Lasso顯著性檢定與向前逐步迴歸變數選取方法之比較 - 政大學術集成
40
0
0
全文
(2) 摘要 迴歸模式的變數選取是很重要的課題,Tibshirani 於 1996 年提出最小絕對壓 縮挑選機制(Least Absolute Shrinkage and Selection Operator;簡稱 Lasso) ,主要 特色是能在估計的過程中自動完成變數選取。但因為 Lasso 本身並沒有牽扯到統 計推論的層面,因此 2014 年時 Lockhart et al.所提出的 Lasso 顯著性檢定是重要 的突破。由於 Lasso 顯著性檢定的建構過程與傳統向前逐步迴歸相近,本研究接 續 Lockhart et al.(2014)對兩種變數選取方法的比較,提出以 Bootstrap 來改良傳統 向前逐步迴歸;最後並比較 Lasso、Lasso 顯著性檢定、傳統向前逐步迴歸、以. 治 政 AIC 決定變數組合的向前逐步迴歸,以及以 Bootstrap 大改良的向前逐步迴歸等五 立 種方法變數選取之效果。最後發現 Lasso 顯著性檢定雖然不容易犯型一錯誤,選 ‧ 國. 學. 取變數時卻過於保守;而以 Bootstrap 改良的向前逐步迴歸跟 Lasso 顯著性檢定. ‧. 一樣不容易犯型一錯誤,而選取變數上又比起 Lasso 顯著性檢定更大膽,因此可. n. al. er. io. sit. y. Nat. 算是理想的方法改良結果。. Ch. engchi. i Un. v. 關鍵詞:變數選取、最小絕對壓縮挑選機制、向前逐步迴歸、拔靴法. I.
(3) Abstract Variable selection of a regression model is an essential topic. In 1996, Tibshirani proposed a method called Lasso (Least Absolute Shrinkage and Selection Operator), which completes the matter of selecting variable set while estimating the parameters. However, the original version of Lasso does not provide a way for making inference. Therefore, the significance test for lasso proposed by Lockhart et al. in 2014 is an important breakthrough. Based on the similarity of construction of statistics between Lasso significance test and forward selection method, continuing the comparisons. 治 政 between the two methods from Lockhart et al. (2014), 大 we propose an improved 立 version of forward selection method by bootstrap. And at the second half of our ‧ 國. 學. research, we compare the variable selection results of Lasso, Lasso significance test,. ‧. forward selection, forward selection by AIC, and forward selection by bootstrap. We. sit. y. Nat. find that although the Type I error probability for Lasso Significance Test is small, the. io. er. testing method is too conservative for including new variables. On the other hand, the. al. Type I error probability for forward selection by bootstrap is also small, yet it is more. n. iv n C aggressive in including new variables. based on our simulation results, the h eTherefore, ngchi U bootstrap improving forward selection is rather an ideal variable selecting method.. Keywords: Variable Selection, Least Absolute Shrinkage and Selection Operator, Forward Stepwise Regression, Bootstrap II.
(4) 目錄 第一章 緒論……………………….......…………………………………...……1 1.1 1.2 1.3. 研究背景與動機……………...…………………………………………1 研究目的……………………...…………………………………………1 研究流程……………………...…………………………………………2. 第二章 文獻回顧…………….……...…………………………….……………3 2.1 2.2 2.3 2.4. Lasso……………………….……………………….……………………3 由統計推論的角度探討 Lasso…..……………………………………...5 Lasso 顯著性檢定….…………….……………………………………...5 由分配的角度比較 Lasso 顯著性檢定與向前逐步迴歸……….……...6. 立. 政 治 大. 第三章 改良向前逐步迴歸……….……………………………………..........9. ‧ 國. 學. 3.1 驗證向前逐步迴歸之缺陷…….........………....................…..................9 3.2 透過 Bootstrap 改良向前逐步迴歸………….……………...................11. ‧. 第四章 模擬資料分析………………………..................................................13. y. Nat. n. al. er. sit. 模擬設計與流程……………………….................................................13 模擬結果……………………….............................................................16. io. 4.1 4.2. iv. 第五章 實證資料分析....C ………………..........................................................24 Un 5.1 5.2 5.3. hengchi. 資料背景.................................................................................................24 定義問題與方法.....................................................................................25 變數選取.................................................................................................26. 第六章 結論與建議...........................................................................................30 6.1 6.2. 結論.........................................................................................................30 限制與建議.............................................................................................31. 參考文獻..................................................................................................................33. III.
(5) 表目錄 表 4.1. 6 種自變數模擬環境之命名.........................................................................14. 表 4.2. Case 1 下不同方法選取之變數組合............................................................17. 表 4.3. Case 2 下不同方法選取之變數組合............................................................18. 表 4.4. Case 3 下不同方法選取之變數組合............................................................19. 表 4.5. Case 4 下不同方法選取之變數組合............................................................20. 表 4.6. Case 5 下不同方法選取之變數組合............................................................21. 表 4.7. 政 治 大 Case 6 下不同方法選取之變數組合............................................................22 立 錯誤率與部分正確率之整理........................................................................23. 表 5.1. 11 個科學變數之中英文名稱.......................................................................24. 表 5.2. 11 個科學變數分別與品質分數建立簡單線性迴歸之結果.......................27. 表 5.3. 11 個科學變數間的 VIF 值..........................................................................27. 表 5.4. 以 Lasso 顯著性檢定與 Bootstrap Forward 挑選之變數...........................28. ‧. ‧ 國. 學. 表 4.8. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 表 5.5. 以 Lasso 顯著性檢定挑選之變數組合下建立之迴歸模式估計結果........29. 表 5.6. 以 Bootstrap Forward 挑選之變數組合下建立之迴歸模式估計結果......29. IV.
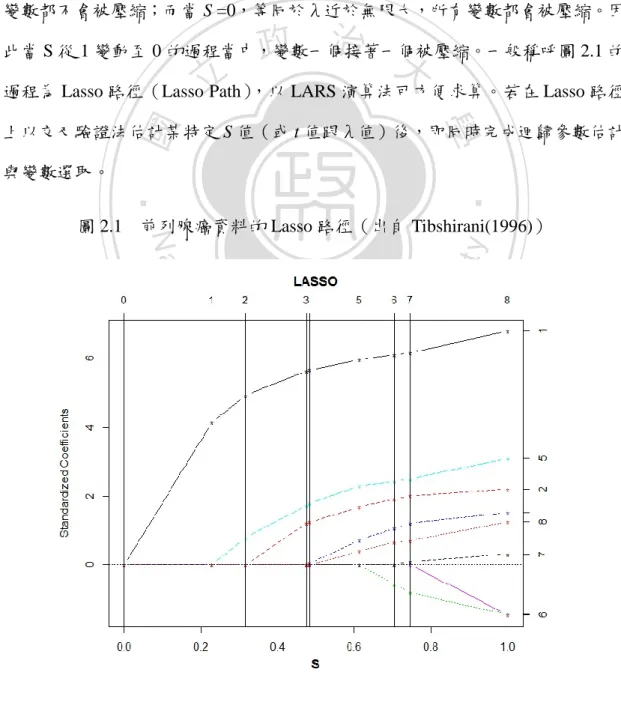
(6) 圖目錄 圖 2.1. 前列腺癌資料的 Lasso 路徑(出自 Tibshirani(1996))...............................4. 圖 3.1. 固定變數(左)與「貪婪的步驟」 (右)向前逐步迴歸與理論分配比較......10. 圖 3.2. 共變異檢定統計量分配與理論分配比較...................................................10. 圖 4.1. 模擬資料設計流程圖...................................................................................15. 圖 5.1. 品質分數之分布情況...................................................................................26. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V. i Un. v.
(7) 第一章 1.1. 緒論. 研究背景與動機 不論在哪種科學領域,找出不同因子間關係是種很重要的研究方式,而單變. 量迴歸分析是最常見的工具,且變數選取的方法也是熱門課題。從一群候選變數 中,把與應變數最有關係的變數組合找出來,往往可替分析者找到許多利於分析 的訊息。例如總體經濟學理論指出一個國家的經濟成長與技術進步、邊際勞動生. 政 治 大 法,可將 GDP 成長率作為應變數,整理出所有可能的經濟變數,利用理想的變 立. 產力提高,還有勞動供給增加等經濟因素有關;經濟學家若想映證經濟理論的說. ‧ 國. 學. 數選取方法,找出適當的自變數選取組合,與 GDP 成長率建構迴歸模式後應證 經濟理論的說法是否接近真實情況。由此可知迴歸變數選取方法的重要性,要找. ‧. 出的並非只有單一變數,而是最理想的變數組合。. sit. y. Nat. Tibshirani 於 1996 年提出最小絕對壓縮挑選機制(Least Absolute Shrinkage. n. al. er. io. and Selection Operator;簡稱 Lasso)方法,在最小平方法估計式後方加入懲罰項,. i Un. v. 使得不顯著的參數壓縮為零,故能在估計的過程中自動完成變數選取。不過 Lasso. Ch. engchi. 終究是在對迴歸係數估計,對於 Lasso 迴歸模式參數檢定的方法上,學界一直有 零星討論與研究。直到 2014 年 Lockhart et al.提出 Lasso 顯著性檢定的方法,以 新的檢定統計量讓 Lasso 迴歸由估計層次提升到統計推論層次上。若將 Lasso、 Lasso 顯著性檢定,與其他傳統方法一同比較變數選取效果將是有趣的課題。. 1.2. 研究目的 本研究的主要方向是將 Lasso 迴歸的方法與傳統方法進行比較,且 Lasso 顯. 著性檢定這個新方法會是主要重點。由於 Lasso 模式和傳統的方法都很多,要怎 麼選擇適合的方法用來比較會是主要挑戰。本研究的主要目的有兩點: 1.
(8) (1) 將具有比較意義的傳統方法與 Lasso 方法互相比較,找出客觀的比較基 準,並整理出方法間明確的結果差異。 (2) 由於本研究預期傳統方法在某些條件下表現會遜於 Lasso 方法,因此在 了解傳統方法的弱點後,會先將傳統方法改良,再將改良前後的傳統方法皆 與 Lasso 方法一起比較,藉此尋找更多研究與討論空間,並將方法間變數選 取效果進行比較。. 1.3. 研究流程. 治 政 由於本研究的研究重點有兩個:方法比較與傳統方法改良。為了找出具體的 大 立 比較方向,也要先了解傳統方法的具體弱點以利方法改良進行,故本研究第二章 ‧ 國. 學. 會先進行文獻探討:回顧 Lasso 迴歸模式、以 Lasso 進行檢定的研究發展,並透. ‧. 過過去的研究,決定適合用來比較的傳統方法為何。第三章會對決定用來與 Lasso. sit. y. Nat. 方法比較的傳統方法分析,從文獻回顧的發現驗證其弱點,並制定改良的具體作. io. er. 法。第四章透過模擬方法比較改良前後的傳統方法,以及與 Lasso 方法間的差異: 先陳述清楚資料模擬的設定與方式,再把方法比較的結果以有系統的形式表達。. al. n. iv n C 第五章會透過實證資料,再來比較不同方法選取變數的效果。第六章會回顧本研 hengchi U 究並整理出主要結論,並對研究的限制提出建議。. 2.
(9) 第二章 文獻回顧 本章主要對 Lasso 方法進行回顧,並藉由文獻探討的方式,尋找可以將 Lasso 方法與傳統方法作比較的切入點。本章分為三個部分:第一部分回顧 Lasso 方法; 第二部分由統計推論層面探討 Lasso 方法的發展;第三部分對 Lasso 顯著性檢定 回顧,並探究此方法與傳統方法的主要差異。. 2.1. Lasso. 政 治 大. Lasso 是 Bridge Regression 的一種變形,Bridge Regression 的概念由 Frank 和. 立. Friedman 在 1993 年提出。對於經過中心化的應變數 yi 和自變數 xij,i =1, 2,…, n,. ‧ 國. 學. j =1, 2,…, p 而言,其 Bridge Regression 之參數估計式為:. ‧. Nat. y. (2.1). v ni. n. al. er. io. sit. 而 Lasso 由 Tibshirani 於 1996 年提出,其參數估計式則為:. Ch. (2.2). U i e h n c g (2.1)式後面的懲罰項(Penalty Term)被稱為 L -norm,而(2.2)式的則被稱為 λ. L1-norm。事實上(2,2)意思與下列的(2.3)式相同,只是(2.2)式是藉由拉格朗治乘 數(Lagrange Multiplier)來表達以進行參數估計。 (2.3) (2.2)式中的參數λ和(2.3)式中的參數 t 被稱為調節參數(Tuning Parameter), 以下以λ說明調節參數的意義:λ估計值的大小會影響迴歸參數估計值被壓縮為 零的個數。因此在給定特定λ估計值下來估計迴歸參數時,會自動將不顯著迴歸. 3.
(10) 參數壓縮為零,而這也是 Lasso 最主要的特色,即能在估計的過程中自動達到變 數選取的目的。而關於λ的估計方式,一般是採用 K 折交叉驗證法(K-fold Cross Validation)或廣義交叉驗證法(Generalized Cross Validation),估計出能使預測 誤差(Prediction Error)達到最小的λ估計值。 Tibshirani 以一筆前列腺癌資料分析,說明調節變數的大小變化對迴歸參數 估計影響的過程,如圖 2.1 所示。圖 2.1 中橫軸變數. ,因此當 S =1,. 等同於λ= 0,此時與 OLS 估計式(Ordinary Least Squares Method)相同,所有 變數都不會被壓縮;而當 S =0,等同於λ近於無限大,所有變數都會被壓縮。因. 政 治 大. 此當 S 從 1 變動至 0 的過程當中,變數一個接著一個被壓縮。一般稱呼圖 2.1 的. 立. 過程為 Lasso 路徑(Lasso Path),以 LARS 演算法可方便求算。若在 Lasso 路徑. ‧ 國. 學. 上以交叉驗證法估計某特定 S 值(或 t 值跟λ值)後,即同時完成迴歸參數估計. ‧. 前列腺癌資料的 Lasso 路徑(出自 Tibshirani(1996)). io. sit. y. Nat. 圖 2.1. n. al. er. 與變數選取。. Ch. engchi. 4. i Un. v.
(11) 2.2. 由統計推論的角度探討 Lasso Lasso 的最大特色是能同時進行估計與變數選取,但本身並不方便進行檢定. 等統計推論的過程。如要在(2.2)式的結構下對參數進行推論,那最重要的就是要 對標準誤進行估計。依據文獻,對 Lasso 標準誤的估計方式方面有累積不少研究, Kyung et al. (2010) 對過去幾種 Lasso 標準誤的估計方法進行評析與整理,包括: Fan and Li (2001) 和 Zou (2006) 都曾以三明治公式對標準誤進行估計,但當迴歸 參數估計值被壓縮為零時,參數估計值的共變異矩陣也會變成零;Obsborne et al.. 政 治 大 不為零的方法,但檢定統計量的分配與常態會有差距。 立. (2000) 則推導出即使參數估計被壓縮的情況下,也能使係數估計值共變異矩陣. ‧ 國. 學. 事實上 Tibshirani 於 1996 年提出 Lasso 方法時,便曾建議可以 Bootstrap 資 料重抽的方法來估計標準誤。但根據 Kyung et al. (2010) 透過模擬資料分析的結. ‧. 果,發現當真實的迴歸參數為零時,依據 Bootstrap 建構的檢定統計量不具有一. y. sit er. io. Lasso 標準誤。. Nat. 致性。除此之外,Kyung et al. (2010) 也認為目前還沒有最理想的方式來估計. n. al. i n C U 2.3 Lasso 顯著性檢定 h e n g c h i. v. Lockhart et al.於 2014 年提出能對 Lasso 迴歸模式參數進行顯著性檢定的方 法,並稱檢定統計量為「共變異檢定統計量」 (Covariance Test Statistic) ,是以圖 2.1 的 Lasso 路徑為精神所發展的:圖 2.1 中,當 S 從 0 出發往 1 的方向走(也就 是λ從∞出發往 0 前進),變數的係數估計值一個接一個從零轉為非零,類似向 前逐步回歸選取法,隨著步數前進,選取的自變數集合越來越大(例如圖 2.1 中 前列腺資料的例子,編號 1 變數、編號 5 變數、編號 2 變數…一個個加入自變數 集合內) 。假設第 k 步時λ值為λk,進入λk 前所選取的變數集合為 A,並假設第. 5.
(12) j 個變數在λk 時進入集合。令 自變數集合是 A∪{j}) ,. 是在λk+1 時迴歸係數的估計值(即模型的 是在λk+1 時僅以 A 作為自變數組合下的迴歸模. 式係數估計值。假設誤差的變異已知,共變異檢定統計量 Tk 可被定義為:. (2.4) Lockhart et al. (2014) 證明在滿足虛無假設(在λk+1 時自變數組合為 A)下, 。因此若誤差的變異未知,以殘差的變異. 估計. ,在虛無假設下. 共變異檢定統計量F 之分配也可確定如(2.5)式,其中 p 是 A∪{j}下參數個數:. 立. F =. 政 治 大. (2.5). ‧ 國. 學. 此外由於 Lasso 顯著性檢定方法並未對截距項進行檢定,因為檢定的對象是 出現在 Lasso 路徑上的候選變數。考慮實際資料分析時會面臨到需要對截距項進. ‧. 行詮釋的狀況,故 Lockhart et al. (2014) 建議執行 Lasso 顯著性檢定前,應先對. y. Nat. n. er. io. al. sit. 應變數與自變數資料中心化。. 2.4. iv. 由分配的角度比較 C Lasso 顯著性檢定與向前逐步迴歸 Un. hengchi. 由上節所探究之共變異檢定統計量發展的過程,可以看出跟傳統的向前逐步 迴歸有相似之處:挑選變數的集合由空集合開始,一個個變數加入,並檢定欲加 入集合的變數是否顯著。此外兩種檢定方法都是以某種方式決定下一步欲加入的 變數是哪一個:共變異檢定是透過 Lasso 路徑,隨著調節變數λ越來越小,將係 數估計值從零轉為非零者納入並檢定其顯著性;而向前逐步迴歸則是從還沒納入 自變數集合的候選變數中選取下一個變數,檢定其顯著性。. 6.
(13) Lockhart et al. (2014) 將所提出的共變異檢定,與傳統的向前逐步迴歸方法 從分配的角度進行比較:假設誤差的變異已知,之前已選取了自變數集合 M,現 在要以向前逐步迴歸法檢定欲納入的變數 j 之顯著性,檢定統計量 可被定義為 下式:. (2.6) RSS 是指 Residual Sum of Squares,可以知道 會服從 χ2(1)。若誤差變異未 知,以殘差變異. 估計. ,那檢定統計量就服從 F 分配。. 政 治 大. 將(2.4)式與(2.6)式比較,雖然同樣都是誤差變異已知的情況,檢定統計量的. 立. 「形式」上也很相近,但 Lockhart et al. (2014)指出最大差異在於要檢定的「變數. ‧ 國. 學. j」所代表的意義不同:. 候選變數」下統計量的分配才會服從理論分配 χ2(1)。. Nat. sit. y. ‧. (1) 在(2.6)式的定義下,要檢定的「變數 j」要固定為「編號為 j 的某特定的. io. al. er. (2) 在 Lasso 顯著性檢定方面,要檢定的「變數 j」並沒有指定是那個特定變. n. 數。以(2.4)式來說,只要是能在λk+1 時其係數估計值從零轉為非零的那個 變數即可。. Ch. engchi. i Un. v. Lasso 顯著性檢定對欲加入的「變數 j」意義上比(2.6)式下統計量之定義來得 寬鬆,事實上從變數選取的角度來看,這也會比較容易選出理想的變數組合。若 以 Lasso 顯著性檢定那樣對「變數 j」的解讀應用於向前逐步迴歸,(2.6)式的「變 數 j」意義會轉變為: 「還沒被選入自變數組合的候選變數中,. 縮減為最. 小的那個變數 j,也就是剩下的候選變數中解釋變異程度最大的那個變數」, Lockhart et al. (2014) 稱呼這樣定義改變之向前逐步迴歸是經過了「貪婪的步驟」 (Greedy Procedure) ,而這才是一般傳統的向前逐步迴歸之定義。但這樣定義下 的統計量分配絕對不會服從 χ2(1),並以模擬資料來驗證,發現這種統計量的分 7.
(14) 配會隨機分布上大於 χ2(1)(stochastically larger than χ2(1)) ,若將 χ2(1)作為理論分 配,容易犯型一誤差;反而共變異檢定統計量的分配的確會趨近於. ,因此. 由此可看出 Lasso 顯著性檢定相較於向前逐步迴歸的優勢。 由於本研究的主要目的是比較 Lasso 方法與傳統方法在迴歸變數選取上的效 果差異,而透過本章文獻回顧的過程,了解到 Lasso 方法由於本質上還是估計, 由於標準誤估計上的不便與爭議,在統計推論的層次上難以突破,因此突顯出 Lasso 顯著性檢定這種對 Lasso 迴歸模式參數檢定之方法的可貴,特別與傳統的 向前逐步迴歸方法相比較,對變數選取的意義上有更深入的了解,也提供本研究. 政 治 大. 在對進行變數選取之方法比較上產生更明確的方向。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 8. i Un. v.
(15) 第三章. 改良向前逐步迴歸. 由上章之探究,可以注意到因為檢定統計量建構思維的相近,將 Lasso 顯著 性檢定與向前逐步迴歸作為比較是很好的研究方向。本章將就「貪婪的步驟」下 的逐步迴歸方法進行探究:首先會透過模擬資料驗證 Lockhart et al. (2014)對向前 逐步迴歸方法之觀察,接下來再提出以 Bootstrap 提升向前逐步迴歸方法。. 3.1. 驗證向前逐步迴歸之缺陷. 政 治 大. 由於實際迴歸分析中,分析者鮮少會掌握誤差的變異程度。因此本節討論將. 立. 來估計 。此外由於 Lasso 顯著性檢定並沒有對截距項進行. 學. ‧ 國. 假設要以殘差變異. 檢定,因此接下來定義的向前逐步迴歸方法下並不會有截距項的存在。故依據. ‧. Efroymson (1960) 的定義,在本研究假設下選取變數 j 的向前逐步迴歸之檢定統 計量 可定義為(3.1)式,p 是 A∪{j}下參數個數:. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. (3.1). v. 假設樣本數為 100 筆,模擬次數為 500 次,候選變數有 10 個,虛無假設下 設定β = [0,0,0,0,0,0,0,0,0,0]T。以(3.1)式統計量的定義(非「貪婪的步驟」)下, 把對第一個變數檢定之檢定統計量. 的實證分配與理論分配. 比較。如圖. 3.1 左圖所示,的確大致上算接近理論分配。 而由圖 3.1 右圖來看,當以「貪婪的步驟」(即實際上向前逐步迴歸選取變 數的意義)來選擇第一個要檢定的候選變數時,檢定統計量 機分布上大於. 的特性,若以. 的分配的確具有隨. 為檢定用的理論分配,會大大提高犯. 型一誤差的機率。. 9.
(16) 圖 3.1. 固定變數(左)與「貪婪的步驟」(右)向前逐步迴歸與理論分配比較. 治 政 同樣設定樣本數為 100 筆,模擬次數為 500 次,候選變數有 10 個,虛無假 大 立 設下設定β = [0,0,0,0,0,0,0,0,0,0] 。以 Lasso 顯著性檢定第一個迴歸係數估計值 T. ‧ 國. 學. 轉為非零的候選變數,檢定統計量F 的分配十分接近理論分配. ,如圖. ‧. 3.2 所示。因此透過模擬資料實證,不論向前逐步迴歸或 Lasso 顯著性檢定皆的. sit er. io. 共變異檢定統計量分配與理論分配比較. al. n. 圖 3.2. y. Nat. 確符合 Lockhart et al. (2014)所言。. Ch. engchi. 10. i Un. v.
(17) 透過 Bootstrap 改良向前逐步迴歸. 3.2. 由圖 3.1 右圖來看,若想採行「貪婪的步驟」下的向前逐步迴歸方法,以理 論的分配假設是不合適的;若想找出這樣定義之下統計量真正的分配,亦不太容 易。因此本研究採用 Bootstrap 的方法改善「貪婪的步驟」下的向前逐步迴歸, 以下是所制定的 Bootstrap 執行程序: (1) 將 n 筆共有 p 個候選變數的原始資料(. )建立. 簡單線性迴歸,估計出 p 個迴歸係數與 n 個殘差值( )。. 立. 政 治 大. (2) 在第一步,令反應變數為. ,定義. ,才能符合虛無假設。對(. ‧ 國. 學. )取出放回重複抽取 n 筆資料,並重複這個資料重抽. 的執行 1000 次。. ‧. Nat. io. 的抽樣分配。並將原始資. 的值,以 p 值決定第一步選取的變數是否顯著。. n. al. er. 料計算統計量. 的值,因此可形成. sit. 驟」下計算第一步時統計量. y. (3) 將 1000 次分別皆有 n 筆資料重抽而來的樣本代入(3.1)式,以「貪婪的步. Ch. i Un. v. (4) 若不顯著,以 Bootstrap 執行的向前逐步迴歸過程在第一步即結束;若第. engchi. 一個變數顯著,進入第二步:若第一步時選出的變數編號為 k,令反應變數 為. ,定義. ,即為進入第二步時的虛無假設。再對. (. )取出放回重複抽取 n 筆資料,並重複這個資. 料重抽的執行 1000 次。 (5) 將 1000 次分別皆有 n 筆資料重抽而來的樣本代入(3.1)式,以「貪婪的步 驟」下計算第二步時統計量 資料計算統計量. 的值,因此可形成. 的抽樣分配。並將原始. 的值,以 p 值決定第二步選取的變數是否顯著。. 11.
(18) (6) 若不顯著,以 Bootstrap 執行的向前逐步迴歸過程在第二步結束;若顯著 則進入第三步:若第二步時選出的變數編號為 l,令第三步時反應變數名為 ,並定義. ,以符合進入第三步時的虛無假設。. 再對(. )進行以上資料重抽的步驟,接下來的執. 行與前面說明的步驟相同,並一直持續下去。 理論上相較於將「貪婪的步驟」之下的向前逐步迴歸統計量以 F 分配近似而 言,透過 Bootstrap 資料重抽方式設定的向前逐步迴歸犯型一誤差的機率會降低 許多。不過關於這點會在第四章以詳細的模擬資料來驗證。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 12. i Un. v.
(19) 第四章 模擬資料分析 本章想透過模擬變數資料,了解「貪婪的步驟」下向前逐步迴歸方法經 Bootstrap 改良後的提升成效,故除了與 Lasso 顯著性檢定比較外,也會與其他傳 統變數選取方法一同比較。而由於不同的變數模擬設定方式勢必會影響比較結果, 因此本章先說明模擬設計的架構與條件;接下來再對模擬的結果解釋,比較不同 方法的變數選取效果。. 模擬設計與流程. 4.1. 立. 政 治 大. 主要概念是已知真實參數值且控制在相同變數下,比較不同變數選取方法從. ‧ 國. 學. 10 個候選自變數中分別選出哪些自變數,來了解不同變數選取方法是否有「猜. ‧. 到」真正有影響力的變數。由於不同方法選取變數的表現可能會因為參數設定的 不同而有所差異(Tibshirani,1996),因此本研究將參數設定分成三種情況:. y. Nat. n. Ch. engchi. er. io. al. 參數設定二:β=[4, 4, 2, 2, 2, 0, 0, 0, 0, 0]T. sit. 參數設定一:β=[4, 4, 0, 0, 0, 0, 0, 0, 0, 0]T. i Un. v. 參數設定三:β=[1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 0, 0]T 三種參數設定分別具有不同意義:參數設定一為所有候選變數中只有少部分 變數跟應變數有關;參數設定二為候選變數中有一半跟應變數有關,但程度最大 的只有少數;參數設定三為候選變數中大部分皆跟應變數有關,但每個程度都不 大。 而由於自變數間的相關性程度會影響參數挑選的情況,故除了三種參數設定 外,也分成高相關與低相關兩種情況分別探討:自變數間共變異數設定為 0.1 是 低相關,為 0.5 則為高相關(葉世弘,2009) 。因此依據參數設定與相關性設定,. 13.
(20) 共有 6 種不同的變數模擬環境。為了方便稱呼,本研究將其命名為 case 1 ~ case 6, 簡示如表 4.1: 表 4.1 參數設定 相關性. 6 種自變數模擬環境之命名 設定一. 設定二. 設定三. Case 1. Case 2. Case 3. Case 4. Case 5. Case 6. 低相關 (自變數間共變異= 0.1) 高相關 (自變數間共變異= 0.5). 治 政 在 case1 ~ case6 下,分別以 R 軟體套件 ”mvtnorm” 大 的函數 rmvnorm 生成 立 10 個候選自變數與 1 個殘差,樣本數為 100 且皆來自 N(0,1)的分配,不同 case ‧ 國. 學. 下設不同種子,種子數以來自 uniform (0,1)的亂數*1000 決定。而為了控制參數. ‧. 設定對應變數資料變異的影響程度,我設定在信噪比(signal-to-noise ratio)為. sit. y. Nat. 5.7 下生成應變數資料(Tibshirani,1996) 。而由於 Lasso 顯著性檢定法下的模型. io. 料減去該變數的樣本平均值(Lockhart et al,2013)。. al. er. 不包含截距項,最後還要將自變數與應變數資料進行中心化,即對每一筆變數資. n. iv n C 重複以上步驟 10 次,即在 6h種不同 10 組樣本數 i U e n gcase c h下環境,分別會生成. 皆為 100 的資料後,才能進入分析階段──即分別在 6 種 case 環境,每種環境 分別有 10 組資料,當控制在同一組資料下,比較不同方法所選取的變數組合差 異並分析優劣。 由於本研究特別著重在 Lasso 顯著性檢定和向前逐步迴歸法的比較,因此選 擇 5 種變數選取方法來比較(顯著水準皆設定為 0.05):. 14.
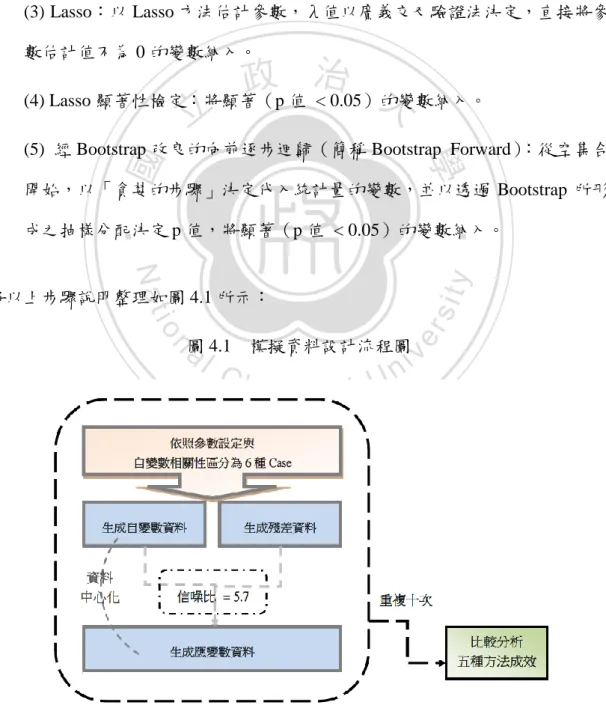
(21) (1) 傳統向前逐步迴歸(簡稱 Forward) :自變數集合從空集合開始,在每一 步將最顯著的變數納入(「貪婪的步驟」) ,但是以理論分配(F 分配)決定 p 值,直到沒有顯著變數可再納入的階段時停止選取變數。 (2) 以 AIC 決定最後選取組合的向前逐步迴歸(簡稱 AIC Forward):以(1) 的方法進行,但計算所經過的每步之下變數選取組合分別的 AIC 值,以 AIC 值最小的組合為最終變數選取組合。 (3) Lasso:以 Lasso 方法估計參數,λ值以廣義交叉驗證法決定,直接將參 數估計值不為 0 的變數納入。. 治 政 大 (4) Lasso 顯著性檢定:將顯著(p 值 < 0.05)的變數納入。 立 ‧ 國. 學. (5) 經 Bootstrap 改良的向前逐步迴歸(簡稱 Bootstrap Forward):從空集合 開始,以「貪婪的步驟」決定代入統計量的變數,並以透過 Bootstrap 所形. ‧. 成之抽樣分配決定 p 值,將顯著(p 值 < 0.05)的變數納入。. y. Nat. er. io. sit. 將以上步驟說明整理如圖 4.1 所示:. n. a圖l 4.1 模擬資料設計流程圖i v n Ch engchi U. 15.
(22) 4.2. 模擬結果. 在對模擬結果分析前,首先說明變數選取的結果呈現方式與比較基準: 在不同 case 下,以表格形式將不同方法對不同樣本組別所選取出的變數組 合整理,如表 4.2 ~表 4.7 所示。由於最後從模擬結果觀察,並沒有出現「完全命 中」真正參數的情況(例如在 case 1 下,某方法對某樣本組別剛好只選取出第 1 和第 2 個自變數的情況),因此先定義以下 3 種變數選取結果,且分別以不同的 表格圖示作記號以易於結果呈現:. 政 治 大. (1) 變數選取結果中包含所有確實有影響力變數:格內塗以紅色表示。. 立. (2) 變數選取結果中包含部分確實有影響力變數:格內塗以藍色表示。. ‧ 國. 學. (3) 變數選取結果中包含沒有影響力變數:格框以粗框表示。. ‧. 因為沒有出現「完全命中」的結果,因此若出現了(1)結果則勢必伴隨(3)結. sit. y. Nat. 果(即若是紅色格子則一定是粗框) 。對某選取方法(即表格的某條直欄)而言,. io. er. 可定義「錯誤率」為 10 格中粗框無色格出現的比例,而「部分正確率」定義為 10 格中非粗框藍色格出現的比例,這兩種量化指標對本研究結果的詮釋上較具. al. n. iv n C 意義。以下本研究對以顏色和邊框視覺化標記後的表格結果逐一解釋,最後再輔 hengchi U 以錯誤率與部分正確率兩種量化指標,對五種變數選取方法綜合比較並分析不同 的優劣勢。 Case 1. 參數設定一(#1 和#2 確實有關),自變數間為低相關: 由表 4.2,Forward、AIC Forward,以及 Lasso 三種傳統方法能把真正有關係 的變數都選入的機會較高;但同時選進錯誤變數的機會也較大,尤其 Forward 和 AIC Forward 皆出現只選取錯誤變數的情況(錯誤率皆為 0.2)。而 Lasso 顯 著性檢定最為保守,10 次中有 9 次都不選擇變數;而 Bootstrap Forward 相較之. 16.
(23) 下較能選出正確變數,且除了在第二組資料受到資料本身影響外,比 Forward 更不容易選到錯誤的變數。 表 4.2. Case 1 下不同方法選取之變數組合. 方法. AIC. Forward. 組樣本. Lasso. Forward. Lasso. Bootstrap. 顯著性檢定. Forward. 第一組. 無. #1. #1. 無. 無. 第二組. #4 #8. #4 #8. #2 #4 #7 #8. 無. #4 #8. 第三組. #2. #2 #6 #8. #2 #6 #8. 無. #2. 第四組. #1. #1 #2 #7 #8. #1 #2 #6 #7. 無. #1. 第五組. #1 #2 #10. 無. 無. #2. #2 #4 #5 #7. #2. 無. 無. #9. #4 #5 #9 #10. 無. 無. 無. #2. #2 #4 #6. #1 #2 #4 #6. 無. y. 無. #2. #1 #2 #10. #1 #2 #10. 無. #2. iv n C 參數設定二(#1~ #5 確實有關) h e n,自變數間為低相關: gchi U n. Case 2.. er. al. sit. #2. io. 第十組. #2. Nat. 第九組. #2. ‧ 國. 第八組. #2. ‧. 第七組. #2. 學. 第六組. #8 #9 #10 政 治 大 #1 #2 #6 #9 #1 #2 #3 #5 立 #10 #6 #9 #10 #9. 不論是哪種方法,當真正有關係的變數個數占所有候選變數的一半,便沒出 現包含所有正確變數集合(紅色粗格)之情況了,但有選到正確變數(藍色格子) 的情況也隨之增加。只是 Forward、AIC Forward,以及 Lasso 三種過去傳統方法 有選到錯誤變數的機會仍然很高,特別 Forward 和 AIC Forward 從第十組樣本都 只有選到錯誤變數(錯誤率分別是 0,1) ;而 Lasso 顯著性檢定和 Bootstrap Forward 都沒有選到過錯誤變數,而選到部分正確的機會也比 Case 1 下更高(部分正確 率分別是 0.4 和 0.5)。. 17.
(24) 表 4.3. Case 2 下不同方法選取之變數組合. 方法 組樣本. AIC. Forward. Lasso. Forward. Lasso. Bootstrap. 顯著性檢定. Forward. #2. #2 #3. #2 #3. #2 #3 #4 #9. 第二組. #2. #1 #2 #7. #1 #2. #2. #2. 第三組. #1 #10. #1 #3 #10. 無. 無. 無. 第四組. #2. #2 #5. #1 #2 #5. 無. 無. 第五組. #2. #2 #3 #4 #7. #2 #3 #4 #5. 無. #2. 第六組. #1 #2 #8. 無. 無. 第七組. #1 #4. #1 #4 #10. #4. #4. 第八組. 無. #1. 無. 學. 無. 無. #5. #2 #4 #5. #2 #4 #5. #5. #5. #6 #9. #6 #8 #9. ‧. #2 #3 #4 #5. 第一組. 無. 第十組. #1 #2 #3 #5 治 政 #9 #6 #8 #9 大. #1 #2 #6 #8. 立#1 #4 #10. ‧ 國. 第九組. #8 #9. #1 #3 #5 #6. 無. #7 #8 #9 #10. sit. y. Nat. n. al. er. io. Case 3. 參數設定三(#1~ #8 確實有關),自變數間為低相關:. Ch. i Un. v. 隨著設定真正有關的變數個數更多,不論哪種方法會選到部分正確變數的機. engchi. 會也提高,除了 Lasso 顯著性檢定過於保守,其他四個方法對十組資料都有選到 正確變數。在選到錯誤變數的程度方面,Lasso 顯著性檢定和 Bootstrap Forward 保持良好,主要是 Forward 比起在 Case 1 和 Case 2 時,沒出現選到錯誤變數的 情況;跟 Forward 相比,AIC Forward 和 Lasso 卻還是會出現選到錯誤變數的情 況。. 18.
(25) Case 3 下不同方法選取之變數組合. 方法. 第三組. 第四組. #5 #6 #8. #5 #6 #8. #1 #2 #4 #5. #1 #2 #4 #5. #1 #2 #3 #4. #7. #7. #5 #6 #7 #10. #2 #4 #5 #6. #2 #5 #6 #7. #7 #8 #10. 全部變數. #1 #2 #7 #8. #1 #2 #7. #10. 第七組. #2. 第八組. #1 #3. 第九組. #6 #7. 第十組. #1 #3 #8. #1 #2 #4 #5 #6 #8. 無. #2 #5 #7. 無. #5 #6 #7. 無. #2. #2 #3 #4 #5 #6 #7 #8 #9 #10. #1 #2 #3 #5 #6 #7 #8 #9 #10. io. #1 #3 #4 #5. #1 #3 #4 #5. #6. #6 #7 #8. #2. #2. 無. #7. ‧. #1 #3 #5 #6. Nat. 第六組. Forward. #2. #1 #2 #3 #4 治 政 #2 #3 #4 #6 #6 #7 #8 #9大 立 #10. #2 #3. 顯著性檢定. 學. 第五組. #1 #2 #3 #4. Bootstrap. #3. #3 #2. y. 第二組. #1 #2 #3 #4. Lasso. #2. er. 第一組. Lasso. Forward. ‧ 國. 組樣本. AIC. Forward. sit. 表 4.4. n. a l#1 #3 #6 #8 #1 #3 #4 #6 i v #1 #3 n #8 #10 Ch engchi U #3 #6 #7. #1 #3 #7 #8. #3 #6 #7 #8. #1 #3 #4 #5 #7 #8. #1 #3. 無. #7. 無. #3 #8. Case 4. 參數設定一(#1 和#2 確實有關),自變數間為高相關: 比起 Case 1 的情況,因為候選變數間相關性提高,用 Forward、AIC Forward, 和 Lasso 這三種過去方法來挑選變數更容易選到錯誤變數,而且錯誤率也跟著上 升;雖然 AIC Forward 和 Lasso 來挑選變數時較「大膽」,因此在參數設定一之 下比較容易同時選到第一和第二個變數。比較值得注意的是,Lasso 顯著性檢定 19.
(26) 和 Bootstrap Forward 即使在自變數間為高相關的情況下,都沒有出現挑選到錯誤 變數的組合,而選到正確變數的機會跟 Case 1 保持相近的水準。 表 4.5. Case 4 下不同方法選取之變數組合. 方法. Lasso. Forward. 第一組. #2 #8. #1 #2 #6 #8. 第二組. #4. #4 #10. 第三組. #1. #1 #4 #6. 第四組. #9. Forward. 無. #2. 無. 無. #1. #1. #6 #8 #2 #3 #4 #6 #10. 政 #1治#4 #5 #6大 #9. 無. #1. #1 #2 #8. #1 #2 #7 #8. #1. #1. #4 #9. #4 #9. #3 #4 #9. 無. #4. #2. #2 #5 #10. #2 #10. 無. ‧. #2. 無. #2 #3 #8 #10. #10. 第九組. #1 #4. #1 #4 #5. #1 #4. 第十組. #2. #2. #1 #2 #5 #6. Nat. #10. io. n. al. Ch. engchi U. y. 無. 無. sit. #2 #5 #7 #9. ‧ 國. #9. 第八組. 第六組. 顯著性檢定. #1 #2 #4 #5. 第七組. 第五組. Bootstrap. 學. 立. Lasso. #1. #1. 無. 無. er. 組樣本. AIC. Forward. v ni. Case 5. 參數設定二(#1 ~ #5 確實有關),自變數間為高相關: 事實上跟在 Case 2 下相比差異不大,以 AIC Forward 和 Lasso 來挑選變數最 容易挑選到錯誤變數,將候選自變數區分為高與低的狀況下,比較沒有突顯出主 要的差異。較值得注意的只有一點:比起在 Case 2,即使在高相關之下 Lasso 顯 著性檢定和 Bootstrap Forward 仍不會選到錯誤變數,而且部分正確率都有成長。. 20.
(27) 表 4.6. Case 5 下不同方法選取之變數組合. 組樣本. AIC. Forward. Lasso. Forward #1 #2 #4 #5. #1 #2 #4 #5. #6. #6. #4. #4 #8. #3 #4 #6 #8. 第三組. #1 #4. #1 #4. 第四組. #3. #3 #9. 第五組. #1. #1 #3 #4. 第六組. #3. 第一組. #1 #5 #6. 第二組. #1. #1 #5. 無. #4. 無. #1. #3. #3. 無. 無. 無. #3. #5. #5. #1. #1. #2. #2. #5 #6 #3 #5 #6 #9. 政 #1治#4 #5 #8大 #1 #2 #3. #5. #5 #7 #8. #2 #5 #8 #10. #1. #1. #1. #2. #2 #3. #2 #3. #2 #7 #9. #2 #9. #2. io. n. al. sit. y. Nat. 第十組. Forward. #2. #2. er. 第九組. 顯著性檢定. ‧. 第八組. Bootstrap. #1 #2 #3 #4. #1 #3. ‧ 國. 第七組. 立. Lasso. 學. 方法. Ch. i Un. v. Case 6. 參數設定三(#1 ~ #8 確實有關),自變數間為高相關:. engchi. 除了在第十組資料,因為其中第 9 個變數解釋反應變數的程度較大,在資料 的影響下,五種方法都選到了第 9 個變數,故 Lasso 顯著性檢定和 Bootstrap Forward 出現了一次完全選錯變數的情況。若不看第十組資料,Forward、Lasso 顯著性檢定,和 Bootstrap Forward 選取變數的效果都算不錯。而以 AIC Forward 和 Lasso 來選取變數,選到錯誤變數的機會仍然較高。. 21.
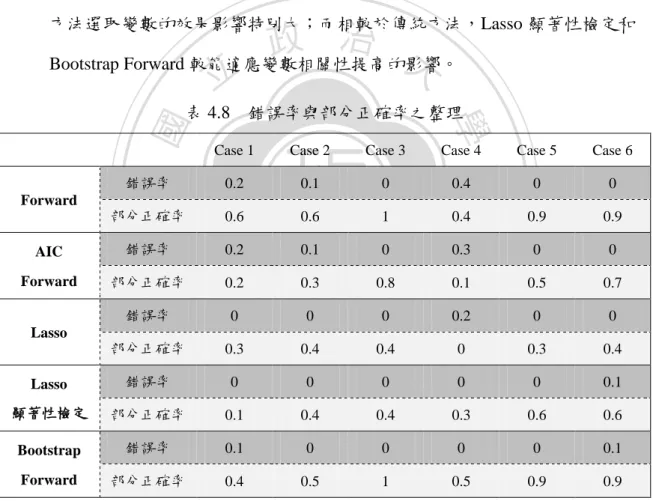
(28) 表 4.7. Case 6 下不同方法選取之變數組合. 方法. #1 #2 #3 #4. #1 #2 #3 #4. #5 #7. #5 #7 #8. #1 #2 #6. 顯著性檢定. Forward. #5 #6 #7 #8. #3. #7. #1 #2 #3 #4 #5 #6 #8 #9. #2 #3 #4 #5. #6 #7 #10 政 治 大. 第四組. #2 #3. #1 #2 #3. 第五組. #2 #4. #2 #4 #5. #3. #3 #4. #7. #5. #1 #2 #3 #4 #5 #6. #3 #4 #5 #6. io. #2 #5 #7 #9. n. e n g#1c #2 #4 h i#3 U. #4. #1 #4 #5 #6. 第十組. #5 #9. #5 #9. #3. #8. #5 #7. 第九組. #2 #3. #2. #1 #2 #6 #9. Ch. 無. #2 #4 #5 #7. #1 #2 #4 #9. al. #4 #5. ‧. Nat. 第八組. #1. 無. 學. 第七組. #1 #2 #6. #6 #7 #4 #5 #6 #9. #2 #4 #3. y. 立. 無. #10. #2 #3 #4 #5. #4 #5. #1 #2 #3 #4. #10. #10. 第三組. 第六組. Bootstrap. #1 #2 #3 #4. #1 #2 #3 #5. ‧ 國. 第二組. Forward. Lasso. sit. 第一組. Lasso. #1. er. 組樣本. AIC. Forward. v ni. #1. #5. #5. #4. #4. #9. #9. 由表 4.2 至 4.7 的觀察可以整理出以下結論,並將所有 Case 下的錯誤率與部 分正確率整理如表 4.8 所示: (1) 要同時選到所有正確變數的機會皆不高,除了真正有關變數只有占所有 候選變數小部分下,Forward、AIC Forward,與 Lasso 較易做到。. 22.
(29) (2) Forward、AIC Forward,與 Lasso 選到錯誤變數的機會較高,特別是 AIC Forward 和 Lasso。 (3) 以部分正確率來看,Lasso 顯著性檢定和 Bootstrap Forward 不高;但當 正確變數占候選變數一半或多數時,Bootstrap Forward 跟傳統方法相近。 (4) Lasso 顯著性檢定和 Bootstrap Forward 選到錯誤變數的可能性都很低,但 用 Lasso 顯著性檢定選擇變數會過於保守,因此部分正確率偏低。 (5) 就候選變數間相關性的影響來看,在真實有相關變數占少數時,對傳統 方法選取變數的效果影響特別大;而相較於傳統方法,Lasso 顯著性檢定和. 表 4.8. 錯誤率與部分正確率之整理. 學. Case 2. Case 3. Case 4. Case 5. Case 6. 錯誤率. 0.2. 0.1. 0. 0.4. 0. 0. 部分正確率. 0.6. 0.6. 1. 0.4. 0.9. 0.9. 0.3. 0. 0. 0.1. 0.5. 0.7. 0. 0. 0. 0.3. 0.4. 0.1. 0. Forward. 部分正確率. 0.2. 0.3. 0.8. 0. 0. a l0. n. 錯誤率 Lasso. Ch. i U e 0.4 n g c h 0.4. y. 0.2. sit. 錯誤率. io. AIC. er. Nat. Case 1. ‧. Forward. ‧ 國. 治 政 大 Bootstrap Forward 較能適應變數相關性提高的影響。 立. v0.2 i n. 部分正確率. 0.3. Lasso. 錯誤率. 0. 0. 0. 0. 0. 0.1. 顯著性檢定. 部分正確率. 0.1. 0.4. 0.4. 0.3. 0.6. 0.6. Bootstrap. 錯誤率. 0.1. 0. 0. 0. 0. 0.1. Forward. 部分正確率. 0.4. 0.5. 1. 0.5. 0.9. 0.9. 23.
(30) 第五章 實證資料分析 5.1. 資料背景 葡萄牙是國際前十大名酒輸出國之一,酒品業對對該國而言是重要的發展產. 業。當一個國家的特定產業發展到一定的規模,通常也會發展出良好的商品開發 與品質監測的系統。本研究由知名的 UCI 資料庫發現到一筆葡萄牙清酒(Vinho Verde)的品質量測資料,記錄多個化學成分與物理量測指標,很適合應用迴歸 變數選取方法來進行分析。. 政 治 大 此資料由葡萄牙清酒委員會(CVRVV)於 2004 年 5 月至 2007 年 2 月間所 立. ‧ 國. 學. 蒐集,以學術研究與品質改良為目的對 4898 個葡萄牙清酒樣本進行物理化學檢 測,記錄下 11 種一般酒類會包含的化學組成與物理量測指標,此 11 種科學變數. Citric Acid. 英文學名. a固定性酸度 Volatile Acidity iv l C n h e n g c hResidual 檸檬酸 i U Sugar. n. Fixed Acidity. 中文意思. er. io. 英文學名. 11 個科學變數之中英文名稱. sit. Nat. 表 5.1. y. ‧. 之中英文名稱列表如表 5.1 所示。. 中文意思 揮發性酸度 剩餘糖分. Chlorides. 氯化物. Free Sulfur Dioxide. 游離二氧化硫. Total Sulfur Dioxide. 總二氧化硫. Density. 密度. pH. pH 酸鹼值. Sulphates. 硫酸鹽. Alcohol. 酒精. 除了 11 種為化學成分與物理量測指標的科學變數外,研究者並請至少三名 品酒師,在不知道樣本的編號與組成成分之情況下,對每一個葡萄牙清酒樣本品 嚐,並在 0 ~ 10 分的整數範圍內對品嚐的樣本打分數,分數越高表示品酒師認為. 24.
(31) 該樣本品質越高;由於每個葡萄牙清酒樣本至少有三個分數值,最後對分數取中 位數作為最後的品質分數。. 5.2. 定義問題與方法 由於研究者以品質改良為目的記錄這些葡萄牙清酒的品質分數、化學組成,. 與物理量測指標。由專業品酒師所打的分數會反映真正的葡萄牙清酒品質,但當 化學組成與物理指標之數值改變時會影響酒的品質分數,因此應以統計方法建構 品質分數與科學變數間的關係。但由於此研究並沒有在控制其他實驗變因下進行. 政 治 大. 量測,再加上科學變數之數值為連續型變數,無法以變異數分析的方法找尋科學. 立. 變數與品質分數間的因果關係。最可行的方式應為找出 11 個科學變數中,哪些. ‧ 國. 學. 變數與品質分數的相關程度最高,將找出的最適當的科學變數組合與品質分數間 建立單變量線性迴歸模式,估計迴歸係數以了解不同科學變數與品質分數的相關. ‧. 程度與方向,以供葡萄牙清酒品質研究相關單位參考。. y. Nat. er. io. sit. 因此可應用本研究探討的變數選取方法,找到最適當的科學變數組合與品質 分數建立迴歸模式。而依據本研究先前的探討,以 Bootstrap 改良的向前逐步迴. n. al. Ch. i Un. v. 歸和透過 Lasso 顯著性檢定選取變數是比較好的方法,因此本研究應用這兩種方 法挑選最適當的科學變數組合。. engchi. 唯一較顧慮的是品質分數之分布狀況:以一般問卷調查之經驗,凡透過人為 打分數之變數值常會極度右偏或左偏。不過由於是透過專業品酒師評分,且研究 者將評分值再取中位數作為最後的品質分數值,因此由圖 5.1 來看事實上品質分 數的分布還頗接近常態。. 25.
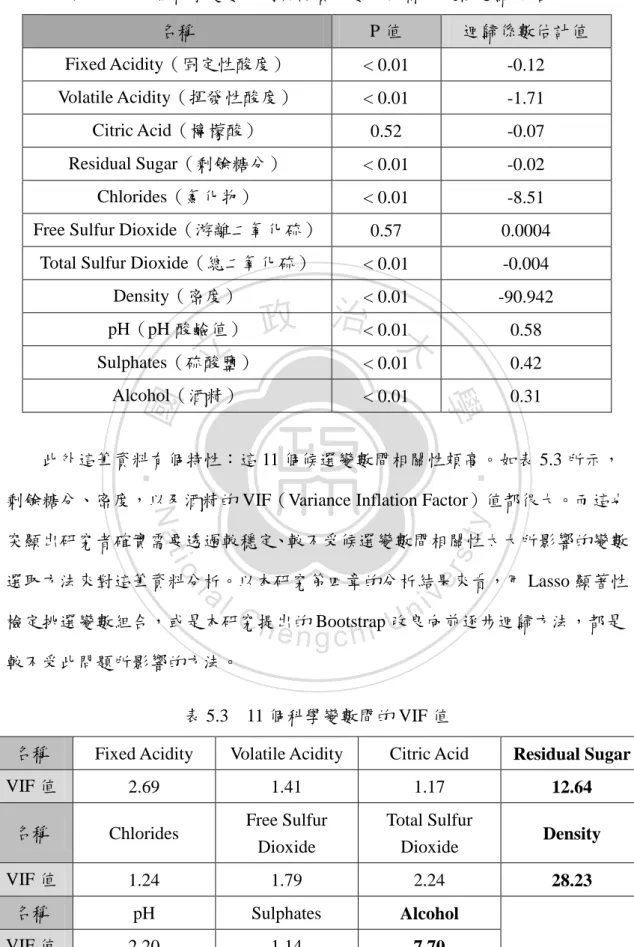
(32) 圖 5.1. 立. 政 治 大. 變數選取. ‧ 國. 學. 5.3. 品質分數之分布情況. ‧. 在挑選最適當的科學變數組合與品質分數建立迴歸模式前,先了解每一個科. sit. y. Nat. 學變數分別與品質分數建立簡單線性迴歸模型下的顯著性與迴歸係數估計值之. io. er. 方向,將顯著水準設定為 0.05。結果如表 5.2 所示,除了檸檬酸與游離二氧化碳 不顯著以外(p 值皆在 0.5 左右) ,其他 9 個科學變數皆與葡萄牙清酒的品質分數. al. n. iv n C 呈顯著相關。而在 9 個顯著的科學變數當中,除了 h e n g c h i UpH 酸鹼值、硫酸鹽,還有酒 精與品質分數間呈正相關外,其他 6 個顯著的科學變數與品質分數間呈負相關。 因此由表 5.2 之整理大致可了解每個科學變數分別與品質分數間的相關性。. 26.
(33) 表 5.2. 11 個科學變數分別與品質分數建立簡單線性迴歸之結果 名稱. P值. 迴歸係數估計值. Fixed Acidity(固定性酸度). < 0.01. -0.12. Volatile Acidity(揮發性酸度). < 0.01. -1.71. Citric Acid(檸檬酸). 0.52. -0.07. Residual Sugar(剩餘糖分). < 0.01. -0.02. Chlorides(氯化物). < 0.01. -8.51. Free Sulfur Dioxide(游離二氧化硫). 0.57. 0.0004. Total Sulfur Dioxide(總二氧化硫). < 0.01. -0.004. Density(密度). < 0.01. -90.942. 政 治< 0.01大. pH(pH 酸鹼值). 立. 0.58 0.42. Alcohol(酒精). < 0.01. 0.31. ‧ 國. < 0.01. 學. Sulphates(硫酸鹽). ‧. 此外這筆資料有個特性:這 11 個候選變數間相關性頗高。如表 5.3 所示,. sit. y. Nat. 剩餘糖分、密度,以及酒精的 VIF(Variance Inflation Factor)值都很大。而這也. io. er. 突顯出研究者確實需要透過較穩定、較不受候選變數間相關性太大所影響的變數 選取方法來對這筆資料分析。以本研究第四章的分析結果來看,用 Lasso 顯著性. al. n. iv n C 檢定挑選變數組合,或是本研究提出的 改良向前逐步迴歸方法,都是 h e n gBootstrap chi U 較不受此問題所影響的方法。 表 5.3. 11 個科學變數間的 VIF 值. 名稱. Fixed Acidity. Volatile Acidity. Citric Acid. Residual Sugar. VIF 值. 2.69. 1.41. 1.17. 12.64. 名稱. Chlorides. Free Sulfur Dioxide. Total Sulfur Dioxide. Density. VIF 值. 1.24. 1.79. 2.24. 28.23. 名稱. pH. Sulphates. Alcohol. VIF 值. 2.20. 1.14. 7.70 27.
(34) 應用兩種方法從 11 個候選變數所挑選之變數組合如表 5.4 所示。兩種方法 皆從 11 個候選變數中挑選出 7 個變數,而且挑選出的變數組合非常接近,都挑 出了揮發性酸度、剩餘糖分、游離二氧化硫、密度、硫酸鹽,與酒精這 6 個變數。 不一樣的最後一個變數:Lasso 顯著性檢定挑出固定性酸度;而 Bootstrap Forward 挑出的是 pH 酸鹼值。 表 5.4. 以 Lasso 顯著性檢定與 Bootstrap Forward 挑選之變數. 方法. 挑選出之科學變數. Lasso 顯著性檢定. Volatile Acidity(揮發性酸度) 、Residual Sugar(剩餘糖分)、 Free Sulfur Dioxide(游離二氧化硫)、Density(密度)、 Sulphates(硫酸鹽)、Alcohol(酒精)、Fixed Acidity(固定 性酸度). 立. 政 治 大. Bootstrap Forward. ‧. ‧ 國. 學. Volatile Acidity(揮發性酸度) 、Residual Sugar(剩餘糖分)、 Free Sulfur Dioxide(游離二氧化硫)、Density(密度)、 Sulphates(硫酸鹽)、Alcohol(酒精)、pH(pH 酸鹼值). sit. y. Nat. 表 5.6 與表 5.7 為分別以 Lasso 顯著性檢定與 Bootstrap Forward 找出之變數. n. al. er. io. 組合與品質分數建立之迴歸模式估計結果。由表 5.6 與 5.7 觀察,每個變數都非. v. 常顯著(顯著水準設定為 0.05),而由於兩種方法選出的變數組合很接近,皆有. Ch. engchi. 選出的 6 個變數之迴歸係數估計值也很類似。. i Un. 然而分析結果有缺陷:剩餘糖分與密度的係數估計值皆大於 0;而在表 5.2 中,這兩個變數分別與品質分數建立迴歸模式下的係數值卻皆小於 0,出現這樣 的情況表示目前挑出的變數組合間存在多重共線性問題。因此雖然本研究第四章 將 Lasso 顯著性檢定和 Bootstrap Forward 與舊有方法比較,認為這兩種方法較不 受候選變數間相關性高之影響;但以本章葡萄牙清酒實證資料之分析經驗,當候 選變數間相關性過高,這兩種方法所挑出的變數組合仍不是很理想。. 28.
(35) 變數. 係數估計值. 固定性酸度. -0.068. 揮發性酸度. -2.037. 剩餘糖分. 0.024. 游離二氧化硫. 0.004. 密度. 1.553. 硫酸鹽. 0.412. 酒精. 0.380. P值. 皆小於 0.001. 政 治 大. 以 Bootstrap Forward 挑選之變數組合下建立之迴歸模式估計結果 係數估計值. 0.025. 游離二氧化硫. 0.004. 密度. 1.279. pH 酸鹼值. 0.286. io. 硫酸鹽. n. al. 0.369. 酒精. Ch. 0.383. engchi. 29. ‧. 剩餘糖分. 學. -2.010. Nat. 揮發性酸度. P值. 皆小於 0.001. y. 立. sit. 變數. er. 表 5.6. 以 Lasso 顯著性檢定挑選之變數組合下建立之迴歸模式估計結果. ‧ 國. 表 5.5. i Un. v.
(36) 第六章 6.1. 結論與建議. 結論 如同 Lockhart et al.(2014)所言,本研究透過模擬資料分析,發現 Lasso 顯著. 性檢定的確極不容易選到事實上與應變數沒有相關的錯誤變數,也就是不容易犯 型一誤差;但與其他變數選取方法比較,用 Lasso 顯著性檢定挑選變數會過於保 守,當確實有關變數占所有候選變數少數時,Lasso 顯著性檢定下可能不會選取. 政 治 大. 變數。此外當候選變數相關性增高時,Lasso 顯著性檢定和 Bootstrap Forward 都 比起傳統方法能適應。. 立. ‧ 國. 學. 三種傳統方法比起 Lasso 顯著性檢定和 Bootstrap Forward 都容易選到錯誤變 數,雖然選取組合中以包含正確變數的情況居多,而其中傳統 Forward 比起 AIC. ‧. Forward 和 Lasso 不容易選到錯誤變數。本研究一直稱呼 Lasso 為傳統方法,是. Nat. sit. y. 因為在後續比較時只要看到係數估計值不為零就選入,並沒有真正進行統計檢定;. n. al. er. io. 而由模擬資料分析的結果來看,若完全以 Lasso 估計係數的方式選取變數容易選. i Un. v. 到錯誤變數,突顯出未來 Lasso 迴歸模式相關研究,可以往利於 Lasso 進行統計. Ch. engchi. 推論的方向走(例如更好的標準誤估計方式等等)。. 以 Bootstrap 改良的 Bootstrap Forward 比起傳統 Forward 更不容易選到錯誤 變數;而且因為本研究改良的 Bootstrap Forward 一樣保有「貪婪的步驟」之特質, 雖與 Lasso 顯著性檢定一樣不容易選到錯誤變數,但比起 Lasso 顯著性更容易選 到正確變數,不會如 Lasso 顯著性檢定下保守。 因此以 Bootstrap 的方式改良,可以在具有「貪婪的步驟」特性下掌握抽樣 分配。雖然當真的有關的變數占所有候選變數少部分時,選取到正確變數的成效 不如傳統方法,但比起傳統方法不容易選取到錯誤變數。此外又比起 Lasso 顯著 30.
(37) 性檢定易於選取到正確變數,加上能適應候選變數間高度相關的影響,本研究改 良傳統向前逐步迴歸而生的 Bootstrap Forward 是很不錯的迴歸變數選取方法。. 6.2. 限制與建議 雖然本研究最後對方法比較上有明確的結論,且將傳統方法改良的新方法也. 有不錯成效,但有幾點仍需努力的方向: (1) 可以再比較以不同標準誤估計方法下 Lasso 檢定方法之成效:本研究以 Lasso 選取變數時只有進行估計而沒有檢定,可以將如 Fan and Li (2001)和. 政 治 大. Zou (2006)所提出的三明治公式法或 Bootstrap 法估計標準誤下選取變數的. 立. 成效,與本研究針對的五種方法一併比較。. ‧ 國. 學. (2) 比較的變因可更多:本研究第四章進行方法比較時,控制變因條件是將. ‧. 相關性分為兩種,真實參數情況分為三種下來比較,可以再增加樣本數不同. sit. y. Nat. 與候選參數個數不同這兩個控制變因進入比較基準;不過當比較的控制變因. io. n. al. er. 增加,比較的流程與結論的整理會更複雜,這是另一種挑戰。. i Un. v. (3) 比較的量化指標可更精緻:本研究第四章進行方法比較時,採行的比較. Ch. engchi. 量化指標是錯誤率與部分正確率,因為所有方法皆沒有「完全擊中」真正的 參數組合。而因為即使是正確變數,也有設定權重之分(參數設定二,10 個變數中 5 個與應變數有關,其中 2 個權重較高),此外方法選到正確變數 的個數多寡也能突顯方法的好壞,因此若能採用比錯誤率和部分正確率更能 反映參數權重與選取個數的指標,則比較的過程會更精緻。 (4) 「貪婪的步驟」下的向前逐步迴歸:Lockhart et al.(2014)最後提出結合 共變異檢定統計量與「貪婪的步驟」下向前逐步迴歸的可行性,以供後續研 究者啟發。. 31.
(38) (5) 本研究的模擬資料分析是將候選變數間相關性分為兩種,比較五種方法 後發現 Lasso 顯著性檢定法或以 Bootstrap 改良之向前逐步迴歸法較不易受 候選變數間相關性太高之影響。然而由第五章之實證資料分析結果,當候選 變數間相關性很高的情況下,兩種方法會挑出不理想的變數組合。因此雖然 在模擬資料分析的結果上,本研究所提出之以 Bootstrap 改良的向前逐步迴 歸方法有不錯的表現(因為較不容易選到錯誤變數),但應用於實證資料分 析時卻不是很理想(因為選出的變數間存在多重共線性,影響參數估計)。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 32. i Un. v.
(39) 參考文獻 [1] Frank I. and Friedman J. (1993) A Statistical View of Some Chemometrics Regression Tools, Technometrics, 35, p.109-148. [2] Tibshirani R. J. (1996). Regression Shrinkage and Selection via the LASSO, Journal of the Royal Statistical Society, Series B, Volume 58, p.267-288. [3] Osborne M. R., Presnell B., and Turlach B. A. (2000) On the Lasso and Its Dual, Journal of Computational and Graphical Statistics 9, p.319-337.. 治 政 大 Penalized Likelihood [4] Fan J. and Li R. (2001) Variable Selection via Nonconcave 立. and Its Oracle Properties, Journal of the American Statistical Association 96,. ‧ 國. 學. p.1348-1360.. ‧. [5] Miller A. (2002) Subset Selection in Regression, Second Edition, Chapman &. sit. y. Nat. Hall/CRC.. n. al. er. io. [6] Zou H. (2006) The Adaptive Lasso and Its Oracle Properties, Journal of the. i Un. American Statistical Association, 101, p.1418-1429.. Ch. engchi. v. [7] 葉世弘(2009),運用 aGLasso 在多變量線性迴歸模型的模型選取,國立成 功大學碩士論文。 [8] Cortez P., Teixeira J., Cerdeira A., Almeida F., Matos T., and Reis J. (2009) Using Data Mining for Wine Quality Assessment, Proceedings of the 12th International Conference on Discovery Science, p.66-79, October 03-05, 2009, Porto, Portugal. [9] Kyung M., Gill J., Ghosh M., and Casella G. (2010) Penalized regression, standard errors, and Bayesian Lassos, Bayesian Analysis, 5, p.369-412.. 33.
(40) [10] Lockhart R., Taylor J., Tibshirani R., and Tibshirani R. J. (2014) A Significance Test for the Lasso, Annals of Statistics, Vol. 42, No. 2, p.413-468. [11] Kass R. E., Eden U. T., and Brown E. N. (2014) Analysis of Neural Data, Springer.. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 34. i Un. v.
(41)
數據
+2

相關文件
在 第一講的開始, 我們就明確地指出: 線性代數是研究線性空間, 即向量空間、 模和其上 的線性變換以及與之相關的問題的數學學科。 這一講中,
(三) 變率與微分、 求和與積分: “變率” 與 “求和” 是函數的兩種定量型 (quantitative) 的基本性質。 但是它們的定義本身就是理論的起點, 有如當年
Keywords: Adaptive Lasso; Cross-validation; Curse of dimensionality; Multi-stage adaptive Lasso; Naive bootstrap; Oracle properties; Single-index; Pseudo least integrated
他做事一向有自己的想法,從不「隨波逐流」 。 「隨波逐流」是指: (A)順著水流而行(B 比 喻事情發展起伏變化大(C)比喻氣勢的雄壯浩大(D 比喻人沒有 確定的方向和目標,只依從
中學中國文學課程分為必修和選修兩部分。必修部分的學習材料
• Similar to futures options except that what is delivered is a forward contract with a delivery price equal to the option’s strike price.. – Exercising a call forward option results
– The futures price at time 0 is (p. 275), the expected value of S at time ∆t in a risk-neutral economy is..
• When a call is exercised, the holder pays the strike price in exchange for the stock.. • When a put is exercised, the holder receives from the writer the strike price in exchange
