行政院國家科學委員會專題研究計畫 成果報告
分散式計算系統中考量可靠度與執行時間之最佳任務配置 之研究(2/2)
計畫類別: 個別型計畫
計畫編號: NSC92-2213-E-006-009-
執行期間: 92 年 08 月 01 日至 93 年 07 月 31 日 執行單位: 國立成功大學工業與資訊管理學系(所)
計畫主持人: 謝中奇
報告類型: 完整報告
處理方式: 本計畫可公開查詢
中 華 民 國 93 年 8 月 2 日
一、 研究計畫中英文摘要 (一) 計畫中文摘要
隨著電腦的盛行及網路的普及,人類開始藉由大量的電腦及網路設備來建構方便 人類生活及控制管理的環境,由於電腦及網路的結合,使得資料可以分散至各個 電腦中儲存,而任務 (task) 之執行也可以經過分解成數個模組(modules),藉由 網路的連結使得模組可分散至網路上各個電腦來進行處理,諸如一般我們常見的 有銀行系統、旅遊代理系統、電力控制系統,及常見的網路資料庫管理系統等,
將程式及資料分散於網路各個處理節點 (processing node) 中,交由各處理節點來 進行資料的儲存及執行,如此系統的可靠度與效能將大為提升,而這由網路及處 理結點所組成的系統成為分散式處理系統(distributed computing system)。分散式處 理系統的可靠度主要取決於執行任務之電腦元件、網路連結的可靠度,以及任務 所分解的模組配置於網路各個處理結點中的情形,在硬體設備固定及網路架構已 知的情況下,利用任務配置來提升系統的效能。以往的研究多重於配置任務總執 行時間之最小化,而未考慮到可靠度;或追求可靠度最大化而未考慮到任務配置 後其執行所需的時間,本研究提出以可靠度與任務執行時間為考量因素,期能獲 得最佳的任務配置。因任務配置問題為一組合問題 (combinatorial problem) ,本研 究發展二啟發式演算法–遺傳演算法 (genetic algorithms) 及 反應式禁忌搜尋法 (reactive tabu search)–解此任務配置之最佳化問題,並比較兩種演算法之效能 (effectiveness)。
(二) 計畫英文摘要
A distributed computing system in general consists of processing nodes, to which the task is allocated, and communication channels, connecting pairs of processing nodes.
Achieving a reliable distributed computing system thus comprises three parts: the realization of reliable task processing, reliable communication among processing nodes, and a good task allocation. The objective of this research is to seek the optimal task allocation strategy for a given distributed computing system such that the system reliability of the distributed computing system is maximized subject to the execution time constraint. Due to the combinatorial nature of the optimization problem, two heuristic methods based on genetic algorithms and reactive tabu search are developed in this study to solve this problem, and compared in terms of effectiveness.
關鍵詞:分散式系統 (Distributed computing system)、遺傳演算法 (genetic algorithms)、系 統可靠度 (system reliability)、反應式禁忌搜尋法 (reactive tabu search)、任務配置 (task allocation)
二、 研究計畫內容
(一) 研究計畫之背景及目的
由於資訊與網路的發達及電腦硬體的個人化,利用電腦及網路設備建構分散式系 統 (distributed computing systems) 已相當普遍 [19, 20]。在分散式系統中,整個系統是 由分散於網路各個處理節點 (processing nodes) 所組成,而處理節點內能建置多個處理 單元 (processors) ,並同時執行所配置的任務;因此,當節點內某一處理單元發生故 障時,不會影響其他處理單元的任務執行,所以,分散式系統擁有高水平的可靠度與 彈性。
分散式系統中令人關心的的兩個因素是系統可靠度 (system reliability) [4, 14] 與 系統的執行效率;系統可靠度關係著系統成功地執行任務的機率 [3, 5, 12, 13, 17, 23, 25],而系統的效率關係著是否能在最短的時間或我們所容許的時間內完成任務的執行 [1, 21,22]。在網路架構 (topology) 以及節點設備建構完成後,基於預算及成本的考量 下,網路架構及處理節點的處理設備短期內通常不易改變,所以,利用增加硬體設施 而增加系統可靠度的方式較不易達成;然而,我們可利用任務模組化的特性,在既有 的網路結構下,配置 (allocate) 任務模組 (task modules) 至不同的處理節點,以提昇系 統可靠度 [2, 7, 8, 9, 10, 11, 15, 16, 17, 18, 24]。同樣地,在系統執行效率方面,我們可 配置任務模組至不同的處理節點來縮短系統執行任務的時間 [1, 21, 22]。
在先前任務配置的研究中,學者僅考量系統可靠度之最佳化而未將分散式系統之 執行效率納入考量,或僅考量任務執行效率之最佳化而未將系統可靠度納入考量。因 此,我們在本研究中考量 (1) 系統可靠度 (2) 同時考量系統可靠度與執行時間,期能 獲得滿足對系統可靠度與執行效率的要求之任務配置。 再者,先前研究專注於正確解 (exact solution) 的求得,然而,因任務配置問題為一組合問題 (combinatorial problem),
在中型或大型的分散式系統或任務模組較多的情況下,正確解的獲得不僅費時且不實 際。所以,本研究發展兩種啟發式演算法–遺傳演算法 (genetic algorithms) 及反應式 禁忌搜尋法 (reactive tabu search) [26]–來解任務配置之最佳化問題,並比較此兩種演 算法之效能 (effectiveness)。
參考文獻
[1] S. P. Ahuja, “Performance based reliability optimization for computer networks,”1997,
Southeastcon '97. Engineering New Century, Proceedings. IEEE, pp.121-125.
[2] A. Billionnet, “Allocating tree structured programs in a distributed system with uniform communication costs,”
IEEE Transactions on Parallel and Distributed Systems, Vol. 5,
pp. 445-448, 1994.[3] C. C. Chiu, Y. S. Yeh, R. S. Chen, “Reduction of the total execution time to achieve the optimal k-node reliability of distributed computing systems using a novel heuristic algorithm,”Computer Communications, Vol. 23, pp. 84-91, 2000.
[4] B. S. Dhillon, C. Singh, Engineering Reliability-New Techniques and Application, Wiley, New York, 1981.
[5] S. Hariri, C. S. Raghavendra, “SYREL: A symbolic reliability algorithm based on path and cutset methods,”
IEEE Transactions on Reliability, Vol. 36, pp. 1224-1232, 1987.
[6] Y. C. Hsieh, T. C. Chen, D. L. Bricker, “Genetic algorithms for reliability design problems,”
Microelectronics Reliability, Vol. 38, pp. 1599-1605, 1998.
[7] S. Kartik, C. S. R. Murthy, “Improved task-allocation algorithms to maximize reliability of redundant distributed computing systems,”
IEEE Transactions on Reliability, Vol. 44,
pp. 575-586, 1995.
[8] S. Kartik, C. S. R. Murthy, “Task allocation algorithms for maximizing reliability of distributed computing systems,”
IEEE Transactions on Computers, Vol. 46, pp. 718-724,
1997.[9] A. Kumar, A. S. Elmaghraby, S. P. Ahuja, “Performance and reliability optimization for distributed computing system,”1998, ISCC '98. Proceedings of the Third IEEE
Symposium on Computers and Communications, pp. 611-615.
[10] C. Y. Lee, “Application of a cross decomposition algorithm to a location and allocation problem in distributed systems,”Computer Communications, Vol. 18, pp. 367-377, 1995.
[11] S. Latifi, “Task allocation in the star graph,” IEEE Transactions on Parallel and
Distributed Systems, Vol. 5, 1994, pp. 1220-1224.
[12] M. S. Lin, D. J. Chen, “Distributed program reliability analysis,”1992, Proceedings of
the Third Workshop on Future Trends of Distributed Computing Systems, pp. 395-401.
[13] M. S. Lin, M. S. Chang, D. J. Chen, “Efficient algorithms for reliability analysis of distributed computing systems,”Information Sciences, Vol. 117, pp. 89-106, 1999.
[14] J. E. Marsden, M. J. Hoffman, Elementary Classical Analysis, 2nd edition, W. H.
Freeman and company, New York, 1993.
[15] R. M. Pathak, A. Kumar, Y. P. Gupta, “Reliability oriented allocation of files on distributed systems,”1991, Proceedings of the Third IEEE Symposium on Parallel and
Distributed Processing, pp. 886-893.
[16] K. Ramamritham, “Allocation and scheduling of precedence-related periodic tasks,”
IEEE Transactions on Parallel and Distributed Systems, Vol. 6, pp. 412-420, 1995.
[17] S. M. Shatz, J. P. Wang, “Models & algorithms for reliability-oriented task-allocation in redundant distributed-computer systems,”IEEE Transactions on Reliability, Vol. 38, pp.
16-27, 1989.
[18] S. M. Shatz, J. P. Wang, “Task allocation for maximizing reliability of distributed computer systems,”IEEE Transactions on Computers, Vol. 41, pp. 1156-1168, 1992.
[19] A. Silberschatz, P. Galvin, Operating System Concepts, Fifth Edition, 1997.
[20] A. S. Tanenbaun, Distributed Operating Systems, 1995.
[21] P. A. Tom, C. S. R. Murthy, “Algorithms for reliability-oriented module allocation in distributed computing systems,”The Journal of Systems and Software, Vol. 40, pp.
125-138, 1998.
[22] P. A. Tom, C. S. R. Murthy, “Optimal task allocation in distributed systems by graph matching and state space search,”The Journal of Systems and Software, Vol. 46, 1999, pp. 59-75.
[23] L.G. Valiant, “The complexity of enumeration and reliability problems,”SIAM J.
Computing, Vol. 8, pp.410-421, 1979.
[24] J. P. Wang, S. M. Shatz, “Task allocation for optimized system reliability,”1988,
Proceedings of the Seventh IEEE Symposium on Reliable Distributed Systems, pp.
82-90.
[25] R. K. Wood, “Factoring algorithms for computing k-terminal network reliability,”IEEE
Transactions on Reliability, Vol. 35, pp. 269-278, 1986.
[26] F. Battiti, G. Tecchiolli, “The reactive tabu search,”ORSA Jornal on Computing, Vol. 6, pp. 126-140, 1994.
(二) 研究方法
1.
A distributed computing system, in the form of tree, consists of processing nodes and bi-directional communication links. Let P = { pk, k=1..n} be the set of processing nodes in an DCS where pk is the kth processing node and n is the total number of the processing nodes, which also represents the size of the DCS. Let L={lk, k=1..l} be the set of communication links connecting the processing nodes, where lkis the kth communication link, and l=(n-1) is the number of communication links. Further, let Pij be the communication path between two arbitrary processing nodes piand pj, and define an indicator function(k,i,j)=1 if lkis on Pij; 0, otherwise.
2.
Consider a task of m modules T = {mi, i=1..m} to be executed on an DCS, where miis the ith module of T. The precedence relations between modules can be represented as a task graph, as shown in Figure 1. In Figure 1, m1is the immediate predecessor of m2and m3, and both m2and m3are the immediate predecessors of m4. That is, module m1 has to be executed before either m2or m3 can be executed, and
m
4cannot be executed until both m2 and m3 are completed. Let be the set of all possible sequences of module ordering that satisfy the precedence relations. In the task graph of Figure 1, for instance, ={1,2}, where 1= (m1,m2,m3,m4) and 2= ( m1,m3,m2,m4).Figure 1. Task precedence for a four-module task
3.
Task T is assigned to the processing nodes P according to an m× n task allocation matrix X=[xik], where entry xik = 1 if module miT is assigned to processing nodep
kP; xik=0, otherwise. Because we do not consider software redundancy, there are exactly m entries of 1's in X. We then define an addition assignment set a, which is equivalent to X, to represent the indices of the assigned processing nodes:a={a
1,···,am} where ai denotes the index of the processing node to which the ith module is assigned, i.e. xiai=1. We will use X and a interchangeably throughout the paper. Since different processing nodes may have varying processing speeds in general, the accumulative execution times (AETs) of a module running at differentprocessing nodes may be different. Let E=[eik] denote the AET matrix, where entry
e
ik is the AET that mi takes to run at processing node pk; eik is if mi cannot be executed at pk. Once T is assigned to the DCS, intermodule communication may be required between two modules during the mission. Let C=[cij] denote the m× m IMC matrix where cij represents the amount of IMC in time unit between modulesm
i and mj, which is assumed to be independent of module allocation. It is also assumed that the IMC between modules allocated at the same processing node is zero.4.
The system reliability R(X) can be represented bywhere
and
5.
The task completion time can be computed asThe task completion time for X is the minimal task completion time for all
possible sequences of module ordering:
6.
Problem formulationThe objective is to find the optimal task allocation that maximizes system reliability
R(X) subject to a task completion time constraint and capacity constraints for
processing nodes.7.
Genetic optimizationThe procedure of the proposed genetic algorithm is as follows:
(a)
Initialize a fixed population, pop_size, of chromosomes.(b)
Evaluate the fitness values of the chromosomes; select the chromosomes according to their fitness values.(c)
If the maximal number of generations, max_gen, is reached, terminate the iteration and return the best chromosome; otherwise, go to Step (d).(d)
Generate a new population of chromosomes by deploying genetic operators to the current chromosomes; repeat Step (b).8. Reactive tabu optimization
The procedure of the proposed reactive tabu search is shown in Figure 2; the method of neighborhood generation, which depends upon the number of processing nodes and the number of task modules, is described as follows.
(a)
When the number of processing nodes n is equal to the number of task modules m, and the capacity of each processing node is=1: This is the
standard task allocation problem, and swapping (of two units) is directly used to find all possible neighboring points of sizeC
2n.(b)
When the number of processing nodes n is more than the number of task modules m, and the capacity of each processing node is=1: This problem is
transformed into the standard task allocation problem by introducing n-m dummy variables into the task allocation array. Then, swapping can also be used to find the neighborhood. Further, if both units to be swapped are the dummy variables, no exchange is necessary.(c)
When the capacity of each processing node is= 2: For this problem, each
processing nodes can execute two task modules at the most, thus, the length of the task allocation array will be increased to n × 2 and the indices 2i and 2i+1 correspond to the same processing node i. Then, swapping can also be used to find all possible neighboring solutions. Further, if the two units to be swapped correspond to the same processing node, no exchange is necessary. Finally, only the first m parts of this task allocation array are used to represent the task allocation strategy.(三) 結果與討論
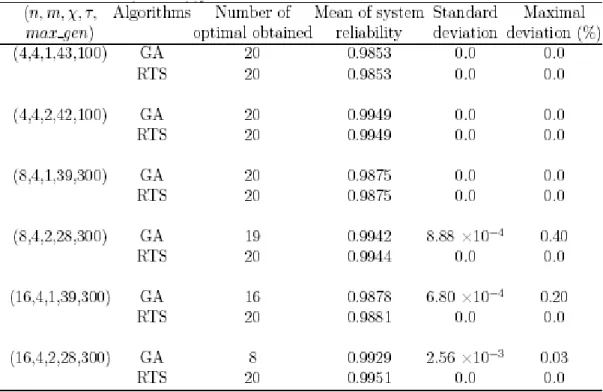
1. We have constructed test problems of three DCS sizes by considering reliability and task completion time. In particular, we show the results for the test problem in which the task of m = 4 modules is to be executed on the DCS of n = 4, n = 8, and n
= 16 processing nodes. (The configuration of the DCS and the AET and IMC of the task are omitted for brevity.) Twenty simulation runs were conducted. With the following GA parameters: the population size pop_size = 16, mutation probability p
m= 0.1, crossover probability p
c= 0.95, and the number of crossover points n
c= 2, and the following RTS parameters: the initial list size list_ size = 1, the maximum repetitions allowed rept = 3, the threshold for escaping chaos = 3, fast-reaction list size increment increase = 1.1, and the long-term list size decrement decrease = 0.9, deploying the proposed two algorithms to solve the problem gives the simulation results in Table 1.
Table 1. Simulation results by deploying GA and RTS over 20 runs
As shown in Table 1, solutions obtained by using GA and RTS may not be of the
same quality. In order to compare the effectiveness with GA and RTS, we used the Mann-Whitney U test to test the obtained solutions; the test results are shown in Table 2.Table 2.
Mann-Whitney U testresults
As shown in Table 2, the solutions obtained by using RTS are better than those by
using GA in the case of n = 16, m = 4, andχ= 2, implying that the RTS is more
effective than the GA when the size of DCS is large in our study.2. We have published a journal paper based upon this two-year research that deals with the reliability maximization problem. The reference of the journal paper is:
Chung-Chi Hsieh, “Optimal task allocation and hardware redundancy policies in distributed computing systems,”European Journal of Operational Research, 147, 430-447, 2003.
三、 研究計畫成果自評
1.
本研究提出以可靠度與任務執行時間為考量因素,從而獲得最佳的任務配置的方法 。 本研究實作遺傳演算法 (genetic algorithms) 及反應式禁忌搜尋法 (reactive tabu search),利用不同大小的分散式計算系統之模擬資料求解其最佳 任務配置,進而比較兩種演算法之效能 (effectiveness)。
2.
在本研究中,雖然我們發現在較大的分散式計算系統中反應式禁忌搜尋法比遺傳演算法來得有效率;但遺傳演算法之參數設定對其績效有很大的影響;因 此,如何設計良好的參數設定是值得繼續研究的課題。
3.
在後續工作方面,我們將整理研究結果與實驗數據,預計在暑假完成期刊論文之撰寫工作,並投稿於 Computers and Operations Research。
Figure 2. The procedure of reactive tabu search (Ref. [26])
![Figure 2. The procedure of reactive tabu search (Ref. [26])](https://thumb-ap.123doks.com/thumbv2/9libinfo/9248212.508836/10.892.158.781.126.851/figure-procedure-reactive-tabu-search-ref.webp)
