國 立 交 通 大 學
電 機 與 控 制 工 程 研 究 所
碩 士 論 文
可重複規劃之里德所羅門解碼器設計
Design on Reconfigurable Reed-Solomon Decoder
研 究 生:陳玉書
指導教授:董蘭榮 博士
可重複規劃之里德所羅門解碼器設計
Design on Reconfigurable Reed-Solomon Decoder
研 究 生:陳玉書 Student:Yu-Shu Chen 指導教授:董蘭榮 Advisor:Lan-Rong Dung 國 立 交 通 大 學 電 機 與 控 制 工 程 學 系 碩 士 論 文 A Thesis
Submitted to Department of Computer and Information Science College of Electrical Engineering and Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering
July 2004
Hsinchu, Taiwan, Republic of China
可重複規劃之里德所羅門解碼器設計
學生:陳玉書
指導教授:董蘭榮 博士
國立交通大學電機與控制工程研究所
摘 要
本篇論文提出了一套里德所羅門解碼器硬體的摺疊架構,其所採 用的摺疊演算法根據處理速率(Throughput)條件的評估,在架構中 使用少量的運算器,規劃其運作時序,就可分時完成工作,如此一來 可以減少硬體中乘加運算器的數目,縮小硬體的面積。摺疊演算法非 常適合於處理速率不需要很高的陣列硬體架構,尤其是對於陣列的運 算單元個數會因規格的不同而有數目上變化的應用。以里德所羅門解 碼器架構為例,解碼器方塊的內部大多數的構成部分是由運算單元陣 列所組成,而且陣列的長度是根據不同的解碼器除錯能力規格來改 變,除錯能力越大,運算單元個數需要越多。當對於這種硬體架構來 實行摺疊時,則以最差狀況的處理速率及陣列長度來估計所需採用的 運算單元個數,摺疊後的架構對於除錯能力較小的規格,只需要減短 運算時序的重複週期即可,這樣的架構展現了硬體可重複使用的特 性,而且摺疊後的硬體架構有相當高的硬體使用率,在各種除錯能力 規格下都很平均。此外,在處理速率規格符合的前提下,若要提升最 大除錯能力,加長陣列長度,只需要增加儲存運算結果的記憶容量大 小,並延長重複週期就可以達成,這也使得摺疊後的硬體更具有擴充 性。Design on Reconfigurable Reed-Solomon Decoder
Student:Yu-Shu Chen Advisor:Dr. Lan-Rong Dung
Department of Electrical and Control Engineering
National Chiao Tung University
ABSTRACT
This thesis presents a folding approach for reconfigurable Reed-Solomon decoder. The reconfigurable Reed-Solomon decoder is targeted on xDSL applications. Under the requirement of the throughput rate, we fold the Reed-Solomon decoding with the minimal number of processing elements (PEs) while the complexity of scheduler is low. The folded architecture is suitable for array processors whose processing rate is not necessary to be optimal. The proposed reconfigurable decoder is highly scalable as the application parameters change. For xDSL applications, the computation requirement of Reed-Solomon decoder is varying with the error-correcting capability t and, thus, a flexible reconfigurable architecture becomes very attractive. Our approach allows the Reed-Solomon decoder to be configured by t without slacking processing elements.
誌 謝
兩年的研究生涯,將以這篇碩士論文作為句點,論文中所留下的 一字一句,不僅記錄了這兩年研究的成果,也蘊藏了這幾年同窗好友 的友誼。 很榮幸能夠在董蘭榮老師門下學習,其不厭其煩地指導與教誨, 讓我在這條研究的道路上,有非常明確的方向。此外,還有陳紹基教 授、吳安宇教授、吳文榕教授的撥冗指導,給予許多寶貴的意見,讓 這篇論文可以更為完整齊備,這一點一滴都讓我感恩在心。 感謝整個實驗室研究團隊的支持與幫助,無論是精神上的鼓勵, 或是研究上的協助,都讓我在這段研究的日子裡得以堅持。謝謝學長 們的指導,謝謝同學們的陪伴,謝謝學弟們的加油打氣,這些都是我 心靈上最溫暖的寄託,研究上最堅強的後盾。 當然還要奉上最深的感謝給我的父母親,你們給予我的優裕環 境,以及全心全力的照顧,讓我在求學的過程中得以順遂的向前邁 進,這篇論文的誕生,表現了碩士研究生涯的成果,在其中所呈現的 進步與成長,以及蘊涵的欣喜與榮耀,將與你們一同分享。 文末,僅以此篇論文獻給所有關心愛護我的人,再次獻上我衷心 的感激,謝謝大家! 玉書 謹誌 國立交通大學 系統晶片實驗室 民國九十三年七月目 錄
中文摘要 ……… i 英文摘要 ……… ii 誌謝 ……….……….…… iii 目錄 …...……….……….…… iv 表目錄 ………...……….………… vii 圖目錄 ………..……….……… viii 第一章 緒論 .……… 1 1.1 研究動機 .……… 1 1.2 論文摘要 .……… 4 第二章 研究背景 .……… 5 2.1 伽羅瓦場(Galois Field)定義介紹 .……… 5 2.1.1 本質多項式與伽羅瓦場的建立 .………….…… 6 2.1.2 伽羅瓦場的乘加運算 .……….…… 7 2.2 里德所羅門(Reed-Solomon)碼定義介紹 .……… 8 2.3 里德所羅門編碼(Encoding)演算法 .……… 9 2.4 里德所羅門解碼(Decoding)演算法 ……….…… 10 2.4.1 收到信號的錯誤症狀(Syndrome)計算 ……. 13 2.4.2 尋找錯誤位置多項式之方法 ………..… 14 2.4.2.1 Berlekamp-Massey 疊代演算法 ……...… 14 2.4.2.2 最高公因式演算法(Euclidean Algorithm) ………. 17 2.4.3 尋找錯誤位置之方法(Chien Search) ……… 19 2.4.4 尋找錯誤大小的佛尼(Forney)演算法 …….. 19第三章 摺疊演算法之推演與建立 ……… 21 3.1 摺疊演算法的硬體架構推導 ……… 22 3.2 以摺疊演算法實現硬體之方法與特色 ……… 27 第四章 硬體實現架構 ……….… 29 4.1 整合里德所羅門解碼器之矽智產合成器的運作流程與完 整電路架構 ………...… 30 4.2 伽羅瓦場乘法器 ………..…… 33 4.3 處理錯誤症狀(Syndrome)之硬體摺疊架構 ..… 36 4.3.1 乘加運算器及暫存器規劃 ………..… 37 4.3.2 位址產生器的設計 ………...… 41 4.3.3 錯誤症狀計算硬體之輸入輸出定義 ………....… 42 4.4 信號症狀計算器與 BM 方塊之資料傳遞介面 …..… 43 4.5 尋找錯誤位置(Error-Locator)多項式以及錯誤大小評估 (Error-Evaluator)多項式之硬體摺疊架構 ………..… 44 4.5.1 RiBM 疊代演算法 ………...… 44 4.5.2 乘加運算器及暫存器規劃 ………..… 47 4.5.3 位址產生器的設計 ………...…… 51 4.5.4 RiBM 硬體之輸入輸出定義 ………..… 52 4.6 BM 方塊與多項式估算器之資料傳遞介面 ….…… 53 4.7 錯誤修正器(Error Corrector)硬體架構 ………..… 54 4.7.1 多項式估算之硬體摺疊架構 ………...… 55 4.7.1.1 乘加運算器及暫存器規劃 ………...… 56 4.7.1.2 位址產生器的設計 ……….… 58 4.7.1.3 多項式估算硬體之輸入輸出定義 …….… 59 4.7.2 伽羅瓦場元素輸出表 ……….… 60 4.7.3 佛尼演算法 ……….… 63
4.7.4 錯誤修正器之輸入輸出定義 ……….. 64 4.8 里德所羅門解碼器之狀態機設計 …..… ………… 65 4.9 實現結果 ………. ..… 68 第五章 結論 ………...… 75 5.1 主要貢獻 ………...…. 75 5.2 未來展望 ………...…. 76 參考文獻 ……….. 78 附錄 ……….. 80
表 目 錄
【表2.1】 利用本質多項式 ( ) 1 2 3 4 8建立之 8 ..… 7 x x x x x h = + + + + GF(2 ) 【表4.1】 里德所羅門解碼器組成方塊之邏輯單元數 ……… 72圖 目 錄
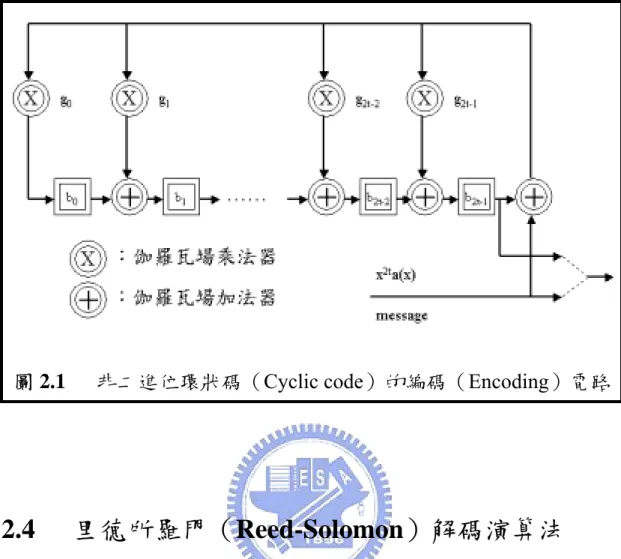
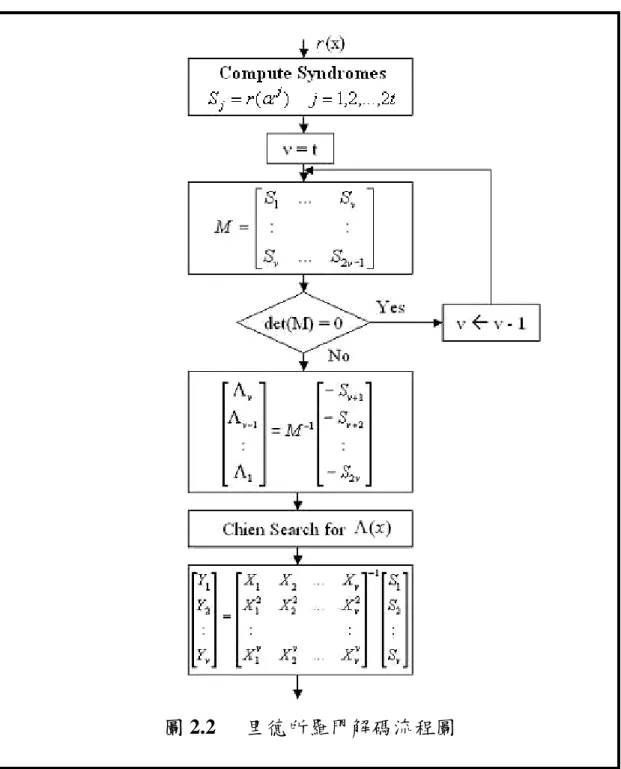
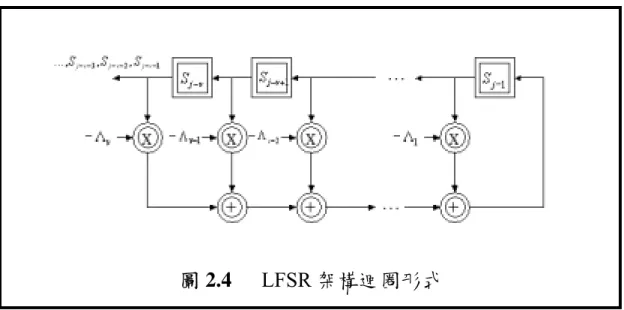
【圖2.1】 非二進位環狀碼(Cyclic code)的編碼(Encoding)電路 …10 【圖2.2】 里德所羅門解碼流程圖 ……….. 12 【圖2.3】 錯誤症狀運算電路 ……….. 13 【圖2.4】 LFSR 架構迴圈形式 ……….…15 【圖3.1】 基本運作單元概略圖 ……….. 23 【圖3.2】 運作單元陣列 ……….. 23 【圖3.3】 運作單元陣列之時序規劃 …………..……… 24 【圖3.4】 運作單元陣列之摺疊架構 ………..……… 25 【圖3.5】 摺疊架構之乘加運算器與暫存器規劃 ……….. 26 【圖3.6】 摺疊架構之暫存器定址 ………..……… 27 【圖4.1】 里德所羅門解碼器硬體概略圖 ……….. 31 【圖4.2】 里德所羅門合成器之處理流程 ………..…… 32 【圖4.3】(a)平衡的互斥樹狀架構(b)非平衡的互斥樹狀架構….. 3 4 【圖4.4】 建立在 GF(24)之非規則全平行乘法器硬體架構 ……….. 35 【圖4.5】 錯誤症狀計算之陣列硬體架構 ………..………… 37 【圖4.6】 除錯能力 t=8 之錯誤症狀計算陣列 …………...………… 38 【圖4.7】 錯誤症狀計算陣列之時序規劃 ……….. 39 【圖4.8】 錯誤症狀計算陣列之摺疊架構 ……….. 39【圖4.9】 錯誤症狀計算硬體之乘加運算器與暫存器規劃 ……….. 40 【圖4.10】 錯誤症狀計算硬體之位址產生器 ……….... 42 【圖4.11】 錯誤症狀計算硬體之輸入輸出定義 ……… 42 【圖4.12】 S2B 方塊定義 ………..…….. 43 【圖4.13】 RiBM 演算法之基本單元 ………. 46 【圖4.14】 RiBM 疊代演算法硬體架構圖 ……… 46 【圖4.15】 除錯能力 t=8 之 RiBM 硬體陣列 ……… 47 【圖4.16】 RiBM 硬體陣列之時序規劃 ……… 48 【圖4.17】 RiBM 硬體陣列之摺疊架構 ……… 49 【圖4.18】 RiBM 硬體之乘加運算器與暫存器規劃 ………. 50 【圖4.19】 RiBM 控制單元方塊圖 ………. 50 【圖4.20】 RiBM 硬體之位址產生器 ……… 51 【圖4.21】 RiBM 硬體之輸入輸出定義 ……… 52 【圖4.22】 B2P 方塊定義 ……… 53 【圖4.23】 錯誤修正器之硬體架構 ……… 54 【圖4.24】 八次多項式估算器之硬體架構 ……… 55 【圖4.25】 八次多項式估算器陣列之時序規劃 ……… 56 【圖4.26】 八次多項式估算器之摺疊架構 ……… 57 【圖4.27】 多項式估算器硬體之乘加運算器與暫存器規劃 ……… 58 【圖4.28】 多項式估算器硬體之位址產生器 ……… 59 【圖4.29】 多項式估算器硬體之輸入輸出定義 ……… 60 【圖4.30】 伽羅瓦場元素輸出表之硬體架構 ……… 62 【圖4.31】 伽羅瓦場元素輸出表之位址產生器 ……… 62 【圖4.32】 錯誤修正器之硬體架構 ……… 64 【圖4.33】 錯誤修正器之輸入輸出定義 ……… 65 【圖4.34】 里德所羅門解碼器之狀態機 ……… 67 【圖4.35】 錯誤症狀計算器之 RTL 模擬 ………... 69
【圖4.36】 RiBM 方塊之 RTL 模擬 ………. 70
【圖4.37】 錯誤修正器之 RTL 模擬 ………... 70
【圖4.38】 里德所羅門解碼器組成方塊之邏輯單元數比例分佈 .... 71
【圖4.39】 模擬測試驗證環境 …………..……….. 73
第一章
緒論
1.1
研究動機
在這個工商業發達的社會,科技生活的來臨,拉近了人與人之間 的距離,而網路通訊也成為人們互相聯絡最普遍、最主要的方式,不 僅是在音訊方面的聽覺交流,甚至在視訊方面的傳輸也漸漸廣泛的被 大眾所採用,在這個繁忙的商業社會中,的確是一個促成了天涯若比 鄰的好方法。 傳輸音訊或視訊除了要求頻寬之外,也必須注重傳輸的正確性, 若正確性無法達到一定的水準,會使得這些訊息產生相當程度的失 真,造成使用者的不便。所以提升訊息錯誤更正的能力,解決信號傳 輸時所受到的干擾與雜訊,便成為如今網路傳輸的重要課題。 在現今普遍使用的非對稱數位用戶線路(ADSL),或是下一代的 超高速數位用戶線路(VDSL)應用中,錯誤更正編解碼(ECC)所採用的是里德所羅門碼(Reed-Solomon Code),主要原因是看上此種 編解碼方式在所有的錯誤更正編解碼中,算是最嚴謹且更正能力最強 的一種,尤其是對於叢集錯誤(Burst Error)或是隨機錯誤(Random Error)的修正能力上,更是讓其他編解碼方式望塵莫及,也因為這個 重要的因素,使得里德所羅門碼被應用在許多的傳輸系統上,例如: 無線通訊系統、纜線數據機、電腦記憶體…等。 在非對稱數位用戶線路(ADSL)與超高速數位用戶線路(VDSL) 中,錯誤更正的里德所羅門解碼方塊是建立在有限伽羅瓦場 GF(28) 上,為了因應各種所需之規格,必須做到可程式化(Programmable), 致使可以任意調整變換錯誤更正能力,其錯誤更正能力最大必須到達 8 個字碼(Codeword)。 2002 年 M. K. Song [12] 提出一種錯誤更正碼字元長度可變的里 德所羅門解碼器硬體,專門應用在超高速數位用戶線路上。一般來 說,在超高速數位用戶線路中,資料的傳遞皆由最高字元開始至最低 字元,但M. K. Song 所提出硬體中,用來尋找錯誤位置與大小的部 份,由於要配合超高速數位用戶線路的要求,必須做到容易程式化, 故其硬體架構會出現輸入是由最高字元到最低字元,但輸出卻是反 相,由最低字元到最高字元,為了這樣子的改變,必須多加了一個字 元位置前後顛倒的硬體,其結果才可以再被下一級所採用,但是要完 成這個動作,必須等到所有的字元都已經準備就緒,才能一次把所有 位元的位置調換過來,故字元位置前後顛倒的動作,似乎會把整個解 碼的時間拖垮。另外,這個硬體在錯誤更正能力不需要很高的情形 下,每個乘加器運算依然比照錯誤更正能力最大的方式動作,在功率 上也造成了不必要的消耗。
為了改善這些問題,在本篇論文中提出一個新的硬體架構,不僅 可以達到程式化的目的,並可以大幅降低功率上不必要的損失。除此 之外,根據處理速率(Throughput)條件的評估,更可以減少硬體中 乘加運算器的數目,縮小硬體的面積,這對於非對稱數位用戶線路 (ADSL)與超高速數位用戶線路(VDSL)等需要可程式化的里德 所羅門解碼器的應用,有一定程度的助益。 本篇論文所設計的里德所羅門解碼器特色如下: 解碼器的整個解碼流程分為三級: 錯誤症狀計算(Syndrome Calculation) 求出錯誤位置及大小評估多項式(Berlekmap-Massey) 錯誤消除(Forney Algorithm、Correction) 其中主要貢獻在於將論文中所發展的摺疊演算法套用於解碼流 程的這三級中,摺疊後架構所產生的可重複使用性,對於不同規 格之除錯能力 t,可以動態的調整規劃,其概念適合應用在超高 速數位用戶線路這類型的動態規格調整之裝置。 使用者可從軟體 C 語言中輸入所需之最大除錯能力參數 t,以及 錯誤症狀計算、求出錯誤位置及大小評估多項式、多項式估算這 三種硬體架構之使用運算單元個數,即可得到VHDL 硬體描述語 言,其為可合成(Synthesizable)之 RTL 程式。 設計之解碼器所能接受之規格: 伽羅瓦場階數 m 為 8 錯誤更正能力 t 可動態設定
1.2
論文摘要
在此小節中先對本篇整個論文架構作個概略性的介紹。 第一章 緒論 提出論文主題、想要解決的問題及其主要應用所在。 第二章 研究背景 介紹里德所羅門碼(Reed-Solomon Code)之基本運作原理:包 含了編碼與解碼,但焦點在於解碼過程中的定義與不同演算法之間的 比較,並點出一些相關硬體實現時所要考慮的問題。 第三章 摺疊演算法之推演與建立 提出一套摺疊演算法之理論,經由圖論上的推導,讓人擁有明確 的流程可以遵循,並指出採用摺疊演算法後的架構,展現了可重複使 用的特性。 第四章 硬體實現 先對整個硬體架構及合成器的運作與操作流程作介紹,之後再對 解碼器中的個別方塊加以詳細解說,並推導其摺疊之硬體架構。最後 則是使用合成器依據所設定的運算單元個數所產生出來的硬體語 言,送入相關合成軟體中,獲得相關面積等資訊,並統計解碼器組成 方塊間相對關係之面積比例。 第五章 結論 本篇論文之結語與未來展望。第二章
研究背景
在深入探討本篇研究論文之前,本章先介紹一些基本的里德所羅 門(Reed-Solomon)的編解碼方式,還有一些將會運用到的基本數學 理論。首先,第一節提到的是里德所羅門編解碼所建立在伽羅瓦場 (Galois Field)其構成的原理,以及在場中的乘加運算;第二節則開 始介紹里德所羅門編解碼的基本定義,進而分別在第三節和第四節中 介紹其編碼與解碼的演算法,其中尤其以解碼較為複雜,必須由許多 步驟接續處理完成。2.1
伽羅瓦場(Galois Field)定義介紹
[1]若有一個場,其中所存在的元素數目是有限值,則稱之為有 限場或伽羅瓦場。有限場是整個錯誤更正碼(Error-Control Coding) 最有用、最基本且最重要的觀念。若一個場F 為有限,則將 F 場的元素個數定義為 F 的階數。一個 q 階的有限場表示為 GF(q)。 在這節中主要探討伽羅瓦場的構成方法,這將運用一些實數系中 較不會用到的數學定義及定理。另外,在此場中乘加運算的動作原 理,也會一併作個簡介。
2.1.1 本質多項式與伽羅瓦場的建立
定義 2.1 不可化簡多項式(Irreducible polynomial) 假設一個多項式f(x)除了 1 和本身之外沒有其他因式,則稱這種 多項式為不可化簡的多項式。 定義 2.2 本質多項式(Primitive polynomial) 一個n 大於一階的不可化簡多項式,假若符合m 且其並不 是1 之因式,則將其稱之為本質多項式。 1 2 − < n m x + [1]利用本質多項式(Primitive polynomial)去建立一個GF 伽 羅瓦場比利用非本質多項式(Non-primitive polynomial)來的容易許 多。令 ) 2 ( n α 代表x 對 h(x)取餘數結果的字元(i.e. x mod h(x)),其中 h(x) 必須是n 階的本質多項式,則在同一數系下所有非零的字元都可以被 表示成α 次方的形式:αi ↔ximod xh( ),而α稱為伽羅瓦場GF 之本 質元素,這個特性讓伽羅瓦場的乘法運算變的更為簡單。除此之外, 在這個有限的伽羅瓦場中一共會有 ) 2 ( n 1 2n − 個截然不同的非零元素,可 以表示為2n −1個α的連續次方,即為{1, α , , … , }。表 2.1 即是一個利用本質多項式h 所建立出GF 的對 照表。 2 α 8 x 2 2n− α 4 x 3 x 2 1 ) (x = +x + + + (28)Word Polynomial in x (modulo h(x)) Power of α 00000000 0 --- 10000000 1 α0 01000000 x α1 00100000 x2 α2 00010000 x3 α3 00001000 x4 α4 00000100 x5 α5 00110000 2 3 27 x x x + ≡ α27 00011000 3 4 28 x x x + ≡ α28 00001100 4 5 29 x x x + ≡ α29 00011011 3 4 6 7 251 x x x x x + + + ≡ α251 10110101 1 2 3 5 7 252 x x x x x + + + ≡ + α252 11100010 1 2 6 253 x x x x+ + ≡ + α253 01110001 2 3 7 254 x x x x x+ + + ≡ α254 表 2.1 利用本質多項式h(x)=1+x2 +x3 +x4 +x8建立之GF(28)
2.1.2 伽羅瓦場的乘加運算
伽羅瓦場的乘法運算,簡單來說,就是直接將伽羅瓦場裡的代表 字元作一般實數系相乘的動作,所得到的字元再依照二進位與伽羅瓦 場的轉換對照表,找出其相對應的二進位值。例:α⋅α2 =α3 =00010000。 反之,伽羅瓦場的加法運算就沒有像乘法運算這麼單純,可以直 接利用該字元進行類似實數系的運算,而是必須先找出運算字元所對應到的二進位表示法的數,然後將兩個二進位表示法的數作 XOR 的 運算,再利用所得到的值去尋找其所對應的伽羅瓦場的字元。例: 。 28 4 3 α 00010000 00001000 00011000 α α + = ⊕ = =
2.2
里德所羅門(Reed-Solomon)碼定義介紹
里德所羅門碼是在西元1960 年由 I. Reed 以及 G. Solomon 在麻省 理工學院(M.I.T.)實驗室所共同發明的,這是一個建立在伽羅瓦場 的編碼方式,並可以將其視為另一種 BCH 編碼的特殊情況,自從里 德所羅門碼被發明之後,近幾年來已經被廣泛的應用在各種方面。 定義 2.3 里德所羅門碼(建立於GF(2m)之元素) 假設α 為 之本質元素,對任意一個正整數 ,必定 存在一組建立於伽羅瓦場 可去除 t 個錯誤符號(Symbol)的里 德所羅門碼[2],其各項參數如下: ) 2 ( m GF t≤2m −1 ) 2 ( m GF 1 2 − = m n (2.1) t k n− =2 (2.2) k n t dmin −1=2 = − (2.3) 其中m 表示字碼長度,n 為編碼後字碼數目,k 則是來源字碼數目。 以RS (255, 223)這組里德所羅門碼為例:經由 n = 255、k = 223 進而可得知 m = 8、t = 16、dmin = 33。同時,這一組規格的里德所羅 門碼也是美國太空總署(NASA)給衛星和太空通訊所採用的標準編 碼。2.3
里德所羅門(Reed-Solomon)編碼演算法
當開始進行編碼之前,首先介紹字碼產生多項式(Codeword generator polynomial),表示如下: t t t t i i m x x g x g g x x g 0 1 2 1 2 1 2 1 2 0 ) ( ) ( = + 0 = + +⋅⋅⋅+ − + − − = +∏
α ) 2 ( m GF g where i∈ (2.4) 一般來說,m0的典型值為 0 或 1。此外,值得一提的是連續 2t 個α 的 次方αm0、αm0+1、…、αm0+ t2−1均為字碼產生多項式 g(x)的根。 假設需要編碼的 k 個 m 位元的來源訊息的多項式表示為: 1 1 1 0 ) ( − − + ⋅ ⋅ ⋅ + + = k k x m x m m x m where mi∈GF(2m) (2.5) 然而這其中的 k 就是訊息長度,並且根據前小節里德所羅門碼的定 義:k ,即原先的訊息長度k 等於編碼後長度 n 扣掉兩倍的除 錯能力t。 t n−2 = 接著,將訊息多項式乘上 ,再除上里德所羅門碼其專屬的字 碼產生多項式 g(x),則可得到一個餘式 b(x)如下: t x2 ) ( ) ( ) ( ) ( 2 x b x g x a x m x t = + 1 2 1 2 1 0 ) ( = + +⋅⋅⋅+ − t− t x b x b b x b where (2.6) 其中 的最低次方為2t,而 b(x)的最高次方為 2t-1,則 所組成的2t +k-1=n-1 次方多項式,就是編碼完成的字碼多項式 c(x), 且編碼後長度即為n。此外,由於 ,為g(x) 的因式,所以連續 2t 個 ) ( 2 x m x t x2tm(x)+b(x) ) (x g ) ( ) ( ) ( ) ( 2 x a x b x m x x c = t + = α 的次方 、 、…、 也均為 c(x) 的根。編碼電路的電路圖如圖 2.1 所示[2]。 0 m α αm0+1 αm0+ t2−1圖 2.1 非二進位環狀碼(Cyclic code)的編碼(Encoding)電路
2.4
里德所羅門(Reed-Solomon)解碼演算法
整個里德所羅門碼比較煩瑣的步驟及主要的問題都是出現在解 碼的過程,再加上本篇論文所提出的主要是解碼器架構,故在此小節 作個較為詳盡的解碼演算法介紹。 一開始先簡介一下整個解碼的過程。令傳送的碼和接收到的碼分 別表示為: ) 2 ( , ) ( 1 1 1 0 m i n n x c GF c x c c x c = + +⋅⋅⋅+ − − ∈ (2.7) ) 2 ( , ) ( 1 1 1 0 m i n n x r GF r x r r x r = + +⋅⋅⋅+ − − ∈ (2.8) 故因為傳輸而產生的雜訊就可以表示為: 1 1 2 2 1 0 ) ( ) ( ) ( = − = + + +⋅⋅⋅+ − n− n x e x e x e e x c x r x e (2.9)其中 ei =ri −ci 也是屬於 GF(2
m)中的元素。假設這個錯誤多項式有 v
個根,即代表存在有 v 個錯誤位置的訊息,其錯誤位置和相關大小的
表示法定義如下:
Error Values (2.10) Y e for l v
l
j =1
=
l ,2,...,
Error Locators X =αjl for l =1 v (2.11)
l ,2,..., 也就是說,在錯誤位置 處出現錯誤值Y,而以錯誤位置為根所形成 的錯誤位置多項式可以表示成: l X l ) 1 ( ) 1 )( 1 ( ) (x = −X1x −X2x ⋅⋅⋅ −Xvx Λ
∏
= − = v i ix X 1 ) 1 ( v vx x x+Λ +⋅⋅⋅+Λ Λ + Λ = 2 2 1 0 (2.12) 有一種解碼BCH Code 或是 RS Code 的方式[1],其整個解碼過程就 好比去解出兩個關鍵的方程式: − − = Λ Λ ⋅ + − − − + + t t t t t t t t t S S S S S S S S S S 2 2 1 1 2 2 2 1 1 3 2 : : : : ... : : : : ... (2.13) − Λ S1 S2 ... St−1 St t St+1 X X ... Xv− Xv Y1 S1 2 2 2 2 1 2 1 1 (2.14) = ⋅ − − v v v v v v v v v v S S Y Y X X X X X X X X : : : : ... : : : : ... 2 2 1 2 1 1 2 1 從方程式(2.13)中可以清楚看出,假若能夠從接受到的信號中 找出錯誤的症狀(Syndrome),便可以利用方程式(2.13)求出剛提 到的錯誤位置多項式(Error-Locator Polynomial)的係數。有了這些係數,利用土法煉鋼的方式,把所有伽羅瓦場裡的元素都代入檢查,
找出能夠使其為零的元素,便為其根,這也就是Chien Search 的演算
法。利用Chien Search 找出錯誤位置( Xl )之後,便可以利用方程式
(2.14)找出錯誤的大小( Yl ),而後再把找出來錯誤的大小和位置加
回原先收到信號上,整個解碼過程才算完整結束。其實這整個觀念就 是熟知的Peterson-Gorenstein-Zierler Decoding Algorithm(P-G-Z 解碼 演算法),整個解碼流程圖如圖 2.2 所示。
2.4.1 收到信號的錯誤症狀(Syndrome)計算
在解碼的過程中,錯誤症狀的計算是所要進行的第一步驟。由前
面的章節得知,接收到的信號可表示為 ,從
2.2 小節得知字碼產生多項式(Codeword Generator Polynomial)的根
為 ,其中t 代表除錯的能力,又因為 1 1 1 0 ) ( − − + ⋅ ⋅ ⋅ + + = n n x r x r r x r ) ( ) ( ) (x m x g x c 1 2 0 0 ~ m+ t− m α α = ,所 以便可以得到以下的關係: 1 2 ,..., 2 , 0 , ) ( ) ( ) ( ) ( 1 0 ) ( 0 0 0 0 0 = + = =
∑
= − − = + + + + + t i e e e c r n j j i m j i m i m i m i m α α α α α (2.15) 因此,所收信號的錯誤症狀即為 ( m0 i),其多項式表示法如下: i r S = α +∑
− = ⋅ =2 1 0 ) ( t j j j x S x S∑
(2.16) = − + − ⋅ = n i i n j m i n j r S where 1 ) ( α 0 整個過程就如同乘累加運算一樣,運算電路如圖 2.3 所示。 (a) (b) 圖 2.3 錯誤症狀運算電路 (a 在 GF(2m)表示法 (b)二進位表示法2.4.2 尋找錯誤位置多項式之方法
由於前述之P-G-Z 解碼演算法,在求錯誤位置多項式的運算過程 關係到一些逆矩陣的運算,所以較沒效率,速度也會減慢,相對變的 比較複雜,其複雜度是跟 t3成正比,故這種方法只比較適用於較小的 除錯能力架構中。而後人想了幾種加快這部分速度的辦法,包括: Berlekamp-Massey 疊代演算法,以及最大公因式演算法(Euclidean Algorithm)。 2.4.2.1 Berlekamp-Massey 疊代演算法 西元1967 年 E. Berlekamp 提出一種極有效率之演算法,同時適合使用於解碼BCH code 及 RS code,再加上後來 Massey 進一步的改
良,其複雜度僅隨著 t2 成長[1],所以是一個求取錯誤位置多項式比 較有效率的演算法,因此適宜用來處理較大除錯能力的里德所羅門解 碼架構。 根據2.4 節方程式(2.13),可以把其表示成此種迴圈形式: , ) ( 1 1 1 1 1 − + − − − = − Λ + ⋅⋅ ⋅ + Λ + Λ − = Λ − =
∑
v v j v v j v j i i j i j S S S S S t v v 1, 2,...,2 j for = + + (2.17) 這個迴圈形式在實際硬體上,可以表示成線性迴授移位暫存器(Linear Feedback Shift Register),如圖 2.4 所示。故原先求錯誤位置多項式之 係數的問題,可以將其轉變成找出最短長度的線性迴授移位暫存器,因而使其輸出的前 2t 個值就是之前錯誤症狀多項式的係數,此時乘
圖 2.4 LFSR 架構迴圈形式 整個演算法的流程是以遞迴的形式,其最主要的精神就在於讓 成為一個最短長度為 k 的連接多項 式(Connection Polynomial),且可滿足 2t 個錯誤症狀多項式的係數。 剛開始先找出 1 ) ( 1 1 1 ) ( =Λ +Λ +⋅⋅⋅+Λ + Λ − − x x x x k k k k k ) 1 ( Λ ,其相對應的輸出即為第一個錯誤症狀。之後再拿 第二個輸出來和第二個錯誤症狀做比較,假如兩者中間有差異值 (Discrepancy),就用這個差異值來建立一個新的連接多項式;相反 的,假如兩者中間沒有差異,就繼續拿此連接多項式去產生第三個輸 出值,再與第三個錯誤症狀做比較。如此循環運作,直到此線性迴授 移位暫存器可以產生 2t 個之前所得到的錯誤症狀。 此演算法有幾個重要的變數符號定義,以及整個演算法的歸納, 將敘述如下[2]: 連接多項式(Connection Polynomial) ( )( ) x k Λ 更正多項式(Correction Polynomial)T(x) 差異值(Discrepancy)∆(k) 線性迴授移位暫存器長度 L
1. 從收到的信號求出 2t 個錯誤症狀。 2. 對演算法中的各項變數初始化: x x T L x k =0 ,Λ(0)( )=1 , =0 , ( )= ) (k ∆
∑
= − − Λ − = ∆ L i i k k i k k S S 1 ) 1 ( ) ( 0 ) (k = ) ( ) ( ) ( ( 1) ( ) ) ( x T x x k k k =Λ −∆ Λ − k L≥ ) ( ) 1 ( ( ) ) ( k k x x =Λ − ∆ ) ( ) (x x T x T = ⋅ ) ( ) ( (2) x x =Λ t Λ 3. 令 k = k + 1,計算差異值 : 4. 假若∆ ,直接跳到 8.。 5. 更新先前之連接方程式: 6. 假若2 ,直接跳到 8.。 7. 令 L= k – L 且T 。 8. 令 。 9. 假若 k < 2t,直接跳到 3.。 10. 找出 的根。 由上述步驟,可以清楚的了解里德所羅門解碼器是利用錯誤症狀 多項式S 去計算錯誤位置。根據已知的錯誤位 置多項式,可以進一步計算出錯誤大小評估多項式(Error-Evaluator Polynomial)而求得該錯誤位置相對應之錯誤大小。定義一組錯誤位 置多項式 ,則錯誤大小評估多項式可得知定 義如下: 1 2 1 2 1 0 ) ( − − + ⋅ ⋅ ⋅ + + = t t x S x S S x tx x x =Λ +Λ +⋅⋅⋅+Λ Λ( ) 0 1 t 1 1 1 0 ) ( = + +⋅⋅⋅+ − t− t x x x ω ω ω ω (2.18) t x x x S x) ( ) ( )mod 2 ( ≡ω Λ (2.19) 方程式(2.19)稱為關鍵方程式(key equation)。後面的章節裡將會 提到的佛尼(Forney)演算法,就是利用錯誤大小評估多項式以及找 到的錯誤位置去求出相關位置之錯誤大小。2.4.2.2 最高公因式演算法(Euclidean Algorithm) 這個演算法主要是應用到數學裡求最高公因式的輾轉相除法,只 是額外作一些改變而已,其方法比較淺顯易懂,但過程較為複雜,運 算量也較Berlekamp 的方法大。 假設有兩個多項式 和 ,其最高公因式(GCD)為 , 則必定存在兩組多項式 和 ,符合 ) (x a ) (x u ) (x b ) (x v ) (x rn ) (x ) ( ) ( ) ( ) (x u x a x v x b rn = + 。一 般所看到的輾轉相除法必定以下面的形式呈現: ) ( ) ( ) ( ) ( 1 1 x a x q x b x r = − ⋅ ) ( ) ( ) ( ) ( 2 1 2 x b x q x r x r = − ⋅ ) ( ) ( ) ( ) ( 1 3 2 3 x r x q x r x r = − ⋅ (2.20) : ) ( ) ( ) ( 0=rn−1 x −qn+1 x ⋅rn x 值得注意的是此遞迴方法不僅找出rn(x),同時也會找到u(x)及v(x)。 根據上述演算法的流程,可以定義一些變數,並延續這些定義, 將演算法歸納出一個遞迴的形式: ) ( ), ( ) ( 0 1 x a x r b x r− = = = − +1(x) r 1(x)r (x) q k k k ) ( ) ( ) ( ) ( ) (x u x a x v x b x rk = k + k (2.21) 0 ) ( , 1 ) ( 0 1 = = − x u x u 1 ) ( , 0 ) ( 0 1 = = − x v x v
) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( 1 1 1 1 1 x r x q x r x b x v x a x u x r k k k k k k + − + + + − = + = ) ( )) ( ) ( ) ( ( ) ( )) ( ) ( ) ( ( )) ( ) ( ) ( ) ( )( ( )) ( ) ( ) ( ) ( ( 1 1 1 1 1 1 1 x b x v x q x v x a x u x q x u x b x v x a x u x q x b x v x a x u k k k k k k k k k k k + − + − + − − − + − = + − + = (2.22) 因此,藉由這些定義及推導,可以統整出一些關係式: ) ( ) ( ) ( ) ( 1 1 1 x r x q x r x rk+ = k− − k+ k (2.23) ) ( ) ( ) ( ) ( 1 1 1 x u x q x u x uk+ = k− − k+ k (2.24) ) ( ) ( ) ( ) ( 1 1 1 x v x q x v x vk+ = k− − k+ k (2.25) = − +1( ) 1( )r (x) x r x q k k k (2.26) 只要一直重複計算(2.23)(2.24)(2.25)和(2.26)四式,直到 ,就可以找到最大公因式 0 ) ( 1 = + x rn rn(x)=un(x)a(x)+vn(x)b(x),以及相 對應的u(x)及v(x)兩個多項式。 Euclidean 演算法就是要用這種精神去計算前面所提到的關鍵方 程式(Key Equation): ,將這個關鍵方程式轉變 為另一種類似最高公因式的描述方式: ,由 此可見,只要擁有錯誤症狀多項式 ,接下來就可以採用Euclidean 演算法來求出最高公因式 t x x S x x) ( ) ( )mod 2 ( =Λ ω x ( ω ) (x S ) (x t x x u x S x) ( ) ( ) 2 ( )=Λ ⋅ + ⋅ ω ,也就是錯誤大小評估多項式,而且還 可以一併得到錯誤位置多項式Λ(x)。 最後針對用於里德所羅門解碼器的 Euclidean 演算法作一個總 結 , 令 2 ( )且 , 則 x a x t ≡ S(x)≡b(x) ω(x)≡rk(x)=GCD(a(x),b(x)) , 以 及 ,終止的條件為 ) (x ) (x ≡v Λ deg(rk(x))<t[1],完整演算法的歸納如下。
1. 從收到的信號求出 2t 個錯誤症狀。 2. 對變數做初始化: t x x x -1 2 1( )=0, r ( )= Λ− ) ( ) ( r , 1 ) ( 0 0 x = x =S x Λ t x ri( ))< deg( ) ( ) ( ) ( ) (x i 2 x Qi 1 x i 1 x i =Λ− − − Λ− Λ ) ( ) ( ) ( ) (x r 2 x Q 1 x r 1 x ri = i− − i− i− = − − − ( ) ( ) ( ) 1 2 1 r x x r x Q i i i 3. 遞迴方式從 i = 1 到 :
2.4.3 尋找錯誤位置之方法(Chien Search)
Chien 尋根演算法說穿了其實很容易,可以說是很系統化的一種 方法,也可以形容為土法煉鋼法,其精神就是把建在的伽羅瓦場中所 有的元素代入錯誤位置多項式測試,假如有一個元素使得 , 代表 即為錯誤的位置,也就是接收信號中的 發生錯誤,找到錯誤 的位置之後,就可以利用下一小節所要介紹的佛尼(Forney)演算法 去找出其相關位置之錯誤大小,然後加以修正。 0 ) ( = Λ α− j j α rj2.4.4 尋找錯誤大小的佛尼(Forney)演算法
此演算法主要也是從錯誤症狀(Syndrome)和關鍵方程式(Key Equation)推導得來[2]: 0 0 0 ) ( ' ) ( ) ( ' ) ( ) ( 1 1 ) 1 ( 1 1 ) 1 ( − − − − − − − − Λ − = Λ − = − =∏
m i m i v i m i i x x x x X X X X X Y ω ω ω (2.27)其中Yi是錯誤大小、Xi是錯誤位置,Λ' x( )是錯誤位置多項式 的微 分,所以整個演算法要配合著 Chien 尋根演算法所找出的錯誤位置 後,再代入求出錯誤大小。 ) (x Λ 這中間有一個比較值得注意的地方是,伽羅瓦場裡的微分,會使 多項式裡的二次項等於零,因為伽羅瓦場裡的加法相當於 XOR 的動 作,才會產生這種效果。 + Λ + Λ + Λ = Λ'( ) ( 2 3 2 ) x x x x x L L L + Λ + Λ = + Λ + Λ = 3 1 2 3 1 3 2 1 ) ( x x x (2.28) 3x 所以 相當於 奇數次方項的總和,這個特性會影響到後面硬 體架構的設計。 ) ( ' x xΛ Λ(x)
第三章
摺疊演算法之推演與建立
現今有許多的硬體設計為了追求簡單化以及規律性,大多採用運 算單元陣列的形式,其中最著名的就是 Systolic 陣列。Systolic 陣列 是由Kung [7] 在 1980 年提出來的一種硬體架構,這種架構是由一些 簡單的基本運作單元(PE)所連接組成,所以擁有規則且簡單的特 性,適合用在超大型積體電路的設計上。此外,Systolic 陣列用到了 大量的管線化(Pipelining)以及多重運作(Multiprocessing),因此, 它可以達到高速的運作效能以及維持很高的處理速率(Throughput)。1995 年 Keiichi Iwamura [8] 提出一篇以 Systolic 陣列架構為基礎 的里德所羅門解碼硬體,其主要的特色就是只使用一種相同基本運作 單元來實現解碼架構,且利用了管線化的技巧,除了讓整個硬體非常 的簡單有規律,也可以高速的運作。
從另一個角度來看,倘若在整個系統中,里德所羅門解碼方塊的 下一級並不需要很高的處理速率(Throughput),那麼這個高處理速
率的優點,勢必可以拿來交換一些其他的好處。摺疊硬體就是一個以 降低處理速率而獲得硬體面積減少的一個方法,將一連串基本運作單 元的陣列經過摺疊方法,使用少量的運算單元,分時完成原本的工 作,雖然完成工作的速度變慢,但運算單元卻減少,對於不必要很高 處理速率的系統,不失為一個好方法,而其最大的好處除了以時間上 的優勢取得空間上的改善外,摺疊後的架構也有可重覆使用性,增加 了硬體的彈性。
3.1
摺疊演算法的硬體架構推導
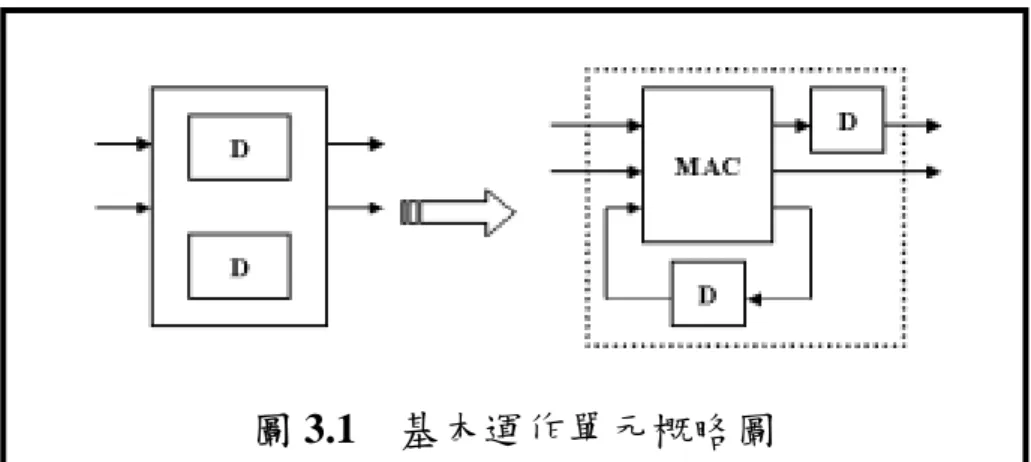
對於硬體摺疊的好處,是讓人顯而易見的,但是對於摺疊方式的 推導,卻沒有一個非常明確的流程讓人遵循,所以在這一個章節中, 首要的目的就是介紹硬體摺疊的步驟,並將其稱為摺疊演算法,只要 依照步驟實行,整個過程是相當有規劃的進行,且摺疊後的架構在時 脈上也不至於出錯。 一般傳統運算單元陣列,對於訊號傳遞的路徑,可分為兩類:向 前路徑(Forward Path)以及回授路徑(Feedback Path)。向前路徑上 的訊號,在兩兩相鄰的運算單元之間互有關係,回授路徑上的訊號, 則只有在本體運算單元中有影響。對於陣列中的每個基本運作單元, 主要區分成乘加器(MAC)與暫存器(Register)兩部分,圖 3.1 即 為一個普遍的基本運作單元,為了演算法上的推導方便,在這裡將乘 加器和暫存器分開表示,往後在運算單元的表示上,也皆以乘加器和 暫存器分開的方式呈現。圖 3.1 基本運作單元概略圖 現在就以一個串接 12 個基本運作單元的陣列為例子,說明摺疊 演算法的推導。一開始在摺疊之前,首先考慮所需要使用的運算單元 個數。假設採用 4 個運算單元,於是可以將 12 個分為 3 列,每一列 的運算單元必須完整的排列對齊,這樣的目的是打算將原本一個回合 內完成的資料計算,分為 3 個的時間點來運作,每一列各分配到一個 時間點進行。圖 3.2 所示就是運算單元的排列方式。 圖 3.2 運作單元陣列
接著,整體的架構開始作一些推導轉換。將每個暫存器變成3 倍 的大小,接著在列與列的每個向前路徑上加入資料銜接的暫存器,這 麼一來,在每回合的第一個時間點時,Ain 及 Bin 送入資料,僅第一 列的四個乘加器開始動作,且將計算後的結果存入該列各暫存器的第 一個位置,同時,第四個向前路徑上暫存器的值,也會傳遞至第一列 與第二列的銜接暫存器中,而第二列及第三列的運算單元則沒有動 作;到了第二個時間點,第二列的第一個乘加器就讀入銜接暫存器的 值,第二列的運算單元開始運作,並且將結果存入該列各暫存器的第 二個位置,其餘兩列的運算單元均不動作,當然第四個向前路徑上暫 存器的值也傳至下一個連接暫存器;到了第三個時間點,第三列的運 算單元會開始計算並將結果存到各暫存器的第三個位置,第一、二列 則無動作;之後進入下一個新的回合,如此一直反覆循環。圖 3.3 說 明了上述的動作。 圖 3.3 運作單元陣列之時序規劃
由此可知,這三列中的第一個乘加器,在每回合的三個動作時間 點中是不重疊的,也就是每列的第一個乘加器不會在同一個時間點同 時動作,而每列的第二、三、四個乘加器亦然。由於在每列中相對位 置的乘加器的工作時間點是兩兩互斥的,也就是工作的時機互相不衝 突,所以可以將三列的運算單元壓縮成一列,成為圖 3.4 所展示的。 於是,只要在一個回合中,送入一個Ain 及 Bin 資料,並且在這個回 合裡,根據不同時間點,調整每個乘加器各自所需輸入的來源暫存 器,以及將每個乘加器輸出所需儲存的計算結果存入正確的暫存器位 置,就可得到正確的運算。這個方法把整體的運算時間拉長了,但卻 減少三分之二的乘加器數目,這就是目的所在。 圖 3.4 運作單元陣列之摺疊架構 原先 12 個運算單元的陣列,經過摺疊演算法調整後,可以明確
的分出乘加器群(MAC Group)及暫存器檔案(Register File),要使 整個運算流程正確的動作,只需要在每個時刻調整暫存器檔案所需輸 出及儲存的資料,以及正確的切換在最前端的多工器(MUX),使其
在Addr = 00 時,由外部 Ain 及 Bin 輸入,其餘時刻則由銜接暫存器
輸入,就可以完成工作,至於乘加器群只要不停的運算就可以了。圖 3.5 是經過摺疊演算法所產生的架構圖。
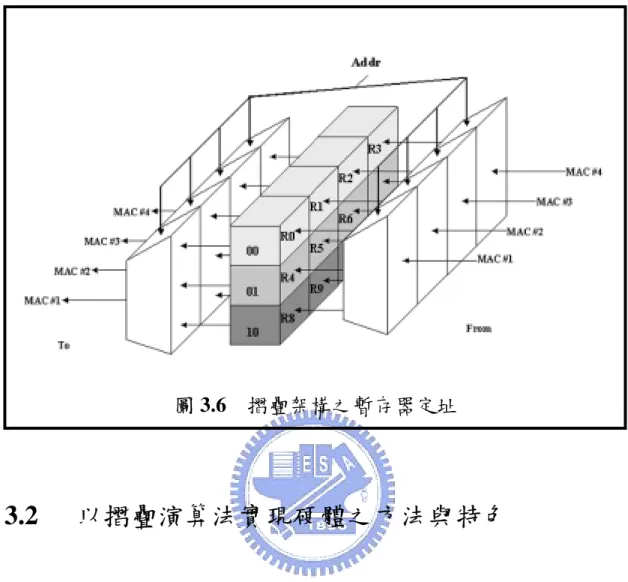
圖 3.5 摺疊架構之乘加運算器與暫存器規劃 值得一提的是,在暫存器檔案中每一行(Column)共有三個暫 存器,就是先前推導過程中三倍暫存器(3D)大小所代表的意思。 另外,暫存器檔案每一列(Row)中也有四個暫存器,同一列的四個 暫存器是必須在同一時刻送到乘加器群運算,因此將每一列的四個暫 存器作捆綁,給予同一個暫存器定址名稱,往後只需要正確控制暫存 器位址,架構就會正常運作,圖 3.6 即為暫存器捆綁及定址的示意圖。 摺疊演算法最主要的精神就是在於時脈上的規劃,將一個回合的 動作分時完成,而依此演算法所推演出的硬體架構,擁有可重複使用 的特性。在下一節中主要說明套用摺疊演算法時運算單元個數的選 擇,以及摺疊硬體架構的好處。
圖 3.6 摺疊架構之暫存器定址
3.2
以摺疊演算法實現硬體之方法與特色
在使用摺疊演算法之前,首要的工作就是決定要使用的乘加器個
數。假設現在系統中有一個方塊,其硬體架構由 N 個運算單元所組
成,且延遲時間(Latency)為t ,而這個方塊的規格所需的處理速
率(Throughput)為 ,於是重複週期(Iteration Period)IP 及所採
用的乘加器數目 m 各為: mac put X mac put t X IP= −1 (3.1) N IP m= (3.2) 藉由上列的式子計算,可以估計出新摺疊架構採用的乘加器數目 m, 且將原本一回合中的計算,分為 IP 個時間點來達成,而摺疊後的架 構不僅符合規格,也比原先乘加器的數目少。
摺疊演算法非常適合於處理速率不需要很高的陣列硬體,尤其是 對於陣列的運算單元個數會因規格不同而有數目上變化的架構。以里 德所羅門解碼器架構為例,解碼器方塊的內部大多數的構成部分是由 運算單元陣列所組成,而且陣列的長度是根據不同的解碼器除錯能力 規格來改變,除錯能力越大,運算單元個數需要越多。當對於這種硬 體架構來實行摺疊時,則以最差狀況的處理速率及陣列長度來估計所 採用的運算單元個數,摺疊後的架構對於除錯能力較小的規格,只需 要減短重複週期,調整每個時刻所指定的輸出及輸入暫存器檔案即 可,這樣的硬體架構展現了硬體可重複使用的特性。此外,摺疊後的 硬體架構在處理速率規格符合的前提下,若要提升最大除錯能力,加 長陣列長度,只需要擴充暫存器檔案大小,延長重複週期,這也使得 摺疊後的硬體更具有彈性。
第四章
硬體實現架構
在介紹這麼多里德所羅門相關演算法以及摺疊理論推導之後,再 來就是要考慮里德所羅門解碼硬體實現的部分。有些在演算法上看似 簡單的問題,在硬體實現上不見得相對單純,在接下來的內容之中, 會作較為詳盡的探討。主要焦點會集中在應用摺疊演算法所架構的硬 體部分,以及合成器的運作流程。 首先,在第一節中會先概括的提到整個里德所羅門的完整電路架 構,以及最後所實現的矽智產合成器運作的流程。第二節會提出一種 低功率消耗及低延遲的伽羅瓦場乘法器。接下來幾個小節會分別介紹 各級運算的摺疊硬體架構,從信號症狀、尋找錯誤位置多項式、錯誤 大小多項式到最後所提出的錯誤修正器,都會一一作仔細的介紹。最 後就是將合成器所產生的硬體語言交給軟體合成分析,並討論與統計 其合成結果。4.1
整合里德所羅門解碼器之矽智產合成器的運作
流程與完整電路架構
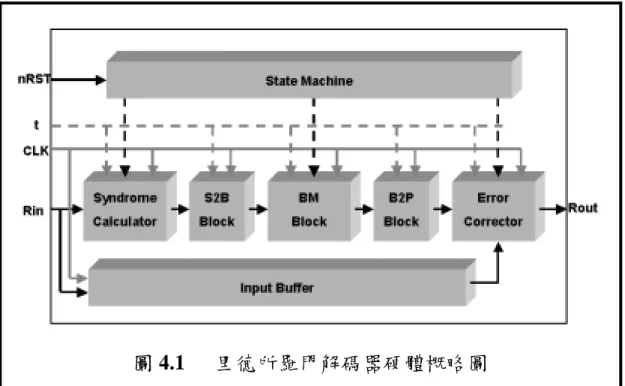
由第二章的里德所羅門解碼基本原理中,可以知道整個解碼過程 是經由: (一)信號症狀計算 (二)尋找錯誤位置多項式及錯誤大小評估多項式 (三)錯誤修正 故設計時將整個系統定義成七個區塊: (一)信號症狀計算方塊(Syndrome Calculator) (二)信號症狀計算器與BM 方塊之資料傳遞介面(S2B Block)(三)BM(Berlekamp-Massey Algorithm)方塊(BM Block) (四)BM 方塊與多項式估算器之資料傳遞介面(B2P Block) (五)錯誤修正器(Error Corrector) (六)輸入信號緩衝器(Input Buffer) (七)狀態機(State Machine) 收到的信號必須先經由信號症狀計算方塊找出其所對應的症狀,接著 再將症狀輸入BM 方塊,找出相對應的錯誤位置多項式以及錯誤大小 評估多項式。找出上述兩個多項式,就可以輸入錯誤修正器,這中間 包括了多項式估計器和計算錯誤大小的佛尼(Forney)演算法實現, 以及將錯誤從收到的信號更正回來的功能。當然,少不了要儲存接收 信號的輸入信號緩衝器,以及協調整體運作的狀態機。另外還有 S2B 與B2P 這兩個資料傳遞介面方塊。整體電路概略圖如圖 4.1 所示。
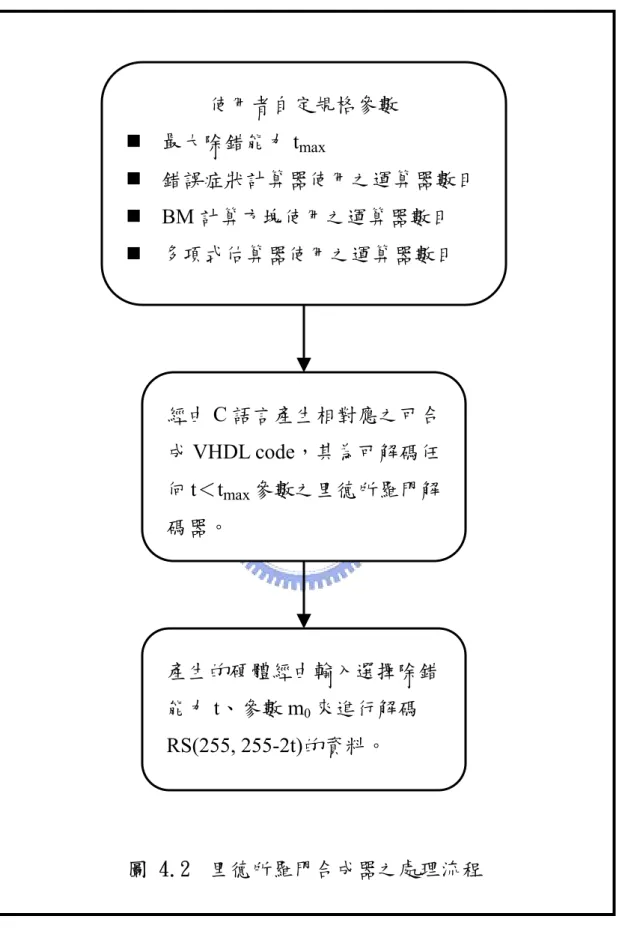
圖 4.1 里德所羅門解碼器硬體概略圖 由於硬體使用摺疊演算法的緣故,使得整體架構變的更有彈性, 可以動態調整不同規格的除錯能力t 值,對於需要動態變換規格的裝 置,有一定程度的助益。 在每一個運算方塊中,硬體的擴充性都很好,可以因應不同的規 格作出有規律性的變化,所以便找出其規則性,設計出里德所羅門解 碼之合成器。使用者可以輸入參數值,經由 C 語言的判斷及運算去 產生符合其要求之可合成的VHDL 硬體語言。 合成器有幾個參數是使用者必須自行設定的,在此作一些說明, 需要設定的資料包括應用所需要最大的除錯能力值,以及錯誤症狀計 算、BM 演算法、多項式估算三大主要計算方塊所需採用的運算單元 個數。因此使用者只要設定以上所需的數值,合成器便會產生相對應 之硬體摺疊架構,而且對於任何除錯能力值小於設定值的規格,皆可 在此硬體架構上實現。此合成器的處理流程在圖 4.2 中統整說明。
圖 4.2 里德所羅門合成器之處理流程 產生的硬體經由輸入選擇除錯 能力t、參數 m0來進行解碼 RS(255, 255-2t)的資料。 經由C 語言產生相對應之可合 成VHDL code,其為可解碼任 何t<tmax參數之里德所羅門解 碼器。 使用者自定規格參數 最大除錯能力 tmax 錯誤症狀計算器使用之運算器數目 BM 計算方塊使用之運算器數目 多項式估算器使用之運算器數目
4.2
伽羅瓦場乘法器
K. K. Parhi [3] 在 2001 年提出了一篇專門為了里德所羅門碼所 設計之低功率且低延遲時間(Latency)之有限場乘法器。 假設現有二多項式 , (2m),則 A 與 B 可表示為基底形式: GF B A ∈∑
∑
− = − = = = 1 0 1 0 , m k k k m k k k B b a A α α (4.1) 若C 為 A 與 B 之乘積,則:∑
∑
∑
= − − = − = = + = ⋅ = k i i k i k m k k k m m k k k d where d a b d B A C 0 1 0 2 2 α α (4.2) 其中αk是GF(2m)中的元素,且一定含有獨特的 (k)使得: i g∑
− = = 1 0 ) ( m i i k i k g α α 2 2 1 0 ≤i≤m− and m≤k≤ m− where (4.3) 這些 (k)都是可以事先算好的。 i g 因此C 可以經由推導化簡為:∑
∑ ∑
∑
∑
− = − = − = − = − = + = + = 1 0 2 2 1 0 ) ( 1 0 2 2 ) ( m k k k m m k m i i k i k m k k k m m k k k d d g d d C α α α α∑
∑
∑
− = − = − = = + = 1 0 1 0 2 2 ) ( ) ( m k k k m k m m j j k j k k c g d d α α (4.4)∑
− = + = 2 2 ( ) m m j j k j k k d d g c where經由上面的推導我們不難發現整個乘法的過程包含了兩個步驟: (一)兩數相乘(Multiplication)(方程式(4.2)得知)
(二)模數的化簡(Modular Reduction)(方程式(4.4)得知)
這兩個步驟之間沒有所謂資料依賴(Data Dependence)的關係, 所以兩者之間可以平行處理。值得注意的是,在這兩部分之中,平衡 的互斥樹狀架構(Balanced XOR Tree)可以達到最短之邏輯路徑效 果。例如:(a3 ANDb0 )XOR( a2 ANDb1 )XOR( a1 ANDb2 )XOR( a0 ANDb3)
(a) (b) 圖 4.3 (a)平衡的互斥樹狀架構 (b)非平衡的互斥樹狀架構 從圖 4.3 中可以看出假如使用(a)樹狀架構,邏輯路徑只需要 經過一個AND 和兩個 XOR 邏輯閘的時間;相反地,假如使用(b) 樹狀架構,邏輯路徑就需要經過一個 AND 和三個 XOR 邏輯閘的時 間,整體時間較(a)多出一個邏輯閘的時間,所以我們當然採用平 衡的互斥樹狀架構。
圖 4.4 是當非規則全平行乘法器建立在 GF(24)時之硬體架構,我 們可以注意到上半部就是前面所提到的第一步驟:兩數相乘;下半部 就是第二步驟:模數化簡。其中 ( ) ( 0≤ ≤3 ,4≤ ≤6)是事先算好的。 k i gik 圖 4.4 建立在 GF(24)之非規則全平行乘法器硬體架構
4.3
處理錯誤症狀(Syndrome)之硬體摺疊架構
由 2.4.1 小節可知,錯誤症狀的計算可以被視為是一連串伽羅瓦 場的乘加運算,根據定義:∑
− = ⋅ =2 1 0 ) ( t j j j x S x S∑
(4.5) = − + − ⋅ = n i i n j m i n j R S where 1 ) ( α 0 然而Sj可以化成下面的形式: 0 3 2 1 0 ) 0 ) ) 0 (( ( R R R R Sj = ⋅ ⋅⋅ n− ⋅αm+j + n− ⋅αm+j + n− ⋅⋅⋅αm +j + (4.6) 這一連串的乘累加運算,進而以演算法之Pseudo-code 表示如下: end j n z end R j i z j i z do n to i for j z begin do to j for begin i n j m ] , [ : S ; ] , 1 [ : ] , [ 1 : ; 0 : ] , 0 [ 1 2t 0 : j 0 = + ⋅ − = = = − = − + α 由許多陣列處理器的參考書中,不難發現到只要能夠將類似上述 之 Pseudo-code 找出來,就有辦法依照變數將其硬體化成一維或二維 之陣列的形式。故依照上述關於錯誤症狀之 Pseudo-code,整理出其 相對應之硬體架構,如圖 4.5 所示,每一個運算單元負責處理一個錯 誤症狀的計算。圖 4.5 錯誤症狀計算之陣列硬體架構
4.3.1 乘加運算器及暫存器規劃
這一節就以上述的陣列架構為起點,開始建構出處理錯誤症狀的 硬體,接著利用摺疊演算法的推導,將摺疊硬體的好處套用在里德所 羅門解碼器上。 在開始摺疊錯誤症狀的陣列架構之前,首先必須考慮採用的運算 單元個數。根據解碼演算法定義,假設除錯能力為 t,則必須計算出 2t 個錯誤症狀,因此其處理錯誤症狀硬體為 2t 個運算單元的陣列。 現在就以除錯能力最大為8 作為例子,而期望使用 4 個運算單元來架 構處理錯誤症狀的硬體。由於除錯能力最大為8,所以原先的陣列長 度為16;採用 4 個運算單元,則可以將 16 個運算單元分為 4 列,如 圖 4.6 所示。圖 4.6 除錯能力 t=8 之錯誤症狀計算陣列 現在打算將一個回合的資料分為4 個的時間點來運算,每一列各 在一個時間點完成,首先將陣列中每個暫存器變成 4 倍大小,接著每 一列在向前路徑上的連接處加入一個資料銜接的暫存器,因此在第一 個時間點時,送入資料 Rn-i,僅第一列的四個乘加器開始動作,且將 計算後的結果存入該列各暫存器的第一個位置中,而此筆Rn-i資料也 會傳至第一列與第二列的銜接暫存器,至於第二、三、四列的乘加器 則均不動作;到了第二個時間點,讀入銜接暫存器中的Rn-i值,第二 列開始運作,並將結果存入該列各暫存器的第二個位置,其餘三列均 不動作,當然Rn-i也傳至下一個連接暫存器;到了第三個時間點,第 三列會開始計算並將結果存到各暫存器的第三個位置,其餘各列無動 作;第四個時間點的動作以此類推,圖 4.7 說明了上述的動作。
圖 4.7 錯誤症狀計算陣列之時序規劃 由此可知,每列中相對應位置之乘加運算器,在四個動作時間點 中是兩兩互斥的,也就是列與列中相對位置的運算器不會在同一個時 間點同時動作,所以可以將這四列壓縮成一列。於是只要在一個回合 中送入一個Rn-i資料,且在這回合裡將四個時間點各自所需的計算結 果存入正確的暫存器位置就可得到正確的運算。因此接下來的工作就 是根據不同時間點,調整每個乘加器所需的輸入來源及輸出目的地, 而讓整體架構正確工作。圖 4.8 展示的是摺疊後的硬體架構。 圖 4.8 錯誤症狀計算陣列之摺疊架構
將摺疊演算法調整後的架構分離為乘加器群及暫存器檔案,其中 每個乘加運算器擁有三個輸入端及兩個輸出端,從暫存器中讀入上一 回合所乘累加結果,乘上該運算器在該時間點對應的α值,再加上此 時刻的外部輸入Rn-i後,再存回暫存器,因此三個輸入來源分別為累 加暫存器、相對應α值以及 Rn-i,輸出則存回累加暫存器,並將 Rn-i 送入銜接暫存器,如圖 4.9 所示。 圖 4.9 錯誤症狀計算硬體之乘加運算器與暫存器規劃 由圖中看來,α資料表及暫存器檔案在每個時間點各會讀入四筆 資料分別送入四個運算器中,因此在兩個資料表中可以將同一列的四 筆資料作綑綁的動作,由 Addr 來給予定址命名。舉例來說,當第一 個時間點時,Addr 送入 00 值,因此α 資料表會送出 ~ 到四個 運算器;同理,暫存器檔案也會送出上一回合儲存在 R0~R3 中的乘 累加結果到運算器去計算;而在第二、三、四個時間點時,則以此類 推,只需要輸入不同的Addr 值就可達成。當然一旦計算完成時,Sout 0 m α αm0+3
所輸出的值即為錯誤症狀,其依照 Addr 的轉換,一個時脈連續輸出 四筆錯誤症狀。另外,一般典型的參數m0值為 0 或 1,所以α 資料表 可經由m0輸入,選擇載入α0~α15或α1~α16兩種模式。
4.3.2 位址產生器的設計
位址產生器(Address Generator)是用來規劃每個時間點所應送 入資料表位址的一個控制機制,依據時脈(Clock)對位址訊號作遞 增的動作,其作用就如同一個有計數上限的計數器。每當一個時脈發 生,位址訊號就會向上加 1,而達到摺疊係數(Fold Factor)這個計 數上限時則歸零。以方才推導的架構為例子來說,當除錯能力 t 為 6 時,摺疊係數等於 3,因為原先的 12 個運算單元只想用 4 個運算器 來完成,所以必須摺成 3 摺,因此位址計數也會從 00 計數,經過 01 到 10,而後又歸回 00;如果除錯能力為 8 時,則摺疊係數等於 4, 也就是計數 00、01、10、11 後歸於 00。 圖 4.10 是位址產生器的方塊圖,其內部有兩個計數器,一個用 作位址訊號遞增的計數用,另一個則是標記硬體運作的回合數,進而 掌握錯誤症狀計算的完成時間。在方塊中的輸入 ini 訊號是一個重置 作用的訊號,使位址計數歸零,此外這個訊號也會傳遞至暫存器檔 案,將累加暫存器作初始化歸零。CLK 則為計數標準,每當在時脈 訊號的上緣觸發時,計數就會向上加1。Fold_factor 訊號是用來規定 計數的上限。輸出的 Done 訊號則是當完成錯誤症狀計算時,Done 訊號升為高準位,告知此時的資料是該截取的,其餘時間Done 訊號 均為低準位。圖 4.10 錯誤症狀計算硬體之位址產生器
4.3.3 錯誤症狀計算硬體之輸入輸出定義
在這小節的最後,對於計算錯誤症狀這個方塊的輸入輸出腳位作 個定義,這樣在整個系統整合時才不易搞混。輸入的部分有接收的到
信號Rin、時脈 CLK、重置 ini、摺疊係數 fold_factor,以及參數 m0;
輸出部分包括四筆錯誤症狀輸出,還有完成旗標Done,如圖 4.11 所
示。