國立台灣師範大學教育心理學系 教育心理學報,民.70, 14期, 18弘-204頁
不完整資料對共變數矩陣估計正確
性的探討:實徵性研究*
吳鐵雄 本研究以電腦模擬資料方式,探討變數取樣各種因素對共變數矩陣估計之影響。這些因 素包括:變數數目,變數間平均相關係數、樣本數、變數取樣比率、設計型態等,全部探討 的設計組合共有56種。並以概化變異數、軌跡、和最大根做為探討估計正確性之數量。一般 地說,估計偏差相當大,尤以概化變異數為甚。在既有因素中,以變數間平均相關係數估計 影響最大,變數數目則無甚作用,其他如取樣比率、設計型態則結果不甚一致。意外地,樣 本數的大小對估計之正確性並無明顯影響。 • 189 • 行為科學研究者在研究過程中,由於涉及多變數、長期追院研究、或其他原因,常遭遇漏失資料 (missing data) 的問題,此種不完整資料的統計分析是一個極難處理的難題,統計學者一直在探究 各種可能的解決途徑。本文郎以變數取樣方法,利用電腦摸摸 (computer simulation) 的方式,產 生系統不完整資料,以探討各種因素對共變數矩陣特質估計的影響。 不完整資料處理的研究,一直是一個熱門的課題,尤以近一、二十年更受重觀。 Wilks (1932的可 能是第一個從事不完整資料之研究的統計學者,他首先建議以組平均數代替不完整資料,然後以最小平 方法(least square me出od) 來估計母數,只是他只研究雙變數的情形。 Matthai (1951)延伸 Wilks的研究到三變數的情形。 Dear (1959)更進一步建議tJ所有完全資料的糖、平均 (grand mean) 來代入
所有的漏失分數,在研究隨機漏失資料的情形,他主張先以完整資料計算因素分數 (factorscores)
和因素負積量 (factor loading) ,再以它們利用主成份分析 (principal component analysis)獲得
R原始分數"。其主要觀念是將資料矩陣分解成已知和未知兩部分,並就已知部分求出主成份解答,來
估計未知部分。
Buck (1960) 首先採用一種第一階迴歸方法 (first order regression method) 的或然性評估
(probabilistic evaluation) 。他發展出一組估計的歷程,此歷程是由所有完整資料的受試者來計算一
系列的迴歸函數 (regression function) 。每一個變數被用為依變項,剩下的變數的可能組合做為自
變項,然後再根攝適當的迴歸函數估計未知的值。 Kosobud (1963) 延伸 Buck 的方法,提出以一
對變項的所有完整資料來計算相關係數,而不踩取在有一聲項資料漏失時即搶棄該受試的方法,他認
為如此可使剩餘變數 (residual variance) 變小。上述兩者, Buck 方法是謀取凡是一個受試者在所 有變項中有一聲項資料漏失,即捨棄不用,而 Kosobud 的方法則採用費項兩兩處理的方法,這兩種
方式目前仍廣被揖用。
有些統計學者則揉用可能性函數(likelihood function) 方法估計不完整資料的母數 (Parame
ters) 0 Wi1ks (1932a) 以常聽雙變項不完整資料樣本,計算出估計的母平均數 (μ) 和母共變數矩
陣(主〉的最大可能性方程式 (maximum likelih∞d equation) 。當不完整資料是樣本里的每一個個
體沒有接受所有的變項時, Lard (1955的考慮一個特例以獲得有殼的估計值而估計常態多變數母畫
。他自不完整資料導出一個估計常屆三變數母數的明確解答 (explicitω,lution) 的最大可能性方程 式,同時他也導出計算最大可能性估計值的樣木,變數和共變數的方程式。
Trawinski 和 Bargmann (1964) 研究一個比較擾雜的漏失資料問題,他們利用系統安排某些
受試者不接受某些變數,然後推導計算平均數向量 μ 和共變數矩陣的最大化可能性方程式。他們並
寫成以反覆法 (iteration) 解方程式的電腦程式,並能做假設的統計考驗。 Hocking 和 Smith (1968) 則研究一般漏失資料的情形,而不局限於系統的不完整資料,他們利用啟發性歷程 (heuri stic prlωedure) 發展具有最大可能性特徵 (properties) ,但他們只能推出巢狀 (nested) 情形的估 計值,未能普及一般情形。 有些統計學者嘗試著比較利用不同方法代入漏失資料及不開估計母數方法的結果,哥哥j 目前尚未有 定論。 Afifi 和 Elashoff (1966, 1967) 評述了不完整資料的研究。他們利用簡單迴歸方法探討四 種不同指派數值給漏失資料的方法: (1)以傳統的方式; (2)用平均數; (3)用簡單迴歸;但)用他們的加權 法。他們演算了這四種的分配理論 (distribution theory) ,並評估它們的有被性,他們的結論是沒右 一種方法在所有情形下都比其他方法為佳,一般來說,第二種方法對非常低相關變數的估計最好,第 四種方法對低相關較佳,第一種方法則對中等相關變數最好,第三種則有利於高相關變數的估計。 Haitovsky (1968) 利用電腦模擬資料研究兩種處理不完整資料方法在迴歸分析的結果,其中一種方 法是捨棄所有不完整資料,然後利用最小平方技術分析完整資料。另一種方法是利用所有完整的一對
分數計算其共變數,並用這些共變數建立常態方程式系統 (systemof normal equation) 。他製造八
組迴歸資料,每一起產生漏失資料的方式都不同,他發現幾乎在所有的情形,用最小平方法分析只包
括完整資料(第一種方式〉的結果最佳。但是,當不完整資料的比倒相當高或當資料之漏失為非隨機 時,則說們必2頁利用某一種方法去填補漏失資料。
Timm (1970) 利用摸摸資料系統地研究四種不同估計方法對共變數矩陣和相關係數矩陣的估計
,他研究的四種方法是 Wilks (1932a), Dear (1959), Buck (1960)' 和傳統只用完整資料將有漏失
資料的個案捨棄的方法。為了避免普遍存在於多變項研究中的混淆現象, Timm有系統的改變接本數
(閱mple size) 、變數數目 (number of variable) 、漏失資料E分比 (percent of missing data) 、
和變數的平均相關係數 (average intercorrelations of variables) ,而探討上述四種方法的教果。他 發現要選擇一個最好的方法估計共變數矩陣比估計相關係數矩陣較少問題。一般來說,每一種方法都
有其優點,完全服各種情境的配合, Buck 和 Dear 的方法則稍佳。但是,在估計相關係數矩陣時,
Wilk 和只利用完整資料的方法有降低聲數平均相關的趨勢, Dear的方法則趨向增高相關,而 Buck
的芳法只在原矩陣為低相關時會降低相關,對其他矩陣則有增高相闊的現象。 上述研究已有統計學者踩用變數取樣的方法,造成系統的不完整資料,用之以探討各種估計母數 的方法。變數取樣缸但l乎源自於 Wi11iam Tu盯1江汀rr曲r 的觀念。此種觀念Lord (1凹95臼5b的)將之應用於割驗以解決瀏驗編製上取模及常模間題。他在 1凹96位2 年 有系統地研究項目取樣的模式對湖驗總分及其他統計數的估計,並發展出若干基本公式。其研究架構 亦鹿為以後項目取樣研究的一個典型。他嘗試瞭解一個包含有70個選擇題的測驗的常模分配是否可以 用項目取樣可靠地估計。他將70個題目合成10個分測驗,每個分測驗7個題目,這10個分測驗好別施 測於10組受試,每組 100 人。並間時用受試取樣的方法,選取 100 個人,每人做所有的70題。他認為 項目取樣的結果,不論對測驗分數的平均數,變異數或分配都有較佳的估計。幾年接他與 Novick (1968) 系統地討論了項目取樣時母平均數 (μ〉和母變異數 (σ2) 的估計問題,他們有聽項結論:第 一,如果增加受試人數,對平均數和標準差估計的標準誤 (standard error) 會還漸降低。第二、如 受試人數一定,則增加分測驗的數目會比增加每一分測驗的題數,或增加每一分割驗的受測人數得到 更佳的估計結果。第三、對某一固定長度的翻驗具有相同數目的受試者的各種取樣,在估計變異數時 ,一般都會有相同的標準誤,但估計平均數的標準誤則不相悶。
不完整資料對共變數矩陣估計正確性的探討 • 191 •
探討不重置取樣 (sampling without replacement) 的問題,均認為項目眾接有較佳的結果。 Cook 和 stufflebeam (1967) 以重置取接(組mplìngwith replacement) 的方法研究各種樣本數的影響, 亦發現項目取樣結果較佳。 Owens 和 Stufflebeam (1968) 比較項目取樣和受試取樣在估計一些 常模統計數 (norm statistics) 的正確性,發現不同比例的試題歡在估計上,對不同能力的受試有不 同的結果。 ]acobs 和 Wildemann (1969) 比較不同比率的試題取樣對教育測驗的影響,結果顯示不 同的取樣比率並沒有產生多大差別,但發現項目取樣偶而會產生負值變異數,此種結果亦經其他研究
證實 (Husek 和 Sirotnik, 1968).0 Shoemaker (1970a, 1970b) 的兩篇研究很有系統地改變聽個變
數:分測驗的數目,每個分割驗的題數,及受試者的人數,他認為在利用項目取攘以估計常模分配時
,要達到最大放呆的關鍵在於實際獲得「觀察」數日,亦即受試者對他們的眉目所傲的全部反應數目,
而不是項目:取樣本身(如分測驗數目,每個分測驗的題數,每一個分測驗施測人數) ,甚至與總分分 配形狀也沒有關係,此結果受到 Hambleton, RovineIIi和Gorth (1971) 的支持。
Lord (1965)曾建議在從事項目取樣研究時,可以利用統計學上的平衡不完全區組設計 (balanced
incomplete bl∞k design, BIBD) 的概念組織題目。 BIBD 一詞首由 Yates (1936) 提出,並與 Fisher (1938) 建立了一些 BIBD 的設計素,不過它們只考慮了區組數少於10的情形,Bose (1939)
更進一步建立較完整的設計衰。 Ramanujacharyulu (1966) 利用數學上 Galois fields的概念討論平 衡不完全區組設計。他導出了 BIBD 設計中一些因素之間的關係。
平衡不完全區組訣計雖有其統計分析上令人滿意的特質 (Clatworthy, 1956) ,但在實驗研究情
形下,殊難做平衡的設計。因此統計學家研究出部分平衡不完全區組設計( partially balanced inco-mplete block design, PBIBD) (Bose, 1951; Bose 和 Clatworthy, 1954; Bose 和 Nair, 1939) 。
Clatworthy (1973) 舖製了相當完整的 PBIBD 衰,分別適用於各種不同的區組設計。 Knapp (1968的應用 BIBD 設計研究項目取樣,他發現在估計平均數,變異數和信度係數時 ,此種設計有相當令人滿意的結果。在另一篇文章, Knapp (1968的比較平衡不完全區組設計及部 分平衡不完全區組設計在項目取樣的欽果,他發現前者的估計結果非常接近母數,但後者的結果則沒 有前者那麼好。 筆者在1979年曾以上述兩種區組設計的方法,設計變數取樣的架構,研究各種不同情形下的不完 整資料對於母共變數矩陣的估計。在該研究中,考慮了不同的變數數目、變數取樣比率、樣本大小、 取樣設計型態、變數間的平均相關、變數間的因素結構等因素,探討對共變數矩陣鐘種歸結數量
(summarizing number) 的估計,這些數量包括概化變異數 (generalized variance) 、軌跡(trace)
、最大根(largest r∞t) 、和估計誤差量等等。結果發現變數取樣造成的不完整資料對各種共變數矩 陣數暈的估計有不同的教果,大概可歸納如下: 1.在幾種因素中,樣本數對估計的影響最大。 2. 兩種不同的區組設計對共變數矩陣的估計,教果差不多,且估計誤差不比傳統的受試取樣大,甚至 為小。 3. 一般地說,對概化變異數的估計誤差較大,而且當變數間的相關高時,常常會產生負值的概化變異 數,但對於軌跡的估計則相當理想。 筆者在該研究中曾指出,為了牽就部分平衡不完全區組設計的有限設計,及顧及共變數的平均人 數相等,結果每一種訣計的總取樣人數及變異數之人數都不相等,因此在比較時產生很大的困難,本 研究針對此問題,兼顧變異數的人數,共變數的平均人數及總取樣人數的陸可能接近,進一步探討共 變數矩陣的估計問題,希望能提供更多資料,以便對不完整資料的使用有更進一步的瞭解。 方法與設計 本研究仍探用筆者 1979 年研究的架構,以蒙地卡羅 (Monte Carlo) 方法,系統地研究各種可
能因素對估計共變數矩陣的教果。這些因素可歸納為兩大額,第一額為界定共變數矩陣的變數,第二 類為涉及取樣設計的變數。本研究首先利用第一類變數,經由因素分析的方法,建立母共變數矩陣, 再由此矩陣,系統地變換第二類變數,利用電腦模擬資料而計算接本共變數矩陣,此種電腦資料的摸 摸,每種取樣設計都重值 200 次,以建立其分配而暸解估計的情形。 一、研究賽項 本研究所揉用的設計共包含下列幾種因素: 1.變數數目 (number of variables) :本研究共用兩種,部 6 個變數和10個變數。
2. 變數闊的平均相關 (average correlation between variables) :也有二層次,平均相鷗在 .65
至 .75 之間,是為高相關變數;平均相關在 .20 至 .30 之間郎為低相關變數。
3. 變數取樣比率 (ratio of variable sampling) 此為每一個變數組包含的變數數目,有二層次
,分別為的包含變數的二分之一及三分之一。倒如在 6 個變數的情形下,每一個變數組包含了 3 個及 2 個變數。
4. 設計型態 (design type只有三個層次,師 BIBD 為一種,再加上兩種 PBIBD 設計。在 BIBD 取援中,構成每一個共變數的人數都一樣,但共變數的人數與變異數的人數則不相等。至於
PBIBD 則不但共變數與變異數的人數不相等,而且其中一種情形是共變數聞之人數不相等
,其不相等情形有兩種,郎 Clatworthy (1973) 所稱之兩種結合類別部分平衡訣計 (two
associate-class partially balanced designs) 其中之一為共變數間人數不相等,但都不等於
零,一部分人數為另一部分的二倍(即 Clatworthy 所用之 Àl =1, À2=2 之設計)一為有 些共變數人數為零(即 Àl=O, À2=1 設計)。 5. 樣本教 (sample size) :接本數之決定係根接聽其數之人數而定,分小接本和大接本兩種,前 者為 80人,後者為 240人,但為牽就 BlBD 和 PBIBD 之設計,部分設計之人數只的等於此 二數目。本研究所周之設計及其人數如表 1 。 表 1 研究蠶計及取撥人數 每人接小接本 大樣本 變數設 計 型 態妥臣費頁麗吾吾吾吾區需要吾吾吾贏讀其聶需要比率*
數數目平均人數人數總人數平均人數人數總人數
6 完全取樣 (15)+ 6 80 80 80 240 240 240 1.00 BIBD (1 日 3 32 80 160 96 240 480 .40 PBIBD1 (12,的 3 32.4 81 162 97.2 243 486 .40 PBIBD2 (12, 3) 3 32 80 160 96 240 480 .40 BIBD (15) 2 16 80 240 48 240 720 .20 PBIBD1 (12, 3) 2 16.2 81 243 48.6 243 729 .20 PBIBD2 (12, 3) 2 16 80 240 48 240 720 .20 10 完全取樣 (45) 10 80 80 80 240 240 240 1.00 BIBD (45) 5 36 81 162 108 243 益86 .44 PBIBD1 (15, 30) 5 36 81 162 108 243 486 .44 PBIBC2 (40, 5) 5 35.6 80 160 106.8 240 480 .44 BIBD (45) 3 18 81 270 54 243 810 ;22 PBIBD1 (15, 30) 3 17.3 78 260 52 234 780 .22 PBIBD2 (30, 15) 3 17.3 78 260 52 234 780 .22 *比率等於共變數平均人數臉於變異數人數。 +:括號內數目是共變數之中,其人數有λ1 '和地結合的數目。不完盤資料對共變數短蟀估計正確性的探討 • 193 • 上述研究變項中,前二項為界定母共變數矩陣的特性因素,共有 4 種 (2x2) 結合,後三項為界 定取攘的特性因素,共有 12 種 (2x3x2) 結合,因此本研究所系統研究的取接情形共有 48 種 (4x 12) ,再加上傳統的完全取樣設計 8 種 (4種母共變數矩陣 x2 種接本數) ,總共研究了 56種取樣的情 形,有關詳細取樣的詩計請參閱筆者 1979年的論文。 二、母共要數提陣的界定和據本共要數提陣的計算 雖然Odell 和 Fieveson (1966) 提出直接概化樣本共變數矩陣的方法,且經一些研究者使用 (Montanelli, 1971; Tatsuo峙, 1973; Daw甜n, 1977) ,但因限於變數取攘的直雜性,本研究仍躲用 Kaiser 和 Dickman (1962) 即提之傳航方法,先由共變數矩陣概化接本多變數常鸝隨機變數,然後
萬計算樣本共變數矩陣。
本研究揖用共有 p 個變數的賞際資料,計算有 q 個因素的因素組型矩陣 (factorpattern matrix)
,然後每一變數的獨特性 (uniquen臨)再由下面公式計算:
Ui=(1-EIP2 月 .5 ,
式中 PJJ2 是第 i 變數在第 j 因素上的因素負椅量 (factor loading) 的平方,然缺整個因素矩陣則由
pxq 的共同因素 (common factor) 和 pxp 的誤差主軸矩陣 (diagonal matrix of random error)
組成。為了按正計算誤差 (runing error) ,因素負荷量(1Jj) 和獨特性 (uJ) 都用于面企式加以校正 並常態化 (normalized): q 1JJ = 1J
i
(互 1Jj2+U仟 5 , uJ = uJj (?:
11j2+UJ2).5, J-l 為了簡化起見,所有變數的變具數都定為 4 ,即有變數的因素負荷量和獨特性再以標準差加以加 權,母共變數短陣(主)因此可用下面公式計算出: ~=pp +U2,
其中P是經由標準差加權後的因素組型矩陣, U2 則是2日權後的獨特性主軸矩陣 o 根攘母共變數矩陣,再利用隨機數目概化函數的電腦程式模擬因素分數自量 (factor score V凹的吟,此隨機數目概化程式係很接 MarsagIia 和 Bray (1964) 的方法所設計,其模擬出的數值平 均數為 0 ,標準差為 1 '因此概化出的因素分數矩陣之共變數矩陣為一同一性矩陣(identity metrix) ,即 ~F=I 。然後每一個人 p 變數的樣本觀察數再根按此 F 向量予以模擬:X1j
主
flkPkj
+aljujI 式中 X!j 是第 i 個人在第 j 變數的觀察數, f!k 是第 i 個人在第 k 個因素的因素分數, PkJ 是第 j 個 變數在第 k 個因素上的因素負椅量, a1j 則是第 i個受試者的第j 個獨特性因素分數,而uj 則是第 j 個變數的獨特性,如用矩陣表示,則上述成為 X=FP'+AU 0 最後,用此樣本觀察數計算樣本共變 數矩陣。缺失的共變數再用 Spearrnan (1927) 所提四分法 (tetrad rnethod) 加以估計。三、分析
在多變數統計分析中,目前對共變數矩陣所採用的歸納性統計數大概可分為兩種,第一為多變數
變異數分析 (MANOVA) 所常用之概化變異數 (generalized variance) ,此為 Wilks (1932b)首提 。 Wilks 界定概化變異數為共變數矩陣的行列式(deterrninant) 。因此它在計算中間時考慮各變數 的變異數及各變數闊的共變數,唯其如此,當變數間為高相關時,概化變異數便接近於零。此種特質
analysis) 等所操用之軌跡 (trace) 觀念。此概念首由 Pear叩n (1901) 提出,再由 Hotelling
(1933; 1936) 延伸應用到因素分析方法 (factor analytic appr凹hes) 的多變數統計。它郎為共變
數矩陣中主軸元索的簡單和 (simple sum) .亦即各變數變異數之和,此種數量的一個特徵是它並不 考慮變數之間的相關。第三,最大根(1缸gest r∞t) 則與軌跡觀念及概化變異數有關,且經常見於 Lawley 之統計方法。最後,在使用項目取樣時,有些研究者發現有變異數為負值之情形,而本研究 中亦會發生,因此,共變數矩陣具有行列式為負值之數目亦加以統計。筆者(民的〉曾對這些統計數 量有過詳細的介輯與討論。本研究因此用這四者作為探討共變數矩陣估計的統計數暈﹒每種統計數量 均利用前述過程重值 200 次,以所得之分配計算其平均數,標準差,偏盤及率度等予以討論。 四、電腦程式
本研究所用之電腦程式 SAMCOV 為筆者於 1979年所設計,其中用了 Farr (1975) 的 XRAN
函數副程式 (function subprogram) 概化隨機常態數目,及 HOW 副程式 (Cooley 和 Lohn間, 1971) 計算特徵值 (eigenvalue) 。本程式需要 60k 來執行。資料則利用美國紐約州立大學之 CDC
Cyber 173 型電子計算機所傲,此型電腦有 60 bit words ,當可提供非常準確之結果。
結果 對上述所提四種描述共變數矩陣之統計數量的估計,將分別討論其結果。針對本研究的設計,每 一個估計數的結果都有四個衰,每個表都包括設計的因素及估計結果的平均數及標準差,其中有一個 設計在資料模擬時發生困難,無法得到結果,在表中以「一」表示。茲將表中的符號分別說明如下: 1. No= 共變數的人數。 2. NÀ1= 具有h 型聯結之共變數數目。 3. NÀ2= 具有地型聯結之共變數數目。 4. Nc= 整個矩陣中共變數的平均人數。 5. Nv= 每一個變異數的人數。 6. Np= 某一設計的全部取樣人數。 7. v!p= 每個受試者所接受變數的數目。 8. rL= 低相關係數矩陣的平均相關係數。 9. rH= 高相關係數矩陣的平均相關係數。 一、軌跡的估計 軌跡依其定義是變異數的和,並不計算共變數在肉,其估計將受取樣時變異數的取樣情形影響較大 。表2 、表3 、表4 、和表5分別為據本軌跡的平均數與標準差。在不影響估計間題之下,本研究值設每 一變數的變異數都是4.00 。因此,在六個變數共變數矩陣的軌跡母數為 24.00 .在十個變數的矩陣則 為 40.00 0 首先,變數闊的平均相關但乎是一個重要因素,從四個表中很顯然地可以發現,對於軌跡 的估計,無論是在六個變數或在十個變數的情形,低相關矩陣的結果比高相關矩陣的結果更接近母數 ,而且相差極為懸殊。但是,無論是低相關矩陣萬高相關矩陣,對於軌跡的估計都不算理想。有君繭 者在估計時的變異情形,高相關矩陣位乎比低相關矩陣稍篇小些。 當比較表2、表3、和表4、表 5 時,意外地發現,當取樣人數增大三倍時,對軌跡的估計卸沒有改變 ,亦 @p大樣本和小接本的結果直接乎完全相間,至於其他取樣設計的因素,諸如取樣比率、設計型態等 ,對於估計結果都沒有什麼影響。 二、械化變異數的估計 Wilks (1932b) 定義概化變異數為共變數矩陣的行列式,因在計算時包含共變數在肉,其數值大小 受變數之間相關的影響甚大,原則上,高相關之矩陣其概化變異數會比較小,而低相關矩陣則較大。此種 現象可以從表6、表7、表8、和表9、看出。這四個表呈現各種取擺設計對概化變異數之估計結果。另方面,
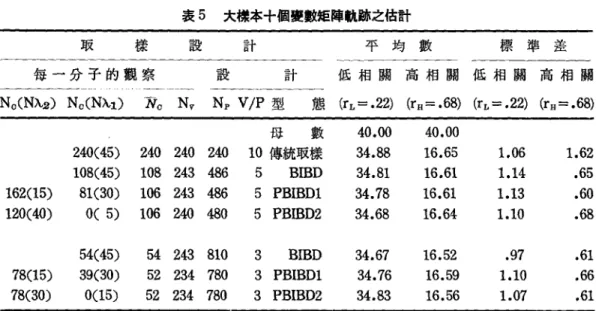
• 195 • 不完整資料對共變數矩陣估計正確性的探討 小據本六個要數拒陣航跡之估計 表 2 差 準 標 數 均
平
計 設 樣 取 高相關 低相關 高相關 低相關 計 設 每一分于的觀察 (rH=.72) (rL == .22) (rL == .22) (rH ==.72) 態 Np VjP 型 Nv Nc Nc(N.λ1) Nc(Mλ2) .84 1.06 .85 .95 1.58 1.61 1.52 1.60 24.00 10.49 10.64 10.46 10.58 24.ω 22.20 22.04 22.30 22.28 母數 6 傳統取樣 3 BIBD 3 PBIBD1 3 PBIBD2 80 160 162 160 nυnU 可inυ nonδnδnδ 的 υq 且 A 唾丹 L nδqu ﹒呵。 qrH qJ 80(15) 32(15) 18( 3) 。( 3) 36(12) 40(12) :.97 僅過'"-:.96 .96 1.62 1.65 1.64 10.61 10.55 10.53 22.24 22.27 22.29 2 BIBD 2 PBIBD1 2 PBIBD2 240 243 240 nu'inu non6n6 16 16.2 16 16(15) 9( 3) 。( 3) 18(12) 20(12) 大據本六個要數矩陣軌跡之估計 表 3 差 準 標 平均數 低相關高相關 計 設 樣 取 高相關 {區相關 設計 Np VjP 型態 每一分子的觀察 (rH=.72) (rL=.22) (rH=.72) (rL=
.22) Nv Nc No(.Nλ.1) No(Nλ.!:>,) .84 1.06 .85 .95 1.58 1.61 1.52 1.60 24. 的 10.49 10.64 10.40 10.58 24.00 22.20 22.04 22.30 22.28 母數 6 傳統取樣 3 BIBD 3 PBIBD1 3 PBIBD2 240 480 486 480 240 240 243 240 240 96 97.2 96 240(15) 96(15) 54( 3) 。( 3) 108(12) 120(12) .97 .96 .96 1.62 1.65 1.64 10.61 10.55 10.55 22.24 22.27 22.29 2 BIBD 2 PBIBD1 3 PBIBD2 720 7泊 729 240 243 240 48 48.6 48 48(15) 27( 3) O( 3) 54(12) 60(12) 11、據本+個變數種陣軌勵之估計 表 4 差 準 標 平均數 低相關高相關 計 設 樣 取 高相關 低相關 計 設 每一分子的觀察 (rH= .68) (rL= .22) (rH= .68) (rL=
.22) 體 Np VjP 型 Nv Nc Nc(N,λ.1) No(N.λ2) 1.17 1.10 1.05 1.18 1.90 1.77
1.89 1.70 40.00 16.65 16.63 16.52 16.52 40.00 34.90 34.81 34.78 34.87 母數 10 傳統取接 5 BIBD 5 PBIBD1 5 PBIBD2 80 162 162 160 AU 可且可 iAυ QOAKUADnδ 仇。戶。戶 ORu nenδ 呵。. FO nd 80(45) 36(45) 27(30) O( 5) 54(15) 40(40) 1.14 .98 1.01 1.85 1072 1.93 16.64 16.61 16.60 35.02 34.78 34.71 3 BmD 3 PBIBD1 3 PBIBD2 hUAUAυ 門 4 戶 Ono nLqLqL 可 Anδnδ n0 月 4 月 4 18 17.3 17.3 18(45) 13(30) 0(15) 261(5) 26(30)表 5 大據本+個變數值陣軌跡之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 一一一一 No(Nλ.2) Nc(Nλ.1) 芳。 Nv Np VjP 型 態 (rL=.22) (rH=.68) (rL=.22) (rH=.68) 母 數 40.00 40.00 240(45) 240 240 240 10 傳統取樣 34.88 16.65 1.06 1.62 108(45) 108 243 486 5 BIBD 34.81 16.61 1.14 .65 162(15) 81(30) 106 243 486 5 PBIBD1 34.78 16.61 1.13 .60 120(40) 。( 5) 106 240 480 5 PBIBD2 34.68 16.64 1.10 .68 54(45) 54 243 810 3 BIBD 34.67 16.52 .97 .61 78(15) 39(30) 52 234 780 3 PBIBD1 34.76 16.59 1.10 .66 78(30) 。(15) 52 234 780 3 PBIBD2 34.83 16.56 1.07 .61 從純理論的觀點,刊國共變數矩陣只能為正定 (positive definite) 萬半正定 (positive semidefinite)
。但是,使用變數取樣估計母共變數時,由於取樣誤差或其他理由 (Thomp叩n, 1962; Sirotnik, 1972) ,估計的共變數矩陣的行列式可能會產生負值,尤以母共變數矩陣的行列式接近零時為然。 本研究發生此種現象,因此上述四個表中亦列舉了兵有負行列式的矩陣數目做為另一種描述估計的數 量。 從四個表中,我們可以發現傳統的取樣方法,無論是六個變數或十個變異的矩陣,矩陣的行列式 都不會有負值,其他的取樣設計型態則多少會產生負值行列式的矩陣。在大樣本時,此種現象較少發 生,但在小樣本則發生的次數比較多。其次,取樣比率也且乎亦與產生負值行列式的數目有闕,當取樣 三分之一聲數時,其產生負值行列式矩陣的數目比取接二分之一變數時為多。在三種設計型態中,
PBIBD1設計產生負值行列式矩陣的可能性位乎比 BIBD 和 PBIBD2 為寓。至於二種界定矩陣的 因素,如同前述,高相關矩陣產生負值行列式矩陣的次數比低相關矩陣所產生的為多。而十個變數樣 本矩陣亦比六個變數的矩陣產生較多的負值行列式。 表 6 小攤六個變數矩陣概化獲具數之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 Nc(Nλ.2) NcCNλ1) Nc N v Np VjP 型 態 (rL=.22) (rH=.72) (rL=.2劫 (rH=.72) 母 數 2273.03 23.10 88(15) 80 80 80 6 傳統取樣 1泊6.92(0戶 3.17(0) 542.75 1.23 32(15) 32 80 160 3 BIBD 808.08(0) 1. 93(5) 408.76 1.20 36(12) 18( 3) 32.4 81 162 3 PBIBD1 746.60(4) 1.80(11) 408.26 1.10 40(12) 。( 3) 32 80 160 3 PBIBD2 1068.58(0) 2.46(0) 502.32 1.23 16(15) 16 80 240 2 BIBD 451.26(71) 1.08(99) 354.13 1.07
‘.
-'~ 18(12) 9( 3) 16.2 81 243 2 PBIBD1 342.73(7的 .87(102)266.42 .67 20(12) 。( 3) 16 80 240 2 PBIBD2 656.59(23) 1.56(45) 422.26 1胸過1.0M喝5 *括號內數目為個矩陣中,出現負行列式矩陣之數目。不完整資料對共變數短陣估計正確性的探討 • 197 • 表 7 大樣本六個變數量巨陣概化變異數2估計 取 樣 設 計 平均數 標準差 每一分于的觀察 設 計 低相關高相關低相關高相關 Nc(Nλ.2) Nc(Nλ.1) Nc N v Np V/p型 態 (rL= .22) (rH=. 72) (rL = .22) (rH=. 72) 母 數 2273.03 23.10 240(15) 240 240 240 6 傳統取樣 1465.90(0)* 3.80(0) 348.22 .80 96(15) 96 240 480 3 BIBD 1316.52(0) 3.13(0) 349.82 .79 108(12) 54( 3) 97.2 243 486 3 PBIBD1 1236.86(0) 3.20(0) 281.25 .85 120(12) O( 3) 96 240 480 3 PBIBD2 1388.09(0) 3.50(0) 331.87 .74 48(15) 48 240 720 2 BIBD 1056.16(0) 2.47(0) 340.88 .98 54(12) 27( 3) 48.6 243 729 2 PBIBD1 1014.25(1) 2.32(1) 292.19 .92 60(12) 。(3) 48 240 729 2 PBIBD2 1210.30(的 343.96 *括號內數目:為在 200 個矩陣中,出現負行列式矩陣之數目 表 8 小據本+個變數矩陣模化要異數之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 Nc(Nλ2) Nc(Nλ1) Nc N v Np VjP 型 態 (rL=.22) (rH=.68) (rL=.22) (rH=.68) 母 數301918.38 151.25 80(45) 80 80 80 10 傳統取緩 90620.73(0)* 9(47(0) 46631.75 4.86 36(45) 36 81 162 5 BIBD 26709.89(12) 264(16) 19035.29 2.18 54(15) 27(30) 36 81 162 5 PBIBD1 21373.76(22) 2.4(27) 19920.81 2.18 40(40) O( 5) 36.5 80 160 5 PBIBD2 46064.85(2) 4.62(3) 28927.81 3.18 18(45) 18 81 270 3 BIBD 9253.97(1 77) 的(179) 13370.92 .76 2治(1 5) 13(30) 17.3 78 260 3 PBIBD1 4406.01(192) 27(193) 3283.72 .29 26(30) 。(15) 17.3 78 260 3 PBIBD2 27166.13(27) 3.25(29) 24897.00 2.81 *括號內數目為在 200 個矩陣中,出現負行列式矩陣之數目 就概化變異數而論,估計的結果都不太理想,樣本數與母數相去甚為懸殊。一般的說,高相關矩 陣的估計比低相關矩陣為差。而十個變數矩陣也比六個變數矩陣不理想。在幾個界定取樣設計的因素 中,樣本數的大小是一個重要的因素,大樣本的結果比小樣本的結果為佳。接本的變兵在十個變數的 矩陣也比小樣本為大,但在六個變數矩陣則反比小樣本為小,這倒是一個有趣的發現。有者,變數眾 樣比率對概化變異數的估計也有影響,當我們取樣三分之一變數時,估計的結果比取樣三分之一變數 時為佳,但一般地說,前者樣本數的變異卸比後者為大,這是可以理解的,因為後者產生負值行列式 矩陣的數目:為大,而這些矩陣則不在計算之內。至於設計型態﹒除了傳統取樣方法的結果稍佳,其他 三種變數取樣芳法的型態之間卸沒有明顯的差異。 三、最大棍的估計 最大根是共變數矩陣的第一個特徵值,就四個母共變數矩陣而言,其值就不會一樣。當變數數目
衰 9 大樣本+個要數植陣都化變異數立估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 No(Nλ.,2) No(Nλ1) Ho Nv Np VjP 型 態 (rL=.22) (rH=.68) (rL=.22) (rH=.68) 母 數 301918.38 151.25 240(45) 240 240 240 10 傳統取樣 133262.(0)* 4.90(0) 37252.72 4.47 108(45) 108 243 銘6 5 BTIBD 100246.18(0) 10.61(0) 33956.53 3.41 132(15) 81(30) 108 243 486 5 PBTIBD1 94686. 閱(的 10.01(0) 29406.54 3.30 120(40) 。( 5) 106 240 480 5 PBTIBD2 108417.16(0) 11.86(0) 謂的0.12 3.92 51(45) 54 243 810 3 BTIBD 51540.34(1) 5.66(0) 22828.94 2.87 78(15) 39(30) 52 234 呵。 3 PBTIBD1 42855.88(3) 4.52(7) 21494.52 2.34 78(30) 。(15) 52 234 780 3 PBTIBD2 98943.07(0) 9.93(的 33877.86 3.64 *括號內數目鑄在 200 個矩陣中,出現負行列式矩陣之數目 相等時,高相關矩陣的最六根將比低相關矩陣的最大根篇大。本研究假設每一變數的變異數都是4.00 .因此,十個變數矩陣的軌跡就此六個變數矩陣的軌跡來得犬,由於矩陣的特徵值 (S) 與它們的變數 有闕,其關係為:軌跡 =~σ12= 芝風,十個變數矩陣的最大根比六個變數的最大根為大是可預期的 ,我們也就不能將兩個矩陣的最大根拿來比較。 從表10 、表11 、表12和表詣,首先我們可以君出在全部情形下,都低估了母數,但在六個變數,低 相關矩陣,變數取樣三分之一,小樣本的情形下,所有的三個設計型態卸都高估了母數,是很意外的 結果。大體說來,低相關矩陣所得之結果比高相關之結果偏差較小,而高相關矩陣所得到的估計值更 小於其相對廳的取樣設計在低相關所得之值,是個很意外的結果。至於取樣標準差,估計值在高相關矩 陣的分散情形卸也比在低相關矩陣的好散來得小。在所有界定取樣設計因素中,變數取樣比率位乎是 比較重要,一般地說,取接三分之一變數的結果比取樣二卦之一的結果偏差較小,而前者估計值的分散 也比後者為大。其次,各種設計型態之間的估計結果雖有不間,其差異卸沒有什麼意義,且不穩定,而 三種取樣設計與傳統取樣所得到的結果也差不多。最後﹒非常意外地,對於最大根的估計,小接本的 這10 小據本六個變數矩陣最大之估計 取 樣 設 計 平均數 標準差 每一分于的觀察 設 計 低相關高相關低相關高相關 一←于于一一一一一一一一一 No(Nλ2) No(NÀ.1) No
N
v Np VjP 型 態 (rL= .22) (rH = .72) (rL = .22) (rH = .72) 母 數 8.60 18.48 8.(15) 80 80 80 6 傳統別樣 7.78 5.69 1.15 .77 32(15) 32 80 160 3 BTIBD 8.06 5.93 1.32 1.04 36(12) 18( 3) 32.4 81 162 3 PBTIBD1 8.31 5.67 2.28 .86 40(12) 。( 3) 32 80 160 3 PBTIBD2 8.05 5.84 1.26 .97 16(15) 16 80 240 2 BTIBD 8.85 6.10 1.39 1.14 18(12) 9( 3) 16.2 81 243 2 PBTIBD1 8.90 6.02 1.61 1.07 20(12) 。( 3) 16 80 鈞。 2 PBIBD2 8.62 5.62 5.86 1.50不完整資料對共變數短陣估計正確性的探討 • 199 • 表11 大據本六個變數量巨陣最大根之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 NoCNλ2) NcCNλ1)
N
o Nv Np VjP 型 態 (rL=.22) (rl\=.72) (rL=.22) (rH=.72) 母 數 8.60 18.48 240(15) 240 240 240 6 傳統取樣 7.62 5.72 .67 .50 96(15) 96 240 480 3 BIBD 7.75 5.70 .71 .54 108(12) 54( 3) 97.2 243 486 3 PBIBD1 7.79 5.71 .70 .54 120(12) O( 3) 96 240 480 3 PBIBD2 7.78 5.69 .77 .56 48(15) 48 240 720 2 BIBD 7.85 5.85 .81 .55 54(12) 27( 3) 48.6 243 729 2 PBIBD1 7.88 5.76 077 .57 60(12) O( 3) 48 240 729 2 PBIBD2 7.86 .76 要12 小據本+個要數種陣最大根之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 矩低相關陣高矩相關陣 低相關高相關 Nc(Nλ,2) No(Nλ1) No Nv Np VjP 型 體 (rL= .22) (rl\ = .68) (rL = .22) (rl\ = .68) 母 數 12.22 28.59 80(45) 80 80 80 10 傳統取樣 8.07 6.16 1.14 1.00 36(45) 36 81 162 5 BIBD 8.76 6.39 1.25 .98 54(15) 27(30) 36 81 162 5 PBIBD1 8.71 6.28 1.24 .91 40(40) 。(5) 36.5 80 160 5 PBIBD2 8.39 6.10 1.13 .96 18(45) 18 81 270 3 BIBD 9.80 6.64 1.39 1.02 13(30) 17.3 78 260 3 PBIBD1 9.74 6.78 1.30 1.02 。(15) , 17.3 78 260 3 PBIBD2 8.57 6.24 1.30 .87 衰13 大據本+個變數矩陣最大根之估計 取 樣 設 計 平均數 標準差 每一分子的觀察 設 計 低相關高相關低相關高相關 No(Nλ2) NcCNλ1) 1'10 Nv Np VjP 型 態 (rL= .22) (rH = .68) (rL = .22) (rH = .68) 母 數 12.22 28.59 240(45) 240 240 240 10 傳統取樣 7.67 6.33 .96 1.30 108(45) 108 243 486 3 BIBD 7.83 6.05 .70 .47 162(15) 81(30) 108 243 486 3 PBIBD1 7.88 6.07 .78 .52 120(40) 。( 5) 106 240 480 5 PBIBD2 7.63 6.07 .66 .59 54(45) 54 243 810 3 BIBD 8.19 6.10 .75 .59 78(15) 39(30) 52 234 780 3 PBIBD1 8.33 6.20 .80 .64 78(30) 。(15) 52 234 780 3 PBIBD2 7.75 6.03 .72 .52結果比犬樣本更接近母數,雖然還種差異並未達到實質的意義。 討論與結論
項目取樣方法曾被研究者多方探討,並證實對平均數及變異數的估計具有與傳統取樣芳法相同的
良好結果 (C∞k 和 Stufflebeam, 1967; Lord, 1962; Plumlee, 1964; Sh個maker, 1970a; 1970b) 。
Knapp (1968a)更進一步利用平衡不完全區組設計建立取樣架構課討估計問題,本研究利用平衡不
完全區組設計及部卦平衡不完全區組設計建立變數眾麓,探討多變數共變數矩陣之估計,為瞭解估計
結果,乃刺用共變數矩陣的聽個歸納數量,諸如概化變異數 (generalized variance) ,軌跡 (trace)
,和最大棍(largest root) 做為指標。 在變數取樣研究中,由於其設計的特質,首先遭到的一個問題是,變異數和共變數的據本數不一 攘,如果利用部分平衡不完全區組設計建立取樣架構的話,不但變異數與共變數人數不相等,而且共 變數間人數也不相等,甚至有些共變數的人數會等於零,取按人數之決定在變數取樣研究也就居於決 定性地位。本研究在考慮取樣設計時,為便利估計結果之比較,求各設計間變異數之取樣人數相近為 目標,亦即在小樣本中變異數之人數儘可能接近 80人,大樣本接近 240人。如此,則各設計間共變數 之平均人數便有所差別,且與變異數之人數相去頗多,從各表之左半邊可以君到此現象,有些設計共 變數之平均人數只有16個人,也許由此原因,本研究之估計結果偏差相當大,尤以軌跡之估計更是出 乎意外。筆者在1979年會從事相倒之研究,唯在該研究中,取接人數以各設計間共變數取樣人數之相 近為考慮,其結果雖對概化變異數之估計不甚理想,對軌跡與最大根之估計則偏差不大,可見,在設 計變數取按時,位乎應以共變數之人數相近為主。 其次,部分平衡木完全區組設計有共變數漏失之取接設計 (~PPBIBD2) ,本研究中這種取接設計之 估計結果雖與其他設計之結果無甚差異,但它具有一個相當困難的問題,亦即在估計概化變異數與最大 根時,因兩者都必求共變數矩陣之特徵值或行列式,當利用 PBIBD2 設計,某些共變數便無法獲得
,欲求其概化變異數便必先估計這些共變數,本研究使用 Spearman 所提之四分法(包trad method)
'求其所有可能之估計值之平均數來代入這些無法獲得之共變數,因此其概化變異數之估計的可靠性
與正確性便有問題,還是值得考慮的。
最後,共變數矩陣產生負定 (negative definite) 結果,乃變數取樣之一個嚴重問題。筆者在
1979年之研究中,曾有過負定矩陣的結果,此問題在本研究依然存在,可見還是個相當普遍的問題。
Hdsek 與 Siroìnik (1968)' 和 Jacobs 與 Wildeman (1969) 在研究項目取樣對變異數之估計時
,亦報告了這些問題的存在, Sirotnik (1970) 認為當 Cronback 的概化係數 (generalizability coefficient 或稱叫係數)在樣本中小於零便會造成真值估計。筆者曾試過幾種芳法 (Mosteller 和
Tukey, 1968; Bock 和 Vandenberg; 1967) ,但都無法解決此問題,就此而言,以軌跡做為共變數
矩陣的歸納數量可能比概化變異數理想。 本研究揉用變數取樣芳法系統地探討各種可能因素對共變數矩陣的估計。幾種因素中,似乎只有 變數的平均相關對估計產生較犬的影響,其他諸如變數的數目、樣本的大小、變數取樣此率、設計型 態等因素都沒有什麼顯著的影響,此結果與筆者(1979) 之另一研究出入頗多。根接 Lord 和 Novick (1968)的研究,增加受試人數及降低變數取樣比率都會減少估計誤差。 Shoemaker (1970a, 1970) 的研究結果則認為變數取樣比率,樣本數等都對估計沒有什麼教果,主要因素為受試者的總反應數, 文位乎與本研究有所符合,到底事實如何,實有待進一步研究 o 參考書目 吳鐵雄:多變數離散觀念的起源和發展。教育學刑,民69年,第 2 期, 199---229 。
不完整資料對共變數矩陣估計正確性的探討 • 201 • the literature. Journal
01
the A1甜~rican Statistical Association, 1966, 徊, 595-604. Afifi,
A. A. & Elashoff,
R. M. Missing ob記rvations in multivariate statistics II. Pointesti-mation in simple Ii扭曲r regression. ]c帥rnal
01
the American StatisticalAssociati仰., 1967, 62, 10-29.Barcikows隘, R. S. A Monte Carlo study of item sampling (versus traditionaI sampling) for norm construction, Journal of Educational M語asureme甜, 1972, 9, 2ω-214.
Bose, R. C. On the construc位on of balanc吋 incomplete block designs. Annals of Eugeni吭 1939, 9, 353-399.
Bose R. C. Partially balanced incomplete designs with two ass∞iate classes involving only two replications. Calcutta Statistical Associati帥:, 1951, 3, 120-125.
Bose, R. C., Clatworthy, W. H. & Shrikhande, S. S. Tables
01
partially balanæd desig.甜 UJÏth two associate classes. North Carolina Agricultural, ExperimentaI and Statistical Bulletin,
No. 107,
1954.Bose, R. C. & Nair, K. R. Partially balanced incomplete block designs, Sm傲lya, 1939, 也 337-372.
Buck, S. F. A method of estimation of missing values in multivariate data suitable for use with an electronic computer. Journal
01
the Royal Statistical Society, Series B, 1960, 妞, 302-307.Clatworthy
,
W. H. Contributions on partially balanæd incom.ρlete block desig描仰的 two as-sociate classes. National Bureau of Standards Applied Mathematics, Series No, 47, 1956. Clatworthy,
W. H. Tables of two-晶sociate-class partially balanæd 為signs. National Bureauof Standards Applied Mathematics
,
Series 63,
1973.C∞k, D. L. & Stufflebeam
,
D. L. Estimating test norms from variable size item and ex-aminee samples. Educational and P.砂'chologicalMeasurement, 1967, 前, 601-610.C∞ley, W. W. & Lohn倡, P. R. Multivariate data analysis. New York: Wi1ey, 1971. Dawson
,
E. K. The sam.ρlling distribution of the canonical redundancy statistic. Unpublisheddoctoral dissertation
,
University of Illinois at Urbana-Champaign,
1977.Dear, R. E. A principal司 component missing data method lor multiple regression motkls. System Development Corporation, T,前hni臼1 Re伊此 SP-86, Santa Monica, California, 1959. Fisher, R. A. & Yates, F. Statistical tables lor biological, agricultural and medical 1ωarch.
London and Edinburgh: Oliver and Boyd, 1938.
Haitovsky, Y. Missing data in regression analysis. ]c翱翔α101the R,砂al Statistical Socie紗, Series B, 1968, 帥, 67-82.
Hambelton, R.氏, Rovinel日, R., & Gorth, W. P. Elficiency
01
vari伽s item-exami1翩翩mPl2, Center for the Study of Evaluation of Instructional Program, University of California at 10s Angeles
,
December,
1967.Jaco恤, S. S.
& Wildemann
, C. Matrixsamplingwith cl,倒51的m l<叫s: ‘ An 仰~ricalin的tigation. Paper presented at the Annual Conv∞ation of the Educational Research Ass∞ia tion of New York State, November, 1969.
Kai甜r, H. F.
&
Dickman,
K. Sample and population score matrices and sample correlation matrices from an arbitrary population correlation matrix. Psyc.枷netri帥> 1962,訝, 179-182.Knapp. T. R. An application of balanced incomplete block designs to the estimation of test norms. Educational and P.砂'chological Meωurement, 1968, 錯, 265-272, (a).
Knapp
,
T. R. BIBD vs. PBIBD: An examPle01
a priori item sam.ρ'ling. Unpublished manu-犯ri阱, University of Roch臼t肘, Augu鈍, 1968, (b).Kosobud
,
R. A note on a problem caused by assignment of missing data in sample surveys.Econometrica, 1963, 缸, 562-563.
Lord
,
F. M. Estimation of parameters from incomplete da且 Journal 01 伽 A仰'ricanStatistical Associati帥i, 1955,帥, 870-876, (a).
1ord, F. M. Sampling fluctuations resulting from the sampling of test items. P.句IChome
trika, 1955, 20, 1-22, (b).
1ord, F. M. Estimating norms by item sampling. Educational and Psychological
Measure-"卿克 1962, 22, 259-267.
Lord, F. M. ltem samþ伽:gin test theory and in research 品sign. Princeton, N.J.: Educational Testing Service Research Bulletin
,
RB-65-22,
1965.Lord, F. M. & Novick, M. R. Statistical theoriω 0111紹ntal test scores. Reading, Mass: Addison-Wesley, 1968.
M訂甜glia, G. & Bray, T. A. A convenient method for generating normal variables. SIAM Review, 1964, 6, 260-264.
Matthai, A. Estimation of parameters from incomplete data with application to design of sample surveys. Sankhya, 1951, 11, 145-152.
Montanelli, R.位, Jr. An in揖stigation
01
the ~ωdness 01 βt01
the maxil慨m likelihood estimation procedure inlactor
analysis. Unpublished d凹toral dissertation,
University ofIllinois
,
Urbana,
1971.Odell
,
P. 1. & Fieveson,
A. H. A numerical procedure to generate a sample covariance matrix. Journal01
the A1n6rican Statistical Associati,棚:. 1966,缸, 1個-203.Owe帥, T. R. & Stufflebeam
,
D. L. An experimental ∞mpariωn of item sampling and ex-aminee sampling for 臼:tima位ng test norms. fi伽rnal01
Educati伽al Measure1n6耐, 1969,6, 75-83.
P個r叩n, K.
on
lines and planes of closest fit to systems of points in space. PhilosoþhicalMagzi:僻" Series 6, 1901, 2, 569-572.
不完整資料對共變數矩陣估計正確性的探討 • 203 •
01
the American Mathematical Socie紗, 1966,白, 1064-1068.Shoemaker, D. M. Allocation of items and examinees in estimating a norm distribution by item-sampling. fi仰rnal
01
Educational Measurement, 1970, 7, 123-128. (a).Shoemaker, D. M. Item-examinee sampIing procedures and associated standard errors in estimating test p:紅ameters. Journal
01
Educational M翩翩mme耐, 1970, 7, 255-262, (b). Sirotnik,
K. An analysis of variance framework for matrix sampling. Educational andPsychological Measurement, 1970, 30, 891-908.
Tatsuo恤, M. M. An examination
01
t,加 statistical þr椒rlies01
a multivariate measure01
stmngth
01
mlationship. Final Report, Project No. 2-E-020, HEW, 1973.Thompson
,
W. A. The problem of negative estimat臼 of variance components. A仿nals o}Mathematical Statistics, 1962, 詞, 273-289.
Timm, N. H. The estimation of variance-covariance and correlation matrices from incom-plete data. pi.句Ichometrika, 1970, 35, 417-437.
Trawins隘, 1. M. & Bargmann, R. E. Maximum likelih飢渴 estimation with incomplete mul-tivariate data. Annals
01
Mathematical Statiscs, 1964, 訝, 647-657.Wilks
,
S. S. Moments and distributions of estimates of population p:arameters from frag-mentary samples. Annals01
M athematical Statistics, 1932, 3, 163-195, (的.Wilks, S. S. Certain generalizations in the analysis of variances. Biometrika, 1932, 訟, 471-484, Cb).
Wu
,
T. H. TI加 ωtimation01
covariance matrices Irom 砂'stematically i附omplete data. Un-published doctoral dissertation,
State University of New York at Buffalo,
1979.Bulletin of Educational Psychology, 1981, 14, 189-204. Taiwan Normal Unìversìty, Taipeì, Taìwan, Chìna.
THE ESTIMATION OF COV ARIANCE MATRICES ON INCOMPLETE
DATA: AN EMPIRICAL STUDY
TIEH-HSIUNG
Wu
This Monte Carlo study
,
utilizing variable sarnpling approach,
is to systernatically in-vestigate the estimation of covariance matrices from incomplete data. The parameters studied were generalized variance,
trace of a rnatrix,
and the largest root. Five facωrs which related to sarnpling plan were included: number of variables,
average ∞nelation arnong variables, sarnple size, proportion of variable sarnpling, pattern of design. The sam-pling plans were organiz吋 by balanced in∞mplete bl∞k design (BIBD) and partially balanced incomplete bl∞k design (PBffiD). There were 56 condi討ons studied.The results of 的timates were quite biased, especially those of generalized variance.
Some negative-definite rnatrices occured for high correlation rnatrices