Bits 數也會愈多,另一方面愈大的 MAD 也 愈容易切成較細block mode,所以在這邊可以將
8×8mode 的 Header Bits 用一階線性的數學式來描 述此關係:
8 8
Hbits× = ×a MAD b+ (7)
而其他的三種Macroblock Mode 的 Header Bits 則
用平均值來代表即可,因此我們將原來 JM 裡的
R-D model(2)改用上面的 model,接下來作實驗觀
表一. P-slice 的 Macroblock Header Bits 成分
成分 說明
Macroblock skip run 記錄是否為skip Macroblock type 記錄為何種moe Motion vector 記錄移動向量資訊 CBP(Coded Block Patterns) 記 錄 被 編 碼 為 零 的 資料 Delta QP 記錄跟前者QP 的差
察最後得到的結果。
Fig. B.11. Header Bits 與 MAD 之間關係
Fig. B.12. 8×8mode 中,不同數目的移動向量和 Header Bits 與 MAD 之間關係
(3) 實驗結果
我們將我們的 model 跟原本 JM 的 model 作 比 較 , 首 先 設 定 Basic Unit 的 大 小 為 一 個 macroblock,畫面的大小使用 QCIF,Profile 設定 在 baseline profile,Frame Rate 設定為 30f/sec, Buffer 大小設定為頻寬的 0.5 倍,GOP 大小為所
有的畫面數,也就是只有第一張為 I-frame,而
RDO(Rat Distortion Optimization)為開啟。在這邊 我們選擇的影像為 Bus、Flower 和 Stefan,頻寬 為64Kb。Fig. B.13 為 buffer 額滿的情形,在這邊
我們先忽略當 buffer 額滿而造成的畫面遺失的問
題,Target Buffer Level 是指預期希望 buffer 的位
置,而使用我們的 model 跟 JM 原本的比較,可
以發現改變R-D model 後,對於 buffer 更能有效 率的控制,也能比較少發生畫面遺失的問題,而 這是因為改變R-D model 後對於符合
(a) Bus sequence
(b)Flower sequence
(c)Stefan sequence
Fig. B.13. Rate Control 過程 Buffer 的狀態
表二. R-D model 預測精確度比較
Sequence JM Our Improvement Bus 569.7 193.7 0.66
Flower 1185.9 995.2 0.16
Target Bits 的誤差有相當的減少,在表 2 我們定義 誤差為實際編碼出來的數量跟預期編碼數量的平 均絕對差值,改善比較是計算改進量對於原本JM 誤差的比值,可以發現都有不小的改善,接下來 將針對每張畫面的PSNR 作比較。經過 model 精 確度的改善,可以發現對於畫面的品質並沒有造 成不好的影響,反而對於 GOP 最後面的幾張影 像,因為 buffer 有效的控制,使得畫面品質有不 小的提升,而對於整體 PSNR 看來也都能有不錯 個改善,最後我們比較此改善對於實際視覺影像 上的改進,Fig. B.15 到 Fig. B.17 是其實際壓縮出 來的影像,可以很明顯的觀察出來改善的結果, 特別是像Bus 跟 Stefan 在地上的線段,還有 Flower 右半邊花的部分,這是因為當編碼到畫面的一半
時,不精確的 model 很容易就將這張畫面所分配
到的Target Bits 用完,而造成剩下 Basic Unit 會使
用過大的 QP 來減少編碼出過多的資料數,所以
對於畫面中後面的 Basic Unit 我們能效果不錯的
改善。 (4) 結論
在這篇報告當中,我們針對H.264/AVC
Rate Control 的 R-D Model 分析,然後我們根據實
驗觀察出MAD、QP 跟 Bits 之間的特性,而設計 出 R-D Model,能有效的利用在影像的傳輸上, 不但能安全的控制 buffer 的狀態,更能對於影像 品質有明顯而重要的影響,分析完R-D Model 的 特性,更進一步的我們需要去討論如何決定Target Bits,不論是以畫面為單位還是 Macroblock 為單 位,決定不同的Target Bits 也會影像畫面的品質, 而這是下一步需要去研究的部分。 (5) 參考文獻
[1] ISO/IEC JTCI/SC29/WG11, Test Model 5, 1993.
[2] ITU-T/SG15, Video Codec Test Model, TMN8, Portland, June 1997.
[3] MPEG-4 Video Verification Model V18.0, Coding of Moving Pictures and Audio N3908, ISO/IEC, JTC1/SC29/WG11, Jan. 2001.
[4] Z. Li et al., "Adaptive Basic Unit Layer Rate Control for JVT," JVT-G012, 7th Meeting: Pattaya, Thailand, March 2003.
(a) Bus sequence
(b) Flower sequence
(c)Stefan sequence Fig. B.14. PSNR 的比較
[5] H. J. Lee and T. H. Chiang and Y.-Q. Zhang, “Scalable rate control for MPEG-4 video,”
IEEE Trans. Circuits Syst. Video Technol., vol.
10, pp. 878-894, 2000.
[6] Thung-Hiung Tsai and Jin-Jang Leou, “A Rate Control scheme for H.264 Video Transmission.” IEEE International Conference on Multimedia and Expo (ICME), 2004.
[7] Satoshi Miyaji, Yasuhiro Takishima and Yoshinori Hatori, “A Novel Rate Control Method for H.264 Video Coding.” IEEE ICIP vol. 2, 11-14 Sept. 2005
[8] Siwei Ma and Wen Gao, “Rate-Distortion Analysis for H.264/AVC Video Coding and its Application to Rate Control.” IEEE Trans. on Circuits and Syst. For Video Technol.,vol.15,No.12,Dec. 2005
[9] Thomas Wiegand, Gary J. Sullivan, Gisle Bjontegaard, and Ajay Luthra, “Overview of the H.264/AVC Video Coding Standard,” IEEE Trans. on Circuits. Syst. Video Technol.,vol.13,No.7,July 2003 (a) JM (b) Proposed approach Fig. B.15 Bus 第 145 張畫面 (a) JM (b) Proposed approach Fig. B.16 Flower 第 220 張畫面 (a) JM (b) Proposed approach Fig. B.17 Stefan 第 50 張畫面
C. 以動作向量修正為基礎的抗錯性編碼技術與 以損失畫面修復為基礎 的錯誤修補技術 (1) 簡介 隨著視訊壓縮技術的提升,如H.264/AVC 的 發展[1-2],增進了編碼的效益,同時 H.264/AVC 也讓視訊傳輸更有效率。另一方面由於無線傳輸 技術的進步,如 3G 行動通訊系統的普及,無線 網路視訊傳遞的發展,如視訊會議或是視訊電話 都是常見的應用。而在使用無線網路傳遞視訊 時,最容易遇到的問題之一就是傳輸時的錯誤造 成傳送的封包損失。 由於壓縮視訊解碼時後面接收的畫面會以前 面的畫面當作參考,當封包損失時,封包內的資 料都會損失,這會讓之後參考這些損失的資料的 畫面發生錯誤,而又進一步讓參考錯誤畫面的繼 續錯下去,這種現象我們稱為錯誤傳遞。 錯誤傳遞會降低解碼的視訊品質,但是由於 通常使用無線網路傳遞的視訊需要即時的解碼, 例如視訊電話,這種情況下我們沒有辦法要求重 新傳送損失的封包。因此為了克服這樣的問題, 常見的一種方式是在解碼端使用錯誤修補技術 (Error Concealment),利用之前或是之後接受到的 資訊對損失的部分進行估測。 傳 統 的 錯 誤 修 補 技 術 是 修 補 以 巨 方 塊 (Macroblock)為單位,利用空間周圍資訊修復損失 的巨方塊[9-17],但是當應用層面為低位元的視訊 傳輸時,封包的損毀很有可能會讓整張畫面的資 訊都損失[22],這種情況下就無法使用空間周圍 附近的資訊針對巨方塊進行修復。這時候必須在 畫面層級對整張畫面用時間上的相鄰資訊進行修 復,由於畫面前後有著動作連續的特性,因此我 們可以利用動作資訊來進行畫面之修復。 因為要使用動作資訊進行錯誤修補,編碼時 的動作向量(motion vector)就是我們最容易使用 的資訊,但是由於一般編碼方式是採用 block matching 的方式,因此動作向量不見得真的符合 真實運動狀況,這樣所修補的畫面就無法達到最 佳狀況。為了讓動作向量接近真實運動軌跡,我 們 提 出 了 動 作 向 量 修 正 技 術(Motion Vector Correction),利用模糊邏輯判斷動作向量的可信 度。 另一方面,我們提出了一種新的畫面修補的 方 式 , 採 用 後 向 的 動 作 投 射(Backward motion projection),可以利用比傳統方法簡單的做法,達 到整張畫面的估測,降低錯誤傳遞對於視訊品質 的影響。 (2) 背景
2.1
H.264/AVC in Wireless EnvironmentH.264/AVC 是 由 ITU-T 視 頻 編 碼 專 家 組 (VCEG)與 ISO/IEC 運動圖像專家組(MPEG)聯合 組成的JVT(Joint Video Team)所提出的視訊編碼 標準,是目前廣泛使用的視訊編碼標準[1]。 經 過 壓 縮 過 後 的 視 訊 會 以 封 包 為 基 礎 (packet-based)進行傳輸[3],每一個封包裡面所包 含的是數個巨方塊的編碼資料,如果經過無線網 路傳輸,由於網路狀況不穩定,所傳送的封包很 有可能會在過程中損失。對於H.264/AVC 來說, 若傳輸的封包損失,會造成整個封包裡的資料都 會損失,也就是封包中所裝的巨方塊都會無法解 碼出來。封包損失不單只損失巨方塊的畫面會受 到影響,由於編碼時我們利用了時間域上的連續 性進行壓縮,例如Inter prediction,後面的畫面會 採用前面的畫面作為參考,當參考畫面中的巨方 塊損失時,連帶會影響到之後解碼的畫面,而再 更後面畫面又會繼續影響更後面的畫面,這種關 係我們稱之為錯誤傳遞(Error Propagation)。為了 讓傳送時的錯誤對於解碼後之視訊品質影響降 低 , 一 般 會 在 解 碼 端 採 用 錯 誤 修 補(Error Concealment)來修補損失的部分,接下來我們會在 之後的小節介紹基本的錯誤修補技術。
2.1.1
Simulation Tools for Video Transmission為了要瞭解編碼後的視訊經過傳輸過程之 後,當傳輸過程中發生封包損失會對解碼後的視
訊造成怎樣的影響,我們可以採用一些傳輸的模 擬。由於傳輸時封包會發生損失的情況,所以在 [4][5]中就是模擬在特定封包損失機率下對於解 碼視訊所造成的影響。不過在這些模擬過程中, 封包的損失是採用固定機率損失的方式,如果要 更進一步接近無線網路的傳輸狀況[6][7],可以再 加入真實的網路傳輸或是模擬,如 Fig. C.2.1 所示[7]。
Fig. C.2.1 Schematic of evaluation framework with NS-2 [7]
2.2
Error Concealment 在前一小節中我們介紹了壓縮視訊在透過無 線網路傳輸之後,封包損失會造成錯誤傳遞而影 響解碼視訊的品質。而這種錯誤傳遞的現象會一 直等到新的Intra Frame 出現時才會停止,所以當 傳輸過程有封包損失時,除非我們要求重新傳送 損失的封包,否則一定會解碼視訊品質造成不好 的影響。但是如果是在即時影像傳輸播放情況 下,傳輸與解碼是在同時進行的,封包的重送會 造成解碼時的時間延遲,也會造成記憶體使用上 的額外負荷,所以一般我們並不允許封包的重 送。在這樣的情況下,我們必須仰賴其他的技術 才能降低封包損失對於解碼視訊所造成的傷害, 而解碼端錯誤修補技術(Error Concealment)就是 一種常被使用的方式。2.2.1
Block-Level Concealment 傳統的錯誤修補方式是將損失的畫面以巨方 塊為層級進行修補,假設與損失的巨方塊相鄰的 仍正確接收的情況下,可以利用周圍資訊來修補 損失的部分,通常可以分成空間域的修補,例如 空間上的內插方法[9-11];或是時間上的修補,例 如Boundary Matching Algorithm(BMA)[12-13];或 是整合性的時間與空間修補方法[14-15]。也有在 空間域進行動作向量的修補,利用鄰近的動作向 量修補損失部分的動作向量的做法[16-17]。 但是前面我們提到的這些做法都必須利用空 間相鄰的資訊修補損失的部分,但是當損失情況 嚴重到周圍也都損失時,甚至整張畫面都失去 時,上面的方法就無法採用,這時候我們就需要 其他的演算法針對整張畫面失去的情況進行修 補。2.2.2
Frame-Level Concealment 當壓縮視訊在低位元傳輸情況下時,舉例來 說:當我們使用 3G 行動通訊系統情況下,我們 使用 64kbits/channel 傳送每秒 10 張的 QCIF 畫 面,換算之後平均每張畫面約為800 bytes,而一 般使用的封包大小約為1 kbyte,因此一個封包可 以裝入整個畫面,所以當封包損失時就會造成整 個畫面的損失[22]。 在我們蒐集的資料中,針對整張畫面進行修 補的演算法最早是由 S. Belfiore et al. 在所提出 的[22],論文中提到在他們資料中,之前沒有針 對全畫面進行修補的方法,所以在這篇論文著作 時間(2003)之前沒有對於全畫面修補的技術,這 原因主要和H.264/AVC 的發展以及低位元壓縮視 訊傳輸發展的狀況有關,在這之後發展的相關論 文有[24][25][26]。這些技術主要都是在時間域上 以 Optical Flow 為基礎,進行動作向量之修復, 我們將在後續的小節中做更詳細的討論。2.2.2.1
Optical FlowOptical Flow (OF)的基本概念是假設在視訊 畫面連續的情況下,畫面中的亮度值(intensity)在
不同時間點只是做了位移,亮度值本身沒有改 變,因此一般最常見的亮度與 OF 之間的關係可 以用式子(2.1)表示[27]。
(
)
0 , , = dt t s s dx H V (2.1)(
) (
)
(
) (
)
(
)
0 , , , , , , , , , , = ∂ + ∂ + ∂ dt t s s x t s s v ds t s s x t s s v ds t s s x V H V H V V V H V H H H V H (2.2) 如果把整個視訊想成以空間上的垂直水平軸 再加上時間軸三個維度所構成的空間,如錯誤! 找不到參照來源。所示,而各個不同時間點的畫 面其實可以想成是在時間軸上做取樣。觀察錯誤! 找不到參照來源。(a)我們會發現在不同時間點的 畫面中圓球位置從中間逐漸往左下移動,由於畫 面前後間隔時間短暫,也就是取樣時間短暫,我 們可以把圓球的運動當成一種連續的運動,會看 到 在 三 維 空 間 中 就 是 一 整 束 的 Optical Flow (OF),而整個視訊就是由許多一束一束的 OF 所 組成的,在不同時間點取樣我們就會得到不同的 畫面。 Optical Flow 的偵測可以用上面我們提到的 公式計算,但是由於我們應用的層面是已經經過 壓縮編碼的視訊,當中已經有MV(motion vector) 提供了畫面中的動作資訊,另一方面由於 OF 的 偵測是因為我們在解碼端要做錯誤修補,但是由 於應用層面是需要即時處理的視訊解碼,此時太 過複雜的做法並不適合採用,因此通常會採用 MV 替代 OF 的方式。 但是我們在此還是得特別說明一下,一般我們編 碼時的MV 是採用 block matching 的方式,到參 考畫面中去尋找最符合待編碼的方塊,把測得的 位移量當作 MV,但是這並不代表找出來的 MV 就是真正的運動軌跡,當畫面中實際上是有亮度 的變化,或是發生物體形變、遮蔽或是進出畫面 等情況,我們找到的MV 其實都很有可能與實際 運動有很大差距,此時如果我們運用一般 OF 特 性時,就會很容易出錯,因此我們在後面的章節 中將介紹如何修正這種錯誤的動作資訊。2.2.2.2
Motion Recovery of Missing Frame當封包損失的情況發生時,會造成畫面損 失,此時也可想成 OF 發生了如斷層般的情況, 如 Fig. C.2.3 所示,在封包損失的同 時,由於動作向量的損失,後續的畫面找不到與 前畫面對應的關係,如Fig. C.2.3 (b)所示。換言 之如果我們能夠修補斷層的OF,我們就可以重建 損毀畫面與前畫面之間的動作關係,就可利用動 作補償來對損失的畫面進行修補。 Fn-2 Fn-1 Fn Fn Fn-1 Fn-2 time Optical Flow Fn-2 Fn-1 Fn Fn Fn-1 Fn-2 time Missing Frame Corrupted OF Missing Frame
(a) Illustration of motion consistency (b) Frame lost and optical flow corruption
Fig. C.2.2 The relationship between optical flow and motion consistency Original Optical Flow Corrupted Optical Flow Packet lost time time
Fig. C.2.3 The Relationship between packet lost and optical flow corruption
由於動作向量有著類似 OF 的特性,因此 S.
Belfiore et al.提出了一種前向動作投射的方法 [22],將前一張畫面的動作向量投射到損失的畫 面中,如Fig. C.2.4 所示。
Fn-1 Fn 1 , − n j i MV (i, j) (iF, jF) 1 , − n j i FMV ⎪⎩ ⎪ ⎨ ⎧ + = + = = − = − − − − − 1 , , 1 , , 1 , , 1 , 1 , where n V j i n H j i n j i n jF iF n j i n j i FMV j jF FMV i iF MV MV MV FMV Missing Frame
Fig. C.2.4 Forward motion projection and MV recovery
系統中為了要讓MV 接近真實的運動軌跡, 會採用空間域的median filter 對 FMV 進行修正再 進行投射,而在 Belfiore 的架構中,被投射的損 失畫面是以像素為單位進行修補的。為了提升修 補效率Baccicht et al.提出了以方塊為基礎的修補 方式[25],如錯誤! 找不到參照來源。所示。 Reference frame buffer Searching of suitable reference Motion vector projection Statistics collection MB-Level MV field estimation Block-Level MV field estimation Picture reconstruction
Fig. C.2.5 Schematic of Baccicht‘s algorithm [25]
(3) Proposed Methods of Concealment
在前面的小節中我們討論了之前的損失畫面 修補技術,利用動作向量的前向投射,修復損失 畫面的動作向量,在這種做法中,被修復的畫面 屬於被動的角色,由於投射的向量不會正好落在 被修復畫面的方塊中,必須額外處理。另一方面 由於不同的 FMV 有可能投射到損失畫面重疊的 地方,或是有的損失畫面有部分可能沒有被投射 到。這些情況都會造成修補上的障礙,尤其當原 始的MV 與真實運動軌跡不符合時更容易影響修 補結果。 為了改善 MV 與真實運動軌跡不符合的現 象,我們提出了利用模糊邏輯的動作向量修復技 術,提升修補效果。另一方面為了改善前向動作 投射遇到的被動性的問題,我們提出了一種新的 主動性修復技術,採用後向的動作投射,可以用 較簡單的方式達到畫面的修補。
3.1
Motion Vector Correction由於一般我們編碼時所測的MV 是找參考畫 面中最接近方塊與目標方塊的位移量,有時候這 樣的MV 並不符合真正的運動軌跡向量,這樣的 情況下做動作投射就會容易造成錯誤的修補,如 Fig. C.3.1 所示。為了讓 MV 能夠接近真實的運動 軌跡,我們提出了一種利用模糊邏輯判斷向量可 靠度,藉此修正錯誤向量的方式。 Intensity time t-2 t-1 t x x x
(a) Motion projection with correct MV Correct MV FMV Intensity time t-2 t-1 t x x x (b) Motion projection with incorrect MV Incorrect MV FMV
Fig. C.3.1 Motion projection with: (a) correct MV; (b) incorrect MV.
3.1.1
Proposed Fuzzy MV Correction一般情況下,物體的運動有著時間上與空間 上的連續性,舉例來說:一台移動的車子,由於 畫面間隔時間短暫,在這短暫時間前後移動的速 度應該是接近的,這指的是時間上的連續性;而 車頭與車尾的運動應該也是接近的,這指的是空 間上的連續性。由於有這樣的特性,當畫面中有 某個MV 時間前後不連續,與周圍動作也不連續
的情況,此MV 很有可能就是錯誤的動作。 我們所提出的動作向量可靠度判斷方式如 Fig. C.3.2 所示,其中 t j i R, 表示在t 時間、位置(i, j) 的MVit,j之可靠度,TDit,j表示時間上的不連續性, t j i SD, 表示空間上的不連續性,如(3.3)、(3.4)所示, 當TDit,j或SDit,j越大的時候,可信度就越低,當 t j i TD, 和SDit,j都小的時候可信度高。 t j i TD, t j i SD, t j i R,
Fig. C.3.2 Temporal-Spatial fuzzy reliability.
[
] [ ]
[
] [ ]
⎪⎩ ⎪ ⎨ ⎧ − = + = − − ⋅ = − + , , , , where 2 , , 1 , 1 , , , t j i t j i t jF iF t jB iB t j i t j i MV j i jF iF MV j i jB iB MV MV MV TD (3.1)(
)
(
)
. 2 else , 2 if , 1 , 1 , , , 1 , 1 , 1 , 1 , , 1 , 1 , , , t j i t j i t j i t j i t j i t j i t j i t j i t j i t j i t j i t j i t j i MV MV MV MV MV MV MV MV MV MV MV MV SD + − + − + − − − + = + = − ≤ − − = (3.2) 我 們 將 時 間 域 與 空 間 域 可 信 度 的 membership function 定義如下:(
( ))
exp 1 1 , , Th t j i t j i TD TD TR − ⋅ + = α (3.3)(
( ))
exp 1 1 , , Th t j i t j i SD SD SR − ⋅ + = β (3.4) 其中TRit,j表示時間域的可信度而SRit,j表示空間 域的可信度,藉由可信度我們可以進行動作向量 的修正將可信度較低的動作向量用附近可信度較 高的向量取代,如下所示,其中N 代表(i,j)鄰近的 點,MVCit,j代表修正後的MV。∑
∑
∈ ∈ ⋅ ⋅ = ⋅ = N j i t j i t j i t j i t j i t j i t j i N j i t j i t j i TR SR TR SR R MV R MVC , , , ' ,' ' ,' ' ,' ' ,' , ' ,' , , (3.5) 1 TDth t j i TR, t j i TD, 0 1 SDth t j i SR, t j i SD, 0 Membership Function of Temporal Reliability Membership Function of Spatial ReliabilityFig. C.3.3 Membership function of temporal reliability and spatial reliability.
3.2
Backward Motion Projection到目前為止我們介紹了許多編碼端錯誤修補 的技術,這些方法都希望能夠將損失的部分修補 回來。回到錯誤修補的最初目的,我們知道我們 之所以要做錯誤修補其實並不是為了損失的那張 畫面資訊,真正最大的目的是為了要降低錯誤傳 遞的影響,因為後面的畫面都要參考前面的畫面 進行解碼,當參考畫面出錯會造成錯誤一直傳遞 下去,為了這個原因我們才需要做錯誤修補。 這時候若我們跳出修補損失部分的想法,有 沒有可能讓後面的解碼略過損失的部分,不參考 錯誤的位置進行解碼的動作?如Fig. C.3.4 所示。
time Error propagation Missing frame time Skip over Missing frame
Fig. C.3.4 Missing frame skipped decoder.
基於這樣的想法,我們發展出來新的錯誤修 補技術,可以略過錯誤的畫面採用更前面的畫面 作為參考畫面,和前面提到的演算法概念最大差 異是我們採用的動作修補方式是用後向的動作投 射,如Fig. C.3.5 所示。理論上前向的投射與後向 的投射原理都相同,都是利用 OF 時間上的連續 性,所以做出來的效果理論上是差不多的,但是 在運算上後向投射的做法會比前向投射的做法容 易實行。 OF Reference Frame Missing Frame Forward projected OF
(a) Forward motion projection
OF Reference Frame Missing Frame OF Backward projected OF
(b)Backward motion projection
Fig. C.3.5 (a) Forward (b) Backward motion projection.
前向投射的做法中,修復的向量場使屬於「被 動」的角色,我們必須從前參考畫面的動作向量 做投射,在投射到的位置紀錄下來動作向量,而 修復的的向量場在投射過程有可能有些區域會發 生沒有被投射到或是重複投射的情況,這些情況 都需要額外的處理[26]。 而若採用後向的投射時,我們是在損毀畫面 的後一張畫面,使用這張畫面自己的動作向量往 參考畫面做延伸,這樣的做法是從修復位置為起 點,屬為「主動」的做法,所以可以避免前面所 說的被動做法遇到的問題。 我們所提出的畫面修復技術如 Fig. C.3.6 所 示,和以往最大差異是我們略過了真正損失的畫 面,而是修正之後會使用損失畫面的後續畫面, 例如Fig. C.3.6 原本 Fn+1必須使用Fn作為參考畫 面,但是Fn是損失的畫面,所以我們就直接把原 本指向Fn的動作向量做線性延伸,向量兩倍延伸 至Fn-1。 Fn-1 Fn [ ] [ ] 1 , 2 , , = + ⋅ n+ j i MV j i jB iB (i, j) (iB, jB) Fn+1 1 , + n j i MV Backward Projected MV Missing frame
Fig. C.3.6 Missing frame recovery with backward motion projection. time Missing frame I P P P P P time Missing frame P I P P P P No MV
這樣的做法最大好處在於運算簡單,只需將 後續動作向量做線性的延伸即可,也不需額外對 於intra frame 做考慮。比較前向動作投射方式, 如Fig. C.3.7 所示,由於是使用損失畫面之前的動 作向量,當在損失畫面之前的是inter frame 時, 我們可以使用它的動作向量,但是當前一張畫面 是intra 時,我們就會需要另外找其他向量來做投 射,這樣就需要額外的處理方式。相對若我們使 用的是後向動作投射時,我們是利用受損畫面的 後一張畫面進行動作向量投射,當它屬於 inter frame 時,很自然就使用他的動作向量進行;而若 當他屬於intra 時,雖然沒有動作向量,但是 intra 本來就不需要參考前面的受損畫面,可以直接正 確解出畫面,這樣是屬於最好的情況。所以當我 們採用後向的動作投射作為修補方式時,無論投 射畫面是 intra 或是 inter 都可以正確的進行,不 需額外的處理。 (4) Experimental Results 我們將經過 H.264 壓縮過的視訊檔案通過 2.1.1 的傳輸模擬系統,設定不同的封包損失機 率,觀察使用我們所提出的演算法補償效果,Fig. C.6.1 是 foreman sequence 經過封包損失率(PLR) 為 1%的通道之後,沒有錯誤修補(without EC)、 前向動作投射(FMP)、以及我們所提出的後向動 作投射(BMP)的 PSNR 比較圖,由於我們的方法 加入了動作向量修正,因此會有比較好的修補效 果。另外由於使用後向動作投射屬於主動性的修 正,在影像邊緣部分也會有比較好的效果,如Fig. C.6.2 所示。另外我們也討論不同視訊在不同 PLR 下,修補的PSNR 比較,如 TABLE C.I 所示。 TABLE C.III Average PSNR for the considered sequence at different packet loss rates (PLRs).
(5) Conclusion and Future Works
在本文中我們提出了一種新的錯誤修補方 法,利用後向的動作投射,讓解碼視訊在惡劣的 傳輸狀況下,即使發生整張畫面都損失的情況, 仍能有效修補,在作法上也較之前的技術簡單。 為了提升修補的效果,我們也提出了一種新 的動作向量修正技術,藉由動作向量時間域與空 間域的連續性,經過模糊邏輯判斷動作向量之可 靠度之後進行修正,能夠讓錯誤修補時使用的動 作向量更接近真實運動軌跡,讓動作投射更加準 確。 再之後的研究中,我們希望能夠將動作向量 修正的技術移至編碼端,這樣能夠讓解碼端的錯 誤修補更為簡潔快速,也可以增進錯誤修補的效 果。除此之外,在編碼端進行動作向量修正將有 助於更多需要正確動作向量的影像處理技術,例 如時間域畫面內插或是畫面解析度增進技術。應 用動作向量修正技術可以改善編碼動作向量與真 實動作不符時所產生的瑕疵問題。 (6) Reference
[1] Thomas Wiegand, Gary J. Sullivan, Gisle Bjontegaard, and Ajay Luthra, “Overview of the H.264/AVC Video Coding Standard,” IEEE
Trans. on Circuits Syst. Video Technol., vol. 13, No. 7, pp.560 – 576, July 2003 Sequence PLR No EC FMP BMP Foreman 1% 32.43 35.26 35.50 2% 29.75 34.51 34.94 5% 24.66 33.52 34.31 Flower 1% 32.66 34.14 34.52 2% 30.45 33.47 34.18 5% 20.65 30.29 32.27 Stefan 1% 31.27 33.43 33.48 2% 26.33 31.91 32.09 5% 18.43 29.20 29.51
![Figure A.2.1 H.264/AVC Encoder [5] (2) 系統環境](https://thumb-ap.123doks.com/thumbv2/9libinfo/8147412.166950/4.892.201.699.111.344/FigureA21H264AVCEncoder52系統環境.webp)
![Figure A.2.2 Block Diagram of MEX board [6]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8147412.166950/5.892.44.432.112.494/figure-block-diagram-mex-board.webp)