Low Power and Power Aware Fractional Motion
Estimation of H.264/AVC for Mobile
Applications
Tung-Chien Chen, Yu-Han Chen, Chuan-Yung Tsai and Liang-Gee Chen
DSP/IC
Design Lab., Graduate Institute of Electronics Engineering and Department of Electrical
Engineering, National Taiwan University; Email: djchen, doliamo, cytsai,
[email protected]
Abstract- In this paper, the low power design techniques from algo- S stem Bus
rithm to architecture levels areproposed for factional motion estimation j inH.264/AVC.TheproposedAMPD algorithm can reduce 50.8%
power0if
with up to 0.1 dB quality drop. The proposed parallel architecture with ef-
-ficientmemory hierarchy can efficiently reuse data and save 61.6% power. RISC SW Local JControMB-level
Furthermore, thepower awarefunctionalityis included. Our design can = DataReuse
gracefully vary the quality degradation of 0.1-3.9 dB in response to the
7--22.58-1.64 mW power consumption. This power-oriented design is very
,
defficient fordifferent mobile applications in various power situations. FrameOn-lineFME Candidate-Memory Interpolation Core level Data
Reuse
I. INTRODUCTION FMEModule Fast
While highly interactive and recreational multimedia appli- Algorithm
cationsappearmuch fasterthanexpected, there seems to be an
inexhaustibledemand forasmuch higher compression ratio and Fig. 1. FMEsystemarchitectureand thecorrespondingpowerreduction
tech-better video quality as possible. The new video coding stan-
niques.
dard of H.264/AVC[1], whichsignificantly outperforms previ- gives a conclusion. ousstandards, undoubtedlyplays animportant role inthis area.
Thenewtechniques [2] of 1/4-pixelresolution, variable block II. FUNDAMENTAL
sizes(VBS), multiple referenceframes (MRF), andLagrangian A. FMESystem Architecture and Power Reduction Techniques mode decisionin motionestimation (ME)induce huge
compu-tationcomplexity, and hardware accelerationis a must. Figure 1 shows the FME system architecture. In reference Classical hardware architecture focuses on latency,
area,
software [7], in order tosupportMEwithquarter-pelresolution, throughput and hardware complexity as the primary parame- all required pixels areinterpolatedin advanceand stored in the ters to beoptimized ortradedoff against each other.However,
frame memory. However, the storage space with 16-times ofpower-orienteddesign methodologyhasemergedas a a key fac- frame size isrequired for each reference frame, which is a con-torfortworeasons: limitedavailability of power in portable or siderable overheadfor hardwareimplementation. Besides, the wearable devices, and limited capacity to dispose of the heat systembandwidth(BW) will become too large during FME pro-of VLSI circuits. Lowpower and power aware are the most cedure. Therefore,theon-chip on-lineinterpolationisgenerally important issues inthepower-oriented design. Thelow-power adopted [6] In this system structure, the power consumption ME canprovide the maximum compression performanceunder mainlycomes from two parts. One is data access power of inte-the specific power constraint. The power-aware ME can ex- ger referencepixels loading from frame memory to FME core. tent the battery life by varying the compression performance The other is computationpower ofinterpolation andmatching andpowerconsumption according to thesystem power status. cost
calculation.
Manypower-oriented fast algorithmsandhardwarearchitecture Several powerreduction techniques aredescribedasfollows. have been proposed forinteger motionestimation (IME)[3] [4] First, because the referred search areas ofneighboring current
[5],butnonefor fractional motion estimation(FME). However, MBs (CMBs) are considerably overlapped, thesearch window
accordingtoouranalysis, theFMEoccupies45% [6] of the run- (SW) SRAMs are firstly embedded to achieve MB-level data time in H.264/AVC inter predictionandupgradesrate-distortion reuse (DR). The BW and power of system memory can be re-efficiency by 2-6 dB in peak signaltonoise ratio (PSNR). The duced. Second, theparallelarchitectureis designedto achieve advancedFMEdesign with optimizationinpower issues is ur- candidate-levelDR, andthe BW and power of local memory can
gentlydemanded by H.264/AVC compressionsystem. be reduced. Third, thehardware-orientedfastalgorithmcanbe Inthis paper, the first low-powerandpower-awareFME de- used to reduce the computationalpower ofinterpolation engine
sign of H.264/AVC is proposed. The rest ofthis paper is or- and FME core. Last but not least, the gatedclocktechniquecan ganized as follows. In Section II, the related power reduction beappliedto turn theinoperative circuits off.
and poweraware techniques will be described. In Section III, oe wr ucinlt
the power-aware fast algorithm areproposed. The
correspond-ing parallel hardware architectureisdesignedin Section IV with Power aware functionality is another important issue for low-power considerations, while theimplementationandsimu- power-oriented design. It can vary thepower consumption ac-lation results are presented in Section V. Finally, Section VI cordingtothepowerstatus at the expense ofcompression
2
FullSearch MPD AMPD (dB) (dB)
37
IntegerMotion IntegerMotion IntegerMotion 3 - - 36
XEstimation Estimation Estimation
pMode Decision M Pre- FN
IMV41pa s Best MVs AsetofIMVs AMPD'(32 -X AMPD(N=3)
,of_t4
l-
MPD(N=l-1)
--MPD(N=1 )Fractional Fractional Fractional 31 30
Motion Motion Motion 60 110 160 210 260(Kbps) 220 420 620 (Kbps)
CL. Estimation Estimation Estimation
Mode Post-
(a)
Foreman(QCIF)
(b)
Stefan(QCIF)
LU ModeDecisionDeiin(B-(d)- Decision~~CtS-S(dB); ; ff
BestFMVs BestFMVs BestFMVs 36 3 366
(a) ()(c) 34
.34
/(a) (b)-(c)FS (N=7) -FS (N=7)F 32 ,A, ---AMPD (N=3) 32 ---AMPD (N=3)
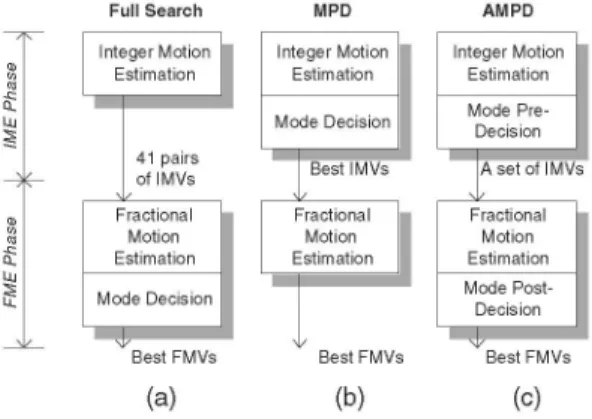
Fig. 2. (a)FS algorithm; (b) MPDfast algorithm; (b) ProposedAMPD fast M (N- MP. (N
algorithm. 30
30-270 470 670 870 (Kbps) 40 90 140 190(Kbps)
formance. ForH.264/AVCstandard,power awarefunctionality
becomesmorenecessary. That is because thecomputationcom- (a) Mobile (QCIF) (b) Table (QCIF) plexity of the video compression algorithm grows much faster Fig. 3. Rate-distortion curves of FS, MPD, and AMPD algorithms. The param-than theprogressofpowersupply. A specifiedpowerconstraint eters are QCIF,30frames/s, I reference frames,±16-pelsearch range(SR),
areusuallymet attheexpenseof considerablequality drop, but and low complexity mode decision.
high quality is usually claimed especially when poweris full. "Mode Pre-Decision" and "Mode Post-Decision". In "Mode The encoder withpower awarefunctionality can notonly have Pre-Decision", not only one but a set of probable modes are se-more adaptability for good balance between compression per- lected after
IME
phase. Firstly, the four sub-modes of each 8 x 8 formance andpower consumption but also extend the battery blockare sortedaccording
totheLagrangian matching
costsin life time. In a well-designed power aware system, the com- integer-pel resolution. The costs of the best sub-modes of four pression performance should be varied gracefully inresponse to 8x8blocksarethen summedupas one8x8partition
costs. The thepower status. Inordertomaximize thecompression perfor- costs of the second sub-modes are summed up as the second manceunder thepowerconstraint, the processing tasks should 8 x 8 partition costs, and so on. There are totally four costs of be turned offaccording
tothepriority,
the 8x8partitions.
Secondly, the costsofsevenpartition,
four III. POWERAWAREFASTALGORITHM 8 x 8 partitions together with the 16 x 8, 8 x 16, and 16 x 16parti-tions, aresorted from low
(best)
tohigh (worst).
N(N
= I1-7)
Full search (FS) algorithm can guarantee the highest com-
of
the best partitions are selected for the FME procedure fol-pressing performance. However, the largepowerconsumption lowed by "Mode Post-Decision". Note that, if more than one is verycritical formanyportable applications. Inthis section, 8 x 8 partitions are selected, the re-combination among the sub-a hardware oriented fast algorithm will beproposed with the modes is allowed in "Mode Post-Decision". When N is equal topower awarefunctionality. one, AMPD has the same performance with MPD. When N is
Figure2(a) shows theconceptof FSalgorithm. H.264/AVC equal to seven, AMPD has the same performance with FS. supportsVBS, and the inter mode decision with FSalgorithmis
donewiththecostsof all blocks andsub-blocks, whichare re-
Figret
3shows
theritortion
Muve
ofaMPdintwhioh
fiedtoarqarerpl esluio. n rertoreucte*o
N is set tothree,
together with FS and MPD. The rate-distortion fined towardquarter-pel
* * **resolution.1 r In1 order1 to1reduce the1 s /r 1com- ~~efficiencvefiiec imroe wihteicesim roveswiththeincreaseoffN,adsostecmN,and so does the com-putation complexity, a simple fast algorithmdenoted as Mode ycPre-Decision (MPD) was evaluated firstly. As shown in Fig. putation complexity. However, this improvement saturates when 2 (b), the inter modedecision ismoved forwardto
IMB
phase. N is set tothree.
That means when N is larger than three, much2b)theine mod deiso is
~
moe fowrd
to IMpase
morecomputation complexity
mustbepaid
withjust
the limited Thatmeanstheselectionofthe best combinationof VBS isdonein integer-pel resolution. The FME is thus responsible forre-
quality improvement,
which is not efficient for power-orientedfining theinteger motion vectors (IMVs) of the selected mode design. Therefore, the parameter of "N=3" is chosen. Simi-toward quarter-pel resolution. In VBS, eachMB can be split larly, as for MRF-ME, the fast algorithm modified from [8] is up into4 kinds ofpartition: 16x16, 16x8,8x16, and 8x8. If used. According to the analysis in [8], more than 80% of the
partition
8x8 isselected, each blockcanbe furthersplit
into4 best reference frames have thetemporal
distance that is smallerkinds ofsub-partitions: 8x8, 8x4,4x8,4x4.Totally41 blocks than two. When the
maximum
reference frame numberis set and sub-blocksareinvolvedperreference frame and havetotally overthan two, thequality improvement
is limited with consid-seven-timespixels ofoneMB.Therefore, theMPDcanreduce erably increased computation complexity. Therefore, the maxi-about 6/7computation complexity. However,the rate-distortion mum number of MRF is set to two in our design.efficiency is seriously degraded for up to one dB in PSNR. That The AMPD can efficiently support power aware functionality. is because the best combination of VBS in integer-pel resolution Because the correlation between mode decision in integer-pel may change after the refinement in quarter-pel resolution. resolution and that in quarter-pel resolution is very high. The To achieve abetter trade-offbetween quality and computation priority of the VBS can be precisely estimated by the sorting complexity, advanced MPD (AMPD) algorithm is proposed. As operation in the "Mode Pre-Decision". By varying the param-shown in Fig. 2 (c), the inter mode decision is divided into eterN,our algorithm can have a good trade-off between power
3
BH SRHSR
~~-
(-B*-X B--H :> MBwideB MBwdeCRretMB CurntM Search Window SRAMS Side InformationB MBheight SRAM
RSR,SHorizontalsearchrange
SRv SRv Veritcal searchrange Interpolation MVRet/Mode
+ BW IwagewideCs
Q
I~
~~~L- SWoftCMBO
mxBeent 4x4Blewent 4x4Blewent
1
~~ ~~~~~~~
~~~~SW
otCMBi PU# PU #1 PU #2 gMode
(a)Level-CDRScheme ent 4x4Element 4x4Elewent Decision
PU#3 PU#4 PU#S w
rX 4x4EBewent 4x4Eiement 4x4EBement
By PU #6 PU#7 PU #8 Output
~~~~~~ ~~~~~~~~~~&B-~~~~~~~~~~~~~~~~~~~~~~~~Butter
+ RowotFourCur.MBPale& 44ImnP
Bv FourInterpolatedRet.Pale xEemnp
L I4 -XP-ht -
-B, SRH X BH 4-aale Si Si
2-DHadaward+ AO
(b) Level-DDRScheme TransformUnit
Fig. 4. MB-level DR schemes. When process is changed from CMBO to CMB 1,
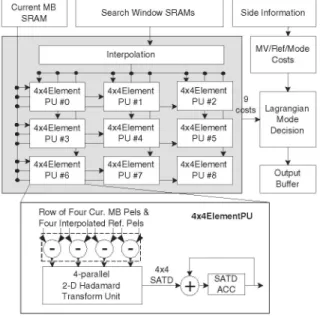
the dark grayregionis the reused data, and the light gray region is the re- Fig.5. Theproposed parallelhardware with candidate-level DR.
quireddata loadedfromsystem memory. TABLE I
consumption and compression performance. Furthermore, if the PERFORMANCE OF
CANDIDATE
LEVEL DR FOR THE PROPOSED PARALLEL poweris verylow,wecan evensupport only half-pel or integer- ARCHITECTURE.pel resolution with onereference frame. In the later case, the
No________________________
FME module will only take care of the MC task. The qualityTechnology
Paral.
level DR level DR Both approachestoMPEG-4simple profile in this situation.RAcandidate-level 74.98
28.12 10.18 3.64IV. LowPOWERARCHITECTURE DESIGN neighboring CMBs. According to Fig. 4 (b), the RA of Level-D
Inthis section,the low-powerdesignmethodology onarchi- scheme is calculatedas:
tecture level is described. The parallel architecture with effi-
BH
XBV
cient memoryhierarchy is used. Two factors are used to evaluate RAmb-level,level-D R
BH
XBVtheperformance of the proposed low-power architecture: the
re-dundancyaccessfactors(RAs)for MB-levelDRand candidate- The Level-D schemecanminimize the system memoryBW, but levelDR,which are defined as follows. ahugelocal memory size of(Wx
SRV)
+(SRH+BH)xBV
pix-els isrequired for each reference frame.
System
BWfor
loading
SWs Inourdesign,
both the level-C and level-D schemesareem-minimum requirement bedded and chosen according to the MRF number. In general SW SRAMBWfor reading ref-pels case,tworeference framesareused for thehighest compression RAcand.
level
= minimum requirement performance. Each reference frame is stored in SW SRAMs and reused in level-C scheme, separately. When thepower isA. MB-levelDataReuse low, the SW SRAMs are configured as the level-D scheme for
For MB-level DR, four
strategies
have beenproposed
with lowestpowerconsumption
insystem
bus. In thissituation,
only
differenttradeoffs between local memory size and system bus onereference framecanbe
supported.
BWandare indexed from level-Ato level-D [9]. Because the B. Candidate-levelDataReuse power consumption to access the system memory is the most
criticalpart, the level-C and level-D, that have lower RA fac-
intHge4/AV, Fhe
uoar-pixel
ara After
tors, arerecommended for memory technology nowadays. The the integerME,rthel
refin
s areperfoRm
level-C scheme reuses the horizontally overlapped region be- around the best integer search positions withi1/2
pixel SR. tween two SWs of theneighboring CMBs as shown inFig. 4 The quarter-pixel ME, as well, is then performed around the (a). Only the lightgray partof BH X(SRV
+BV)
pixels is re- best halfsearch position withh1/4
pixel SR. Therefore, eachquiredtoloaded from externalmemoryforeveryCMB.TheRa half and quarter refinement has nine candidates including the of Level-schemecn be calclated
as:refinement
center and its eight neighborhoods. For AMPD al-of Level-Cschemecanbecalculatedas:gorithm,
thisrefinementprocedure
willbeiteratively
processed
RAmb
~~~~BH
X(SRV
+BV
) _ SRV on the selected blocks and sub-blocks. The best mode is selectedRAblevel.leve!
BH X BV + B~ by considering both the distortion of SATD and the rate parts. Based on the analysis in [6], the hardware architecture is Therequired SW SRAMs' size is (SRH +BH) (SRV+BV)pixels shown in Fig. 5. The 4x4 block is the smallest element of VBS, for each reference frame. As for the Level-D scheme, it can and the SATD is also based on 4x4 blocks. Every blockand fully reuse the horizontally and vertically overlapped SWs of subblock can be decomposed into several 4x4-elements with4
PSNR(dB)
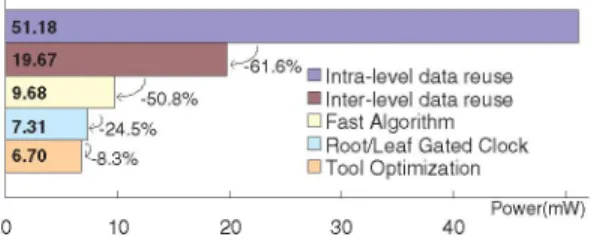
9l68llll Intra-leveldata reuse
9.4i8 -50.8% * Inter-leveldatareuse
731 &-24.5% EliFastAlgorithm 38
_)8~~~~~~~Io1Root/LeafGatedClockl =l
-ToolOptimization 3
Power(mnW) l
0 10 20 30 40 36 9- MemoryPower
36 ECorePower
Fig. 6. Performance of the power reduction techniques on each level. The pa- 35
rameters areforeman CIF video,30frames/s, 1 reference frames, and AMPD 0 4 8 12 16 20 Power
with N=3. (mW)
PSNR (dB)
40 _ Fig. 8. Performance ofpower awarefunctionality. Theparameters areforeman
38 CIF video, 30frames/s,and
700kbps.
36 - 2 sumption inFMEis saved after theoptimization in each level.
Figure
7 shows thecompression performance
ofourdesign.
34 The best rate-distortioncurvehas
only
0.1dBquality drop
com-JM,2Ref. -=7 pared with reference software. Because the tasks ofFME can
32 X 1 Ref'N=3 be
dynamically
turned offaccording
tothecontentinformation,
-~1 Ref,N=2
30 1 Ref'N=1 our
design
cangracefully
varythecompression performance
in1 Ref,N-1 (HalfPrecision) response to the
powerstatus.
Thepowerconsumption
versus1Ref,N=1(integerPrecision) oe oe
28 Bitrates compression performance is shown in Fig. 8. The power of SW
160 320 480 640 800 (Kbps) SRAMs is included. Our design cangracefully vary the
com-pressionperformance of 0.1-3.9 dB with the 22.58-1.64 mW
Fig. 7. The rate-distortion curves of the proposed hardware with power aware power consumption, and is very efficient for different mobile functionality. The test video isforeman,CIF and 30frames/s. applications in variable power situations.
the same MV. Therefore, a 4x4-elementPU is designed and V CONCLUSION
reused for all larger blocks by folding technique. Forthe low
powerconsideration, the intra-candidate and inter-candidateDR In this paper, we contributedalow-powerandpower-aware schemesareapplied. Forintra-candidate DR, each4x4-element designfor FME of H.264/AVC. The fastalgorithmof AMPD is PUisarranged with four degrees of parallelismtoprocessfour proposedto notonlyreduce computation complexity, but also horizontally adjacent pixels ofonecandidate.Forhorizontal fil- provide efficientadaptivitybetweenqualityandpower. The ef-tering, six integer pixels arerequired for interpolating onehalf ficientmemory hierarchy and reconfigurable SW SRAMs are pixel, while night integer pixels are required for four half pix- usedtoachieve MB-level datareuse,while theparallel architec-els. Mosthorizontally adjacent integer pixels canbe reusedby tureisdesignedtoachieve candidate-level datareuse. As shown horizontal filters, and the on-chipmemory BWof SWSRAMs in
experimental
results, the 87% ofpowerconsumptioncanbe canbe reduced. Forinter-candidate DR, wearrangenine4x4- saved after lowpowerconsiderations. The powerconsumptionelementPUs to processthe nine candidates simultaneously. In of 22.58-1.64 mWcan be
efficiently
variedatexpense of 0.1-thisway,theinterpolated fractional pixelscanbereuseby these 3.9 dB quality drop.4 x4-elementPUs. The redundant computation of interpolation REFERENCES
canbe saved.Besides,theon-chipmemory BWof SW SRAMs
canbe further reduced. TableIsummarizes theperformanceof [1] Joint Video Team, Draft ITU-T Recommendation and Final Draft Inter-national Standardof Joint Video Specification, ITU-TRecommendation candidate levelDR for theproposed parallel architecture. Af- H.264 and ISO/IEC14496-10AVC, May 2003.
ter candidate-level DR, the reference pixel data canbereused [2] T.Wiegand,G. J.Sullivan, G.Bj0ntegaard, and A.Luthra, "Overviewof 20-timesmoreefficiently. [3] M. Miyama, J. Miyakoshi, Y Kuroda, K. Imamura, H. Hashimoto, andtheH.264/AVCvideocodingstandard,"IEEETransactionsonCSVT,2003.
M.Yoshimoto, "Asub-mW MPEG-4 motion estimation processor core for
V. IMPLEMENTATIONAND SIMULATION RESULT mobile video application," IEEE Journal ofSolid-State Circuits, 2004. [4] S.-S. Lin;P.-C.Tseng;C.-P.Lin;L.-G.Chen;, "Multi-modecontent-aware
Theproposed low-power architecture with power-aware fast Proceedingsmotion estimationofIEEEalgorithm for power-aware videoWorkshoponSIPS,2004. coding systems," in
algorithm is implemented in TSMC
0.18,u
1P6M technology. [5] H.-W. Cheng and L.-R. Dung, "A content-based methodologyfor power-The totallogicgate countis 125K with maximumoperation fre- awaremotion estimation architecture," IEEE TransactionsonCASII,2005.of 27MHz. This designcansupportreal-time encoding [6] T.-C
Chen,
Y-W.Huang,
and L.-G.Chen,
"Fullyutilized and reusablear-chitecture
forfractional motion estimation
ofH.264/AVC," inProceedingsCIF30fpsvideos withtwoMRF.ThesupportedSRis±32 hor- ofICASSP, 2004.
izontally and ±16 vertically. Figure 6 shows the power reduc- [7] Joint Video Team Reference Software JM8.5,
afterhe
[8]http://bs.hhi.de/ suehring/tmlldownload/,
Sept. 2004.tion
performance oflogic circuits
(SRAM excluded) atrhe 8Y-
W. Huang,B.-Y.
Hsieh, T.-C. Wang,S.-Y.
Chien,S.-Y.
Ma, C.-F. Shen, low-power techniques that are applied on each level. Note that and L.-G. Chen, "Analysis and reduction ofreference frames for motionSynopsys Prime Power is used to estimate the power consump- estimation in MPEG-4 AVC/JVT/H.264," in Proceedings ofICASSP, 2003. tionhere Thhon hee.Thelnnovaons onalgorlhminnvatons n agorihm ad achitctue leelsandarchltcture evels [9] J. C.ory bandwidth analysis for full-search block-matching VLSI architecture,"
Tuan,
T. S. Chang, and C. W. Jen, "On the data reuse andmem-contribute the most power reduction. Totally 87% ofpowercon- IEEE Transactions on CSVT, 2002. 5334