國 立 交 通 大 學
電信工程研究所
碩士論文
中文語音停頓韻律標記預估之改進
An Improvement on Break Tag Prediction for
Mandarin Speech
研 究 生:陳睿詮
指導教授:陳信宏 博士
中文語音停頓韻律標記預估之改進
An Improvement on Break Tag Prediction for
Mandarin Speech
研 究 生:陳睿詮 Student:Jui-Chuan Chen
指導教授:陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學 電 信 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science in Communication Engineering
July 2012
Hsinchu, Taiwan, Republic of China
I
中文語音停頓韻律標記預估之改進
研 究 生:陳睿詮
指導教授:陳信宏
博士
國立交通大學電信工程研究所碩士班
中文摘要
中文摘要
中文摘要
中文摘要
此論文將針對中文語音合成器中的停頓韻律標記預估做改進,由於文字轉語音的系統裡沒 有聲學參數的輔助,我們只能利用文字分析器得到的語言參數來預估停頓韻律標記,而一般來 說文字分析器所能得到的語言參數大多是詞階層以及語句階層的語言參數,即使有了這些參數, 語法以及語意上的資訊仍略顯得不足。要增進中文語音停頓韻律的預估,我們還需要更豐富的 語言參數,以描述中文語音裡語法及語意結構的資訊。本研究採取人工分類、標記的方式找出 一些常見或特殊的詞組、片語,並且以統計的方式分析詞組及片語內特殊位置的音節邊界的停 頓分布,以及這些音節邊界相對於詞組及片語邊界的韻律斷點相對強度。 分析結果發現,在大多數的詞組內的詞邊界不會出現停頓,詞組及片語內特殊位置的停頓 會受到詞組及片語結構的影響,且結構愈短的詞組愈不會違反詞組及片語邊界的韻律斷點相對 強度。 實驗的結果也證明了加入詞組及片語的語言參數,對於停頓韻律標記的預估的確會有幫助,不 論是在靜態地利用語言參數預估每個音節邊界的停頓,或是輔助動態地搜尋韻律單元邊界,都 有還不錯的效果,表示加入詞組以及片語的語言資訊能夠更正確的描述中文語法結構,進而增 進停頓韻律的預估。II
An Improvement on Break Tag Prediction for
Mandarin Speech
Student:Jui-Chuan Chen Advisor:Dr. Sin-Horng Chen
Institute of Commumication Engineering
National Chiao Tung University
Abstract
This thesis proposed an improvement method on break tag prediction for Mandarin speech synthesis. The linguistic features given from parser were utilized for the prediction of break tags due to the lack of prosodic-acoustic features in TTS. Generally, the linguistic features generated by parser belong to the word-level and sentence-level. However, the syntactic and semantic
information still remain insufficient even the word-level and sentence-level features are given. In order to improve the break prediction for Mandarin speech, more linguistic features for describing the syntactic and semantic information are needed. This research classifies and labels the common and special word chunk as well as the phrase artificially, analyze the inter-syllable break appeared at special position in word chunk or phrase by using statistic distribution and decision tree, and
investigate at last the mutual strength between these special position and the boundary of word chunk and phrase.
III
mostly non-break, while the break of special position in word chunk or phrase are affected by the structure of word chunk or phrase. Furthermore, the smaller structure of word chunk and phrase posseses higher probability to follow the rule of mutual strength related between special position and the boundary of word chunk or phrase.
The experiment results also showed that the adding of linguistic features of word chunk and phrase can in fact improve the prediction of break tags. Either using the linguistic features to predict inter-syllable break tags statically, or assisting the dynamic search for boundary of prosodic unit could the TTS achieve a more effective capability of break tags prediction. It virtually showed that the addition of word chunk and phrase information is capable of describing the syntactic structure more correctly, and then improve a more precise prediction of break tags.
IV
致謝
致謝
致謝
致謝
在碩士班做研究的這兩年,首先感謝陳信宏老師對我研究的指導以及照顧,感謝陳老師在 百忙之中能關心我的研究,使得我能順利完成碩士學業,跟著陳老師做研究真的學到很多如何 分析問題的能力。感謝王逸如老師在我們碩一時能夠嚴格的要求我們做研究的方法,以及在我 的研究中給我很多的指點,並且也讓我從一個只會考試交作業的大學生,變成一個能面對並解 決問題的研究生。感謝實驗室的江振宇學長,每每在我不知所措時能給我方向,以及指點我如 何分析思考這些問題,以及很多實務方面的技巧。 接著要感謝實驗室的所有同學,感謝智合學長以及阿德學長提供了很多的建議,感謝打球 很厲害的大胖學長、聰明的文良學長、阿沙力的小蝦學長、帥氣的智誠學長、很厲害的銘傑學 長、工作經驗豐富的進竹學長、很壯的豆腐學長對我的照顧,也讓我碩一時的生活能多采多姿。 感謝又帥又厲害的邱哥、以及思路很有條理的企鵝、研究課業打球把妹一把罩的 kiwi、單純 可愛的未來同事俊翰,有這三顆輪子外加一隻企鵝,是我研究及課業上最好的夥伴,感謝樂觀 的雅婷、打球超強的小高、認真又誠懇的昌祐、很有理財頭腦的昂星,有大家在這個實驗室裡 一起同肝共苦,也讓我更有拼勁地完成每一道關卡。感謝 707 小霸王仲銘、聰明且負責的子睿、 柔道很厲害的良基、信仰虔誠的婉君、按摩超舒服的奕勳,可愛漂亮的俏助理靖觀,因為有你 們,使得我碩二的生活可以充滿歡笑,也祝福你們碩二的生活能順順利利。 最後感謝我的爸爸、媽媽,感謝爸媽無私的付出讓我在學業的道路上可以無憂無慮,感謝 爸媽對我的教誨讓我人生的路沒有走歪,感謝爸媽辛苦地養我到現在,感謝姊姊對我的關心及 照顧,感謝我所有的家人對我的照顧和支持,感謝所有同學及朋友一路走來互相的扶持,以及 感謝我的女朋友能陪我度過碩二下艱苦的時刻,最後僅以此論文獻給以上的各位。
V
目錄
目錄
目錄
目錄
中文摘要 ... I Abstract ... II 致謝... IV 目錄... V 表目錄 ... VIII 圖目錄 ... X 第一章 緒論 ... 1 1.1 研究動機 ... 1 1.2 文獻回顧 ... 1 1.3 研究方向 ... 2 1.4 資料庫簡介 ... 3 1.5 章節概要說明 ... 4 第二章 階層式語音韻律模型與停頓標記 ... 5 2.1 中文階層式韻律架構 ... 5 2.2 中文階層式韻律模型 ... 6 2.2.1 中文韻律架構 ... 6 2.2.2 韻律模型設計 ... 8 2.2.3 韻律模型訓練與停頓韻律標記 ... 13 第三章 停頓標記語言模型 ... 16 3.1 名詞詞組 ... 16 3.1.1 一般的名詞詞組 ... 17 3.1.2 結構較緊密的名詞詞組 ... 20 3.1.3 構成詞的名詞詞組 ... 21VI 3.1.4 組織架構的名詞詞組 ... 22 3.1.5 地址的名詞詞組 ... 24 3.1.6 職稱接人名的名詞詞組 ... 25 3.1.7 時間的名詞詞組 ... 26 3.1.8 並列結合的名詞詞組 ... 28 3.1.9 重複強調的名詞詞組 ... 31 3.2 副詞、動詞、介系詞詞組... 32 3.2.1 一般的副詞、動詞、介系詞詞組 ... 33 3.2.2 構成詞的副詞、動詞、介系詞詞組... 34 3.2.3 並列結合的副詞、動詞、介系詞詞組 ... 36 3.3 省略數詞的詞組 ... 36 3.4 連接詞詞組 ... 38 3.5「的」字結構片語分析 ... 40 3.5.1 副詞性「的」字結構片語 ... 41 3.5.2 省略性「的」字結構片語 ... 43 3.5.3 名詞性「的」字結構片語 ... 45 3.5.4 形容詞性「的」字結構片語 ... 46 3.6 頓號的分析 ... 47 3.6.1 單一頓號單字詞 ... 48 3.6.2 單一頓號非單字詞 ... 49 3.6.3 連續頓號單字詞 ... 51 3.6.4 連續頓號非單字詞 ... 52 3.6.5 條列式的頓號 ... 53 第四章 停頓韻律標記產生器 ... 54 4.1 利用決策樹預估四大停頓類別標記 ... 55
VII 4.2 加入長度資訊動態預估四大停頓類別標記 ... 59 4.3 加入韻律斷點相對強度模型 ... 64 4.4 利用決策樹預估 NB 中四小類的停頓標記 ... 67 第五章 結論與未來展望 ... 70 5.1 結論 ... 70 5.2 未來展望 ... 70 參考文獻 ... 71 附錄一 ... 73
VIII
表目
表目
表目
表目錄
錄
錄
錄
表 1.1 : 訓練資料、發展資料以及測試資料的各類統計表... 3 表 2.1 : 本研究所使用的停頓分類 ... 7 表 2.2 : 韻律標記、聲學參數以及語言參數之數學符號 ... 9 表 3.1 : 名詞詞組決策樹分析中使用的問題及其涵義 ... 16 表 3.2 : 訓練資料中名詞詞組的各個類別的音節個數統計... 17 表 3.3 : 副詞、動詞、介系詞詞組決策樹分析中使用的問題及其涵義 ... 32 表 3.4 : 訓練資料中副詞、動詞、介系詞詞組的各個類別的音節個數統計 ... 32 表 3.5 : 訓練資料中省略數詞詞組的音節個數統計 ... 37 表 3.6 : 連接詞詞組決策樹分析中使用的問題及其涵義 ... 38 表 3.7 : 訓練資料中連接詞詞組的各個類別的音節個數統計 ... 38 表 3.8 : 「的」字結構片語決策樹分析中使用的問題及其涵義 ... 40 表 3.9 : 訓練資料中「的」字結構片語的各個類別的音節個數統計 ... 41 表 3.10 : 頓號結構句決策樹分析中使用的問題及其涵義 ... 48 表 3.11 : 訓練資料中頓號結構句的各個類別的音節個數統計 ... 48 表 4.1 : 詞組階層的語言參數列表 ... 56 表 4.2 : 連接詞詞組的語言參數列表 ... 56 表 4.3 : 「的」字結構片語的語言參數列表 ... 56 表 4.4 : 頓號的語言參數列表 ... 56 表 4.5 : 詞階層以及語句階層的語言參數列表 ... 56 表 4.6 : 對測試語料使用決策樹訓練及預估結果(a)方法一 (b)方法二 ... 58 表 4.7 : 列舉方法一與方法二之決策樹預估結果 ... 58 表 4.8 : 各個長度模型所使用的權重值(a)方法一 (b)方法二 ... 61 表 4.9 : 加入長度模型後動態搜尋的結果(a)方法一 (b)方法二 ... 62IX 表 4.10 : 列舉方法二加入長度模型前、後之預估結果的比較 ... 62 表 4.11 : 列舉方法一與方法二加入長度模型後之預估結果 ... 63 表 4.12 : 韻律斷點相對強度和雙詞結構詞組的層次關係 ... 64 表 4.13 : 韻律斷點相對強度和三詞結構詞組的層次關係 ... 65 表 4.14 : 韻律斷點相對強度和「的」字結構片語的層次關係 ... 65 表 4.15 : 使用方法二對測試語料加入長度模型及韻律斷點相對強度模型的結果 .... 66 表 4.16 : 列舉方法二加入韻律斷點相對強度模型前、後之預估結果 ... 66 表 4.17 : 詞階層、語句階層以及音節階層的語言參數列表 ... 68 表 4.18 : 測試資料七類停頓類別之預估結果 ... 69
X
圖目錄
圖目錄
圖目錄
圖目錄
圖 2.1: 階層式多短語韻律句群(Hierarchical Prosodic Phrase Grouping,HPG)架構 [9]。
... 6 圖 2.2: 音節停頓分布 ... 7 圖 2.3: 本研究所使用的中文階層式韻律結構 ... 8 圖 2.4: 音節音高軌跡與影響因素的關係圖 ... 11 圖 2.5: 使用決策樹分類法初始停頓韻律標記示意圖 ... 14 圖 3.1: 一般的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果 ... 19 圖 3.2: 緊密結合的名詞詞組的四類停頓類別分布 ... 21 圖 3.3: 構成詞的名詞詞組的四類停頓類別分布 ... 22 圖 3.4: 組織架構的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果... 24 圖 3.5: 地址的名詞詞組的四類停頓類別分布 ... 24 圖 3.6: 職稱接人名的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果 ... 26 圖 3.7: 緊密結合的時間名詞詞組的四類停頓類別分布 ... 28 圖 3.12: 一般的副詞、動詞、介系詞詞組的(a)四類停頓類別分布(b)決策樹分析結果 ... 34 圖 3.13: 構成詞的副詞、動詞、介系詞詞組的四類停頓類別分布 ... 35 圖 3.14: 平行結合的副詞、動詞、介系詞詞組的四類停頓類別分布 ... 36 圖 3.15: 省略數詞詞組的四類停頓類別分布 ... 37 圖 3.16: 連接詞前邊界的(a)四類停頓類別分布及(b)決策樹分析結果 ... 39 圖 3.17: 連接詞後邊界的四類停頓類別分布 ... 40 圖 3.18: 「的」字前邊界的四類停頓類別分布 ... 41 圖 3.19:「的」字後邊界的四類停頓類別分布 ... 41 圖 3.20: 副詞性「的」字後邊界的(a)四類停頓類別分布及(b)決策樹分析結果 ... 43
XI 圖 3.21: 省略性「的」字後邊界的(a)四類停頓類別分布及(b)決策樹分析結果 ... 44 圖 3.22: 名詞性「的」字後邊界的四類停頓類別分布 ... 45 圖 3.23: 形容詞性「的」字後邊界的四類停頓類別分布 ... 47 圖 3.24: 名詞性與形容詞性「的」字後邊界的決策樹分析結果 ... 47 圖 3.25: 單一頓號單字詞頓號的四類停頓類別分布 ... 49 圖 3.26: 單一頓號非單字詞頓號的(a)四類停頓類別分布及(b)決策樹分析結果 ... 50 圖 3.27: 連續頓號單字詞頓號的四類停頓類別分布 ... 51 圖 3.28: 連續頓號非單字詞頓號的(a)四類停頓類別分布及(b)決策樹分析結果 ... 53 圖 3.29: 列舉式的頓號的四類停頓類別分布 ... 53 圖 4.2: 決策樹的(a)訓練階段,(b)預估停頓標記 ... 55 圖 4.3: (a)呼吸群/韻律群 (b)韻律片語 (c)韻律詞 音節長度機率分布 ... 60 圖 4.4: 決策樹的(a)訓練階段 (b)預估停頓 ... 67 圖 4.5: 停頓標記語言模型之決策樹 ... 68
1
第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
1.1 研究動機
研究動機
研究動機
研究動機
在語音合成中為了使合成出來的聲音能夠聽起來更覺得舒適,以及使聽者更容易了解這段 語音所帶有的資訊,或者是使合成出來的語音更貼近於人講話的模式,除了原本合成出來的聲 音品質要好之外,必須再加入關於韻律的資訊,幫助使合成出來的聲音更為自然,目前關於中 文語音的韻律問題正在被廣泛的研究。韻律的參數包括語音的音高軌跡變化、能量強度、語音 長度以及停頓,而影響韻律最多的則是音節與音節之間的停頓,一句話中若是在不該停頓的地 方出現停頓,則容易使聽的人混淆這段語音的語意。眾多的研究顯示一段語句的語法資訊或語 意資訊會影響該語句的停頓,而目前一般語音合成器仍使用較低階層的語言參數,包括詞長 (word length)、詞性(part of speech)、特殊的詞綴以及在句子中的位置資訊等等的語言參數,來 預估韻律,已經可以達到不錯的準確度,但是如此的參數所考慮的範圍比較小,無法充分表現 出較大範圍的語言特性,若考慮句子的長短,則範圍又太大,無法精確的描述句子中詞組以及 片語的特性,因此本研究除考慮詞層的語言資訊外,更進一步的標記以及分析較大範圍的詞組 與片語階層的語言資訊,來增加對中文語音停頓韻律標記的預估。而此階段分析的詞組以及片 語希望能在以後使用機器學習的方法自動產生標記,達到自動化產生詞組及片語資訊並且預估 停頓韻律標記的效果。1.2 文獻回顧
文獻回顧
文獻回顧
文獻回顧
2
語言參數(Sentence-level linguistic feature)來預估停頓韻律,並利用不同的訓練方式來訓練出停 頓語法模型,如使用階層式統計模型[1]、分類與回歸樹[2]、馬可夫模型[3]或 Maximum entropy model[4]等等的方法,不同的訓練方法對於預估停頓韻律會有不同的表現,在[5]也有針對不同 的訓練方法做比較。 另一方面,語言學的研究人員也提出了階層式韻律模型(Prosodic hierarchy),指出人說出 來的一段話語是由不同的韻律單元(Prosodic units)層層建構而成,而不同韻律單元的邊界為不 同長度的停頓,愈上層的韻律單元其邊界的停頓愈長,反之愈下層的韻律單元其邊界的停頓愈 短。[6]使用語法樹層級的語言參數(Tree-level linguistic feature)來預估階層式韻律模型中不同韻 律單元的邊界,但缺點是這需要很精確的語法資訊才可以得到比較好的效果,且目前大多數的 斷詞系統仍無法精確的斷出詞組或是片語等等的語法樹層級的語言參數。在[7]的研究裡指出 由斷詞系統斷出來的詞(Lexical word)與韻律單元裡的韻律詞(Prosodic word),兩者邊界的對應 並不是很一致,而是有一段不小的落差,[7]並驗證了若能使用一些策略或規則將一些詞組合 成詞組,則對於韻律詞邊界的預估是很有效果的。韻律單元邊界的標記也是一個問題,傳統人 工標記的方式標記韻律單元的邊界很容易出現不一致的現象,導致機器學習的效果有限,江振 宇博士提出了使用非監督式的方法[8]使電腦能自動的依據語言參數以及聲學參數標記出韻律 單元的邊界,解決了人工標記不一致的現象,並使得後續對於韻律單元邊界以及語言參數關係 的研究能夠更準確。
1.3 研究方向
研究方向
研究方向
研究方向
傳統上語音合成器對於語言資訊的分析還不夠精確,雖然使用詞性、詞長以及標點符號等 等的語言資訊已經能包含大多重要的語言資訊,由[7, 8]我們知道只考慮詞層次的語言資訊是 不夠精確的,因為很多的在語法或語意上關係緊密的詞應該構成一個詞、詞組、或甚至是更大 的片語,光靠詞長與詞性的資訊是無法正確的描述這些詞組以及片語的資訊,且這些資訊是目3 前斷詞器斷詞出來的結果所沒有或是不夠精確的資訊,若是能更精確的掌握住詞組及片語的資 訊,則對於韻律單元邊界,或是停頓標記的預估將會有幫助,進一步使得其它的韻律參數預估 變好,故本研究會先以人工的方式將本研究所使用的資料庫裡的資料標記出詞組以及片語階層 的資訊,再由決策樹分析的方式來討論這些音節邊界的停頓的分布是否受到詞組以及片語結構 的影響,期望能引入較精確的語言資訊來分析,並增進停頓標記的預估能力。
1.4 資料庫簡介
資料庫簡介
資料庫簡介
資料庫簡介
本研究所使用的語料庫為中央研究院的 Sinica Treebank Version 3.0 中選出來的新聞語料, 且由一位專業的女性播音員讀稿錄製而成的語音,總計 422 個音檔,共 55,949 個音節,平均 每個音檔有 133 個音節。而本研究將原本選定 376 個訓練的音檔(Utterance)中選取 60 個音檔 當作用來調整參數的發展資料。選取時考慮因為有出現頓號的例子的音檔較少,故先由含有頓 號音檔裡挑出了 30 個音檔,而這 30 個音檔裡除了條列式的頓號之外其他的例子皆有收錄,接 著再由有出現連接詞詞組的例子的音檔中選出 20 個音檔,接著再依據出現有其他類型較少的 例子的音檔中選出 5 個音檔,剩下最後 5 個音檔的選取是隨機挑選,發展資料的選取會盡量平 均包括每一個我們要測試的參數的例子,並占原始訓練資料的 15.95%。而測試資料共有 46 個 音檔。表 1.1 為訓練資料、發展資料以及測試資料的各類統計表 表 1.1 : 訓練資料、發展資料以及測試資料的各類統計表 音檔數 詞數 音節數 Training data 316 25132 43457 Development data 60 4799 8411 Testing data 46 2176 4081
4
1.5 章節概要說明
章節概要說明
章節概要說明
章節概要說明
本論文的內容共分成五章: 第一章 : 緒論,介紹研究動機、文獻回顧、研究方向以及語料庫介紹 第二章 : 中文階層式韻律模型與停頓標記 第三章 : 停頓韻律標記語言模型 第四章 : 停頓韻律標記產生器 第五章 : 結論與未來展望5
第二章
第二章
第二章
第二章 階層式語音韻律模型與停頓標記
階層式語音韻律模型與停頓標記
階層式語音韻律模型與停頓標記
階層式語音韻律模型與停頓標記
本章以江振宇博士提出的韻律模型[8]為基礎,介紹其定義的各類韻律標記,並著重於本 研究所使用的停頓韻律標記的產生。2.1 節介紹中文階層式韻律架構,2.2 節介紹本研究所使用 的階層式中文語音韻律模型,包含韻律模型的設計、訓練、以及韻律標記的產生。2.1 中文階層式韻律架構
中文階層式韻律架構
中文階層式韻律架構
中文階層式韻律架構
由過去對於中文韻律的研究顯示,中文的韻律結構為階層式的韻律結構,[6]將其分成四 層的韻律結構,分別為音節層次(Syllable)、韻律詞層次(Prosodic word)、韻律片語層次(Prosodic phrase)以及語調短語層次(Intonation phrase)。中文為一字一音節的語言,故音節為最底層的韻 律單元,而音節又有不同的聲調,不同的聲調大都會有不同的語意,且聲調會強烈的影響音節 的基頻軌跡(F0 contour)、音節長度(Syllable duration)以及音節能量(Syllable energy),故聲調為 影響音節層次的韻律最主要的因素。第二層的韻律詞由兩個或數個音節組成,在語法或語意裡 是較緊密連結的一個單位,或是使用上較常一起出現,故易將韻律詞視為一個發音單位。而第 三層的韻律片語由一個或數個韻律詞組成,而邊界為一個可察覺但不明顯的停頓。語調短語層 次是這個中文韻律架構的最上層,由一個或數個韻律片語組成,且其邊界會有一個長而明顯的 停頓,音高的變化會受到此層的影響。 鄭秋豫博士[9]將中文的韻律架構由底層至上層分為音節(Syllable)、韻律詞(Prosodic word)、 韻律片語(Prosodic phrase)、呼吸群(Breath group)、韻律群(Prosodic group)等五層,而區分這些 層次的架 構主要是依據六種停頓標記,由短到長依 序為 B0(reduced syllable boundary) 、 B1(normal syllable boundary)、B2(prosodic word boundary)、B3(prosodic phrase boundary)、 B4(breath group boundary)、B5(prosodic group boundary)。以韻律詞來說,通常是由一或多個音6
節構成,而音節語音節中間主要為 B0/B1 的停頓;韻律片語也是由一個或多個韻律詞構成, 而韻律詞中間的邊界主要為 B2 的停頓;而一個呼吸群主要由一個或數個韻律片語構成,而韻 律片語中間的停頓為 B3;韻律群再由呼吸群構成,呼吸群中間的停頓為 B4;最後韻律群與韻 律群中間的停頓為 B5,如圖 2.1 所示。
圖 2.1: 階層式多短語韻律句群(Hierarchical Prosodic Phrase Grouping,HPG)架構 [9]。
2.2 中文階層式韻律模型
中文階層式韻律模型
中文階層式韻律模型
中文階層式韻律模型
本節介紹本研究所使用的中文韻律架構,以及韻律模型裡的停頓標記的訓練以及產生。2.2.1
中文韻律架構
中文韻律架構
中文韻律架構
中文韻律架構
本研究將鄭秋豫博士提出的階層式韻律架構加以修改,因為在原本 B2 裡還有其他不同聲 學特性的停頓類別,只用一種停頓表示是不夠的,故將原本的 B2 再分成三類,分別為 B2-1、 B2-2 以及 B2-3,B2-1 代表的是有明顯的音高重置(pitch reset)的停頓,B2-2 代表的是可察覺的 短停頓(short pause),B2-3 代表的是音節延長效應(duration lengthening)的停頓。且因為呼吸群 的邊界停頓與韻律群的邊界停頓聲學特性相近,所以將這兩個類別合併成一類,並以 B4 做為
7 其停頓的邊界,故本研究將使用七種停頓類別,由短至長依序為 B0、B1、B2-3、B2-1、B2-2、 B3、B4,以及四個層次的韻律單元,由下往上依序為音節、韻律詞、韻律片語、呼吸群/韻律 群。 由音節停頓分布(圖 2.2),我們可以得知 B0、B1、B2-1 以及 B2-3 的停頓都是比較短的短 停頓,而 B2-2 的停頓較長,但是又比 B3 的停頓短得多,且 B2-2、B3、B4 的停頓很明顯的有 不同的長度,所以我們又將這七類停頓分成四個大類,分別為 NB(non-break)、B2-2、B3、B4, 其對應關係如表 2.1 所示。 圖 2.2: 音節停頓分布 表 2.1 : 本研究所使用的停頓分類 NB B0, B1, B2-3, B2-1 B2-2 B2-2 B3 B3 B4 B4
8 我們將用這四個大類的停頓,來標記四個層次的中文階層式韻律架構,如圖 2.3 所示。 圖 2.3: 本研究所使用的中文階層式韻律結構 階層式韻律架構的韻律現象除了韻律邊界的停頓之外,另外還有用來描述韻律單元變化的 參數或標記。本論文將採用三種不同的韻律狀態,分別為量化及正規化後的音高、量化後的音 長以及量化後的能量強度。而為了將較低層次(音節層次)與較高層次(韻律詞層次、韻律片語層 次以及呼吸群/韻律群層次)的影響因素分開,使得複雜的高層次韻律影響因素都由韻律狀態表 示,這三種韻律狀態須分離音節層次對韻律狀態的貢獻,使得三種韻律狀態表示的是韻律詞層 次、韻律片語層次以及呼吸群/韻律群層次對音高、音長以及能量的貢獻。
2.2.2 韻律模型設計
韻律模型設計
韻律模型設計
韻律模型設計
韻律標記的問題可以被視為再給定聲學參數以及語言參數的情況下,尋找一個最佳韻律標 記序列的問題,其公式如(2-1),其中T 為韻律標記序列,A 為聲學參數序列,L 為語言參數序列。 *
arg max (P , ) arg max ( ,P | )
= = T T T T | A L T A L (2-1) 韻律標記總共有兩個大類,一為音節停頓標記(Break type),本研究使用的音節停頓標記總 共有 B0、B1、B2-1、B2-2、B2-3、B3、B4 七類,而這些停頓標記是用來定義階層式韻律架 構中不同層次的邊界。另一個為音節韻律狀態(Prosodic state),包含量化及正規化的音高、音 長以及能量。故定義韻律標記序列 T 可以視為停頓韻律標記序列 B 以及韻律狀態標記序列 PS 的組合,而 PS 又包含量化及正規化的音節基頻韻律狀態 p 、音長韻律狀態 q 以及音節能量狀態
9 r。 聲學參數主要分成兩類,一為與韻律狀態標記關係較密切,與停頓狀態關係較不密切,而 此類的參數主要是音節的基頻軌跡、音節長度以及音節能量位階。另一類與音節邊界的停頓標 記關係較為密切,與韻律狀態標記關係較不密切,此類的參數主要是停頓的長度、音節邊界的 energy-dip level、正規化的能量與基頻差以及正規化的音節長度拉長音子。故定義聲學參數序 列 A 包括音節的基頻軌跡 sp 、音節長度 sd 、音節能量位階se、停頓的長度pd、音節邊界的 energy-dip leveled 、正規化的基頻差pj以及正規化的音節長度拉長音子 df 及 dl 。再依據參數 的特性不同,分成音節韻律參數X={ ,sp sd se, }、音節內韻律參數Y={pd ed, }以及音節差韻律 參數Z={pj,df,dl}等三類。 語言參數的部分包含的範圍較廣,且因結構的大小有不同的層級,在音節層級(syllable
level)的部分,有音節聲調以及音節的聲母或韻母等等的資訊。而在詞層級(word level)的部分 有音節邊界類型(inter-word and intra-word)、詞長、詞性(part-of-speech, POS)以及標點符號類型 等等的資訊。而因為音節聲調、基本音節類型與音節韻母會嚴重影響音節基頻軌跡、音節長度 與音節的能量位階,所以將這三類的語言參數獨立出來,並且再把兩個在語句層級中會因說話 的語速不同而影響音節長度以及因音量不同而影響音節能量位階的正規化因子獨立出來。故扣 除掉音節聲調 t、基本音節邊界 s、音節韻母類型 f 以及語句層級中獨立出來的正規化因子 u , 剩下的語言參數集合定義為 l。韻律標記、聲學參數及語言參數的數學符號定義如表2.2所示。 表 2.2 : 韻律標記、聲學參數以及語言參數之數學符號 T: prosodic tag B: break type ={B0, B1, B2-1, B2-2, B2-3, B3, B4 } PS: prosodic state
p: pitch prosodic state q: duration prosodic state r: energy prosodic state A: prosodic feature X: syllable prosodic feature
sp: syllable pitch contour sd: syllable duration
10
se: syllable energy level Y: inter-syllabic prosodic feature
pd: pause duration ed: energy-dip level Z: differential prosodic features
pj: normalized pitch jump
df: normalized duration lengthening factor
L: linguistic feature
l: reduced linguistic feature set t: syllable tone sequence s: base-syllable type f: final type u: utterance sequence 依據上面的討論,我們將(2-1)式改寫為 ( , | ) ( | , ) ( | ) ( , , | , , ) ( , | ) ( | , , ) ( , | , ) ( | ) ( | ) (2-2) P P P P P P P P P = = ≈ T A L A T L T L X Y Z B PS L B PS L X B PS L Y Z B L PS B B L 其中P X B PS L( | , , )為描述音節韻律參數變化的音節韻律模型,P Y Z B L( , | , )為描述音節間停頓 的停頓聲學模型,P PS B( | )為描述韻律狀態變化的韻律狀態標記模型,P B L( | )為描述停頓類 別與語言參數之間的關係的停頓標記語言模型。 接著可以將音節韻律模型拆成三個模型,分別為模擬音節基頻軌跡序列 sp 、音節長度序 列 sd 以及音節能量位階序列 se ,並且假設這三個模型主要受到以下這幾種影響因子影響,分 別為音節聲調 t 、基本音節邊界 s 、音節韻母 f 、語句層次的參數 u 、韻律狀態標記 PS 以及韻 律停頓標記 B 。如(2-3)的公式 1 1 1 1 1 1 ( | , , ) ( | , , ) ( | , , , ) ( | , , , ) ( | , , ) ( | , , , ) ( | , , , ) (2-3) N N N n n n n n n n n n n n n n n n n n n n P P P P P sp B − p t−+ P sd q t s u P se r t f u = = = ≈ ≈
∏
∏
∏
X B PS L sp B p t sd q t s u se r t f u11 其中的 1 1 1 ( n| nn , n, nn ) P sp B− p t−+ 是描述音節基頻軌跡受到各種影響因素影響,而式子的意思是第 n 個音節的基頻軌跡會受到Bn−1及Bn的韻律邊界停頓、目前的基頻韻律狀態pn以及前後相鄰音 節的聲調tn−1、tn和tn+1造成的連音影響,spn為將音節基頻正交軌跡投影到四個Legendre多項 式基底得到的四維正交參數。經由上述的分析,我們可以將spn表示成如(2-4)的公式 -1, -1 , for 1 (2-4) n n n n n n r f b n n t p B tp B tp ≤ ≤n N sp = sp + β + β + β + β + u 上式中的β 為音節音高影響因素為x x的AP,tp 是n tone pair tnn+1=( ,t tn n+1), -1, -1 n n f B tp β 及 , n n b B tp β 分 別表示第n-1個音節與第n+1個音節影響第n個音節的音節影響效應的APs,而在語句的開始 與結束分別用B 與b B 表示,e AP分別為 0 , b f B tp β 及 , e N b B tp β 。 r n sp 為扣除掉 n t β 、 n p β 、 0 , b f B tp β 、 , e N b B tp β 以 及殘餘值u的正規化的sp 。圖n 2.4 為表示sp 以及各個影響因素的關係圖,並且假設n sp 是一rn
個zero-mean的normal distribution N sp( rn;0, )R ,依據上述的推論可以得到如(2-5)的式子
-1 -1 1 1 1 , , ( | , , ) ( ; , ) for 1 (2-5) n n n n n n n n r f b n n n n n t p B tp B tp P sp B − p t−+ =N sp β + β + β + β + u R ≤ ≤n N 1 n− sp Bn−1 spn Bn spn+1 1, 1 n n f B− tp− β , n n b B tp β n t β n p β 圖 2.4: 音節音高軌跡與影響因素的關係圖 音節長度模型sd 以及音節能量模型n se 可以分別表示成n
12 ( | , , , ) ( ; , ) for 1 (2-6) n n n n n n n n n n t q s u d d P sd q t s u =N sd
γ
+γ
+γ
+γ
+u R ≤ ≤n N ( | , , , ) ( ; , ) for 1 (2-7) n n n n n n n n n n t r f u e e P se r t f u =N seα
+α
+α
+α
+u R ≤ ≤n N 其中γ
與α分別表示了音節長度模型與音節能量模型的各個影響因素的 APs。u 與d R 分別為d音長的 global mean 以及音長殘餘值的共變異數矩陣,而u 與e R 分別為音節能量的 global meane
以及音節能量殘餘值的共變異數矩陣。 接著化簡停頓聲學模型 ( , | , )P Y Z B L ,得(2-8)的公式 1 ( , | , ) ( , | , ( , , , , | , ) (2-8) N n n n n n n n n P P P pd ed pj dl df B = ≈ ≈
∏
Y Z B L Y Z B l) l其中 (P pd edn, n,pj dl dfn, n, n|B ln, )n 是由分類回歸樹(Classification and Regression Tree, CART)推
導得到,其結點的分裂準則是最大概似函數增益(Maximum Likelihood Gain),將pd 、n ed 、n pj 、n
n
dl 、df 對於不同的停頓類別n B ,依據語言參數設計好的問題集做分類而得。而n 由一個
gamma distribution 來模擬, 、 、 、 分別由四個 normal distribution 來模擬,則我
們可以將 改寫成上述五個機率分布的乘積 , , , 2 2 2 , , , , , 2 2 , , ( , , , , | , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) n n n n n n n n Bn n n n Bn n n n Bn n n n pj n n n n n n n n B B n B B n B dl dl df df n B n B P pd ed pj dl df B g pd N ed N pj N dl N df α β µ σ µ σ µ σ µ σ = l l l l l l l l l l l (2-9) 接著針對三種韻律狀態,拆解韻律狀態模型 (P PS B 為三個子模型 | ) ( | ) ( | ) ( | ) ( | ) (2-10) P PS B ≈P p B P q B P r B 每個子模型可用 bigram model 表示為 n pd n ed pjn dln dfn ( n, n, n, n, n| n, )n P pd ed pj dl df B l
13 1 1, 1 2 ( | ) ( ) ( | ) (2-11) N n n n n P P p P p p− B− = ≈
∏
p B 1 1, 1 2 ( | ) ( ) ( | ) (2-12) N n n n n P P q P q q− B− = ≈ ∏
q B 1 1, 1 2 ( | ) ( ) ( | ) (2-13) N n n n n P P r P r r− B− = ≈ ∏
r B 1 ( ) P p 、P q 以及( )1 P r 分別表示音節音高韻律狀態、音節長度韻律狀態以及音節能量韻律狀( )1 態的起始機率,P p( n| pn−1,Bn−1)、P q( n|qn−1,Bn−1)及P r( |n rn−1,Bn−1)則分別表示在不同的停頓標記 下,第n-1個音節韻律狀態到第n個音節韻律狀態的轉移機率。 最後化簡停頓語法模型P B L( | ),並且假設每個音節邊界的停頓標記只受該音節邊界的語 言參數影響,故將P B L( | )表示成如公式(2-14) 1 ( | ) ( | ) ( | ) (2-14) N n n n P P P B l = ≈ =∏
B L B l 利用語言參數l設計出來的問題集,以CART演算法訓練並依據最大概似函數增益的分裂準則 而得。2.2.3
韻律模型訓練與停頓韻律標記
韻律模型訓練與停頓韻律標記
韻律模型訓練與停頓韻律標記
韻律模型訓練與停頓韻律標記
中文A-PLM在建立時依據最大似然法則(Maximum likelihood),同時預估上述八種韻律模 型參數以及標記語句中各個韻律標記,韻律模型在訓練時主要有初始化以及疊代這兩個步驟。
14 在初始化時先對所有的語句做初始的韻律標記,以及預估出八種韻律模型參數的初始值,而停 頓韻律標記的初始化過程為,依據聲學參數預估出的初始音節停頓長度(pd)、音節能量低點(ed)、 正規化基頻跳躍值(pj)以及正規化音節延長因子(dl、、、、df)的韻律參數,使用[8]所提出的決策樹 的方法,針對語句中所有的音節邊界預估初始的停頓韻律標記(B),如圖2.5所示。 1 n pd ≥Th 2 n pd ≥Th 3 n pd ≥Th 6 and n Ye ≥Th 6 and n ed ≥Th 圖 2.5: 使用決策樹分類法初始停頓韻律標記示意圖 音節停頓長度是影響停頓韻律標記最重要的韻律參數,大多數出現標點符號的詞邊界 (Inter-word)會有較長的停頓,如B3、B4,其中B4的音節長度較B3的音節長度還長,故我們 可以利用音節長度停頓來區分 B3、B4;而大多數的詞內邊界(Intra-word)會有不停頓或是較短 的停頓,如B0、B1,其中B0是音節間基頻停頓(pitch pause duration)很短的停頓,故我們可以
利用很短的音節間基頻停頓以及較高的音節能量低點來區分B0、B1;剩下不是出現標點符號
的詞邊界則是有中等程度以上的音節停頓長度、基頻跳躍值以及音節延長,我們分別歸類為
B2-2、B2-1、B2-3。由以上所敘述的聲學及語言參數的關係,我們可以設計一套演算法來制定 此決策樹中的 Threshold Th1~Th8,由此方法自動得到初始的韻律標記,也解決了人工標記不 一致的問題。關於Threshold Th1~Th8更詳細的說明請參考[8, 12]。有了初始的停頓韻律標記,
15 接下來就可以用來求取初始的韻律狀態轉移模型P PS B( | )及停頓標記語言模型P B L( | )。 在疊代時,我們先對所有的語句定義一個概似函數,如(2-15)所示,接著進行反複疊代, 使得概似函數收斂,確保可以得到可靠的韻律標記以及其它韻律模型參數,而最後得到的停頓 韻律標記,即為本研究接下來所使用的停頓韻律標記。 1 -1 1 1 1 1 1 1 1 1 1 1 1 2 ( | , , ) ( | , , , ) ( | , , , ) ( ) ( ) ( ) ( | , ) ( | , ) ( | , ) ( , , N n n n n n n n n n n n n n n n n n N n n n n n n n n n n n n Q P p B t P sd q t s u P se r t f u P p P q P r P p p B P q q B P r r B p pd ed + − = − − − − − − = =
∏
∏
sp(
)
1 1 , , | , ) ( | ) N n n n n n n n n pj dl df B P B − = ∏
l l (2-15)16
第三章
第三章
第三章
第三章 停頓標記語言模型
停頓標記語言模型
停頓標記語言模型
停頓標記語言模型
停頓是影響韻律的一個非常重要的因素,而一段句子裡會產生停頓除了是因為句子太長而 沒辦法一次唸完之外,另一個很重要的原因是為了能完整傳達語意給聽這段語音的人,使聽的 人可以了解這段語音所傳達的訊息。而對於母語是漢語的人,就算沒有學過漢語語法的分析, 其在唸一段中文的語句時,大多還是會符合漢語語法的結構來做停頓,而不符合漢語語法結構 的停頓,則可能是ㄧ些特殊且常用的詞組,或片語及俚語等句子。而由詞階層的語言參數預估 停頓韻律已經能有不錯的效果,但是若只看詞階層的語言參數似乎不太準確,因為我們知道在 一段語句中會出現很多一塊塊的詞組,有些詞組中間出現停頓的機會不高,像是名詞詞組以及 的副詞、動詞、介系詞詞組,有些詞組裡通常會有一個地方有特別的停頓韻律,像是連接詞前 邊界、「的」字的前邊界以及一些特殊情況的名詞詞組,以語法的角度來看這些詞組的角色與 一般詞類似,只是結構較大且可能會出現停頓。本章節將一一介紹本研究考慮的詞組階層的語 言參數標記,並透過決策樹的分析來說明考慮到詞組以及片語單元的分析是有效的。決策樹的 分類準則為最大概似函數增益,且每個節點最少需要五個樣本數才可以被分出來。3.1 名詞詞組
名詞詞組
名詞詞組
名詞詞組
名詞詞組的分析主要是先依據中央研究院的 Sinica Treebank 語料庫中已經分析好的語法 樹(syntactic tree)裡的名詞片語的資訊,然後再對其做修正以及分類,並且重新標記出我們要使 用的語言資訊。表 3.1 為名詞詞組決策樹分析中使用的問題及其涵義,表 3.2 為訓練資料中名 詞詞組的各個類別的音節個數統計,以下將一一介紹分類和修正的例子以及對於停頓的影響。 表 3.1 : 名詞詞組決策樹分析中使用的問題及其涵義 問題 涵義 NP F syll num <= n 名詞詞組內的詞邊界距離名詞詞組前邊界的音節數是否小於等於 1, 2, 3, 4, 5, 617 NP B syll num <= n 名詞詞組內的詞邊界距離名詞詞組後邊界的音節數是否小於等於 1, 2, 3, 4, 5, 6 表 3.2 : 訓練資料中名詞詞組的各個類別的音節個數統計 類別 類別類別 類別 子類別子類別子類別子類別 音節邊界個數音節邊界個數音節邊界個數音節邊界個數 名詞詞組 一般的名詞詞組 1732 緊密結合的名詞詞組 667 構成詞的名詞詞組 712 組織架構的名詞詞組 18 地址的名詞詞組 6 職稱加人名的名詞詞組 137 時間的名詞詞組 94 並列結合的名詞詞組 13 重複強調的名詞詞組 22
3.1.1
一般
一般
一般
一般的名詞詞組
的名詞詞組
的名詞詞組
的名詞詞組
一般的名詞詞組是普通的兩個或是兩個以上的名詞構成的詞組,如例子 Ex.1~Ex.5 裡底線 框起來的部分,名詞之間不具有較緊密的關係,名詞與名詞結合在一起也不具有其他的意思, 或者是在這些名詞詞組在語句中不常一起出現,使得這一類的名詞詞組唸起來可能會出現停頓, 所以這類例子的邊界我們標記為可能出現停頓的 type-2 intra-word。值得一提的是,這類的例 子可能會出現很多個詞構起來成為一個長的名詞詞組的現象,如 Ex.4 及 Ex.5,我們會依據詞 邊界在語法樹結構的深度,來標記他們相接的階層結構,如 Ex.4 及 Ex.5 例子裡中括號內的數 字,數字愈大者代表其在樹狀結構中深度愈深。
18
Ex.2 : …,其實(Dbb) B2-1 雙方(Nhab) B1 感情(Nad) B1 好(VH11) B3,...
Ex.3 : …,為了(P03) B1 避免(VE2) B0 引起(VC2) B1 市場(Ncb) B2-2 注意(Nv2) B3,...
Ex.4 : …,二十六歲(DM) B0 那年(DM) B3 交(VC2) B1 過(Di) B0 一個(DM) [1] B2-2
一百七十七公分(DM) [2] B2-3 男士(Nab) B4,...
以 Ex.4 這個例子來說,“
一百七十七公分”先與“
男士”構成一個比較下層的名詞詞組,而“一個” 與“一百七十七公分男士”構成一個比較上層的名詞詞組,因為結構上來說比較上層的結構相對 於下層的結構較不緊密,且下層結構的字數已經夠長,所以比較有可能出現停頓。Ex.5 : …,人們(Naeb) B1 常(Dd) B2-3 見(VE2) B0 一種(DM) [1] B2-2 大型(Nad) [2] B1
卷毛(Nab) [3]B2-1 黑犬(Nab) B3,...
以 Ex.5 這個例子來說,“
捲毛”先與“
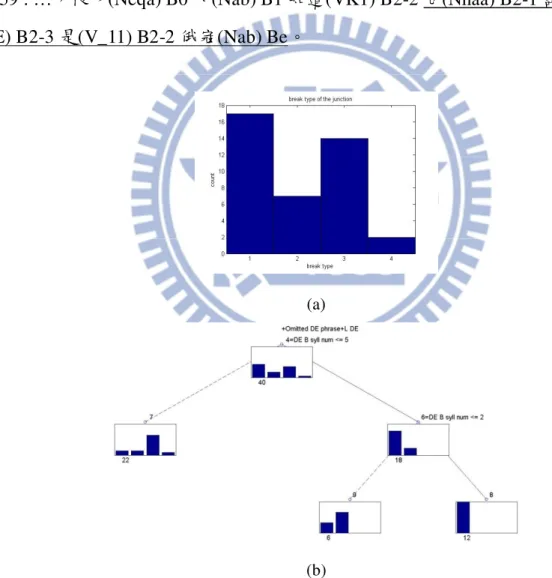
黑犬”構成一個緊密結合的名詞詞組,而“大型”與“捲毛黑 犬”構成一個比較下層的名詞詞組,接著“一種”與“大型捲毛黑犬”構成一個比較上層的名詞詞 組,同樣因為結構上來說比較上層的結構相對於下層的結構較不緊密,且因為後面的音節數的 長度夠長的關係,所以比較有可能出現停頓。 圖 3.1 為一般的名詞詞組之四類停頓分布以及決策樹的分析結果,由圖 3.1(a)的統計結果 可以得知,一般的名詞詞組的停頓還是以短停頓居多,這說明了雖然這些詞組的結合性並不高, 但是人們還是習慣會將這些詞組一起唸。但是這類的例子還是可能會出現停頓,但停頓出現的 邊界通常為結構較上層或是因為前、後接的音節數較多所導致。圖 3.1(b)為決策樹分析的結果, 每個節點內的圖示為這組分類的停頓標記分布,節點編號旁邊的文字表示此節點問的問題,實 線表示父節點問題為“是”,虛線表示父節點問題為“否”。由圖 3.1(b)的決策樹分析結果可19 以得知若一個詞組內邊界距離詞組前邊界或詞組後邊界愈長,則愈有可能出現停頓,反之距離 愈短,愈偏向於不停頓,所以詞組內詞邊界距離詞組前邊界或詞組後邊界的長度會是影響詞組 內詞邊界會不會出現停頓的一個主要的因素。 (a) (b) 圖 3.1: 一般的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果 (註:停頓類別依序為 NB、B2-2、B3、B4)
20
3.1.2
結構較緊密的名詞詞組
結構較緊密的名詞詞組
結構較緊密的名詞詞組
結構較緊密的名詞詞組
較緊密結合的名詞詞組的選定法則,是這些詞組在句子之中表達一個完整的意思,若這些 詞拆開來則沒辦法表示它們組合在一起的名詞的意思,或是我們時常會連在一起唸的常用詞組, 這一類的詞有點類似複合詞(Compound word)的概念,可以看成是由兩個比較大的自由詞素 (Free morpheme)構成一個比較大的詞,所以在唸法上這些詞組中間的停頓大多是很短的停頓, 如 Ex.6~Ex.8。若是 將這些詞組看成是一個詞來看待,則裡 面原本的詞邊界就是 Type-1 intra-words,故這類的詞組我們標記為 Type-1 intra-words。
Ex.6 : …,我國(B2-1)出口(B2-2)及(B2-1)進口(B1)金額(B3)比起(B2-1)去年(B1)同期
(B2-2)均(B0)有(B1)增加(B4),…
由 Ex.6 我們看到
“
進口”與“
金額”、“
去年”與“
同期”這類的詞在語法結構裡皆構成較緊密結合 的名詞詞組,所以中間的停頓皆較短。Ex.7 : ...,默尼黑(Ncb) B0 大學(Ncb) B1 的(DE) B2-2 福耳克(Nba) B2-1 秀斯瑞阿拉
(Nba) B1 博士(Nab) B1 說(VE2) B4,...
在 Ex.7 這個例子裡,“默尼黑”與“大學”應是緊密結合的兩的詞組,構成“默尼黑大學”的意思, 所以為緊密結合的名詞詞組。
Ex.8 : ...,哈立曼(Nba) B2-3 先生(Nab) B3 向(P62) B2-2 杜魯門(Nba) B2-1 總統(Nab)
B2-2 報告(VE12) B2-1 稱(VE2) B4,...
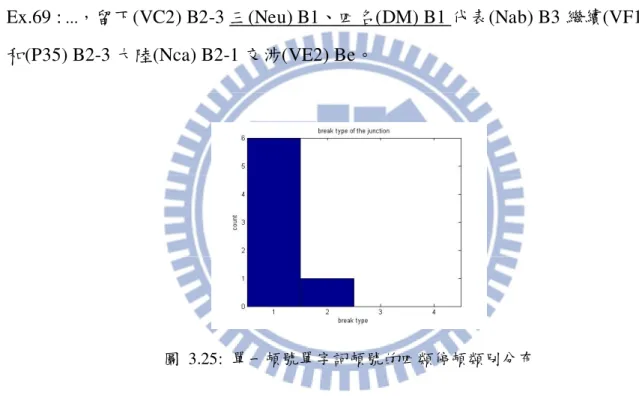
21 連在一起唸,故這些詞與其前面接的人名應該視為一個緊密結合的名詞詞組。 圖 3.2 為緊密結合的名詞詞組的四類停頓類別分布,由圖 3.2 可以得知這些緊密結合的詞 組停頓的類別幾乎都為短停頓,且出現 B2-2 與 B3 的停頓又比一般的名詞詞組少了很多,這 表示這些詞組相較於一般的名詞詞組更緊密,更不容易出現停頓。 圖 3.2: 緊密結合的名詞詞組的四類停頓類別分布
3.1.3
構成詞的名詞詞組
構成詞的名詞詞組
構成詞的名詞詞組
構成詞的名詞詞組
構成詞的名詞詞組主要是因為兩個相鄰的詞之中有一個詞是一字詞,容易與另一個名詞結 合。通常是一字詞會跟其相鄰的名詞結合成一種意義比較大的名詞,所以這類的例子裡兩個相 鄰的名詞之中幾乎都是不停頓的 B0/B1 停頓類別居多,如 Ex.9~Ex.12。若以這兩個名詞就是 一個詞來看待,則其中間的詞邊界為 Type-1 intra-words,故這類的詞組我們標記為 Type-1 intra-words。
Ex.9 : ..., 該(Nes) B2-1 會(Nac) B0 理事長(Nab) B3 莊榮兆(Nba) B1 表示(VE2) B4,...
22
此(Nep) B1 去(VC1) B3,...
Ex.11 : ..., 朝野(Naea) B0 兩(Neu) B2-3 黨(Nac) B3 可以(Dbab) B1 按照(P43) B2-1
自己(Nhab) B0 立場(Nac) B2-3 解釋(VE2) B3,...
Ex.12 : ..., 或(Caa) B0 在(P21) B1 市區(Ncb) B0 內(Ncda) B2-3 大(VH13) B2-3 飯店
(Ncb) B2-3 用餐(VA4) B4 然後(Dd) B2-3 看(VC2) B1 場(DM) B1 電影(Nac) B4。
Ex.12 這個例子是“市區”與“內”、“大”與“飯店”分別為兩個應該看成一個詞的名詞詞組,也就 是將“市區內”與“大飯店”直接視為一個名詞。接著“市區內”與“大飯店”構成一個一般的名詞詞組。 圖 3.3 為構成詞的名詞詞組的四類停頓類別分布,由圖 3.3 的統計結果可以得知,這類的 例子幾乎都是 NB 的停頓居多,與原本 Intra-words 的停頓是類似的統計分布。 圖 3.3: 構成詞的名詞詞組的四類停頓類別分布3.1.4
組織架構的名詞詞組
組織架構的名詞詞組
組織架構的名詞詞組
組織架構的名詞詞組
組織架構的名詞詞組是兩個以上的機構名詞連起來的名詞詞組,為了使聽的人可以更了解 組織架構的關係,通常我們在唸組織架構名詞詞組時中間可能會出現停頓,如 Ex.13~Ex.15, 故這類我們標記為 Type-2 intra-words,並且也標記它是一個組織架構的名詞詞組標記。
23
Ex.13 : 依據(P43)行政院(Nca) B2-3 主計處(Ncb)的(DE)統計(Nad),...
Ex.14 : 台灣省(Nca) B2-2 發明人(Nab) B1 協會(Nac) B3 於(P23) B2-1 今日(Ndabd) B1
下午(Ndabe) B0 兩點(Ndabe) B3 假(P28) B2-1 經濟部(Ncb) B2-2 商品(Nab) B1 檢驗局
(Nca) B2-1 大禮堂(Ncb) B3 舉行(VC31) B1 會員(Nab) B1 大會(Nac) B4。...
Ex.14 這個例子是“發明人”與“協會”先構成一緊密結合的名詞詞組,而“台灣省”與“發明人協會” 是一個組織架構的名詞詞組。同理,“商品”與“檢驗局”先構成一緊密結合的名詞詞組,而“經 濟部”與“商品檢驗局”構成一個組織架構的名詞詞組。
Ex.15 : ...,未(Dc) B0 能(Dbab) B1 返回(VC1) B0 紐約(Nca) B2-1 參加(VC2) B3 聖若
望(Nba) B1 大學(Ncb) B3 亞洲(Nca) B1 學院(Ncb) B1 舉辦(VC2) B1 的(DE) B3 中華
民國(Nca) B2-3 研討會(Nac) B4,...
Ex.15 這個例子是,“聖若望”與“大學”以及“亞洲”與“學院”分別構成兩個緊密結合的名詞詞組, 而“聖若望大學”與“亞洲學院”構成一個組織架構的名詞詞組。 圖 3.4 為組織架構的名詞詞組的四類停頓類別分布及決策樹分析結果,圖 3.4(a)說明了在 組織架構的名詞組中相較於一般的名詞詞組更可能出現停頓,且由圖 3.4(b)也可以觀察到當詞 組內邊界距離詞組後邊界的音節數大於三時,則詞組中間的邊界愈有可能出現停頓。 (a)24 (b) 圖 3.4: 組織架構的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果
3.1.5
地址的名詞詞組
地址的名詞詞組
地址的名詞詞組
地址的名詞詞組
通常地址的名詞詞組都會是結構比較長的詞組,為了能使聽者清楚知道地址與地點是在哪 裡,所以每個地名詞與地名詞之間通常會有短停頓,如 Ex.16。故標記這類的例子為一個 Type-2 intra-word,同時給予這些例子為一個地址的名詞詞組標記。
Ex.16 : ...,至(P61) B1 台北市(Nca) B2-2 鎮江街(Ncb) B2-23號(Ncb) B2-26樓之2
(Ncb) B3,...
圖 3.5 為地址的名詞詞組的四類停頓類別分布,
由圖 3.5 的停頓分布可以得知這類的例子 大多都會有停頓。 圖 3.5: 地址的名詞詞組的四類停頓類別分布25
3.1.6
職稱接人名的名詞詞組
職稱接人名的名詞詞組
職稱接人名的名詞詞組
職稱接人名的名詞詞組
職稱接人名的名詞詞組在職稱與人名的之間通常會有停頓,其原因是因為要唸一個人名前 需要有停頓,使得聽的人可以聽清楚職稱與人名的關係,如 Ex.17~Ex.19。但若是常用或是較 短的詞組,則中間可能不會有停頓,如 Ex.19 的例子。故標記這類的例子為 Type-2 intra-word, 同時給予這些例子為一個職稱接人名的名詞詞組標記。
Ex.17 : ...,經(P26) B2-2 美國(Nca) B2-1 總統(Nab) B2-2 杜魯門(Nba) B1 同意(VK1)
B4,...
Ex.18 : ...,昨日(Ndabd) B2-2 招致(VL4) B2-1 國民黨(Nba) B0 立委(Nab) B2-2 趙少康
(Nba) B3 和(Caa) B2-1 黃主文(Nba) B2-1 的(DE) B1 抨擊(Nad) B4,...
Ex.19 : ...,而(Cbca) B2-1 行政院長(Nab) B1 郝柏村(Nba) B3 更(Dfa) B1 是(Dbaa) B2-1
斬釘截鐵(VH11) B1 地(DE) B1 表示(VE2) B4,...
圖 3.6 為職稱接人名的名詞詞組的四類停頓類別分布及決策樹分析結果,由圖 3.6(a)可以 得知這類的例子比較常出現停頓,且也有可出現 B3 或甚至是 B4 等等更長的停頓,而由圖 3.6(b) 節點 2 問的問題可知若此邊界後面接的人名大於三個音節的話,則由節點 5 可以發現最有可能 出現 B3 的停頓,而人名的音節數大於三的例子也常出現在外國人名中,也可能是因為唸這段 語音的人不熟外國人名的關係,造成出現 B3 的停頓。26 (a) (b) 圖 3.6: 職稱接人名的名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果
3.1.7
時間的名詞詞組
時間的名詞詞組
時間的名詞詞組
時間的名詞詞組
時間的名詞詞組我們有以下的處理,依據對文本的觀察,大多數的“年”接“月”, “月”接“日”, “時”接“分”比較不容易出現有停頓,以及“民國”接“年”也比較不會出現停頓,所以以上這幾類 我們視為較緊密結合的時間名詞詞組,標記為 Type-1 intra-words,而其他的部份視為一般的時 間名詞詞組,標記為 Type-2 intra-words,且如果長度夠長,就會出現停頓,如以下的例子。
27
B2-2 二月(Ndabc) B2-2 二十五日(Ndabd) B4,...
Ex.20 這個例子,我們會先將“民國”以及“四十二年”看成是一個緊密結合的時間名詞詞組,“二 月”及“二十五日”也視為一個緊密結合的時間名詞詞組,接著“民國四十二年”與“二月二十五日” 構成一個一般的時間名詞詞組。
Ex.21 : ...,中華民國(Ndaab)[2] B2-2 三十四年(Ndaad)[1] B2-2 八月(Ndabc) B1 十四
日(Ndabb) B3,...
Ex.21 這個例子,因為“中華民國”與後面的“年”常常會有停頓出現,所以“中華民國”與“三十四 年”構成一個一般的時間名詞詞組,而“八月”與“十四日”構成一個緊密結合的時間名詞詞組, 接著“中華民國三十四年”與“八月十四日”構成一個更上層的時間名詞詞組,層次結構的關係如 中括號內的數字所標示。
Ex.22 : ...,七月(Ndabc) B2-1 十九日(Ndabd) B2-3 下午(Ndabe) B0 六時(Ndabe) B4,...
Ex.22 這個例子,“七月”與“十九日”構成一個緊密結合的時間名詞詞組,“下午”與“六時”也構 成一個緊密結合的時間名詞詞組,“七月十九日”與“下午六時”更成一個一般的時間名詞詞組。
Ex.23 : ...,公民(Nab) B1 投票(VA4) B3 於(P23) B2-1 三十四年(Ndaad) B2-3 十月
(Ndabc) B2-1 二十日(Ndabd) B2-2 上午(Ndabe) B2-1 六時(Ndabe) B1 起(Ng) B3,...
Ex.23 這個例子,“十月”與“二十一日”以及“上午”與“六時”先構成一個緊密結合的時間名詞詞 組,接著“三十四年”、“十月二十一四”以及“上午六時”構成一個一般的時間名詞詞組。
圖 3.7 與圖 3.8 分別為緊密結合的時間名詞詞組與一般的時間名詞詞組的統計分析,由圖 3.7 可以發現在我們標記為緊密結合的時間名詞詞組中間並不太會有停頓的出現,由圖 3.8 可 以知道一般的時間名詞詞組就可能會出現停頓,且停頓仍然會受到詞組的結構影響。
28 圖 3.7: 緊密結合的時間名詞詞組的四類停頓類別分布 (a) (b) 圖 3.8: 一般的時間名詞詞組的(a)四類停頓類別分布及(b)決策樹分析結果
3.1.8
並列結合的名詞詞組
並列結合的名詞詞組
並列結合的名詞詞組
並列結合的名詞詞組
並列結合的名詞詞組為兩個或兩個以上的同類詞組合成詞組,上一詞與下一詞彼此沒有主
29
從的關係且地位是平等的。根據觀察,通常在兩個單字詞並列結合的情況下不會出現停頓,為 了 避 免 這 一 類 的 例 子 與 其 他 的 結 構 合 併, 所 以 這 一 類 的 標 記 為 Type-1 intra-word , 如 Ex.24~Ex.27。圖 3.9 為此類例子的停頓標記分布統計,可以得知在單字詞平行結合的情況下是 不會有停頓的出現。
Ex.24 : ...,在(P21)新婚(VH11)後(Ng)的(DE)一(Neu) B0 兩(Neu)年(Nfg),...
Ex.25 : ...,下令(VE2)廢除(VC2)中(Nca) B1 蘇(Nca)友好(VH11)同盟(VH11)條約
(Nac),...
Ex.26 : ...,率(VF2)蒙(Nca) B1 藏(Nca)委員會(Ncb),...
Ex.27 : ...,針對(P31)近日(Nddc)流傳(VK2)國安局(Nca)內部(Ncdb)失和(VH11)以及
(Caa)所謂(VK2)郝(Nbc) B2-1 宋(Nbc)失和(Nv4)的(DE)傳聞(Nac),...
圖 3.9: 兩個單字詞並列結合的名詞詞組的四類停頓類別分布 而在並列的詞為二字詞或二字以上的詞時,通常會出現一個短停頓,如 Ex.28~Ex.29。在 連續一字詞對等的情況下,可能會有完全不停頓或是出現幾次停頓的情況,而有出現停頓時通 常最後一個的停頓會比較短,如 Ex.30~Ex.32。這兩種的例子都可能會出現停頓,故標記為30
Type-2 intra-word,並給予並列結合的名詞詞組標記。圖 3.10 為這類例子的停頓標記分布,可 以得知這類例子還是會出現停頓,而沒有停頓的地方只會出現在連續一字詞對等的情況。
Ex.28 : ...,回(VC1)娘家(Ncb) B2-2 婆家(Ncb)吃(VC31),...
Ex.29 : ...,銀牌(Nab) B2-2 銅牌(Nab)也(Dbb)掙(VC31)了(Di)二十多面(DM),...
Ex.30 : ...,她(Nhaa)絕對(Dbaa)不(Dc)碰(VC2)柴(Naa) B2-3 米(Nab) B1 油(Naa) B0
鹽(Naa)。
Ex.31 : ...,而(Cbca)郝柏村(Nba)率領(VF2)軍(Nad) B2-2 政(Nad) B2-2 黨(Nac) B2-1
官(Nab)意氣風發(VH11)列隊(Dh)開上(VC32)果嶺(Nca)打(VC2)高爾夫球(Nab)
Ex.32 : ...,表達(VC31)妳(Nhaa)的(DE)感受(Nad)及(Caa)妳(Nhaa)為(P03)婆(Nab) B1
媳(Nab) B1 孫(Nab)三(Neu)代(Nac)間(Ng)所(Dab)做(VC31)的(DE)努力(Nv4)
31
3.1.9
重複強調的名詞詞組
重複強調的名詞詞組
重複強調的名詞詞組
重複強調的名詞詞組
重複強調的名詞詞組如 Ex.33~Ex.35,通常後面的詞是在重複說明與前面的詞的關係,達 到強調的效果,圖 3.11 為這類例子的統計及分析結果,由圖 3.11(a)可以知道這類的例子並不 太會出現停頓,由圖 3.11(b)可以得知若是詞組內詞邊界距離詞組前邊界大於兩個音節的話, 則可能會出現停頓,如 Ex.36 這個例子所示。
Ex.33 : ...,要不然(Cbca) B2-2 就是(Cbba) B0 我(Nhaa) B2-1 自己(Nhab) B1 下廚(VA4)
B3,...
Ex.34 : ...,遲早(Dd) B0 有一天(DM) B3 太太(Nab) B2-1 自己(Nhab) B1 會(Dbaa) B2-1
要求(VF2) B1 投降(VA4) B2-2 的(Ta) B4。
Ex.35 : ...,恐怕(Dbaa) B2-3 王曉波(Nba) B1 先生(Nab) B2-2 自己(Nhab) B2-2 也(Dbb)
B0 要(Dbab) B2-3 負起(VC2) B1 相當(VH11) B1 的(DE) B1 責任(Nac) B1 罷(Tb) Be?
32 (b) 圖 3.11: 重複強調的名詞詞組的(a)四類停頓類別分布(b)決策樹分析結果
3.2 副詞
副詞
副詞、
副詞
、
、
、動詞
動詞、
動詞
動詞
、
、介系詞
、
介系詞
介系詞
介系詞詞組
詞組
詞組
詞組
表 3.3 為副詞、動詞、介系詞詞組決策樹分析中使用的問題及其涵義,表 3.4 為訓練資料 中副詞、動詞、介系詞詞組的各個類別的音節個數統計。以下將一一介紹本研究所分析的副詞、 動詞、介系詞詞組。 表 3.3 : 副詞、動詞、介系詞詞組決策樹分析中使用的問題及其涵義 問題 涵義 DVP F syll num <= n 副詞、動詞、介系詞詞組內的詞邊界距離副詞、動詞、介系詞詞組 前邊界的音節數是否小於等於 1, 2, 3, 4, 5, 6 DVP B syll num <= n 副詞、動詞、介系詞詞組內的詞邊界距離副詞、動詞、介系詞詞組 後邊界的音節數是否小於等於 1, 2, 3, 4, 5, 6 表 3.4 : 訓練資料中副詞、動詞、介系詞詞組的各個類別的音節個數統計 類別 類別類別 類別 子類別子類別子類別子類別 音節邊界個數音節邊界個數音節邊界個數音節邊界個數 副詞、動詞、介系詞詞組 一般 1904 構成詞 1283 並列結合 733
3.2.1
一般
一般
一般
一般的
的
的副詞
的
副詞
副詞
副詞、
、動詞
、
、
動詞
動詞、
動詞
、
、
、介系詞
介系詞
介系詞
介系詞詞組
詞組
詞組
詞組
一般的副詞、動詞、介系詞詞組是普通的兩個或是兩個以上的副詞、動詞或介系詞構成的 詞組,在這類的例子裡的詞與詞之間不具有較緊密的關係,主要是副詞修飾動詞,動詞後接介 系詞,或是副詞、動詞、與介系詞一起出現,如 Ex.36~Ex.39,這類例子的邊界我們歸類為可 能出現停頓的 Type-2 intra-word。值得一提的是,這類的例子可能會出現很多詞構起來成為一 個長的副詞、動詞、介系詞詞組的現象,所以我們會依據詞邊界在樹狀結構的深度,來標記它 們相接的階層結構,如 Ex.36 例子裡中括號內的數字。
Ex.36 : ...,使(VL4) B1 牠(Nhaa) B2-1 可(Dbab) [1] B2-1 輕易(Dh) [2] B2-3 逃避(VC2)
B2-2 外來(A) B2-1 動物(Nab) B2-2 傷及(VC2) B2-1 體膚(Naea) B3,...
Ex.36 這個例子是一個典型的連續多個副詞修飾動詞的例子,以這個例子來說,依照語意上的 結構來判斷,“輕易”與“逃避”會先構成一個比較底層的一般的副詞、動詞、介系詞詞組,接著 “可”與“輕易逃避”構成一個較上層的副詞、動詞、介系詞詞組。
Ex.37 : ...,還(Dbb) B0 有(V_2) B1 哪些(Neqa) B2-1 動物(Nab) B1 坑洞(Naeb) B1 中
(Ncda) B3 可以(Dbab) B1 找到(VC2) B2-1 雨水(Naa) B4,...
Ex.38 : ...,她(Nhaa) B0 的(DE) B2-3 人生觀(Nad) B3 似乎(Dbaa) B1 寄託(VC32) B1
在(P21) B0 那隻(DM) B1 小鳥(Nab) B1 身(Nab) B1 上(Ncda) Be。
Ex.38 的例子為“寄託”與“在”先構成一個緊密結合的詞組,因為“寄託在”算是一個常常會和在 一起唸的詞組,應該以一個詞來看待,而“似乎”與“寄託在”的連接就沒有那麼強烈了,“似乎” 只是用來修飾“寄託在”這個動作,所以這兩個詞構成一個一般的副詞、動詞、介系詞詞組。
34 (a) (b) 圖 3.12: 一般的副詞、動詞、介系詞詞組的(a)四類停頓類別分布(b)決策樹分析結果
3.2.2
構成詞的
構成詞的
構成詞的
構成詞的副詞
副詞
副詞
副詞、
、
、動詞
、
動詞、
動詞
動詞
、
、
、介系詞
介系詞
介系詞詞組
介系詞
詞組
詞組
詞組
構成詞的副詞、動詞、介系詞詞組主要是因為這些詞組結構小,應該合併起來當作一個詞 看待。通常是一字詞的副詞接動詞、動詞接一字的副詞或介系詞,或是其中有一字詞的副詞接 介系詞的組合,合併起來成為一種意義比較大的詞,或是兩個詞應合併起來當作一個詞看待, 如 Ex.39~Ex.42。所以這類的例子裡兩個相鄰的詞之中幾乎都是不停頓的 B0/B1 停頓類別居多。
35
若將這些詞組就是一個詞來看待,則其中間的詞邊界為 Type-1 intra-words,故我們將這類的例 子標記為 Type-1 intra-words。由圖 3.13 的停頓標記分布統計可以看到這類的例子幾乎都是不 停頓的情況,與構成詞的名詞詞組統計分布相似。
![圖 2.1: 階層式多短語韻律句群(Hierarchical Prosodic Phrase Grouping,HPG)架構 [9]。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8052613.162468/19.918.136.787.268.757/圖21階層式多短語韻律句群HierarchicalProsodicPhraseGroupingHPG架構9.webp)