股票群的隨機行走模型與內在結構 - 以1996-1999年美國股票S&P500為例之初步分析 - 政大學術集成
66
0
0
全文
(2) Abstract. By means of calculating the correlation matrix of the price of stock and using the results of random matrix theorems,we learned that the stock market does not match the prediction of stochastic processes and the stock-stock is correlated。However, stock’s price log-return changes under long time scale will appear random walk model. Therefore,we propose two kinds of the different coupled random walk model,that try. 政 治 大 coupled random walk model,and using the mean square log-return( MSLR) to 立. to explain the correlation between the stock markets can be integrated into the. investigate this issue。. ‧ 國. 學. Finally,to understand the relationship of correlation matrix and by using it to know the characteristics of the underlying structure of the stock market,we use the. ‧. correlation matrix of the price to construct the minimum spanning tree for analysis。. Nat. sit. y. The results showed that when the time scale is greater, the graphics are more intensive,. al. er. io. and the center is almost the same company,"GE", indicating that the stock market. n. has a certain judgment index。. Ch. engchi. i n U. v. Keyword:correlation matrix,random matrix theorem,coupled random walk minimum spanning tree. 1.
(3) 摘要. 我們從計算股價的相關矩陣,然後利用隨機矩陣定理的結果,了解到股票市 場並非符合隨機過程的預測,進而得知股票對股票之間具有關聯性,然其長時距 下股票價格對數報酬的變化會呈現隨機行走的模式,因此我們對其結果提出二種 不同的耦合隨機行走模型,試圖闡釋股票市場間的關聯性可融合到耦合隨機行走 模型之中,並藉由均方對數報酬(mean square log-return,MSLR)來探討此事情。 最後,為了瞭解關聯性的關係,並利用其來了解股票市場內部結構的特性,. 政 治 大. 因此我們利用股價的相關矩陣來建構最小展開樹進行分析,發現當時間尺度越大. 立. 其圖形越密集,中心幾乎為「GE」這家公司,因此其股票市場具有一定的判斷. ‧. ‧ 國. 學. Nat. y. 指標。. n. al. er. io. sit. 關鍵字: 相關矩陣,隨機矩陣定理,耦合隨機行走,最小展開樹. Ch. engchi. 2. i n U. v.
(4) 目錄 Abstract ..................................................................................................................................... 1 摘要 ........................................................................................................................................... 2 Chapter 1 簡介 ....................................................................................................................... 4 Chapter 2 理論與方法 ........................................................................................................... 8 2.1 隨機行走簡介 ................................................................................................................ 8 2.2 一維隨機行走 .............................................................................................................. 12 2.3 隨機矩陣理論 .............................................................................................................. 17 2.3.1 Wishart matrix 特徵值分布 ................................................................................ 17. 政 治 大. 2.4 耦合隨機行走 .............................................................................................................. 18. 立. 2.4.1 耦合隨機行走模型 I ........................................................................................... 18. ‧ 國. 學. 2.4.2 耦合隨機行走模型 II ......................................................................................... 20 2.5 網路介紹 ...................................................................................................................... 23. ‧. 2.5.1 無尺度網路 .......................................................................................................... 25. y. Nat. sit. 2.5.2 BA 模型 ............................................................................................................... 26. n. al. er. io. 2.5.3 最小展開樹模型 .................................................................................................. 30. i n U. v. Chapter 3 實證分析 ............................................................................................................. 35. Ch. engchi. 3.1 相關矩陣之特徵值分布 ............................................................................................... 35 3.2 耦合隨機行走模型 ....................................................................................................... 37 3.2.1 耦合隨機行走模型 I ............................................................................................ 37 3.2.2 耦合隨機行走模型 II .......................................................................................... 41 3.3 最小展開樹圖形的定量性分析 ................................................................................... 43 Chapter 4 結論 ..................................................................................................................... 62 文獻參考 ................................................................................................................................. 64. 3.
(5) Chapter 1 簡介 金融市場是一種複雜的動力學系統,其性質可以經由連續的紀錄過程來記錄, 其特徵可以由所得的時間序列來描述。對於此類動力學系統,大部分基於實際數 據的研究多聚焦於現象上的解釋,因此數據的分析方法在獲得研究結果與結論的 過程中扮演非常重要的角色,因此選擇不適當的方法可能導致錯誤的結果。 在二次世界大戰之後,開始有大量的物理學家投入華爾街,從事金融相關的 工作,而這些擅長處理複雜多變數系統的物理學家,處理同樣可被歸類為複雜系. 政 治 大 作,並以不同於經濟學的角度來看待金融市場。 立. 統的金融市場,絕對是相輔相成的,同時也可為金融市場開發出一番新的研究工. ‧ 國. 學. 過去,經濟學家的研究多偏重於單一資產價格本身的特性,而對於不同資產 的價格變動中彼此相互的關聯性,則是最近才被經濟學家Engle列為未來研究的. ‧. 方向之一[1],其原因在於探討這樣的問題所遇到的困難是,隨著考慮的資產項. sit. y. Nat. 目增加,其作為計量經濟研究的多變量統計需要有新的說法來提供線索。而面對. io. er. 這樣的問題,物理學家利用多體物理系統的方式來探討問題:對於多體物理系統, 有效掌握系統的方式不再是追蹤個別粒子變動間相互影響的因果關係,而是在考. al. n. v i n Ch 慮整體運動,加上由許多群體模式疊加而成的起伏 e n g c h i 。U對應到金融市場價格的變動, 可經由計算相關係數矩陣的特徵值與特徵向量來分析其起伏變動,其中,每一特. 徵向量含有一種由個別資產(股票)的價格變動所共同構成的模式,而造成整體變 動起伏的原因之一。[2,3,4] 1999年Laloux等人發表Noise Dressing of Financial Correlation Matrices[3]此 篇論文,其計算1991-1996年美國股市S&P500中的406家公司在時間尺度為一天 的相關係數矩陣,而同年,Plerou等人發表Universal and Nonuniversal Properties of Cross Correlations in Financial Time Series[4]這篇論文,其計算1994-1995年價格變 動最大的1000家公司在時間尺度為30分鐘的相關係數矩陣,其兩個團隊均發現在 4.
(6) 相關係數矩陣的特徵值分布中,最大的特徵值均比在股票隨機行走模型下的預測 還要大很多。而其相關係數矩陣中最大特徵值的特徵向量在整個股票市場中具有 相同的趨勢,我們亦稱為是「市場模式」(market mode)。上述這些結果與單純 的隨機行走模型的預測不相符,因此從中我們可以得知股票跟股票之間不是毫無 關係的個體,而是一個具有彼此相互關聯的群體。因此,在2000年Noh發表了 Model for correlations in stock markets[5]這篇論文,提出了一個簡單的模型來描述 金融市場價格變動的型態,亦為第一個對1999年Laloux和Plerou等人的論文提出 一個初步的解釋。. 政 治 大 質系統密度起伏的關聯性常用結構因子來衡量,其亦為將密度起伏的關聯算子由 立 然其計算相關矩陣的物理意涵可由多體物理系統裡的訊息來說明,在液態物. 實體空間轉換到動量空間,成為一個可測量的量[2]。然在股票市場中並無一個. ‧ 國. 學. 實體的空間或其對應的實驗可供參考,但影響股價變動起伏的關聯算子為其相關. ‧. 係數 Cij ,我們可根據本身的結構找出其適當的基底向量,將關聯性以一組新的. sit. y. Nat. 基底來呈現。因此,相關係數矩陣的特徵值相當於結構因子,而其最大的特徵值. n. al. er. io. 所對應的特徵向量,代表系統最顯著的成分。. i n U. v. 由上述可知,影響股價的變動起伏是由相關係數 Cij 所造成的,而相關係數. Ch. engchi. 卻可由其市場背後隱藏的抽象網路所定義的連結來表現它的效應。因此,在長時 間觀察股票市場價格對數報酬的波動現象中,我們可以發現其會有呈現隨機過程 的現象,但並非是整個過程均為是隨機過程,在此我們可從隨機矩陣的特徵值分 布裡看出端倪,其因發現與隨機過程的預測不符,因此我們認為股票與股票之間 必然發生了交互用的現象,因此,在 2004 年 Ma、Hu 和 Amritkar 發表 Stochastic dynamical model for stock-stock correlations[6]這篇論文中,提出了一個新的模型: 耦合隨機行走模型(coupled random walk),在本論文中以「模型 I」來稱呼。其在 隨機行走的過程中,我們將各個行走者(walk)彼此之間建立關聯性,用來模擬真 實股票市場價格變動的狀況。 5.
(7) 而我們的分析發現在均方對數報酬(mean square log-return,MSLR)對時間的 過程中有一亞擴散(subdiffusion)的區段,其原因為可類比於粒子與周遭的粒子在 相互影響的過程中開始與周遭粒子相互作用,讓粒子運動產生了遲滯的效應。在 2013年Ma、Wang、Chen和Hu發表Crossover behavior of stock returns and mean square displacements of particles governed by the Langevin equation[7]此篇論文中, 進一步指出多粒子物理系統與股價變化的相似性,可從MSD和MSLR的分析中了 解,然將粗化後的股市價格變動類比於粒子的位移,故MSLR對時間的變化可用 朗之萬方程式(Langevin equation)的行為來描述,進一步建立起與粒子的相似. 政 治 大 因而我們認為整個股價變動是由彼此的關聯性所影響,故在其真實市場我們 立. 性。. 常可見一個政策,一場暴動,抑或是一個事件潛在性的效益等等均有可能會造成. ‧ 國. 學. 整個市場的變動,而這正是說明了股價彼此關聯性的重要,然而,我們觀察長時. ‧. 間的股票價格的變動中,發現其各種因素雖會造成當下的價格波動,但在一段時. y. Nat. 間之後其彼此相互影響的關係將被遺忘。對此,我們承續在2013年Ma、Wang、. er. io. sit. Chen和Hu發表的論文分析中,對未經粗化的MSLR有段非亞擴散行為的時域做解 釋。而我們發現當模型I的行走者(股票)越來越龐大時,其模型特性無法表現出擴. al. n. v i n 散行為的區段,因此我們認為模型I有其缺陷,故在耦合隨機行走模型中加入一 Ch engchi U 個共同因子的成分[5],其在本論文中我們以「模型II」稱之。其模擬結果亦符合. 金融市場上出現的特徵:在長時距下股票價格對數報酬的變化為隨機過程,而其 短時間交互作用的現象,即產生亞擴散的區段(subdiffusion的現象)亦可從此模型 中預見,因此,我們知道模型II能夠保留股票之間關聯性的現象,又能夠描述在 長時距下股票價格對數報酬變動的隨機過程,故理論模型提供我們更進一步去分 析金融市場的特性,並試著闡述其各種相關的問題。 由上述發現,股票對股票之間的關聯性會影響整個市場價格的變動,而從股 價的變化中,可以我們觀察到許多市場訊息。因此,我們想利用關聯性的分析來 6.
(8) 了解股票市場內部結構的特性。所以我們從1996-1999年美國股市S&P 500中選取 345公司(資料來源:TAQ)來計算金融市場中的關聯性,可以讓我們了解那些公 司或是那些群體在市場上受到較多各方因素的影響,或是具有重要的溝通性,其 可藉由最小展開樹的圖像化來呈現。而我們在8個不同的時間尺度下觀察其圖形 的結果,發現中心大多為「GE」這家公司,這說明了其在整個股票市場上受到 較多因素變動的影響或為各股之間重要的樞紐。然隨這時間尺度的增加,其結構 變得較為密集,不易有零散連結的現象,且中心點也更為顯著,甚至副中心與分 層分群的情形也逐漸顯現。然而在不同的時間尺度下,並非所有的中心都是唯一. 政 治 大. 的,此亦說明了在不同的時間點會有不同的股票公司受到各種因素的影響進而與 其他公司產生關連。. 立. 最小展開樹雖能以最佳的方式在平面上呈現各點之間的關聯性,然因其定義. ‧ 國. 學. 的問題會失去一些市場訊息,故我們將其整個市場資訊利用相關矩陣來表現其各. ‧. 點的關聯強度,並定義4個不同的點計算其各自的4個原級動差[25],其結果發現. y. Nat. 與我們利用最小展開樹所獲得的中心結果非常相近,因此,我們可以知道最小展. n. er. io. al. sit. 開樹對其股票市場具有一定的判斷指標。. Ch. engchi. 7. i n U. v.
(9) Chapter 2 理論與方法 2.1 隨機行走簡介 1827年布朗(Robert Brown)在研究花粉在水中懸浮狀態的微觀行為時,發現 花粉有不規則的運動,而後來他觀察微細顆粒如灰塵也有相同的現象。而西元 1905年愛因斯坦(Albert Einstein)對於其運動形式提出了物理的解釋:利用隨機行 走的模型去描述此種形式的運動[8]。雖然布朗他並沒有能從理論解釋這種現象, 但後來的科學家使用他的名字命名為布朗運動(Brownian Motion)。事實上布朗並 非第一個發現布朗運動者。布朗在提到1819年Bywater 發表的一篇文章時曾說:. 治 政 「不但是有機物質,無機物質也包含他(指 Bywater)所謂活潑的或激應性的粒 大 立 子」 。而科學家發現布朗運動有下列主要特性:(1)粒子的運動由平移及及轉移所 ‧ 國. 學. 構成,顯得非常沒規則而且其軌跡幾乎是處處沒有切線。(2)粒子之移動顯然互. ‧. 不相關,甚至於當粒子互相接近至比其直徑小的距離時也是如此。(3)粒子越小 或液體粘性越低或溫度越高時,粒子的運動越活潑。(4)粒子的成分及密度對其. y. Nat. io. sit. 運動沒有影響。(5)粒子的運動永不停止。[9]. n. al. er. 而在金融上的隨機行走假說是主張價格的變動是隨機性的,不會有系統性的. Ch. i n U. v. 改變。當隨機行走理論成立時,表示金融市場的未來價格無法預測,因此市面上. engchi. 各種基本面分析或技術分析策略,皆無法正確預測未來的價格,換言之,無論採 用何種系統或公式作為投資市場的依據,其所獲得的報酬均值皆不會超過市場的 基準指數。然而從歷史的角度來看,法國數學家 Bachelier (1900)是第一位將布朗 運動量化,且利用隨機行走去描述價格走勢,並建立其數學模型的學者,但他的 說法卻不為當時的人們所接受。他假設價格 S ( ∆ ) = ( S k( ∆∆ ) ) 在瞬間 ∆ , 2∆ , 的表 現為 S k( ∆∆ ) = S0 + ζ ∆ + ζ 2 ∆ + + ζ k ∆. 8. (2.1.1).
(10) 其中 S0 為初始價格, (ζ i∆ ) 為獨立同為二項分佈的隨機變數,且取值在 σ ∆ 及. −σ ∆ 的機率各為 0.5。因此 (2.1.2). E( S k( ∆∆ ) ) = S0 , Var( S k( ∆∆ ) ) = σ 2 ⋅ (k ∆). t 令 k = ,t > 0 以及讓 ∆ → 0,Bachelier 發現 S k( ∆∆ ) 中,取其極限過程為 S = ( St )t ≥0, ∆. 其中 St = lim S ( ∆t ) ∆→ 0. ∆ ∆ . ,在特定的機率下,且有下列表示式: (2.1.3). S= S0 + σ Wt t. 政 治 大 Brownian motion)。此為最早描述價格的模型,雖然其數學性質簡單,但它的缺 立 其中 W = (Wt ) , t ≥ 0 , (W0 = 0 , E(Wt ) = 0 , E(Wt 2 ) = t ) 為標準布朗運動(standard. ‧ 國. 學. 點為價格可能為負值而與實際狀況不相符。[10,11]. 在 1930 年代,一群統計學家對一些財務資料做了實證分析,試圖去了解價. ‧. 格的走勢是否可以預測,然在經由大量數據的統計分析之後,發現一個有趣的結. y. sit. n. al. (2.1.4). er. Sn , 其中 S n 表示在時間 n 時的價格, n ≥ 1 S n −1. io. Rn = ln. Nat. 果為:. Ch. i n U. v. 而 Rn 在此為一獨立的序列。但此結果卻與一般大眾認為價格可經由節奏性,週. engchi. 期性,趨勢性等現象來預測的值觀想法相異,故未能引起廣泛的注意[12,13, 14]。 然而在 1953 年肯德爾(Maurice Kendall)發表分析經濟時間序列第一部分: 價格(The analysis of economic time-series. Part 1. Prices)[15]這篇文章,其想經由 對股票及商品價格的分析來找出其週期性,但在分析實際資料之後,發現這些價 格並無任何節奏性,週期性,趨勢性等現象,進而他發現 Rn = ln. Sn 的行為像是 S n −1. 一隨機行走。也因此產生了隨機行走假說:股票的價格波動是相互獨立的,其複 雜程度趨近於隨機行走。 9.
(11) . 股價對數報酬(Log-Return) 股價對數報酬亦即是在描述股價漲跌變動率的情形。 第 i 家公司在時間 t 的股價對數報酬如下所示:. = ri (t ) log( Pi (t + ∆t )) − log( Pi (t )) ≈ log( Pi (t ) + ∆Pi (t )) − log( Pi (t )) =. ∆Pi (t ) Pt (t ). (2.1.5). Pi :第 i 家公司的股票價格 ∆t :股價對數報酬的時間差. . 政 治 大 股價對數報酬之相關函數(Correlation function) 立. 學. ‧ 國. 變異數(variance):. T. i. t =1. 2. i. ‧. σ i2 = E (ri − ri ) 2 =. ∑ (r − r ) T. io. σ i=. al. ∑ (r − r ). E (ri − ri ) 2 =. t =1. i. T. i. 2. er. T. sit. y. Nat. 標準差(standard deviation):. (2.1.6). (2.1.7). n. v i n 共變異數(covariance):股價對數報酬的共變異數代表不同公司變動的關聯性。 Ch engchi U. 例如:兩變數同時增加或同時減少時共變異數為正值,一增一減時為負值,由此 可知,共變異數為正值時,兩變數間的變化具有同向性,反之,為負值時,變數 間的變化具有反向性。. Cov(ri , rj ) = E (ri − ri )(rj − rj ) = E (ri rj ) − ri rj T. =. ∑ (r − r )(r t =1. i. i. T. 10. j. − rj ) (2.1.8).
(12) 將共變異數除以個別的標準差做歸一化,即為相關函數(Correlation function) T. Cov(r , r ) E (r r ) − r r = Cij = =. T. ∑ (r − r )(r. ∑ (r − r )(r. −r ) =. i i j j i j i j i j = t 1 =t 1. σ iσ j. σ iσ j. T σ iσ j. i. i. T. ∑ (ri − ri )2. j. − rj ). T. ∑ (r. =t 1 =t 1. j. − rj ) 2. (2.1.9). ri :第 i 家公司的股價對數報酬. ri :第 i 家公司的股價對數報酬在長度 T 的平均數 其中 T 為取股價對數報酬後時間序列的長度 相關函數的特性:. 立. 學. ‧ 國. (1) −1 < Cij < 1. 政 治 大. (2) Cij = C ji & Cii = 1. ‧. 股價對數報酬的交叉相關矩陣. y. Nat. io. sit. 股價對數報酬的交叉相關矩陣(cross-correlation matrix):由 N 家公司的股價 對數報酬的相關函數組成一 N × N 的對稱矩陣。. n. al. er. . i n CU . C12 i 1N CC 11 h e ngch C C C 21 22 2 N C= CN 1 CN 2 CNN . 11. v. (2.1.10).
(13) 2.2 一維隨機行走 我們考慮一個簡單的情況,在一維空間作白努利(Benoulli)試驗的隨機行走。 一試驗若滿足(1)試驗的結果可分成互斥的兩部分,這兩部分我們已成功(success) 和失敗(failure)來代表,(2)在此試驗下,成功的機率固定不變,(3)試驗間彼此 獨立。則稱此試驗為白努利試驗[16]。現在我們有一個在直線上做隨機行走的運 動(圖 2.2.1),每次向右 L 單位長度的機率為 p ,向左 L 單位長度的機率為. q (= 1 − p ) ,且每一步 ξi 均為獨立不受任何因素影響的運動,所以每單一步的平 均位移為. 治 政 E (ξ ) = pL + q (− L) = ( p − 大 q) L 立. (2.2.1). i. E (ξi 2 )= pL2 + (1 − p )(− L) 2= L2. (2.2.2). ‧. 故變異數為 Var (ξi ) =E (ξi 2 ) − ( E (ξi )) 2 =L2 − (( p − q ) L) 2. Nat. al. er. io. sit. = L2 (1 − ( p − q ) 2 ) = L2 (1 − p 2 + 2 pq − q 2 ). y. ‧ 國. 學. 其二階原動差(second moment)為. n. = L2 {(1 + p )(1 − p ) + 2 pq − q 2 } = L2 {(1 + p )q + 2 pq − q 2 } = 4 pqL. 2. Ch. engchi. i n U. v. (2.2.3). 若 t 步後,其位置為 X t = ξ1 + ξ 2 + + ξt ,而 t 步後的平均位移為. E( X t ) = E (ξ1 ) + E (ξ 2 ) + + E (ξt ) = tE (ξi ) = ( p − q )tL p=q E (= X t ) ( p − q )tL →0. (2.2.4). 其變異數為 Var ( X t = ) Var (ξ1 ) + Var (ξ 2 ) + + Var (ξt = ) tVar (ξi = ) 4 pqtL2 p=q Var ( X t ) 4 pqtL2 = → tL2. (2.2.5). 如果 p = q ,我們可以發現 E ( X t 2 ) ∝ t1 。 12.
(14) 圖 2.2.1、呈現每一步在位置上隨機行走的過程,此圖告訴我們如果當 t = 6 時,. 政 治 大 其位置為 X ≡ S = 立 2。 t. ‧ 國. 學. 現在我們可以利用二項分布的試行來嚴格計算上面的結果,意即在走了 t 步的過. ‧. 程中,若向右方向走了 k 步,則向左方向必走了 (t − k ) 步,所以 t 步後的位置 (2.2.6). io. sit. y. Nat. X t = kL + (t − k ) L = (2k − t ) L. v ni. (2.2.7). 1. (2.2.8). n. al. er. t t! 藉由相同物排列方法得知,向左向右走法的排列數為 = , k k !(t − k )! 又因二項式定理得知. Ch. engchi U. = ( p + q )t. t . t. ∑ k= p q k =0. k. t −k. . 二項分佈(binomial distribution)[16]的機率密度函數 �. 𝑡!. 𝑃𝑡 (𝑘) = 𝑘!(𝑡−𝑘)! 𝑝𝑘 𝑞 𝑡−𝑘 , 𝑘 = 0,1,2, … … ,𝑡 0. , 𝑜𝑜ℎ𝑒𝑒𝑒𝑒𝑒𝑒. 13. (2.2.9).
(15) 二項分佈的期望值(平均數) t. t. t t! t! k t −k E (k ) ∑ kPt (k ) ∑ k p q k p k qt −k = = = ∑ k !(t − k )! =k 1 k !(t − k )! = k 0= k 0 t t! (t − 1)! k t −k = ∑ = p q tp ∑ p k −1q t − k (k − 1)!(t − k )! = k 1= k 1 ( k − 1)!(t − k )! t. (t − 1)! = tp= p k q t − k −1 tp ∑ k = 0 k !(t − k − 1)! t −1. (2.2.10). 二項分佈的二階動差 E (k (k − 1)) =. t. ∑ k (k − 1) Pt (k=). t. = k 0= k 0 t. k. t −k. 政 治 大. t t! t! p k qt −k = p k qt −k ∑ k !( t k )! ( k 2)!( t k )! − − − k 2 2=. = ∑ k (k − 1). = k. t!. ∑ k (k − 1) k !(t − k )! p q. 立. ‧ 國. 學. t t −2 (t − 2)! (t − 2)! t (t − 1) p 2 ∑ p k −2 qt −k = = t (t − 1) p 2 ∑ p k qt −k −2 − − − − ( 2)!( )! !( k t k k 2)! t k k 2= k 0 =. = t (t − 1) p 2. ‧. E (k 2 ) = E (k (k − 1)) + E (k ) = t (t − 1) p 2 + tp. (2.2.12). n. al. er. io. sit. y. Nat 二項分佈的變異數. (2.2.11). i n U. v. Var (k ) = E (k 2 ) − ( E (k )) 2 = tp (1 − p ) = tpq. (2.2.13). p=q E (= X t ) (2 E (k ) − = t ) L ( p − q )tL →0. (2.2.14). p=q = → tL2 Var ( X t ) E ( X t 2 ) − (= E ( X t )) 2 4 pqtL2 . (2.2.15). 由(2.2.13)結果可知. Ch. engchi. 同理其位置的變異數. 所以如果 p = q ,我們可以發現 E ( X t 2 ) ∝ t1 其結果與白努利分佈一致。. 14.
(16) 一維的隨機行走其現在的位置是由前一步各種可能的情況而來的,即為. P( x, t += ∆t ) pP( x − l , t ) + qP( x + l , t ). (2.2.16). 如果 p = q 以下我們可以就由這個式子來推導出其機率密度函數 P( x, t + ∆t ) − P( x, t ) l 2 P ( x + l ) − 2 P ( x, t ) + P ( x − l , t ) = ∆t 2∆t l2. (2.2.17). 由(2.2.17)可得一擴散方程式的型態. ∂P( x, t ) ∂ 2 P ( x, t ) l2 =D D = , ∂t ∂x 2 2Dt. (2.2.18). D 為常數,則此式為線性微分方程 我們知道傅立葉轉換與逆轉換的型態為. 立. 將微分方程式帶入(2.2.19)中 ∂2 − ikx ( , ) = P k t e dk D ∫−∞ ∂x 2 ∞. 1 2π. P(k , t )e − ikx dk −∞ . ∫. ‧. ∂ 1 ∂t 2π. (2.2.19). 學. ‧ 國. 政 治 大. P(k , t ) = ∞ P( x, t )eikx dx ∫−∞ 1 ∞ P ( x, t ) = P(k , t )e − ikx dk ∫ −∞ 2π . ∞. y. Nat. sit. n. al. er. io. ∞ ∂ P(k , t ) 0 ⇒∫ + Dk 2 P(k , t ) e − ikx dk = −∞ t ∂ . ⇒. Ch. ∂ P(k , t ) = − Dk 2 P(k , t ) ∂t. engchi. i n U. v. (2.2.20). 其解為. P(k , t ) = e − Dk t 2. (2.2.21). 初始條件:當 t = 0 時,其位置在 x = 0 處,即 P(k , 0) = 1 再將其解帶回傅立葉轉換 1 ∞ − Dk 2t − ikx = P ( x, t ) = e e dk 2π ∫−∞. 15. 1 4π Dt. e. − x2 4 Dt. (2.2.22).
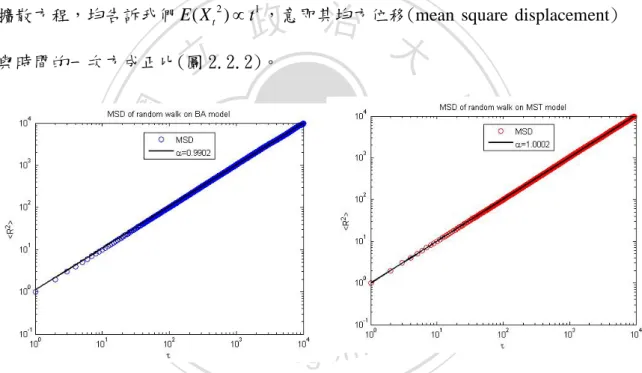
(17) 由(2.2.22)表明,其機率密度分佈是與 t 有關的高斯分佈,隨著 t 的增加,會逐 漸向兩邊擴散。其二階動差為. E( x2 ) =. ∞. x 2 P( x, t )dx 2 Dt ∫=. (2.2.23). −∞. 接著可計算出平均位移與變異數. = E ( x). ∞. xP( x, t )dx ∫= −∞. (2.2.24). 0. Var ( x) =E ( x 2 ) − ( E ( x)) 2 =E ( x 2 ) =2 Dt. (2.2.25). 由上述的計算我們發現不管是白努利試行,二項分佈的隨機行走,亦或是一維的. 政 治 大 與時間的一次方成正比(圖 立2.2.2)。. 擴散方程,均告訴我們 E ( X t 2 ) ∝ t1 ,意即其均方位移(mean square displacement). ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2.2.2、各個行走者彼此獨立的情況下,在 BA 模型與 MST 模型下的隨機行走 由電腦模擬可知其 MSD ∝ t1 。. 16.
(18) 2.3 隨機矩陣理論 隨機矩陣理論(Random matrix theory)已發展了相當長的一段時間,最初是用 來處理多體量子系統的特徵值與特徵函數問題。在 1950 年代,其迅速發展並廣 泛的應用於處理原子核物理的能接問題。. 2.3.1 Wishart matrix 特徵值分布 隨機矩陣理論描述 Wishart matrix 特徵值分布 ρ (λ ; σ 2 ) 如下[17]: 𝑄 �(𝜆𝑚𝑚𝑚 − 𝜆)(𝜆 − 𝜆𝑚𝑚𝑚 ) , 𝜆 ∈ [𝜆𝑚𝑚𝑚 ,𝜆𝑚𝑚𝑚 ] ρ�λ;𝜎 � = �2𝜋 𝜆𝜎 2 0 , 𝑜𝑜ℎ𝑒𝑒𝑒𝑒𝑒𝑒 2. 立. T 1 2 ) , λmin= σ 2 (1 + − ) , Q= + Q Q N Q Q. (2.3.1). 學. ‧ 國. λmax= σ 2 (1 +. 政 治 大 1 2. T:股價報酬時間序列的長度 N:選擇股票公司的個數. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2.3.1、N=345,T=3250 在不同時間序列的變異數下的特徵值的分布 17.
(19) 2.4 耦合隨機行走 從過去的研究讓我們了解到股票價格隨時間的演變並非全然無序的,甚至可 以根據過去的數據對短期的未來做預測,因此,在金融市場裡,藉由分析各股票 價格的起伏,便能夠知道不同股票價格變動的關聯性,並利用這些關聯性來掌握 市場的特性,進而操作獲利。因此我們研究的主題不在是單一資產價格變動的特 性,而是對不同資產價格變動之間的關聯性。 股票對股票之間的相關性是建構在假設股票價格的變動是經由調整個別股 票的預期售價與其相關股票影響性的基礎上,藉此我們使用了一個隨機動態模型. 政 治 大. 來研究我們的課題,其模型我們稱之為:耦合隨機行走(coupled random walk)模. 立. 型[6]。. ‧ 國. 學. 2.4.1 耦合隨機行走模型 I. ‧. sit. y. Nat. 假設我們的模型有 N 個股票(行走者,walkers), xi (t ) , i = 1, 2, N 為在時間. n. al. er. io. t 時第 i 個股票(行走者)的價格(位置), ξi (t ) 是為一序列具有相同分布的隨機亂. i n U. v. 數(而其意涵為未調整的價格變動),而在彼此都沒有關聯性的情形下為簡單的隨 機過程. Ch. engchi. xi (t + 1)= xi (t ) + xi (t ). (2.4.1). 然股票市場的結果卻與單純的隨機行走模型的預測不符,由此可知,其股票市場 彼此之間必有關聯性,因此我們可利用耦合隨機行走模型來描述其市場特性,其 模型 I 定義為[6]. xi (t += 1) xi (t ) + xi (t ) + ε ⋅ ∆( xi (t ) + xi (t )). (2.4.2). ri (t += 1) xi (t + 1) − xi (= t ) xi (t ) + ε ⋅ ∆( xi (t ) + xi (t )). (2.4.3). 18.
(20) ri :為 N 個股票(行走者)的價格變動(位移) xi :為 N 個股票(行走者)的價格(位置). ξi :為未調整的價格變動,隨機噪音(random noise). ε :為耦合常數(coupling constant) ∆ :相當於拉普拉斯算子的對稱矩陣,其作用在引導調整以消除由隨機噪音 ξi 所 產生的不平衡。而所謂股票間的關聯性即是由 ∆ 背後隱藏的抽象網路所定義 的連結來表現它的效應。. 政 治 大. 立. 首先我們對模型 I 做簡單的分析,因我們知道隨機噪音 ξi (t ) , i = 1 , ,N. ‧ 國. 學. 是一獨立且分布相同的隨機變數,故. ‧. )ξ j ( s ) s 2δ ij f (t − s ) , :為求其平均數 , f (0) = 1 ξi (t=. n. al. 使其滿足. 𝜖𝑀 𝑁. ×�. Ch. (1 − 𝑁) , 𝑖𝑖 𝑖 = 𝑗 1. ,𝑜𝑜ℎ𝑒𝑒𝑒𝑒𝑒𝑒. er. io. (Δ𝑀 )𝑖𝑖 =. sit. y. Nat. 而拉普拉斯算子的定義為. (2.4.4). engchi. i n U. v. ∆ M =− ( ε M )( n −1) ∆ M , n > 0 n. (2.4.5). (2.4.6). 因此 t −1. r (t= ) x (t − 1) + ∆ M (1 − ε M )t −1−t0 x(t0 ) + ∆ M ∑ (1 − ε M )t −1− s x ( s ). (2.4.7). s = t0. 當擴展至全體時. ri (t ) = xi (t − 1) + ∑ ∆ M (1 − ε M ) k. t −1−t0. t −1. xk (t0 ) + ∑ ∆ M ∑ (1 − ε M )t −1− s x k ( s ) k. 19. s = t0. (2.4.8).
(21) 所以 t0 = 0 且 xi (t0 ) = 0 ri (t= )rj ( s ) s 2δ ij f (t − s ) t −1 s −1. −ε M ( ∆ M )ij s 2 ∑∑ (1 − ε M )t + s − 2−v − w f (v − w) = v 0= w 0. t −1. + ( ∆ M )ij s 2 ∑ (1 − ε M )t −1−v f ( s − 1 − v) v =0 t −1. + ( ∆ M )ij s 2 ∑ (1 − ε M ) s −1−v f (t − 1 − v). (2.4.9). v =0. 2.4.2 耦合隨機行走模型 II. 政 治 大 在模型 I 裡面我們認為整個股價變動是由彼此的關聯性所影響,故在其真實 立. ‧ 國. 學. 市場我們常常可見一個政策,一場暴動,抑或是一個事件潛在性的效益等等均有 可能會造成整個市場的變動,而這正是說明了股票之間彼此關聯性的重要,而我. ‧. 們在觀察長時間的股票價格的變動中,發現其各種因素雖會造成當下的價格波動, 但在一段時間之後其彼此相互影響的關係將被遺忘,形成隨機過程的型態。然而. Nat. sit. y. 我們發現當模型 I 的行走者(股票)越來越龐大時,其模型特性無法表現出擴散行. al. er. io. 為的區段,對應於股票市場即我們無法預見在長時距下股票價格對數報酬的變化. n. 為隨機過程,因此,我們對模型 I 的部分做其修正,將一共同影響的因子 β ⋅ ξ 0 (t ). Ch. engchi. 加入其模型中,然其參數將修正為. i n U. v. ξi ' (t= ) ξi (t ) + β ⋅ ξ 0 (t ) , 而 β ⋅ ξ 0 (t ) 為共有的影響因子. (2.4.10). 因此,模型 II 為 xi (t += 1) xi (t ) + xi ' (t ) + ε ⋅ ∆ ( xi (t ) + xi ' (t )). (2.4.11). ri (t += 1) xi (t + 1) − xi (= t ) xi ' (t ) + ε ⋅ ∆( xi (t ) + xi ' (t )). (2.4.12). ri :為 N 個股票(行走者)的價格變動(位移) xi :為 N 個股票(行走者)的價格(位置). ξi ' :為未調整的價格變動,隨機噪音(random noise) 20.
(22) ε :為耦合常數(coupling constant) ∆ :相當於拉普拉斯算子的對稱矩陣,其作用在引導調整以消除由隨機噪音 ξi 所 產生的不平衡。而所謂股票間的關聯性即是由 ∆ 背後隱藏的抽象網路所定義 的連結來表現它的效應。. 相同的,我們也將對模型 II 做簡單的分析,從模型 I 的分析中我們知道 )ξ j ( s ) s 2δ ij f (t − s ) , :為求其平均數 ξi (t=. (2.4.13). 然我們對價格波動作修正, ξi ' (t= ) ξi (t ) + β ⋅ ξ 0 (t ) ,而 β ⋅ ξ 0 (t ) 為共有的影響因子 因此. 立. 政 治 大. ξi (t )ξ j ( s ) =ξi (t )ξ j ( s ) + β ξ 0 (t )ξi ( s ) + β ξ 0 (t )ξ j ( s ) + β 2 ξ 0 (t )ξ 0 ( s ) '. 學. ‧ 國. '. = s 2 (δ ij f (t − s ) + β 2 f (t − s ) ). ‧. =s 2 (δ ij + β 2 ) f (t − s ). al. er. io. sit. y. Nat. 所以. t −1. n. r (= t ) x ' (t − 1) + ∆ M (1 − ε M )t −1−t0 x(t0 ) + ∆ M ∑ (1 − ε M )t −1− s x ' ( s). Ch. ri (t ) = xi (t − 1) + ∑ ∆ M (1 − ε M ) '. k. (2.4.14). engchi. t −1−t0. i n U. s = t0. v. t −1. xk (t0 ) + ∑ ∆ M ∑ (1 − ε M )t −1− s x k ' ( s ) k. (2.4.15). (2.4.16). s = t0. 故 ri (t )rj ( s ) =s 2 (δ ij + β 2 ) f (t − s ) t −1 s −1. −ε M ( ∆ M )ij s 2 ∑∑ (1 − ε M )t + s − 2−v − w f (v − w) = v 0= w 0. t −1. + ( ∆ M )ij s 2 ∑ (1 − ε M )t −1−v f ( s − 1 − v) v =0 s −1. + ( ∆ M )ij s 2 ∑ (1 − ε M ) s −1−v f (t − 1 − v) v =0. 21. (2.4.17).
(23) 因此我們將計算其均方位移(MSD) t +t. ∑. t +t. ri (t ' )ri (t '' ) ∑=. t' = t +1 t '' = t +1. t +t. t +t. ∑ ∑σ. 2. t' = t +1 t '' = t +1 t +t. −∑. (1 + β 2 )δ t 't ''. t +t. ∑ ε (∆ ) M. M. t' = t +1 t '' = t +1. + ( ∆ M )ii σ 2. t +t. ii. σ. min( t ' ,t '' ) −1 2. ∑ v =0. t +t. ∑ ∑ (1 − ε. t' = t +1 t '' = t +1. '. ''. )|t −t | + δ t 't '' '. M. (1 − ε M )t +t − 2− 2 v ''. (2.4.18). 而我們從 MSD 式子中,在長時間過後,含有時間 τ 的部分求算出來. ( ∆ M )ii 2 ( ∆ M )ii (1 − ε M ) 2 ( ∆ M )ii 2 2 τ + σ τ + σ τ εM − 2 ε M (ε M − 2) εM . σ 2 (1 + β 2 )τ + σ 2 . ‧ 國. 立. 2 σ τ . 學. ( ∆ M )ii =1 + β 2 + εM . 政 治 大. (2.4.19). 由(2.4.19)發現在長時間下其 MSD 為時間 τ 的一次方。. ‧ y. Nat. ri (t ' )ri (t '' ) = σ 2 (1 + β 2 +. al. n. t' = t +1 t '' = t +1. +. ∆M. εM. )t. er. t +t. io. t +t. ∑∑. sit. 而其整體 MSD 為. i n U. v. C−hε M ) + 2(1 − ε M )τ +1 2 ε M − 1 −2(1 e n2g c h i σ (∆ M )ii εM − 2 εM. (1 − ε M ) − [ (1 − ε M )ε M − 2(1 − ε M )(ε M − 2) − 2(1 − ε M ) ] (ε M − 2) 2 ε M 2 +2 2(1 − ε M )τττ (ε M − 2) + 2(1 − ε M ) 2 + 2 − (1 − ε M ) 2 + 2 ε M + (ε M − 2) 2 ε M 2 . ×σ 2 (∆ M )ii (1 − ε M ) 2τ. (2.4.20). 22.
(24) 2.5 網路介紹 最早研究關於圖論的資料是柯尼斯堡七橋問題,亦為網路的起源[18]。. 圖 2.5.1、柯尼斯堡七橋問題的示意圖 雖然當時為了解決如何一次走遍七座橋,而且每座橋只經一次,最後又能返回起. 政 治 大. 點,然而這件事卻和管理科學中的最佳化問題有著密切的關連性(這其中包含要. 立. 讓你的收益最大或支出最少的問題)。舉例來說,如何讓郵差、水電(或瓦斯). ‧ 國. 學. 的抄表員或清潔車最有效率地完成工作?以郵差送信的問題來說,達成目的的方 法是要設計一個路徑,讓郵差由所屬的郵局出發,走過需要經過的每一條街,而. ‧. 且盡量避免經過同一條街兩次,最後再回到郵局。. Nat. sit. y. 自從尤拉(Euler)在 1736 年曆用途的模型解決了七橋問題之後,從此圖形理. n. al. er. io. 論便開始成為數學的一個主要領域,並且也帶動了計算機科學、生物學、社會學. i n U. v. 或經濟學等等之類學科的發展。好比是生態網路(Ecological webs),軟體地圖. Ch. engchi. (software maps),基因圖組(Genomes),大腦網路(Brain networks)[19]或是網 際網路架構網(Internet Architectures),這些應用皆代表網路在現代科學中是 相當重大的發明。而網路的廣義定義是,相互不同的物件,透過共同特性或特定 標準將彼此相連,整個物件之連結的集合就稱之為網路。. . 網路結構(network structure) 定義圖形 G = (V, E),V 是點(vertices,nodes,points)的集合,E 是線(edges,. arcs,lines)的集合。. 23.
(25) 圖 2.5.2、基本的網路結構 G = (V,E) V = {1,2,3,4} . E = {a,b,c,d} = { (1,2),(1,3),(2,3),(3,4)}. 政 治 大 為了利用電腦來解決圖形問題,我們必須要將圖形儲放在記憶體裡,因此我 立 鄰接矩陣(adjacency matrix). 們須考慮將圖形網路表示成一種資料結構的型態,而鄰接矩陣 A 即是一種非常. 1 ,如果節點𝑖與節點𝑗有相連結 0 ,𝑜𝑜ℎ𝑒𝑒𝑒𝑒𝑒𝑒. y. Nat. 𝐴𝑖𝑖 = �. n. er. io. . 0 1 1 0 CAh= 1 0 1 0 e1n 1g c0 h1i 0 0 1 0. sit. 圖 2.5.2 中的圖形表示成鄰接矩陣的型態為. al. ‧. ‧ 國. 學. 好的結構型態的表現。. i n U. v. 度(鄰居數)(degree) 最基本的網路研究通常從如何去描述網路開始,這些描述的指標包含了點的. 數目和線的數目去描述一個網路的大小(network size)。然而這些資訊是不足於 描述一個網路的結構(network structure),而描述一個網路的結構,我們必須要 了解每個點是如何與其他點連接的,即是了解每個點它的鄰居數 ki (degree),而 它能利用鄰接矩陣來告訴我們。. 24.
(26) n. ki = ∑ Aij. (2.5.1). j =1. 我們知道鄰接矩陣是對稱矩陣,若對鄰接矩陣求其平方之後的結果為何呢?. A112 + A12 2 + + A1N 2 A2 = . A + A22 + + A2 N 2 21. 2. 2. 2 2 2 AN 1 + AN 2 + ANN . (2.5.2). 政 治 大 為 ∑ A ,而其結果等同於degree。這性質我們接下來將可以應用在相關矩陣轉 立 因鄰接矩陣為0與1的對稱矩陣,所以平方之後其對角線的結果可以讓我們表示成 n. j =1. ij. ‧. ‧ 國. 學. 換成距離矩陣後其各點關聯性的大小。. 2.5.1 無尺度網路. y. Nat. io. sit. 「無尺度」(scale free)網路是指在一網路連結的架構中,大部分的節點(node). n. al. er. 擁有少數的連結數(degree),但有些集散點的連結數卻多到沒有限制,即為冪次. Ch. i n U. v. (power law)現象,因此,在無尺度網路中,新節點出現時,往往會與連結性較高. engchi. 的節點相連,也因此種連結特性,使得大部分的無尺度網路也是小世界網路。 無尺度網路是圖論裡一個重要的概念,其特點是網路中的絕大部分節點指和 很少量的其他節點相連,而極少數的節點和大量的其他節點相連,這一特點令無 尺度網路擁有幾個優勢:一,穩定可靠,即使多達 80%的隨機節點因為故障無法 工作,整個網路也不會癱瘓;不過,萬一中樞節點出現故障,整個網路就會癱瘓。 二,小世界網路特性(small world property),任何節點只需要經過少量節點就可到 達任何其他節點。 目前已有很多研究顯示,在許多真實世界所存在的統計現象,都會呈現無尺 度現象或是後尾分布(heavy tail distribution),像是 WWW 網頁的連結分布或是電 25.
(27) 子信箱各帳號之間相互傳遞信件的情形都會有上述現象的產生。以下我們將介紹 一個典型無尺度網路的模型:BA 模型。. 2.5.2 BA 模型 Albert-László Barabási 與 Réka Albert 在 1999 年的論文[20]中提出了一個模 型來解釋複雜網路(complex network)的無尺度特性,稱為 BA 模型。這個模型基 於兩個假設: (1)增長模式:不少現實網路是不斷擴大不斷增長而來的,例如網際網路中. 政 治 大. 新網頁的誕生,人際網路中新朋友的加入,新的論文的發表,航空網路中新機場. 立. 的建造等等。. ‧ 國. 學. (2)優先連接模式:新的節點在加入時會傾向於與有更多連接的節點相連接, 例如新的論文傾向於引用已被廣泛引用的著名文獻,新機場會優先考慮建立與大. ‧. 機場之間的航線等等。. sit. y. Nat. 在這種假設下,BA 模型的具體構造為:. n. al. er. io. (1)增長:從一個較小的網路 G0 開始(這個網路有 n0 個節點, m0 條邊),逐 步加入新的節點,每次加入一個。. Ch. engchi. i n U. v. (2)連接:假設原來的網路已經有 n 個節點(𝑠1 ,𝑠2 , … . . . ,𝑠𝑛 )。在新增一. 個節點sn+1時,從這個新節點向原有的 n 個節點連出 m ≤ m0 個連結。. (3)優先連接:連接方式為優先考慮高連結數(degree)的節點。對於某個原有 節點𝑠𝑖( 1 ≤ i ≤ n ) ,將其在原網路中的度數(degree)記作 ki ,那麼新節點與之相連 的機率為 Pi , Pi =. n. ki. ,其中 ∑ k j 為在意時間點所有節點的連接數的總和。. n. ∑k j =1. j =1. j. 如此,在經過 t 次之後,得到的新網路有𝑛0 + 𝑡個節點,一共有 m0 + mt 條邊。. 而現在我們考慮一個節點 i 在時間 t 之後連接數對 t 的函數用 k (i, t ) 表示,所以 26.
(28) k (i, t + 1) = k (i, t ) + p (i, t )k (t + 1, t + 1). (2.5.3). 這裡. k (t + 1, t + 1) = m. (2.5.4). 顯示在 t + 1 時間新加入節點的 degree,也是這新節點要連到舊節點上的連接數。. p (i, t ) =. k (i, t ). (2.5.5). t. ∑ k ( j, t ) j =1. 表示新節點中的任一條邊連到舊節點 i 的機率。 我們可以將其改寫成. k (i, t ). k (t + 1, t + 1) 治 政 ∑ k ( j, t ) 大. k (i, t + 1) = − k (i, t ). 立. (2.5.6). t. j =1. t. 學. ‧ 國. 同時對等式兩邊做求和計算. t. ∑ k (i, t + 1) − ∑ k (i, t ) = k (t + 1, t + 1). (2.5.7). =i 1 =i 1. ‧. 利用(2.5.7),藉由遞迴關係可得 t −1. y. Nat. k (t , t ) + ∑ k (i, t ). =i 1 =i 1. = k (t , t ) + k (t , t ) + ∑ k (i, t − 1). er. io. t −1. sit. t. (i, t ) ∑ k=. al. n. i =1. Ch. t. k (i, i ) e=n2∑ gchi i =1. i n U. v. (2.5.8). 將. k (i, i ) = m , i ≠ 0. (2.5.9). 帶回(2.5.8)可得 t. ∑ k (i, t ) = 2mt. (2.5.10). i =1. 由(2.5.6)與(2.5.10)可得. (i, t ) k (i, t + 1) − k=. mk (i, t ) k (i, t ) = 2mt 2t. 因 t >> 1 ,所以 27. (2.5.11).
(29) ∂k (i, t ) k (i, t ) = ∂t 2t. (2.5.12). 起始條件為: t = ti , k (i, ti ) = m ,可解得. t k (= i, t ) k= m i (t ) ti . 0.5. (2.5.13). 由(2.5.13)可知新節點增長的速度遠慢於舊節點,所以在單位時間 ki (t ) < k 因此 t 0.5 m 2t m 2t p [ ki (t ) < k ] =p m < k =p (ti > 2 ) =1 − p (ti ≤ 2 ) k k ti . (2.5.14). 政 治 大 如果我們在這個網路系統中,新加入一個節點的時間區間是一樣的,那我們可以 立 1 ,並將其帶回(2.5.14)中,可得. ‧ 國. (2.5.15). y. n. al. ∂p [ ki (t ) < k ] 2m 2t 1 = ⋅ m0 + t k 3 ∂k. Ch. engchi. p(k ) ≈. 2m 2 ≈ k −3 3 k. sit. io. = p(k ). 當時間夠久之後. ‧. Nat. 所以. m 2t p [ ki (t ) < k ] =1 − 2 k (m0 + t ). er. m0 + t. 學. 發現 p (ti ) =. i n U. v. (2.5.16). (2.5.17). 由 (2.5.17) 我 們 可 知 BA 模 型 當 時 間 就 久 之 後 , 其 網 路 會 呈 現 出 冪 次 現 象. p (k ) ≈ k −γ 其 γ 會近似 3。這式子也顯示了 degree 高的點出現的機率非常的小, 而大部分的點的 degree 會集中在比較小的範圍內(圖 2.5.3),在現實生活中也 可以用這個結果來解釋小地震發生的頻率非常的高,而大地震發生的頻率很稀少, 但還是會發生。. 28.
(30) 立. 政 治 大. ‧ 國. 學 ‧. 圖 2.5.3、無尺度網路具有冪次現象其 γ 介於 2~3 之間. y. Nat. er. io. sit. 本論文以起始網路為 4 個節點,4 條邊,每新增一個節點給予 2 條邊的連結 方式來建立 BA 模型。而我們以美國股市 S&P500 中資料數較為齊全的 345 家公. n. al. i n 司的參數為標準,建立節點大小為 C h 345 的 BA 模型。 engchi U. v. 圖 2.5.4、BA 模型的簡單起始模型 29.
(31) 2.5.3 最小展開樹模型 最小展開樹的定義,在 N 個節點的複雜網路中,我們取 N-1 條不會構成迴 圈的連線來連結所有的節點,此種圖形稱為展開樹。而在所有展開樹中,邊長(權 重)的總和為最小的展開樹,稱為此圖形為 N 個節點的最小展開樹。因此我們從 定義知道,最小展開樹的總連接數(degree)為 2(N-1),故平均的連接數 2(N-1)/N ~ 2,且圖形無迴圈的緣故,導致群聚係數為零,所以可以從最小展開樹的圖形及 冪次法則(power law),來研究最小展開樹的圖形結構。 最小展開樹的演算法. 政 治 大. 以下將介紹兩種常見的演算法[21,22,23]. 立. (1)Kruskal 演算法(圖 2.5.5). ‧ 國. 學. 此演算法可在 n 個節點的加權圖 G 中找出最小展開樹的圖形,其中 n ≥ 2 , 且 S 和 T 為 G 邊集合。. ‧. 步驟 1:(a) T = φ. Nat. sit. y. (b) S 為 G 所有邊的集合,並 S 將內所有的連結由小到大做排序。. n. al. er. io. 步驟 2:while | T |< n − 1 & S 不為空集合. i n U. v. (a)從 S 中選擇一個權重為最小的邊 e (若權重相同時,可任意挑. Ch. engchi. 選其中任何一個). if e 與 T 內的任何邊不會使圖形產生迴圈 (b)將 e 加到 T 中 (c)從 S 中移除 e else (d)回到(a)重新挑選新的邊 e ' ( e < e ' ≤ S − {e} ) end end. 30.
(32) 步驟 3:if | T |< n − 1 G 沒有做小展開樹,因為此加權圖不是連通圖. else. T 的邊與其伴隨的頂點形成一個最小展開樹 end. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 2.5.5、Kruskal 演算法的示意圖. n. al. (2)Prime 演算法(圖 2.5.6). Ch. engchi. i n U. v. 此演算法中,T 是一組用來收集最小展開樹邊的集合,U 是伴隨 T 而來的節 點集合,V 是加權圖 G 中所有節點的集合,由此方法可在 n 個節點的加權圖 G 中 找出最小展開樹的圖形。 步驟 1:在加權圖 G 中任意選取一個頂點 v0 , {v0 } ∈ V 令 {v0 } = U , T = φ , V= V − {v0 } 步驟 2:while | U |< n. 31.
(33) (a)選取 = eij ' min(dij | ∀vi ∈ U , v j ∈ V ) 的邊上的節點相連(若權重相 同時,任意挑選其中任何一個) if v j 與 U 內的任何邊不會使圖形產生迴圈 (b)將 v j 加到 U 中 (c)從 V 中移除 v j (d)再將 eij ' 加到 T 中 else. 政 治 大. (e)回到(a)重新挑選新的節點 v j ' ( v j ' ∈ V − {v j } ). 立. end. 步驟 3:if | U |< n. y. sit. io. er. else. Nat. G 沒有做小展開樹,因為此加權圖不是連通圖. ‧. ‧ 國. 學. end. T 的邊與其伴隨的頂點 U 形成一個最小展開樹. n. al. end. Ch. engchi. 32. i n U. v.
(34) 政 治 大 圖 立2.5.6、Prime 演算法的示意圖. ‧ 國. 學. Kruskal 演算法與 Prime 演算法雖然方法不同,但其計算效率相近且結果也. ‧. 幾乎相同,不過當在某些特殊狀況下,相同的資料會出現不同的 MST 圖形,其. sit. y. Nat. 原因為不同的邊具有相同權重,然圖形最終所有連接的邊上的權重和是不變的. n. al. er. io. (其值為最小),本論文將權重取至小數點後 8 位,可避免出現上述現象。. . 定義 MST 網路上的權重. Ch. engchi. i n U. v. 為了瞭解股票市場中股價的互動性,所以我們計算了股價報酬率的相關係數 Cij ,利用其來描述個股票間報酬的關聯性,而因為相關係數 Cij 介於 ±1 之間,其. 數值越大代表關聯性越強,轉換為空間上的表現,可視為距離越近,因此可藉由 相關係數來定義各股票間的距離 dij ≡ 2T (1 − Cij ) [24]。以下我們將介紹如何利 用股票對數報酬來定義網路上的權重。 首先我們先定義兩個 T 維度的時間序列空間 ri、rj ,ri 和 rj 均為是一組向量, 並對 ri 和 rj 做歸一化動作得 X i 、Y j ,而我們知道 X i 和 Y j 向量的餘弦值為 cos θij , 33.
(35) 其餘弦值即為 ri 和 rj 向量的相關係數。. ri (t ) = ( x1 , x2 , , xT ). (2.5.18). rj (t ) = ( y1 , y2 , , yT ) Xi =. ri (t ) − ri (t ). σi. T. ∑(. X i ⋅Yj cos θij = = | X i || Y j |. ∑(. rj (t ) − rj (t ). ss i j. ri (t ) − ri (t ). T. =t 1 = t 1 i T. =. ). rj (t ) − rj (t ). ∑( ss )2. (2.5.19). σj. ri (t ) − ri (t ) rj (t ) − rj (t ). t =1. T. Yj =. 與. )2. j. 政 治 大. (ri (t ) − ri (t ))(rj (t ) − rj (t )) ∑ t =1 = Cij. 立 T. T. j. j. 2. ‧. ‧ 國. 2 i i =t 1 =t 1. 學. ∑ (r (t ) − r (t )) ∑ (r (t ) − r (t )). = X i 是 ri 歸一化後的向量, Y j 是 rj 歸一化後的向量,所以 | X i |. = T | Yj |. y. Nat. er. io. sit. X i 與 Y j 兩向量的距離為 dij. dij 2 =| X i − Y j |2 =| X i |2 + | Y j |2 −2 | X i || Y j | cos θij =2T (1 − Cij ). al. n. dij =. (2.5.20). 2T (1 − Cij ). Ch. engchi. 34. i n U. v. (2.5.21).
(36) 實證分析. Chapter 3 3.1 相關矩陣之特徵值分布. 在相關係數矩陣中,我們先將數列作歸一化,其變異數 σ 2 = 1 ,從 Wishart matrix 特徵值分布得知 ρ (λ ) 如下: 𝑄 �(𝜆𝑚𝑚𝑚 − 𝜆)(𝜆 − 𝜆𝑚𝑚𝑚 ) , 𝜆 ∈ [𝜆𝑚𝑚𝑚 ,𝜆𝑚𝑚𝑚 ] ρ(λ) = �2𝜋 𝜆 0 , 𝑜𝑜ℎ𝑒𝑒𝑒𝑒𝑒𝑒. λmax = (1 +. T 1 2 1 2 ) , λmin = (1 + − ) , Q= + Q Q N Q Q. T:股價報酬時間序列的長度. 立. N:選擇股票公司的個數. (3.1.1). 政 治 大. ‧ 國. 學. 我們由美國股市 S&P500 中選取 345 家股票公司在 1998 年的 30 分鐘價格對. ‧. 數變動,即為時間尺度為 30 分鐘的對數報酬,並計算其相關係數矩陣 C 的特徵. sit. y. Nat. 值,而其獲得的特徵值分布特性為:一大塊連續分布的特徵值(圖 3.1.1 藍色)與. io. er. 遠大於這些的特徵值(圖 3.1.2(左))。而最大的特徵值其特徵向量均為同號(圖. al. n. 3.1.2(右)),亦被稱為「市場模式」,然其這些結果與單純的隨機行走模型的預測. i n C 不符,故我們可以發現其股票市場並非是隨機的[6]。 hengchi U. 35. v.
(37) 立. 政 治 大. ‧ 國. 學. 圖 3.1.1、真實市場數據與隨機理論下的特徵值的分布. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.1.2、(左)為 1998 年/30min 的特徵值後半部的分布。(右)為其最大特徵值 的特徵向量,發現其均為同號,代表具有共同的市場模式。. 36.
(38) 3.2 耦合隨機行走模型 3.2.1 耦合隨機行走模型 I 在其模型 I 中 xi (t += 1) xi (t ) + xi (t ) + ε ⋅ ∆( xi (t ) + xi (t )) ,我們知道若沒有關聯 結構的影響下,其價格變化的均方位移(MSD)服從簡單隨機行走模型(圖 3.2.1). 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.2.1、無耦合常數模型時價格的均方位移(MSD)服從簡單隨機行走模型 在長時間觀察股票市場價格的波動現象中,我們可以發現其會有呈現隨機過 程的現象,但並非是整個過程均為是隨機過程(圖 3.2.5),這部份我們其實可從 隨機矩陣的特徵值分布裡看出端倪(圖 3.1.1),因其中發現與隨機過程的預測不 符,因此我們認為股票與股票之間必發生了彼此互作用的影響,因此,我們提出 了耦合隨機行走模型 I,其在隨機行走過程中加入了關聯結構,將各個行走者彼 此之間建立關聯性,用來模擬真實的股票市場狀況,而其模擬結果出現了一亞擴 散(subdiffusion) 的區段(圖 3.2.2),其原因為可看作是粒子與周遭的粒子在相互影 37.
(39) 響的過程中,其開始與周遭粒子作用,讓粒子運動產生了遲滯的效應,因而出現 亞擴散的現象。. subdiffusion. 立. 政 治 大. ‧ 國. 學. 圖 3.2.2、金融市場其經粗化的 MSLR 可用 Langevin equation 描述 (Ma、Wang、Chen and Hu , 2013). ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.2.3、模型 I 在充分連結模型下對不同的耦合常數解析解的結果 38.
(40) 學 圖 3.2.4、1996 年 3 月真實市場的 MSD. ‧. ‧ 國. 立. 政 治 大. sit. y. Nat. 由此解析解可知,當耦合常數越大,其粒子之間的關聯性越強,其發生亞擴. al. er. io. 散的時間就越早(圖 3.2.3)。而圖形前段部分的行為,即未進入亞擴散區段的部分,. v. n. 其原因類比於粒子在發生關聯之後並不會馬上產生大幅度的變動,對應於金融市. Ch. engchi. i n U. 場可知,股票與股票之間發生關聯後,並不會立即發生大幅度的變化,而是以一 種漸進的方式演變。而我們發現模型 I 在充分連結(平均場,mean field)的網路結 構中,其長時距下的均方位移具有擴散的現象,亦即在長時間下具有隨機過程(圖 3.2.3),與真實市場在長時距下股票價格對數報酬的變動為隨機過程(圖 3.2.4)的 結果相符合,其原因可類比粒子在長時間下彼此相互影響的關聯性被遺忘,形成 簡單的隨機運動。. 39.
(41) 政 治 大. 圖 3.2.5、模型 I 在 mean field 模型與 BA 模型下對不同的耦合常數模擬的結果. 立. ‧ 國. 學. 從模擬結果發現充分連結(平均場,meanfield)的均方位移進入亞擴散區段的 時間較 BA 模型快,其可知充分連結的網路結構其關聯性較 BA 模型的網路結構. ‧. 強,故發生交互作用的時間較早。. sit. y. Nat. 2004 年 Ma、Hu 和 Amritkar 發表的論文結果發現,其在充分連結的網路結. io. al. n. 果較為符合。. er. 構,耦合常數為𝜖=0.8 以此計算均方位移,與真實市場的均方對數報酬的型態結. Ch. engchi. 40. i n U. v.
(42) 3.2.2 耦合隨機行走模型 II 然而我們發現當模型 I 的行走者(股票)變得很龐大時,其模型特性較無法呈 現出擴散行為的區段,對應於股票市場即我們無法預見在長時距下股票價格對數 報酬的變化為隨機過程(圖 3.2.6)。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n C h I 在不同 n 值下的結果 圖 3.2.6、模型 engchi U. 因此,我們對模型 I 的部分做其修正,將一共同影響的因子 β ⋅ ξ 0 (t ) 加入其模型 中,然其參數將修正為. ξi ' (t= ) ξi (t ) + β ⋅ ξ 0 (t ) , 而 β ⋅ ξ 0 (t ) 為共有的影響因子 其修正後的模型為 xi (t += 1) xi (t ) + xi ' (t ) + ε ⋅ ∆ ( xi (t ) + xi ' (t )) ri (t += 1) xi (t + 1) − xi (= t ) xi ' (t ) + ε ⋅ ∆( xi (t ) + xi ' (t )). 41. (3.2.1).
(43) 立. 政 治 大. ‧ 國. 學 ‧. 圖 3.2.7、模型 II n=15000 在不同的 β 值下的結果. y. Nat. sit. 由圖 3.2.7 發現,當加入了一外在共同影響的因子後,其結果保留了彼此互. n. al. er. io. 作用影響,又能讓我們看見在長時距下隨機過程的現象。. Ch. engchi. 42. i n U. v.
(44) 3.3 最小展開樹圖形的定量性分析 最小展開樹(MST):其意涵為把所有的連接點以線相連而使其網路上權重總 和(距離)為最小,但不能有迴圈的存在。這樣的樹狀圖可以以平面的方式呈現出 其各點的相關程度,雖然無法完全呈現所有點之間的關聯性,不過這卻是一個能 以較佳的方式呈現股票分類的狀況與其關聯強度,意為能對股票之間的關係做一 個簡單的說明。我們以下將部分呈現美國股市 S&P500 中資料數較為齊全的 345 家公司在不同時間尺度 36 秒、72 秒、3 分鐘、6 分鐘、468 秒、15 分鐘、30 分 鐘、78 分鐘下的最小展開樹圖形。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.3.1、時間尺度為 36 秒的 MST 圖形,其中心為「T」這家公司(紅色部分). 43.
(45) 政 治 大. 立. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 3.3.2、時間尺度為 36 秒的 MST 圖形,其中心為「MXIM」這家公司. n. al. Ch. engchi. i n U. v. 時間尺度為 36 秒的 MST 圖形其資料數有 144 筆 中心. T. 次數 12.5%. MXIM 7.6%. LTD. CSX. BSX MER BMY. 4.9% 4.9% 4.1% 4.1%. STI. 4.1% 3.5%. HBAN … 3.5%. …. 在時間尺度為 36 秒的 MST 圖形中,取其中心次數最多的前兩名來代表。從 圖形中可發現除中心之外並無出現副中心的現象,即使是中心的部分也沒有非常 集中的趨勢,這可以說明在這時間尺度下彼此的關聯性較為平均。. 44.
(46) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.3、時間尺度為 72C 秒的 MST 圖形,其中心為「NSC」這家公司 hengchi U. 45.
(47) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 3.3.4、時間尺度為 72 秒的 MST 圖形,其中心為「WFC」這家公司. n. al. Ch. engchi. i n U. v. 時間尺度為 72 秒的 MST 圖形其資料數有 31 筆 中心. NSC. WFC. FRE. GE. BAC. 次數 25.8% 16.1% 12.9% 9.7% 9.7%. CI. PG. 6.5% 3.2%. AIG. MER. …. 3.2%. 3.2%. …. 在時間尺度為 72 秒的 MST 圖形中,取其中心次數最多的前兩名來代表。從 圖形中可發現除中心之外並無出現副中心的現象,然中心點開始慢慢有集中的趨 勢了。. 46.
(48) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.5、時間尺度為 3 分鐘的 C h MST 圖形,其中心為「GE」這家公司 engchi U. 47.
(49) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 3.3.6、時間尺度為 3 分鐘的 MST 圖形,其中心為「WFC」這家公司,其副中. n. al. Ch. 心為「FER」,「BAC」這兩家公司。. engchi. i n U. v. 時間尺度為 3 分鐘的 MST 圖形其資料數有 48 筆 中心. GE. WFC. NSC. FER. MRK. PG. KO. BAC. 次數. 68.7%. 8.3%. 6.2%. 4.2%. 4.2%. 4.2%. 2.1%. 2.1%. 在時間尺度為 3min 的 MST 圖形中,取其中心次數最多的前兩名來代表。 從中心次數表格中可知「GE」這家公司在此時間尺度具有一定的影響,而其為 中心時與其他家公司具有高度的相關性;當中心改變時,有副中心的出現,而其 密集度也越來越高。 48.
(50) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.7、時間尺度為 6 分鐘的 CMST h e 圖形,其中心為「GE」這家公司,其副中 ngchi U 心為「KO」,「NSC」這兩家公司。. 時間尺度為 6 分鐘的 MST 圖形其資料數有 4 筆 中心. GE. 次數. 100%. 在時間尺度為 6min 的 MST 圖形中,其中心均為「GE」這家公司,然我們 發現其副中心的 degree 與中心的 degree 差距並不是很大,代表著「KO」 , 「NSC」 這兩家公司有他們關聯性的群體。 49.
(51) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.3.8、時間尺度為 468 秒的 MST 圖形,其中心為「GE」這家公司。. 50.
(52) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.9、時間尺度為 468 秒的 CMST h e圖形,其中心為「PG」這家公司,其副中心 ngchi U 為「JPM」,「MRK」這兩家公司。. 時間尺度為 468 秒的 MST 圖形其資料數有 12 筆 中心. GE. PG. 次數. 91.7%. 8.3%. 在時間尺度為 468 秒的 MST 圖形中,我們可以發現 1997Q3 這時間「GE」 這家公司與其他家公司有相當強烈的關聯性,然 1997Q2 這時間卻形成多中心現 象,代表著市場上有群組類別的區分。 51.
(53) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.10、時間尺度為 15 分鐘的 C hMST 圖形,其中心為「T」這家公司,其副中 engchi U 心為「HBAN」這家公司。. 時間尺度為 15 分鐘的 MST 圖形其資料數有 6 筆 中心. T. 次數. 100%. 在時間尺度為 15min 的 MST 圖形中,其中心均為「T」這家公司,在其代 表圖上我們發現其中心公司的關聯性很高,而副中心與中心距離相距較遠,說明 了其彼此間關連並不強烈。 52.
(54) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3.3.11、時間尺度為 30 分鐘的 C hMST 圖形,其中心為「GE」這家公司,其副中 engchi U 心為「CSCO」這家公司。. 53.
(55) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 3.3.12、時間尺度為 30 分鐘的 MST 圖形,其中心為「STI」這家公司,其副. n. al. Ch. 中心為「GE」這家公司。. engchi. i n U. v. 時間尺度為 30min 的 MST 圖形其資料數有 4 筆 中心. GE. STI. 次數. 75%. 25%. 在時間尺度為 30min 的 MST 圖形中,其中心出現有「GE」與「STI」兩家 家公司。我們發現在 1997 年這時間的圖形中,雖然中心為「STI」,但其副中心 「GE」的 degree 與中心的 degree 非常相近,亦可說明他們具有雙中心的現象。. 54.
(56) 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. 圖 3.3.13、時間尺度為 78 分鐘的 MST 圖形,其中心為「GE」這家公司,其副. n. al. i n 中心為「STI」,「CSCO」這家公司。 Ch engchi U. v. 時間尺度為 78min 的 MST 圖形其資料數有 67 筆 中心. GE. 次數. 100%. 在時間尺度為 78min 的 MST 圖形中,其中心均為「GE」這家公司,從圖形 上可發現中心與副中心上的點較為集中,慢慢呈現出分層的現象,但不散亂,所 以說明了在這時間尺度上的關聯性較為集中。. 55.
(57) 在這 8 個不同的時間尺度下,我們可以發現中心大多為「GE」這家公司, 這代表著「GE」與其他家公司有很強烈的關聯性,亦說明了其在整個股票市場 具有重要的影響力或者是為各股之間重要的樞紐。並隨著時間尺度的增加,其網 路圖形逐漸變得較為密集,不易有零散連結的現象,中心點的出現也更為明顯, 甚至副中心與分層分群的情形也逐漸顯現。而在這長時間不同尺度下的 MST 圖 形其中心並非獨一無二的,這其實也說明在不同的時間點會有不同的股票公司來 影響或是主導整個市場的變動。 最小展開樹圖形雖然能夠利用距離概念呈現出各點之間的相關性,但卻無法. 政 治 大 實最小展開樹圖形結果的缺陷或是能夠增強我們的論點,亦或是還有其隱藏的意 立 完全呈現出所有點之間的關聯性,而這些被犧牲掉的關聯性是否能夠幫助我們充. CN 2. C1N C2 N 1 . y. 1 . . sit. io. al. C12. er. Nat. 1 C C = 21 C N 1. ‧. ‧ 國. 學. 涵。因此我們從 N × N 的相關矩陣(correlation matrix)出發,其中 Cij = C ji. n. v i n Ch 將相關係數轉成空間上距離的想法,即 e n gd c≡ h2iT (1U− C ) ,如此可獲得一組對角 ij. ij. 線為 0 的 N × N 的距離矩陣(distance matrix),其中 dij = d ji. d12 0 d 0 d = 21 d N1 d N 2. . d1N d 2 N 0 . 因為我們從鄰接矩陣(adjacency matrix)知道,鄰接矩陣的平方所得矩陣中的對角 線即為各點的 degree 數,因此我們將其應用在從相關矩陣轉換成的距離矩陣上, 即可得到其對角線上的數值為各點與其他所有點的關聯強度,關聯性越強其距離 56.
(58) 越短,反之,關聯性越弱其距離越長。. 0 + d12 2 + d132 + 3 + d1N 2 d 212 + 0 + d 232 + 3 + d 2 N 2 2 d = 2 2 2 d N 1 + d N 2 + 3 + d NN −1 + 0 . 由上式可知,我們能藉此找出關聯性最強的點,即為關聯性最強的公司,而它呈 現的是整個網路的訊息,不像最小展開樹只挑最強關聯的點來連結,也因此他能. 政 治 大. 補足最小展開樹的遺漏。我們取其最強關聯的點來當作整個網路的中心,並與最 小展開樹網路的中心做比較。. 立. BSX MER. BMY. STI. HBAN. …. 4.1% 4.1%. 4.1%. 3.5%. 3.5%. …. ‧. MST T MXIM LTD CSX 次數 12.5% 7.6% 4.9% 4.9% 關聯 T MXIM LTD BSX 次數 14.6% 11% 8.3% 8.3%. 學. ‧ 國. 時時間尺度為 36 秒的 MST 圖形中心與整體關聯最強中心. CSX MER ALTR BMY HBAN. …. 4.1% 4.1%. …. 3.5%. 2.8%. Nat. io. sit. y. 2.8%. al. er. 時間尺度為 72 秒的 MST 圖形中心與整體關聯最強中心. v PG i n C h 9.7% 6.5%U 3.2% 12.9% 9.7% engchi. n MST NSC 次數 25.8% 關聯 NSC. WFC 16.1%. 次數 22.6%. 19.3%. WFC. FRE. FRE. GE GE. 12.9% 9.7%. BAC. CI. AIG. MER. …. 3.2%. 3.2%. …. BAC. CI. PG. AIG. MER. …. 3.2%. 3.2%. 3.2%. 3.2%. 3.2%. …. 時間尺度為 3 分鐘的 MST 圖形中心與整體關聯最強中心 MST 次數. GE. WFC. NSC. FER. MRK. PG. KO. BAC. 68.7%. 8.3%. 6.2%. 4.2%. 4.2%. 4.2%. 2.1%. 2.1%. 關聯. GE. WFC. PG. FER. MRK. NSC. KO. BAC. 次數. 70.8%. 8.3%. 6.2%. 4.2%. 4.2%. 2.1%. 2.1%. 2.1%. 57.
(59) 時間尺度為 6 分鐘的 MST 圖形中心與整體關聯最強中心 MST 次數. GE 100%. 關聯. GE. 次數. 100%. 時間尺度為 468 秒的 MST 圖形中心與整體關聯最強中心 MST 次數. GE. PG. 91.7%. 8.3%. 關聯. GE. PG. 次數. 91.7%. 8.3%. 政 治 大. MST 與關聯強度的中心為「PG」的時間點均為 1997Q2. 立. ‧ 國. 學. 時間尺度為 15 分鐘的 MST 圖形中心與整體關聯最強中心 T 100%. 關聯. T. ‧. MST 次數. Nat. 次數. al. er. io. sit. y. 100%. v. n. 時間尺度為 30min 的 MST 圖形中心與整體關聯最強中心 MST 次數. Ch. eGEn g c h i. i n U. STI. 75%. 25%. 關聯. GE. 次數. 100%. MST 中心於 1997 年為「STI」,然其此時「GE」與「STI」的 degree 非常接近. 時間尺度為 78min 的 MST 圖形中心與整體關聯最強中心 MST 次數. GE 100%. 關聯. GE. 次數. 100% 58.
(60) 由上述整理結果我們發現,當時間尺度越大其 MST 圖形中心與關聯強度的 中心會相同,其原因是:最小展開樹圖形其定義是在不產生迴圈的前提下,優先 與關聯性越強的相連接,並由其圖形可發現,時間尺度越大其中心的連結就越明 顯,也越集中;而由關聯強度定義出的中心是由各點與所有點的關聯性取其最強 的為中心,所以如果圖形中心具有越密集的連結其關聯的強度越大,反之,中心 的連結越稀疏則其關聯性越小,如同時間尺度在 36 秒與 72 秒的時候,我們可發 現其網路結構較為稀疏,所以由 MST 圖形所決定出的中心與關聯強度的中心會 有些差異,但對於稍具有中心趨勢的點,兩者的結果卻也非常相近。如此,我們. 政 治 大 果中心點稍具集中趨勢,那麼 MST 圖形中心與關聯強度的中心亦會相同。 立. 即可說明為何時間尺度越大其 MST 圖形中心與關聯強度的中心會相同,並且如. 在知道最小展開樹網路圖形會失去一些原本結構的訊息後,我們便使用相關. ‧ 國. 學. 矩陣來做全面的處理,而且我們也希望能夠利用定量的方式來對不同時間尺度進. ‧. 行研究,所以我們利用距離矩陣定義 I,J,K,L 這四個點[25]。. y. Nat. I:關聯性最強的點,可以從距離矩陣中獲得。. n. al. er. io. K:距離 I 最遠的點,亦即與 I 點關聯性最弱的點。. sit. J:距離 I 最近的點,亦即與 I 點關聯性最強的點。. i L:距離 K 最遠的點,亦即與 C K 點關聯性最弱的點。 n hengchi U. v. 在定義完這四個點之後,我們將計算各點四個原級動差,m1、m2、m3、m4, m16 。 以各點為例,四個原級動差分別為 n. = (I ) m1 E=. ∑ dI j =1. n. n. j. , = (I 2 ) m2 E=. n. (I 3 ) = m3 E=. ∑ dI j 3 j =1. n. ∑ dI j =1. 2 j. n n. , = (I 4 ) m4 E= . 59. ∑ dI j =1. n. 4 j.
(61) n. = ( L3 ) m15 E=. 立. ∑ dL j 3 j =1. n. n. ∑ dL j =1. , ( L4 ) = m16 E=. 4 j. n. 政 治 大. ‧. ‧ 國. 學. 圖 3.3.14 時間尺度在 36sec 與 78min 的所有的動差. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3.3.15 時間尺度在 36sec 至 78min 的所有個別點的動差平均 60. (3.3.1).
(62) 由上述計算結果,當 i = 1 ~ 4 ,此為 I 點的四個動差值,其隨著時間尺度越 大其值越小。I 為與其他點關聯性最強的點,在空間上的概念,即為與其他點距 離平方和為最小的點。所以當其動差值越小,它與其他點距離平方和亦為越小, 而距離越小,其關聯性越強,圖形則越有集中趨勢;反之,如果動差值越大,其 關聯性越弱,圖形則越稀疏。因此,我們可以知道若 MST 圖形具有明顯的中心 與強烈的集中性,那麼在相關係數矩陣求算其中心點的四個動差值將越小,又由 前面圖形與計算發現,隨這時間尺度越大,其圖形越有集中趨勢,那麼中心點的 動差值亦會隨著時間尺度放大其值越小。 而當 i = 9 ~ 12 ,此為 K 點的四個動差值,其隨著時間尺度的變化其值並無顯. 政 治 大 著的差異。K 為距離 I 最遠的點,亦為是距離中心最遠的點,那麼在所有 MST 立 圖形中我們可以看出整個外圍輪廓的情形,亦即圖形末端地的分支很明顯地呈現. ‧ 國. 學. 稀疏不集中的現象,且在不同的圖形中並無明顯差異,因此,藉由相關係數矩陣. ‧. 所計算的結果與 MST 圖形的呈現相符合。. n. er. io. sit. y. Nat. al. Ch. engchi. 61. i n U. v.
(63) Chapter 4 結論 多粒子物理系統與隨機矩陣理論(Random matrix theory,RMT)是為了解決物 理問題而發展出來的理論,然對於股票市場的研究卻有其適用性,其為股票市場 可看作是一多變量的系統,且大部分的變數無法精確掌握,當這些變數相互疊加 的時候,便會以類似亂數的型態產生,但我們可以利用其當中的關聯性來抓取其 性質,所以耦合隨機行走模型幫助我們有效闡釋了股票市場會有相互影響的效應 (亞擴散的部分)。其模型 I 的結果發現,真實股票市場的 MSLR(mean square. 政 治 大 關聯性所造成的。然其股票與股票交互作用一段時間之後,彼此關聯性將被遺忘 立 log-return)會有一亞擴散的區段的過程,其原因為股票與股票之間的交互作用或. ‧ 國. 學. 而呈現隨機過程的現象,然當模型 I 結構變得很龐大的時候,其模型特性無法呈 現出擴散行為的區段,對應於股票市場即我們無法預見在長時距下股票價格對數. ‧. 報酬的變化為隨機過程,因此,我們修正其模型,使其保留了彼此互作用影響,. sit. y. Nat. 又能讓我們看見在長時距下隨機過程的現象。而當 β 值越來越大時會使 ξi ' 值的. al. n. 是有限制的。. er. io. 效應越來越強,當效應強過彼此之間的關聯時,其耦合效應將會消失,因此 β 值. Ch. engchi. i n U. v. 然從我們的研究發現,股票與股票之間的關聯性對整個市場是重要的,而最 小展開樹能從其關聯性中了解市場的結構,以幫助我們對其市場上重要的節點作 出了明顯的區別,有效的讓我們了解那些股票公司具有其對市場較大的影響或是 具有其重要的溝通性,藉此在操作市場投資時可做為參照的一個指標。 雖然從模型中我們能夠抓住一些金融市場的特性,但還是不夠完整,因此, 未來我們將對圖4.1計算 θ (ε , β ) 與 D(ε , β ) 的關係[7],並改進我們的模型,以利 完善整個耦合隨機行走模型,藉此能完整描述真實市場的現象與各種特徵,進而 實現預測其變化。而我們也希望能從最小展開樹所獲得的中心點公司,探究其背 後原因及成為中心的因素,並結合耦合隨機行走模型來做為市場投資判斷的指 62.
(64) 標。. 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 圖4.1、在meanfield解析解公式下,不同的 ε 與 β 的結果. Ch. engchi. 63. i n U. v.
數據
Outline
相關文件
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
For pedagogical purposes, let us start consideration from a simple one-dimensional (1D) system, where electrons are confined to a chain parallel to the x axis. As it is well known
The observed small neutrino masses strongly suggest the presence of super heavy Majorana neutrinos N. Out-of-thermal equilibrium processes may be easily realized around the
Define instead the imaginary.. potential, magnetic field, lattice…) Dirac-BdG Hamiltonian:. with small, and matrix
incapable to extract any quantities from QCD, nor to tackle the most interesting physics, namely, the spontaneously chiral symmetry breaking and the color confinement..
(1) Determine a hypersurface on which matching condition is given.. (2) Determine a
• Formation of massive primordial stars as origin of objects in the early universe. • Supernova explosions might be visible to the most
The difference resulted from the co- existence of two kinds of words in Buddhist scriptures a foreign words in which di- syllabic words are dominant, and most of them are the
