CHAPTER FOUR RESULTS AND DISCUSSION
This chapter is comprised of two major parts. The first part will present readers with the results of the study and the second part will be the discussion of the results.
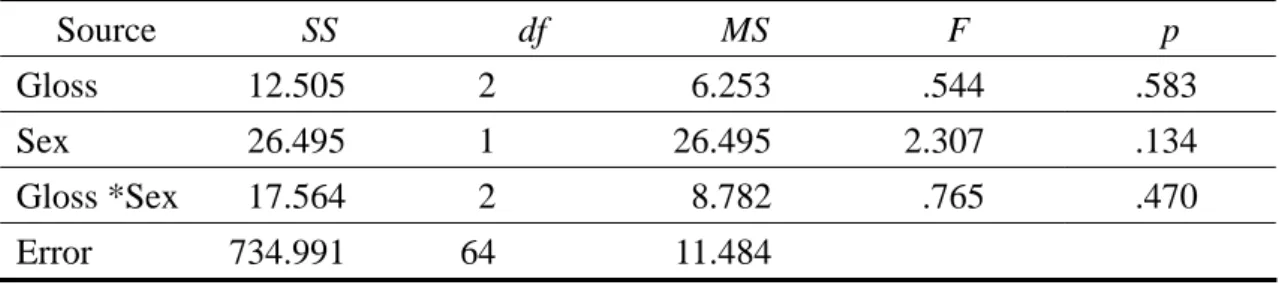
Section 4.1.1 presents students’ overall test scores. Analyses of Variance were used to detect the interaction effects between Sex and Gloss Types and the main effects of Gloss Types. The purpose is to see whether students having access to visual glosses (graphics and animation) had a better performance than those without. In section 4.1.2, students’ vocabulary gain and retention will be presented. Section 4.1.3 examines the effect of test types: production tests and recognition tests.
In the second part of the chapter, readers will be first presented with the discussion of the effects of sex and test types. Then, section 4.2.2 and section 4.2.3 will provide explanations to the results in relation to the two research questions of this study. Finally, students’ feedback on the questionnaires will be presented in section 4.2.4.
4.1 Results
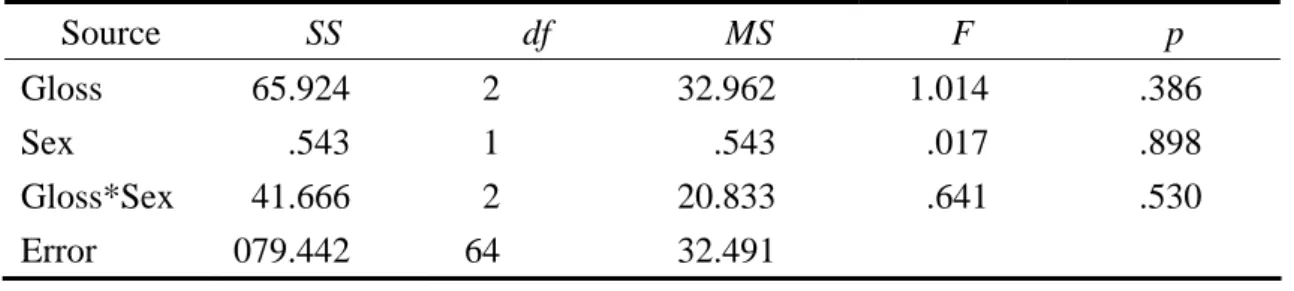
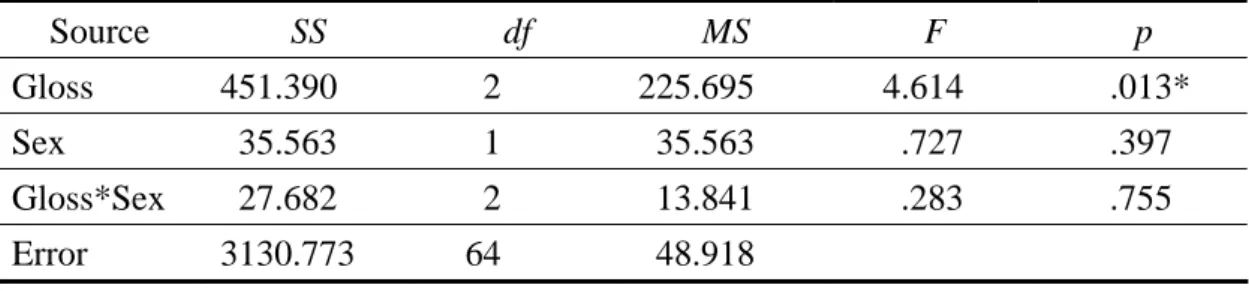
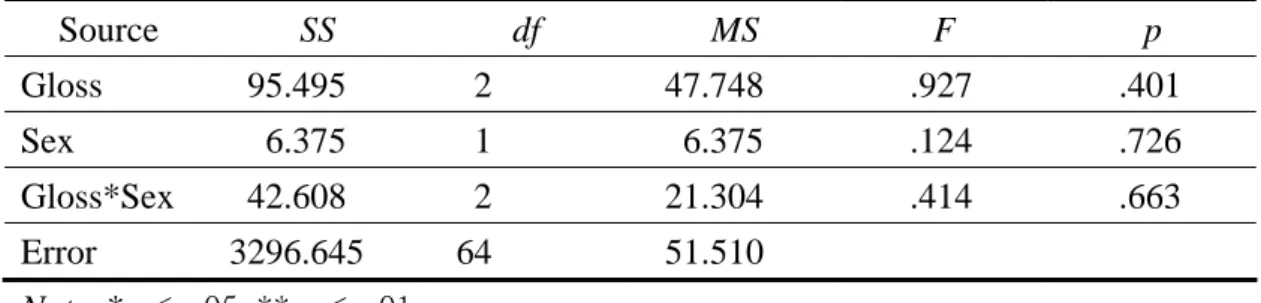
In order to see the overall patterns of gloss type effects, students’ vocabulary test scores before, immediate after and two weeks after the treatment were first analyzed by descriptive statistics and two-way ANOVA using a 3×2 factorial design.
Next, vocabulary gain and vocabulary retention were computed and also analyzed by two-way ANOVA. Finally, production test scores and recognition test scores were examined respectively.
4.1.1 The Results of Pretest, Immediate Posttest, and Delayed Posttest
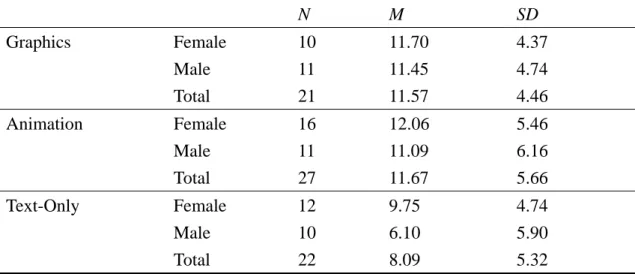
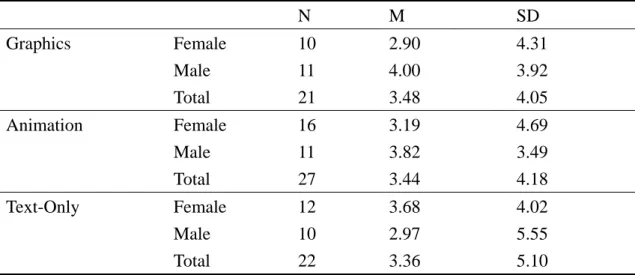
The mean scores and standard deviation of the three groups on pretest,
immediate posttest, and on the delayed posttest are shown in Table 4-1. The three
kinds of tests all included 20 points on production tests and 20 points on recognition
tests, totaling 40 points.
For immediate posttest results, the mean score of Graphics Group is the highest while the mean score of Text-only Group is the lowest. As to the sex differences, the female students in Animation Group did better than those in Graphics Group.
For delayed posttest results, the Graphics Group got the highest mean score and the Text-only Group got the lowest. Female students in Animation Group still did better than those in Graphics Group, of which pattern is the same as in immediate posttest results.
The female students in Animation Group also got higher scores than those in
Graphics Group on recognition test of immediate posttest and on production test of
delayed posttest.
Table 4- 1 Descriptive Statistics of Pretest, Immediate Posttest, and Delayed Posttest Results of Graphics, Animation, and Text-Only Groups
Note.
1. G+T= graphics + text gloss; A+T= animation + text gloss; T= text-only gloss.
2. F= female; M= male; T= total.
Pretest Immediate Posttest Delayed Posttest
Production Recognition Total Production Recognition Total Production Recognition Total
N M SD M SD M SD M SD M SD M SD M SD M SD M SD G+T F
M T
10 11 21
1.80 1.91 1.86
1.81 2.34 2.06
11.60 12.00 11.81
3.50 3.80 3.57
13.40 13.91 13.67
4.88 5.65 5.17
8.70 9.18 8.95
3.30 4.42 3.84
16.40 16.18 16.29
2.95 3.55 3.20
25.10 25.36 25.24
5.04 7.30 6.17
3.80 4.45 4.14
2.66 3.39 3.01
12.50 13.45 13.00
3.72 5.72 4.78
16.30 17.91 17.14
6.04 8.08 7.05 A+T F
M T
16 11 27
1.88 1.82 1.85
1.82 2.18 1.94
11.31 9.55 10.59
4.70 4.25 4.53
13.19 11.36 12.44
6.24 6.33 6.22
8.50 7.91 8.26
4.62 5.82 5.04
16.75 14.55 15.85
3.86 4.82 4.33
25.25 22.45 24.11
8.05 9.67 8.68
4.06 3.82 3.96
2.96 2.52 2.74
12.31 11.36 11.93
5.74 5.16 5.43
16.38 15.18 15.89
8.35 7.59 7.92 T F
M T
12 10 22
1.00 2.00 1.45
1.28 2.45 1.92
4.26 3.83 9.25
10.10 9.64
3.75 3.76 3.69
10.25 12.10 11.09
4.81 5.84 5.26
5.17 5.20 5.18
2.37 3.62 2.92
14.83 13.00 14.00
4.00 3.71 3.89
20.00 18.20 19.18
4.73 4.89 4.78
3.42 3.30 3.36
2.28 2.06 2.13
11.83 9.70 10.86 4.12
15.25 13.00 14.23
6.31 5.33 5.86