國立臺灣大學電機資訊學院電信工程學研究所 碩士論文
Graduate Institute of Communication Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
最小音素錯誤訓練法及其改進方法在國語大字彙辨識 上之評估與分析
Evaluation and Analysis of Minimum Phone Error Training and Its Modified Versions for Large Vocabulary
Mandarin Speech Recognition
程永任 Cheng Yung-Jen
指導教授:李琳山 博士 Advisor: Lee Lin-Shan, Ph.D.
中華民國 97 年 6 月
June, 2008
中文摘要
~ i ~
中文摘要
傳統的語音模型訓練以最大相似度(Maximum Likelihood, ML)來訓練聲學模 型,雖然可以使正確的轉寫在訓練語料中有最大的事後機率,卻無法保證錯誤的 聲學特徵(feature)不會產生更大的事後機率。鑑別式訓練(discriminative training)同 時將可能的辨識結果與正確轉寫納入訓練,設法避免不正確的聲學特徵產生高於 正確轉寫的事後機率。
本論文以最小音素錯誤訓練法(Minimum Phone Error, MPE)以及其改進方法為 主軸,詳細介紹鑑別式訓練法的背景知識、理論基礎以及實驗結果。本論文可分 為五個部份:
第一部份為鑑別式訓練的基礎理論,從貝氏風險(Bayes Risk)開始,介紹目前 廣泛研究的若干種模型訓練法,包括最大相似度估測法、最大相互資訊(Maximum Mutual Information, MMI) 估 測 法 、 全 面 風 險 法 則 估 測 (Overall Risk Criterion Estimation, ORCE)、最小分類錯誤(Minimum Classification Error, MCE)訓練法以及 最小音素錯誤(Minimum Phone Error, MPE)訓練法,這些訓練法的目標函數都可以 視為貝氏風險的延伸。
第二部份為本論文的實驗架構:包括師大的新聞語料庫;實驗的前端處理方 式,梅爾倒頻譜係數(Mel-Frequency Cepstrum Coefficient, MFCC);初始聲學模型 的訓練,由HTK 以最大相似度估測法訓練而成;詞典及語言模型的建立,以中央 通訊社收集的文字語料由SRILM 訓練而成;以及語音辨識工具,為台大語音實驗 室的TTK。基礎實驗為初始聲學模型的辨識結果。
第三部份為最小音素錯誤訓練法,先介紹目標函數最佳化的理論推導過程,
求得模型參數的更新公式。再介紹模型參數的更新公式中,各項統計值在實作上 的計算方法,其中包含正確度的定義,以及詞弧正確度和詞圖期望正確度的算法。
實驗結果最小音素錯誤訓練法有約2.4%字正確率的進步。
第四部份介紹最小音素錯誤訓練法的改進方法,包括最小音素音框錯誤
中文摘要
~ ii ~
(Minimum Phone Frame Error, MPFE)訓練法、狀態層級最小貝氏風險(physical state level Minimum Bayes Risk, sMBR)訓練法和最小歧異度(Minimum Divergence, MD) 訓練法,這些方法主要差異在於目標函數中正確度的定義。實驗結果包括最小音 素錯誤訓練法的四種方法之中,除了最小歧異度訓練法之外的三種方法都可以在 詞正確率以及字正確率上進步,其中又以最小音素錯誤訓練法在字正確率的表現 最好,而詞正確率則是以最小音素音框錯誤訓練法表現最好。此外,本論文也在 目標函數中正確度的定義做了更進一步的改進:在正確度中加入了錯誤處罰以及 音素長度正規化,實驗結果這個正確度的改進版本會產生字正確率進步,而在詞 正確率上退步的情形。
第五部份介紹基於詞弧期望正確度的資料選取方法,目標是篩選出較具有鑑 別力的詞弧納入訓練,實驗在最小音素錯誤訓練法和最小音素音框錯誤訓練法的 其中一種修改版本上,實驗結果顯示資料選取對於正確率的變化並沒有很大的影 響,不過可以加快訓練的收斂速度。
目錄
~ iii ~
目錄
中文摘要 ··· i
目錄 ··· iii
圖目錄 ··· vii
表目錄 ··· xi
第1 章 緒論 ··· 1
1.1 研究動機 ··· 1
1.2 統計式語音辨識 ··· 2
1.2.1 聲學模型 ··· 2
1.2.2 語言模型 ··· 4
1.3 研究主題與主要成果 ··· 4
1.4 論文架構 ··· 5
第2 章 背景知識 ··· 6
2.1 鑑別式訓練法則 ··· 6
2.2 貝氏風險(Bayes Risk) ··· 7
2.3 最大相似度(Maximum Likelihood, ML) ··· 8
2.4 最大相互資訊(Maximum Mutual Information, MMI) ··· 10
2.5 全面風險法則估測(Overall Risk Criterion Estimation, ORCE) ··· 11
2.6 最小分類錯誤(Minimum Classification Error, MCE) ··· 13
2.7 最小音素錯誤(Minimum Phone Error, MPE) ··· 14
2.8 綜合各種訓練法之目標函數推導流程 ··· 15
2.9 本章結論 ··· 15
第3 章 實驗基礎架構及語料庫 ··· 17
3.1 實驗語料 ··· 17
3.2 訓練與辨識系統 ··· 17
3.2.1 前端處理 ··· 18
3.2.2 聲學模型設定 ··· 18
3.2.3 詞典建立與語言模型設定 ··· 19
3.2.4 語音辨識工具 ··· 19
3.3 基礎實驗(baseline) ··· 20
目錄
~ iv ~
3.4 本章結論 ··· 22
第4 章 最小音素錯誤訓練 ··· 23
4.1 目標函數 ··· 23
4.1.1 目標函數之最佳化 ··· 23
4.1.2 目標函數之微分 ··· 24
4.1.3 聲學模型參數更新 ··· 27
4.1.4 I 平滑 ··· 30
4.2 實作流程 ··· 31
4.2.1 詞圖 ··· 31
4.2.2 詞弧正確度 ··· 32
4.2.3 詞圖期望正確度 ··· 34
4.2.4 詞圖前向後向演算法 ··· 36
4.3 實驗結果 ··· 38
4.4 本章結論 ··· 39
第5 章 基於最小音素錯誤改進之鑑別式訓練法 ··· 48
5.1 最小音素音框錯誤訓練 ··· 48
5.1.1 目標函數 ··· 48
5.1.2 加入錯誤處罰與音素長度正規化的詞弧正確度 ··· 51
5.1.3 實驗結果 ··· 52
5.2 狀態層級最小貝氏風險訓練 ··· 66
5.2.1 目標函數 ··· 66
5.2.2 加入錯誤處罰的詞弧正確度 ··· 68
5.2.3 加入錯誤處罰與音素長度正規化的詞弧正確度 ··· 69
5.2.4 實驗結果 ··· 71
5.3 最小歧異度訓練 ··· 81
5.3.1 目標函數 ··· 81
5.3.2 實驗結果 ··· 82
5.4 本章結論 ··· 84
第6 章 最小音素錯誤與最小音素音框錯誤的資料選取 ··· 86
6.1 基於詞弧期望正確度的資料選取 ··· 86
6.2 實驗結果 ··· 88
目錄
~ v ~
6.3 各實驗綜合整理 ··· 100
第7 章 結論與展望 ··· 105
7.1 總結 ··· 105
7.2 未來展望 ··· 106
附錄A 右相關聲韻母模型 ··· 107
附錄B 輔助函數(Auxiliary Function) ···111
B.1 強性輔助函數(Strong-Sense Auxiliary Function) ··· 112
B.2 弱性輔助函數(Weak-Sense Auxiliary Function) ··· 115
參考文獻 ··· 116
圖目錄
~ vii ~
圖目錄
圖 1.1 聲學模型訓練流程 ··· 3
圖 1.2 連續密度隱藏式馬可夫模型示意圖 ··· 3
圖 2.1 最大相似度估測法造成混淆的情形 ··· 6
圖 2.2 編輯距離之計算方式 ··· 12
圖 2.3 各種目標函數之推導流程 ··· 16
圖 3.1 MFCC 特徵抽取流程 ··· 18
圖 4.1 詞圖範例 ··· 31
圖 4.2 音素正確度的近似及精確計算範例 ··· 33
圖 4.3 Cq與 Cavg計算範例 ··· 35
圖 4.4 詞圖前向演算法 ··· 36
圖 4.5 詞圖後向演算法 ··· 37
圖 4.6 根據詞圖前向後向演法計算 Cq與 Cavg ··· 37
圖 4.7 最小音素錯誤訓練法-詞圖N-詞正確率 ··· 40
圖 4.8 最小音素錯誤訓練法-詞圖N-字正確率 ··· 41
圖 4.9 最小音素錯誤訓練法-詞圖N-音節正確率 ··· 42
圖 4.10 最小音素錯誤訓練法-詞圖N-聲韻母正確率 ··· 43
圖 4.11 最小音素錯誤訓練法-詞圖T-詞正確率 ··· 44
圖 4.12 最小音素錯誤訓練法-詞圖T-字正確率 ··· 45
圖 4.13 最小音素錯誤訓練法-詞圖T-音節正確率 ··· 46
圖 4.14 最小音素錯誤訓練法-詞圖T-聲韻母正確率 ··· 47
圖 5.1 音素音框正確度的計算範例 ··· 49
圖 5.2 音素正確度與音素音框正度之比較範例··· 50
圖 5.3 加入錯誤處罰與音素長度正規化的音素音框正確度的計算範例 ··· 51
圖 5.4 最小音素音框錯誤訓練法-詞圖N-詞正確率 ··· 55
圖 5.5 最小音素音框錯誤訓練法-詞圖N-字正確率 ··· 56
圖 5.6 最小音素音框錯誤訓練法-詞圖N-音節正確率 ··· 57
圖 5.7 最小音素音框錯誤訓練法-詞圖N-聲韻母正確率 ··· 58
圖目錄
~ viii ~
圖 5.8 最小音素音框錯誤訓練法-詞圖T-詞正確率 ··· 59
圖 5.9 最小音素音框錯誤訓練法-詞圖T-字正確率 ··· 60
圖 5.10 最小音素音框錯誤訓練法-詞圖T-音節正確率 ··· 61
圖 5.11 最小音素音框錯誤訓練法-詞圖T-聲韻母正確率 ··· 62
圖 5.12 最小音素音框錯誤-錯誤處罰音素正規化-詞圖N-詞正確率 ··· 64
圖 5.13 最小音素音框錯誤-錯誤處罰音素正規化-詞圖N-字正確率 ··· 64
圖 5.14 最小音素音框錯誤-錯誤處罰音素正規化-詞圖N-音節正確率 ··· 64
圖 5.15 最小音素音框錯誤-錯誤處罰音素正規化-詞圖N-聲韻母正確率 ·· 65
圖 5.16 最小音素音框錯誤-錯誤處罰音素正規化-詞圖T-詞正確率 ··· 65
圖 5.17 最小音素音框錯誤-錯誤處罰音素正規化-詞圖T-字正確率 ··· 65
圖 5.18 最小音素音框錯誤-錯誤處罰音素正規化-詞圖T-音素正確率 ··· 66
圖 5.19 最小音素音框錯誤-錯誤處罰音素正規化-詞圖T-聲韻母正確率 · 66 圖 5.20 狀態音框正確度的計算範例 ··· 67
圖 5.21 加入錯誤處罰的狀態音框正確度的計算範例 ··· 69
圖 5.22 加入錯誤處罰與音素長度正規化的狀態音框正確度的計算範例 ··· 70
圖 5.23 狀態層級最小貝氏風險-詞圖N-詞正確率 ··· 73
圖 5.24 狀態層級最小貝氏風險-詞圖N-字正確率 ··· 74
圖 5.25 狀態層級最小貝氏風險-詞圖N-音節正確率 ··· 75
圖 5.26 狀態層級最小貝氏風險-詞圖N-聲韻母正確率 ··· 76
圖 5.27 狀態層級最小貝氏風險-詞圖T-詞正確率 ··· 77
圖 5.28 狀態層級最小貝氏風險-詞圖T-字正確率 ··· 78
圖 5.29 狀態層級最小貝氏風險-詞圖T-音節正確率 ··· 79
圖 5.30 狀態層級最小貝氏風險-詞圖T-聲韻母正確率 ··· 80
圖 5.31 最小歧異度訓練法-詞圖N-詞正確率 ··· 82
圖 5.32 最小歧異度訓練法-詞圖N-字正確率 ··· 83
圖 5.33 最小歧異度訓練法-詞圖T-詞正確率 ··· 83
圖 5.34 最小歧異度訓練法-詞圖T-字正確率 ··· 83
圖 5.35 三種訓練法之比較-詞圖N-詞正確率 ··· 84
圖 5.36 三種訓練法之比較-詞圖N-字正確率 ··· 85
圖目錄
~ ix ~
圖 5.37 三種訓練法之比較-詞圖T-詞正確率 ··· 85
圖 5.38 三種訓練法之比較-詞圖T-詞正確率 ··· 85
圖 6.1 分類邊際的最大化 ··· 86
圖 6.2 最小音素錯誤-詞弧篩選-詞圖N-過度訓練情形 ··· 88
圖 6.3 最小音素錯誤-詞圖N-詞弧正確度分佈 ··· 90
圖 6.4 最小音素錯誤-詞圖T-詞弧正確度分佈 ··· 90
圖 6.5 MPFE+pen+len-詞圖 N-詞弧正確度分佈 ··· 91
圖 6.6 MPFE+pen+len-詞圖 T-詞弧正確度分佈 ··· 91
圖 6.7 詞弧篩選-詞圖N-詞正確率 ··· 92
圖 6.8 詞弧篩選-詞圖N-字正確率 ··· 93
圖 6.9 詞弧篩選-詞圖N-音節正確率 ··· 94
圖 6.10 詞弧篩選-詞圖N-聲韻母正確率 ··· 95
圖 6.11 詞弧篩選-詞圖T-詞正確率 ··· 96
圖 6.12 詞弧篩選-詞圖T-字正確率 ··· 97
圖 6.13 詞弧篩選-詞圖T-音節正確率 ··· 98
圖 6.14 詞弧篩選-詞圖T-聲韻母正確率 ··· 99
圖 6.15 各方法最佳值之綜合比較-最佳詞正確率 ··· 103
圖 6.16 各方法最佳值之綜合比較-最佳字正確率 ··· 103
圖 6.17 各方法最佳值之綜合比較-最佳音節正確率 ··· 104
圖 6.18 各方法最佳值之綜合比較-最佳聲韻母正確率 ··· 104
圖 B.1 輔助函數示意圖,橫軸代表 值 ···111
圖 B.2 弱性輔助函數示意圖,橫軸代表 值 ··· 112
圖 B.3 平滑函數示意圖,橫軸代表 值 ··· 113
圖 B.4 弱性輔助函數加上平滑函數之示意圖,橫軸代表 值 ··· 115
表目錄
~ xi ~
表目錄
表 3.1 訓練集與評估集的語料資訊 ··· 17
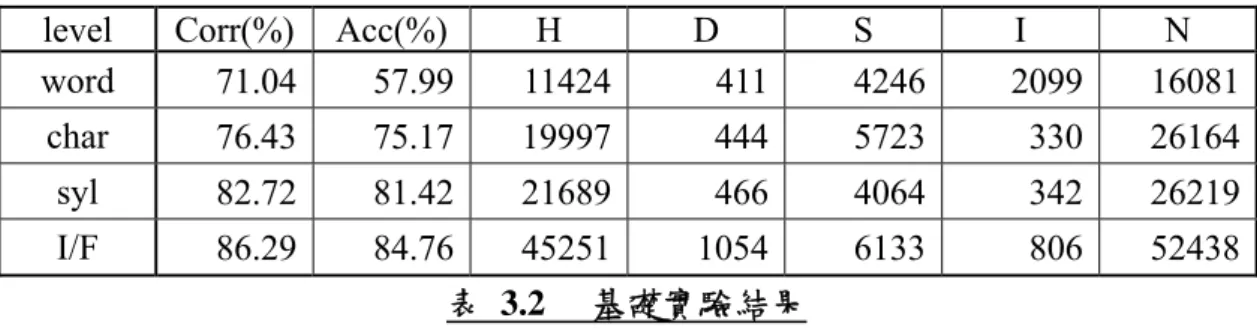
表 3.2 基礎實驗結果 ··· 21
表 4.1 最小音素錯誤訓練法-詞圖N-詞正確率 ··· 40
表 4.2 最小音素錯誤訓練法-詞圖N-音節正確率 ··· 41
表 4.3 最小音素錯誤訓練法-詞圖N-音節正確率 ··· 42
表 4.4 最小音素錯誤訓練法-詞圖N-聲韻母正確率 ··· 43
表 4.5 最小音素錯誤訓練法-詞圖T-詞正確率 ··· 44
表 4.6 最小音素錯誤訓練法-詞圖T-字正確率 ··· 45
表 4.7 最小音素錯誤訓練法-詞圖T-音節正確率 ··· 46
表 4.8 最小音素錯誤訓練法-詞圖T-聲韻母正確率 ··· 47
表 5.1 平滑係數最佳值之估測 ··· 52
表 5.2 最小音素音框錯誤訓練法-詞圖N-詞正確率 ··· 55
表 5.3 最小音素音框錯誤訓練法-詞圖N-字正確率 ··· 56
表 5.4 最小音素音框錯誤訓練法-詞圖N-音節正確率 ··· 57
表 5.5 最小音素音框錯誤訓練法-詞圖N-聲韻母正確率 ··· 58
表 5.6 最小音素音框錯誤訓練法-詞圖T-詞正確率 ··· 59
表 5.7 最小音素音框錯誤訓練法-詞圖T-字正確率 ··· 60
表 5.8 最小音素音框錯誤訓練法-詞圖T-音節正確率 ··· 61
表 5.9 最小音素音框錯誤訓練法-詞圖T-聲韻母正確率 ··· 62
表 5.10 最小音素音框錯誤-加入錯誤處罰與音素正規化-詞圖N ··· 63
表 5.11 最小音素音框錯誤-加入錯誤處罰與音素正規化-詞圖T ··· 63
表 5.12 狀態層級最小貝氏風險-平滑係數最佳值之估測 ··· 71
表 5.13 狀態層級最小貝氏風險-詞圖N-詞正確率 ··· 73
表 5.14 狀態層級最小貝氏風險-詞圖N-字正確率 ··· 74
表 5.15 狀態層級最小貝氏風險-詞圖N-音節正確率 ··· 75
表 5.16 狀態層級最小貝氏風險-詞圖N-聲韻母正確率 ··· 76
表 5.17 狀態層級最小貝氏風險-詞圖T-詞正確率 ··· 77
表目錄
~ xii ~
表 5.18 狀態層級最小貝氏風險-詞圖T-字正確率 ··· 78
表 5.19 狀態層級最小貝氏風險-詞圖T-音節正確率 ··· 79
表 5.20 狀態層級最小貝氏風險-詞圖T-聲韻母正確率 ··· 80
表 6.1 最小音素錯誤訓練-詞弧選擇閥值 ··· 88
表 6.2 MPFE-加入錯誤處罰音素長度正規化-詞弧選擇閥值-詞圖 N ··· 89
表 6.3 MPFE-加入錯誤處罰音素長度正規化-詞弧選擇閥值-詞圖 T ··· 89
表 6.4 詞弧篩選-詞圖N-詞正確率 ··· 92
表 6.5 詞弧篩選-詞圖N-字正確率 ··· 93
表 6.6 詞弧篩選-詞圖N-音節正確率 ··· 94
表 6.7 詞弧篩選-詞圖N-聲韻母正確率 ··· 95
表 6.8 詞弧篩選-詞圖T-詞正確率 ··· 96
表 6.9 詞弧篩選-詞圖T-字正確率 ··· 97
表 6.10 詞弧篩選-詞圖T-音節正確率 ··· 98
表 6.11 詞弧篩選-詞圖T-聲韻母正確率 ··· 99
表 6.12 各方法目標函數之詞弧正確度計算方法··· 101
表 6.13 詞圖N-最高正確率 ··· 102
表 6.14 詞圖T-最高正確率 ··· 102
表 A.1 韻母模型列表 ··· 107
表 A.2 右相關聲母模型列表 ··· 108
表 A.3 聲韻母聲學模型在訓練語料的出現次數與狀態中的高斯混合數 ··· 110
第1 章 緒論 1.1 研究動機
~ 1 ~
第1章 緒論
1.1 研究動機
在傳統的語音模型訓練中,模型參數的估測是由最大相似度估測法(Maximum Likelihood Estimation, MLE)求得,此方法的目標是讓正確轉寫(transcription)在訓練 語料中產生最大的事後機率(posterior probability),然而最大相似度估測法並未考慮 到競爭字串(competing word sequence),以致於在辨識的語料時,正確轉寫的聲學 模型相似度(likelihood)未必高於競爭字串的聲學模型相似度,而造成辨識的錯誤。
鑑別式訓練(discriminative training)的目的在於訓練過程中,加入對於競爭字串的考 慮,目標是使正確轉寫的聲學模型相似度高於競爭字串的聲學模型相似度,將混 淆的模型有效地分開,以達成提高辨識率的效果。
鑑別式訓練法在約二十年前首先由 IBM 提出的最大相互資訊 (Maximum Mutual Information, MMI) 估測法【1】開始,之後亦有最小分類錯誤(Minimum Classification Error, MCE)估測法【2】提出,都表現出比最大相似度估測法更好的 成效,到了2002 年劍橋大學又更進一步提出了最小音素錯誤(Minimum Phone Error, MPE)模型訓練法【3】,以降低音素錯誤率為目標,充份利用詞圖(word graph)資訊,
並且找到了更有效率的參數最佳化方法,讓鑑別式訓練法在大字彙辨識上也有顯 著的成效,因而最小音素錯誤模型訓練法成為目前鑑別式聲學模型訓練法中最具 代表性的方法之一。
在最小音素錯誤模型訓練法之後,又提出了許多根據此方法改進而來的鑑別 式聲學模型訓練法,如最小音素音框錯誤(Minimum Phone Frame Error, MPFE)模型 訓練法【4】,是在錯誤率的計算上,使用比音素(phone)更小的音框(frame)為單位。
以及最小歧異度(Minimum Divergence, MD)模型訓練法【5】,是在計算錯誤率時針 對不同的比對錯誤給與不同的扣分因素(penalty),這些方法都能讓鑑別式聲學模型 訓練法的辨識率有更近一步的提升。
1.2 統計式語音辨識 1.2.1 聲學模型
~ 2 ~
1.2 統計式語音辨識
語音辨識的直覺上的做法可以理解成:「找出聽起來最像、最可能的句子」,
而相像、可能概念的量化,可以用機率來表示,這就是統計式語音辨識的基本概 念。因此,「找出聽起來最像、最可能的句子」就可理解成「找出機率最高的句子」。 若O是給定的觀測語句(observation),要從所有文句W 中找出機率最大的文句 s 可h 表示成:
( )
arg max |
u Wh
s P u O
= ∈ (1.1)
其中 u 為所有文句Wh中的某一句,P u O
(
|)
代表在 O 發生時,文句 u 的事後機率。進一步使用貝氏定理(Bayes’ Theorem)將P u O
(
|)
展開可以得到:( ) ( ) ( )
( )
| P O u P u| P u O
= P O (1.2)
(
|)
P O u 表示給定文句 u 其聲音是語句 O 的相似度或機率,通常使用機率分佈
(probability distribution)來呈現,由於這個機率分佈主要用來決定聲學特徵的機率,
故稱為聲學模型(acoustic model),而此機率分佈中的參數便稱為聲學模型參數;
( )
P u 則是文句 u 的事前機率,表示語言中出現 u 的機率,同樣使用機率分佈來呈 現,由於這個機率用來決定語言機率,故稱為語言模型(language model)。P O
( )
則是指觀測語句 O 的出現機率,由於在(1.2)中P O
( )
與 u 無關,因此拿掉此項對於尋 找機率最大的文句 u 並無影響,因此(1.1)可以簡化為:( ) ( )
arg max |
u Wh
s P O u P u
= ∈ (1.3)
1.2.1 聲學模型
聲學模型的主要功能,便是對於觀測語句,能夠針對不同的發音可能,給與 相對應的機率或相似度,即(1.3)中的P O u
(
|)
,一般使用機率密度函數(probability density function)來近似。而聲學模型訓練,就是在訓練語料中給定的觀測語句,以1.2.1 聲學模型
~ 3 ~
及其對應的正確轉寫,在訓練過程中調整聲學模型參數,使得正確轉寫和其對應 的發音產生最大的事後機率,簡易流程如圖 1.1。
本論文中,使用連續密度隱藏式馬可夫模型(Continuous Density Hidden Markov Models, CDHMM)【6】做為聲學模型,模型的結構如圖 1.2 所示,每一個模型都 由連續的數個狀態(state),以及狀態間的轉移(transition)構成,每一個轉移均有其 轉移機率(transition probability),一般語音的聲學模型,狀態轉移只允許停留在原 狀態或跳至鄰接的下一狀態,而其中每一個狀態對一音框的聲學特徵觀測機率 (observation probability),則使用連續的高斯混合模型(Gaussian Mixture Model, GMM)來決定。
S1 S2 S3
圓圈代表狀態
箭號代表狀態的轉移 狀態內為高斯混合模型
圖 1.2 連續密度隱藏式馬可夫模型示意圖
訓練語料 聲學模型訓練 聲學模型
特徵抽取 正確轉寫
圖 1.1 聲學模型訓練流程
1.2.2 語言模型
1.3 研究主題與主要成果
~ 4 ~
1.2.2 語言模型
語言模型的主要功能,便是針對不同的文句,給與一個該文句在語言中的使 用 機 率 , 即(1.3) 中 的 P u
( )
, 若 文 句 u 由 N 個 詞 w w1, 2,...,wN 組 成 , 則( ) (
1, 2,..., N)
P u =P w w w ,為w w1, 2,...,w 的聯合機率(joint probability)。由於語言機N 率是離散的分佈,故語言模型的建立不使用機率密度函式來近似,而是對個別的 機率作直接估測。由於需要估測的參數量很大,存在資料稀疏的問題,故將聯合 機率P w w
(
1, 2,...,wN)
展開成條件機率的連乘(
1 2 1)
1
| , ,...,
N
k k
k
P w w w w−
∏
= ,再使用n−1階馬可夫假設(n-1 order Markov Assumption)來簡化,稱為 n 連(n-gram)語言模型,
可表示為:
( ) (
1 2) (
1 2 1)
1
, ,..., N N k| k n , k n ,..., k
k
P u P w w w P w w − + w− + w−
=
= ≈
∏
(1.4)1, 2,..., N
w w w 為歷史詞序列(history word sequences),條件機率P w
(
k | ,w w1 2,...,wk−1)
可以解釋為根據歷史詞預測下一個詞為w 的機率,故建立 n 連語言模型即是為每k 一種詞序列建立各自的條件機率分佈。實作上,常見的有使用一階馬可夫假設的 詞雙連(bigram)語言模型,可表示為:
(
k | k n 1, k n 2,..., k 1) (
k| k 1)
P w w− + w − + w− ≈P w w− (1.5) 以及使用二階馬可夫假設的詞三連(trigram)語言模型,可表示為:
(
k | k n 1, k n 2,..., k 1) (
k | k 2, k 1)
P w w− + w − + w− ≈P w w− w− (1.6) n 連語言模型的機率常以最大相似度估測法來做測,配合使用語言模型平滑技術,
對無法由訓練語料估測的詞序機率加以平滑化。
1.3 研究主題與主要成果
本論文主要探討最小音素錯誤訓練法、最小音素音框錯誤訓練法、狀態層級 最小貝氏風險訓練法,以及最小歧異度訓練法,這四種方法在中文大字彙辨識上 的成效。以及基於這四種方法,針對詞弧正確度做進一步改進的方法之比較。實
1.4 論文架構
~ 5 ~
驗結果發現這些方法在詞正確率與字正確率會有不一致的變化,其中最小音素錯 誤訓練法是偏好字正確率的方法,字正確率的表現較其它方法好;最小音素音框 錯誤訓練法和狀態層級最小貝氏風險訓練法則是偏好詞正確率的方法,詞正確率 的表現較其它方法好。而將詞弧正確度做進一步改進的方法實行在這兩種偏好詞 正確率的方法上,會產生詞正確率下降而字正確率上升的變化,表示將詞弧正確 度做進一步改進之後,這兩種原本偏好詞正確率的方法會轉變成偏好字正確率的 方法。
另外,本論文也實驗詞弧篩選的資料選取方法在最小音素錯誤訓練和將詞弧正確 度改進後的最小音素音框錯誤上,實驗結果顯示資料選取對於正確率的變化並沒 有很大的影響,不過可以加快訓練的收斂速度。
1.4 論文架構
本論文第二章將介紹鑑別式訓練法則,從貝氏風險出發,回顧並介紹鑑別式 訓練法的發展流程。
第三章將介紹本論文的實驗系統以及基礎實驗設定和實驗結果。
第四章將介紹最小音素錯誤訓練法的理論基礎以及實作的方法。
第五章將介紹最小音素音框錯誤訓練法、狀態層級最小貝氏風險訓練法、最 小歧異度訓練法,以及這三種方法進一步的修改版本。
第六章將介紹基於詞弧期望正確度的資料選取方法,實驗在最小音素錯誤訓 練法和第五章中最小音素音框錯誤訓練法的其中一種修改版本上。
第七章會提出總結以及未來展望。
第2 章 背景知識 2.1 鑑別式訓練法則
~ 6 ~
第2章 背景知識
2.1 鑑別式訓練法則
鑑別式訓練法的主要概念,在於訓練模型時,不以訓練語料相似度的最大化 為目標,而是以分類錯誤的最小化為目標,進而增進辨識率。傳統的聲學模型訓 練,以最大相似度估測法為原則,在訓練時調整模型參數的目標是使得正確的語 音聲學特徵在此聲學模型的相似度變大,但是這種訓練方式沒有考慮到模型間彼 此的關係,所以在使正確的語音聲學特徵在對應的模型上的相似度增加時,可能 同時使不正確的語音聲學特徵在此聲學模型的相似度也變大,造成辨識上的混淆,
舉例如圖 2.1,(a)表示一個正確轉寫為 u 的觀測語句 Ou,在模型M 上可以得到一 相似度 P(Ou|M),在訓練時以相似度的最大化為目標的過程就如(b)所示,訓練時會 調整模型A 使得正確轉寫為 A 的觀測語句 OA落在模型A 上的相似度 P(OA|A)增加,
M
P(Ou|M) Ou
正確轉寫為 u 的觀測語句 Ou,落 在模型M 裡的相似度 P(Ou|M)
A
P(OA|A) OA
B
P(OB|B) OB
訓練時,調整模型A、B,使得 P(OA|A) > P(OB|A)且 P(OB|B) > P(OA|B)
A
P(OB|A)
OB B
P(OA|B) OA
辨識時,可能發生 P(OB|A) > P(OB|B)的情形而將 B 錯誤辨識為 A;
或是 P(OA|B) > P(OA|A)的情形而將 A 錯誤辨識為 B。
圖 2.1 最大相似度估測法造成混淆的情形 (a)
(b)
(c)
2.2 貝氏風險(Bayes Risk)
~ 7 ~
大於其它正確轉寫不為A 的觀測語句落在模型 A 上的相似度,同樣的也調整模型 B 使得 OB落在模型B 上的相似度 P(OA|B)增加,大於其它正確轉寫不為 B 的觀測 語句落在模型B 上的相似度,這樣的訓練自然會有 P(OA|A) > P(OB|A)且 P(OB|B) >
P(OA|B)的結果,然而在(c)的辨識時,辨識的準則是測試觀測語句落在每個模型裡 的相似度,再挑選出落在哪個模型裡的相似度最大,而採定為辨識結果,這與相 似度最大化的訓練原則並不一致,在(b)中雖然訓練結果會使正確轉譯為 A 的觀測 語句 OA落在模型 A 的相似度一定大於 OB落在模型 A 的相似度,卻無法確定確 OA落在模型 B 的相似度是否會更大,意即發生 P(OB|B) > P(OA|B) > P(OA|A) >
P(OB|A)的情況,如此一來雖然 B 可以正確辨識為 B,A 卻會被錯誤辨識為 B;反 之發生 P(OA|A) > P(OB|A) > P(OB|B) > P(OA|B)的情況一樣會造成辨識錯誤,然而這 兩種情況皆不違反在(b)中的訓練原則。
鑑別式訓練法便是針對這個缺點改進,企圖在訓練模型時同時考慮正確與不 正確的語音聲學特徵,使得正確的語音聲學特徵在其聲學模型上的相似度可以大 於不正確的語音聲學特徵在此聲學模型上的相似度,意即在圖 2.1 中的(b)訓練目 標是 P(OA|A) > P(OB|A)且 P(OB|B) > P(OA|B)。
以下幾節將從貝氏風險開始,以鑑別式訓練方法的演進,介紹數個廣泛研究 過的模型訓練法,包括其目標函數(objective function)及物理意義。
2.2 貝氏風險(Bayes Risk)
如果將語音辨識視為一個分類的行為,即對一語句O 分類至一文句 s ,而辨r 識所做的分類未必正確,因此存在一個分類錯誤的風險,用一個函數R s O
(
| r)
代表 將語句O 分類至文句 s 的風險,這個風險函數可以定義如下: r(
|) (
|) ( )
,h
r r
u W
R s O P u O L s u
∈
=
∑
(2.1)O 表示觀測語句的特徵向量,r W 表示所有可能文句之集合,h P u O
(
| r)
表示給定觀 測語句的特徵向量O 時,文句 u 的事後機率,r L s u( )
, 為一減損函數(loss function),2.3 最大相似度(Maximum Likelihood, ML)
~ 8 ~
表示文句 s 和 u 之問的差異造成的損失;因此R s O
(
| r)
就是將O 辨識為 s 的損失r 期望值。在實作語音辨識的解碼上,會以風險值最小化的s 作為辨識結果: *( ) ( ) ( )
* arg min | arg min | ,
h
r r
s s
u W
s R s O P u O L s u
∈
= =
∑
(2.2)這個風險的最小值即為貝氏風險RBayes:
( ) ( ) ( )
min | min | ,
h
Bayes r r
s s
u W
R R s O P u O L s u
∈
= =
∑
(2.3)目前許多辨識的解碼方法都是以最小貝氏風險為原則,如最大事後機率解碼 (Maximum a posterior decoding, MAP decoding)【7】、最小貝氏風險(Minimum Bayesian Risk decoding, MBR decoding)【8】,以及最小詞錯誤解碼(word error minimization decoding)【9】,都是這個方法的應用。
至於將貝氏風險運用在模型訓練上,則是把風險函數作為目標函數:
( ) ( )
( ) ( )
* *
,
, ,
, arg min |
arg min | ,
r r
r
r r
r u
R s O
P u O L s u
λ
λ λ
λ Γ
Γ Γ
Γ =
=
∑
∑∑
(2.4)其中λ,Γ 分別是聲學模型與語言模型的參數集,s 是r O 的正確轉寫,r r是訓練語 句(utterance)的索引,Pλ Γ,
(
u O| r)
表示 u 基於聲學模型與語言模型的事後機率。模 型訓練的目標可以視為將訓練語句的整體風險總合最小化。以下將介紹數種聲學模型訓練法,其目標函數皆由貝氏風險而來,但也各有 所不同,以下會介紹其目標函數與貝氏風險之間的關係。
2.3 最大相似度(Maximum Likelihood, ML)
最大相似度估測法的目標函數是將貝氏風險中的減損函數定義為零壹函數 (zero-one function),即是將(2.4)中的L s u
(
r,)
定義如下:(
,)
0 ,1 ,
r r
r
u s L s u
u s
⎧ =
= ⎨⎩ ≠ (2.5)
也就是當文句s 與 u 相同時損失為 0,否則損失為 1。則(2.4)可推導為: r
2.3 最大相似度(Maximum Likelihood, ML)
~ 9 ~
( ) ( ) ( )
( )
( )
( )
* *
, ,
, ,
, ,
, arg min | , arg min |
arg min 1 |
r
r r
r u
r r u s
r r
r
P u O L s u P u O
P s O
λ λ
λ λ
λ λ
λ Γ
Γ
Γ ≠ Γ
Γ Γ
Γ =
=
= −
∑∑
∑∑
∑
(2.6)
倘若將(2.6)繼續代換如下:
( ) ( ( ) )
( )
* *
, ,
, ,
, arg min 1 | arg max |
r r
r
r r
r
P s O P s O
λ λ
λ λ
λ Γ
Γ
Γ Γ
Γ = −
=
∑
∑
(2.7)(2.7)的結果就是所謂的最大事後機率(maximum a posterior, MAP)。
如果再將(2.6)的結果套用詹氏不等式(Jensen’s inequality):
( ) ( )
, ,
1−PλΓ s Or | r ≤ −logPλΓ s Or | r (2.8) (2.6)就會進一步變成:
( ) ( ( ) )
( )
( )
( )
* *
, ,
, ,
, ,
, arg min 1 | arg min log | arg max log |
r r
r
r r
r
r r
r
P s O P s O P s O
λ λ
λ λ
λ λ
λ Γ
Γ
Γ Γ
Γ Γ
Γ = −
= −
=
∑
∑
∑
(2.9)
之後再使用貝氏定理(Bayes' theorem)推導如下:
( ) ( )
( ) ( )
( )
* *
, ,
,
, arg max log | arg max log |
r r
r
r r r
r r
P s O P O s P s
P O
λ λ
λ λ
λ Γ
Γ
Γ Γ
Γ =
=
∑
∑
(2.10)由於假設所有的O 為均勻分布(uniform distribution),因此在(2.10)中又可以省略此r 項:
(
*, *)
arg max, log(
r| r) ( )
r rP O s P Oλ
λ λ Γ
Γ = Γ
∑
(2.11)最後因為最大相似度估測法只訓練聲學模型,因此只保留與聲學模型λ 有關的項 目,於是就成為最大相似度估測法的目標函數FML
( )
λ :2.4 最大相互資訊(Maximum Mutual Information, MMI)
~ 10 ~
( )
log(
|)
ML r r
r
F
λ
=∑
P O sλ (2.12)而最大相似度聲學模型參數的估測就是其目標函數的最大化:
( ) ( )
argmax argmax log |
ML ML r r
r
F P O sλ
λ λ
λ
=λ
=∑
(2.13)2.4 最大相互資訊(Maximum Mutual Information, MMI)
對於(2.10)的結果,如果對分母項P O( )
r 使用貝氏定理展開:( ) (
|) ( )
h
r r
u W
P O P O u P uλ Γ
∈
=
∑
(2.14)其中W 表示所有可能的辨識結果,u 為可能辨識結果的其中一句,則(2.10)可以進h 一步推導為:
(
*, *)
arg max, log( (
| |) ( ) ) ( )
h
r r r
r r
u W
P O s P s P O u P u
λ
λ λ
λ Γ
Γ Γ
∈
Γ =
∑ ∑
(2.15)這裡如(2.12)同樣的省略掉P sΓ
( )
r 後,就成為最大相互資訊估測法的目標函數MMI
( )
F λ :
( ) ( )
( ) ( )
log |
|
h
r r
MMI
r r
u W
P O s
F P O u P u
λ λ
λ
Γ
∈
=
∑ ∑
(2.16)而最大相互資訊聲學模型參數的估測就是其目標函數的最大化:
( ) ( )
( ) ( )
arg max arg max log |
|
h
r r
ML MMI
r r
u W
P O s
F P O u P u
λ
λ λ
λ
λ λ
Γ
∈
= =
∑ ∑
(2.17)而在(2.17)中由於:
( )
( ) ( ) ( )
( ) ( )
( ) ( )
| | ,
log log log
|
h
r r r r r r
r r r r
u W
P O s P O s P O s
P O u P u P O P O P s
λ λ λ
λ Γ
∈
= =
∑
(2.18)表示觀測語句O 與正確轉寫r s 的相互資訊(mutual information),是故最大相互資訊r 估測法就是在最大化觀測語句O 與正確轉寫r s 的相互資訊。 r
2.5 全面風險法則估測(Overall Risk Criterion Estimation, ORCE)
~ 11 ~
將最大相互資訊用於聲學模型的訓練,最早是由IBM 在 1986 年提出【1】,在 辨識2000 個獨立的詞的辨識實驗中,比最大相似度估測法降低了 18%的詞錯誤率。
布氏(Brown)在 1987 年時使用最大相互資訊估測法訓練連續隱藏式馬可夫模型
【10】,可以產生 18%的相對進步率,由於最佳化的過程十分複雜,所以使用了斜 率遞減法(gradient descent)來求解。之後在 1995 年,諾氏(Normandin)更將延伸式波 氏重估(extended Baum-Welch re-estimation, EBW)【11】演算法用於連續隱藏式馬 可夫模型的參數最佳化上【12】。之後范氏(Valtchev)等人則將最大相互資訊估測法 應 用 到 大 字 彙 連 續 語 音 辨 識(Large Vocabulary Continuous Speech Recognition, LVCSR)上【13】,在 64000 個詞彙的實驗中,可以產生約 5~10%的相對進步率,
此時的實驗已經使用語音辨識產生的詞圖作為可能的辨識結果((2.14)中的W )的近h 似,進而利用(2.14)近似出觀測語句的事前機率P O
( )
r 。2002 年由伍氏(Woodland)等人於劍橋大學提出 I 平滑(I-Smoothing)技術【14】,
由訓練語料中使用最大相似度估測之統計資訊,作為待測模型的事前機率分佈,
來加強最大相互資訊估測模型的強健性。
2.5 全面風險法則估測(Overall Risk Criterion Estimation, ORCE)
在上述的最大相似度及最大相互資訊中,皆使用零壹函數作為減損函數,零 壹函數可以視為句錯誤率的計算,但在語音辨識結果的評量上,英文習慣使用詞 錯誤率(word error rate, WER),中文則使用字錯誤率(character error rate, CER)較為 合理,兩種評量方式皆與零壹函數的錯誤率計算方式相左,因此,以零壹函數的 減損函數為最小化的目標並不一定帶來較低的辨識錯誤率,為了克服這個問題,
在全面風險法則估測中便提出了使用編輯距離(Levenshtein distance)取代零壹函數 為減損函數的作法,編輯距離的定義如圖 2.2 及(2.19)式所示【15】:
2.5 全面風險法則估測(Overall Risk Criterion Estimation, ORCE)
~ 12 ~
(
r,)
Edit(
r,) [
,]
L s u =L s u =d m n (2.19)
編輯距離為計算文句 u 與正確轉寫s 之間的距離,將文句中的字詞一一比對r (圖 2.2 中之 u 的 1 到 m 個字詞及s 的 1 到 n 個字詞),過程中可以統計出字詞的遺r 失(deletion)、插入(insertion)、取代(substitution),用來計算辨識正確率。將(2.4)中 的Pλ Γ,
(
u O| r)
同(2.10)般展開,再將P O( )
r 如同(2.14)般展開,並將編輯距離作為減 損函數,便可推導出全面風險法則估測:(
*, *)
arg min, h(
|( ) ( )
|) ( ) (
,)
h
r r r Edit r
u W
r r
u W
P O s P s L s u P O u P u
λ
λ λ
λ
Γ
∈
Γ Γ
∈
Γ =
∑
∑ ∑
(2.20)全面風險法則估測在 2002 由凱氏(Kaiser)等人提出以編輯距離取代零壹函數 作為減損函數,以N 最佳路徑(N-best)作為所有辨識可能的近似,並使用延伸式波 氏重估演算法來實行模型最佳化【16】,在 TIMIT 的音素辨識實驗中,約可降低 20.8%的詞錯誤率。
int LevenshteinDistance(char sr[1..m], char u[1..n]) // d is a table with m+1 rows and n+1 columns declare int d[0..m, 0..n]
for i from 0 to m d[i, 0] := i for j from 0 to n d[0, j] := j for i from 1 to m for j from 1 to n
if sr[i] = u[j] then cost := 0 else cost := 1
d[i, j] := minimum(
d[i-1, j] + 1, // deletion d[i, j-1] + 1, // insertion d[i-1, j-1] + cost // substitution )
return d[m, n]
圖 2.2 編輯距離之計算方式
2.6 最小分類錯誤(Minimum Classification Error, MCE)
~ 13 ~
2.6 最小分類錯誤(Minimum Classification Error, MCE)
在(2.1)中,一般均使用零壹函數作為減損函數來計算貝氏風險,然而最小分類 錯誤訓練法則重新定義風險函數,並套用至S 形函數(Sigmoid function):
(
r | r)
1 exp{
1,(
r | r) }
R s O
dλ O s
γ Γ θ
= + − + (2.21)
其中dλ Γ,
(
Or |sr)
為錯誤分類計量(misclassification measure),定義為:( ) ( ) ( )
( ) ( )
1
, ,
1 |
| log 1
|
h r
r u W u s
r r
r r r
P O u P u d O s M
P O s P s
η η η λ
λ η η
λ
∈ ≠ Γ Γ
Γ
⎛ ⎞
⎜ − ⎟
⎜ ⎟
= ⎜ ⎟
⎜ ⎟
⎝ ⎠
∑
(2.22)
其中 M 表示所有辨識可能W 的文句數目,h γ 、θ 為 S 形函數的控制參數,
h, r
u W u∈ ≠ 表示s s 的競爭文句,r η 為比例控制參數,可以決定競爭文句中不同機 率文句的影響程度差異,η 越大會使得機率高的文句具有越大的影響,而 S 形函 數的功能是將錯誤分類計量的數值投影到 0 與 1 之間。如果定義分類條件相似度 函數(class conditional likelihood functions)g Ov
(
; ,λ Γ)
如下:(
; ,)
log(
|) ( )
g Ov λ Γ = P O v P vλ Γ (2.23)
則(2.22)可以代換如下:
( ) ( ) { ( ) }
1,
,
| ; , log 1 exp ; ,
1
r
h r
r r s r u r
u W u s
d O s g O g O
M
η
λΓ λ λ η
∈ ≠
⎛ ⎞
= − Γ + ⎜⎝ −
∑
Γ ⎟⎠ (2.24) 由(2.24)可以將錯誤分類計量理解為競爭文句的平均相似度與正確轉寫的相似度的 比值,越小表示錯誤越低,會計算出越小的錯誤分類計量。因此最小分類錯誤的 目標函數FMCE(
λ,Γ)
可以表示如下:( ) ( ) ( )
( ) ( )
1
,
, 1 |
1 |
1 h r
r r r
MCE
r
r u W u s
P O s P s
F e
P O u P u M
γ η
η η
θ λ
η η
λ
λ
−
Γ
∈ ≠ Γ
⎛ ⎛ ⎞ ⎞
⎜ ⎜ ⎟ ⎟
⎜ ⎜ ⎟ ⎟
Γ = ⎜ + ⎜ ⎟ ⎟
⎜ ⎜ ⎟ ⎟
⎜ ⎝ − ⎠ ⎟
⎝ ⎠
∑ ∑
(2.25)2.7 最小音素錯誤(Minimum Phone Error, MPE)
~ 14 ~
而使用最小分類錯誤訓練聲學模型時,就是在最大化其目標函數,因為目標只有 訓練聲學模型,因此將語言模型視為已知:
( )
( ) ( )
( ) ( )
1
,
arg max
arg max 1 |
1 |
1 h r
MCE MCE
r r r
r
r u W u s
F
P O s P s e
P O u P u M
λ
γ η
η η
θ λ
λ η η
λ
λ λ
−
Γ
∈ ≠ Γ
=
⎛ ⎛ ⎞ ⎞
⎜ ⎜ ⎟ ⎟
⎜ ⎜ ⎟ ⎟
= ⎜ + ⎜ ⎟ ⎟
⎜ ⎜ ⎟ ⎟
⎜ ⎝ − ⎠ ⎟
⎝ ⎠
∑ ∑
(2.26)
最小分類錯誤在 1992 年由莊氏(Juang)等人提出【17】【2】,使用一般化機率 遞減法(generalized probability descent, GPD)來進行最佳化。有許多成果在小字彙訓 練上提出,如周氏(Chou)在 TI Digit String 的實驗可以降低 25%的字串錯誤率【18】,
薛氏(Sual)等人在小型及中型詞彙辨識上也能產生 10%的相對進步率【19】。而在 2000 年,舒氏(Schlüter)則將最小分類錯誤訓練法應用到大字彙連續音辨識上【20】,
利用詞圖作為競爭文句的近似。
2.7 最小音素錯誤(Minimum Phone Error, MPE)
最小音素錯誤模型訓練法在2002 年由劍橋大學的波氏(Povey)等人提出,相較 於最大相互資訊估測法是將正確轉寫的事後機率最大化,最小音素錯誤模型訓練 法是將訓練語料的音素正確度(Raw Pone Accuracy)期望值最大化【3】,將(2.4)中的 減損函數改為音素的正確率,將原本對減損函數的最小化改為對音素正確率的極 大化,可得如下:
( ) ( ) ( )
( ) ( ) ( )
( ) ( )
* *
, ,
,
, arg max | ,
| ,
arg max
|
h
h
r r
r u
r r
u W
r r
u W
P u O Acc s u P O u P u Acc s u
P O u P u
λ λ
λ
λ λ
λ Γ
Γ
∈ Γ
Γ Γ
∈
Γ =
=
∑∑
∑ ∑ ∑
(2.27)
是故最小音素錯誤訓練法的目標函數FMPE
( )
λ 為:2.8 綜合各種訓練法之目標函數推導流程 2.9 本章結論
~ 15 ~
( ) ( ) ( ) ( )
( ) ( )
| ,
|
h
h
r r
u W MPE
r r
u W
P O u P u Acc s u
F P O u P u
λ
λ
λ ∈ Γ
Γ
∈
=
∑
∑ ∑
(2.28)此目標函數可視為音素正確度的期望值,也就是將辨識可能 u 的音素正確度
(
r,)
Acc s u 乘上 u 的事後機率Pλ Γ,
(
u O| r)
做為權重再累加起來。實作上以詞圖來近 似所有的辨識可能,如(2.14)。在數學式上,最小音素錯誤模型訓練法類似於全面風險法則估測的一種變化 形,然而在實作上,全面風險法則估測一般使用N 最佳路徑作為辨識可能的近似,
並以詞錯誤率的最小化為目標;而最小音素錯誤模型訓練法則使用詞圖作為辨識 可能的近似,並以音素正確率的最大化為目標,此外還有引進待測模型的事前分 布(prior distribution)來增加模型的強健性。
而在實作上,最小音素錯誤模型訓練法類似於最大相互資訊估測法的一種變 化形,其中差別在於最大相互資訊估測法只將正確轉寫當成分子詞圖(numerator lattices),將整個詞圖當成分母詞圖(denominator lattices);最小音素錯誤模型訓練 法則會統計整個詞圖的音素正確度平均值,將正確度高於平均值的辨識可能當成 分子詞圖,將正確度低於平均值的辨識可能當成分母詞圖。
2.8 綜合各種訓練法之目標函數推導流程
綜合本章節之前的討論及推導,可知各種模型訓練的目標函數概念皆源自於 貝氏風險的最小化,經由使用不同的減損函數定義、事前機率的假設以及函式推 導的近似方式,發展出各式的模型估測法,如圖 2.3 所示。
2.9 本章結論
本章回顧了鑑別式訓練法發展的歷程,從貝氏風險的觀念開始,介紹了最大 相似度估測法,和諸多著名的鑑別式訓練法:最大相互資訊、全面風險法則估測、
最小分類錯誤,以及最小音素錯誤,最後再以這些訓練法目標函數的差異流程做 為結束。
2.9 本章結論
~ 16 ~
( ) ( )
, | r r,
r u
Pλ Γ u O L s u
∑∑
貝式風險
( ) ( ) ( ) ( )
1
,
1 |
1 |
1 h r
r r r
r
r u W u s
P O s P s e
P O u P u M
γ η
η η
θ λ
η η
λ
−
Γ
Γ
∈ ≠
⎛ ⎛ ⎞ ⎞
⎜ ⎜ ⎟ ⎟
⎜ + ⎜ ⎟ ⎟
⎜ ⎜ ⎟ ⎟
⎜ ⎜ − ⎟ ⎟
⎜ ⎝ ⎠ ⎟
⎝ ⎠
∑ ∑
最小分類錯誤
( ) ( ) ( )
( ) ( )
| ,
|
h
h
r r r r
u W
r r
u W
P O s P s Acc s u P O u P u
λ
λ Γ
∈
Γ
∈
∑ ∑ ∑
最小音素錯誤
( )
, r| r
r
Pλ Γ s O
∑
最大事後機率
( )
( ) ( )
( )
log , | log |
r r
r
r r r
r r
P s O P O s P s
P O
λ λ Γ
= Γ
∑
∑
( )
(
|) ( )
log |
h
r r
r r
u W
P O s P O u P u
λ
λ Γ
∑ ∑
∈最大相互資訊 使用零壹函數
為減損函數 不使用零壹函
數為減損函數
以詹氏不等式近似
( )
log r| r
r
P O sλ
∑
最大相似度 假設P O
( )
r為均勻分佈
( ) ( ) ( )
( ) ( )
| ,
|
h
h
r r r Edit r
u W
r r
u W
P O s P s L s u P O u P u
λ
λ Γ
∈
Γ
∈
∑ ∑ ∑
全面風險法則估測 使用近似的辨識可能
( | ) ( )
h r u W
P Oλ u P uΓ
∑
∈使用近似的 辨識可能
( | ) ( )
h
r u W
P Oλ u P uΓ
∑
∈圖 2.3 各種目標函數之推導流程