國立臺南大學
資訊工程學系
碩 士 論 文
能量限制下可規劃計算機架構的即時排程
Real-Time Scheduling Tasks for Parallel Reconfigurable Computing Architecture with Energy Constraints
指導教授:高啟洲 教授 研 究 生:陳泰林
中 華 民 國 一百零八年 七 月
能量限制下可規劃計算機架構的即時排程
Real-Time Scheduling Tasks for
Parallel Reconfigurable Computing Architecture with Energy Constraints
by
Tai Lin Chen陳泰林
A thesis submitted in partial fulfillment of the requirements for the Master of Science degree
in Computer Science and Information Engineering in the College of Science and Engineering
at the National University of Tainan Tainan, Taiwan
Advisor: Professor Chi-Chou Kao(高啟洲 教授)
誌謝
在台南大學的這些日子當中讓我獲得了不少寶貴的事物,學到了 很多東西也修了很多其他資訊相關課程。我之所以可以完成這論 文多虧了很多人的幫助,特別要感謝指導教授 高啟洲老師,在研 究的過程中提供很多的建議以及協助,給我們足夠的空間與規範,
並使我們突破固有的思維,不單單侷限在自己的研究領域,而是多 方面且廣泛的思考。
也要感謝實驗室的學長學弟,感謝學長們給我許多的教學與經驗,
以及學弟們在實驗室給予的幫助和討論。再來感謝系上的各個老 師和系上相關的人員,在課業與事務都得到很多的幫助。
最後要感謝家人們,感謝家人們給的支持以及各種支援讓我能夠 專心的完成課業。
陳泰林 筆,2019 年 7 月。
能量限制下可規劃計算機架構的即時排程
學生:陳泰林 指導教授:高啟洲
國立臺南大學資訊工程學系碩士班
中文摘要
如今即時性調度這項技術已經被運用在能量限制的環境下,本文目的在於提供了在 有限能量下即時任務系統的調度有良好的配置效率。在許多的文獻中,即時調度中單處 理器存在最佳化排程演算法,但是如今大部份的處理器都是複數的,多處理器可以大幅 提升系統效能以降大幅降低能量消耗,所以近年來有許許多多的人對多處理器的能量限 制下即時調度展開研究。
在我們的論文裡,我們有系統地同時考慮所有耗能的情況,提出了一個平行可規劃 排程算法(Parallel Reconfigurable Scheduling, PRS) ;以及基於能量限制的排程演算法架 構以及動態能量限制管理方法。
實驗結果表明平行可規劃計算機可以有效的提升效能,比起其他調度算法上實驗結 果表現出最高的配置成功率,本篇架構上處理速度有不錯的表現,並且在本論文所提架 構上能量消耗亦有不錯的表現,而比較起來也不輸給其他演算法。
關鍵詞:能量限制、平行化、可規劃計算、即時排程
Real-Time Scheduling Tasks for Parallel Reconfigurable Computing Architecture with
Energy Constraints
Student:Tai-Lin Chen Advisor(s):Chi-Chou Kao Department of Computer Science and Information Engineering
National University of Tainan Tainan, Taiwan, R.O.C
Abstract
Nowadays, this technology has been applied in an energy-constrained environment. The purpose of this paper is to provide a good configuration efficiency for scheduling of real-time task scheduling under energy constraints. In many documents, there is an optimal scheduling algorithm for single-processor in real-time scheduling, but most of today's processors are complex, and multi-processors can greatly improve system performance to reduce energy consumption, so in recent years. There are many people who are investigating the real-time scheduling of multi-processor energy constraints.
In our paper, we systematically consider all energy-consuming situations at the same time, and propose a Parallel Reconfigurable Scheduling (PRS) algorithm; and an energy- constraints scheduling algorithm architecture and dynamic energy constraints management. method.
The experimental results show that parallel plannable computers can effectively improve the performance. Compared with other scheduling algorithms, the experimental results show the highest configuration success rate. The processing speed of this architecture has a good performance, and the energy consumption in the architecture proposed in this paper. There are also good performances, and compared to other algorithms.
Keywords: Energy Constraints, Parallel, Reconfigurable Computing, Real-Time Scheduling
目次
誌謝 ... i
中文摘要 ... ii
Abstract ... iii
目次 ... iv
圖次 ... vi
表次 ... vii
第一章 緒論 ... 1
1.1 研究背景 ... 1
1.2 研究目標與動機 ... 2
1.3 論文架構 ... 3
第二章 文獻探討與設計考量 ... 4
2.1 計算機架構 ... 4
2.1.1 微處理器 (Microprocessor) ... 4
2.1.2 數位訊號處理器(Digital signal processing, DSP) ... 5
2.1.3 多處理器晶片(Chip multi-processor, CMP) ... 5
2.1.4 可規劃計算機架構(Reconfigurable computing) ... 6
2.2 平行可規劃計算機架構 ... 8
2.3 即時排程演算法 ... 10
2.3.1 最早截止日優先排程 ... 10
2.3.2 最短剩餘時間優先排程 ... 12
2.4 能源相關調度演算法 ... 15
第三章 能量限制下平行可規劃排程算法 ... 16
3.1 平行可規劃計算機 ... 16
3.2 系統架構圖 ... 17
3.3 可規劃的即時調度 ... 18
3.3.1 時間可行性 ... 18
3.3.2 能源可行性 ... 18
3.3.3 任務排程平行化 ... 19
3.3.4 意外事件處理 ... 25
3.4 動態能量管理方法 ... 26
第四章 實驗結果 ... 27
第五章 結論 ... 35 參考文獻 ... 36
圖次
圖 2-1. 傳統可規劃性計算機架構圖 ... 7
圖 2-2. 平行可規劃性計算機架構圖 ... 9
圖 2-3. 單處理器 EDF 排程演算法 ... 11
圖 2-4. 雙處理器排程演算法 ... 12
圖 2-5. 單處理器 SRTF 排程演算法 ... 13
圖 2-6. 雙處理器排程演算法 ... 14
圖 3-1. 平行可規劃計算計架構 ... 16
圖 3-2. 基於能量限制的排程演算法架構 ... 17
圖 3-3. 無迴圈圖(DAG)... 19
圖 3-4 .DAG 平行可已規劃計算機排程(1) ... 20
圖 3-5. DAG 平行可已規劃計算機排程(2) ... 21
圖 3-6. DAG 平行可已規劃計算機排程(3) ... 21
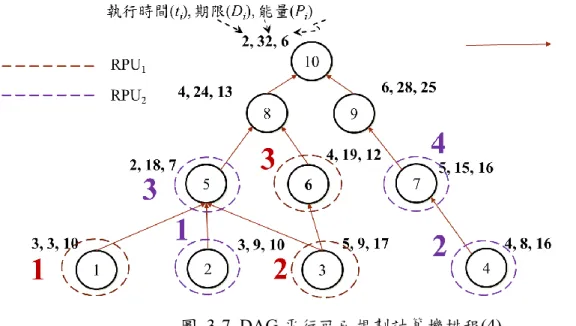
圖 3-7. DAG 平行可已規劃計算機排程(4) ... 22
圖 3-8. DAG 平行可已規劃計算機排程(5) ... 22
圖 3-9. DAG 平行可已規劃計算機排程(6) ... 23
圖 3-10. DAG 平行可已規劃計算機排程(7) ... 23
圖 3-11. 排程結果(RPU1) ... 24
圖 3-12. 排程結果(RPU2) ... 24
圖 3-13. 動態能量管理方法 ... 26
圖 4-1. AC7015 核心板正面圖 ... 28
圖 4-2. 兩個可規劃處理單元下能源消耗比較 ... 29
圖 4-3. 四個可規劃處理單元下能源消耗比較 ... 30
圖 4-4. 兩個可規劃處理單元下計算時間比較 ... 31
圖 4-5. 四個可規劃處理單元下計算時間比較 ... 32
圖 4-6. 兩個可規劃處理單元下任務調度成功率比較 ... 33
圖 4-7. 四個可規劃處理單元下任務調度成功率比較 ... 34
表次
表 4-1. 在 2 個 RPU 下能源消耗 ... 29
表 4-2. 在 4 個 RPU 下能源消耗 ... 30
表 4-3. 在 2 個 RPU 下計算時間比較 ... 31
表 4-4. 在 4 個 RPU 下計算時間比較表 ... 32
表 4-5. 在 2 個 RPU 下任務調度成功率比較 ... 33
表 4-6. 在 4 個 RPU 下任務調度成功率比較 ... 34
第一章 緒論
1.1 研究背景
現今嵌入式裝置的蓬勃發展,早就成為人們不可或缺的工具,並且隨處可見,其中 包括了電視、電視遊戲機、數位相機、VR(虛擬實境)、平板電腦、智慧型手機、智慧型 手錶等等。然而隨著現今科技的進步與發展,嵌入式系統的應用以及技術也越來越廣泛,
越來越精進,在市場上對於裝置的要求也越來越高,包括有更快速的計算,更低的能量 消耗,更小的空間,而且在很多的時候裝置會要求在有限的資源下達到某種功能的必要。
嵌入式系統的應用領域不斷增加,而且這些應用程式大多數是有時間限制的,所以 時序行為是非常重要的,並且其執行完整性亦是標準的一部分。即時系統的完整性不僅 僅取決於準確的結果,還取決於結果的期限,而且期限內完成是必須要。
嵌入式系統的趨勢是在共同的平臺上實現具有不同關鍵的功能,關鍵程度主要分為 任務的功能和操作,系統設計者自己定義系統中每個任務的關鍵程度。這些功能中有一 些是即時的,只要有一個不能期限內達成就可能會產生嚴重後果。除了這些以外,現今 即時嵌入式系統設計也有能量的限制,因此,符合能量限制的技術也是非常需要的。
多處理器系統變得越來越重要,因為在與單處理器系統相比下,在相同的性能要求 下,多處理器系統具有低功耗、低溫、低成本和指令級平行處理。現在嵌入式系統的一 般情況下,也面臨著應用到廣泛的多媒體軟體應用的需求。即便大多數單處理器嵌入式 系統通常提供一些特殊的 IP(Intelligent Property) ,或使用數位訊號處理(Digital signal processing) 加快速度,單處理器系統性能仍然是一個主要瓶頸。我們必須充分利用多 處理器系統的優點,它仍然能夠應付大量的 3D 圖形應用或更複雜的計算。隨著嵌入式 多處理器系統的大量普及之下,僅僅使用單處理器調度方法,是無法實現令人滿意的性 能。因此,嵌入式系統將朝著多處理器、多執行緒的方向發展。
1.2 研究目標與動機
現今的可規劃計算機正在快速發展,目前的市場要求更高的性能,並且能夠擁有多 元的功能,還要能降低能耗。而且在於硬體資源方面,攜帶型裝置的規格又比傳統上有 著更高的規範要求。因此設計上必須要考量計算能力、花費成本,以及能源的消耗等方 面。
多處理器即時系統具有許多不同於單處理器即時系統的特點。如果在多處理器系統 中直接使用單處理器調度演算法會相當沒有效率。
本文將討論在多處理器系統中應用這些演算法的問題。換句話說,多處理器系統的 調度程式必須保證在不錯過所有的最後期限的情況下執行所有任務。即使系統負載過重, 也必須具備有良好的調度能力。除此之外,多處理器即時系統的調度也會考慮在系統中 可規劃處理單元(Reconfigurable Processing Unit)數量可能會增加。
為了提供一種能夠有效地調度任務的調度演算法,本文提出了平行可規劃計算機調 度演算法,並且可以即時(Real Time)完成,以及提出一個以平行可規劃計算機為架構的 排程方法解決可規劃計算機的能量限制(Energy Constraints)。
1.3 論文架構
本論文其他章節安排如下:
1. 第二章節描述以往各種計算機,包含其計算機架構,以及排程演算法與能量相關研究。
2. 第三章節描述本研究所提出之架構以及排程方法。
3. 第四章節描述實驗環境、開發環境、實驗結果、以及比較結果。
4. 第五章節根據實驗及果以及本研究提出的架構總結與未來可以研究的方向。
第二章 文獻探討與設計考量
2.1 計算機架構
當我們實驗數據的採用計算量相當龐大的程式時,我們可以發現一些問題,因為計 算資訊量龐大的程式是需要連續執行,這些程式必須要要求計算速度以及即時性如影播 放處理及各種大量執行系統,因此如何幫助系統提升計算能力和運算速度為我們所必須 要研究的。然而隨著行動設備如此快速的發展,硬體的可用能源的消耗以及資源執行開 始有了嚴格的規範,設計上也需要滿足即時計算能力、能源消耗控制,甚至成本和靈活 性等方面。程式執行處理還有另一個很重要的特性是資料流( data streaming )以及資料計 算平行性(computing parallelism ),這代表著計算工作有可能分佈在多個處理元件之中。
一般來說,平行性計算可以分為兩類:空間平行性和時間平行性。在時間平行性中,
管線化(pipeline)技術常被使用在指令級或工作級中,其中指令代碼或計算工作被分成多 個階段。幾個指令或工作在不同階段於相同管線中重疊以提高系統輸送量。
另一方面,空間平行性將資料和工作分配到不同的計算節點平行處理。在資料流應 用程式中,資料平行性(data-level parallelism)通常可以被利用,因為它們之間沒有資料依 賴性不同的輸入資料塊。在這種情況下,單指令多資料(SIMD)計算方式可被廣泛用於將 相同的內核函數應用於不同的資料元素。同樣地,工作級平行(task-level parallelism)通常 用於執行不同的應用資料流應用程式中的線程。在許多情況下,計算工作涉及流處理可 以分解為多個階段。這些階段可以重疊轉換成多個計算資源以通過其並行處理不同的資 料集管道。給定充分的平行性,它是計算架構的關鍵要求資料流應用程式的設計應該能 夠有效地利用和映射可用硬體資源的平行性。
在瞭解程式處理的特徵之後,需要設計合適的計算架構以符合低能耗高性能的需求,
更重要的是希望能降低能源的需求,為達成這個目標,創新的計算機結構設計是必要的。
以下介紹現今的計算機處理器的幾個方案和相關的優缺點比較分析:
2.1.1 微處理器 (Microprocessor)
微處理器是一種一個可程式化特殊單元或大規模積體電路組成的可程式化特殊單 元組,又可以稱為半導體中央處理器(CPU)。微處理器的目標是高性能並能廣泛應用於 桌上和筆記本電腦。傳統上,多管線化(deep pipeline)和製程縮減(process shrinking)是提 高系統性能的關鍵技術,製程縮減(process shrinking)是一個降低晶體尺寸的高效率的方 式,以實現性能和集成能力的改進,但是由於製程技術的進步讓正反器的延遲已接近到 組合邏輯的延遲,多管線化的所獲得的高效益使得頻率提高變得越來越不重要,預計在 將不久的將來會由於晶體尺寸將能接近原子的尺寸,使得當以微處理器應用於高規格程 式處理中時,高功耗會是難以避免的,因此使用微處理器來做為程式處理的架構並不是 一種好的選擇。
2.1.2 數位訊號處理器(Digital signal processing, DSP)
數位信號處理器((Digital signal processing, DSP)是一種快速的處理器,可以即時的處 理資料,適合運作在不能容許延遲的應用上面。數位信號處理器(DSP)常被設計為提供 高計算性能的數字信號應用。與微處理器相比下,通常 DSP 可以提供更多的專用計算資 源,例如乘法器和累加器,以及提供更高的頻寬。最近,還引入了一些新功能到 DSP 架 構,其中包括超長指令字(VLIW)結構,例如 TI 的 8 路 VLIW TMS320C64X DSP [1]可 以實現高性能達每秒 8k 百萬兆指令 (MIPS) 且消耗的功率在 6W。與微處理器相比,
DSP 提供了能量效率增益管線長度,較少的通信開銷和更多並行的有利架構。然而,
VLIW DSP 共用控制結構使用全域性的暫存器,讓檔案可以在不同處理單元之間的數據 共用,這使得難以包括大量的處理單元。在[2]的研究中發現可以在這兩個的區域中可以 比專用電路的效率高以及低三個量級能源消耗。
2.1.3 多處理器晶片(Chip multi-processor, CMP)
多處理器晶片(Chip multi-processor, CMP)已經被提出作為通用處理器架構的設計並 能實現更高的性能甚至更低的頻率。AMD 首次推出的 Athlon 64 2X [3],CMP 集成了
有的平行性,因為它們主要是針對整數線性規劃(ILP)進行了優化,並且對於並行處理具 有有限的計算能力。最近,已經開發了集成大型多核系統在單個晶片上的簡化處理器核 的數目,例如視頻/圖像處理,遊戲,超級計算等網路應用。
與 CMP 相比,多核系統通常涉及更多的處理其中具有特定通信結構的單元。例如,
英特爾 80 核系統[4]在一個 10 乘 8 的 2D 網格結構中集成了 80 個晶片,每個晶片包 含一個計算元件和 5 埠路由器單元。動態消息傳遞協議被實現以提供高速和晶片網路 (network-on-a-chip)數據通信,這比當今的 CMP 互連更加具可擴展性。據報導英特爾的 80 核可以實現每秒 1.28 T 的浮點運算(TFLOPS)。多核結構是實現用於數據流應用高計 算能力的解決方案。但是基於處理器結構,多核系統通常具有高功耗,這通常不能滿足 便攜式設備的功耗要求。
2.1.4 可規劃計算機架構(Reconfigurable computing)
在眾多的解決方案中,通用處理器(GPP)雖然容易使用而且靈活性高,但效能不合 乎要求。特殊應用積體電路(ASIC)可以在特定的應用上提供最高的性能,但電路的結構 不能更動。以上這些架構均無法在硬體資源上兼顧效能和提供彈性,傳統上,應用程式 特定的 DSP 或 FPGA 是與通用處理器(GPP)配合以加快計算速度和提高整個系統的能 源使用效率。然而,它們在速度,功耗,成本和延展性等大範圍的設計空間中僅提升一 個或兩個領域[5]。
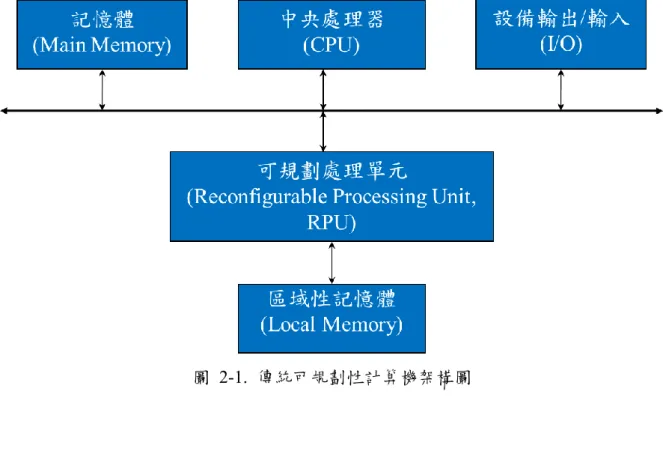
大多數 FPGA 提供低細細微性(fine-grained)平行性與高度的靈活性,但付出功率的 代價和只能在開機時進行配置[6]。相比之下,雖然 DSP 易於編程和具有相對較低的功 率消耗,其計算量卻受範紐曼型架構[7]讀取和執行指令架構的限制。圖 2-1 顯示傳統可 規劃性計算機的架構圖。
可規劃計算(Reconfigurable computing)已被大多數建議使用的一種能平衡性能、成 本、靈活性高,和容易使用等等優點的方法。粗細微性(coarse-grained)可規劃計算機架構 落在 DSP 和 FPGA 之間,並且它們提供不能由上述兩種或其他執行技術同時解決的功 能,該處理器聚集可規劃計算元件,其能夠執行各種算術運算,因此非常高的計算輸送 量可以實現通過多級可規劃的計算元件並行。可規劃計算(Reconfigurable computing)架
構能作為橋接性能的方式 ASIC 和 GPP 之間的間隙,同時保持靈活性和易用性的處理 器。如今,FPGA 仍然是主導的半導體技術在可規劃計算區域。但是如前所述,位元細 粒度 FPGA 架構導致面積,功率和速度方面的巨大成本。可規劃性計算機的基本架構基 本構成以現場可程式邏輯閘陣列 (Field Programmable Gate Array , FPGA) 為主,連接固 定可規劃性接線組成,能夠依照使用的需求規劃更變邏輯閘[8],比起常規的微處理器擁 有改變硬體的能力。程序在運行時重新配置(run-time reconfiguration, RTR)硬體,RTR 類 似虛擬記憶體的概念允許在程序執行期間執行[9-10]。
圖 2-1. 傳統可規劃性計算機架構圖
2.2 平行可規劃計算機架構
可規劃計算機系統有數種記憶體方案可供選擇,單一本文是一個可程式化晶片,這 個晶片具有可以依一定順序來全部重新規劃程式內容的特性。比如 Dharma [11] 還有 Time-Multiplexed FPGA (TM-FPGA) [12] 的架構。
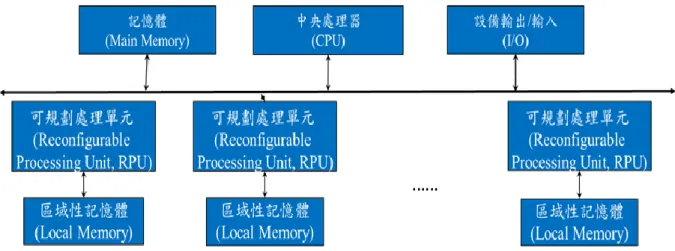
對 多 本 文裝 置 而來 說, 動 態 可程 式 陣 列 Dynamically programmable gate arrays (DPGAs) [13] 可以視為多個單一本文組成,每一個單一本文在任何時候都能夠改變。進 一步的優化系統能使用多指令多資料流(multiple instructions, multiple data , MIMD)的平 行處理技術,MIMD 具有多個處理器和 I/O 處理器可以透過公共匯流排存取一個或多 個記憶體。但因為存取記憶體必須透過公共匯流排,系統性能會被這存取動作導致效能 延遲。為解決這問題,我們將每個處理器配置一個記憶體,可以減少存取匯流排的次數。
可規劃計算機結合平行處理技術,就成為平行可規劃計算機 (parallel reconfigurable computing, PRC)。圖 2-2 顯示平行可規劃計算機的架構圖。
另一方面,粗細微性可規劃架構包括字級(16 位)或雙字級(32 位)組件作為基本計 算和通信單位。受益於低得多的計算和路由開銷,粗細微性可規劃架構(CGRA)具有改進 的潛力,基於 FPGA 功率和能量效率,同時提供高系統性能。CGRAs 利用了許多計算 任務對多位數據進行操作的事實具有強烈的計算要求。涉及的計算組件不需要像微處理 器一樣複雜和強大。簡化的功能塊通常可以實現更高的面積和功率效率,並可以提高系 統的可擴展性。基於晶片上硬體資源,CGRA 也可以分類為異構的系統和均勻系統。異 構 CGRAs 整合計算方塊(ALU)和儲存器於同一晶片。同質 CGRA 使用相同的計算塊和 統一通信結構遍佈整個晶片。計算和通信規律性的同源 CGRA 具有提高系統可擴展性 和緩解的潛力設計和測試工作。這部分解釋了 CGRA 研究的趨勢粗細微性可規劃處理 器設計已經呈現在許多文獻中,在過去十年。一個名為 DAPDNA-2 針對多媒體應用動 態可規劃處理器被提出[14-15]。
圖 2-2 . 平行可規劃性計算機架構圖
2.3 即時排程演算法
早期的單一處理器調度演算法的主要目的是確保任務不超過該截止期限,並且提高 系統的利用率,演算法可分為可搶占的以及不可搶占。可搶占的演算法從最簡單的排程 方式就是先到先執行(First Come First Served Scheduling)演算法簡寫為 FCFS,就是把處 理器分配給第一個要求執行的任務。FCFS 的程式很容易寫也容易瞭解。但是在 FCFS 方 法下的平均等待時間幾乎是很長的。
最早截止日優先(Early Deadline First, EDF) 調度演算法[16]以及最短剩餘時間優先 (Shortest Remaining Time First, SRTF) 調度演算法在單處理器即時系統中得到了廣泛的 應用。我們將在以下幾節中討論單處理器即時系統中的 EDF 調度演算法以及 SRTF 調 度演算法的問題。
2.3.1 最早截止日優先排程
EDF 調度算法是即時操作系統中最著名和最有效的。 在單處理器系統中,EDF 是 一種最優的調度算法[16]。 它是一種動態優先級調度算法,任務優先權不是固定的,但 可以根據截止日期期限的靠近而調整優先權重。 在這樣的框架中,我們假設如前所述 存在多個任務,每個任務均有相對應的截止日期。 如果任務的總利用率不大於 1,則任 務集可以是通過 EDF 算法在單處理器系統上進行可行調度,如下面的公式所示:
總利用率(utilization, U)=Σ(ti/Di)
系統 n 設有 i 個工作任務{1, 2, … , i},其中任務i的抵達時間是 Ci ,任務i的執 行時間是 ti,任務i的截止日期是 Di。
執行任務上需要計算時間和截止日期。上面的公式也可以告知系統最大利用率為 1。
換句話說, EDF 如果無法在單處理器系統上完成即時調度任務,那麼就沒有其他調度 演算法可以完成[17]。 但是,即便在單一處理器平台上具有最佳效能的算法,也無法保 證該調度算法可以在多處理器平台中發揮良好作用[18]。 眾所皆知的是,多處理器系統 或多核心系統的最優調度算法是 NP-Hard 問題[19]。
EDF 排程演算法範例:在單一處理器下設有 3 個工作任務{1, 2, 3},任務i的 抵達時間是Ci,任務i的執行時間是 ti,任務i的截止日期是Di。
1 ( C1=0, t1=7, D1=18 ), 2 ( C2=3, t2=5, D2=14 ), 3( C3=4, t3=2, D3=15 )
1. 單處理器排程演算法
當時間為 0 個單位的時候任務開始,首先只有任務一到達所以先執行任務一,當時 間為 3 個單位的時候任務二抵達,由於任務二的截止日期為 14 低於任務一,所以演算 法執行搶占任務,優先執行任務二。
當時間為 4 個單位的時候任務三抵達,由於任務三的截止日期為 15 高於任務二,
所以演算法不執行搶占任務。
當時間為 8 個單位的時候任務二完成,由於任務三的截止日期為 15 低於任務一,
所以優先執行任務三。
當時間為 10 個單位的時候任務三完成,執行剩餘的任務一。
EDF 單處理器排程演算法範例結果附圖 2-3
圖 2-3. 單處理器 EDF 排程演算法
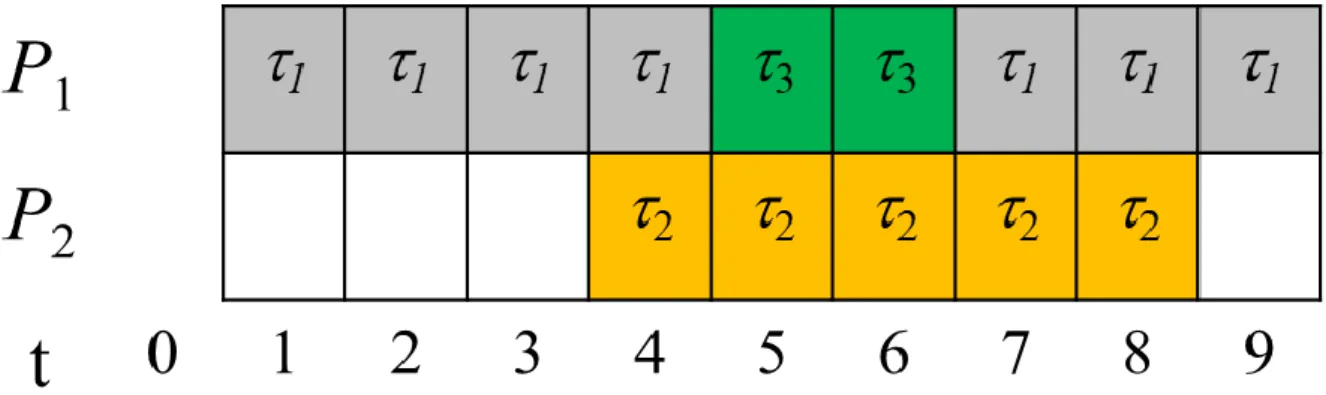
2. 雙處理器排程演算法
當時間為 0 個單位的時候任務開始,首先只有任務一到達所以處理器 P1先執行任務一。
當時間為 4 個單位的時候任務三抵達,由於任務二的截止日期為 14 低於任務三,處理 器 P2不執行搶占,由於任務三的截止日期為 15 低於任務一,所以處理器 P1執行搶占任 務,優先執行任務三。
當時間為 6 個單位的時候任務三執行完成,處理器 1 號繼續執行任務一。
當時間為 8 個單位的時候任務二執行完成。
當時間為 9 個單位的時候任務一執行完成。
EDF 雙處理器排程演算法範例結果附圖 2-4
圖 2-4. 雙處理器排程演算法
2.3.2 最短剩餘時間優先排程
最短工作優先排程演算法有最小的平均等待時間,若以等待時間評估任何一個方法 的好壞,最短工作優先排程演算法是最佳的演算法。
也就是最短工作優先排程法在理論上是最佳的演算法,但實際上是不太可行,因為 處理程序尚未執行前,無法知道或預估它使用處理器時間。
以下為 SRTF 排程演算法範例:
在單一處理器下設有 3 個工作任務{1, 2, 3},任務i的抵達時間是Ci,任務i的執行 時間是 ti,任務i的截止日期是Di。
1 ( C1=0, t1=7, D1=18 ), 2 ( C2=3, t2=5, D2=14 ), 3( C3=4, t3=2, D3=15 ) ,假 設只有一個處理器。
1. 單處理器排程演算法
當時間為 0 個單位的時候任務開始,首先只有任務一到達所以先執行任務一,當時 間為 3 個單位的時候任務二抵達,由於任務二的執行時間為 5 高低於任務一剩餘時間 3,
所以演算法不執行搶占任務。
當時間為 4 個單位的時候任務三抵達,由於任務三的剩餘執行時間為 2 低於任務一 剩餘時間 3,所以演算法執行搶占任務。
當時間為 6 個單位的時候任務二完成,由於任務一的剩餘時間為 3 低於任務二,所 以優先執行任務一。
當時間為 9 個單位的時候任務一完成,執行剩餘的任務二。
單處理器排程演算法範例結果附圖 2-5。
圖 2-5. 單處理器 SRTF 排程演算法
2. 雙處理器排程演算法
當時間為 0 個單位的時候任務開始,首先只有任務 1 到達所以處理器 P1先執行任務一。
當時間為 6 個單位的時候任務三執行完成,處理器 P1繼續執行任務一。
當時間為 8 個單位的時候任務二執行完成。
當時間為9 個單位的時候任務一執行完成。
雙處理器排程演算法範例結果附圖 2-6。
圖 2-6. 雙處理器排程演算法
2.4 能源相關調度演算法
基於能量限制系統的單處理器即時調度一直是好幾年來的重點研究,包括有[20-22]。
近年來開始了對多處理器案例進行了研究工作。H. El Ghor, M. Chetto, and R. Hage Chehade [23] 提出了一種稱為能量收穫-最早截止日優先(EH-EDF) 的有效的特定 EDF 調度演算法。有在運行時進行決定,而無需事先瞭解未來的能源生產的任務特徵。模擬 顯示所提出的演算法 EH-EDF 的性能,並且證明有限調度程式不能在即時能量收集環 境中達到最佳性。
B. Zhang, R. Simon, and H. Aydin [24] 提出了一種基於能量收集的性能受限無線傳 感器網路(WSN)中的時代的能量管理方法。所提出的方法採用動態電壓調節(DVS)和動 態調製縮放(DMS)兩種能量管理技術。為了滿足性能要求,該方法調整無線電的調製級 別和 CPU 頻率。數個模擬顯示,在正常和緊急情況下,所提出的演算法實現比基線方 法顯著更高的性能。
J. Lu and Q. Qiu [25] 的工作為能量收集的多核心即時嵌入式系統提出了任務映射、
任務調度和電源管理方法,其方法是基於任務 CPU 利用率的概念,其被定義為最壞情 況任務執行時間除以其週期。該方法結合具有能量收集意識和任務鬆弛管理(TSM)的新 動態電壓頻率選擇(DVFS)演算法,形成了提出的基於利用的(UTB)演算法。近年來已經 進行了幾項研究工作重點是可規劃嵌入式系統 [26-27] 。
第三章 能量限制下平行可規劃排程算法
本章節將介紹如何在一段規定下的時間區間內完成全部的工作,及如何使整個系統達到 最低耗能
3.1 平行可規劃計算機
可規劃架構主要的設計問題應包括 ;透過複數可規劃處理單元(Reconfigurable Processing Unit, RPU)的平行處理,並通過內部片上網路並連接在一起,硬體互相連接,
包括拓撲結構的互連和路由器設計;晶片上的存儲結構,包括內存的分層結構和輸入/輸 出(I / O)接口。一個可規劃架構的優點是,結構和整個或電路的部件的功能性可以在製 造完成後進行動態重新配置。
具體工作流程:某個工作一開始由中央處理器的 CPU 執行,當這個子工作執行完畢 後把一些參數放在主記憶體中,再透過內部網路連接 RPU 接手繼續執行此工作的後續 動作;當 RPU 完成目前的工作後也將一些參數放在共享記憶體中,如果工作已經沒有 後續的動作,則 RPU 等待下一次的工作進來,如果還有後續動作的話,RPU 透過內部 網路連接呼叫 CPU 接手繼續執行此工作的指揮後續的動作,一直到此項工作中的所有 子工作都執行完畢。圖 7 為平行可規劃計算計架構。
圖 3-1 平行可規劃計算計架構
3.2 系統架構圖
系統具體工作流程:根據系統大該需求透過計算機架構配置適合的可規劃處理單元 (RPU)數量,工作一開始由中央處理器的 CPU 執行,之後把一些參數放在主記憶體中,
再透過內部網路連接RPU 接手繼續執行此工作的後續動作。
透過平行可規劃排程算法(Parallel Reconfigurable Scheduling, PRS)執行調度任務,判 斷任務是否有即時達成,如果任務都有在時限內完成,之後檢是否可以在能量限制下達 成任務配置,如果不能完成將採取動態能量管理辦法解決能量不足的處理。下圖3-2 基 於能量限制的排程演算法架構。
圖 3-2. 基於能量限制的排程演算法架構 平行可規劃排程算法(PRS)
增加RPU 平行處理數量 能量限制下判斷有無任務無法即時
完成 配置RPU
有
否 動態能量管理方法
3.3 可規劃的即時調度
我們假設應用程式ψ 由 i 個工作{𝜏1, 𝜏2 ,…, 𝜏𝑖}組成,任務會依序執行,有順 序之分,其特性在於:
1.任務i的執行時間是ti
2.任務i的截止日期是Di
3.能量消耗的限制是𝑃𝑖
4.定義其應用重要性的優先度𝑑𝑖度。
優先程度被定義為任務的功能和操作重要性。系統的設計者定義(手動)系統中每 個任務的關鍵程度。認為任務有隱含的最後期限,即最後期限等於期限。一個任務τi的 特徵是(ti , Di, Pi , di )。此外, 在論文中,考慮了半分割方法,能量限制下的 可規劃平行可規劃計算計系統中的調度問題,有兩個要遵守的約束條件。
3.3.1 時間可行性
不考慮能源需求下,RPU 調度的準確可調度性測試給定𝑈𝑗 ≤ 1,𝑈𝑗可規劃處理單元 (RPU)j的利用率,也就是如果處理器已經是在不停的執行情況下也不能完成工作任務的 情況下,該任務被判定不可執行。
3.3.2 能源可行性
每一個可規劃處理單元(RPU)的能源需求為 P,能源需求在本系統中必須要小於系 統的能源供應的量E。其中(RPU)j在任務ψ的時間t1跟t2之間的能源需求為Pj,任務ψ 中的能量負荷 Uj (t1, t2) 分別在可規劃處理單元(RPU)j的配置如下式子:
U𝑗 (t1, t2) =Pj 𝐸j
⁄ ≤ 1, U𝑗 = 0≤𝑡 U𝑗 (t1, t2)
1,𝑡2≤𝐻 𝑠𝑢𝑝
H 為上界,𝑈𝑗 ≤ 1
在實際應用場景中,任務的執行表徵大多為條件結構(如 if-then-else, statement)。
3.3.3 任務排程平行化
我們將系統模型以如圖 3-3 之方向無迴圈圖(DAG)表示。
DAG 任務圖,每個任務 𝜏𝑖,i ∈ {1, … ,N} ,𝑉𝑖 = {𝜏1, … , 𝜏𝑛}為節點集合𝜏𝑖為 𝑉𝑖的子任務;𝑛𝑖為𝐺𝑖中的子任務數量;𝐸𝑖為有向邊的集合代表𝐺𝑖裡的節點間的依賴關係。
該DAG 任務圖有唯一來源點,也就是沒有指向他的頂點,也有唯一一個終結點,也就
是沒有直向別人的點。而每個頂點代表一個子任務,每個邊代表一個可能的流程。
以下為平行可規劃排程算法範例:
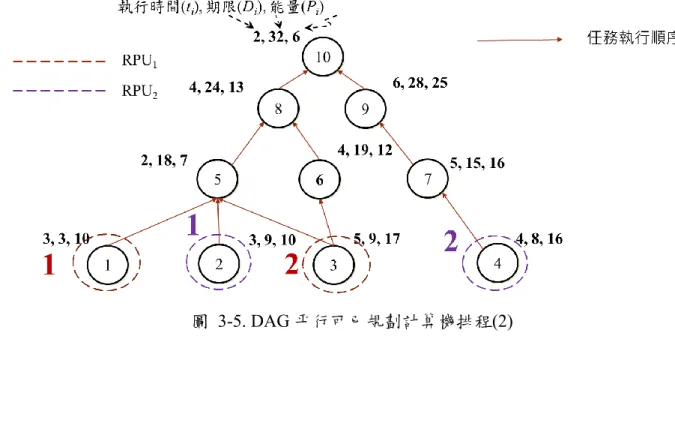
設系統配置2 個 RPU,下圖為程式執行之任務圖,以 DAG 模型表示。
時間為 0 個單位的時候任務開始,首先任務一、任務二、任務三、任務四到達,因 圖 3-3. 無迴圈圖(DAG)
執行時間為 3 個單位,任務一、任務二執行完成,任務三由 RPU1執行,任務四由 RPU2執行。執行結果如下圖 3-4。
執行時間為 7 個單位,任務四執行完成,執行時間為 8 個單位,任務三執行完成,
任務五由 RPU2執行,任務六由 RPU1執行。執行結果如下圖 3-5。
執行時間為 10 個單位,任務五執行完成,任務七由 RPU2執行。執行結果如下圖 13。
執行時間為 12 個單位,任務六執行完成,任務八由 RPU1執行。執行結果如下圖 14。
執行時間為 15 個單位,任務七執行完成,任務九由 RPU2執行。執行結果如下圖 15。
執行時間為 16 個單位,任務八執行完成執行。時間為 21 個單位,任務九執行完成,
任務十由 RPU1執行。執行時間為 23 個單位,任務十執行完成執行。執行結果如下圖 16。
下圖為平行可已規劃計算機排程流程步驟1。
圖 3-4 . DAG 平行可已規劃計算機排程(1)
下圖為平行可已規劃計算機排程流程步驟 2。
下圖為平行可已規劃計算機排程流程步驟 3。
圖 3-5. DAG 平行可已規劃計算機排程(2)
圖 3-6. DAG 平行可已規劃計算機排程(3)
下圖為平行可已規劃計算機排程流程步驟 4。
下圖為平行可已規劃計算機排程流程步驟 5。
圖 3-7. DAG 平行可已規劃計算機排程(4)
圖 3-8. DAG 平行可已規劃計算機排程(5)
下圖為平行可已規劃計算機排程流程步驟 6。
下圖為平行可已規劃計算機排程流程步驟 7。
圖 3-9. DAG 平行可已規劃計算機排程(6)
圖 3-10. DAG 平行可已規劃計算機排程(7)
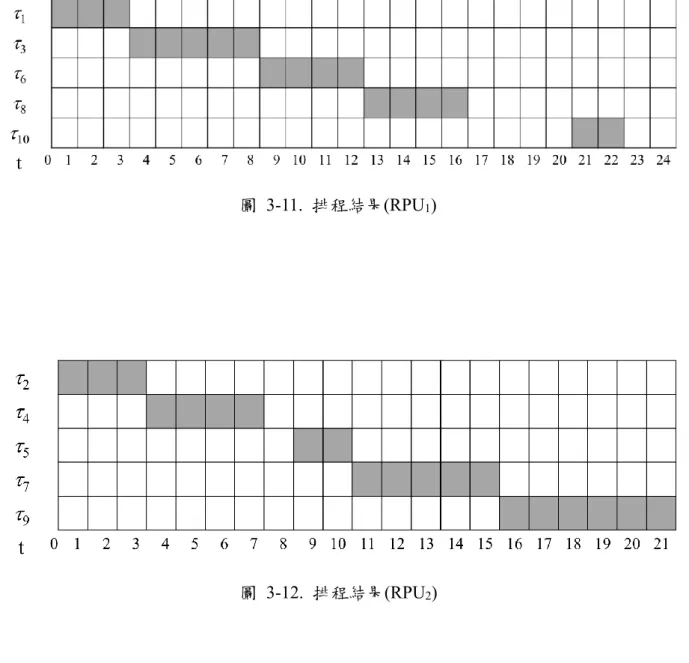
透過我 PRS 排程演算法,執行時間為 t,一格代表一個時間單位。
下圖 3-11.為可規劃處理單元(RPU1)的排程結果。
下圖 3-12.為可規劃處理單元(RPU2)的排程結果。
圖 3-11. 排程結果(RPU1)
圖 3-12. 排程結果(RPU2)
3.3.4 意外事件處理
為了應對任何不可預測的外部事件,例如硬體故障或新的任務到達。我們提出了兩 個適應策略的解決方案,以便在運行時重新配置系統。
(a) 分解和遷移模塊:
首先是分支選擇啟發式。選擇一個分支或一組分支來遷移到其他非故障處理器,以 重新建立系統可行性。具有最低危害程度的任務將被分解成一組分支。然後關鍵執行流 程將從DAG 中刪除。
然後是處理器選擇啟發式。遷移分支將被分配到的處理器的選擇。按照儲存單元中能源 可用性的遞增順序對候選處理器組進行排序。
(b) 降級模塊:
降低每個故障處理器的調度。在這種情況下,可以根據用戶要求在約束下執行具有 最低關鍵程度的任務,這代表任何k 個連續任務中的至少 m 個在期限完成。假設任務集 合𝜑𝑗可以調度,定義為:
𝑈𝑚,𝑘= ∑ 𝑈𝑖
𝑛 𝑖=1
×𝑚𝑖 𝑘𝑖 ≤ 1
3.4 動態能量管理方法
能量能量管理方法採取動態任務鬆弛處理,透過系統休眠時間,當系統閒置時會進 入低功率的模式。為了達到高效能的目的,我們將建立一個功率狀態模型,希望可以確 立一個最適合的能源策略,將沒有使用的閒置單元進入低功率狀態,以達到減少功率的 消耗。
我們此採取機器學習中強化學習的方法來規劃能源策略,強化學習會因環境不同而 自我改進,以取得最大化的預期利益,這代表我們的能源策略是會隨時改變自我進化,
是一種動態能量管理(Dynamic power management ,DPM) 大致的流程如下圖 3-13。
如圖3-13 所示,首先動態能量管理有一個閒置時間。當系統處於睡眠狀態時,管理 會檢查系統休眠時間St(省電時間)。如果系統已經處於休眠狀態而且超過所閒置時間,
代理獎勵當前策略 rt,其中該系統設置為休眠狀態。反之,該代理懲罰電流控制策略,
並修正改變下一策略at。接下來的策略嘗試賺取代理的報酬和獎勵都存儲在獎勵表。因
此,代理學習繼續直到模擬結束。最後,DPM 通過強化學習試劑的方法預測最合適的政 策,並提供必要的功率優化。
圖 3-13. 動態能量管理方法
第四章 實驗結果
本章介紹該系統與其他系統各項數據的比較結果。我們會敘述實驗環境,提出我們 的測試方法,並且客觀分析我們系統的性能優劣。
4.1 實驗環境
AC7015(核心板型號)核心板,ZYNQ 晶片是基於 XILINX 公司的 ZYNQ7000 系 列的 XC7Z015-2CLG485I。其中具有 FPGA 同時又包含了的 PS 系統集成了兩個 ARM Cortex™-A9 處理器,AMBA®互連,內部記憶體,外部記憶體介面和外設。ZYNQ 晶 片的 FPGA 內部含有豐富的可程式設計邏輯單元,DSP 和內部 RAM。
這款核心板使用了 2 片 SK Hynix 公司的 H5TQ4G63AFR-PBI 這款 DDR3 晶片,
每片 DDR 的容量為 4Gbit;2 片 DDR 晶片組合成 32bit 的資料匯流排寬度,ZYNQ 和 DDR3 之間的讀寫資料時鐘頻率高達 533Mhz;這樣的配置,可以滿足系統的高頻寬 的資料處理的需求。
此開發板可以在Windows、Linux、Android,或其他 OS/ RTOS 的設計,可以運用 在各種大型程式處理、影像處理、機電控制及軟體加速等等地方。除此之外,當中可擴 展介面讓使用者可以方便訪問處理系統和可程式設計邏輯,AC7015 開發板的外觀如下 圖4-1 所示。
AC7015(核心板型號)核心板的系統部分的主要參數如下:
基於 ARM 雙核 CortexA9 的應用處理器,ARM-v7 架構 高達 766MHz
每個 CPU 32KB 1 級指令和資料緩存,512KB 2 級緩存 2 個 CPU 共用
片上 boot ROM 和 256KB 片內 RAM
外部存儲介面,支援 16/32 bit DDR2、DDR3 介面
兩個千兆網卡支援:發散-聚集 DMA ,GMII,RGMII,SGMII 介面
兩個 USB2.0 OTG 介面,每個最多支援 12 節點
兩個 CAN2.0B 匯流排界面
兩個 SD 卡、SDIO、MMC 相容控制器
PS 內和 PS 到 PL 的高頻寬連接
圖 4-1. AC7015 核心板正面圖
利用Vivado 套件將我們的平行可規劃計算機架構建立起來,然後結合軟體開發 Xilinx Vivado Design Suite 是作為專業的 FPGA 設計解決很好的方案,他提供了廣泛的 強大功能,使設計過程非常方便。它提供了許多強大的工具,完整的設計解決方案,集 成DSP 的設計,並提供了基於 IP,SOC 和基於系統的開發工具,透過 AC7015(核心板 型號)核心板實現了本論文架構,不論軟體還是硬體都能透過 Vivado 套件的 GUI 環境中 開發完成。
4.2 能源消耗比較
在 2 個 RPU 執行下,透過能量限制管理方法結合平行可規劃排程算法(PRS) 與使 用EDF 即時排程演算法以及 EH-EDF 即時排程演算法的能量消耗做比較。如圖 4-2。
圖 4-2. 兩個可規劃處理單元下能源消耗比較 表1 為 2 個 RPU 執行下的能量消耗比較表
表 4-1. 在 2 個 RPU 下能源消耗比較
PRS EH-EDF EDF
10 個任務 68.6(mW) 70.2(mW) 80(mW) 15 個任務 78.3(mW) 80.3(mW) 92.2(mW) 25 個任務 107.2(mW) 116(mW) 128(mW)
以及當在4 個 RPU 執行下,我的平行可規劃排程(PRS) 與使用 EDF 即時排程演算 法以及EH-EDF 即時排程演算法的能量消耗做比較圖如下圖 4-3。
68.6 80.0 70.2
78.3
92.2 80.3
107.2
128.0 116.0
0 20 40 60 80 100 120 140
PRS EDF EH-EDF
單位(mW)
2 RPU下能源消耗比較
25個任務 15個任務 10個任務
圖 4-3. 四個可規劃處理單元下能源消耗比較
表 4-2. 在 4 個 RPU 下能源消耗比較
PRS EH-EDF EDF
10 個任務 56.5(mW) 58.5(mW) 66.7(mW)
15 個任務 65.3(mW) 67(mW) 76.9(mW)
25 個任務 80.1(mW) 96.7(mW) 106.7(mW)
從比較圖表來看我們所做的PRS 的演算法比起其他演算法有最低的能量消耗。
56.5 66.7 58.5
65.3
76.9 67.0
80.1
106.7 96.7
0 20 40 60 80 100 120
PRS EDF EH-EDF
單位(mW)
4 RPU下能源消耗比較
25個任務 15個任務 10個任務
4.3 計算時間比較
在 2 個 RPU 執行下,透過能量限制管理方法結合平行可規劃排程算法(PRS) 與使 用EDF 即時排程演算法以及 EH-EDF 即時排程演算法的配置計算時間做比較。如圖 4- 4。
圖 4-4. 兩個可規劃處理單元下計算時間比較
表 4-3. 在 2 個 RPU 下計算時間比較
PRS EH-EDF EDF
15 個任務 1.2(s) 1(s) 1.5(s)
20 個任務 1.4(s) 1.4(s) 1.9(s)
25 個任務 1.7(s) 1.6(s) 2.4(s)
30 個任務 1.8(s) 1.8(s) 2.6(s)
35 個任務 1.9(s) 1.9(s) 2.8(s)
1.2 1.4
1.7 1.8 1.9
1.0
1.4 1.6 1.8 1.9
1.5
1.9
2.4 2.6 2.8
0 0.5 1 1.5 2 2.5 3
15 20 25 30 35
計算時間(S)
執行任務數量
2 RPU下計算時間比較
PRS EH-EDF EDF
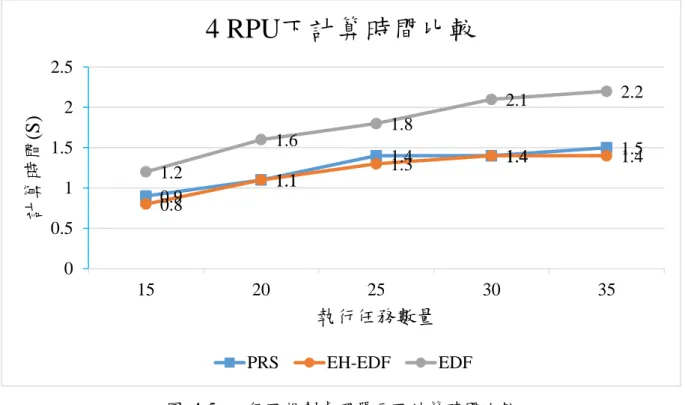
圖 4-5. 四個可規劃處理單元下計算時間比較
表 4-4. 在 4 個 RPU 下計算時間比較
PRS EH-EDF EDF
15 個任務 0.9(s) 0.8(s) 1.2(s)
20 個任務 1.1(s) 1.1(s) 1.6(s)
25 個任務 1.4(s) 1.3(s) 1.8(s)
30 個任務 1.4(s) 1.4(s) 2.1(s)
35 個任務 1.5(s) 1.4(s) 2.2(s)
0.9 1.1
1.4 1.4 1.5
0.8
1.1
1.3 1.4 1.4
1.2
1.6 1.8
2.1 2.2
0 0.5 1 1.5 2 2.5
15 20 25 30 35
計算時間(S)
執行任務數量
4 RPU下計算時間比較
PRS EH-EDF EDF
4.4 任務調度執行成功率比較
在能量限制下本論文所提之平行可規劃計算機架構之任務配置成功率與其他配置 結果比較,結果顯示本論文架構任務配置成功率相較於其他架構底下之成功率高。
在 2 個 RPU 執行下,透過能量限制管理方法結合平行可規劃排程算法(PRS) 與使 用EDF 即時排程演算法以及 EH-EDF 即時排程演算法的配置成功率做比較。如圖 4-6。
圖 4-6. 兩個可規劃處理單元下任務調度成功率比較
表 4-5. 在 2 個 RPU 下任務調度成功率比較
PRS EH-EDF EDF
15 個任務 100.00% 100.00% 100.00%
20 個任務 100.00% 100.00% 100.00%
25 個任務 100.00% 100.00% 96.00%
30 個任務 100.00% 96.67% 86.67%
35 個任務 100.00% 94.28% 80.00%
40 個任務 97.50% 90.00% 72.50%
50.0%
60.0%
70.0%
80.0%
90.0%
100.0%
110.0%
15 20 25 30 35 40
執行任務數量
2RPU下任務成功率
PRS EH-EDF EDF
圖 4-7. 四個可規劃處理單元下任務調度成功率比較
表 4-6. 在 4 個 RPU 下任務調度成功率比較
PRS EH-EDF EDF
15 個任務 100.00% 100.00% 100.00%
20 個任務 100.00% 100.00% 100.00%
25 個任務 100.00% 100.00% 100.00%
30 個任務 100.00% 100.00% 100.00%
35 個任務 100.00% 97.10% 91.42%
40 個任務 97.50% 90.00% 80.00%
比較結果明確顯示出本論文所提出的 PRS 調度成功率明顯高於其他多處理器調度 演算法。
50.0%
60.0%
70.0%
80.0%
90.0%
100.0%
110.0%
15 20 25 30 35 40
執行任務數量
4RPU下任務成功率
PRS EH-EDF EDF
第五章 結論
本文提出了一個平行可規劃排程算法(Parallel Reconfigurable Scheduling, PRS) 。 實驗結果表明平行可規劃計算機可以有效的提升效能,比起其他架構上實驗結果表 示本篇架構上處理速度有不錯的表現。
本文亦提出了基於能量限制的排程演算法架構以及動態能量限制管理方法,實驗結 果表示在本篇架構上能量消耗亦有不錯的表現,而比較起來也不輸給其他演算法。
並且比起其他架構上實驗結果顯示本演算法在能量限制下,有很高的配置成功率。
在本架構在節省能源消耗方面有不錯的成效,而運算效能也僅次於 EH-EDF 的系 統但也相去不遠,可規劃計算機架構可以運用其他在應用上靈活度勝過EH-EDF 系統,
平行可規劃配置的記憶體成功的降低傳輸的延遲。
所提出的架構在計算能力、能源消耗等方面的數據有所提升,證明所提出的計算機 架構確實為相較下是比較可行的方案。
最後,縱使本論文架構在各方面都有所優化,但是對於整體計算計架構的最佳化設 計來說,還是有相當大的研究空間。
參考文獻
1. S. Agarwala and etc., “A 65nm c64x+ multi-core DSP platform for communication infrastructure,” In proceeding of IEEE International Solid-State Circuits Conference, 2007.
2. B. Khailany, W. Dally, U. Kapasi, P. Mattson, J. Namkoong, J. Owens, B. Towles,A. Chang, and S. Rixner, “Imagine: media processing with streams,” IEEE Micro, vol. 21, no. 2, pp.
35–46, 2001.
3. “AMD Athlon 64 X2 Dual-Core Processor Product Data Sheet,” 2005.
4. S. Vangal, J. Howard, G. Ruhl, S. Dighe, H. Wilson, J. Tschanz, D. Finan, P. Lyer, A. Singh, T. Jacb, S. Jain, S. Venkataraman, Y. Hoskote, and N. Borkar, “An 80-tile1.28 TFLOPS
network-on-chip in 65nm CMOS,” in Proceedings of IEEE International Solid-State Circuits Conference, pp. 98–99, 2007.
5. J. L. Tripp, J. Frigo, and P. Graham, “A survey of multi-core coarsegrained reconfigurable arrays for embedded applications,” in Proc. 11th Annu. Workshop High Performance
Embedded Comput., 2007.
6. K. Compton and S. Hauck, “Reconfigurable computing: A survey of systems and software,”
ACM Comput. Surv., vol. 34, no. 2, pp. 171–210, 2002.
7. S. J. Park, B. Henz, and D. Shires, “Reconfigurable computing for high performance computing computational science,” in Proc. DoD High Performance Comput.
Modernization Program Users Group Conf., 2007, pp. 350–358.
8. Compton, Katherine, and Scott Hauck. "Reconfigurable computing: a survey of systems and software." ACM Computing Surveys (csuR) 34.2 (2002): 171-210.
9. T. Beierlein, D. Frohlich, and B. Steinbach, “UML-based Codesign of Reconfigurable Architectures,” Proc. of the Forum on Specification and Design Languages, pp. 285-
196,2003
10. T. Heng and R. F. DeMara, “A multilayer framework supporting autonomous run-time partial reconfiguration,” IEEE Trans. Very Large Scale Integr. Syst., vol. 16, no. 5, pp. 504–
516, May 2008.
11. S. Wray, W. Luk, and P. Pietzuch, “Run-time reconfiguration for a reconfigurable algorithmic trading engine,” in Proc. Int. Conf. Field Programmable Logic and Appl., Jul.
2010, pp. 163–166.
12. C. H. Lin, C. Y. Chen, and A. Y. Wu, “Area-efficient scalable MAP processor design for high-throughput multistandard convolutional turbo decoding,” IEEE Trans. Very Large
13. H. Liu, X. Chen, and Y. Ha, “An area-efficient timing-driven routing algorithm for scalable FPGAs with time-multiplexed interconnects,” in Proc. Int. Symp. Field-Programmable Custom Comput. Mach., Apr. 2008, pp. 275–276.
14. T. Sato, H. Watanabe, and K. Shiba, “Implementation of dynamically reconfigurable processor: DAPDNA-2,” in Proc. IEEE VLSI-TSA Int. Symp. VLSI Design, Automat. Test, Apr. 2005, pp. 323–324.
15. S. Gao, T. Kihara, S. Shimizu, Y. Arakawa, N. Yamanaka, and A. Watanabe, “A novel traffic engineering method using on-chip diorama network on dynamically reconfigurable processor DAPDNA-2,” in Proc. Int. Conf. High Performance Switching and Routing, 2009, pp.1–6.
16. Kuan-Yu Chen, Alan Liu and Chiung-Hui Leon Lee, “A Multiprocessor Real-Time Process Scheduling Method,” Proceeding of Multimedia Software Engineering Fifth International
Symposium on Multimedia Software Engineering, pp. 29 – 36, 2003.
17. Joel Goossens, Shelby Funk and Sanjoy, Baruah, “Priority-Driven Scheduling of Periodic Task Systems on Multiprocessors,” Real-time Systems, vol. 25, no.2-3, pp. 187-205, Sep.
2003.
18. Dertouzos, M.L., Mok, A.K., " Multiprocessor On-Line Scheduling of Hard-Real-Time Tasks ", IEEE Transactions on Software Engineering , v.15, n.12 , pp. 1497-1506 , 1989
19. Josep M. Banús, Alex Arenas and Jesús Labarta, “Dual Priority Algorithm to Schedule Real-Time Tasks in a Shared Memory Multiprocessor,” IEEE Computer Society Washington, DC, pp. 2-12, 2003.
20. M. Chetto and A. Queudet, “A note on edf scheduling for real-time energy harvesting systems,” IEEE Transactions on Computers, vol. 63, no. 4, pp. 1037–1040, 2014.
21. M. Chetto, “Optimal scheduling for real-time jobs in energy harvesting computing systems,”
IEEE Trans. Emerging Topics in Computing, vol. 2, no. 2, pp. 122–133, 2014.
22. H. E. Ghor, M. Chetto, and R. H. Chehade, “A real-time scheduling framework for embedded systems with environmental energy harvesting,” Computers & Electrical
Engineering, vol. 37, no. 4, pp. 498–510, 2011.
23. H. El Ghor, M. Chetto, and R. Hage Chehade, “A nonclairvoyant realtime scheduler for ambient energy harvesting sensors,” International Journal of Distributed Sensor Networks,
vol. 2013, 2013.
24. B. Zhang, R. Simon, and H. Aydin, “Harvesting-aware energy management for time-critical wireless sensor networks with joint voltage and modulation scaling,” IEEE Trans. Industrial
Informatics, vol. 9, no. 1, pp. 514–526, 2013.
25. J. Lu and Q. Qiu, “Scheduling and mapping of periodic tasks on multicore embedded systems with energy harvesting,” in Green Computing Conference and Workshops (IGCC),
2011 International. IEEE, 2011, pp. 1–6.