行政院國家科學委員會專題研究計畫成果報告
漢語語音合成之信號清晰度與流暢度的改進研究
Improving of Signal Clarity and Fluency for Chinese Speech Synthesis 計畫編號:NSC 96-2221-E-011-163
執行期限:96 年 8 月 1 日至 97 年 7 月 31 日 主持人:古鴻炎 國立台灣科技大學資訊工程系 計畫參與人員:吳昌益、朱楠群
e-mail: [email protected]
一、中文摘要
雖然採取 corpus-based 的作法可以 避免信號清晰度和流暢度的衰退,但是這 樣也會失去一些功能,如失去說話速度快 慢、及音調高低等因素的調整的彈性。因 此本計畫在說話速度、音調可變換的前提 下,去研究信號清晰度與流暢度改進的語 音合成方法。我們改進了諧波加雜音模 型,用以改善信號的清晰度;研究以類神 經網路模型來對音節內的頻譜演進路徑作 學習和產生。目前,我們可以只用一個人 的錄音,來合成出多種說話速度和音調、
且音質清晰的語音信號。
關鍵詞:語音合成、信號清晰度、流暢度、
諧波加雜音模型、頻譜演進
ABSTRACT
In speech synthesis, a corpus-based approach is usually adopted to prevent the degradation of signal clarity and fluency. The adoption of such approach also implies that some functions must be given up, including the flexibilities in adjusting speaking rate and pitch-heights. In this project, we hence studied speech synthesis methods to improve signal clarity and fluency while keeping the capabilities of adjusting speaking rate and pitch-height. In fact, we have improved harmonic-plus-noise model (HNM) to promote signal clarity, and constructed an artificial neural network (ANN) based model
to learn and generate spectrum-progression path for a syllable. Now, recorded speech signals of a person can used to synthesize speech signals of multiple speaking rates and different pitch heights.
Keywords: speech synthesis, signal clarity, fluency level, harmonic-plus-noise model, spectrum progression
二、緣由與目的
在國語、閩南語、客家語等語言的語 音合成之研究領域,過去被研究過的語音 信 號 合 成 技 術 , 包 括 了 線 性 預 測(linear prediction) 合 成 , 幅 峰 (formant) 合 成 , PSOLA (pitch synchronous overlap and add) , 及 錄 大 量 發 音 以 作 單 元 選 取 之 re-sequencing 合成方法。
線性預測合成之方法,一個常被提及 的缺憾是,鼻音的 zero 特性以 all pole model 來模擬會有明顯的誤差存在,而讓 合成的信號變得模糊而不清晰。幅峰合成 之方法,一般來說可以合成出非常清晰的 語音信號,但是幅峰合成器裡,需去控制 的參數非常多,並且這些參數的數值不是 經過formant tracking 之分析就能夠確定。
PSOLA 是目前較常被採用的語音信 號合成方法,因為它的控制參數(pitch peak) 數值容易決定,且信號合成的處理程序也 是容易製作。然而PSOLA 有一嚴重的缺點 是,當合成單元音長(duration)或音調(pitch) 改變太大時,合成出的語音信號會明顯地
變得不清晰,甚至於會出現合唱(chorus)、
迴音(reverberation)等副作用。
若 採 取 純 粹 的 單 元 選 取 之 corpus- based 的合成方法,則必須錄製非常大量的 語音,且合成單元的切割與標示,也需花 費人力來作程式處理後的校對、更正。所 以,實作上大多是採取混合式的作法,亦 即仍然會對一些合成單元作韻律特性的調 整 處 理 , 而 一 般 選 取 的 處 理 方 法 多 是 PSOLA,此時就會面臨清晰度和流暢度的 抉擇的兩難問題,例如想要保持清晰度,
就不對音長差異(原始值、目標值之間)較大 者作處理,結果可能造成合成語音的說話 速度忽快忽慢地改變,而降低了流暢性。
三、清晰度改進之研究
在此我們以HNM (harmonic plus noise model)為基礎,對它作改進,以便用來合 成出清晰的國語語音信號。HNM 是由 Y.
Stylianou 所提出的一種語音信號的模型,
希望在作語音處理(編碼,合成)時,仍能保 持信號的清晰度與自然度。HNM 可看成是 弦波模型的改進,它對於語音高頻部分的 雜 音(noise)信號成分,建立了較好的模 型。HNM 的模型參數分析程序裡,提供了 最 大 有 聲 頻 率 MVF (maximum voiced frequency) 的一個偵測方法,依 MVF 值可 將一個語音音框(frame)的頻譜分割成低 頻、高頻之兩個部分,對於低頻部分的信 號成分,採取以諧波成分(harmonic partials) 的加總來塑模(modeling),而對於高頻部分 的信號成分,則採取以平滑的頻譜包絡 (spectral envelope)來塑模,實際上是以少數 的倒頻譜(cepstrum)係數來代表此頻譜包 絡。
3.1 音色一致性及音長調整
當應用 HNM 來合成國語語音時,我 們發現有幾個議題,其解決方法並未能在 HNM 的文獻上找到,第一個議題是,如何 讓合成的音節信號保持音色(timbre)的一 致性(consistency)? 由於我們只希望對各 種國語音節錄製一次發音,然後透過修改 一個音節的基週軌跡的高度及形狀,來合
成出其它聲調的音節信號,因此當一個欲 合成音節的基週軌跡被指定時,我們必需 使用一種適當的方法來調整 HNM 各諧波 成分的參數值,以同時滿足基週軌跡及音 色一致性的要求。
第二個議題是,對於一個放置於欲合 成音節之時間軸上的一個控制點(control point),如何決定此控制點上的 HNM 參數 的數值? 在合成一個音節的信號時,我們 需要調整該音節原始錄音的音長以滿足韻 律單元所指派的合成音節之音長,因此在 合成音節時間軸上的一個控制點,當它被 對映(mapping)至一個位於原始音節兩分析 音框之間的時間點時,我們必需使用一種 適 當 的 內 差 方 法 來 計 算 此 控 制 點 上 的 HNM 參數值。
我們研究了前述二項議題的解決方 法,當要合成一個音節的信號時,程序上 先作控制點的佈放、對映(mapping),對映 是指對映至原始音節之音框;再去內差出 音高(pitch)未變之控制點上的 HNM 參數;
然後,進行可保持音色之另一種內差處 理,以求取音調改變後之 HNM 參數數值。
前述步驟的作法細節,可參考我們已發表 之研討會論文: 古鴻炎、周彥佐,「基於 HNM 之國語音節信號的合成方法」,第十 九 屆 自 然 語 言 與 語 音 處 理 研 討 會 (ROCLING 2007),台北,第 233-243 頁,
2007。
3.2 信號合成之主流程
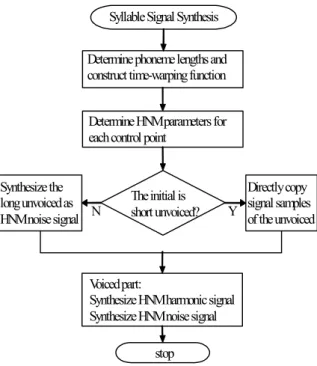
此外,我們也依據前述的解決方法建 造出了一個由 HNM 作改進的國語音節信 號合成系統,此系統的主要處理流程如圖 1 所示。當要合成一個音節的信號時,很 明顯地此音節的各個韻律參數值已經由韻 律單元訂定、指派好了,因此圖 1 裡的第 一個方塊首先作的是,將合成音節的音長 規劃、分割成此音節的組成音素(phoneme) 的時長(duration),接著依據相連音素的時 長來建造一個片斷線性(piece-wise linear) 的時間校正函數,以便將合成音時間軸上 的時間點對映至原始音的時間軸上;在圖 1 裡的第二個方塊,先均勻地在合成音的
時間軸上佈放控制點,然後對各個控制點 求取該點上的 HNM 參數值;接著在圖 1 裡的後面三個方塊,將信號分類成三種形 態分別去作合成處理,對於短時間的無聲 (unvoiced)聲母(syllable initial),其信號片斷 直接由原始音裡複製到合成音裡,對於長 時間的無聲聲母,其信號則當作是 HNM 的雜音信號成分來作合成,至於音節的有 聲(voiced)部分,包括有聲子音及母音,則 先分別合成出諧波和雜音成分,再作相加。
3.3 測試與聽測評估
首先以觀察聲紋圖(spectrogram)的方 式,來比較我們研究的 HNM 合成法和一 般常用的PSOLA 合成法。兩方法分別去合 成出國語短句〝旋轉力〞/syuen-2 zhuan-3 li-4/ 的語音信號,然後以聲紋分析軟體 (wavesurfer)作分析來得到聲紋圖,圖 2 的 聲紋是對 HNM 法所合成的信號作分析而 得到,圖3 的則是對 PSOLA 法合成的信號 作分析而得到。從圖2 和 3 我們可觀察倒,
圖3 裡的諧波紋路顯得比圖 2 裡的較為零 碎、較多斷裂的地方,並且圖 2 裡的諧波 條紋較為平滑,而不像圖 3 裡的顯得有一 些毛燥、扭曲,因此 HNM 法合成出的信 號應會比PSOLA 的清晰。
/syuen-2/ /zhuan-3/ /li-4/
圖2 HNM 法所合成信號的聲紋圖
/syuen-2/ /zhuan-3/ /li-4/
圖3 PSOLA 法所合成信號的聲紋圖 此外,我們選了一篇短文來讓這兩種 方法去合成出語音信號,並且存成波形檔 案,短文是一篇小學生的作文,有 132 個 音節。接著我們將這兩個波形檔以隨機次 序播放給15 位參加聽覺測試者聆聽,然後 請他們對前、後播放的檔案作清晰度的比 較,評分的規則是,兩者無法區分時給 0 分,如果後者(前者)比前者(後者)稍好一 些,則給 1 分(-1 分),而如果是明顯地好 或好很多則給 2 分(-2 分),結果我們得到 的平均分數是1.2 分,也就是 HNM 法會合 成出比較清晰的語音。另外,為了讓有興 趣者能夠試聽這兩種方法所合成出的語音 信號,我們設定了一個網頁以供人瀏覽,
其 網 址 是 http://guhy.csie.ntust.edu.tw/trhnm/
sentence.html。
四、流暢度改進之研究
最近回顧一些文獻後發現,我們所關 心的流暢性不足的問題,其實已經有其他 研究者注意到了,他們提出的一種作法 是,以HMM (hidden Markov Model)模型的 數個狀態,來切割一個音節的時長成為數 個時間片斷,再分別去掌握各片段上的頻 圖1、基於 HNM 之音節信號合成的主流程
SyllableSignal Synthesis
DetermineHNMparametersfor eachcontrol point
Determinephonemelengthsand construct time-warpingfunction functionmeters
Theinitial is short unvoiced?
Voicedpart:
SynthesizeHNMharmonicsignal SynthesizeHNMnoisesignal
stop
Directlycopy signal samples of theunvoiced Y
N Synthesizethe longunvoicedas HNMnoisesignal
譜特性(例如頻譜包絡, spectrum envelope, 的 形 狀) , 並 且 以特定的狀態駐留(state staying)機率分佈來掌握在各個狀態上所應 停留的時間長度。這樣的作法,以我們的 觀點來看,就是在於作更細緻的規劃,把 一個音節的時長以某一種非均勻的方法作 切割,而讓不同的狀態(也就是頻譜包絡) 分配到不等的時間長度,以便更細緻地模 仿真人發音(articulation)時的頻譜隨著時間 變化的關係。
4.1 頻譜演進
前述頻譜(包絡形狀)隨著時間演變的 關 係 , 在 本 文 裡 簡 稱 之 為 頻 譜 演 進 (spectrum progression),而頻譜演進路徑(簡 稱為頻演路徑)指的是,當把欲合成的音節 放在橫軸上,而把相同拼音的原始錄音音 節放在縱軸上,此時橫軸上各時間點所應 對應的縱軸時間點,需要一條曲線來描述 此對映(mapping)關係,一個例子如圖 4 所 示,這樣的對映曲線就是本文所謂的頻演 路徑。過去很多的國語語音合成系統,其 合成出的語音的流暢性不佳的一個主要原 因,我們認為是因為它們直接把頻演路徑 設定為直線,而沒有特別考慮頻演路徑的
塑模(modeling),再據以產生出逼近真人講 話方式的頻演路徑。
圖4 頻譜對映曲線之例子
因此,我們便開始研究頻演路徑塑模 及產生的問題,在此我們不追隨前人採取 HMM 來建立頻演路徑的模型,原因是 HMM 未 去 掌 握 時 間 上 相 鄰 的 觀 測
(observation)向量之間的依存(dependency) 性,這相當於假設時刻t 的觀測向量 Ot 和 Ot+1 (或 Ot-1)之間沒有依存關係,而只有 去掌握 Ot 和它所停留的狀態之間的關連 性,這樣的modeling 方式令我們懷疑其是 否可以滿足語音合成上的需求;此外,一 個合成音節的頻演路徑並不會是只有固定 的一條而已,而是會隨著左右鄰接音節的 不同,去行走不同的路徑(也就是 context dependent),在此情形下,一個 HMM 的各 個狀態如果只是各自去考慮 state duration 的機率分佈,而沒有考慮鄰接狀態和鄰接 音節之間的相關性,則不免讓我們懷疑其 完善性。
4.2 頻演模型
基於前述的考量,我們逐決定以ANN (artificial neural network)來建立頻演路徑 的模型,而模型的訓練步驟是: (a)錄製單獨 發音的參考音節和句子發音的語句,然後 把語句裡的音節切割成各別的目標音節檔 案;(b)逐一將整句發音裡的音節信號放在 橫軸,而把相同拼音的單獨發音音節信號 放在縱軸,再以DTW(dynamic time warping) 來匹配出一條頻演路徑;(c)將橫、縱軸上 的音節信號的時間範圍各自正規化成 0 至 1 之間,然後在橫軸音節上均勻放 32 個正 規化的時間點,各點再依頻演路徑對映至 縱軸而得到介於 0~1 之間且隨著橫軸作非 線性漸增的32 的數值;(d)將各個句子發音 裡的音節對映出的 32 個正規化的時間值 (稱為頻演參數)作為 ANN 模型學習的目 標,並且把該音節及其前、後鄰接音節的 資訊(也就是語境資料)作為 ANN 的輸入資 料,去訓練頻演參數的ANN 模型。
目前我們只錄了 375 個訓練語句,共 2,926 個音節,來訓練頻演模型。頻演模型 建立後,就可用它來產生出一個欲合成音 節的32 個頻演參數,再依這些頻演參數去 作片段線性內差而得到如圖 4 所示的對映 函數。然後,這個對映函數就可帶入第三 節的 HNM 合成法裡,去對映合成音節的 一個控制點至原始音節上的分析音框,來 取得控制點上所需的HNM 參數。
欲合成音節/yao/
原 始 音 節 /yao/
將前述的頻演模型和 HNM 合成法作 整合後,拿來合成一篇短文的文字成為語 音檔,另外也把對映曲線以直接設定為直 線的方式,去合成出第二個音檔。然後,
依據這2 個合成的音檔,請了 9 個試聽者,
來作聽測評估,初步結果顯示,我們提出 的頻演模型,的確可明顯地提升合成語音 的流暢性。
五、成果與討論
經由本計畫的執行,我們對 HNM 信 號模型作了研究、改進,解決它的(a)音色 一致性、(b)控制點上 HNM 參數訂定之問 題。再者,我們以改進的 HNM 為基礎,
提 出 一 個 合 成 國 語 音 節 信 號 的 作 法 (scheme),將它實作成程式後,用以合成出 語音檔,並且我們也使用PSOLA 的作法去 合成出語音檔,然後拿兩者的語音檔去作 聽測評估,結果顯示我們的HNM 合成法,
的確可以獲得較高的語音清晰度。
此外,我們也研究、提出了一個以 DTW 加上 ANN 來建立頻演參數模型的方 法。當建立頻演模型之後,將它和 HNM 合成模組作整合,用以合成出國語語音信 號,再拿合成出的語音去作聽測實驗,初 步結果顯示,我們的頻演參數模型的確可 用以提升合成語音的流暢度。
原先本計畫是規劃為多年期的,預備 第二年作漢語中閩南語、客家語的語音信 號合成的研究,但後來被砍成為一年,所 以就只能研究國語語音信號的合成而已。
六、參考文獻
[1] Chiou, H. B., H. C. Wang, and Y. C. Chang,
“Synthesis of Mandarin Speech Based on Hybrid Concatenation”, Computer Proc- essing of Chinese and Oriental Languages, Vol. 5, pp. 217-231, 1991.
[2] 盧鵬任, 中文文句翻語音系統之改進, 碩 士論文, 國立交通大學電信研究所, 1996.
[3] 林顯易, 一套基於類神經網路與模糊邏輯 之中文語音合成系統, 碩士論文, 國立交 通大學電機與控制工程系, 1998.
[4] Chou, Fu-chiang, Corpus-based Technologies for Chinese text-to-Speech
Synthesis, Ph.D. Dissertation, Department of Electrical Engineering, National Taiwan University, Taipei, Taiwan, 1999.
[5] 張唐瑜, 以大量詞彙作為合成單元的中文 文轉音系統, 碩士論文, 國立中興大學資 訊科學研究所, 2004.
[6] 吳佩穎, 以語料庫為基礎之中文文句翻語 音系統中合成單元之選取, 碩士論文, 國 立交通大學電信工程系所, 2004.
[7] O`Shaughnessy, D., Speech Communi- cation: Human and Machine, 2’nd ed., IEEE Press, 2000.
[8] Klatt, D. H., "Software for a Cascade / Parallel Formant Synthesizer", J. Acoust.
Soc. Am., Vol. 67, pp. 971-995, 1980.
[9] Modulines, E. and F. Charpentier, "Pitch- Synchronous Waveform Processing Techniques for Text-to-Speech Synthesis Using Diphones", Speech Communication, pp. 453-467, 1990.
[10] Yannis Stylianou, Harmonic plus Noise Models for Speech, combined with Statistical Methods, for Speech and Speaker Modification, Ph.D. Dissertation, Ecole Nationale Sup e rieure des T e l e communications, Paris, France, 1996.
[11]Chollet, G., A. Esposito, M. Faundez-Zanuy, and M. Marinaro (Eds.), Nonlinear Speech Modeling and Applications, Springer- Verlag, 2005.
[12] Tokuda, K., Zen, H. and Black,A.W.,“An HMM-based speech synthesis system applied to English”, 2002 IEEE Speech Synthesis Workshop, Santa Monica, California, Sep. 11-13, 2002.
[13] Qian, Y., F. Soong, Y. Chen, and M. Chu,
“An HMM-Based Mandarin Chinese Text-to-Speech System”, International Symposium on Chinese Spoken Language Processing 2006, Singapore, Vol. I, pp.
223-232, 2006.
[14] Yeh, Cheng-Yu, A Study on Acoustic Module for Mandarin Text-to-Speech, Ph.D.
Dissertation, Graduate Institute of Mechanical and Electrical Engineering, National Taipei University of Technology, Taipei, Taiwan, 2006.