SQL 语法参考
文档版本 01
发布日期 2021-06-16
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
华为技术有限公司
地址: 深圳市龙岗区坂田华为总部办公楼 邮编:518129
网址:
https://www.huawei.com
客户服务邮箱:
[email protected]
客户服务电话:4008302118目 录
1 批作业 SQL 语法...1
1.1 批作业 SQL 常用配置项说明... 1
1.2 批作业 SQL 语法概览... 2
1.3 数据库... 4
1.3.1 创建数据库... 4
1.3.2 删除数据库... 5
1.3.3 查看指定数据库... 6
1.3.4 查看所有数据库... 7
1.4 创建 OBS 表... 7
1.4.1 使用 DataSource 语法创建 OBS 表...7
1.4.2 使用 Hive 语法创建 OBS 表... 10
1.5 创建 DLI 表... 13
1.5.1 使用 DataSource 语法创建 DLI 表... 13
1.5.2 使用 Hive 语法创建 DLI 表... 15
1.6 删除表...17
1.7 查看表...18
1.7.1 查看所有表... 18
1.7.2 查看建表语句... 19
1.7.3 查看表属性... 20
1.7.4 查看指定表所有列... 20
1.7.5 查看指定表所有分区... 21
1.7.6 查看表统计信息...22
1.8 修改表...23
1.8.1 添加列... 23
1.8.2 开启或关闭数据多版本...24
1.9 分区表相关... 25
1.9.1 添加分区(只支持 OBS 表)... 25
1.9.2 重命名分区... 27
1.9.3 删除分区... 28
1.9.4 指定筛选条件删除分区...29
1.9.5 修改表分区位置(只支持 OBS 表)... 30
1.9.6 修改表分区 SerDe 属性(只支持 OBS 表)... 31
1.9.7 更新表分区信息(只支持 OBS 表)... 32
1.9.8 REFRESH TABLE 刷新表元数据...33
1.10 导入数据... 33
1.11 插入数据... 37
1.12 清空数据... 39
1.13 导出查询结果... 40
1.14 多版本备份恢复数据... 41
1.14.1 设置多版本备份数据保留周期... 41
1.14.2 查看多版本备份数据...42
1.14.3 恢复多版本备份数据...43
1.14.4 配置多版本过期数据回收站...44
1.14.5 清理多版本数据... 45
1.15 跨源连接 HBase 表... 46
1.15.1 创建 DLI 表关联 HBase...46
1.15.2 插入数据至 HBase 表... 48
1.15.3 查询 HBase 表... 49
1.16 跨源连接 OpenTSDB 表... 51
1.16.1 创建 DLI 表关联 OpenTSDB... 51
1.16.2 插入数据至 OpenTSDB 表... 52
1.16.3 查询 OpenTSDB 表... 53
1.17 跨源连接 DWS 表...54
1.17.1 创建 DLI 表关联 DWS... 54
1.17.2 插入数据至 DWS 表... 56
1.17.3 查询 DWS 表... 57
1.18 跨源连接 RDS 表... 57
1.18.1 创建 DLI 表关联 RDS... 57
1.18.2 插入数据至 RDS 表... 60
1.18.3 查询 RDS 表... 61
1.19 跨源连接 CSS 表... 62
1.19.1 创建 DLI 表关联 CSS... 62
1.19.2 插入数据至 CSS 表... 63
1.19.3 查询 CSS 表... 65
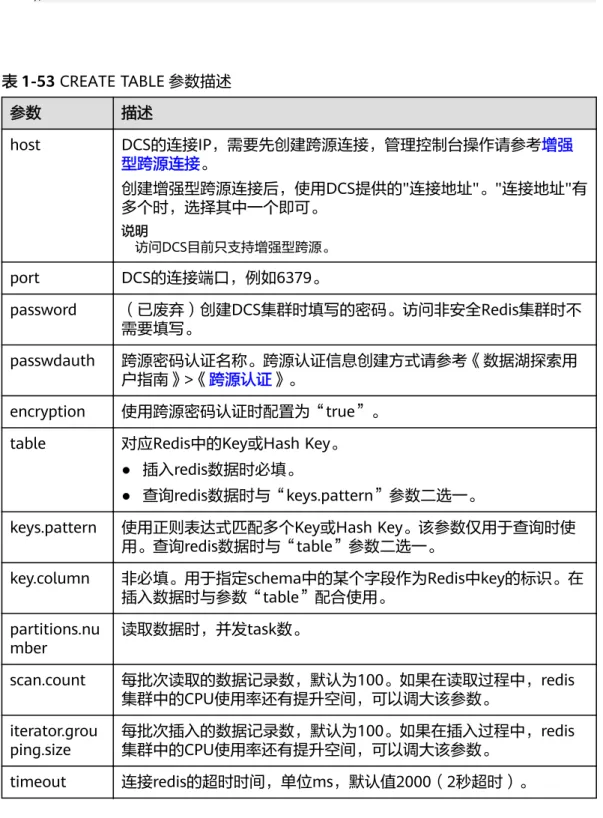
1.20 跨源连接 DCS 表... 65
1.20.1 创建 DLI 表关联 DCS... 65
1.20.2 插入数据至 DCS 表... 67
1.20.3 查询 DCS 表... 69
1.21 跨源连接 DDS 表...69
1.21.1 创建 DLI 表关联 DDS...69
1.21.2 插入数据至 DDS 表... 71
1.21.3 查询 DDS 表... 72
1.22 视图... 72
1.22.1 创建视图... 73
1.22.2 删除视图... 73
1.23 查看计划... 74
1.24 数据权限管理... 74
1.24.1 数据权限列表...74
1.24.2 创建角色... 77
1.24.3 删除角色... 77
1.24.4 绑定角色... 78
1.24.5 解绑角色... 78
1.24.6 显示角色... 78
1.24.7 分配权限... 79
1.24.8 回收权限... 80
1.24.9 显示已授权限...81
1.24.10 显示所有角色和用户的绑定关系...82
1.25 数据类型... 82
1.25.1 概述... 82
1.25.2 原生数据类型...82
1.25.3 复杂数据类型...86
1.26 自定义函数... 88
1.26.1 创建函数... 88
1.26.2 删除函数... 89
1.26.3 显示函数详情...89
1.26.4 显示所有函数...90
1.27 内置函数... 91
1.27.1 数学函数... 91
1.27.2 日期函数... 94
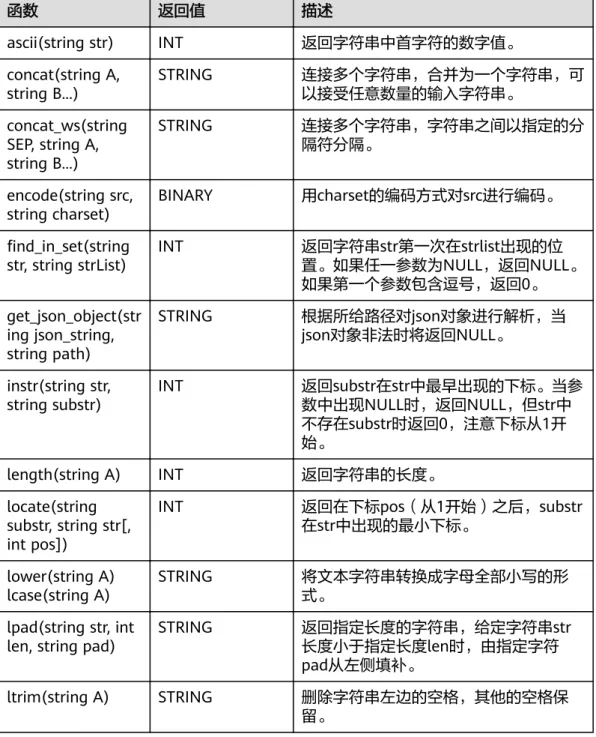
1.27.3 字符串函数... 95
1.27.4 聚合函数... 98
1.27.5 分析窗口函数...99
1.28 SELECT 基本语句... 100
1.29 过滤 SELECT...101
1.29.1 WHERE 过滤子句... 101
1.29.2 HAVING 过滤子句... 102
1.30 排序 SELECT...102
1.30.1 ORDER BY...102
1.30.2 SORT BY... 103
1.30.3 CLUSTER BY... 104
1.30.4 DISTRIBUTE BY... 104
1.31 分组 SELECT...105
1.31.1 按列 GROUP BY... 105
1.31.2 用表达式 GROUP BY...105
1.31.3 GROUP BY 中使用 HAVING 过滤...106
1.31.4 ROLLUP... 106
1.31.5 GROUPING SETS... 107
1.32 连接操作 SELECT... 108
1.32.1 内连接... 108
1.32.2 左外连接... 109
1.32.3 右外连接... 109
1.32.4 全外连接... 110
1.32.5 隐式连接... 110
1.32.6 笛卡尔连接...111
1.32.7 左半连接... 111
1.32.8 不等值连接...112
1.33 子查询...112
1.33.1 WHERE 嵌套子查询...113
1.33.2 FROM 子句嵌套子查询... 113
1.33.3 HAVING 子句嵌套子查询... 114
1.33.4 多层嵌套子查询... 114
1.34 别名 SELECT...115
1.34.1 表别名... 115
1.34.2 列别名... 116
1.35 集合运算 SELECT... 116
1.35.1 UNION... 116
1.35.2 INTERSECT...117
1.35.3 EXCEPT... 117
1.36 WITH...AS... 118
1.37 CASE...WHEN... 118
1.37.1 简单 CASE 函数...118
1.37.2 CASE 搜索函数...119
1.38 OVER 子句... 120
2 流作业 SQL 语法... 122
2.1 SQL 语法约束与定义...122
2.2 流作业 SQL 语法概览...123
2.3 创建输入流... 124
2.3.1 CloudTable HBase 输入流... 124
2.3.2 DIS 输入流... 126
2.3.3 DMS 输入流... 131
2.3.4 EdgeHub 输入流...131
2.3.5 MRS Kafka 输入流... 132
2.3.6 开源 Kafka 输入流...136
2.3.7 OBS 输入流... 139
2.4 创建输出流... 142
2.4.1 CloudTable HBase 输出流... 142
2.4.2 CloudTable OpenTSDB 输出流... 144
2.4.3 MRS OpenTSDB 输出流... 146
2.4.4 CSS Elasticsearch 输出流... 147
2.4.5 DCS 输出流... 149
2.4.6 DDS 输出流... 151
2.4.7 DIS 输出流... 153
2.4.8 DMS 输出流... 155
2.4.9 DWS 输出流(通过 JDBC 方式)... 155
2.4.10 DWS 输出流(通过 OBS 转储方式)... 158
2.4.11 EdgeHub 输出流... 160
2.4.12 MRS HBase 输出流... 162
2.4.13 MRS Kafka 输出流...164
2.4.14 开源 Kafka 输出流... 166
2.4.15 文件系统输出流(推荐)... 168
2.4.16 OBS 输出流... 171
2.4.17 RDS 输出流... 174
2.4.18 SMN 输出流...177
2.5 创建中间流... 178
2.6 创建维表... 178
2.6.1 创建 Redis 表... 178
2.6.2 创建 RDS 表... 180
2.7 自拓展生态... 182
2.7.1 自拓展输入流...182
2.7.2 自拓展输出流...183
2.8 数据类型... 185
2.9 内置函数... 189
2.9.1 数学运算函数...189
2.9.2 字符串函数... 193
2.9.3 时间函数... 206
2.9.4 类型转换函数...209
2.9.5 聚合函数... 212
2.9.6 表值函数... 216
2.9.7 其他函数... 217
2.10 自定义函数... 217
2.11 地理函数... 221
2.12 SELECT... 227
2.13 条件表达式... 231
2.14 窗口... 232
2.15 流表 JOIN... 234
2.16 配置时间模型...236
2.17 CEP 模式匹配... 238
2.18 StreamingML... 242
2.18.1 异常检测... 242
2.18.2 时间序列预测... 243
2.18.3 实时聚类... 245
2.18.4 深度学习模型预测...246
2.19 保留关键字... 247
3 标示符... 267
3.1 aggregate_func...267
3.2 alias... 267
3.3 attr_expr... 268
3.4 attr_expr_list... 269
3.5 attrs_value_set_expr... 269
3.6 boolean_expression...270
3.7 col... 270
3.8 col_comment...270
3.9 col_name... 270
3.10 col_name_list... 271
3.11 condition... 272
3.12 condition_list...274
3.13 cte_name...274
3.14 data_type... 275
3.15 db_comment... 275
3.16 db_name...275
3.17 else_result_expression...275
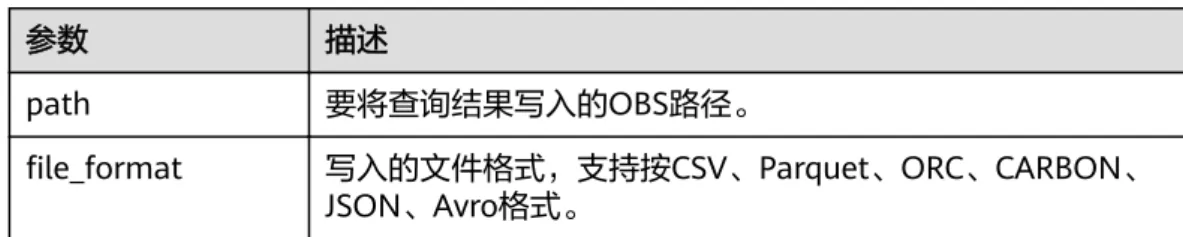
3.18 file_format... 275
3.19 file_path...276
3.20 function_name... 276
3.21 groupby_expression... 276
3.22 having_condition... 277
3.23 input_expression... 278
3.24 join_condition... 279
3.25 non_equi_join_condition... 280
3.26 number... 280
3.27 partition_col_name... 280
3.28 partition_col_value...281
3.29 partition_specs... 281
3.30 property_name... 281
3.31 property_value... 281
3.32 regex_expression... 282
3.33 result_expression... 282
3.34 select_statement...282
3.35 separator... 282
3.36 sql_containing_cte_name... 282
3.37 sub_query...283
3.38 table_comment... 283
3.39 table_name...283
3.40 table_properties... 283
3.41 table_reference...284
3.42 when_expression... 284
3.43 where_condition... 284
3.44 window_function... 285
4 运算符... 286
4.1 关系运算符... 286
4.2 算术运算符... 287
4.3 逻辑运算符... 288
1 批作业 SQL 语法
1.1 批作业 SQL 常用配置项说明
本章节为您介绍DLI 批作业SQL语法的常用配置项。
表1-1 常用配置项
名称 默认值 描述
spark.sql.files.maxR
ecordsPerFile 0 要写入单个文件的最大记录数。如果该值为 零或为负,则没有限制。
spark.sql.autoBroad
castJoinThreshold 209715200 配置执行连接时显示所有工作节点的表的最 大字节大小。通过将此值设置为“-1”,可 以禁用显示。
说明当前仅支持运行命令ANALYZE TABLE COMPUTE statistics noscan的配置单元元存储表,和直接根 据数据文件计算统计信息的基于文件的数据源 表。
spark.sql.shuffle.par
titions 200 为连接或聚合过滤数据时使用的默认分区 数。
spark.sql.dynamicP artitionOverwrite.e nabled
false 在动态模式下,Spark不会删除前面的分区,
只覆盖那些运行时没有写入数据的分区。
spark.sql.files.maxP
artitionBytes 134217728 读取文件时要打包到单个分区中的最大字节 数。
spark.sql.badRecord
sPath - Bad Records的路径。
1.2 批作业 SQL 语法概览
本章节介绍了目前DLI所提供的Spark SQL语法列表。参数说明,示例等详细信息请参 考具体的语法说明。
表1-2 批作业 SQL 语法
语法分类 功能描述
数据库相关语法
创建数据库
删除数据库 查看指定数据库 查看所有数据库
创建OBS表相关语法
使用DataSource语法创建OBS表 使用Hive语法创建OBS表
创建DLI表相关语法
使用DataSource语法创建DLI表 使用Hive语法创建DLI表
删除表相关语法
删除表
查看表相关语法
查看所有表
查看建表语句 查看表属性 查看指定表所有列 查看指定表所有分区 查看表统计信息
修改表相关语法
添加列
分区表相关语法
添加分区(只支持OBS表)
重命名分区 删除分区
修改表分区位置(只支持OBS表)
修改表分区SerDe属性(只支持OBS表)
更新表分区信息(只支持OBS表)
导入数据相关语法
导入数据
插入数据相关语法
插入数据
清空数据相关语法
清空数据
语法分类 功能描述 导出查询结果相关语法
导出查询结果
跨源连接HBase表相关语法创建表关联HBase
插入数据至HBase表 查询HBase表
跨源连接OpenTSDB表相关语法
创建表关联OpenTSDB
插入数据至OpenTSDB 查询OpenTSDB表
跨源连接DWS表相关语法创建表关联DWS
插入数据至DWS表 查询DWS表
跨源连接RDS表相关语法创建表关联RDS
插入数据至RDS表 查询RDS表
跨源连接CSS表相关语法创建表关联CSS
插入数据至CSS表 查询CSS表
跨源连接DCS表相关语法创建表关联DCS
插入数据至DCS表 查询DCS表
跨源连接DDS表相关语法创建表关联DDS
插入数据至DDS表 查询DDS表
视图相关语法
创建视图
删除视图
查看计划相关语法
查看计划
数据权限相关语法
创建角色
删除角色
绑定角色
解绑角色
显示角色
语法分类 功能描述
分配权限 回收权限 显示已授权限
显示所有角色和用户的绑定关系
自定义函数相关语法
创建函数
删除函数 显示函数详情 显示所有函数
数据多版本相关语法
创建OBS表时开启数据多版本 修改表时开启或关闭数据多版本 设置多版本备份数据保留周期 查看多版本备份数据
恢复多版本备份数据 配置多版本过期数据回收站 清理多版本数据
1.3 数据库
1.3.1 创建数据库
功能描述
创建数据库。
语法格式
CREATE [DATABASE | SCHEMA] [IF NOT EXISTS] db_name [COMMENT db_comment]
[WITH DBPROPERTIES (property_name=property_value, ...)];
关键字
● IF NOT EXISTS:所需创建的数据库已存在时使用,可避免系统报错。
● COMMENT:对数据库的描述。
● DBPROPERTIES:数据库的属性,且属性名和属性值成对出现。
参数说明
表1-3 参数说明
参数 描述
db_name 数据库名称,由字母、数字和下划线(_)组成。不能是纯数字,
且不能以数字和下划线开头。
db_comment 数据库描述。
property_name 数据库属性名。
property_value 数据库属性值。
注意事项
● DATABASE与SCHEMA两者没有区别,可替换使用,建议使用DATABASE。
● “default”为内置数据库,不能创建名为“default”的数据库。
示例
说明
完整的SQL作业提交流程您可以参考《用户指南》中的《提交SQL作业》等章节描述。
1. 队列是使用DLI服务的基础,执行SQL前需要先创建队列。具体可以参考《用户指 南》中的“创建队列”章节。
2. 在DLI管理控制台,单击左侧导航栏中的“SQL编辑器”,可进入SQL作业“SQL 编辑器”页面。
3. 在“SQL编辑器”页面右侧的编辑窗口中,输入如下创建数据库的SQL语句,单击
“执行”。阅读并同意隐私协议,单击“确定”。
若testdb数据库不存在,则创建数据库testdb。
CREATE DATABASE IF NOT EXISTS testdb;
1.3.2 删除数据库
功能描述
删除数据库。
语法格式
DROP [DATABASE | SCHEMA] [IF EXISTS] db_name [RESTRICT|CASCADE];
关键字
IF EXISTS:所需删除的数据库不存在时使用,可避免系统报错。
注意事项
● DATABASE与SCHEMA两者没有区别,可替换使用,建议使用DATABASE。
● RESTRICT表示如果该database不为空(有表存在),DROP操作会报错,执行失 败,RESTRICT是默认逻辑。
● CASCADE表示即使该database不为空(有表存在),DROP也会级联删除下面的 所有表,需要谨慎使用该功能。
参数说明
表1-4 参数说明
参数 描述
db_name 数据库名称,由字母、数字和下划线(_)组成。不能是纯数字,
且不能以数字和下划线开头。
示例
1. 已参考示例中描述创建对应的数据库,如testdb。
2. 若存在testdb数据库,则删除数据库testdb。
DROP DATABASE IF EXISTS testdb;
1.3.3 查看指定数据库
功能描述
查看指定数据库的相关信息,包括数据库名称、数据库的描述等。
语法格式
DESCRIBE DATABASE [EXTENDED] db_name;
关键字
EXTENDED:除了显示上述信息外,还会额外显示数据库的属性信息。
参数说明
表1-5 参数说明
参数 描述
db_name 数据库名称,由字母、数字和下划线(_)组成。不能是纯数字,
且不能以数字和下划线开头。
注意事项
如果所要查看的数据库不存在,则系统报错。
示例
1. 已参考示例中描述创建对应的数据库,如testdb。
2. 查看testdb数据库的相关信息。
DESCRIBE DATABASE testdb;
1.3.4 查看所有数据库
功能描述
查看当前工程下所有的数据库。
语法格式
SHOW [DATABASES | SCHEMAS] [LIKE regex_expression];
关键字
无。
参数说明
表1-6 参数说明
参数 描述
regex_expressi
on 数据库名称。
注意事项
DATABASES与SCHEMAS是等效的,都将返回所有的数据库名称。
示例
查看当前的所有数据库。
SHOW DATABASES;
查看当前的所有以test开头的数据库。
SHOW DATABASES LIKE "test.*";
1.4 创建 OBS 表
1.4.1 使用 DataSource 语法创建 OBS 表
功能描述
使用DataSource语法创建OBS表。DataSource语法和Hive语法主要区别在于支持的表 数据存储格式范围、支持的分区数等有差异,详细请参考语法格式和注意事项说明。
语法格式
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING file_format
[OPTIONS (path 'obs_path', key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[COMMENT table_comment]
[AS select_statement];
关键字
● IF NOT EXISTS:指定该关键字以避免表已经存在时报错。
● USING:指定存储格式。
● OPTIONS:指定建表时的属性名与属性值。
● COMMENT:字段或表描述。
● PARTITIONED BY:指定分区字段。
● AS:使用CTAS创建表。
参数说明
表1-7 参数说明
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以数字和下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是 纯数字,且不能以数字和下划线开头。匹配规则为:^(?!_)(?!
[0-9]+$)[A-Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包 围起来。
col_name 字段名称。
col_type 字段类型。
col_comment 字段描述。
file_format OBS表数据存储格式,支持orc,parquet,json,csv,carbon,
avro类型。
path 数据存储路径。
table_commen
t 表描述。
select_stateme
nt 用于CTAS命令,将源表的select查询结果或某条数据插入到新创 建的OBS表中。
表1-8 OPTIONS 参数描述
参数 描述 默认值
path 指定的表路径,即OBS存储路径。 -
multiLevelDirE
nable 是否迭代查询子目录中的数据。当配置为true 时,查询该表时会迭代读取该表路径中所有文 件,包含子目录中的文件。
false
dataDelegated 是否需要在删除表或分区时,清除path路径下的
数据。 false
当file_format为csv时,还可以设置以下OPTIONS参数。
表1-9 CSV 数据格式 OPTIONS 参数说明
参数 描述 默认值
delimiter 数据分隔符。 逗号(即",”)
quote 引用字符。 双引号(即
“"”)
escape 转义字符。 反斜杠(即
“\”)
multiLine 列数据中是否包含回车符或转行符,true为包
含,false为不包含 false
dateFormat 指定CSV文件中date字段的日期格式 yyyy-MM-dd timestampF
ormat 指定CSV文件中timestamp字段的日期格式 yyyy-MM-dd HH:mm:ss mode 指定解析CSV时的模式,有三种模式。
● PERMISSIVE:宽容模式,遇到错误的字段 时,设置该行整行为Null
● DROPMALFORMED: 遇到错误的字段时,丢 弃整行。
● FAILFAST:报错模式,遇到错误的字段时直 接报错。
PERMISSIVE
header CSV是否包含表头信息,true表示包含表头信
息,false为不包含。 false
nullValue 设置代表null的字符,例如,nullValue=“\
\N”表示设置\N 代表null。 - comment 设置代表注释开头的字符,例如,
comment='#'表示以#开头的行为注释。 -
注意事项
● 表名与列名为大小写不敏感,即不区分大小写。
● 表名及列名的描述仅支持字符串常量。
● 创建表时要声明列名及对应的数据类型,数据类型为原生类型。
● 当OBS的目录下文件夹与文件同名时,创建OBS表指向的路径会优先指向文件而 非文件夹。
● 创建表时,若指定路径为OBS上的目录,且该目录下包含子目录(或嵌套子目 录),则子目录下的所有文件类型及其内容也是表内容。用户需要保证所指定的 目录及其子目录下所有文件类型和建表语句中指定的存储格式一致,所有文件内 容和表中的字段一致,否则查询将报错。用户可以在建表语句OPTIONS中设置
“multiLevelDirEnable”为true以查询子目录下的内容,此参数默认值为false
(注意,此配置项为表属性,请谨慎配置)(Hive表不支持此配置项)。
● OBS存储路径必须为OBS上的目录,该目录必须事先创建好,且为空。
● 创建分区表时,PARTITONED BY中指定分区列必须是表中的列,且必须在 Column列表中指定类型。分区列只支持string, boolean, tinyint, smallint, short, int, bigint, long, decimal, float, double, date, timestamp类型。
● 创建分区表时,分区字段必须是表字段的最后一个字段或几个字段,且多分区字 段的顺序也必须对应。否则将出错。
● 单表分区数最多允许7000个。
● CTAS建表语句不能指定表的属性,不支持创建分区表。
示例
说明
执行创建表操作前,需要参考示例中先创建队列和数据库。再在“SQL编辑器”页面右侧的编辑 窗口上方,选择队列和数据库,执行以下SQL语句。
● 创建名为parquetTable的OBS表。
CREATE TABLE parquetTable (name string, id int) USING parquet OPTIONS (path "obs://bucketName/
filePath");
● 以班级号(classNo)为分区字段,创建一张名为student的表,包含姓名
(name)与分数(score)两个字段。
CREATE TABLE IF NOT EXISTS student(name STRING, score DOUBLE, classNo INT) USING csv OPTIONS (PATH 'obs://bucketName/filePath') PARTITIONED BY (classNo);
说明
“classNo”为分区字段,在表字段中要放在最后一个,即“student(name STRING, score DOUBLE, classNo INT)”。
● 创建表t1,并将表t2的数据插入到表t1中。
CREATE TABLE t1 USING parquet OPTIONS(path 'obs://bucketName/tblPath') AS select * from t2;
1.4.2 使用 Hive 语法创建 OBS 表
功能描述
使用Hive语法创建OBS表。DataSource语法和Hive语法主要区别在于支持的表数据存 储格式范围、支持的分区数等有差异,详细请参考语法格式和注意事项说明。
语法格式
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1 col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name2 col_type2, [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
LOCATION 'obs_path'
[TBLPROPERTIES (key = value)]
[AS select_statement];
row_format:
: SERDE serde_cls [WITH SERDEPROPERTIES (key1=val1, key2=val2, ...)]
| DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
关键字
● EXTERNAL:指创建OBS表。
● IF NOT EXISTS:指定该关键字以避免表已经存在时报错。
● COMMENT:字段或表描述。
● PARTITIONED BY:指定分区字段。
● ROW FORMAT:行数据格式。
● STORED AS:指定所存储的文件格式,当前该关键字只支持指定TEXTFILE, AVRO, ORC, SEQUENCEFILE, RCFILE, PARQUET, CARBON格式。
● LOCATION:指定OBS的路径。创建OBS表时必须指定此关键字。
● TBLPROPERTIES:TBLPROPERTIES子句允许用户给表添加key/value的属性。
比如开启数据多版本功能,用于表数据的备份与恢复。开启多版本功能后,在进 行删除或修改表数据时(insert overwrite或者truncate操作),系统会自动备份 历史表数据并保留一定时间,后续您可以对保留周期内的数据进行快速恢复,避 免因误操作而丢失数据。多版本功能其他SQL语法请参考开启或关闭数据多版本 和多版本备份恢复数据章节描述。
创建OBS表时,通过指定TBLPROPERTIES ("dli.multi.version.enable"="true") 开启DLI数据多版本功能,具体可以参考示例说明。
表1-10 TBLPROPERTIES 主要参数说明
key值 value说明
dli.multi.version.enable ● true:开启DLI数据多版本功能。
● false:关闭DLI数据多版本功能。
comment 表描述信息。
orc.compress orc存储格式表的一个属性,用来指定orc存储的压缩 方式。支持取值为:
● ZLIB
● SNAPPY
● NONE
key值 value说明
auto.purge 当设置为true时,删除或者覆盖的数据会不经过回收 站,直接被删除。
● AS:使用CTAS创建表。
参数说明
表1-11 参数说明
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能 是纯数字,且不能以数字和下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。
不能是纯数字,且不能以数字和下划线开头。匹配规则 为:^(?!_)(?![0-9]+$)[A-Za-z0-9_$]*$。如果特殊字符需 要使用单引号('')包围起来。
col_name 字段名称。
col_type 字段类型。
col_comment 字段描述。
row_format 行数据格式。
file_format OBS表存储格式,支持TEXTFILE, AVRO, ORC, SEQUENCEFILE, RCFILE, PARQUET, CARBON table_comment 表描述。
obs_path OBS存储路径。
key = value 设置TBLPROPERTIES具体属性和值。
例如开启DLI数据多版本时,可以设置
"dli.multi.version.enable"="true"来开启该功能。
select_statement 用于CTAS命令,将源表的select查询结果或某条数据插入 到新创建的OBS表中。
注意事项
● 表名与列名为大小写不敏感,即不区分大小写。
● 表名及列名的描述仅支持字符串常量。
● 创建表时要声明列名及对应的数据类型,数据类型为原生类型。
● 当OBS的目录下文件夹与文件同名时,创建OBS表指向的路径会优先指向文件而 非文件夹。
● 创建分区表时,PARTITONED BY中指定分区列必须是不在表中的列,且需要指定 数据类型。分区列支持string, boolean, tinyint, smallint, short, int, bigint, long, decimal, float, double, date, timestamp等hive开源支持的类型。
● 支持指定多个分区字段,分区字段只需在PARTITIONED BY关键字后指定,不能像 普通字段一样在表名后指定,否则将出错。
● 单表分区数最多允许100000个。
● CTAS建表语句不能指定表的属性,不支持创建分区表。
示例
说明
执行创建表操作前,需要参考示例中先创建队列和数据库。再在“SQL编辑器”页面右侧的编辑 窗口上方,选择队列和数据库,执行以下SQL语句。
● 创建一张名为student的parquet格式表,该表包含字段id,name,score,其对应 的数据类型分别是INT,STRING,FLOAT。
CREATE TABLE student (id INT, name STRING, score FLOAT) STORED AS PARQUET LOCATION 'obs://
bucketName/filePath';
● 以班级号(classNo)为分区字段,创建一张名为student的表,包含姓名
(name)与分数(score)两个字段。
CREATE TABLE IF NOT EXISTS student(name STRING, score DOUBLE) PARTITIONED BY (classNo INT) STORED AS PARQUET LOCATION 'obs://bucketName/filePath';
说明
“classNo”为分区字段,需要在PARTITIONED BY关键字后指定,即“PARTITIONED BY (classNo INT)”,不能放在表名后作为表字段指定。
● 创建表t1,并将表t2的数据插入到表t1中(Hive语法)。
CREATE TABLE t1 STORED AS parquet LOCATION 'obs://bucketName/filePath' as select * from t2;
● 创建表student,并开启数据多版本功能(Hive语法)。
CREATE TABLE student (id INT, name STRING, score FLOAT) STORED AS PARQUET LOCATION 'obs://
bucketName/filePath' TBLPROPERTIES ("dli.multi.version.enable"="true");
1.5 创建 DLI 表
1.5.1 使用 DataSource 语法创建 DLI 表
功能描述
使用DataSource语法创建DLI表。DataSource语法和Hive语法主要区别在于支持的表 数据存储格式范围、支持的分区数等有差异,详细请参考语法格式和注意事项说明。
语法格式
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING file_format
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[COMMENT table_comment]
[AS select_statement];
关键字
● IF NOT EXISTS:指定该关键字以避免表已经存在时报错。
● USING:指定存储格式。
● OPTIONS:指定建表时的属性名与属性值。
● COMMENT:字段或表描述。
● PARTITIONED BY:指定分区字段。
● AS:使用CTAS创建表。
参数说明
表1-12 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以数字和下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是纯 数字,且不能以数字和下划线开头。匹配规则为:^(?!_)(?![0-9]+
$)[A-Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包围起 来。
col_name 以逗号分隔的带数据类型的列名。列名由字母、数字和下划线
(_)组成。不能是纯数字,且至少包含一个字母。
col_type 字段类型。
col_comment 字段描述。
file_format DLI表数据存储格式,支持:parquet、carbon和carbondata格 式。
table_comme
nt 表描述。
select_stateme
nt 用于CTAS命令,将源表的select查询结果或某条数据插入到新创建 的DLI表中。
表1-13 OPTIONS 参数描述
参数 描述 默认值
multiLevelDirE
nable 是否迭代查询子目录中的数据。当配置为true 时,查询该表时会迭代读取该表路径中所有文 件,包含子目录中的文件。
false
注意事项
● 若没有指定分隔符,则默认为逗号(,)。
● 创建分区表时,PARTITONED BY中指定分区列必须是表中的列,且必须在 Column列表中指定类型。分区列只支持string, boolean, tinyint, smallint, short, int, bigint, long, decimal, float, double, date, timestamp类型。
● 创建分区表时,分区字段必须是表字段的最后一个字段或几个字段,且多分区字 段的顺序也必须对应。否则将出错。
● 单表分区数最多允许7000个。
● CTAS建表语句不能指定表的属性,不支持创建分区表。
示例
说明
执行创建表操作前,需要参考示例中先创建队列和数据库。再在“SQL编辑器”页面右侧的编辑 窗口上方,选择队列和数据库,执行以下SQL语句。
● 创建一张名为src的表,该表包含字段key、value,其对应的数据类型分别是 INT、STRING,并可根据需要指定属性。
CREATE TABLE src(key INT, value STRING) USING PARQUET OPTIONS('key1' = 'value1');
● 创建一张名为tb_carbon的表,存储数据格式为carbon,该表包含字段key、
value,其对应的数据类型分别是INT、STRING,并可根据需要指定属性。
CREATE TABLE tb_carbon(key INT, value STRING) USING CARBON OPTIONS('key1' = 'value1');
● 以班级号(classNo)为分区字段,创建一张名为student的表,包含姓名
(name)与分数(score)两个字段,存储格式为parquet。
CREATE TABLE student(name STRING, score INT, classNo INT) USING PARQUET OPTIONS('key1' = 'value1') PARTITIONED BY(classNo) ;
说明
“classNo”为分区字段,在表字段中要放在最后一个,即“student(name STRING, score INT, classNo INT)”。
● 以班级号(classNo)为分区字段,创建一张名为student的表,包含姓名
(name)与分数(score)两个字段,存储格式为carbon。
CREATE TABLE student(name STRING, score INT, classNo INT) USING CARBON OPTIONS('key1' = 'value1') PARTITIONED BY(classNo) ;
说明
“classNo”为分区字段,在表字段中要放在最后一个,即“student(name STRING, score INT, classNo INT)”。
● 创建表t1,并将表t2的数据插入到表t1中。
CREATE TABLE t1 USING parquet AS select * from t2;
1.5.2 使用 Hive 语法创建 DLI 表
功能描述
使用Hive语法创建DLI表。DataSource语法和Hive语法主要区别在于支持的表数据存 储格式范围、支持的分区数等有差异,详细请参考语法格式和注意事项说明。
语法格式
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1 col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name2 col_type2, [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
STORED AS file_format
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement];
row_format:
: SERDE serde_cls [WITH SERDEPROPERTIES (key1=val1, key2=val2, ...)]
| DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
关键字
● IF NOT EXISTS:指定该关键字以避免表已经存在时报错。
● COMMENT:字段或表描述。
● PARTITIONED BY:指定分区字段。
● ROW FORMAT:行数据格式。
● STORED AS:指定所存储的文件格式,当前该关键字只支持指定TEXTFILE, AVRO, ORC, SEQUENCEFILE, RCFILE, PARQUET, CARBON几种格式。创建DLI表 时必须指定此关键字。
● TBLPROPERTIES:TBLPROPERTIES子句允许用户给表添加key/value的属性。
● AS:使用CTAS创建表。
参数说明
表1-14 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以数字和下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是 纯数字,且不能以数字和下划线开头。匹配规则为:^(?!_)(?!
[0-9]+$)[A-Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包 围起来。
col_name 以逗号分隔的带数据类型的列名。列名由字母、数字和下划线
(_)组成。不能是纯数字,且至少包含一个字母。
col_type 字段类型。
col_comment 字段描述。
row_format 行数据格式。
file_format DLI表数据存储格式:支持TEXTFILE, AVRO, ORC, SEQUENCEFILE, RCFILE, PARQUET, CARBON。
table_comment 表描述。
select_stateme
nt 用于CTAS命令,将源表的select查询结果或某条数据插入到新创 建的DLI表中。
注意事项
● 创建分区表时,PARTITONED BY中指定分区列必须是不在表中的列,且需要指定 数据类型。分区列支持string, boolean, tinyint, smallint, short, int, bigint, long, decimal, float, double, date, timestamp等hive开源支持的类型。
● 支持指定多个分区字段,分区字段只需在PARTITIONED BY关键字后指定,不能像 普通字段一样在表名后指定,否则将出错。
● 单表分区数最多允许100000个。
● CTAS建表语句不能指定表的属性,不支持创建分区表。
示例
说明
执行创建表操作前,需要参考示例中先创建队列和数据库。再在“SQL编辑器”页面右侧的编辑 窗口上方,选择队列和数据库,执行以下SQL语句。
● 创建一张名为src的表,该表包含字段key、value,其对应的数据类型分别是 INT、STRING,并可根据需要指定属性。
CREATE TABLE src (key INT, value STRING) STORED AS PARQUET
TBLPROPERTIES('key1' = 'value1');
● 以班级号(classNo)为分区字段,创建一张名为student的表,包含姓名
(name)与分数(score)两个字段。
CREATE TABLE student (name STRING, score INT) STORED AS PARQUET
TBLPROPERTIES('key1' = 'value1') PARTITIONED BY(classNo INT);
● 创建表t1,并将表t2的数据插入到表t1中。
CREATE TABLE t1 STORED AS PARQUET AS select * from t2;
1.6 删除表
功能描述
删除表。
语法格式
DROP TABLE [IF EXISTS] [db_name.]table_name;
关键字
● OBS表:仅删除其元数据信息,不删除存放在OBS上的数据。
● DLI表:删除其数据及相应的元数据信息。
参数说明
表1-15 参数说明
参数 描述
db_name 数据库名称,由字母、数字和下划线(_)组成。不能是纯数字,且不能 以数字和下划线开头。
table_na
me 表名称。
注意事项
所要删除的表必须是当前数据库下存在的,否则会出错,可以通过添加IF EXISTS来避 免出错。
示例
1. 参考创建OBS表或者创建DLI表章节中的示例描述已创建对应的表,如student。
2. 在当前所在数据库下删除名为student的表。
DROP TABLE IF EXISTS student;
1.7 查看表
1.7.1 查看所有表
功能描述
查看当前数据库下所有的表。显示当前数据库下的所有表及视图。
语法格式
SHOW TABLES [IN | FROM db_name] [LIKE regex_expression];
关键字
FROM/IN:指定数据库名,显示特定数据库下的表及视图。
参数说明
表1-16 参数说明
参数 描述
db_name 数据库名称,由字母、数字和下划线(_)组成。不能是纯数字,且 不能以数字和下划线开头。
参数 描述 regex_expres
sion 数据库下的表名称。
注意事项
无。
示例
1. 参考创建OBS表或者创建DLI表章节中的示例描述已创建对应的表。
2. 查看当前所在数据库中的所有表与视图。
SHOW TABLES;
3. 查看testdb数据库下所有以test开头的表。
SHOW TABLES IN testdb LIKE "test*";
1.7.2 查看建表语句
功能描述
返回对应表的建表语句。
语法格式
SHOW CREATE TABLE table_name;
关键字
CREATE TABLE:建表语句。
参数说明
表1-17 参数说明
参数 描述
table_nam
e 表名称。
注意事项
语句所涉及的表必须存在,否则会出错。
示例
1. 参考创建OBS表或者创建DLI表章节中的示例描述已创建对应的表,如test。
2. 返回test表的建表语句。
SHOW CREATE TABLE test;
1.7.3 查看表属性
功能描述
查看表的属性。
语法格式
SHOW TBLPROPERTIES table_name [('property_name')];
关键字
TBLPROPERTIES:TBLPROPERTIES子句允许用户给表添加key/value的属性。
参数说明
表1-18 参数说明
参数 描述
table_nam
e 表名称。
property_n
ame ● 命令中不指定property_name时,将返回所有属性及其值;
● 命令中指定property_name时,将返回该特定property_name所对 应的值。
注意事项
property_name大小写敏感,不能同时指定多个property_name,否则会出错。
示例
返回test表中属性property_key1的值。
SHOW TBLPROPERTIES test ('property_key1');
1.7.4 查看指定表所有列
功能描述
查看指定表中的所有列。
语法格式
SHOW COLUMNS {FROM | IN} table_name [{FROM | IN} db_name];
关键字
● COLUMNS:表中的列。
● FROM/IN:指定数据库,显示指定数据库下的表的列名。FROM和IN没有区别,
可替换使用。
参数说明
表1-19 参数说明
参数 描述
table_nam
e 表名称。
db_name 数据库名称。
注意事项
所指定的表必须是数据库中存在的表,否则会出错。
示例
查看student表中的所有列。
SHOW COLUMNS IN student;
1.7.5 查看指定表所有分区
功能描述
查看指定表的所有分区。
语法格式
SHOW PARTITIONS [db_name.]table_name [PARTITION partition_specs];
关键字
● PARTITIONS:表中的分区。
● PARTITION:分区。
参数说明
表1-20 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是纯 数字,且不能以下划线开头。匹配规则为:^(?!_)(?![0-9]+$)[A- Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包围起来。
参数 描述 partition_spe
cs 分区信息,key=value形式,key为分区字段,value为分区值。若分 区字段为多个字段,可以不包含所有的字段,会显示匹配上的所有 分区信息。
注意事项
所要查看分区的表必须存在且是分区表,否则会出错。
示例
● 查看student表下面的所有的分区。
SHOW PARTITIONS student;
● 查看student表中dt='2010-10-10'的分区。
SHOW PARTITIONS student PARTITION(dt='2010-10-10')。
1.7.6 查看表统计信息
功能描述
查看表统计信息。返回所有列的列名和列数据类型。
语法格式
DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name;
关键字
● EXTENDED:显示表的所有元数据,通常只在debug时用到。
● FORMATTED:使用表格形式显示所有表的元数据。
参数说明
表1-21 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数字,且 不能以下划线开头。
table_na
me Database中的表名,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以下划线开头。匹配规则为:^(?!_)(?![0-9]+$)[A-Za-z0-9_
$]*$。如果特殊字符需要使用单引号('')包围起来。
注意事项
若所查看的表不存在,将会出错。
示例
查看student表的所有列的列名与列数据类型。
DESCRIBE student;
1.8 修改表
1.8.1 添加列
功能描述
添加一个或多个新列到表上。
语法格式
ALTER TABLE [db_name.]table_name ADD COLUMNS (col_name1 col_type1 [COMMENT col_comment1], ...);
关键字
● ADD COLUMNS:添加列。
● COMMENT:列描述。
参数说明
表1-22 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数字,
且不能以下划线开头。
table_nam
e 表名称。
col_name 列字段名称。
col_type 列字段类型。
col_comm
ent 列描述。
注意事项
无。
示例
ALTER TABLE t1 ADD COLUMNS (column2 int, column3 string);
1.8.2 开启或关闭数据多版本
功能描述
DLI提供多版本功能,用于数据的备份与恢复。开启多版本功能后,在进行删除或修改 表数据时(insert overwrite或者truncate操作),系统会自动备份历史数据并保留一 定时间,后续您可以对保留周期内的数据进行快速恢复,避免因误操作丢失数据。其 他多版本SQL语法请参考多版本备份恢复数据。
DLI数据多版本功能当前仅支持通过Hive语法创建的OBS表,具体建表语法可以参考使
用Hive语法创建OBS表。
语法格式
● 开启多版本功能
ALTER TABLE [db_name.]table_name
SET TBLPROPERTIES ("dli.multi.version.enable"="true");
● 关闭多版本功能
ALTER TABLE [db_name.]table_name
UNSET TBLPROPERTIES ("dli.multi.version.enable");
开启多版本功能后,在执行insert overwrite或者truncate操作时会自动在OBS存 储路径下存储多版本数据。关闭多版本功能后,需要通过如下命令把多版本数据 目录回收。
RESTORE TABLE [db_name.]table_name TO initial layout;
关键字
● SET TBLPROPERTIES:设置表属性,开启多版本功能。
● UNSET TBLPROPERTIES:取消表属性,关闭多版本功能。
参数说明
表1-23 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数字,
且不能以下划线开头。
table_nam
e 表名称。
注意事项
DLI数据多版本功能当前仅支持通过Hive语法创建的OBS表,具体建表语法可以参考使
用Hive语法创建OBS表。
示例
● 修改表test_table,开启多版本功能。
ALTER TABLE test_table
SET TBLPROPERTIES ("dli.multi.version.enable"="true");
● 修改表test_table,关闭多版本功能。
ALTER TABLE test_table
UNSET TBLPROPERTIES ("dli.multi.version.enable");
回退多版本路径。
RESTORE TABLE test_table TO initial layout;
1.9 分区表相关
1.9.1 添加分区(只支持 OBS 表)
功能描述
创建OBS分区表成功后,OBS表实际还没有生成分区信息。生成分区信息主要有以下 两种场景:
● 给OBS分区表插入对应的分区数据,数据插入成功后OBS表才会生成分区元数据 信息,后续则可以根据对应分区列进行查询等操作。
● 手工拷贝分区目录和数据到OBS分区表路径下,执行本章节介绍的分区添加命令 生成分区元数据信息,后续即可根据对应分区列进行查询等操作。
本章节重点介绍使用ALTER TABLE命令添加分区的基本操作和使用说明。
语法格式
ALTER TABLE table_name ADD [IF NOT EXISTS]
PARTITION partition_specs1 [LOCATION 'obs_path1']
PARTITION partition_specs2 [LOCATION 'obs_path2'];
关键字
● IF NOT EXISTS:指定该关键字以避免分区重复添加时报错。
● PARTITION:分区。
● LOCATION:分区路径。
参数说明
表1-24 参数描述
参数 描述
table_name 表名称。
partition_sp
ecs 分区字段。
obs_path OBS存储路径。
注意事项
● 向表中添加分区时,此表和分区列(建表时PARTITIONED BY指定的列)必须已存 在,而所要添加的分区不能重复添加,否则将出错。已添加的分区可通过IF NOT EXISTS避免报错。
● 若分区表是按照多个字段进行分区的,添加分区时需要指定所有的分区字段,指 定字段的顺序可任意。
● “partition_specs”中的参数默认带有“( )”,例如:PARTITION (dt='2009-09-09',city='Shanghai')。
● 在添加分区时若指定OBS路径,则该OBS路径必须是已经存在的,否则会出错。
● 若添加多个分区,每组PARTITION partition_specs LOCATION 'obs_path'之间用 空格隔开。例如:
PARTITION partition_specs LOCATION 'obs_path' PARTITION partition_specs LOCATION 'obs_path'。
● 若新增分区指定的路径包含子目录(或嵌套子目录),则子目录下面的所有文件 类型及内容也将作为该分区的记录。用户需要保证该分区目录下所有文件类型和 文件内容与表的字段一致,否则查询将报错。
示例
● 建OBS表时仅有一个分区列,建表成功后添加分区数据。
a. 先使用DataSource语法创建一个OBS分区表,分区列为external_data,数据 存储在obs://bucketName/datapath路径下。
create table testobstable(id varchar(128), external_data varchar(16)) using JSON OPTIONS (path 'obs://bucketName/datapath') PARTITIONED by (external_data);
b. 拷贝分区数据目录到obs://bucketName/datapath路径下。例如当前拷贝 external_data=22的分区目录下所有文件到obs://bucketName/datapath路径 下。
c. 执行添加分区命令,将分区的元数据信息生效。
ALTER TABLE testobstable ADD PARTITION (external_data='22')
LOCATION 'obs://bucketName/datapath/external_data=22';
d. 添加分区成功后,即可根据分区列进行数据查询等操作。
select * from testobstable where external_data='22';
● 建OBS表时有多个分区列,建表成功后添加分区数据。
a. 先使用DataSource语法创建一个OBS分区表,分区列为external_data和dt,
数据存储在obs://bucketName/datapath路径下。
create table testobstable(
id varchar(128),
external_data varchar(16), dt varchar(16)
) using JSON OPTIONS (path 'obs://bucketName/datapath') PARTITIONED by (external_data, dt);
b. 拷贝分区数据目录到obs://bucketName/datapath路径下。例如拷贝 external_data=22及其子目录dt=2021-07-27和目录下文件到obs://
bucketName/datapath路径下。
c. 执行添加分区命令,将分区的元数据信息生效。
ALTER TABLE testobstable
ADD PARTITION (external_data = '22', dt = '2021-07-27') LOCATION 'obs://bucketName/datapath/
external_data=22/dt=2021-07-27';
d. 添加分区成功后,即可根据分区列进行数据查询等操作。
select * from testobstable where external_data = '22';
select * from testobstable where external_data = '22' and dt='2021-07-27';
1.9.2 重命名分区
功能描述
重命名分区。
语法格式
ALTER TABLE table_name PARTITION partition_specs
RENAME TO PARTITION partition_specs;
关键字
● PARTITION:分区。
● RENAME:重命名。
参数说明
表1-25 参数描述
参数 描述
table_name 表名称。
partition_spec
s 分区字段。
注意事项
● 所要重命名分区的表和分区必须已存在,否则会出错。新分区名不能与其他分区 重名,否则将出错。
● 若分区表是按照多个字段进行分区的,重命名分区时需要指定所有的分区字段,
指定字段的顺序可任意。
● “partition_specs”中的参数默认带有“( )”,例如:PARTITION (dt='2009-09-09',city='Shanghai')。
示例
将student表中的分区city='Hangzhou',dt='2008-08-08'重命名为 city='Wenzhou',dt='2009-09-09'。
ALTER TABLE student
PARTITION (city='Hangzhou',dt='2008-08-08')
RENAME TO PARTITION (city='Wenzhou',dt='2009-09-09');
1.9.3 删除分区
功能描述
删除分区表的一个或多个分区。
注意事项
● 所要删除分区的表必须是已经存在的表,否则会出错。
● 所要删除的分区必须是已经存在的,否则会出错,可通过语句中添加IF EXISTS避 免该错误。
语法格式
ALTER TABLE [db_name.]table_name DROP [IF EXISTS]
PARTITION partition_spec1[,PARTITION partition_spec2,...];
关键字
● DROP:删除表分区。
● IF EXISTS:所要删除的分区必须是已经存在的,否则会出错。
● PARTITION:分区。
参数说明
表1-26 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是纯 数字,且不能以下划线开头。匹配规则为:^(?!_)(?![0-9]+$)[A- Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包围起来。
partition_spec
s 分区信息,key=value形式,key为分区字段,value为分区值。若 分区字段为多个字段,可以不包含所有的字段,会删除匹配上的所 有分区。“partition_specs”中的参数默认带有“( )”,例如:
PARTITION (dt='2009-09-09',city='Shanghai')。
示例
将分区表student的分区dt = '2008-08-08', city = 'Hangzhou'删除。
ALTER TABLE student DROP
PARTITION (dt = '2008-08-08', city = 'Hangzhou');
1.9.4 指定筛选条件删除分区
功能描述
指定筛选条件删除分区表的一个或多个分区。
注意事项
● 该命令仅支持操作OBS表,不支持对DLI表进行操作。
● 所要删除分区的表必须是已经存在的表,否则会出错。
● 所要删除的分区必须是已经存在的,否则会出错,可通过语句中添加IF EXISTS避 免该错误。
语法格式
ALTER TABLE [db_name.]table_name DROP [IF EXISTS]
PARTITIONS partition_filtercondition;
关键字
● DROP:删除表分区。
● IF EXISTS:所要删除的分区必须是已经存在的,否则会出错。
● PARTITIONS:分区。
参数说明
表1-27 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以下划线开头。
table_name Database中的表名,由字母、数字和下划线(_)组成。不能是纯 数字,且不能以下划线开头。匹配规则为:^(?!_)(?![0-9]+$)[A- Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包围起来。
该命令仅支持操作OBS表,不支持对DLI表进行操作。
partition_filter
condition 分区筛选条件。具体可以为以下格式:
● <分区列名> <运算符> <分区列比较值>
例如:start_date < '201911'
● <partition_filtercondition1> AND|OR
<partition_filtercondition2>
例如:start_date < '201911' OR start_date >= '202006'
● (<partition_filtercondition1>)[,partitions (<partition_filtercondition2>), ...]
例如:(start_date <> '202007'), partitions(start_date <
'201912')
示例
将分区表student的分区dt,按照各种筛选过滤条件删除。
alter table student drop partitions(start_date < '201911');
alter table student drop partitions(start_date >= '202007');
alter table student drop partitions(start_date BETWEEN '202001' AND '202007');
alter table student drop partitions(start_date < '201912' OR start_date >= '202006');
alter table student drop partitions(start_date > '201912' AND start_date <= '202004');
alter table student drop partitions(start_date != '202007');
alter table student drop partitions(start_date <> '202007');
alter table student drop partitions(start_date <> '202007'), partitions(start_date < '201912');
1.9.5 修改表分区位置(只支持 OBS 表)
功能描述
修改表分区的位置。
语法格式
ALTER TABLE table_name PARTITION partition_specs SET LOCATION obs_path;
关键字
● PARTITION:分区。
● LOCATION:分区路径。
参数说明
表1-28 参数描述
参数 描述
table_name 表名称。
partition_spe
cs 分区字段。
obs_path OBS存储路径。
注意事项
● 所要修改位置的表分区必须是已经存在的,否则将报错。
● “partition_specs”中的参数默认带有“( )”,例如:PARTITION (dt='2009-09-09',city='Shanghai')。
● 所指定的新的OBS路径必须是已经存在的绝对路径,否则将报错。
● 若新增分区指定的路径包含子目录(或嵌套子目录),则子目录下面的所有文件 类型及内容也将作为该分区的记录。用户需要保证该分区目录下所有文件类型和 文件内容与表的字段一致,否则查询将报错。
示例
将student表的分区dt='2008-08-08',city='Hangzhou'的OBS路径设置为“obs://
bucketName/fileName/student/dt=2008-08-08/city=Hangzhou_bk”。
ALTER TABLE student
PARTITION(dt='2008-08-08',city='Hangzhou')
SET LOCATION 'obs://bucketName/fileName/student/dt=2008-08-08/city=Hangzhou_bk';
1.9.6 修改表分区 SerDe 属性(只支持 OBS 表)
功能描述
修改表分区Serde属性。
语法格式
ALTER TABLE table_name [PARTITION partition_specs]
SET SERDE serde
[WITH SERDEPROPERTIES (property_name=property_value,...)];
ALTER TABLE table_name [PARTITION partition_specs]
SET SERDEPROPERTIES (property_name=property_value,...);
关键字
● PARTITION:分区。
● SERDEPROPERTIES:Serde属性。
参数说明
表1-29 参数描述
参数 描述
table_name 表名称。
partition_spec
s 分区字段。
obs_path OBS存储路径。
注意事项
● 假如Serde属性已经存在,新的值将会覆盖老的值。
● 仅允许针对OBS表设置Serde属性。
示例
alter table test
set serdeproperties (creator = "test");
1.9.7 更新表分区信息(只支持 OBS 表)
功能描述
更新表在元数据库中的分区信息。
语法格式
MSCK REPAIR TABLE table_name;
或
ALTER TABLE table_name RECOVER PARTITIONS;
关键字
● PARTITIONS:分区。
● SERDEPROPERTIES:Serde属性。
参数说明
表1-30 参数描述
参数 描述
table_name 表名称。
partition_spe
cs 分区字段。
obs_path OBS存储路径。
注意事项
● 该命令的主要应用场景是针对分区表,如当手动在OBS上面添加分区目录时,再 通过上述命令将该新增的分区信息刷新到元数据库中,通过“SHOW
PARTITIONS table_name”命令查看新增的分区。
● 分区目录名称必须按照指定的格式输入,即“tablepath/
partition_column_name=partition_column_value”。
示例
下述两语句都将更新表ptable在元数据库中的分区信息。
MSCK REPAIR TABLE ptable;
或
ALTER TABLE ptable RECOVER PARTITIONS;
1.9.8 REFRESH TABLE 刷新表元数据
功能描述
Spark为了提高性能会缓存Parquet的元数据信息。当更新了Parquet表时,缓存的元数 据信息未更新,导致Spark SQL查询不到新插入的数据作业执行报错,报错信息参考如 下:DLI.0002: FileNotFoundException: getFileStatus on error message
该场景下就需要使用REFRESH TABLE来解决该问题。REFRESH TABLE是用于重新整理 某个分区的文件,重用之前的表元数据信息,能够检测到表的字段的增加或者减少,
主要用于表中元数据未修改,表的数据修改的场景。
语法格式
REFRESH TABLE [db_name.]table_name;
关键字
无。
参数说明
表1-31 参数描述
参数 描述
db_name Database名称,由字母、数字和下划线(_)组成。不能是纯数 字,且不能以下划线开头。
table_name 表名称。Database中的表名,由字母、数字和下划线(_)组成。
不能是纯数字,且不能以下划线开头。匹配规则为:^(?!_)(?!
[0-9]+$)[A-Za-z0-9_$]*$。如果特殊字符需要使用单引号('')包围 起来。
注意事项
无。
示例
刷新表test的元数据信息。
REFRESH TABLE test;
1.10 导入数据
功能描述
LOAD DATA可用于导入CSV、Parquet、ORC、JSON、Avro格式的数据,内部将转换 成Parquet数据格式进行存储。
语法格式
LOAD DATA INPATH 'folder_path' INTO TABLE [db_name.]table_name OPTIONS(property_name=property_value, ...);
关键字
● INPATH:数据路径。
● OPTIONS:属性列表。
参数说明
表1-32 参数描述
参数 描述
folder_path 原始数据文件夹或者文件的OBS路径。
db_name 数据库名称。若未指定,则使用当前数据库。
table_name 需要导入数据的DLI表的名称。
以下是可以在导入数据时使用的配置选项:
● DATA_TYPE: 指定导入的数据类型,当前支持CSV、Parquet、ORC、JSON、Avro 类型,默认值为“CSV”。
配置项为OPTIONS('DATA_TYPE'='CSV')
导入CSV和JSON文件时,有三种模式可以选择:
– PERMISSIVE:选择PERMISSIVE模式时,如果某一列数据类型与目标表列数 据类型不匹配,则该行数据将被设置为null。
– DROPMALFORMED:选择DROPMALFORMED模式时,如果某一列数据类 型与目标表列数据类型不匹配,则不导入该行数据。
– FAILFAST:选择FAILFAST模式时,如果某一列类型不匹配,则会抛出异常,
导入失败。
模式设置可通过在OPTIONS中添加 OPTIONS('MODE'='PERMISSIVE')进行设置。
● DELIMITER:可以在导入命令中指定分隔符,默认值为“,”。
配置项为OPTIONS('DELIMITER'=',')。
对于CSV数据,支持如下所述分隔符:
– 制表符tab,例如:'DELIMITER'='\t'。
– 任意的二进制字符,例如:'DELIMITER'='\u0001(^A)'。
– 单引号('),单引号必须在双引号(" ")内。例如:'DELIMITER'= "'"。
– DLI表还支持\001(^A)和\017(^Q),例如:'DELIMITER'='\001(^A)',
'DELIMITER'='\017(^Q)'。
● QUOTECHAR:可以在导入命令中指定引号字符。默认值为"。
配置项为OPTIONS('QUOTECHAR'='"')
● COMMENTCHAR:可以在导入命令中指定注释字符。在导入操作期间,如果在行 的开头遇到注释字符,那么该行将被视为注释,并且不会被导入。默认值为#。
配置项为OPTIONS('COMMENTCHAR'='#')
● HEADER:用来表示源文件是否有表头。取值范围为“true”和“false”。
“true”表示有表头,“false”表示无表头。默认值为“false”。如果没有表 头,可以在导入命令中指定FILEHEADER参数提供表头。
配置项为OPTIONS('HEADER'='true')
● FILEHEADER:如果源文件中没有表头,可在LOAD DATA命令中提供表头。
OPTIONS('FILEHEADER'='column1,column2')
● ESCAPECHAR:如果用户想在CSV上对Escape字符进行严格验证,可以提供 Escape字符。默认值为“\\”。
配置项为OPTIONS('ESCAPECHAR'='\\') 说明
如果在CSV数据中输入ESCAPECHAR,该ESCAPECHAR必须在双引号(" ")内。例如:"a
\b"。
● MAXCOLUMNS:该可选参数指定了在一行中,CSV解析器解析的最大列数。
配置项为OPTIONS('MAXCOLUMNS'='400')
表1-33 MAXCOLUMNS
可选参数名称 默认值 最大值
MAXCOLUMNS 2000 20000
说明
设置MAXCOLUMNS Option的值后,导入数据会对executor的内存有要求,所以导入数据 可能会由于executor内存不足而失败。
● DATEFORMAT:指定列的日期格式。
OPTIONS('DATEFORMAT'='dateFormat') 说明
● 默认值为:yyyy-MM-dd。
● 日期格式由Java的日期模式字符串指定。在Java的日期和时间模式字符串中,未加单引 号(')的字符'A' 到'Z' 和'a' 到'z' 被解释为模式字符,用来表示日期或时间字符串元素。
若模式字符使用单引号 (') 引起来,则在解析时只进行文本匹配,而不进行解析。Java 模式字符定义请参见表1-34。
表1-34 日期及时间模式字符定义 模式字符 日期或时间元素 示例
G 纪元标识符 AD
y 年份 1996; 96
M 月份 July; Jul; 07 w 年中的周数 27(该年的第27周)