特徵值大於一方法正確決定因素數目之再探
劉心筠
1翁儷禎
2李俊霆
3摘要
特徵值大於一是決定因素數目最常用的方法,但錯估因素數目的情形亦較其他 方法嚴重。為因應實徵研究多以李克特式量尺資料題目進行分析之現狀,本模擬研 究探討特徵值大於一於李克特式量尺資料的表現,提出該方法能建議合宜因素數目 的情境,作為因素分析應用研究之參考。模擬資料為正交多因素模式,操弄因素負 荷量、樣本人數、變項因素比、因素數目、量尺點數及分配型態。結果顯示,特徵 值大於一於李克特式量尺資料之表現,主要受因素負荷量與樣本人數的影響,惜僅 當因素負荷量高且樣本人數大時,方能建議合宜的因素數目。此結果除表示研究者 應謹慎使用特徵值大於一決定因素數目外,更重要的,基於此方法之常用率,本研 究之發現亦提醒研究者或許需要重新檢視以往因素分析研究結果之合宜性;尤其是 對過去單以特徵值大於一決定因素數目所得到的因素結構,研究者或宜再次確認之 前的結論是否合宜,以提升研究結論的適當性。 關鍵詞:因素數目決定法、李克特式量尺、特徵值大於一 1.劉心筠,國立台灣大學心理學系博士生 2.翁儷禎,國立台灣大學心理學系教授 3.李俊霆,美國聖母院大學心理學系博士生 收件日期:2009.02.17;完成修改:2009.05.14;正式接受:2009.08.07 通訊作者:翁儷禎;Email:[email protected] 地址:台北市羅斯福路四段 1 號 國立台灣大學心理學系Reexaming the Rule of
Eigenvalue-Greater-Than-One to Correctly Identify
the Number of Factors
The eigenvalue-greater-than-one rule, also known as the Kaiser-Guttman rule, is wid-ely used in factor analysis to determine the number of factors. Because the most frequently seen factor analysis involves item level data measured by Likert-type scales, a thorough evaluation of the performance of this rule with Likert-type data is called for. The present simulation therefore manipulated factor loading, sample size, number of factors, variable-to-factor ratio, number of response categories on the Likert-type scales, and distribution of the Likert-type variables to examine the behavior of this popular method when using Lik-ert-type data. The results indicated that the size of major factor loading and sample size played the most significant roles in affecting the behavior of the method. Unless high factor loadings and large sample sizes were utilized, the method failed to detect the correct num-ber of factors. The findings of this study suggest that the eigenvalue-greater-than-one rule should be used with care. Moreover, considering its widespread use, there is a need for re-searchers to reexamine past factor analysis research results, especially those that solely em-ployed the eigenvalue-greater-than-one rule to determine the number of factors.
Keywords: eigenvalue-greater-than-one rule, Likert-type scale, number of factors
1. Hsin-Yun Liu, Doctoral Student, Department of Psychology, National Taiwan University 2. Li-Jen Weng, Professor, Department of Psychology, National Taiwan University 3. Chun-Ting Lee, Doctoral Student, Department of Psychology, University of Notre Dame Received: 2009.02.17; Revised: 2009.05.14; Accepted: 2009.08.07
Corresponding Author: Li-Jen Weng; Email: [email protected] Address: 1, Section 4, Roosevelt Road, Taipei, Taiwan
壹、緒論
因素數目之取決是因素分析流程的關鍵步驟,倘若錯誤決定因素數目, 則可能產生偏差的分析結果。Fava 和 Velicer(1992, 1996)曾以模擬研究探 討錯估因素數目對因素分析結果的影響,結果顯示,保留過多的因素數目, 可能僅是得到一些較不重要的因素,若母群因素負荷量低且樣本數少時,情 況尤其嚴重。反之,選定過少的因素數目,則可能遺漏重要的潛在變項,以 致扭曲分析變項的因素結構。是故,選擇適當的因素數目決定方法一直是學 者重視的議題。 決定因素數目的方法有特徵值大於一(Kaiser-Guttman rule)(Kaiser,1960)、陡階檢定(scree test)(Cattell,
1966)、最大概似卡方檢定(maxi-mum likelihood chi-square test)(Lawley, 1940)、平行分析(parallel
analy-sis)(Horn, 1965),以及最小平均淨相關法(minimum average partial
corre-lation)(Velicer, 1976)等,其中最常被使用的方法乃為特徵值大於一(王
嘉寧、翁儷禎,2002;翁儷禎,1995;Fabrigar, Wegener, MacCallum, &
Stra-han, 1999; Ford, MacCallum, & Tait, 1986; Henson & Roberts, 2006; Russell,
2002),亦即以研究變項之相關係數矩陣特徵值中大於一的個數為因素數
目。特徵值大於一使用率最高的原因之一,可能是因為該方法為統計套裝軟 體的內設作法(李俊霆,2005;Henson & Roberts, 2006; Russell, 2002);再 者,該方法決定因素數目的過程較其他方法簡便,因此簡單易操作亦可能為 研究者選用之因(Velicer, Eaton, & Fava, 2000)。然過去研究顯示,相較於其 他決定因素數目的方法,特徵值大於一錯估因素數目的情形最為嚴重(王嘉 寧,2001;Velicer et al., 2000; Zwick & Velicer, 1982, 1986)。鑑於特徵值大於 一的高使用率,李俊霆(2005)以模擬研究探討變項為常態時,此方法可以 建議適當因素數目的情境。但是,相當多的實徵研究均以李克特式量尺資料 進行因素分析(王嘉寧、翁儷禎,2002;Gorsuch, 1983, 1997),而非採用連 續性資料,資料型態極可能影響相關係數的估計,進而影響到此相關矩陣進 行的因素分析結果,故李克特式量尺資料型態對特徵值大於一的影響乃值得 研究。因此,本研究探討特徵值大於一於李克特式量尺資料的表現,除可對 於因素分析之應用研究提供因素數目決定的參考依據外,更重要的,面對過 去諸多以特徵值大於一決定因素數目之研究結果,研究者可藉本研究建議的
適用情境,檢視過去研究中因素數目的適當性,以評估是否需要再次分析或 是修正現行研究之結果與理論。
相較於其他決定因素數目的方法,特徵值大於一的表現並不佳,在連續 性資料中,大約僅有 50%的機率得以正確決定因素數目(李俊霆,2005;
Velicer et al., 2000)。有學者認為,該方法表現不佳是因未考慮抽樣誤差的影
響(Horn, 1965; Linn, 1968)。Horn(1965)指出,特徵值大於一的理論是建 立在母群相關係數上,但是實徵研究中無法避免樣本抽樣誤差的產生,因此 會讓原本無相關變項的樣本相關係數不為零,亦即若母群中沒有共同因素的 存在,樣本相關係數矩陣求得的特徵值仍可能不恆為一。故 Horn 認為,不 應以一為樣本相關係數矩陣特徵值的比較基準,因以一為基準容易忽略了抽 樣誤差對相關係數矩陣的影響。同樣地,Linn (1968)認為,特徵值大於一 的理論基礎乃建立在心理計量取向(psychometric approach),該取向針對測 驗內容領域(universe of content)進行推論,故特徵值大於一可能因未考慮 受測者的抽樣誤差而易錯估因素數目。 為評估抽樣誤差對於特徵值大於一表現的影響,Hakstian、Rogers 和 Cattell(1982)於研究中加入樣本抽樣誤差的考量,分為母群研究與樣本研 究兩部分。母群研究模擬母群相關係數矩陣,模式設定為基本模式(formal
model)與中間模式(middle model),基本模式假設觀察分數是因素分數與
獨特因素的線性組合,中間模式則假設觀察分數除因素分數與獨特因素的線 性組合外,再加上隨機決定且影響力成幾何下降之次要因素分數,因素分 數、次要因素分數與獨特因素的期望值為零、變異數為 1,且互為零相關。 母群研究操弄變項數目(12、30 和 50 個變項)、變項因素比(2~6)、變項 共通值(communality)的水準(高:.6 ~.8、低:.2~.4),以及四種程度 的因素複雜度,進行特徵值大於一與陡階檢定等兩種方法的比較。樣本研究 則再加上樣本數(150 和 400 人)的操弄,以模擬包含抽樣誤差的樣本相關 係數矩陣,進行特徵值大於一、陡階檢定,以及最大概似卡方檢定等三種方 法的比較。由母群與樣本研究的結果發現,抽樣誤差的確會影響特徵值大於 一的正確率。Hakstian 等人並對特徵值大於一可使用的情境提出建議:當樣 本人數至少 250 人且平均變項之共通值為 .6 以上時,特徵值大於一的正確率 相當高,若再加上變項因素比高於 3 以上的情境,研究者更可以放心使用該 方法決定因素數目。而當平均變項之共通值低(約為 .3),或是變項因素比 低於 3 以下時,特徵值大於一容易高估因素數目。然在 Hakstian 等人的樣本
研究中,樣本數為 150 和 400 人,由此二情境並無法推知該研究如何得到樣 本人數至少 250 人的建議。因此,對於 Hakstian 等人有關樣本人數的建議, 仍有進一步釐清的必要。
Humphreys(1964)檢測特徵值大於一在樣本人數極大時(8,158 人)的
表現,針對 21 個變項的「空軍人員分類量表」(Air Crew Classification
Bat-tery),特徵值大於一方法建議 5 個因素,但Humphreys根據理論與因素的可
解釋性,認為以 10 個因素的架構較適當,故認為特徵值大於一方法在樣本數 很大時容易決定過少的因素數目。Mote(1970)分析 170 位學生在「學習習 慣與態度調查」(Survey of Study Habits and Attitudes)、「狀態特質焦慮問 卷」(The State-Trait Anxiety Inventory)、「成 就 焦 慮 測 驗」(The
Achie-vement Anxiety Test),以及「學生對成績態度問卷」等量表的測驗分數,以
特徵值大於一方法選取 4 個因素。Mote比較 4 到 10 個因素數目的分析結果, 發現特徵值大於一建議的因素數目可能不是最佳的數目,因此建議研究者在 進行因素分析時,若能保留比特徵值大於一建議之因素數目更多的因素,或 者能發現更適於解釋研究資料的因素結構。此二項實徵資料檢視特徵值大於 一之研究均發現,特徵值大於一可能低估因素數目。 李俊霆(2005)以模擬研究探討特徵值大於一於連續資料的表現,發現 因素負荷量之高低與樣本人數的大小,對特徵值大於一是否能正確估計因素 數目具交互作用。該研究進一步分析樣本特徵值的平均數與標準誤,以了解 樣本相關係數矩陣特徵值逼近母群特徵值的情境。結果顯示,當因素負荷量 為 .8 時,樣本人數需約 200 人,樣本特徵值方會逼近母群特徵值;當因素負 荷量為 .6 時,約需 500 人才能得到樣本特徵值與母群特徵值近似的結果;而 當因素負荷量為 .4 時,約需 1,000 人,樣本特徵值才能接近母群特徵值。此 結果亦說明隨著因素負荷量的高低,樣本特徵值逼近母群特徵值所需的樣本 數有所不同。所以,利用特徵值大於一方法決定因素數目時,需將因素負荷 量與樣本人數同時納入考量,才能得到較合宜的結果。 除李俊霆(2005)之模擬研究外,其餘研究多是進行數個因素數目決定 方法之間的比較。如 Linn(1968)以模擬研究比較特徵值大於一、特徵值大 於零、陡階檢定等三種方法的表現。該研究固定因素數目(7),操弄變項 數目(20 和 40 個變項)、變項共通值(communality)的水準(高:.6~ .8、 低:.2~.4),以及樣本人數(100 和 500 人),因素模式設定為基本模式與 模擬模式(simulation model)。基本模式假設觀察分數為共同因素分數、獨
特因素(specific factor)與誤差分數的線性組合,共同因素分數、獨特因素 與誤差分數的期望值為零、變異數為 1,且互為零相關;模擬模式則假設模 式中獨特因素間存有相關。結果顯示,三種決定因素數目的方法中特徵值大 於一的表現不佳,Linn 亦建議,研究者決定因素數目時應考慮變項共通值高 低、每因素有幾個測量變項與適當的樣本人數,才會得到合宜的分析結果。
Zwick和 Velicer(1982)以模擬研究系統性的比較 Bartlett 檢定、特徵值
大於一、陡階檢定、最小平均淨相關法等四種方法,操弄樣本數(75、150 和 450 人)、變項數目(36、72 和 144 個變項),因素數目(3、6 和 12), 以及因素負荷量( .5 和 .8),其因素模式為每一個變項僅受單一因素影響, 其餘因素負荷量皆設為零,每因素影響相同數目的觀察變項。結果顯示, Bartlett檢定的表現較不穩定,陡階檢定及最小平均淨相關法的表現最好,特 徵值大於一的表現不佳。研究中亦顯示,在因素負荷量低( .5)的因素架構 下,特徵值大於一容易高估因素數目;因素負荷量高( .8)時則可正確決定 因素數目。除了樣本人數少於 75 人且變項數目在 72 個變項以上,或是樣本 人數在 150 人以上且變項數目為 144 時,特徵值大於一會建議過多因素。 Zwick和 Velicer(1986)延續 1982 年的研究,加入平行分析,再比較各方法 的表現,操弄變項包括變項數目、樣本人數、因素負荷量,以及因素模式複 雜度。結果以平行分析表現最佳,Bartlett 檢定及特徵值大於一的表現最差。 Zwick 和 Velicer 並建議,若有電腦軟體的配合,宜以平行分析或是最小平均 淨相關法決定因素數目。
Velicer等人(2000)回顧自 Zwick 和 Velicer(1986)後因素數目研究的
發展,並比較特徵值大於一、最小平均淨相關法,以及平行分析等三種方法 的表現。在正交因素模型下,操弄因素負荷量( .4、.6 和 .8)、樣本人數 (75、150 和 300 人)、變項因素比(4 和 8),以及變項數目(24、48 和 72 個變項)。結果與 Zwick 和 Velicer 的結論一致,亦顯示特徵值大於一的表現 最差且不穩定,平行分析優於其他方法。
Zwick和 Velicer(1982, 1986)以及 Velicer 等人(2000)的研究設計雖均
具系統性,但並未詳細探討不同情境組合下各個方法的表現,是故仍未釐清 特徵值大於一的適用情境,而無法對因素分析之應用研究提出實務建議。因 此,李俊霆(2005)整理過去有關特徵值大於一方法的模擬研究,歸納出影 響該方法是否能正確決定因素數目的因子以及相關水準,系統性地探討特徵 值大於一於連續變項的適用情境。該研究操弄因素負荷量( .4、 .6 和 .8)、
樣本數(100、200、500 和 1,000 人)、變項因素比(2、4 和 6)、因素數目 (3、6 和 12),以及因素模式複雜度,模擬連續資料下特徵值大於一在各個 情境中正確決定因素數目的可能性。在此研究操弄的變項中,因素負荷量對 特徵值大於一能否正確決定因素數目的影響最大,變項因素比次之,樣本人 數再次之,因素模式複雜度與因素數目的多寡則無顯著影響。該研究發現, 若題目能充份測量所欲探討的構念(反映於高因素負荷量 .8),同時每個因 素具有足夠之觀察變項予以測量(反映於變項因素比 4 以上)時,特徵值大 於一正確決定因素數目的機率非常高。李俊霆並根據研究結果,建議特徵值 大於一於連續資料的適用情境,當因素負荷量高(如 .8)且變項因素比為 4 以上時,此法應能建議正確的因素數目(正確率約為 96%);當因素負荷量 為中等(如 .6),適用範圍隨變項因素比與樣本人數而異;當變項因素比為 4,樣本人數達 200 人以上時,此法仍能建議適當的因素數目;若變項因素比 為 6 與 8 時,則樣本人數需要至少 500 人方能建議適當的因素數目;至於其 餘的情境,特徵值大於一的表現並不佳。 由上述文獻回顧可知,學者均認為當因素負荷量高、樣本數適當與變項 因素比合宜時,特徵值大於一會有高正確率,但是上述研究皆未涉及非連續 性的李克特式量尺資料。Gorsuch(1997)發現,在 1990 至 1995 年間的心理 學期刊中,約有 300 至 375 篇研究以題目層次的資料進行因素分析,而不是 分析較具連續性之分量表資料,且題目層次資料以李克特式量尺資料型態最 為普遍。王嘉寧、翁儷禎(2002)回顧 1993 至 1999 年間國內心理、教育、 管理等社會科學領域中因素分析的應用情形,亦發現使用因素分析的研究中 有九成以上是以題目層次的資料進行分析,並多以李克特式量尺測量受測者 的 反 應,其 中 使 用 比 例 最 高 的 量 尺 點 數 為 5 點(34%),其 次 是 7 點 (19%)。 多位學者認為,以李克特式量尺測量受測者反應容易低估變項間的相 關,進而影響因素分析的結果。Gorsuch(1983, 1997)指出,當使用題目層 次資料進行因素分析時,由於各個題目分數為非連續的量尺點數,會因低估 以連續資料為假設的題目間相關值,以致影響因素分析結果的正確性。亦有 學者認為,當連續的個人特質分數以不連續的點數資料反應時,因為訊息的 流失會使得皮爾森相關係數被低估(Cohen, 1983)。Martin(1973, 1978)的 模擬研究發現,不論題間量尺點數相同或不相同,皮爾森相關係數會低估題 目間的相關;若量尺點數低於 10 點以下,低估的程度較明顯,且反應點數愈
少,原始相關係數被低估的程度愈大,Bedrick(1995)亦有相同看法。Bol-len 和 Barb(1981)的模擬研究計算常態連續變項被轉換為點數資料之相關 係數與原始相關係數的差距,發現若當變項間原始相關高且量尺點數少(比 如點數為 2),皮爾森相關係數低估原始相關的差距較明顯。當量尺點數為 5 點以及 5 點以上時,點數資料得到的相關係數非常接近原始相關係數,故 Bollen和 Barb 建議,應至少採用 5 點或 5 點以上的量尺進行測量。因為皮爾 森相關係數低估真實相關係數,使得樣本相關係數矩陣較原始相關係數矩陣 更接近單位矩陣,可能造成樣本相關係數矩陣接近一的特徵值個數產生變 動,導致特徵值大於一的方法無法正確決定因素數目。故量尺點數對特徵值 大於一的正確率影響,可預期該方法正確率會低於連續資料的表現,且隨著 量尺點數減少,正確率也會下降。 針對李克特式的資料,學者建議以多序類相關係數(polychoric
correla-tion coefficient)進行分析(例如:Olsson, 1980; Wothke, 1993),因為多序類
相關係數假設觀察到的類別資料背後為連續常態的潛在反應變項,而多序類 相關係數可以直接估計潛在反應變項之相關,所以不會因實際觀測到的點數 資料型態而影響相關係數的估計。吳柏儒(2003)針對次序類別的李克特式 資料,分別以皮爾森相關係數與多序類相關係數進行因素分析,發現兩種相 關係數在因素數目取決的正確率上表現相似,因素數目的正確率均主要受到 因素負荷量與樣本人數的影響,然而多序類相關係數有無法估算出完整相關 係數矩陣的限制(吳柏儒,2003;Zhang & Browne, 2006),故本研究仍是以 皮爾森相關係數矩陣進行分析。 以題目層次資料進行因素分析,除量尺點數對正確決定因素數目會有影 響外,亦需考量變項數目的多寡。Gorsuch(1983)認為,特徵值大於一建 議的因素數目約介於變項數目的五分之一到三分之一之間,李俊霆(2005) 根據過去的研究亦認為,該方法建議的因素數目會落在變項數目的六分之一 至三分之一間。故當以題目層次進行因素分析時,若測驗的題數很多,或是 變項因素比偏高即變項數目多時,特徵值大於一容易高估因素數目,然亦有 低估因素數目之可能(例如:Humphreys, 1964; Mote, 1970)。 王嘉寧(2001)曾探討李克特式量尺資料對正確決定因素數目的影響, 在單因素與雙因素模型下,操弄反應點數(2、3、5 和 7)、分配型態(偏態 為 0、-0.5、-1.0、-1.5、-2.0 和變項為正負偏均有,共九種)、樣本人數 (100、200、500 和 1,000 人)、變項因素比(4、6、8 和 12),以及因素負
荷量( .4、 .6 和 .8),比較特徵值大於一、平行分析、最大概似卡方檢定, 與以 SMC(squared multiple correlation)為對角線的相關係數矩陣特徵值大於 零等四種方法的表現。研究結果顯示,當因素負荷量增高、樣本人數增大, 與變項因素比降低時,均會提升特徵值大於一正確決定因素數目的比率;當 反應點數愈少,偏態程度愈大,變項間的分配不同,正確決定因素的比率也 會下降;但相較於其他方法,特徵值大於一的表現相當不理想。該研究雖然 討論李克特式量尺資料型態對特徵值大於一的影響,然對不同情境組合下該 方法的表現並未多琢磨,且侷限於單因素與雙因素模型。針對其限制,本研 究模擬多因素模式,以增加研究結果的適用性。 本研究延續王嘉寧、翁儷禎(2002)的研究,調查近年《教育與心理研 究》、《中華心理學刊》、《管理學報》,以及《師大學報──教育類》等 重要社會科學期刊中因素分析的應用論文,發現在 2001 至 2007 年間,共有 51篇應用因素分析的論文。在此 51 篇論文中,有 29 篇(55%)單獨使用特 徵值大於一的方法決定因素數目,更有 40 篇(78%)使用李克特式量尺進行 研究,顯示特徵值大於一仍是國內研究者主要決定因素數目的方法,並且使 用李克特式資料進行分析仍占多數。有鑑於特徵值大於一在實徵研究之常用 性,以及因素數目是否合宜對研究結果的關鍵性影響,特徵值大於一於李克 特式資料的適用情境仍是值得探究之議題。更重要的,面對過去以特徵值大 於一決定因素數目的諸多相關研究結果,本研究提出的適用情境將可以提供 具體建議,協助研究者檢視已有的研究結論,並評估是否需要重新分析原有 資料,以避免不適當之研究結論。
貳、研究方法
一、研究設計
本模擬研究探討特徵值大於一在李克特式量尺正交因素模型因素數目決 定之表現,每個變項僅受單一因素影響,操弄變項包括樣本人數、因素負荷 量、變項因素比、因素數目、量尺點數,以及變項分配偏態。樣本人數有 100、200、500 和 1,000 人,因素負荷量設定為 .4、 .6 和 .8(代表共通值低 .16、中 .36 和高 .64 三種水準),變項因素比包含 4、6 和 8 三種層次,因素 數目則設為三因素與六因素。量尺點數考量 2 點、3 點、5 點和 7 點等四種研究者常用情境,對於變項分配的操弄,則是設定所有的變項為對稱(偏態係 數為 0)、偏態係數為 -1 與偏態係數為 -2 等三種。本研究設計總共有 864 種 組合(4 樣本人數×3 因素負荷量×3 變項因素比×2 因素數目×4 量尺點 數×3 分配偏態),每種組合各產生 500 個模擬樣本,以計算各個情境組合 之因素數目的正確率,據之衡量特徵值大於一的表現。
二、模擬流程
本研究先依模式設定產生連續資料,再將連續資料轉換為不同偏態與點 數的李克特式量尺資料型態(王嘉寧,2001;Bernstein & Teng, 1989; Muthén& Kaplan, 1985, 1992; Weng & Cheng, 2005)。首先利用 SAS 的 RANNOR 函
數產生平均數為 0,變異數為 1 之常態分配的因素分數與誤差分數,依式 求算各受測者在各個連續觀察變項上的分數: Xpn= q m=1 apmFmn+
(
1 q m=1 a2 pm)
Epn 其中, Xpn代表第 n 個人在第 p 個觀察變項上的觀察分數, apm為第 p 個 觀察變項在第 m 個因素之因素負荷量, Fmn為第 n 個人在第 m 個因素上的因 素分數,q 為因素數目, Epn則為第 n 個人在第 p 個觀察變項所對應之誤差分 數。依式所得之觀察分數亦為平均數 0,變異數為 1 之常態分配,乃偏態 為零的對稱連續資料。 其次,依循王嘉寧(2001)的作法,將所得之連續資料根據不同的閾限 值轉換為不同分配型態與點數的資料。以偏態 -1 的 3 點量尺為例,其閾限值 為 -1.28 和 -0.25,當連續的觀察分數 Xpn≦ -1.28 時,轉換後的點數資料數值 為 1,若-1.28 < Xpn≦ -0.25,轉換後的點數資料數值為 2,當 Xpn> -0.25時, 轉換後的點數資料數值為 3。經此轉換後,變項數值為 1、2 和 3 的發生機率 分別為 .1、 .3 和 .6,點數資料的偏態為 -1,其他偏態與點數的資料亦依循此 原則轉換。三、資料分析
本研究首先計算每個模擬樣本資料的相關係數矩陣,再以 SAS 中 call eigen 的副程式求得該相關係數矩陣之特徵值,並評估每個樣本相關係數矩 陣特徵值大於一的個數是否為正確的因素數目,再將其結果設為二元變項,正確為 1,錯誤為 0,此二元變項於 500 個模擬樣本的平均數即為特徵值大於 一在該情境決定因素數目的正確率。為評估因素負荷量、樣本數、變項因素 比、因素數目、量尺點數,以及分配偏態等因素對特徵值大於一表現的影 響,乃剖析不同操弄變項情境組合之因素數目正確決定率。在此之前,先以 變異數分析探討影響特徵值大於一是否正確決定因素數目的因子,以各情境 下之二元變項為依變項,六個操弄變項為獨變項,進行固定效果的六因子變 異數分析(Lunney, 1970)。繼之計算各個變項與交互作用項的效果量 2, 亦即以各變項與交互作用項的離均差平方和為分子,總離均差平方和為分 母,並根據 Cohen(1988)之建議,以 2大於 .14、 .06 和 .01 分別代表大、 中、小之效果量,比較各個變項與交互作用項對特徵值大於一正確與否的相 對影響力。
參、研究結果
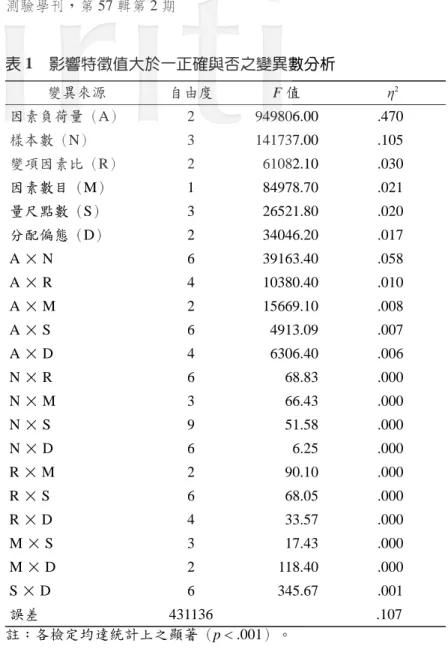
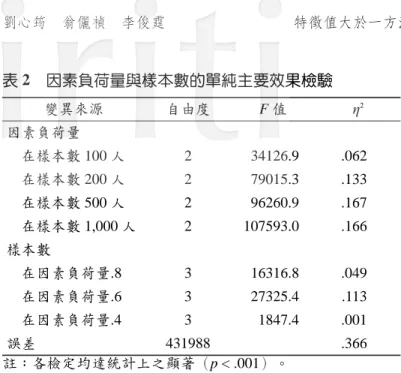
本研究針對李克特式量尺資料,探討特徵值大於一在正確決定因素數目 上的表現,以下將先討論變異數分析的結果,以了解模擬研究中各個操弄因 子對特徵值大於一正確與否的相對影響程度。接著分析不同情境下特徵值大 於一在因素數目決定上的正確率,期能歸納出特徵值大於一的可能適用範 圍。 在六因子變異數分析中,三階交互作用項的效果量最高僅至 .02,未達 中效果,其餘更高階交互作用項的效果量均未達到小效果,故表 1 僅呈現主 要效果與二階交互作用項的變異數分析結果,其中各項變異來源均達 .001 的 統計顯著水準。結果發現,因素負荷量高低為影響特徵值大於一正確與否的 最主要變項,效果量約為 .47,其次是樣本數大小,效果量為 .105,因素負 荷量與樣本數交互作用項的效果量為 .058。相較於因素負荷量與樣本數大小 的影響,本研究中的其他四個變項,變項因素比、因素數目、量尺點數與分 配偏態,對特徵值大於一是否正確決定因素數目的影響不大,效果量均未達 中效果。表 1 影響特徵值大於一正確與否之變異數分析 變異來源 自由度 F值 2 因素負荷量(A) 2 949806.00 .470 樣本數(N) 3 141737.00 .105 變項因素比(R) 2 61082.10 .030 因素數目(M) 1 84978.70 .021 量尺點數(S) 3 26521.80 .020 分配偏態(D) 2 34046.20 .017 A× N 6 39163.40 .058 A× R 4 10380.40 .010 A× M 2 15669.10 .008 A× S 6 4913.09 .007 A× D 4 6306.40 .006 N× R 6 68.83 .000 N× M 3 66.43 .000 N× S 9 51.58 .000 N× D 6 6.25 .000 R× M 2 90.10 .000 R× S 6 68.05 .000 R× D 4 33.57 .000 M× S 3 17.43 .000 M× D 2 118.40 .000 S× D 6 345.67 .001 誤差 431136 .107 註:各檢定均達統計上之顯著(p < .001)。 由於六因子變異數分析中因素負荷量與樣本數的交互作用接近中效果, 故乃進一步進行簡單主要效果分析(如表 2 所示)。由因素負荷量的簡單主 要效果分析顯示,不論在樣本數 100、200、500 或 1,000 人時,高、中、低三 種水準的因素負荷量對特徵值大於一是否正確決定因素數目的影響有顯著差 異存在,效果量達中效果以上( 2≧ .062)。由樣本數的簡單主要效果分析 顯示,不論在因素負荷量 .8、.6 或 .4 時,四種不同大小的樣本數對是否正確 決定因素數目的影響亦都有顯著差異,但在因素負荷量 .4 時,其效果量未達 小效果( 2= .001),表示在因素負荷量 .4 時,樣本數的簡單主要效果實際 上並不大。
表 2 因素負荷量與樣本數的單純主要效果檢驗 變異來源 自由度 F值 2 因素負荷量 在樣本數 100 人 2 34126.9 .062 在樣本數 200 人 2 79015.3 .133 在樣本數 500 人 2 96260.9 .167 在樣本數 1,000 人 2 107593.0 .166 樣本數 在因素負荷量.8 3 16316.8 .049 在因素負荷量.6 3 27325.4 .113 在因素負荷量.4 3 1847.4 .001 誤差 431988 .366 註:各檢定均達統計上之顯著(p < .001)。 為更清楚了解樣本數的簡單主要效果,乃將各個因素負荷量在不同樣本 數之正確率呈現於圖 1。當因素負荷量高(如 .8)時,特徵值大於一的正確 率均高,除非樣本人數低於 100 人;當因素負荷量為 .6 時,正確率隨著樣本 數增加明顯上升;當因素負荷量低(如 .4)時,無論樣本數為何,特徵值大 於一的平均正確率均非常低。由圖 1 可知,樣本數大小對正確率的影響會隨 著因素負荷量的高低而有所差異,因素負荷量中等程度以上時(如 .6),平 均正確率會隨著樣本數的增加而提高,低因素負荷量時(如 .4),樣本數的 增加對平均正確率的提升則無明顯助益。李俊霆(2005)以連續資料進行的 模擬研究發現,當資料為常態分配且因素負荷量高(如 .8)時,樣本人數並 未明顯影響特徵值大於一在因素數目取決上的正確率,此與本研究發現並不 一致。比較兩個研究的設計,此不一致結果應是來自資料特性的差異,樣本人 數對特徵值大於一能否正確估計因素數目的影響在非連續資料情境( 2= .105) 大於連續資料( 2= .056)時。分析非連續資料時,即使是高因素負荷量, 仍需樣本人數 200 人以上,方能有 .8 的平均正確率。
為評估特徵值大於一於李克特式量尺之表現,本研究計算不同操弄變項 情境組合中,特徵值大於一正確決定因素數目的比率,表 3、表 4 和表 5 分別 列出特徵值大於一於因素負荷量 .8、 .6 和 .4 的各個操弄變項情境組合之正確 率。結果顯示,特徵值大於一的正確率主要隨著因素負荷量提高、樣本人數 增加、點數增加與分配趨近對稱而提升,亦隨著變項因素比增加與因素數目 增加而下降。其中,變項因素比固定而因素數目增加,或是因素數目固定而 變項因素比提高,均表示變項數目增加,是故本研究中特徵值大於一的正確 率隨著變項因素比或因素數目增加而降低,亦反映變項數目的增加很可能會 降低特徵值大於一界定因素數目的正確率。 為歸納特徵值大於一能正確建議因素數目的情境,乃參照表 1 各個變項 效果量的相對大小,依序討論各個情境組合之正確率。表 3 為因素負荷量為 .8 時,特徵值大於一在各個組合情境的平均正確率,當樣本人數為 500 人以 上時,正確率都相當高,平均正確率接近 100%,特徵值大於一的表現相當 準確;當樣本人數為 200 人時,變項因素比若為 4,則整體平均正確率約為 98%,特徵值大於一仍可以準確估計因素數目。但是,當變項因素比為 6 或 6 以上時,則需考量其他影響變項之水準,方能推估特徵值大於一能建議合宜 因素數目的情境;譬如,因素數目為 3 的平均正確率(88%)優於因素數目 為 6 的表現(58%),兩者的主要差異是在量尺點數為 2 或是偏態係數為 -2 圖 1 特徵值大於一於因素負荷量(A)與樣本人數組合之正確率 樣本人數 正 確 率( % )
表 3 特徵值大於一於因素負荷量 .8 之正確率 單位: % 2 -2 56 4 2 0 0 0 96 56 52 0 4 0 100 100 99 92 97 15 100 100 100 100 100 100 -1 90 21 25 0 1 0 99 96 95 10 55 0 100 100 100 100 100 96 100 100 100 100 100 100 0 97 50 51 0 4 0 100 99 99 38 89 0 100 100 100 100 100 100 100 100 100 100 100 100 3 -2 85 32 29 0 1 0 99 95 92 16 55 0 100 100 100 100 100 98 100 100 100 100 100 100 -1 100 91 93 9 51 0 100 100 100 97 100 42 100 100 100 100 100 100 100 100 100 100 100 100 0 100 98 99 41 85 0 100 100 100 100 100 91 100 100 100 100 100 100 100 100 100 100 100 100 5 -2 95 60 50 0 10 0 100 99 98 60 81 2 100 100 100 100 100 100 100 100 100 100 100 100 -1 100 100 100 62 91 3 100 100 100 99 100 97 100 100 100 100 100 100 100 100 100 100 100 100 0 100 99 100 84 99 12 100 100 100 100 100 99 100 100 100 100 100 100 100 100 100 100 100 100 7 -2 98 86 83 7 33 0 100 100 100 95 99 36 100 100 100 100 100 100 100 100 100 100 100 100 -1 100 100 99 86 97 12 100 100 100 100 100 99 100 100 100 100 100 100 100 100 100 100 100 100 0 100 100 100 97 100 47 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 量 尺 點 數 分 配 偏 態 樣本數 100 200 500 1000 變項因素比 變項因素比 變項因素比 變項因素比 468468468468 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 363636363636363636363636
表 4 特徵值大於一於因素負荷量 .6 之正確率 單位: % 2 -2000000200000 5 000000 9 8 2 7 4 3 000 -1 100000 2 100000 9 2 9 1 6000 1 0 0 9 0 9 6 0 5 40 0 4 0 0 0 0 0 35 0 0 0 0 0 97 25 50 0 0 0 100 98 99 16 89 0 3 -2100000 1 000000 8 7 4 1 1000 1 0 0 8 4 8 8 0 2 60 -1 12 0 0 0 0 0 62 0 2 0 0 0 99 70 88 0 20 0 100 100 100 87 99 3 0 33 0 0 0 0 0 83 3 12 0 0 0 100 96 98 4 69 0 100 100 100 99 100 63 5 -2300000 2 200000 9 4 1 5 2 9 000 9 9 9 8 9 8 8 6 90 -1 32 0 0 0 0 0 90 7 16 0 0 0 100 98 99 13 80 0 100 100 100 100 100 77 0 49 0 0 0 0 0 95 17 36 0 1 0 100 99 100 43 96 0 100 100 100 100 100 98 7 -2 7 0 0 0 0 0 46 0 0 0 0 0 99 54 67 0 6 0 100 99 99 62 96 0 -1 43 0 0 0 0 0 94 17 28 0 0 0 100 99 100 32 92 0 100 100 100 100 100 95 0 59 1 1 0 0 0 97 37 55 0 3 0 100 100 99 76 99 1 100 100 100 100 100 100 量 尺 點 數 分 配 偏 態 樣本數 100 200 500 1000 變項因素比 變項因素比 變項因素比 變項因素比 468468468468 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 363636363636363636363636
表 5 特徵值大於一於因素負荷量 .4 之正確率 單位: % 2 -2000000000000000000000000 -1 000000000000000000400000 0000000000000000000 1 000000 3 -2000000000000000000200000 -1 000000000000200000 3 200000 0000000000000500000 6 000000 5 -2000000000000000000500000 -1 000000000000800000 5 901000 0000000000000 1 100000 7 703000 7 -2000000000000000000 1 400000 -1 000000000000 1 200000 6 702000 0000000000000 2 100000 8 317000 量 尺 點 數 分 配 偏 態 樣本數 100 200 500 1000 變項因素比 變項因素比 變項因素比 變項因素比 468468468468 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 因素數目 363636363636363636363636
的情境,其餘情境大部分仍能維持高正確率。當樣本人數為 100 人時,特徵 值大於一能達高正確率的情境多數集中在量尺點數 5 以上且資料分配偏態係 數在±1 以內的情境。 整體觀之,當因素負荷量高(如 .8)時,若樣本人數為 500 人以上,則 特徵值大於一可以建議適當的因素數目;但倘樣本為 200 人左右的中樣本, 應考慮適當的變項因素比(如 4),並宜避免使用於量尺點數為 2 且偏態嚴 重(如偏態係數 ±2)的資料;若樣本為 100 人左右時,特徵值大於一可能無 法建議合宜的因素數目,除非點數多且分配不至於太偏。 表 4 為因素負荷量為 .6 時,特徵值大於一在各個組合情境的正確率,結 果顯示,即使當樣本人數高達 1,000 人時,正確率未必均高,仍需考量其他 變項的影響。以變項因素比為例,當變項因素比為 4 時,特徵值大於一的平 均正確率約為 96%,變項因素比為 6 的平均正確率則下降至 75%,若變項因 素比為 8 更降至 57%。當量尺點數為 2 或是偏態係數為 -2 情境下的平均正確 率,亦分別僅有 51%和 54%。當樣本人數為 500 人,高正確率的情境更是有 限,多數為低變項因素比與低因素數目之情境。此表示當因素負荷量為 .6 時,在非連續資料的情況下,即使樣本數高達 500 人,特徵值大於一仍可能 無法建議合宜的因素數目,除非變項因素比或變項數目偏低。當人數低如 200或 100 時,特徵值大於一的正確率則相當低。 李俊霆(2005)在連續資料的研究結果顯示,當因素負荷量為 .6,變項 因素比為 4,樣本人數為 200 人以上時,特徵值大於一多能正確決定因素數 目;當變項因素比為 6 和 8 時,則需達到 500 人以上,才能正確決定因素數 目,此與表 4 的結果有明顯差異,比較兩研究設計,主要原因應是李克特式 量尺資料特性的影響。因此,鑑於特徵值大於一於本研究中各變項情境組合 之低正確率,研究者若以李克特式量尺測量受測者反應時,即使因素負荷量 為 .6 左右,仍需審慎評估特徵值大於一建議的因素數目是否合宜。 表 5 為因素負荷量為.4 時,特徵值大於一在各個組合情境決定因素數目 的正確率,絕大多數的數值均為零。故當因素負荷量低時,特徵值大於一難 以得到正確的因素數目,此與李俊霆(2005)以及王嘉寧(2001)的結論一 致。因此,研究者若未仔細考量題目內涵,致使測量題目與理論構念間的關 係薄弱,則特徵值大於一難以建議適當的因素數目。 過去有學者認為,變項數目多寡會影響特徵值大於一的表現(李俊霆, 2005;Gorsuch, 1983),雖然本模擬研究未直接操弄變項數目,但藉由變項
因素比與因素數目的組合,可推知變項數目如何影響特徵值大於一在因素數 目決定上的表現。本研究之變項因素比包括 4、6 和 8,因素數目為 3 和 6, 可得變項數目分別為 12、18、24、36 和 48 之情境。結果顯示,特徵值大於 一的平均正確率果然隨著變項數目的增加而降低。其中變項數目為 24 包含兩 種情境︰變項因素比為 4 且因素數目為 6,以及變項因素比為 8 且因素數目為 3,兩者中前者的平均正確率優於後者。由此推之,若變項數目相同,變項 因素比低但因素數目偏高的正確率,優於變項因素比偏高但因素數目較少的 組合。 整體來看,相較於連續常態變項,特徵值大於一於李克特式量尺資料的 表現更不佳,所有情境之整體平均正確率僅 41%,低於連續性資料的 50% (李俊霆,2005;Velicer et al., 2000),與本研究預期相符。進一步比較模擬 之連續資料與轉換後李克特式量尺資料,其相關係數矩陣特徵值之平均數可 發現,經過轉換後的李克特式資料的相關係數矩陣特徵值中,大於一但接近 一之個數會增加(如附錄 1 所示,以三因素模式為例)。此顯示當連續資料 轉換為量尺點數致低估相關係數時,特徵值大於一方法可能會建議過多的因 素數目,並且隨著因素負荷量下降、樣本人數減少,以及變項數目增加,高 估因素數目的現象益形嚴重。此結果均支持本研究推論。 根據本研究結果,歸納特徵值大於一於李克特式量尺之適用情境如下︰ 當因素負荷量高(如 .8)時,特徵值大於一方法可以建議合宜因素數目的情 境為︰樣本數為 500 人以上,或樣本數為 200 人且變項因素比為 4,或變項因 素比為 4 以上、量尺點數為 3 或 3 以上,且變項分配趨近對稱的情境。當因 素負荷量為 .6,可適用情境包括︰樣本人數 1,000 人且變項因素比為 4,或樣 本人數 1,000 人、變項因素比為 6 或 8 且量尺點數為 5 或 5 以上,但不包括變 項分配嚴重偏離對稱的情境;若樣本人數降至 500 人,特徵值大於一能正確 決定因素數目的情境有限,需同時考慮變項因素比(4)、量尺點數(≧ 5)、 分配型態(偏態係數在 [-1, 1] 區間內)等。當因素負荷量為 .4,各情境正確 率均偏低,故不建議單獨以此法決定因素數目。雖然此適用情境受限於研究 變項的條件,尤其正交因素的設計,然過去的研究顯示,特徵值大於一於斜 交多因素模式的正確率均低於正交因素模式的正確率(李俊霆,2005),所 以對於斜交因素模式,研究者仍可以由本研究結果推估特徵值大於一決定因 素數目的可能最高正確率。倘若得到的正確率不理想,建議應同時考量其他 決定因素數目的方法,以避免錯估因素數目。
肆、討論與建議
本模擬研究主要探討特徵值大於一在李克特式量表資料的表現,操弄樣 本人數、因素負荷量、變項因素比、因素數目、量尺點數,以及變項分配偏 態等,影響特徵值大於一正確決定因素數目的變項,提出特徵值大於一的適 用情境供研究者參考。結果顯示,因素負荷量是主要影響特徵值大於一表現 的變項,樣本人數次之,當因素負荷量高且樣本數夠大時,特徵值大於一可 以建議合宜的因素數目。由於因素負荷量代表題目反應潛在變項特質的程 度,故編寫能反應潛在變項特質的題目,對於因素數目的取決非常重要。MacCallum、Widaman、Zhang 和 Hong(1999)對題目能代表潛在特質程度
之重要性亦有相似的發現,他們的模擬研究發現,當分析變項的共通值均 ≧ .6 時(相當於因素負荷量 .8 左右),即使樣本人數少(如 100 人),因素 負荷量的估計仍然可以相當精準。因此,研究者欲進行因素分析前,致力於 編寫能反應潛在變項特質的題目當是首要之務,以提升因素分析結果之品 質,以及研究結論之適當性。 本研究提出的適用情境與過去研究相比較,譬如 Hakstian 等人(1982) 或李俊霆(2005)的模擬研究,此研究與其最大差異在於樣本人數的條件, 造成其差異的主要原因,應是資料特性的影響。因此,以特徵值大於一方法 分析李克特式量尺資料時,比分析連續資料需要更多的樣本人數,方能建議 合宜的因素數目。 過去研究顯示,在單因素與雙因素模型中,反應點數 5 點以及 5 點以上 的對稱點數資料且樣本數足夠大的情境下(比如樣本人數 1,000 人),特徵 值大於一方可得到較正確的因素數目(王嘉寧,2001)。本模擬研究將因素 模型延伸至多因素情境,結果亦得到相近的結論,在足夠的樣本數,因素負 荷量為 .6 與 .6 以上,量尺點數為 5 點以及 5 點以上,若變項分配趨近對稱的 情況下,特徵值大於一可以建議合宜的因素數目。然實徵研究的變項分配常 嚴重偏離對稱,根據本研究結果顯示,變項分配愈偏離對稱,特徵值大於一 的正確率愈低,所以可以預期特徵值大於一在李克特式量尺進行測量的實徵 研究中,僅在有限的條件下,才能建議合宜的因素數目。因此,研究者實應 謹慎考量特徵值大於一決定因素數目之適合性。 雖然特徵值大於一在李克特式量尺資料的整體表現並不佳,但卻是過去
國內許多研究決定因素數目的唯一方法。如果此方法表現不理想,過去研究 的結論是否可能因此而有所偏誤?有鑑於此,在討論特徵值大於一於李克特 式量尺的適用情境之餘,我們其實更期待學者能依據本研究的結果,重新檢 視過去單獨以此法決定因素數目的研究,以評估所得之因素結構是否需要重 新驗證。表 3、表 4 和表 5 的正確率可提供研究者參考,據之評估過去研究以 特徵值大於一決定的因素數目是否合宜。以下我們將以黃君瑜、許文耀 (2003)的「青少年憂鬱量表」編製的研究二為例,說明如何應用本研究的 結果,評估以往研究中特徵值大於一建議之因素數目的合宜性。 「青少年憂鬱量表」(黃君瑜、許文耀,2003)將兒童或青少年憂鬱症 診斷標準的症狀,區分為情緒、認知、行為、生理等四種症狀類型,並根據 專家評定,選出 31 項憂鬱症的主要症狀為量表內容。量表為二分試題,受測 者根據自己的狀況回答是否有題目所描述的情形,答「是」者得 1 分,答 「否」者得 0 分。該研究針對 672 名一般組之國中及高中職學生資料進行因 素分析,研究者根據特徵值大於一選取七個因素,分別命名為「冷漠」、 「失去興趣」、「無望」、「心理動作遲滯」、「在乎他人」、「失去精 力」、「躁動與沮喪」。針對此七因素的結果,作者在文中(第 180 頁)指 出,「因為抽取出來的七個因素與原先量表的構念不盡相同,所以有必要在 未來的研究再進行探討」。為此,我們將嘗試依此研究呈現的資料,對應本 研究之模擬結果,探討該研究以特徵值大於一選取的因素數目是否合宜。 為應用本模擬研究之結果,除了已知的二分變項特性外,需先了解黃君 瑜、許文耀(2003)研究中因素負荷量的數值、約略的變項因素比、因素數 目與變項的分配。根據該研究表 7 的因素分析結果,七個因素影響的主要變 項之因素負荷量的絕對值介於 .332 和 .671 間,平均約為 .513。若以量表原先 設計的四個構念推估變項因素比,則約為 8 左右。至於變項分配,囿於該研 究呈現的數據,則僅能由該研究表 5 間接推測。表 5 中一般組男性受測者(N = 259)在「青少年憂鬱量表」的平均數為 9.54,由此推估平均每題答「是」 的機率約為 .31(9.54/31),對應的偏態係數約為 .82。將上述推估的資料依 序對應本研究表 4 因素負荷量為 .6 之結果,當點數為 2、偏態係數為 -1、樣 本人數 500 或 1,000、變項因素比 6 或 8,特徵值大於一的正確率均偏低,除 非變項數低(如 18)。由此結果觀之,特徵值大於一能於該研究建議正確因 素數目的機率非常低,該研究所得到的七個因素,恐非該量表最適合的因素 數目。由於因素數目的取決是因素分析的關鍵,該研究呈現的七個因素結
果,恐亦非表徵「青少年憂鬱量表」的最佳因素結構,而如原作者所言需要 進一步探究。
要正確決定因素數目,選擇適當的方法,才是根本解決之道。在決定因 素數目的各個方法中,平行分析無論在連續或點數資料表現均極佳(王嘉 寧,2001;Humphreys & Montanelli, 1975; Turner, 1998; Velicer et al., 2000;
Weng & Cheng, 2005; Zwick & Velicer, 1986)。Horn 於 1965 年提出平行分析,
建議用與實徵資料有相同樣本人數與變項數目的隨機零相關矩陣之特徵值為 決定因素數目的比較基準,以避免特徵值大於一未考慮抽樣誤差的偏誤,期 能得到較正確的因素數目。為避免單一矩陣之不穩定性,Horn 乃建議產生多 個隨機零相關矩陣,以其特徵值之平均數與實徵資料樣本相關矩陣的特徵值 相比較,樣本相關矩陣特徵值大於隨機零相關矩陣特徵值平均數的個數,即 為因素數目。黃君瑜、許文耀(2003)研究二得到的前七個樣本相關矩陣之 特徵值為 6.56、1.81、1.47、1.40、1.15、1.12 和 1.08,而若根據 100 個樣本人 數 672、變項數 31 之零相關矩陣,求算前七個特徵值的平均數,則分別為 1.42、1.37、1.33、1.29、1.26、1.22 和 1.20。因為樣本相關矩陣的第五個特徵 值 1.15,小於隨機零相關係數矩陣第五個特徵值的平均數 1.26,故平行分析 建議的因素數目將為 4,恰為量表原本的構念數目。就如原作者所言,「青 少年憂鬱量表」的因素結構或有必要再加探討。至於該量表是否為四因素模 式,則有待實際資料分析予以檢視。 因素分析主要是以潛在因素來解釋觀察變項間的相關,因此研究者針對 所欲探索的構念,需廣泛蒐集相關文獻,分析討論文獻的結果,提出合理的 假設架構進行分析(Comrey & Lee, 1992)。是故,合宜的因素數目對於研究 結果之正確性是重要關鍵。本研究考量樣本人數、因素負荷量、變項因素 比、因素數目、量尺點數,以及變項分配偏態等變項,提出特徵值大於一方 法正確決定因素數目的適用情境,供研究者參考,並可藉之審視過去的研究 結果之合宜性。由於特徵值大於一正確決定因素數目的情境有限,藉由本研 究結果重新檢視以往研究之合宜性,對單獨以特徵值大於一方法決定因素數 目的研究尤其重要,研究者可由本研究結果評估以往的研究結論是否可能有 所偏誤,以更適當地建構研究變項之因素結構,提升心理學研究與理論發展 之正確性。在因素數目決定方法的選擇上,鑑於特徵值大於一的表現不佳, 未來研究者應避免單獨使用特徵值大於一方法,可考慮改以其他方法,比如 學者建議的平行分析與最小平均淨相關法(例如:Henson & Roberts, 2006;
Patil, Singh, Mishra, & Donavan, 2008; Velicer et al., 2000; Zwick & Velicer, 1982) 選取因素數目。
謝誌
感謝國立政治大學心理學系許文耀教授慨允以其文章為例,比較特徵值 大於一與平行分析建議的因素數目。同時,非常感謝兩位匿名審查人提供的 寶貴意見與建議,使本文得以更臻完善。參考文獻
中文部分
王嘉寧(2001)。量尺點數與分配型態對因素分析的影響。國立台灣大學心理學 研究所碩士論文,未出版,台北市。 王嘉寧、翁儷禎(2002)。探索性因素分析國內應用之評估──1993 至 1999。 中華心理學刊,44,239-251。 吳柏儒(2003)。次序資料之因素分析──皮爾森與多序類相關係數之比較。國 立台灣大學心理學研究所碩士論文,未出版,台北市。 李俊霆(2005)。因素數目決定法──特徵值大於一之再探。國立台灣大學心理 學研究所碩士論文,未出版,台北市。 翁 儷 禎 (1995)。因 素 分 析 應 用 之 一 覽。載 於 章 英 華、傅 仰 止、瞿 海 源(主 編),社會調查與分析(頁 245-259)。台北市:中央研究院民族學研究 所。 黃君瑜、許文耀(2003)。青少年憂鬱量表編製研究。教育與心理研究,26, 167-190。英文部分
Bedrick, E. J. (1995). A note on the attenuation of correlation. British Journal of
Mathema-tical and StatisMathema-tical Psychology, 48, 271-280.
Bernstein, I. H., & Teng, G. (1989). Factoring items and factoring scales are different: Spu-rious evidence for multidimensionality due to item categorization. Psychological
Bulletin, 105, 467-477.
Bollen, K. A., & Barb, K. H. (1981). Pearson’s R and coarsely categorized measures.
American Sociological Review, 46, 232-239.
Cattell, R. B. (1966). The scree test for the number of factors. Multivariate Behavioral
Re-search, 27, 245-276.
Cohen, J. (1983). The cost of dichotomization. Applied Psychological Measurement, 7, 249-253.
NJ: Lawrence Erlbaum Associates.
Comrey, A. L., & Lee, H. B. (1992). A first course in factor analysis (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum Associates.
Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). Evaluating the use of exploratory factor analysis in psychological research. Psychological Methods,
4, 272-299.
Fava, J. L., & Velicer, W. F. (1992). The effects of overextraction on factor and component analysis. Multivariate Behavioral Research, 27, 387-415.
Fava, J. L., & Velicer, W. F. (1996). The effects of underextraction in factor and component analyses. Educational and Psychological Measurement, 56, 907-929.
Ford, J. K., MacCallum, R. C., & Tait, M. (1986). The application of exploratory factor analysis in applied psychology: A critical review and analysis. Personnel Psychology,
39, 291-314.
Gorsuch, R. L. (1983). Factor analysis (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum Asso-ciates.
Gorsuch, R. L. (1997). Exploratory factor analysis: Its role in item analysis. Journal of
Per-sonality Assessment, 68, 532-560.
Hakstian, A. R., Rogers, W. T., & Cattell, R. B. (1982). The behavior of number-of-factors rules with simulated data. Multivariate Behavioral Research, 17, 193-219.
Henson, R. K., & Roberts, J. K. (2006). Use of exploratory factor analysis in published re-search: Common errors and some comment on improved practice. Educational and
Psychological Measurement, 66, 393-416.
Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis.
Psycho-metrika, 30, 179-185.
Humphreys, L. G. (1964). Number of cases and number of factors: An example where N is very large. Educational and Psychological Measurement, 24, 457-466.
Humphreys, L. G., & Montanelli, R. G. (1975). An investigation of the parallel analysis cri-terion for determining the number of common factors. Multivariate Behavioral
Re-search, 10, 193-205.
Kaiser, H. F. (1960). The application of electronic computers to factor analysis.
Educa-tional and Psychological Measurement, 20, 141-151.
Lawley, D. N. (1940). The estimation of factor loadings by the method of maximum like-lihood. Proceedings of the Royal Society of Edinburgh, 60, 64-82.
Linn, R. L. (1968). A Monte Carlo approach to the number of factors problem.
Lunney, G. H. (1970). Using analysis of variance with a dichotomous dependent variable: An empirical study. Journal of Educational Measurement, 7, 263-269.
MacCallum, R. C., Widaman, K. F., Zhang, S., & Hong, S. (1999). Sample size in factor analysis. Psychological Methods, 4, 84-99.
Martin, W. S. (1973). The effects of scaling on the correlation coefficient: A test of validity.
Journal of Marketing Research, 10, 316-318.
Martin, W. S. (1978). Effects of scaling on the correlation coefficient: Additional consider-ations. Journal of Marketing Research, 15, 304-308.
Mote, T. A. (1970). An artifact of the rotation of too few factors: Study orientation vs. trait anxiety. Journal of Psychology, 4, 171-173.
Muthén, B., & Kaplan, D. (1985). A comparison of some methodologies for the factor analysis of non-normal Likert variables. British Journal of Mathematical and
Statis-tical Psychology, 38, 171-189.
Muthén, B., & Kaplan, D. (1992). A comparison of some methodologies for the factor analysis of non-normal Likert variables: A note on the size of the model. British
Jour-nal of Mathematical and Statistical Psychology, 45, 19-30.
Olsson, U. (1980). Measuring correlation in ordered two-way contingency tables. Journal
of Marketing Research, 17, 391-394.
Patil, V. H., Singh, S. N., Mishra, S., & Donavan, D. T. (2008). Efficient theory develop-ment and factor retention criteria: Abandon the ‘eigenvalue greater than one’ criterion.
Journal of Business Research, 61, 162-170.
Russell, D. W. (2002). In search of underlying dimensions: The use (and abuse) of factor analysis in personality and social psychology bulletin. Personality and Social
Psy-chology Bulletin, 28, 1629-1646.
Turner, N. E. (1998). The effect of common variance and structure pattern on random data eigenvalues: Implications for the accuracy of parallel analysis. Educational and
Psy-chological Measurement, 58, 541-568.
Velicer, W. F. (1976). Determining the number of components from the matrix of partial correlations. Psychometrika, 41, 321-327.
Velicer, W. F., Eaton, C. A., & Fava, J. L. (2000). Construct explication through factor or component analysis: A review and evaluation of alternative procedures for determi-ning the number of factors or components. In R. D. Goffin & E. Helmes (Eds.),
Prob-lems and solutions in human assessment: Honoring Douglas N. Jackson at seventy
(pp. 41-71). Boston, MA: Kluwer Academic.
Educational and Psychological Measurement, 65, 697-716.
Wothke, W. (1993). Nonpositive definite matrices in structural modeling. In K. A. Bollen & J. S. Long (Eds.), Testing structural equation models (pp. 256-293). Newbury Park, CA: Sage.
Zhang, G., & Browne M. W. (2006). Bootstrap fit testing, confidence intervals, and stan-dard error estimation in the factor analysis of ploychoric correlation matrices.
Beha-viormetrika, 33, 61-74.
Zwick, W. R., & Velicer, W. F. (1982). Factors influencing four rules for determining the number of components to retain. Multivariate Behavioral Research, 17, 253-269. Zwick, W. R., & Velicer, W. F. (1986). Comparison of five rules for determining the number
附錄 1 三因素模式連續與李克特式量尺資料之相關係數矩陣特徵值之平均數 A= .4 A= .6 A= .8 樣本數 樣本數 樣本數 R P 1000 500 200 100 P 1000 500 200 100 P 1000 500 200 100 4 1.48 1.44 1.49 1.62 1.78 2.08 1.91 1.97 2.08 2.22 2.92 2.66 2.72 2.85 3.00 1.48 1.36 1.38 1.44 1.53 2.08 1.81 1.82 1.84 1.88 2.92 2.52 2.52 2.53 2.54 1.48 1.28 1.27 1.29 1.35 2.08 1.70 1.67 1.62 1.58 2.92 2.38 2.33 2.23 2.13 0.84 1.01 1.06 1.14 1.20 0.64 0.85 0.90 0.99 1.09 0.36 0.58 0.62 0.69 0.78 0.84 0.97 1.00 1.05 1.08 0.64 0.81 0.84 0.90 0.95 0.36 0.55 0.58 0.62 0.67 0.84 0.94 0.95 0.97 0.98 0.64 0.78 0.80 0.83 0.85 0.36 0.53 0.54 0.57 0.59 6 1.8 1.69 1.76 1.92 2.13 2.80 2.49 2.56 2.71 2.91 4.20 3.73 3.82 4.00 4.21 1.8 1.60 1.62 1.70 1.84 2.80 2.35 2.36 2.39 2.46 4.20 3.53 3.54 3.55 3.57 1.8 1.50 1.49 1.52 1.61 2.80 2.21 2.17 2.10 2.06 4.20 3.34 3.27 3.13 2.98 0.84 1.07 1.15 1.29 1.42 0.64 0.90 0.97 1.11 1.27 0.36 0.62 0.67 0.78 0.91 0.84 1.03 1.09 1.19 1.29 0.64 0.86 0.92 1.02 1.13 0.36 0.59 0.63 0.71 0.80 0.84 1.00 1.04 1.12 1.19 0.64 0.83 0.88 0.95 1.03 0.36 0.57 0.60 0.66 0.72 0.84 0.97 1.00 1.05 1.10 0.64 0.81 0.84 0.89 0.94 0.36 0.55 0.57 0.61 0.65 0.84 0.95 0.97 1.00 1.01 0.64 0.79 0.81 0.84 0.86 0.36 0.53 0.55 0.57 0.59 0.84 0.92 0.93 0.94 0.94 0.64 0.77 0.78 0.79 0.79 0.36 0.52 0.53 0.54 0.54 8 2.12 1.94 2.02 2.21 2.47 3.52 3.06 3.15 3.34 3.59 5.48 4.80 4.91 5.16 5.43 2.12 1.83 1.86 1.96 2.13 3.52 2.88 2.90 2.95 3.03 5.48 4.54 4.55 4.57 4.60 2.12 1.72 1.71 1.75 1.86 3.52 2.71 2.66 2.58 2.52 5.48 4.29 4.20 4.02 3.84 0.84 1.12 1.22 1.42 1.62 0.64 0.94 1.03 1.22 1.44 0.36 0.65 0.71 0.86 1.03 0.84 1.08 1.16 1.32 1.48 0.64 0.90 0.98 1.12 1.29 0.36 0.62 0.67 0.78 0.92 0.84 1.05 1.12 1.24 1.37 0.64 0.88 0.94 1.05 1.18 0.36 0.60 0.64 0.73 0.83 0.84 1.02 1.08 1.18 1.27 0.64 0.85 0.90 1.00 1.09 0.36 0.58 0.62 0.69 0.76 0.84 1.00 1.04 1.12 1.18 0.64 0.83 0.87 0.94 1.01 0.36 0.57 0.59 0.65 0.70 0.84 0.98 1.01 1.06 1.11 0.64 0.81 0.84 0.89 0.94 0.36 0.55 0.57 0.61 0.65 0.84 0.95 0.98 1.01 1.03 0.64 0.79 0.82 0.85 0.88 0.36 0.54 0.55 0.58 0.60 0.84 0.93 0.95 0.96 0.97 0.64 0.78 0.79 0.81 0.81 0.36 0.53 0.54 0.55 0.55 0.84 0.91 0.92 0.92 0.90 0.64 0.76 0.76 0.77 0.76 0.36 0.51 0.52 0.52 0.51 註:粗體字為平均數值大於一者,為精簡表格,僅呈現各情境前半特徵值之平均數。 A=因素負荷量,R=變項因素比,P=母群特徵值。