國
立
交
通
大
學
資訊學院 資訊學程
碩
碩
碩
碩
士
士
士
士
論
論
論
論
文
文
文
文
利用階層式支持向量機演算法建立應用於行動化視覺
搜尋之影像字彙樹
Using Hierarchical SVM Algorithm to Construct a
Vocabulary Tree for Mobile Visual Search
Applications
研 究 生:蕭仁惠
指導教授:彭文孝 教授
中
中
中
中
華
華
華
華
民
民
民
民
國
國
國
國
九
九
九
九
十
十
十
十
九
九
九
九
年
年
年
年
七
七
七
七
月
月
月
月
利用階層式支持向量機演算法建立應用於行動化視覺
搜尋之影像字彙樹
Using Hierarchical SVM Algorithm to Construct a
Vocabulary Tree for Mobile Visual Search Applications
研 究 生: 蕭仁惠 Student: Jen-Hui Hsiao
指導教授: 彭文孝 博士 Advisor: Dr. Wen-Hsiao
Peng
國 立 交 通 大 學
資訊學院 資訊學程
碩 士 論 文
A Thesis
Submitted to
College of Computer Science
National Chiao Tung University
In partial Fulfillment of the Requirements
For the Degree of
Master of Science
In
Computer Science
July 2010
Hsinchu Taiwan, Republic of China
利用階層式支持向量機演算法建立應用於行動
化視覺搜尋之影像字彙樹
研究生 : 蕭仁惠 指導教授:彭文孝 博士
國立交通大學 資訊學院 資訊學程碩士班
摘要
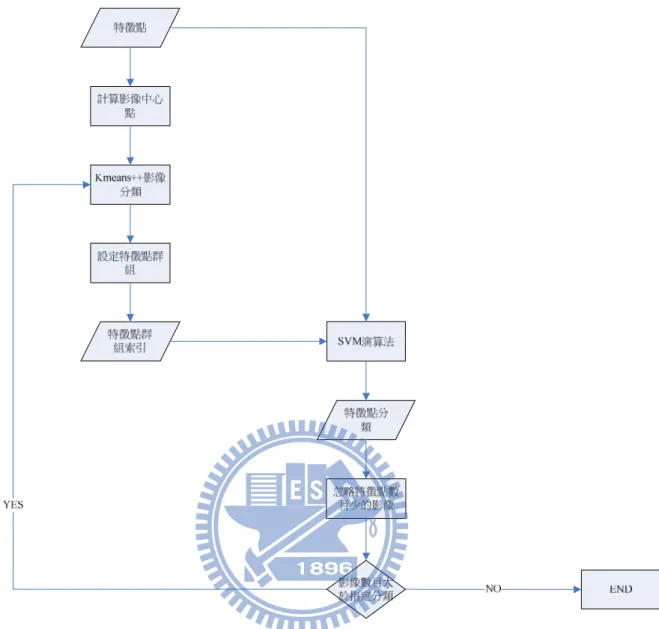
在 Mobile Visual Search 的系統中,scalable recognition 是其 中一個很重要的環結,在之前的研究中,Vocabulary Tree 提供了一個很好 的方式,能夠有效地進行影像的辨識。但是,在 Vocabulary Tree 的方法 中,使用 Hierarchical K-means 演算法將所有影像的特徵點進行分類,由 於 Hierarchical K-means 演算法是利用 K-means 演算法進行階層的分類, 首先使用 K-means 演算法進行分類,分類的結果會受到選擇初始中心點的 影響,造成分類隨著實驗變動,使得影像辨識的困難,再者在每一層分類 上,分類的數目都是小於實際分類的數目,即使選擇分類中心點是實際分 類的中心點,其他類別的特徵點就很容易被均勻分布在分類中心點,也造 成影像分辨不正確的結果。
分類一群未知影像的特徵點是屬於 unsupervised machine learning, 但是真正想要分類是影像而不完全是影像的特徵點,特徵點屬於那個影像 是一個有效而且有用的資訊;於是在建立 Vocabulary Tree 的每一層分類 時,本論文加入了特徵點的影像資訊,利用影像中心點,先將影像使用 K-means++演算法進行初步分類,再將初步分類的結果,使用 supervised machine learning 的 Support Vector Machine 演算法做真正特徵點的分 類,使得影像的特徵點能夠更有效地分類,也提升了影像辨識的正確率。
Using Hierarchical SVM Algorithm to Construct a Vocabulary Tree for Mobile Visual Search Applications
Student: Jen-Hui Hsiao Advisor: Wen-Hsiao Peng Degree program of Computer Science
National Chaio Tung University Abstract
Abstract Abstract Abstract
In the Mobile Visual Search system, scalable recognition is a very important part. On the previous study, a Vocabulary Tree provides a good way to effectively recognize image. However, in the Vocabulary Tree approach, Hierarchical K-means algorithm is used to classify all feature points of images and K-means algorithm is used at each level of classification. First, to use K-means algorithm, classification result is impacted by selection of initial class points and is changed with the experiment. Second, at each level classification, the number of classification is less than the number of actual classification, even if the classification result are actually the center of some images, feature points of other images can easily be distributed in the classification centers to cause images are not matching.
In this paper, K-means algorithm is not used to classify feature points of images at each level of a Vocabulary Tree. Centers of feature points on each image are used to group images at the beginning and then Support Vector Machine algorithm is used to classify feature points on each group of image. According to theory and experiment, Hierarchical SVM has outstanding result on matching rate and complexity of scalable recognition.
誌謝
誌謝
誌謝
誌謝
回顧幾年的研究所生涯,首先,我要感謝我的指導教授—彭文孝 博士,給 予我於學問研究上的指導。彭老師實事求是的精神,與深入剖析問題的態度,以 及追根究柢與契而不捨的指導方式,已經成為我在學習與研究路上的典範與楷 模。 有榮幸進入多媒體架構與處理實驗室,可以在這個優良的環境下不斷學 習,又有熱心與親切的實驗室成員們的切磋與討論,是我在學士後時代最充實的 時光。感謝我的學長姐們,引領我進入研究生的階段;感謝我的同學,不論是課 業上或研究上,他們總是可以一針見血地提出問題的核心要點,給予最直接協 助;感謝我的學弟吳思賢、王澤瑋、陳孟傑、與吳崇豪,在最後這一年內,給予 許多無私的協助。 最後,我要感謝我的家人,在爭取碩士學位的路上,給予百分之百的支持, 讓我免去許多後顧之憂與煩擾。感謝我的太太—黃靖芸,這幾年來辛苦地陪伴、 體諒與關心。感謝我的上司、同事、與朋友們,是你們的支持,使我有信心取得 這個學位,謝謝你們。目錄
目錄
目錄
目錄
1. 1.1. 1. 序論序論序論 ...序論... 111 1 1.1. 研究動機與背景...1 1.2. 背景知識...2 1.3. 問題陳述...3 1.4. 貢獻...4 1.5. 論文架構...4 2. 2.2. 2. 背景知識與相關研究背景知識與相關研究背景知識與相關研究 ...背景知識與相關研究 ... 6...66 6 2.1. Mobile Visual Search 架構 ...62.2. K-means 演算法 ...7
2.3. K-means++演算法...9
2.4. Scalable recognition with vocabulary tree...10
2.4.1. Hierarchical K-means 演算法 ...10
2.4.2. 影像比對...12
2.4.3. 分析...14
2.5. Support Vector Machine...17
2.5.1. Support Vector Machine 介紹 ...17
2.5.2. 二類別線性 Support Vector Machine ...18
2.5.3. 二類別非線性 Support Vector Machine ...20
2.5.4. 多類別 Support Vector Machine ...22
2.6. SURF 演算法 ...23
2.6.1. 快速 Hessian 特徵點偵測...23
2.6.2. SURF 特徵點描述式 ...25
3. 3.3. 3. 基於基於基於 Hierarchical SVM基於Hierarchical SVMHierarchical SVMHierarchical SVM 演算法建立演算法建立 Vocabulary Tree演算法建立演算法建立Vocabulary TreeVocabulary Tree ...Vocabulary Tree... 272727 27 3.1. 簡介...27
3.2. Hierarchical SVM 演算法 ...28 3.3. 影像比對...32 3.4. 分析...33 3.4.1. 比對正確率...33 3.4.2. 葉節點上比對複雜度比較...34 4. 4.4. 4. 實驗結果實驗結果實驗結果 ...實驗結果... 383838 38 4.1. 實驗環境...38 4.2. 方法[9]的實驗結果與探討...39 4.3. Hierarchical SVM 演算法的實驗結果與探討 ...45 4.4. 葉節點比對複雜度的實驗結果與探討...50 5. 5.5. 5. 結論與未來研究方向結論與未來研究方向結論與未來研究方向 ...結論與未來研究方向 ... 53...5353 53 參考文獻 參考文獻參考文獻 參考文獻 ... 545454 54 自傳 自傳自傳 自傳 ... 57...5757 57
圖目錄
圖目錄
圖目錄
圖目錄
圖 1.1 K-means 演算法初始中心點不同的影響示意圖 ...3 圖 1.2 K-means 演算法分類數目不同的影響示意圖 ...3圖 2.1 Mobile Visual Search 架構圖 (資料來源:[1]) ...7
圖 2.2 K-means 演算法收斂中心點 ...9
圖 2.3 建構 Vocabulary Tree 的流程 (資料來源:[9])...12
圖 2.4 K-means 演算法分類範例 I...15
圖 2.5 K-means 演算法分類範例 II...15
圖 2.6 分類假想示意圖...16
圖 2.7 Support Vector Machine 分類 ...18
圖 2.8 Support Vector Machine 分類範例 I...21
圖 2.9 Support Vector Machine 分類範例 II...21
圖 2.10 積分影像與區域像素值的和(資料來源:[8])...24
圖 2.11 使用 Box Filter 來近似 Laplacian of Gaussian (資料來源:[22]) ...24 圖 2.12 Lowe[7]與 Bay[9]尺度空間示意圖 (資料來源:[22]) ...25 圖 2.13 計算特徵點方向(資料來源:[8])...26 圖 2.14 特徵點描述式的計算(資料來源:[22])...26 圖 3.1 Hierarchical SVM 演算法的流程 ...30 圖 3.2 Hierarchical SVM 演算法分類範例 I...31 圖 3.3 Hierarchical SVM 演算法分類範例 II...31
圖 3.4 Hierarchical K-means 與 Hierarchical SVM 分類示意圖 ...34
圖 3.5 Hierarchical SVM 葉節點再分類示意圖 ...34
圖 4.1 實驗一 40 種影像不同實驗次數與不同分類數目的比對正確率...39
圖 4.3 實驗二之二 40 種影像不同分類數目與不同階層數目的比對正確率 ...41 圖 4.4 實驗三 40 種影像不同 IDF 定義的比對正確率 ...44 圖 4.5 實驗四 40 種影像使用誤差和以及餘弦相似度的比對正確率 ...45 圖 4.6 實驗五 20 種影像不同實驗次數與不同分類數目的比對正確率...46 圖 4.7 實驗六之一 20 種影像不同分類數目與不同階層數目的比對正確率 ...47 圖 4.8 實驗六之二 40 種影像不同分類數目與不同階層數目的比對正確率 ...48 圖 4.9 實驗七比較[9]方法與 Hierarchical SVM 演算法的比對正確率...48 圖 4.10 實驗八 RBF 函數不同 Sigma 值的比對正確率 ...49 圖 4.11 Hierarchical SVM 不同分類與階層數目的 Complexity...51
圖 4.12 Hierarchical K-means 不同分類與階層數目的 Complexity ...52
1
1
1
1.
.
.
.
序論
序論
序論
序論
1
1
1
1.
.
.
.1
1
1
1.
.
.
.
研究動機與背景
研究動機與背景
研究動機與背景
研究動機與背景
近年來,手持裝置的普及率不斷上升,手持裝置上的應用也不斷推成出新,Mobile Visual Search 就是一個手持裝置上展新與熱門的應用程式。與一般電腦裝置比較起 來,手持裝置的輸入裝置有很大的不同,對一般電腦而言,電腦鍵盤可以輕易地輸入文 字,但由於體積的限制,在手持裝置上要輸入文字,並不是一件容易的事,於是要在手 持裝置上進行以文字為基礎的資料搜尋並不方便;但相對於電腦裝置來說,相機已經是 手持裝置上的基本配備,一張照片只要按一個按鈕就可以完成,於是基於手持裝置影像 的資料搜尋,也成為了新的應用與熱門起來,包括了 Standford 大學[1][2][3][4]與 MIT 學院[5][6],也有許多相關的研究。Mobile Visual Search 不單是一個手持裝置的應用程式,而是一個結合手持裝置 與雲端運算的應用,手持裝置所拍攝的照片影像利用網路傳回雲端伺服器,雲端伺服器 搜尋既有的影像資料庫,找出最接近照片影像的影像,之後將找出影像的相關資訊傳回 至手機上;在 Standford 大學的研究中[1][2][3][4],他們在雲端伺服器建立一個 CD 封面的影像資料庫,並連結至 CD 內音樂的 Track,當使用者在 CD 商店選購 CD 時,可以 馬上利用手持裝置將 CD 封面利用照相機拍下並傳回雲端伺服器,雲端伺服器利用影像 搜尋的技術,找出相對映的 CD,將實際 CD 內的音樂 track 直接傳回手持裝置上,使用 者可以透過試聽音樂 track 之後,在決定是否要購買 CD;另外,例如利用建築物照片找 出建築物的介紹,利用街景照片找出位置或是附近商店資訊等等,也是常見 Mobile Visual Search 的應用。
在 Mobile Visual Search 的系統中,影像快速搜尋成為這個系統的主要關鍵之一, 其中包括了影像特徵點的萃取與描述,以及建立以特徵點為基礎的影像資料庫這兩大部 分;在特徵點的萃取與描述上,已經有許多這方面研究的論文,包括著名的 SIFT(Scale
Invariant Feature Transform)與 SURF(Speed up Robust Features)演算法[7][8],這 兩個演算法不僅能夠正確地找出影像特徵點以及有很好的描述式,還具備了速度快的優 點,本論文選擇使用 SURF 演算法做為影像特徵點的萃取與描述;但在建立影像資料庫 上,國內外的研究比較少見,最有名的就是 D. Nist´er and H. Stew´enius [9]這篇論 文,不論是 Standford 與 MIT 的研究中,都是選用[9]這篇論文所提出方式來建立影像 資料庫的索引,以達成快速找到對應影像的目標;於是本論文針對了[9]這篇論文做了 深入的研究,最後提出 Hierarchical SVM 演算法建立 Vocabulary Tree,來改善研究過 程中一些發現[9]方法的問題,最後提高了比對正確率以及降低比對複雜度。
1
1
1
1.
.
.
.2
2
2
2.
.
.
.
背景知識
背景知識
背景知識
背景知識
在[9]方法的研究中主要分成兩大部分,一是使用 Hierarchical K-means 演算法 建立 Vocabulary Tree,二是將影像資料庫與搜尋影像特徵點歸類於 Vocabulary Tree 的葉節點上,然後找出影像資料庫中所有影像在葉節點上特徵點數目的比例,與搜尋影 像在葉節點上特徵點數目比例最相近的影像為相似影像。Hierarchical K-means 演算法的做法為使用 K-means 演算法將所有影像特徵點分 成 K 類,然後將每一個分類的影像特徵點依序再分成 K 類,依此類推直到一個定義的階 層數目 L,或是每一個類別中影像的特徵點數目已經小於 K 做為停止,最後將每層 K-means 演算法所產生的分類中心點串成階層樹,形成所謂的 Vocabulary Tree,在 Vocabulary Tree 上,最上面的節點為根節點,最下面的節點為葉節點。
影像資料庫所有影像的特徵點將會歸類至 Vocabulary Tree 上的葉節點,歸類的 方式為從 Vocabulary Tree 的根節點開始,找尋距離最近的節點,依此類推往下尋找最 接近節點,直到葉節點為止;同樣地方式將搜尋影像的所有特徵點歸類於葉節點,之後 根據葉節點上特徵點的比例,找出比例最接近的影像就是相似影像。
(A) (B) 圖 1.1 K-means 演算法初始中心點不同的影響示意圖 (A) (B) 圖 1.2 K-means 演算法分類數目不同的影響示意圖
1
1
1
1.
.
.
.3
3
3
3.
.
.
.
問題陳述
問題陳述
問題陳述
問題陳述
使用[9]研究中的方法,證實可以提供很好的分類方式,達到快速比對的目的,但 是在其方法中,使用 Hierarchical K-means 演算法將所有影像的特徵點進行階層式分 類,主要的問題如下:1. 首先,由於 Hierarchical K-means 演算法是利用 K-means 演算法在每個階層上進
行分類,使用 K-mean 演算法進行分類,其分類的結果會受到選擇初始中心點的影 響,造成分類隨著實驗變動,使得影像辨識的困難,如圖 1.1 所示。
為初始值選擇的不同,有不同的分類結果;圖 1.1(A)顯示 K-means 演算法正確地將 資料分成四類,但圖 1.1(B)因為初始點的不同,使得分類結果與原始資料大不相同。 2. 再者在每一層分類上,分類的類別數目都是小於實際分類的類別數目,即使選擇的 分類中心點接近實際分類的中心點,其他類別的特徵點就很容易被均勻分割在不同 分類,也容易造成影像分辨不正確的結果,如圖 1.2 所示。 在圖 1.2(A)中,一個四個類別的資料使用 K-means 演算法分成兩類,即使所計算之 後的中心點接近於紅色與紫紅色的中心點,原本綠色與藍色的資料卻被均勻地被分 割在兩類別上如圖 1.2(B)所示,之後要利用綠色與藍色資料在兩類別的比例,來分 辨與綠色或藍色資料的相似度,就容易產生辨識上的錯誤,辨識正確率的期望值只 有 75%,造成辨識率不高的情況。 3. 最後,由於無法能夠將特徵點有效地分類,必需要利用葉節點上特徵點的比例來判 斷相似影像,隨著分類數目與階層數目的增加,葉節點的數目也隨著增加,比對的 複雜度也會相對的增加,另外,隨著影像數目的增加,也會使得比對複雜度的增加。
1
1
1
1.
.
.
.4
4
4
4.
.
.
.
貢獻
貢獻
貢獻
貢獻
雖然,在分類一群未知影像的特徵點是屬於 unsupervised machine learning,但 是事實上,真正想要分類的是影像本身,而不是想要分類影像的特徵點,特徵點屬於那 個影像是一個有效而且有用的資訊;於是本論文的主要貢獻為建立了 Hierarchical SVM 演算法取代 Hierarchical K-means 演算法,在每一層分類時,將影像資訊做為指導特 徵點分類的索引,然後使用 SVM 演算法將特徵點分類,使得影像的特徵點可以集中分類 到某一節點上,於是之後在進行影像辨識時,不會因為有影像分類比例相近而分辨錯誤 的問題,也因此經過 Vocabulary Tree 的搜尋之後就可以找到正確相似影像,使得整體 的比對複雜度,不會因為分類數目以及階層數目的增加而增加。
1
1
1
1.
.
.
.5
5
5
5.
.
.
.
論文架構
論文架構
論文架構
論文架構
第二章為背景知識與相關研究,包括 Mobile Visual Search 的架構[1][2][3][4]、 K-means 演算法[10]、K-means++演算法[11]、[9]的方法與 Support Vector Machine 演算法[16][17][18]。
第三章詳細說明如何使用本論文提出方法,包括使用 K-means++演算法將影像初步 分類、如何應用 Hierarchical SVM 演算法建立 Vocabulary Tree 以及最後搜尋影像的 比對。
第四章為相關的實驗結果。 第五章為結論與未來工作。
2
2
2
2.
.
.
.
背景知識與相關研究
背景知識與相關研究
背景知識與相關研究
背景知識與相關研究
2
2
2
2.
.
.
.1
1
1
1.
.
.
.
Mobile Visual Search
Mobile Visual Search
Mobile Visual Search
Mobile Visual Search 架構
架構
架構
架構
Mobile Visual Search 不僅是手持裝置上的應用程式,而是結合手持裝置與雲端 運算的應用,Mobile Visual Search 的詳細架構如圖 2.1 所示。由圖 2.1 可知,Mobile Visual Search 可分為三大部分,第一部分是關於特徵點的萃取與描述,第二部分是關 於影像資料庫的建立,最後一部分是關於手持裝置與雲端伺服器交換影像或特徵資料。
關於特徵點的萃取與描述,其中較廣為使用的演算法是由 David Lowe 所提出 SIFT 演算法[7];SIFT 演算法不但能夠正確地找出影像的邊角,還具備尺度不變(scale invariant)與速度快的特性;除了 SIFT 演算法,SURF 演算法[8]是既 SIFT 演算法之後, 另外一個廣被使用的演算法,與 SIFT 演算法比較起來,SURF 演算法不但具備 SIFT 演算 法的優點,在特徵點的描述上,SURF 演算法只需要 64 維度的向量來描述特徵點,比 SIFT 演算法的 128 維度向量少了一半,之後不論是使用 Hierarchical K-means 演算法或是 本論文提出的 Hierarchical SVM 演算法來分類,都可以大大降低計算量,於是本論文 選擇使用 SURF 演算法來進行特徵點的萃取與描述,在下面的章節也簡單地介紹 SURF 演 算法的內容。 在建立影像資料庫方面,[9]的方法,廣泛地被使用各種研究上;為了瞭解本論文 所提出的 Hierarchical SVM 演算法,必須要對[9]的方法有深入地認識,本論文在下面 的章節將會詳細說明[9]方法的細節,並探討其優缺點。 最後關於手持裝置與雲端伺服器的溝通,手持裝置可以直接將影像傳至雲端伺服 器,另外也可以選擇將特徵點的描述經過壓縮之後,再傳給伺服器作比對;根據 Standford 大學的研究,如果在網路頻寬不夠的情況之下,選擇傳輸壓縮過的特徵點描 述,是比較好的方式,也有許多的研究再探討這個部分[2][3][4]。
圖 2.1 Mobile Visual Search 架構圖 (資料來源:[1])
2
2
2
2.
.
.2
.
2
2
2.
.
.
.
K
K-
K
K
-
-
-mean
mean
mean
means
s
s
s 演算法
演算法
演算法
演算法
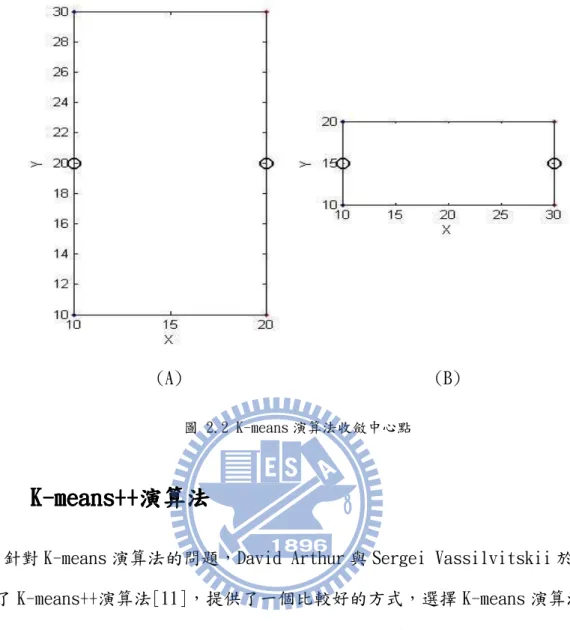
由於建立 Vocabulary Tree 是基於 Hierarchical K-means 演算法,Hierarchical K-means 演算法又是基於 K-mean 演算法[10],首先必須要對 K-means 演算法有所了解。 K-means 演算法的內容如下: 1. N個資料點的集合X 為式(1): 1 { ,..., N | i d} X = x x x ⊂R (1) 2. 將X分成K類,K <N。 3. 隨機從N的點中選出K個點做為初始中心點為式(2): 1 { ,..., k} c= c c (2) 4. 對於i∈{1,..., }K ,Ci為所有X 中的點,距離ci比cj短的集合,其中i≠ j。 5. 對於i∈{1,..., }K ,根據Ci中所有的點,重新計算ci為式(3): 1 | | i i x C i c x C ∈ =
∑
(3) 6. 重覆步驟 4, 直到ci不再變動為止。本稱為 Lloyd 演算法,因為廣泛地在學術界被使用於解決 K-means 問題,所以就被稱為 K-means 演算法,大部分的人都誤認 K-means 演算法是解決 K-means 問題的演算法,但 其實 K-means 演算法是 K-means 問題的一個近似解演算法(heuristic algorithm)。 K-means 問題的定義如下: 1. N 個資料點的集合X為式(4): 1 { ,..., N | i d} X = x x x ⊂R (4) 2. 將X分成K類的S集合,S={ ,...,s1 sK |K <N},使得所有分類的 sum of squares 能夠最小為式(5): 2 1 1 arg min | | , | | j i j i K s j i i j i x s j x s x u u x x = ∈ ∈ − =
∑ ∑
∑
(5) 根據許多的研究顯示,K-means 的問題是一個 NP-Hard 的問題[12][13],於是有許 多的 heuristic algorithm 來解決 K-means 的問題[10][11][14][15],K-means 演算法 就是其中之一。事實上,K-means 演算法是利用 local optimum 的方式來解決 K-means 問題,回顧之前 K-means 的演算法可以發現,K-means 演算法是找出已經分類好的最佳 解,而不是整體的最佳解;在這樣地情況下,選擇初始點的好壞,決定 K-means 演算法 結果的好壞。以圖 2.2 為例,在圖 2.2(A)中,長方形(10, 10)、(15, 10)、(10, 20)、 (15, 20),選擇最下方兩個點進行 K-means 演算法之後,收斂至長方形長的邊;但在圖 2.2(B)中,長方形(10, 10)、(20, 10)、(10, 15)、(20, 15),選擇最下方兩個點進行 K-means 演算法之後,收斂至長方形長短的邊,但是不論是圖 2.2(A)或是圖 2.2(B),真 正的最佳解應該是短的邊。因此初始點的選擇對 K-means 演算法有很大的影響,也會對 所建立的 Vocabulary Tree 產生影響。(A) (B)
圖 2.2 K-means 演算法收斂中心點
2
2
2
2.
.
.3
.
3
3
3.
.
.
.
K
K
K
K-
-mean
-
-
mean
mean
means
s
s
s++
++
++
++演算法
演算法
演算法
演算法
針對 K-means 演算法的問題,David Arthur 與 Sergei Vassilvitskii 於 2007 年 提出了 K-means++演算法[11],提供了一個比較好的方式,選擇 K-means 演算法的初始
點,在 David Arthur 的研究中,證明了 K-means++演算法是O(log )k 近似於最佳解。
K-means++演算法的內容如下: 1. N 個資料點的集合X 為式(6): 1 { ,..., N | i d} X = x x x ⊂R (6) 2. 將X分成K類,K <N。 3. 從集合X中,隨機選擇一個點做為第一個中心點C1。 4. 從集合X中,根據 2 2 ( ) ( ) x X D x D x ∈
∑
的機率,選擇下一個中心點,其中D x( )代表 x 到最接 中心點的距離。 5. 重覆步驟 4, 直到找到K個中心點為式(7):1 { ,..., k} c= c c (7) 6. 對於i∈{1,..., }K ,Ci為所有X 中的點,距離ci比cj短的集合,其中i≠ j。 7. 對於i∈{1,..., }K ,根據Ci中所有的點,重新計算ci為式(8): 1 | | i i x C i c x C ∈ =
∑
(8) 8. 重覆步驟 6, 直到ci不再變動為止。 在 K-means++演算法中,除了步驟 3 到 5 之外,其他的步驟與 K-means 演算法完全 一樣。原本 K-means 演算法是使用隨機的方式來選擇初始中心點,但是在 K-means++演 算法的步驟 4 中,是以資料與最接近初始中心點的距離為機率來選擇初始中心點,也就 是說距離現有初始中心點遠的資料,有比較大的機會被挑選到成為下一個初始中心點, 於是初始中心點會比較分散,不會集中於相近的資料,而得到比 K-means 演算法較佳的 結果。 之後本論文的方法將先使用影像中心點進行初步分類,在分類時,一是希望相似 影像分成同類,二是希望不同類別的影像可以越遠越好,於是選用 K-means++演算法來 進行影像初步分類,以達到更好的分類結果。2
2
2
2.
.
.
.4
4
4
4.
.
.
.
Scalable recognition with vocabulary tree
Scalable recognition with vocabulary tree
Scalable recognition with vocabulary tree
Scalable recognition with vocabulary tree
本節詳細說明[9]所提出的方法,包括使用 Hierarchical K-means 演算法建立影 像資料庫的 Vocabulary Tree,以及建立影像資料庫的 Vocabulary Tree 之後,如何利 用 Vocabulary Tree 來做影像比對,最後也將詳細說明 Hierarchical K-means 演算法 的問題。
2
2
2
2.
.
.
.4
4
4
4.
.1
.
.
1
1
1.
.
.
.
Hierarchical K
Hierarchical
Hierarchical
Hierarchical
K
K
K-
-
-
-mean
means
mean
mean
s
s 演算法
s
演算法
演算法
演算法
Hierarchical K-means 演算法的內容如下:
1. 一個包含了N張影像的影像資料庫為集合T為式(9):
1
{ ,..., N}
2. 每張影像是由mi個特徵點所構成Ii為式(10): 1 { ,..., | } i i i i d i m j I = f f f ⊂R (10) 其中對於影像Ii與Ij來說,mi與mj可以不相等,d 決定於使用的特徵點描述式, 由於本論文使用 SURF 演算法的特徵點描述式,所以 d 會等於 64。 3. 將所有影像的特徵點形成集合 F 為式(11): 1 1 1 1,..., 1,..., { ,..., } N N N m m F = f f f f 1 N f i i N m = =
∑
(11) 4. 使用 K-means 演算法將 F 分成 M 類得到集合 K 與集合 K 的中心點集合為 C,其中ci 為Ki的中心點為式(12)與式(13): 1 { ,..., M | f} K = K K M <N C={ ,...,c1 cM} (12) ' { | (1... )} i j K = I j⊂ N ' { i | (1,..., )} i j i I = f j⊂ m (13) 假設Ki中有 ' N 的影像數目,而且每Ki中的 ' i I 影像有 ' i m 個特徵點。於是Ki的特徵 點集合為為式(14): ' ' ' ' 1 ' 1 1 1,..., 1,..., { ,..., } i N N N K m m F = f f f f ' ' 1 i N K j j N m = =∑
' ' 1 1 1 j i m N j i k j k K c f N = = =∑ ∑
(14) 5. 將 , 1,..., i K F ∀ =i M 重覆步驟 4,直到 i K N <M ,或者是重覆步驟 4 的次數,超過了 一個定義的階層次數L。6. 所有不同層的ci將構成 Vocabulary Tree,ci是 Vocabulary Tree 上面的一個節點, 如果一個節點下面的沒有其他的節點,這個節點將形成葉節點,影像中所有的特 徵點將被指定葉節點上。
以圖 2.3 為例,說明建構 Vocabulary Tree 的流程。
1. 一開始使用 K-means 演算法,將所有影像的特徵點分為三個類別,如圖 2.3 左上方
圖 2.3 建構 Vocabulary Tree 的流程 (資料來源:[9])
2. 以在最下方的分類為例,將所有屬於這個分類的特徵點再利用 K-means 演算法分成
三類,如圖 2.3 右上方圖所示。
3. 依此類推,將分類好的類別再使用 K-means 演算法分類,如圖 2.3 下方圖所示。
4. 每個階層 K-means 演算法計算之後的中心點形成 Vocabulary Tree,每個中心點是
Vocabulary Tree 的節點,最下面的節點是葉節點,所有的特徵點最後將被指定葉 節點。
2
2
2
2.
.
.4
.
4
4
4.
.
.
.2
2.
2
2
.
.
.
影像比對
影像比對
影像比對
影像比對
建立好 Vocabulary Tree 之後,就可以利用 Vocabulary Tree 做影像比對,在 scalable recognition with vocabulary tree 中,是利用計算葉節點上特徵點的數量 比 例 為 分 數 , 來 做 影 像 辨 識 的 根 據 。 特 徵 點 數 量 比 例 的 分 數 是 利 用 TF(Term Frequency)-IDF(Inversed Document Frequency)來計算,然後算出搜尋影像與所有影 像資料庫在每一葉節點上 TF-IDF 的誤差和,最小的誤差和為就是 match 的影像。
Tree 的葉節點之中;指定方式是由 Vocabulary Tree 的最上層到最下層,首先在最上層 找尋與特徵點距離最近的節點,然後往這個節點下一層,再找尋最近的節點,依次類推 一直找到葉節點為止,最後所有搜尋影像的特徵點,都會被指定到特定的葉節點;之後 就可以根據葉節點所擁有特徵點的數量,來計算 TF-IDF。下面是計算 TF-IDF 分數的方 法: 1. 假設 Vocabulary Tree 的葉節點的集合為VL為式(15): 1 { ,..., T | L} VL= LT LT M ≤ ≤T M (15) 2. 影像Ii在LTi的 Term Frequency 定義為影像Ii在LTi特徵點的數目除以影像Ii的特 徵點的數目為式(16): | | i i i i i I LT I LT I m TF m = (16)
3. 每一個葉節點LTi來說,其 Inversed Document Frequency 定義為所有影像數目除
以在葉節點影像數目取 log 為式(17): log i i LT LT N IDF N = (17) 4. 影像Ii在LTi的 TF-IDF 定義為 | i i I LT W 為式(18): | | * i i i i i i I LT I LT I LT m N W Log m N = (18) 搜尋影像q在LTi的 TF-IDF 定義為 | i q LT W 為式(19): | | * i i i q LT q LT q LT m N W Log m N = (19) 5. 搜尋影像對影像Ii的分數為式(20): ( , ) | | | | | | i i I q i q I W W S q I W W = − (20) 6. 最後計算出所有影像與搜尋影像的S q I( , )i ,最小 S 的影像就是根搜尋影像最相似
地影像。
2
2
2
2.
.
.4
.
4
4
4.
.
.
.3
3.
3
3
.
.
.
分析
分析
分析
分析
Hierarchical K-means 演算法提供了一個有效的方式建立 Vocabulary Tree,加 速之後的影像比對,但是由於 Hierarchical K-means 演算法是基於 K-means 演算法, 而 K-means 演算法又不見得每次都是最佳解,所以計算的結果常常隨著每次實驗有所不 同。
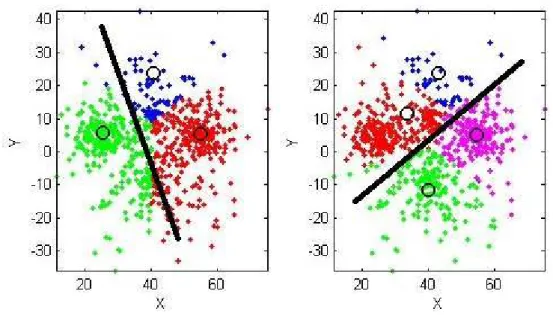
即使有一個最佳解的演算法來處理 K-means 問題,Hierarchical K-means 演算法 還是有一個的問題存在;回顧 Hierarchical K-means 演算法中,在步驟 4 使用 K-means 演算法進行分類時,Hierarchical K-means 演算法將 F 分成 M 類別,此時,M 將遠小於 真正影像類別,即使選擇的初始點都在部分影像的中心點上,其他影像的特徵點有很大 的機率散落於不同的類別,造成之後再分類或比對的困難,尤其是在分類遠小於真正類 別的情況。下面是利用一個簡單的範例來說明,分類的問題: 1. 假設一個實際有三群混在一起的資料要進行分類。 2. 如果使用 K-means 演算法將其三類,雖然可能分類的結果每次不同,但大部分都可 以得到很好的結果如圖 2.4(A)所示。由圖 2.4(A)可知,K-means 演算法可以正確地 將資料分成三群,也就是說如果使用 K-means 演算法,經過重覆計算找出最小誤差 的情況之下,K-means 演算法可以接近最佳解。 3. 但是如果將上面三群的資料分成兩群,得到的結果如圖 2.4(B)所示。由圖 2.4(B) 可知,即使在最佳解的情況之下,原本圖 2.4(A)的藍色資料被均分到另外綠色與紅 色資料之中,而造成藍色資料分配不佳。 再利用另外一個範例說明分類與比對的問題: 1. 假設一個實際有四群混在一起的資料要進行分類。 2. 使用 K-means 演算法將其四類,雖然可能分類的結果每次不同,但大部分都可以得 到很好的結果如圖 2.5(A)所示。
(A) (B) 圖 2.4 K-means 演算法分類範例 I (A) (B) 圖 2.5 K-means 演算法分類範例 II 3. 但是如果將上面四群的資料分成兩群,得到的結果如圖 2.5(B)所示。由圖 2.5(B) 可知,原本圖 2.5(A)的藍色與紅色資料被均分到另外綠色與紫紅色資料之中,之後 如果想要利用 TF-IDF 分辨這兩個被分散的資料,時常會有錯誤的情況發生,於是當 分類的數目越小於真正的群組數目,越容易發生這樣地現象。
圖 2.6 分類假想示意圖 如果想要將上面三群或四群資料分成兩類,所希望的結果如圖 2.6 所示。也就是 說,其實希望能夠將同類的點盡量分在同一群,這樣相同資料要進行比對比較容易,也 比較不會有錯誤,另外要再進行分類也能夠比較正確地分類;但是,這樣地結果是因為 已經知道了資料有三群與四群,在完全不知道真正群組的情況下,只能使用 K-means 演 算法來進行分類。
事實上,K-means 演算法是屬於 unsupervised machine learning 的方式,也就是 在不知道群組的情況進行分類,如果可以知道群組資訊,使用 supervised machine learning 的方式,例如 SVM(Support Vector Machine),KNN(K-nearest neighbor), 或是 Neural Network,都可以得到比 K-means 演算法更好的結果,因為多了群組的資訊, 可以使得分類器能夠正確的分類。以上面三群分兩群或四群分兩群的例子來說,使用 K-means 演算法是得到最小誤差的解,但是想要的結果並不是最小誤差,於是即使是最 佳解的 K-means 演算法,也無法得到好的分類結果。 但是問題在於進行影像特徵點的分類,群組資訊在那裡呢?再回顧 Hierarchical K-means 演算法,在每一層都是使用 K-means 演算法將特徵點分類,但是真正的目的希 望分類影像而非影像的特徵點;也就是說雖然是分類影像的特徵點,但希望相同影像的
以將原本使用 Unsupervised machine learning 的 K-means 演算法,改成 supervised machine learning 的 演 算 法 ; 因 此 本 論 文 選 擇 了 Support Vector Machine 這 個 supervised machine learning 的演算法取代 K-means 演算法,最後形成了 Hierarchical SVM 演算法取代 Hierarchical K-means 演算法建立 Vocabulary Tree。
2
2
2
2.
.
.
.5
5
5
5.
.
.
.
Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine
2
2
2
2.
.
.
.5
5
5
5.
.
.
.1
1.
1
1
.
.
.
Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine 介紹
介紹
介紹
介紹
支持向量機(Support Vector Machines)[16][17][18],簡稱 SVM)是一種以統計學 習理論為基礎,發展出來的機器學習系統,屬於有監督學習的方法(supervised machine learning),廣泛的應用於統計分類以及回歸分析中;SVM 原為處理二元類別分類,運
算兩類別樣本空間之最佳分割超平面(Optimal Separate Hyperplane),確立最小分類
錯誤。
以圖 2.7(A)為例,在兩群資料中,找尋一個 Hyperplane,來分割這兩群資料,但 是可能有 N 個或無限多個的 Hyperplane 存在,於是要找一個 Hyperplane 如圖 2.7(B) 所示,使得這個 Hyperplane 到這兩群資料邊界的距離能夠最大。
由於 Support Vector Machine 廣泛地被使用在各種研究上,到今天除了二類別線 性的 Support Vector Machine,也發展出不同種類非線性與多類別的 Support Vector Machine[19]。下面的章節,本論文先介紹二類別線性的 Support Vector Machine,之 後再延伸至二類別非線性與多類別的 Support Vector Machine。
(A) (B)
圖 2.7 Support Vector Machine 分類
2
2
2
2.
.
.5
.
5
5
5.
.
.
.2
2
2
2.
.
.
.
二類別
二類別
二類別
二類別線性
線性
線性
線性 Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine
二類別線性 Support Vector Machine 就是要在兩類別中,找出 Hyperplane,使得 超平面到兩類別邊界的距離達到最大。其內容如下: 1. 一個包含兩類別資料的集合X定義為式(21): 1 1 2 2 {( , ), ( , )..., ( m, m)} X = x y x y x y d i x ∈R yi∈ + −{ 1, 1} (21) 2. 假設可以將yi為+1 與-1 區分的平面為式(22): 0 w x b⋅ + = (22)
其中W為法向量(Normal Vector),b偏移量(bias)。
3. 於是對於所有的xi會滿足式(23)與式(24): 1 i w x⋅ + ≥ +b for yi = +1 (23) 1 i w x⋅ + ≤ −b for yi = −1 (24) 合並上面兩式可以得到式(25): ( ) 1 0 i i y w x⋅ + − ≥b ∀i (25)
4. 邊界的距離為 2 |w|要使其最大化,於是超平面將滿足式(26)與式(27): Minimum 2 | | 2 w (26) Subject to y w xi( ⋅ + − ≥i b) 1 0 ∀i (27)
5. 使用 Langrange multiplier method 來解上面式子。滿足式(26)與式(27)的
Lagrange equation 定義為式(28): 2 1 1 ( , , ) | | [ ( ) 1] 2 m p i i i i L w b a w a y w x b = = −
∑
⋅ + − ai∈R (28) 要求Lp的最小值。 6. 對 w 與b取偏微分為零以求取Lp的最小值為式(29)與式(30): 1 ( , , ) 0 m p i i i i L w b a w a y x w = ∂ = − = ∂∑
1 m i i i i w a y x = =∑
(29) 1 ( , , ) 0 m p i i i L w b a a y b = ∂ = = ∂∑
(30) 7. 將上面兩式帶回為Lp得到式(31): 1 , 1 1 ( ) 2 m m D i i j i j i j i i j L a a a a y y x x = = =∑
−∑
⋅ (31) 於是ai ≥0為Lp限制式,因此可將求解Lp的最小值的問題,轉換成LD最大值的對 偶問題(dual problem) 為式(32)與式(33): Maximum 1 , 1 1 ( ) 2 m m D i i j i j i j i i j L a a a a y y x x = = =∑
−∑
⋅ (32) Subject to 1 0 m i i i a y = =∑
∀ai (33) 8. 由上式可解出ai並帶回上面式子求的 w ,使用由 Fletcher 提出的 KKT 條件,可以 解出b,最後可以得到一個決策函數(decision function)來判斷 ' x屬於那一個類 別如式(34)。 ' ' ( ) sgn( ) f i i i i SV D x a y x x b ∈ =∑
⋅ + (34)2
2
2
2.
.
.5
.
5
5
5.
.
.
.3
3
3
3.
.
.
.
二類別
二類別
二類別
二類別非線性
非線性
非線性
非線性 Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine
雖然線性 Support Vector Machine 提供了一個好的方式來分類,但是常常要能夠 找到一個線性 Hyperplane 不是件容易的事情。於是 Boser et al.[19]提出了將低維度
的原始資料,利用一個映射函數φ( )x 投影到高維度的空間,再從高維度空間的找出 Hyperplane 進行分類。其內容如下: 1. 經過φ( )x 轉換之後,超平面將滿足式(35)與式(36): Minimum 2 | | 2 i i w C ξ +
∑
ξi ≥0 (35) Subject to y wi( ⋅φ( )xi + − + ≥b) 1 ξi 0 ∀i (36) 2. 轉換 Lagrange 的對偶問題(dual problem)為式(37):Maximum 1 , 1 1 ( ) ( ) 2 m m D i i j i j i j i i j L a a a a y y k x x = = =
∑
−∑
⋅ k x x( ,i j)=φ( )xi ⋅φ(xj) Subject to 1 0 m i i i a y = =∑
∀ ≥ ≥C ai 0 (37) 3. 最後可以得到一個決策函數(decision function)來判斷 ' x屬於那一個類別如式 (38)。 ' ' ( ) sgn( ( , ) ) f i i i i SV D x a y k x x b ∈ =∑
+ (38)其中K x x( i, j)稱為 Kernel 函數。當使用非線性 Support Vector Machine 時,必須先選 擇 Kernel 函數。目前比較常見的 Kernel 數如下: 1. linear kernel ( ,i j) i j k x x = ⋅x x (39) 2. polynomial kernel ( ,i j) ( ( i j) ) ,d 0, 0, 0 k x x = γ x x⋅ +k r≥ k≥ d ≥ (40)
3. multi-layer perception(MLP kernel) ( ,i j) tanh( ( i j) ), 0, 0
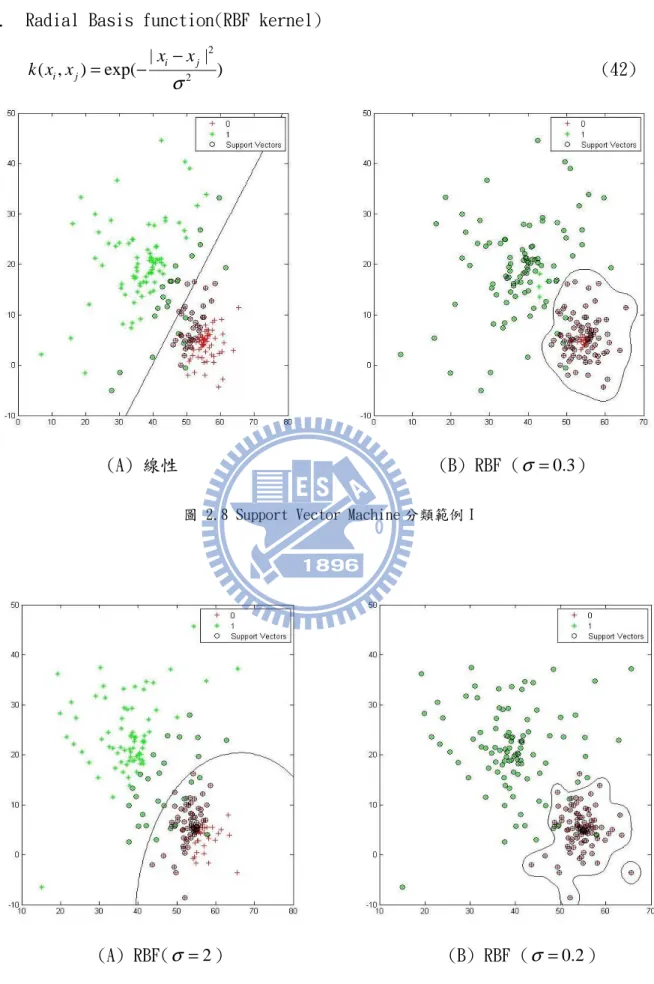
4. Radial Basis function(RBF kernel) 2 2 | | ( ,i j) exp( xi xj ) k x x σ − = − (42) (A) 線性 (B) RBF (σ =0.3)
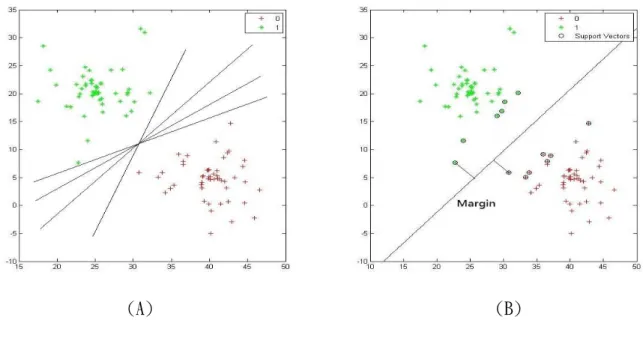
圖 2.8 Support Vector Machine 分類範例 I
(A) RBF(σ =2) (B) RBF (σ =0.2)
圖 2.8 的例子為線性與非線性的不同,圖 2.8(B)使用 RBF kernel 函數能夠得到更佳的 分類。圖 2.9 的例子為 RBF Sigma 不同的結果,Sigma 越小分類越精確,但由於分類的 區域越小,之後判斷錯誤的機率也會提高。 本論文之後的實驗將使用非線性的 RBF Kernel 函數。
2
2
2
2.
.
.
.5
5
5
5.
.
.
.4
4.
4
4
.
.
.
多類別
多類別
多類別
多類別 Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine
Support Vector Machine 是一個二元的分類器,如要解決多類別(Multi-class) 分類的方式,必需結合多個二分法來達成多分類的目標。目前 Support Vector Machine 常 見 處 理 多 類 別 問 題大 致 上 可 分 為 One-against-all method 與 One-against-one method 這兩種方式。 1. One-against-all method 假設要分成 K 個類別,此方式會產生 K 個 SVM。其中第 i 個 SVM 產生的方式,是將 第 i 類別的資料標記成+1,其他類別的所有資料則標記成-1,而得到 i f D 的決策函數為 式(43) ' ' ( ) sgn( ( , ) ) i i i i i f j j j j SV D x a y k x x b ∈ =
∑
+ (43) 某一個測試資料 ' x經過每一類 SVM 的決策函數可以得到一個決策值,最大決策值 的類別則為 ' x的類別。 2. One-against-one method 假設要分成 K 個類別,此方式會產生 ( 1) 2 k⋅ −k 個 SVM。也就是說任兩個類別產生一 個 SVM,而得到 ij f D 的決策函數為式(44) ' ' ( ) sgn( ( , ) ) ij ij ij ij ij f k k k k SV D x a y k x x b ∈ =∑
+ i≠ j (44) 對測試資料 'x,one-against-one 採取投票策略(voting strategy),如果決策函
數 ij f
D 決定為 i 類別,則 i 類別多一票,反之 j 類別多一票,最高票的類別則為 '
2
2
2
2.
.
.
.6
6
6
6.
.
.
.
SURF
SURF
SURF
SURF 演算法
演算法
演算法
演算法
SURF 演算法包括了兩個部分,一是快速 Hessian 特徵點偵測,二是 SURF 特徵點描 述子。
2
2
2
2.
.
.6
.
6
6
6.
.
.
.1
1
1
1.
.
.
.
快速
快速
快速
快速 Hessian
Hessian
Hessian
Hessian 特徵點偵測
特徵點偵測
特徵點偵測
特徵點偵測
首先 SURF 演算法定義積分影像(Integral Image)IΣ,假設X =( , )x y 代表影像上
的像素點,I X( )為X點上的像素值,積分影像定義為從原點到 X 點的區域中,所有像 素值的和,如式(45)所示。 0 0 ( ) ( , ) y x i j IΣ X I x y = = =
∑∑
(45) 將影像上所有像素點的積分影像計算之後,要計算一個矩形區域像素值的和,可 以利用矩形上左上方與右下方像素點的積分影像和,減去左下方與右上方像素點的積分 影像和,如圖 2.10 所示。在平面上 discriminant of Hessian Matrix 可以用來偵測區域的極點代表特徵 點,將其延伸至尺度空間(scale space),Hessian Matrix 與 discriminant 分別為式(46) 與(47)。 ( , ) ( , ) ( , ) ( , ) ( , ) xx xy xy yy L X L X H X L X L X σ σ σ = σ σ (46) 2 det(H)=L Lxx yy −(Lxy) (47) 其中Lxx與Lyy 為I X( )在影像上對 x 方向上的二次微分,也就是 Laplacian of Gaussian,同樣地Lxy為I X( )在影像上對 x 方向上的一次微分與y方向上的一次微分。
Lowe[7]使用了 Difference of Gaussian 來近似 Laplacian of Gaussian 以簡化 計算的複雜度;同樣地概念,Bay[8]提出 Box Filter 的方式來近似 Laplacian of Gaussian,如圖 2.11 所示。
圖 2.10 積分影像與區域像素值的和(資料來源:[8])
圖 2.11 使用 Box Filter 來近似 Laplacian of Gaussian (資料來源:[22])
原本 Laplacian of Gaussian 的計算,可以使用圖 2.11 上半部Lxx、Lyy與Lxy的 mask 跟影像做 convolution 來求得,Bay[8]將其簡化成圖 2.11 下半部Dxx、Dyy與Dxy的
mask,其中Dxx與Dyy黑色部分為 2、Dxy黑色部分為 1、其他白色部分為-1、灰色部分
為 0,原本也可以跟影像做 convolution 來求得,但是可以使用上面的積分影像快速求 得。
圖 2.12 Lowe[7]與 Bay[9]尺度空間示意圖 (資料來源:[22])
由於 Bay[8]使用Dxx、Dyy與Dxy來近似Lxx、Lyy與Lxy,於是近似 discriminant of Hessian Matrix 定義為式(48)。
2
det(Happrox)=D Dxx yy −(0.9Dxy) (48)
求得在平面空間與尺度空間近似 discriminant of Hessian Matrix 的極值,其所 在像素位置就是要尋找的特徵點。
尺度空間的建立與 Lowe[7]的方式不同,Lowe[7]是將影像縮小構成金字塔的尺度 空間,Bay[8]使用放大 Box filter 構成倒金字塔的尺度空間,如圖 2.12 所示。
2
2
2
2.
.
.
.6
6
6
6.
.
.
.2
2.
2
2
.
.
.
SURF
SURF
SURF
SURF 特徵點描述式
特徵點描述式
特徵點描述式
特徵點描述式
找出影像中所有的特徵點之後,接下來計算特徵點的描述式來表示特徵點。SURF 演算法計算的特徵點描述式有兩個步驟,一是計算特徵點的方向,二是根據特徵點的方 向建構矩形區域,計算矩形區域的像素值變化量為描述式。 特徵點方向的計算,是以特徵點為中心建構一個6σ 為半徑的圓,計算在圓中所有 點 x 與 y 的 Haar 小波響應,其中 Haar 小波響應區域為4σ 的矩形區域;之後在圓上以 60 度為窗口,將所有的 x 與 y 的 Haar 小波響應加其來形成一個向量代表方向,最後最 大的向量和為特徵點方向,如圖 2.13 所示。 圖 2.3 中,圖 2.13(A)表示建構6σ的圓;圖 2.13(B)為計算 x 與 y 的 Haar 小波響
應,其中黑色部分為 1 白色部分為-1,事實上就是近似一階微分的值也就是代表斜率或 是方向,也可以使用 integral image 來計算;圖 2.13(C)表示每 60 度計算出向量和, 最大的向量和為特徵點的方向。 最後特徵點描述式的計算,如圖 2.14 所示。根據特徵點的方向,建構一個20σ 大 小的矩形區域,並將這個矩形區域分成 4x4 的子區域;每個子區域以 5x5 為大小做取樣, 在每個取樣點上,計算對於特徵點垂直與水平方向的 Haar 小波響應為dx與dy,並乘以 一個高斯濾波,將子區域中計算所有取樣點dx與dy的和與絕對值和,得到
∑
dx 、 y d∑
、∑
|dx|與∑
|dy|四個值,所有 4x4 子區域形成 64 個值的向量,為特徵點的描述 式。 (A) (B) (C) 圖 2.13 計算特徵點方向(資料來源:[8]) 2.14 特徵點描述式的計算(資料來源:[22])3
3
3
3.
.
.
.
基於
基於
基於
基於 Hierarchical SVM
Hierarchical SVM 演算法
Hierarchical SVM
Hierarchical SVM
演算法
演算法建立
演算法
建立
建立
建立 Vocabulary
Vocabulary
Vocabulary
Vocabulary
Tree
Tree
Tree
Tree
3
3
3
3.
.
.
.1
1
1
1.
.
.
.
簡介
簡介
簡介
簡介
本論文所提出的方法主要也是先利用 hierarchical 的方式建立 vocabulary tree,然後使用所建立的 Vocabulary Tree 加速影像比對。在建立每一層 Vocabulary Tree 的分類時,本論文捨棄了使用 K-means 演算法, 主要的步驟更改為:
1 在建立 Vocabulary Tree 的每一層分類時,本論文加入了特徵點的影像資訊,首先
計算影像特徵點的平均值為影像中心點,之後將影像中心點使用 K-means++演算法 [11]進行初步分類,使得相近的影像歸於同類。
2 再將初步分類的結果,將所有相同類別中所有影像的特徵點,設定為相同的索引值,
使用 supervised machine learning 的 Support Vector Machine 演算法[16][17][18] 進行特徵點真正的分類。
由於是使用 Hierarchical 的方式而且主要使用 SVM 來分類,於是將這個方式稱為 Hierarchical SVM 演算法建立 Vocabulary Tree。
Vocabulary Tree 建立之後,就可以在每一層的 Vocabulary Tree 節點上,使用 SVM 的決策函數將搜索影像做分類,從 Vocabulary Tree 最上層的節點開始,利用節點 上的決策函數,將搜尋影像的特徵點做分類,其中特徵點數目最多的分類,將分類上所 有搜尋影像的特徵點再往下一層做分類,直到沒有下一層節點的葉節點為止,葉節點 上,最多特徵點的影像就是最相似的影像。
3
3
3
3.
.
.
.2
2
2
2.
.
.
.
Hierarchical SVM
Hierarchical SVM
Hierarchical SVM
Hierarchical SVM 演算法
演算法
演算法
演算法
本小節詳細說明 Hierarchical SVM 演算法,包括了詳細步驟、流程以及實際的範例。 首先是 Hierarchical SVM 的詳細步驟如下: 1. 一個包含了N張影像的影像資料庫為集合T為式(49): 1 { ,..., N} T = I I (49) 2. 每張影像是由mi個特徵點所構成Ii為式(50): 1 { ,..., | } i i i i d i m j I = f f f ⊂R (50) 其中對於影像Ii與Ij來說,mi ≠mj,d決定於使用的特徵點描述式,由於本論文 使用 SURF 演算法的特徵點描述式,所以d會等於 64。 3. 將所有影像的特徵點形成集合 F 為式(51): 1 1 1 1,..., 1,..., { ,..., } N N N m m F = f f f f 1 N f i i N m = =
∑
(51) 4. 對於每張影像Ii,其中心點Ci定義為所有特徵點的平均值為式(52): 1 1 mi i i j j i C f m = =∑
(52) 5. 所有影像的中心點形成集合C為式(53) { ,...,i N} C= C C (53) 6. 使用 K-means++演算法將C集合分成M 類形成集合K,集合K是由中心點Ci所對 應的每張影像Ii所組成為式(54)與式(55): 1 { ,..., M | } K = K K M <N (54) 其中 { | (1,..., )} i j K = I j⊂ N 1 M i i K N = =∑
Ki∩Kj = ∀ ≠φ, i j (55) 假設Ki中的影像數目為 ' i N ,每個影像的特徵點數目為 ' i m ,於是Ki的特徵點集合 為式(56):' ' ' 1 ' ' 1 1 1,..., 1,..., { ,..., i i } i N i N N K m m F = f f f f (56) 7. 根據 i k F 建立類別索引集合 i K Y 以及 SVM 分類初始資料集合 i K X 為式(57): ' 1 1 1 ' ' 1 1 ,..., ,..., { ,..., i i | } i m N i N N K j j j m Y = y y y y ∀ =y i ' ' ' ' ' ' ' 1 1 ' 1 1 1 1 1 1 ,..., 1 1 ,..., 1 {( , ) ( , ),..., ( i , i ) ( i , i )} i N i N N N N K m m m X = f y f y f y f y (57) 8. 使用多類別與非線性的 SVM 演算法將 , 1,..., i K X ∀ =i M進行分類,可以得到 M 類別 的集合 W,以及 SVM 的特徵函數為式(58)與式(59): 1 { ,..., M | } W = W W M <N (58) 其中 ' { | (1... )} i j W = I j⊂ N ' { i | (1,..., )} i j i I = f j⊂ m ' 1 M i i Nw m = =
∑
(59) 而且 SVM 的決策函數為式(60): ' ' ( ) sgn( j j ( j , ) ) f i i i D f =∑
a y k f f +b (60) 9. 如果 ' i i m m 小於 50%, ' i I 將會被忽略,而得到 ' i W 為式(61): ' ' ' ''' '' ''' { ,..., | } i j N W = I I N ≤N (61) 10.如果 ''' N 大於M ,則重覆步驟 4,或者是重覆步驟 4 的次數,小於一個定義的階層 次數L。11.將所有的 SVM 特徵函數構成 Vocabulary Tree,每一個特徵函數為 Vocabulary Tree
上面的節點,最下面的節點稱為葉節點。 其中所有步驟的流程如下:
1. 1-3 為影像資料庫的定義。
2. 4-8 為建構 Vocabulary Tree 每一層的步驟,包括了 3-6 使用 K-means++演算法做影
圖 3.1 Hierarchical SVM 演算法的流程
3. 9-10 為判斷是否要往下一層繼續分類,如果是則重覆 4-8。
4. 11 將每一層的特徵函數建構成 Vocabulary Tree,每一個特徵函數為 Vocabulary
Tree 上面的節點,最下面的節點稱為葉節點。 整個流程如圖 3.1 的流程圖所示。 下面使用一個實際的範例來說明 Hierarchical SVM 演算法。將以上小節四類別混 合的資料為例子來說明: 1. 圖 3.2(A)的範例為四個影像的例子,四個影像為I1、I2、I3與I4,特徵點假設為二 維,圖上的黑色圓圈為中心點,設定每層 Hierarchical SVM 的類別數目為 2 以及 階層數目為 2。
(A) (B) 圖 3.2 Hierarchical SVM 演算法分類範例 I (A) (B) 圖 3.3 Hierarchical SVM 演算法分類範例 II 2. 經由影像分類之後,I2、I3與I4為一類,I1獨自為一類,經過 SVM 分類之後,得到 圖 3.2(B)的結果。 3. 根據上面 9-10 的判斷,I2、I3與I4重覆 4-8 的步驟再進行分類。 4. 經由影像分類之後,I3與I4為一類,I2獨自為一類,經過 SVM 分類之後,得到圖 3.3(A) 的結果。 5. 根據上面 9-10 的判斷,I3與I4重覆 4-8 的步驟再進行分類。 6. 經由影像分類之後,I3與I4各為一類,經過 SVM 分類之後,得到圖 3.3(B)的結果。
7. 最後使用圖 3.2(B)、圖 3.3(A)與圖 3.3(B) SVM 所計算的決策函數做為 Vocabulary Tree 的節點,建立 Vocabulary Tree 以利之後的比對。
3
3
3
3.
.
.
.3
3
3
3.
.
.
.
影像比對
影像比對
影像比對
影像比對
使用 Hierarchical SVM 演算法建立 Vocabulary Tree 之後,就可以利用建立的 Vocabulary Tree 進行影像比對。其詳細步驟如下: 1. 搜尋影像是由 m 個特徵點所構成S為式(62): 1 { s ,..., sm| sj d} S= f f f ⊂R (62) 搜尋影像使用 SURF 演算法的找出特徵點與特徵點描述式,d 等於 64,並將S代入
Vocabulary Tree,從 Vocabulary Tree 最上層的根節點開始。
2. 使用節點上 SVM 的決策函數找出搜尋影像所有特徵點的決策值,也就是特徵點所 分到的類別。 ( s ) sgn( j j ( j , s ) ) f k i i i k D f =
∑
a y k f f +b (63) 3. 計算相同類別上,搜尋影像特徵點的數目,最大數目類別上的特徵點形成集合 ' S ' ' ' ' ' ' { si,..., sm | s j d,1 } S = f f f ⊂R ≤ ≤i m ≤m (64) 4. 如果最大類別的節點下面還有其他節點,將 ' S 重覆步驟 2。 5. 反之最大類別的節點下面沒有其他節點,此時最多的特徵點將落於葉節點,如果 葉節點上只有一張影像,則此張影像為相似影像,反之如果葉節點上有多張影像, 使用 SVM 演算法再將影像分類,並使用分類之後的結果來判斷正確的相似影像。 本論文的比對方式與[9]方法有很大的不同,[9]方法使用 TF-IDF 的計算,但是本論 文的方式由於分類比較正確,所以只須要將找出最多特徵點的葉節點,最後在找出葉節 點上最相似的影像;如果葉節點上的影像只有一張影像,此張影像就是最相似的影像, 反之必須判斷最相似影像,判斷的方式可以還是 SVM 演算法,或是 nearest neighbor、 K-means 演算法等等,也就是說將所有葉節點上的影像在使用 SVM,nearest neighbor、用了 SVM 演算法來做的分類,為了方便起見,影像比對也使用 SVM 演算法來分類。
3
3
3
3.
.
.
.4
4
4
4.
.
.
.
分析
分析
分析
分析
3
3
3
3.
.
.4
.
4
4
4.
.
.
.1
1.
1
1
.
.
.
比對正確率
比對正確率
比對正確率
比對正確率
由於 Hierarchical SVM 演算法能夠有效地將影像分類,所以可以得到更好的比對正 率。下面利用一個範例舉例來說明。 還是以一 個實 際有四 群混在一 起的 資料為 例子,將 此資 料使 用 Hierarchical K-means 演算法與 Hierarchical SVM 演算法建立 Vocabulary Tree,不論是 Hierarchical K-means 演算法或 Hierarchical SVM 演算法,每層分類數目為 2 以及階層數目為 1;假 設 Hierarchical K-means 演算法剛好將兩群資料分成兩半,Hierarchical SVM 演算法 將兩群資料切開如圖 3.4 所示,其中圖 3.4(A)為 Hierarchical K-means 演算法的結果, 圖 3.4(B)為 Hierarchical SVM 演算法的結果。如果相似於 I1 與 I4 的資料,利用 Hierarchical K-means 演 算法所建立的 Vocabulary Tree 進行計算 TF-IDF 進行比對,比對的正確率會是 100%;但是如果是相 似於 I2 與 I3 的資料用同樣的方法來進行比對,可能就會有誤判的情況,所以正確率將 是 50%,因此比對正確率的期望值將會是 75%。 同樣地情況,使用 Hierarchical SVM 演算法來比對,由於每個分類上有兩個明顯的 資料,在比對之前還必須將資料分開才能分辨,於是使用 SVM 演算法再分類,如圖 3.5 所示。 因此不論是 I1、I2、I3 與 I4 的資料來比對,比對正確率的期望值將會是 100%,也 因此 Hierarchical SVM 演算法可以得到更好的比對正確率。
(A) (B)
圖 3.4 Hierarchical K-means 與 Hierarchical SVM 分類示意圖
圖 3.5 Hierarchical SVM 葉節點再分類示意圖
3
3
3
3.
.
.4
.
4
4
4.
.
.
.2
2.
2
2
.
.
.
葉節點上比對複雜度比較
葉節點上比對複雜度比較
葉節點上比對複雜度比較
葉節點上比對複雜度比較
本小節將分析[9]與本論文方法的比對複雜度。首先,不論是[9]還是本論文的方法, 都是將所有要比對的特徵點,找到 Vocabulary Tree 的葉節點上,在本論文的方法中, 只取每層最多特徵點的節點往下尋找,也許在尋找葉節點會有一點優勢,但為了比較方 便起見,假設尋找葉節點的複雜度兩個方法是一樣的,於是對於複雜度的比較來說,在[9]方法是誤差和的計算,而本論文則是分類的比較。 [9]方法的比對方式是計算誤差和為分數,將葉節點上比對影像特徵點的 TF-IDF, 減去在葉節點所有影像的 TF-IDF 形成所謂的誤差,然後將每張影像所有葉節點的誤差 值加起來形成誤差和,誤差和最小的是就是相似的影像;如果將計算誤差的複雜度定義 為Cerror,以及每層分類的數目為K與階層數目為L,於是[9]方法的複雜度為比對影像 葉節點數目的期望值E X( ),乘以每個葉節點上影像數目的期望值E N( LT)再乘以Cerror, 如式(65)所示。 [9] ( ) ( LT) error Complexity =E X ⋅E N ⋅C (65) 當分類數目K與階層數目L很小的情況下,使用 Hierarchical K-means 演算法會 使得E X( )剛好等於葉解點的數目 L K ,以及E N( LT)剛好等於影像的數目N,於是比對 的複雜度為式(66)所示。 [9] L error Complexity =K ⋅ ⋅N C (66) 本論文的比對方式是找到最多特徵點所在的葉節點,如果葉節點上只有一個影像, 此影像就是相似影像,此時複雜度可以視為 0,但是如果有一個以上的影像,就必須進 行影像比對;假設使用 SVM 演算法分類,所有的特徵點必須進行 SVM 特徵函數運算,如 果將運算 SVM 特徵函數的複雜度定義為CSVM,於是本論文方法的複雜度為比對影像特徵 點數目的期望值E N( f)乘以每個葉節點上影像數目的期望值 ' ( LT) E N 再乘以CSVM,如式 (67)所示。 ' ( f) ( LT) SVM Complexity=E N ⋅E N ⋅C (67) 其中如果分類可以做的很好的情況之下,可以將 ' ( LT) E N 估計為影像數目N 除以葉 節點數目 L K ,於是複雜度為式(68)所示。 f L SVM N Complexity N C K = ⋅ ⋅ (68) 經過式(66)與式(68)的整理之後,可以得到當葉節點數目大於特徵點數目的平方根
![圖 2.1 Mobile Visual Search 架構圖 (資料來源:[1])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8255357.171865/16.892.161.784.117.429/圖21MobileVisualSearch架構圖資料來源1.webp)
![圖 2.3 建構 Vocabulary Tree 的流程 (資料來源:[9])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8255357.171865/21.892.173.787.114.505/圖23建構VocabularyTree的流程資料來源9.webp)

![圖 2.11 使用 Box Filter 來近似 Laplacian of Gaussian (資料來源:[22])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8255357.171865/33.892.267.674.530.829/圖211使用BoxFilter來近似LaplacianofGaussian資料來源22.webp)
![圖 2.12 Lowe[7]與 Bay[9]尺度空間示意圖 (資料來源:[22])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8255357.171865/34.892.174.777.110.344/圖212Lowe7與Bay9尺度空間示意圖資料來源22.webp)