An Initial
Study
on A Segmental Probability Model Approach
t o Large-Vocabulary Continuous Mandarin Speech Recognition
Jia-lin Shen, Hsin-min Wang, Bo-ren Bai and Lin-shan Lee Department of Electrical Engineering, National Taiwan Gniversity
Taipei, Taiwan, Republic of China
ABSTRACT
This paper presents an initial study to perform Iarge-vocabuIary continuous Mandarin speech recognition based on a Segmental Probability Model(SPM) approach. SPM was first proposed for recognition of isolated Mandarin syllables, in which every syllable must be equally segmented be- fore recognition. Therefore, A concatenated sylla-
ble matching algorithm in place of the conventional Viterbi search algorithm is therefore introduced t o perform the recognition process based on SPM.
In
addition, a training procedure is also proposed to reestimate the SPM parameters for continuous speech. Preliminary simulation results indicate that significant improvements in both recognition rates and speed can be achieved as compared to the conventional HMM-based Viterbi search approach- es.1
INTRODUCTION
Mandarin Chinese is a tonal language. Each Mandarin syllable is assigned a tone, and there ex- ists 4 lexical tones and 1 neutral tone. When the differences in tones are disregarded, the total of
1333 different Mandarin syllables can be reduced
t o only 408 base syllables. In this research, the recognition of the total of 408 base syllables disre- garding the tones for large-vocabulary continuous Mandarin speech is considered based on a Segmen- tal Probability Model(SPM) approach. The Seg- mental Probability Model(SPM) was first proposed for recognition of isolated Mandarin syllables con- sidering the monosyllablic structure of Chinese lan- guage[l]. This model is very similar t o continuous
hidden markov model(CHMM), except that the state transition probabilities are deleted and the N states equally segment the syllable. In other words, the stochastic state transition behavior in CHMM is replaced by a deterministic process, while the stochastic observation behavior remains un- changed, represented by Gaussian mixtures. This model was found to be very suitable for Mandarin syllables due to their relatively simple phonetic structures, with improved recognition rates achiev- able at much higher speed[l]. This is why we try t o extend the application of this model to continuous Mandarin speech recognition. The Viterbi search algorithm is applied to the HMM-based continuous speech recognition.[2][3][4] Howerer, it is impossi- ble to directly implement any Viterbi search al- gorithm in a SPM-based continuous speech recog- nition task, because using SPM every syllable in an utterance must be equally segmented and thus the beginning and ending point of a syllable must be known. We therefore introduce a concatenat- ed syllable matching algorithm based on dynamic programming concept [ j j such that the recognition process can be performed syllable by syllable based
on SPM, instead of fiame by frame as in the HMM- based approaches. Furthermore, a training proce- dure is also introduced to segment an utterance into syllables and reestimate the SPM parameters by interpolation.
This paper is organized as follows. In section 2, we introduce the concatenated syllable match- ing algorithm. In section 3, the training proce- dure is discussed based on the concatenated syl- lable matching concept. The experimental results are presented in section 4. Section 5 finally gives
the concluding remarks.
11-133
2
THE CONCATENATED
SYLLABLE
MATCHING
ALGORITHM
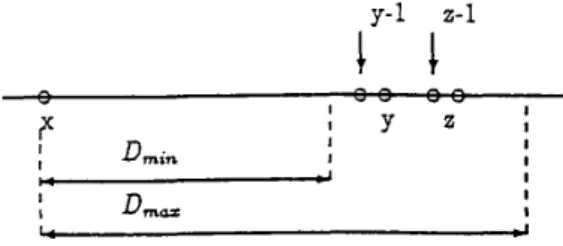
The concatenated syllable matching algorithm for continuous speech recognition using SPM is first presented below. For a given test utterance, all possible syllable beginning frames can be first ob- tained by picking up all the dips in the energy con- tour, such as x, y, a in Fig.1. The possible end- ing frames such as y-1 and 2-1 corresponding to each beginning frame such as x in Fig.1 can then be found using estimated minimum and m a x i " duration of a syllable
D,;,
andD,,,
as in Fig.1.y-1 2-1
Figure 1: A part of an example utterance. x,y,and
I are possible beginning points, where y-1 and a-1 are ending points corresponding to x.
With beginning and ending points of a syllable estimated as above, the accumulated score at an ending point y-1 is then determined by the dynamic programming approach:
T[y
-
11 =T[.
-
11+
m a [Si(., y-
l)]1 5 ~ 5 4 0 8
where T[u] is the accumulated score at a point U, and S ~ ( U , V ) is the score when the
SPM
for the syl- lable i was matched with utterance section (u,v), and the total number of different Mandarin sylla- bles is 408 when the tone is disregarded. At the end of the utterance, the optimal syllable sequence c a n then be easily obtained by backtracking the entire utterance. In this way, the SPM can be eas- ily applied and the recognition can be performed syllable by syllable. This is similar t o a previously reported method[5][6] except that the recognition process starts fiom the possible beginning points instead of ending points. In this way, it is more eas- ier to implement on a real-time system because wecan start the recogition process right at the begin- ning of an utterance. In addition, when a Viterbi search operation is performed, the computation for all possible ending points for a given possible be- ginning point need not be repeated because their starting point is exactly the same.
In order to reduce the computation due to the overlap of some possible syllable sections, a table of size Dm, is dynamically used to store the like- lihood scores of SPM. In addition, for those possi- ble syllable sections with the same starting point, the likelihood scores of the same segment of SPM would not be calculated repeatedly. Therefore the recognition speed can be improved significantly.
3
THE TRAINING PROCEDURE
In the training process, a similar iterative re- estimation procedure based on the above men- tioned concatenated syllable matching concept waa developed. For the j-th training sentence with n syllables ( 1 1 , 12,...,
l,),,
where lk is the k-th sylla- ble in the sentence, we can first find the average syllable duration for this sentence and then use some estimated parameters to determine the mini- mum and maximum syllable duration,Dmin,j
a n d Dma=,jl of this sentence. With the help of the dips in short-time energy contour, the possible begin- ning and ending points can be similarly found justas above in Fig.1. For an utterance section (x,y-l), the possible syllable occupying this section is esti- mated as I k , where the range of possible values of k is determined by x, Dmin,j and D,,,,,,j. The rest of the training process is very similar to that in recognition discussed above, except that only the SPM for the few possible syllables lk in the sen- tence estimated in the above need to be matched. The dynamic programming approach just as above can be used:
where T[U,lk] k the accumulated score at a point U
when the last syllable matched is It. When the end of the sentence is reached, backtracking through the utterance gives the optimal syllable segmen- tation, and the optimally segmented syllables for
all
the training utterances are used to re-train the SPM forall
the syllables.T h e parameters of each segrr.ent in SPM are esti- mated by a multivariate Gaussian distribution. In this study, only diagonal covariance matrices are considered for the multivariate Gaussian distribu- tions. Therefore the interpolation for different sta- tistical parameters is relatively easy:
0 where pjtji and U’. are the mean and variance of
the j-th mixture component of the isolated mod- el for a certain syllable, while p j c and ufe are the mean and variance of training samples observed in continuous speech for that mixture j. w l and w2 are the interpolation weights for the prior mean and the observed sample mean respectively. The obtained models defined by the new parameters
( P , , , ~ ~ , ojneW) are then taken as new initial models and the above training procedure can be performed iteratively.
1%
4
EXPERIMENTS AND
DISCUSSION
47.61 In the preliminary simulation study for speaker
dependent task, a speech database produced by two m a l e speakers is used. Each speaker produced one isolated utterance for each of the 1333 s y l b
bles, a set of 112 phonetically balanced continuous sentences including a total of 891 syllables covering all the 408 base syllables, and one continuous ut- terance each for a set of 200 sentences taken &om primary school Chinese textbook with a total of 1289 syllables. The average speaking rates of iso- lated and continuous utterances are 0.5 and 0.3
sec/sylkabie respectively. Cepstral coefficients of order 14 and the corresponding 14 delta cepstral coefficients are derived from the
LPC
coefficients. The 1333 isolated syllables are used in trainingini-
tial models, the 112 phonetically balanced continu-
ous sentences are used in re-estimating the coatin-
uous model parameters, and the rest of 200 contin- uous textbook sentences are used in testing. The recognition rates in the following experiments are evaluated as the percentages of correctly recog- nized syllables minus insertion rates. The aver- age error rates when the continuous training utter- ances were used in testing after the iterative train- ing procedure are listed in Figure 2.
It
is noted1
t h a t the training procedure improved the model performance significantly and the error rate is al-
most unchanged after 2 iterations. Table 2 lists the average recognition rates of the test utterances
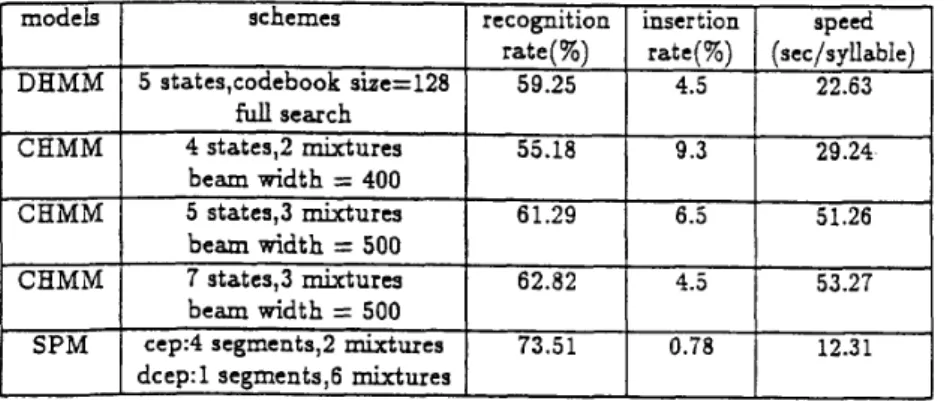
after the iterative training procedure. The exper- imental results for HMM-based Viterbi search are also listed in Table 2 for comparison where sylla- ble is also used as the recognition unit. In table 2, all the HMM models are trained using the is- lated utterance as initial models and reestimated by the 112 phonetically balanced continuous utter- ance using segmental k-means algorithm with 10 iterations. It can be found that for HMM-based approaches DHMM has the fastest speed even in full search, while the highest achievable rate is 63% for CHMM with 7 states and 3 mixtures per state. But when SPM-based approach is used, more than 73% recognition rate can be easily obtained with smaller number of states(segments) using less than
a quarter of time.
After careful examination on the test results, it was found that one major reason that SPM- based approach can outperform HMM-based a p proach is the significant reduction of the insertion rates, which are also listed in Table 2. Recall that SPM approach replaces the stochastic state tran- sition process by deterministic segment transition process, uses extra knowledge such a3energy con- tour dips to detect syllable end-points, and per- form the recognition operation syllable by syllable instead of fiame by h m e . All these character- istics of SPM approach apparently provides extra advantages in recognizing an unknown utterance with unknown number of syllables. Note that the results here are obtained from acoustic information only. With the help of knowledge
in
tone, lexicon, context and assisted by language modeling, it is ex- pected that much higher recognition rates can be achieved.73.06
I
iteration numberI
recognition rate(%)1
t
2I
73.401
I
3I
73.511
I
Table 1:
training procedure
the recognition results after iterative
5
C O N C L U S I O N
References
In this paper, we applied Segmental Probability Model(SPM) to large-vocabulary continuous Man- darin speech recognition and achieved very good performance. Because the conventional Viterbi search algorithm can not be applied in a SPM- based continuous speech recognition task due to the unknown beginnig and ending points of the syl- lable in an utterance, we first introduced the con- catenated syllable matching algorithm for continu- ous speech recognition using SPM. Then a training procedure is proposed t o reestimate the SPM p" rameters. The experimental results show that SPM is very useful not only in isolated syllable recogni- tion, but also for continuous speech in Mandarin Chinese.
e . 9 5
4
0 1 2 3
iteration times
Figure 2: The error rates of continuous training utterance after iterative training procedure
modeis schemes
full
search 4 states,2 mixtures CHMM CHMMSPM
beam width=
400 5 states,3 mixtures beam width=
500 7 states,3 mixture3 beam width=
500 cep:4 segments,2 m i x t u r e sI
dcep:l segments.6 mixtures(11 Lin-Shan Leelet al, "Golden ?+landarin(II)-An improved Single-chip Real-time Mandarin Dic- tation Machine for Chinese Language with Very Large Vocabulary" ICASSP 1993, pp.503-506. [2] Picone,J. "Continuous Speech recognition Us- ing Hidden Markov Model" IEEE ASSP Mag- azine, pp.26-41, July 1990.
[3] Lee,K., Hon,H.and FLeddy,R.
,
"An Overview of the SPHINX Speech Recognition System" IEEE Trans. on ASSP, Jan. pp.35-45. [4] L.R.Rabiner, B.H.Juang, S.E.Levinson andM.M.Sondhi,
"
Recognition of isolated digits using Hidden Markov Modek with continuous mixture densities" AT&T
Technical Jouna1,voI64,No 6, pp.1211-1234, 1985.
[5] T.Ukita, E.Saito, T.Nitta, and S.Watanabe, "A speaker-independent connected digit recogni- tion system concatenating statistically discrim- inated words" IEEE %nu. on Signal Process-
ing ~ 0 1 . 4 0 N0.10 1992.
[SI
Mari
Ostendorf, Salim Roukos, "A stochas- tic segment model for phonemebased continu- ous speech recognition" IEEE Truns. o n ASSP ~01.37 1V0.12 1989. 55.18 29.24- 61.29 51.26 62.82 53.27 73.51 0.78 12.31 I ITable 2: continuous speech recognition rate of base syllables for HMM and SPM (all experiments are conducted in a Sun Sparc 2 station)