國
立
交
通
大
學
資訊科學與工程所
博
士
論
文
高效能快閃記憶體轉換層設計之研究
A Study on the Design of High Performance
Flash Translation Layers
指導教授:張瑞川 張大緯 教授
研 究 生:喬夢麟
高效能快閃記憶體轉換層設計之研究
A Study on the Design of High Performance
Flash Translation Layers
指導教授:張瑞川 張大緯 Advisor:Dr. Ruei-Chuan Chang and Dr. Da-Wei Chang 研 究 生:喬夢麟 Student:Mong-Ling Chiao 國 立 交 通 大 學 資 訊 科 學 與 工 程 所 博 士 論 文 A Dissertation Submitted to Department of Computer Science
College of Computer Science National Chiao Tung University In partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science
December 2013
Hsinchu, Taiwan, Republic of China
高效能快閃記憶體轉換層設計之研究
研究生: 喬夢麟 指導教授: 張瑞川 博士 張大緯 博士國立交通大學
資訊科學與工程研究所
摘要
快閃記憶體在支援磁碟使用的檔案系統時,需要在快閃記憶體上增加一 個快閃記憶體轉換層,提供區塊裝置式介面。因為快閃記憶體有寫入前需 抹除的特性,快閃記憶體轉換層使用異地更新及清除流程去回收含廢棄資 料的區塊。這些回收的成本是快閃記憶體轉換層效能的關鍵,因為清除流 程使用的動作,例如複製頁、抹除區塊等等,都非常耗時。為達高效能的 目的,快閃記憶體轉換層應該要最小化清除成本。 為了索引邏輯頁的實體頁位置,快閃記憶體轉換層負責維護兩者之間的 對映表格。混合式位置轉換快閃記憶體轉換層將快閃記憶體區分為兩個區 域,大的資料區域使用邏輯區塊對應實體區塊的管理;小的日誌區域使用 邏輯頁對實體頁管理。藉此控制對映資訊的數量,並且達到良好的效能。 本論文提出了兩個混合式位置轉換快閃記憶體轉換層。第一個名為 ROSE,其中包含了三項用來降低清除成本的新技術。首先,它透過避免連 續寫入整個區塊的頁落入不同的區塊,藉此降低回收的成本;同時,不會 將隨機寫入、不完全連續寫入,誤判為連續寫入,避免因誤判隨之而來的 代價。其次,採用針對混合式位置轉換快閃記憶體轉換層來設計、同時考量區塊的新舊與合併成本的清除方針,藉此提高清除的效率。最後,藉由 延遲抹除尚有空白頁的廢棄區塊,並回收使用這些空白頁。 第二個快閃記憶體轉換層名為 HybridLog。透過有效率的使用備用區域, HybridLog 在所有的區塊進行日誌式的寫入,有效率的支援新型的 NAND 快閃記憶體。日誌式寫入能夠避免寫入無謂的空白資料進入頁,以及降低 因為資料區域目標頁已經被寫過、而寫入日誌區域的機率。 我們透過模擬評估上述兩個我們所提出的快閃記憶體轉換層的效能。我 們使用三個知名的混合式位置轉換快閃記憶體轉換層作為效能比較對象。 評估結果顯示,我們所提出的快閃記憶體轉換層的表現優於比較對象。
A Study on the Design of High Performance
Flash Translation Layers
Student:Mong-Ling Chiao Advisors:Dr. Ruei-Chuan Chang Dr. Da-Wei Chang
Department of Computer Science National Chiao Tung University
ABSTRACT
A Flash Translation Layer (FTL) provides a block device interface on top of
flash memory to support disk-based file systems. Due to the erase-before-write
feature of flash memory, an FTL usually performs out-of-place updates and uses
a cleaning procedure to reclaim blocks with stale data. The cost of cleaning is a
key factor to the performance of an FTL since cleaning involves
time-consuming operations such as live page copying and block erasure. To
achieve high performance, an FTL should minimize the cleaning cost.
To locate each logical page, an FTL manages the mapping (i.e., address
translation) between logical page numbers (LPNs) and physical page numbers
(PPNs). By dividing the flash memory into two areas, a large data area managed
by coarse-grained address translation and a small area managed by fine-grained
address translation, a hybrid address translation (HAT)-based FTL can achieve
In this thesis, two novel HAT-based FTLs are proposed. The first FTL,
called ROSE, includes three novel techniques for reducing the cleaning cost.
First, it reduces high-cost reclamation by preventing data in an entire-block
sequential write from being placed into multiple physical blocks while
eliminating the cleaning cost resulting from mispredicting random or
semi-sequential writes as sequential ones. Second, it uses a novel cleaning
policy that considers both the block age and the cleaning cost in a HAT-based
FTL for improving the cleaning efficiency. Third, it delays the erasure of
obsolete blocks and reuses their free pages for buffering more writes.
The
second FTL, called HybridLog, supports modern NAND flashmemories by enabling log-style write in all the blocks and efficient use of spare
area. The use of log-style write also achieves low cleaning cost by eliminating
writes of dummy pages to the data blocks and by reducing the write traffic to the
small-sized log area.
The performance of the two proposed FTLs is evaluated through simulation.
Three well-known HAT-based FTLs are used for performance comparison. The
evaluation results show that the two proposed FTLs outperform the HAT-based
誌
謝
進入交大資工所九年了。首先要感謝的是我的指導教授張瑞川博士,給 我一窺門徑的機會。在有限的時間內,讓門外漢的我有機會學習到學術的 嚴謹與趣味。其次要感謝的是目前任職於成功大學,共同指導我的張大緯 學長。張大緯學長細心指導我研究方法與撰寫論文的諸多細節,令我大開 眼界且茅塞頓開。 感謝我的家人,體諒我在這九年中冷落了他們,卻還是鼓勵我、支持我。 感謝我的母親,沒有她含辛茹苦的培養我,我不可能有此機會來學習;感謝 我的父親,讓我學習到敦厚待人的重要。感謝我的妻子,這段時間一個人 操持家務、照顧小孩,讓我沒有後顧之憂。
Table of Contents
摘要 ... i
Abstract ... iii
誌謝 ... 錯誤! 尚未定義書籤。 Table of Contents ... iii
List of Tables ... iiix
List of Figures ... x
Chapter 1 Introduction ... 1
Chapter 2 Background and Related Work ... 6
2.1 Background and Terminology ... 6
2.2 Flash Translation Layers ... 8
2.2.1 BAST ... 13 2.2.2 FAST ... 13 2.2.3 AFTL ... 14 2.2.4 Superblock ... 15 2.2.5 LAST ... 15 2.3 Cleaning Policies ... 16
Chapter 3 The ROSE FTL ... 18
3.1 Architecture of ROSE ... 18
3.2 Entire-Block Writing ... 19
3.3 Merge-Aware Cleaning Policy ... 25
3.4 Free Page Reuse ... 33
3.5 Metadata Management in ROSE ... 37
Chapter 4 The HybridLog FTL ... 39
4.1 Architecture of HybridLog ... 40
4.2 Log-Style Writes ... 42
4.3 Spare Area Requirement of HybridLog ... 47
4.4 Reconstruction of Metadata ... 49
Chapter 5Performance Evaluation ... 51
5.1 Experimental Setup and Traces ... 51
5.2 Performance Evaluation of ROSE ... 55
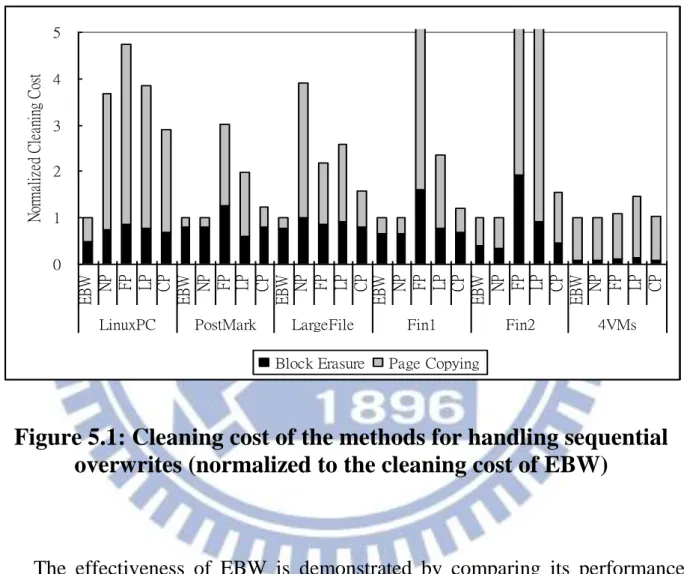
5.2.1 Effect of Entire-Block Writing ... 55
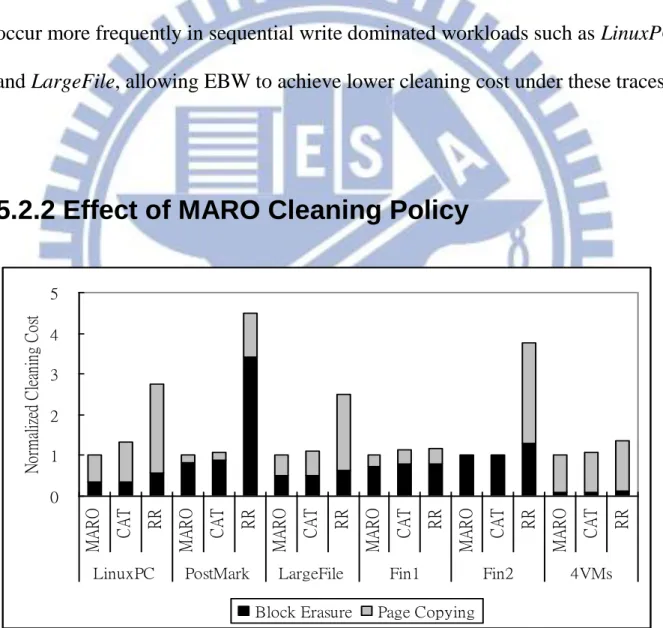
5.2.2 Effect of MARO Cleaning Policy ... 58
5.2.3 Effect of Free Page Reuse ... 64
5.2.4 Overall Performance of ROSE ... 66
5.3 Performance Evaluation of HybridLog ... 71
5.3.2 Cache Hit Ratio ... 74
5.3.3 Overall Performance of HybridLog ... 75
Chapter 6 Conclusions and Future Work ... 77
6.1 Conclusions ... 77
6.2 Future Work ... 78
Bibliography ... 80
L
IST OF
T
ABLES
TABLE 4.1:COMMON FLASH MEMORY CONFIGURATION AND THE CORRESPONDING GROUP SIZES ... 48
TABLE 5.1:DEFAULT VALUES OF THE PARAMETERS ... 52
TABLE 5.2:TRACES ... 54
TABLE 5.3:PORTIONS OF ENTIRE-BLOCK WRITES ... 57
TABLE 5.4:STATISTICS OF FPR ... 66
TABLE 5.5:CLEANING COST WITH DIFFERENT LOG AREA SIZES (SECONDS) ... 69
L
IST OF
F
IGURES
FIGURE 2.1:THREE TYPES OF MERGE OPERATIONS ... 12
FIGURE 3.1:ARCHITECTURE OF ROSE ... 18
FIGURE 3.2:WRITE HANDLING UNDER FAST(A) AND EBW(B) ... 23
FIGURE 3.3:AN EXAMPLE OF THE SWAP OPERATION ... 35
FIGURE 4.1:TRADITIONAL HAT ARCHITECTURE VS HYBRIDLOG ARCHITECTURE. ... 40
FIGURE 4.2:TWO-LEVEL INTRA-BLOCK MAPPING ... 42
FIGURE 4.3:THE SPARE AREA FORMAT OF EACH WRITTEN PAGE ... 44
FIGURE 4.4:STEPS OF WRITING A PAGE ... 45
FIGURE 5.1:CLEANING COST OF THE METHODS FOR HANDLING SEQUENTIAL OVERWRITES (NORMALIZED TO THE CLEANING COST OF EBW) ... 55
FIGURE 5.2:MISPREDICTION RATIOS AND COST OF PARTIALLY-FULL SW LOG BLOCK MERGES IN THE SEQUENTIALITY PREDICTION METHODS ... 57
FIGURE 5.3:CLEANING COST OF DIFFERENT CLEANING POLICIES (NORMALIZED TO THE CLEANING COST OF MARO) ... 58
FIGURE 5.4:CLEANING COST OF MARO AND LAST(NORMALIZED TO THE CLEANING COST OF MARO) ... 59
FIGURE 5.5:CLEANING COST WITH DIFFERENT WAGE ... 61
FIGURE 5.6:CLEANING COST WITH DIFFERENT Α ... 61
FIGURE 5.7:CLEANING COST W/ AND W/O FPR(NORMALIZED TO THE CLEANING COST W/FPR) ... 64
FIGURE 5.8:AVERAGE SPACE UTILIZATIONS W/ AND W/O FPR ... 65
FIGURE 5.9:CLEANING COST OF FAST,LAST AND ROSE(NORMALIZED TO THE CLEANING COST OF ROSE) ... 67
FIGURE 5.10:WRITE AMPLIFICATION RATIOS OF FAST,LAST AND ROSE ... 68
FIGURE 5.11:EFFECT OF THE NUMBER OF SEQUENTIAL WRITE LOG BLOCKS ... 68
FIGURE 5.12:NORMALIZED CLEANING COST W/ AND W/O LOG-STYLE WRITES ... 71
FIGURE 5.13:AVERAGE NUMBER OF DUMMY PAGES IN A DATA BLOCK ... 72
FIGURE 5.14:AVERAGE NUMBER OF PAGES COLLISION IN A DATA BLOCK WITH FREE PAGES ... 73
Chapter 1
Introduction
NAND flash memory is widely applied in computer and consumer
electronic devices due to its small size, shock resistance, non-volatility and low
power consumption. A NAND flash module is composed of a number of blocks,
each of which is in turn composed of a number of pages. Typically, a NAND
flash block contains 32 to 128 pages, and read/write operations are performed in
units of a single page. In addition, a software component called Flash
Translation Layer (FTL) is usually used to emulate a block device on top of the
flash memory to support traditional disk-based file systems.
In contrast to RAM and disk, a page in the flash memory cannot be
overwritten before being erased, and erase operations are performed in units of a
whole block. Compared to the other flash operations, the erase operation is
time-consuming. Moreover, the number of erase operations that can be done on
a specific block is limited, usually between ten thousand and hundred thousand.
To avoid erasing an entire block for each logical page overwrite, therefore, an
FTL usually directs each page collision to a free physical page. The page
containing the stale data is then reclaimed by a cleaning procedure. The cost of
cleaning is a key factor to the performance of an FTL since cleaning involves
achieve high performance, an FTL should minimize the cleaning cost.
To locate each logical page, an FTL manages the mapping (i.e., address
translation) between logical page numbers (LPNs) and physical page numbers
(PPNs). Typically, the mapping can be done at two different granularities:
page-level and block-level. Page level address translation (PAT) scheme maps
each logical page to an individual physical page. Pages belonging to the same
logical block can be mapped to different physical blocks. For a large NAND
flash memory, such a fine-grained address translation scheme requires a large
memory space to maintain the mapping table since each logical page has a
corresponding entry in the table. In order to reduce the space requirement of the
mapping table, block level address translation (BAT) scheme uses a more
coarse-grained address translation approach that translates each logical block
number (LBN) to a physical block number (PBN). Therefore, the number of
entries in the mapping table can be greatly reduced. However, due to the block
level address translation, BAT requires each logical page to be written only to its
corresponding offset in a physical block, resulting in poor performance.
To combine the benefits of PAT and BAT, several FTLs based on the
hybrid level address translation (HAT) scheme have been proposed [7, 18, 49,
51, 55, 57, 58, 59, 61, 74, 80, 84, 87, 88, 90]. In this scheme, most of the data
are stored in data blocks managed via the BAT scheme. However, by storing hot
is managed by the PAT scheme, the HAT scheme can delay the erasure of some
data blocks that are not fully occupied, increasing the space utilization.
Moreover, the memory requirement is comparable to that of the BAT scheme
since the pages managed via the PAT scheme are limited to a small number.
Cleaning in HAT-based FTLs is done by reclaiming log blocks. When a log
block needs to be reclaimed, it is merged with its corresponding data blocks.
In this thesis, we propose two HAT-based FTLs, ROSE and HybridLog.
ROSE incorporates three novel techniques for reducing the cleaning cost. Firstly,
it utilizes a technique called Entire-Block Writing (EBW) to prevent pages of an
entire-block sequential write from being placed into multiple physical blocks,
reducing the possibility of high-cost reclamation. Previous HAT-based FTLs
achieve this by predicting sequentiality. However, mispredicting random or
less-than-a-block writes as sequential writes leads to increased cleaning cost.
EBW eliminates such misprediction, resulting in a lower cleaning cost. Secondly,
ROSE uses a novel policy called Merge-Aware Round rObin (MARO) to select
a victim log block for reclamation when the log area has run out of its free space.
In contrast to the previous cleaning policies that consider only the state of the
candidates, MARO considers not only the state of the candidates (i.e., log blocks)
but also the state of the data blocks that correspond to those candidates.
Moreover, different from previous HAT-based FTLs, both the ages and the
shown in the section 5.1, such consideration reduces the cleaning cost. Thirdly,
ROSE utilizes a technique called Free Page Reuse (FPR) to increase the space
utilization. FPR delays the erasure of a low-utilized data block and allows the
free pages in that block to buffer further page overwrites, resulting in a lower
cleaning cost.
HybridLog supports modern NAND flash memory by following the
consecutive programming restriction in all the blocks and efficient using the
spare area. With the development of flash memory, new restrictions are imposed
on flash memory chips, and an FTL should follow these new restrictions so as to
be applied on these modern chips. Specifically, a new programming (i.e., write)
restriction called consecutive programming is imposed on most modern flash
memories [13, 63], whereby pages have to be programmed in consecutive order
(i.e., from lower-numbered pages towards higher-numbered pages) within a
block. Moreover, Multiple Level Cell (MLC) NAND achieves lower cost by
allowing multiple bits to be stored in a single cell. However, compared to Single
Level Cell (SLC), MLC has a higher bit error rate and thus requires stronger
ECC [17], which consumes more spare area space, preventing FTLs requiring
large space of the spare area from being applied on it. To allow consecutive
programming, HybridLog enables log-style writes to all the blocks (including
the data blocks) in the flash memory. The log-style writes also helps to reduce
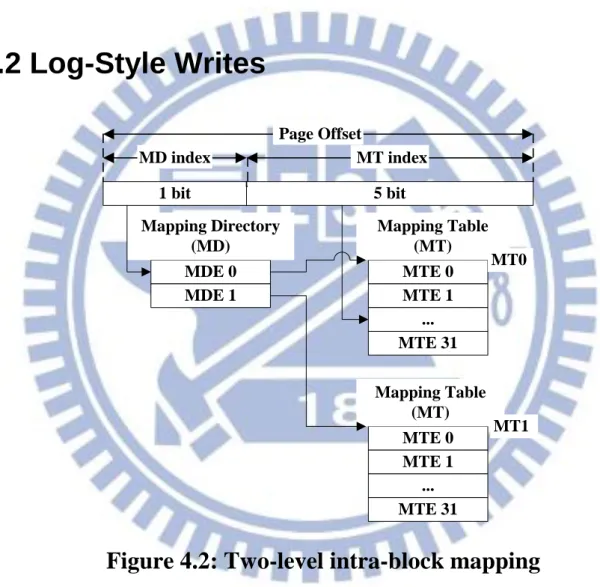
writes to all blocks, intra-block mapping information is stored in the spare area
of each written page. Since only a small space is required in the spare area for
the mapping information, many modern SLC/MLC flash memories can be
supported.
Through simulation, we show the performance improvements of each of the
three proposed techniques in ROSE. We also compare the performance of ROSE
with FAST and LAST, two well-known and efficient HAT-based FTLs, under a
variety of benchmarking and realistic workloads. The results show that ROSE
outperforms the existing HAT-based FTLs by up to 47 times in terms of the
cleaning cost. Due to the reduction on the cleaning cost, the flash write time is
reduced by up to 1.6 times. The performance of HybridLog and two well-known
FTLs are also compared. The performance results show that, HybridLog
outperforms these two HAT-based FTLs by up to 17.8 times in terms of
cleaning cost.
The rest of this thesis is organized as follows. The related efforts are
described in Chapter 2. In Chapters 3 and 4, we describe the design and
implementation of ROSE and HybridLog, respectively. The performance results
are presented in Chapter 5. Finally, conclusions and future work are given in
Chapter 2
Background and Related Work
2.1 Background and Terminology
An FTL maintains the state of all the pages in a flash storage. A page is free
if the page has not been written after its last erasure. Free pages can be used to
accommodate page writes. A free page becomes live after it has been written with
user data. Since a live page cannot be overwritten before being erased, updating
data in place is inefficient because each update should be preceded by a
time-consuming erase operation. Thus, most FTLs handle page overwrites by
adopting the out-of-place update mechanism, in which the new data are written to
another free page and the live page that contains the old data becomes dead. Dead
pages should be reclaimed by a cleaning procedure, which works as follows. First,
one or more victim blocks are selected to be reclaimed according to a cleaning
policy. Second, the live pages in the victim blocks are copied to free pages of
other blocks. Finally, the victim blocks are erased. After the cleaning, all the
pages in the selected blocks become free and can be used to satisfy future data
writes. Cleaning is time consuming since it involves live page copying and block
erasure. Therefore, the cost of cleaning is a key factor to the performance of an
the performance of an FTL. The first one is the cleaning cost, which is defined as
the time spent on the cleaning procedure resulting from the execution of a given
workload. The second one is the Write Amplification Ratio (WAR) [29], which is
defined as
(1) where W and C represent the total request write time and the cleaning cost of the
workload, respectively. The ratio 1.5 means that the time spent on cleaning is half
of the total request write time of the given workload.
An FTL may erase a block that still contains free pages, which wastes the
free pages. The free pages could have been used to buffer more writes and this
waste could increase the cleaning cost. We define space utilization as the ratio of
the number of occupied (i.e., nonfree) pages in a block to the total number of
pages per block when the block is going to be erased. The value is 100% if a
to-be-erased block contains no free pages. Increasing space utilization usually
leads to reduction of the cleaning cost.
With the development of flash memory, new restrictions are imposed on
flash memory chips, and an FTL should follow these new restrictions so as to be
applied on these modern chips. Specifically, a new programming (i.e., write)
restriction called consecutive programming is imposed on most modern flash
memories [13, 63], whereby pages have to be programmed in consecutive order
Moreover, Multiple Level Cell (MLC) NAND achieves lower cost by allowing
multiple bits to be stored in a single cell. However, compared to Single Level
Cell (SLC), MLC has a higher bit error rate and thus requires stronger ECC,
which consumes more spare area space, preventing FTLs requiring large space of
the spare area from being applied on it.
2.2 Flash Translation Layers
An FTL emulates a block device on top of flash memory to support
traditional disk-based file systems. Typically, a request issued from a file system
consists of a single or multiple adjacent sectors. In a flash storage system, the
sector numbers are translated into logical page numbers and the translation is
usually independent of the FTLs. In this thesis, the sizes of a sector and a page
are 512 bytes and 2 Kbytes, respectively, and therefore, LPNs can be obtained by
dividing the sector numbers by 4. Such translation can be regarded as a
preprocessing task before the invocation of an FTL. An FTL hence treats each
request as a number of adjacent logical pages and focuses on the address
translation between LPNs and PPNs.
The address translation can be done at page level (i.e., the PAT scheme) or
block level (i.e., the BAT scheme). PAT-based FTLs [4, 6, 9, 10, 13, 27, 30, 31,
32, 36, 47, 54, 60, 65, 66, 67, 75, 89] directly translate each LPN to a PPN and
a logical page can be written to any physical page and cleaning is needed only
when there are almost no free pages in the storage. Therefore, the cleaning cost is
relatively small. However, this scheme requires a large memory space for a
large-sized flash memory. For example, for an 8-Gbyte flash memory with page
size 2 Kbytes, four million entries (i.e., 16 Mbytes if the size of each entry is 4
bytes) are needed in the mapping table.
Recently, several RAM-space-efficient PAT-based FTLs address this
problem by storing the mapping information in the flash memory and caching the
recently used information in RAM [25]. Cleaning in PAT-based FTLs is done by
reclaiming blocks (i.e., copying live pages in victim blocks to blocks with free
pages and then erasing victim blocks). After the reclamation, the erased blocks
can be used to accommodate future writes.
After a PAT-based FTL has selected a victim block for cleaning, it has to
identify the live pages of the victim block. Querying/updating the mapping
information of the live pages is needed during cleaning. If the FTL stores the
page state and mapping information of each page in RAM, query/update of the
mapping information can just be done in RAM. However, as mentioned above, a
large RAM space would be required for a large sized flash memory. In
memory-constrained consumer storages such as SDs or UFDs, mapping
information of a PAT-based FTL can only be stored in the flash memory (and
cached in RAM). Thus, after a victim block has been selected, extra flash
the victim block and to locate the physical locations of the mapping information
of the live pages. Note that, victim blocks are cold blocks and thus their
information is seldom cached in RAM. If there are many live pages in the victim
block (i.e., high storage utilization) and the mapping information of the live pages
are stored in many different mapping pages, many flash memory reads/writes are
required for querying and updating the mapping information.
BAT-based FTLs achieve lower RAM consumption for the mapping
information by using coarse-grained mapping [3, 19, 50, 70, 71, 72]. In the BAT
scheme, each logical block has a corresponding data block to accommodate page
writes to that logical block. The LPN is divided by the number of pages in a
block to get the logical block number (i.e., the quotient) and the page offset (i.e.,
the remainder). The former is used to index the mapping table to get the physical
address of the data block, and the latter is used to locate the target page in the
data block. If the target page is live (i.e., page collision), in-place update is used.
That is, the data block, say D, is reclaimed by copying all the up-to-date data of
the logical block from D and the write request to a free block F and then erasing
D. After the reclamation, F is used as the new data block. This reclamation is
needed due to the limitation that each logical page can be written only to a fixed
offset of a physical block. Such limitation usually leads to low space utilization
since a significant amount of free pages might exist in the to-be-erased blocks
(i.e., the block D mentioned above). For example, frequently updating a small
the corresponding data block. Erasing these free pages, instead of using them to
buffer page writes, increases the frequency of block reclamation. Moreover, in
modern flash memory the consecutive programming restriction, if the target page
is not consecutive to the last written page of the data block, dummy pages has to
be written between the last written page and the target page (i.e., page padding).
Several hybrid-mapped FTLs have been proposed to achieve performance
superior to block-mapped FTLs, while retaining the small size of the mapping
information. In these FTLs, most of the blocks (i.e., data blocks) are managed via
the BAT scheme. However, by managing a small number of log blocks via the
PAT scheme to accommodate frequently updated pages, the space utilization is
increased. HAT also utilizes the out-of-place update mechanism. Page writes that
cannot be accommodated by the data blocks are satisfied by the log blocks, and
the pages containing the old data become dead. Since the blocks managed by
PAT are limited to a small number, the memory requirement of HAT is
comparable to that of BAT. Cleaning in HAT-based FTLs is done by reclaiming
log blocks. When a log block needs to be reclaimed, it is merged with its
corresponding data blocks. After the merge, a free log block is obtained to
0 1 2 3 Data Free Copy Copy Copy 2 3 2 3 Copy Free Live Dead Log Free 0 1 2 3 Data Free Erase Erase 0 1 2 3 Data Free Erase 0 1 Log Copy Copy 0 1 2 3 Data 0 1 2 3 Data Free Erase 0 1 2 3 Log 0 1 2 3 Data
(a) Full Merge (b) Partial Merge (c) Switch Merge
Figure 2.1: Three types of merge operations
As shown in Figure 2.1, three types of merge could occur depending on the
status of the data and the log blocks. In Figure 2.1(a), a full merge can be done by
copying the live pages either from the data block or the log block to a free block
F, erasing both the data and log blocks, and then using F as the new data block.
In Figure 2.1(b), a partial merge can be done by copying the live pages in the
data block to the free space of the log block, erasing the data block, and then
prompting the log block as the new data block. In Figure 2.1(c), all the up-to-date
data were written in the log block sequentially and thus the merge operation can
be done simply by switching the roles of the log and data blocks and erasing the
original data block, which is called switch merge. Of the three types of merge
operations, the switch merge has the lowest cost while the full merge results in
to multiple data blocks (i.e., the log block accommodates page overwrites
belonging to multiple logical blocks) and thus reclaiming the log block requires
multiple merges, each of which corresponds to a data block. In this thesis, we
define the page density of a log block as the number of data blocks corresponding
to it. In the following, several well-known HAT-based FTLs are described.
2.2.1 BAST
BAST [45] allows each data block to have at most one dynamically allocated
log block accommodating overwrites of that data block. When an allocated log
block cannot accommodate the current write, it is reclaimed by merging with its
data block. Moreover, if all the log blocks have been allocated, a further log
block allocation would cause one of the allocated log block to be reclaimed. This
FTL suffers from the log block thrashing problem [53] (i.e., frequent erasure of
log blocks with low utilization) if the number of frequently updated blocks
accommodating small random writes is larger than the number of log blocks.
2.2.2 FAST
FAST [53] eliminates the above problem of BAST by using fully associative
log blocks. That is, a log block can accommodate page overwrites of any data
blocks. In FAST, one special log block called the SW log block is reserved for
random overwrites. The SW log block corresponds to a single data block. If a
sequential overwrite cannot be satisfied by the current SW log block, the SW log
block is merged with its corresponding data block to get a free SW log block. A
RW log block can correspond to multiple data blocks. If a random overwrite
cannot be satisfied by the RW log blocks because all the RW log blocks are fully
occupied, FAST selects a victim RW log block in a round-robin (RR) fashion and
merges the victim with its corresponding data blocks. FAST may still erase
low-utilized blocks. For example, a victim log block may be merged with
multiple low-utilized data blocks.
2.2.3 AFTL
AFTL [83] allows each data block to have at most one log block for
satisfying overwrites of that data block. When a log block becomes full, its live
pages are regarded as hot and the mapping information corresponding to these
live pages is inserted into a page-level mapping table, which may cause the
eviction of the mapping information of some other hot pages due to the limited
memory space reserved for the mapping table. The eviction is based on LRU and
each selected victim hot page will be migrated back to the corresponding data
block or log block. Since each log block corresponds to a single data block,
2.2.4 Superblock
Superblock [35, 37] allows a group of adjacent logical blocks to share a
number of log blocks so as to increase the space utilization while keeping the
page density of the log blocks low. The limitation of Superblock is that it stores
the page-level mapping information of a block group in the spare area, which
reduces the space for Error Correction Code (ECC). For example, Superblock
requires 44 bytes of each per-page spare area, whose typical size is 64 bytes, on
flash memory modules with 64 pages per block. As a consequence, only a
20-byte space is left for ECC, reducing the quality of the ECC. This problem gets
worse for NAND flash modules with even more pages per block (e.g., 128) [78].
Based on the block grouping concept of Superblock, Park et al. proposed an
offline method [64] to determine the values of the block group size and the
maximum number of log blocks allocated for a block group, which can be
applied on systems with fixed workloads.
2.2.5 LAST
Similar to FAST, the LAST FTL [52] serves sequential and random
overwrites by using different log blocks. In LAST, multiple SW log blocks are
used to satisfy concurrent write streams, and the set of the RW log blocks is
divided into hot and cold blocks to reduce the merge cost. Although multiple SW
less-than-a-block sequential writes corresponding to a significant number of
logical blocks are presented.
2.3 Cleaning Policies
A number of cleaning policies [8, 9, 11, 16, 21, 23] that consider reclamation
efficiency, such as greedy [77], cost-benefit [47], Cost-Age-Time (CAT) [15],
and CICL [43], have been proposed. The greedy policy selects the block with the
minimum number of live pages as the victim in order to minimize the cost of
page copying. The cost-benefit policy selects the block with the maximum value
of the following formula as the victim:
where u represents the ratio of number of live pages to the total number of pages
in the candidate block, and age denotes the time since the last modification of the
block. In the formula, (1 - u) and 2u represent the benefit and cost of the
reclamation, respectively. The age is considered to avoid reclaiming young
blocks, whose pages are likely to be invalidated in the near future.
The CAT and CICL policies consider both reclamation efficiency and wear
leveling [8, 12, 34, 68, 81, 82]. CAT selects the block with the minimum value of
the following formula as the victim:
where e and age represent the number of times the candidate block has been
erased and the elapsed time since the last reclamation of candidate block,
respectively. CICL selects the block with the minimum value of the following
formula as the victim:
λ * e / ( 1 + e
max) + ( 1 - λ ) * v
,where 0 < λ < 1. In this formula, emax denotes the maximum value of e among
all the candidate blocks, and v represents the ratio of number of live pages to the
total number of non-free pages in the candidate block. As shown in the formula,
CICL selects the victim based mainly on wear leveling whenλ is close to 1,
which happens when the difference between the maximum and the minimum
numbers of e among the candidates is large. On the contrary, it selects the victim
mainly based on the reclamation efficiency when λ is close to 0, which
happens when the difference between the maximum and the minimum numbers
of e among the candidates is small.
Basically, these policies are used in PAT-based FTLs. They select a victim
block for reclamation based on the condition of the candidate block, which is not
sufficient for log block reclamation in HAT-based FTLs. Specifically, log block
reclamation involves merging the victim log block with its corresponding data
Chapter 3
The ROSE FTL
In this Chapter, we describe the ROSE FTL. ROSE incorporates three novel
techniques to reduce the cleaning cost, namely, entire-block writing, merge-aware
round robin cleaning policy, and free page reuse. In the following, the
architecture of ROSE is first described, which is followed by the description of
the techniques used in ROSE.
3.1 Architecture of ROSE
Data Area Log Area
LBN
PBN
0
D0
D3
3
D2
2
D1
1
Free Live Dead 0 1 4 5 6 8 0 1 0 8 0 1 4 5 D0 D1 D2 D3 L0 L1Block-level Mapping Table
Figure 3.1: Architecture of ROSE
As shown in Figure 3.1, ROSE utilizes the HAT scheme, which divides the
flash memory into two areas, a large data area managed by BAT and a small log
area managed by PAT. The former contains a set of data blocks while the latter
for accommodating the writes to that logical block. For each write to a logical
page, ROSE writes the data to the target physical page in the data block if the
physical page is free. If the write cannot be accommodated by the data block (i.e.,
the target page is not free), the data are written to the log area in the log order. In
contrast to FAST and LAST, ROSE does not have special log blocks for storing
sequential (over)writes. Instead, it relies on the entire-block writing technique
mentioned in Section 3.2 to handle sequential writes. When the log area has run
out of free pages, a victim log block is selected to be merged with its
corresponding data blocks. That is, for each live page p in the victim log block,
the live pages belonging to the same logical block as p are copied from the
corresponding data block and log blocks (including the victim log block) to a new
block, which serves as the new data block for the logical block. After the page
copying, the victim log block and the corresponding data blocks become obsolete
and can be erased.
3.2 Entire-Block Writing
In some HAT-based FTLs, a log block may correspond to multiple logical
blocks. This leads to a higher cleaning cost for reclaiming the log block since
merging the block with all its corresponding data blocks is required. To reduce
the possibility of such high-cost reclamation, several HAT-based FTLs such as
overwrites. Each of such log blocks, called a sequential write log block,
corresponds to a single logical block. In an SW log block, each logical page is
written to its corresponding offset (i.e., the data in ith logical page of a logical
block are written to the ith physical page of the SW log block), hoping that the
log block can be promoted as a new data block later in a switch merge.
Under the SW log block approach, with a given overwrite request R that
contains pages belonging to a logical block B, the FTLs have to predict whether
or not the other pages belonging to B will be overwritten in the near future. If
they will, all the pages belonging to B should be placed in the same log block so
that the reclamation of this log block can be done in a switch merge (i.e., erasing
the data block corresponding to B and promoting the log block as the new data
block). Therefore, if the other pages are predicted to be overwritten in the near
future, R would be served by an SW log block.
The main problem of the SW log block approach is that frequent
misprediction would cause frequent block erasure. Specifically, FAST uses a
single SW log block and serves an overwrite to a logical page by the SW log
block if the page is the first page of a logical block or the page corresponds to the
first free page of the SW log block. That is, FAST predicts that an overwrite to
the first page of a logical block will be followed by overwrites to the other pages
in that block. As a consequence, in FAST, a workload that repeatedly overwrites
the first page of a logical block may cause the (partially full) SW log block to be
of SW log blocks and serves a write request via an SW log block if the size of the
request is equal to or larger than a predefined threshold (e.g., 4 Kbytes). As a
consequence, semisequential write requests (i.e., requests with sizes smaller than
the block size but larger than or equal to the threshold) corresponding to a large
number of logical blocks could lead to a large number of merges between
partially full SW log blocks and their corresponding data blocks.
ROSE utilizes a fundamentally different approach for handling sequential
overwrites. Specifically, it adopts a technique called Entire-Block Writing (EBW),
which detects sequentiality in the current write request instead of predicting
sequentiality. Therefore, misprediction would never occur. EBW detects
entire-block overwrites and utilizes free blocks, instead of SW log blocks, to
serve those writes. With EBW, each write request is divided into a number of
page-level subrequests and block-level ones. For example, on a NAND flash
module with 64-page blocks, a write request with 130 pages starting from LPN 0
will be divided into two block-level subrequests (i.e., for LPNs 0 to 63 and LPNs
64 to 127) and two page-level subrequests (i.e., for LPNs 128 and 129). For each
page-level subrequest, the data are written to the log area in the log order if the
subrequest is an overwrite. However, each block-level subrequest is served by a
free block. Specifically, given a block-level subrequest that corresponds to
logical block B, the data are written to the data block corresponding to B if the
data block is originally free. Otherwise, the subrequest overwrites one or more
serve this subrequest. After the subrequest has been served, F becomes the new
data block corresponding to B, and the original data block (which contains no live
pages) can be erased if cleaning is needed. Note that, such a free block is always
available since HAT-based FTLs always reserve at least one free block for
buffering the result of a full merge. With the FPR technique mentioned in Section
3.3, the erasure of the original data block can be delayed and the free pages in it
Free Live Dead Initial state A B C LBN 0 LBN 2 LBN 1 Log area L M RW SW 1 0 2 4 6 5 98 A B C L M
Step 1. write request (LPN):(0,1,2,3),(5),(9) A Block-level mapping table B C LBN 0 LBN 2 LBN 1 Log area L M RW SW 1 0 2 4 6 5 98 A B C L M 3 2 1 0 9 5 Step 2. write request (LPN):(4) L B C LBN 0 LBN 2 LBN 1 Log area A M RW SW 1 0 2 4 6 5 98 L B C A M 3 4 9 5 1 0 2 A 3 L 2 1 0 Partial merge Step 3. write request (LPN):(8) L A C LBN 0 LBN 2 LBN 1 Log area B M RW SW 1 0 2 4 6 5 98 L A C B M 3 8 9 5 4 6 5 B A 4 M 9 5
Free Live Dead
Initial state A B C Log area L M 1 0 2 4 6 5 9 8 A B C L M Step 1. write request (LPN): (0,1,2,3),(5),(9) L B C LBN 0 LBN 2 LBN 1 Log area A M 1 0 2 4 6 5 98 L B C A M 3 9 5
Step 2. write request (LPN):(4) L B C Log area A M 1 0 2 4 6 5 98 L B C A M 3 4 9 5 Step 3. write request
(LPN):(8) L B C Log area A M 1 0 2 4 6 5 98 L B C A M 3 8 4 9 5 1 0 2 A 1 0 2 L 3 Switch merge Block-level mapping table Block-level mapping table Block-level mapping table LBN 0 LBN 2 LBN 1 LBN 0 LBN 2 LBN 1 LBN 0 LBN 2 LBN 1 Block-level mapping table Block-level mapping table Block-level mapping table Block-level mapping table (a) (b)
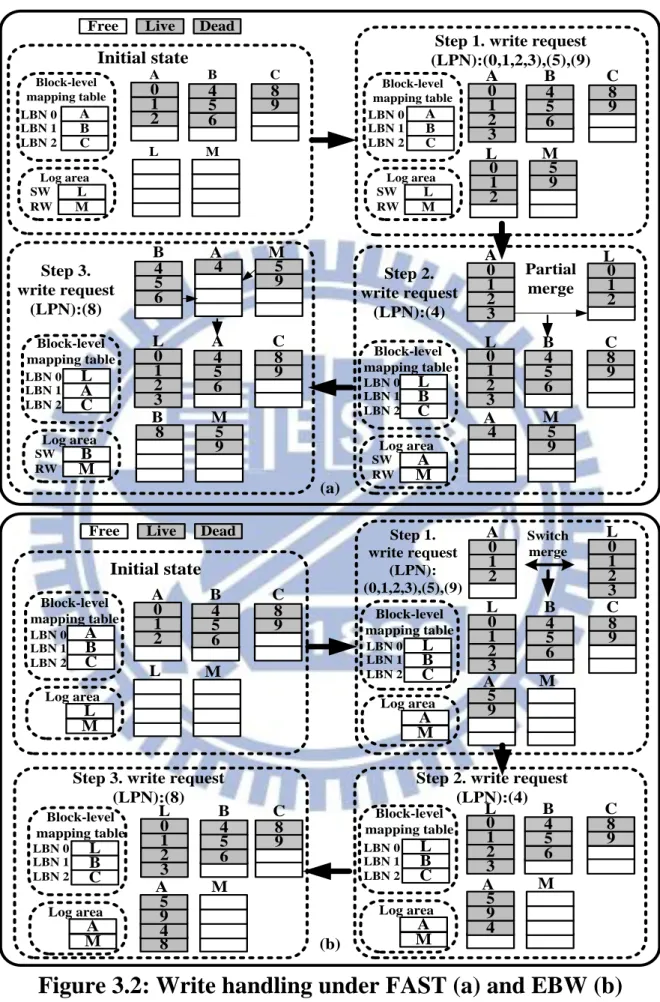
Figure 3.2 illustrates an example showing the difference between EBW and
the SW log block approach in FAST. Assume that the flash memory consists of
three data blocks and two log blocks, with each block containing four pages, and
initially blocks A, B, and C are the data blocks of logical blocks 0, 1, and 2,
respectively. Figures 3.2(a) and 3.2(b) illustrate the handling of the page write
sequence (0, 1, 2, 3, 5, 9, 4, 8) under the SW log block approach in FAST and the
EBW approach, respectively. In Figure 3.2(a), pages 0, 1, and 2 are written to the
SW log block L since page 0 is the first page of a logical block and pages 1 and 2
correspond to the first two free pages of the SW log block after the write of page
0. Page 3 can be served by the data block A, and pages 5 and 9 are served by the
RW log block M. The same as page 0, page 4 also needs to be written to the SW
log block since it is the first page of a logical block. This requires merging L with
A. After the merge, L becomes the new data block. The old data block A is erased
and becomes the new SW log block to accommodate page 4. Similarly, serving
page 8 requires another merge. After the merge, A becomes the new data block.
The old data block B is erased and becomes the new SW log block to
accommodate page 8. Therefore, the cleaning cost under FAST involves erasing
two blocks and copying three pages. In Figure 3.2(b), pages 0, 1, 2, 3 are served
by a free block, say L, which then becomes the new data block of logical block 0
via a switch merge. The old data block A is erased. Since writes to pages 5, 9, 4, 8
Therefore, the cleaning cost under EBW is only the erasure of one block.
As a result, EBW prevents the pages of an entire-block write from being
placed into multiple log blocks, reducing the possibility of high-cost reclamation
and achieving the goal of SW log blocks without using them. Moreover, since
there is no need to predict whether or not a request should be served by an SW
log block, log block reclamation resulting from misprediction is eliminated.
The effectiveness of EBW depends on the frequency of entire-block writes.
Using MLC flash memory and multi-channel architectures in SSDs might lead to
increased block size and reduced frequency of entire-block writes. Nevertheless,
modern operating systems such as Windows 8 and new versions of Linux tend to
issue very large write requests (e.g., larger than 2 Mbytes). Moreover, several
flash-aware cache management techniques [1, 26, 28, 38, 41] such as FAB [33],
BPLRU [42], and CFLRU [69] tend to produce entire-block writes. These help
EBW to remain effective in modern computing systems.
3.3 Merge-Aware Cleaning Policy
As described in Section 2.3, many cleaning policies such as greedy,
cost-benefit, and CAT, select a victim block based on the condition of the
candidate blocks. For example, the greedy policy selects the block with the
minimum number of live pages as the victim in order to minimize the cost of
not suitable for HAT-based FTLs since log block reclamation in a HAT-based
FTL is different from block reclamation in a PAT-based FTL. Specifically, the
former involves merging with data blocks, which was not considered in the above
policies. For example, the cost of reclaiming a log block with three live pages is
not necessarily lower than that of reclaiming another log block with six live pages
since the former may involve copying more pages from the corresponding data
blocks and erasing more blocks.
In this thesis, we propose a new cleaning policy called MARO for a
HAT-based FTL. Similar to round robin, which is used in FAST, MARO
prevents reclaiming young blocks. According to temporal locality, live pages in
the young blocks might be invalidated in the near future. Therefore, delaying the
reclamation of a young block will likely lead to less page copying and block
erasing overhead. Moreover, when reclaiming a log block, MARO considers the
merge cost, which is related not only to the state of the log blocks but also to the
state of the data blocks corresponding to those log blocks.
In MARO, dead blocks will first be selected as the victims. If no such blocks
are available, MARO selects an old block that has a low merge cost as the victim.
Specifically, it selects the log block with the maximum value of score, where the
score of a log block Li can be expressed as
(2)
block Li, W age denotes the weight of the block age, and cost(i) denotes the
merge cost of Li. As mentioned before, a log block Li may correspond to multiple
data blocks and thus reclaiming Li involves merging it with all its corresponding
data blocks. For ease of computation, we assume a full merge is performed
between Li and each of its data blocks. For each data block Dj, two sets of live
pages should be copied to a new data block Dj’, which replaces the role of Dj
after the merge. The first set is the live pages of Dj, and the second set is the live
pages that correspond to the dead pages of Dj. The second set of live pages is
stored in the log area (including the victim log block Li). After merging with all
the corresponding data blocks, the victim log block and the data blocks are erased.
Therefore, the merge cost can be expressed as
nlpc
jdpc
jC
pcn
C
erasei
cost
1*
)
1
(
*
)
(
)
(
(3)In (3), n denotes the number of data blocks corresponding to Li. The lpcj and
dpcj denote the numbers of live pages and dead pages in data block Dj, where 1
<= j <= n, respectively. Finally, Cpc and Cerase denote the cost of copying a page
and erasing a block, respectively. Note that in (3), the first part represents the cost
of page copying and the second part represents the cost of block erasure. Since
both page copying and block erasure can be done in either the foreground or the
background, we consider the overall cost instead of dividing the cost into
From (3), the merge cost is related to the page density of the log block (i.e.,
the value of n). Higher page density tends to result in higher merge cost.
Moreover, the cost is also related to the state (i.e., number of live/dead pages) of
data blocks corresponding to the log block. A larger number of live pages in the
data blocks lead to higher merge cost. Similarly, since each dead page in the data
block has a corresponding live page in the log area, which also needs be copied to
the new data block, a larger number of dead pages also lead to higher merge cost.
In summary, the merge cost is related to the state of the log block and the
corresponding data blocks, and the cost of block erasure and page copying. As
shown in Figure 5.3, considering the merge cost in a cleaning policy results in
more efficient reclamation than the previous policies that consider only the state
of the log blocks such as CAT.
Although a dead page in the data block also results in the copying of a page,
the net cost of a dead page is lower than that of a live page. This is because page
copying corresponding to a dead page does have some benefits. Specifically, it
causes the invalidation of a log page, say p, and hence reduces the cost of
reclaiming the log block that contains p in the future. For example, it might
reduce the page density of that log block so that the reclamation of that log block
in the future will involve less erase operations. Therefore, (3) is modified as
nlpc
jdpc
jC
p cn
C
era sei
cost
1,
*
)
1
(
*
)
*
(
)
(
(4)where < 1 and it denotes the ratio of the net cost of a dead page, when compared with the net cost of a live page. Traditional merge cost evaluation
approach, in which is always equal to 1, completely ignores the benefit of the dead pages. On the contrary, MARO respects the benefit and hence always
setting as smaller than 1. Substituting (4) to (2) yields
1
,
1
n erase pc j j ageC
n
C
dpc
lpc
W
i
age
i
score
(5)where < 1. In (5), W age and are controlled by the system designers. A large value of Wage leads to a policy similar to round robin, and a zero value of Wage
leads to a purely cost-driven policy. The parameter determines whether the benefit of the dead pages is regarded as significant. Other variables in (5) can be
obtained from the runtime information or the datasheet of the flash device.
The differences between MARO and previous log block reclamation policies
in HAT-based FTLs are as follows. First, MARO considers the age and the merge
cost of a log block at the same time. FAST considers only the block age and thus
could reclaim high-cost log blocks. LAST considers the merge cost. However,
the block age is not considered when selecting a victim according to the merge
cost. As mentioned above, live pages in the young blocks might be invalidated in
the near future and thus delaying the reclamation of these blocks, as the MARO
lower cleaning cost can be achieved by considering both factors at the same time.
Second, MARO uses a different merge cost evaluation approach that treats the
net cost of copying a page corresponding to a dead page in a data block as lower
than that of copying a page corresponding to a live page in a data block, and it
uses the parameter to control the ratio of the former to the latter. In the previous approach such as that used in LAST, the two types of cost are treated as equal
since the benefit of copying a page corresponding to a dead page in a data block
is totally ignored. In Figure 5.6, we show that respecting the benefit and setting smaller than 1 could result in the reduction of the cleaning cost.
Although MARO tends to select an old block as the victim, which is helpful
in wearing the log blocks evenly, global wear leveling that considers both the log
blocks and the data blocks is beyond the scope of MARO. To achieve global
wear leveling, an erased block is not used to serve the incoming write directly.
Instead, it is returned to the free block pool of the storage, and the free block with
the minimum erase count in the pool is used to serve the write. The erase count of
a block represents the number of times the block has been erased. Moreover, a
simple wear-leveling technique proposed in eNvy [84] is utilized. Assume that
the blocks with the minimum and maximum erase counts are C and H,
respectively. If the difference between the erase counts of C and H is larger than a
threshold Thc, , the data of C and H are swapped.
Note that, the computation overhead needs to be addressed for the
every time when cleaning is required, we amortize the score computation and the
search of the maximum score over multiple flash memory operations. We
maintain Sdata(j), the sub-score of each data block Dj, expressed as
,
*
)
*
(
)
(
j j pc dataj
lpc
dpc
C
S
(6)which is a part of (5) related to the state of a data block. When a page write
causes the association between a data block D and a log block L (i.e., the write
causes L to correspond to D), the sub-score of D is added to the score of L. Each
time when a page write changes the state of D, the sub-score of D is updated and
the scores of the log blocks corresponding to D are also updated. Finally, when a
page write causes the disassociation between D and L, the sub-score of D is
subtracted from the score of L. Similarly, according to (5), the score of a log
block L is added/subtracted by (-1* Cerase) each time when the page density of L
is increased/decreased by 1.
Upon the first page write to a log block, the score of the log block is
initialized as H minus Cerase, where H represents the initial block age multiplied
by Wage and Cerase reflects the cost of erasing the log block. As mentioned before,
the block age represents the elapsed time since the last reclamation of a log block,
which can be implemented by using 0 as the initial block age and adding the ages
of all the log blocks other than the erased log block by 1 when a log block is
erased. However, this requires updating a large number of scores upon block
blocks intact and subtract the initial block age by 1. Consequently, H is decreased
by Wage each time when a log block is erased.
Searching the maximum scores efficiently is also an implementation issue.
To reduce the search time during the cleaning procedure, the log area is divided
into multiple clusters, each of which is in turn divided into multiple 8-block
segments. Each time the score of a log block is updated, the maximum score in
the corresponding cluster is searched and recorded. Therefore, during the
cleaning procedure, only the maximum scores of the clusters need to be
compared. To speed up the search time further, hardware circuits were
implemented for the search of the intra-cluster maximum scores and the
maximum score among the clusters.
From the above description, amortizing the score computation eliminates the
multiplication operations. In addition, although is a floating point value, floating point operations can be avoided by multiplying (5) by a constant so that
all the terms in (5) become integers. The multiplication can be done offline. As a
result, the implementation of MARO does not require the SSD controller to
perform multiplications or floating-point operations, suitable for current
integer-processor based SSD controllers.
With the above amortization method, the worst case execution time of a page
write occurs when the write changes the state of a data block associated with K
log blocks, where K is equal to the number of pages per block. In this case, K
need to be searched and recorded, which take O(K*NSC) time where NSC is the
number of segments in a cluster. Since K and NSC are both constants, the time
complexity of a page write is O(1). The time complexity of the cleaning
procedure is O(NL), where NL is the number of log blocks in the storage. Such
complexity is the same as LAST. In addition, the space complexity of ROSE is
O(ND+NL), where ND is the number of data blocks in the storage, the same as
many HAT-based FTLs such as FAST and LAST.
3.4 Free Page Reuse
As mentioned above, low space utilization can lead to high cleaning cost. In
ROSE, we propose the Free Page Reuse (FPR) technique to increase the space
utilization. FPR reuses free pages of obsolete blocks, which are to-be-erased
blocks whose live pages have already been copied out. Therefore, an obsolete
block contains only dead or free pages and FPR tries to reuse these free pages to
buffer more page writes.
In ROSE, log blocks become obsolete only after they are full. However,
obsolete data blocks could still contain free pages since they are managed by
BAT [83]. Thus, FPR considers reusing free pages of obsolete data blocks.
Instead of erasing an obsolete block O, FPR tries to select a full log block, say L,
and swaps the roles of O and L. The procedure of the swap operation is as follows.
(i.e., become a new log block) and L is erased. Note, L is not migrated to the data
area since it is not swapped with a valid data block. Instead, it is swapped with an
obsolete block that originally needs to be erased.
The cost and benefit of the swap operation depends highly on both the
number of free pages in the obsolete block, say f, and the number of live pages in
the full log block selected for swap, say l. Specifically, l page copy operations are
required and (f – l) free pages can be obtained to buffer further page overwrites
after the swap. For effectiveness of the swap, FPR selects the full log block with
the minimum number of live pages to swap. Note that a swap is performed only
when the value of (f – l) is larger than zero. Otherwise, no swap is performed and
ROSE just erases the obsolete block.
After merge
LBN 1
Erase
LBN 2 Block-level mapping table
LBN 0 LBN 1
LBN 0 LBN 2
Block-level mapping table
Step1. merge Step2.swap procedure Before merge Copy Free Dead Live 1 0 4 5 8 0 1 4 0 1 0 0 1 6 4 5 8 4 8 8 0 1 4 5 0 1 4 5 8 5 Swap A B C M N L F A B C L M N
Become the data block of LBN 2
Erase
Log area Free
A B
F
M N
C L
Log area Free
F C L
Figure 3.3: An example of the swap operation
Figure 3.3 illustrates an example of the swap procedure. Assume that the
flash memory consists of three data blocks (A, B, C) and three log blocks (L, M,
N) (and an extra free block F for buffering the result of a full merge), with each
block contains four pages. We also assume that data blocks A, B, and C
correspond to logical blocks 0, 1, and 2, respectively. The top of Figure 3.3
illustrates the state of the blocks after the page write sequence (0, 1, 0, 1, 4, 5, 8,
4, 5, 0, 1, 0, 8, 0, 1, 4, 4, 6). When a further write to logical page 6 arrives, the log
area is full and thus a log block, say M, is reclaimed by merging the block with its
corresponding data block (i.e., data block C). The merge involves not only live
page copying but also erasure of the two blocks. Specifically, without swapping,
M and C are erased after the merge. FPR tries to avoid erasing C since it still has
plenty of free pages. To avoid erasing C, FPR swaps log block L with C since the
former is the full log block with the minimum number of live pages. As a result,
page 5 is copied to C, which replaces the role of log block L, and L is erased.
Therefore, with swapping, M and L are erased. Two more free pages are obtained
due to the swap operation, and the cost is the copying of one page.
The above example illustrates the reclamation of a log block with page
density of 1. In general, reclaiming a log block with page density of n may trigger
m swap operations, where 0 <= m <= n, and the benefit Bswap and extra cost Cswap