國 立 交 通 大 學
管理學院(經營管理學程)碩士班
碩士論文
巨量資料生態雲端策略集群分析
-以財務績效指標探討
Cloud clustering Strategy Analysis On Big Data
Ecosystem
- Investigate for Financial Indicators
研 究 生:黃博文
指導教授:楊 千 教授
巨量資料生態雲端策略集群分析-以財務績效指標探討
Cloud Clustering Strategy Analysis on Big data Ecosystem
- Investigate for Financial Indicators
研 究 生:黃博文 Student: Bowen Huang
指導教授:楊 千
Advisor: Chyan Yang
國 立 交 通 大 學
管理學院(經營管理學程)碩士班
碩 士 論 文
A Thesis
Submitted to Degree Program of Business and Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Business Administration June 2013 Taipei,Taiwan,Republic of China
中華民國
一○二
年六月
巨量資料生態雲端策略集群分析-以財務績效指標探討
研究生:黃博文
指導教授:楊千 教授
國立交通大學管理學院(經營管理學程)碩士班
摘要
企業內部獨特運用資源能力,其優勢可經由財務指標觀察了解,企業藉由了解本 身競爭優勢與財務指標間是否能夠持續優勢發展。運用杜邦等式推導財務指標, 將企業競爭優勢因素基礎在資產管理、供應商關係管理、客戶關係管理以及知識 管理四項能力,採用 146 家上市企業為研究對象,研究時間點以金融風暴(西元 2008)為分界,分前期及後期。本研究發現,巨量資料生態下雲端產業可分三個 策略集群,後期比前期多出 5 家企業,這 5 家企業中有 4 家占 75%為「雲端服務 策略集群」,1 家企業占 25%為「雲端設備整合策略集群」 。巨量資料蓬勃發展, 帶動「雲」之使用者平台、資訊分析處理,「端」之運算處理需求及商機,知名 廠商如 Facebook 及 PEGATRON 等新的競爭對手進入。運用 distribution 分析得 知雲端產業呈穩定成長分佈發展,其雲端產業未來前景看好。關鍵詞:巨量資料、伺服器、雲端運算、資源基礎理論、競爭優勢、杜邦等式、 因素分析、集群分析
Cloud Clustering Strategy Analysis on Big data ecosystem
- Investigate for Financial Indicators
Student: Bowen-Wen Huang
Advisor: Dr. Chyan Yang
Degree Program of Business and Management
College of Management
National Chiao Tung University
Abstract
The enterprise internal unique utilization resource,its superiority may by way of the financial norm observation understanding , the enterprise between the understanding itself competitive advantages and financial indicator whether can continue the superior development。Using the DuPont identity inferential reasoning financial indicator,the enterprise competitive advantage factor foundation in the asset、 supplier relationship 、 and customer management as well as the knowledge management four abilities,with 146 listed enterprises is the object of study,the research time point takes the financial storm (A.D. 2008) as the dividing line,divides the earlier period and later。 This research result, the cloud computing industry in big data ecosystem can be separable three strategy clusters,later period are more than 5 enterprises the earlier period,in 5 has 4 to occupy for 75% as "clouds service strategy cluster",one enterprise is occupy for 25% as " clouds equipment conformity strategy cluster"。Big data ecosystem vigorous development leads "cloud" the user platform and information analysis processing and "end" the operation processing demand and opportunity , the well-known facilitator and manufacturer such as Facebook 、 PEGATRON and other new competitors enter。using the distribution analysis knew that the clouds industry assumes the stable growth distribution development,its cloud computing industry prospect will look good。
Keyword: Big Data、Server、Cloud Computing 、Resource-Based Theory RBT、 Competitive Advantage、Du Pond Identity、 Factor Analysis、Cluster Analysis
誌謝
在交大經管兩年間,接受一系列有系統性之課程訓練,加上團隊合作精神一 起並肩作戰完成每次作業及報告,如此可達事半功倍效率。感謝交大教授們無私 傳授專業學術領域知識並結合時事,注重學生們組織及分析能力。本人除了專科 及大學接受專業工程領域教育外,藉由交大經管傳授管理、財務、企業倫理等課 程,並了解公司、證劵等相關法規讓我受益良多,有利於往後職場或生活上對於 人與人間溝通協調、事物看法上,有系統方式去思考及領悟,並利用不同角度並 以正面積極態度去面對。另外,這兩年間擁有同窗同學一起互相學習、鼓勵及交 流,這是我在交大兩年間,除了求得知識外另外一個寶貴收穫。 這兩年的學習課程中難免需要犧牲了一些與家人相處時間,感謝家人體諒及 支持,讓我能夠讓我專心深入研究管理相關課程。 感謝指導老師楊千老師,平常與他談話或聽他演講中,感受為人處事上不同 觀點,讓學生獲益匪淺。感謝楊老師指導此論文,讓我在迷惘不知研究方向時, 提醒學生如何往下一步前進,方能完成此論文順利完成。黃博文 謹誌於
國立交通大學管理學院
(經營管理學程)碩士班
中華民國 102 年 6 月
目錄
中文摘要 ... i 英文摘要 ... ii 誌謝 ... iii 目錄 ... iv 表目錄 ... v 圖目錄 ... vi 一、 緒論………...1 1.1 研究背景與動機...1 1.2 研究目的 ... 2 1.3 研究範圍及對象 ... 3 1.4 研究流程 ... 4 二、 產業介紹及文獻探討 ... 5 2.1 產業介紹 ... 5 2.1.1 ICT 與 IT ... 5 2.1.2 雲端運算(Cloud Computing) ... 6 2.1.3 雲端資料安全(Security)、防破壞(breaches)及法規(Rule) ... 92.1.4 雲端運算伺服器(Cloud Computing Server) ... 10
2.1.5 巨量資料(Big Data) ... 12
2.2 文獻探討 ... 14
2.2.1 價值鏈與競爭優勢(Value Chain and competitive advantage)... 14
2.2.2 資源基礎理論(Resoure Based Theory,RBT) ... 14
2.2.3 資源優勢理論(Resource advantage Theory,RA-Theory) ... 15
2.2.4 企業財務績效指標 ... 16
2.2.5 多變量統計分析(Multivariate statistical analysis) ... 17
2.2.5.1 因素分析(Factor Analysis) ... 17 2.2.5.2 集群分析法(Cluster Analysis) ... 20 三、 研究方法 ... 21 3.1 研究架構 ... 21 3.2 資料來源 ... 23 3.3 變數分析及分析軟體 ... 23 3.4 資料分析方法 ... 24 3.4.1 因素分析法(Factor Analysis) ... 24 3.4.2 集群分析法(Cluster analysis) ... 24 3.5 財務指標之敘述統計(Descriptive Statistics)... 25 3.5.1 「檢定研究資料是否為常態分配」之敘述性統計 ... 25
3.5.2 「資料分散程度」或「離散程度」之敘述性統計 ... 25 3.5.3 「資料形狀及對稱分配」之敘述性統計 ... 28 四、 資料分析與結果 ... 31 4.1 各財務指標敘述性統計 ... 31 4.2 因素分析(Factory Analysis) ... 35 4.2.1 因素取樣適當性分析 ... 35 4.2.2 決定因素個數 ... 36 4.2.3 因素命名 ... 37 4.3 集群分析(Cluster Analysis) ... 39 4.3.1 階層式分層法(Hierarchical)-決定群集個數 ... 39 4.3.2 ANOVA(Analysis of Variance)變異數分析 ... 41 4.3.3 非階層式法(Nonhierarchical)-集群分類 ... 42 4.4 集群命名 ... 42 五、 結論與建議 ... 45 5.1 研究結論 ... 45 5.2 管理意涵 ... 48 5.3 研究限制 ... 49 5.4 後續研究建議 ... 49 參考文獻 ... 52
表目錄
表1伺服器種類及優缺點比較 ... 11 表 2 新古典主義和競爭優勢理論之比較 ... 15 表 3 KMO 值解釋規則 ... 24 表 4 財務指標敘述統計彙整總表 ... 31 表 5 後期相較於前期之變異係數% (CV=σ/μ)敘述性統計分析 ... 32 表 6 因素分析之 Kaiser 取樣適當性量數-前期 ... 35 表 7 因素分析之 Kaiser 取樣適當性量數-後期 ... 35 表 8 因素分析經最大變異數法(Varimax)之前期與後期比較表 ... 37 表 9 前期因素命名 ... 38 表 10 後期因素命名 ... 38表 11 集群分析 R-Squared, CCC and Pseudo F-前期 ... 39
表 12 集群分析 R-Squared, CCC and Pseudo F-後期 ... 40
表 13 前後期之 3 因素與 3 集群間 ANOVA 變異數分析 ... 41 表 14 群集 K-means 平均值 (前期) ... 42 表 15 群集 K-means 平均值 (後期) ... 42 表 16 集群 1 命名 ... 43 表 17 集群 2 命名 ... 43 表 18 集群 3 命名 ... 44 表 19 後期崛起企業 ... 45 表 20 全球 PC、超行動、平板電腦與手機出貨量預測(單位:千台) ... 45 表 21 各國雲端運算政策綜整分析 ... 50
圖目錄
圖 1 The cloud computing value chain ... 3
圖 2 研究架構圖 ... 4
圖 3 雲端運算及服務演進 ... 6
圖 4 雲端運算 9 個挑戰 ... 9
圖 5 伺服器類型 ... 12
圖 6 巨量資料市場預測,2011-2016 (in $US billions) ... 13
圖 7 以資源為基礎的策略分析:一個可實現的五階段架構 ... 14 圖 8 可持續的競爭優勢 ... 16 圖 9 因素分析概略圖 ... 18 圖 10 主成分分析概略圖 ... 18 圖 11 研究架構 ... 22 圖 12 偏度分配 Skweness Distribution ... 28 圖 13 對稱分配 No Skwen Distribution ... 29
圖 14 正偏態分配 Positively Skwed Distribution ... 29
圖 15 負偏態分配 Negative Skwed Distribution ... 30
圖 16 峰度分配 Kurtosis Distribution ... 30 圖 17 前期及後期之變異係數 CV(%)比較 ... 32 圖 18 前期及後期峰態系數(Bk)比較 ... 33 圖 19 前期及後期偏態系數(SK)比較 ... 34 圖 20 雲端產業之分配(Distribution)概似圖 ... 34 圖 21 因素分析相關矩陣的特徵值-前期 ... 36 圖 22 因素分析相關矩陣的特徵值-後期 ... 36
圖 23 集群個數分析 R-Squared, CCC and Pseudo-F (前期) ... 40
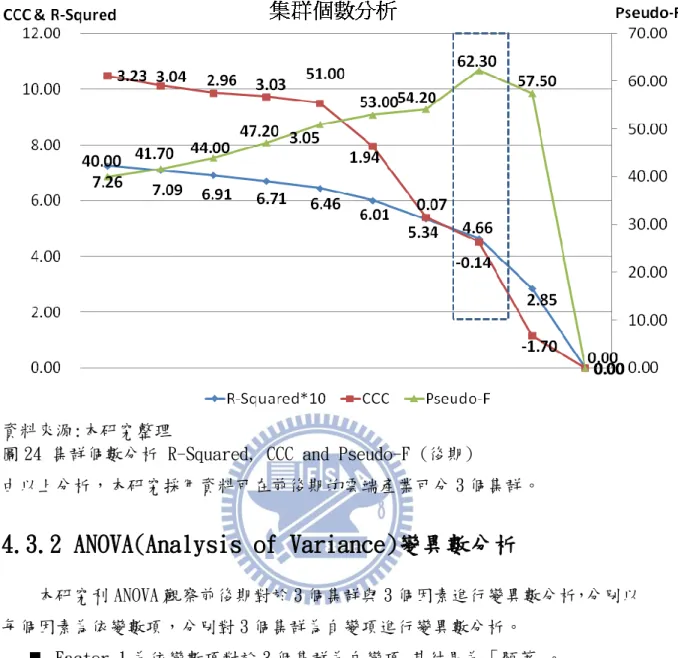
圖 24 集群個數分析 R-Squared, CCC and Pseudo-F (後期) ... 41
圖 25 全球 PC、超行動、平板電腦與手機出貨量預測(單位:千台) ... 46
圖 26 創造張力(Creative Tension) ... 48
第一章 緒論
1.1 研究背景及動機
巨量資料(Big Data)讓雲端運算資訊與儲存量大量增長。根據 IDC 預估,全 球資料量每年成長率高達 45%,2015 年將達到 7.9 兆 GB。從網路社群、企業客服、 工廠製程到觀光、交通、醫療、安全等領域都蘊藏巨量資料處理及分析全新商機。 而研究報告指出全球資料量單位進入 zetta bytes1 為 1 兆 GB 時代,才能符合巨量 資料的儲存、管理、處理、搜尋及分析。處理及分析巨量資料的雲端運算(Cloud Computing)軟硬體技術及產品勢必提升來符合雲端產業市場需求。處於雲端產業 價值鏈企業也極力加碼投資在企業軟硬體研發人員及預算、調整企業組織架構並招 攬產業優秀人才,添加生產及研發設備增加其出貨產能及質量。具國際競爭優勢的 產業更可以幫助產業進行技術創新、增加生產效率、提升產品性能、降低成本以及 爭取時效(楊千,2007)[39],此說法更能反應在雲端運算相關產業。而資源基礎理 論(resource-based theory; RBT)學者們(Barney,1986;楊千,2007)[4][39] 所提出的資源的特性包括:價值性(value)、稀少性(rareness)、不可模仿性 (inimitability)以及不可替代性(non-substitutability),持續優異的財務績 效也反應出企業運用資源能力靈活彈性方能創造永續競爭優勢。其他學者也提出利 用企業財務報表找出財務績效指標來檢視企業是否具有創造超額利潤及檢視企業 是否具有競爭力指標參考(Firer,1999;Tang、Liou,2010)[10][32]。 1 zetta bytes(ZB):以 10 進制算法為 1021,以 2 進制算法為 270。以市面上 1 顆 1TB 單位硬碟為基本 單位容量,1ZB 就需要用 10 億顆 1TB 硬碟才能容下巨大的 1 兆 GB 容量。
1.2 研究目的
據產業情報研究所(MIC)分析,美國、日本、中國及韓國發展其雲端運算政策, 各國政府在雲端運算領域的投資金額與項目之外,有助於雲端產業的後續應用、雲 端業者規劃研發方向以及國際間的市場進入策略(相元翰,2012)[37]。雲端產業遍 布亞洲及北美洲各地,另外,處於亞洲之臺灣廠商於雲端運算技術上已經累積相關 豐富經驗及技術,又有優異的量產能力與經濟規模,加上多年製造與研發的經驗, 有別於其他國家更能發揮及創造出真正的競爭優勢,在整個雲端價值鏈上扮演舉足 輕重的角色。能夠了解相關全球雲端產業軟硬體、製造及服務商之間投入雲端運算 狀況及掌握關鍵因素符合時勢及需求方能掌握契機增加企業本身競爭優勢。 就資源基礎理論主張,產業內之差異來自企業內部所擁有的資源及如何善用使 其成為企業本身競爭優勢,而核心能力(Core Competence)與無形資產則是企業 的優勢資源,使企業能夠創造出核心技術及關鍵成功因素轉換或製造出產品或服務 方 案 並 加 以 行 銷 出 售 , 俾 能 使 企 業 能 獲 得 超 額 報 酬 並 最 終 可 達 到 持 續 發 展 (Sustainability)或成為獨占(Appropriability)事業。 資源基礎理論定義企業對於資源基本分類有財務,人力,技術,組織,名聲及 有形資產,本研究將採用財務資源類別並依據杜邦等式導出之企業財務指標特性, 將企業競爭優勢資源劃分為資產管理能力、供應商關係管理、客戶關係管理以及知 識資產等四類。 本研究採 146 家上市企業為觀察體,研究時間從 2005 至 2012 年 8 年間財務資 料,運用杜邦等式(Firer,1999;Tang、Liou,2010)[10][32]分析財務指標,將 財務變數進行與上市企業在因素及集群分析結果,並觀察 2008 年全球性金融風暴 前期及後期,雲端產業策略集群分佈情況。1.3 研究範圍及對象
何謂「雲端運算」?依據美國國家標準與技術研究院(National Institute of Standards and Technology, NIST)於2012年9月發佈Special Publication 800-145
之特刊中,定義雲端運算為一種模型,此模型特點為「隨時隨地可使用」、「便捷」、 「依需求」,並透過網路進入一個共享池(Pool)並可配置運算資源(如不同網路形式、 伺服器、儲存、應用程式和各種服務)。雲端運算可快速配置和發布,用最少的管 理工作與服務提供商間互動(Mell、Grance,2011)[25]。 何謂「巨量資料」?參考NIST在2013年1月15日至17日舉辦的雲計算論壇和系列 研討會中所提到雲端運算(Brown,2013)[7],提供依使用者需求透過網路共享,並 可配置運算資源,而在這龐大而複雜的共享的資源所產生資訊(information)可稱 為巨量資料(Big data)。 而本研究認為所謂的「雲」,為雲端運算及巨量資料之間對於資訊分析及處理 關係所產生較為抽象的概念。簡單來說,此「雲」之資訊形成可藉由「端」(如一 般使用者之手持裝置、企業、政府及教育機關等)經由網路傳送至「雲」做資訊處 理及分析,最終可回傳至「端」或利用儲存設備存放於「雲」中。
圖1所示雲端運算產業價值鏈,IT infrastructure(OEM/SC and OEM),Facility, systems infrastructure software,Application development/deployment, Application 為本研究雲端產業範圍,而Presentation access不在本研究對象 內。
1.4 研究流程
本研究流程如圖2,分成5個章節,每章節概述如下: 第一章 緒論,簡述本論文研究背景及動機、研究目的、研究範圍對象及研究流程。 第二章 產業介紹及文獻探討,收集相關雲端產業及文獻探討資源基礎、資源優勢 理論、企業財務指標及多變量分析。 第三章 研究方法,說明本研究變數定義及資料來源、範圍、選取、使用分析軟體 簡介。 第四章 資料分析與結果,先對本研究變數做敘述性分析,運用因素分析及集群分 析求得實証結果並解析之。 第五章 結論與建議,本章最後將對研究實證結果加以彙總結論及管理意涵,並說 明本研究限制並提供後續研究之建議。第二章 產業介紹及文獻探討
2.1. 產業介紹
2.1.1 ICT 與 IT
聯合國貿易暨發展會議(UNCTAD)報告中指出最新技術及產業的成長機會將包 含全球資訊與通訊科技(Information and communications technology)(McCredie, 2012)[23],全球 ICT 及 IT 產業將重視並投資在這塊領域上。
資訊及通訊科技(ICT)
ITC 是資訊技術(IT)的總稱。更早以前資訊科技(Information Technology) 與通訊科技(Communications Technology)是兩個完全不同的範疇,「通訊科技」 著重於訊息傳送技術,而「資訊科技」著重於處理分析資訊接收後的編碼或解碼。 隨著技術的發展,這兩種技術慢慢變得密不可分,從而漸漸融合成為一個範疇。更 具體來說,資訊科技主要目的在於管理和處理資訊所運用的各種相關技術總稱,並 應用於電腦科學和通訊技術來研發、安置和製作資訊系統及應用軟體。而通訊技術 主要包含資料傳輸、網路交換、行動通訊、無線通訊等技術。
資訊技術(IT)
它涵蓋了從半導體設計和生產(包括在電子,伺服器,個人電腦和移動設備) 透過硬體製造、軟件、數據存儲、備份和檢索結合網絡運用於全球性的互聯網上。 電腦的發展歷史我們可以回朔到西元 1965~1970 年開始,當時都還是大型電腦主 機及終端機架構,一切資料和應用軟體都是在此大型主機內做運算處理及列印,這 些運用只能在政府機構及企業才有機會使用,這些大型主機造價昂貴且處理能力有 限,所以只能限定學術研究及商業運用。隨著網際網路的發展帶動了人類運用電腦 的新頁,影響後世電腦發展新紀元。 1970~1980 年代電腦運算能力不斷提升加上區域網路(LAN)以及網際網路 (Internet)快速蓬勃發展進而將個人、企業、政府及全世界電腦都作一系列分享 連結。區域網路、個人及企業擁有自己的伺服器,把資料庫集中管理,此時個人及 企業資料仍然存於私人儲存裝置為主。2011 年後以「雲」為基礎,演進發展出雲端運算(Cloud Computing),且終 端裝置的 PC 或手持裝置功能及處理速度比過去強多了也更普及化,在這基礎上也 奠定了雲端運算及雲端服務(Cloud Services)的產生及迅速發展,但儲存及運算 已由私人漸漸依賴他方儲存裝置及運算處理(如 Google),參考圖 3,雲端運算電 腦作業系統在 ICT 產業的發展演進簡介,而本研究以 2008 年為時間分界分前後期, 探討雲端產業趨勢。 資料來源:本研究整理 圖 3 雲端運算及服務演進
2.1.2 雲端運算(Cloud Computing)
長久以來,雲端運算已經作為一種實用技術,它改變了很大部分的 IT 產業生 態,做出軟件更具吸引力的服務並塑造 IT 硬件的設計和購買服務的方式。 (Armbrust et al.,2010)[3],不需大量的費用支出在硬體部署及人員操作,也不 用太擔心過度的配置服務而超出預期進而浪費昂貴的資源,或者少估算配置服務無 法提供現有及潛在的客戶而影響營收。此外,雲端運算可以有彈性及快速地擴展批 量的配置服務,例如使用 1,000 台伺服器一小時的費用不會超過 1,000 小時使用一 台伺服器。這種彈性的資源服務,無需購置龐大的運算伺服器的費用,是 IT 歷史 上前所未有的,也是未來趨勢。分散式運算(Distributed Computing)
、網格運算(Grid Computing)
與雲端運算(Cloud Computing):
所謂「分散式運算(Distributed Computing)」,使用者需要大量計算時卻沒 有超級電腦可以負荷處理,此時將資料做切割分別交給多台較低階的電腦運算再將 結果彙整。也就是將一個工作分成許多小塊後,分別交由眾多電腦各自進行運算然 後再彙整結果,完成單一電腦無法勝任與運算完成的工作。 「網格運算(Grid Computing)」,類似分散式運算,但其特色為支援跨管理 域計算的能力並共享「異質性結構資源」,可支援在不同平台,硬體及軟體結構等,讓不同等級的電腦及不同類型作業系統(例如 Windows and Linux)之間可以透過 通訊標準協定來互相傳輸溝通,分享彼此的軟硬體運算資源。在 2.1.1 章節討論, 在網際網路還未發達年代,只有大型企業及政府機關才能採用網格運算,採用主要 的原因是為了讓企業內部各組織的網路資源達到更良好的使用率及相容性,這樣的 運用後來促成了網際網路及電腦的蓬勃發展,強調不同電腦及作業系統之間可互相 的溝通以及合作。 新一代的雲端運算及雲端服務架構衍生出像Google、Yahoo、Amazon等網路巨 擘,他們有足夠資本及技術去購買及建置數以萬計的伺服器,並且把這些電腦連結 產生容納全球龐大需求的雲端運算及資料中心(Data center),而龐大的運算資源 需求就需要相對之雲端服務,衍生出基礎建設即服務(Infrastructure as a Service,IaaS);平台即服務(Platform as a Service,PaaS);軟體即服務(Software as a Service,SaaS)。
雲端服務模式與內容:
雲端運算提供許多應用程序在企業內部網路(Intranet)或網際網路(Internet)
的服務,出現了許多專業術語之的特徵層雲端運算解決方案包含 IaaS、PaaS 和 SaaS(Helland,2012)[17]。
基礎架構即服務(Infrastructure as a Service; IaaS)
也可稱為「公用運算(Utility Computing)」,這是在 Web 上提供虛擬化的硬 體和運算。一個 IaaS 的用戶可藉由網路訪問虛擬機器(Virtual Machine)和存儲 設備以符合租用服務(Helland,2012)[17],例如:Amazon 的 EC2、Rackspace 以 及 GoGrid 等。終端客戶不需額外成本去布署及管理底層的雲端基礎架構,但是能 夠藉由 IaaS 服務商提供基礎架構來分享高速運算、大量資料儲存及高頻寬網路服
務資源。IaaS 服務商需維護硬體及監控元件穩定性,如資料中心建置,讓企業使 用者利用付費機制節省龐大的伺服器建構成本,可將此建置預算運用於其他重要資 源增加其企業競爭力。
平台即服務(Platform as a Service; PaaS)
這是一個高層次的應用服務領域,服務供應商的有兩個目標:第一,提供容易 使用的開發中介軟體、資料庫及 API 平台;第二,將客戶開發的應用程式部署到雲 端的服務,例如:Salesforce 及 Google 的 App Engine(Helland,2012)[17]。藉 由 PaaS 讓專業的開發人員開發出屬於企業及一般使用者之應用服務軟體並結合網 際連線功能,例如:Google 的 Andrio APP、Microsoft Azure、Amazon 線上購物 平台及 Facebook 社群平台。
軟體即服務(Software as a Service; SaaS)
用戶使用終端設備並執行開發完成應用程序透過企業內部網路(Internet)或 網際網路(Intranet)的能力可以在 Web 上找尋所資料及其他應用(Helland, 2012)[17]。日常生活中用戶使用個人電腦桌機或手持式通訊設備如 Smartphone、 Notebook 或平板電腦等等,透過網際網路與 PaaS 開發完成之應用軟體如 Android APP 連結即時資訊,YouTube 觀賞影片及最熱門 Facebook 社交軟體與朋友分享資 訊。SaaS 服務是雲端運算中最多服務需求應用,因應為技術門檻較低、擁有較彈 性設計空間及最低的建置成本,所以最多競爭者來搶食這塊龐大商機。
雲端布署模式(Cloud Deployment Models):
企業或政府機關尋找有能力雲端佈署提供商,需考量本身佈署隱含的風險、資 訊存取程度及傳遞模式可以分為:公有雲(Public cloud),私有雲(Private Clod) 及混和雲(hybrid Cloud),依照託管方案可分為:內部(internal),外部(external), 或結合(combined)(Archer et al.,2011)[2]。「公有雲」服務模式為企業提供 共享平台服務給任何客戶,佈署成本較合理,但是資料安全性堪慮。「私有雲」服 務模式常使用於企業或政府機關,考慮資料保密及非公開資訊之安全性,相對來說 佈署成本費用較高。而「混合雲」結合私有雲保密性及公有雲之即時資訊分享方式, 企業或政府機關可以可視其組織及服務需求選擇其適合之傳遞模式從中獲取最低 成本、資訊安全佳及最高運算能力佈署模式。
2.1.3 雲端資料安全(Security)、防破壞(breaches)及法
規(Rule)保密性(Security)
雲端運算有九個重要的挑戰參考圖 4,其中就有兩項關於資料安全方面一是資 訊安全(Information Security)另外為個人資訊 data Privacy(Booz&Company, 2012)[6]。
資料來源:Booz & Company 圖 4 雲端運算 9 個挑戰
防破壞性(breaches),一般人認為有了隱私及安全的保護下,資料就安全?
這可不完全正確,在 Compuwar 和研究機構 Ponemon Institute 在取樣超過 1,000 個 IT 專業人士在世界各地調查收集後的一項新的調查結果摘錄結果如下: 80%的公司承認資訊洩露。 43%的公司過去 24 個月經歷了兩個或兩個以上資訊遭破壞。 75%的公司遭受了員工的意外或錯誤的的破壞。 26%的公司遭受員工的惡意破壞。 34%的公司並不知道他們的資訊遭受了多少破壞。 只有 1%來自公司資料遭受外部的破壞。 由此可知實體儲存設備在備份及保護資料也是企業及雲端運算提供商需要注 意的部分,目前法規(Rule)制定,在歐洲,對於雲端運算相關策略及法規制定單
位(歐盟電信監管機構)正加快推動其公共機構及私人企業對於「雲端運算」相關 策略及法規,藉由這些策略、法規,將可助歐盟各國生產總值(GDP)在未來八年 內提升近 160 億歐元(hundred-and-sixty-billion-euro)(Brussels,2012)[8]。 歐盟委員會(European Commission)此政策推動主要藉由電腦系統、網際網路及雲 端運算架構下對於資料安全制定法規來保障數據儲存隱私及機密問題。經由數據分 析專家參予有助於數據隱私及機密所面臨複雜法律問題,開發一套適用於全球性的 標準來徹底消除人們的疑慮及擔心。雲端運算相關服務供應商遵循法規加強資料安 全及軟硬體部署機制,保障極為重要個人資料相關服務。
2.1.4 雲端運算伺服器(Cloud Computing Server)
伺服器為一個資源管理平台設備,包含外殼機箱(Chassis)、主機板而主機板
內含運算處理器(CPU)、記憶體(Memory)、晶片組(Chipset)及 BIOS(Basic Input Output System)等,集成於電路印刷版上並提供遠端管理者服務的電腦軟體來讓主 機板有效運作於雲端運算。伺服器在不同應用環境有不一樣外型及功能來符合各企
業需求(如 Google、Amazon、甲骨文等),伺服器依構造、成本、環境需求其種類
介紹如下:
塔式伺服器(Tower server)/直立式伺服器(Pedestal server)
外型結構類似家用一般桌上型電腦,可以放在桌上或地板上,其特色為較多的 PCIE 擴充槽,不需額外支撐機架,插上電源後即可使用。運用場合通常為教育單 位或中小型企業 MIS 機房,不適合運用在資料流量龐大的雲端運算環境。
機架式(Rack Mount)
直立式伺服器體積龐大又佔空間,大型企業運用多台伺服器時,主機存放空間 更是一個限制條件,機架式(Rack Mount)伺服器將數台 1U 高度主機橫向放置於 機箱中統一管理控制。機架式伺服器可委託專業的服務器託管商進行託管維護,企 業每年只需支付託管費節省自行管理伺服器人員、電力及設備成本,另外一項優點 為每一刀(1U)讓機箱可預留內部空間以便日後進行硬碟和冗餘電源(Redundant power)擴展及更換,符合雲端伺服器特殊需求其優點為配置靈活性高,也因高彈性 配置應用高故產業應用範圍非常廣,為目前採用率最高之伺服器。一般機架式伺服 器的業界標準寬度為 19 英寸,高度以 U 為單位(1U=1.75 英寸=44.45 毫米),有 1U,2U,3U,4U,5U,7U 等標準的伺服器,可供企業依照合理成本、運用環境選擇考量,但需配合機櫃統一使用。機架式伺服器也可以是一種優化結構的塔式伺服 器,其設計目的主要盡可能減少伺服器龐大體積佔用企業機房空間,減少空間的直 接好處就是在機房託管的時候價格會便宜很多。
刀鋒伺服器(Blade Server)
一種單板型態的伺服器於 2001 年由 RLX 公司提出並改良依據於機架式伺服器 架構及其網路卡設計再優化更符合商業經濟考量(Kelly,2013)[21]。比起機架式 (Rack Mount)主機更省空間,刀鋒伺服器有一個完整的機座,統一集中的方式, 提供電源、風扇散熱、網路通訊等功能。而每個基座上可插置多張單板電腦,因狀 似刀片(Blade),因此稱之為刀鋒伺服器。刀鋒伺服器架構屬於 HAHD(HighAvailability High Density,高可用高密度)適合處理器運算高速且高記憶體容 量型工作場合,舉例如,資料庫應用、企業應用程式和虛擬化(維基百科,2013a)[40]。 其中每一刀實際上就是一塊系統主板,它們可以通過本地自我啟動機制(BMC)來 啟動並選擇硬碟及作業系統(例如 Windows server、Linux 等),可以獨立運作的伺 服器架構。當啟動每一刀系統使其獨立運作時,每一系統將運行自己的系統或不同 作業系統如 Linux 或 Windows server,各自服務指定的遠端管理員,之間沒有相 互關聯。當利用特殊系統管理機制(透過 BMC)將每一刀集合成一個伺服器集群, 在此集中管理模式時,所有的主板可以連接起來提供高速的網路環境並且共用資源 (如 CPU、記憶體及硬碟儲存)給予同一遠端管理者更有效運用,參考表 1 伺服器 種類及優缺點比較及圖 5 伺服器類型。 表 1 伺服器種類及優缺點比較 資料來源:本研究整理
資料來源:本研究整理 圖 5 伺服器類型
2.1.5 巨量資料(Big Data)
全球的資料量正在迅速擴大!每天大量的資料數據產生大多來自科學實驗,企
業和最終用戶的活動,這些大量資料集稱為「巨量資料(Big Data)」(Bohlouli et
al.,2013)[5],而計算機科學的研究人員和 IT 專業人士提出了大量且新一代的挑
戰在於存儲,處理和分析基礎上。巨量資料有三種特質,資料量大(volume)。速
度快(velocity)及多樣化(variety)(Gobble,2013;Gupta et al.,2012)[14][16]。
此三特性在資料數據大過於傳統的系統處理所能處理的量(volume),處理大量資 訊量其分析處理速度必需更快速(velocity),快速處理過程中對於資料結構來說, 非單一而是多樣化且繁雜之結構(variety)。 例如 Google 在 2008 年每天處理資料高達 20 petabytes,而在 2011 年運用 8,000 台伺服器在 33 分鐘內處理 100 個位元字節的 1 petabytes 資料量。2010 年 零售業巨擘-沃爾瑪(Walmart)在 1 小時可以達到處理市場交易量超過 1 億美元。 Amazon.com 統計在 2011 年 11 月 29 日達到單日銷售高峰期,每秒可以售出 158 產 品項目。現今週遭環境中也可看見其巨量資料趨勢,例如醫療器材、大賣場及快遞 倉管業務及自動感應器 RFID 標籤其移動性資料量遠遠超越人類產生的數據。在一 架波音 747 飛機在飛行六小時過程中就可以產生 240 TB 的感應器數據,另外據藍
色巨人 IBM 估計每天由人類及機器產生出來的原始數據就有 2.5 exabyte(10 的
18 次方)。在雲端處理這些巨量資料處理技術運用,關於交易性的資料,經常利用
關聯式資料庫進行儲存然後轉換為資料庫作為分析之用稱為 SQL 資料處理。相反, 處理非交易性的非結構化資料結構則稱 NOSQL 資料處理。目前最廣為採用資料結構 管理技術有 NoSQL、Hadoop 和 DSMS(Gupta et al.,2012)[16],也使得這些雲端 資料管理上也產生出一套使用者付費機制(pay-as-you-go)的商機。
巨量資料在雲端產業之商機及競爭優勢:
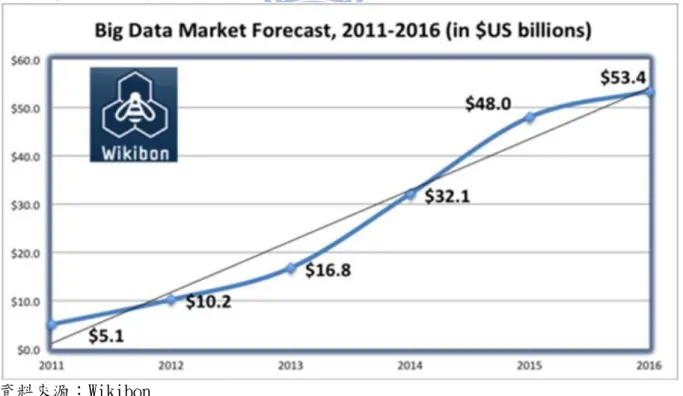
2011 年全球巨量資料市場之商業價值已經廣泛應用並快速成長,預測到 2016 年 5 年間,每年將超過 50%成長,高達 534 億美元市場價值請參考圖 6(Bohlouli et al.,2013;Kelly,2013)[5][21]。巨量資料帶來商業巨潤,其相關軟體、硬體研 發和提供服務的企業不但可以提升企業運營效率,不斷投資在巨量資料相關分析的 功能應用技術,得以符合客戶在巨量資料與雲端運算所需技術及服務,從而獲得持 續競爭優勢及超額利潤。 資料來源:Wikibon圖 6 巨量資料市場預測,2011-2016 (in $US billions)
另外,根據 IDC 分析處理巨量資料將帶來技術與服務上的龐大商機,從 2010 年的 32 億美元提升至 2015 年 169 億美元,五年複合成長率達 39%。其中,服務、 軟體市場份額約為 60~70%;其餘則是伺服器、儲存與網路市場。
2.2. 文獻探討
2.2.1 價 值 鏈 與 競 爭 優 勢 (Value Chain and competitive
advantage)
企業在產業中價值鏈有所不同,可以反映出企業的歷史、執行之策略及成功的 過程,重要的是經由價值鏈在不同競爭對手使企業創造出競爭優勢 (Porter、 Chandler,1985)[29],在雲端產業各企業製造商品及提供服務能讓客戶創造更多 附加價值,並且在產生這些商品及服務的過程中建立起企業經營模式及經營策略, 讓產品本身之技術、品質、價格、通路及品牌在市場上具有競爭優勢。2.2.2 資源基礎理論(Resource Based Theory; RBT)
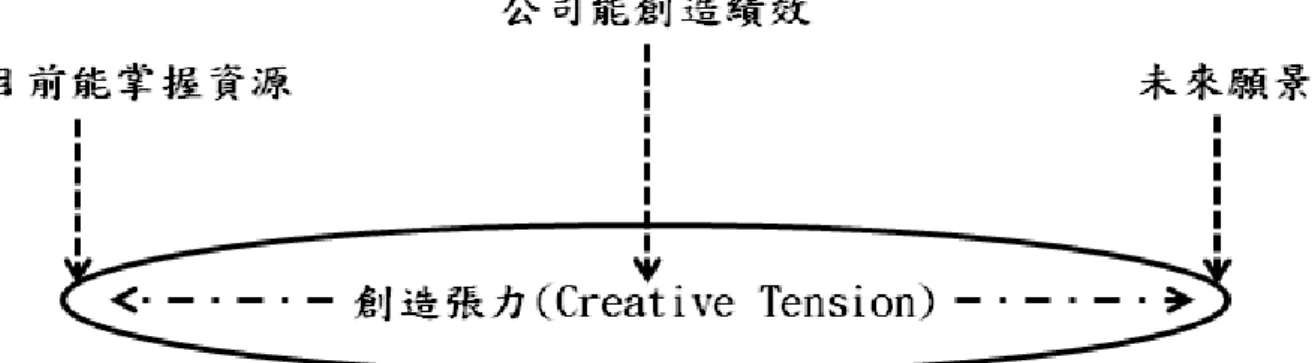
企業文化必須產生持續及獨特競爭優勢(Barney,1986)[4]。企業文化屬性將 是競爭優勢的源頭,從事組織活動過程中適時調整企業文化順應市場及產業趨勢, 必能產生持續卓越財務績效。因此,卓越財務績效可以了解一家企業文化及企業本 身良劣。相較之下基於資源基礎理論(Resource Based Theory)可以被看做是一 種 inside-out 過程所規劃的策略(Grant,1991)[15]。首先,我們必須了解企業擁 有甚麼樣的資源,找出並評估這些資源的潛在可以創造出何種價值。最終,我們需 要制定策略以永續方式來獲取及投資這些資源的最大價值,參考圖 7。資料來源:Grant1991
2.2.3 資 源 優 勢 理 論 ( Resource advantage Theory;
RA-Theory)
由表 2 可知,在相同產業的競爭下對於新古典主義及競爭優勢理論之間的比較 (Hunt、Morgan,1995)[19],企業目標制定由利潤最大化轉變為優越的財務績效, 企業獲取利潤並不代表這家公司在產業是擁有市場競爭優勢。管理者所扮演的角色 內容,也由單純只顧及出貨確認及順利生產,演變成需多了解企業財務金融及法律, 實體設備資源規劃、人力資源、組織結構、科技資訊和人際關係。本研究認為,管 理者角色需符合動態市場要求需要及擁有多樣化的管理知識才能在產業界中為企 業創造競爭優勢。 表 2 新古典主義和競爭優勢理論之比較2.2.4 企業財務績效指標
有關於客戶和創新資產對於企業的財務績效是非常重要的,使用配置理論及資 源基礎觀點,資產在互相作用下影響企業經營績效取決於運用資產能力之深度和廣 度(Fang et al.,2011)[9]。企業善用資源並且讓資源達到最高的效率表現財務指 標,例如資產報酬率(Return On Assets, ROA)高低來加以衡量,ROA 比率越高 表示該企業營運期間運用整體資產所獲得的報酬效率越好,最終將反映在稅後淨利 得到非常好的利潤報酬。資產報酬率(ROA)= 稅後淨利÷總資產×100%(比率越 高,表示公司的營運使整體資產的報酬運用效率越高),而 投入資本報酬率 (return on invested capital, ROIC)為 ROE 之改良指標,用以衡量實際現金投 入所獲取之現金報酬(cash-on-cash return),且反映企業運用資源之能力(Liou、 Huang,2009)[22]。杜邦等式(Du Pond Identity)可以了解企業依循國際慣例下 財務健康狀況,永續發展競爭優勢的概念可以運用杜邦等式,提供企業財務分析和 財務規劃之間的聯繫(Firer,1999)[10]。另外策略管理的一個核心問題是如何推 論出「可持續的競爭優勢」可以被找出其優勢並付諸實行(Tang、Liou,2010)[32], 以杜邦等式為基礎的理論框架,了解企業需要衡量本身對於永續競爭優勢、資源配 置、動態學習能力及永續發展的卓越績效,由這些條件了解企業與競爭對手對於未 來在產業生存及與競爭之間策略分析之依據,參考圖 8。
資料來源: Tang and Liou 2010[32] 圖 8 可持續的競爭優勢
2.2.5 多 變 量 統 計 分 析 (Multivariate statistical
analysis)
多變量統計(Multivariate statistics,或做 Multivariate statistical analysis、Multivariate analysis,多因素分析、多重變數分析)是社會學、醫 學、金融、數量心理學、市場營銷等常用的一系列在一個時點觀察並分析多個統計 變數的實證分析方法的總稱(維基百科,2013b)[41],最常見分析法有邏輯斯回歸 分析(Logistic Analysis)、區別分析(Discriminant Analysis)、集群分析(Cluster Analysis)、線性結構相關模式(Linear Structure Relation)等。研究者通常收 集眾多變數資料,想了解變數資料間是否有相關,嘗試找出研究數據結構或加以分 類探討,與其他統計方法需要假設檢定方式是有差別,端看研究者資料變數及研究 方 法 來 決 定 。 本 研 究 採 因 素 分 析 (Factor Analysis) 及 集 群 分 析 法 (Cluster Analysis)探討策略集群分佈。
2.2.5.1 因素分析(Factor Analysis)
進行因素分析時需要考慮若干問題如下列四點(Ford et al.,1986)[11],經 過這幾項分析所做出的結果,每一被選擇因素都有實質性的影響最終解釋分析:(1) 選擇使用之因素模型:
採用因素分析時,研究人員面臨的第一個決定就是該採用哪種因素模型。因素 分析目前應用上分兩種不同的方法:因素分析和主成分分析,這兩種方法都允許研 究人員,對於研究變數間的差異性分析。與因素分析法近似之主成分分析法 (Principal Components)是有些差異的,因素分析重於分析解釋變數間的關係。 另外,主成份分析與探索性因素分析這二種多變量方法均屬構面縮減技術,其 意義在於能夠以較原變量個數少之新的構面來解釋原始變量所呈現的訊息,透過構 面縮減可將資料精簡以利資料分析與資訊掌握(丁承,2011)[34]。探索性因素分析 係透過因素模式(此處限於正交模式)表達構面縮減的含意,目的在尋找彼此無關 的共同因素(其個數較原始變數個數少)來代表原始變數的意義以精簡資料。根據 因素模式,每一原始變數皆是共同因素的線性組合加上一誤差項(error)或稱為獨 特因素(specific factor)(丁承,2011)[34],參考圖 9。資料來源:本研究整理 圖 9 因素分析概略圖 主成份分析是最基本的構面縮減工具,係以共變數矩陣 (covariance matrix) S 或相關係數矩陣 (correlation matrix) R 為基礎進行分析,所求得的新變數是 原變數的線性組合,滿足各新變數的變異數極大、次大、. . .,且新變數彼此間 無關(uncorrelated) 的條件,這些新變數依其變異數的大小依次稱之為第一主成 份、第二主成份、. . .等(丁承,2011)[34],參考圖 10。 資料來源:本研究整理 圖 10 主成分分析概略圖
「探索性」與「驗證性」因素分析:
兩者的差異在於前者並未有關聯理論基礎,僅藉由資料所呈現之特性試圖爲相 關性較高之變數萃取其共同因素;後者則係針對已存在之因素結構 (包括共同因素 個數及其所對應之指標變數),以資料進行實證,此時在統計推論上有更細緻的處 理。在 SAS 中探索性因素分析係採用 PROC FACTOR 參考,驗證性因素分析則採用 PROC CALIS(丁承,2011)[34]。
(2) 決定保留相關因素的個數:
因素分析旋轉之前的結果在絕大部分取決於諸多因素中怎麼樣去保留因素個 數。不幸的是,保留因素的標準是不確定的(Ford et al.,1986)[11],而在成分 分析(Components Analysis),使用 Kaiser 準則讓特徵值(Eigen values)大於 1 之因素予以保留,尤其是當樣本數量大於變數其比例為 10:1 較適當。
(3) 選擇主成分分析及因素轉軸方法:
因素模式,每一原始變數皆是共同因素的線性組合加上一誤差項或稱為獨特因 素,線性組合的係數稱為因素負荷量(factor loadings),因素負荷量矩陣則稱為 pattern matrix (or pattern),如何決定因素個數並估計因素負荷量是因素分析 的重點,通常我們可採用主成份法(principal component method)與最大概似法 (maximum likelihood method , 此 時 資 料 須 滿 足 多 變 量 常 態 ) 為 之 ( 丁 承 , 2011)[34]。
經過主成分法後可得負荷量矩陣,可進一步藉由因素轉軸(factor rotation) 獲致 simple structure 以增進解釋能力,其中最大變異 (varimax)正交轉軸 (orthogonal rotation)法常可達此目的,且又能維持共同因素原有的特性(含共同 因素間無關),作法上係藉由 PROC FACTOR 中 ROTATE=PROMAX 的指令為之(丁承, 2011)[34]。由以上主成分分析及轉軸後得到結果,可以儲存成另外的資料集(Data Set)供後續回歸、集群、MDS 等分析之所需的資料。
(4) 解釋(Interpretation)因素的解決方案:
因素分析,最終的目標是將分析的眾多變數歸類並定義一個有意義的因素,通 常這是很主觀判別,為了減少其主觀性需有一個規則來加以解釋,常用規則是指定 大於 0.4 的因素負荷量此唯一的變數應視為「顯著」,用來定義該因素採用規則 (Ford et al.,1986)[11]。2.2.5.2 集群分析(Cluster Analysis)
集群分析法利用已知的分類標準,將欲觀察對象以不同特徵加以集群歸類,歸 類之同一集群內觀察對象彼此特徵相似度越接近越好,而不同類別之集群異質性越 高越好。而常見集群分析的方法,可分為兩大類,4 種基本方法(Gatignon, 2003)[12]: 階層式集群方法(hierarchical methods) (1)單一連結法(single linkage) (2)質心法(centroid method)(3)華德最小變異法(Ward's minimum variance method) 非階層式集群方法(non-hierarchical methods)
(4)K 平均數法(k-means methods)
階層式集群方法使用各觀察體間距離或組內差異值比較兩個觀察體最接近合 併為同一集群內,合併後觀察體間距離或組間內差異值再次比較,直到研究觀察體 都被合併到適合的集群內。本研究採華德最小變異法(Ward's minimum variance
method),採用此法可得合併後集群內的聯合組內變異量可達到最小差距。 非層次集群方法是將研究者已知(known)或假設(assumed)預先假設群集個 數 k,每個觀察體會依照與每個集群 k 之質心(centroid)最小距離加以比較分配 到最短距離之集群,每個觀察體依照此標準(criterion)驗證直到完全到適合的 集群內。最常使用為 k 平均數法(k-means methods)來分群分類。本研究運用此 法做為分類策略及群標準。
第三章 研究方法
3.1 研究架構
本研究參考紅鯡魚(Herring,2013)[18]及雲端運算期刊(Ulitzer,2012)[33] 選出 146 家上市企業,雲端產業價值鏈相關軟硬體研發、製造及服務商,並經由 (McGraw-Hill,2013)[24]之 S&P compustat 的北美(North America)及全球(Global) 資料庫蒐集財務數據將研究數據以金融風暴(2008 年)為分界點分為前期及後期, 分為此兩期目的,主要是利於了解雲端產業在金融風暴後期發展,因資料量需求暴 增,讓資料儲存量及應用進入另一個新紀元即巨量資料(Big data),前期是期間為 2005 年到 2008 年月共 4 年,後期 2009 年到 2012 年共 4 年,供本研究之因素及集 群財務數據資料分析。財務數據採用(Tang、Liou,2010)[32]杜邦等式為基礎的理 論框架,擷取出財務指標分析雲端產業在前期及後期間差異分析試圖了解這 8 年間 雲端產業發展概況。 參考杜邦等式及企業財務指標為基礎,探討企業配置資源能力有四個方向,分 別 為 客 戶 關 係 管 理 (Customer Relationship Management) 、 供 應 商 關 係 管 理 (Supplier relationship Management)、智慧財產權管理(Intellectual Property Management)和固定資產管理(Fixed Asset Management)這四大方向供後續因素分 析命名參考,如 2.2.4 章之圖 8。
採用因素分析法(Factor Analysis)將財務指標以 KMO 檢定分析,其分析結果 了解採用變數是否可進行初步因素分析程度,如果檢驗結果不適合,建議刪除或更 換指標直到符合 KMO 檢定條件,經過符合檢定適合因素分析法後之財務指標即適合 進行下一步驟之因素轉軸,以利後續進行因素命名並供後續集群分類命名參考,故 因素分析主要是將本研究「財務指標變數」加以簡化並且得到合理因素解釋。最後, 針 對 本 研 究 採 用 146 家 上 市 企 業 進 行 分 類 , 使 用 方 法 為 集 群 分 析 (Cluster Analysis),需要分析可以分類多少集群個數?本研究採華德法最小變異數分析法,
判斷 R-Squared、CCC(Cubic clustering criterion)和 Pseudo-F 結果決定群集 個數之準則,得知適合的分類集群個數,採因素分析之合理因素來做為命名集群的 參考依據,研究架構流程如圖 11 所示。
資料來源:本研究整理 圖 11 研究架構
3.2 資料來源
本研究參考紅鯡魚(Herring,2013)[18]評選出北美、歐洲與亞洲之百大創新 公司雲端運算服務業者及雲端運算期刊(Ulitzer,2012)[33]評選出上百家雲端運 算公司等媒體來源(相元翰,2011)[36],收集全球雲端產業價值鏈相關企業之軟硬 體供應及製造商共 146 家上市企業,並經由 S&P compustat 的北美(North America) 及全球(Global)資料庫蒐集財務數據,蒐集時間分為前期西元 2005 至 2008 年共 4 年及後期西元 2009 至 2012 年共 4 年,供本研究之因素及集群財務數據資料分析 之用。
3.3 變數分析及分析軟體
SAS/STAT 是 SAS 公司所發展的一項具強大統計分析功能的軟體,須配合 SAS/BASE 使用,由基本的單變量分析至複雜的多變量分析,皆能透過交談方式獲 得兼具準確度及效率的計算結果,且操作簡易、富彈性,故使用上十分普及(丁承, 2011)[34]。多變量分析通常收集眾多變數資料需要仰賴複雜且大量的計算,藉助 電腦來進行運算,本研究採 SAS 軟體其版本為 9.3。本研究參考(Tang、Liou, 2007)[31]之杜邦等式財務變數分析,並從 S&P Compustat 下載財務指標如下: SALE(Sales Turnover Net):銷售淨額,出售商品所產生的淨收入。 EBIT :(Earnings Before Interest and Taxes):利息與營業稅前的盈餘,其公式為 EBIT * (1–t) + 遞延所得稅調整項(若有;但本研究不包含此項)。
ICAPT(Invested Capital Total):投入總資本額。
NOPAT(投入資本報酬率):利息與營業稅前的盈餘(EBIT)-所得稅費用(TXT) ROIC(投入資本報酬率):ROIC COGS_S(銷貨成本/銷售淨額):COGS_S AP_S(應付帳款/銷售淨額):AP_S INVCH_S(存貨/銷售淨額):INVCH_S CH_S(現金/銷售淨額):CH_S XRD_S(研究及開發費用/銷售淨額):XRD_S XSGA_S(管銷費用/銷售淨額):XSGA_S TXT_S(營業所得稅/銷售淨額):TXT_S RECCH_S(應收帳款/銷售淨額):RECCH_S FA_S(固定資產/銷售淨額):FA_S DPACT_S(折舊及攤銷/銷售淨額):DPACT_S
3.4 資料分析方法
3.4.1 因素分析法(Factor analysis)
因素分析過程中,利用KMO檢定來判斷研究資料之變數是否適合進行因素分析。 KMO是Kaiser-Meyer-Olkin的取樣適當性衡量,當KMO值越大,表示變數間的共同因 素越多,越適合進行因素分析。根據Kaiser的觀點,若KMO>0.8表示很好 (meritorious),KMO>0.7表示中等(middling),KMO>0.6表示普通(mediocre), 若KMO<0.5則表示不能接受(unaccept)(Gazzaz et al.,2012)[13],定義如表3 所示。 表 3 KMO 值解釋規則 資料來源:Kaiser(1974)3.4.2 集群分析法(Cluster analysis)
因素分析中我們研究目的是要將變數項目(本研究為財務指標)加以分類,而 運用群集分析雲端產業觀察體(146 家上市企業)而加以分類進而分析最終的策略 集群命名及分析。本研究採兩階段法,第一階段為階層式分層法(Hierarchical) 之 華 德 (Wards) 最 小 變 異 法 , 決 定 群 組 個 數 。 第 二 階 段 為 非 階 層 式 法 (Nonhierarchical),運用 K-means 進行群集命名及分析。3.5 財務指標之敘述性統計
敘述性統計分析主要目的,是要將原始資料加以組織、彙整並描述其特性,從 而使資料有系統的呈現出來。敘述性統計分析欲了解分析資料「中央趨勢情況」可 採平均數、中位數與眾數用以表示資料的中心位置,但中位數與眾數缺點為容易受 到極端值(extreme value)的影響或研究資料排列當中資料漏掉幾筆時,中位數即 失去代表性,如有資料呈現分散情形將會影響分析結果。本研究將對於資料離散程 度、形狀及對稱分配、常態分配作其敘述性統計分析。3.5.1「檢定研究資料是否為常態分配」之敘述性統計方法
統計方法中通常假設資料來自於常態母體,故需檢測資料的常態性,以確保分析 的結果是「可信的」。本研究以 Kolmogorov-Smirnov 來統計檢定的顯著水準, 若是達 到顯著水準 p-value <0.001 則符合常態分配。3.5.2 「資料分散程度」或「離散程度」之敘述性統計
「資料分散程度」或「離散程度」可知資料變異的原因和性質,目前常見分析 資料分散情形有:全距(Range, R)
,資料中的最大值與最小值之差即為全距(range),通常以 R 來 表示,通常研究資料尚未分組時候全距計算如(1)式,R =Max. value - Min. Value (1) 如果研究資料進行分組齊全距如(2)式,
R =upper limit -lower limit (2)
四分位差(Quartile Deviation)
,是將四分位距(Inter-Quartile Range;IQR)將資料去掉兩端最大( )及最小值( )各 25%的觀察值,只剩中間 50%部分的資料,
之後再求這 50%資料的全距,如(3)式的 代表第一個四分位數, 代表第二個四
分位數而 =IQR 稱為四分位距(Inter-Quartile Range)
平均絕對離差(Mean Absolute Deviation;MAD)
,將研究資料各觀察值與 平均數的距離總和取其算術平均數,而不討論離均差之正負號,稱為平均絕對離差 (mean absolute deviation),如下列未分組資料的平均絕對差如(4)式所示,n 為觀察值個數,x為 n 各觀察值加總後取其絕對值。 n x x MAD n i i
1 (4) 分組資料的平均絕對差如(5)式所示,其中代表 i 組的值 xi 及次數 f i N x x f MAD n i i i
1 (5)變異數(Variance;
或
分別代表母體及樣本的變異數)
,代表研究 資料與其平均數之間的離差平方後再加總除以總項數後即為變異數,研究資料為母 體變異數時用符號2表示如(7)式,
N i i x N 1 2 2 2 1 (7) 研究資料為樣本變異數時用符號s2 表示如(8)式,其中分母為 n-1 時而非 n 是因為 用x來估計因此s2失去一個自由度導致,
n i i x x n s 1 2 2 ) ( 1 1 (8)標準差(Standard Deviation)
,研究資料未被分組資料的母體標準差σ及樣 本標準差,如(9)式和(10)式所示,其中,N、n 分別代表母體及樣本的資料個數。 、x分別代表母體及樣本的平均數。 2 1 2 2 1
N i i x N (9) 1 1 2 2 2
n x n x s s n i i (10) 在已分組資料的母體及樣品標準差,如(11)式 and (12)式所示,其中, k為母體資料之組數,m為樣本資料之組數, N x f k i i i
1 為母體平均數, n x f x m i i i
1 為樣 本平均數。
i k i i f x N
1 2 2 1 (11) 1 ) ( 1 2 2
n x x f s s m i i i (12) 研究母體與樣本所得到「標準差」或「變異數」其值越大,代表資料表示資料離散 (差異)的程度也就越高,以投資觀點而言其投資的所冒的風險也越高。變異係數(Coefficient of Variation,CV)
,變異係數為標準差與平均數比 值的百分數且變異係數值的大小,顯現出研究觀察值變動的大小,數值越大其變動 的情況也就越大。如(13)式,當與為已知時,母體變異係數 % 100 CV 。如 (14)式,當與未知時,我們用樣本變異係數 x100% s cv 來估計母體變異係數, 其中,、s 分別為母體及樣本的標準差,與x分別為母體及樣本的平均數。 σ μ (13) X 100% (14) 變異係數值可顯現出觀察值(以平均值為基準)變動的大小,數值越大,變動(浮動) 的情況也就越大。3.5.3「資料形狀及對稱分配」之敘述性統計
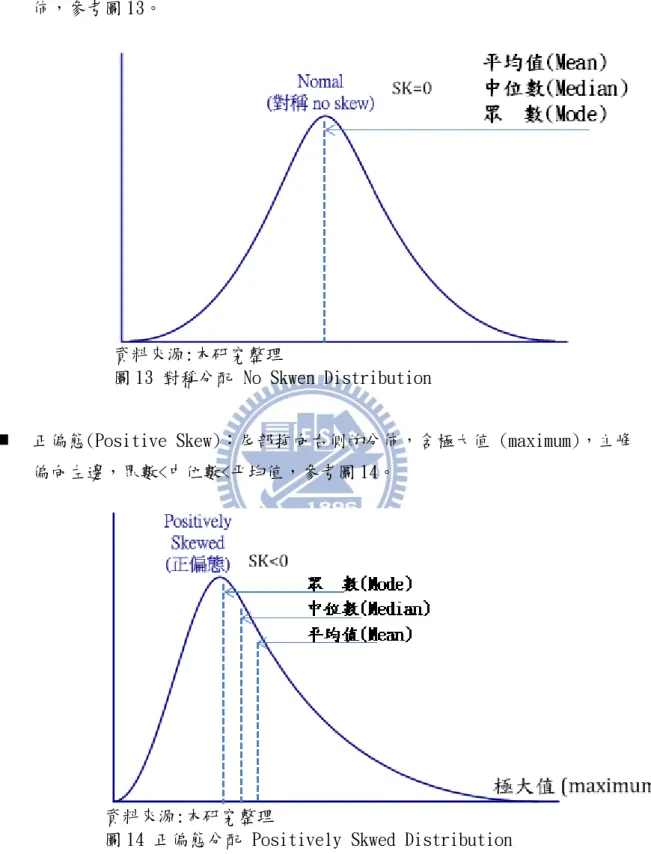
偏度分配(Skewness Distribution)和峰度分配(Kurtosis Distribution)常被 用來描述一個「分佈」的形狀特徵,也用於在常態驗證(Joanes、Gill,1998)[20], 研究資料的「資料形狀及對稱分配」最常用採用參考為偏態係數(coefficient of skewness,SK) 及 峰 態 係 數 (coefficient of kurtosis; ) 。 有 關 偏 度 分 配 (Skewness Distribution)分布可分三種型態,參考圖 12。 資料來源:本研究整理 圖 12 偏度分配 Skweness Distribution 其中偏度係數(Coefficient of Skewness, SK)用來度量分佈是否對稱,如對 稱分佈左右是對稱的,偏度係數為 0。偏態分為負偏態 (Negative Skewed) 與正偏態 (Positively Skewed) 二種表示,都是屬於單峰分配偏態的一種係數,如(15)式所示 主要觀察值為母體,如(16)式所示主要觀察值為樣本,其中與x分別代表母體平均 數與樣本平均數,Me是中位數, 與s 分別代表母體標準差與樣本標準差。 ) ( 3 Me Sk (15) s Me x Sk 3( ) (16)
對稱分佈(No Skew):SK=0,左右是對稱的,其眾數=中位數=平均值之對稱分 佈,參考圖 13。資料來源:本研究整理
圖 13 對稱分配 No Skwen Distribution
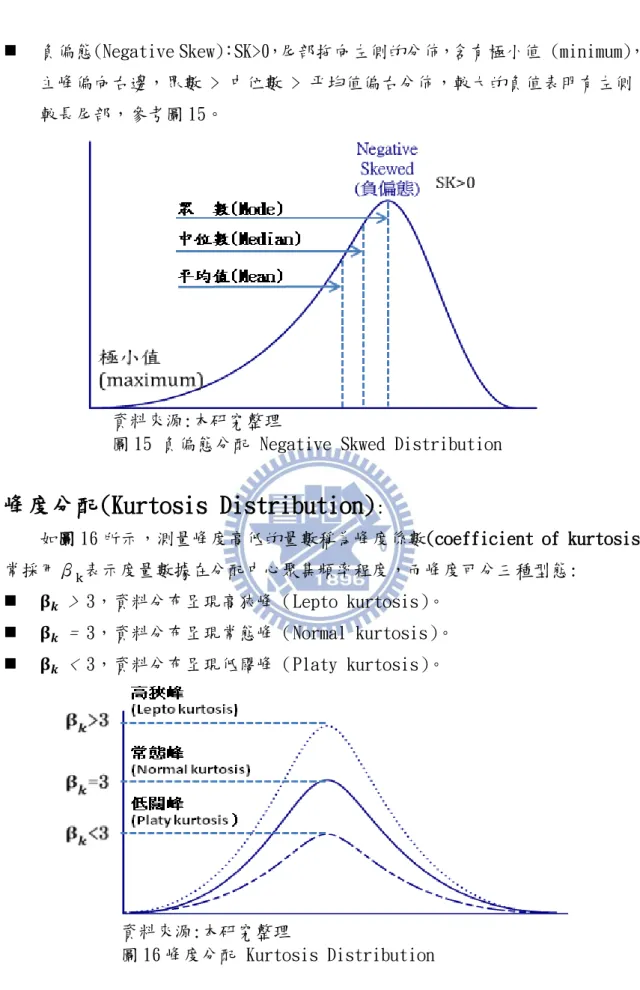
正偏態(Positive Skew):尾部拖向右側的分佈,含極大值 (maximum),主峰 偏向左邊,眾數<中位數<平均值,參考圖 14。
資料來源:本研究整理
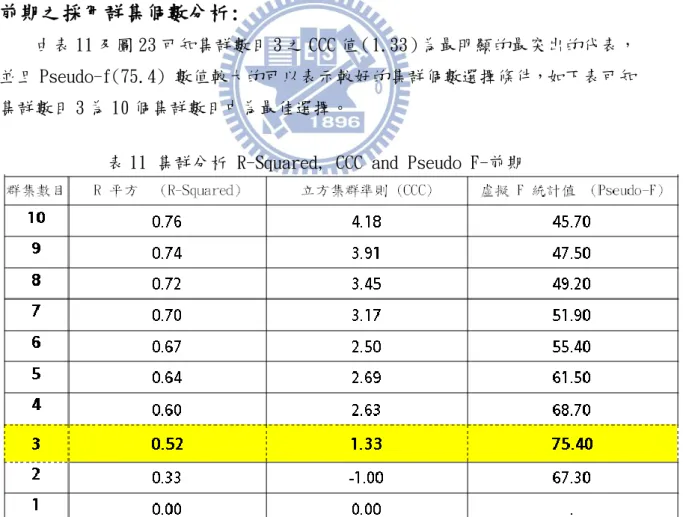
負偏態(Negative Skew):SK>0,尾部拖向左側的分佈,含有極小值 (minimum), 主峰偏向右邊,眾數 > 中位數 > 平均值偏右分佈,較大的負值表明有左側 較長尾部,參考圖 15。
資料來源:本研究整理
圖 15 負偏態分配 Negative Skwed Distribution
峰度分配(Kurtosis Distribution):
如圖 16 所示,測量峰度高低的量數稱為峰度係數(coefficient of kurtosis)通 常採用 表示度量數據在分配中心聚集頻率程度,而峰度可分三種型態: > 3,資料分布呈現高狹峰(Lepto kurtosis)。 = 3,資料分布呈現常態峰(Normal kurtosis)。 < 3,資料分布呈現低闊峰(Platy kurtosis)。 資料來源:本研究整理 圖 16 峰度分配 Kurtosis Distribution 峰度的頻率分佈不能描述實際物理特性的頻率(Pearson,1905)[28],峰度及偏度可 應用分析資料形狀及頻率、對稱性分配之特性。第四章 資料分析與結果
4.1 各財務指標敘述性統計分析
本研究以 2008 年金融風暴為界分前後兩個時期,前期為西元 2005 年至 2008 年 共 4 年,後期為西元 2009 年至 2012 年共 4 年。並以變異係數(Coefficient of Variation, CV)分析整體產業,以平均值為基準看其變動大小幅度(%),以偏態係數 (coefficient of skewness)及峰態係數(coefficient of kurtosis)觀察整體產業之 分配輪廓。 而財務指標分別為 ROIC(投入資本報酬率)、CH_S(現金/銷售淨額)、DPACT_S (折舊及攤銷/銷售淨額)、COGS_S(銷貨成本/銷售淨額)、FA_S(固定資產/銷售 淨額)、XSGA_S(管銷費用/銷售淨額)、XRD_S(研究及開發費用/銷售淨額)、INVCH_S (存貨/銷售淨額)、RECCH_S(應收帳款/銷售淨額)、TXT_S(營業所得稅/銷售淨 額)及 AP_S(應付帳款/銷售淨額)綜合彙整以上分析結果參考表 4。 表 4 財務指標敘述統計彙整總表 資料來源:本研究整理
變異係數(CV)之前後期比較:
變異係數(CV)可顯現出資料變動的大小,彙整前後期之變異系數對應分析參考圖 17,後期相較於前期之變異係數%敘述性統計分析參考表 5。 資料來源:本研究整理 圖 17 前期及後期之變異係數 CV(%)比較 表 5 後期相較於前期之變異係數% (CV=σ/μ)敘述性統計分析 資料來源:本研究整理峰態係數 (
)之前後期比較:
如圖 18,峰度係數之 = 3 為基準點(常態峰),分析資料分布度量數據在 分配中心聚集頻率程度由圖可知雲端產業趨向於低闊峰,詳細分布敘述如下: > 3,資料分布呈現高狹峰之財務指標為 TXT_S 營業所得稅/銷售淨額。並且包含後期之 AP_S 應付帳款/銷售淨額。 = 3,資料分布呈現常態峰: 前期之 XRD_S(研究及開發費用/銷售淨額)。 < 3,資料分布呈現低闊峰: 包含前後期之 DPACT_S(折舊及攤銷/銷售淨額) 、 INVCH_S(存貨/銷售淨額)、RECCH_S(應收帳款/銷售淨額) 、FA_S(固定資產/銷 售淨額)、CH_S(現金/銷售淨額)、XRD_S(研究及開發費用/銷售淨額)、XSGA_S(管 銷費用/銷售淨額)、ROIC(投資報酬率) 資料來源:本研究整理 圖 18 前期及後期峰態系數(Bk)比較偏態係數 (SK)之前後期比較:
如圖 19 所示,偏態係數之 SK= 0 為基準點對稱分佈(No Skew),由圖各財務指 標偏態係數可知,雲端產業趨向於正偏態(Positive Skew)。 資料來源:本研究整理 圖 19 前期及後期偏態系數(SK)比較雲端產業之 Distribution 分析:
綜合以前後期之正偏態及低闊峰結果參考圖 20,並對照其正常分佈圖( = 3 為常態峰和 SK=0 為正偏態)可知雲端產業呈現穩定成長趨勢。 資料來源:本研究整理 圖 20 雲端產業之分配(Distribution)概似圖4.2 因素分析(Factory Analysis)
本研究採因素分析其萃取方法採主成分分析法(PRINCIPAL),並採用複相關係 數平方法(SCM),採用此法可用變數中的一個變數最為基礎變數,用此基礎變數和 其他變數之複相關係數的平方之值做為變數共通性,其好處為被分析變數與其他變 數間的關係都會考量在內。4.2.1 因素取樣適當性分析
本研究進行因素分析前,先確定各變數分數間具有共同變異之存在,如此才值 得做因素 分析 。 本研 究運用 KMO 判斷 資 料是否適 合進 行因素 分析, KMO 是 Kaiser-Meyer-LOkin 的 取 樣 適 當 性 量 數 (Kaiser-Meyer-Olkin measure of sampling adequacy),當 KMO 值越大,代表變數間的共同因素愈多,越適合進行因 素分析。根據 Kaiser 的觀點(Gazzaz et al.,2012)[13],可以了解變數進行因素 分析可行性程度,若 KMO>0.8 表示很好(meritorious),KMO>0.7 表示中等 (middling),KMO>0.6 表示普通(mediocre),若 KMO<0.5 則表示不能接受(unaccept)。由表 6 及表 7 可看出本研究採用前後期財務指標其取樣適當性量數 (MSA)係數皆大於 0.6,表示該資料分析結果可接受進行因素分析。 前期由表 6 可知其取樣適當性量數(MSA)為 0.709 並符合 KMO>0.5 之條件表示 本研究採取財務變數適合並且可接受做進一步的因素分析。 表 6 因素分析之 Kaiser 取樣適當性量數-前期 資料來源:本研究整理 後期由表 7 可知,其取樣適當性量數(MSA)為 0.65 並符合 KMO>0.5 之條件表示 本研究採取財務變數適合並且可接受做進一步的因素分析。 表 7 因素分析之 Kaiser 取樣適當性量數-後期 資料來源:本研究整理
4.2.2 決定因素個數
前期如圖 21 所示,前 3 個因素以特徵值大於 1 予以保留,3 個因素累積解釋 率為 59%,期代表意義為此 3 個因素可以解釋整體因素能力達 59%可供本研究分析。 資料來源:本研究整理 圖 21 因素分析相關矩陣的特徵值-前期 後期如圖 22 所示,前 3 個因素以特徵值大於 1 予以保留,3 個因素累積解釋 率為 59%,期代表意義為此 3 個因素可以解釋整體因素能力達 59%可供本研究分析。 資料來源:本研究整理 圖 22 因素分析相關矩陣的特徵值-後期4.2.3 因素命名
如表 8 所示,本研究運用因素分析(Factor analysis)進行構面縮減分析, 旋轉方法採因素轉軸法中 Varimax 最大變異數轉換法,它使因素負荷表中變異最 大,其目的是將因素負荷矩陣的行做簡化,並將相關係數及因素負荷量的值相乘再 做四捨五入後可得大於 0.4 以上的因素用旗標「*」表示做為因素歸納分析參考 (Ford et al.,1986)[11]。 表 8 因素分析經最大變異數法(Varimax)之前期與後期比較表 資料來源:本研究整理 參考表 9 及表 10,本研究將前後期之 3 個因素整理如下: 「知識管理能力」 :因素 1 在前後期有相同顯著變數 XSGA_S(管銷費用/銷售淨額)、 XRD_S(研究及開發費用/銷售淨額)、AP_S(應付帳款/銷售淨額)、COGS_S(銷售成 本/銷售淨額)、 CH_S(現金/銷售淨額),本研究將此因素命名為知識管理能力。 「運用資產管理能力」:前後期之因素 2 有顯著的共同之變數有 DPACT_S(折舊及攤 銷/銷售淨額)、FA_S(固定資產/銷售淨額),本研究將此因素命名為運用資產管 理能力。 「供應商與客戶管理能力」:因素 3 之顯著的共同之變數 INVCH_S(存貨/銷售淨額)、 TXT_S(營業所得稅/銷售淨額),本研究將此因素命名為供應商與客戶管理能力, RECCH_S(應收帳款/銷售淨額)在前後期有明顯差別,在前期歸納在「運用資產管理能力」因素上,而後期歸納在「供應商與客戶管理能力」。 表 9 前期因素命名
資料來源:本研究整理 表 10 後期因素命名
4.3 集群分析(Cluster Analysis)
4.3.1 階層式分層法(Hierarchical)-決定群集個數
運用群集分析之華德法最小變異數分析法,判斷 R-Squared、CCC(Cubic clustering criterion)和 Pseudo-F 結果決定群集個數之準則:
Pseudo-F: Pseudo-F 公式 ,其中 G 是群集數,T 是平方的總和, 和 PG 是組內的平方總和。由公式可知,集群中 Pseudo-F 數值較大的可以表示較好 的集群個數選擇條件。 R-Squared: 代表集群間相異性程度,R-Squared 值大一點較佳。 CCC(Cubic Clustering Criterion):
立方集群準則主要判別方法為均勻分布值中取出其偏差值較明顯值。
前期之採用群集個數分析:
由表 11 及圖 23 可知集群數目 3 之 CCC 值(1.33)為最明顯的最突出的代表, 並且 Pseudo-f(75.4) 數值較大的可以表示較好的集群個數選擇條件,如下表可知 集群數目 3 為 10 個集群數目中為最佳選擇。
表 11 集群分析 R-Squared, CCC and Pseudo F-前期
資料來源:本研究整理
圖 23 集群個數分析 R-Squared, CCC and Pseudo-F (前期)
後期之採用群集個數分析:
由表 12 及圖 24 可知集群數目 3 之 CCC 值(-0.14)為最明顯的最突出的代表, 並且 Pseudo-f(62.3) 數值較大的可以表示較好的集群個數選擇條件,如下表可知 集群數目 3 為 10 個集群數目中為最佳選擇。
表 12 集群分析 R-Squared, CCC and Pseudo F-後期
資料來源:本研究整理
圖 24 集群個數分析 R-Squared, CCC and Pseudo-F (後期)
由以上分析,本研究採用資料可在前後期的雲端產業可分 3 個集群。
4.3.2 ANOVA(Analysis of Variance)變異數分析
本研究利 ANOVA 觀察前後期對於 3 個集群與 3 個因素進行變異數分析,分別以 每個因素為依變數項,分別對 3 個集群為自變項進行變異數分析。 Factor 1 為依變數項對於 3 個集群為自變項,其結果為「顯著」。 Factor 2 為依變數項對於 3 個集群為自變項,其結果為「顯著」。 Factor 3 為依變數項對於 3 個集群為自變項,其結果為「顯著」。 由表 13 可知,分析前期及後期三個因素皆有顯著差異,有利於後續集群命名分析。 表 13 前後期之 3 因素與 3 集群間 ANOVA 變異數分析 資料來源:本研究整理4.3.3 非階層式法(Nonhierarchical)-集群分類
運用因素分析及集群個數分析後,運用 K-means 可得集群之平均值分析將其因 素特質做為集群依據,如表 14 為前期集群 K-means 平均值,表 15 為後期集群 K-means 平均值,並且後期(146 家)比前期(141 家)多出 5 家企業。 表 14 群集 K-means 平均值(前期) 資料來源:本研究整理 表 15 群集 K-means 平均值(後期) 資料來源:本研究整理4.4 集群命名
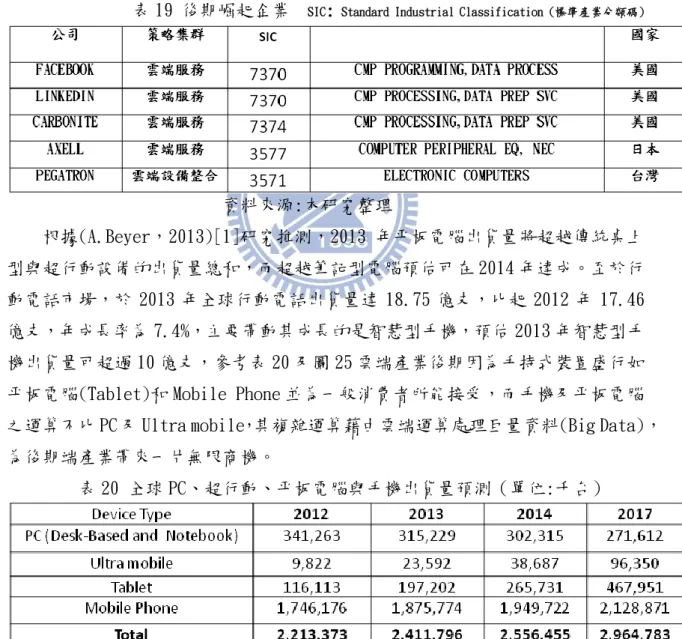
本研究將對雲端產業後期,進一步將集群間代表性的企業列出做為參考,並與 因素間相關性質並加以命名: 「雲端服務策略集群」: 集群 1 命名為雲端服務策略集群參考表 16,此集群內多為提供雲端軟體及網 路服務,提供服務給予企業及一般消費者獲取利潤。這裡就是最高速也最巨量服務 的集群代表企業如 Microsoft、Google、FACEBOOK、YAHOO 及 EBAY 等。REDHAT 及 ARM 為目前新一代伺服器節能及低成本解決方案為明日伺服器之星。以上企業其優 勢競爭因素特質為知識管理能力,企業面對日益快速及巨量資料需求,需要不斷提 升網路設備增加網路速度,所以對於供應商應付帳款應控制得宜,對於研發費投資因應巨量資料其資料處理分析能力及管理軟體、平台研發,讓企業本身競爭力提升。 管銷費用管理用來高吸引消費者及產品可見度,創新研發得以適當控制銷售成本以 提升產品銷售增加企業利潤。 表 16 集群 1 命名 資料來源:本研究整理 「雲端設備整合策略集群」: 集群 2 命名為雲端設備整合策略集群參考表 17,企業主要供應為巨量資料生態 下雲端基礎建設製造及提供商,這些企業有折舊攤銷及固定資產優勢因素運用, 以確保雲端產業相關伺服器及硬體裝置在亞洲,美洲及歐洲供貨無虞。臺灣雲 端伺服器製造商神達、緯創、鴻海、英業達、廣達及技嘉等運用資產管理能力 皆有不錯的表現,而國外雲端伺服器製造商 Super-micro 表現力度上也相當不 錯。有關伺服器基本介紹,請參考本文第 2.1.4 節有關雲端運算伺服器(Cloud Computing Server)簡介。而 APPLE、Amazon 和 IBM 採購一批可觀伺服器做為 淘汰更新或新添設備,符合雲端伺服器運用服務平台上龐大巨量資料需求其固 定資產及折舊攤銷為其企業節省固定成本優勢。
表 17 集群 2 命名