行政院國家科學委員會專題研究計畫 期末報告
符號式字串驗證:對網路應用程式自動化弱點掃描與補正的
正規方法研究與工具開發(第 3 年)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 99-2218-E-004-002-MY3 執 行 期 間 : 101 年 08 月 01 日至 102 年 07 月 31 日 執 行 單 位 : 國立政治大學資訊管理學系 計 畫 主 持 人 : 郁方 計畫參與人員: 碩士班研究生-兼任助理人員:戴睿宸 碩士班研究生-兼任助理人員:董亦揚 碩士班研究生-兼任助理人員:李聖瑋 碩士班研究生-兼任助理人員:邱莉晴 碩士班研究生-兼任助理人員:薛慶源 大專生-兼任助理人員:吳威翰 大專生-兼任助理人員:曾柏崴 大專生-兼任助理人員:李元傑 大專生-兼任助理人員:張子豪 大專生-兼任助理人員:邱鈺雯 大專生-兼任助理人員:梁瑞君 大專生-兼任助理人員:唐維佋 大專生-兼任助理人員:林君翰 報 告 附 件 : 出席國際會議研究心得報告及發表論文 公 開 資 訊 : 本計畫可公開查詢中 文 摘 要 : 本計畫之主要研究方向為以自動機進行靜態字串分析,以此 方法進行原碼檢測。偵測網頁應用程式可能招受的惡意攻擊 點與計算可能的惡意輸入,從而自動產生除錯的程式碼以預 防攻擊。我們採用正規驗證,相對於傳統的黑箱測試,我們 可以保證其除錯後的正確性但也增加偵錯分析的複雜度。在 這份報告中我們先講述自動機的字串分析技術並提出新的除 錯碼生成技術,接著提出字串抽象技術,其可顯著的減少計 算與記憶體需求從而進行更有效率的偵錯分析。最後結合行 動與視覺化技術,實現所提技術於一新的雲端網站應用程式 除錯服務。本研究之成果已發表于 ICSE, SPIN, HICSS 等國 際會議與 FMSD 和 IJFCS 二 SCI 期刊.
中文關鍵詞: 字串分析, 自動機, 正規驗證, 資訊安全, 網路應用程式分 析, 跨腳本攻擊
英 文 摘 要 : Verifying string manipulating programs is a crucial problem for computer security. String operations are used extensively within web applications to
manipulate user input, and their erroneous use is the most common cause of security vulnerabilities in web applications. Unfortunately, verifying string
manipulating programs is a difficult problem that has an inherent tension between practical efficiency and useful precision. We investigate a set of automata-based string analysis techniques with sound
abstractions for strings and string operations that allow for both efficient and precise verification of string manipulating programs. The project contributes in three folds. First, we propose forward and
backward symbolic reachability analysis for detecting and patching string vulnerabilities in Web
applications. Second, we investigate string abastrction techniques to adjuct precision and efficiency on regular model checking of realtional string analysis. Third, we realize the presented approach in a new online service for detecting, viewing and patching Web application vulnerabilities. 英文關鍵詞: automata, symbolic string analysis, web application
行政院國家科學委員會補助專題研究計畫
期末報告
符號式字串驗證:對網路應用程式自動化弱點掃描與補正的正規方法研究與工具開發計畫類別:v 個別型計畫 □整合型計畫
計畫編號:
NSC 99-2218-E-004-002-MY3
執行期間: 99 年 11 月 1 日至 102 年 7 月 31 日
執行機構及系所:政治大學資訊管理學系
計畫主持人:郁 方
成果報告類型(依經費核定清單規定繳交):□精簡報告 v 完整報告
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
□出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢Content Index Abstract
I. Introduction
II. Automata-based Vulnerability Detection Techniques III. Patch Synthesis Techniques
IV. String Abstraction Techniques V. The Patcher Service
VI. Conclusion VII. References
TITLE: Symbolic String Verfication: Automatic Vulnerability Detection and Patch Synthesis of Web Application Vulnerabilities
符號式字串驗證:對網路應用程式自動化弱點掃描與補正的正規方法研究與工具開發
Abstract
Verifying string manipulating programs is a crucial problem for computer security. String operations are used extensively within web applications to manipulate user input, and their erroneous use is the most common cause of security vulnerabilities in web applications. Unfortunately, verifying string manipulating programs is a difficult problem that has an inherent tension between practical efficiency and useful precision. We investigate a set of automata-based string analysis techniques with sound abstractions for strings and string operations that allow for both efficient and precise verification of string manipulating programs. The project contributes in three folds. First, we propose forward and backward symbolic reachability analysis for detecting and patching string vulnerabilities in Web applications. Second, we investigate string abastrction techniques to adjuct precision and efficiency on regular model checking of realtional string analysis. Third, we realize the presented approach in a new online service for detecting, viewing and patching Web application vulnerabilities.
中文摘要 本計畫之主要研究方向為以自動機進行靜態字串分析,以此方法進行原碼檢測。偵測網頁應用程 式可能招受的惡意攻擊點與計算可能的惡意輸入,從而自動產生除錯的程式碼以預防攻擊。我們 採用正規驗證,相對於傳統的黑箱測試,我們可以保證其除錯後的正確性但也增加偵錯分析的複 雜度。在這份報告中我們先講述自動機的字串分析技術並提出新的除錯碼生成技術,接著提出字串 抽象技術,其可顯著的減少計算與記憶體需求從而進行更有效率的偵錯分析。最後結合行動與視 覺化技術,實現所提技術於一新的雲端網站應用程式除錯服務。本研究之成果已發表于 ICSE, SPIN, HICSS 等國際會議與 FMSD 和 IJFCS 二 SCI 期刊.
Symbolic String Verfication: Automatic Vulnerability Detection and Patch Synthesis
of Web Application Vulnerabilities
Fang Yu
Software Security Lab
Department of Management Information Systems National Chengchi University
I. Introduction
Software defects in web applications can result in compromised security. Malicious users who successfully leverage software vulnerabilities can cause damage both at the server and the client side leading to catastrophic failures. Viewing web application vulnerabilities as a secure information flow problem, we proposed taint analysis [HYHTLK04a, HYHTLK04b] (the U.S. patent [HYHTLK11]), to detect such vulnerabilities without taking string contents into account. Taint analysis is a scalable technique for detecting vulnerabilities but suffers from poor precision, generating a large amount of false positives. Additionally, taint analysis is not capable of assessing the correctness of sanitization routines/filters that are inserted by developers to prevent attacks. In fact, taint analysis techniques can incorrectly report that an application using inadequate sanitization is not vulnerable, leading to unsound results. During my PhD study, I proposed symbolic string verification to analyze string manipulating programs (Web applications). We developed a sound automata-based approach based on symbolic string analysis [YBCI08][YAB09]. String analysis is a static analysis technique that determines the values that a string expression can take during program execution at a given program point. This information can be used to verify that string values are sanitized properly and to detect and prevent security vulnerabilities such as SQL Injections and Cross-Site Scripting (the top two vulnerabilities of Web Applications in OWASP Top 10 2007, 2010 and 2013). During my PhD study, we have also proposed the composite analysis [YBI09] to verify string and interger programs, and realize the string analysis approach in the tool Stranger [YAB10] to detect vulnerabilities in web applicaiotns.
Funded by this NSC project (99-2218-E-004-002-MY3, 2010.11-2013.7), I have worked on automatic patch synthesis [YAB11], string abstraction [YBH11], relational string analysis [YBI11], and the develpoment of online service with vulnerability visualization [YY14]. The recent journal publication in FMSD [YABI13] gives detailed alogorithms on string analysis with theoretical proofs, as well as intensive experiments on large-scale (350000+ lines of code) applications.
Particularly, in our ICSE paper [YAB11] (ICSE is listed as the top one conference in software engineering in all years by Microsoft academic search), we presented a set of techniques that (1) identify vulnerabilities that are due to string manipulation, (2) generate a characterization of inputs that can exploit the vulnerability, and (3) generate sanitization statements that eliminate the vulnerability approach. We construct sanitization statements that check if a given input matches the vulnerability signature and modify the input in a minimal way so that the modified input does not match the vulnerability signature. Our approach is capable of generating relational vulnerability signatures (and
corresponding sanitization statements) for vulnerabilities that are due to more than one input. An ongoing work is constructing optimal patch synthesizer based on finding minimal word differences.
In the IJFCS paper [YBI11], we propose multi-track automata and propose realtional string analysis, verifying properties that involve implicit relations among string variables. Our multi-track automata encoding not only improves the precision of the string analysis but also enables verification of properties that cannot be verified with the previous approaches. We have also investigated the boundary of decidability for the string verification problem. Bjorner et al. [BTV09] show the undecidability result with replacement operation. In [YBI11], we consider only concatenation and show that string verification problem is undecidable even for deterministic string systems with only three unary string variables and non-deterministic string systems with only two string variables if the comparison of two variables are allowed.
In the SPIN paper [YBH11], we present a set of sound abstractions for strings and string operations that allow for both efficient and precise verification of string manipulating programs. We first describe an abstraction called regular abstraction which enables us to perform string analysis using multi-track automata as a symbolic representation. We then introduce two other abstractions -alphabet abstraction and relation abstraction- that can be used in combination to tune the analysis precision and efficiency. We show that these abstractions form an abstraction lattice that generalizes the string analysis techniques studied previously in isolation, such as size analysis or non-relational string analysis. We also empirically evaluate the effectiveness of these abstraction techniques with respect to several benchmarks and an open source application, demonstrating that our techniques can improve the performance without loss of accuracy of the analysis when a suitable abstraction class is selected. This presented techniques can be further used to other contexts, e.g., using string abstracttion to abstract call sequences for malicious pattern recognization.
For practical impacts, we have implemented an online service platform that users can access and upload their code to check potential vulnerabilities. The recent work on the online public service development with visualization techniques [YY14] has been accepted to be published in HICSS 2014. Users can detect and view potential vulnerabilities in their applications, and insert patches that are automatically generated to prevent malicious exploits of these software defects (with respect to an given attack pattern). While deploying new web services, it is essential to build the confidence on a sound security mechanism. To the best of our knowledge, this is the first public online service that secures web applications using formal verification techniques. In the following sections, I detail our research ideas, related work and methods in each fold. Interested readers are encouraged to read our papers for more details.
II. Automata-based Symbolic Sring Verification
Web applications provide critical services over the Internet and frequently handle sensitive data. Unfortunately, Web application development is error prone and results in applications that are vulnerable to attacks by malicious users. The global accessibility of Web applications makes this an extremely serious problem. According to the Open Web Application Security Project (OWASP)'s top ten list that identifies the most serious web application vulnerabilities, the top three vulnerabilities in 2007 were:
1) Cross Site Scripting (XSS), 2) Injection Flaws (such as SQL Injection) and 3) Malicious File Execution (MFE). Even after it has been widely reported that web applications suffer from these vulnerabilities, the top two of the vulnerabilities were still listed in the top three of the OWASP's top ten list in 2010 and 2013. That is to say, in the past decade, even with the increased awareness about their importance due to OWAPS reports, these vulnerabilities continued to be widely spread in modern web applications, causing great damage.
A XSS vulnerability results from the application inserting part of the user's input in the next HTML page that it renders. Once the attacker convinces a victim to click on a URL that contains malicious HTML/JavaScript code, the user's browser will then display HTML and execute JavaScript that can result in stealing of browser cookies and other sensitive data. An SQL Injection vulnerability, on the other hand, results from the application's use of user input in constructing database statements. The attacker can invoke the application with a malicious input that is part of an SQL command that the application executes. This permits the attacker to damage or get unauthorized access to data stored in a database. Finally, MFE vulnerabilities occur if developers directly use or concatenate potentially hostile input with file or stream functions, or improperly trust input files.
One important observation is, all these vulnerabilities are caused by improper string manipulation. Programs that propagate and use malicious user inputs without sanitization or with improper sanitization are vulnerable to these well-known attacks. In this project, we focus on vulnerabilities related to string manipulation, and we propose a string analysis technique that identifies if a web application is vulnerable to the types of attacks we discussed above.
Attacks that exploit the vulnerabilities related to string manipulation can be characterized as attack patterns, i.e., regular expressions that specify potential attack strings for sensitive operations (called sinks). Given an application and an attack pattern, our vulnerability analysis identifies if there are any input values that a user can provide to the application that could lead to an attack string to be passed to a sensitive operation. We use automata-based string analysis techniques for vulnerability analysis. Our tool takes an attack pattern specified as a regular expression and a PHP program as input and identifies if there is any vulnerability with respect to the given attack pattern.
Our string analysis framework uses deterministic finite automaton (DFA) to represent values that string expressions can take. At each program point, each string variable is associated with a DFA. To determine if a program has any vulnerabilities, we use a symbolic forward reachability analysis that computes an over-approximation of all possible values that string variables can take at each program point. Intersecting the results of the forward analysis with the attack pattern gives us the potential attack strings if the program is vulnerable.
The string analysis technique we present is a symbolic forward reachability computation that uses DFAs as a symbolic representation. Furthermore, we use the symbolic DFA representation provided by the MONA DFA library, in which transition relations of the DFAs are represented as Multi-terminal Binary Decision Diagrams (MBDDs). We iteratively compute an over approximation of the least fixpoint that
corresponds to the reachable values of the string expressions. In each iteration, given the current state DFAs for all the variables, we compute the next state DFAs.
In [FMSD 2013], we investigate algorithms of next state computation for string operations such as concatenation and language-based replacement on DFAs. Particularly, the language-based replacement operation is defined as Replace($M_1$, $M_2$, $M_3$ where $M_1$, $M_2$, and $M_3$ are DFAs that accept the set of original strings, the set of match strings, and the set of replacement strings, respectively. We detail the DFA constructions (without using $\epsilon$ transitions) for three common cases on $M_3$:
(1) $M_3$ accepts an empty string, (2) $M_3$ accepts single characters, and (3) $M_3$ accepts words with more than one single character.
For general cases of $M_3$, the construction can be done using $\epsilon$ transitions.
Our language-based replacement operation is essential for modeling PHP replacement commands,
such as, preg_replace() and str_replace(), and many PHP sanitization routines, such as htmlspecialchars(), that are commonly used to perform input validation. These functions provide mechanisms for scanning a string for matches to a given pattern, expressed as a regular expression, and replacing the matched text with a replacement string. As an example of modeling these functions, consider the following statement: $username = ereg_replace("<script *>", "", $_GET["username"]);
The expression $_GET["username"] returns the string entered by the user, and ereg_replace call replaces all matches of the search pattern <script *> with the empty string, and the result is assigned to the variable $username. This statement can be modeled by our language-based replacement operation, Replace($M_1$, $M_2$, $M_3$), where $M_1$ accepts arbitrary strings (modeling the user input), $M_2$ accepts the set of strings that start with <script followed by zero or more spaces and terminated by the character >, and $M_3$ accepts the empty string.
To the best of our knowledge we are the first to extend the MONA automata package to analyze these complex string operations with loops on real programs. Tateishi, Pistoia, and Tripp [TPT11] apply MONA to analyze strings and their index of programs without loops. In addition to computation of the language-based replacement operation, another difficulty is implementing the string operations required for our analysis without using the standard constructions based on the $\epsilon$-transitions. The MBDD-based automata representation used by MONA does not allow $\epsilon$-transitions. We model nondeterminism by extending the alphabet with extra bits and then project them away using the on-the-fly subset construction algorithm provided by MONA. We apply the projection one bit at a time, and after projecting each bit away, we use the MBDD-based automata minimization to reduce the size of the resulting automaton.
Since DFAs can represent infinite sets of strings, the fixpoint computations are not guaranteed to converge. To alleviate this problem, we use the automata widening technique proposed by Bartzis and Bultan [BB04] to compute an over-approximation of the least fixpoint. Briefly, we merge those states
belonging to the same equivalence class identified by certain conditions. This widening operator was originally proposed for automata representation of arithmetic constraints but the intuition behind it is applicable to any symbolic fixpoint computation that uses automata.
We implemented our approach in a tool called Stranger (STRing AutomatoN GEneratoR) that analyzes PHP programs. Stranger takes a PHP program as input and automatically analyzes it and outputs the possible XSS, SQL Injection, or MFE vulnerabilities in the program. For each input that leads to a vulnerability, it also outputs an automaton (in the dot format) that characterizes all possible string values for this sink which may exploit the vulnerability. Stranger uses the front-end of Pixy, a vulnerability analysis tool for PHP that is based on taint analysis [JKK06]. Stranger also uses the automata package of MONA to store the automata constructed during string analysis symbolically. We used Stranger to analyze public web applications downloaded from sourceforge including one with 350,000+ lines of code. Our results demonstrate that our tool not only detects vulnerabilities in vulnerable Web applications, but also proves the correctness of sanitization routines in secure Web applications.
Contribution:
In this research direction we extend the regular model checking techniques to verification of string manipulation operations in PHP programs. The results of this part have been published in the journal paper of Formal Methods in System Design [YABI13]. Our key contributions include:
1. an automatic automata-based approach for detecting or proving the absence of vulnerabilities in string manipulating programs,
2. a new algorithm to language-based replacement that can be used to model commonly used sanitization routines in Web applications,
3. a new forward reachability analysis with automata widening to accelerate/guarantee termination of fixpoint computation on strings
4. a new tool that implements our string analysis techniques, combined with a PHP front end and string manipulation library built on MONA.
5. an experimental study on XSS vulnerability checking against public and large-size Web applications. III Patch Synthesis
As we have mentioned, Web applications are notorious for security vulnerabilities that can be exploited by malicious users, and due to global accessibility of web applications, malicious users all around the world can exploit a vulnerable web application and cause serious damage. So, it is critical that vulnerabilities are not only discovered fast, but they are also repaired fast.
In our ICSE paper [YAB11], we extend vulnerability detection to patch synthesis, presenting automata-based string analysis techniques for automatically detecting and patching string related vulnerabilities in web applications. We start with a set of attack patterns (regular expressions) that characterize possible attacks (either taken from an attack pattern specification library or written by the web application developer). Given an attack pattern, our string analysis approach works in three phases: Phase 1: Vulnerability Analysis:
First, we use automata-based static string analysis techniques to determine if the web application is vulnerable to attacks characterized by the given attack pattern and generate a characterization of the potential attack strings if the application is vulnerable.
Phase 2: Vulnerability Signature Generation: We then project these attack strings to user inputs and compute an over-approximation of all possible inputs that can cause an attack. This characterization of potentially harmful user inputs is called the vulnerability signature for a given attack pattern.
Phase 3: Sanitization Generation: Once we have the vulnerability signature, we automatically synthesize patches that eliminate the vulnerability using two strategies:
(1) Match-and-block: We insert match statements to vulnerable web applications and halt the execution when an input that matches a vulnerability signature is detected. (2) Match-and-sanitize: We insert both match and replace statements to vulnerable web applications. When an input that matches a vulnerability signature is detected, instead of halting the execution, the replace statement is executed. The replace statement deletes a small set of characters from the input such that the modified string no longer matches the vulnerability signature.
For vulnerability analysis, we use a forward symbolic reachability analysis as we proposed in [YABI13]. Intersecting the results of the forward analysis at sinks (i.e., sensitive functions that can cause a vulnerability) with the attack pattern gives us the potential attack strings if the program is vulnerable. We use two different techniques for vulnerability signature generation. In the first one, we start with the DFA that represents the attack strings at the sink, and then use a backward symbolic reachability analysis to compute an over-approximation of all possible inputs that can generate those attack strings. The result is a DFA that characterizes the vulnerability signature for the given attack pattern.
However, this approach does not work for vulnerabilities that are due to more than one input. For example, if an attack string is generated by concatenating two input strings, it might not be possible to prevent the attack by blocking only one of the inputs, since a string coming from one input can lead to an attack if it is concatenated with a suitably constructed string coming from another input. In such cases the vulnerability signature can include all possible input strings. Using such a vulnerability signature for automated patch generation would mean blocking or erasing all the user input, which would make the web application unusable. However, if we can do an analysis that keeps track of the relationships among different string variables, then we can block only the combinations of input strings that lead to an attack string.
We present a relational vulnerability signature generation algorithm based on multi-track deterministic finite automata (MDFA). An MDFA has multiple tracks and reads one symbol for each track in each transition. I.e., an MDFA recognizes tuples of strings rather than a single string. We use a forward symbolic reachability analysis where each generated MDFA has one track for each input variable and represents the relation between the inputs and the string expression at a particular program point. Intersecting the MDFA at a sink with the attack pattern and projecting the resulting MDFA to the input tracks gives us the vulnerability signature. The vulnerability signature MDFA accepts all combinations of
inputs that can exploit the vulnerability.
Once we generate the vulnerability signature we generate match and replace statements based on the vulnerability signature. The match statement basically simulates the vulnerability signature automaton and reports a match if the input string is accepted by the automaton. In the match-and-block strategy this is all we need, and we halt the execution if there is a match. In the match-and-sanitize strategy, however, we also generate a replace statement that will modify the input so that it does not match the vulnerability signature. Since inputs that match the vulnerability signature may come from normal, non-malicious users (who, for example, may have accidentally typed a suspicious character), it is preferable to change the input in a minimal way. We present an automata theoretic characterization of this minimality and show that solving it precisely is intractable. We show that we can generate a replace statement which is close to optimal in practice by adopting a polynomial-time min-cut algorithm. We implemented all the techniques mentioned above for PHP programs on top of Stranger [YAB10] and report our results in [YAB11] against several open source applications.
Contribution
In sum, most critical security vulnerabilities in web applications are caused by inadequate manipulation of input strings. The contribution of this work consists of the following:
1. We identify severe vulnerabilities in Web applications that are due to string manipulation 2. We generate a characterization of inputs that can exploit the vulnerability
3. We generate sanitization statements that eliminate the vulnerability
In our earlier work, we have used single-track DFA based symbolic reachability analysis to verify the correctness of string sanitization operations in PHP programs [YBCI08, YAB10]. Our preliminary results on generating (non-relational) vulnerability signatures using single-track DFA were reported earlier [YAB09]. We have also reported our results on foundations of string analysis using multi-track automata [YBI11]. These earlier results do not address the sanitization synthesis problem we discuss in this direction. Moreover, to the best of our knowledge this is the first paper that presents a relational vulnerability signature (i.e., a vulnerability signature that involves more than one input) generation technique for strings.There has been previous work on automatically generating filters for blocking bad inputs [CCZ07]. Although this is similar to our match-and-block strategy, there are several significant differences with our work. First, earlier work [CCZ07] focuses on buffer-overflow vulnerabilities which are different than the string vulnerabilities we investigate here. Second, in earlier work [CCZ07] the generation of filters is done starting with an existing exploit, whereas we start with an attack pattern. Finally, unlike prior results, in this paper, we generate sanitization statements that repair bad inputs using the match-and-sanitize strategy. We also give an automata-theoretic characterization of the match-and-sanitize strategy, prove that generating optimum modifications is an intractable problem, and present a heuristic approach based on a min-cut algorithm.
IV. String Abstraction
To deal with large scale applications, it is needed to have some light weight analysis. To resolve string properties, we focus on a relational string analysis that can be used to verify string manipulation
operations in Web applications; the high complexity of such analysis could hinder its ability from practical applications. To address the scalability issue, we presented two string abstraction techniques called alphabet and relation abstraction. These abstraction techniques enable us to adjust the precision and performance of our string analysis techniques. We also proposed a heuristic to statically determine the abstraction level and empirically demonstrated the effectiveness of our approach on open source web applications.
In our string analysis, we use forward symbolic reachability analysis techniques to compute an over-approximation of the reachable states of string manipulating programs using widening and summarization. To verify properties among string variables, we use multi-track deterministic finite automata (DFAs) as a symbolic representation to encode the set of possible values that string variables can take at a given program point [YBI11]. Our analysis is relational, i.e., it is able to keep track of the relationships among the string variables, improving the precision of the string analysis and enabling verification of invariants such as $X_1=X_2$ where $X_1$ and $X_2$ are string variables.
However, relational string analysis based on multi-track automata has some disadvantages. First, for some string relations, the size of the multi-track automaton representing the relation can be exponentially larger than the single-track-automata representing the projections of the same relation. For example, the size of the two-track automaton representing the string relation $X_1=cX_2$ is exponential in the length of the string constant $c$ [YBI10]. However, the projection of this relation to the individual variables $X_1$ and $X_2$ (which are $c\Sigma^*$ and $\Sigma^*$, respectively) can be represented with two single-track DFAs, one with linear number of states with respect to the length of the string constant $c$ and the other one with two states. Of course, the projections give an over-approximation of the original relation and may not be precise enough to prove some properties. An abstraction technique that can be selectively used to adjust the precision of the relational string analysis may avoid the exponential representation cost, particularly useful in cases that the extra precision gained by the multi-track automata representation is not necessary for proving the property of interest.
Second, the alphabet size for the multi-track automata increases exponentially with the number of variables. For example, based on the ASCII character set the alphabet size for single-track automata is: 128, for 2-track automata it is: 16384, for 3-track automata it is: 2097152, and for 4-track automata it is: 268435456. In order to be able to handle these large alphabets we use the symbolic DFA representation provided by the MONA automata package, in which transition relations of the DFA are represented as Multi-terminal Binary Decision Diagrams (MBDDs). Still the exponential increase in the alphabet size presents a significant challenge for the scalability of relational string analysis. An abstraction technique that can reduce the alphabet size by ignoring the characters that may not be relevant for the verification of the property of interest can improve the scalability of relational string analysis.
In this project, we propose two string abstraction techniques, called alphabet and relation abstractions, to address these two problems and improve the efficiency of the symbolic string analysis. In alphabet
abstraction, we identify a set of characters that we are interested in and use a special symbol to represent
them as a single multi-track automata. For those that are not related, we use multiple single-track automata to encode their values, where relations among them are abstracted away. We further define an abstraction lattice that combines these abstractions under one framework and show that earlier results on string analysis can be mapped to several points in this abstraction lattice. We also extend our symbolic analysis technique by presenting algorithms for computing the post condition of complex string manipulation operations such as replacement.
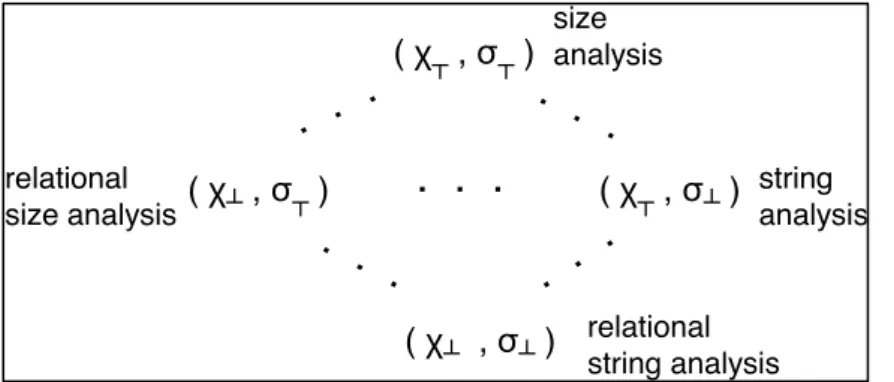
Both alphabet and relation abstractions form abstraction lattices which allow different levels of abstraction. Combining these abstractions leads to a product lattice where each point in this lattice corresponds to the combination of a particular alphabet abstraction with a particular relation abstraction. This creates an even larger set of Galois connections, one for each possible combination of alphabet and relation abstractions. Furthermore, we can select any abstraction class in the product lattice during our analysis. The selected abstraction class $(\chi, \gs)$ determines the precision and efficiency of our analysis. If we select the abstraction class $(\chi_\bot, \gs_\bot)$, we conduct our most precise relational string analysis. The relations among $\overline{X}$ will be kept using one $n$-track DFA at each program point. If we select $(\chi_\top, \gs_\top)$, we only keep track of the {\it length} of each string variable individually. Although we abstract away almost all string relations and contents in this case, this kind of path-sensitive (w.r.t length conditions on a single variable) size analysis can be used to detect buffer overflow vulnerabilities [DRS03, WFBA00]. If we select $(\chi_\bot, \gs_\top)$, then we will be conducting relational size analysis. Finally, earlier string analysis techniques that use DFA, such as [YBCI08], correspond to the abstraction class $(\chi_\top, \gs_\bot)$, where multiple single-track DFAs are used to encode reachable states. As shown in [YBCI08,YAB09], this type of analysis is useful for detecting XSS and SQLCI vulnerabilities.
Figure 1. Some abstractions from the abstraction lattice and corresponding analyses
Figure 1 summarizes the different types of abstractions that can be obtained using our abstraction framework. The alphabet and relation abstractions can be seen as two knobs that determine the level of the precision of our string analysis. The alphabet abstraction knob determines how much of the string content is abstracted away. In the limit, the only information left about the string values is their lengths. On the other hand, the relation abstraction knob determines which set of variables should be analyzed in relation to each other. In the limit, all values are projected to individual variables. Different abstraction classes can be useful in different cases.
( , ) ( , ) ( , ) ( , ) size analysis relational size analysis string analysis relational string analysis
. . .
Since the space of total possible abstractions using the relation and alphabet abstractions defined above is very large, we must have some means to decide which specific abstractions to employ in order to prove a given property. Our choice should be as abstract as possible (for efficiency) while remaining precise enough to prove the property in question. We propose a set of heuristics for making this decision. The intuition behind these heuristics is to let the property under question guide our choice of abstraction. Consider the set of string variables $X_i$ that appear in the assertion of a property. Let $G$ be the dependence graph for $X_i$ generated from the program being verified. Finally, let $\overline{X}$ be the set of string variables appearing in $G$ and $\overline{C}$ be the set of characters used in any string constants that appear in $G$ or in the assertion itself. It is the characters in $\overline{C}$ and the relations between the variables in $\overline{X}$ that are most relevant for proving the given property, and therefore these relations and characters should be preserved by the abstraction - the remaining variables and characters can be safely abstracted away without jeopardizing the verification. In choosing the alphabet abstraction, our heuristic keeps distinct all characters appearing in $C \subseteq \overline{C}$ and merges all remaining characters of the alphabet together into the special character $\star$. Initially, $C$ is the set of characters that appear in the assertion itself. $C$ can be iteratively refined by adding selected characters in $\overline{C}$. In choosing the relation abstraction, it is possible to simply group all variables in $\overline{X}$ together and track them relationally while tracking all other variables independently, but this choice might be more precise than necessary. Consider a hypothetical property $(X_1 =X_2 \land X_3 = X_4)$. It is not necessary to track the relations between $X_1$ and either of $X_3$ or $X_4$ (and similarly for $X_2$)---it is sufficient to track the relations between $X_1$ and $X_2$ and separately the relations between $X_2$ and $X_3$. Therefore our heuristic partitions $\overline{X}$ into distinct groups such that the variables within each group are tracked relationally with each other. To partition $\overline{X}$, our heuristic first groups together variables that appear in the same word equation in the property being verified (e.g., $X_1$ with $X_2$ and $X_3$ with $X_4$). The partition can be iteratively refined by using the dependency graph $G$ to merge groups containing variables that depend on each other. This heuristic can also be extended to take into account path sensitivity.
Contriobution
We show how string abstraction techniques that can be composed to form an abstraction lattice that subsumes the previous work on string analysis and size analysis. Our previous results, e.g., string analysis [YBCI08], composite (string+size) analysis [YBI09], and relational string analysis [YBI11] all become part of this abstraction lattice. This is the first such generalized string analysis result as far as we know. Other technical contributions include:
1. We propose string abstractions and formalize regular abstraction, alphabet abstraction and relation abastraction in string verification problems
2. We propose heuristics to select abstraction classes regarding programs and properties
3. We implement string abstractions with our string analysis tool and report the results against various public Web applications
V. Patcher Service
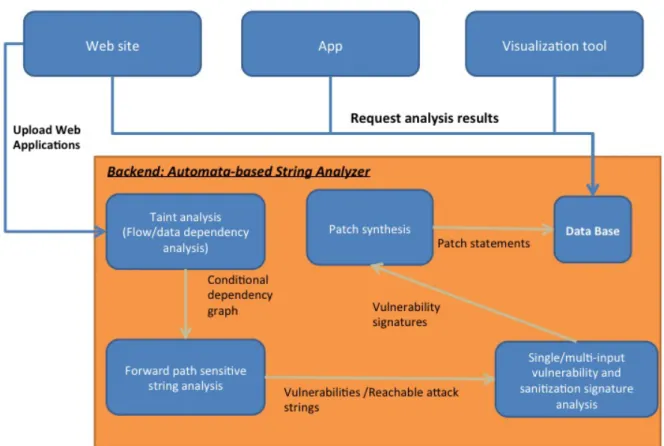
vulnerabilities. We incorporate the service with presented string analysis techniques. The service provides public users not only to check whether a web application is vulnerable to the types of attacks we discussed above, but also to generate the corresponding patches that ensure the applications free from malicious exploits of identified vulnerabilities. Users can access and upload their code to check potential vulnerabilities. Users can also insert patches that are automatically generated to prevent malicious exploits of their programs. While deploying new web services, it is essential to build the confidence on their security mechanisms. To the best of our knowledge, this is the first public online service that secures web applications using formal verification techniques. Another feature of Patcher is a user-friendly interface that aims at improving users’ comprehension on where the program vulnerabilities are and how they get exploited and patched. Particularly, we develop an interactive 3D interface/presentation for users to access and view the risk status of their applications and vulnerabilities. The service provides users a clear view of vulnerabilities of target applications and a quick fix to reduce their risks.
The architecture of Patcher is shown in Figure 2. Patcher can automatically analyze PHP programs from end-to-end without user interventions. We have also provided the web version of Patcher so that users can directly upload their code and view the results through the web pages. One can first write the script or upload a local file to Patcher. Patcher analyzes the script, detects potential vulnerability in the program, and generates its patches as the sanitization statement(s) with proper positions to insert. Developers can also upload a compressed file of the whole application as a package. Patcher will check all the execution entries of PHP scripts in the application automatically, and report and synthesize all vulnerabilities and their sanitization statements. Figure 2 also shows the front end of Patcher that includes an app for mobile devices, a web site for the web service, and a display device for 3D graphic visualization.
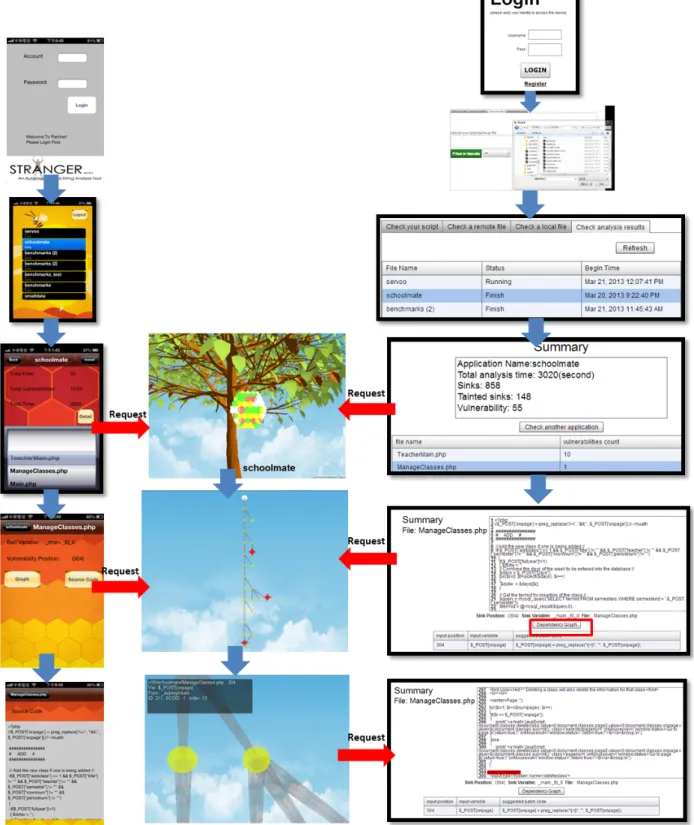
Figure 3. A Sample Execution Sequence of Patcher
Figure 3 shows a sample sequence of our web service in which we integrate our mobile device with the web service and visualization. First users can login and upload the application through the website, then view the analysis result from the mobile app or the website, and launch the visualization tool. When users choose an application from the list, the visualization tool shows the status graph (bee comb) of the application. Both the website and the app provide functions to view details of vulnerable files for users drilling down to exam vulnerabilities and their patches. By clicking a listed file, users can check its vulnerabilities and source code. For each vulnerability, users can click its Dependency Graph to generate the interactive dependency graphs to trace how values of input nodes flow to the sink node. To patch the
vulnerability, users can insert the corresponding patch code at the identified line to sanitize user inputs. Our main purpose of the design of Patcher is to enhance the comprehension about the vulnerability and the program execution of applications or files. We represent the result analysis in six levels as proposed in [Pacione 04]; each level provides analysis result of applications in different aspects.
• Level 0: In this code level representation, the source code and lines related to a specific vulnerability is presented. Users can insert the generated patches to prevent malicious exploits of vulnerabilities. • Level 1: In this exploit execution level representation, the simulation of a potential exploit on the
dependency graph is provided. Users can traverse how tainted data flows from user inputs to sensitive functions.
• Level 2: In the vulnerability structure level representation, an interactive dependency graph is presented with sink nodes, function nodes, and input nodes in different shapes. Users can check the dependency graph as a whole to reason the structure of the vulnerability.
• Level 3: In the file level representation, a list of vulnerabilities in a file is represented along with a brief summary on how many vulnerabilities exist for each kind. Each vulnerability also has a brief description on the variable, the sink location, the input location(s), etc. System developers can figure out what vulnerabilties exist in this file.
• Level 4: In the application level representation, a bee comb is used to show the risk status from the entire view of an application. Users can realize the security status overall by viewing the bee comb and choose most dangerous files to patch. A list of files with a brief summary on total number of vulnerabilities is also presented.
• Level 5: In the user level presentation, a list of applications that have been uploaded by the same user is presented along with a brief summary of status of each application.
Information in a large-scale view (higher level) gives users a clear view about high level components and the architecture. Information in a small-scale view that provides users detailed information from specific aspects. Our visualization tool provides browsing facilities to answer users’ questions that are generally broad at beginning and then narrow down to specific issues. That is to say, users check the vulnerable file in applications when vulnerability is reported and then drill down to examine the source code to reveal how the vulnerability is raised. Program visualization also requests data from various sources to display different views as the dimension changes. It improves the comprehension to provide information from different platforms.
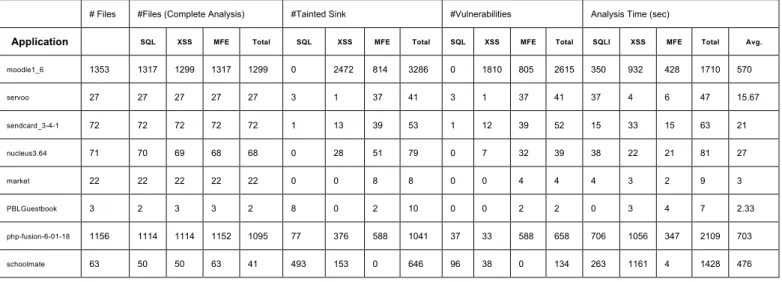
Finally, to evaluate our platform, we have uploaded various open source Web applications to Patcher. Table 1 summarizes the analysis results. There are ten applications that contain 3000+ files in total. 2800+ out of 3000+ PHP scripts have been analyzed successfully under 4000 seconds (1.3 second per file on average). The success rate is about 95%. Within these applications, Patcher reveals 2823 vulnerabilities. Most of them are previously unknown. The complete list can be found at
# Files #Files (Complete Analysis) #Tainted Sink #Vulnerabilities Analysis Time (sec)
Application SQL XSS MFE Total SQL XSS MFE Total SQL XSS MFE Total SQLI XSS MFE Total Avg.
moodle1_6 1353 1317 1299 1317 1299 0 2472 814 3286 0 1810 805 2615 350 932 428 1710 570 servoo 27 27 27 27 27 3 1 37 41 3 1 37 41 37 4 6 47 15.67 sendcard_3-4-1 72 72 72 72 72 1 13 39 53 1 12 39 52 15 33 15 63 21 nucleus3.64 71 70 69 68 68 0 28 51 79 0 7 32 39 38 22 21 81 27 market 22 22 22 22 22 0 0 8 8 0 0 4 4 4 3 2 9 3 PBLGuestbook 3 2 3 3 2 8 0 2 10 0 0 2 2 0 3 4 7 2.33 php-fusion-6-01-18 1156 1114 1114 1152 1095 77 376 588 1041 37 33 588 658 706 1056 347 2109 703 schoolmate 63 50 50 63 41 493 153 0 646 96 38 0 134 263 1161 4 1428 476
Table 1. The analysis results on public open-source applications
Contribution
To sum up, we provide a new service platform for patching and viewing web application vulnerabilities, combining advance static string analysis techniques as the back end and visualization techniques as the front end. We believe this service would certainly reduce the risks of Web applications and improve their security quality.
VI. Conclusion
We list several core techniques that are developed/used in this project. Intergrating these techniquees provides us a solid mechanism to strengthen the web application security in a sound and formal way.
1. A sound symbolic analysis technique [YABI13] for string verification that over-approximates the reachable states of a given string system using automata with a novel hierarchical abstraction framework [YBH11]
2. A novel algorithm for string analysis and pre- and post-image derivation of values of string operations [YABI13] using symbolic automata encoding with multi-terminal binary decision diagrams and efficient implementation of automata manipulations
3. A novel relational string analysis [YBI11] (meaning the analysis keeps track of relationships between string variables) based on multi-track automata. We have also investigated the boundary of decidability for the string verification problem.
4. A novel algorithm to generate effective patches of vulnerable web applications [YAB11] 5. Advance program comprehension and visualization [YY14]
6. An online public service for detecting, viewing and patching PHP web application vulnerabilities [YY14]
Web application vulnerabilities have been shown constantly threatening modern web applications in a decade. We have developed and shown how to detect and patch most severe vulnerabilities effectively with formal verification techniques. From the theoretical perspective, we contribute the study on automata theory, word equations, and string analysis. In practice, we address an important and unsolved security problem on web applications. We believe that parts of the presented techniques have great potential to be commercialized.
VII. References
[YT14] Fang Yu and Yi-Yang Tung. “Patcher: A New Online Service for Detecting, Viewing and Patching Web Application Vulnerabilities.” Accepted by the 47th Hawaii International Conference on System Sciences (HICSS 47). Big Island, U.S., Jan. 2014 [YABI13] Fang Yu, Muath Alkhalaf, Tevfik Bultan, Oscar H. Ibarra. “Automata-based Symbolic
String Analysis for Vulnerability Detection.” International Journal of Formal Methods in System Design, pp. 1-27, September 2013.
[HYHTLK11] Yao-Wen Huang, Fang Yu, Christian Hang, Chung-Hung Tsai, Der-Tsai Lee, Sy-Yen Kuo. “System and Method for Securing Web Application Code and Verifying Correctness of Software.” US Patent 7,779,399. Published in August 2011.
[YBI11] Fang Yu, Tevfik Bultan, Oscar H. Ibarra. “Relational String Verification Using Multi-track Automata.” International Journal of Foundations of Computer Science 22 (8), pp. 1909-1924, 2011.
[YBH11] Fang Yu, Tevfik Bultan, Ben Hardkopf. “String Abstractions for String Verification.” In Proceedings of the 18th International SPIN Workshop on Software Model Checking (SPIN 2011), Snowbird, Utah, U.S., July 2011.
[YAB11] Fang Yu, Muath Alkhalaf, Tevfik Bultan. “Patching Vulnerabilities with Sanitization Synthesis.” In Proceedings of the 33th International Conference on Software Engineering (ICSE 2011), Honolulu, U.S., May 2011.
[YAB10] Fang Yu, Muath Alkhalaf, Tevfik Bultan. “Stranger: An Automata-based String Analysis Tool for PHP.” Tool paper. In Proceedings of the 16th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS 2010), Paphos, Cyprus, March 2010.
[YAB09] Fang Yu, Muath Alkhalaf, Tevfik Bultan. “Generating Vulnerability Signatures for String Manipulating Programs Using Automata-based Forward and Backward Symbolic Analyses.” Short paper. In Proceedings of the 24th IEEE/ACM International Conference on Automated Software Engineering (ASE 2009), Auckland, NZ, November 2009.
[YBI09] Fang Yu, Tevfik Bultan, and Oscar H. Ibarra. "Symbolic String Verification: Combining String Analysis and Size Analysis," In Proceedings of the 15th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS 2009), York, U.K., March 2009.
[YBCI08] Fang Yu, Tevfik Bultan, Marco Cova, Oscar H. Ibarra. "Symbolic String Verification: An Automata-based Approach," In Proceedings of the 15th International SPIN Workshop on Model Checking of Software (SPIN 2008), Los Angeles, CA, August 2008.
[HYHTLK04b] Yao-Wen Huang, Fang Yu, Christian Hang, Chung-Hung Tsai, Der-Tsai Lee, Sy-Yen Kuo. "Verifying Web Applications Using Bounded Model Checking." In Proceedings of the 2004 International Conference on Dependable Systems and Networks (DSN 2004), pages 199-208, Florence, Italy, Jun 28-Jul 1, 2004.
[HYHTLK04a] Yao-Wen Huang, Fang Yu, Christian Hang, Chung-Hung Tsai, Der-Tsai Lee, Sy-Yen Kuo. "Securing Web Application Code by Static Analysis and Runtime Protection." In Proceedings of the 13th International World Wide Web Conference (WWW 2004), pages 40-52, New York, US, May 2004.
1
國科會補助專題研究計畫項下出席國際學術會議心得報
告
日期:2012 年 11 月 30 日計畫編號
NSC 99-2218-E-004-002-MY3
計畫名稱
符號式字串驗證
:對網路應用程式自動化弱點掃描與補正的正規方
法研究與工具開發
出國人員姓名
郁方
服務機構及職稱
國立政治大學資訊管理學系 助理教授會議時間
2012/11/17 至
2012/11/20
會議地點
美國舊金山
會議名稱
The 2012 Annual Meeting of Decision Sciences Institute (DSI)
發表論文題目 The Dual Approach for Decision Support
B y By Fang Yu Nov. 30, 2012 Department of Management Information Systems
2
Summary
This report summarizes my experience attending the 2012 annual meeting of
decision science institute (DSI) in San Francisco. DSI is recognized as one of the
most important annual event in decision science, management science, operating
research, and information systems, gathering lots of active faculties, researchers
and young scholars in the field. It also provides the placement service where many
recruiters of universities and companies with top management programs join and
provide on-site interview with fresh/qualified PhD students. There are three other
faculties from National Chengchi University attending DSI this year, including
Prof. Kwei Tang, the dean of the college of commerce, and Prof. Rua-Huan Tsaih
and Prof. Eldon Lee. Both are the distinguished professors in the MIS department.
According to the officer on the conference site, the number of registered
participants achieves around 1000 this year.
Objective
Our work “the dual approach for decision support” is accepted as a regular paper
and the oral presentation is scheduled in the track: Decision Making and Problem
Solving (MS/OR/Statistics). This is a joint work with Prof. Tsaih, the
distinguished professor in the MIS department, NCCU, and his PhD student,
Michell Huang. Prof. Tsaih presented the work. This work is about applying
advance neural network techniques to classify and detect fraudulent financial
reporting (FFR). The Growing Hierarchical Self-Organizing Map (GHSOM) is
extended from the Self-Organizing Map (SOM) with the unsupervised learning
nature. This study pioneers a novel dual GHSOM approach for classification and
decision support in detecting the fraudulent financial reporting. With the same
training parameters, the proposed dual GHSOM approach uses fraud samples and
non-fraud samples to train two GHSOMs, respectively. Featuring the counterpart
relationship amongst subgroups of this pair of dual GHSOMs, the proposed
approach is able to examine the spatial relationship among high-dimensional
inputs. Taking advantage of the identified spatial relationship and the extracted
patterns/features from each subgroup, the proposed approach provides an effective
expert-competitive decision support in identifying suspicious samples and
3
pinpointing their potential fraud behaviors for further investigation.
Talks
Most decision making is superficial. I was surprised to hear the comment in the
first keynote. In Prof. Liker’s keynote speech, he mentioned the famous book
thinking fast and slow, and discussed the following two different systems.
Sys1-Fast thinking: jump to conclusions and react to immediate associations, and
Sys2- Slow thinking: take time to reflect and collect more information if needed.
Toyota maintains a disciplined approach to developing slow thinking. Capable
people and teams can be aligned to strategy, which is the key point for becoming a
learning organization. On the other hand, he suggested us that “don’t jump to
solutions when you don’t fully understand the question.” When you understand the
question, jump and discover ideas.
In the Monday morning session, researchers discuss more depth in the study of
supply relationship. The theme is how to connect supply chains to those in the
informal economy. The idea is to explore creative methods to improve efficiencies
in emerging market supply chain activities, particularly for sustainable operation.
There are also other concerns: moral and ethic considerations, sustainability
idiosyncrasies, and mix of evaluative judgments, and legitimacy judgment
outcomes. As for an innovation internalization process, it is rather important to
discover a model, its management process, and its judgment process.
4
In another talk about Green IT, the term is defined as meeting the needs of present
generation without compromising the ability of future generation. The idea is to
maximize energy efficiency and decrease energy use, particularly for those
emerging ICT enabled services where green and information technology has been
widely adopted. It is essential to deal with environment pollution and energy
resource consumption. Two issues are discussed: (1) Greening IT such as power
management, cloud computing, data center reconfiguration, energy-efficient
cooling, and (2) Greening by IT such as monitoring energy usage, smart building,
smart power grid, process optimization. By addressing these issues, it is possible
to achieve lower pollution and transportation. Actually, IT already contributes
CO2 emission reduction, possibly to 25% reduction by 2020 if using all the IT
techs. Large organizations and companies also get involved such as Microsoft,
Cisco, US government, Emerging Contexts.
Prof. Jack Meredith discusses journal publications in his keynote. He is the chief
editor of the journal of operation management. The main issue is to bridging the
research practice gap. Particularly, he listed the rank of operation journals: MS,
Haverd Business Review, JOM, DS, IJOPM, IJPR, SMR, OR, AMR, SMJ, PM,
POM, AMJ, CMR, ASO, INT, EJOR, IE, IIET. From his point of view, a
successful draft should consist of importance, accessibility, suitability, practical
interests. It is worth to mention that he points out what kinds of idea is interesting.
I listed as below: denies our assumption, exogenous to endogenous, complex to
simple, small effect to large, and improve performance to actually harm it.
Suggestions
The work presented in this paper can be extended to software. One extension could
be malware analysis behavior characterization.
Documents
- 2012 Annual Meeting Program
- Proceeding in DVD: contains detailed information of the conference and the full
paper of each presentation
1
出國報告(出國類別:會議論文發表)
IEEE 2013 世界服務大會出國報告
IEEE 2013 World Congress on Services
The 9
thInternational Conference on Service Computing and The 2
ndInternational Conference on Mobile Services
Joint with International Conference on Cloud Computing/
International Conference on Web Services/International Conference
on Big Data
服務機關:資訊管理系
姓名職稱:郁方 助理教授
派赴國家:美國
出國期間:June 25-July 3
報告日期:August 25
2
出國成果報告書(格式)
計畫編號
1執行單位
2出國人員
郁方
出國日期
102 年 6 月 25
日 至
102 年
7 月 3 日,共
9 日
報告內容摘要(請以 200 字~300 字說明) 本次出國參加國際電子電機協會主辦的IEEE世界服務大會,主要目的是分別 在第九屆IEEE服務計算國際研討會議與第二屆IEEE行動服務國際 研討會議口頭發表最新研究成果,與與會者交流並汲取相關研究經驗與意見 作為日後研究改進之參考。本次世界服務大會包含五個國際會議除前述二者 尚有IEEE雲端運算國際研討會議,IEEE巨量資料國際研討會議以及 IEEE網站服務國際研討會議,與多個場次 Keynote 演講與 Panel 討論, 針 對目前服務科學與系統的研究主流在理論與實務上的發展作廣泛的探討. 尤以巨量資料的處理困難與未來挑戰琢磨甚深.一千多名與會者來自世界各地研究機構與頂尖大學如NSTC, IBM T. J. Watson, Lawrence Berkeley Lab, HP Lab, Stanford, MIT, UW, UM, UCSB, KAIST, U. Singapore 等.
(本文3)
目的
本次出國參加國際電子電機協會主辦的IEEE世界服務大會,主要目的是分別 在第九屆IEEE服務計算國際研討會議與第二屆IEEE行動服務國際 研討會議口頭發表最新研究成果,與與會者交流並汲取相關研究經驗與意見 作為日後研究改進之參考。過程
本次世界服務大會包含五個國際會議除前述二者尚有IEEE雲端運算國際研 討會議,IEEE巨量資料國際研討會議以及IEEE網站服務國際研討會 議,與多個場次 Keynote 演講與 Panel 討論, 針對目前服務科學與系統的研究 主流在理論與實務上的發展作廣泛的探討. 尤以巨量資料的處理困難與未 來挑戰琢磨甚深.一千多名與會者來自世界各地研究機構與頂尖大學如 NSTC, IBM T. J. Watson, Lawrence Berkeley Lab, HP Lab, Stanford, MIT,UW, UM, UCSB, KAIST, U. Singapore 等.
1 單位出國案如有 1 案以上,計畫編號請以頂大計畫辦公室核給之單位計畫編號 + 「-XX(單位自編 2
位數出國案序號)」型式為之。如僅有1 案,則以頂大計畫單位編號為之即可。
2 執行單位係指頂大計畫單位編號對應之單位。
3 本人首場發表的論文主題在多媒體串流服務的數量分析,尤針對雲端服務的線上 遊戲頻道與影音頻道以排隊理論為基礎推導出服務品質與資源配置的關係 公式, 透過模擬的方式呈現多個顧客滿意度指標作為系統開發者與決策者 設置系統的依據。本次演講獲得參與者廣大回響,尤對我們引用 80 年代的立 論至當今的雲端服務印象深刻。回餽意見如傳輸偏移的分佈也將納入作為日 後修改期刊論文的參考。本文是發表在服務計算國際會議的研究論文。
4 本人也在行動服務國際會議上發表另一篇應用導向的論文。當行動應用程式充斥 生活之中, 對其真實行為進行正規與系統性的分析變得格外重要。在本次的發表 論文中我們提出以靜態二元分析技術對行動應用程式碼進行行為分析與特徵 化。運用分析工具與反轉工程技術,重建行動應用程式的原碼特徵。蒐集與分析 惡意程式的行為特徵,針對外部/使用者開發的行動應用程式,偵測其可能包含 的惡意行為,從而預防濳藏的隱私洩露與後門攻擊。技術面運用雲端架構達成分 散式字元分析並運用統計與人工智慧進行應用程式分類與特徵萃取。我們也開發 出一自動化分析行動程式工具。
5
會後與會者有諸多討論. 歷屆 IEEE Service Society 的主席進行合影。
感想與建議
本次與系上資深教授蔡老師同行,收獲頗豐。同住期間有多次對研究領域密集的 討論交換意見,對日後撰寫論文有顯著助益。會議期間也遇到多位不論是資 深或新進的研究學者, 也能對各個不同領域的研究有所涉獵。尤其與同是台 灣來的黃老師討論多媒體加解密的問題,對本人在故宮影音頻道的運用與資 安技術研發有所啓發。6
在Santa Clara 的陽光加州午後, 感覺思路清晰。
對於未來的研究建議,可以看出雲端運算還回流行好一陣子,其上的相關議題不
僅有研究的價值,在實務應用上更有其實質的影響。而當雲端運算普及,背後所 衍生的管理議題,安全議題也將被廣泛討論。
國科會補助計畫衍生研發成果推廣資料表
日期:2013/10/30國科會補助計畫
計畫名稱: 符號式字串驗證:對網路應用程式自動化弱點掃描與補正的正規方法研究與工 具開發 計畫主持人: 郁方 計畫編號: 99-2218-E-004-002-MY3 學門領域: 程式語言與軟體工程無研發成果推廣資料
99 年度專題研究計畫研究成果彙整表
計畫主持人:郁方 計畫編號:99-2218-E-004-002-MY3 計畫名稱:符號式字串驗證:對網路應用程式自動化弱點掃描與補正的正規方法研究與工具開發 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 0 0 100% 篇 論文著作 專書 0 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 2 2 100% We have published two journal papers: one in IJFCS (SCI) and theother in FMSD(SCI) 研究報告/技術報告 0 0 100% 研討會論文 6 6 100% 篇 Within the support period, we have published 6 conference papers: including ICSE 2011 (ranked top 1 in software engineering), SPIN 2011, LETCS 2012, DSI 2012, SCC 2013 and MS 2013. 論文著作 專書 0 0 100% 章/本 國外 專利 申請中件數 0 0 100% 件
已獲得件數 0 0 100% 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 3 3 100% 博士生 0 0 100% 博士後研究員 0 0 100% 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次 其他成果