國立臺灣大學電機資訊學院資訊工程學研究所 碩士論文
Department of Computer Science & Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
使用生成式對抗網路及最佳補全蒸餾法之多標籤分類 技術
Multi-label Classification Techniques with Generative Adversarial Network and Optimal Completion Distillation
蔡哲平 Che-Ping Tsai
指導教授:李琳山 教授 Advisor: Lin-shan Lee, Ph.D.
中華民國一百零八年七月
July, 2019
誌謝
碩士兩年的時光,說長不長,說短也不短,在台大待了六年的時光也即將畫 下句點。做研究、出遊、出國開會、忙著趕論文,碩士兩年實在有太多事值得回 憶了。過程中,我得到了許多人的幫忙,不僅讓我在知識上有所長進,也從許多 人的身上學習到待人處事和對生活的態度,受到的大恩大德也許無法用文字好好 表達,但這些感些都會長存我心。
首先要感謝的是我的指導老師李琳山教授,從大三上學期選了老師的專題到 現在碩二要結束了,也有四年的時光,從我還什麼都不懂,在老師的指導下,到 現在能寫出幾篇學術論文,真的由衷的感謝老師四年來的栽培與教導。從老師身 上真的學習到了很多東西,不僅僅是課堂上的知識或是論文的寫法,也學習到了 很多人生哲學,讓我能在接下來的人生道路上,能更堅定自己的選擇,這份恩情 永生難忘。
再來要感謝宏毅哥,老師平常就像我們的朋友一樣,會和我們一起出去吃 飯,也會討論一些生活大小事或八卦,真的很好相處,但聊到研究時,老師認真 的態度和專業的見解又讓我好生佩服。每次跟老師討論完,都會得到新的啟發,
也會有新的動力朝向新的研究方向前進。雖然有時候老師您會用對你很期待的語 氣祝福你成功,讓我懷疑老師的方向是不是對的,但後來成功訓練後,才發現老 師真的有先見之明,讓我很佩服老師對研究的直覺。
還要感謝實驗室的學長們,柏儒哥、水靜、致緯哥、邦齊哥、家宏哥、舜博 哥、瓊之、育軒哥、棋宇哥、佩宏哥,謝謝你們在我還在懞懂的碩一時,報了很 多paper,讓我迅速學習到最新領域的進展,和你們請教問題時,你們也不厭其煩 地教導我。和學長們出國開會的經驗也令我永生難忘,謝謝你們。
感謝實驗室的麻吉們,耀文、冠宇、淞楓、儒杰、政杰、靖平、耀賢、宗
嫄、奕禎、上銘、佳軒、達榮、思霖、元魁、逸林,真的很幸運碩士生涯有你 們的陪伴,其中有幾位甚至從高中就開始了,這段時間一起打球、一起熬夜、
一起趕論文、一起吃飯、一起出遊...,太多太多的事和難關是跟你們一起完 成,電腦出問的時候有你們的幫忙真的感激涕零。過程中有太多珍貴的回憶,
在實驗室的時間有你們一起,帶給我許多的能量能夠繼續前進。謝謝靖平和佳 軒,不僅是好同學也是好室友。謝謝儒政雙杰,資工系的梗總是特別又好笑。
謝謝耀賢,在supercell的羈絆我永遠不會忘記。謝謝辛苦的網管耀文,戰艦系統 實在太厲害了,我電腦有問題的時候總是向你求救,真的是十萬分的感謝,你 也不厭其煩地幫我解決。謝謝奕禎,除了隊醫以外,其他方面真的都是我的老 師。謝謝淞楓,從國中就認識了,謝謝你12年來的凱瑞。謝謝冠宇帶我發了一 篇interspeech的paper。謝謝QA組的上銘和宗嫄,坐在你們旁邊聽你們講話真的很 有趣。謝謝KGB好隊友思霖和達榮,你們修課的時候很凱瑞,嘴砲的時候也很有 趣。謝謝元魁在籃球和傳說上的教導。謝謝專題時期的隊友逸林,和你合作時總 是感到十分安心。雖然畢業後有些人要離去了,大家也往不同的方向前進了,但 大家都會是我一輩子的麻吉。
感謝實驗室的學弟和助理,雖然只有一年的相處時間,但看到你們那麼認 真,學長壓力也大了起來,也會督促自己努力一點。感謝浩然和培傑去英國的時 候凱瑞了很多事,浩然也讓我問了許多影像相關的問題,也感謝元瑞、杜濤陪我 們這些人打球,也謝謝君璇每次我去實驗室都會跟我打招呼,謝謝網管記良、瑞 陽讓我們有戰艦用,也謝謝神賢、海濱、瑞陽、博竣、仲翊、柏文、昭誼、廷緯 這一年來的陪伴,實驗室有你們一定能夠更上層樓。
感謝彤恩姐許多行政事務上的協助,像我們的媽媽一樣,打理了我們各種瑣 事,平常也會關心我們過得如何,我也可以和你抱怨各種瑣事,讓我心情舒坦不
少。祝你接下來在實驗室能夠事事順心,不會遇到麻煩事。
最後要感謝我的家人,不僅在這兩年給我金錢上的援助,一直以來也都支持 我做的決定,讓我能沒有牽掛的做我想做的事,每次回家的時候總覺得十分的放 鬆,對我的養育之恩我一輩子都償還不完。
摘要
本論文的主軸是多標籤分類(Multi-Label Classification)之新技術。隨著機器學 習技術的日新月異,基於深層類神經網路(Deep Neural Network)的解決方法陸續被 提出,前人的研究指出考慮標籤間的關聯性,是增進模型表現的關鍵。
本論文的第一個大方向是以生成對抗網路(Generative Adversarial Network)來 模擬標籤關聯性。在此架構下,分類器扮演生成器(Generator)的角色,其輸入是 一個物件,輸出是屬於此物件的標籤集(Label set),鑑別器(Discriminator)則需要學 習標籤之間的關聯性,來分辨此標籤集是從生成器產生還是來自真實的資料;分類 器不只需要學會標籤和物件間的關係,也需要使產生出的標籤集具有正確的關聯 性,以欺騙鑑別器。
本論文第二個方向是改進基於遞迴式類神經網路(Recurrent Neural Network)的 多標籤分類器;這種模型使用遞迴式類神經網路解碼器來模擬標籤關聯性,並依序 預測標籤。然而,此模型在訓練時,需要人為定義的標籤順序,用來將標籤集轉 變成標籤序列,為訓練遞迴式類神經網路的目標序列;前人的研究已指出標籤順序 對模型表現有相當大的影響,人為強加的順序性也可能會和機器推斷的標籤關係 不一致。因此,本論文提出最佳補全蒸餾法(Optimal Completion Distillation),使 模型不需要標籤順序便可訓練。透過分析實驗數據,我們也證實我們提出的模型 不只表現較好,廣泛化能力(Generalization ability)也較強,能夠預測出在訓練集沒 有出現過的標籤集。
本論文也提供了上述兩種方法在多標籤影像分類、文件分類、環境音分類上 相當豐富的測試結果。
Abstract
Multi-label classification (MLC) assigns multiple labels to each sample. This paper proposes two methods that improves performance of multi-label classifiers.
Recent work has shown that exploiting relations between labels improves the perfor- mance of multi-label classification. The first direction in this paper is to use Generative Adversarial Network (GAN) to model label dependencies. The discriminator learns to model label dependency by discriminating real and generated label sets. To fool the dis- criminator, the classifier, or generator, learns to generate label sets with dependencies close to real data.
The second direction is to improve state-of-the-art multi-label classifiers , which utilize a recurrent neural network (RNN) decoder to model the label dependency. How- ever, training a RNN decoder requires a predefined order of labels, which is not directly available in the MLC specification. Besides, RNN thus trained tends to overfit the label combinations in the training set and have difficulty generating unseen label sequences.
Therefore, we propose a new framework for MLC which does not rely on a predefined label order and thus alleviates exposure bias. We also find the proposed approach has a higher probability of generating label combinations not seen during training than the baseline models. The result shows that the proposed approach has better generalization capability.
This paper also provides experimental results on multiple multi-label classification benchmark datasets in different domains, including text classification, image classifica- tion and sound-event classification.
Contents
口試委員會審定書 . . . i
誌謝 . . . ii
中文摘要 . . . v
英文摘要 . . . vi
一、導論 . . . 1
1.1 研究動機 . . . 1
1.2 研究方向 . . . 3
1.3 章節安排 . . . 4
二、背景知識 . . . 5
2.1 多標籤分類(multi-label classification) . . . 5
2.1.1 簡介 . . . 5
2.1.2 常見的解決方法 . . . 5
2.2 序列到序列(sequence-to-sequence)模型 . . . 8
2.2.1 類神經網路(Neural Network, NN) . . . 8
2.2.2 遞迴式類神經網路(Recurrent Neural Network, RNN) . . . 13
2.2.3 序列到序列模型 . . . 15
2.2.4 序列到序列模型應用於多標籤分類 . . . 19
2.2.5 強化學習(Reinforcement Learning, RL)應用於序列到序列模型 20 2.3 生成對抗網路(Generative Adversarial Network, GAN) . . . 23
2.3.1 簡介 . . . 23
2.3.2 條件式生成對抗網路 . . . 25
2.3.3 霍式生成對抗網路(Wasserstein GAN) . . . 26
2.4 本章總結 . . . 30
三、以生成式對抗網路幫助多標籤分類器 . . . 31
3.1 簡介 . . . 31
3.1.1 研究動機 . . . 31
3.2 本論文所提出之模型 . . . 32
3.3 模型之訓練方式 . . . 34
3.3.1 分類器之訓練方式 . . . 34
3.3.2 鑑別器之訓練方式 . . . 35
3.4 系統評估 . . . 37
3.4.1 實驗設定 . . . 37
3.4.2 實驗結果 . . . 42
3.4.3 實驗結果分析 . . . 44
3.4.4 切除研究 . . . 46
3.4.5 模型輸出範例 . . . 48
3.5 本章總結 . . . 50
四、最佳補全蒸餾法應用於多標籤分類 . . . 51
4.1 簡介 . . . 51
4.1.1 研究動機 . . . 51
4.2 模型簡介 . . . 52
4.2.1 編碼器E架構 . . . 53
4.2.2 遞迴式類神經網路解碼器Drnn架構 . . . 53
4.2.3 二元關聯解碼器Dbr架構 . . . 54
4.3 訓練方式 . . . 55
4.3.1 訓練遞迴式類神經網路解碼器 . . . 55
4.3.2 訓練二元關聯解碼器 . . . 57
4.3.3 多目標訓練 . . . 58
4.4 測試方式 . . . 60
4.4.1 基本的測試方式 . . . 60
4.4.2 結合兩解碼器的測試方式 . . . 60
4.5 模型表現評估 . . . 61
4.5.1 實驗資料集 . . . 62
4.5.2 基準模型介紹 . . . 62
4.5.3 評估指標介紹 . . . 65
4.5.4 實驗設定 . . . 66
4.5.5 實驗結果 . . . 67
4.5.6 實驗結果討論 . . . 75
4.6 與基於生成對抗網路的多標籤分類器比較 . . . 78
4.6.1 實驗資料集 . . . 78
4.6.2 模型介紹 . . . 79
4.6.3 實驗設定 . . . 83
4.6.4 實驗結果 . . . 84
4.7 本章總結 . . . 87
五、結論與展望 . . . 88
5.1 研究貢獻 . . . 88
5.2 未來展望 . . . 89
5.2.1 以生成式對抗網路幫助多標籤分類器 . . . 89
5.2.2 最佳補全蒸餾法應用於多標籤分類 . . . 89
參考文獻 . . . 91
圖
圖 圖目 目 目錄 錄 錄
2.1 (a)二元關聯示意圖,將原本A,B,C三個標籤分別用三個二元分類器 來做預測(b)分類器鏈示意圖,黃色部份是指分類器的輸入,白色的
部分則是分類器需要預測的標籤。 . . . 7
2.2 標籤冪集示意圖,因為X1, X2的標籤集相同,因此屬於同一個類別。 7 2.3 神經示意圖 . . . 8
2.4 類神經網路示意圖 . . . 9
2.5 運算神經元示意圖 . . . 9
2.6 二元關聯應用於深度深層模型之示意圖 . . . 13
2.7 基本的遞迴式類神經網路 . . . 14
2.8 長短期記憶單元示意圖 . . . 15
2.9 長短期記憶單元示意圖 . . . 16
2.10 長短期記憶單元示意圖 . . . 17
2.11 時序採樣示意圖 . . . 19
2.12 強化學習示意圖 . . . 20
2.13 強化學習應用於序列到序列模型示意圖 . . . 22
2.14 生成對抗網路基本架構 . . . 23
2.15 生成對抗網路的訓練方法 . . . 24
2.16 條件式生成對抗網路基本架構 . . . 25
2.17 梯度懲罰分佈 . . . 29
2.18 增進版霍式生成對抗網路的訓練方法 . . . 30
3.1 模型架構示意圖 . . . 33
3.2 分類器的訓練示意圖 . . . 34
3.3 訓練鑑別器的三種輸入,第一種是正確的特徵-標籤集對,兩者皆 是從真實數據取樣而得,第二種是生成的特徵-標籤集對,標籤集 是從生成器的輸出而得,第三種是不匹配的特徵-標籤集對,特徵 和標籤集雖然皆是從真實數據而得,卻是不匹配的。鑑別器需要學 習最大化第一種配對的分數,而最小化後兩個配對的分數。 . . . 36
3.4 MS-COCO和NUS-WIDE兩個資料集的一些範例。 . . . 40
3.5 一些Resnet-101在MS-COCO資料集多標籤分類的結果。若使用WGAN- gp進行訓練,分類器可以將較小的物件預測得較準確,例如在範 例(A)中,Resnet-101 + WGAN-gp模型基於人和棒球棍,而正確的 預測出棒球手套和球,然而在範例(D)中,它錯誤的將和筆電相關 的鍵盤和滑鼠納入了預測結果。 . . . 49
4.1 模型概觀 . . . 53
4.2 最佳補全蒸餾法的訓練過程示意圖,和表4.1的範例相同。在進行 取樣時,輸出機率會先經過一個遮罩,防止模型輸出重複的標籤。
而模型會向最佳策略學習,學習的方法便是最小化兩機率分佈的克
雷散度。 . . . 59
4.3 最 佳 補 全蒸餾法、二元關聯和最佳補全蒸餾法+多目標學習模 型(3種解碼方式),在Arxiv學術論文資料集的驗證集上,子集正確 率和微F1分數的在模型訓練時的變化示意圖。x軸表示模型的更新 次數,y軸則是評分標準的變化。 . . . 69
4.4 每個模型在三個資料集上,在每個評分標準下的平均排名,排名的 值越小,代表模型表現越好,其中,最佳補全蒸餾法+多目標學習 模型是使用對數機率共同解碼。 . . . 75
4.5 在Arxiv學術論文資料集上,各個模型對於標籤組合在訓練集出現 次數的基於實例的F1分數。0 ∼ 10代表此類的測試資料的標籤組合 在訓練集中只出現0 ∼ 10次。 . . . 76
4.6 編碼器架構示意圖。 . . . 80
4.7 專注模組示意圖。 . . . 81
4.8 基於生成對抗網路的多標籤分類器示意圖。 . . . 81
4.9 遞迴式神經網路的多標籤分類器示意圖。 . . . 82
4.10 多目標訓練的多標籤分類器示意圖 . . . 83
表
表 表目 目 目錄 錄 錄
3.1 MS-COCO多標籤分類的實驗結果。其中,WARP, CNN-RNN, 和RLSD的 結果是取前三高分標籤作為預測標籤集。WGAN+gp是指增進版霍 氏生成對抗網路 . . . 43 3.2 NUS-WIDE多標籤分類的實驗結果。其中,WARP, CNN-RNN, 和RLSD的
結果是取前三高分標籤作為預測標籤集。WGAN+gp是指增進版霍 氏生成對抗網路 . . . 45 3.3 模型VGG-16、VGG-16 + WGAN-gp、Resnet-101和Resnet-101 + WGAN-
gp在資料集MS-COCO的Sseen, Sunseen上分別的微/宏F1分數。其中Sseen中 的正確標籤集組合是在訓練集中有出現的,Sunseen則否。 . . . 46 3.4 模型在MS-COCO測試集上,產生沒有在MS-COCO訓練集見過的標
籤集組合的種類數(Stest−train),其中正確答案欄代表測試集的正確 標籤集有多少種沒有出現在訓練集過。 . . . 47 3.5 在MS-COCO資料集上,Resnet-101模型有/無本章提出的訓練方法
的微/宏F1分數。 . . . 47 4.1 一個由最佳補全蒸餾法的範例,和圖4.2的範例相同。在此範例
中,總共有4種標籤A,B,C,D和heosi,而此物件的正確標籤有A,B,D三 種。標籤的最佳Q值和最佳策略的向量中的每個值分別代表標 籤A,B,C,D和heosi的最佳Q值和策略的機率。我們在此將軟性最大 化的溫度τ設為一個接近0的數值,因此最佳策略只會在有最大的 最佳Q值的動作上有機率。例如,在時間點t = 1時,有兩個最佳 補全蒸餾法的目標標籤,分別是A和D,能最大化最佳Q值(0),然 後我們從模型的輸出分佈取樣而得標籤C,作為t = 2時的輸入,因 為C不在正確標籤集中,而使模型能拿到最大的獎勵值變為−1。 . . 58 4.2 資料集的統計資料。Ntraining、Nval、Ntest分別是指訓練集、驗證
集、測試集的資料筆數。 . . . 63 4.3 三個多標籤文件分類的資料集中的例子。 . . . 64 4.4 一些在不同資料集使用的超參數,其中,長短期記憶單元的層
數(2,3)是指在編碼器長短期記憶單元的層數為2,而在解碼器為3。 . 67 4.5 Arxiv學術論文資料集上的實驗結果。 . . . 70 4.6 路透社-21758上的實驗結果。 . . . 72 4.7 路透社資料集卷一上的實驗結果。 . . . 74 4.8 在各個資料集的測試集上,不同模型產生出的標籤組合的種類
數(Stest),還有產生出在訓練集中沒有出現過的標籤組合的種類 數(Stest−train)。 . . . 77 4.9 一些模型在Arxiv學術論文資料集上的預測結果的例子 . . . 78 4.10 谷歌音訊集標籤的一些例子。 . . . 79
4.11 谷歌聲音集上的實驗結果。 . . . 86
第 第
第 一 一 一 章 章 章 導 導 導論 論 論
1.1 研 研 研究 究 究 動 動 動機 機 機
過去,人類在文件、圖像、語音等資訊的管理,大多仰賴人力進行。近年來隨著 科技快速發展,電腦處理的資訊也越來越豐富且多元,使用人力管理的成本也越 來越高,如何快速有效的進行分類及管理,變成了現今世界的重要問題。在過去 已有許多利用電腦進行的資訊分類系統,並普及應用於生活中,例如圖像分類、
文本分類、垃圾信分辨等等。一般的分類系統大多是只能分出單一種類別,也稱 作單標籤分類器(Single-lable Classifier),例如垃圾信分類器只需要簡單的分辨是或 不是垃圾信、某些動物的圖像分類器只能區分出一種動物。在這種單標籤分類 中,每一個類別是不會重複的,並且每一個物件(instance)只會屬於某一個類別。
然而,在現實生活中,有許多任務是更加複雜的,有許多物件可以同時被區分 成好幾種類別,舉文件分類作為例子,一個職棒打假球的新聞,是可以被分到 社會類和體育類兩種類別的。因此,單標籤分類器漸漸不敷使用,而多標籤分 類(Multi-label Classification)受到越來越多的重視及研究。
在多標籤問題中,標籤中是互相有關聯性的,例如在影像分類的問題中,沙 灘和海洋十分容易出現在一起,但沙灘和大象卻鮮少出現在同一張圖片上,因 此,標籤之間常有一定的關聯性,某些標籤可能常常會在同一物件中出現,某些 標籤卻不會一起出現。如何使模型同時學習到標籤與物體之間的對應關係和標籤 間的關聯性,是多標籤分類研究的一大方向。近年來由於深層學習的興起,基 於深度類神經網路的方法也陸續被提出,例如用機率圖模型(Probabilistic graphical networks) [1]、遞迴式類神經網路(Recursive Neural Network, RNN) [2] 等來模擬標 籤間的關聯性。
本 論 文 第 一 個 重 點 是 利 用 生 成 對 抗 網 路(Generative Adversarial Network, GAN) [3] 來模擬標籤之間的關聯性。對抗生成網路是近年來迅速火紅的深 度 生 成 模型,在圖像生成(Image Generation)有非常好的效果,是由一個生成 器(Generator)和一個鑑別器(Discriminator)所組成,藉由交互對抗式的訓練,最終 能使生成器產生鑑別器無法分辨真偽的圖片。在此鑑別器的工作是引導生成器學 習,使生成器能產生出更貼近真實、更結構化(structural)的圖片,因此,鑑別器也 能應用在其他任務上,例如在語音合成(Text to Speech, TTS)中引導模型生出更貼 近真實的聲音 [4] 或是在語音辨識(Automatic Speech Recognition, ASR)系統裡讓模 型生出更貼近真實的句子 [5]。同樣的,若將鑑別器應用於多標籤分類,應該也能 引導模型產生真實會出現的標籤集(Label set)。換句話說,鑑別器應能使生成器學 習到標籤之間的關聯性,從而了解到哪些標籤較容易一起出現,哪些標籤鮮少同 時出現在同一個情境中。
本論文第二個重點是改善基於遞迴式類神經網路的多標籤分類器,先前有人 將多標籤分類轉變成一個順序預測(sequential prediction)問題 [2,6],其精神是在分 類器產生標籤是順序性一個一個產生的,換句話說,在產生標籤時,會基於之前 預測的標籤來做預測,而這樣的模型會接一個遞迴式類神經網路來達成這個效 果,並利用此模擬標籤之間的關聯性。然而,使用這種方法需要先將訓練用的標 籤排序;而排序標籤的方法會對結果的影響十分顯著,因為對原本無序的標籤集套 用人為定義的順序是不自然的,況且順序的可能組合千千萬萬種,找到一個完美 的順序也十分的困難,本論文提出的方法便可以不需要人為順序,便可訓練此類 型的多標籤分類器。
另外,在這種基於遞迴式類神經網路的多標籤分類器,在訓練時只會基於來 自正確解答的前輟(prefix),然而在測試時,模型會基於自己的預測的前輟來做預
測,而這個前輟可能會是錯的,而這種錯誤可能會一連串的發生下去,而導致錯 誤越來越大,這種問題在序列到序列訓練(Sequence to Sequence Learning)中稱為曝 露偏差(Exposure bias)。本論文也提出一個二元關聯(Binary Relevance, BR)的解碼 器(decoder)來輔助模型訓練,在多目標學習(Multi Task Learning, MTL)的框架下讓 模型能學習的更好,而另一個好處是,在測試時能同時考慮兩種解碼器的預測 值,進而增進預測的表現。
因此,本論文引入最佳補全蒸餾法(Optimal Completion Distillation, OCD) [7]並 提出與二元關聯解碼器共同訓練的的多目標學習來改善基於遞迴式神經網路的多 標籤分類器,其中,最佳補全蒸餾法能使遞迴式類神經網路不用依賴於人為定義 的順序,並且在訓練時皆是使用目前模型的預測來當前輟,從而避免了曝露偏差 的問題。
1.2 研 研 研究 究 究方 方 方向 向 向
本論文之研究方向為如何增進多標籤分類器的表現,主要分為兩個方向,其一是 利用生成對抗網路增進分類效能,另一者則是利用最佳補全蒸餾法和多目標學習 來幫助基於遞迴式類神經網路的多標籤分類器的訓練。
• 在前人的研究已經顯示在多標籤問題中,標籤之間的關聯性是增進分類器表 現的關鍵,本論文提出了一個基於生成對抗網路的方法,讓分類器不只能學 到物體與標籤的對應關係,更能了解標籤之間的關聯性,進而增進分類器的 表現。
• 更進一步的,由於現今對如何訓練生成對抗網路與增進其表現仍無明確的定 論,因此,論文中比較了不同的訓練方法與結構,並提出一個效能最好的模 型和訓練方法,並證明了加入生成對抗網路確實能幫助多標籤分類器,在實
驗中,也會比較各種訓練方法及最基礎的多標籤分類器模型的優劣,並分析 加入生成對抗網路後,模型更加進步的原因。
• 另一方面,因為以往基於遞迴式類神經網路的多標籤分類器需要人為定義的 標籤順序,也會有上述曝露偏差的問題,因此在本論文中引入最佳補全蒸餾 法來解決,
• 另外,本論文中提出利用多目標學習的方式,引進二元關聯解碼器,不但能 夠使模型學得更好,並在測試階段時,也可以結合兩者的預測結果,得到一 個更好的分類結果。
• 就上述更進一步,將最佳補全蒸餾法和多目標學習結合,能得到最好的模 型。論文的實驗中,比較了五種不同的測量標準,不僅證明了上述方法皆能 使模型表現更好,也證明了使用最佳補全蒸餾法能改善曝露偏差的問題,最 後也比較了與基於生成對抗網路的模型的優劣。
1.3 章 章 章 節 節 節安 安 安排 排 排
本論文之章節安排如下:
• 第二章:介紹本論文相關背景知識。
• 第三章:介紹如何用生成對抗網路使多標籤分類器學得更好。
• 第四章:介紹如何利用最佳補全蒸餾法於多標籤分類,並與前一章之方法比 較。
• 第五章:本論文之結論與未來研究方向。
第
第 第 二 二 二 章 章 章 背 背 背景 景 景知 知 知識 識 識
2.1 多 多 多標 標 標籤 籤 籤分 分 分類 類 類(multi-label classification)
2.1.1 簡 簡 簡介 介 介
在機器學習領域中,多標籤分類問題是一個歷史悠久且具有挑戰性的問題,多標 籤分類不只有多種類別(class),每個物件更可能有許多標籤。相對於多類別分類 器(multi-class classifier)只需要將物件分類至某一類別,多標籤分類更加的困難,
因為每個物件的標籤數是未知的。多標籤分類也有許多應用,例如:新聞或電 影的分類、生物學的基因分類、醫療中的疾病分類、聲音事件檢測(sound event detection)等等都可以同時有多個標籤。
在多標籤分類中,標籤之間是有關聯性的,以多標籤圖片分類作為例子,沙 灘和海洋十分容易出現在同一張圖片裡,而沙灘和大象則鮮少一起出現。因此,
有些標籤較容易一起出現,有些則不是。如何模型標籤之間的關聯性來幫助分類 器,是多標籤分類問題主要的一個研究方向。
2.1.2 常 常 常見 見 見的 的 的解 解 解決 決 決方 方 方法 法 法
多標籤分類問題常見的解決方法有:二元關聯(Binary Relevance, BR) [8]、分類器 鏈(Classifier Chain, CC) [9]、標籤冪集(Label Powerset, LP) [10,11]等等,接下來會 逐一介紹這些方法。
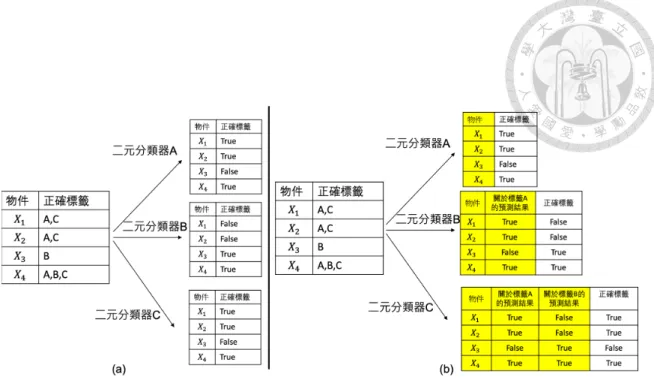
• 二元關聯:如圖2.1(a),此類的方法將多標籤分類問題轉變至多個二元分 類(binary classification)問題。假設在多標籤問題中有L種類別,此種方法 將L個類別分開來看,變成L個二元分類問題,則這L個二元分類器便分別判
斷某類的標籤是有是無。此類的方法將所有的類別分開判斷,因此,此類的 方法缺乏考慮標籤之間的關聯性。
• 分類器鏈:此類的方法如同二元關聯,將多標籤分類問題轉變至多個二元分 類問題,不同的地方是分類器鏈會依順序性預測,每個二元分類器皆會依照 之前的標籤的預測結果來做預測。如圖2.1(b),黃色部分是每個二元分類器 的輸入,在二元分類器B和C,其不只考慮了物件的特徵(feature),更會考慮 到之前標籤的分類結果。此類的方法可以考慮到類別之間的關聯性,但卻需 要人類事先定義的標籤順序來做預測。
• 標籤冪集:標籤冪集將多標籤分類問題轉變成多類別分類問題(multi-class classification),標籤冪集先訓練集中的標籤集(label set)作統計,將同樣的標 籤集分做一類,因此,若有L種標籤,最多會有2L種獨特的類別,因此,每 一個物件只會屬於某一個獨特的類別,如圖2.2,物件X1, X2具有相同的標籤 集A, C,因此這兩個物件的標籤是屬於同一類。此類的方法在標籤集種類很 多時便不適用,且無法預測沒有在訓練集中出現過的標籤集。
另一類的方法 [12–15],是基於潛在空間(latent space),他們將標籤集利用降 維轉換至此連續空間,並訓練模型在此連續空間內學習到標籤之間的變化,進而 學習到標籤關聯性。在解碼時,則在此潛在空間找尋輸入物件對應的標籤集。另 外,由於近年來深層學習的興起,近年來基於上述方法的深層模型也被提出,在 章節2.2.1和2.2.4也會多做介紹。
圖 2.1: (a)二元關聯示意圖,將原本A,B,C三個標籤分別用三個二元分類器來做預 測(b)分類器鏈示意圖,黃色部份是指分類器的輸入,白色的部分則是分類器需要 預測的標籤。
圖 2.2: 標籤冪集示意圖,因為X1, X2的標籤集相同,因此屬於同一個類別。
2.2 序 序 序 列 列 列到 到 到序 序 序 列 列 列(sequence-to-sequence)模 模 模型 型 型
2.2.1 類 類 類神 神 神經 經 經網 網 網路 路 路(Neural Network, NN)
簡 簡簡介介介
在機器學習領域中,類神經網路是一種模仿生物類神經網路的結構和功能的數學 模型或計算機模型。在生物的結構上來看(如圖2.3),神經系統是由非常多的神經 元組成,彼此以樹突、軸突與突觸連結,每個神經元有活化閾值決定是否變成激 發態。同樣的架構應用至電腦科學領域時,前人也設計可以計算的神經元,彼此 層層連結(如圖 2.4),每個神經元也必須被激發,才會有資訊流入下一層,此即為 類神經網路的全貌。類神經網路已經被用於解決各種各樣的問題,例如電腦視覺 和語音辨識。這些問題都是很難直接用傳統基於規則的程序所解決的。
運 運
運作作作原原原理理理
類神經網路的架構如圖2.4,是由許多的感知器(Perceptron)(圖2.5)串接而成,因 此深層類神經網路又被稱為多層感知器(Multi-layer Perceptron, MLP)。每一層的 感知器個數稱為此類神經網路的寬度(width),而所有含感知器的層數稱之為深 度(depth),因為近期推出的圖形處理器(Graphics Processing Unit, GPU)大幅提高矩 陣運算的速度,現今使用的類神經網路都相當多層,因此此類神經網路可稱之為 深層類神經網路(Deep Neural Network, DNN)。每一層根據所在位置的不同,可以
圖 2.3: 神經示意圖
圖 2.4: 類神經網路示意圖
圖 2.5: 運算神經元示意圖
分為三種:
• 輸入層(Input Layer):類神經網路由此層輸入特徵向量,輸入的訊息稱為輸入 向量。
• 輸出層(Output Layer):訊息在神經元連結中經傳輸、運算,輸出的訊息稱為 輸出向量。
• 隱藏層(Hidden Layer):是輸入層和輸出層中間的各個層。可以有一層或是多 層,深度和寬度數目不定。
在圖2.5中,{a1, a2, ....an}是輸入向量的各個分量,n是前一層的神經元個數,
而{w1, w2, ..., wn}是每個神經元的加權值,b = {b1, b2, ...bn}是偏移量(bias),f則是 活化函數(activation function),常見的是S函數(sigmoid),整流線性單元(Rectified Linear Unit, ReLU),運算的數學式分別如下:
t = f (
n
X
i=1
wiai+ b) (2.1)
sigmoid(x) = 1/(1 + e−x) (2.2)
ReLU (x) = max(0, x) (2.3)
若寫成矩陣的形式,則每層之間的轉換可以當作是一個從M維實數空間映射 至N維空間的函數RN ← RM,M和N分別是輸入向量X和輸出向量Y 的維度。
Y = f (W X + b) (2.4)
訓 訓
訓練練練類類類神神神經經經網網網路路路
在深層類神經網路內,最常見的訓練方法為反向傳播演算法(back propogation),
通常會搭配一些最佳化演算法,例如梯度下降法(gradient descent algorithm)。在訓 練時,會先定義一個特定的減損函數(loss function)PNn=1L(yn, ˆyn, θ),來衡量目前 的模型的輸出ˆyn和正確答案yn的差距有多少,一般來說,減損函數愈大,代表誤 差愈大,而訓練的目的就是減小誤差。其訓練的目標可以表示成如下的最佳化的 問題:
minθ N
X
n=1
L(yn, ˆyn, θ) (2.5) 常用的減損函數有多類別分類問題使用交叉熵(Cross Entropy, CE)或在二元分 類上使用的對數機率回歸(logistic regression)。以多類別分類器為例,假設有C個 類別,在機器學習領域中,會先將其表示成一個維度C的獨一餘零(1-hot)的向
量y = [0, 0...1, ..., 0]T,只有在正確類別l的維度是1,而其餘是0。分類器的輸出也 會是一個維度C且總和為1的向量ˆy,第i個維度代表屬於第i類的機率,是一個機率 分佈。訓練需要使y和ˆy的距離越近越好,因此通常會使用交叉熵作為減損函數,
定義為:
LCE(y, ˆy) =
C
X
i=1
yilog(ˆyi) (2.6)
其中,減少交叉熵等同於減少兩機率分佈y和ˆy的庫雷散度(Kullback-Leibler divergence),值越小代表兩機率分佈的距離越近,反之則代表兩分佈越不相似。
對於二元分類,通常使用對數機率回歸的減損函數,定義如下:
Llogistic(y, ˆy) = ylog(ˆy) + (1 − y)log(1 − ˆy) (2.7)
其 中 ,y ∈ {0, 1}代 表 是 否 屬 於 此 類 別 , 屬 於 的 話 是1, 反 之 則 為0,ˆy ∈ [0, 1]為 分 類 器 的 輸 出 機 率 , 代 表 屬 於 此 類 別 的 機 率 , 此 減 損 函 數 是 交 叉 熵 在C = 2時的特例,此時只有兩個類別,分別代表“屬於”和“不屬於”,因此可以只 用一個數字1或0來表達。
當設計者決定好減損函數後,接下來就是要找到模型的參數集θ,使得減損函 數最小。
θ∗ = arg min
θ N
X
n=1
L(yn, ˆyn, θ) (2.8) 其中N為資料量的個數。由於θ的參數空間太大,很難直接找到公式2.5最佳 解(optimal solution),因此常用的方法是用梯度下降法,藉由一步一步的更新參 數,使減損函數愈來愈小。因此,減損函數通常是定義成可微分的。簡單的演算 法是統計式梯度降低(Stochastic Gradient Descent, SGD),損失函數沿著該參數上的
梯度方向更新,可以表達成:
θk+1 → θk− η4θk 4θk = ∂L
∂θ θ=θk
(2.9)
其中η為學習率(learning rate),調控最佳化的速度與精細度,k為更新的迭代 次數,隨著k的增加,減損函數的值能逐步減少,模型就能訓練得更好。
在使用統計式梯度降低訓練類神經網路時,在模型完成順向預測(forward prediction)後,為了要算每層神經元的梯度,會先算出減損函數對輸出層的梯度,
再一層一層使用鏈鎖律(chain rule)往反向的算至輸入層,也就是反向傳播演算 法。近年來,也有許多對於學習率的研究,例如基於物理學的動量(momentum)的 演算法,對於學習率有限制的Adagrad更新法,和融合上述的Adam更新法,都是 目前深層學習廣泛應用的演算法。
然而,深層學習常常遇到過度貼合(overfitting)的問題,也就是說,模型在 訓練集(training set)的表現遠遠優於在驗證集(validation set)的表現,這代表類神 經網路已經偏向在“記憶”訓練集的正確答案,而缺乏廣泛化能力(generalization ability),因此,在訓練類神經網路時,我們常會使用L1,L2正規化(regularization)或 是丟棄法(dropout) [16],避免過度貼合的問題。
深
深深度度度深深深層層層模模模型型型如如如何何何應應應用用用於於於多多多標標標籤籤籤分分分類類類
類神經網路的架構可以輕易地和二元關聯的方法做結合,也就是說,可以將多標 籤分類轉變成多個二元分類問題,但是所有的分類器使用同一個類神經網路。假 設總共有L個類別,則類神經網路可以如圖2.6架構設計。
其中,使用的減損函數是L個二元分類的減損函數總和,如式2.10
圖 2.6: 二元關聯應用於深度深層模型之示意圖
Llogistic(y, ˆy) =
L
X
i=1
[yilog( ˆyi) + (1 − yi)log(1 − ˆyi)] (2.10) 如此便是使用深度類神經網路在多標籤分類上的一個基本架構。
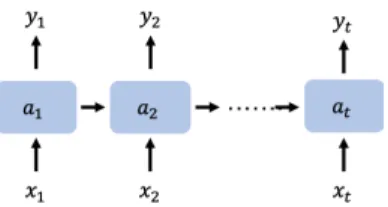
2.2.2 遞 遞 遞 迴 迴 迴式 式 式類 類 類神 神 神經 經 經網 網 網路 路 路(Recurrent Neural Network, RNN)
上述類神經網路是深層學習中的基本網路架構,可以應用於許多問題,但是在圖 像、聲音、文字這種訊號時,因為訊號十分複雜,如果每層都使用都全連接(fully connected)的深度深層網路,會使訓練參數過大,效果也十分不好。因此,便 有了針對圖像的卷積式類神經網路(Convolutional Neural Network, CNN)和對於時 間序列所設計的遞迴式類神經網路。遞迴類神經網路的隱藏層具有「記憶」功 能,除了考慮當下時間點的資訊外,也會參考過去所輸入的資訊,因此,對於 處理文字和聲音訊號這種時間序列經常使用此類型的類神經網路。以下我們將 分別介紹遞迴類神經網路的基本數學原理以及長短期記憶單元(Long Short-Term
圖 2.7: 基本的遞迴式類神經網路
Memory,LSTM) 。
數 數
數學學學原原原理理理
圖2.7為基本的遞迴式類神經網路,圖中的a是指該網路的記憶單元,而此記憶單 元at−1在時間點t,會與該時間點的輸入xt,經過一連串的矩陣變換,爾後產生輸 出yt,如此一來,在輸出yt時,此網路不只會考慮該時間點的輸入xt,更會融合時 間t之前所保留下來的資訊,因此在訓練類神經網路時,此網路不只會學習到輸入 和輸出之間的對應關係,更會學習到哪些資訊需要保留下來,而哪些資訊可以捨 棄。
長 長
長短短短期期期記記記憶憶憶單單單元元元
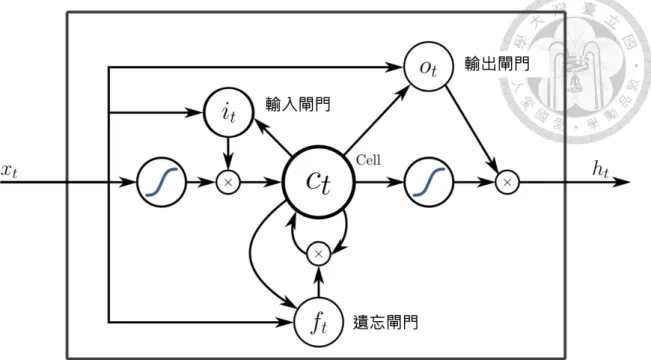
然而,遞迴式類神經網路也存在了許多問題,例如梯度消失(gradient vanishing),
原因是因為遞迴式類神經網路在傳遞梯度時,會經過許多活化函數,而此活化函 數若沒有設計好,則容易造成梯度越來越小,而此類網路又會輸入十分長的時間 序列,梯度每個時間點皆會經過一次記憶單元,因此會有梯度便會越來越小。因 此,在後人的研究中,提出了長短期記憶單元模型,其概念如圖2.8所示。
長短期記憶單元是更加複雜的遞迴式類神經網路的組成單元,其透過不同 的閘門(gate)來控制網路中資訊的流動,而閘門的設計是輸出介於0到1的S函數,
其值代表這個閘的輸出和輸入的比例。如圖2.8,共有三種閘門,分別是輸入閘
圖 2.8: 長短期記憶單元示意圖
門(input gate)、輸出閘門(output gate)和遺忘閘門(forget gate),輸入閘門負責控制 輸入的資訊量有多少需要存入記憶,輸出閘門負責決定多少比例的記憶需要用來 輸出,而遺忘閘門則負責決定多少比例的記憶資訊可以被拋棄,如此一來,梯度 便只會影響到開關開啟的時候,而減少梯度消失的問題。
2.2.3 序 序 序 列 列 列到 到 到序 序 序 列 列 列模 模 模型 型 型
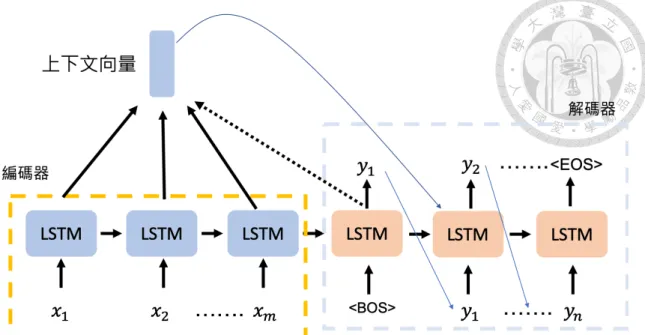
序列到序列模型是由兩個部分組成,分別是編碼器(encoder)和解碼器(decoder),
皆是由遞迴式類神經網路所組成,如圖2.9。當我們需要處理輸入和輸出皆是序列 的情況時,特別是輸入輸出序列不等長的時候,便會使用此種模型,如機器翻 譯(machine translation)、語音辨識等等。其中,{x1, x2, ..., xm}, {y1, y2, ..., yn}分別 代表編碼器和解碼器的輸入資料序列和輸出資料序列。編碼器負責將輸入資料編 碼成一個維度固定的代表向量,而解碼器需要根據此代表向量,進行解碼,而得 到一串輸出序列。然而,解碼器在產生資料序列時,是一個一個單位生成的,並
圖 2.9: 長短期記憶單元示意圖
且會基於之前所做的預測來產生這一步的輸出,因此,解碼器在每一步的輸入 皆會包括上一個時間點的輸出。而因為解碼器可以無限制的產生序列,我們會 用SOS和EOS來代表開始(start-of-sentence)和結束(end-of-sentence),在第一個時間 點輸入SOS來告訴解碼器這是序列的開始,而解碼器輸出EOS時,就是這個序列 的結束。
在訓練序列到序列模型時,我們常會使用最大似然估計(Maximum Likelihood Estimation, MLE),訓練使用的減損函數如下:
LM LE(y, ˆy) = −E(x,y∗)∼data
|y∗|
X
t=1
logpθ,t(y∗t|y∗<t, x) (2.11) 其中,x, y∗是配對好的資料(paired data),訓練的目標是最大化目標資料序 列y∗,也就是說,在每一個時間點t,會基於時間t之前的正確答案y<t∗ ,而做出時 間t的預測,而訓練的目標便是最大化時間t產生正確結果的機率,此訓練方法也 稱之為教師強迫(teacher forcing)。
然而,因為序列到序列模型中,輸入序列通常會十分的長,而輸入序列的資 訊又只由代表向量提供,因此輸入序列前段的訊息很難傳到解碼器,而且會有梯 度消失的問題,因此 就有人提出專注(attention)機制的想法,將在下一小節做介
圖 2.10: 長短期記憶單元示意圖
紹。
專
專專注注注機機機制制制
專注機制可以使解碼器直接取到編碼器的資訊,而不是只從代表向量中得到,因 此梯度較容易傳回編碼器,而能夠使一般序列到序列模型能表現更好。另外,因 為在在解碼時的每一個時間點,解碼器考慮每個輸入的權重不應相同,像是在機 器翻譯中,每個詞之間應有對應語言的翻譯,因此,在解碼每個詞的時候,需要 考慮對應的輸入文字也不盡相同。專注機制給予了模型這個彈性,使模型可以在 訓練時,動態的調整對於輸入序列的權重。以下我們以數學式來解釋專注機制,
給定編碼器的隱藏層序列he1, he2, ...hem及解碼器在時間t − 1的隱藏層hdt−1,上下文向 量如以下的方法計算。
etj = vaTtanh(Wahdt−1+ Uahej) (2.12)
αtj = exp(etj) Pm
k=1exp(etk) (2.13)
ct=
m
X
j=1
αtjhej (2.14)
hdt = LST M (hdt−1, [e(˜yt−1); ct−1]) (2.15)
其中,[e(˜yt−1); ct−1]是指將標籤˜yt−1的嵌入向量(embedding vector)和上下文向 量ct−1做連接,Wa和Ua是專注機制的參數。如圖2.10,上下文向量的計算先是由 解碼器的隱藏層和編碼器每個時間點的隱藏層做一些矩陣運算,計算出每一個時 間點的重要性etj(式2.12),爾後,式2.13藉由此重要性的數值來算出對於每個時間 點的權重αtj,上下文向量便是編碼器隱藏層的加權平均(式2.12),此上下文向量 會加入記憶單元的隱藏層中,並算出解碼器的下一個時間點t的隱藏層(式2.15)。
解碼時的每一個時間點都會重新計算一次前後文向量,使不同的時間點的輸 出可以根據不同的輸入序列資訊做計算,因此專注機制可以解決序列到序列模型 因輸入序列過長造成梯度消失的問題。
時 時
時序序序採採採樣樣樣(Scheduled Sampling, SS)
在訓練序列到序列模型時,因為使用教師強迫進行訓練,解碼器皆是基於正確的
前綴y<t∗ 來做時間t的預測,然而,在測試階段時,模型可能會產生錯誤的前綴,
若模型根據錯誤的結果繼續做預測,這個結果可能會更加糟糕,此現象又稱為曝 光偏差(exposure bias),因此,有人提出了時序採樣 [17]來解決此問題。
圖2.11是序列到序列模型的解碼器。在訓練模型階段,解碼器中的每個時 刻t,皆會擲硬幣或隨機決定是否使用正確的標籤yt−1或從上一時間點的預測的分
圖 2.11: 時序採樣示意圖
佈隨機採樣來作為時間點t的輸入。在訓練初期,使用正確標籤的機率會大一些,
讓模型較好訓練;在訓練末期,此機率則會較小,讓模型能夠多學習發生錯誤前綴 時的情況。
2.2.4 序 序 序 列 列 列到 到 到序 序 序 列 列 列模 模 模型 型 型應 應 應用 用 用於 於 於多 多 多標 標 標籤 籤 籤分 分 分類 類 類
序列到序列模型可以和2.1.2中提到的分類器鏈方法做結合。所謂分類器鏈是指分 類器會基於先前預測標籤的結果,來預測之後的標籤,此特性和遞迴式類神經網 路十分相似,因為此類神經網路會囊括先前的預測結果,來做下一步的預測。結 合的方法便是由遞迴式類神經網路所構成的解碼器,順序性的預測每一個屬於此 物件的標籤。若分類器的輸入也是序列,例如文章、音訊等,可以用遞迴式類神 經網路來做編碼,此模型便是序列到序列模型,由編碼器編碼輸入訊息,再由解 碼器依照順序解碼標籤。
因為序列到序列模型的輸出也是一串有順序性的序列,因此訓練時必須將標
圖 2.12: 強化學習示意圖
籤進行排序,經前人的研究,將標籤依照出現次數由最多次到最少次來做排序,
能使序列到序列模型有較好的表現。
2.2.5 強 強 強化 化 化學 學 學習 習 習(Reinforcement Learning, RL)應 應 應用 用 用於 於 於序 序 序 列 列 列到 到 到序 序 序 列 列 列模 模 模 型
型 型
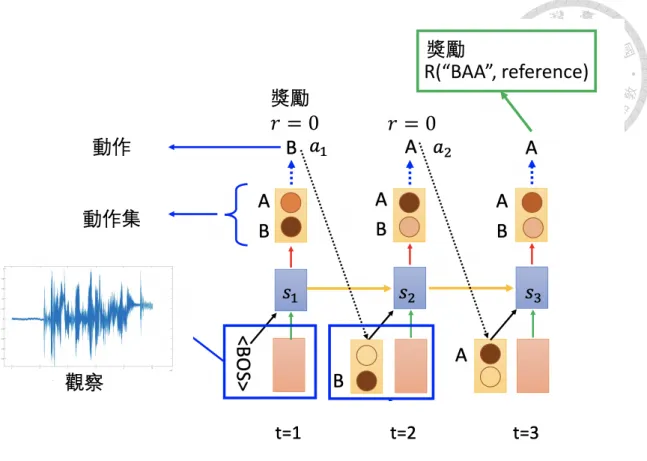
本章將介紹如何將強化學習中的訓練方法應用至序列到序列模型,會先介紹基本 的強化學習,爾後介紹如何將強化學習應用於訓練序列到序列模型。
強 強
強化化化學學學習習習簡簡簡介介介
強 化 學 習 是 機 器 學 習 中 的 一 個 領 域 , 和 先 前 提 到 的 監 督 式 學 習(supervised learning)不同,它並沒有資料的標籤,學習的方法是由模型和環境(environment)互 動,藉由環境給予的獎勵(reward)來做學習。
圖2.12中,大腦代表模型(agent),在深層學習中,此模型便是一個類神經網
路,地球代表環境,而獎勵是指環境給與模型的反饋,通常是由人事先定義的。
訓練模型的目標便是訓練出一個模型來適應環境且最大化預期獎勵。在每個時間 點t中,模型做出一個動作at,而環境會接收模型的動作而改變,並給予模型相對 的獎勵rt及觀察(observation)ot,模型再根據觀察ot來更新策略(policy)πθ,θ是指模 型的參數集,直到互動結束。其中,模型的狀態(state)st是指模型從開始互動後所 有的觀察、動作和得到的獎勵所構成的函數:
st= f (o1, r1, a1, ..., at−1, ot, rt) (2.16)
而訓練模型其中一個著名的方法便是策略梯度(policy gradient),這是一種策 略基礎(policy based)的方法,其所想要最大化的就是根據策略所能得到的獎勵的 期望值Jθ = E[R(s, a)|πθ],其中,R(s, a)是指環境在狀態s對模型做動作a給予的獎 勵,πθ則是動作的分佈,πθ(s)是指模型在狀態s下執行每個動作的機率分佈。為 了能使用梯度下降法更新模型,需要對此數學式微分,而得到:
∇θJ (θ) = E[∇θlogπθR(s, a)] (2.17)
此數學是可以用以下方式理解,若獎勵R(s, a)是正的,則鼓勵模型在狀態s時 做動作a,反之若獎勵是負的,則使模型在狀態s時做動作a的機率少一點。
強 強
強化化化學學學習習習應應應用用用於於於序序序列列列到到到序序序列列列模模模型型型
如圖2.13,在基於遞迴式類神經網路的解碼器中,每個時間點t的隱藏層紀錄了 狀態st,儲存了先前輸出和編碼器的資訊,而輸出的分佈可以看作是策略的分 佈πθ(st),而下一個時間點的輸入便是由策略分佈取樣得到at,而與環境互動結束 時,環境會比對輸出序列和正確的標籤序列的分數,並給予模型獎勵R,而模型
圖 2.13: 強化學習應用於序列到序列模型示意圖
更新的方法便是上一節講到的策略梯度。例如在語音辨識中,獎勵便是由詞錯誤 率計算的,錯誤的越少,獎勵就會越多,模型輸出此序列的機率便會上升。
與基於最大似然估計的訓練方法最大的不同點是,其輸入的是由上一時間點 輸出分佈做隨機取樣得到的結果,而不是正確標籤,且強化學習可以使用不可微 分的值做為獎勵,而原本的訓練方法則不行。強化學習應用於訓練序列到序列模 型一個有名的例子便是在序列到序列語音辨識模型上最小化詞錯誤率(Word Error Rate, WER),因為詞錯誤率的算法是離散而無法微分的,需要使用強化學習的方 法來最小化詞錯誤率。然而,因為此種方法皆需要模型做完預測後,才能拿到一 個值進行更新,因此這種方法不容易訓練類神經網路,通常需要使用最大似然估 計來作預訓練(pretrain)。
圖 2.14: 生成對抗網路基本架構
2.3 生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路(Generative Adversarial Network, GAN)
2.3.1 簡 簡 簡介 介 介
生成對抗網路 [3]是現今被廣泛研究的生成模型之一,除了在在圖片生成(image generation),在風格轉換(style transfer) [18]、語音增強(speech enhancement) [19]、
聲音轉換(voice conversion) [4]等領域都有生成對抗網路的應用。
模 模
模型型型架架架構構構
圖2.14是 生 成 對 抗 網 路 的 基 本 架 構 , 其 主 要 分 成 兩 個 部 分 , 分 別 為 生 成 器(generator)G和 鑑 別 器(discriminator)D, 生 成 器 的 輸 入 是 從 人 定 義 的 事 前 機 率pg隨機取樣的一個點,而輸出為一張圖片,並希望能生成接近真實的圖片,以 欺騙鑑別器。而鑑別器的工作是判別此圖片是來自於生成器或從真實圖片分佈取 樣得到的圖片x ∼ pdata,生成器的目標是欺騙鑑別器,然而,鑑別器的目標是鑑 別出生成器產生的圖片,兩者目標相反。生成式對抗網路便藉由兩個部分輪流更 新來訓練。訓練完成時,理想狀況是生成器能夠學習到如何從事前機率分佈映射 到真實的圖片分佈,換句話說,便是生成器生成的圖片分佈,和真實圖片的分佈 相同,在這個理想情況下,鑑別器便無法分辨真實和生成的圖片。
減
減減損損損函函函數數數與與與訓訓訓練練練方方方法法法
接下來要介紹生成對抗網路的數學式,也就是生成對抗網路的價值函數(Value function),定義如下:
min
G max
D V (G, D) = Ex∼pdata[log(D(x))] + Ez∼pz(z)[log(1 − D(G(z)))] (2.18) 其 中 ,D(x)的 輸 出 表 示 此 圖 片 是 真 實 圖 片 的 機 率 , 介 於 零 到 一 之 間 。 式2.18的第一項表示鑑別器需最大化真實圖片的機率,第二項表示鑑別器需最 小化生成器圖片的機率,然而生成器需要最大化此值。式中的minGmaxD則表 示D和G是互相拮抗的。在一般的情況下,G和D是交互訓練的,訓練方法如下 圖2.15描述: 其中,k是生成器和鑑別器訓練次數的比例,上面的演算法是更新k次
1: for number of iterations do
2: for k steps do
3: 從事前機率pg(z)中抽樣出m筆資料{z1, z2, ..., zm}
4: 藉由梯度下降更新生成器: ∇θG
1 m
Pm
i=1[log(1 − D(G(zi)))]
5: end for
6: 從事前機率pg(z)中抽樣出m筆資料{z1, z2, ..., zm}
7: 從真實資料pdata(z)中抽樣出m筆資料{x1, x2, ..., xm}
8: 藉由梯度下降更新鑑別器: ∇θD
−1 m
Pm
i=1[log(D(xi)) + log(1 − D(G(zi)))]
9: end for
圖 2.15: 生成對抗網路的訓練方法
生成器後,更新一次鑑別器,通常k是一個敏感的超參數(hyperparameter),對訓練 成功與否有相當大的影響。
圖 2.16: 條件式生成對抗網路基本架構
2.3.2 條 條 條件 件 件式 式 式生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路
簡 簡簡介介介
在生成式對抗網路中,生成器的輸入是事前機率隨機取樣一個點,然後生成圖 片。然而,真實的圖片卻有非常多種類別,若需要生成特定種類的圖片時,例如 貓、狗等,則需要在訓練過程中,使用圖片的類別標籤,使生成對抗網路了解圖 片和標籤的對應關係。
模 模
模型型型架架架構構構
如圖2.16,訓練條件式生成對抗網路需要有標記的圖片標籤配對(x, y),加入條件 的方法是在生成器和鑑別器的輸入都加入條件y(或y0),生成器必須產生符合條 件y(或y0)的圖片,鑑別器不只需要考慮圖片的真實程度,也需要考量輸入圖片是 否符合條件y(或y0)。
減
減減損損損函函函數數數與與與訓訓訓練練練方方方法法法
條件式生成對抗網路的價值函數可以寫成下式:
min
G max
D V (G, D) = E(x,y)∼pdata[log(D(x|y))] + Ez∼pz(z),y0∼py[log(1 − D(G(z)|y0))]
(2.19) 訓練方法和一般的生成對抗網路大同小異,只是在訓練生成器時,除了要 從pz取樣,還要隨機選取一個類別y0,使生成器生成屬於類別y0的圖片,此y0也會 是鑑別器的輸入,在從真實數據取樣時,也需要取樣和圖片相符的類別y。生成器 需要最小化式2.19的第二項,然而,鑑別器兩項都需要最大化。
2.3.3 霍 霍 霍式 式 式生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路(Wasserstein GAN)
然而,上述都只是最基本的生成對抗網路,基本的模型有許多問題,例如其訓練 過程十分困難、對於超參數十分敏感、模式崩潰(mode collapsed)等等,其中,模 式崩潰是指生成的圖片缺乏多樣性,生成器只能生成特定幾個種類的圖片。霍式 生成對抗網路 [20]解決了底下幾個問題:
• 讓生成對抗網路的訓練更加穩定,使其對超參數較不敏感。
• 解決了模式崩潰的問題,確保了生成圖片的多樣性。
基 基
基本本本的的的生生生成成成對對對抗抗抗網網網路路路遇遇遇到到到的的的問問問題題題
霍式生成對抗網路的作者在論文中提到了基本的生成對抗網路遇到的問題。在最 優(optimal)鑑別器的情況下,其實鑑別器的數值是衡量真實分佈pdata和生成的分 佈pg的JS散度(Jensen-Shannon Divergence)(式2.20),但是JS散度在衡量兩分佈的距 離時,若兩分佈沒有交集,他們的JS散度就會是一個定值log2,因此,微分後便 會是0,梯度便會消失。因此訓練初期兩分佈相差甚遠或鑑別器訓練得較好時,就 有可能遇到這個狀況,導致訓練變得困難。
max
D V (G, D) = −2log2 + 2J SD(pdata||pg) (2.20) 霍
霍
霍氏氏氏距距距離離離
在霍氏生成對抗網路中,作者引用了霍氏距離來代替JS散度,並將其作為優化目 標,霍氏距離相對於JS散度平滑,因此較不容易有梯度消失的問題。其中,霍氏 距離可以用以下式子表達:
W (pg, pdata) = sup
kf kL≤1{Ex∼pg[f (x)] − Ex∼pdata[f (x)]} (2.21) 其 中 ,kfkL ≤ 1 代 表 所 有1-Lipschitz的 函 數 , 也 就 是 所 有 滿 足|f(x1) − f (x2)| ≤ |x1 − x2|, ∀x1, x2的函數,而sup表示最小上界(supremum),式2.21代表對 所有滿足1-Lipschitz的函數取到Ex∼pg[f (x)] − Ex∼pdata[f (x)]的上界。 然而,若我們 使用一組參數集為w的類神經網路fw來表示1-Lipschitz的函數,則式2.21可以近似 成:
W (pg, pdata) = max
w:kfwkL≤1{Ex∼pg[f (x)] − Ex∼pdata[f (x)]} (2.22) 因此,這個式子就和就可以和原本生成對抗網路的式2.18十分相似,將fw改 寫成D後,霍氏生成對抗網路的價值函數便可以寫成式2.23。
minG max
D V (G, D) = Ex∼pdata[D(x)] − Ez∼pz(z)[D(G(z))] (2.23) 而因為fw需要是1-Lipschitz的函數,作者限制所有類神經網路的參數不得超 過某個範圍[−c, c],因此,鑑別器D的微分值也會被限制在某個常數內,就滿足
了1-Lipschitz的條件,在實作上也十分簡單,只要將每次更新完的參數超過範 圍[−c, c]的部分扣掉就好了。
因此,霍式生成對抗網路的改進部分主要是下列幾點:
• 去掉鑑別器最後的sigmoid層,因為不需要限制輸出至0到1之間。
• 改寫價值函數,使鑑別器改為計算霍氏距離。
• 限制鑑別器的所有參數在更新完後皆不超過範圍[−c, c]。
增
增增進進進版版版霍霍霍式式式生生生成成成對對對抗抗抗網網網路路路(Improved Wasserstein GAN)
增進版霍式生成對抗網路 [21]是改良版的霍式生成對抗網路,其作者發現了原本 霍式生成對抗網路為了要限制1-Lipschitz的條件,限制了參數的範圍,然而在實際 訓練時,模型對於限制範圍的大小的數值十分敏感,且大部分的參數都會集中在 範圍的邊界,因此,他提出了增進版霍式生成對抗網路,使用了不同的方法限 制1-Lipschitz的條件。
作者提出的方法是梯度懲罰(Gradient Penalty, GP),原理是限制鑑別器的梯 度,若鑑別器的梯度小於一 (k∇xD(x)k ≤ 1, ∀x),則鑑別器必然滿足1-Lipschitz的 條件,因此梯度懲罰鼓勵鑑別器的梯度越接近1越好,數學式如下:
Lgp = Ex∼pˆ penalty[(k∇xD(ˆx)k − 1)2] (2.24)
其中,ppenalty是指梯度懲罰分佈。下列對此做簡短說明,因為若要限制
空間中的每一個點的梯度是十分困難的。然而,在此空間中較重要的點就 是pg和pdata中的點,還有這兩個分佈中間的點,因此,作者認為只需要限制這三 個範圍內的點的梯度,因此做法便是隨機取樣pg和pdata中的點,並使用此兩點隨
圖 2.17: 梯度懲罰分佈
機內差得到一個新的點,並限制這個點梯度的大小,在實作中此方法較為容易,
且有好的效果,如圖2.17。
表2.18是增進版霍式生成對抗網路的訓練方法,其中λ是一個超參數,調控梯 度懲罰損失的大小。
1: for number of iterations do
2: for k steps do
3: 從事前機率pg(z)中抽樣出m筆資料{z1, z2, ..., zm}
4: 藉由梯度下降更新生成器: ∇θG
1 m
Pm
i=1[−D(G(zi))]
5: end for
6: 從事前機率pg(z)中抽樣出m筆資料{z1, z2, ..., zm}
7: 從真實資料pdata(z)中抽樣出m筆資料{x1, x2, ..., xm}
8: 藉由梯度下降更新鑑別器: ∇θD
−1 m
Pm
i=1[D(xi) − D(G(zi))]
9: 從均勻分佈U(0, 1)中隨機取樣m個點{α1, α2, ..., αm}
10: 計算內差的點{ˆxi = αizi+ (1 − αi)xi|i = 1, 2, ..., m}
11: 藉由梯度下降更新鑑別器: λ∇θD
Pm
i=1[(k∇xD(ˆxi)k − 1)2]
12: end for
圖 2.18: 增進版霍式生成對抗網路的訓練方法
2.4 本 本 本章 章 章總 總 總結 結 結
本章一開始先介紹多標籤分類的基本算法,爾後,從基本的類神經網路開始,介 紹遞迴式類神經網路及序列到序列模型,以及其如何應用在多標籤分類問題上,
也稍微簡介了如何利用強化學習訓練序列到序列模型。在本章的後半段,主要是 介紹生成對抗網路,從條件式生成對抗網路的架構,並演進到霍氏生成對抗網 路,以及說明其解決了原本生成對抗網路的什麼問題。
第
第 第 三 三 三 章 章 章 以 以 以生 生 生成 成 成式 式 式對 對 對抗 抗 抗網 網 網路 路 路幫 幫 幫 助 助 助多 多 多標 標 標籤 籤 籤分 分 分類 類 類 器 器 器
3.1 簡 簡 簡介 介 介
3.1.1 研 研 研究 究 究 動 動 動機 機 機
多標籤分類是一個基本卻十分困難的問題,並且有許多應用,像是音樂中的曲風 分類、文章分類、醫療疾病分類等等,相對於單標籤分類,多標籤分類器不只需 要了解物件和標籤之間的關係,更需要了解標籤之間的關聯性。例如在一張圖片 中,海洋和沙灘比較容易一起出現,而沙灘和大象就不容易一起出現在同一張圖 片裡。
多標籤分類在深層學習中有許多方法,像是利用深層神經網路搭配對數機率 回歸,近年來,也有人利用機率圖模型(probabilistic graphical networks)、遞迴式類 神經網路來模擬標籤間的關聯性。而在本論文,將介紹如何使用生成式對抗網路 來模擬此標籤關聯性。
本章介紹的模型是以條件式生成網路作為基礎,分類器在此扮演生成器的角 色,其輸入是一個物件,而輸出是屬於此物件的標籤集,鑑別器則需要學習標籤 之間的關聯性,其輸入是標籤集和一個物件,而鑑別器需要輸出一個值。此標籤 集可能來自真實的資料也可能來自生成器的輸出,而鑑別器需要學習如何分辨此 標籤集是從生成器產生還是從真實的資料,因此,鑑別器不只需要了解標籤之間 的關聯性,還需要了解物件和標籤集的關係,才能學習到如何分辨真偽。而在此 生成對抗網路的架構下,分類器(生成器)也需要學習如何從輸入的物件,讓產生
之標籤集的關聯性更貼近真實資料,以欺騙鑑別器。如同一般的生成對抗網路,
分類器和鑑別器會交替訓練。
本論文提出的架構是和分類器的結構無關的,因此,我們相信這個架構可以 套用在其他模型上,使其他模型學習如何模擬標籤間的關聯性。模型架構將會在 章節3.2中說明,而生成對抗網路中的分類器和鑑別器的訓練,將會在章節3.3.1和 章節3.3.2說明,最後的實驗部分會在章節3.4做說明。
3.2 本 本 本論 論 論文 文 文所 所 所提 提 提出 出 出之 之 之模 模 模型 型 型
本論文所提出之模型如圖3.1,在此,以多標籤影像分類作為解釋多標籤分類的一 個例子,x是指輸入影像,而對應的正確答案標籤集y ∈ {0, 1}|S|, |S|是指標籤的種 類數。
模型包含分類器(生成器)和鑑別器,生成器G是一個輸出層是S函數作為激 活函數的類神經網路。此生成器在此可以有很多種架構,例如,VGG-16 [22], Inception v3 [23], Resnet-101 [24], 或Resnet-152 [24]等。G 將一張圖片x當作輸入,
並輸出圖片x的標籤集機率分佈˜y ∈ R|S|,˜y的每一維皆介於0和1之間,代表具有某 個標籤的機率。在訓練時,預測的標籤集ˆy會從˜y取樣,取樣的機率會根據每個標 籤輸出機率的大小,而有所不同。在測試階段,則不會有取樣的步驟,而是選輸 出機率大於0.5的標籤當作模型預測的標籤集。
鑑別器D的輸入是標籤集y(或ˆy)和圖片x,並產出一個分數D(y, x)(或D(ˆy, x)),
代表這個標籤集有多”真實”或標籤集和此圖片的匹配程度。其中,特徵抽取 器fext是用來抽取圖片x的特徵z = fext(x),並包含在鑑別器裡。爾後接了一個全 連接(fully-connected)的類神經網路,此全連接層的輸入是z和y(或ˆy),並輸出一個 值D(y, x)(或D(ˆy, x))。在測試階段,不需要鑑別器,只需要分類器的輸出作為預
圖 3.1: 模型架構示意圖
測結果。

![圖 2.6: 二元關聯應用於深度深層模型之示意圖 L logistic (y, ˆ y) = L X i=1 [y i log( ˆy i ) + (1 − y i )log(1 − ˆy i )] (2.10) 如此便是使用深度類神經網路在多標籤分類上的一個基本架構。](https://thumb-ap.123doks.com/thumbv2/9libinfo/9597099.628149/26.892.167.781.145.472/二元關聯應用於深度深層模型之示意ˆ=Lˆ+−−.webp)